

Unique and conserved features of genome and proteome of SARS-coronavirus, an early split-off from the coronavirus group 2 lineage
- PMID: 12927536
- PMCID: PMC7159028
- DOI: 10.1016/s0022-2836(03)00865-9
Unique and conserved features of genome and proteome of SARS-coronavirus, an early split-off from the coronavirus group 2 lineage
Abstract
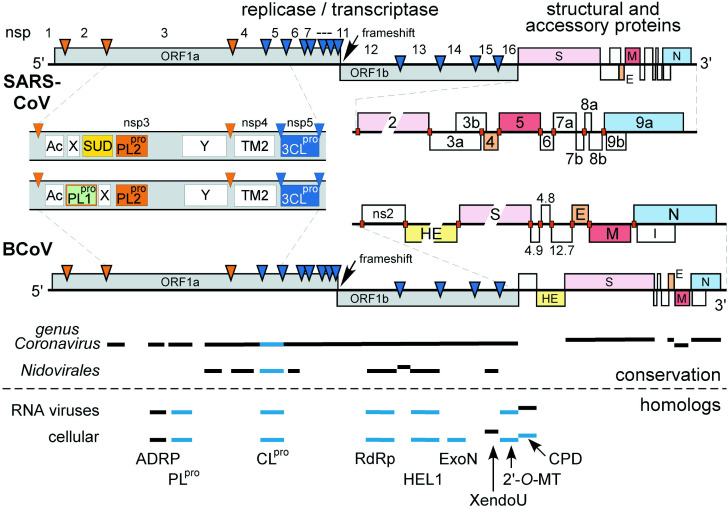
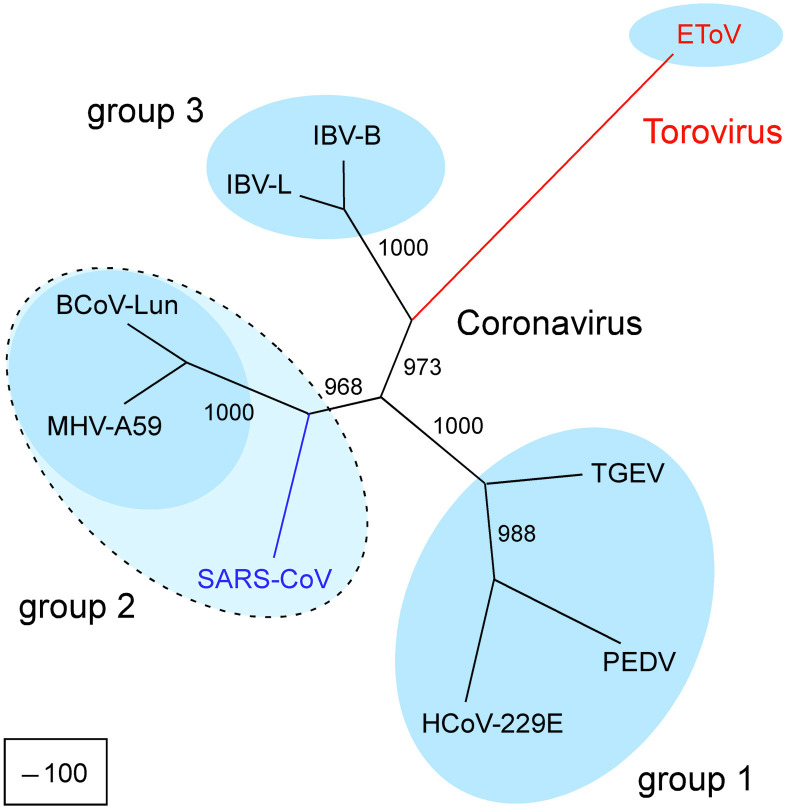
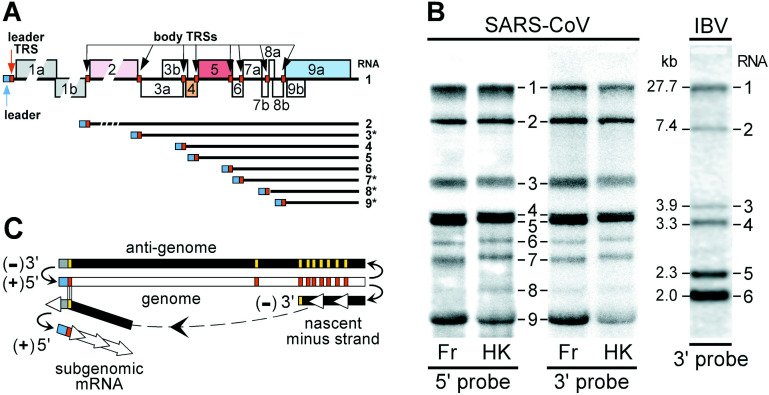
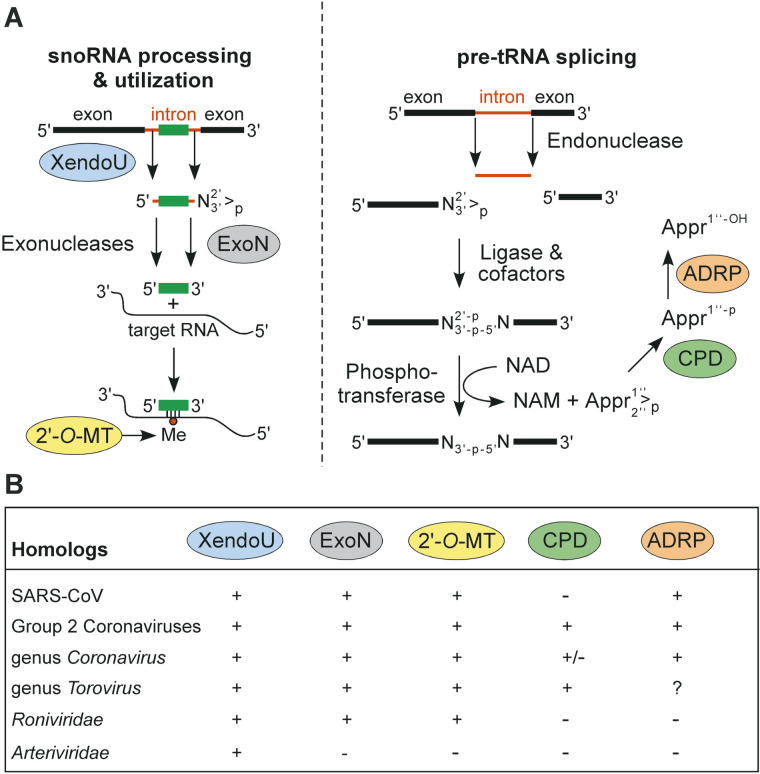
The genome organization and expression strategy of the newly identified severe acute respiratory syndrome coronavirus (SARS-CoV) were predicted using recently published genome sequences. Fourteen putative open reading frames were identified, 12 of which were predicted to be expressed from a nested set of eight subgenomic mRNAs. The synthesis of these mRNAs in SARS-CoV-infected cells was confirmed experimentally. The 4382- and 7073 amino acid residue SARS-CoV replicase polyproteins are predicted to be cleaved into 16 subunits by two viral proteinases (bringing the total number of SARS-CoV proteins to 28). A phylogenetic analysis of the replicase gene, using a distantly related torovirus as an outgroup, demonstrated that, despite a number of unique features, SARS-CoV is most closely related to group 2 coronaviruses. Distant homologs of cellular RNA processing enzymes were identified in group 2 coronaviruses, with four of them being conserved in SARS-CoV. These newly recognized viral enzymes place the mechanism of coronavirus RNA synthesis in a completely new perspective. Furthermore, together with previously described viral enzymes, they will be important targets for the design of antiviral strategies aimed at controlling the further spread of SARS-CoV.
