

Highly accurate protein structure prediction with AlphaFold
- PMID: 34265844
- PMCID: PMC8371605
- DOI: 10.1038/s41586-021-03819-2
Highly accurate protein structure prediction with AlphaFold
Abstract
Proteins are essential to life, and understanding their structure can facilitate a mechanistic understanding of their function. Through an enormous experimental effort1-4, the structures of around 100,000 unique proteins have been determined5, but this represents a small fraction of the billions of known protein sequences6,7. Structural coverage is bottlenecked by the months to years of painstaking effort required to determine a single protein structure. Accurate computational approaches are needed to address this gap and to enable large-scale structural bioinformatics. Predicting the three-dimensional structure that a protein will adopt based solely on its amino acid sequence-the structure prediction component of the 'protein folding problem'8-has been an important open research problem for more than 50 years9. Despite recent progress10-14, existing methods fall far short of atomic accuracy, especially when no homologous structure is available. Here we provide the first computational method that can regularly predict protein structures with atomic accuracy even in cases in which no similar structure is known. We validated an entirely redesigned version of our neural network-based model, AlphaFold, in the challenging 14th Critical Assessment of protein Structure Prediction (CASP14)15, demonstrating accuracy competitive with experimental structures in a majority of cases and greatly outperforming other methods. Underpinning the latest version of AlphaFold is a novel machine learning approach that incorporates physical and biological knowledge about protein structure, leveraging multi-sequence alignments, into the design of the deep learning algorithm.
© 2021. The Author(s).
Conflict of interest statement
J.J., R.E., A. Pritzel, T.G., M.F., O.R., R.B., A.B., S.A.A.K., D.R. and A.W.S. have filed non-provisional patent applications 16/701,070 and PCT/EP2020/084238, and provisional patent applications 63/107,362, 63/118,917, 63/118,918, 63/118,921 and 63/118,919, each in the name of DeepMind Technologies Limited, each pending, relating to machine learning for predicting protein structures. The other authors declare no competing interests.
Figures


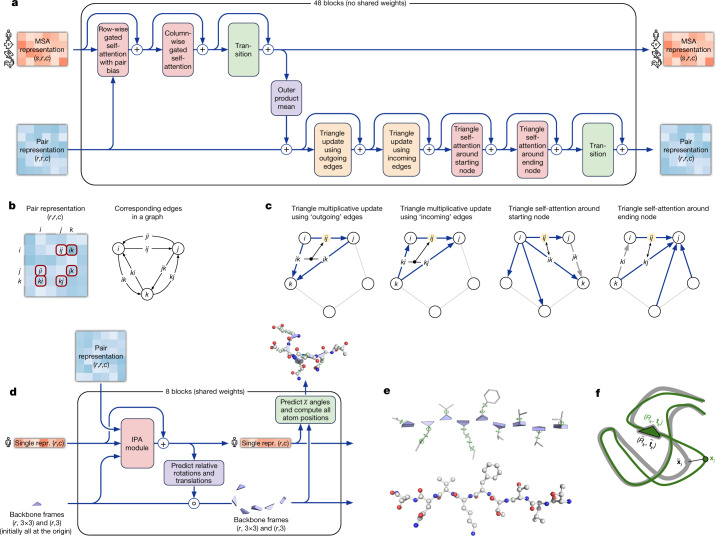
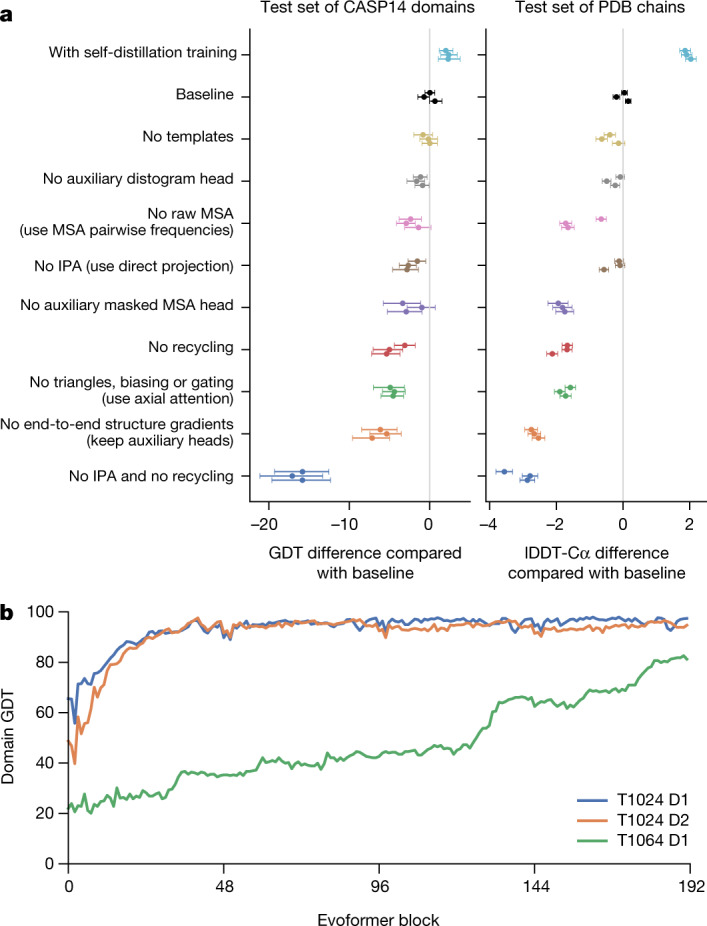

