diff --git a/.travis.yml b/.travis.yml
new file mode 100644
index 00000000..7f7498fb
--- /dev/null
+++ b/.travis.yml
@@ -0,0 +1,24 @@
+# 持续集成 CI
+# @see https://docs.travis-ci.com/user/tutorial/
+
+language: node_js
+
+sudo: required
+
+node_js: stable
+
+branches:
+ only:
+ - master
+
+before_install:
+ - export TZ=Asia/Shanghai
+
+script: bash ./scripts/deploy.sh
+
+notifications:
+ email:
+ recipients:
+ - forbreak@163.com
+ on_success: change
+ on_failure: always
diff --git a/README.md b/README.md
index a1603b96..22d425b0 100644
--- a/README.md
+++ b/README.md
@@ -7,7 +7,7 @@
## 关系型数据库
-> [关系型数据库](docs/sql/README.md)
+> [关系型数据库](docs/sql) 整理主流关系型数据库知识点。
- [关系型数据库面试题 💯](docs/sql/sql-interview.md)
- [SQL Cheat Sheet](docs/sql/sql-cheat-sheet.md)
@@ -15,13 +15,13 @@
- [Mysql 原理](docs/sql/mysql/mysql-theory.md)
- [Mysql 运维 🔨](docs/sql/mysql/mysql-ops.md)
- [Mysql 配置](docs/sql/mysql/mysql-config.md)
-- [H2 快速指南](docs/sql/h2.md)
-- [SqLite 快速指南](docs/sql/sqlite.md)
-- [PostgreSQL 快速指南](docs/sql/postgresql.md)
+- [H2 入门指南](docs/sql/h2.md)
+- [SqLite 入门指南](docs/sql/sqlite.md)
+- [PostgreSQL 入门指南](docs/sql/postgresql.md)
## Nosql 数据库
-> [Nosql 数据库](docs/nosql/README.md)
+> [Nosql 数据库](docs/nosql) 整理主流 Nosql 数据库知识点。
- [Nosql 技术选型](docs/nosql/nosql-selection.md)
- [Redis](docs/nosql/redis/README.md)
@@ -34,4 +34,5 @@
## 中间件
-- [数据库中间件 flyway](docs/sql/middleware/flyway.md)
+- [版本管理中间件 flyway](docs/middleware/flyway.md)
+- [分库分表中间件 ShardingSphere](docs/middleware/shardingsphere.md)
diff --git a/docs/.vuepress/config.js b/docs/.vuepress/config.js
index 5a1912c0..1981d671 100644
--- a/docs/.vuepress/config.js
+++ b/docs/.vuepress/config.js
@@ -15,7 +15,7 @@ module.exports = {
}
},
themeConfig: {
- logo: `images/dunwu-logo-100.png`,
+ logo: "images/dunwu-logo-100.png",
repo: "dunwu/db-tutorial",
repoLabel: "Github",
editLinks: true,
diff --git a/docs/README.md b/docs/README.md
index e1c563e5..d714e401 100644
--- a/docs/README.md
+++ b/docs/README.md
@@ -16,7 +16,7 @@ footer: CC-BY-SA-4.0 Licensed | Copyright © 2018-Now Dunwu
## 关系型数据库
-> [关系型数据库](sql/README.md)
+> [关系型数据库](sql) 整理主流关系型数据库知识点。
- [关系型数据库面试题 💯](sql/sql-interview.md)
- [SQL Cheat Sheet](sql/sql-cheat-sheet.md)
@@ -24,13 +24,13 @@ footer: CC-BY-SA-4.0 Licensed | Copyright © 2018-Now Dunwu
- [Mysql 原理](sql/mysql/mysql-theory.md)
- [Mysql 运维 🔨](sql/mysql/mysql-ops.md)
- [Mysql 配置](sql/mysql/mysql-config.md)
-- [H2 快速指南](sql/h2.md)
-- [SqLite 快速指南](sql/sqlite.md)
-- [PostgreSQL 快速指南](sql/postgresql.md)
+- [H2 入门指南](sql/h2.md)
+- [SqLite 入门指南](sql/sqlite.md)
+- [PostgreSQL 入门指南](sql/postgresql.md)
## Nosql 数据库
-> [Nosql 数据库](nosql/README.md)
+> [Nosql 数据库](nosql) 整理主流 Nosql 数据库知识点。
- [Nosql 技术选型](nosql/nosql-selection.md)
- [Redis](nosql/redis/README.md)
@@ -43,4 +43,5 @@ footer: CC-BY-SA-4.0 Licensed | Copyright © 2018-Now Dunwu
## 中间件
-- [数据库中间件 flyway](sql/middleware/flyway.md)
+- [版本管理中间件 flyway](middleware/flyway.md)
+- [分库分表中间件 ShardingSphere](middleware/shardingsphere.md)
diff --git a/docs/sql/middleware/flyway.md b/docs/middleware/flyway.md
similarity index 91%
rename from docs/sql/middleware/flyway.md
rename to docs/middleware/flyway.md
index 8a390929..2a00c9b6 100644
--- a/docs/sql/middleware/flyway.md
+++ b/docs/middleware/flyway.md
@@ -4,33 +4,13 @@
>
> 关键词:
-
-
-- [简介](#简介)
- - [什么是 Flyway?](#什么是-flyway)
- - [为什么要使用数据迁移?](#为什么要使用数据迁移)
- - [Flyway 如何工作?](#flyway-如何工作)
-- [快速上手](#快速上手)
- - [命令行](#命令行)
- - [JAVA API](#java-api)
- - [Maven](#maven)
- - [Gradle](#gradle)
-- [入门篇](#入门篇)
- - [概念](#概念)
- - [命令](#命令)
- - [支持的数据库](#支持的数据库)
-- [资料](#资料)
-- [:door: 传送门](#door-传送门)
-
-
-
## 简介
-### 什么是 Flyway?
+### 什么是 Flyway
**Flyway 是一个开源的数据库迁移工具。**
-### 为什么要使用数据迁移?
+### 为什么要使用数据迁移
为了说明数据迁移的作用,我们来举一个示例:
@@ -38,7 +18,7 @@
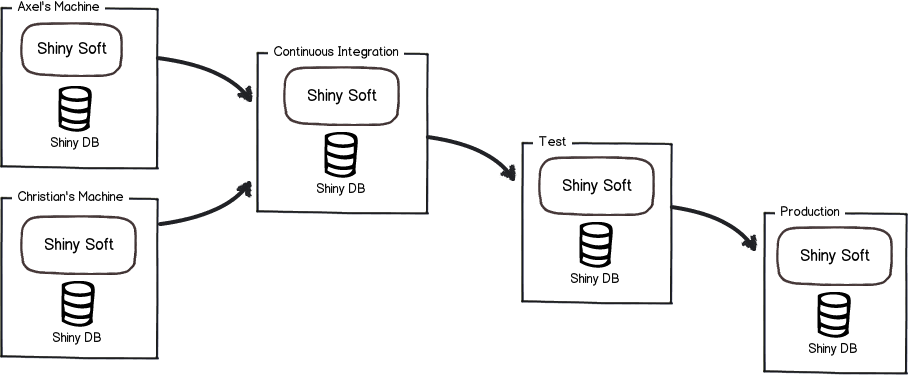
(2)对于大多数项目而言,最简单的持续集成场景如下所示:
-
+
这意味着,我们不仅仅要处理一份环境中的修改,由此会引入一些版本冲突问题:
@@ -69,13 +49,13 @@
最简单的场景是指定 Flyway 迁移到一个空的数据库。
-

+
Flyway 会尝试查找它的 schema 历史表,如果数据库是空的,Flyway 就不再查找,而是直接创建数据库。
现再你就有了一个仅包含一张空表的数据库,默认情况下,这张表叫 _flyway_schema_history_。
-

+
这张表将被用于追踪数据库的状态。
@@ -83,17 +63,17 @@ Flyway 会尝试查找它的 schema 历史表,如果数据库是空的,Flywa
这些 **migrations** 将根据他们的版本号进行排序。
-

+
任意 migration 应用后,schema 历史表将更新。当元数据和初始状态替换后,可以称之为:迁移到新版本。
Flyway 一旦扫描了文件系统或应用 classpath 下的 migrations,这些 migrations 会检查 schema 历史表。如果它们的版本号低于或等于当前的版本,将被忽略。保留下来的 migrations 是等待的 migrations,有效但没有应用。
-

+
migrations 将根据版本号排序并按序执行。
-

+
## 快速上手
@@ -406,7 +386,7 @@ migrations 最常用的编写形式就是 SQL。
为了被 Flyway 自动识别,SQL migrations 的文件命名必须遵循规定的模式:
-

+
- **Prefix** - `V` 代表 versioned migrations (可配置), `U` 代表 undo migrations (可配置)、 `R` 代表 repeatable migrations (可配置)
- **Version** - 版本号通过`.`(点)或`_`(下划线)分隔 (repeatable migrations 不需要)
@@ -425,7 +405,7 @@ migrations 最常用的编写形式就是 SQL。
为了被 Flyway 自动识别,JAVA migrations 的文件命名必须遵循规定的模式:
-

+
- **Prefix** - `V` 代表 versioned migrations (可配置), `U` 代表 undo migrations (可配置)、 `R` 代表 repeatable migrations (可配置)
