

doi: 10.1038/nmeth.3314.
Epub 2015 Mar 2.
Genome sequence-independent identification of RNA editing sites
Affiliations
- PMID: 25730491
- PMCID: PMC4382388
- DOI: 10.1038/nmeth.3314
Item in Clipboard
Genome sequence-independent identification of RNA editing sites
Nat Methods.
2015 Apr.
Abstract
RNA editing generates post-transcriptional sequence changes that can be deduced from RNA-seq data, but detection typically requires matched genomic sequence or multiple related expression data sets. We developed the GIREMI tool (genome-independent identification of RNA editing by mutual information; https://www.ibp.ucla.edu/research/xiao/GIREMI.html) to predict adenosine-to-inosine editing accurately and sensitively from a single RNA-seq data set of modest sequencing depth. Using GIREMI on existing data, we observed tissue-specific and evolutionary patterns in editing sites in the human population.
Figures
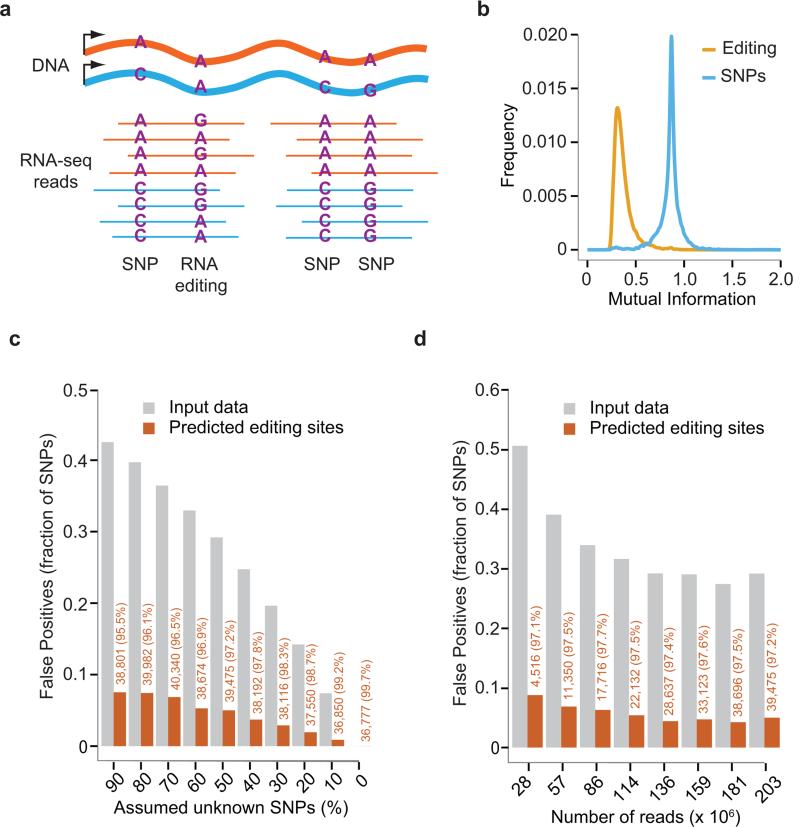
(a) RNA-Seq reads harboring multiple SNPs and/or RNA editing sites. The allelic combinations of two SNPs in the same reads are the same as their DNA haplotypes. In contrast, a SNP and an RNA editing site (or a pair of RNA editing sites) exhibit variable allelic linkage. (b) Distributions of MI associated with SNPs and RNA editing sites, respectively, estimated using GM12878 RNA-Seq data (ENCODE, cytosolic, polyA+) and its associated genome sequencing data. Our previous genome-dependent method was applied to identify RNA editing sites. (c) Predicted RNA editing sites by GIREMI in the GM12878 data. Different fractions of genomic SNPs of GM12878 were assumed as unknown by excluding them from dbSNP. For each fraction, the SNPs were selected randomly and the procedure was repeated 9 times. Results shown here are averages of the 9 randomized trials. Gray bars: percentage of GM12878 SNPs among all single-nucleotide mismatches in the mapped RNA-Seq reads after filtering for artifacts (Online Methods). Orange bars: percentage of false positives (GM12878 SNPs) among all predicted editing sites (i.e., FDR). The number of predicted editing sites and % A-to-G editing are shown in orange. (d) Performance of GIREMI at different sequencing depth (down-sampled GM12878 data). Number of mapped reads (singletons) is shown along the x-axis. Fifty percent of the GM12878 SNPs were assumed to be unknown. Labels are similar as in (c).
