Logic Pro User Guide for iPad
-
- What is Logic Pro?
- Working areas
- Work with function buttons
- Work with numeric values
-
- Intro to tracks
- Create tracks
- Create tracks using drag and drop
- Choose the default region type for a software instrument track
- Select tracks
- Duplicate tracks
- Reorder tracks
- Rename tracks
- Change track icons
- Change track colors
- Use the tuner on an audio track
- Show the output track in the Tracks area
- Delete tracks
- Edit track parameters
- Start a Logic Pro subscription
- How to get help
-
- Intro to recording
-
- Before recording software instruments
- Record software instruments
- Record additional software instrument takes
- Record to multiple software instrument tracks
- Record multiple MIDI devices to multiple tracks
- Record software instruments and audio simultaneously
- Merge software instrument recordings
- Spot erase software instrument recordings
- Replace software instrument recordings
- Capture your most recent MIDI performance
- Route MIDI internally to software instrument tracks
- Record with Low Latency Monitoring mode
- Use the metronome
- Use the count-in
-
- Intro to arranging
-
- Intro to regions
- Select regions
- Cut, copy, and paste regions
- Move regions
- Remove gaps between regions
- Delay region playback
- Trim regions
- Loop regions
- Repeat regions
- Mute regions
- Split and join regions
- Stretch regions
- Separate a MIDI region by note pitch
- Bounce regions in place
- Change the gain of audio regions
- Create regions in the Tracks area
- Convert a MIDI region to a Session Player region or a pattern region
- Rename regions
- Change the color of regions
- Delete regions
-
- Intro to chords
- Add and delete chords
- Select chords
- Cut, copy, and paste chords
- Move and resize chords
- Loop chords on the Chord track
- Edit chords
- Work with chord groups
- Use chord progressions
- Change the chord rhythm
- Choose which chords a Session Player region follows
- Analyze the key signature of a range of chords
- Create fades on audio regions
- Extract vocal and instrumental stems with Stem Splitter
- Access mixing functions using the Fader
-
- Intro to Step Sequencer
- Use Step Sequencer with Drum Machine Designer
- Record Step Sequencer patterns live
- Step record Step Sequencer patterns
- Load and save patterns
- Modify pattern playback
- Edit steps
- Edit rows
- Edit Step Sequencer pattern, row, and step settings in the inspector
- Customize Step Sequencer
-
- Effect plug-ins overview
-
- Instrument plug-ins overview
-
- ES2 overview
- Interface overview
-
- Modulation overview
- Use the Mod Pad
-
- Vector Envelope overview
- Use Vector Envelope points
- Use Vector Envelope solo and sustain points
- Set Vector Envelope segment times
- Vector Envelope XY pad controls
- Vector Envelope Actions menu
- Vector Envelope loop controls
- Vector Envelope point transition shapes
- Vector Envelope release phase behavior
- Use Vector Envelope time scaling
- Modulation source reference
- Via modulation source reference
-
- Sample Alchemy overview
- Interface overview
- Add source material
- Save a preset
- Edit mode
- Play modes
- Source overview
- Synthesis modes
- Granular controls
- Additive effects
- Additive effect controls
- Spectral effect
- Spectral effect controls
- Filter module
- Low, bandpass, and highpass filters
- Comb PM filter
- Downsampler filter
- FM filter
- Envelope generators
- Mod Matrix
- Modulation routing
- Motion mode
- Trim mode
- More menu
- Sampler
- Studio Piano
- Copyright
EVOC 20 PS Un/Voiced detection in Logic Pro for iPad
Human speech consists of a series of voiced sounds—tonal sounds or formants—and unvoiced (U/V) sounds. The main distinction between voiced and unvoiced sounds is that voiced sounds are produced by an oscillation of the vocal cords, whereas unvoiced sounds are produced by blocking and restricting the air flow with lips, tongue, palate, throat, and larynx.
If speech containing voiced and unvoiced sounds is used as a vocoder analysis signal but the synthesis engine doesn’t differentiate between voiced and unvoiced sounds, the result sounds rather weak. To avoid this problem, the synthesis section of the vocoder must produce different sounds for the voiced and unvoiced parts of the signal.
EVOC 20 PS includes an Unvoiced/Voiced detector for this specific purpose. This unit detects the unvoiced portions of the sound in the analysis signal and then substitutes the corresponding portions in the synthesis signal with noise, with a mixture of noise and synthesizer signal, or with the original signal. If the U/V detector detects voiced parts, it passes this information to the Synthesis section, which uses the normal synthesis signal for these portions.
A formant is a peak in the frequency spectrum of a sound. In the context of human voices, formants are the key component that enables humans to distinguish between different vowel sounds—based purely on the frequency of the sounds. Formants in human speech and singing are produced by the vocal tract, with most vowel sounds containing four or more formants.
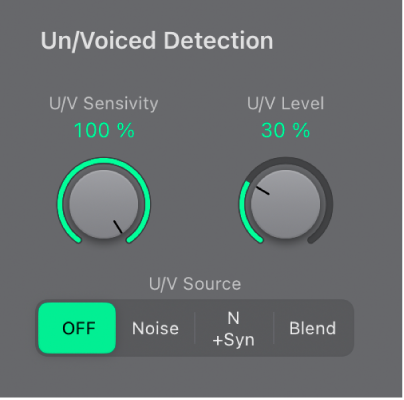
Un/Voiced detection parameters
U/V Sensitivity knob and field: Determine how responsive U/V detection is. Use higher settings to recognize more of the individual, unvoiced portions of the input signal. When high settings are used, the increased sensitivity to unvoiced signals can lead to the U/V sound source being used on the majority of the input signal, including voiced signals. Sonically, this results in a sound that resembles a radio signal that is breaking up and contains a lot of static, or noise. The U/V sound source is determined by the Mode pop-up menu.
U/V Level knob and field: Set the volume of the signal used to replace the unvoiced content in the input signal.
Important: Take care with the Level knob, particularly when a high Sensitivity value is used, to avoid internally overloading EVOC 20 PS.
U/V Source buttons: Choose the sound source used to replace the unvoiced content in the input signal.
Noise: Uses noise alone for the unvoiced portions of the sound.
N(oise) + Syn(th): Uses noise and the synthesizer for the unvoiced portions of the sound.
Blend: Uses the analysis signal after it has passed through a highpass filter for the unvoiced portions of the sound. The Sensitivity parameter has no effect when this setting is used.
Download this guide: PDF