{kind=link}
![]()
tqdm (read taqadum, تقدّم) means "progress" in arabic.
Instantly make your loops show a smart progress meter - just wrap any iterable with "tqdm(iterable)", and you're done!
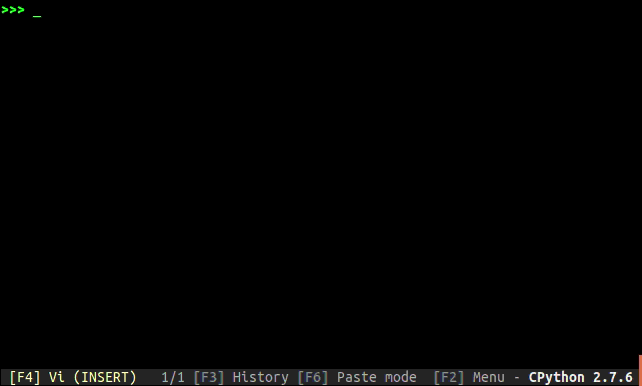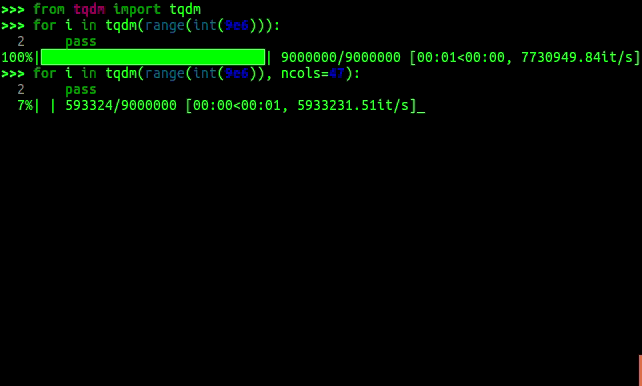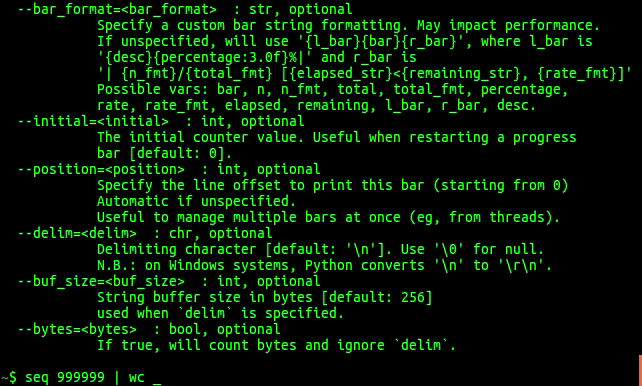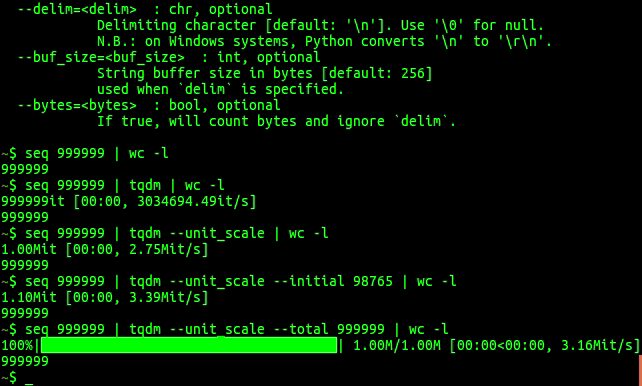
from tqdm import tqdm
for i in tqdm(range(9)):
...Here's what the output looks like:
76%|████████████████████ | 7641/10000 [00:34<00:10, 222.22 it/s]
trange(N) can be also used as a convenient shortcut for
tqdm(xrange(N)).
It can also be executed as a module with pipes:
$ seq 9999999 | tqdm --unit_scale | wc -l
10.0Mit [00:02, 3.58Mit/s]
9999999Overhead is low -- about 60ns per iteration (80ns with tqdm_gui), and is
unit tested against performance regression.
By comparison, the well established
ProgressBar has
an 800ns/iter overhead.
