

CRISPR screening uncovers a long-range enhancer for ONECUT1 in pancreatic differentiation and links a diabetes risk variant
- PMID: 39163202
- PMCID: PMC11406439
- DOI: 10.1016/j.celrep.2024.114640
CRISPR screening uncovers a long-range enhancer for ONECUT1 in pancreatic differentiation and links a diabetes risk variant
Abstract
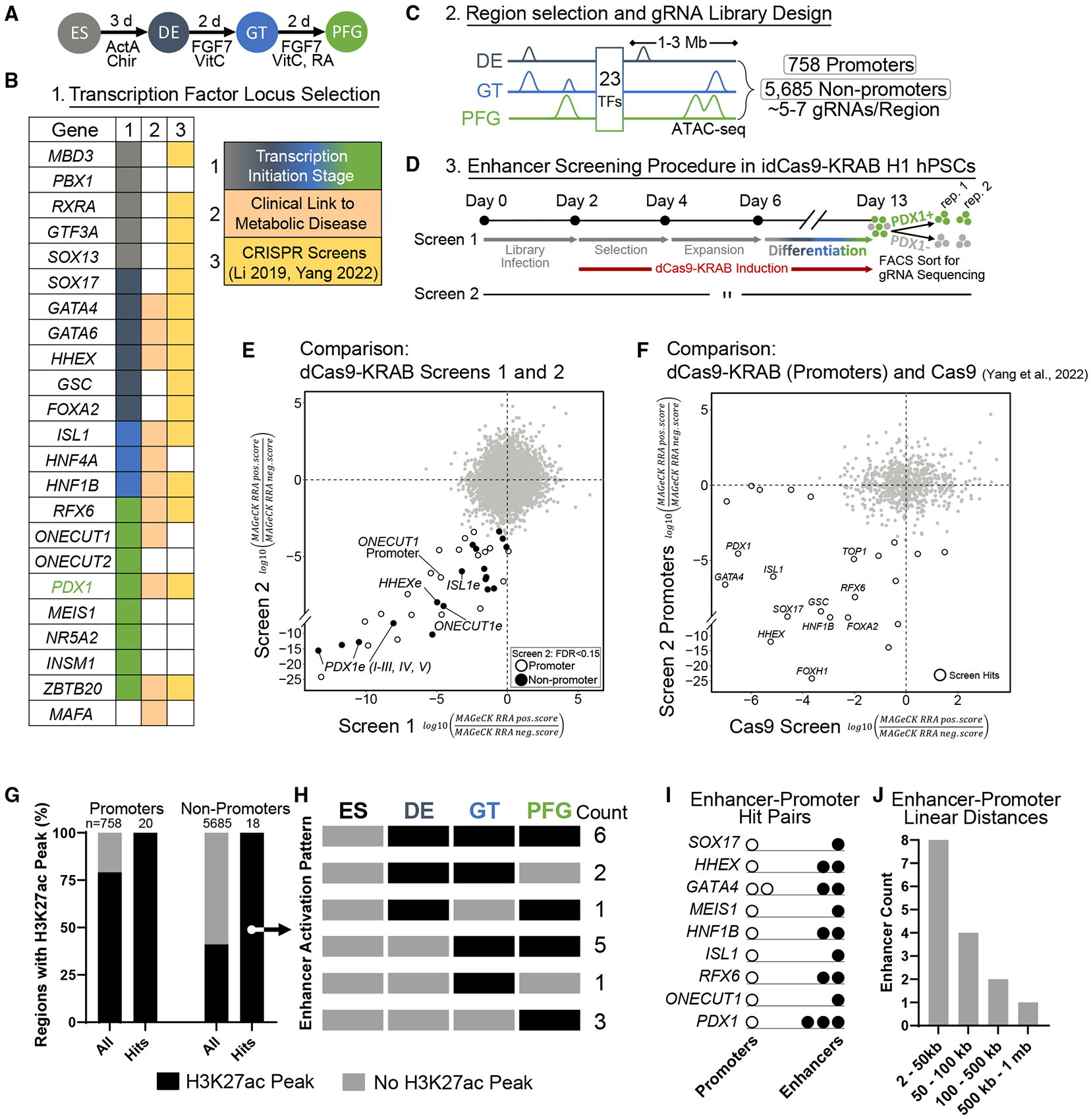
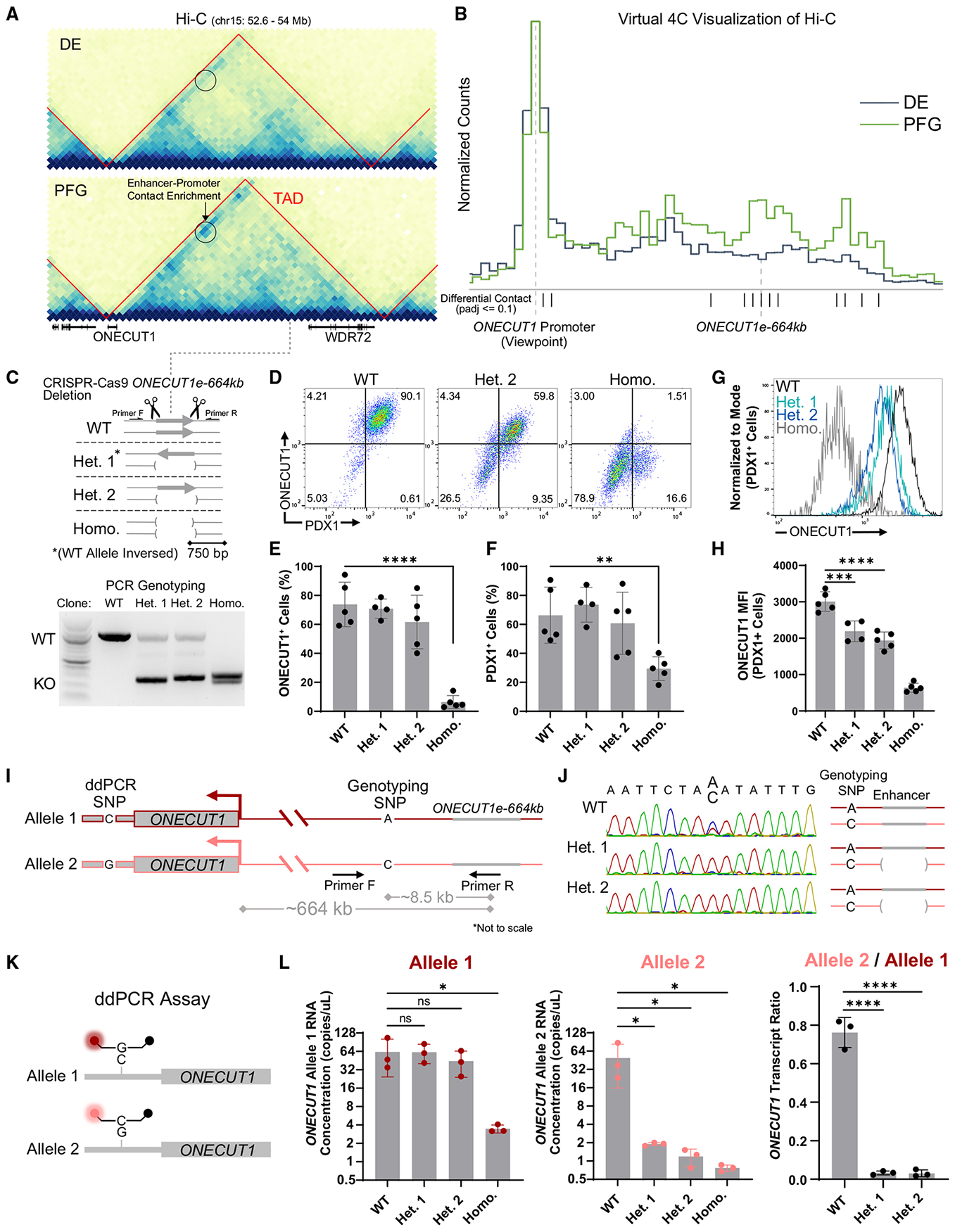
