

Language Individuation and Marker Words: Shakespeare and His Maxwell's Demon
- PMID: 23826143
- PMCID: PMC3694980
- DOI: 10.1371/journal.pone.0066813
Language Individuation and Marker Words: Shakespeare and His Maxwell's Demon
Abstract
Background: Within the structural and grammatical bounds of a common language, all authors develop their own distinctive writing styles. Whether the relative occurrence of common words can be measured to produce accurate models of authorship is of particular interest. This work introduces a new score that helps to highlight such variations in word occurrence, and is applied to produce models of authorship of a large group of plays from the Shakespearean era.
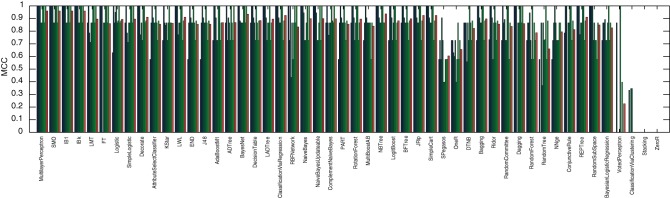
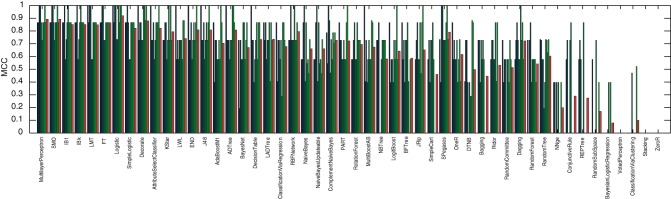
Methodology: A text corpus containing 55,055 unique words was generated from 168 plays from the Shakespearean era (16th and 17th centuries) of undisputed authorship. A new score, CM1, is introduced to measure variation patterns based on the frequency of occurrence of each word for the authors John Fletcher, Ben Jonson, Thomas Middleton and William Shakespeare, compared to the rest of the authors in the study (which provides a reference of relative word usage at that time). A total of 50 WEKA methods were applied for Fletcher, Jonson and Middleton, to identify those which were able to produce models yielding over 90% classification accuracy. This ensemble of WEKA methods was then applied to model Shakespearean authorship across all 168 plays, yielding a Matthews' correlation coefficient (MCC) performance of over 90%. Furthermore, the best model yielded an MCC of 99%.
Conclusions: Our results suggest that different authors, while adhering to the structural and grammatical bounds of a common language, develop measurably distinct styles by the tendency to over-utilise or avoid particular common words and phrasings. Considering language and the potential of words as an abstract chaotic system with a high entropy, similarities can be drawn to the Maxwell's Demon thought experiment; authors subconsciously favour or filter certain words, modifying the probability profile in ways that could reflect their individuality and style.
Conflict of interest statement
Figures
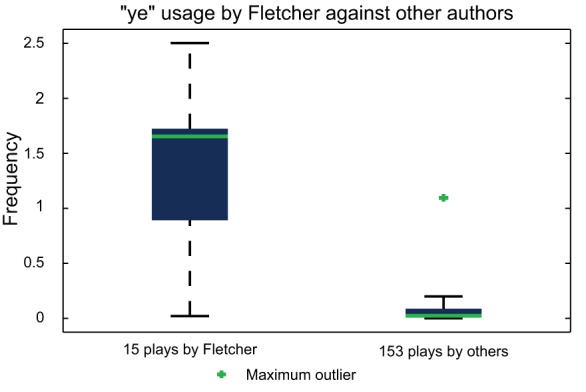
 ’ usage by Fletcher is demonstrated, indicating ‘
’ usage by Fletcher is demonstrated, indicating ‘ ’ as an appropriate choice of marker to assist in the classification of his plays. Fletcher's predilection for the word ‘
’ as an appropriate choice of marker to assist in the classification of his plays. Fletcher's predilection for the word ‘ ’ has been previously shown by Hoy .
