

Characterization of Proteoforms with Unknown Post-translational Modifications Using the MIScore
- PMID: 27291504
- PMCID: PMC5359983
- DOI: 10.1021/acs.jproteome.5b01098
Characterization of Proteoforms with Unknown Post-translational Modifications Using the MIScore
Abstract
Various proteoforms may be generated from a single gene due to primary structure alterations (PSAs) such as genetic variations, alternative splicing, and post-translational modifications (PTMs). Top-down mass spectrometry is capable of analyzing intact proteins and identifying patterns of multiple PSAs, making it the method of choice for studying complex proteoforms. In top-down proteomics, proteoform identification is often performed by searching tandem mass spectra against a protein sequence database that contains only one reference protein sequence for each gene or transcript variant in a proteome. Because of the incompleteness of the protein database, an identified proteoform may contain unknown PSAs compared with the reference sequence. Proteoform characterization is to identify and localize PSAs in a proteoform. Although many software tools have been proposed for proteoform identification by top-down mass spectrometry, the characterization of proteoforms in identified proteoform-spectrum matches still relies mainly on manual annotation. We propose to use the Modification Identification Score (MIScore), which is based on Bayesian models, to automatically identify and localize PTMs in proteoforms. Experiments showed that the MIScore is accurate in identifying and localizing one or two modifications.
Keywords: post-translational modification; proteoform.
Figures
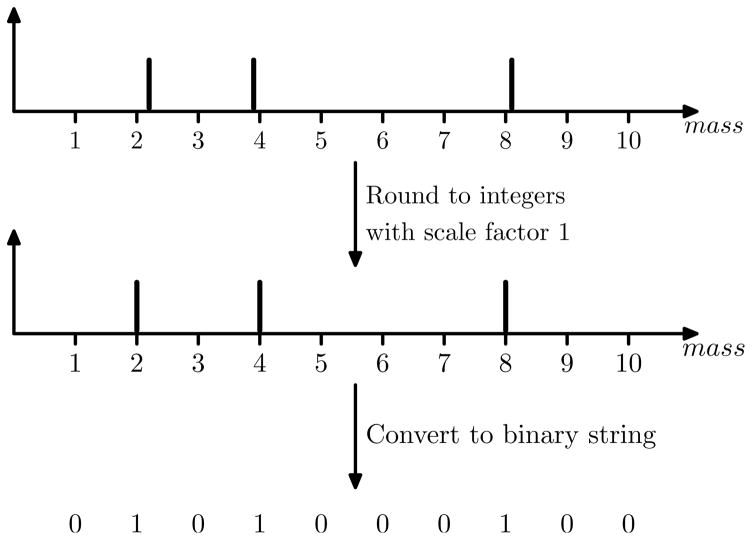
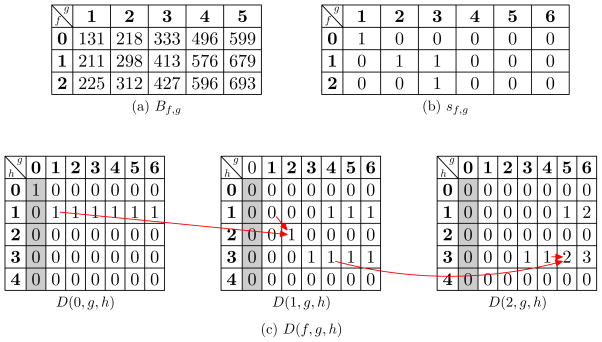
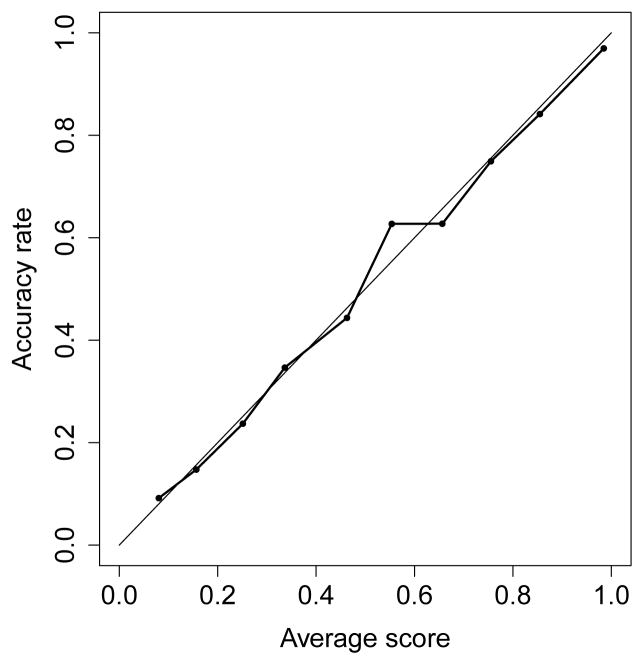
Similar articles
-
Systematic Evaluation of Protein Sequence Filtering Algorithms for Proteoform Identification Using Top-Down Mass Spectrometry.Proteomics. 2018 Feb;18(3-4):10.1002/pmic.201700306. doi: 10.1002/pmic.201700306. Epub 2018 Feb 6. Proteomics. 2018. PMID: 29327814 Free PMC article.
