Work-in-Progress | See also: SixtyPical ∘ Shelta
PolyRical is a successor language to SixtyPical. It explores a few (but by no means all) of the avenues mentioned in the Future directions for SixtyPical document.
Like SixtyPical, it is a very low-level language that nonetheless supports advanced forms of static analysis. It aims to be based on a cleaner, more general theory of operation than SixtyPical, and thus (hopefully) able to target architectures other than the 6502. PolyRical is also more like a macro assembler than SixtyPical, and there is less emphasis on permitting optimizations.
This document is still at the design stage. It is also poorly organized. No code has been written, and all of the decisions described here are subject to change.
A PolyRical program consists of directives, template definitions, and global declarations. Typically, a program would import a set of templates from a library using a directive, but to convey the flavour of the the language, here is a self-contained example program:
word[8] register A
word[8] location score @ 0xc000
template load(out A, word[8] value val) {
/* LDA immediate */ 0xA9 val
}
template store(in A, out word[8] location dest) {
/* STA absolute */ 0x8D lo(dest) hi(dest)
}
routine(out score, trash A) main {
load(A, 0)
store(A, score)
}
(The text within /* and */ is comments and is ignored by the compiler. It is
supplied in the example to clarify what opcodes these templates will emit.)
Observe that this is enough information to consider main, shown above, to be a valid
routine, and to (almost) produce a machine-language program for it, while rejecting
routine(out score, trash A) main {
store(A, score)
}
with a message such as 'store' expects 'A' to be meaningful but in 'main' it is not necessarily so,
and also rejecting
routine(out score, trash A) main {
load(A, 0)
}
with a message such as 'main' does not give a meaningful value to 'score'.
You can also read a more involved example below.
A global declaration consists of a type, a role, a name, an optional initializer, and
an optional location. Some combinations are not valid — for instance, any declaration
with the role value must include the initializer.
Global declarations declare global variables, constants, and routines. A routine is
just a constant of routine type. (More specifically, it is a read-only initialized
location of routine type.)
Each routine type is parameterized with a set of global references, and constraints on those globals.
There are no parameters to a routine, and no local variables. All variables are
global. But each routine must conform to the constraints that its type imposes on
the globals in the program. So, if the type declares that the variable A
will be given a meaningful value by the routine, then the routine must give it a
meaningful value, or the implementation should signal an error condition.
Templates, too, have such constraints. Unlike routines, templates do have a list of parameters. Also unlike routines, the constraints declared by a template are not checked by the implementation (often they would not be checkable, as templates provide machine-level details for implementing an operation). But they are propagated to the rest of the program. Most programmers would use a library of templates instead of writing their own.
A routine body consists of a list of template applications. The template
definition used in a template application is selected based on the types and
roles of the parameters, each of which may be a global or a literal value. This is
like method overloading in languages such as Java. Actually, it goes further,
in that a template definition can list a particular global, rather than just a
type and role, as one of its parameters. This definition will be selected when
this exact global is given as the parameter. The load and store templates in
the above example demonstrate this for the global A.
The most prominent property of global declarations that PolyRical tracks is meaningfulness. This is very similar to how many C compilers track defineness of variables, and are able to warn the user if the code uses a variable that is not defined, or may not be defined in all cases.
Meaningfulness is controlled by three constraints on each routine type and on each template:
inasserts that the global must be meaningful before the routine or template is appliedoutasserts that the global will be meaningful after the routine or template is appliedtrashasserts that the global will not be meaningful after the routine or template is applied
The meaningfulness of all other globals is preserved when a routine or template is applied.
In particular, in asserts the meaningfulness of a global during input, so
in the absence of trash on the same global, that global is assumed to
also be meaningful on output.
Other properties of globals beyond meaningfulness, such as range, and whether a routine is ever called, are trackable by symbolic execution. SixtyPical already tracks several of these, and one day PolyRical might as well.
The most basic data type is the word, which, because we want the possibility
of targeting systems other than the 6502, is parameterized by its size. An
8-bit byte is word[8] and a 16-bit word is word[16]. Following this pattern,
a single-bit flag register is word[1].
Routine types have already been discussed.
There is also an array (or table) type, which represents a contiguous section of memory, when applied to a location. There could, in theory, also be table values, to represent things like string constants, but this area is not well worked out.
Although there may one day be a pointer type, there are two types which are related but more relevant.