Figures

Similar articles
-
Characterization of a novel coronavirus associated with severe acute respiratory syndrome.Science. 2003 May 30;300(5624):1394-9. doi: 10.1126/science.1085952. Epub 2003 May 1. Science. 2003. PMID: 12730500
-
Identification and characterization of severe acute respiratory syndrome coronavirus replicase proteins.J Virol. 2004 Sep;78(18):9977-86. doi: 10.1128/JVI.78.18.9977-9986.2004. J Virol. 2004. PMID: 15331731 Free PMC article.
-
The Genome sequence of the SARS-associated coronavirus.Science. 2003 May 30;300(5624):1399-404. doi: 10.1126/science.1085953. Epub 2003 May 1. Science. 2003. PMID: 12730501
-
Characterization of viral proteins encoded by the SARS-coronavirus genome.Antiviral Res. 2005 Feb;65(2):69-78. doi: 10.1016/j.antiviral.2004.10.001. Antiviral Res. 2005. PMID: 15708633 Free PMC article. Review.
-
Molecular biology of severe acute respiratory syndrome coronavirus.Curr Opin Microbiol. 2004 Aug;7(4):412-9. doi: 10.1016/j.mib.2004.06.007. Curr Opin Microbiol. 2004. PMID: 15358261 Free PMC article. Review.
Cited by
-
The emerging role of SARS-CoV-2 nonstructural protein 1 (nsp1) in epigenetic regulation of host gene expression.FEMS Microbiol Rev. 2024 Sep 18;48(5):fuae023. doi: 10.1093/femsre/fuae023. FEMS Microbiol Rev. 2024. PMID: 39231808 Free PMC article. Review.
-
Comparative Atlas of SARS-CoV-2 Substitution Mutations: A Focus on Iranian Strains Amidst Global Trends.Viruses. 2024 Aug 20;16(8):1331. doi: 10.3390/v16081331. Viruses. 2024. PMID: 39205305 Free PMC article.
-
Torsional Twist of the SARS-CoV and SARS-CoV-2 SUD-N and SUD-M domains.bioRxiv [Preprint]. 2024 Aug 14:2024.08.13.607777. doi: 10.1101/2024.08.13.607777. bioRxiv. 2024. PMID: 39185168 Free PMC article. Preprint.
-
A genus-specific nsp12 region impacts polymerase assembly in Alpha- and Gammacoronaviruses.bioRxiv [Preprint]. 2024 Jul 24:2024.07.23.604833. doi: 10.1101/2024.07.23.604833. bioRxiv. 2024. Update in: J Biol Chem. 2024 Sep 21;300(11):107802. doi: 10.1016/j.jbc.2024.107802. PMID: 39091740 Free PMC article. Updated. Preprint.
-
Deep mining of the Sequence Read Archive reveals major genetic innovations in coronaviruses and other nidoviruses of aquatic vertebrates.PLoS Pathog. 2024 Apr 22;20(4):e1012163. doi: 10.1371/journal.ppat.1012163. eCollection 2024 Apr. PLoS Pathog. 2024. PMID: 38648214 Free PMC article.
References
-
- Ksiazek T.G., Erdman D., Goldsmith C.S., Zaki S.R., Peret T., Emery S. A novel coronavirus associated with severe acute respiratory syndrome. N. Engl. J. Med. 2003;348:1953–1966. - PubMed
-
- Drosten C., Gunther S., Preiser W., van der Werf S., Brodt H.R., Becker S. Identification of a novel coronavirus in patients with severe acute respiratory syndrome. N. Engl. J. Med. 2003;348:1967–1976. - PubMed
-
- Marra M.A., Jones S.J., Astell C.R., Holt R.A., Brooks-Wilson A., Butterfield Y.S. The Genome sequence of the SARS-associated coronavirus. Science. 2003;300:1399–1404. - PubMed
-
- Rota P.A., Oberste M.S., Monroe S.S., Nix W.A., Campagnoli R., Icenogle J.P. Characterization of a novel coronavirus associated with severe acute respiratory syndrome. Science. 2003;300:1394–1399. - PubMed
Publication types
MeSH terms
Substances
Associated data
- Actions
- Actions
- Actions
LinkOut - more resources
Full Text Sources
Other Literature Sources
Miscellaneous
