

Automatic annotation of eukaryotic genes, pseudogenes and promoters
- PMID: 16925832
- PMCID: PMC1810547
- DOI: 10.1186/gb-2006-7-s1-s10
Automatic annotation of eukaryotic genes, pseudogenes and promoters
Abstract
Background: The ENCODE gene prediction workshop (EGASP) has been organized to evaluate how well state-of-the-art automatic gene finding methods are able to reproduce the manual and experimental gene annotation of the human genome. We have used Softberry gene finding software to predict genes, pseudogenes and promoters in 44 selected ENCODE sequences representing approximately 1% (30 Mb) of the human genome. Predictions of gene finding programs were evaluated in terms of their ability to reproduce the ENCODE-HAVANA annotation.
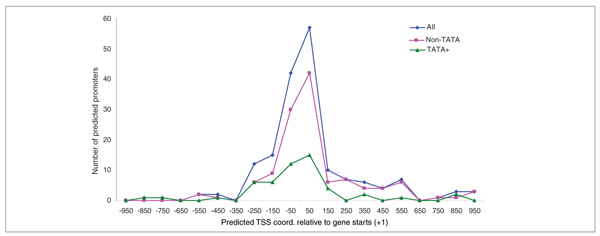
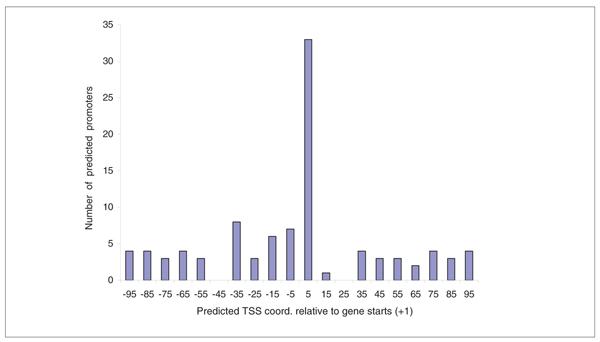
Results: The Fgenesh++ gene prediction pipeline can identify 91% of coding nucleotides with a specificity of 90%. Our automatic pseudogene finder (PSF program) found 90% of the manually annotated pseudogenes and some new ones. The Fprom promoter prediction program identifies 80% of TATA promoters sequences with one false positive prediction per 2,000 base-pairs (bp) and 50% of TATA-less promoters with one false positive prediction per 650 bp. It can be used to identify transcription start sites upstream of annotated coding parts of genes found by gene prediction software.
Conclusion: We review our software and underlying methods for identifying these three important structural and functional genome components and discuss the accuracy of predictions, recent advances and open problems in annotating genomic sequences. We have demonstrated that our methods can be effectively used for initial automatic annotation of the eukaryotic genome.
Figures



Similar articles
-
Performance assessment of promoter predictions on ENCODE regions in the EGASP experiment.Genome Biol. 2006;7 Suppl 1(Suppl 1):S3.1-13. doi: 10.1186/gb-2006-7-s1-s3. Epub 2006 Aug 7. Genome Biol. 2006. PMID: 16925837 Free PMC article. Review.
-
GENCODE: producing a reference annotation for ENCODE.Genome Biol. 2006;7 Suppl 1(Suppl 1):S4.1-9. doi: 10.1186/gb-2006-7-s1-s4. Epub 2006 Aug 7. Genome Biol. 2006. PMID: 16925838 Free PMC article.
-
AUGUSTUS at EGASP: using EST, protein and genomic alignments for improved gene prediction in the human genome.Genome Biol. 2006;7 Suppl 1(Suppl 1):S11.1-8. doi: 10.1186/gb-2006-7-s1-s11. Epub 2006 Aug 7. Genome Biol. 2006. PMID: 16925833 Free PMC article.
-
Ab initio gene finding in Drosophila genomic DNA.Genome Res. 2000 Apr;10(4):516-22. doi: 10.1101/gr.10.4.516. Genome Res. 2000. PMID: 10779491 Free PMC article.
-
EGASP: the human ENCODE Genome Annotation Assessment Project.Genome Biol. 2006;7 Suppl 1(Suppl 1):S2.1-31. doi: 10.1186/gb-2006-7-s1-s2. Epub 2006 Aug 7. Genome Biol. 2006. PMID: 16925836 Free PMC article. Review.
Cited by
-
Transgenic Kalanchoë blossfeldiana, Containing Individual rol Genes and Open Reading Frames Under 35S Promoter, Exhibit Compact Habit, Reduced Plant Growth, and Altered Ethylene Tolerance in Flowers.Front Plant Sci. 2021 May 7;12:672023. doi: 10.3389/fpls.2021.672023. eCollection 2021. Front Plant Sci. 2021. PMID: 34025708 Free PMC article.
-
Genomes of parasitic nematodes (Meloidogyne hapla, Meloidogyne incognita, Ascaris suum and Brugia malayi) have a reduced complement of small RNA interference pathway genes: knockdown can reduce host infectivity of M. incognita.Funct Integr Genomics. 2016 Jul;16(4):441-57. doi: 10.1007/s10142-016-0495-y. Epub 2016 Apr 28. Funct Integr Genomics. 2016. PMID: 27126863
-
Genomic, Transcriptomic, and Proteomic Analysis Provide Insights Into the Cold Adaptation Mechanism of the Obligate Psychrophilic Fungus Mrakia psychrophila.G3 (Bethesda). 2016 Nov 8;6(11):3603-3613. doi: 10.1534/g3.116.033308. G3 (Bethesda). 2016. PMID: 27633791 Free PMC article.
-
Molecular Cloning and Functional Analysis of Gene Clusters for the Biosynthesis of Indole-Diterpenes in Penicillium crustosum and P. janthinellum.Toxins (Basel). 2015 Jul 23;7(8):2701-22. doi: 10.3390/toxins7082701. Toxins (Basel). 2015. PMID: 26213965 Free PMC article.
-
Gene Expression Patterns for Proteins With Lectin Domains in Flax Stem Tissues Are Related to Deposition of Distinct Cell Wall Types.Front Plant Sci. 2021 Apr 26;12:634594. doi: 10.3389/fpls.2021.634594. eCollection 2021. Front Plant Sci. 2021. PMID: 33995436 Free PMC article.
References
-
- ENCODE Project http://genome.ucsc.edu/ENCODE/
Publication types
MeSH terms
LinkOut - more resources
Full Text Sources
Other Literature Sources
Medical
Miscellaneous