-
A mass graph-based approach for the identification of modified proteoforms using top-down tandem mass spectra.Bioinformatics. 2017 May 1;33(9):1309-1316. doi: 10.1093/bioinformatics/btw806. Bioinformatics. 2017. PMID: 28453668 Free PMC article.
-
Improving Proteoform Identifications in Complex Systems Through Integration of Bottom-Up and Top-Down Data.J Proteome Res. 2020 Aug 7;19(8):3510-3517. doi: 10.1021/acs.jproteome.0c00332. Epub 2020 Jul 10. J Proteome Res. 2020. PMID: 32584579 Free PMC article.
-
Top-Down Proteomics and the Challenges of True Proteoform Characterization.J Proteome Res. 2023 Dec 1;22(12):3663-3675. doi: 10.1021/acs.jproteome.3c00416. Epub 2023 Nov 8. J Proteome Res. 2023. PMID: 37937372 Free PMC article. Review.
-
Identification and Quantification of Proteoforms by Mass Spectrometry.Proteomics. 2019 May;19(10):e1800361. doi: 10.1002/pmic.201800361. Proteomics. 2019. PMID: 31050378 Free PMC article. Review.
Cited by
-
Expanding Proteoform Identifications in Top-Down Proteomic Analyses by Constructing Proteoform Families.Anal Chem. 2018 Jan 16;90(2):1325-1333. doi: 10.1021/acs.analchem.7b04221. Epub 2017 Dec 22. Anal Chem. 2018. PMID: 29227670 Free PMC article.
-
TopPIC: a software tool for top-down mass spectrometry-based proteoform identification and characterization.Bioinformatics. 2016 Nov 15;32(22):3495-3497. doi: 10.1093/bioinformatics/btw398. Epub 2016 Jul 16. Bioinformatics. 2016. PMID: 27423895 Free PMC article.
-
Top-down proteomics.Nat Rev Methods Primers. 2024;4(1):38. doi: 10.1038/s43586-024-00318-2. Epub 2024 Jun 13. Nat Rev Methods Primers. 2024. PMID: 39006170 Free PMC article.
-
TopMSV: A Web-Based Tool for Top-Down Mass Spectrometry Data Visualization.J Am Soc Mass Spectrom. 2021 Jun 2;32(6):1312-1318. doi: 10.1021/jasms.0c00460. Epub 2021 Mar 29. J Am Soc Mass Spectrom. 2021. PMID: 33780241 Free PMC article.
-
Characterization of Proteoform Post-Translational Modifications by Top-Down and Bottom-Up Mass Spectrometry in Conjunction with Annotations.J Proteome Res. 2023 Oct 6;22(10):3178-3189. doi: 10.1021/acs.jproteome.3c00207. Epub 2023 Sep 20. J Proteome Res. 2023. PMID: 37728997 Free PMC article.
References
MeSH terms
Substances
Grants and funding
LinkOut - more resources
Full Text Sources
Other Literature Sources
Miscellaneous