In addition to its low overhead, tqdm uses smart algorithms to predict
the remaining time and to skip unnecessary iteration displays, which allows
for a negligible overhead in most cases.
tqdm works on any platform (Linux, Windows, Mac, FreeBSD, Solaris/SunOS),
in any console or in a GUI, and is also friendly with IPython/Jupyter notebooks.
tqdm does not require any library (not even curses!) to run, just a
vanilla Python interpreter will do and an environment supporting carriage
return \r and line feed \n control characters.
Table of contents
pip install tqdm
Pull and install in the current directory:
pip install -e git+https://github.com/tqdm/tqdm.git@master#egg=tqdmThe list of all changes is available either on Github's Releases:
or on crawlers such as
allmychanges.com.
tqdm is very versatile and can be used in a number of ways.
The three main ones are given below.
Wrap tqdm() around any iterable:
text = ""
for char in tqdm(["a", "b", "c", "d"]):
text = text + chartrange(i) is a special optimised instance of tqdm(range(i)):
for i in trange(100):
passInstantiation outside of the loop allows for manual control over tqdm():
pbar = tqdm(["a", "b", "c", "d"])
for char in pbar:
pbar.set_description("Processing %s" % char)Manual control on tqdm() updates by using a with statement:
with tqdm(total=100) as pbar:
for i in range(10):
pbar.update(10)If the optional variable total (or an iterable with len()) is
provided, predictive stats are displayed.
with is also optional (you can just assign tqdm() to a variable,
but in this case don't forget to del or close() at the end:
pbar = tqdm(total=100)
for i in range(10):
pbar.update(10)
pbar.close()Perhaps the most wonderful use of tqdm is in a script or on the command
line. Simply inserting tqdm (or python -m tqdm) between pipes will pass
through all stdin to stdout while printing progress to stderr.
The example below demonstrated counting the number of lines in all python files in the current directory, with timing information included.
$ time find . -name '*.py' -exec cat \{} \; | wc -l
857365
real 0m3.458s
user 0m0.274s
sys 0m3.325s
$ time find . -name '*.py' -exec cat \{} \; | tqdm | wc -l
857366it [00:03, 246471.31it/s]
857365
real 0m3.585s
user 0m0.862s
sys 0m3.358sNote that the usual arguments for tqdm can also be specified.
$ find . -name '*.py' -exec cat \{} \; |
tqdm --unit loc --unit_scale --total 857366 >> /dev/null
100%|███████████████████████████████████| 857K/857K [00:04<00:00, 246Kloc/s]Backing up a large directory?
$ 7z a -bd -r backup.7z docs/ | grep Compressing |
tqdm --total $(find docs/ -type f | wc -l) --unit files >> backup.log
100%|███████████████████████████████▉| 8014/8014 [01:37<00:00, 82.29files/s]
(Since 19 May 2016)
class tqdm(object):
"""
Decorate an iterable object, returning an iterator which acts exactly
like the original iterable, but prints a dynamically updating
progressbar every time a value is requested.
"""
def __init__(self, iterable=None, desc=None, total=None, leave=True,
file=sys.stderr, ncols=None, mininterval=0.1,
maxinterval=10.0, miniters=None, ascii=None, disable=False,
unit='it', unit_scale=False, dynamic_ncols=False,
smoothing=0.3, bar_format=None, initial=0, position=None):- iterable : iterable, optional
Iterable to decorate with a progressbar. Leave blank to manually manage the updates.
- desc : str, optional
Prefix for the progressbar.
- total : int, optional
The number of expected iterations. If (default: None), len(iterable) is used if possible. As a last resort, only basic progress statistics are displayed (no ETA, no progressbar). If gui is True and this parameter needs subsequent updating, specify an initial arbitrary large positive integer, e.g. int(9e9).
- leave : bool, optional
If [default: True], keeps all traces of the progressbar upon termination of iteration.
- file : io.TextIOWrapper or io.StringIO, optional
Specifies where to output the progress messages [default: sys.stderr]. Uses file.write(str) and file.flush() methods.
- ncols : int, optional
The width of the entire output message. If specified, dynamically resizes the progressbar to stay within this bound. If unspecified, attempts to use environment width. The fallback is a meter width of 10 and no limit for the counter and statistics. If 0, will not print any meter (only stats).
- mininterval : float, optional
Minimum progress update interval, in seconds [default: 0.1].