- **Version** - 版本号通过`.`(点)或`_`(下划线)分隔 (repeatable migrations 不需要)
diff --git a/docs/middleware/shardingsphere.md b/docs/middleware/shardingsphere.md
new file mode 100644
index 00000000..fe6a8610
--- /dev/null
+++ b/docs/middleware/shardingsphere.md
@@ -0,0 +1,55 @@
+# ShardingSphere
+
+> ShardingSphere 是一套开源的分布式数据库中间件解决方案组成的生态圈,它由 Sharding-JDBC、Sharding-Proxy 和 Sharding-Sidecar(计划中)这 3 款相互独立的产品组成。 他们均提供标准化的数据分片、分布式事务和数据库治理功能,可适用于如 Java 同构、异构语言、云原生等各种多样化的应用场景。
+
+## 架构
+
+
+
+### Sharding-JDBC
+
+定位为轻量级 Java 框架,在 Java 的 JDBC 层提供的额外服务。 它使用客户端直连数据库,以 jar 包形式提供服务,无需额外部署和依赖,可理解为增强版的 JDBC 驱动,完全兼容 JDBC 和各种 ORM 框架。
+
+- 适用于任何基于 Java 的 ORM 框架,如:JPA, Hibernate, Mybatis, Spring JDBC Template 或直接使用 JDBC。
+- 基于任何第三方的数据库连接池,如:DBCP, C3P0, BoneCP, Druid, HikariCP 等。
+- 支持任意实现 JDBC 规范的数据库。目前支持 MySQL,Oracle,SQLServer 和 PostgreSQL。
+
+
+
+### Sharding-Proxy
+
+定位为透明化的数据库代理端,提供封装了数据库二进制协议的服务端版本,用于完成对异构语言的支持。 目前先提供 MySQL/PostgreSQL 版本,它可以使用任何兼容 MySQL/PostgreSQL 协议的访问客户端(如:MySQL Command Client, MySQL Workbench, Navicat 等)操作数据,对 DBA 更加友好。
+
+- 向应用程序完全透明,可直接当做 MySQL/PostgreSQL 使用。
+- 适用于任何兼容 MySQL/PostgreSQL 协议的的客户端。
+
+
+
+### Sharding-Sidecar(TODO)
+
+定位为 Kubernetes 的云原生数据库代理,以 Sidecar 的形式代理所有对数据库的访问。 通过无中心、零侵入的方案提供与数据库交互的的啮合层,即 Database Mesh,又可称数据网格。
+
+Database Mesh 的关注重点在于如何将分布式的数据访问应用与数据库有机串联起来,它更加关注的是交互,是将杂乱无章的应用与数据库之间的交互有效的梳理。使用 Database Mesh,访问数据库的应用和数据库终将形成一个巨大的网格体系,应用和数据库只需在网格体系中对号入座即可,它们都是被啮合层所治理的对象。
+
+
+
+| _Sharding-JDBC_ | _Sharding-Proxy_ | _Sharding-Sidecar_ | |
+| :-------------- | :--------------- | :----------------- | ------ |
+| 数据库 | 任意 | MySQL | MySQL |
+| 连接消耗数 | 高 | 低 | 高 |
+| 异构语言 | 仅 Java | 任意 | 任意 |
+| 性能 | 损耗低 | 损耗略高 | 损耗低 |
+| 无中心化 | 是 | 否 | 是 |
+| 静态入口 | 无 | 有 | 无 |
+
+### 混合架构
+
+Sharding-JDBC 采用无中心化架构,适用于 Java 开发的高性能的轻量级 OLTP 应用;Sharding-Proxy 提供静态入口以及异构语言的支持,适用于 OLAP 应用以及对分片数据库进行管理和运维的场景。
+
+ShardingSphere 是多接入端共同组成的生态圈。 通过混合使用 Sharding-JDBC 和 Sharding-Proxy,并采用同一注册中心统一配置分片策略,能够灵活的搭建适用于各种场景的应用系统,架构师可以更加自由的调整适合于当前业务的最佳系统架构。
+
+
+
+## 参考资料
+
+- [shardingsphere](https://github.com/apache/incubator-shardingsphere)
diff --git a/docs/nosql/README.md b/docs/nosql/README.md
index 7e6ef151..fd3661b4 100644
--- a/docs/nosql/README.md
+++ b/docs/nosql/README.md
@@ -1,22 +1,28 @@
-# 非关系型数据库
+# Nosql 数据库
-## :memo: 知识点
+## 📖 内容
-### 非关系型数据库
+### 列式数据库
+
+- [HBase](hbase.md)
+
+### K-V 数据库
- [Redis](redis/README.md)
+- [Cassandra](cassandra.md)
+
+### 文档数据库
+
- [MongoDB](mongodb)
-- [Cassandra](Cassandra.md)
-### 非关系型数据库对比
+### 搜索引擎数据库
+
+- [Elasticsearch](elasticsearch.md)
-| 名称 | 类型 | 数据类型 | 查询类型 | 附加功能 |
-| ------- | ---------------------------- | ------------------------------------------------------------ | -------------------------------------------------- | ------------------------------------------- |
-| Redis | 基于内存存储的非关系型数据库 | String、List、Set、Hash、Sorted Set | 每种数据类型都有自己的专属操作和不完全的事务支持。 | 发布订阅、主从复制、持久化、脚本。 |
-| MongoDB | 基于硬盘存储的文档数据库 | 每个数据库可以包含多个表,每个表可以包含多个无 schema 的 BSON 文档。 | 创建、读取、更新、删除、条件查询命令等。 | map-reduce 操作、主从复制、分片、空间索引。 |
+### 图数据库
-## 📚 学习资源
+TODO: 待补充
-## :door: 传送门
+## 🚪 传送门
-| [我的 Github 博客](https://github.com/dunwu/blog) | [db-tutorial 首页](https://github.com/dunwu/db-tutorial) |
+◾ 🏠 [DB-TUTORIAL 首页](https://github.com/dunwu/db-tutorial) ◾ 🎯 [我的博客](https://github.com/dunwu/blog) ◾
diff --git a/docs/nosql/Cassandra.md b/docs/nosql/cassandra.md
similarity index 100%
rename from docs/nosql/Cassandra.md
rename to docs/nosql/cassandra.md
diff --git a/docs/nosql/elasticsearch.md b/docs/nosql/elasticsearch.md
new file mode 100644
index 00000000..c8dc39be
--- /dev/null
+++ b/docs/nosql/elasticsearch.md
@@ -0,0 +1,536 @@
+# Elasticsearch
+
+> **[Elasticsearch](https://github.com/elastic/elasticsearch) 是一个分布式、RESTful 风格的搜索和数据分析引擎**,能够解决不断涌现出的各种用例。 作为 Elastic Stack 的核心,它集中存储您的数据,帮助您发现意料之中以及意料之外的情况。
+>
+> [Elasticsearch](https://github.com/elastic/elasticsearch) 基于搜索库 [Lucene](https://github.com/apache/lucene-solr) 开发。ElasticSearch 隐藏了 Lucene 的复杂性,提供了简单易用的 REST API / Java API 接口(另外还有其他语言的 API 接口)。
+>
+> _以下简称 ES。_
+
+## 一、Elasticsearch 简介
+
+### 1.1. 什么是 Elasticsearch
+
+**[Elasticsearch](https://github.com/elastic/elasticsearch) 是一个分布式、RESTful 风格的搜索和数据分析引擎**,能够解决不断涌现出的各种用例。 作为 Elastic Stack 的核心,它集中存储您的数据,帮助您发现意料之中以及意料之外的情况。
+
+[Elasticsearch](https://github.com/elastic/elasticsearch) **基于搜索库 [Lucene](https://github.com/apache/lucene-solr) 开发**。ElasticSearch 隐藏了 Lucene 的复杂性,提供了简单易用的 REST API / Java API 接口(另外还有其他语言的 API 接口)。
+
+ElasticSearch 可以视为一个文档存储,它**将复杂数据结构序列化为 JSON 存储**。
+
+**ElasticSearch 是近乎于实时的全文搜素**,这是指:
+
+- 从写入数据到数据可以被搜索,存在较小的延迟(大概是 1s)
+- 基于 ES 执行搜索和分析可以达到秒级
+
+### 1.2. 核心概念
+
+#### 1.2.1. Index
+
+**可以认为是文档(document)的优化集合。**
+
+ES 会为所有字段建立索引,经过处理后写入一个反向索引(Inverted Index)。查找数据的时候,直接查找该索引。
+
+所以,ES 数据管理的顶层单位就叫做 Index(索引)。它是单个数据库的同义词。每个 Index (即数据库)的名字必须是小写。
+
+#### 1.2.2. Document
+
