

Viral genome sequencing methods: benefits and pitfalls of current approaches
- PMID: 38747720
- PMCID: PMC11346438
- DOI: 10.1042/BST20231322
Viral genome sequencing methods: benefits and pitfalls of current approaches
Abstract
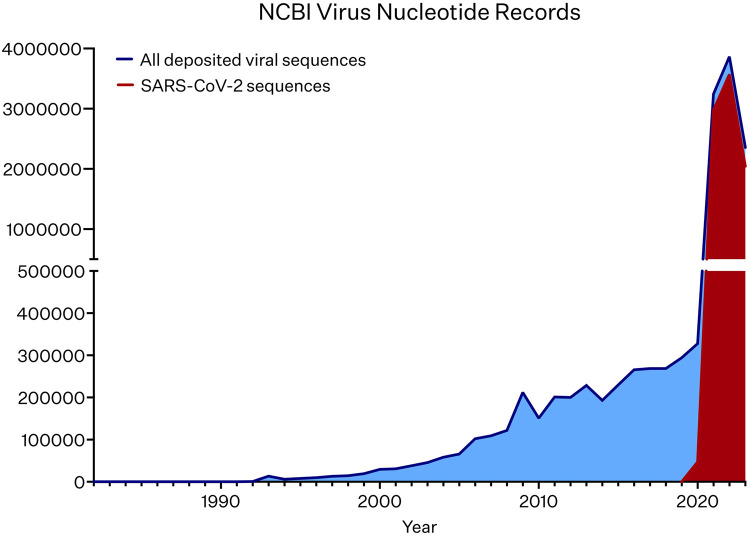
Whole genome sequencing of viruses provides high-resolution molecular insights, enhancing our understanding of viral genome function and phylogeny. Beyond fundamental research, viral sequencing is increasingly vital for pathogen surveillance, epidemiology, and clinical applications. As sequencing methods rapidly evolve, the diversity of viral genomics applications and catalogued genomes continues to expand. Advances in long-read, single molecule, real-time sequencing methodologies present opportunities to sequence contiguous, haplotype resolved viral genomes in a range of research and applied settings. Here we present an overview of nucleic acid sequencing methods and their applications in studying viral genomes. We emphasise the advantages of different viral sequencing approaches, with a particular focus on the benefits of third-generation sequencing technologies in elucidating viral evolution, transmission networks, and pathogenesis.
Keywords: DNA sequencing; genomics; virology.
© 2024 The Author(s).
Conflict of interest statement
The authors declare that there are no competing interests associated with the manuscript.
Figures


Similar articles
-
Embracing Complexity: What Novel Sequencing Methods Are Teaching Us About Herpesvirus Genomic Diversity.Annu Rev Virol. 2024 Sep;11(1):67-87. doi: 10.1146/annurev-virology-100422-010336. Epub 2024 Aug 30. Annu Rev Virol. 2024. PMID: 38848592 Review.
-
Analyzing Modern Biomolecules: The Revolution of Nucleic-Acid Sequencing - Review.Biomolecules. 2021 Jul 28;11(8):1111. doi: 10.3390/biom11081111. Biomolecules. 2021. PMID: 34439777 Free PMC article. Review.
-
Human whole genome sequencing in South Africa.Sci Rep. 2021 Jan 12;11(1):606. doi: 10.1038/s41598-020-79794-x. Sci Rep. 2021. PMID: 33436733 Free PMC article.
-
High-throughput sequencing (HTS) for the analysis of viral populations.Infect Genet Evol. 2020 Jun;80:104208. doi: 10.1016/j.meegid.2020.104208. Epub 2020 Jan 27. Infect Genet Evol. 2020. PMID: 32001386 Review.
-
Application and Challenge of 3rd Generation Sequencing for Clinical Bacterial Studies.Int J Mol Sci. 2022 Jan 26;23(3):1395. doi: 10.3390/ijms23031395. Int J Mol Sci. 2022. PMID: 35163319 Free PMC article. Review.
Cited by
-
SARS-CoV-2 Genomic Epidemiology Dashboards: A Review of Functionality and Technological Frameworks for the Public Health Response.Genes (Basel). 2024 Jul 3;15(7):876. doi: 10.3390/genes15070876. Genes (Basel). 2024. PMID: 39062655 Free PMC article. Review.
References
Publication types
MeSH terms
LinkOut - more resources
Full Text Sources
Research Materials