Building large AI models has a learning curve, and is both time and resource intensive. Until recently, we thought of a pre-trained AI’s model weights as ambiguous 2d arrays of decimal numbers, but what if there was something more.
Today we want to share how we are exploring AI model weights, but first let’s see how we got here.
-
We read these key papers
-
Takeaways / Highlights
- Transformers and attention are used for encoding and decoding training data
- Architecture enables making predictions using math and matrices by hosting the weights in memory
- Everything needed to reproduce Transformer behaviors are stored and shared as weights in model files
- Weights are saved as numerical data in a model file (usually 2d float 32 arrays)
-
Key Questions
-
What else works with matrices and high resolution float 32 data? (TIFF images)?
- Graphics / gaming engines / ffmpeg
- Brain image scanning with FMRI / CAT / MEG
- Nasa Earthdata GeoTiff
-
Why can’t we reuse similar techniques from these systems that have large, high resolution datasets to navigate “the weights” with a different type of iterator? With the current rust and mmap performance loading a 100 GB file on disk, who knows maybe this approach could work without a GPU for smaller models constrained to CPU-only.
-
What technical pieces are missing/required to get started?
- What do the weights look like?
- How can we teach AI to learn what weights mean?
- What can we do with time series training data based on how an AI model’s weights changed over time?
-
-
What
-
We have built a prototype for extracting and hopefully identifying how weights:
-
relate back to the original source training data
-
change over many training generations
-
appear to represent a dense 3d field of training knowledge saved as embedded “weights” (unproven but this is our hypothesis based on the techniques that appear to be working)
-
-
-
Why
-