- maxinterval : float, optional
Maximum progress update interval, in seconds [default: 10.0].
- miniters : int, optional
Minimum progress update interval, in iterations. If specified, will set mininterval to 0.
- ascii : bool, optional
If unspecified or False, use unicode (smooth blocks) to fill the meter. The fallback is to use ASCII characters 1-9 #.
- disable : bool, optional
Whether to disable the entire progressbar wrapper [default: False].
- unit : str, optional
String that will be used to define the unit of each iteration [default: it].
- unit_scale : bool, optional
If set, the number of iterations will be reduced/scaled automatically and a metric prefix following the International System of Units standard will be added (kilo, mega, etc.) [default: False].
- dynamic_ncols : bool, optional
If set, constantly alters ncols to the environment (allowing for window resizes) [default: False].
- smoothing : float, optional
Exponential moving average smoothing factor for speed estimates (ignored in GUI mode). Ranges from 0 (average speed) to 1 (current/instantaneous speed) [default: 0.3].
- bar_format : str, optional
Specify a custom bar string formatting. May impact performance. If unspecified, will use '{l_bar}{bar}{r_bar}', where l_bar is '{desc}{percentage:3.0f}%|' and r_bar is '| {n_fmt}/{total_fmt} [{elapsed_str}<{remaining_str}, {rate_fmt}]' Possible vars: bar, n, n_fmt, total, total_fmt, percentage, rate, rate_fmt, elapsed, remaining, l_bar, r_bar, desc.
- initial : int, optional
The initial counter value. Useful when restarting a progress bar [default: 0].
- position : int, optional
Specify the line offset to print this bar (starting from 0) Automatic if unspecified. Useful to manage multiple bars at once (eg, from threads).
- delim : chr, optional
- Delimiting character [default: 'n']. Use '0' for null. N.B.: on Windows systems, Python converts 'n' to 'rn'.
- buf_size : int, optional
- String buffer size in bytes [default: 256] used when delim is specified.
- out : decorated iterator.
def update(self, n=1):
"""
Manually update the progress bar, useful for streams
such as reading files.
E.g.:
>>> t = tqdm(total=filesize) # Initialise
>>> for current_buffer in stream:
... ...
... t.update(len(current_buffer))
>>> t.close()
The last line is highly recommended, but possibly not necessary if
`t.update()` will be called in such a way that `filesize` will be
exactly reached and printed.
Parameters
----------
n : int
Increment to add to the internal counter of iterations
[default: 1].
"""
def close(self):
"""
Cleanup and (if leave=False) close the progressbar.
"""
def clear(self):
"""
Clear current bar display
"""
def refresh(self):
"""
Force refresh the display of this bar
"""
def write(cls, s, file=sys.stdout, end="\n"):
"""
Print a message via tqdm (without overlap with bars)
"""
def trange(*args, **kwargs):
"""
A shortcut for tqdm(xrange(*args), **kwargs).
On Python3+ range is used instead of xrange.
"""
class tqdm_gui(tqdm):
"""
Experimental GUI version of tqdm!
"""
def tgrange(*args, **kwargs):
"""
Experimental GUI version of trange!
"""
class tqdm_notebook(tqdm):
"""
Experimental IPython/Jupyter Notebook widget using tqdm!
"""
def tnrange(*args, **kwargs):
"""
Experimental IPython/Jupyter Notebook widget using tqdm!
"""See the examples
folder or import the module and run help().
tqdm supports nested progress bars. Here's an example:
from tqdm import trange
from time import sleep
for i in trange(10, desc='1st loop'):
for j in trange(5, desc='2nd loop', leave=False):
for k in trange(100, desc='3nd loop'):
sleep(0.01)On Windows colorama will be used if available to produce a beautiful nested display.
For manual control over positioning (e.g. for multi-threaded use), you may specify position=n where n=0 for the outermost bar, n=1 for the next, and so on.
tqdm can easily support callbacks/hooks and manual updates.
Here's an example with urllib:
urllib.urlretrieve documentation
[...]If present, the hook function will be called onceon establishment of the network connection and once after each block readthereafter. The hook will be passed three arguments; a count of blockstransferred so far, a block size in bytes, and the total size of the file.[...]
import urllib
from tqdm import tqdm
def my_hook(t):
"""
Wraps tqdm instance. Don't forget to close() or __exit__()
the tqdm instance once you're done with it (easiest using `with` syntax).
