

RSAT peak-motifs: motif analysis in full-size ChIP-seq datasets
- PMID: 22156162
- PMCID: PMC3287167
- DOI: 10.1093/nar/gkr1104
RSAT peak-motifs: motif analysis in full-size ChIP-seq datasets
Abstract
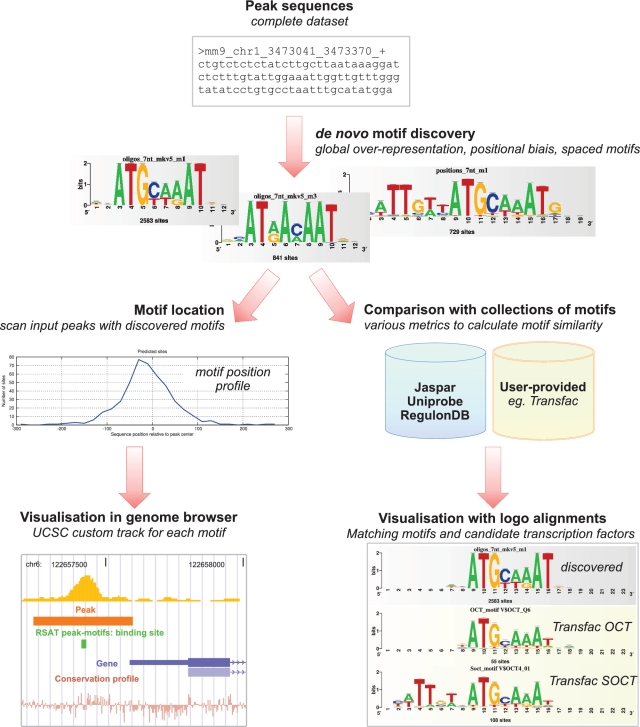
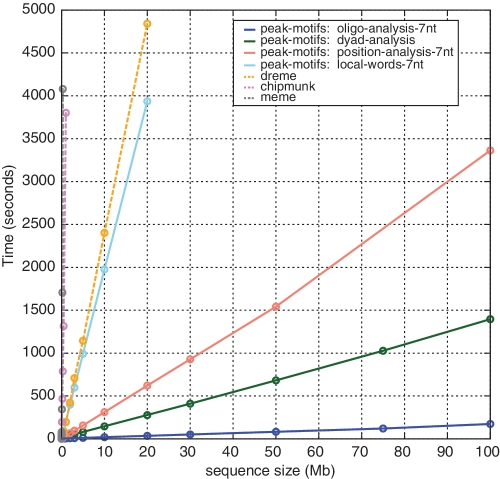
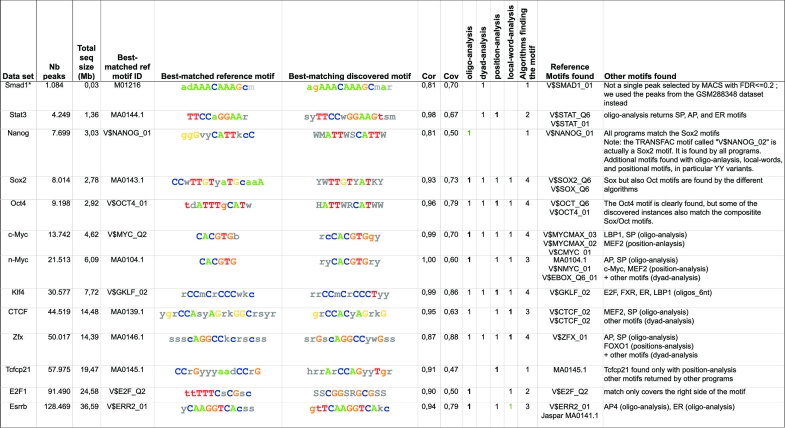
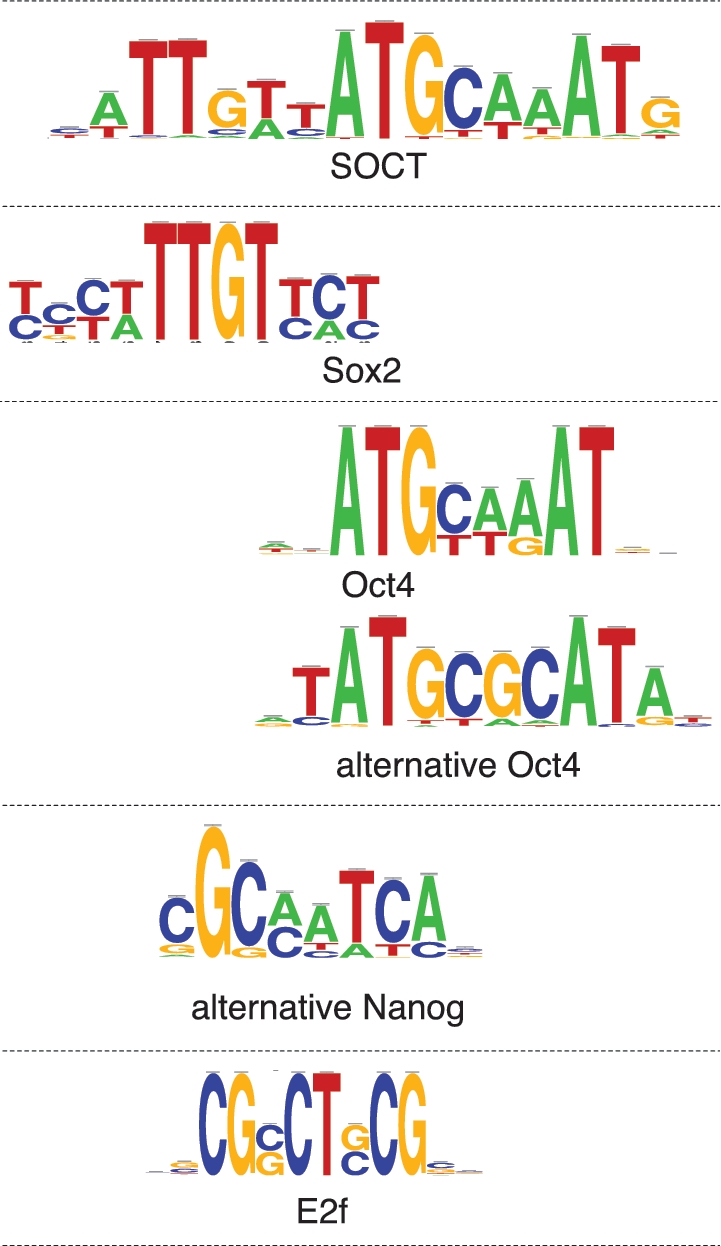
ChIP-seq is increasingly used to characterize transcription factor binding and chromatin marks at a genomic scale. Various tools are now available to extract binding motifs from peak data sets. However, most approaches are only available as command-line programs, or via a website but with size restrictions. We present peak-motifs, a computational pipeline that discovers motifs in peak sequences, compares them with databases, exports putative binding sites for visualization in the UCSC genome browser and generates an extensive report suited for both naive and expert users. It relies on time- and memory-efficient algorithms enabling the treatment of several thousand peaks within minutes. Regarding time efficiency, peak-motifs outperforms all comparable tools by several orders of magnitude. We demonstrate its accuracy by analyzing data sets ranging from 4000 to 1,28,000 peaks for 12 embryonic stem cell-specific transcription factors. In all cases, the program finds the expected motifs and returns additional motifs potentially bound by cofactors. We further apply peak-motifs to discover tissue-specific motifs in peak collections for the p300 transcriptional co-activator. To our knowledge, peak-motifs is the only tool that performs a complete motif analysis and offers a user-friendly web interface without any restriction on sequence size or number of peaks.
Figures

Similar articles
-
A complete workflow for the analysis of full-size ChIP-seq (and similar) data sets using peak-motifs.Nat Protoc. 2012 Jul 26;7(8):1551-68. doi: 10.1038/nprot.2012.088. Nat Protoc. 2012. PMID: 22836136
-
MEME-ChIP: motif analysis of large DNA datasets.Bioinformatics. 2011 Jun 15;27(12):1696-7. doi: 10.1093/bioinformatics/btr189. Epub 2011 Apr 12. Bioinformatics. 2011. PMID: 21486936 Free PMC article.
-
RSAT::Plants: Motif Discovery in ChIP-Seq Peaks of Plant Genomes.Methods Mol Biol. 2016;1482:297-322. doi: 10.1007/978-1-4939-6396-6_19. Methods Mol Biol. 2016. PMID: 27557775
