

Neuronal Reward and Decision Signals: From Theories to Data
- PMID: 26109341
- PMCID: PMC4491543
- DOI: 10.1152/physrev.00023.2014
Neuronal Reward and Decision Signals: From Theories to Data
Abstract
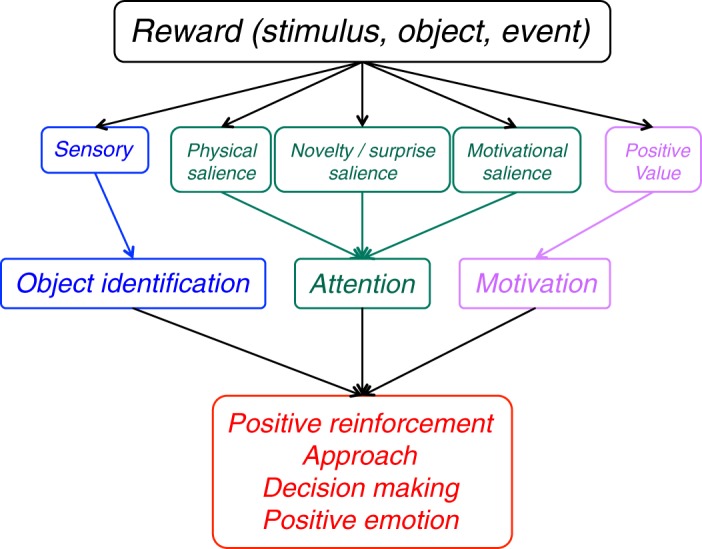
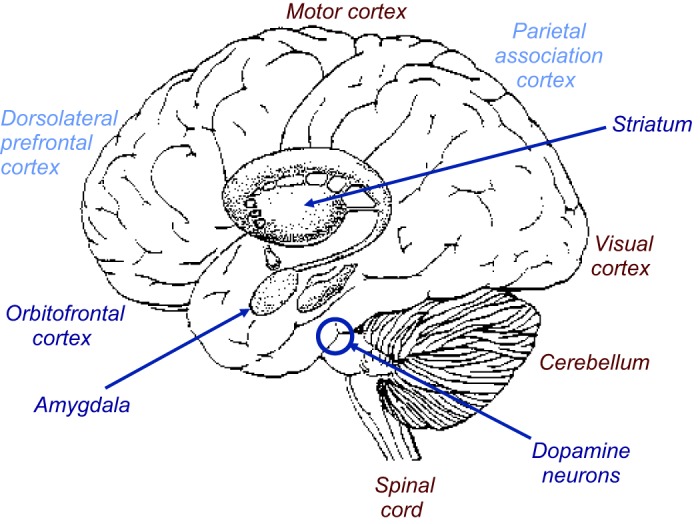
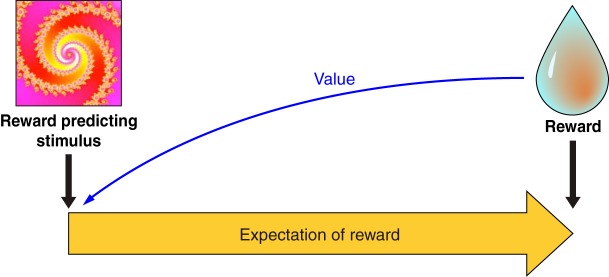
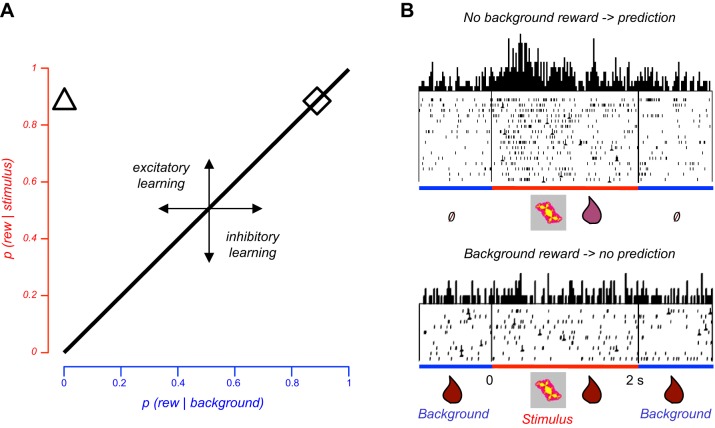
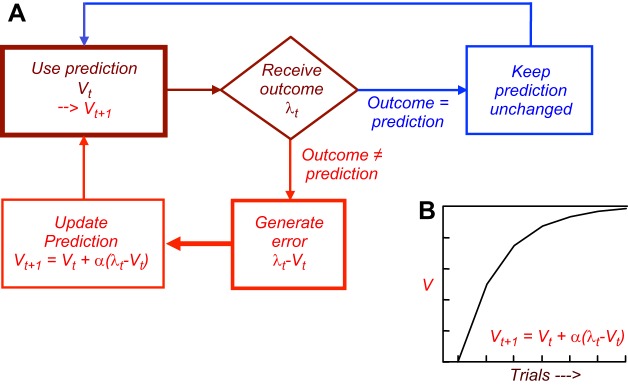
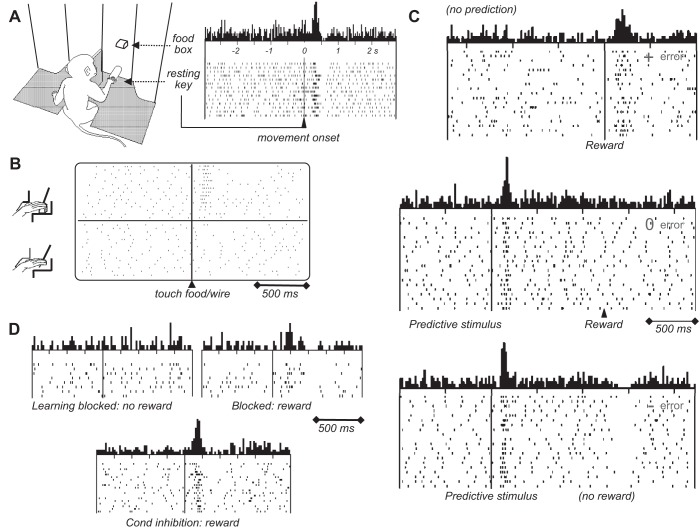
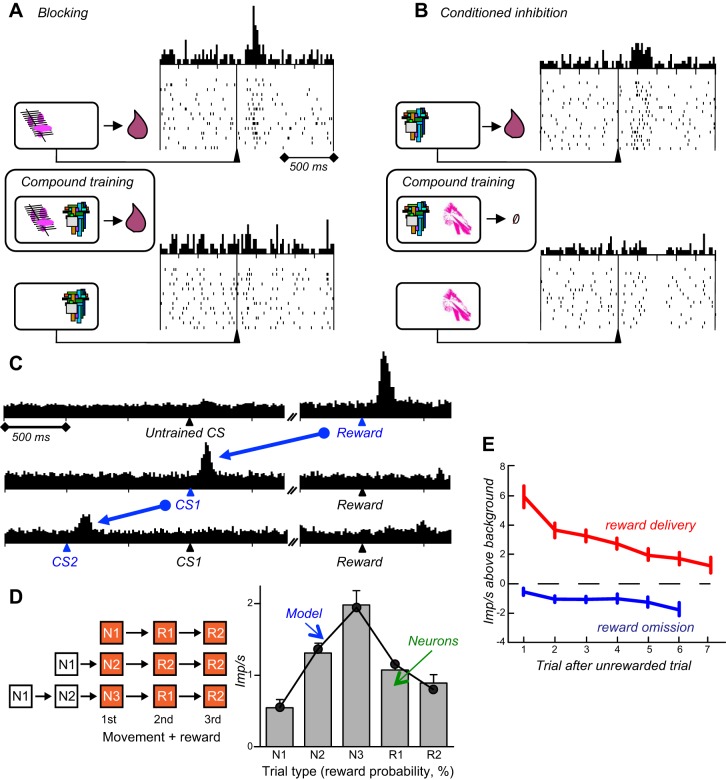
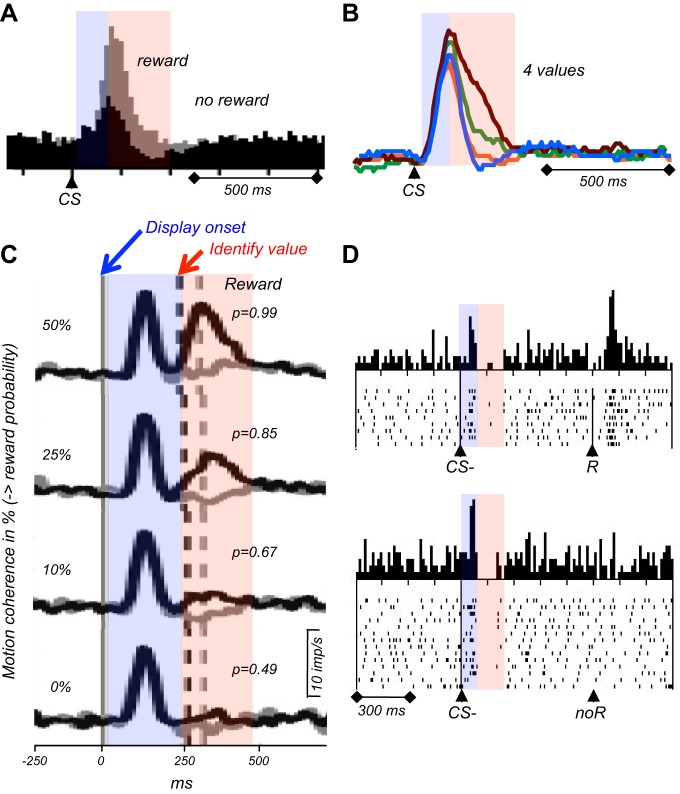
Rewards are crucial objects that induce learning, approach behavior, choices, and emotions. Whereas emotions are difficult to investigate in animals, the learning function is mediated by neuronal reward prediction error signals which implement basic constructs of reinforcement learning theory. These signals are found in dopamine neurons, which emit a global reward signal to striatum and frontal cortex, and in specific neurons in striatum, amygdala, and frontal cortex projecting to select neuronal populations. The approach and choice functions involve subjective value, which is objectively assessed by behavioral choices eliciting internal, subjective reward preferences. Utility is the formal mathematical characterization of subjective value and a prime decision variable in economic choice theory. It is coded as utility prediction error by phasic dopamine responses. Utility can incorporate various influences, including risk, delay, effort, and social interaction. Appropriate for formal decision mechanisms, rewards are coded as object value, action value, difference value, and chosen value by specific neurons. Although all reward, reinforcement, and decision variables are theoretical constructs, their neuronal signals constitute measurable physical implementations and as such confirm the validity of these concepts. The neuronal reward signals provide guidance for behavior while constraining the free will to act.
