

Abstract
The underwater target detection is the most important part of monitoring for environment, ocean, and other fields. However, the detection accuracy is greatly decreased by the poor image quality resulted from the complex underwater environments. The storage and computing power of underwater equipments are not enough for complex underwater target detection technology. Therefore, many YOLO series algorithms have been applied to underwater target detection. On the basis of YOLOv8, a lightweight underwater detector enhanced by Attention mechanism, GSConv and WIoU, AGW-YOLOv8, is proposed in this paper. Firstly, by the combination of limited contrast adaptive histogram equalization and wavelet transform(LCAHE-WT), the fidelity and detail of images are improved; Secondly, by CBAM, the key channel features can be effectively extracted with retaining spatial information to improve the performance of the network when dealing with complex image tasks; Thirdly, by GSConv, composed of depth-wise separable convolution and regular convolution, the model parameters and computational complexity are reduced; Fourth, the SE attention mechanism is integrated into the C2f module of the neck, and the channel dimension is weighted to make the network more focus on important features, and to further enhance the feature extraction capability; Finally, by the dynamic nonmonotonic mechanism of WIoU, the gradient gain can be reasonably distributed, the harmful gradients of extreme samples can be reduced, and the generalization ability and overall performance of the model are improved. By the experiments on the URPC2020 data-set, it can been proved that the mAP of AGW-YOLOv8 can reaches 82.9%, is 2.5% higher than that of YOLOv8; and the parameters is 2.95M, is lower than 3.01M of YOLOv8.
Keywords: Underwater target detection, Lightweight, Attention mechanism, Image enhancement
Subject terms: Computational science, Information technology, Software
Introduction
The object detection is one of the fundamental and challenging problems in computer vision, and can be used in various scenarios1,2. Furthermore, the underwater target detection is one of the most challenging areas. The underwater environment of the ocean is extremely complex, and very dangerous. So, it is very difficult and challenging for the development and exploration of the ocean. Now, with the development of artificial intelligence and robotics industry, the underwater robots became an important method for ocean exploration3,4.
The maim task of underwater robots is to detect and recognize the potential targets in underwater environments5. The object detection technology has performed very well on traditional datasets. However, there are some unique challenges in the underwater field, such as, low visibility and color distortion6. Especially, it is difficult for small targets in underwater images to cluster, shelter, and express features sufficiently. So, it is difficult to accurately identify underwater targets7.
Recently, many works have been done to improve poor image quality. Hitam et al.8 proposed a hybrid LCAHE(Limited Contrast Adaptive Histogram Equalization) algorithm. In the hybrid LCAHE, both LCAHE as the enhancement method and Euclidean norm as the fusion method are used for processing HSV and RGB images to significantly improve image quality and contrast. Huang et al.9 adopted an adaptive relative global histogram stretching method, which includes contrast correction and color correction, to process low-quality shallow water images, and obtain high quality, rich information, normal color and low noise shallow images. Jia et al.10 proposed an enhancement method on the basis of HSI model and improved Retinex to improve the contrast of underwater images, and to highlight the details of the images. Wang et al.11 designed a wavelet-based multistage underwater image enhancement network (MWEN) for color compensation before the frequency domain and the spatial domain to reduce the color distortion of different water types. Awan et al.12 effectively extracted feature by discrete wavelet transform and inverse discrete wavelet transform, and enhanced the contrast and color of the recovered image by the added chrominance adaptation transform layer of the network, performed a better underwater image restoration.
YOLO series algorithms are lightweight, many YOLO series algorithms have been applied for underwater target detection recently to reduce complexity. On the basis of YOLOv4, an attention feature fusion module is used both to integrate semantic features better, and to improve accuracy13. On the basis of YOLOX, The EloU loss function is used to improve detection accuracy and speed, the Poisson fusion is used to balance the number of targets, and the wavelet transform is used to restore image14. However, it is still not a successful lightweight model because of its large model parameters. On the basis of YOLOv5, a BoT3 module with multiple head attention mechanism is used to improve the detection effect in dense target scenes15. On the basis of YOLOv7, CBAM (Convolutional Block Attention Module) is used not only to made the model more focused on target feature16, but also to improve its detection ability for small targets. In order to improve accuracy and reduce complexity further, an enhanced lightweight underwater detector with Attention Mechanism, GSCon17 and WIoU on YOLOv8 (AGW-YOLOv8) is proposed in this paper. The key points of our work are shown as following:
(1) By the proposed LCAHE-WT, the combination of LCAHE and Wavelet Transform, the color is compensated for better restoring low-quality underwater datasets.
(2) By CBAM module, the feature maps of channel dimension and space dimension are weighted respectively for the network to pay more attention to important features.
(3) By replacing the Conv module with the GSConv module, the model is light-weighted, and the parameters are reduced greatly without sacrificing too much accuracy.
(4) By replacing the C2f module of the neck with SE-C2f module, the required features are dynamically selected in the feature fusion stage, and the representation of the fused features is improved.
(5) By replacing the CIoU of head with WloU, more attention is paid to low-quality underwater samples, the generalization ability and overall performance of the model are improved.
Related works
YOLOv8 algorithm
The object detector can be classified into a single-stage detector and a two-stage detector. The two-stage detectors, such as Fast R-CNN18, Faster R-CNN19, Mask R-CNN20, firstly generate candidate regions, and then classify them. So, its inference speed is reduced greatly by its large number of repeated calculation operations. A single-stage object detector directly maps input images to bounding boxes and class probabilities. YOLOv821, a single-stage object detector, is developed by Ultralytics on basis on the YOLOv7 architecture22 to improve accuracy and speed. The YOLOv8 model consists of input, backbone, and head.
In backbone, firstly, by the convolution, containing batch normalization and SiLU activation functions, the down-sampling is done for feature extractions; and then, by the more connections among branches with cross layers of the C2f module, referring to the E-ELAN structure22, the gradient flow of model is enriched for further feature extraction to improve detection results; Lastly, by the joint of three max pooling layers in SPPF block, which is at the end of the backbone network, the various scale of features are processed for enhancing the feature abstraction ability of network.
In neck network, by FPN23 and PAN24 structures, the information of various size feature maps are fused for the head.
In the head, a decoupled detection is used to calculate the loss of regression and category by the convolutions of two parallel branches, each of which focuses on its own tasks to improve the detection accuracy of model greatly.
There are five models, YOLOv8n, YOLOv8s, YOLOv8m, YOLOv8l, and YOLOv8x in YOLOv8 series. The computing complexity of YOLOv8n is the lowest of them. So, the improvement of this paper is done on the basis of YOLOv8n.
Data-set
The data-set of Underwater Robotics Competition (URPC) 2020 is used here (shown in Fig. 1). In Fig. 1, a and b show small targets in the data set, c and d show complex terrain, and e and f show dim waters. There are 5543 training images of echinus, holothurian, scallops and starfish in the data-set. The data-set are divided into training, validation, and testing sets in the 7:2:1 ratio. There are some complex situations in the data-set, such as the masking of underwater biological aggregation, the uneven lighting, the blurring of motion lens, the uneven distribution of samples, and their different resolutions of categories. So, all these above make the model training significantly challenging.
Fig. 1.