-
A survey of motif finding Web tools for detecting binding site motifs in ChIP-Seq data.Biol Direct. 2014 Feb 20;9:4. doi: 10.1186/1745-6150-9-4. Biol Direct. 2014. PMID: 24555784 Free PMC article. Review.
-
Role of ChIP-seq in the discovery of transcription factor binding sites, differential gene regulation mechanism, epigenetic marks and beyond.Cell Cycle. 2014;13(18):2847-52. doi: 10.4161/15384101.2014.949201. Cell Cycle. 2014. PMID: 25486472 Free PMC article. Review.
Cited by
-
i-cisTarget 2015 update: generalized cis-regulatory enrichment analysis in human, mouse and fly.Nucleic Acids Res. 2015 Jul 1;43(W1):W57-64. doi: 10.1093/nar/gkv395. Epub 2015 Apr 29. Nucleic Acids Res. 2015. PMID: 25925574 Free PMC article.
-
Functional characterization of the Arabidopsis transcription factor bZIP29 reveals its role in leaf and root development.J Exp Bot. 2016 Oct;67(19):5825-5840. doi: 10.1093/jxb/erw347. Epub 2016 Sep 22. J Exp Bot. 2016. PMID: 27660483 Free PMC article.
-
The Arabidopsis hnRNP-Q Protein LIF2 and the PRC1 Subunit LHP1 Function in Concert to Regulate the Transcription of Stress-Responsive Genes.Plant Cell. 2016 Sep;28(9):2197-2211. doi: 10.1105/tpc.16.00244. Epub 2016 Aug 5. Plant Cell. 2016. PMID: 27495811 Free PMC article.
-
Small molecule inhibition of cAMP response element binding protein in human acute myeloid leukemia cells.Leukemia. 2016 Dec;30(12):2302-2311. doi: 10.1038/leu.2016.139. Epub 2016 May 23. Leukemia. 2016. PMID: 27211267 Free PMC article.
-
Discriminative motif optimization based on perceptron training.Bioinformatics. 2014 Apr 1;30(7):941-8. doi: 10.1093/bioinformatics/btt748. Epub 2013 Dec 24. Bioinformatics. 2014. PMID: 24369152 Free PMC article.
References
-
- Robertson G, Hirst M, Bainbridge M, Bilenky M, Zhao Y, Zeng T, Euskirchen G, Bernier B, Varhol R, Delaney A, et al. Genome-wide profiles of STAT1 DNA association using chromatin immunoprecipitation and massively parallel sequencing. Nat. Methods. 2007;4:651–657. - PubMed
-
- Johnson DS, Mortazavi A, Myers RM, Wold B. Genome-wide mapping of in vivo protein–DNA interactions. Science. 2007;316:1497–1502. - PubMed
Publication types
MeSH terms
Substances
LinkOut - more resources
Full Text Sources
Miscellaneous
