

Tamping Ramping: Algorithmic, Implementational, and Computational Explanations of Phasic Dopamine Signals in the Accumbens
- PMID: 26699940
- PMCID: PMC4689534
- DOI: 10.1371/journal.pcbi.1004622
Tamping Ramping: Algorithmic, Implementational, and Computational Explanations of Phasic Dopamine Signals in the Accumbens
Abstract
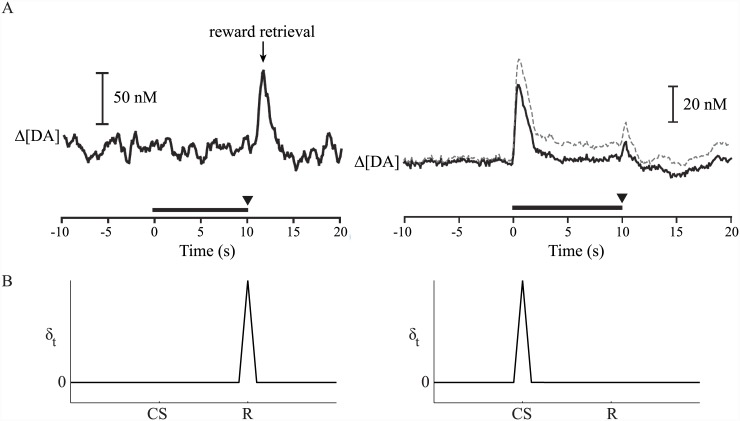
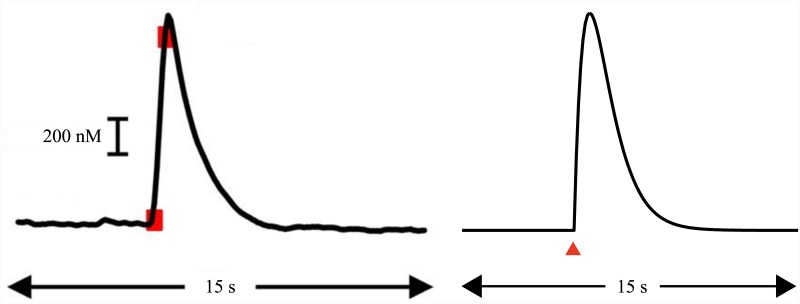
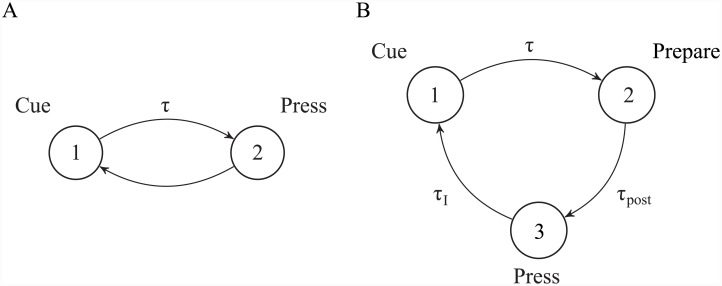
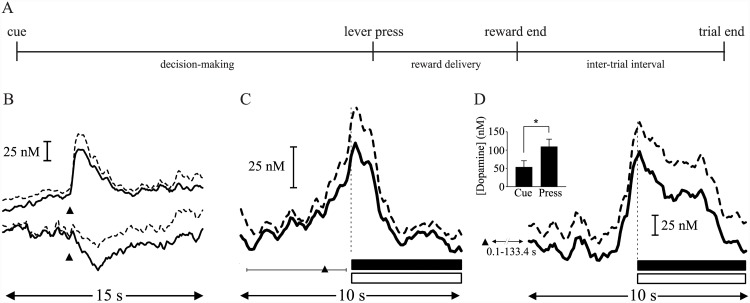
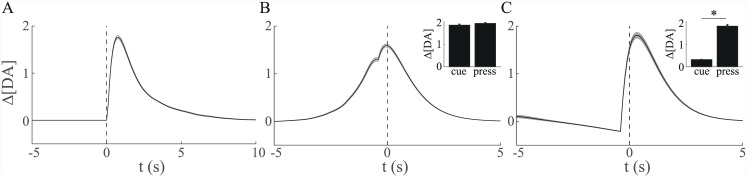
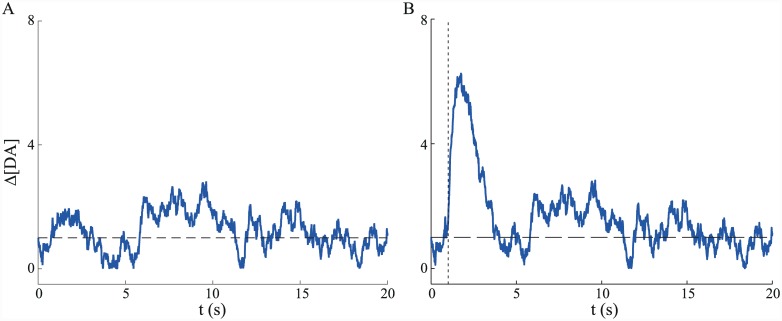
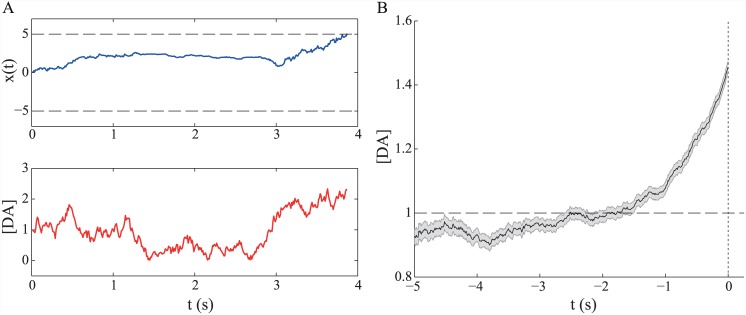
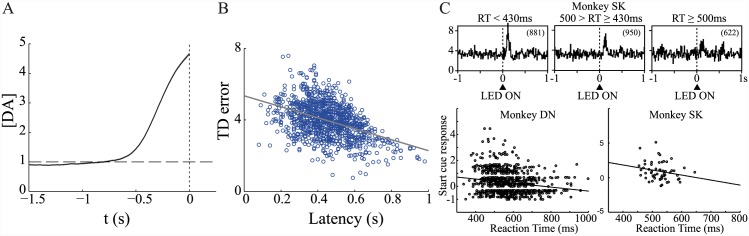
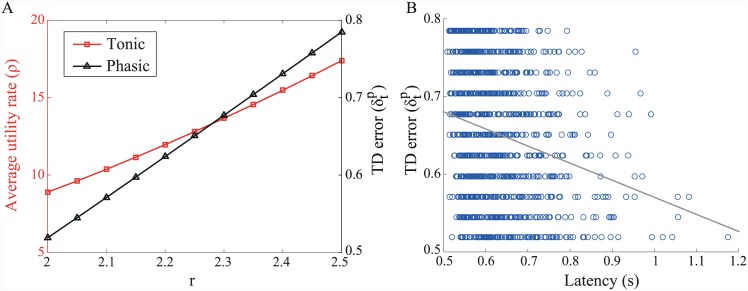
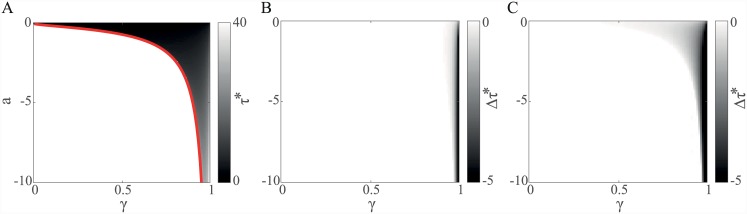
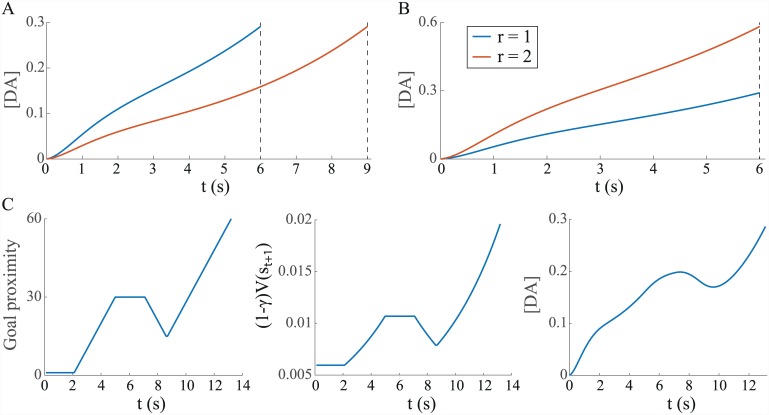
Substantial evidence suggests that the phasic activity of dopamine neurons represents reinforcement learning's temporal difference prediction error. However, recent reports of ramp-like increases in dopamine concentration in the striatum when animals are about to act, or are about to reach rewards, appear to pose a challenge to established thinking. This is because the implied activity is persistently predictable by preceding stimuli, and so cannot arise as this sort of prediction error. Here, we explore three possible accounts of such ramping signals: (a) the resolution of uncertainty about the timing of action; (b) the direct influence of dopamine over mechanisms associated with making choices; and (c) a new model of discounted vigour. Collectively, these suggest that dopamine ramps may be explained, with only minor disturbance, by standard theoretical ideas, though urgent questions remain regarding their proximal cause. We suggest experimental approaches to disentangling which of the proposed mechanisms are responsible for dopamine ramps.
