feat: add Database.list_tables method
#219
Conversation
google/cloud/spanner_v1/table.py
Outdated
| self.table_id = table_id | ||
| self._database = database | ||
|
|
||
| def get_schema(self): |
There was a problem hiding this comment.
I think instead of having get_schema, it would make more sense to match the rest of the library and the BigQuery implementation by having this as a property. What do you think?
There was a problem hiding this comment.
That would be more consistent. My main worry with a property is it might be less clear that table.schema makes an API call compared to table.get_schema().
There was a problem hiding this comment.
That is a good point. For the other resource objects (i.e. Instance, Backup, Database) we store local copies of properties and have a reload() method to make an RPC call to update them. I think it may make sense to stick to this design, especially if we decide to support create, update, and delete on the Table object.
I would initialize a private schema attribute as None and then call reload in schema if it is None. This means the property would make one API call at most. Then, if the user is expecting the schema to change frequently, they can all reload themselves to ensure the schema remains in sync with production. WDYT?
There was a problem hiding this comment.
I would initialize a private schema attribute as None and then call reload in schema if it is None. This means the property would make one API call at most. Then, if the user is expecting the schema to change frequently, they can all reload themselves to ensure the schema remains in sync with production. WDYT?
I think that's a good approach. In BigQuery we didn't have this logic, so customers would surprisingly get None values, which caused all sorts of issues. I'll make this a property and add a reload method.
There was a problem hiding this comment.
Updated. Also added a exists() method to match Database.reload()'s NotFound exception behavior.
134f1c8 to
40a60e3
Compare
The NUMERIC column is not included in the emulator system tests.
|
I'm marking this as ready for review, though I suspect I'll need to add some unit tests for coverage. |
