
Recognise bots/crawlers/spiders using the user agent string.
import { isbot } from "isbot";
// Nodejs HTTP
isbot(request.getHeader("User-Agent"));
// ExpressJS
isbot(req.get("user-agent"));
// Browser
isbot(navigator.userAgent);
// User Agent string
isbot(
"Mozilla/5.0 (iPhone; CPU iPhone OS 6_0 like Mac OS X) AppleWebKit/536.26 (KHTML, like Gecko) Version/6.0 Mobile/10A5376e Safari/8536.25 (compatible; Googlebot/2.1; +http://www.google.com/bot.html)",
); // true
isbot(
"Mozilla/5.0 (Windows NT 6.1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/41.0.2228.0 Safari/537.36",
); // falseUsing JSDeliver CDN you can import an iife script
See specific versions https://www.jsdelivr.com/package/npm/isbot or https://cdn.jsdelivr.net/npm/isbot
<script src="https://cdn.jsdelivr.net/npm/isbot@4"></script>
// isbot is global isbot(navigator.userAgent)| import | Type | Description |
|---|---|---|
| pattern | {RegExp} | The regular expression used to identify bots |
| list | {string[]} | List of all individual pattern parts |
| isbotMatch | {(userAgent: string): string | null} | The substring matched by the regular expression |
| isbotMatches | {(userAgent: string): string[]} | All substrings matched by the regular expression |
| isbotPattern | {(userAgent: string): string | null} | The regular expression used to identify bot substring in the user agent |
| isbotPatterns | {(userAgent: string): string[]} | All regular expressions used to identify bot substrings in the user agent |
| createIsbot | {(pattern: RegExp): (userAgent: string): boolean} | Create a custom isbot function |
| createIsbotFromList | {(list: string): (userAgent: string): boolean} | Create a custom isbot function from a list of string representation patterns |
Create a custom isbot that does not consider Chrome Lighthouse user agent as bots.
import { createIsbotFromList, isbotMatches, list } from "isbot";
const ChromeLighthouseUserAgentStrings: string[] = [
"mozilla/5.0 (macintosh; intel mac os x 10_15_7) applewebkit/537.36 (khtml, like gecko) chrome/94.0.4590.2 safari/537.36 chrome-lighthouse",
"mozilla/5.0 (linux; android 7.0; moto g (4)) applewebkit/537.36 (khtml, like gecko) chrome/94.0.4590.2 mobile safari/537.36 chrome-lighthouse",
];
const patternsToRemove: Set<string> = new Set(
ChromeLighthouseUserAgentStrings.map(isbotMatches).flat(),
);
const isbot = createIsbotFromList(
list.filter((record) => patternsToRemove.has(record) === false),
);Create a custom isbot that considers another pattern as a bot, which is not included in the package originally.
import { createIsbotFromList, list } from "isbot";
const isbot = createIsbotFromList(list.concat("shmulik"));- Bot. Autonomous program imitating or replacing some aspect of a human behaviour, performing repetitive tasks much faster than human users could.
- Good bot. Automated programs who visit websites in order to collect useful information. Web crawlers, site scrapers, stress testers, preview builders and other programs are welcomed on most websites because they serve purposes of mutual benefits.
- Bad bot. Programs which are designed to perform malicious actions, ultimately hurting businesses. Testing credential databases, DDoS attacks, spam bots.
This package aims to identify "Good bots". Those who voluntarily identify themselves by setting a unique, preferably descriptive, user agent, usually by setting a dedicated request header.
It does not try to recognise malicious bots or programs disguising themselves as real users.
Recognising good bots such as web crawlers is useful for multiple purposes. Although it is not recommended to serve different content to web crawlers like Googlebot, you can still elect to
- Flag pageviews to consider with business analysis.
- Prefer to serve cached content and relieve service load.
- Omit third party solutions' code (tags, pixels) and reduce costs.
It is not recommended to whitelist requests for any reason based on user agent header only. Instead other methods of identification can be added such as reverse dns lookup.
We use external data sources on top of our own lists to keep up to date
- user-agents.net
- crawler-user-agents repo
- myip.ms
- matomo.org
- A Manual list
- user-agents npm package
- A Manual list
Missing something? Please open an issue
Major releases breaking changes (full changelog)
Remove isbot function default export in favour of a named export.
import { isbot } from "isbot";Remove testing for node 6 and 8
Change return value for isbot: true instead of matched string
No functional change
| Execution times in milliseconds |
|---|
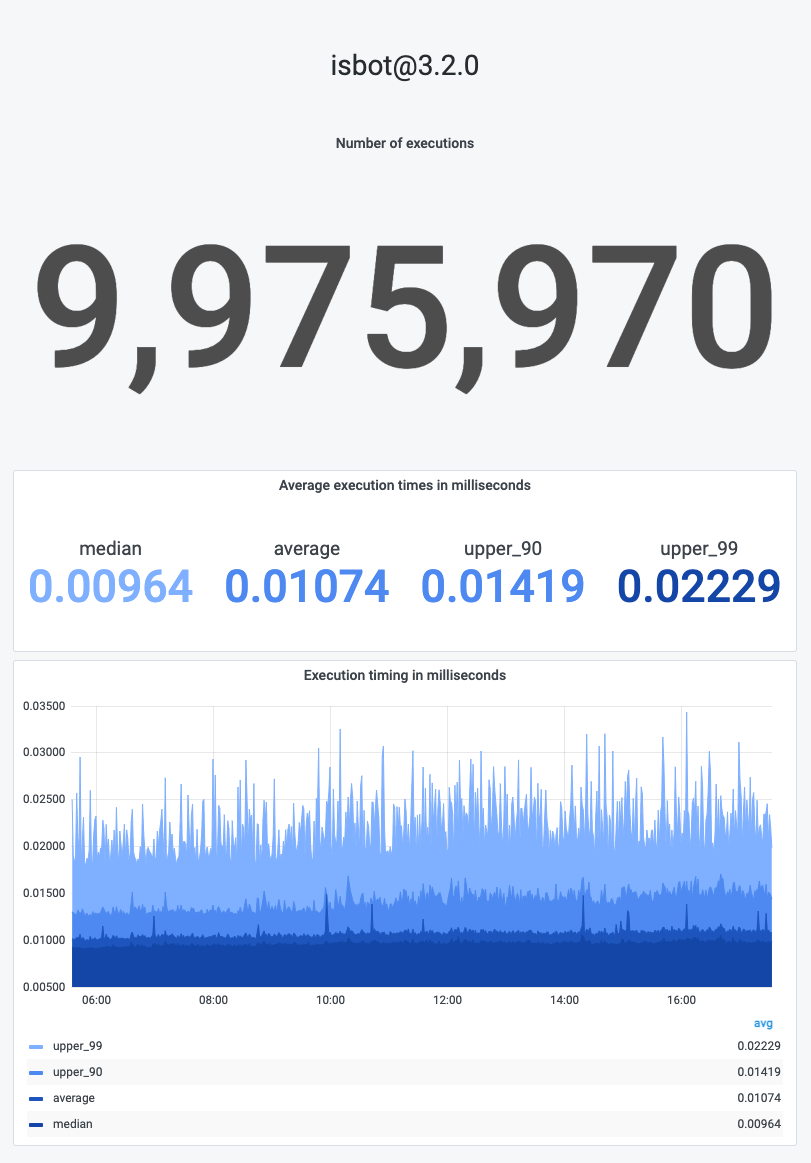 |