

A neural network model of differentiation and integration of competing memories
- PMID: 39319791
- PMCID: PMC11424095
- DOI: 10.7554/eLife.88608
A neural network model of differentiation and integration of competing memories
Abstract
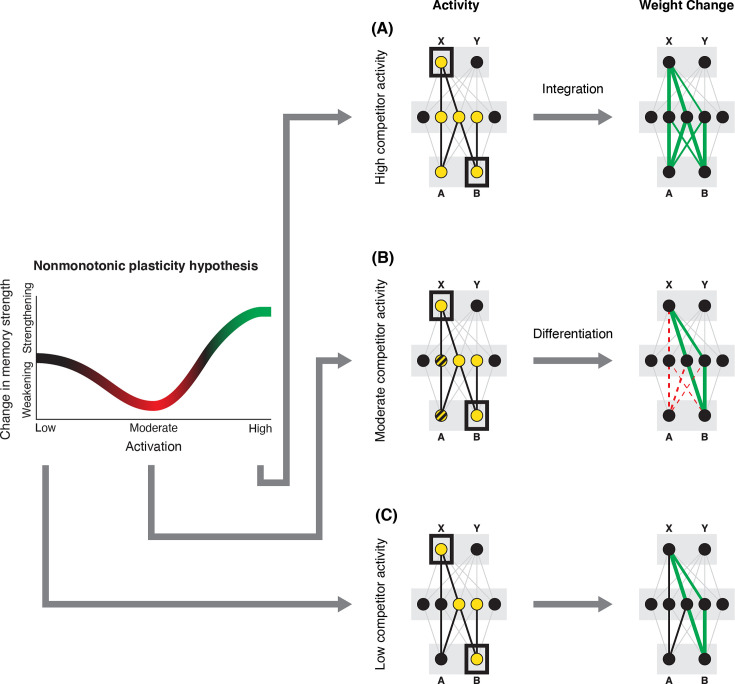
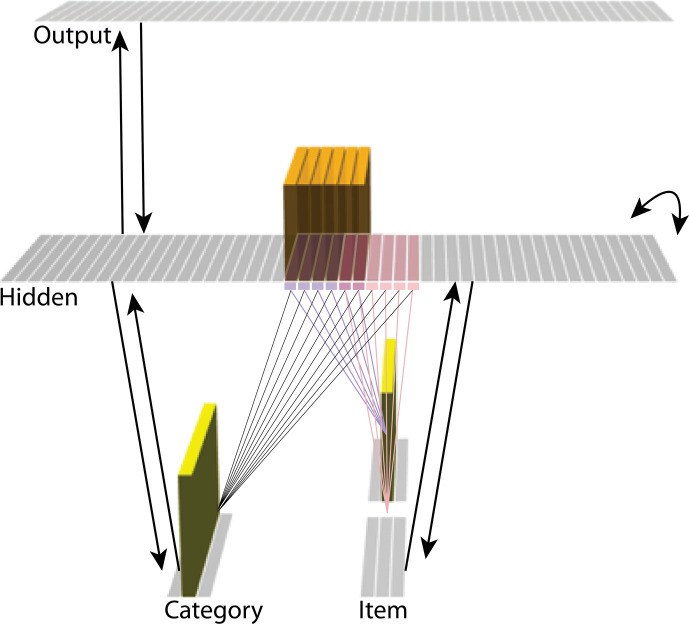
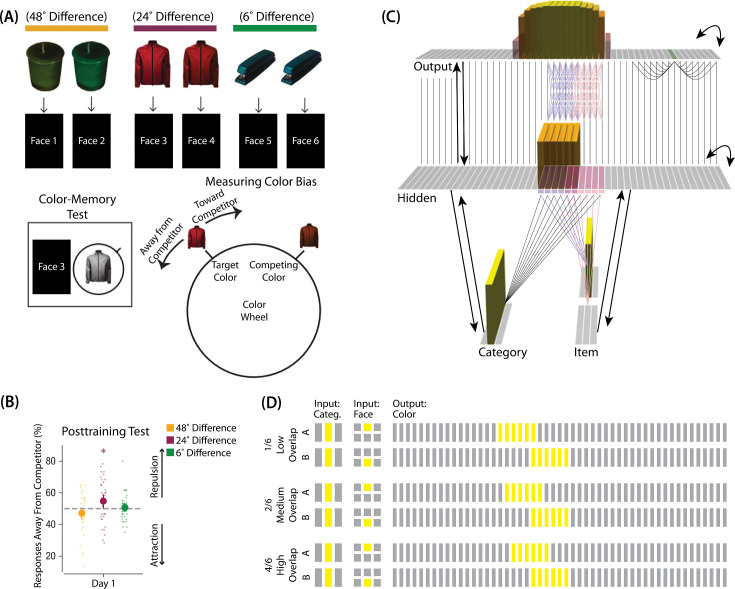
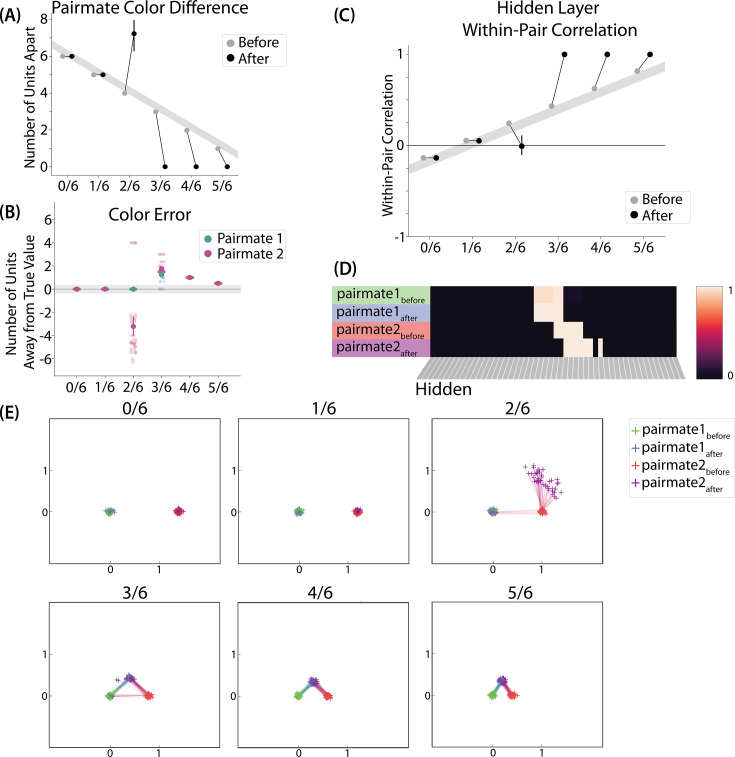
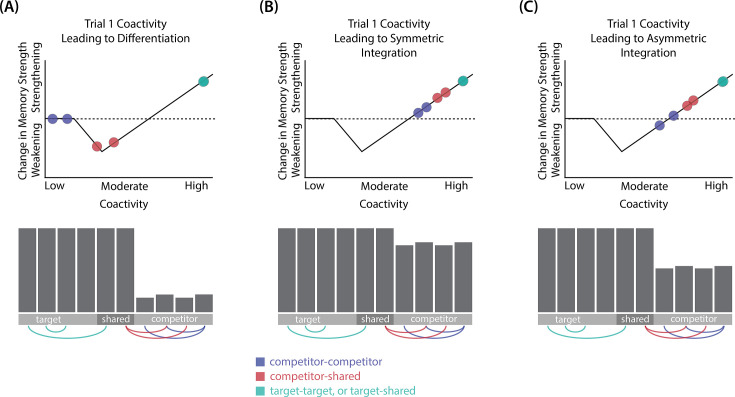
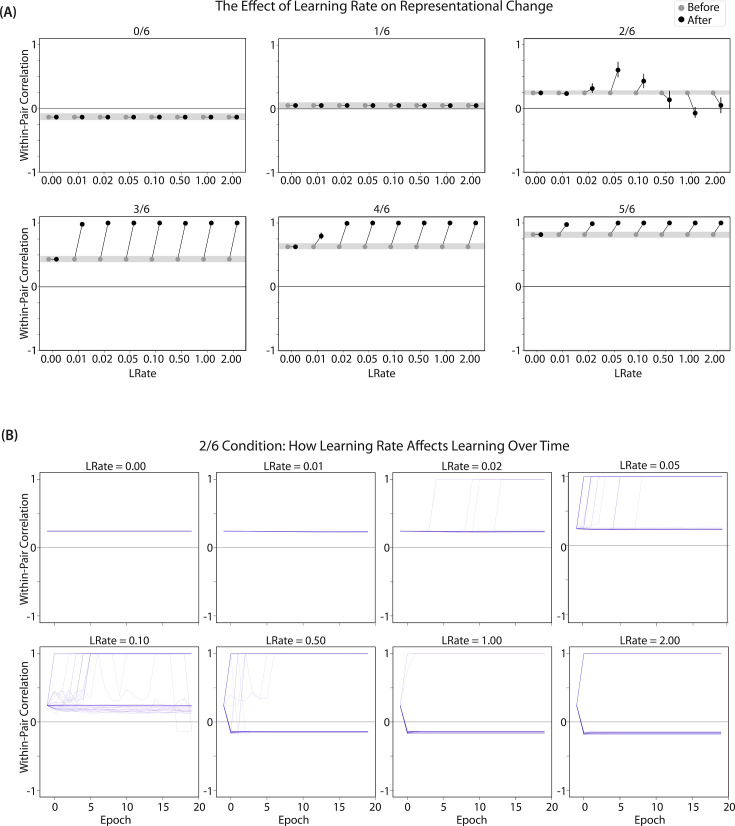
