Atlassian Cloud
Atlassian Cloud-architectuur en operationele werkwijzen
Leer meer over de Atlassian Cloud-architectuur en de operationele werkwijzen die we gebruiken
Introductie
Atlassian Cloud-producten en -gegevens worden gehost op de toonaangevende cloudprovider: Amazon Web Services (AWS). Onze producten draaien op een PaaS-omgeving (Platform as a Service) die is opgedeeld in twee primaire infrastructuursets. Deze primaire sets noemen we Micros en niet-Micros. Jira, Confluence, Jira Product Discovery, Statuspage, Guard en Bitbucket draaien op het Micros-platform, terwijl Opsgenie en Trello op het niet-Macros-platform draaien.
Architectuur voor gedistribueerde services
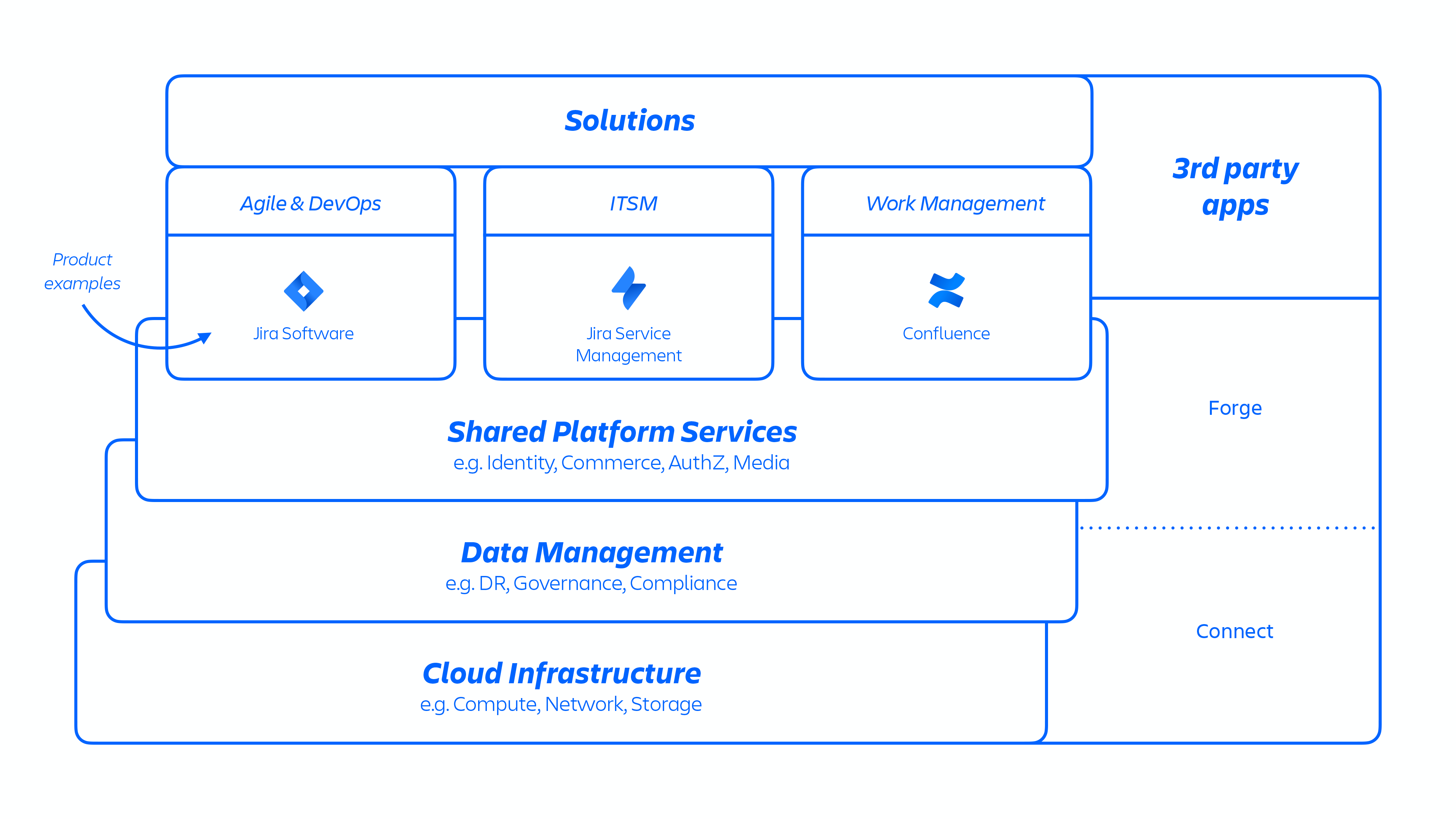
Met deze AWS-architectuur hosten we een aantal platform- en productservices die in onze oplossingen worden gebruikt. Dit omvat platformmogelijkheden die worden gedeeld en gebruikt voor meerdere Atlassian-producten, zoals Media, Identity en Commerce, ervaringen zoals onze Editor en productspecifieke mogelijkheden, zoals de Jira Issue-service en Confluence Analyses.