Sample images of URPC2020.
Data augmentation
The poor detection performance of models is resulted from the insufficient training samples and the imbalanced data-set categories. To alleviate these unfavorable conditions, some data augmentations are applied to provide better training data for the models, and to improve both performance and generalization ability25:
In underwater target detection, the movement, shape, and direction of underwater organisms are uncertain. So, the training effect of the model can be improved by flipping (shown in Fig. 2).
Fig. 2.

Flip, Zoom, Crop.
Mosaic concatenates four images by random scaling, cropping, and layout26. So, the background of detecting objects, especially the background of the small targets is enriched by Mosaic (shown in Fig. 3).
Fig. 3.

Mosaic enhancement.
Haar wavelet transformation27 is used for style transfer and image restoration. Haar wavelet transform produces four sub-bands, namely LLT, LHT, HLT and HHT low-pass and high-pass filters. In this paper, the low-frequency sub-band (LL) is used to capture the smooth surface and texture information of the image, and the high-frequency sub-band (LH, HL, HH) is used to extract the edge information. By high-fidelity image restoration, the overall contrast is enhanced, the impact of noise on the image is reduced, the distorted images are restored and enhanced without affecting their original details (shown in Figs. 4,5). In Fig. 5, a is the original image, b is the image after wavelet change, and c is the image after LCAHE-WT transformation. The top image shows images of deep water, and the bottom image shows images of shallow water
Fig. 4.
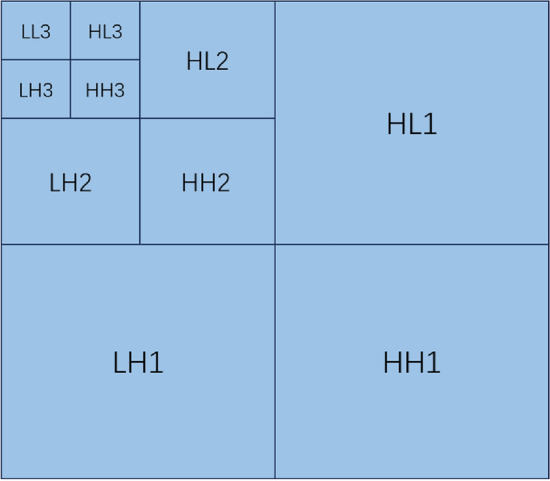
Haar Wavelet Pool.
Fig. 5.

The result of wavelet transform and LCAHE-WT.
When the sunlight passes through water, the energy of red light is absorbed by the water molecules, and the energy of the red band rapidly weakens. The blue and green bands of light have relatively higher energy, and propagate easier in deep water. So, the blue and green band are more pronounced in the images of deep water areas. However, the normal wavelet transform is only used to analyze local features, edges, textures, and other information of an image, and cannot deal with a specific color band. Therefore, the influence of green waves or other color bands cannot be directly reduced.
LCAHE (Limited Contrast Adaptive Histogram Equalization) is a local contrast enhancement method. By LCAHE, the image is divided into small regions, and then histogram equalization is performed in each region to avoid excessive enhancement and noise limitation. The LCAHE and Wavelet Transform are combined (called LCAHE-WT) in this paper to improve fidelity and detail of images, and to adapt to underwater environments. For the images of deep water areas, it works as following (shown In Fig. 6):
The images are firstly normalized to the range of 0-1 for wavelet transform;
The LL, LH, HL, and HH coefficients are extracted. For low-frequency coefficients, the LL coefficient is enhanced by linearly combining the original LL and its mean. For high-frequency coefficients, the green channels of the HL coefficient are suppressed to reduce the influence of green waves;
The enhanced frequency domain information is reconstructed to restore the enhanced image from the range of [0,1] to [0,255].
LCAHE-WT is used to improve the local contrast of the image, to make the details of the image clearer in different regions.
Fig. 6.

