

The MicroArray Quality Control (MAQC) project shows inter- and intraplatform reproducibility of gene expression measurements
- PMID: 16964229
- PMCID: PMC3272078
- DOI: 10.1038/nbt1239
The MicroArray Quality Control (MAQC) project shows inter- and intraplatform reproducibility of gene expression measurements
Abstract
Over the last decade, the introduction of microarray technology has had a profound impact on gene expression research. The publication of studies with dissimilar or altogether contradictory results, obtained using different microarray platforms to analyze identical RNA samples, has raised concerns about the reliability of this technology. The MicroArray Quality Control (MAQC) project was initiated to address these concerns, as well as other performance and data analysis issues. Expression data on four titration pools from two distinct reference RNA samples were generated at multiple test sites using a variety of microarray-based and alternative technology platforms. Here we describe the experimental design and probe mapping efforts behind the MAQC project. We show intraplatform consistency across test sites as well as a high level of interplatform concordance in terms of genes identified as differentially expressed. This study provides a resource that represents an important first step toward establishing a framework for the use of microarrays in clinical and regulatory settings.
Figures
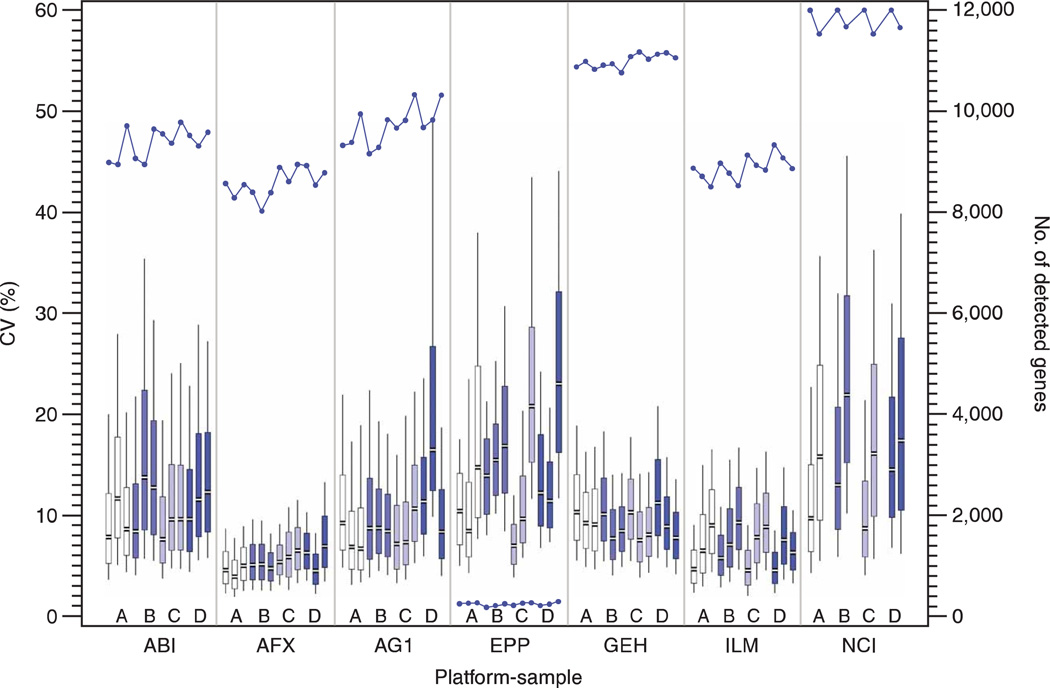
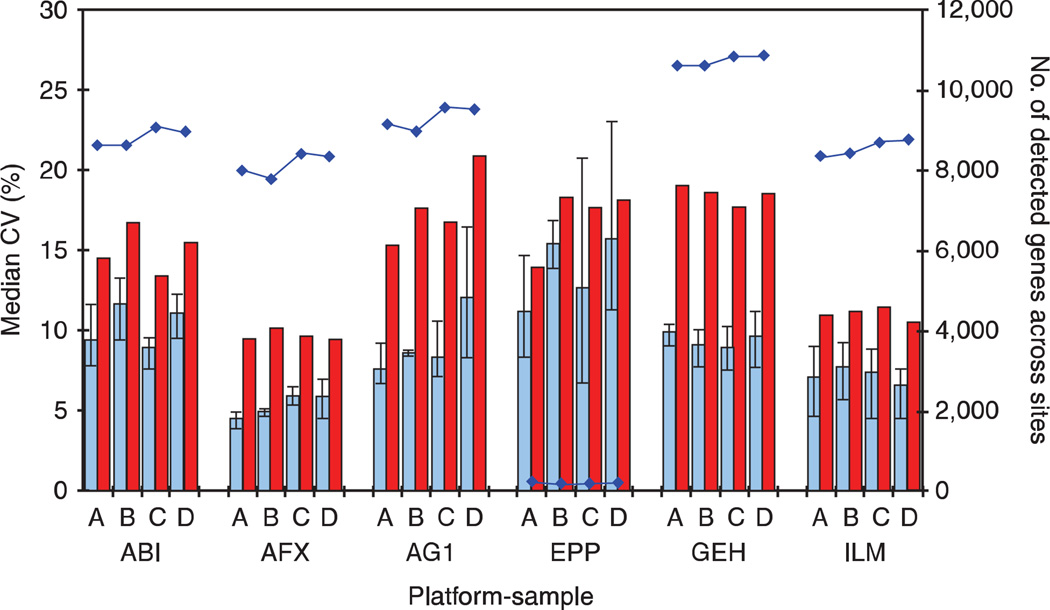
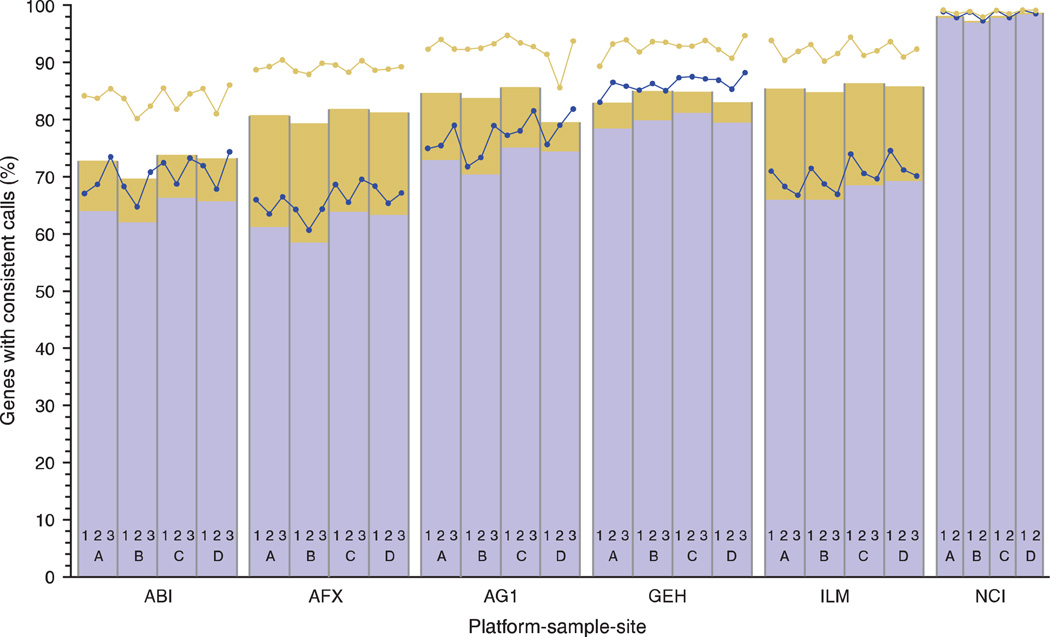
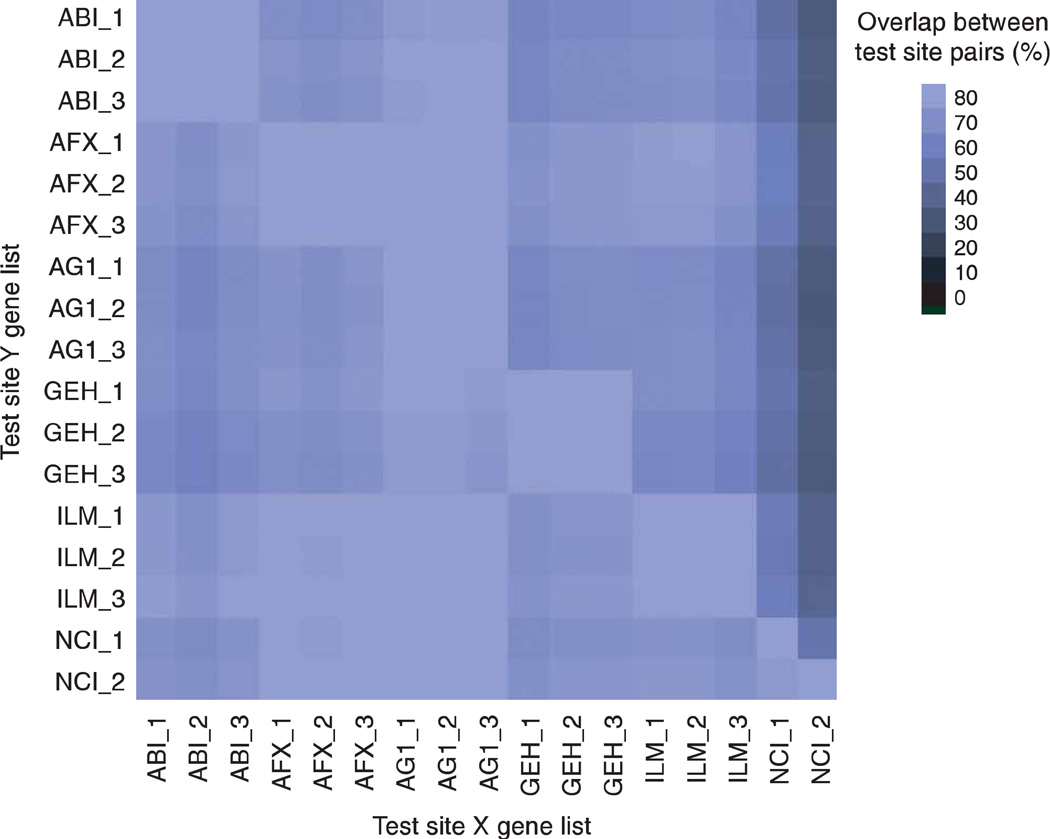
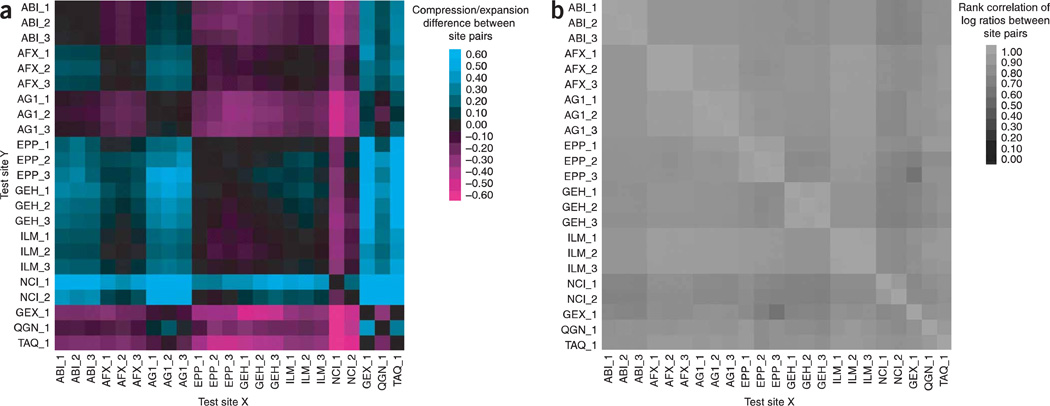
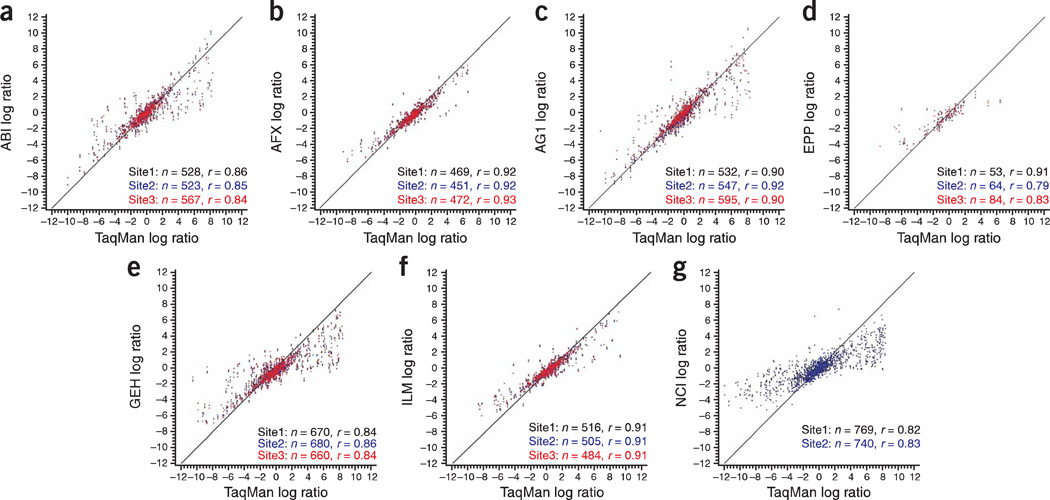
Comment in
-
Reproducibility Probability Score--incorporating measurement variability across laboratories for gene selection.Nat Biotechnol. 2006 Dec;24(12):1476-7. doi: 10.1038/nbt1206-1476. Nat Biotechnol. 2006. PMID: 17160039 No abstract available.
