

Replication and control of circular bacterial plasmids
- PMID: 9618448
- PMCID: PMC98921
- DOI: 10.1128/MMBR.62.2.434-464.1998
Replication and control of circular bacterial plasmids
Abstract
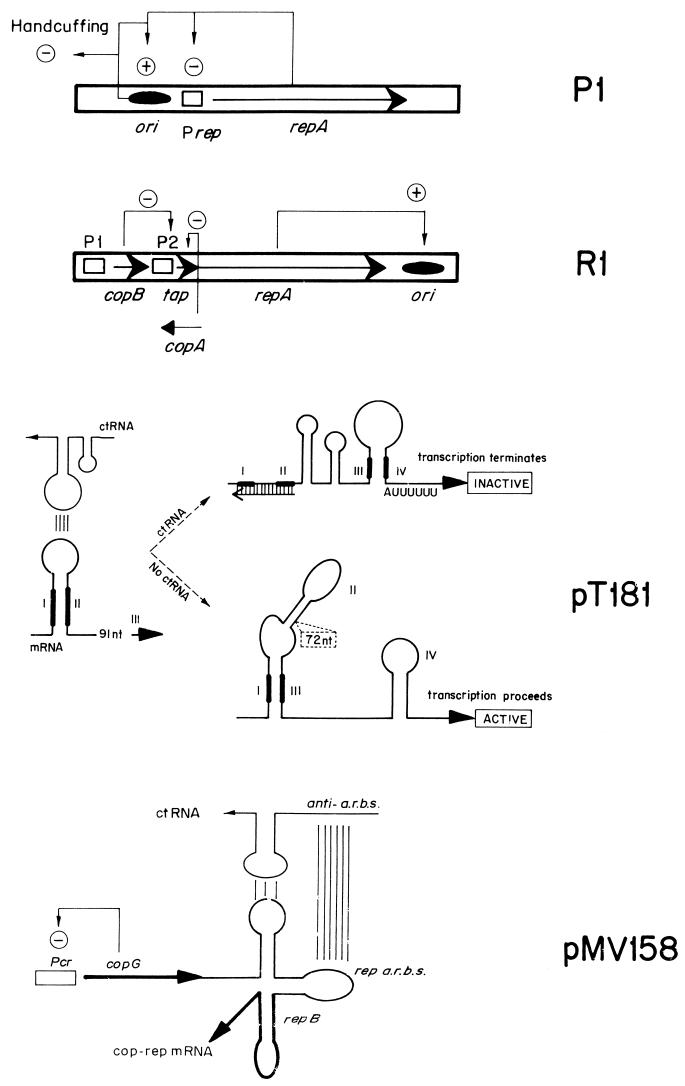
An essential feature of bacterial plasmids is their ability to replicate as autonomous genetic elements in a controlled way within the host. Therefore, they can be used to explore the mechanisms involved in DNA replication and to analyze the different strategies that couple DNA replication to other critical events in the cell cycle. In this review, we focus on replication and its control in circular plasmids. Plasmid replication can be conveniently divided into three stages: initiation, elongation, and termination. The inability of DNA polymerases to initiate de novo replication makes necessary the independent generation of a primer. This is solved, in circular plasmids, by two main strategies: (i) opening of the strands followed by RNA priming (theta and strand displacement replication) or (ii) cleavage of one of the DNA strands to generate a 3'-OH end (rolling-circle replication). Initiation is catalyzed most frequently by one or a few plasmid-encoded initiation proteins that recognize plasmid-specific DNA sequences and determine the point from which replication starts (the origin of replication). In some cases, these proteins also participate directly in the generation of the primer. These initiators can also play the role of pilot proteins that guide the assembly of the host replisome at the plasmid origin. Elongation of plasmid replication is carried out basically by DNA polymerase III holoenzyme (and, in some cases, by DNA polymerase I at an early stage), with the participation of other host proteins that form the replisome. Termination of replication has specific requirements and implications for reinitiation, studies of which have started. The initiation stage plays an additional role: it is the stage at which mechanisms controlling replication operate. The objective of this control is to maintain a fixed concentration of plasmid molecules in a growing bacterial population (duplication of the plasmid pool paced with duplication of the bacterial population). The molecules involved directly in this control can be (i) RNA (antisense RNA), (ii) DNA sequences (iterons), or (iii) antisense RNA and proteins acting in concert. The control elements maintain an average frequency of one plasmid replication per plasmid copy per cell cycle and can "sense" and correct deviations from this average. Most of the current knowledge on plasmid replication and its control is based on the results of analyses performed with pure cultures under steady-state growth conditions. This knowledge sets important parameters needed to understand the maintenance of these genetic elements in mixed populations and under environmental conditions.