+Index 里面单条的记录称为 Document(文档)。许多条 Document 构成了一个 Index。
+
+每个 **`文档(document)`** 都是字段(field)的集合。
+
+Document 使用 JSON 格式表示,下面是一个例子。
+
+```javascript
+{
+"user": "张三",
+"title": "工程师",
+"desc": "数据库管理"
+}
+```
+
+同一个 Index 里面的 Document,不要求有相同的结构(scheme),但是最好保持相同,这样有利于提高搜索效率。
+
+#### 1.2.3. Field
+
+**`字段(field)`** 是包含数据的键值对。
+
+默认情况下,Elasticsearch 对每个字段中的所有数据建立索引,并且每个索引字段都具有专用的优化数据结构。
+
+#### 1.2.4. Type
+
+每个索引里可以有一个或者多个类型(type)。`类型(type)` 是 index 的一个逻辑分类。
+
+不同的 Type 应该有相似的结构(schema),举例来说,`id`字段不能在这个组是字符串,在另一个组是数值。这是与关系型数据库的表的[一个区别](https://www.elastic.co/guide/en/elasticsearch/guide/current/mapping.html)。性质完全不同的数据(比如`products`和`logs`)应该存成两个 Index,而不是一个 Index 里面的两个 Type(虽然可以做到)。
+
+> 注意:根据[规划](https://www.elastic.co/blog/index-type-parent-child-join-now-future-in-elasticsearch),Elastic 6.x 版只允许每个 Index 包含一个 Type,7.x 版将会彻底移除 Type。
+
+#### 1.2.5. Shard
+
+当单台机器不足以存储大量数据时,Elasticsearch 可以将一个索引中的数据切分为多个 **`分片(shard)`** 。 **`分片(shard)`** 分布在多台服务器上存储。有了 shard 就可以横向扩展,存储更多数据,让搜索和分析等操作分布到多台服务器上去执行,提升吞吐量和性能。每个 shard 都是一个 lucene index。
+
+#### 1.2.6. Replica
+
+任何一个服务器随时可能故障或宕机,此时 shard 可能就会丢失,因此可以为每个 shard 创建多个 **`副本(replica)`**。replica 可以在 shard 故障时提供备用服务,保证数据不丢失,多个 replica 还可以提升搜索操作的吞吐量和性能。primary shard(建立索引时一次设置,不能修改,默认 5 个),replica shard(随时修改数量,默认 1 个),默认每个索引 10 个 shard,5 个 primary shard,5 个 replica shard,最小的高可用配置,是 2 台服务器。
+
+## 二、REST API
+
+> REST API 最详尽的文档应该参考:[ES 官方 REST API](https://www.elastic.co/guide/en/elasticsearch/reference/current/rest-apis.html)
+
+### 3.1. 索引
+
+新建 Index,可以直接向 ES 服务器发出 `PUT` 请求。
+
+#### 3.1.1. 创建索引
+
+示例:直接创建索引
+
+```bash
+$ curl -X POST 'localhost:9200/user'
+```
+
+服务器返回一个 JSON 对象,里面的 `acknowledged` 字段表示操作成功。
+
+```javascript
+{"acknowledged":true,"shards_acknowledged":true,"index":"user"}
+```
+
+示例:创建索引时指定配置
+
+```bash
+$ curl -X PUT -H 'Content-Type: application/json' 'localhost:9200/user' -d '
+{
+ "settings" : {
+ "index" : {
+ "number_of_shards" : 3,
+ "number_of_replicas" : 2
+ }
+ }
+}'
+```
+
+示例:创建索引时指定 `mappings`
+
+```bash
+$ curl -X PUT -H 'Content-Type: application/json' 'localhost:9200/user' -d '
+{
+ "settings" : {
+ "index" : {
+ "number_of_shards" : 3,
+ "number_of_replicas" : 2
+ }
+ }
+}'
+```
+
+#### 3.1.2. 删除索引
+
+然后,我们可以通过发送 `DELETE` 请求,删除这个 Index。
+
+```bash
+$ curl -X DELETE 'localhost:9200/user'
+```
+
+#### 3.1.3. 查看索引
+
+可以通过 GET 请求查看索引信息
+
+```bash
+$ curl -X GET 'localhost:9200/user'
+```
+
+#### 3.1.4. 打开/关闭索引
+
+通过在 `POST` 中添加 `_close` 或 `_open` 可以打开、关闭索引。
+关闭索引
+
+```bash
+$ curl -X POST 'localhost:9200/user/_close'
+```
+
+打开索引
+
+```bash
+$ curl -X POST 'localhost:9200/user/_open'
+```
+
+### 3.2. 文档
+
+#### 3.2.1. 新增记录
+
+向指定的 `/Index/type` 发送 PUT 请求,就可以在 Index 里面新增一条记录。比如,向 `/user/admin` 发送请求,就可以新增一条人员记录。
+
+```bash
+$ curl -X PUT -H 'Content-Type: application/json' 'localhost:9200/user/admin/1' -d '
+{
+"user": "张三",
+"title": "工程师",
+"desc": "数据库管理"
+}'
+```
+
+服务器返回的 JSON 对象,会给出 Index、Type、Id、Version 等信息。
+
+```json
+{
+ "_index": "user",
+ "_type": "admin",
+ "_id": "1",
+ "_version": 1,
+ "result": "created",
+ "_shards": { "total": 3, "successful": 1, "failed": 0 },
+ "_seq_no": 0,
+ "_primary_term": 2
+}
+```
+
+如果你仔细看,会发现请求路径是`/user/admin/1`,最后的`1`是该条记录的 Id。它不一定是数字,任意字符串(比如`abc`)都可以。
+
+新增记录的时候,也可以不指定 Id,这时要改成 POST 请求。
+
+```bash
+$ curl -X POST -H 'Content-Type: application/json' 'localhost:9200/user/admin' -d '
+{
+"user": "李四",
+"title": "工程师",
+"desc": "系统管理"
+}'
+```
+
+上面代码中,向`/user/admin`发出一个 POST 请求,添加一个记录。这时,服务器返回的 JSON 对象里面,`_id`字段就是一个随机字符串。
+
+```json
+{
+ "_index": "user",
+ "_type": "admin",
+ "_id": "WWuoDG8BHwECs7SiYn93",
+ "_version": 1,
+ "result": "created",
+ "_shards": { "total": 3, "successful": 1, "failed": 0 },
+ "_seq_no": 1,
+ "_primary_term": 2
+}
+```
+
+注意,如果没有先创建 Index(这个例子是`accounts`),直接执行上面的命令,Elastic 也不会报错,而是直接生成指定的 Index。所以,打字的时候要小心,不要写错 Index 的名称。
+
+#### 3.2.2. 删除记录
+
+删除记录就是发出 `DELETE` 请求。
+
+```bash
+$ curl -X DELETE 'localhost:9200/user/admin/2'
+```
+
+#### 3.2.3. 更新记录
+
+更新记录就是使用 `PUT` 请求,重新发送一次数据。
+
+```bash
+$ curl -X PUT -H 'Content-Type: application/json' 'localhost:9200/user/admin/1' -d '
+{
+"user": "张三",
+"title": "工程师",
+"desc": "超级管理员"
+}'
+```
+
+#### 3.2.4. 查询记录
+
+向`/Index/Type/Id`发出 GET 请求,就可以查看这条记录。
+
+```bash
+$ curl 'localhost:9200/user/admin/1?pretty'
+```
+
+上面代码请求查看 `/user/admin/1` 这条记录,URL 的参数 `pretty=true` 表示以易读的格式返回。
+
+返回的数据中,`found` 字段表示查询成功,`_source`字段返回原始记录。
+
+```json
+{
+ "_index": "user",
+ "_type": "admin",
+ "_id": "1",
+ "_version": 2,
+ "found": true,
+ "_source": {
+ "user": "张三",
+ "title": "工程师",
+ "desc": "超级管理员"
+ }
+}
+```
+
+如果 Id 不正确,就查不到数据,`found` 字段就是 `false`
+
+#### 3.2.5. 查询所有记录
+
+使用 `GET` 方法,直接请求 `/index/type/_search`,就会返回所有记录。
+
+```bash
+$ curl 'localhost:9200/user/admin/_search?pretty'
+{
+ "took" : 1,
+ "timed_out" : false,
+ "_shards" : {
+ "total" : 3,
+ "successful" : 3,
+ "skipped" : 0,
