

Proteomics analysis unravels the functional repertoire of coronavirus nonstructural protein 3
- PMID: 18367524
- PMCID: PMC2395186
- DOI: 10.1128/JVI.02631-07
Proteomics analysis unravels the functional repertoire of coronavirus nonstructural protein 3
Abstract
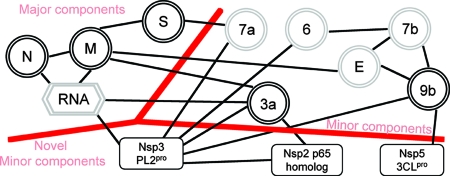
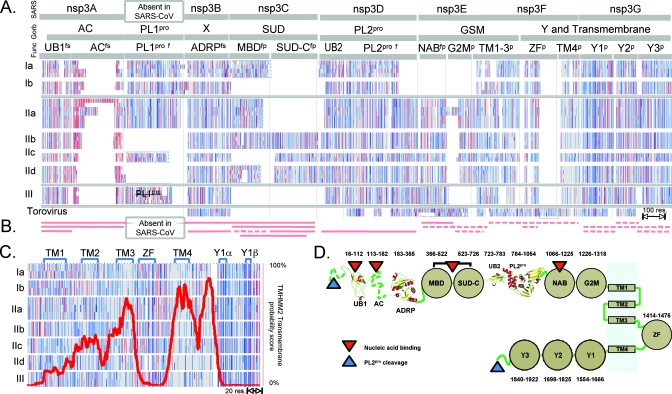
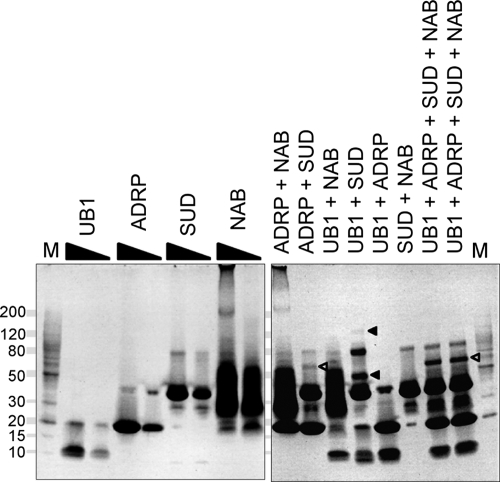
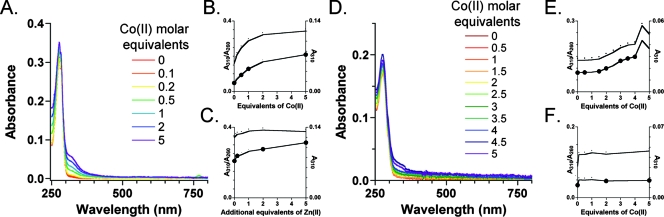
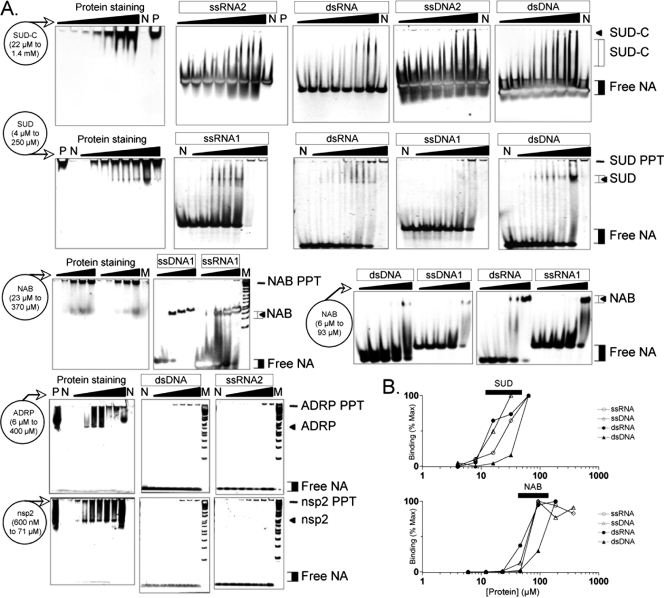
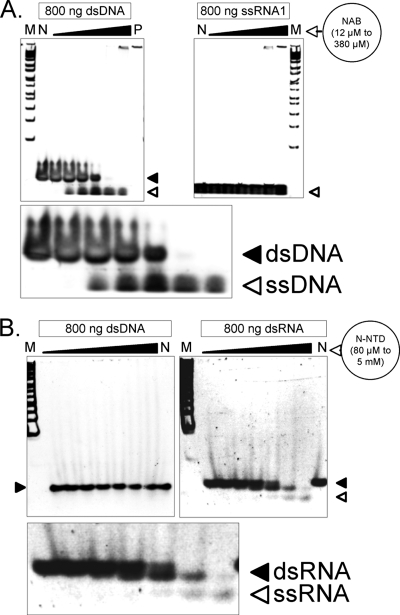
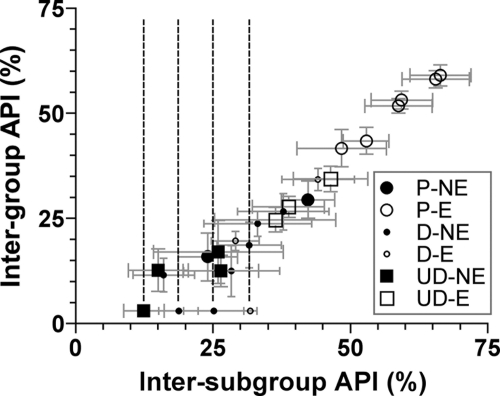
Severe acute respiratory syndrome (SARS) coronavirus infection and growth are dependent on initiating signaling and enzyme actions upon viral entry into the host cell. Proteins packaged during virus assembly may subsequently form the first line of attack and host manipulation upon infection. A complete characterization of virion components is therefore important to understanding the dynamics of early stages of infection. Mass spectrometry and kinase profiling techniques identified nearly 200 incorporated host and viral proteins. We used published interaction data to identify hubs of connectivity with potential significance for virion formation. Surprisingly, the hub with the most potential connections was not the viral M protein but the nonstructural protein 3 (nsp3), which is one of the novel virion components identified by mass spectrometry. Based on new experimental data and a bioinformatics analysis across the Coronaviridae, we propose a higher-resolution functional domain architecture for nsp3 that determines the interaction capacity of this protein. Using recombinant protein domains expressed in Escherichia coli, we identified two additional RNA-binding domains of nsp3. One of these domains is located within the previously described SARS-unique domain, and there is a nucleic acid chaperone-like domain located immediately downstream of the papain-like proteinase domain. We also identified a novel cysteine-coordinated metal ion-binding domain. Analyses of interdomain interactions and provisional functional annotation of the remaining, so-far-uncharacterized domains are presented. Overall, the ensemble of data surveyed here paint a more complete picture of nsp3 as a conserved component of the viral protein processing machinery, which is intimately associated with viral RNA in its role as a virion component.