Comment in
-
Protein-structure prediction revolutionized.Nature. 2021 Aug;596(7873):487-488. doi: 10.1038/d41586-021-02265-4. Nature. 2021. PMID: 34426694 No abstract available.
-
Solution of the protein structure prediction problem at last: crucial innovations and next frontiers.Fac Rev. 2022 Dec 14;11:38. doi: 10.12703/r-01-0000020. eCollection 2022. Fac Rev. 2022. PMID: 36644294 Free PMC article.
Similar articles
-
Applying and improving AlphaFold at CASP14.Proteins. 2021 Dec;89(12):1711-1721. doi: 10.1002/prot.26257. Proteins. 2021. PMID: 34599769 Free PMC article.
-
Evaluation of Deep Neural Network ProSPr for Accurate Protein Distance Predictions on CASP14 Targets.Int J Mol Sci. 2021 Nov 27;22(23):12835. doi: 10.3390/ijms222312835. Int J Mol Sci. 2021. PMID: 34884640 Free PMC article.
-
Deep Learning-Based Advances in Protein Structure Prediction.Int J Mol Sci. 2021 May 24;22(11):5553. doi: 10.3390/ijms22115553. Int J Mol Sci. 2021. PMID: 34074028 Free PMC article. Review.
-
Improved protein structure prediction using potentials from deep learning.Nature. 2020 Jan;577(7792):706-710. doi: 10.1038/s41586-019-1923-7. Epub 2020 Jan 15. Nature. 2020. PMID: 31942072
-
Recent Progress of Protein Tertiary Structure Prediction.Molecules. 2024 Feb 13;29(4):832. doi: 10.3390/molecules29040832. Molecules. 2024. PMID: 38398585 Free PMC article. Review.
Cited by
-
GLP-1 and its derived peptides mediate pain relief through direct TRPV1 inhibition without affecting thermoregulation.Exp Mol Med. 2024 Nov 1. doi: 10.1038/s12276-024-01342-8. Online ahead of print. Exp Mol Med. 2024. PMID: 39482537
-
MYH1 deficiency disrupts outer hair cell electromotility, resulting in hearing loss.Exp Mol Med. 2024 Nov 1. doi: 10.1038/s12276-024-01338-4. Online ahead of print. Exp Mol Med. 2024. PMID: 39482536
-
Insights into genomic sequence diversity of the SAG surface antigen superfamily in geographically diverse Eimeria tenella isolates.Sci Rep. 2024 Nov 1;14(1):26251. doi: 10.1038/s41598-024-77580-7. Sci Rep. 2024. PMID: 39482455
-
Self-assembly antimicrobial peptide for treatment of multidrug-resistant bacterial infection.J Nanobiotechnology. 2024 Oct 30;22(1):668. doi: 10.1186/s12951-024-02896-5. J Nanobiotechnology. 2024. PMID: 39478570 Free PMC article.
-
GASIDN: identification of sub-Golgi proteins with multi-scale feature fusion.BMC Genomics. 2024 Oct 30;25(1):1019. doi: 10.1186/s12864-024-10954-3. BMC Genomics. 2024. PMID: 39478465 Free PMC article.
References
Publication types
MeSH terms
Substances
LinkOut - more resources
Full Text Sources
Other Literature Sources
Miscellaneous
