

Automatic, context-specific generation of Gene Ontology slims
- PMID: 20929524
- PMCID: PMC3098080
- DOI: 10.1186/1471-2105-11-498
Automatic, context-specific generation of Gene Ontology slims
Abstract
Background: The use of ontologies to control vocabulary and structure annotation has added value to genome-scale data, and contributed to the capture and re-use of knowledge across research domains. Gene Ontology (GO) is widely used to capture detailed expert knowledge in genomic-scale datasets and as a consequence has grown to contain many terms, making it unwieldy for many applications. To increase its ease of manipulation and efficiency of use, subsets called GO slims are often created by collapsing terms upward into more general, high-level terms relevant to a particular context. Creation of a GO slim currently requires manipulation and editing of GO by an expert (or community) familiar with both the ontology and the biological context. Decisions about which terms to include are necessarily subjective, and the creation process itself and subsequent curation are time-consuming and largely manual.
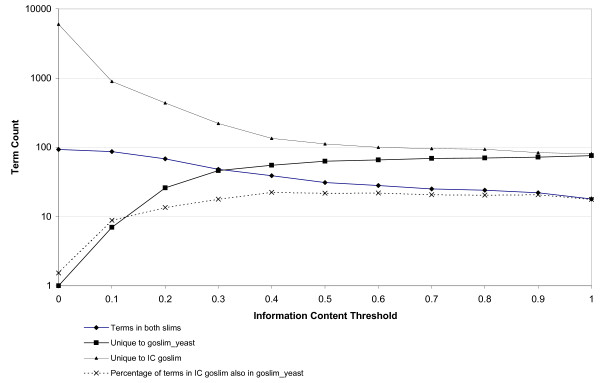
Results: Here we present an objective framework for generating customised ontology slims for specific annotated datasets, exploiting information latent in the structure of the ontology graph and in the annotation data. This framework combines ontology engineering approaches, and a data-driven algorithm that draws on graph and information theory. We illustrate this method by application to GO, generating GO slims at different information thresholds, characterising their depth of semantics and demonstrating the resulting gains in statistical power.
Conclusions: Our GO slim creation pipeline is available for use in conjunction with any GO-annotated dataset, and creates dataset-specific, objectively defined slims. This method is fast and scalable for application to other biomedical ontologies.
Figures






Similar articles
-
GOcats: A tool for categorizing Gene Ontology into subgraphs of user-defined concepts.PLoS One. 2020 Jun 11;15(6):e0233311. doi: 10.1371/journal.pone.0233311. eCollection 2020. PLoS One. 2020. PMID: 32525872 Free PMC article.
-
Extracting Cross-Ontology Weighted Association Rules from Gene Ontology Annotations.IEEE/ACM Trans Comput Biol Bioinform. 2016 Mar-Apr;13(2):197-208. doi: 10.1109/TCBB.2015.2462348. IEEE/ACM Trans Comput Biol Bioinform. 2016. PMID: 27045823
-
How to link ontologies and protein-protein interactions to literature: text-mining approaches and the BioCreative experience.Database (Oxford). 2012 Mar 21;2012:bas017. doi: 10.1093/database/bas017. Print 2012. Database (Oxford). 2012. PMID: 22438567 Free PMC article.
-
Gene Ontology annotation of the rice blast fungus, Magnaporthe oryzae.BMC Microbiol. 2009 Feb 19;9 Suppl 1(Suppl 1):S8. doi: 10.1186/1471-2180-9-S1-S8. BMC Microbiol. 2009. PMID: 19278556 Free PMC article. Review.
-
How Does the Scientific Community Contribute to Gene Ontology?Methods Mol Biol. 2017;1446:85-93. doi: 10.1007/978-1-4939-3743-1_7. Methods Mol Biol. 2017. PMID: 27812937 Review.
Cited by
-
A new method for evaluating the impacts of semantic similarity measures on the annotation of gene sets.PLoS One. 2018 Nov 27;13(11):e0208037. doi: 10.1371/journal.pone.0208037. eCollection 2018. PLoS One. 2018. PMID: 30481204 Free PMC article.
-
Comparative Proteomic Analysis of Cotton Fiber Development and Protein Extraction Method Comparison in Late Stage Fibers.Proteomes. 2016 Feb 3;4(1):7. doi: 10.3390/proteomes4010007. Proteomes. 2016. PMID: 28248216 Free PMC article.
-
Using predictive specificity to determine when gene set analysis is biologically meaningful.Nucleic Acids Res. 2017 Feb 28;45(4):e20. doi: 10.1093/nar/gkw957. Nucleic Acids Res. 2017. PMID: 28204549 Free PMC article.
-
Gene set selection via LASSO penalized regression (SLPR).Nucleic Acids Res. 2017 Jul 7;45(12):e114. doi: 10.1093/nar/gkx291. Nucleic Acids Res. 2017. PMID: 28472344 Free PMC article.
-
Prediction of protein group function by iterative classification on functional relevance network.Bioinformatics. 2019 Apr 15;35(8):1388-1394. doi: 10.1093/bioinformatics/bty787. Bioinformatics. 2019. PMID: 30192921 Free PMC article.
References
-
- Huala E, Dickerman AW, Garcia-Hernandez M, Weems D, Reiser L, LaFond F, Hanley D, Kiphart D, Zhuang M, Huang W. et al.The Arabidopsis Information Resource (TAIR): a comprehensive database and web-based information retrieval, analysis, and visualization system for a model plant. Nucleic Acids Research. 2001;29(1):102–105. doi: 10.1093/nar/29.1.102. - DOI - PMC - PubMed
Publication types
MeSH terms
LinkOut - more resources
Full Text Sources
Research Materials