Conflict of interest statement
The authors have declared that no competing interests exist.
Figures
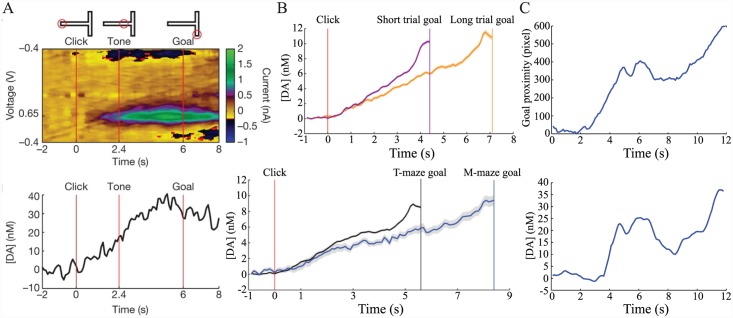
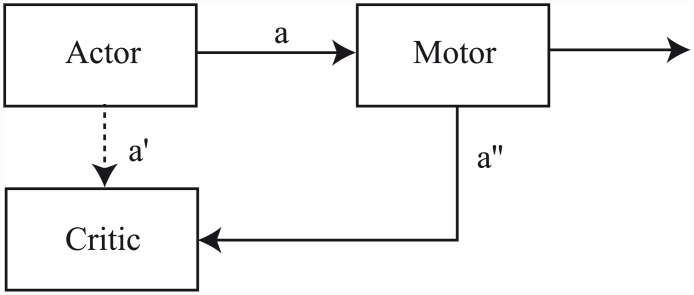
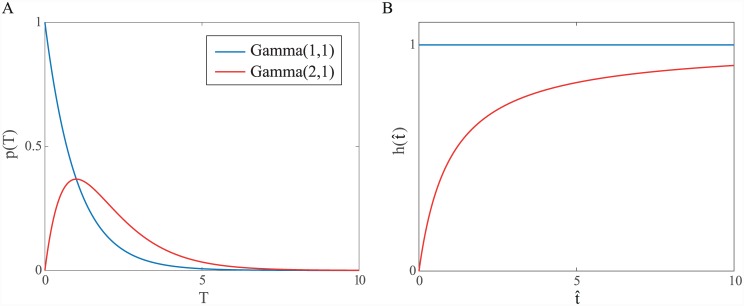
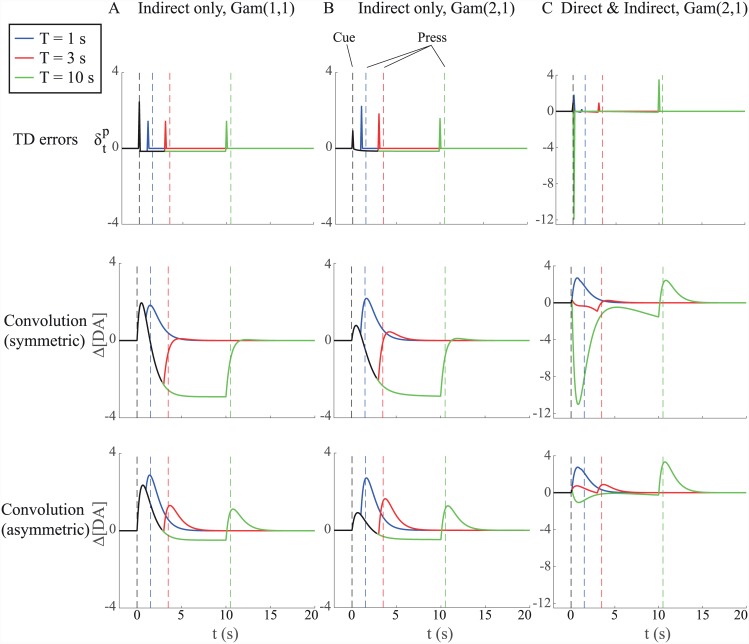
Similar articles
-
The nucleus accumbens as part of a basal ganglia action selection circuit.Psychopharmacology (Berl). 2007 Apr;191(3):521-50. doi: 10.1007/s00213-006-0510-4. Epub 2006 Sep 16. Psychopharmacology (Berl). 2007. PMID: 16983543 Review.