We wanted to understand why LLMs are special and how the weights fit into this innovative technology.
-
By choosing to spend our time trying to view what LLM weights are, we believe we can apply well-known visualization techniques for analyzing human brain scans to extract, identify, reuse and audit what the weights are.
-
Before large generative AI Transformer weights were widely available, these types of dense, high resolution training datasets were very expensive and not frequently shared
-
-
How
-
We built this prototype using digital signal processing algorithms (DSP) for volumetric analysis of high resolution data and combined the analysis engine with Blender (an open source visualization tool).
-
We will open source and track how an AI learns from the ground up and use Blender to export and share what the weights look like as we go.
-
By choosing to use Blender to analyze model weights in a 3d volume, we built in animation capabilities that let us design our initial v1 API for capturing a time series training dataset. This training dataset is focused on capturing how an AI foundational model learns through each training phase using high performance weight analysis on volumetric data.
-
We believe we need to share how these models look so we can understand them and train AI’s to build and audit themselves.
-
We want to see what mixtures of experts looks like too (download the newest Dolphin 2.5 Mixtral 8x7B STL/glTF mesh versions below).
-
This repository is for profiling, extracting, visualizing and reusing generative AI weights to hopefully build more accurate AI models and audit/scan weights at rest to identify knowledge domains for risk(s).
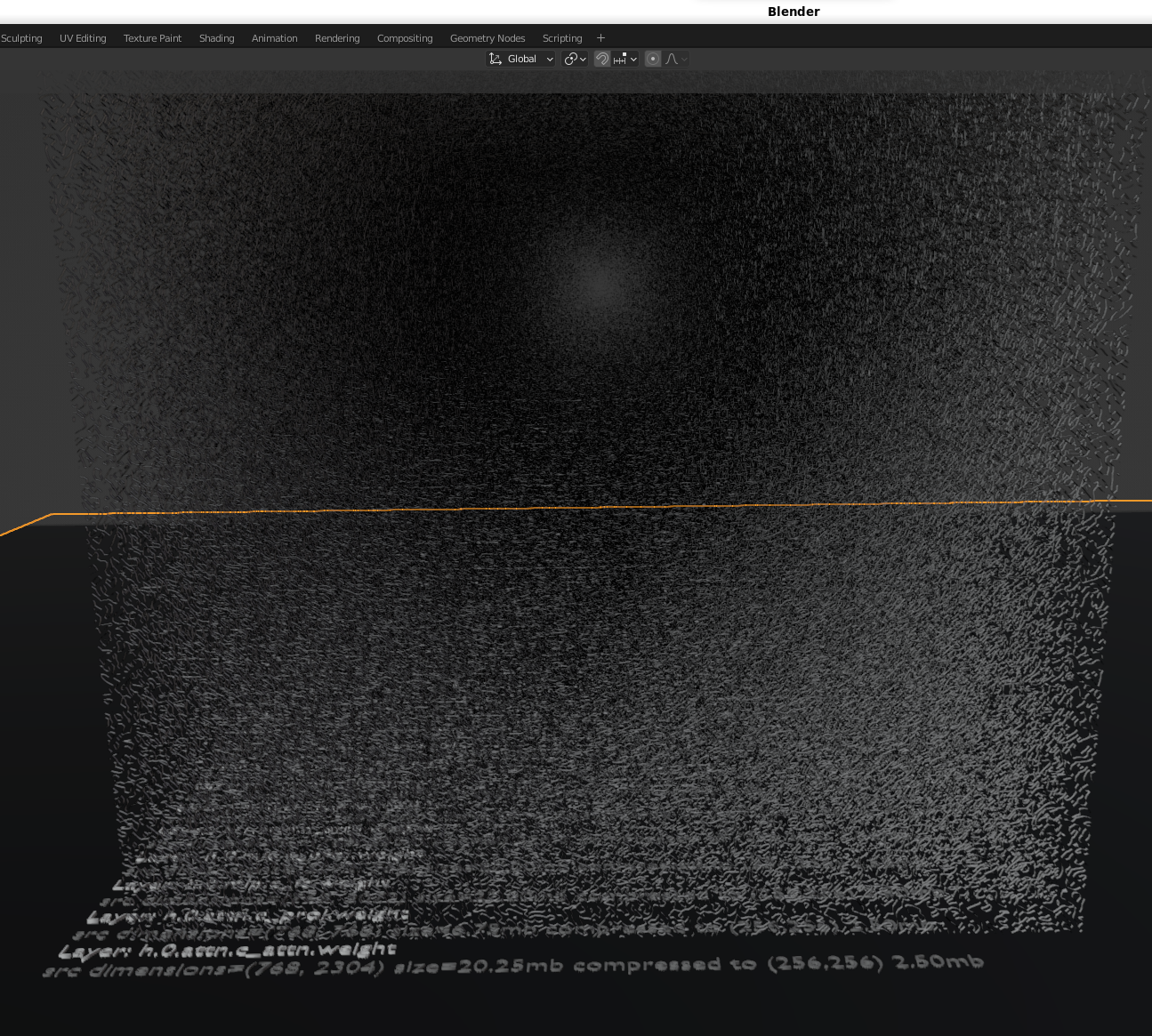
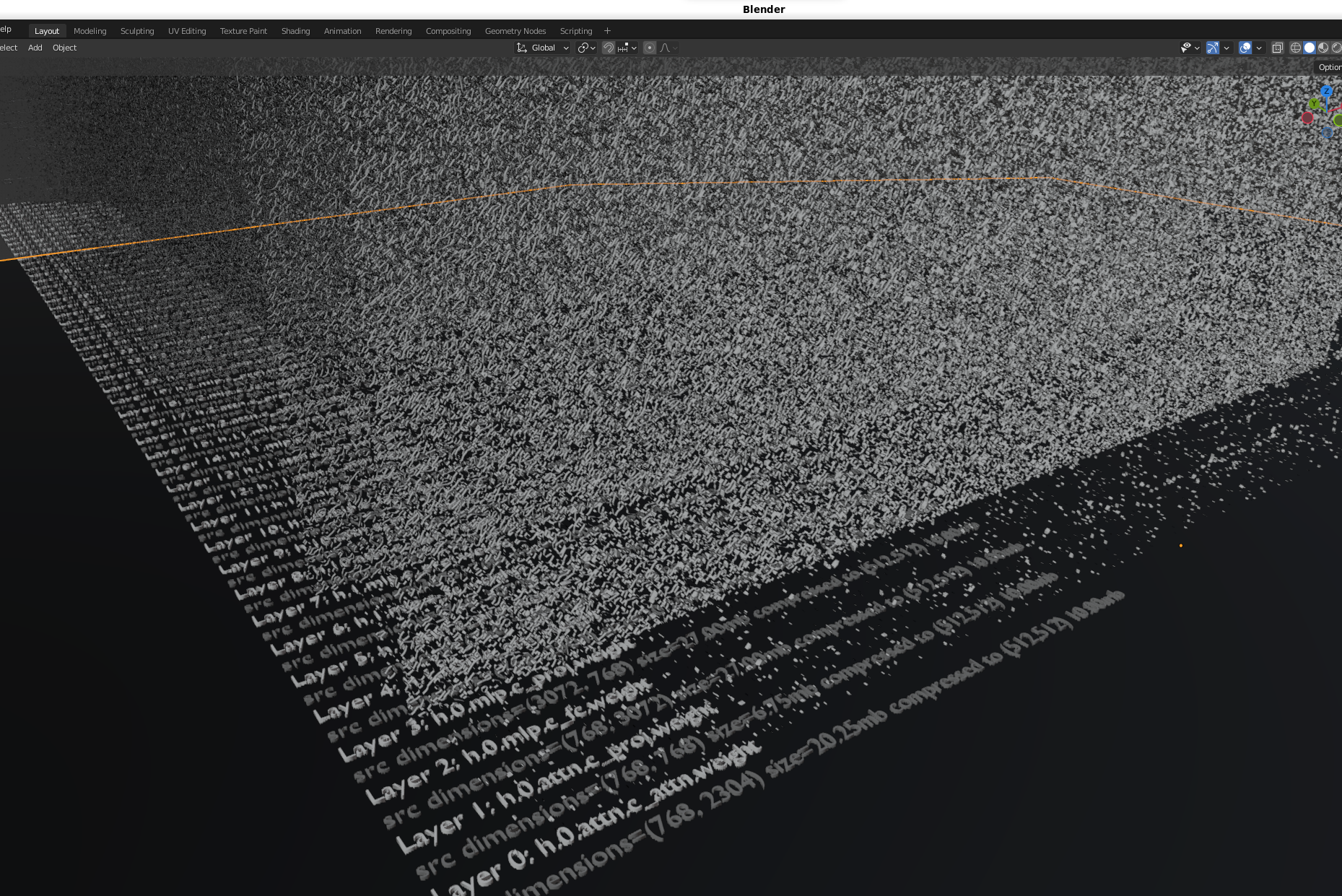
Note: today's version only includes how to profile, extract and visualize existing model weights. Now that we can visualize how AI models learn, foundational model training is next. The training visualization will start by teaching a new AI model about "how the bampe-weights repository integrated numpy, pandas and Blender". We have ~190 python/(task,prompt,answer) files to organize before sharing.