+ "failed" : 0
+ },
+ "hits" : {
+ "total" : 2,
+ "max_score" : 1.0,
+ "hits" : [
+ {
+ "_index" : "user",
+ "_type" : "admin",
+ "_id" : "WWuoDG8BHwECs7SiYn93",
+ "_score" : 1.0,
+ "_source" : {
+ "user" : "李四",
+ "title" : "工程师",
+ "desc" : "系统管理"
+ }
+ },
+ {
+ "_index" : "user",
+ "_type" : "admin",
+ "_id" : "1",
+ "_score" : 1.0,
+ "_source" : {
+ "user" : "张三",
+ "title" : "工程师",
+ "desc" : "超级管理员"
+ }
+ }
+ ]
+ }
+}
+```
+
+上面代码中,返回结果的 `took`字段表示该操作的耗时(单位为毫秒),`timed_out`字段表示是否超时,`hits`字段表示命中的记录,里面子字段的含义如下。
+
+- `total`:返回记录数,本例是 2 条。
+- `max_score`:最高的匹配程度,本例是`1.0`。
+- `hits`:返回的记录组成的数组。
+
+返回的记录中,每条记录都有一个`_score`字段,表示匹配的程序,默认是按照这个字段降序排列。
+
+#### 3.2.6. 全文搜索
+
+ES 的查询非常特别,使用自己的[查询语法](https://www.elastic.co/guide/en/elasticsearch/reference/5.5/query-dsl.html),要求 GET 请求带有数据体。
+
+```bash
+$ curl -H 'Content-Type: application/json' 'localhost:9200/user/admin/_search?pretty' -d '
+{
+"query" : { "match" : { "desc" : "管理" }}
+}'
+```
+
+上面代码使用 [Match 查询](https://www.elastic.co/guide/en/elasticsearch/reference/5.5/query-dsl-match-query.html),指定的匹配条件是`desc`字段里面包含"软件"这个词。返回结果如下。
+
+```javascript
+{
+ "took" : 2,
+ "timed_out" : false,
+ "_shards" : {
+ "total" : 3,
+ "successful" : 3,
+ "skipped" : 0,
+ "failed" : 0
+ },
+ "hits" : {
+ "total" : 2,
+ "max_score" : 0.38200712,
+ "hits" : [
+ {
+ "_index" : "user",
+ "_type" : "admin",
+ "_id" : "WWuoDG8BHwECs7SiYn93",
+ "_score" : 0.38200712,
+ "_source" : {
+ "user" : "李四",
+ "title" : "工程师",
+ "desc" : "系统管理"
+ }
+ },
+ {
+ "_index" : "user",
+ "_type" : "admin",
+ "_id" : "1",
+ "_score" : 0.3487891,
+ "_source" : {
+ "user" : "张三",
+ "title" : "工程师",
+ "desc" : "超级管理员"
+ }
+ }
+ ]
+ }
+}
+```
+
+Elastic 默认一次返回 10 条结果,可以通过`size`字段改变这个设置,还可以通过`from`字段,指定位移。
+
+```bash
+$ curl 'localhost:9200/user/admin/_search' -d '
+{
+ "query" : { "match" : { "desc" : "管理" }},
+ "from": 1,
+ "size": 1
+}'
+```
+
+上面代码指定,从位置 1 开始(默认是从位置 0 开始),只返回一条结果。
+
+#### 3.2.7. 逻辑运算
+
+如果有多个搜索关键字, Elastic 认为它们是`or`关系。
+
+```bash
+$ curl 'localhost:9200/user/admin/_search' -d '
+{
+"query" : { "match" : { "desc" : "软件 系统" }}
+}'
+```
+
+上面代码搜索的是`软件 or 系统`。
+
+如果要执行多个关键词的`and`搜索,必须使用[布尔查询](https://www.elastic.co/guide/en/elasticsearch/reference/5.5/query-dsl-bool-query.html)。
+
+```bash
+$ curl -H 'Content-Type: application/json' 'localhost:9200/user/admin/_search?pretty' -d '
+{
+ "query": {
+ "bool": {
+ "must": [
+ { "match": { "desc": "管理" } },
+ { "match": { "desc": "超级" } }
+ ]
+ }
+ }
+}'
+```
+
+## 三、ElasticSearch 基本原理
+
+### 2.1. ES 写数据过程
+
+- 客户端选择一个 node 发送请求过去,这个 node 就是 `coordinating node`(协调节点)。
+- `coordinating node` 对 document 进行**路由**,将请求转发给对应的 node(有 primary shard)。
+- 实际的 node 上的 `primary shard` 处理请求,然后将数据同步到 `replica node`。
+- `coordinating node` 如果发现 `primary node` 和所有 `replica node` 都搞定之后,就返回响应结果给客户端。
+
+### 2.2. ES 读数据过程
+
+可以通过 `doc id` 来查询,会根据 `doc id` 进行 hash,判断出来当时把 `doc id` 分配到了哪个 shard 上面去,从那个 shard 去查询。
+
+- 客户端发送请求到**任意**一个 node,成为 `coordinate node`。
+- `coordinate node` 对 `doc id` 进行哈希路由,将请求转发到对应的 node,此时会使用 `round-robin` **随机轮询算法**,在 `primary shard` 以及其所有 replica 中随机选择一个,让读请求负载均衡。
+- 接收请求的 node 返回 document 给 `coordinate node`。
+- `coordinate node` 返回 document 给客户端。
+
+### 2.3. 写数据底层原理
+
+先写入内存 buffer,在 buffer 里的时候数据是搜索不到的;同时将数据写入 translog 日志文件。
+
+如果 buffer 快满了,或者到一定时间,就会将内存 buffer 数据 `refresh` 到一个新的 `segment file` 中,但是此时数据不是直接进入 `segment file` 磁盘文件,而是先进入 `os cache` 。这个过程就是 `refresh`。
+
+每隔 1 秒钟,es 将 buffer 中的数据写入一个**新的** `segment file`,每秒钟会产生一个**新的磁盘文件** `segment file`,这个 `segment file` 中就存储最近 1 秒内 buffer 中写入的数据。
+
+但是如果 buffer 里面此时没有数据,那当然不会执行 refresh 操作,如果 buffer 里面有数据,默认 1 秒钟执行一次 refresh 操作,刷入一个新的 segment file 中。
+
+操作系统里面,磁盘文件其实都有一个东西,叫做 `os cache`,即操作系统缓存,就是说数据写入磁盘文件之前,会先进入 `os cache`,先进入操作系统级别的一个内存缓存中去。只要 `buffer` 中的数据被 refresh 操作刷入 `os cache`中,这个数据就可以被搜索到了。
+
+为什么叫 es 是**准实时**的? `NRT`,全称 `near real-time`。默认是每隔 1 秒 refresh 一次的,所以 es 是准实时的,因为写入的数据 1 秒之后才能被看到。可以通过 es 的 `restful api` 或者 `java api`,**手动**执行一次 refresh 操作,就是手动将 buffer 中的数据刷入 `os cache`中,让数据立马就可以被搜索到。只要数据被输入 `os cache` 中,buffer 就会被清空了,因为不需要保留 buffer 了,数据在 translog 里面已经持久化到磁盘去一份了。
+
+重复上面的步骤,新的数据不断进入 buffer 和 translog,不断将 `buffer` 数据写入一个又一个新的 `segment file` 中去,每次 `refresh` 完 buffer 清空,translog 保留。随着这个过程推进,translog 会变得越来越大。当 translog 达到一定长度的时候,就会触发 `commit` 操作。
+
+commit 操作发生第一步,就是将 buffer 中现有数据 `refresh` 到 `os cache` 中去,清空 buffer。然后,将一个 `commit point` 写入磁盘文件,里面标识着这个 `commit point` 对应的所有 `segment file`,同时强行将 `os cache` 中目前所有的数据都 `fsync` 到磁盘文件中去。最后**清空** 现有 translog 日志文件,重启一个 translog,此时 commit 操作完成。
+
+这个 commit 操作叫做 `flush`。默认 30 分钟自动执行一次 `flush`,但如果 translog 过大,也会触发 `flush`。flush 操作就对应着 commit 的全过程,我们可以通过 es api,手动执行 flush 操作,手动将 os cache 中的数据 fsync 强刷到磁盘上去。
+
+translog 日志文件的作用是什么?你执行 commit 操作之前,数据要么是停留在 buffer 中,要么是停留在 os cache 中,无论是 buffer 还是 os cache 都是内存,一旦这台机器死了,内存中的数据就全丢了。所以需要将数据对应的操作写入一个专门的日志文件 `translog` 中,一旦此时机器宕机,再次重启的时候,es 会自动读取 translog 日志文件中的数据,恢复到内存 buffer 和 os cache 中去。