-
Dynamic resource allocation during reinforcement learning accounts for ramping and phasic dopamine activity.Neural Netw. 2020 Jun;126:95-107. doi: 10.1016/j.neunet.2020.03.005. Epub 2020 Mar 10. Neural Netw. 2020. PMID: 32203877
-
Dopamine ramps are a consequence of reward prediction errors.Neural Comput. 2014 Mar;26(3):467-71. doi: 10.1162/NECO_a_00559. Epub 2013 Dec 9. Neural Comput. 2014. PMID: 24320851
-
Axiomatic methods, dopamine and reward prediction error.Curr Opin Neurobiol. 2008 Apr;18(2):197-202. doi: 10.1016/j.conb.2008.07.007. Epub 2008 Aug 12. Curr Opin Neurobiol. 2008. PMID: 18678251 Review.
-
Stimulus representation and the timing of reward-prediction errors in models of the dopamine system.Neural Comput. 2008 Dec;20(12):3034-54. doi: 10.1162/neco.2008.11-07-654. Neural Comput. 2008. PMID: 18624657
Cited by
-
Midbrain dopamine neurons signal phasic and ramping reward prediction error during goal-directed navigation.Cell Rep. 2022 Oct 11;41(2):111470. doi: 10.1016/j.celrep.2022.111470. Cell Rep. 2022. PMID: 36223748 Free PMC article.
-
Recent advances in understanding the role of phasic dopamine activity.F1000Res. 2019 Sep 24;8:F1000 Faculty Rev-1680. doi: 10.12688/f1000research.19793.1. eCollection 2019. F1000Res. 2019. PMID: 31588354 Free PMC article. Review.
-
Premotor Ramping of Thalamic Neuronal Activity Is Modulated by Nigral Inputs and Contributes to Control the Timing of Action Release.J Neurosci. 2021 Mar 3;41(9):1878-1891. doi: 10.1523/JNEUROSCI.1204-20.2020. Epub 2021 Jan 14. J Neurosci. 2021. PMID: 33446518 Free PMC article.
-
Wave-like dopamine dynamics as a mechanism for spatiotemporal credit assignment.Cell. 2021 May 13;184(10):2733-2749.e16. doi: 10.1016/j.cell.2021.03.046. Epub 2021 Apr 15. Cell. 2021. PMID: 33861952 Free PMC article.
-
Serotonin receptors contribute to dopamine depression of lateral inhibition in the nucleus accumbens.Cell Rep. 2022 May 10;39(6):110795. doi: 10.1016/j.celrep.2022.110795. Cell Rep. 2022. PMID: 35545050 Free PMC article.
References
-
- Sutton RS. Learning to predict by the methods of temporal differences. Machine Learning. 1988;3(1):9–44. 10.1023/A:1022633531479 - DOI
-
- Sutton RS, Barto AG. Reinforcement learning: An introduction. MIT Press; 1998.
Publication types
MeSH terms
Substances
Grants and funding
LinkOut - more resources
Full Text Sources
Other Literature Sources