The first is an index type, which is effectively a pointer within a particular table. It is possibly a role, rather than a type, because it is also effectively just an integer value with a limited range (and the concept of limited range can be applied to any value.)
Whichever way it is, templates for operations which access or update a location within a table will take an index and use it. The template decides exactly how to compute the offset to within the table. So, for example, a table of 16-bit values can be implemented as a single memory table, multiplying the index by two, and retrieving the byte at the index, and the next byte in memory; or it can be implemented by two memory tables, accessed with the same index, with the high byte stored in one and the low byte in the other. A template for either kind of access ought to be constructible.
The second is a pointer to code. The routine type covers most of these cases, e.g. a jump table is a table of values of routine type. But for conditional templates (see below) we may need to expose a "label" type which is a pointer to an instruction somewhere inside a routine. Because of how much these things complicate analysis, it's likely their use will be highly restricted.
Meaningfulness has "at least as much as" properties when it comes to using values of
routine type. Such a table might be defined with a type of routines that
trash a given global (for example, A). This should be thought of as
saying "In the worst case, the routines stored in this table trash A". It
should be entirely possible to assign a routine that does not trash A, to
a cell in that table.
Along with a type, each global has a role. There are two main roles, which
are location and value. These are similar to the concepts of lvalue and
rvalue respectively, in languages such as C. A global which is a
location supports the operation of having its address taken; it does not
directly support having its value set or read, but there may be machine
instructions which do this, and one or more templates defined which use them.
A value, on the other hand, does not support having its address taken, but
does directly support having its value taken.
Roles are considered when selecting a template for given actual parameters. This prevents such things as trying to assign a value to another value; there will typically be no such template with that signature.
Every literal constant is considered a value.
There are other, more specialized roles. register is like location but
does not support having its address taken.
Static analysis is easy if all programs are entirely straight-line code — the complications come up when branching occurs.
But branching is also an opportunity, because every time a branch occurs, the analyzer has more information about what conditions must pertain in each branch. (cf. flow typing)
For example, if we branch on the carry flag, we know that, in the code that we branch to, the carry flag must necessarily be set; and in the code where the branch was failed to be taken, the carry flag must necessarily be clear.
Ideally, we'd like to capture control flow in templates; templates should take
blocks as parameters, allowing the programmer to, for example, define a template
called ifzero that works like so:
template ifzero(block) {
/* BNE */ 0xd0 rel(label)
block
label:
}
That is, it takes a block and generates the machine code for making a conditional branch against the Z flag, and machine code for the entire passed-in block. This allows us to implement control structures in an architecture-agnostic way.
However, this complicates analysis significantly. If the user is allowed to write arbitrary combinations of branches and labels inside a template, the analyzer needs to be able to handle arbitrary combinations of branches and labels. We'd prefer to avoid that.
We can avoid that by providing only canned control structures, such as if
and repeat, at either the template level or the routine level. But machine
languages usually have many specialized branch instructions. It is unclear
currently how best to allow these control structures to use these instructions.
For other purposes, there are facilities we can use which are somewhat easier to handle. One such facility is templates that are employed implicitly.
For instance, the reason we said the motivating example given above is only "almost"
enough information to produce a machine-language program, is that we haven't defined
what the main routine should do when it's finished. Presumably it should return to
its caller, but the program doesn't provide a way to say that in machine language.
But we can provide this information by defining an implicit template like
template _return() {
/* RTS */ 0x90
}
and the compiler would insert this at the end of each routine as necessary.
Correspondingly, we need to define what it means to the machine language to call a routine:
template _call(routine r) {
/* JSR */ 0x20 lo(r) hi(r)
}
It might be the case that implicit templates can be used for control structures as well, but it is less clear in what exact manner that would happen.
One part of it would probably be an implicit template for an unconditional jump:
template _jump(label r) {
/* JMP absolute */ 0x4c lo(r) hi(r)
}
(And, just as an aside, the library might define symbolic constants for opcodes instead of writing them in comments like we've been doing here. Like so:
word[8] value JMP_abs = 0x4c
template _jump(label r) {
JMP_abs lo(r) hi(r)
}
In subsequent examples we'll start assuming such symbolic constants have been defined.)
It might be possible to have condition templates which represent the possible
conditions in an if or repeat test. The condition name would be passed
to the control structure, and the control structure would select the condition
template for that name, when generating the test part of the control structure.
One complication is that the condition template needs to know the location in the program to branch to. Unlike most locations, this is the address of a machine instruction. So it might have its own special role.