CBAM structure diagram.
The green waves are efficiently suppressed in the high-frequency coefficients of wavelet transform. The reduction degree of green wave can be controlled more finely by preserving other features of the image better. For the images of shallow water areas, it works similarly. But, the red wave coefficients of all frequency band is enhanced to compensate for color shift, and to make the underwater image closer to the real image.
Convolutional block attention module
The attention mechanism is used to shrink and lock the focus area of the network, and to ultimately form an attention focus, which is crucial for object detection. By attention mechanisms, the perceptual information is refined, and the contextual connections are enhanced. There are channel, spatial, and combined channel-spatial attention mechanism, which dynamically measure the significance of input features to improve detection by suppressing noise and capturing relevant information. It is proved that the integration of attention mechanisms into deep neural networks is effective for boosting performance in computer vision tasks. In last years, lots of works have been done to integrate various attention mechanisms into deep convolutional neural network architectures to improve the performance of detection tasks effectively, and they have been proven effective28.
The CBAM (Convolutional Block Attention Module) (shown in Fig. 6)29 enhances the representation capability of network by introducing attention mechanisms. It consists of the channel attention module and the spatial attention module. In CBAM, by emphasizing the meaningful features of both channel and spatial dimensions, essential information is focused on, the unnecessary details are suppressed, and the target recognition of network is more accurate. Moreover, CBAM is a lightweight module, and its parameters and computational overhead is almost no in most cases. So, it is widely applied to enhance the representation capability of convolutional neural networks.
CBAM is divided into two parts, spatial attention and channel attention. In the channel attention, firstly, the global average of each channel is pooled and normalized in each feature graph; Secondly, a channel weight vector is generated by a series of linear transformations (usually fully connected layers); Thirdly, the vector is converted into probability distribution by softmax function, which indicates the importance of each channel; Finally, the important features are enhanced, and the unimportant features are suppressed through weighting channel by channel. In spatial attention, the maximum value and the average value of each position are captured by maximum pooling and average pooling; And then, the local spatial attention is calculated by the same linear transformation, where the softmax function is applied to determine the position importance of each pixel. Normally, These two modules are connected in series, with spatial attention following channel attention, to obtain more comprehensive feature context information.
The backbone plays the role of feature extraction in the whole YOLOv8 network. So, the CBAM module is added here to enforce the importance of the correct information, and to remove some useless information for improving the feature extraction ability and detection accuracy of the network.
GSConv module
The storage and computing resources of underwater equipment are so limited that it is necessary for underwater detection to acquire high accuracy with low computing overhead30. Now, the model compression and the lightweight network architecture design are the two main ways of lightweight.
Knowledge distillation31 and network pruning32 are the two main methods for model compression. In knowledge distillation, model size and computing requirements are reduced without affecting performance by a lighter and smaller student model, which are trained from a teacher model. In pruning, the model redundancy is reduced, and the network is made sparsity by removing unimportant channels or convolutional kernels.
The design of lightweight network architecture is to make convolutional neural networks more lightweight by different convolutional methods and structures. Such as SqueezeNet33, MobileNet34, ShuffleNet35, etc. In SqueezeNet, a fire module structure, which is the pioneer in model compression, is introduced. In MobileNet, the standard convolution is divided into depth-wise convolution and point-wise convolution to reduce computing overhead. In ShuffleNets, the computing complexity of convolution is reduced by grouping convolution, the speed and accuracy are balanced better by the channel shuffling for channel information interaction. In GSConv (Grouped Spatial Convolution) module, there are standard Conv module, DWConv module (consist of Depth-wise Separable Convolution and point-wise convolution module), Concat module, and shuffle module (shown in Fig. 7). GSConv has the advantages of both MobileNet and ShuffleNet, and is used in this paper for both accuracy and lightweight. In Fig. 7, C1 is the number of channels for the input feature map; C2 is the number of channels for outputting feature maps (shown in formula (1)).
Fig. 8.

depth-wise separable convolution module structure diagram.
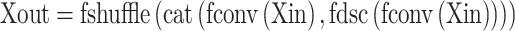 |
1 |
Fig. 7.

GSConv module structure diagram.
DSConv (Depth-wise Separable Convolution), which consists of two different convolutional modules (shown in Fig. 8), is performed after a SC (Standard Convolution)36. The output channel number of both convolutions are half of C2. So, a new feature map can be formed by the concatenation of the two convolution results along the channel dimension. Finally, shuffle shuffling is performed, and an output tensor, reordered along the channel dimension, is returned.
Fig. 11.

SE-C2f module structure diagram.
The parameter number and the computational cost of DSC are much lower than that of SC. However, the information of different layers on the same spatial position is not effectively utilized. So, the feature maps, generated in depth-wise separable convolution, are weightly combined to generate a new feature maps with expanded interaction feature in the following point-wise convolution module (shown in Fig. 9), whose convolution kernel size is 1.
Fig. 9.

point-wise convolution module structure diagram.
By the DSC, the speed of the detector can be greatly improved; By the SC, the interaction information among channels can be effectively preserved to ensure their accuracy. So, the SC, DSC, and the mixing operations are all utilized simultaneously in GSConv to light-weight without losing its accuracy. When GSConv is used in the backbone network, the layers of the backbone network are deepen, the resistance of data flow is exacerbated, the inference time is significantly increased, and some semantic information loses. So, the GSConv module is used in the neck in this paper.
SE-C2f
The channel-wise attention of SE (Squeeze-and-Excitation) attention mechanism is used to enhance the performance of convolutional neural networks. Squeeze and Excitation are two main steps of SE module (shown in Fig. 10).
Fig. 10.