’ has been previously shown by Hoy .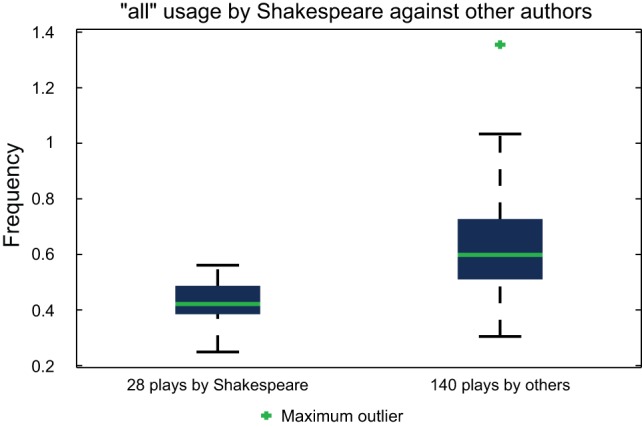
 ’ usage by Shakespeare is demonstrated, indicating ‘
’ usage by Shakespeare is demonstrated, indicating ‘ ’ as an appropriate choice of marker to assist in the classification of his plays.
’ as an appropriate choice of marker to assist in the classification of his plays.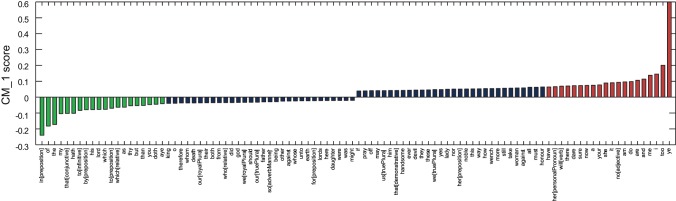
 ’ is significantly higher than that of any other marker word.
’ is significantly higher than that of any other marker word.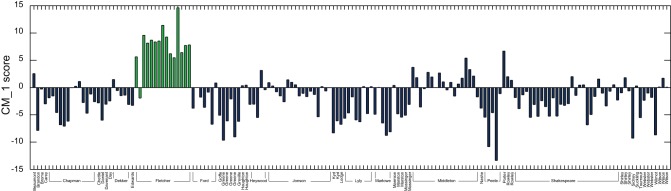
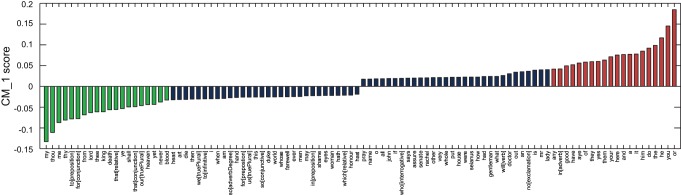
 ’ and ‘
’ and ‘ ’ as words that Jonson distinctively overuses, in contrast to ‘
’ as words that Jonson distinctively overuses, in contrast to ‘ ’ and ‘
’ and ‘ ’, which are distinctively underused.
’, which are distinctively underused.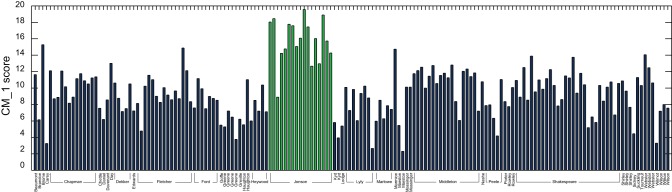
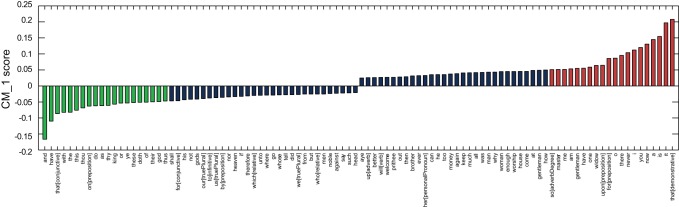
 ’, ‘
’, ‘ ’, ‘
’, ‘ ’ and the demonstrative form of ‘
’ and the demonstrative form of ‘ ’ among the words that Middleton distinctively overuses; ‘
’ among the words that Middleton distinctively overuses; ‘ ’ is ranked amongst the words that Middleton underuses, as opposed to plays by Jonson, for which ‘
’ is ranked amongst the words that Middleton underuses, as opposed to plays by Jonson, for which ‘ ’ is a strong positive marker.