Another complication is that sometimes it is advantageous for the compiler to generate a branch for when the condition is true, and sometimes the branch for when it is not true.
So, condition templates take two extra parameters, supplied by the system: the label to jump to and the sense of the test that is being generated. The template library should provide templates to cover both cases. For example,
template zero?(label, true, in A) {
BEQ rel(label)
}
template zero?(label, false, in A) {
BNE rel(label)
}
In a routine, this template would be invoked when compiling a control
structure like if or repeat that takes a condition, like so:
routine(out score, in A) main {
if zero?(A) {
store(A, score)
}
}
What sense of test the compiler wants to generate for this, is up to the compiler. The library has supplied both templates, it will pick the needed one.
The formal arguments of the template are given in a list; in, out, and
trash modifiers are attached to them directly.
Only location role arguments can be given in, out, and trash
modifiers; they don't make sense on those of value role.
The template may involve the state of the machine beyond just the arguments
it is given. When it does this, it should give a list of globals that
are involved, and in, out, and trash modifiers on them as necessary.
This is not an ordered list, it is a set, and it appears after the list of
arguments.
Example (not necessarily a good template, but demonstrates the features):
template lda(word[8] value val) : (out A) {
0xA9 val
}
The body of the template consists of a list of 8-bit bytes. (Certainly one could argue this is not the apex of architecture-agnosticism, but, we will accept some limitations in the name of getting something done.)
These emitted bytes are specified by literal values, or functions of parameter or global names.
Literal values are emitted directly in the output binary. They are usually given in hexadecimal, and correspond to opcodes or constant operands.
Parameters or globals of the value role resolve to their value. If the
value consists of more than 8 bits, a function must be used to extract 8 bits
at a time.
Parameters or globals of the location role resolve to their address.
If the address consists of more than 8 bits, again, a function must be used
to extract 8 bits at a time.
Other functions should be available to, say, convert an absolute address into one relative to the current emitting address (for relative branches).
In the above examples, the functions lo(), hi(), and rel() have served
these purposes.
Can templates call other templates? On the one hand this seems like it could be useful. On the other hand it complicates analysis. In a sense, templates should be considered "atomic units" with respect to analysis. They simply tell us what it is they affect; we take their word for it, and shouldn't have to check them. Also, any aggregation of template bodies could be done by hand, so templates-calling-other-templates isn't strictly necessary.
What happens when one of the parameters is the same as one of the globals in the "this template also involves" set? This, too, complicates analysis. It's tempting to say that the situation should be just disallowed, because it's hard to see how it leads to more utility in a clean way, and easy to see how template-hygiene-violation-like errors could happen with it.
Templates should still be able to take blocks, to support things like
SixtyPical's with interrupts off and save. Blocks are OK, it's unrestricted
use of labels we want to avoid.
Some architectures have a data stack that is shared between routines. This should be a global of stack type. Routines should ideally be able to notate how they affect the stack. Think: type declarations for Forths.
Zero-page versus 16-bit addresses (in 6502). Generalizing this means supporting "different kinds of pointers". Another example is segment:offset references on 80286. Possibly type qualifiers a la Dieter would work here.
This is the "echo" program from SITU-SOL (hand-assembled version) converted to PolyRical.
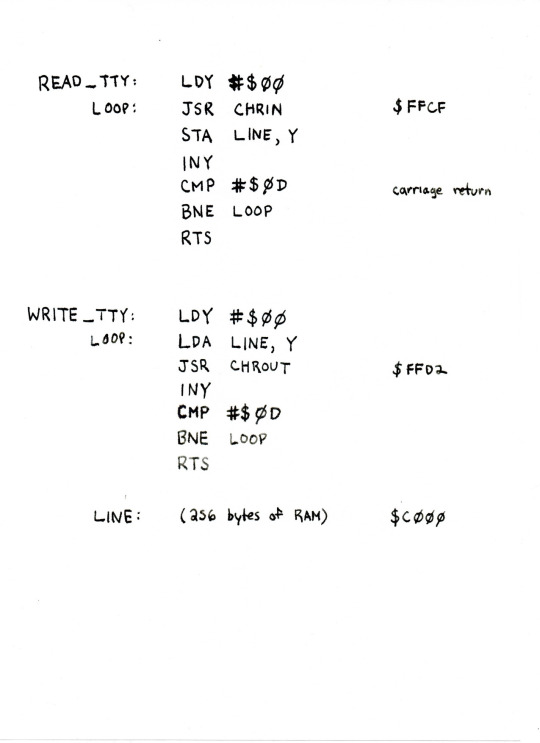{kind=link}
{kind=link}
Given that none of this is implemented yet, there are almost certainly shortcomings in this code, and you are urged to treat it as a sketch.