Figures

Similar articles
-
The SARS-Coronavirus PLnc domain of nsp3 as a replication/transcription scaffolding protein.Virus Res. 2008 May;133(2):136-48. doi: 10.1016/j.virusres.2007.11.017. Epub 2008 Feb 5. Virus Res. 2008. PMID: 18255185 Free PMC article.
-
Nsp3 of coronaviruses: Structures and functions of a large multi-domain protein.Antiviral Res. 2018 Jan;149:58-74. doi: 10.1016/j.antiviral.2017.11.001. Epub 2017 Nov 8. Antiviral Res. 2018. PMID: 29128390 Free PMC article. Review.
-
Structural and Functional Characterization of Host FHL1 Protein Interaction with Hypervariable Domain of Chikungunya Virus nsP3 Protein.J Virol. 2020 Dec 9;95(1):e01672-20. doi: 10.1128/JVI.01672-20. Print 2020 Dec 9. J Virol. 2020. PMID: 33055253 Free PMC article.
-
Dissection of amino-terminal functional domains of murine coronavirus nonstructural protein 3.J Virol. 2015 Jun;89(11):6033-47. doi: 10.1128/JVI.00197-15. Epub 2015 Mar 25. J Virol. 2015. PMID: 25810552 Free PMC article.
-
The Enigmatic Alphavirus Non-Structural Protein 3 (nsP3) Revealing Its Secrets at Last.Viruses. 2018 Feb 28;10(3):105. doi: 10.3390/v10030105. Viruses. 2018. PMID: 29495654 Free PMC article. Review.
Cited by
-
Comparative Genomic Analysis of Rapidly Evolving SARS-CoV-2 Reveals Mosaic Pattern of Phylogeographical Distribution.mSystems. 2020 Jul 28;5(4):e00505-20. doi: 10.1128/mSystems.00505-20. mSystems. 2020. PMID: 32723797 Free PMC article.
-
Proteomic analysis of purified turkey adenovirus 3 virions.Vet Res. 2015 Jul 9;46(1):79. doi: 10.1186/s13567-015-0214-z. Vet Res. 2015. PMID: 26159706 Free PMC article.
-
Utility of Proteomics in Emerging and Re-Emerging Infectious Diseases Caused by RNA Viruses.J Proteome Res. 2020 Nov 6;19(11):4259-4274. doi: 10.1021/acs.jproteome.0c00380. Epub 2020 Oct 23. J Proteome Res. 2020. PMID: 33095583 Free PMC article. Review.
-
A new cistron in the murine hepatitis virus replicase gene.J Virol. 2010 Oct;84(19):10148-58. doi: 10.1128/JVI.00901-10. Epub 2010 Jul 28. J Virol. 2010. PMID: 20668085 Free PMC article.
-
SARS-coronavirus replication is supported by a reticulovesicular network of modified endoplasmic reticulum.PLoS Biol. 2008 Sep 16;6(9):e226. doi: 10.1371/journal.pbio.0060226. PLoS Biol. 2008. PMID: 18798692 Free PMC article.
References
-
- Altschul, S. F., W. Gish, W. Miller, E. W. Myers, and D. J. Lipman. 1990. Basic local alignment search tool. J. Mol. Biol. 215403-410. - PubMed
-
- Barabási, A. L., and Z. N. Oltvai. 2004. Network biology: understanding the cell's functional organization. Nat. Rev. Genet. 5101-113. - PubMed
-
- Bern, M., D. Goldberg, W. H. McDonald, and J. R. Yates III. 2004. Automatic quality assessment of peptide tandem mass spectra. Bioinformatics 20(Suppl. 1)i49-i54. - PubMed
-
- Bertini, I., and C. Luchinat. 1984. High spin cobalt(II) as a probe for the investigation of metalloproteins. Adv. Inorg. Biochem. 671-111. - PubMed
Publication types
MeSH terms
Substances
Grants and funding
LinkOut - more resources
Full Text Sources
Other Literature Sources
Miscellaneous