’ is a strong positive marker.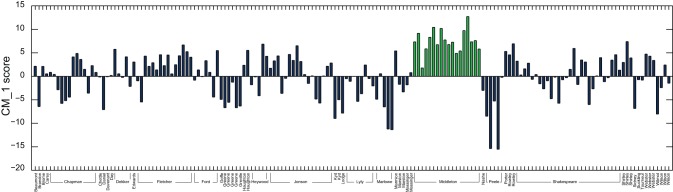
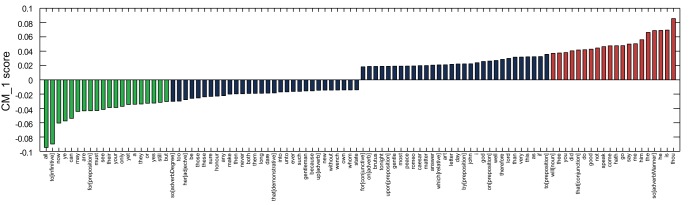
 ’, ‘
’, ‘ ’ and ‘
’ and ‘ ’ as words that Shakespeare distinctively overuses, in contrast to ‘
’ as words that Shakespeare distinctively overuses, in contrast to ‘ ’ (as discussed by Craig [29]), ‘
’ (as discussed by Craig [29]), ‘ ’ and the infinitive form of ‘
’ and the infinitive form of ‘ ’, which are distinctively underused.
’, which are distinctively underused.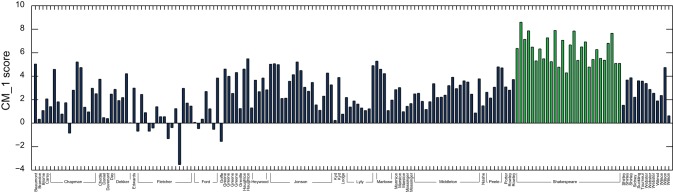
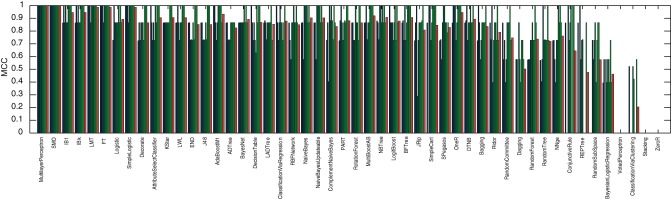
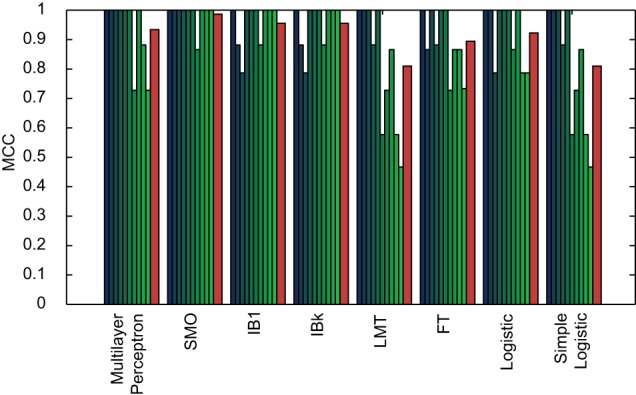
 ) yielding classification performance of 99%.
) yielding classification performance of 99%.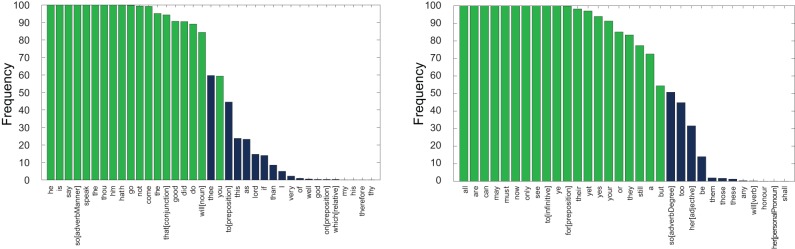
 combinations), and for each, a random selection of 14 plays by other authors. The marker words determined across the full text corpus are highlighted in green. This demonstrates this selection of words as valid for classification, and that the CM–1 score is robust against the removal and addition of plays.