Copyright © 2015 the American Physiological Society.
Figures

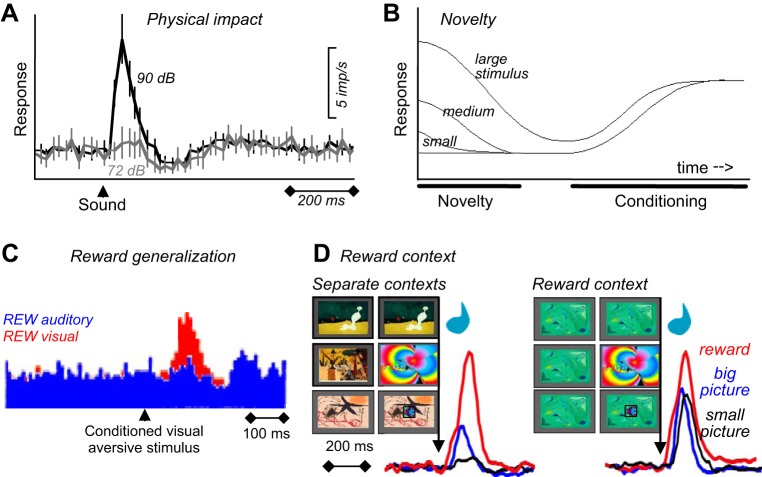
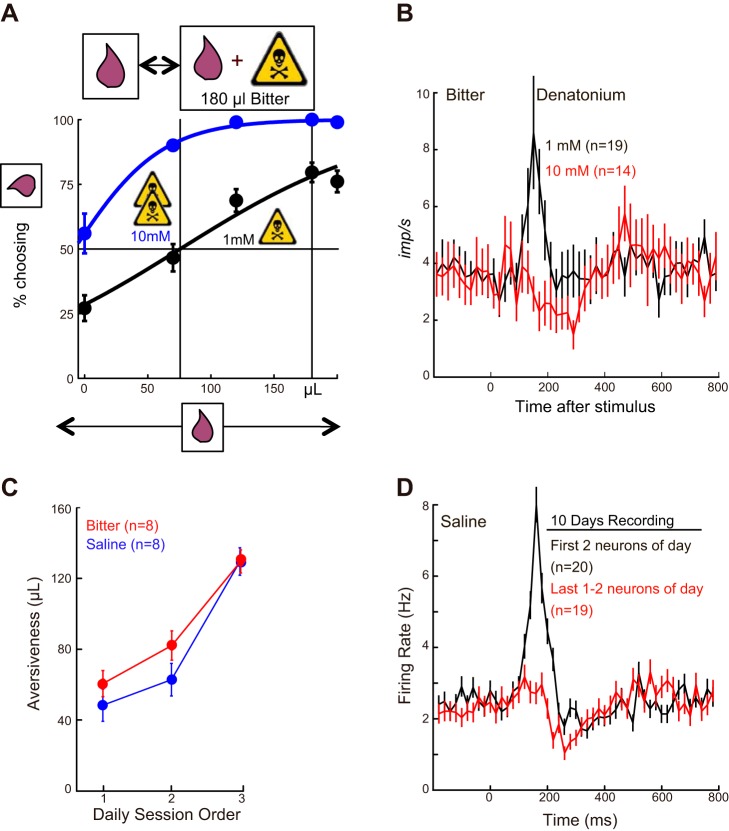
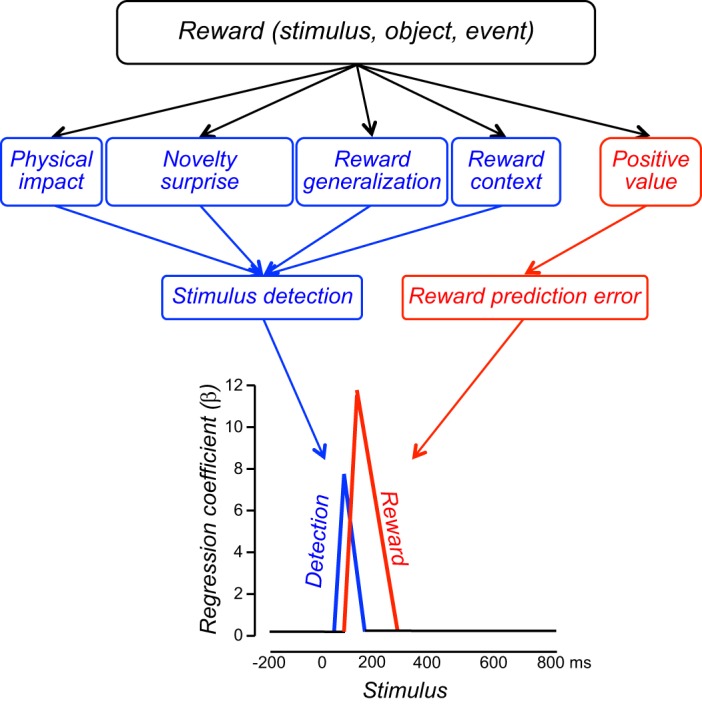
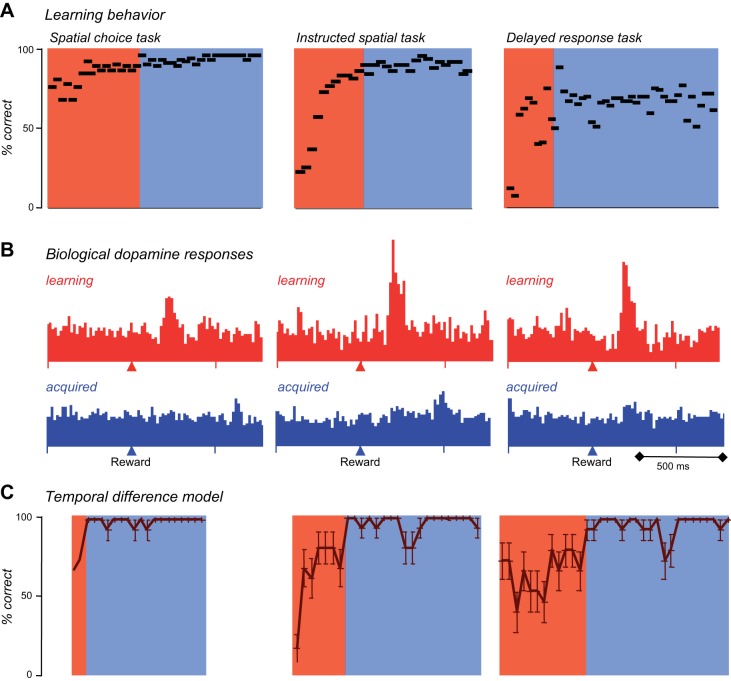
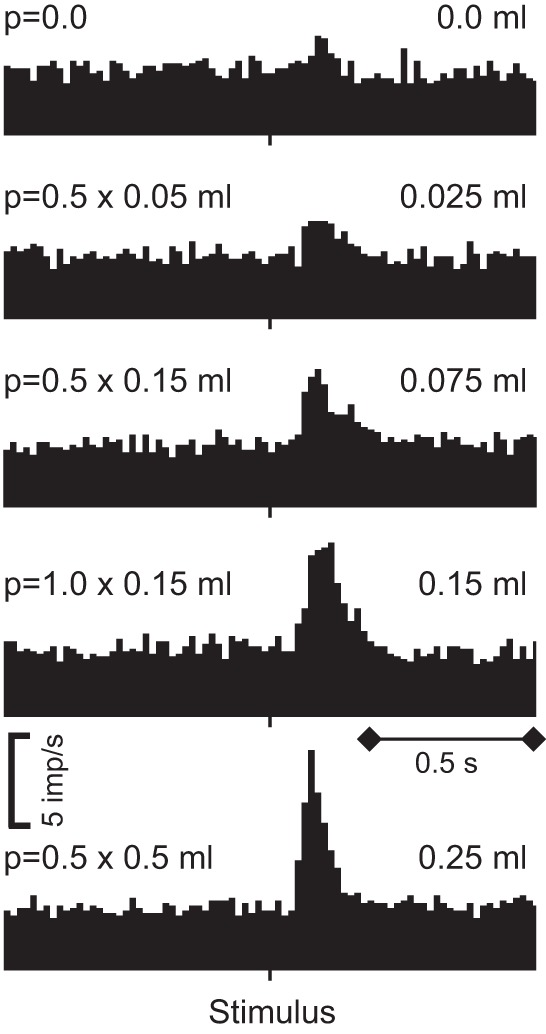
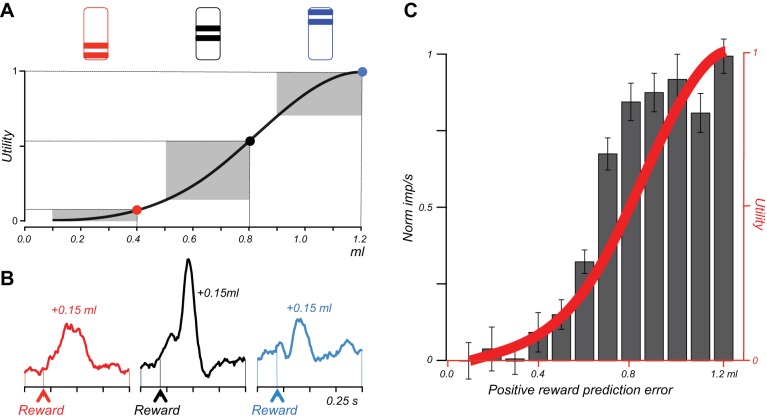
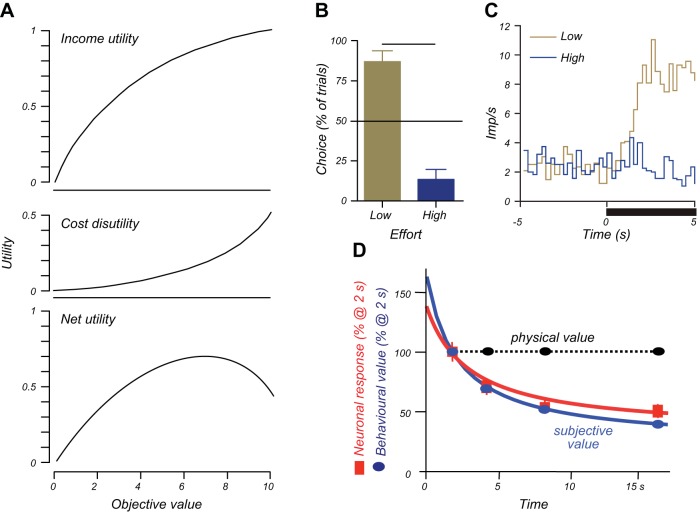
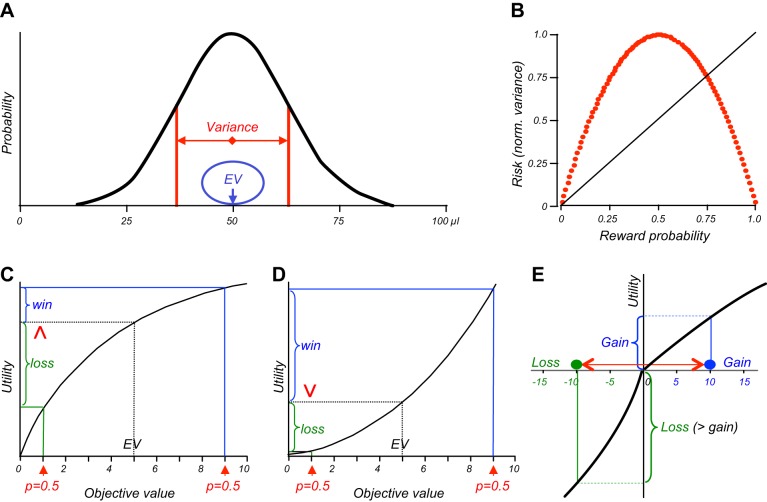
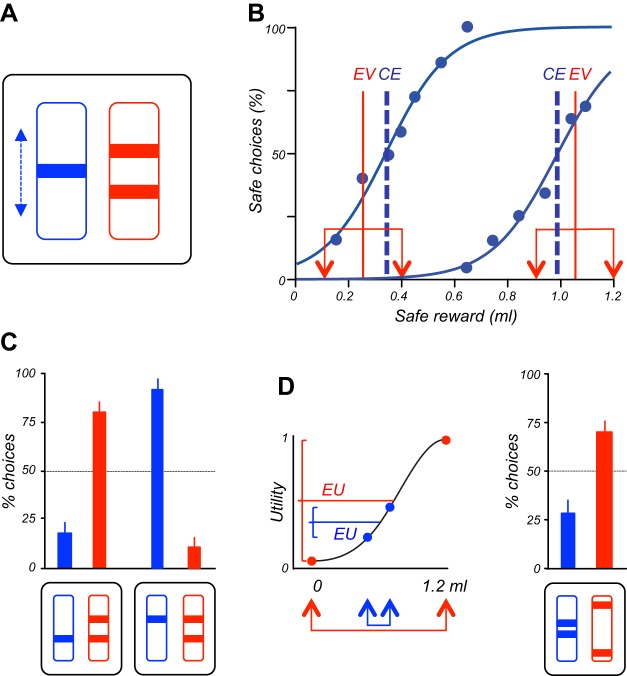
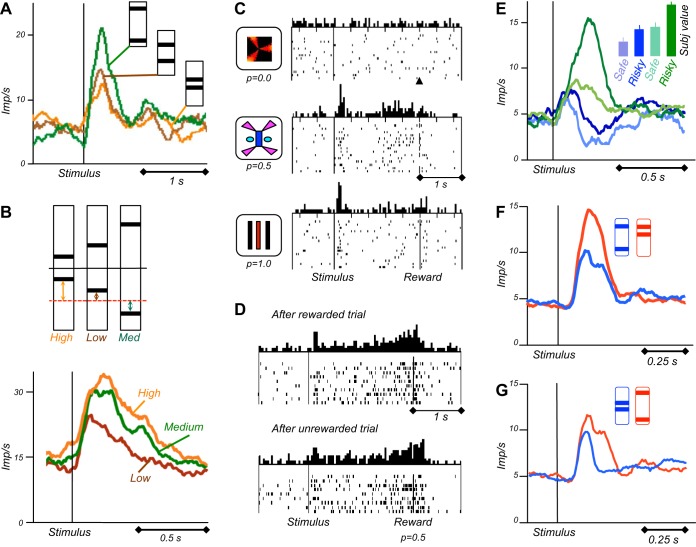
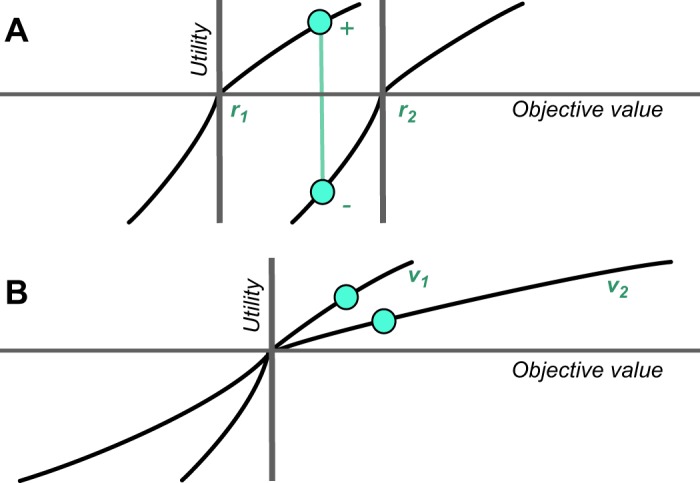
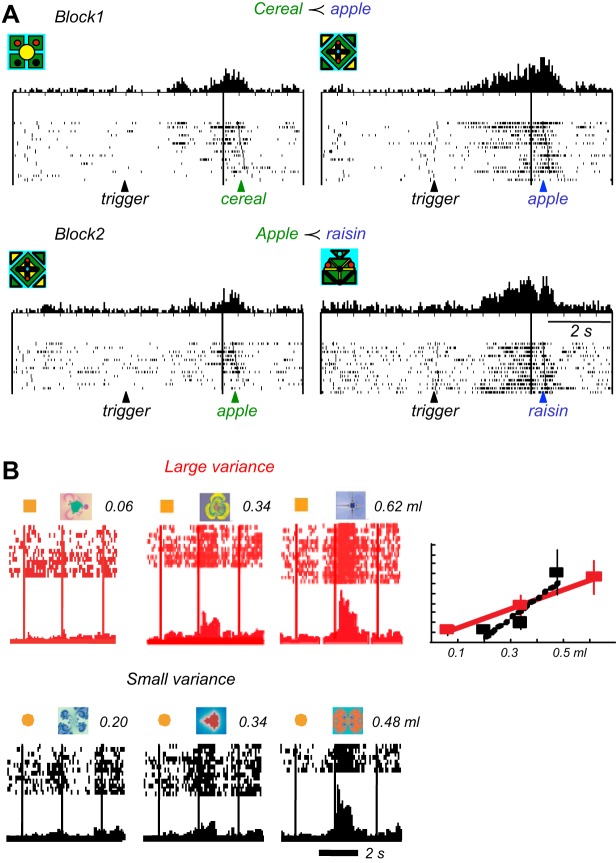