SE attention mechanism structure diagram.
In the Squeeze step, by global average pooling, each channel of the feature map is compressed into a scalar, which represents the overall global information, and reflects the comprehensive importance of each channel.
In the Excitation step, a weight vector is generated by two fully connected layers. Firstly, the dimension of scalar, obtained from the Squeeze step, is reduced; And then, the dimension is expanded by ReLU activation; Finally, the weights are limited among 0 and 1 by the Sigmoid activation function. So, the relative importance of each channel can be indicated by the weight vectors.
In SE attention mechanism, by multiplying the original feature map with this weight vector, an enhanced feature map can be obtained to increase attention, the inter-channel information can be better utilized to improve the performance, and the representation power of convolutional neural networks can be effectively enhanced. The parameter number of the SE module is so relatively small that the overall parameter number of the network module is hardly increased when it is integrated into the C2f module of the neck(the structure is shown in Figs. 11,12).
Fig. 12.

Block_SE module structure diagram.
Loss function
In the field of object detection, the accuracy are directly affected by the effectiveness of bounding box loss functions, such as CloU37, EloU38, and SloU39. The positional error between the predicted bounding box and the ground truth is optimized by the loss function for gradually approaching a minimum. In most research data-sets, the objects are annotated with high quality for bounding boxes to highly effectively improve fitting accuracy.
CloU is an earlier bounding box regression loss function, and is used in the original YOLOv8 model. However, CLoU has the following drawbacks: (1) it does not consider the balance between high-quality and low-quality samples; (2) the aspect ratio is used as a penalty factor for the loss function, and cannot effectively reflect the real aspect ratios because the predicted aspect ratios significantly differs from the real aspect ratios. The CloU formula is as follows:
| 2 |
where, IoU represents the Intersection Over Union between the predicted box and the true box. The remain parameters are shown in Fig. 13
Fig. 13.

Entity Diagram of Loss Function.
Subsequently, EIoU improved CIoU by using length and width as penalty terms, which can more accurately reflect the length and width difference between the real box and the predicted box. The formula for EIoU is shown in formula (3):
| 3 |
Based on EloU, the angle between the predicted box and the actual box is used as a penalty factor of SIoU. So, the predicted box can quickly move towards the nearest axis, regress to the actual box, and accelerate the convergence speed.
The above loss functions all adopt a static focusing mechanism, whose effect on data-sets with high-quality images is good. However, for data-sets with large number of low-quality images, the detection performance improvement of model with the above loss function is limited. In WIoU40, considering the slope direction, overlapping area, and centroid distance, a dynamic non-monotonic focusing mechanism, the outliers for evaluating anchor boxes, and a reasonable gradient gain strategy are used for focusing on low-quality anchor boxes to improve overall accuracy. Now, WIoU has three versions. In WIoUv1, the distance attention is constructed on distance measurement; In WIoUv2, a monotonic focusing mechanism is designed for cross entropy to focus on low-quality samples better; In WIoUv3, a small gradient gain is added furthermore to reduce harmful gradients generated by low-quality samples. The formula of WIoUv1 is defined as follows:
| 4 |
| 5 |
| 6 |
The formula of WIoUv2 is defined as follows:
| 7 |
The formula of WIoUv3 is defined as follows:
| 8 |
| 9 |
| 10 |
where, β is defined as the quality of the anchor box, and is assigned a small gradient gain; δ and α are adjustable hyper-parameters, which can adapt to different models.
WIoU has the advantages of both EIoU and SIoU. Therefore, in response to the adverse conditions and poor datasets quality of underwater target detection tasks, WIoU is used as the bounding box loss function to obtain more accurate detection results.
Algorithm
On the basis of YOLOv8, an enhanced lightweight underwater detector with Attention mechanism, CSCon and WIoU, AGW-YOLOv8, is proposed. The structure of AGW-YOLOv8 is shown in Fig. 14. In Fig. 14, the improved network is discribed by backbone, neck, and head respectively:
Fig. 14.