combinations), and for each, a random selection of 14 plays by other authors. The marker words determined across the full text corpus are highlighted in green. This demonstrates this selection of words as valid for classification, and that the CM–1 score is robust against the removal and addition of plays.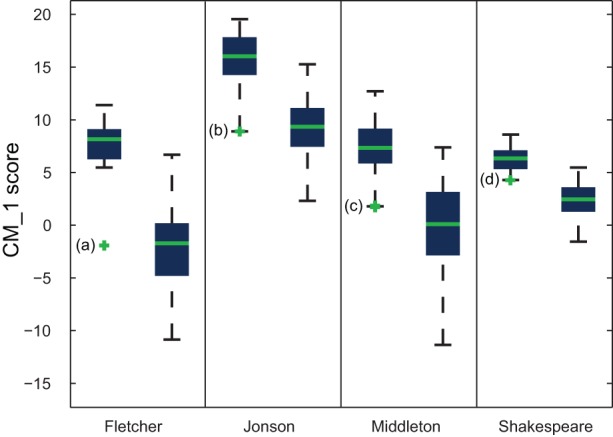
Similar articles
-
An information theoretic clustering approach for unveiling authorship affinities in Shakespearean era plays and poems.PLoS One. 2014 Oct 27;9(10):e111445. doi: 10.1371/journal.pone.0111445. eCollection 2014. PLoS One. 2014. PMID: 25347727 Free PMC article.
-
FREUD AND THE CONTROVERSY OVER SHAKESPEAREAN AUTHORSHIP.J Am Psychoanal Assoc. 1965 Jul;13:475-98. doi: 10.1177/000306516501300301. J Am Psychoanal Assoc. 1965. PMID: 14341733 No abstract available.
-
Did Shakespeare write double falsehood? Identifying individuals by creating psychological signatures with text analysis.Psychol Sci. 2015 May;26(5):570-82. doi: 10.1177/0956797614566658. Epub 2015 Apr 8. Psychol Sci. 2015. PMID: 25854277
-
A psychoanalytic study of Edward de Vere's The Tempest.J Am Acad Psychoanal Dyn Psychiatry. 2009 Winter;37(4):627-43. doi: 10.1521/jaap.2009.37.4.627. J Am Acad Psychoanal Dyn Psychiatry. 2009. PMID: 20001197 Review.
-
Chapter 33: the history of movement disorders.Handb Clin Neurol. 2010;95:501-46. doi: 10.1016/S0072-9752(08)02133-7. Handb Clin Neurol. 2010. PMID: 19892136 Review.
Cited by
-
Clustering consumers based on trust, confidence and giving behaviour: data-driven model building for charitable involvement in the Australian not-for-profit sector.PLoS One. 2015 Apr 7;10(4):e0122133. doi: 10.1371/journal.pone.0122133. eCollection 2015. PLoS One. 2015. PMID: 25849547 Free PMC article.
-
FlexDM: Simple, parallel and fault-tolerant data mining using WEKA.Source Code Biol Med. 2015 Nov 17;10:13. doi: 10.1186/s13029-015-0045-3. eCollection 2015. Source Code Biol Med. 2015. PMID: 26579209 Free PMC article.
-
'Neuroinflammation' differs categorically from inflammation: transcriptomes of Alzheimer's disease, Parkinson's disease, schizophrenia and inflammatory diseases compared.Neurogenetics. 2014 Aug;15(3):201-12. doi: 10.1007/s10048-014-0409-x. Epub 2014 Jun 15. Neurogenetics. 2014. PMID: 24928144
-
An information theoretic clustering approach for unveiling authorship affinities in Shakespearean era plays and poems.PLoS One. 2014 Oct 27;9(10):e111445. doi: 10.1371/journal.pone.0111445. eCollection 2014. PLoS One. 2014. PMID: 25347727 Free PMC article.
-
Iteratively refining breast cancer intrinsic subtypes in the METABRIC dataset.BioData Min. 2016 Jan 13;9:2. doi: 10.1186/s13040-015-0078-9. eCollection 2016. BioData Min. 2016. PMID: 26770261 Free PMC article.
References
-
- De Saussure F (2011) Course in general linguistics. Columbia University Press.
-
- Johnstone B, Bean JM (1997) Self-expression and linguistic variation. Language in Society 26: 221–246.
-
- Ellegård A (1962) A statistical method for determining authorship: The Junius Letters, 1769–1772. Acta Universitatis Gothoburgensis.
-
- Mosteller F, Wallace D (1964) Inference and disputed authorship: The Federalist. Addison-Wesley.
-
- Burrows J (1987) Word-patterns and story-shapes: The statistical analysis of narrative style. Literary and Linguistic Computing 2: 61–70.
Publication types
MeSH terms
Personal name as subject
- Actions
Grants and funding
LinkOut - more resources
Full Text Sources
Other Literature Sources