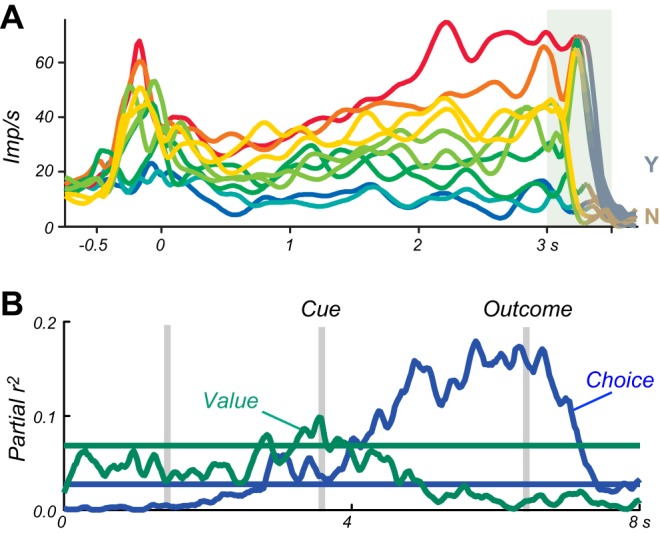
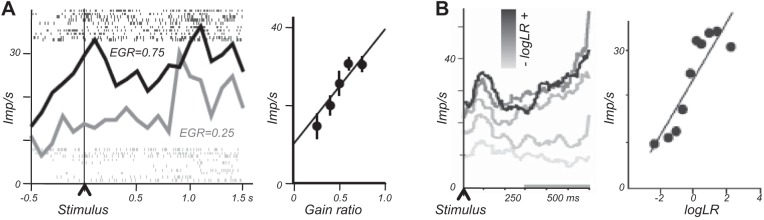
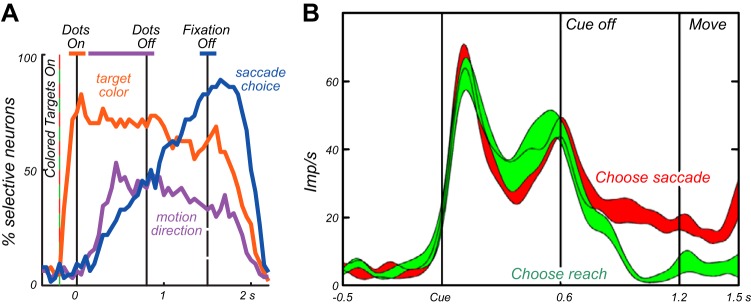
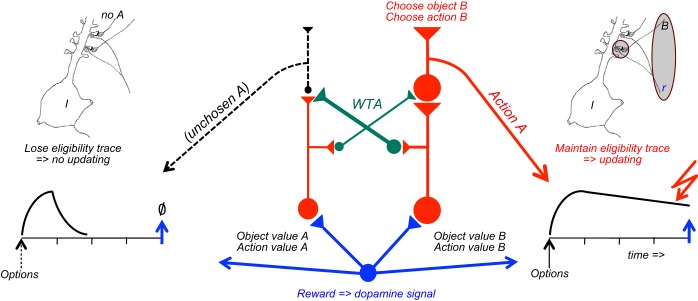
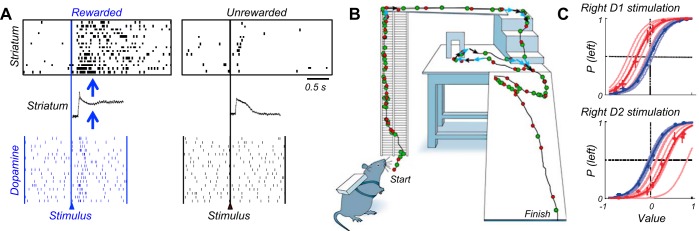
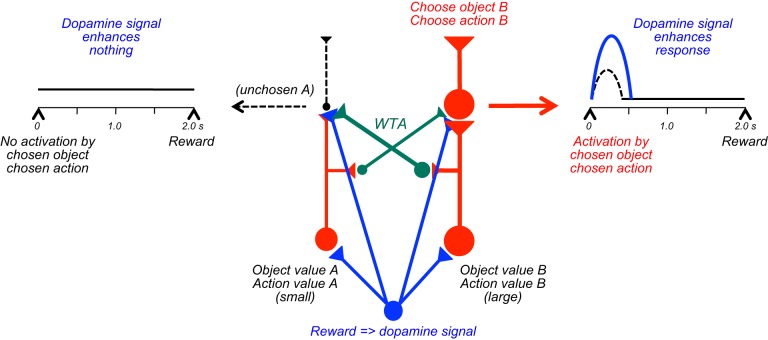
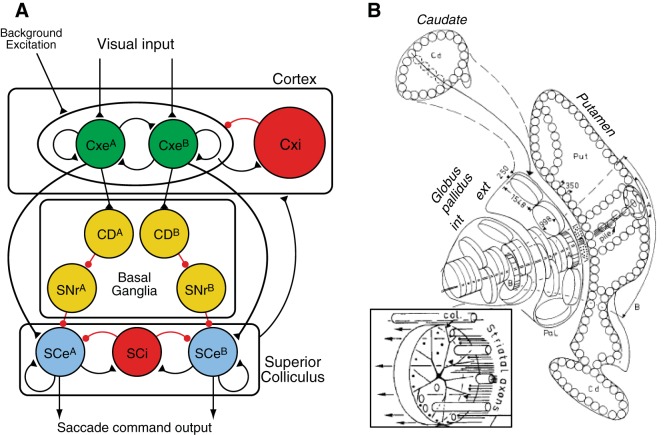
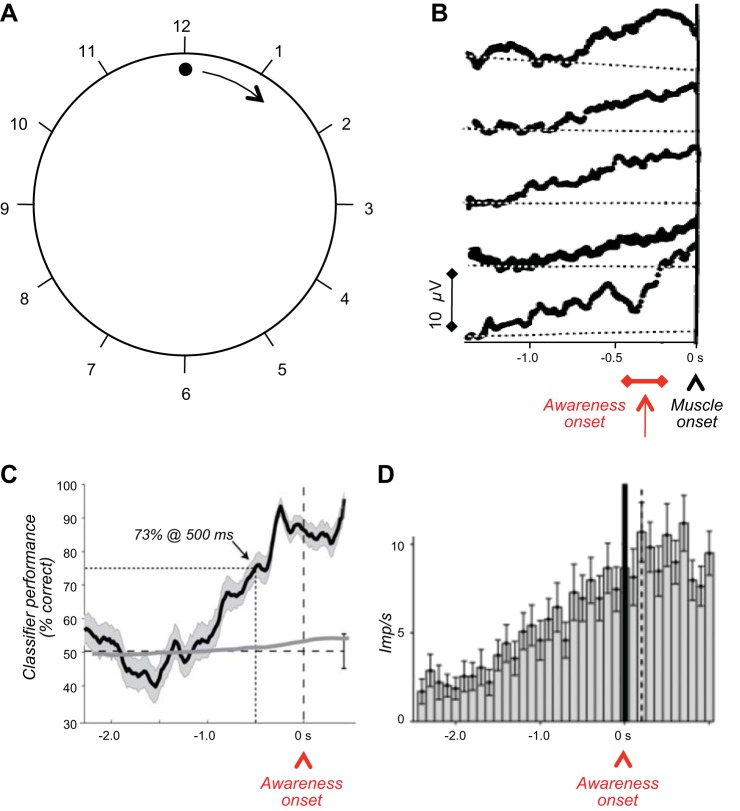
Similar articles
-
Components and characteristics of the dopamine reward utility signal.J Comp Neurol. 2016 Jun 1;524(8):1699-711. doi: 10.1002/cne.23880. Epub 2015 Sep 8. J Comp Neurol. 2016. PMID: 26272220 Free PMC article. Review.