Afbeelding 1
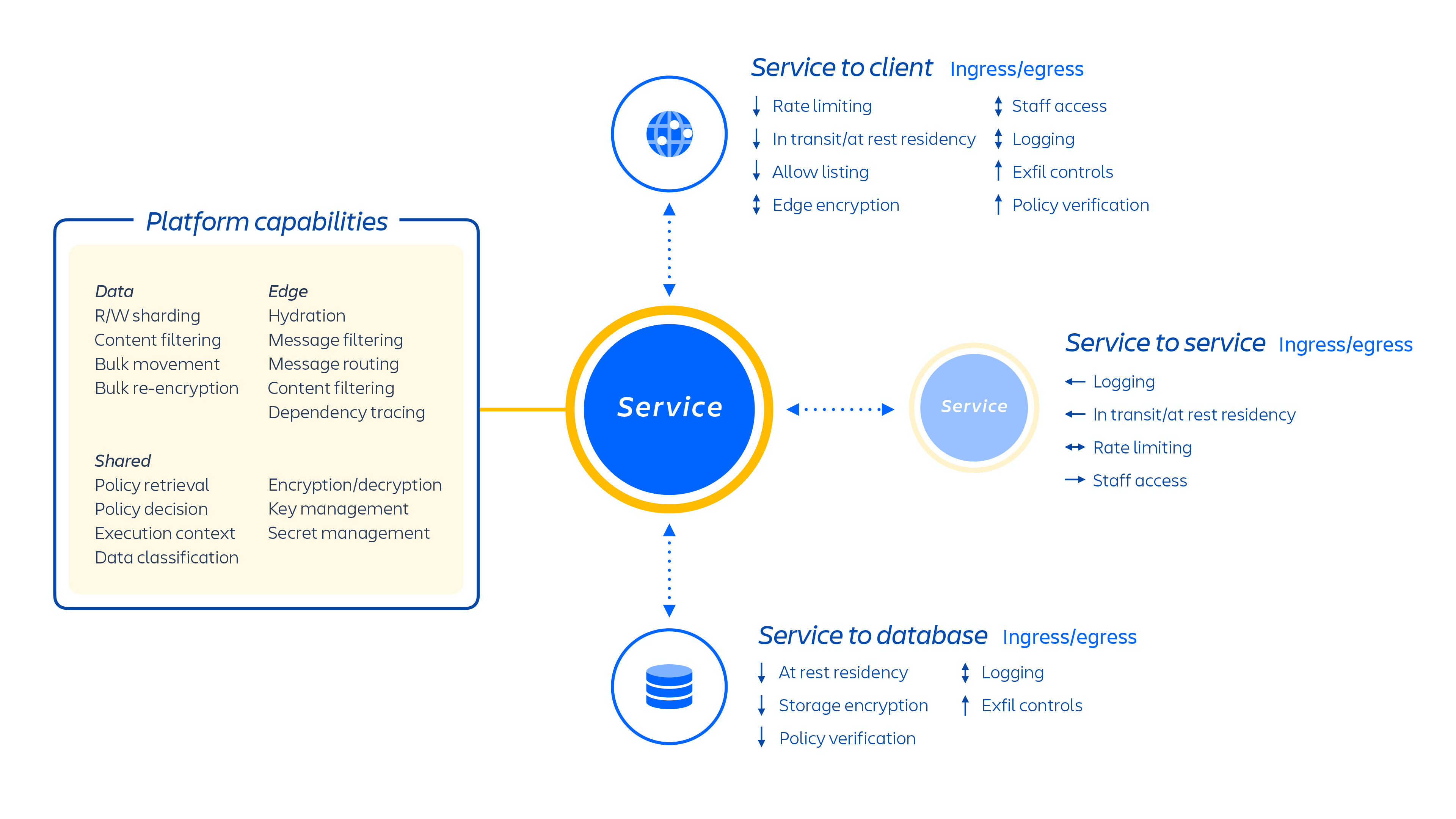
Atlassian-ontwikkelaars leveren deze services via kubermetes of via een intern ontwikkeld platform-as-a-service (PaaS), genaamd Micros. Hierdoor wordt automatisch de implementatie van gedeelde services, infrastructuur, gegevensopslag en hun beheermogelijkheden georkestreerd, inclusief beveiligings- en compliance-controlevereisten (zie figuur 1 hierboven). Een Atlassian-product bestaat doorgaans uit meerdere 'containerservices' die op AWS worden geïmplementeerd met behulp van Micros en kubermetes. Atlassian-producten maken gebruik van kernplatformmogelijkheden (zie figuur 2 hieronder) die variëren van verzoekroutering tot binaire objectopslag, authenticatie/autorisatie, transactionele door gebruikers gegenereerde inhoud (UGC) en entiteitsrelaties, data lakes, gemeenschappelijke logboekregistratie, verzoektracering, waarneembaarheid