+
+translog 其实也是先写入 os cache 的,默认每隔 5 秒刷一次到磁盘中去,所以默认情况下,可能有 5 秒的数据会仅仅停留在 buffer 或者 translog 文件的 os cache 中,如果此时机器挂了,会**丢失** 5 秒钟的数据。但是这样性能比较好,最多丢 5 秒的数据。也可以将 translog 设置成每次写操作必须是直接 `fsync` 到磁盘,但是性能会差很多。
+
+实际上你在这里,如果面试官没有问你 es 丢数据的问题,你可以在这里给面试官炫一把,你说,其实 es 第一是准实时的,数据写入 1 秒后可以搜索到;可能会丢失数据的。有 5 秒的数据,停留在 buffer、translog os cache、segment file os cache 中,而不在磁盘上,此时如果宕机,会导致 5 秒的**数据丢失**。
+
+**总结一下**,数据先写入内存 buffer,然后每隔 1s,将数据 refresh 到 os cache,到了 os cache 数据就能被搜索到(所以我们才说 es 从写入到能被搜索到,中间有 1s 的延迟)。每隔 5s,将数据写入 translog 文件(这样如果机器宕机,内存数据全没,最多会有 5s 的数据丢失),translog 大到一定程度,或者默认每隔 30mins,会触发 commit 操作,将缓冲区的数据都 flush 到 segment file 磁盘文件中。
+
+> 数据写入 segment file 之后,同时就建立好了倒排索引。
+
+### 2.4. 删除/更新数据底层原理
+
+如果是删除操作,commit 的时候会生成一个 `.del` 文件,里面将某个 doc 标识为 `deleted` 状态,那么搜索的时候根据 `.del` 文件就知道这个 doc 是否被删除了。
+
+如果是更新操作,就是将原来的 doc 标识为 `deleted` 状态,然后新写入一条数据。
+
+buffer 每 refresh 一次,就会产生一个 `segment file`,所以默认情况下是 1 秒钟一个 `segment file`,这样下来 `segment file` 会越来越多,此时会定期执行 merge。每次 merge 的时候,会将多个 `segment file` 合并成一个,同时这里会将标识为 `deleted` 的 doc 给**物理删除掉**,然后将新的 `segment file` 写入磁盘,这里会写一个 `commit point`,标识所有新的 `segment file`,然后打开 `segment file` 供搜索使用,同时删除旧的 `segment file`。
+
+### 2.5. 底层 lucene
+
+简单来说,lucene 就是一个 jar 包,里面包含了封装好的各种建立倒排索引的算法代码。我们用 Java 开发的时候,引入 lucene jar,然后基于 lucene 的 api 去开发就可以了。
+
+通过 lucene,我们可以将已有的数据建立索引,lucene 会在本地磁盘上面,给我们组织索引的数据结构。
+
+### 2.6. 倒排索引
+
+在搜索引擎中,每个文档都有一个对应的文档 ID,文档内容被表示为一系列关键词的集合。例如,文档 1 经过分词,提取了 20 个关键词,每个关键词都会记录它在文档中出现的次数和出现位置。
+
+那么,倒排索引就是**关键词到文档** ID 的映射,每个关键词都对应着一系列的文件,这些文件中都出现了关键词。
+
+举个栗子。
+
+有以下文档:
+
+| DocId | Doc |
+| ----- | ---------------------------------------------- |
+| 1 | 谷歌地图之父跳槽 Facebook |
+| 2 | 谷歌地图之父加盟 Facebook |
+| 3 | 谷歌地图创始人拉斯离开谷歌加盟 Facebook |
+| 4 | 谷歌地图之父跳槽 Facebook 与 Wave 项目取消有关 |
+| 5 | 谷歌地图之父拉斯加盟社交网站 Facebook |
+
+对文档进行分词之后,得到以下**倒排索引**。
+
+| WordId | Word | DocIds |
+| ------ | -------- | --------- |
+| 1 | 谷歌 | 1,2,3,4,5 |
+| 2 | 地图 | 1,2,3,4,5 |
+| 3 | 之父 | 1,2,4,5 |
+| 4 | 跳槽 | 1,4 |
+| 5 | Facebook | 1,2,3,4,5 |
+| 6 | 加盟 | 2,3,5 |
+| 7 | 创始人 | 3 |
+| 8 | 拉斯 | 3,5 |
+| 9 | 离开 | 3 |
+| 10 | 与 | 4 |
+| .. | .. | .. |
+
+另外,实用的倒排索引还可以记录更多的信息,比如文档频率信息,表示在文档集合中有多少个文档包含某个单词。
+
+那么,有了倒排索引,搜索引擎可以很方便地响应用户的查询。比如用户输入查询 `Facebook`,搜索系统查找倒排索引,从中读出包含这个单词的文档,这些文档就是提供给用户的搜索结果。
+
+要注意倒排索引的两个重要细节:
+
+- 倒排索引中的所有词项对应一个或多个文档;
+- 倒排索引中的词项**根据字典顺序升序排列**
+
+> 上面只是一个简单的栗子,并没有严格按照字典顺序升序排列。
+
+## Elastic 技术栈系列
+
+- [ElasticSearch 运维](elasticsearch-ops.md) - ElasticSearch 安装、配置、命令详解。
+
+## 参考资料
+
+- **官方**
+ - [Elasticsearch 官网](https://www.elastic.co/cn/products/elasticsearch)
+ - [Elasticsearch Github](https://github.com/elastic/elasticsearch)
+ - [Elasticsearch 官方文档](https://www.elastic.co/guide/en/elasticsearch/reference/current/index.html)
+- **文章**
+ - [Install Elasticsearch with RPM](https://www.elastic.co/guide/en/elasticsearch/reference/current/rpm.html#rpm)
+ - https://www.ruanyifeng.com/blog/2017/08/elasticsearch.html
+ - [es-introduction](https://github.com/doocs/advanced-java/blob/master/docs/high-concurrency/es-introduction.md)
+ - [es-write-query-search](https://github.com/doocs/advanced-java/blob/master/docs/high-concurrency/es-write-query-search.md)
diff --git a/docs/nosql/HBase.md b/docs/nosql/hbase.md
similarity index 98%
rename from docs/nosql/HBase.md
rename to docs/nosql/hbase.md
index ed00e9ee..548e0ae8 100644
--- a/docs/nosql/HBase.md
+++ b/docs/nosql/hbase.md
@@ -140,4 +140,4 @@ HBase 命令行可以参考这里:[HBase 命令行](hbase-cli.md)
#### 文章
- [Bigtable: A Distributed Storage System for Structured Data](https://static.googleusercontent.com/media/research.google.com/zh-CN//archive/bigtable-osdi06.pdf)
-- https://mapr.com/blog/in-depth-look-hbase-architecture/
+- [An In-Depth Look at the HBase Architecture](https://mapr.com/blog/in-depth-look-hbase-architecture)
diff --git a/docs/nosql/mongodb/mongodb-ops.md b/docs/nosql/mongodb/mongodb-ops.md
index 5fbf2312..0b0c590c 100644
--- a/docs/nosql/mongodb/mongodb-ops.md
+++ b/docs/nosql/mongodb/mongodb-ops.md
@@ -14,9 +14,9 @@
(1)下载并解压到本地
-进入官网下载地址:https://www.mongodb.com/download-center#community ,选择合适的版本下载。
+进入官网下载地址:[官方下载地址](https://www.mongodb.com/download-center#community) ,选择合适的版本下载。
-我选择的是最新稳定版本 3.6.3:https://fastdl.mongodb.org/linux/mongodb-linux-x86_64-3.6.3.tgz
+我选择的是最新稳定版本 3.6.3:[下载地址](https://fastdl.mongodb.org/linux/mongodb-linux-x86_64-3.6.3.tgz)
我个人喜欢存放在:`/opt/mongodb`
@@ -46,4 +46,4 @@ cd /opt/mongodb/mongodb-3.6.3/bin
## 脚本
-| [安装脚本](https://github.com/dunwu/linux-tutorial/tree/master/codes/linux/soft) |
+- [安装脚本](https://github.com/dunwu/linux-tutorial/tree/master/codes/linux/soft)
diff --git a/docs/nosql/redis/README.md b/docs/nosql/redis/README.md
index 526b4996..57b0e879 100644
--- a/docs/nosql/redis/README.md
+++ b/docs/nosql/redis/README.md
@@ -1,5 +1,7 @@
# Redis 教程
+## 📖 内容
+
- [Redis 入门指南 ⚡](redis-quickstart.md)
