

Protein-nucleic acid interactions of LINE-1 ORF1p
- PMID: 29596909
- PMCID: PMC6428221
- DOI: 10.1016/j.semcdb.2018.03.019
Protein-nucleic acid interactions of LINE-1 ORF1p
Abstract
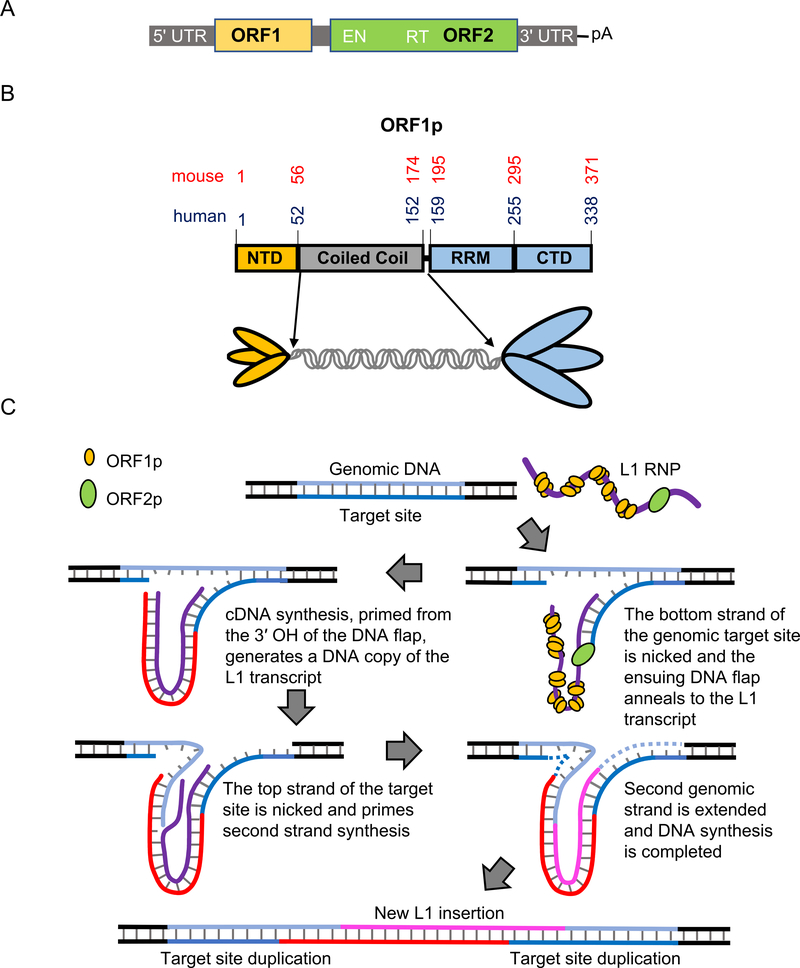
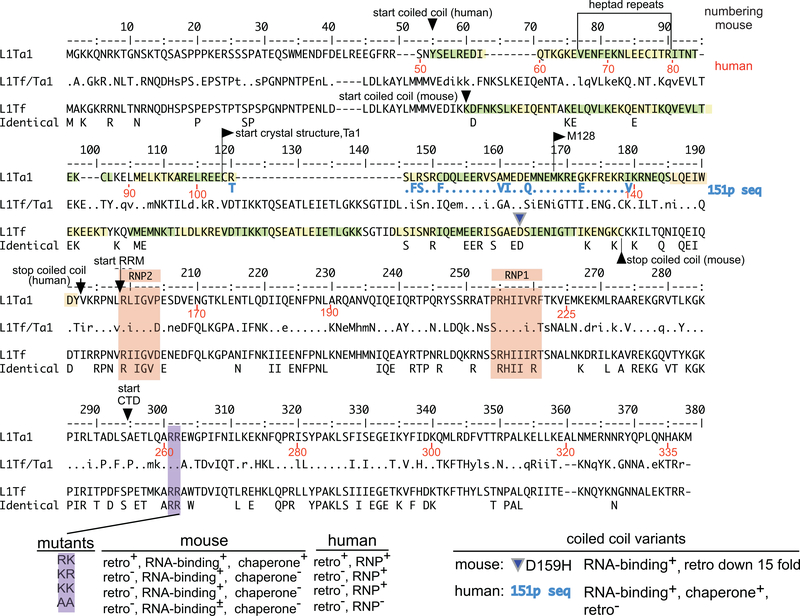
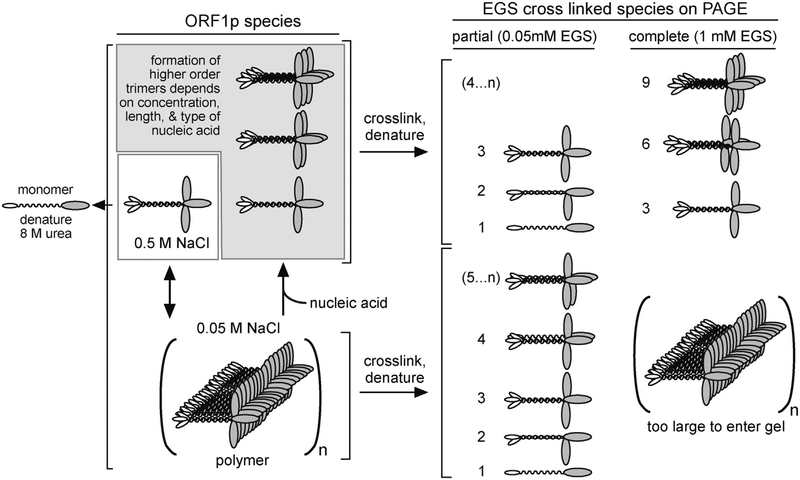
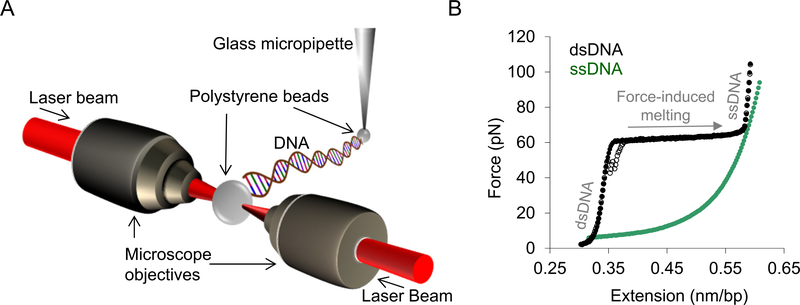
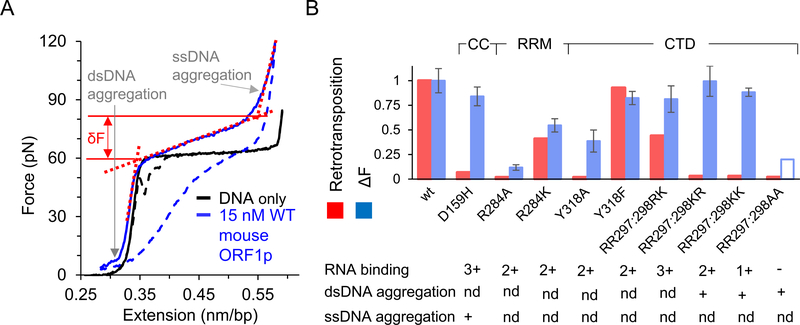
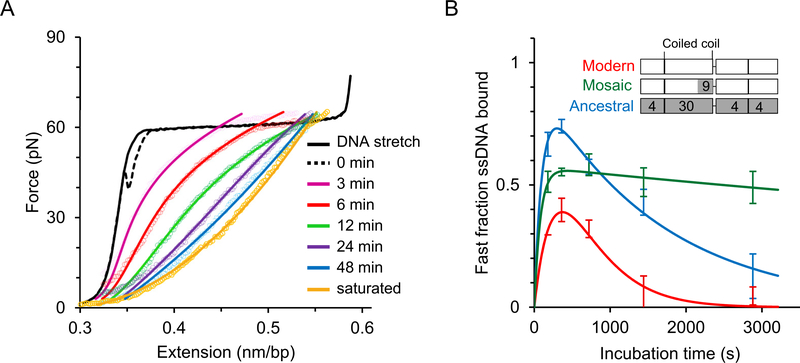
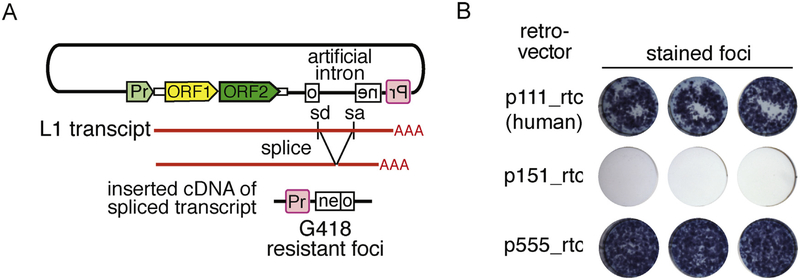
Long interspersed nuclear element 1 (LINE-1 or L1) is the dominant retrotransposon in mammalian genomes. L1 encodes two proteins ORF1p and ORF2p that are required for retrotransposition. ORF2p functions as the replicase. ORF1p is a coiled coil-mediated trimeric, high affinity RNA binding protein that packages its full- length coding transcript into an ORF2p-containing ribonucleoprotein (RNP) complex, the retrotransposition intermediate. ORF1p also is a nucleic acid chaperone that presumably facilitates the proposed nucleic acid remodeling steps involved in retrotransposition. Although detailed mechanistic understanding of ORF1p function in this process is lacking, recent studies showed that the rate at which ORF1p can form stable nucleic acid-bound oligomers in vitro is positively correlated with formation of an active L1 RNP as assayed in vivo using a cell culture-based retrotransposition assay. This rate was sensitive to minor amino acid changes in the coiled coil domain, which had no effect on nucleic acid chaperone activity. Additional studies linking the complex nucleic acid binding properties to the conformational changes of the protein are needed to understand how ORF1p facilitates retrotransposition.