en analytische services. Deze microservices worden gebouwd met behulp van goedgekeurde technische stapels die zijn gestandaardiseerd op platformniveau:
Afbeelding 2
Architectuur met meerdere tenants
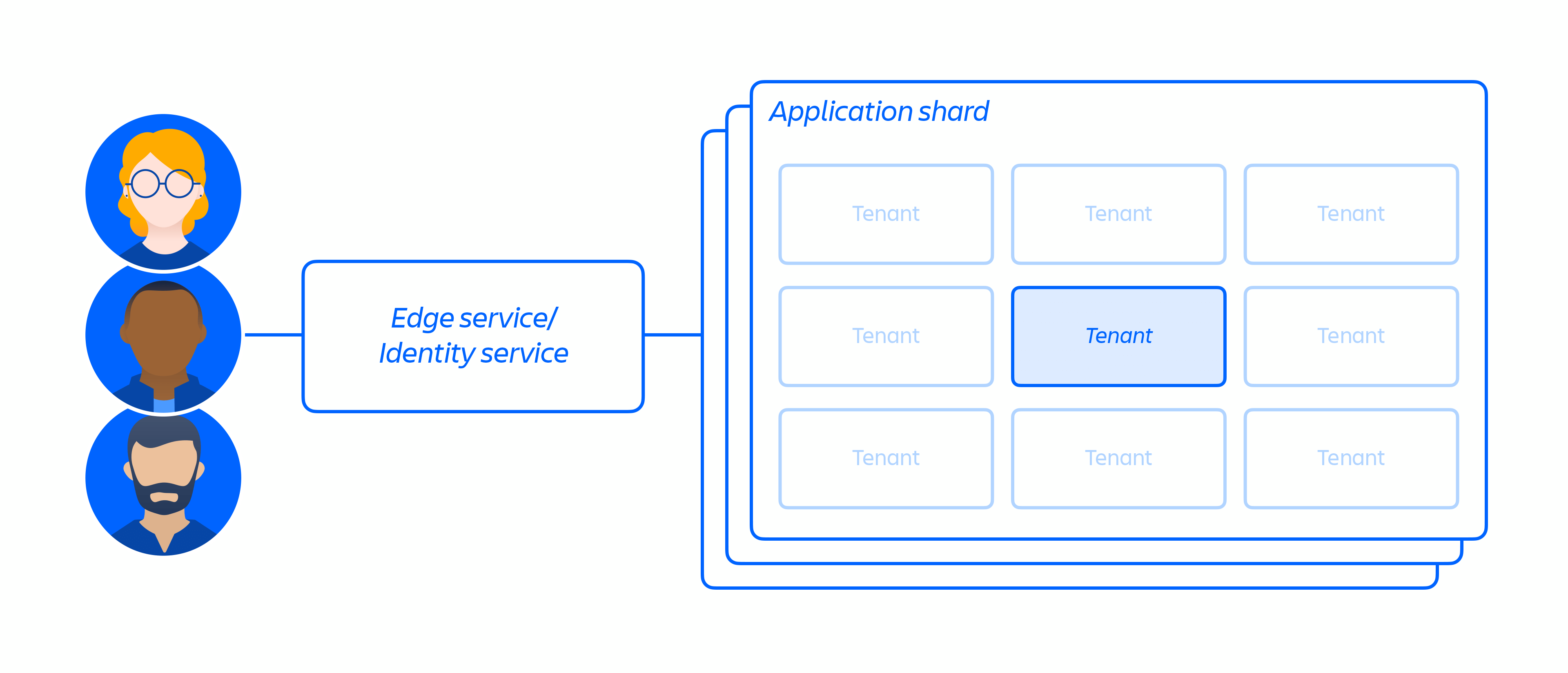
Naast onze cloudinfrastructuur hebben we een multi-tenant microservices-architectuur opgezet met een gedeeld platform dat onze producten ondersteunt. In een multi-tenantarchitectuur bedient één enkele service meerdere organisaties, waaronder de databases en computerinstallaties die nodig zijn om onze cloudproducten te kunnen draaien. Elke scherf (in wezen een container – zie figuur 3 hieronder) bevat de gegevens voor meerdere huurders, maar de gegevens van elke huurder zijn geïsoleerd en ontoegankelijk voor andere huurders. Het is belangrijk op te merken dat we geen single-tenantarchitectuur aanbieden.