Figures

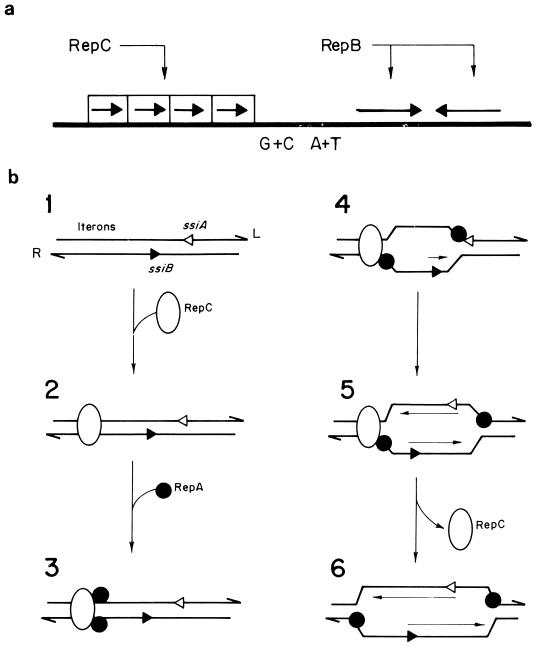
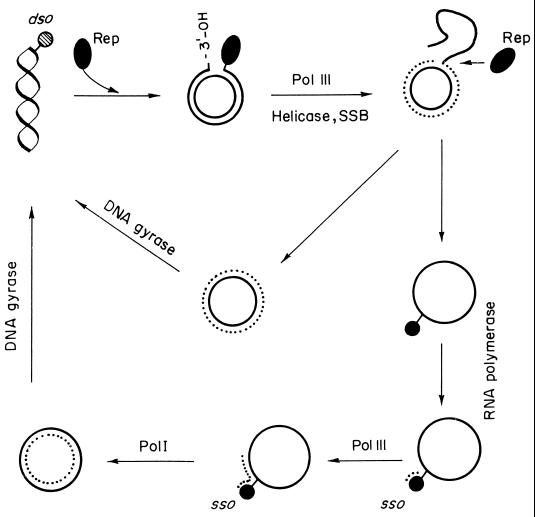
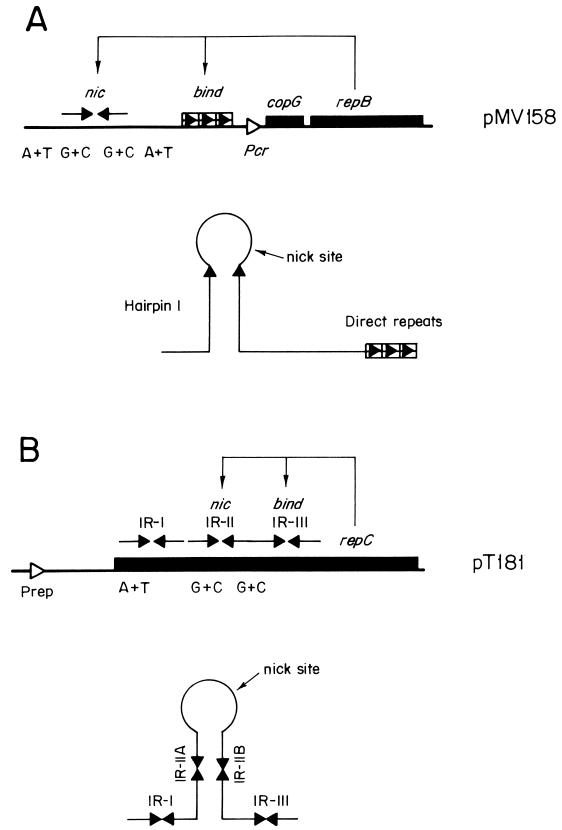
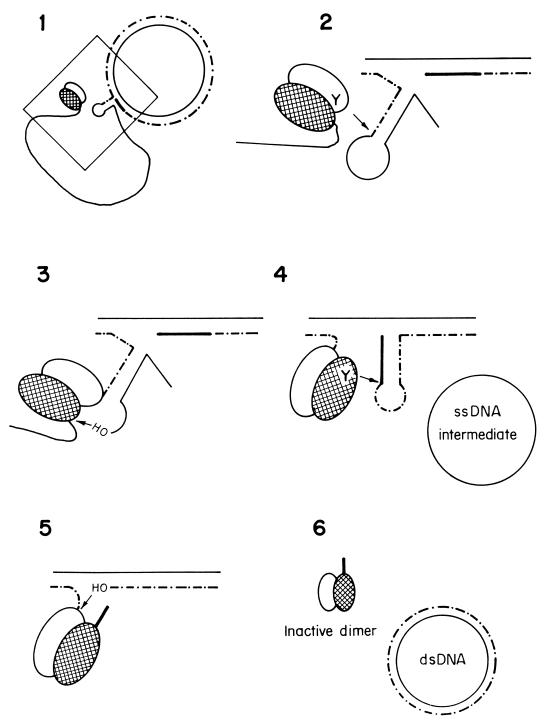
Similar articles
-
Replication of plasmids in gram-negative bacteria.Microbiol Rev. 1989 Dec;53(4):491-516. doi: 10.1128/mr.53.4.491-516.1989. Microbiol Rev. 1989. PMID: 2687680 Free PMC article. Review.
-
DNA-protein interactions during the initiation and termination of plasmid pT181 rolling-circle replication.Prog Nucleic Acid Res Mol Biol. 2003;75:113-37. doi: 10.1016/s0079-6603(03)75004-1. Prog Nucleic Acid Res Mol Biol. 2003. PMID: 14604011 Review.
-
Antisense and yet sensitive: Copy number control of rolling circle-replicating plasmids by small RNAs.Wiley Interdiscip Rev RNA. 2018 Nov;9(6):e1500. doi: 10.1002/wrna.1500. Epub 2018 Aug 3. Wiley Interdiscip Rev RNA. 2018. PMID: 30074293 Review.
-
Rolling circle-replicating plasmids from gram-positive and gram-negative bacteria: a wall falls.Mol Microbiol. 1993 May;8(5):789-96. doi: 10.1111/j.1365-2958.1993.tb01625.x. Mol Microbiol. 1993. PMID: 8355606 Review.
-
Plasmid Rolling-Circle Replication.Microbiol Spectr. 2015 Feb;3(1):PLAS-0035-2014. doi: 10.1128/microbiolspec.PLAS-0035-2014. Microbiol Spectr. 2015. PMID: 26104557 Review.
Cited by
-
