

The Pfam protein families database
- PMID: 22127870
- PMCID: PMC3245129
- DOI: 10.1093/nar/gkr1065
The Pfam protein families database
Abstract
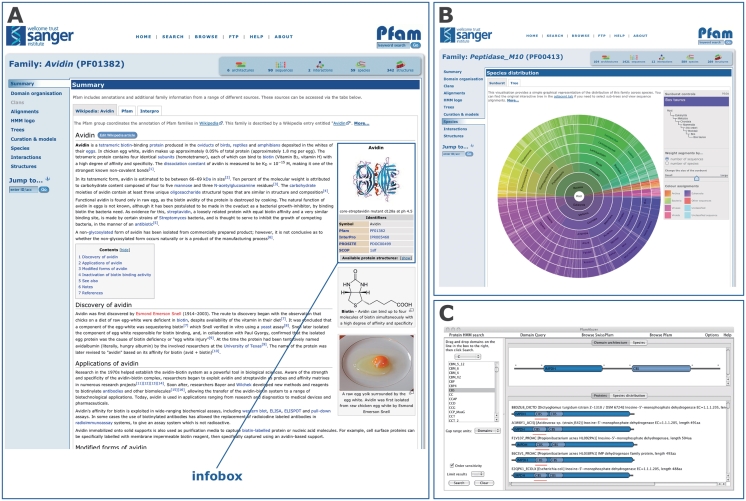
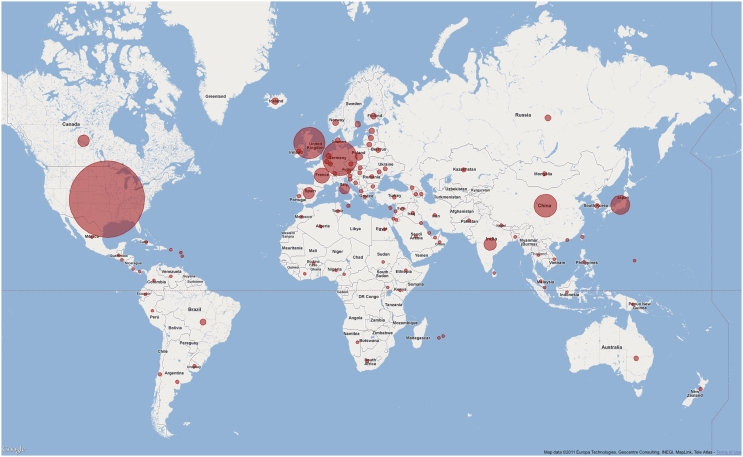
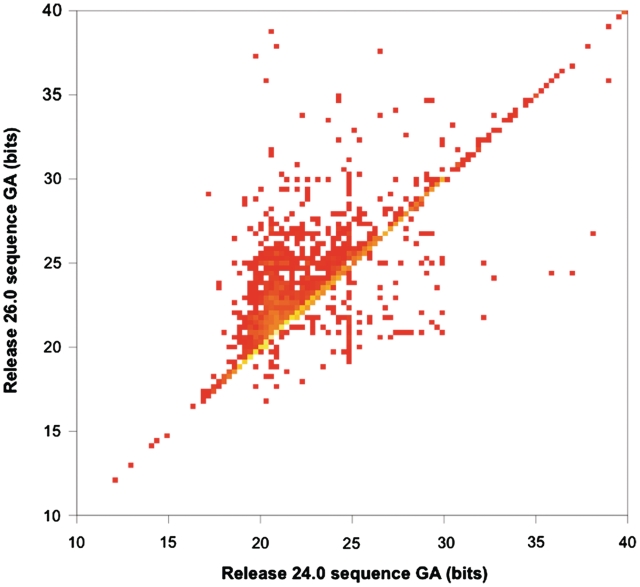
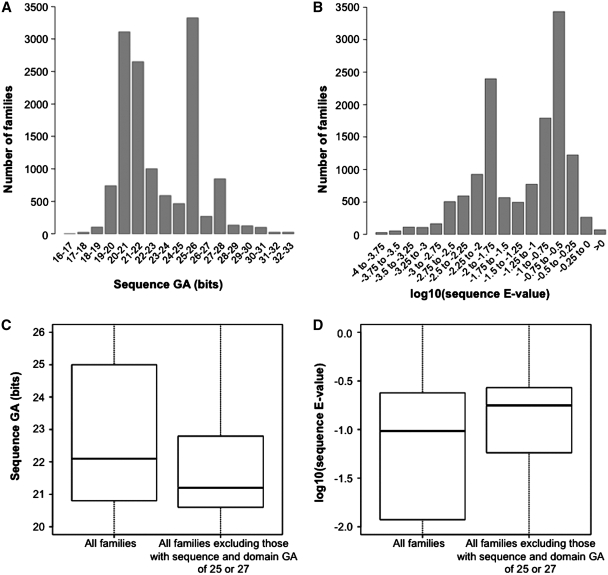
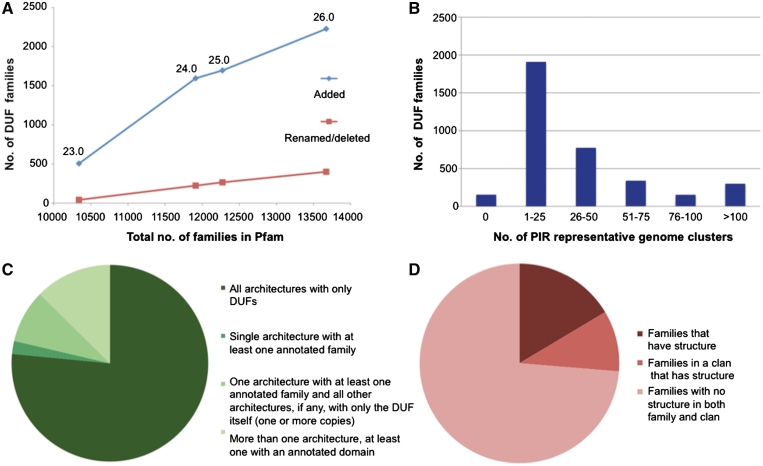
Pfam is a widely used database of protein families, currently containing more than 13,000 manually curated protein families as of release 26.0. Pfam is available via servers in the UK (http://pfam.sanger.ac.uk/), the USA (http://pfam.janelia.org/) and Sweden (http://pfam.sbc.su.se/). Here, we report on changes that have occurred since our 2010 NAR paper (release 24.0). Over the last 2 years, we have generated 1840 new families and increased coverage of the UniProt Knowledgebase (UniProtKB) to nearly 80%. Notably, we have taken the step of opening up the annotation of our families to the Wikipedia community, by linking Pfam families to relevant Wikipedia pages and encouraging the Pfam and Wikipedia communities to improve and expand those pages. We continue to improve the Pfam website and add new visualizations, such as the 'sunburst' representation of taxonomic distribution of families. In this work we additionally address two topics that will be of particular interest to the Pfam community. First, we explain the definition and use of family-specific, manually curated gathering thresholds. Second, we discuss some of the features of domains of unknown function (also known as DUFs), which constitute a rapidly growing class of families within Pfam.
Figures
Similar articles
-
Pfam: the protein families database.Nucleic Acids Res. 2014 Jan;42(Database issue):D222-30. doi: 10.1093/nar/gkt1223. Epub 2013 Nov 27. Nucleic Acids Res. 2014. PMID: 24288371 Free PMC article.
-
The Pfam protein families database.Nucleic Acids Res. 2008 Jan;36(Database issue):D281-8. doi: 10.1093/nar/gkm960. Epub 2007 Nov 26. Nucleic Acids Res. 2008. PMID: 18039703 Free PMC article.