include "lib/c64.polyrical"
word[8][256] location line @ 0xC000
routine (out line, trash a, trash y) read_tty {
load(Y, 0)
repeat {
chrin()
store(A, line, Y)
inc(Y)
} until equal?(A, 0x0d)
}
routine (in line, trash a, trash y) write_tty {
load(Y, 0)
repeat {
load(A, line, Y)
chrout()
inc(Y)
} until equal?(A, 0x0d)
}
routine (trash a, trash y, trash line) main {
repeat {
read_tty()
write_tty()
} forever
}
where "lib/c64.polyrical" would contain something like
include "lib/6502.polyrical"
extern routine(out a) chrin @ 0xFFCF
extern routine(in a, trash a) chrout @ 0xFFD2
and "lib/6502.polyrical" would contain something like
word[8] register A
word[8] register Y
template load(out Y, word[8] value val) {
/* LDY immediate */ 0xA0 val
}
template load(out A, in word[8][*] location addr, in Y) {
/* LDA absolute, Y */ 0xB9 lo(addr) hi(addr)
}
template store(in A, out word[8][*] location dest, in Y) {
/* STA absolute, Y */ 0x99 lo(dest) hi(dest)
}
template inc(in out Y) {
/* INY */ 0xC8
}
template equal?(label, true, in A, word[8] value v) {
/* CMP immediate */ 0xC9 v
/* BEQ */ 0xF0 rel(label)
}
template equal?(label, false, in A, word[8] value v) {
/* CMP immediate */ 0xC9 v
/* BNE */ 0xD0 rel(label)
}
Note that in reality, INY and other opcodes here set some flags, so
a more realistic version of this file would have
word[1] register Z
word[1] register N
template inc(in out Y) : (out Z, out N) {
/* INY */ 0xC8
}
and so forth.
In EBNF. Likely quite incomplete at this stage.
Program ::= {Directive | GlobalDecl | TemplateDefn}.
Directive ::= "include" StringLit.
GlobalDecl ::= Type Role Ident<new:global> ["=" Initializer] ["@" Address].
Type ::= PrimType [TableSize].
PrimType ::= "word" "[" WordSize "]"
| "routine" "(" DeclUsageList ")".
Role ::= "location" | "register" | "value".
DeclUsageList ::= DeclUsage {"," DeclUsage}.
DeclUsage ::= {AccessQualifier} Type Ident<global>.
AccessQualifier ::= "in" | "out" | "trash".
Address ::= IntLit.
Initializer ::= IntLit | RoutineLit.
TemplateDefn ::= "template" Ident<new:global> "(" [TemplateFormals] ")" [":" "(" DeclUsageList ")"] TemplateBlock.
TemplateFormals ::= TemplateFormal {"," TemplateFormal}.
TemplateFormal ::= {AccessQualifier} Type Ident<new:param>.
TemplateBlock ::= "{" {Emittable} "}".
Emittable ::= IntLit | Ident<global/param> | EmitFunc "(" Emittable ")".
EmitFunc ::= "lo" | "hi" | "rel".
Ident ::= <<alphabetic (alphanumeric|'?')*>>.
StringLit ::= <<'"' any* '"'>>.
IntLit ::= <<('0x' hexdigit+|digit+)>>.
RoutineLit ::= RoutineBlock.
RoutineBlock ::= "{" Operation {"," Operation} "}".
Operation ::= Ident<global> "(" [Actuals] ")".
Actuals ::= Actual {"," Actual}.
Actual ::= Ident<global> | IntLit.
The control-flow graph is derived from the AST. This can be done either explicitly (traversing the AST and constructing a separate control-flow graph) or implicitly (to traverse the control-flow graph, traverse the AST in the manner which results in the control-flow graph; no explicit data structure is constructed.)
Some of the most convoluted parts of the SixtyPical compiler can be traced to traversing the control-flow graph implicitly, via the AST. For the PolyRical compiler, it would probably be a better idea to construct an explicit control-flow graph (with explicit join nodes and so forth) on an early pass, then to traverse that graph, instead of the AST, during static analyses and code generation.