SwiftKV from Snowflake AI Research Reduces Inference Costs of Meta Llama LLMs up to 75% on Cortex AI
Large language models (LLMs) are at the heart of generative AI transformations, driving solutions across industries — from efficient customer support to simplified data analysis. Enterprises need performant, cost-effective and low-latency inference to scale their gen AI solutions. Yet, the complexity and computational demands of LLM inference present a challenge. Inference costs remain prohibitive for many workloads. That’s where SwiftKV and Snowflake Cortex AI come in.
SwiftKV optimizations developed and integrated into vLLM by the Snowflake AI Research team significantly improve LLM inference throughput to lower the cost. SwiftKV-optimized Llama 3.3 70B and Llama 3.1 405B models, referred to as Snowflake-LLama-3.3-70B and Snowflake-Llama-3.1-405B, are now available for serverless inference in Cortex AI with an inference cost reduction of up to 75% compared to the baseline Meta Llama models in Cortex AI that are not SwiftKV optimized. Customers can access these in Cortex AI via the complete function. To continue enabling organizations to efficiently and cost-effectively take their AI apps to production, we are considering bringing the same optimizations to other model families available in Snowflake Cortex AI.
SwiftKV overview
Let us review how SwiftKV achieves this performance. Enterprise use cases often involve long input prompts with minimal output (almost 10:1). This implies that the majority of computational resources are consumed during the input (or prefill stage) of key-value (KV) cache generation. SwiftKV reuses the hidden states of earlier transformer layers to generate a KV cache for later layers. This eliminates redundant computations in the prefill stage, significantly reducing computational overhead. As a result, SwiftKV achieves up to a 50% reduction in prefill compute while maintaining the accuracy levels demanded by enterprise applications. This optimization helps improve throughput and deliver a more cost-effective inference stack.
SwiftKV achieves higher throughput performance with minimal accuracy loss (see Tables 1 and 2). This is done by combining parameter preserving model rewiring with lightweight fine-tuning to minimize the likelihood of knowledge being lost in the process. Using self-distillation, the rewired model replicates the original behavior, achieving near-identical performance. Accuracy loss is limited to around one point in the average of multiple benchmarks (see Tables 1 and 2). This surgical approach to optimization ensures that enterprises can benefit from SwiftKV’s computational efficiencies without compromising the quality of their gen AI outputs.


Based on our benchmarking, SwiftKV consistently outperforms standard KV cache implementations and traditional KV cache compression methods in real-world production use cases. For instance, in production environments using high-end GPUs such as NVIDIA H100s, SwiftKV achieves up to two times higher throughput (see Figure 1) for models such as the Llama-3.3-70B. These improvements translate to faster job completion, lower latency for interactive applications (see Table 3) and substantial cost savings for enterprises operating at scale.