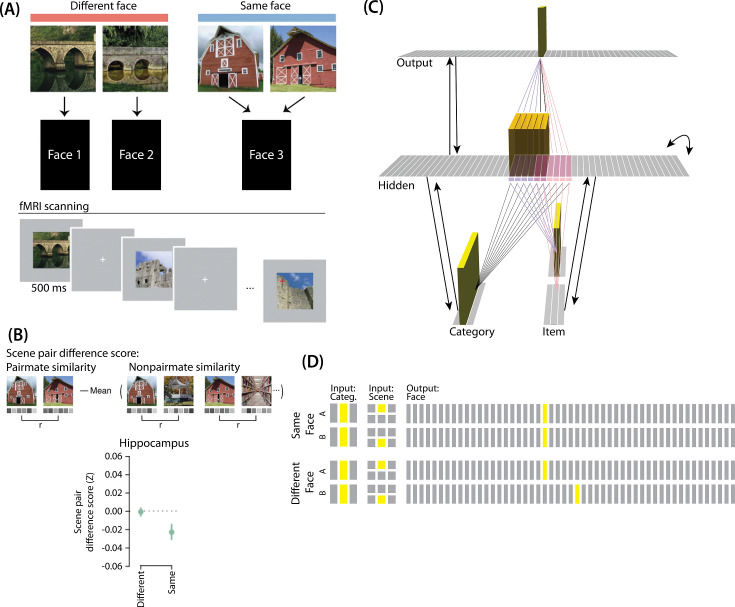
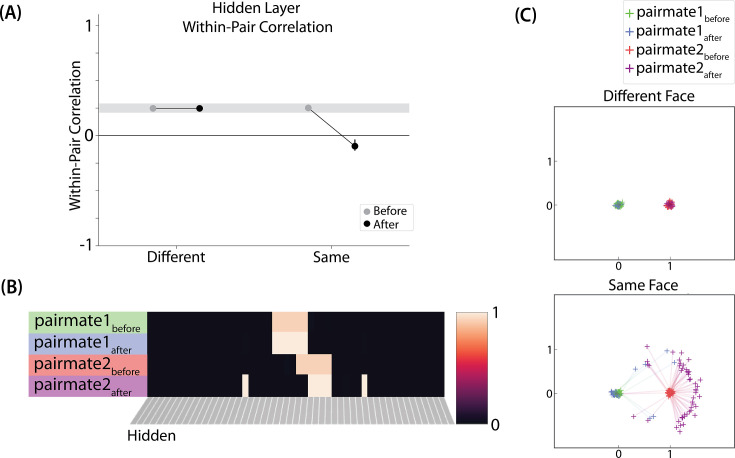
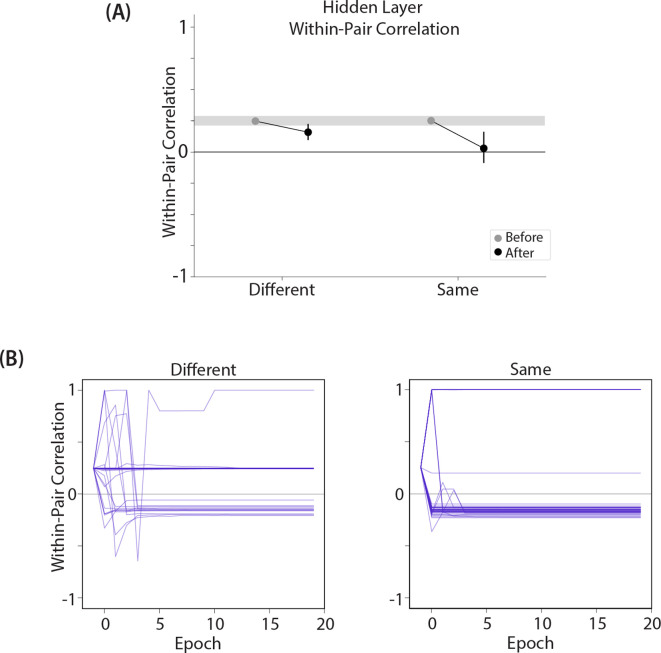
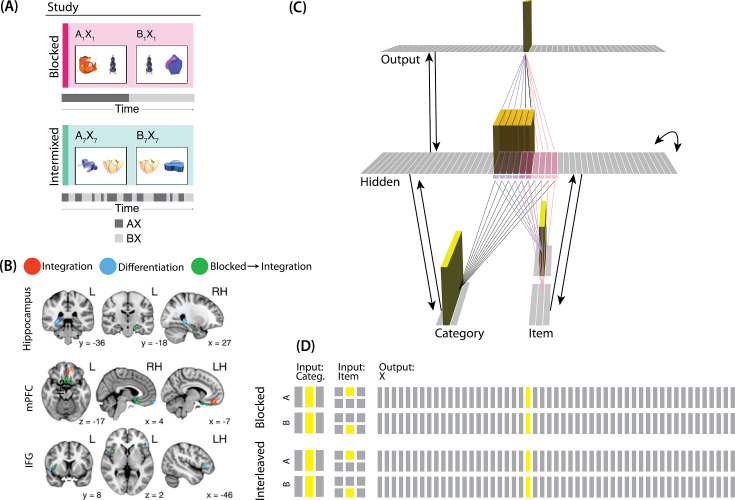
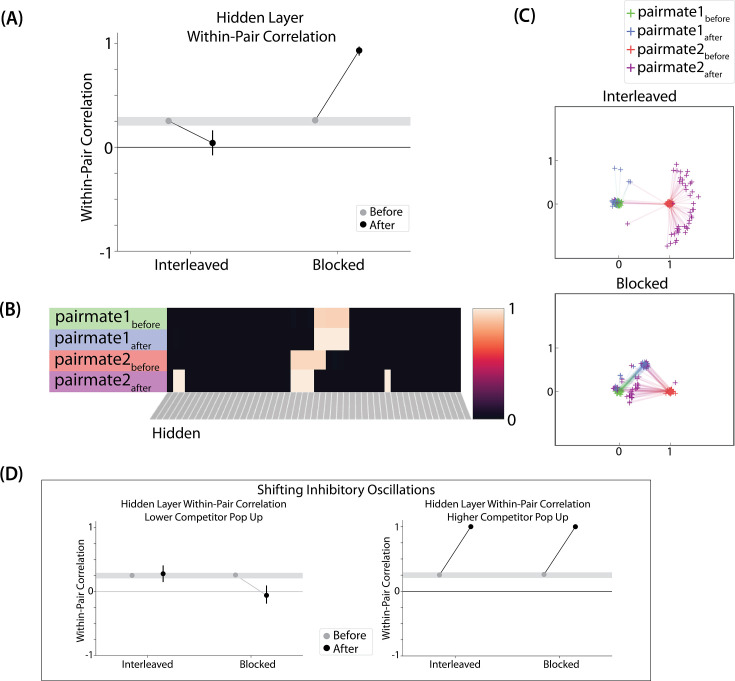
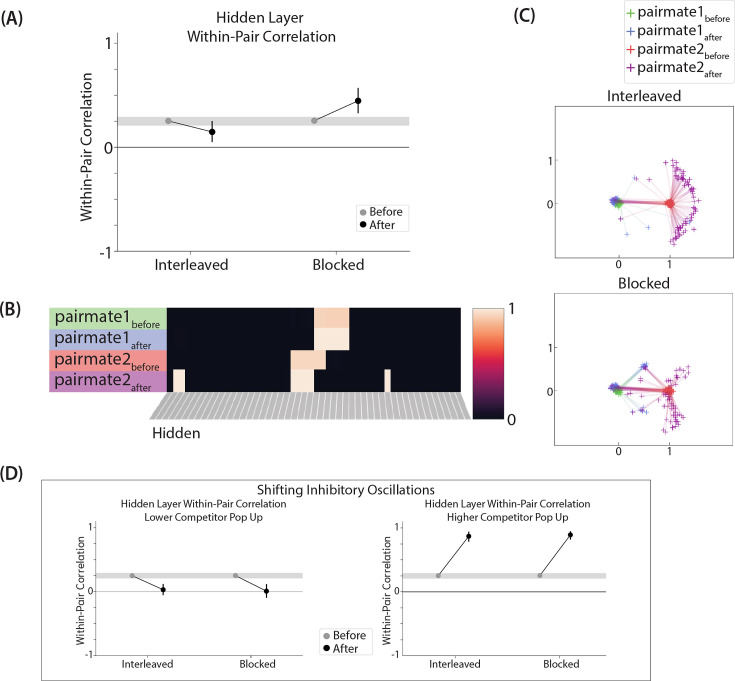
What determines when neural representations of memories move together (integrate) or apart (differentiate)? Classic supervised learning models posit that, when two stimuli predict similar outcomes, their representations should integrate. However, these models have recently been challenged by studies showing that pairing two stimuli with a shared associate can sometimes cause differentiation, depending on the parameters of the study and the brain region being examined. Here, we provide a purely unsupervised neural network model that can explain these and other related findings. The model can exhibit integration or differentiation depending on the amount of activity allowed to spread to competitors - inactive memories are not modified, connections to moderately active competitors are weakened (leading to differentiation), and connections to highly active competitors are strengthened (leading to integration). The model also makes several novel predictions - most importantly, that when differentiation occurs as a result of this unsupervised learning mechanism, it will be rapid and asymmetric, and it will give rise to anticorrelated representations in the region of the brain that is the source of the differentiation. Overall, these modeling results provide a computational explanation for a diverse set of seemingly contradictory empirical findings in the memory literature, as well as new insights into the dynamics at play during learning.
Keywords: computational modeling; fMRI; memory; neural networks; neuroscience; none; representational change; unsupervised learning.
© 2023, Ritvo et al.