AGW-YOLOv8 model diagram.
(1) By CBAM of the backbone, the detection accuracy is improved;
(2) By replacing regular convolution of the neck with GSConv module, the detection speed is improved further;
(3) By integrating the SE attention mechanism with the C2f module of the neck, the ability of feature extraction is improved.
(4) By replacing normal loss function of the head with WIoU, the accuracy is improved.
Experiments and results (Supplementary Information)
Parameter settings
The experimental environment configuration of this paper are shown in Table 1. The Pytorch version 1.12.0 + cu113 deep learning framework was used, with an Intel(R) Core (TM) (TM) i7-13620H CPU, 8G memory, NVIDIA GeForce GTX 4060 graphics cards, and Windows 11 operating system; the software programming environment was Python 3.9.
Table 1.
Experimental configuration and parameters.
| argument | disposition |
|---|---|
| CPU | Intel(R) Core (TM) i7-13620H |
| GPU | NVIDIA GeForce GTX 4060 |
| CUDA | V 11.3 |
| PyTorch | V 1.12.0 + cu113 |
| Operating system | Win11 |
Evaluation indicators
In this paper, representative evaluation indicators, the AP and mAP, of target detection models are used. AP (Average Precision) refers to the model average recognition accuracy of each class. The AP value is approximated by smoothing the area calculation of the P-R (Precision-Recall) curve, where recall is the horizontal axis and precision is the vertical axis in the coordinate system. mAP (mean Average Precision) refers to the average AP value of all categories. The mAP can be obtained by calculating recall and accuracy metrics.
The formula for calculating the recall rate is defined as following:
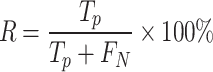 |
11 |
The formula for calculating accuracy is defined as following:
| 12 |
where, TP represents positive samples that have been correctly identified as positive; FN represents positive samples that have been incorrectly identified as negative; FP represents negative samples that have been incorrectly identified as positive.
The average accuracy (mAP) of all categories is obtained by calculating the average value of each category. The formula for calculating mAP is definde as following:
| 13 |
In the above equation, N represents the category number of objects, detected in the data-set. In the our experiments, N = 4, corresponding to echinus, holothurian, starfish, and scallops.
Detection results on URPC dataset
In this subsection, our proposed model is experimented on the augmented URPC2020 data-set. The initial learning rate is 0.01, the momentum is 0.9, the weight decay of optimizer is 0.0005, the epoch is 200, batch size is 4, and the other training parameters is set to the default values of YOLOv8 network. The RP curve is shown in Fig. 15.
Fig. 15.
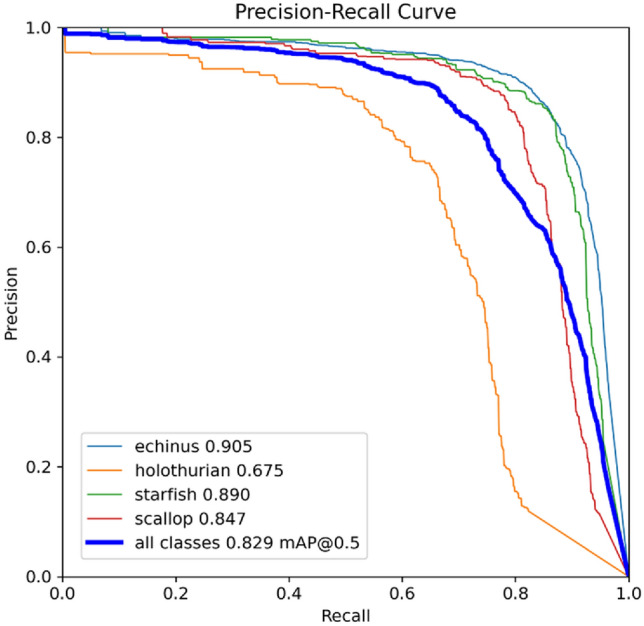
PR curve of the proposed model.
The recall and accuracy of the model are two key performance indicators of object detection tasks. The PR curves in the above Fig. 15 demonstrate that our detection efficiencies of various target categories are much high. Especially, the average accuracy (AP) of sea urchins is 90.1%, and the calculated average accuracy (mAP) is 82.9%, Our model performs excellently.
Ablation experiments
In this section, ablation experiments are conducted to verify the effectiveness of different sub-modules. The mAP represents the detection accuracy of the algorithm. The higher the value of mAP, the better the performance of detection and recognition. In addition, the parameter size of the model is another important indicator. The fewer parameters, the faster the speed. The different modules are sequentially used to improve the YOLOv8 algorithm. The results of this ablation experiment are shown in Table 2. In the first row of the Table 2, The detection results of the original YOLOv8 network are shown as benchmark.
Table 2.
Ablation experiment results.
| Modules | mAP(%) Parameters(M) | |
|---|---|---|
| YOLOv8n | 80.4 | 3.01 |
| YOLOv8n + GSConv | 80.4 | 2.92 |
| YOLOv8n + CBAM | 80.7 | 3.03 |
| YOLOv8n + SE-C2f | 81.1 | 3.02 |
| YOLOv8n + WIoU | 81.4 | 3.01 |
| YOLOv8n + Data enhancement | 81 | 3.01 |
| AGW-YOLOv8 | 82.9 | 2.95 |
In the second row of Table 2, The detection results of improved YOLOv8 only with GSConv module are shown. Compared with the original YOLOv8, the parameter quantity is reduced, the accuracy remains unchanged. That is, the efficiency is improve by the depth-wise separable convolution of GSConv module. Simultaneously, the information exchanges among channels are still retained by the common convolution and channel shuffling, and the accuracy of model can be ensured by the richer learned feature representations.