Example
-------
>>> with tqdm(...) as t:
... reporthook = my_hook(t)
... urllib.urlretrieve(..., reporthook=reporthook)
"""
last_b = [0]
def inner(b=1, bsize=1, tsize=None):
"""
b : int, optional
Number of blocks just transferred [default: 1].
bsize : int, optional
Size of each block (in tqdm units) [default: 1].
tsize : int, optional
Total size (in tqdm units). If [default: None] remains unchanged.
"""
if tsize is not None:
t.total = tsize
t.update((b - last_b[0]) * bsize)
last_b[0] = b
return inner
eg_link = 'http://www.doc.ic.ac.uk/~cod11/matryoshka.zip'
with tqdm(unit='B', unit_scale=True, miniters=1,
desc=eg_link.split('/')[-1]) as t: # all optional kwargs
urllib.urlretrieve(eg_link, filename='/dev/null',
reporthook=my_hook(t), data=None)It is recommend to use miniters=1 whenever there is potentially
large differences in iteration speed (e.g. downloading a file over
a patchy connection).
Due to popular demand we've added support for pandas -- here's an example
for DataFrame.progress_apply and DataFrameGroupBy.progress_apply:
import pandas as pd
import numpy as np
from tqdm import tqdm, tqdm_pandas
...
df = pd.DataFrame(np.random.randint(0, 100, (100000, 6)))
# Create and register a new `tqdm` instance with `pandas`
# (can use tqdm_gui, optional kwargs, etc.)
tqdm_pandas(tqdm())
# Now you can use `progress_apply` instead of `apply`
df.progress_apply(lambda x: x**2)
# can also groupby:
# df.groupby(0).progress_apply(lambda x: x**2)In case you're interested in how this works (and how to modify it for your
own callbacks), see the
examples
folder or import the module and run help().
IPython/Jupyter is supported via the tqdm_notebook submodule:
from tqdm import tnrange, tqdm_notebook
from time import sleep
for i in tnrange(10, desc='1st loop'):
for j in tqdm_notebook(xrange(100), desc='2nd loop'):
sleep(0.01)In addition to tqdm features, the submodule provides a native Jupyter widget (compatible with IPython v1-v4 and Jupyter), fully working nested bars and color hints (blue: normal, green: completed, red: error/interrupt, light blue: no ETA); as demonstrated below.



Since tqdm uses a simple printing mechanism to display progress bars,
you should not write any message in the terminal using print().
To write messages in the terminal without any collision with tqdm bar
display, a .write() method is provided:
from tqdm import tqdm, trange
from time import sleep
bar = trange(10)
for i in bar:
# Print using tqdm class method .write()
sleep(0.1)
if not (i % 3):
tqdm.write("Done task %i" % i)
# Can also use bar.write()By default, this will print to standard output sys.stdout. but you can
specify any file-like object using the file argument. For example, this
can be used to redirect the messages writing to a log file or class.
If using a library that can print messages to the console, editing the library
by replacing print() with tqdm.write() may not be desirable.
In that case, redirecting sys.stdout to tqdm.write() is an option.
To redirect sys.stdout, create a file-like class that will write
any input string to tqdm.write(), and supply the arguments
file=sys.stdout, dynamic_ncols=True.
A reusable canonical example is given below:
from time import sleep
import contextlib
import sys
from tqdm import tqdm
class DummyTqdmFile(object):
"""Dummy file-like that will write to tqdm"""
file = None
def __init__(self, file):
self.file = file
def write(self, x):
# Avoid print() second call (useless \n)
if len(x.rstrip()) > 0:
tqdm.write(x, file=self.file)
@contextlib.contextmanager
def stdout_redirect_to_tqdm():
save_stdout = sys.stdout
try:
sys.stdout = DummyTqdmFile(sys.stdout)
yield save_stdout
# Relay exceptions
except Exception as exc:
raise exc
# Always restore sys.stdout if necessary
finally:
sys.stdout = save_stdout
def blabla():
print("Foo blabla")
# Redirect stdout to tqdm.write() (don't forget the `as save_stdout`)
with stdout_redirect_to_tqdm() as save_stdout:
# tqdm call need to specify sys.stdout, not sys.stderr (default)
# and dynamic_ncols=True to autodetect console width
for _ in tqdm(range(3), file=save_stdout, dynamic_ncols=True):
blabla()
sleep(.5)
# After the `with`, printing is restored
print('Done!')A good progress bar is a useful progress bar. To be useful, tqdm displays
statistics and uses smart algorithms to predict and automagically adapt to
a variety of use cases with no or minimal configuration.
