

A general statistical framework for subgroup identification and comparative treatment scoring
- PMID: 28211943
- PMCID: PMC5561419
- DOI: 10.1111/biom.12676
A general statistical framework for subgroup identification and comparative treatment scoring
Abstract
Many statistical methods have recently been developed for identifying subgroups of patients who may benefit from different available treatments. Compared with the traditional outcome-modeling approaches, these methods focus on modeling interactions between the treatments and covariates while by-pass or minimize modeling the main effects of covariates because the subgroup identification only depends on the sign of the interaction. However, these methods are scattered and often narrow in scope. In this article, we propose a general framework, by weighting and A-learning, for subgroup identification in both randomized clinical trials and observational studies. Our framework involves minimum modeling for the relationship between the outcome and covariates pertinent to the subgroup identification. Under the proposed framework, we may also estimate the magnitude of the interaction, which leads to the construction of scoring system measuring the individualized treatment effect. The proposed methods are quite flexible and include many recently proposed estimators as special cases. As a result, some estimators originally proposed for randomized clinical trials can be extended to observational studies, and procedures based on the weighting method can be converted to an A-learning method and vice versa. Our approaches also allow straightforward incorporation of regularization methods for high-dimensional data, as well as possible efficiency augmentation and generalization to multiple treatments. We examine the empirical performance of several procedures belonging to the proposed framework through extensive numerical studies.
Keywords: A-learning; Individualized treatment rules; Observational studies; Propensity score; Regularization.
© 2017, The International Biometric Society.
Figures
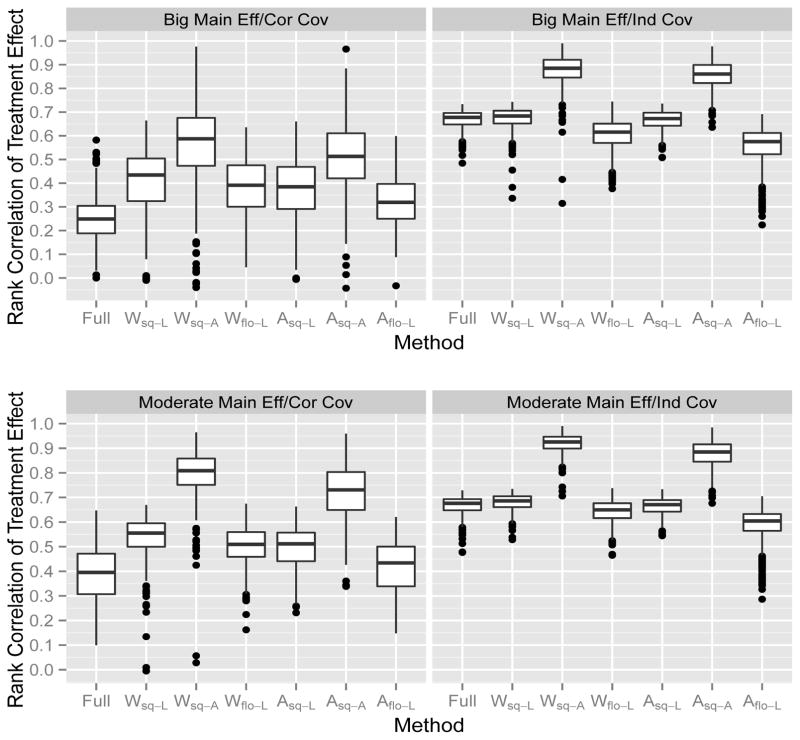
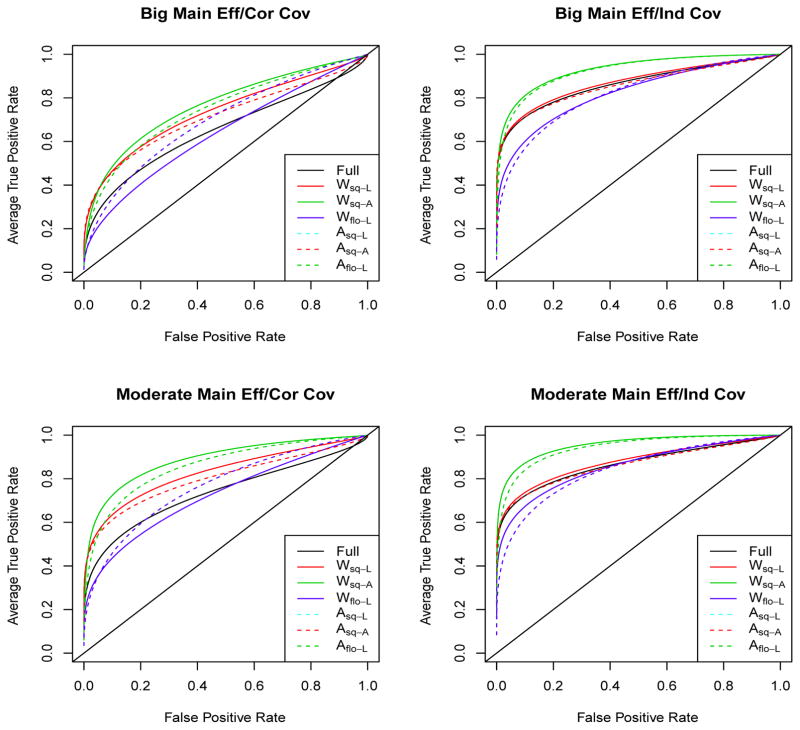
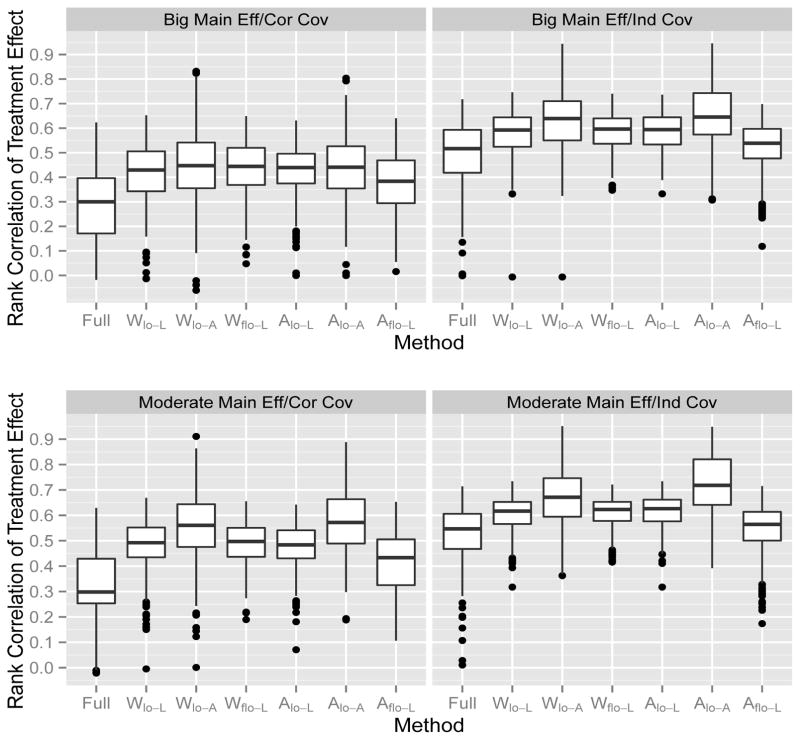
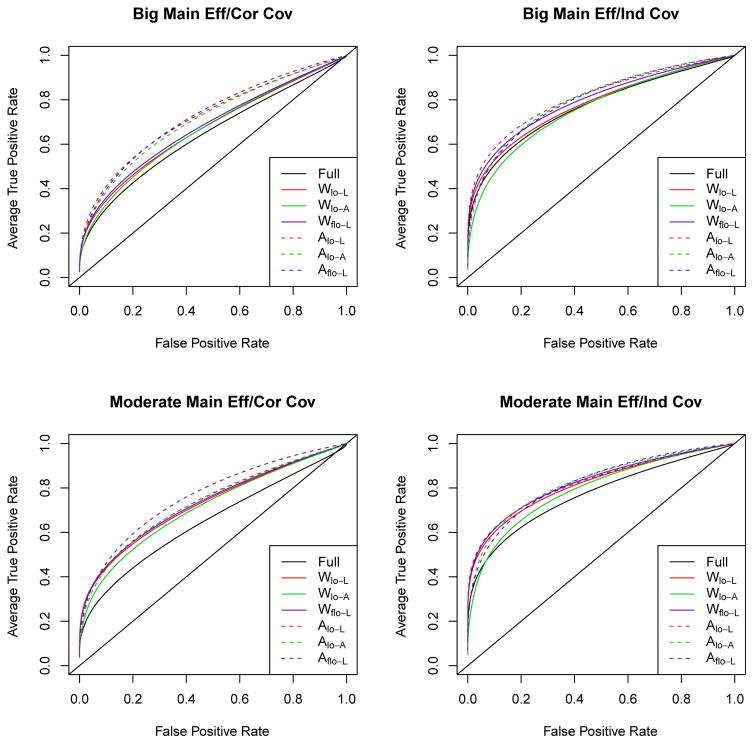
Similar articles
-
Estimating optimal treatment regimes via subgroup identification in randomized control trials and observational studies.Stat Med. 2016 Aug 30;35(19):3285-302. doi: 10.1002/sim.6920. Epub 2016 Feb 18. Stat Med. 2016. PMID: 26892174
-
Studying treatment-effect heterogeneity in precision medicine through induced subgroups.J Biopharm Stat. 2019;29(3):491-507. doi: 10.1080/10543406.2019.1579220. Epub 2019 Feb 22. J Biopharm Stat. 2019. PMID: 30794033
-
Regularized outcome weighted subgroup identification for differential treatment effects.Biometrics. 2015 Sep;71(3):645-53. doi: 10.1111/biom.12322. Epub 2015 May 11. Biometrics. 2015. PMID: 25962845 Free PMC article.
-
Treatment decisions based on scalar and functional baseline covariates.Biometrics. 2015 Dec;71(4):884-94. doi: 10.1111/biom.12346. Epub 2015 Jun 25. Biometrics. 2015. PMID: 26111145 Free PMC article.
-
A Bayesian approach to subgroup identification.J Biopharm Stat. 2014;24(1):110-29. doi: 10.1080/10543406.2013.856026. J Biopharm Stat. 2014. PMID: 24392981 Review.
Cited by
-