In the third row of Table 2, the detection results of YOLOv8 + CBAM are shown. The global weight distribution can be learned by CBAM. So, the task key parts of the input can be more focused, and the attention of irrelevant (or noisy) information can be reduced. Therefore, the accuracy and robustness of the model can be improved, and the accuracy increases 0.9%.
In the fourth row of Table 2, the detection results of YOLOv8 + SE-C2f are shown. SE attention mechanism focuses on channels, and improves the network representation ability by explicitly modeling the interdependence among convolution feature channels. By Integrating SE attention mechanism into C2f module of neck, the feature fusion effect of neck and the feature extraction ability of the model can be enhanced, and the accuracy can be increased by 0.7% with similar parameters.
In the fifth row of Table 2, The detection results of YOLOv8 + WIoU lose function are shown. The accuracy of YOLOv8n + WIoU is 0.8% higer than that of original YOLOv8. WIoU uses dynamic non-monotonic focusing mechanism, evaluates the quality of anchor frame by using “outlier” instead of IoU, and provides a wise gradient gain allocation strategy. This strategy not only reduces the competitiveness of high-quality anchor frames, but also reduces the harmful gradient caused by low-quality examples. This allows WIoU to focus on the anchor frame of ordinary quality and improve the overall performance of the detector. It is proven that WIoU is an effective method without side effects.
In the sixth row of Table 2, the detection results of YOLOv8n + Data enhancement are shown. The accuracy of the model reaches 80.7%. It is proved that image enhancement is a very effective method to improve the accuracy of underwater targets.
In the last row of Table 2, the detection results of AGW-YOLOv8 are shown. From the table, it can be seen that the parameter number is reduced from 3.01 to 2.95M at the little cost of accuracy decrease by AGW-YOLOv8. However, the accuracy is still 82.9%, and is 2.5% higher than the benchmark model.
It is proved that our improvements are practical and effective by the above experiments. So, it can be said that our improvements is very successful, and lays a better foundation for the future research.
In addition, LCAHE-WT is compared with Wavelet Transform, and the experimental results show that the accuracy of our proposed method has been improved slightly, As shown in Table 3. This method is proved to be effective.
Table 3.
Contrast experiment results of LCAHE-WT and Wavelet Transformation.
| mAP(%) | |
|---|---|
| Wavelet Transform | 82.82 |
| LCAHE-WT | 82.90 |
Comparison with other algorithms
In this subsection, our proposed algorithm is compared with YOLOv441, YOLOv5-s42, YOLOX-s43, YOLOv8s, YOLOv8l, improved YOLOv413 and B-YOLOX-S14 on the augmented URPC2020 data-set. All experiments were performed with the same parameters in the same environment. The results are shown in Table 4:
Table 4.
Comparative experimental results.
| module | mAP(%) Parameters (M) | |
|---|---|---|
| YOLOv4-tiny | 75.6 | 6.1 |
| The improved YOLOv4 | 79.5 | 10.73 |
| YOLOv5-s | 77.8 | 7 |
| YOLOX-s | 79.9 | 8.94 |
| YOLOv8s | 81.4 | 11.2 |
| YOLOv8l | 83.5 | 43.7 |
| B-YOLOX-S | 82.7 | 12.32 |
| AGW-YOLOv8 | 82.9 | 2.95 |
It can be seen from the table that, compared with YOLOv4-tiny, YOLOv5-s, YOLOX-s, YOLOv8s, and the improved YOLOv4, our accuracy is 7.3%, 5.1%, 3.0%, 1.5%, and 3.4% higher respectively, and the number of parameters slightly decreases simultaneously. Compared with YOLOv8l and B-YOLOX-S, the similar precision values can be achieved at the only cost of 6.7% and 23.9% parameters. That is, the satisfactory results can be achieved by AGW-YOLOv8 at the low cost. Therefore, AGW-YOLOv8 is more suitable for underwater target detection.
Visualization analysis
The heat map is a key visualization tool of object detection based on deep learning44. The position information of the detected object can be reflected by heat map. So, a part of an image can be selected by heat map to help neural network making the final classification decision.
The necessary information is provided by the high response areas in the heatmap to support the final discrimination of the target detection network 45. Some images are selected from the URPC data-set, and the comparative experiments of heat map visualization is done (shown in Fig. 16). In Fig. 16, the detection capabilities of YOLOv8 and AGW_YOLOv8 for echinus, starfish, holothurian, and scallop are respectively demonstrated.
Fig. 16.