Performance by use case
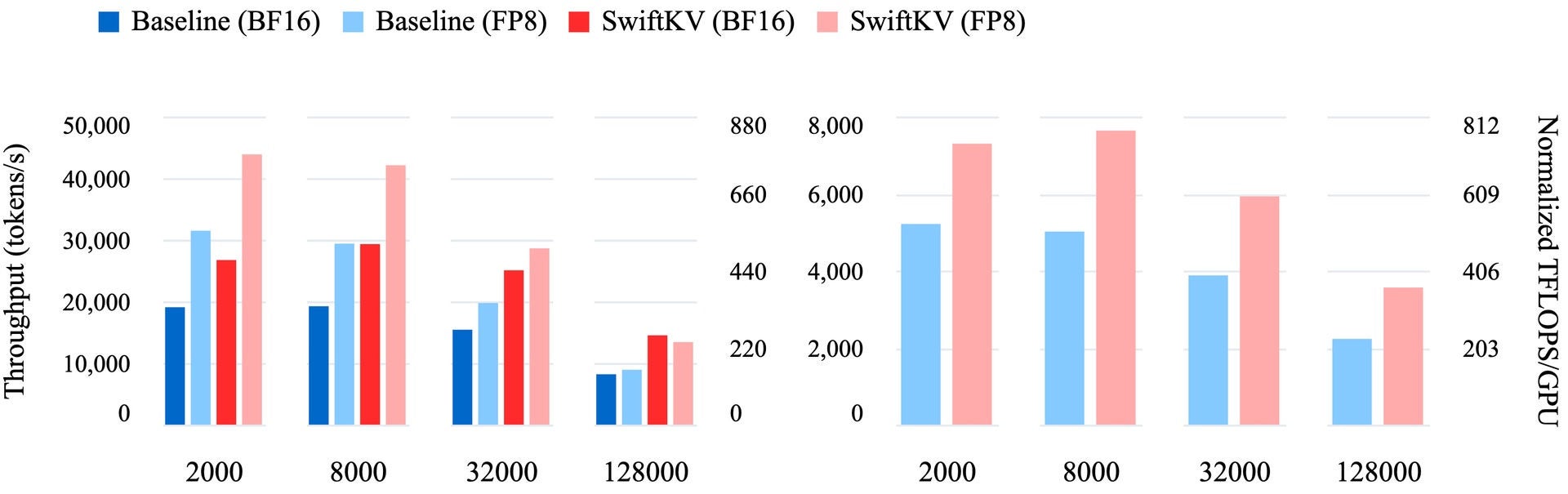
SwiftKV enables performance optimizations on a range of use cases. For large-scale inference tasks, such as unstructured text processing (for instance, summarization, translation or sentiment analysis), SwiftKV improves combined throughput (see Figure 1), enabling enterprises to process more data in less time. In latency-sensitive scenarios, such as chatbots or AI copilots, SwiftKV reduces the time to first token by up to 50% (see Table 4), leading to faster, more responsive user experiences. Further, SwiftKV integrates seamlessly with vLLM without major changes to enable a wide range of complementary optimization techniques, including attention optimization and speculative decoding. This integration makes SwiftKV a versatile and practical solution for enterprise workloads.


SwiftKV on Snowflake Cortex AI
SwiftKV’s introduction comes at a critical moment for enterprises embracing LLM technologies. With the growth of use cases, organizations need solutions that deliver both immediate performance gains and long-term scalability. By tackling the computational bottlenecks of inference directly, SwiftKV offers a new path forward, enabling enterprises to unlock the full potential of their LLM production deployments. We are excited to provide the SwiftKV innovation on the Llama models with the launch of Snowflake-Llama-3.3-70B and Snowflake-Llama-3.1-405B with inference at a fraction of the cost (75% and 68% lower cost, respectively). The Snowflake-derived Llama models are a game changer for enterprises navigating the challenges of scaling gen AI innovation in their organizations in an easy and cost-effective way.
SwiftKV open source
Getting started: Run a your own SwiftKV training by following this quickstart.
Because SwiftKV is fully open source, you can also deploy it on your own with model checkpoints on Hugging Face and optimized inference on vLLM. You can learn more in our SwiftKV research blog post.
We are also making knowledge distillation pipelines via ArcticTraining Framework open source so you can build your own SwiftKV models for your enterprise or academic needs. The ArcticTraining Framework is a powerful post-training library for streamlining research and development. It is designed to facilitate research and prototype new ideas for post-training without getting overwhelmed by complex abstraction layers or generalizations. It offers a high-quality, user-friendly synthetic data generation pipeline and a scalable, adaptable training framework for algorithmic innovation, as well as an out-of–the-box recipe for training your own SwiftKV models.
As gen AI innovation continues to expand across industries and use cases, optimizations such as SwiftKV are critical in bringing AI to end users in a cost-effective and performant manner. Now available as open source, SwiftKV makes enterprise-grade gen AI faster and less expensive to run. Taking it a step further, we are also launching Llama models optimized with SwiftKV in Snowflake Cortex AI. With Snowflake-Llama-3.3-70B and Snowflake-Llama-3.1-405B models, customers are seeing up to 75% lower inference costs. We are helping them build gen AI solutions that are both cost effective and high performing.
Authors