This repository is exploring visualizations of model's learning over time and building training datasets from extracted "weight shapes" to build and predict new AI model weights (hopefully faster than traditional training methods too).
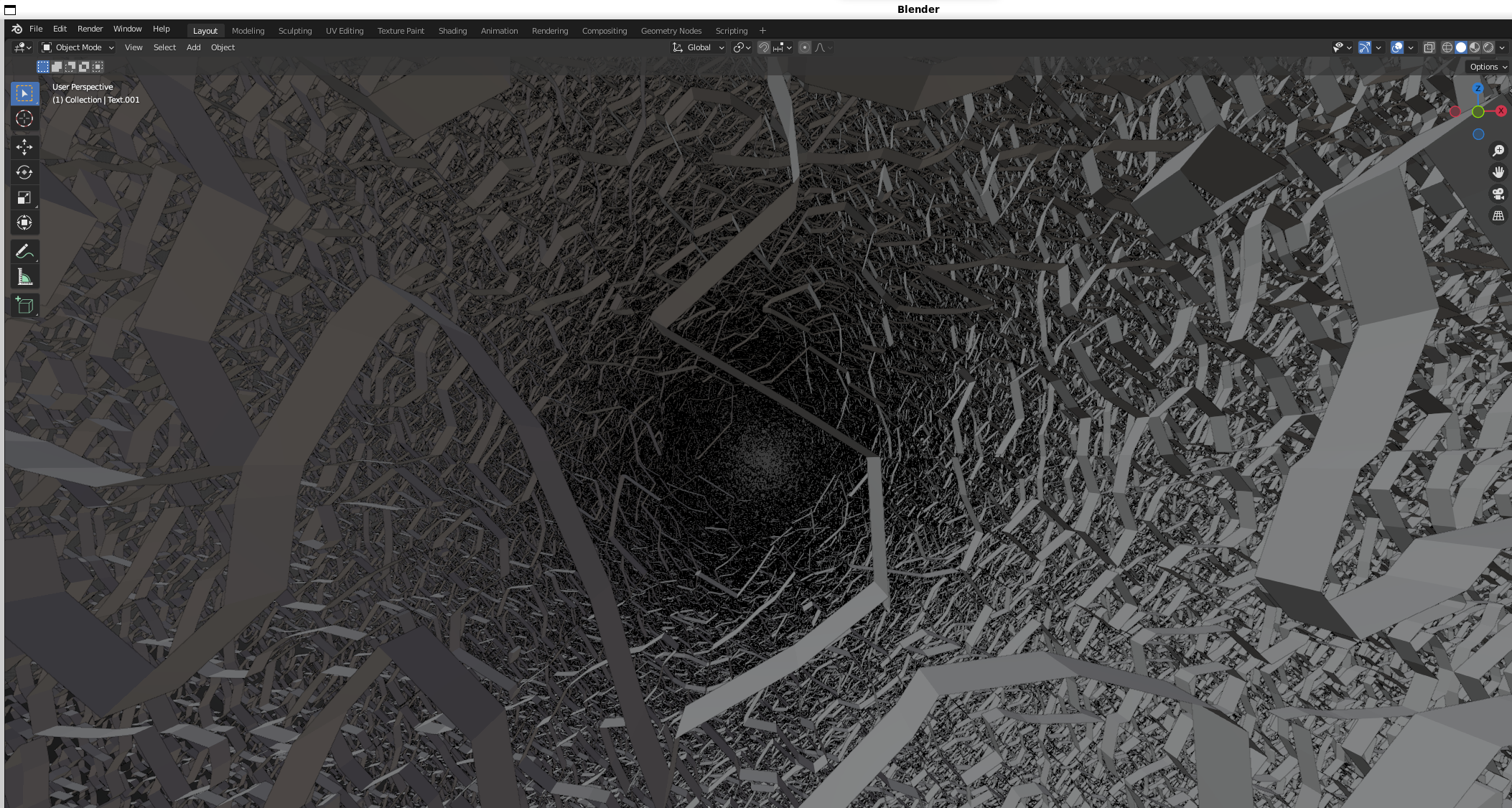
Here's what Llama 2 7B Chat GPTQ looks like inside Blender and exported as a gif using this repository:
Catalog of Available Generative AI Blender 3D Visualizations in glTF and STL files hosted on Google Drive
The following google drive folders contain the emerging index of large language model glTF and STL visualizations. The files range from ~1 MB to +2 GB.
Reach out if you want to see a new model/density!
- Dolphin 2.5 Mixtral 8x7B GPTQ
- Phind CodeLlama 34B v2 GPTQ
- DeepSeek Coder 34B GPTQ
- Mistral 7B OpenOrca GPTQ
- Llama 2 7B Chat GPTQ
- GPT 2
If an STL file is small enough, then GitHub can automatically render the 3d meshes. Note: viewing GitHub STL on mobile is not ideal at the moment, but on a desktop you can zoom into the layers using a mouse wheel in reverse and rotate with the left/right mouse buttons:
We try to stay under the 50 MB limit and store assets on our repo on GitHub - https://github.com/matlok-ai/gen-ai-datasets-for-bampe-weights/docs/images/blender
Self-host Blender in a container to help see what generative AI weights look like locally:
-
Blender Demo Container Image with exported STL/GLB files already included
The matlok/blender-ai-demos image was created from the LinuxServer Blender image and includes 3D STL and GLB files that you can view in a browser. The blender-ai-demos extracted container image is >4.0 GB on disk and uses about 3 GB ram to process STL or glTF files >40 MB:
The demo visualizations are found in this directory inside the container:
/config/bampe-visualizations
Docker
docker rm blender; docker-compose -f compose/blender-demos.yaml up -dPodman
podman rm -t 0 -f blender; podman-compose -f compose/blender-demos.yaml up -d -
Base LinuxServer image
Run the LinuxServer/docker-blender image (lscr.io/linuxserver/blender:latest) and generate new STL/GLB files that are ready to view using an already-mounted volume between the host and the Blender container (.blender directory). The docker-blender extracted container image is ~3 GB on disk.
Docker
docker rm blender; docker-compose -f compose/blender-demos.yaml up -dPodman
podman rm -t 0 -f blender; podman-compose -f compose/base.yaml up -dNote: newly-created visual artifacts (STL and glTF glb files) only show up once the container is restarted in this directory inside the Blender container:
/config/bampe
-
Open up Blender in a browser
Blender is listening at this url:
-
Load a 3D Blender AI Visualization Manually
Once Blender is running in the browser, you can import STL or glTF files by clicking these menus:
-
File
-
Import
-
STL or glTF
-
Files are either in the /config/bampe or /config/bampe-visualizations depending on the running container version
-
-
Use Shift + ` to enable navigation mode with the mouse and W, A, S, D for first person movement.
-
Holding the Shift button will move with turbo speed too.
-
Open Edit -> Preferences -> Navigation -> Fly & Walk -> Walk Toggle Arrow
-
Adjust Mouse Sensitivity -> 0.1
-
Adjust Walk Speed -> 20 m/s
This repository is for researching alternative approaches to building AI using pretrained AI weights. It is a work in progress so please refer to the Setting up a Development Environment for more details on running this from the command line.
We can share and view these shapes using online tools.
This repository was tested on the following platforms:
- Blender 3 on Ubuntu 22.04 (apt package) - wsl2 Windows 11 gpu
- Blender 4 on Ubuntu 22.04 (snap package) - hypervisor no gpu