Multi-Armed Angle-Based Direct Learning for Estimating Optimal Individualized Treatment Rules With Various Outcomes.J Am Stat Assoc. 2020;115(530):678-691. doi: 10.1080/01621459.2018.1529597. Epub 2019 Apr 11. J Am Stat Assoc. 2020. PMID: 34219848 Free PMC article.
-
Multithreshold change plane model: Estimation theory and applications in subgroup identification.Stat Med. 2021 Jul 10;40(15):3440-3459. doi: 10.1002/sim.8976. Epub 2021 Apr 11. Stat Med. 2021. PMID: 33843100 Free PMC article.
-
Meta-analysis of individualized treatment rules via sign-coherency.Proc Mach Learn Res. 2022;193:171-198. Epub 2022 Nov 28. Proc Mach Learn Res. 2022. PMID: 37786410 Free PMC article.
-
The Oncology Biomarker Discovery framework reveals cetuximab and bevacizumab response patterns in metastatic colorectal cancer.Nat Commun. 2023 Sep 4;14(1):5391. doi: 10.1038/s41467-023-41011-4. Nat Commun. 2023. PMID: 37666855 Free PMC article.
-
Variable selection for individualised treatment rules with discrete outcomes.J R Stat Soc Ser C Appl Stat. 2023 Nov 2;73(2):298-313. doi: 10.1093/jrsssc/qlad096. eCollection 2024 Mar. J R Stat Soc Ser C Appl Stat. 2023. PMID: 38487498 Free PMC article.
References
-
- Gabriel S, Normand S. Getting the methods right–the foundation of patient-centered outcomes research. N Engl J Med. 2012;367:787–90. - PubMed
-
- Hastie TJ, Tibshirani RJ, Friedman JH. Springer series in statistics. Springer; New York: 2009. The elements of statistical learning: data mining, inference, and prediction.
Publication types
MeSH terms
Grants and funding
LinkOut - more resources
Full Text Sources
Other Literature Sources
Research Materials