Figuur 3
Onze microservices zijn gebouwd op basis van het principe 'minste privilege' en ontworpen om de scope van een 'zero-day'-aanval te minimaliseren en om de kans op laterale bewegingen binnen onze cloudomgeving te verkleinen. Elke microservice heeft zijn eigen gegevensopslag die alleen toegankelijk is met het verificatieprotocol voor die specifieke service. Dit betekent dat geen enkele andere service lees- of schrijftoegang heeft tot die API.
We hebben ons gericht op het isoleren van microservices en gegevens, in plaats van een speciale infrastructuur per tenant aan te bieden, omdat het de toegang tot het beperkte gegevensbereik van één systeem voor veel klanten beperkt. Omdat de logica is losgekoppeld en gegevensverificatie en autorisatie op de applicatielaag plaatsvindt, fungeert dit als een aanvullende beveiligingscontrole omdat aanvragen naar deze services worden verzonden. Dus als een microservice wordt aangetast, zal dit slechts resulteren in beperkte toegang tot de gegevens die een bepaalde service vereist.
Registratie en levenscyclus van tenants
Wanneer een nieuwe klant wordt geregistreerd, activeert een reeks gebeurtenissen de orkestratie van gedistribueerde services en het registreren van gegevensopslag. Deze gebeurtenissen kunnen over het algemeen worden toegewezen aan een van de zeven stappen in de levenscyclus:
1. Commerce-systemen worden onmiddellijk bijgewerkt met de nieuwste metagegevens en toegangsbeheerinformatie voor die klant, en vervolgens stemt een provisioning-orkestratiesysteem de "status van de geregistreerde resources" af op de licentiestatus via een reeks tenant- en productgebeurtenissen.
Tenantgebeurtenissen
Deze gebeurtenissen hebben gevolgen voor de tenant als geheel en kunnen mogelijk deze opties zijn:
- Creatie: er wordt een tenant gemaakt en gebruikt voor gloednieuwe sites
- Vernietiging: een volledige tenant wordt verwijderd
Productgebeurtenissen
- Activering: na de activering van gelicentieerde producten of apps van derden
- Deactivering: na het deactiveren van bepaalde producten of apps
- Opschorting: na de opschorting van een bepaald bestaand product, waardoor de toegang tot een bepaalde site waarvan zij eigenaar zijn, wordt uitgeschakeld
- Opschorting opheffen: na de opheffing van de opschorting van een bepaald bestaand product, waardoor toegang wordt verleend tot een site waarvan zij eigenaar zijn
- Licentie-update: bevat informatie over het aantal licenties voor een bepaald product en de status ervan (actief/inactief)
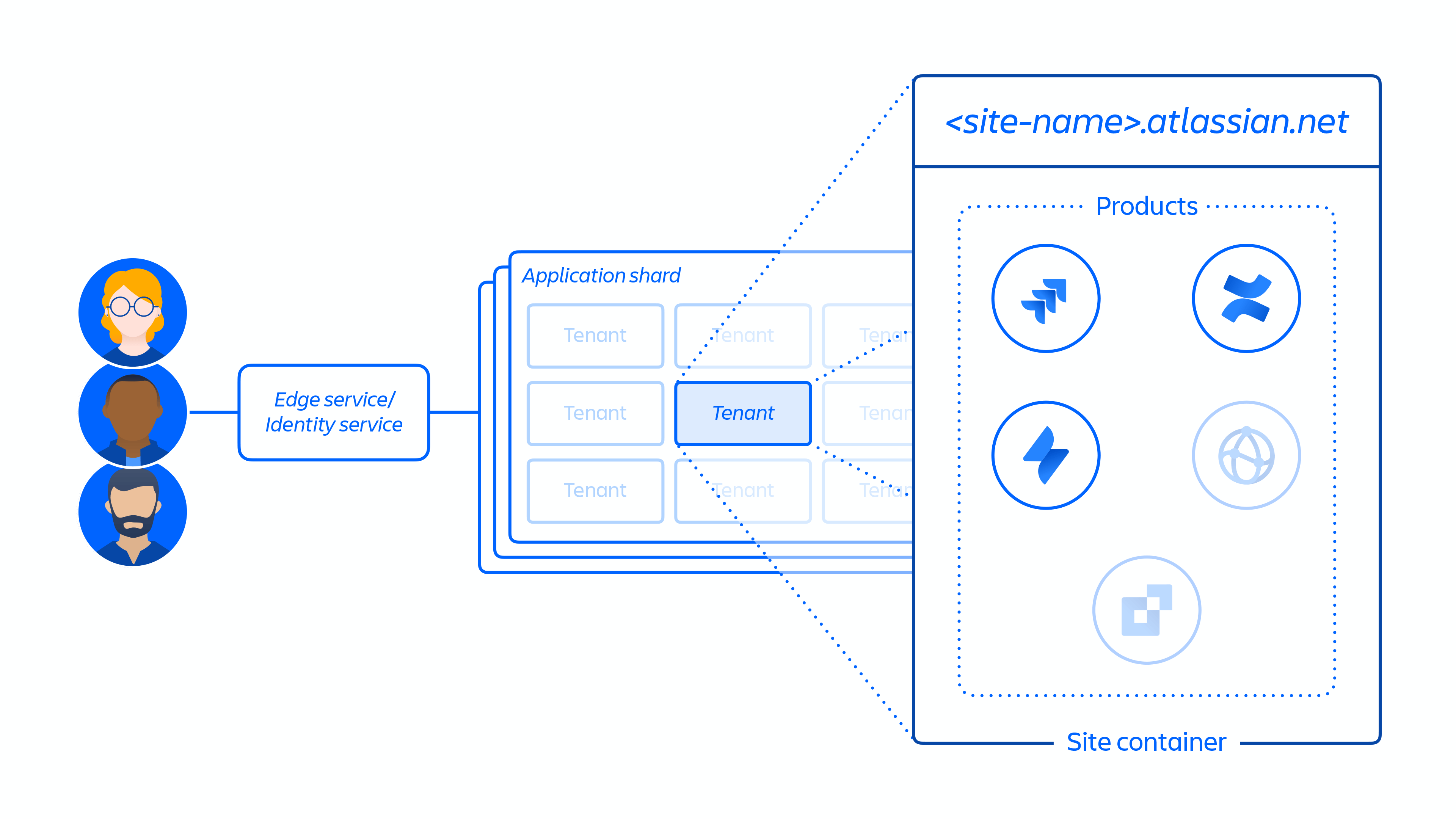
2. Creatie van de klantsite en activering van de juiste set producten voor de klant. Het concept van een site is de container van meerdere producten die gelicenseerd zijn aan een bepaalde klant. (bijv. Confluence en Jira Software voor <site-name>.atlassian.net).
Figuur 4
3. Registratie van producten binnen de klantlocatie in de aangewezen regio.
Wanneer een product wordt geregistreerd, wordt het grootste deel van de inhoud in de buurt gehost van de plaats waar gebruikers het openen. Om de productprestaties te optimaliseren, beperken we de verplaatsing van gegevens niet wanneer deze wereldwijd wordt gehost en kunnen we indien nodig gegevens tussen regio's verplaatsen.
Voor sommige van onze producten bieden we ook gegevenslocatie aan. Gegevenslocatie stelt klanten in staat om te kiezen of productgegevens wereldwijd worden verspreid of op hun plaats worden gehouden op een van onze gedefinieerde geografische locaties.