-
The Pfam protein families database.Nucleic Acids Res. 2010 Jan;38(Database issue):D211-22. doi: 10.1093/nar/gkp985. Epub 2009 Nov 17. Nucleic Acids Res. 2010. PMID: 19920124 Free PMC article.
-
Pfam 10 years on: 10,000 families and still growing.Brief Bioinform. 2008 May;9(3):210-9. doi: 10.1093/bib/bbn010. Epub 2008 Mar 15. Brief Bioinform. 2008. PMID: 18344544 Review.
-
Domain of unknown function (DUF) proteins in plants: function and perspective.Protoplasma. 2024 May;261(3):397-410. doi: 10.1007/s00709-023-01917-8. Epub 2023 Dec 30. Protoplasma. 2024. PMID: 38158398 Review.
Cited by
-
Genome-Wide Identification of the Maize Chitinase Gene Family and Analysis of Its Response to Biotic and Abiotic Stresses.Genes (Basel). 2024 Oct 15;15(10):1327. doi: 10.3390/genes15101327. Genes (Basel). 2024. PMID: 39457451 Free PMC article.
-
High-quality chromosome-level genome assembly of female Artemia franciscana reveals sex chromosome and Hox gene organization.Heliyon. 2024 Sep 28;10(19):e38687. doi: 10.1016/j.heliyon.2024.e38687. eCollection 2024 Oct 15. Heliyon. 2024. PMID: 39435060 Free PMC article.
-
Transcriptional rewiring in CD8+ T cells: implications for CAR-T cell therapy against solid tumours.Front Immunol. 2024 Sep 27;15:1412731. doi: 10.3389/fimmu.2024.1412731. eCollection 2024. Front Immunol. 2024. PMID: 39399500 Free PMC article. Review.
-
Regulatory logic and transposable element dynamics in nematode worm genomes.bioRxiv [Preprint]. 2024 Sep 16:2024.09.15.613132. doi: 10.1101/2024.09.15.613132. bioRxiv. 2024. PMID: 39345564 Free PMC article. Preprint.
-
Candidate gene analysis of rice grain shape based on genome-wide association study.Theor Appl Genet. 2024 Sep 29;137(10):241. doi: 10.1007/s00122-024-04724-8. Theor Appl Genet. 2024. PMID: 39342533
References
Publication types
MeSH terms
Substances
Grants and funding
LinkOut - more resources
Full Text Sources
Other Literature Sources