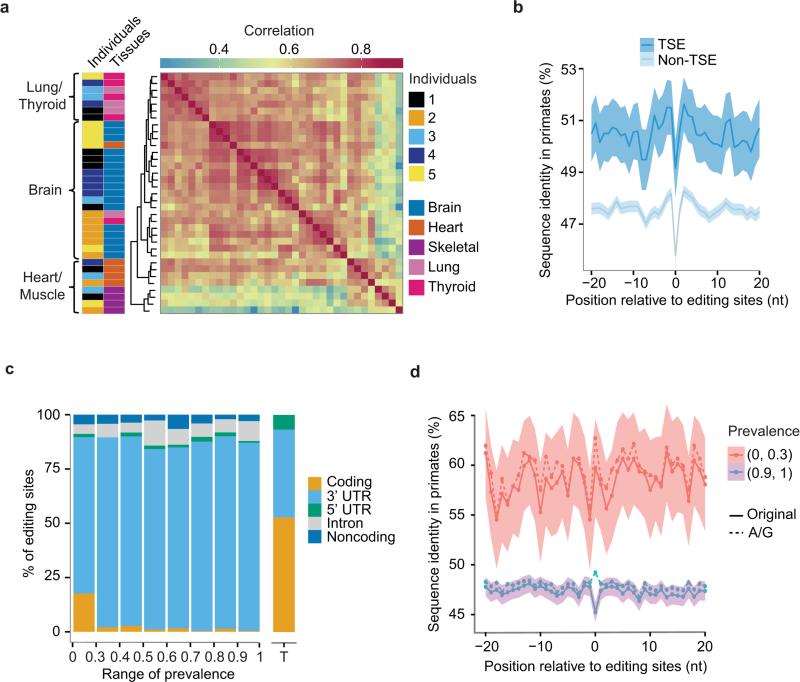
(a) Comparison of RNA editing sites across human tissues. Hierarchical clustering of Pearson correlation coefficients is shown (calculated for editing ratios of all editing sites that are present in 35 samples). Samples are labeled by the rows with indicated color codes for individuals and tissues, respectively. Different brain regions are represented in the same color given their highly similar editing profiles. (b) Conservation of the immediate neighborhood of tissue specific editing (TSE) sites in 3’ UTRs. Sequence conservation (percentage of sequence identity in primates) of each position flanking editing sites (position 0) is shown. Shaded regions represent 95% confidence interval. A similar plot for non-TSE sites is included for comparison purpose. (c) Distribution of editing sites of 93 human individuals in different types of intragenic regions. Editing sites were grouped according to their prevalence values in this population. “Noncoding” refers to noncoding genes or noncoding transcripts of coding genes. Regional distribution of nucleotides in the entire transcriptome of coding genes (without introns) is shown as a reference (rightmost bar labeled as T). (d) Conservation of 3’ UTR regions flanking two groups of editing sites with different prevalence levels (solid lines), similar as in (b). Dashed lines correspond to the sequence identity if Gs in other genomes were assumed as a conserved base given a reference nucleotide A in human.
Similar articles
-
Analysis of RNA Editing Sites from RNA-Seq Data Using GIREMI.Methods Mol Biol. 2018;1751:101-108. doi: 10.1007/978-1-4939-7710-9_7. Methods Mol Biol. 2018. PMID: 29508292
-
L-GIREMI uncovers RNA editing sites in long-read RNA-seq.Genome Biol. 2023 Jul 20;24(1):171. doi: 10.1186/s13059-023-03012-w. Genome Biol. 2023. PMID: 37474948 Free PMC article.
-
Biochemical and Transcriptome-Wide Identification of A-to-I RNA Editing Sites by ICE-Seq.Methods Enzymol. 2015;560:331-53. doi: 10.1016/bs.mie.2015.03.014. Epub 2015 Jul 9. Methods Enzymol. 2015. PMID: 26253977
-
Sequence based identification of RNA editing sites.RNA Biol. 2010 Mar-Apr;7(2):248-52. doi: 10.4161/rna.7.2.11565. Epub 2010 Mar 17. RNA Biol. 2010. PMID: 20215866 Review.
-
The evolution and adaptation of A-to-I RNA editing.PLoS Genet. 2017 Nov 28;13(11):e1007064. doi: 10.1371/journal.pgen.1007064. eCollection 2017 Nov. PLoS Genet. 2017. PMID: 29182635 Free PMC article. Review.
Cited by
-
RNA editing regulates lncRNA splicing in human early embryo development.PLoS Comput Biol. 2021 Dec 1;17(12):e1009630. doi: 10.1371/journal.pcbi.1009630. eCollection 2021 Dec. PLoS Comput Biol. 2021. PMID: 34851956 Free PMC article.
-
Repurposing RNA sequencing for discovery of RNA modifications in clinical cohorts.Sci Adv. 2021 Aug 4;7(32):eabd2605. doi: 10.1126/sciadv.abd2605. Print 2021 Aug. Sci Adv. 2021. PMID: 34348892 Free PMC article.
-
Retrospect of the Two-Year Debate: What Fuels the Evolution of SARS-CoV-2: RNA Editing or Replication Error?Curr Microbiol. 2023 Mar 28;80(5):151. doi: 10.1007/s00284-023-03279-z. Curr Microbiol. 2023. PMID: 36976379 Free PMC article.
-
RED: A Java-MySQL Software for Identifying and Visualizing RNA Editing Sites Using Rule-Based and Statistical Filters.PLoS One. 2016 Mar 1;11(3):e0150465. doi: 10.1371/journal.pone.0150465. eCollection 2016. PLoS One. 2016. PMID: 26930599 Free PMC article.
-
SPRINT: an SNP-free toolkit for identifying RNA editing sites.Bioinformatics. 2017 Nov 15;33(22):3538-3548. doi: 10.1093/bioinformatics/btx473. Bioinformatics. 2017. PMID: 29036410 Free PMC article.
References
Publication types
MeSH terms
Grants and funding
LinkOut - more resources
Full Text Sources
Other Literature Sources