-
Statistical methods and microarray data.Nat Biotechnol. 2007 Jan;25(1):25-6; author reply 26-7. doi: 10.1038/nbt0107-25. Nat Biotechnol. 2007. PMID: 17211383 No abstract available.
-
MAQC papers over the cracks.Nat Biotechnol. 2007 Jan;25(1):27-8; author reply 28-9. doi: 10.1038/nbt0107-27. Nat Biotechnol. 2007. PMID: 17211385 No abstract available.
Similar articles
-
Performance comparison of one-color and two-color platforms within the MicroArray Quality Control (MAQC) project.Nat Biotechnol. 2006 Sep;24(9):1140-50. doi: 10.1038/nbt1242. Nat Biotechnol. 2006. PMID: 16964228
-
Reproducibility of microarray data: a further analysis of microarray quality control (MAQC) data.BMC Bioinformatics. 2007 Oct 25;8:412. doi: 10.1186/1471-2105-8-412. BMC Bioinformatics. 2007. PMID: 17961233 Free PMC article.
-
Evaluation of DNA microarray results with quantitative gene expression platforms.Nat Biotechnol. 2006 Sep;24(9):1115-22. doi: 10.1038/nbt1236. Nat Biotechnol. 2006. PMID: 16964225
-
Microarray RNA transcriptional profiling: part I. Platforms, experimental design and standardization.Expert Rev Mol Diagn. 2006 Jul;6(4):535-50. doi: 10.1586/14737159.6.4.535. Expert Rev Mol Diagn. 2006. PMID: 16824028 Review.
-
Expression Profiling Using Affymetrix GeneChip Microarrays.Methods Mol Biol. 2009;509:35-46. doi: 10.1007/978-1-59745-372-1_3. Methods Mol Biol. 2009. PMID: 19212713 Review.
Cited by
-
Investigating the concordance of Gene Ontology terms reveals the intra- and inter-platform reproducibility of enrichment analysis.BMC Bioinformatics. 2013 Apr 29;14:143. doi: 10.1186/1471-2105-14-143. BMC Bioinformatics. 2013. PMID: 23627640 Free PMC article.
-
A note on an exon-based strategy to identify differentially expressed genes in RNA-seq experiments.PLoS One. 2014 Dec 26;9(12):e115964. doi: 10.1371/journal.pone.0115964. eCollection 2014. PLoS One. 2014. PMID: 25541961 Free PMC article.
-
Transcriptomic profiling of human peritumoral neocortex tissues revealed genes possibly involved in tumor-induced epilepsy.PLoS One. 2013;8(2):e56077. doi: 10.1371/journal.pone.0056077. Epub 2013 Feb 13. PLoS One. 2013. PMID: 23418513 Free PMC article.
-
Transcriptional Profiling of SARS-CoV-2-Infected Calu-3 Cells Reveals Immune-Related Signaling Pathways.Pathogens. 2023 Nov 20;12(11):1373. doi: 10.3390/pathogens12111373. Pathogens. 2023. PMID: 38003837 Free PMC article.
-
Basic helix-loop-helix transcription factors JASMONATE-ASSOCIATED MYC2-LIKE1 (JAM1), JAM2, and JAM3 are negative regulators of jasmonate responses in Arabidopsis.Plant Physiol. 2013 Sep;163(1):291-304. doi: 10.1104/pp.113.220129. Epub 2013 Jul 12. Plant Physiol. 2013. PMID: 23852442 Free PMC article.
References
-
- Lesko LJ, Woodcock J. Translation of pharmacogenomics and pharmacogenetics: a regulatory perspective. Nat. Rev. Drug Discov. 2004;3:763–769. - PubMed
-
- Frueh FW. Impact of microarray data quality on genomic data submissions to the FDA. Nat. Biotechnol. 2006;24:1105–1107. - PubMed
-
- Dix DJ, et al. A framework for the use of genomics data at the EPA. Nat. Biotechnol. 2006;24:1108–1111. - PubMed
-
- Ramalho-Santos M, Yoon S, Matsuzaki Y, Mulligan RC, Melton DA. “Stemness”: transcriptional profiling of embryonic and adult stem cells. Science. 2002;298:597–600. - PubMed
Publication types
MeSH terms
Associated data
- Actions
Grants and funding
LinkOut - more resources
Full Text Sources
Other Literature Sources
Molecular Biology Databases