Heat map.
From the prominent hotspots, it can be seen that it is difficult for YOLOv8 to focus on objects of interest due to the large receptive domain of the feature information, which leads to imprecise detection and recognition, when detecting and recognizing sea urchins, starfish and scallop. Therefore, in AGW-YOLOv8, attention mechanism is used to improve the ability of feature extraction, WIoU is used increase the performance of detection and recognition by measuring the matching degree between the detection box and the actual box better.
However, there are some issues of both YOLOv8n and AGW-YOLOv8 during the detection of sea cucumbers, not only because of the limited parameters and computing resources, but also because of lots of sea cucumbers being obstructed by seaweed and coral. So, the mAP of sea cucumbers is only 69%, and is significantly lower than that of others. Therefore, researches should be done furthermore.
The performance analysis is done in three representative complex underwater scenes of data-set to prove the feasibility of AGW-YOLOv8 (shown in Figs. 17,18,19). In these figures, the detection results of YOLOv8 is in the first column; the detection results of AGW-YOLOv8 is in the second column.
Fig. 17.

Comparison of the results of two models for small target detection.
Fig. 18.

Comparison of the results of the two models for the detection of complex terrain.
Fig. 19.

Comparison of the results of the two models for the detection of dark water.
In Fig. 17 the missed detection rate of the detector is relatively high when the target volume is small with weak feature expression ability. There are 10 and 24 targets respectively in the tested scenario. YOLOv8n can detect 9 and 20 targets respectively; AGW-YOLOv8 can detect 10 and 22 targets respectively. So, it is proved that, by attention mechanism, the global information can be captured more effectively, the data understanding and expression ability of model is higher, and targets of different scales and positions can be adapted better. That is, it is very effective for Attention Mechanism to detect small objects.
In Fig. 18, the sea cucumbers, aquatic plants and reefs are highly similar. The targets are missed for seaweed and reefs by detector with any carelessness. So, the recognition is much low, and the detection is more difficult. From Fig. 18, it can be seen that YOLOv8n has missed detection; AGW-YOLOv8 does not has any missed detection, and localizes accurate. So, the recognition of AGW-YOLOv8 is much better than that of YOLOv8n. That is, in complex terrain, the labeling quality of the target object may not be high. WIoU can perform well in this case, because it will not produce a large IoU loss when generating high-quality anchor frames for low-quality examples.
In Fig. 19, the seawater is turbid with limited lighting, the detection is more difficult. The two detectors loss some detection. However, there are false detection in YOLOv8n because of the overly fuzzy data. In AGW-YOLOv8, the distorted images are repaired, and the image details are restored by data augmentation. So, its detection is better. Therefore, it is important for detection accuracy improvement to make images clearer by effective data augmentation methods in the deep-sea.
Overall, by AGW-YOLOv8, the missed and false detection can be reduced, and the optimization effect is improved in complex underwater environments. Especially, the excellent accuracy and detection speed can be guaranteed under the circumstances of many small targets, complex terrain, and distorted images. That is, our work is effective.
Conclusion
A lightweight underwater target detection algorithm based on YOLOv8 is proposed this article to improve its slow detection speed, which are caused by large model parameters and complex calculations, and to improve the detection accuracy of small targets with underwater blurred images. The main contributions of AGW-YOLOv8 are as follows:
By CBAM, the feature extraction ability of the model is enhanced, and the detection accuracy is improved;
By GSConv, the parameters and computational complexity are reduced to improve detection speed;
By SE-C2f, the interdependence among feature graph channels of convolutional neural network is enhanced, and the representation ability of networ is improved.
By the WIoU, more attention is paid to low-quality underwater samples, and the generalization ability and overall performance of the model are improved.
By data enhancement, the image quality is improved, the data volume is increased, and the robustness of the model is greatly improved.
Compared with other YOLO algorithms, the accuracy of AGW-YOLOv8 is ultra-high with minimal parameters and the lowest computational complexity on the augmented URPC2020 data-set. AGW-YOLOv8 performs much better than the others.
From the above analysis, it can be seen that the high quality underwater image is one of the most important factors in underwater environmental target detection, and our work of data augmentation is not perfect enough for high precision underwater detection. Therefore, our future research efforts will be more focused on effective image enhancement techniques to improve the overall quality of underwater images.
Supplementary Information
Author contributions
Shaobin Cai designed the research scheme, analyzed the data and made charts 1–4 and visualized the data. Xiangkui Zhang wrote the main manuscript text and prepared Figs. 1–19. Yuchang Mo collected and arranged the experimental data. All authors reviewed the manuscript.
Funding
Huzhou Normal University research start-up fund
Data availability
The datasets used and/or analysed during the current study available from the corresponding author on reasonable request.
Declarations
Competing interests
The authors declare no competing interests.
Footnotes
Publisher’s note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Supplementary Information
The online version contains supplementary material, which is code for experiments, and is available at 10.1038/s41598-024-75809-z.
References
- 1.Zou Z, Chen K, Shi Z, et al. Object detection in 20 years: A survey[J]. Proceedings of the IEEE, (2023).
- 2.Fu, H., Song, G. & Wang, Y. Improved YOLOv4 marine target detection combined with CBAM. Symmetry 13(4), 623 (2021). [Google Scholar]
- 3.Liu, Y. et al. Ocean explorations using autonomy: Technologies, strategies and applications[C]//Offshore Robotics: I(1). Springer Singapore 2022, 35–58 (2021). [Google Scholar]
- 4.Yuh, J. & West, M. Underwater robotics. Adv. Robot. 15(5), 609–639 (2001). [Google Scholar]
- 5.Liu, C. et al. A new dataset, Poisson GAN and AquaNet for underwater object grabbing. IEEE Trans. Circuits Syst. Video Technol. 32(5), 2831–2844 (2021). [Google Scholar]
- 6.Peng, F. et al. S-FPN: A shortcut feature pyramid network for sea cucumber detection in underwater images. Expert Syst. Appl. 182, 115306 (2021). [Google Scholar]