- [Redis 持久化](redis-persistence.md)
- [Redis 复制](redis-replication.md)
@@ -9,7 +11,7 @@
- Redis 事务
- [Redis 运维 🔨](redis-ops.md)
-## 参考资料
+## 📚 资料
- **官网**
- [Redis 官网](https://redis.io/)
@@ -27,3 +29,7 @@
- [redisson 官方文档(英文)](https://github.com/redisson/redisson/wiki/Table-of-Content)
- [CRUG | Redisson PRO vs. Jedis: Which Is Faster? 翻译](https://www.jianshu.com/p/82f0d5abb002)
- [redis 分布锁 Redisson 性能测试](https://blog.csdn.net/everlasting_188/article/details/51073505)
+
+## 🚪 传送门
+
+◾ 🏠 [DB-TUTORIAL 首页](https://github.com/dunwu/db-tutorial) ◾ 🎯 [我的博客](https://github.com/dunwu/blog) ◾
diff --git a/docs/sql/README.md b/docs/sql/README.md
index 91ac3852..e1b51962 100644
--- a/docs/sql/README.md
+++ b/docs/sql/README.md
@@ -2,9 +2,18 @@
> 关系数据库,是建立在关系模型基础上的数据库,借助于集合代数等数学概念和方法来处理数据库中的数据。现实世界中的各种实体以及实体之间的各种联系均用关系模型来表示。关系模型由关系数据结构、关系操作集合、关系完整性约束三部分组成。
-- [关系型数据库面试题](sql-interview.md)
-- [关系型数据库基本原理](sql-theory.md)
-- [SQL 基本语法](sql-cheat-sheet.md)
-- [H2 快速指南](h2.md)
-- [PostgreSQL 快速指南](postgresql.md)
-- [数据库中间件 flyway](middleware/flyway.md)
+## 📖 内容
+
+- [关系型数据库面试题 💯](sql-interview.md)
+- [SQL Cheat Sheet](sql-cheat-sheet.md)
+- [Mysql](mysql/README.md)
+ - [Mysql 原理](mysql/mysql-theory.md)
+ - [Mysql 运维 🔨](mysql/mysql-ops.md)
+ - [Mysql 配置](mysql/mysql-config.md)
+- [H2 入门指南](h2.md)
+- [SqLite 入门指南](sqlite.md)
+- [PostgreSQL 入门指南](postgresql.md)
+
+## 🚪 传送门
+
+◾ 🏠 [DB-TUTORIAL 首页](https://github.com/dunwu/db-tutorial) ◾ 🎯 [我的博客](https://github.com/dunwu/blog) ◾
diff --git a/docs/sql/h2.md b/docs/sql/h2.md
index 30ebc60e..f6f1a90c 100644
--- a/docs/sql/h2.md
+++ b/docs/sql/h2.md
@@ -1,4 +1,4 @@
-# H2 快速指南
+# H2 入门指南
@@ -25,13 +25,13 @@ H2 允许用户通过浏览器接口方式访问 SQL 数据库。
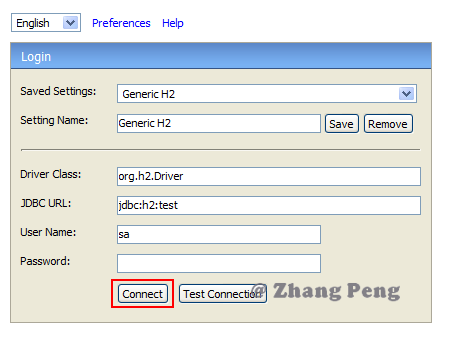
1. 进入[官方下载地址](http://www.h2database.com/html/download.html),选择合适版本,下载并安装到本地。
2. 启动方式:在 bin 目录下,双击 jar 包;执行 `java -jar h2*.jar`;执行脚本:`h2.bat` 或 `h2.sh`。
-3. 在浏览器中访问:http://localhost:8082,应该可以看到下图中的页面:
+3. 在浏览器中访问:`http://localhost:8082`,应该可以看到下图中的页面:
-
+
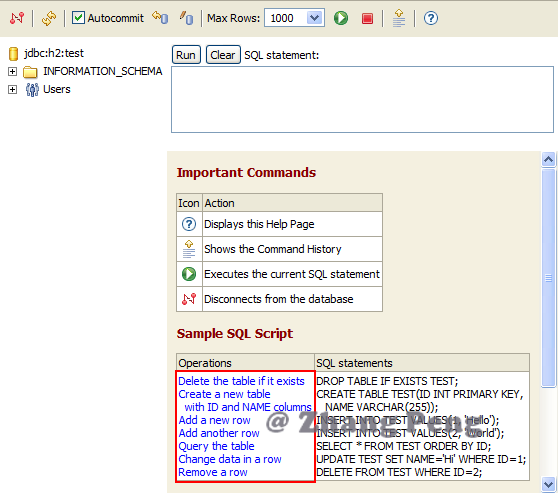
点击 **Connect** ,可以进入操作界面:
-
+
操作界面十分简单,不一一细说。
@@ -139,7 +139,7 @@ java -cp h2*.jar org.h2.tools.Server -?
常见的选项如下:
- -web:启动支持 H2 Console 的服务
-- -webPort :服务启动端口,默认为 8082
+- -webPort ``:服务启动端口,默认为 8082
- -browser:启动 H2 Console web 管理页面
- -tcp:使用 TCP server 模式启动
- -pg:使用 PG server 模式启动
@@ -207,7 +207,7 @@ java -jar h2-1.3.168.jar -web -webPort 8090 -browser
## Spring 整合 H2
-1. 添加依赖
+(1)添加依赖
```xml
@@ -217,7 +217,7 @@ java -jar h2-1.3.168.jar -web -webPort 8090 -browser
```
-2. spring 配置
+(2)spring 配置
```xml
@@ -263,184 +263,184 @@ java -jar h2-1.3.168.jar -web -webPort 8090 -browser
### SELECT
-

+
### INSERT
-

+
### UPDATE
-

+
### DELETE
-

+
### BACKUP
-

+
### EXPLAIN
-

+
7、MERGE
-

+
### RUNSCRIPT
运行 sql 脚本文件
-

+
### SCRIPT
根据数据库创建 sql 脚本
-

+
### SHOW
-

+
### ALTER
#### ALTER INDEX RENAME
-

+
#### ALTER SCHEMA RENAME
-

+
#### ALTER SEQUENCE
-

+
#### ALTER TABLE
-

+
##### 增加约束
-

+
##### 修改列
-

+
##### 删除列
-

+
##### 删除序列
-

+
#### ALTER USER
##### 修改用户名
-

+
##### 修改用户密码
-

+
#### ALTER VIEW
-

+
### COMMENT
-

+
### CREATE CONSTANT
-

+
### CREATE INDEX
-

+
### CREATE ROLE
-

+
### CREATE SCHEMA
-

+
### CREATE SEQUENCE
-

+
### CREATE TABLE
-

+
### CREATE TRIGGER
-

+
### CREATE USER
-

+
### CREATE VIEW
-

+
### DROP
-

+
### GRANT RIGHT
给 schema 授权授权
-

+
给 schema 授权给 schema 授权
-

+
#### 复制角色的权限
-

+
### REVOKE RIGHT
#### 移除授权
-

+
#### 移除角色具有的权限
-

+
### ROLLBACK
#### 从某个还原点(savepoint)回滚
-

+
#### 回滚事务
-

+
#### 创建 savepoint
-

+
## 数据类型
-

+
### INT Type
-

+
## 集群
diff --git a/docs/sql/mysql/README.md b/docs/sql/mysql/README.md
index 3f32ecfc..e62feac2 100644
--- a/docs/sql/mysql/README.md
+++ b/docs/sql/mysql/README.md
@@ -1,12 +1,12 @@
# Mysql 教程
-## :memo: 知识点
+## 📖 内容
- [Mysql 原理](mysql-theory.md)
- [Mysql 运维 🔨](mysql-ops.md)
- [Mysql 服务器配置说明](mysql-config.md)
-## 📚 资源
+## 📚 资料
- **官方**
- [Mysql 官网](https://www.mysql.com/)
@@ -21,6 +21,6 @@
- **更多资源**
- [awesome-mysql](https://github.com/jobbole/awesome-mysql-cn)
-## :door: 传送门
+## 🚪 传送门
-| [我的 Github 博客](https://github.com/dunwu/blog) | [db-tutorial 首页](https://github.com/dunwu/db-tutorial) |
+◾ 🏠 [DB-TUTORIAL 首页](https://github.com/dunwu/db-tutorial) ◾ 🎯 [我的博客](https://github.com/dunwu/blog) ◾
diff --git a/docs/sql/mysql/mysql-theory.md b/docs/sql/mysql/mysql-theory.md
index e38beb06..61599e44 100644
--- a/docs/sql/mysql/mysql-theory.md
+++ b/docs/sql/mysql/mysql-theory.md
@@ -10,7 +10,7 @@
#### 1.1.1. Mysql 内置的存储引擎
-```
+```shell
mysql> SHOW ENGINES;
+--------------------+---------+----------------------------------------------------------------+--------------+------+------------+
| Engine | Support | Comment | Transactions | XA | Savepoints |
@@ -34,7 +34,7 @@ mysql> SHOW ENGINES;
- **Memory** - 适合快速访问数据,且数据不会被修改,重启丢失也没有关系。
- **NDB** - 用于 Mysql 集群场景。
-#### 1.1.2. 如何选择合适的存储引擎?