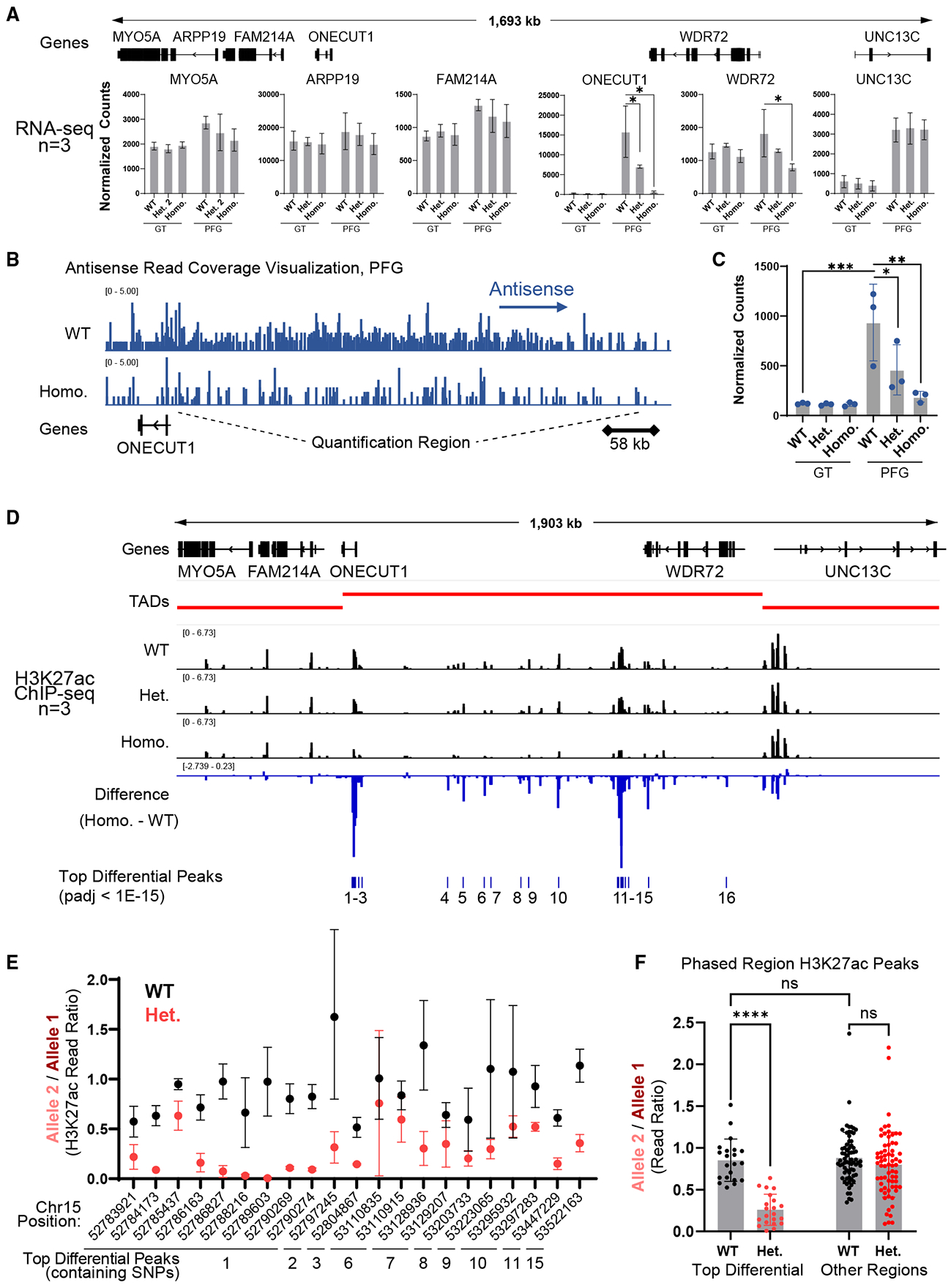
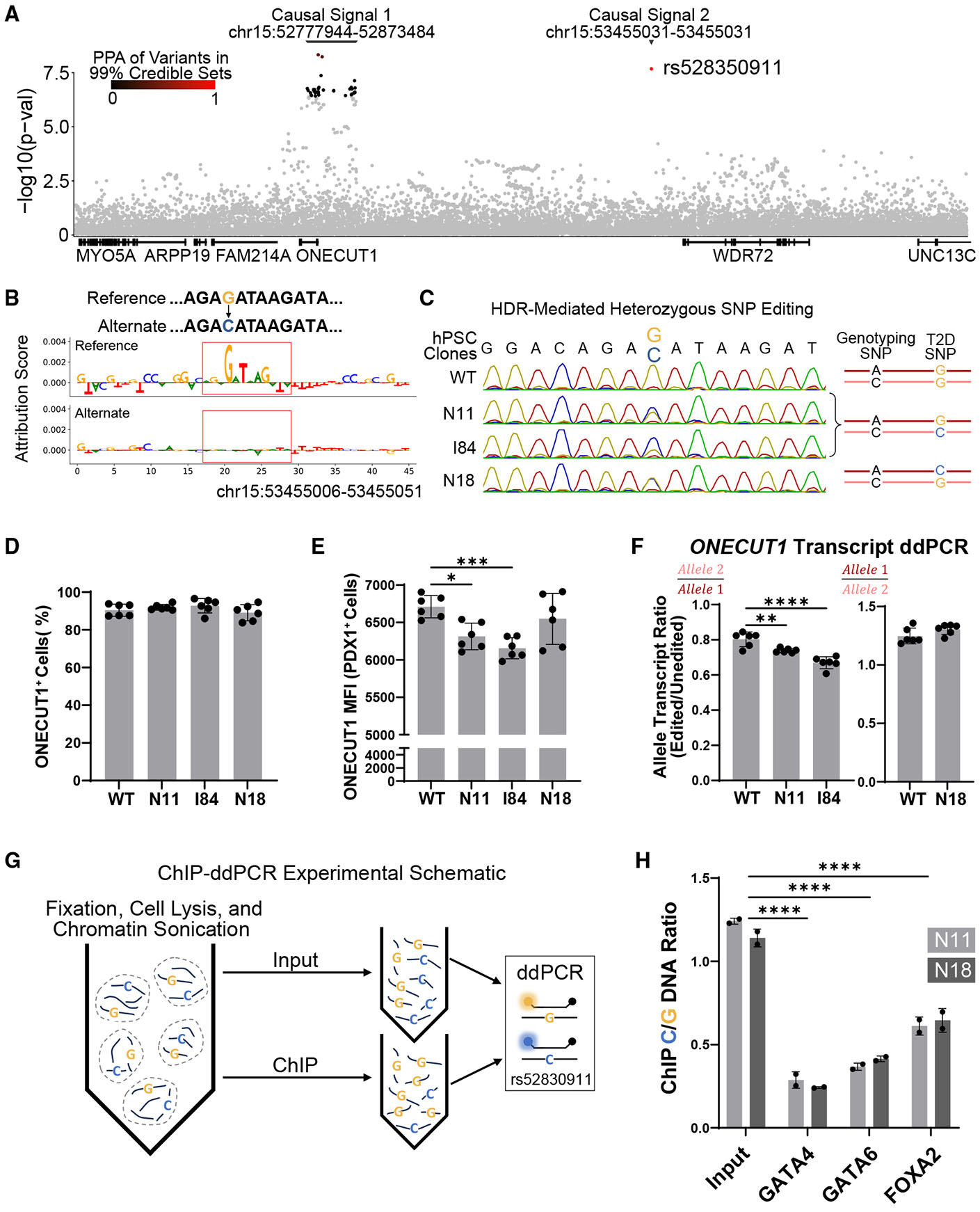
Functional enhancer annotation is critical for understanding tissue-specific transcriptional regulation and prioritizing disease-associated non-coding variants. However, unbiased enhancer discovery in disease-relevant contexts remains challenging. To identify enhancers pertinent to diabetes, we conducted a CRISPR interference (CRISPRi) screen in the human pluripotent stem cell (hPSC) pancreatic differentiation system. Among the enhancers identified, we focused on an enhancer we named ONECUT1e-664kb, ∼664 kb from the ONECUT1 promoter. Previous studies have linked ONECUT1 coding mutations to pancreatic hypoplasia and neonatal diabetes. We found that homozygous deletion of ONECUT1e-664kb in hPSCs leads to a near-complete loss of ONECUT1 expression and impaired pancreatic differentiation. ONECUT1e-664kb contains a type 2 diabetes-associated variant (rs528350911) disrupting a GATA motif. Introducing the risk variant into hPSCs reduced binding of key pancreatic transcription factors (GATA4, GATA6, and FOXA2), supporting its causal role in diabetes. This work highlights the utility of unbiased enhancer discovery in disease-relevant settings for understanding monogenic and complex disease.