Copyright © 2018 The Authors. Published by Elsevier Ltd.. All rights reserved.
Figures
Similar articles
-
Deletion analysis defines distinct functional domains for protein-protein and nucleic acid interactions in the ORF1 protein of mouse LINE-1.J Mol Biol. 2000 Nov 17;304(1):11-20. doi: 10.1006/jmbi.2000.4182. J Mol Biol. 2000. PMID: 11071806
-
The L1-ORF1p coiled coil enables formation of a tightly compacted nucleic acid-bound complex that is associated with retrotransposition.Nucleic Acids Res. 2022 Aug 26;50(15):8690-8699. doi: 10.1093/nar/gkac628. Nucleic Acids Res. 2022. PMID: 35871298 Free PMC article.
-
Characterization of LINE-1 ribonucleoprotein particles.PLoS Genet. 2010 Oct 7;6(10):e1001150. doi: 10.1371/journal.pgen.1001150. PLoS Genet. 2010. PMID: 20949108 Free PMC article.
-
Nucleic acid chaperone properties of ORF1p from the non-LTR retrotransposon, LINE-1.RNA Biol. 2010 Nov-Dec;7(6):706-11. doi: 10.4161/rna.7.6.13766. Epub 2010 Nov 1. RNA Biol. 2010. PMID: 21045547 Free PMC article. Review.
-
Post-Transcriptional Control of LINE-1 Retrotransposition by Cellular Host Factors in Somatic Cells.Front Cell Dev Biol. 2016 Mar 7;4:14. doi: 10.3389/fcell.2016.00014. eCollection 2016. Front Cell Dev Biol. 2016. PMID: 27014690 Free PMC article. Review.
Cited by
-
Cryptic genetic variation enhances primate L1 retrotransposon survival by enlarging the functional coiled coil sequence space of ORF1p.PLoS Genet. 2020 Aug 14;16(8):e1008991. doi: 10.1371/journal.pgen.1008991. eCollection 2020 Aug. PLoS Genet. 2020. PMID: 32797042 Free PMC article.
-
The Ultraviolet Irradiation of Keratinocytes Induces Ectopic Expression of LINE-1 Retrotransposon Machinery and Leads to Cellular Senescence.Biomedicines. 2023 Nov 10;11(11):3017. doi: 10.3390/biomedicines11113017. Biomedicines. 2023. PMID: 38002016 Free PMC article.
-
Research progress of LINE-1 in the diagnosis, prognosis, and treatment of gynecologic tumors.Front Oncol. 2023 Jul 20;13:1201568. doi: 10.3389/fonc.2023.1201568. eCollection 2023. Front Oncol. 2023. PMID: 37546391 Free PMC article. Review.
-
Reactivity of IgG With the p40 Protein Encoded by the Long Interspersed Nuclear Element 1 Retroelement: Comment on the Article by Carter et al.Arthritis Rheumatol. 2020 Feb;72(2):374-376. doi: 10.1002/art.41102. Epub 2019 Dec 27. Arthritis Rheumatol. 2020. PMID: 31513361 Free PMC article. No abstract available.
-
LINE1-Mediated Reverse Transcription and Genomic Integration of SARS-CoV-2 mRNA Detected in Virus-Infected but Not in Viral mRNA-Transfected Cells.Viruses. 2023 Feb 25;15(3):629. doi: 10.3390/v15030629. Viruses. 2023. PMID: 36992338 Free PMC article.
References
-
- Furano AV, The biological properties and evolutionary dynamics of mammalian LINE-1 retrotransposons, Prog. Nucleic Acid Res. Mol. Biol 64 (2000) 255–294. - PubMed
-
- Lander ES, Linton LM, Birren B, Nusbaum C, Zody MC, et al., Initial sequencing and analysis of the human genome, Nature 409 (6822) (2001) 860–921. - PubMed
-
- Esnault C, Maestre J, Heidmann T, Human LINE retrotransposons generate processed pseudogenes, Nat. Genet 24 (4) (2000) 363–367. - PubMed
Publication types
MeSH terms
Substances
Grants and funding
LinkOut - more resources
Full Text Sources
Other Literature Sources