Conflict of interest statement
VR, AN, NT, KN No competing interests declared
Figures
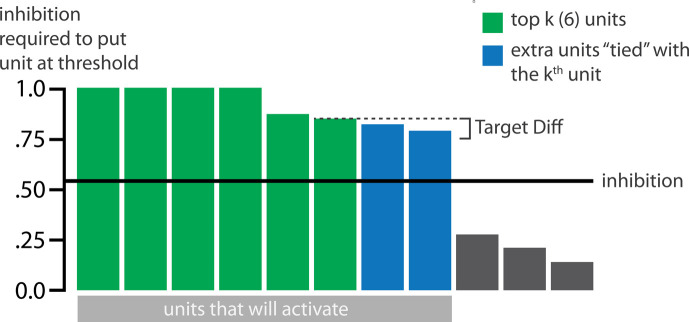
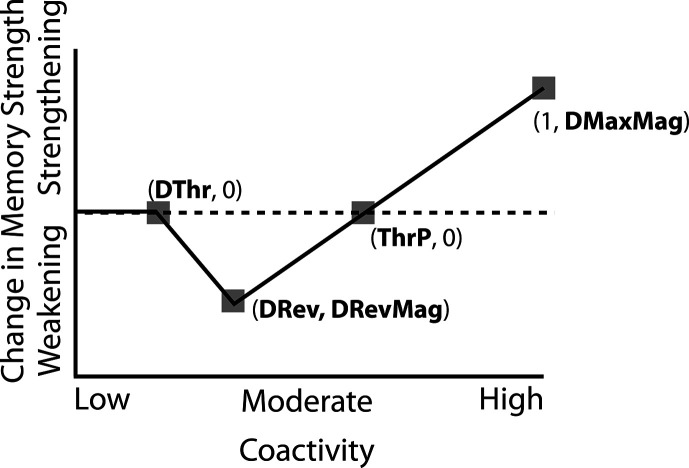
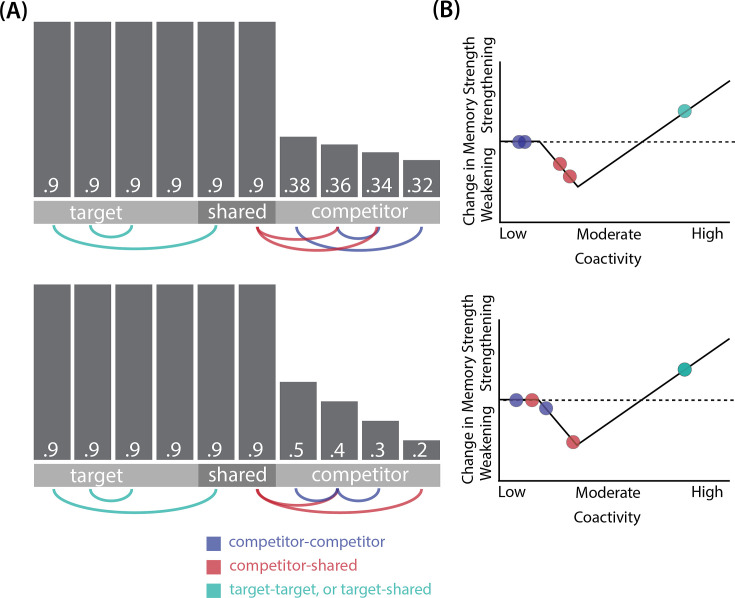
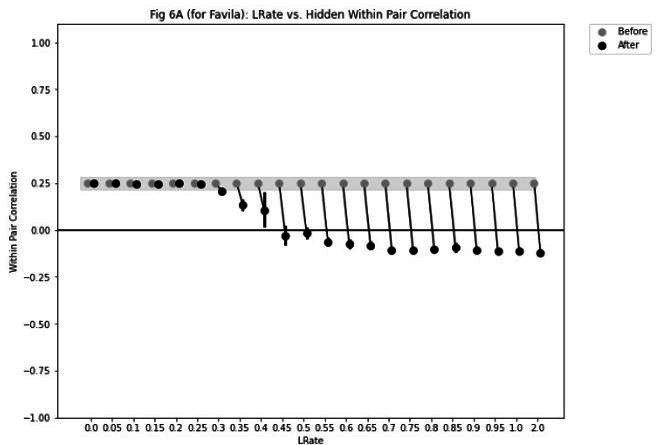
Update of
-
Differentiation and Integration of Competing Memories: A Neural Network Model.bioRxiv [Preprint]. 2024 Jun 25:2023.04.02.535239. doi: 10.1101/2023.04.02.535239. bioRxiv. 2024. Update in: Elife. 2024 Sep 25;12:RP88608. doi: 10.7554/eLife.88608. PMID: 37066178 Free PMC article. Updated. Preprint.
