

SelenoDB 1.0 : a database of selenoprotein genes, proteins and SECIS elements
- PMID: 18174224
- PMCID: PMC2238826
- DOI: 10.1093/nar/gkm731
SelenoDB 1.0 : a database of selenoprotein genes, proteins and SECIS elements
Abstract
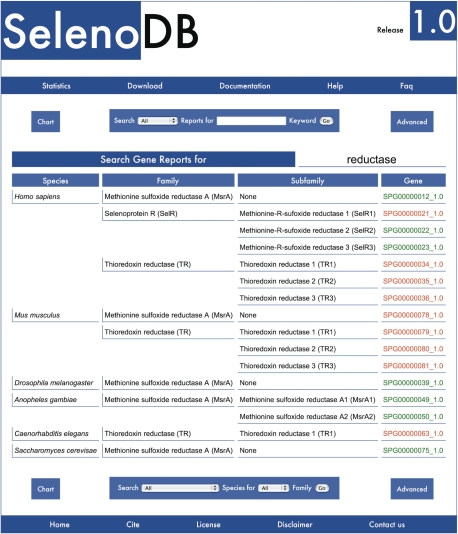
Selenoproteins are a diverse group of proteins usually misidentified and misannotated in sequence databases. The presence of an in-frame UGA (stop) codon in the coding sequence of selenoprotein genes precludes their identification and correct annotation. The in-frame UGA codons are recoded to cotranslationally incorporate selenocysteine, a rare selenium-containing amino acid. The development of ad hoc experimental and, more recently, computational approaches have allowed the efficient identification and characterization of the selenoproteomes of a growing number of species. Today, dozens of selenoprotein families have been described and more are being discovered in recently sequenced species, but the correct genomic annotation is not available for the majority of these genes. SelenoDB is a long-term project that aims to provide, through the collaborative effort of experimental and computational researchers, automatic and manually curated annotations of selenoprotein genes, proteins and SECIS elements. Version 1.0 of the database includes an initial set of eukaryotic genomic annotations, with special emphasis on the human selenoproteome, for immediate inspection by selenium researchers or incorporation into more general databases. SelenoDB is freely available at http://www.selenodb.org.
Figures


Similar articles
-
SelenoDB 2.0: annotation of selenoprotein genes in animals and their genetic diversity in humans.Nucleic Acids Res. 2014 Jan;42(Database issue):D437-43. doi: 10.1093/nar/gkt1045. Epub 2013 Nov 4. Nucleic Acids Res. 2014. PMID: 24194593 Free PMC article.
-
Selenoprofiles: A Computational Pipeline for Annotation of Selenoproteins.Methods Mol Biol. 2018;1661:17-28. doi: 10.1007/978-1-4939-7258-6_2. Methods Mol Biol. 2018. PMID: 28917034
-
SECISaln, a web-based tool for the creation of structure-based alignments of eukaryotic SECIS elements.Bioinformatics. 2009 Mar 1;25(5):674-5. doi: 10.1093/bioinformatics/btp020. Epub 2009 Jan 29. Bioinformatics. 2009. PMID: 19179357 Free PMC article.
-
Computational genomic analysis of hemorrhagic fever viruses. Viral selenoproteins as a potential factor in pathogenesis.Biol Trace Elem Res. 1997 Jan;56(1):93-106. doi: 10.1007/BF02778985. Biol Trace Elem Res. 1997. PMID: 9152513 Review.
-
Update on selenoprotein biosynthesis.Antioxid Redox Signal. 2015 Oct 1;23(10):775-94. doi: 10.1089/ars.2015.6391. Epub 2015 Aug 25. Antioxid Redox Signal. 2015. PMID: 26154496 Review.
Cited by
-
Novel structural determinants in human SECIS elements modulate the translational recoding of UGA as selenocysteine.Nucleic Acids Res. 2009 Sep;37(17):5868-80. doi: 10.1093/nar/gkp635. Epub 2009 Aug 3. Nucleic Acids Res. 2009. PMID: 19651878 Free PMC article.
-
Engineered mRNA-ribosome fusions for facile biosynthesis of selenoproteins.Proc Natl Acad Sci U S A. 2024 Mar 12;121(11):e2321700121. doi: 10.1073/pnas.2321700121. Epub 2024 Mar 5. Proc Natl Acad Sci U S A. 2024. PMID: 38442159 Free PMC article.
-
The Micronutrient Genomics Project: a community-driven knowledge base for micronutrient research.Genes Nutr. 2010 Dec;5(4):285-96. doi: 10.1007/s12263-010-0192-8. Epub 2010 Oct 30. Genes Nutr. 2010. PMID: 21189865 Free PMC article.
-
Tuning the engine: an introduction to resources on post-transcriptional regulation of gene expression.RNA Biol. 2012 Oct;9(10):1224-32. doi: 10.4161/rna.22035. Epub 2012 Sep 20. RNA Biol. 2012. PMID: 22995832 Free PMC article. Review.
-
Bioinformatics of Selenoproteins.Antioxid Redox Signal. 2020 Sep 1;33(7):525-536. doi: 10.1089/ars.2020.8044. Epub 2020 Apr 23. Antioxid Redox Signal. 2020. PMID: 32031018 Free PMC article. Review.