-
Predictive reward signal of dopamine neurons.J Neurophysiol. 1998 Jul;80(1):1-27. doi: 10.1152/jn.1998.80.1.1. J Neurophysiol. 1998. PMID: 9658025 Review.
-
A neural network model with dopamine-like reinforcement signal that learns a spatial delayed response task.Neuroscience. 1999;91(3):871-90. doi: 10.1016/s0306-4522(98)00697-6. Neuroscience. 1999. PMID: 10391468
-
Dopamine neurons learn relative chosen value from probabilistic rewards.Elife. 2016 Oct 27;5:e18044. doi: 10.7554/eLife.18044. Elife. 2016. PMID: 27787196 Free PMC article.
-
Timing in reward and decision processes.Philos Trans R Soc Lond B Biol Sci. 2014 Jan 20;369(1637):20120468. doi: 10.1098/rstb.2012.0468. Print 2014 Mar 5. Philos Trans R Soc Lond B Biol Sci. 2014. PMID: 24446502 Free PMC article. Review.
Cited by
-
A Multidimensional View on Social and Non-Social Rewards.Front Psychiatry. 2020 Aug 19;11:818. doi: 10.3389/fpsyt.2020.00818. eCollection 2020. Front Psychiatry. 2020. PMID: 32973574 Free PMC article.
-
Role of the Perigenual Anterior Cingulate and Orbitofrontal Cortex in Contingency Learning in the Marmoset.Cereb Cortex. 