4. Creatie en opslag van de klantsite en de kernmetadata en configuratie van het product.
5. Creatie en opslag van de site en de identiteitsgegevens van het product, zoals gebruikers, groepen, rechten, etc.
6. Registratie van productdatabases binnen een site, bijv. Jira-reeks van producten, Confluence, Compass, Atlas.
7. Registratie van de gelicentieerde apps van het product.
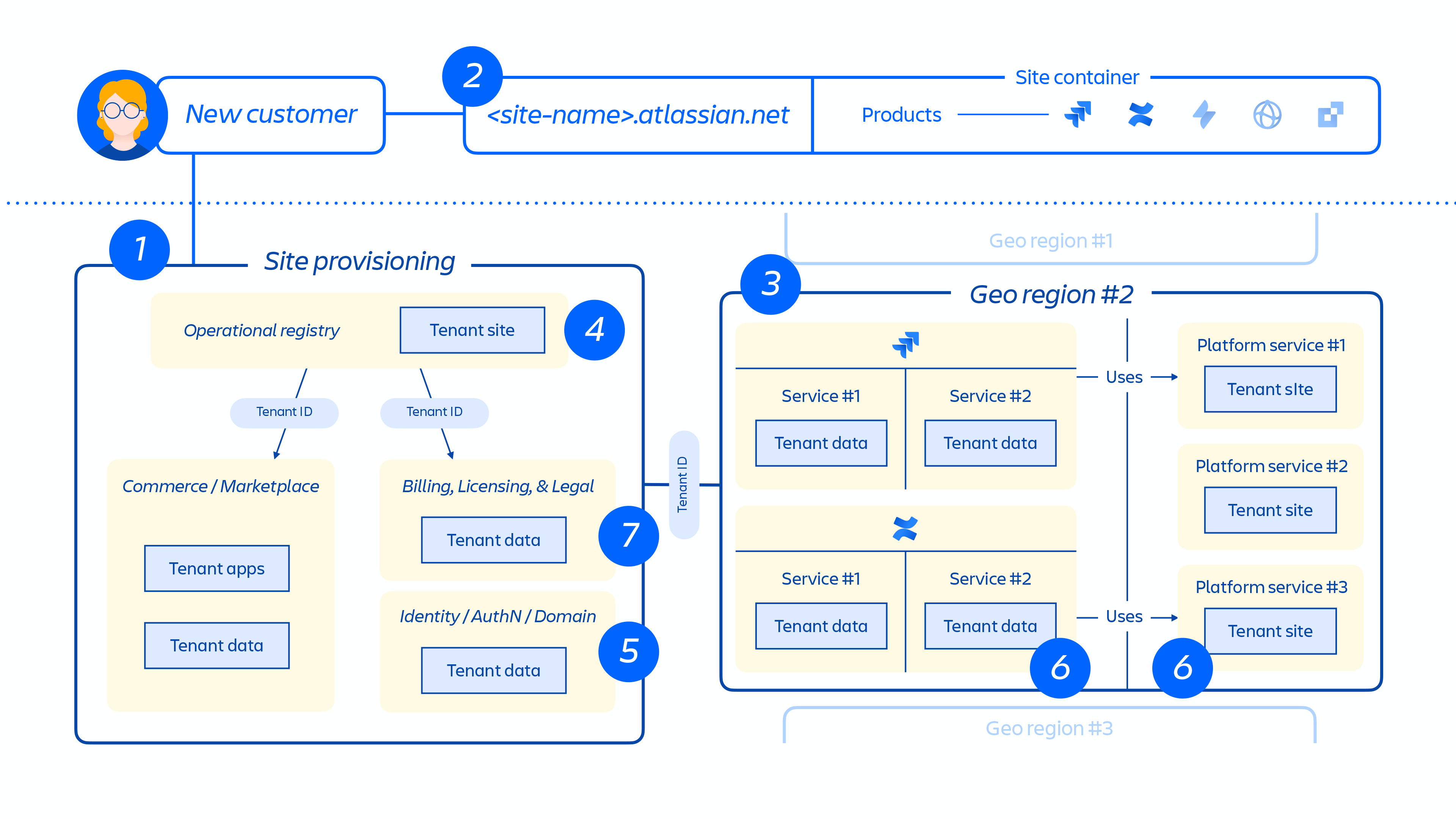
Figuur 5
Figuur 5 hierboven laat zien hoe de site van een klant wordt geïmplementeerd in onze gedistribueerde architectuur, niet alleen in één database of opslag. Dit omvat meerdere fysieke en logische locaties die metagegevens, configuratiegegevens, productgegevens, platformgegevens en andere gerelateerde site-informatie opslaan.