- 7.Jalal, A. et al. Fish detection and species classification in underwater environments using deep learning with temporal information. Ecol. Inform. 57, 101088 (2020). [Google Scholar]
- 8.Hitam M S, Awalludin E A, Yussof W N J H W, et al. Mixture contrast limited adaptive histogram equalization for underwater image enhancement[C]//2013 International conference on computer applications technology (ICCAT). IEEE, 1–5. (2013).
- 9.Huang D, Wang Y, Song W, et al. Shallow-water image enhancement using relative global histogram stretching based on adaptive parameter acquisition[C]//MultiMedia Modeling: 24th International Conference, MMM 2018, Bangkok, Thailand, February 5–7, 2018, Proceedings, Part I 24. Springer International Publishing, 453–465. (2018).
- 10.Jia, P., Li, B. & Zhao, X. L. Improved Retinex underwater image enhancement algorithm based on HSI model. Res. Explo. Lab 39(12), 1–4 (2020). [Google Scholar]
- 11.Wang, Y. et al. A multi-level wavelet-based underwater image enhancement network with color compensation prior. Expert Syst. Appl. 242, 122710 (2024). [Google Scholar]
- 12.Awan, H. S. A. & Mahmood, M. T. Underwater image restoration through colour correction and UW-Net. Electronics 13(1), 199 (2024). [Google Scholar]
- 13.Zhang, M. et al. Lightweight underwater object detection based on yolo v4 and multi-scale attentional feature fusion. Remote Sens. 13(22), 4706 (2021). [Google Scholar]
- 14.Wang, J. et al. B-YOLOX-S: a lightweight method for underwater object detection based on data augmentation and multiscale feature Fusion. J. Mar. Sci. Eng. 10(11), 1764 (2022). [Google Scholar]
- 15.Zhang, J. et al. An improved YOLOv5-based underwater object-detection framework. Sensors 23(7), 3693 (2023). [DOI] [PMC free article] [PubMed] [Google Scholar]
- 16.Chen, L. et al. Underwater target detection algorithm based on feature fusion enhancement. Electronics 12(13), 2756 (2023). [Google Scholar]
- 17.Li H, Li J, Wei H, et al. Slim-neck by GSConv: A better design paradigm of detector architectures for autonomous vehicles. ar**v preprint ar**v:2206.02424, (2022).
- 18.Girshick R. Fast r-cnn, Proc. IEEE international conference on computer vision. 1440–1448. (2015).
- 19.Ren S, He K, Girshick R, et al. Faster r-cnn: Towards real-time object detection with region proposal networks, Advances in neural information processing systems, 28. (2015). [DOI] [PubMed]
- 20.He K, Gkioxari G, Dollár P, et al. Mask r-cnn[C]//Proceedings of the IEEE international conference on computer vision. 2961–2969. (2017).
- 21.Jocher G, Chaurasia A, Qiu J. Ultralytics yolov8. (2023).
- 22.Wang C Y, Bochkovskiy A, Liao H Y M. YOLOv7: Trainable bag-of-freebies sets new state-of-the-art for real-time object detectors, Proc. IEEE/CVF Conference on Computer Vision and Pattern Recognition. 7464–7475. (2023).
- 23.Lin T Y, Dollár P, Girshick R, et al. Feature pyramid networks for object detection, Proc. IEEE conference on computer vision and pattern recognition. 2117–2125. (2017).
- 24.Li H, Xiong P, An J, et al. Pyramid attention network for semantic segmentation. arXiv preprint at http: arXiv:1805.10180, (2018).
- 25.Qi Y, Yang Z, Sun W, et al. A comprehensive overview of image enhancement techniques. Archives of Computational Methods in Engineering, 1–25. (2021).
- 26.Friendly, M. Mosaic displays for multi-way contingency tables. J. Am. Stat. Assoc. 89(425), 190–200 (1994). [Google Scholar]
- 27.Zhang D, Zhang D. Wavelet transform. Fundamentals of image data mining: Analysis, Features, Classification and Retrieval, 35–44. (2019).
- 28.Niu, Z., Zhong, G. & Yu, H. A review on the attention mechanism of deep learning. Neurocomputing 452, 48–62 (2021). [Google Scholar]
- 29.Woo S, Park J, Lee J Y, et al. Cbam: Convolutional block attention module, Proc. European conference on computer vision (ECCV), 3–19. (2018).
- 30.Kim B, Yu S C. Imaging sonar based real-time underwater object detection utilizing AdaBoost method, 2017 IEEE Underwater Technology (UT). IEEE, (2017), 1–5.
- 31.Hinton G, Vinyals O, Dean J. Distilling the knowledge in a neural network. arXiv preprint at http://arXiv:1503.02531, (2015).
- 32.Liu Z, Sun M, Zhou T, et al. Rethinking the value of network pruning[J]. arXiv preprint at http://arXiv:1810.05270, (2018).
- 33.Iandola F N, Han S, Moskewicz M W, et al. SqueezeNet: AlexNet-level accuracy with 50x fewer parameters and< 0.5 MB model size. preprint at http://arXiv:1602.07360, (2016).
- 34.Howard A G, Zhu M, Chen B, et al. Mobilenets: Efficient convolutional neural networks for mobile vision applications. arXiv preprint at http:// arXiv:1704.04861, (2017).
- 35.Zhang X, Zhou X, Lin M, et al. Shufflenet: An extremely efficient convolutional neural network for mobile devices, Proc. IEEE conference on computer vision and pattern recognition. (2018).
- 36.Kaiser L, Gomez A N, Chollet F. Depthwise separable convolutions for neural machine translation, preprint at http://arXiv:1706.03059, (2017).
- 37.Rezatofighi H, Tsoi N, Gwak J Y, et al. 2019 Generalized intersection over union: A metric and a loss for bounding box regression, Proc. IEEE/CVF Conference on computer vision and pattern recognition. (2019).
- 38.Zheng, Z. et al. Distance-IoU loss: Faster and better learning for bounding box regression. Proc. AAAI Conf. Artif. Intell. 34(07), 12993–13000 (2020). [Google Scholar]
- 39.Gevorgyan Z. SIoU loss: More powerful learning for bounding box regression. preprint at http://arXiv:2205.12740, 2022.
- 40.Tong Z, Chen Y, Xu Z, et al. Wise-IoU: bounding box regression loss with dynamic focusing mechanism. Preprint at http://arXiv:2301.10051, (2023).
- 41.Bochkovskiy A, Wang C Y, Liao H Y M. Yolov4: Optimal speed and accuracy of object detection. Preprint at http://arXiv:2004.10934, (2020).
- 42.Jocher G, Stoken A, Borovec J, et al. ultralytics/yolov5: v3. Zenodo, (2020).
- 43.Ge Z, Liu S, Wang F, et al. Yolox: Exceeding yolo series in 2021. Preprint at http://arXiv:2107.08430, (2021).
- 44.Metsalu, T. & Vilo, J. ClustVis: a web tool for visualizing clustering of multivariate data using Principal Component Analysis and heatmap. Nucleic Acids Res. 43(W1), W566–W570 (2015). [DOI] [PMC free article] [PubMed] [Google Scholar]
- 45.Pryke A, Mostaghim S, Nazemi A. Heatmap visualization of population based multi objective algorithms[C]//Evolutionary Multi-Criterion Optimization: 4th International Conference, EMO 2007, Matsushima, Japan, March 5-8, 2007. Proceedings 4. Springer Berlin Heidelberg, 361-375, (2007).
Associated Data
This section collects any data citations, data availability statements, or supplementary materials included in this article.
Supplementary Materials
Data Availability Statement
The datasets used and/or analysed during the current study available from the corresponding author on reasonable request.