2016 Jul;26(7):3273-84. doi: 10.1093/cercor/bhw067. Epub 2016 Apr 29. Cereb Cortex. 2016. PMID: 27130662 Free PMC article.
-
Plasticity of synapses and reward circuit function in the genesis and treatment of depression.Neuropsychopharmacology. 2023 Jan;48(1):90-103. doi: 10.1038/s41386-022-01422-1. Epub 2022 Sep 3. Neuropsychopharmacology. 2023. PMID: 36057649 Free PMC article. Review.
-
Dopamine receptor activation regulates reward expectancy signals during cognitive control in primate prefrontal neurons.Nat Commun. 2023 Nov 20;14(1):7537. doi: 10.1038/s41467-023-43271-6. Nat Commun. 2023. PMID: 37985776 Free PMC article.
-
Shedding light on neurons: optical approaches for neuromodulation.Natl Sci Rev. 2022 Jan 18;9(10):nwac007. doi: 10.1093/nsr/nwac007. eCollection 2022 Oct. Natl Sci Rev. 2022. PMID: 36196122 Free PMC article. Review.
References
-
- Ainslie GW. Specious rewards: a behavioral theory of impulsiveness and impulse control. Psych Bull 82: 463–496, 1975. - PubMed
Publication types
MeSH terms
Grants and funding
LinkOut - more resources
Full Text Sources
Other Literature Sources