Keywords: CP: Developmental biology; CP: Molecular biology; CRISPRi screen; ONECUT1; T2D; VUS; enhancer; neonatal diabetes; non-coding variant; pancreas development; type 2 diabetes; variant of uncertain significance.
Copyright © 2024 The Authors. Published by Elsevier Inc. All rights reserved.
Conflict of interest statement
Declaration of interests The authors declare no competing interests.
Figures
Update of
-
CRISPR Screening Uncovers a Long-Range Enhancer for ONECUT1 in Pancreatic Differentiation and Links a Diabetes Risk Variant.bioRxiv [Preprint]. 2024 Jun 28:2024.04.26.591412. doi: 10.1101/2024.04.26.591412. bioRxiv. 2024. Update in: Cell Rep. 2024 Aug 27;43(8):114640. doi: 10.1016/j.celrep.2024.114640 PMID: 38746154 Free PMC article. Updated. Preprint.
Similar articles
-
CRISPR Screening Uncovers a Long-Range Enhancer for ONECUT1 in Pancreatic Differentiation and Links a Diabetes Risk Variant.bioRxiv [Preprint]. 2024 Jun 28:2024.04.26.591412. doi: 10.1101/2024.04.26.591412. bioRxiv. 2024. Update in: Cell Rep. 2024 Aug 27;43(8):114640. doi: 10.1016/j.celrep.2024.114640 PMID: 38746154 Free PMC article. Updated. Preprint.
-
A ONECUT1 regulatory, non-coding region in pancreatic development and diabetes.Cell Rep. 2024 Nov 26;43(11):114853. doi: 10.1016/j.celrep.2024.114853. Epub 2024 Oct 19. Cell Rep. 2024. PMID: 39427318
-
A dose-response model for statistical analysis of chemical genetic interactions in CRISPRi screens.PLoS Comput Biol. 2024 May 20;20(5):e1011408. doi: 10.1371/journal.pcbi.1011408. eCollection 2024 May. PLoS Comput Biol. 2024. PMID: 38768228 Free PMC article.
-
Depressing time: Waiting, melancholia, and the psychoanalytic practice of care.In: Kirtsoglou E, Simpson B, editors. The Time of Anthropology: Studies of Contemporary Chronopolitics. Abingdon: Routledge; 2020. Chapter 5. In: Kirtsoglou E, Simpson B, editors. The Time of Anthropology: Studies of Contemporary Chronopolitics. Abingdon: Routledge; 2020. Chapter 5. PMID: 36137063 Free Books & Documents. Review.
-
Gestational Diabetes Mellitus: Unveiling Maternal Health Dynamics from Pregnancy Through Postpartum Perspectives.Open Res Eur. 2024 Nov 12;4:164. doi: 10.12688/openreseurope.18026.1. eCollection 2024. Open Res Eur. 2024. PMID: 39355538 Free PMC article. Review.
References
MeSH terms
Substances
Grants and funding
LinkOut - more resources
Full Text Sources
Miscellaneous