+#### 1.1.2. 如何选择合适的存储引擎
大多数情况下,InnoDB 都是正确的选择,除非需要用到 InnoDB 不具备的特性。
@@ -392,7 +392,7 @@ COUNT(*)
FROM payment;
```
-```
+```batch
staff_id_selectivity: 0.0001
customer_id_selectivity: 0.0373
COUNT(*): 16049
@@ -408,7 +408,7 @@ customer_id_selectivity: 0.0373
例如下面的查询不能使用 actor_id 列的索引:
-```
+```sql
SELECT actor_id FROM sakila.actor WHERE actor_id + 1 = 5;
```
@@ -420,7 +420,7 @@ SELECT actor_id FROM sakila.actor WHERE actor_id + 1 = 5;
在需要使用多个列作为条件进行查询时,使用多列索引比使用多个单列索引性能更好。例如下面的语句中,最好把 actor_id 和 film_id 设置为多列索引。
-```
+```sql
SELECT film_id, actor_ id FROM sakila.film_actor
WhERE actor_id = 1 AND film_id = 1;
```
@@ -461,7 +461,7 @@ Explain 用来分析 SELECT 查询语句,开发人员可以通过分析 Explai
(一)只返回必要的列
-最好不要使用 SELECT \* 语句。
+最好不要使用 `SELECT *` 语句。
(二)只返回必要的行
@@ -481,11 +481,11 @@ Explain 用来分析 SELECT 查询语句,开发人员可以通过分析 Explai
一个大查询如果一次性执行的话,可能一次锁住很多数据、占满整个事务日志、耗尽系统资源、阻塞很多小的但重要的查询。
-```
+```sql
DELEFT FROM messages WHERE create < DATE_SUB(NOW(), INTERVAL 3 MONTH);
```
-```
+```sql
rows_affected = 0
do {
rows_affected = do_query(
@@ -503,14 +503,14 @@ do {
- 在应用层进行连接,可以更容易对数据库进行拆分,从而更容易做到高性能和可扩展。
- 查询本身效率也可能会有所提升。例如下面的例子中,使用 IN() 代替连接查询,可以让 MySQL 按照 ID 顺序进行查询,这可能比随机的连接要更高效。
-```
+```sql
SELECT * FROM tag
JOIN tag_post ON tag_post.tag_id=tag.id
JOIN post ON tag_post.post_id=post.id
WHERE tag.tag='mysql';
```
-```
+```sql
SELECT * FROM tag WHERE tag='mysql';
SELECT * FROM tag_post WHERE tag_id=1234;
SELECT * FROM post WHERE post.id IN (123,456,567,9098,8904);
diff --git a/docs/sql/postgresql.md b/docs/sql/postgresql.md
index b721f067..ad4ef16f 100644
--- a/docs/sql/postgresql.md
+++ b/docs/sql/postgresql.md
@@ -1,10 +1,10 @@
-# PostgreSQL 快速指南
+# PostgreSQL 入门指南
> [PostgreSQL](https://www.postgresql.org/) 是一个关系型数据库(RDBM)。
>
> 关键词:Database, RDBM, psql
-

+
@@ -15,6 +15,7 @@
- [数据库操作](#数据库操作)
- [备份和恢复](#备份和恢复)
- [参考资料](#参考资料)
+- [:door: 传送门](#door-传送门)
@@ -26,7 +27,7 @@
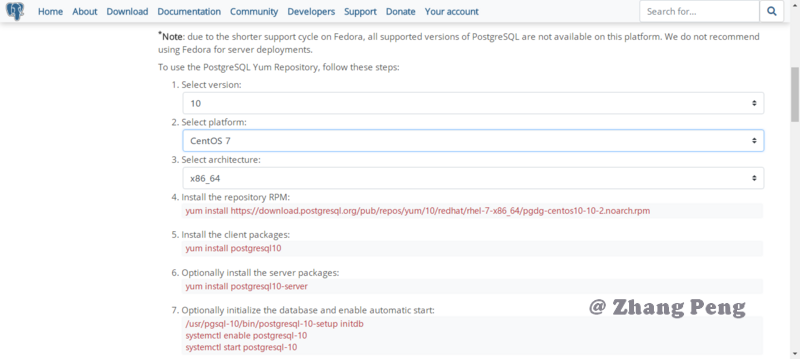
官方下载页面要求用户选择相应版本,然后动态的给出安装提示,如下图所示:
-
+
前 3 步要求用户选择,后 4 步是根据选择动态提示的安装步骤
@@ -183,8 +184,8 @@ DROP TABLE IF EXISTS backup_tbl;
## 备份和恢复
```shell
-$ pg_dump --format=t -d db_name -U user_name -h 127.0.0.1 -O -W > dump.sql
-$ psql -h 127.0.0.1 -U user_name db_name < dump.sql
+pg_dump --format=t -d db_name -U user_name -h 127.0.0.1 -O -W > dump.sql
+psql -h 127.0.0.1 -U user_name db_name < dump.sql
```
## 参考资料
diff --git a/docs/sql/sql-cheat-sheet.md b/docs/sql/sql-cheat-sheet.md
index 7d7255b8..7b9cbec0 100644
--- a/docs/sql/sql-cheat-sheet.md
+++ b/docs/sql/sql-cheat-sheet.md
@@ -2,7 +2,7 @@
> 本文针对关系型数据库的一般语法。限于篇幅,本文侧重说明用法,不会展开讲解特性、原理。
-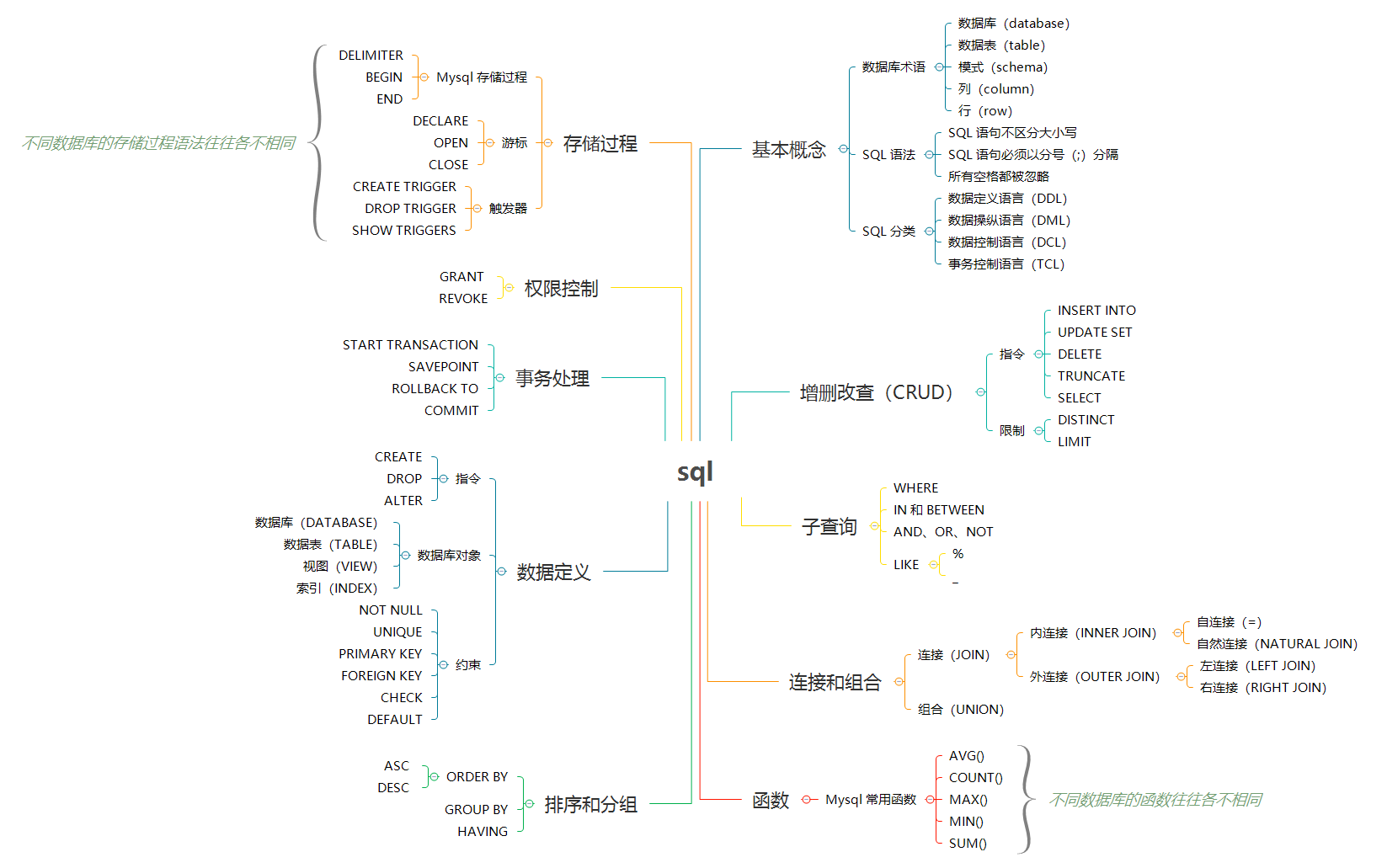
+
diff --git a/docs/sql/sql-interview.md b/docs/sql/sql-interview.md
index 9f3fc9ea..82fce876 100644
--- a/docs/sql/sql-interview.md
+++ b/docs/sql/sql-interview.md
@@ -21,7 +21,6 @@
- [意向锁](#意向锁)
- [MVCC](#mvcc)
- [Next-key 锁](#next-key-锁)
- - [锁协议](#锁协议)
- [四、分库分表](#四分库分表)
- [什么是分库分表](#什么是分库分表)
- [分库分表中间件](#分库分表中间件)
@@ -40,7 +39,6 @@
- [范式](#范式)
- [八、Mysql 特性](#八mysql-特性)
- [存储引擎](#存储引擎)
- - [数据类型](#数据类型)
- [九、数据库比较](#九数据库比较)
- [常见数据库比较](#常见数据库比较)
- [Oracle vs. Mysql](#oracle-vs-mysql)
diff --git a/docs/sql/sqlite.md b/docs/sql/sqlite.md
index 97cc4cc1..70f5c45f 100644
--- a/docs/sql/sqlite.md
+++ b/docs/sql/sqlite.md
@@ -3,40 +3,6 @@
> SQLite 是一个实现了自给自足的、无服务器的、零配置的、事务性的 SQL 数据库引擎。
> :point_right: [完整示例源码](https://github.com/dunwu/db-tutorial/tree/master/codes/javadb/javadb-sqlite)
-
-
-- [简介](#简介)
- - [优点](#优点)
- - [局限](#局限)
- - [安装](#安装)
-- [语法](#语法)
- - [大小写敏感](#大小写敏感)
- - [注释](#注释)
- - [创建数据库](#创建数据库)
- - [查看数据库](#查看数据库)
- - [退出数据库](#退出数据库)
- - [附加数据库](#附加数据库)
- - [分离数据库](#分离数据库)
- - [备份数据库](#备份数据库)
- - [恢复数据库](#恢复数据库)
-- [数据类型](#数据类型)
- - [SQLite 存储类](#sqlite-存储类)
- - [SQLite 亲和(Affinity)类型](#sqlite-亲和affinity类型)
- - [SQLite 亲和类型(Affinity)及类型名称](#sqlite-亲和类型affinity及类型名称)
- - [Boolean 数据类型](#boolean-数据类型)
- - [Date 与 Time 数据类型](#date-与-time-数据类型)
-- [SQLite 命令](#sqlite-命令)
- - [快速开始](#快速开始)
- - [常用命令清单](#常用命令清单)
- - [实战](#实战)
-- [JAVA Client](#java-client)
- - [如何指定数据库文件](#如何指定数据库文件)
- - [如何使用内存数据库](#如何使用内存数据库)