Study of the effects of 3.1 THz radiation on the expression of recombinant red fluorescent protein (RFP) in E. coli.Biomed Opt Express. 2020 Jun 22;11(7):3890-3899. doi: 10.1364/BOE.392838. eCollection 2020 Jul 1. Biomed Opt Express. 2020. PMID: 33014573 Free PMC article.
-
Multiple consecutive initiation of replication producing novel brush-like intermediates at the termini of linear viral dsDNA genomes with hairpin ends.Nucleic Acids Res. 2016 Oct 14;44(18):8799-8809. doi: 10.1093/nar/gkw636. Epub 2016 Jul 12. Nucleic Acids Res. 2016. PMID: 27407114 Free PMC article.
-
The LE1 bacteriophage replicates as a plasmid within Leptospira biflexa: construction of an L. biflexa-Escherichia coli shuttle vector.J Bacteriol. 2000 Oct;182(20):5700-5. doi: 10.1128/JB.182.20.5700-5705.2000. J Bacteriol. 2000. PMID: 11004167 Free PMC article.
-
Analyzing DNA strand compositional asymmetry to identify candidate replication origins of Borrelia burgdorferi linear and circular plasmids.Genome Res. 2000 Oct;10(10):1594-604. doi: 10.1101/gr.124000. Genome Res. 2000. PMID: 11042157 Free PMC article.
-
Structure-based functional analysis of the replication protein of plasmid R6K: key amino acids at the pi/DNA interface.J Bacteriol. 2007 Jul;189(13):4953-6. doi: 10.1128/JB.00109-07. Epub 2007 Apr 20. J Bacteriol. 2007. PMID: 17449630 Free PMC article.
References
Publication types
MeSH terms
Substances
LinkOut - more resources
Full Text Sources
Other Literature Sources