Similar articles
-
Differentiation and Integration of Competing Memories: A Neural Network Model.bioRxiv [Preprint]. 2024 Jun 25:2023.04.02.535239. doi: 10.1101/2023.04.02.535239. bioRxiv. 2024. Update in: Elife. 2024 Sep 25;12:RP88608. doi: 10.7554/eLife.88608. PMID: 37066178 Free PMC article. Updated. Preprint.
-
Nonmonotonic Plasticity: How Memory Retrieval Drives Learning.Trends Cogn Sci. 2019 Sep;23(9):726-742. doi: 10.1016/j.tics.2019.06.007. Epub 2019 Jul 26. Trends Cogn Sci. 2019. PMID: 31358438 Free PMC article. Review.
-
Memory Reactivation during Learning Simultaneously Promotes Dentate Gyrus/CA2,3 Pattern Differentiation and CA1 Memory Integration.J Neurosci. 2021 Jan 27;41(4):726-738. doi: 10.1523/JNEUROSCI.0394-20.2020. Epub 2020 Nov 25. J Neurosci. 2021. PMID: 33239402 Free PMC article.
-
Neural Differentiation of Incorrectly Predicted Memories.J Neurosci. 2017 Feb 22;37(8):2022-2031. doi: 10.1523/JNEUROSCI.3272-16.2017. Epub 2017 Jan 23. J Neurosci. 2017. PMID: 28115478 Free PMC article.
-
NeuCube: a spiking neural network architecture for mapping, learning and understanding of spatio-temporal brain data.Neural Netw. 2014 Apr;52:62-76. doi: 10.1016/j.neunet.2014.01.006. Epub 2014 Jan 20. Neural Netw. 2014. PMID: 24508754 Review.
Cited by
-
The role of REM sleep in neural differentiation of memories in the hippocampus.bioRxiv [Preprint]. 2024 Nov 3:2024.11.01.621588. doi: 10.1101/2024.11.01.621588. bioRxiv. 2024. PMID: 39553942 Free PMC article. Preprint.
-
INDUCING REPRESENTATIONAL CHANGE IN THE HIPPOCAMPUS THROUGH REAL-TIME NEUROFEEDBACK.bioRxiv [Preprint]. 2023 Dec 4:2023.12.01.569487. doi: 10.1101/2023.12.01.569487. bioRxiv. 2023. Update in: Philos Trans R Soc Lond B Biol Sci. 2024 Dec 2;379(1915):20230091. doi: 10.1098/rstb.2023.0091. PMID: 38106228 Free PMC article. Updated. Preprint.
-
Inducing representational change in the hippocampus through real-time neurofeedback.Philos Trans R Soc Lond B Biol Sci. 2024 Dec 2;379(1915):20230091. doi: 10.1098/rstb.2023.0091. Epub 2024 Oct 21. Philos Trans R Soc Lond B Biol Sci. 2024. PMID: 39428880 Free PMC article.
-
Hippocampal mechanisms resolve competition in memory and perception.bioRxiv [Preprint]. 2023 Nov 3:2023.10.09.561548. doi: 10.1101/2023.10.09.561548. bioRxiv. 2023. PMID: 37873400 Free PMC article. Preprint.
References
MeSH terms
Grants and funding
LinkOut - more resources
Full Text Sources
Medical