-- [参考资料](#参考资料)
-- [:door: 传送门](#door-传送门)
-
-
-
## 简介
### 优点
@@ -91,7 +57,7 @@ SQLite 是**不区分大小写**的,但也有一些命令是大小写敏感的
如下,创建一个名为 test 的数据库:
-```bash
+```shell
$ sqlite3 test.db
SQLite version 3.7.17 2013-05-20 00:56:22
Enter ".help" for instructions
@@ -100,7 +66,7 @@ Enter SQL statements terminated with a ";"
### 查看数据库
-```bash
+```shell
sqlite> .databases
seq name file
--- --------------- ----------------------------------------------------------
@@ -109,7 +75,7 @@ seq name file
### 退出数据库
-```
+```shell
sqlite> .quit
```
@@ -119,7 +85,7 @@ sqlite> .quit
SQLite 的 **`ATTACH DATABASE`** 语句是用来选择一个特定的数据库,使用该命令后,所有的 SQLite 语句将在附加的数据库下执行。
-```bash
+```shell
sqlite> ATTACH DATABASE 'test.db' AS 'test';
sqlite> .databases
seq name file
@@ -134,7 +100,7 @@ seq name file
SQLite 的 **`DETACH DATABASE`** 语句是用来把命名数据库从一个数据库连接分离和游离出来,连接是之前使用 **`ATTACH`** 语句附加的。
-```bash
+```shell
sqlite> .databases
seq name file
--- --------------- ----------------------------------------------------------
@@ -151,16 +117,16 @@ seq name file
如下,备份 test 数据库到 `/home/test.sql`
-```bash
-$ sqlite3 test.db .dump > /home/test.sql
+```shell
+sqlite3 test.db .dump > /home/test.sql
```
### 恢复数据库
如下,根据 `/home/test.sql` 恢复 test 数据库
-```bash
-$ sqlite3 test.db < test.sql
+```shell
+sqlite3 test.db < test.sql
```
## 数据类型
@@ -227,7 +193,7 @@ SQLite 没有一个单独的用于存储日期和/或时间的存储类,但 SQ
#### 进入 SQLite 控制台
-```bash
+```shell
$ sqlite3
SQLite version 3.7.17 2013-05-20 00:56:22
Enter ".help" for instructions
@@ -237,7 +203,7 @@ sqlite>
#### 进入 SQLite 控制台并指定数据库
-```bash
+```shell
$ sqlite3 test.db
SQLite version 3.7.17 2013-05-20 00:56:22
Enter ".help" for instructions
@@ -247,13 +213,13 @@ sqlite>
#### 退出 SQLite 控制台
-```bash
+```shell
sqlite>.quit
```
#### 查看命令帮助
-```bash
+```shell
sqlite>.help
```
@@ -304,7 +270,7 @@ sqlite>
#### 输出结果到文件
-```bash
+```shell
sqlite> .mode list
sqlite> .separator |
sqlite> .output teyptest_file_1.txt
@@ -324,7 +290,7 @@ $
执行方法:
-```
+```shell
> javac Sample.java
> java -classpath ".;sqlite-jdbc-(VERSION).jar" Sample # in Windows
or
@@ -378,19 +344,19 @@ public class Sample {
Windows
-```
+```properties
Connection connection = DriverManager.getConnection("jdbc:sqlite:C:/work/mydatabase.db");
```
Unix (Linux, Mac OS X, etc)
-```
+```properties
Connection connection = DriverManager.getConnection("jdbc:sqlite:/home/leo/work/mydatabase.db");
```
### 如何使用内存数据库
-```
+```properties
Connection connection = DriverManager.getConnection("jdbc:sqlite::memory:");
```
@@ -406,4 +372,3 @@ Connection connection = DriverManager.getConnection("jdbc:sqlite::memory:");
## :door: 传送门
| [我的 Github 博客](https://github.com/dunwu/blog) | [db-tutorial 首页](https://github.com/dunwu/db-tutorial) |
-
diff --git a/scripts/deploy.sh b/scripts/deploy.sh
new file mode 100644
index 00000000..3596f5ee
--- /dev/null
+++ b/scripts/deploy.sh
@@ -0,0 +1,46 @@
+#!/usr/bin/env sh
+
+# ------------------------------------------------------------------------------
+# gh-pages 部署脚本
+# @author Zhang Peng
+# @since 2020/2/10
+# ------------------------------------------------------------------------------
+
+# 装载其它库
+ROOT_DIR=$(cd `dirname $0`/..; pwd)
+
+# 确保脚本抛出遇到的错误
+set -e
+
+cd ${ROOT_DIR}/docs
+
+# 生成静态文件
+npm install
+npm run build
+
+# 进入生成的文件夹
+cd dist
+
+# 如果是发布到自定义域名
+# echo 'www.example.com' > CNAME
+
+git init
+git checkout -b gh-pages && git add .
+git commit -m 'deploy'
+
+# 如果发布到 https://.github.io/
+GITHUB_REPO=github.com/dunwu/db-tutorial.git
+GITEE_REPO=gitee.com/turnon/db-tutorial.git
+if [[ ${GITHUB_TOKEN} && ${GITEE_TOKEN} ]]; then
+ echo "使用 token 公钥部署 gh-pages"
+ # ${GITHUB_TOKEN} 是 Github 私人令牌;${GITEE_TOKEN} 是 Gitee 私人令牌
+ # ${GITHUB_TOKEN} 和 ${GITEE_TOKEN} 都是环境变量;travis-ci 构建时会传入变量
+ git push --force --quiet "https://dunwu:${GITHUB_TOKEN}@${GITHUB_REPO}" gh-pages
+ git push --force --quiet "https://turnon:${GITEE_TOKEN}@${GITEE_REPO}" gh-pages
+else
+ echo "使用 ssh 公钥部署 gh-pages"
+ git push -f git@github.com:dunwu/db-tutorial.git gh-pages
+ git push -f git@gitee.com:turnon/db-tutorial.git gh-pages
+fi
+
+cd ${ROOT_DIR}