|
The new Table type will also need documentation similar to |
|
Docs added:
|
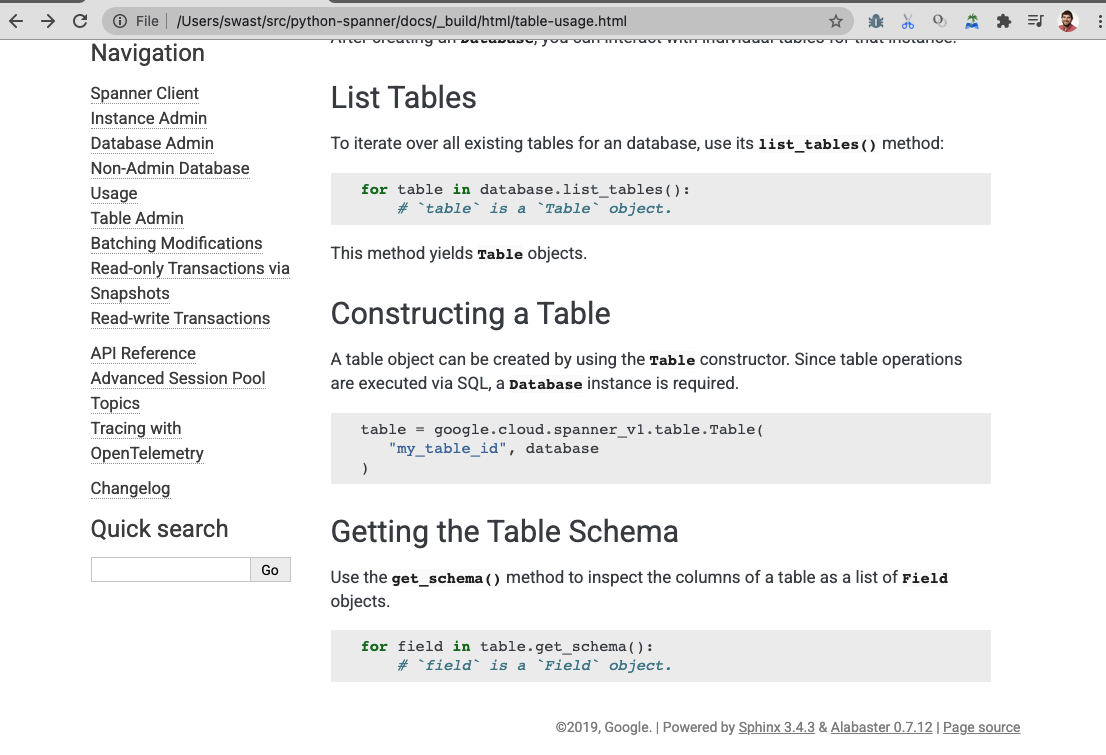
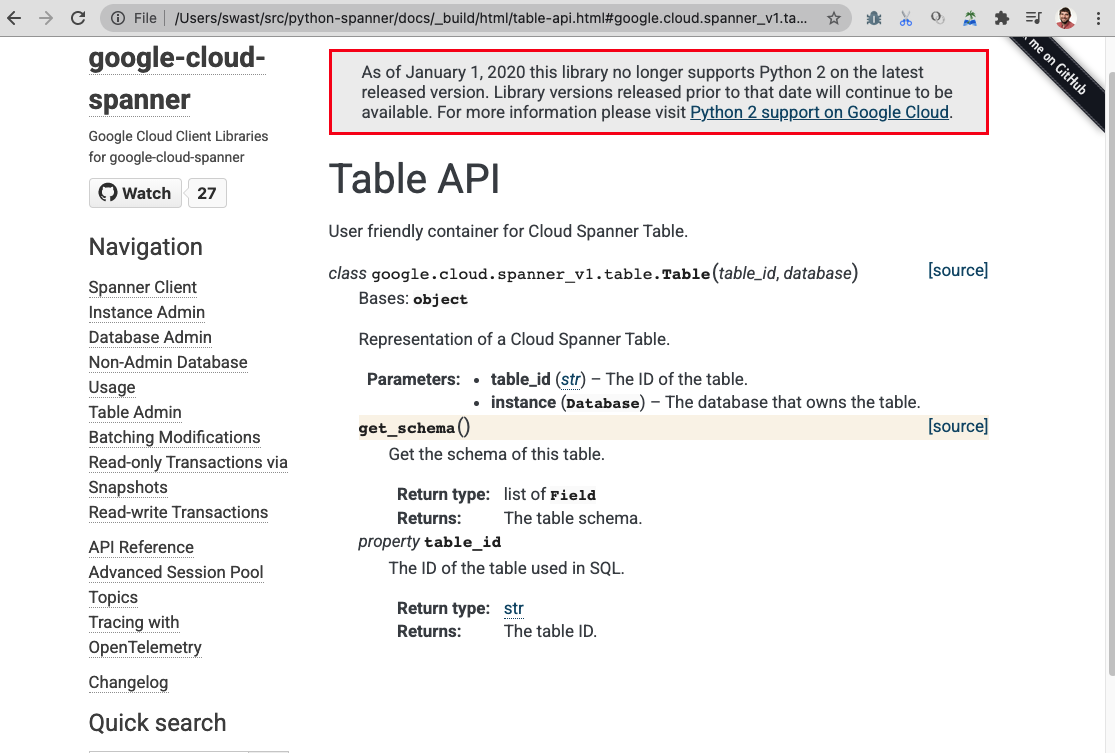
docs/table-usage.rst
Outdated
|
|
||
| .. code:: python | ||
|
|
||
| table = google.cloud.spanner_v1.table.Table( |
There was a problem hiding this comment.
Please add a table() method on the Database object which creates the Table object to be consistent with the other classes e.g.
client = spanner.Client()
instance = client.instance(instance_id)
database = instance.database(database_id)
table = database.table(table_id)
There was a problem hiding this comment.
Done! Thanks for your patience while I was OOO.
Edit: added in the following commit: 1250d8a
|
@larkee I've made the requested changes and synced with latest |
|
Test failure appears to be a problem with |
🤖 I have created a release \*beep\* \*boop\* --- ## [3.2.0](https://www.github.com/googleapis/python-spanner/compare/v3.1.0...v3.2.0) (2021-03-02) ### Features * add `Database.list_tables` method ([#219](https://www.github.com/googleapis/python-spanner/issues/219)) ([28bde8c](https://www.github.com/googleapis/python-spanner/commit/28bde8c18fd76b25ec1b64c44db7c1600255256f)) * add sample for commit stats ([#241](https://www.github.com/googleapis/python-spanner/issues/241)) ([1343656](https://www.github.com/googleapis/python-spanner/commit/1343656ad43dbc41c119b652d8fe9360fa2b0e78)) * add samples for PITR ([#222](https://www.github.com/googleapis/python-spanner/issues/222)) ([da146b7](https://www.github.com/googleapis/python-spanner/commit/da146b7a5d1d2ab6795c53301656d39e5594962f)) ### Bug Fixes * remove print statement ([#245](https://www.github.com/googleapis/python-spanner/issues/245)) ([1c2a64f](https://www.github.com/googleapis/python-spanner/commit/1c2a64fd06404bb7c2dfb4a8f65edd64c7710340)) --- This PR was generated with [Release Please](https://github.com/googleapis/release-please). See [documentation](https://github.com/googleapis/release-please#release-please).
Adds Table-management methods required by PSO data validation tool.
Fixes #156 🦕