However, there is one thing that tqdm cannot do: choose a pertinent
progress indicator. To display a useful progress bar, it is very important that
tqdm is supplied with the most pertinent progress indicator.
This will reflect most accurately the current state of your program.
Usually, a good way is to preprocess quickly to first evaluate the total amount
of work to do before beginning the real processing.
To illustrate the importance of a good progress indicator, take the following example: you want to walk through all files of a directory and process their contents with some external function:
import os
from tqdm import tqdm, trange
from time import sleep
def dosomething(buf):
"""Do something with the content of a file"""
sleep(0.01)
pass
def walkdir(folder):
"""Walk through each files in a directory"""
for dirpath, dirs, files in os.walk(folder):
for filename in files:
yield os.path.abspath(os.path.join(dirpath, filename))
def process_content_no_progress(inputpath, blocksize=1024):
for filepath in walkdir(inputpath):
with open(filepath, 'rb') as fh:
buf = 1
while (buf):
buf = fh.read(blocksize)
dosomething(buf)process_content_no_progress() does the job, but does not show
any information about the current progress, nor how long it will take.
To quickly fix that using tqdm, we can use this naive approach:
def process_content_with_progress1(inputpath, blocksize=1024):
for filepath in tqdm(walkdir(inputpath)):
with open(filepath, 'rb') as fh:
buf = 1
while (buf):
buf = fh.read(blocksize)
dosomething(buf)process_content_with_progress1() will load tqdm(), but since the
iterator does not provide any length (os.walkdir() does not have a
__len__() method for the total files count), there is only an indication
of the current and past program state, no prediction:
4it [00:03, 2.79it/s]
The way to get predictive information is to know the total amount of work to be
done. Since os.walkdir() cannot give us this information, we need to
precompute this by ourselves:
def process_content_with_progress2(inputpath, blocksize=1024):
# Preprocess the total files count
filecounter = 0
for dirpath, dirs, files in tqdm(os.walk(inputpath)):
for filename in files:
filecounter += 1
for filepath in tqdm(walkdir(inputpath), total=filecounter):
with open(filepath, 'rb') as fh:
buf = 1
while (buf):
buf = fh.read(blocksize)
dosomething(buf)process_content_with_progress2() is better than the naive approach because
now we have predictive information:
50%|████████████ | 2/4 [00:00<00:00, 4.06it/s]
However, the progress is not smooth: it increments in steps, 1 step being 1 file processed. The problem is that we do not just walk through files tree, but we process the files contents. Thus, if we stumble on one very large file which takes a great deal more time to process than other smaller files, the progress bar will still considers that file is of equal processing weight.
To fix this, we should use another indicator than the files count: the total sum of all files sizes. This would be more pertinent since the data we process is the files' content, so there is a direct relation between size and content.
Below we implement this approach using a manually updated tqdm bar, where
tqdm will work on size, while the for loop works on files paths:
def process_content_with_progress3(inputpath, blocksize=1024):
# Preprocess the total files sizes
sizecounter = 0
for dirpath, dirs, files in tqdm(os.walk(inputpath)):
for filename in files:
fullpath = os.path.abspath(os.path.join(dirpath, filename))
sizecounter += os.stat(fullpath).st_size
# Load tqdm with size counter instead of files counter
with tqdm(total=sizecounter, unit='B', unit_scale=True) as pbar:
for dirpath, dirs, files in os.walk(inputpath):
for filename in files:
fullpath = os.path.abspath(os.path.join(dirpath, filename))
with open(fullpath, 'rb') as fh:
buf = 1
while (buf):
buf = fh.read(blocksize)
dosomething(buf)
if buf: pbar.update(len(buf))And here is the result: a much smoother progress bar with meaningful predicted time and statistics:
47%|████████████ | 152K/321K [00:03<00:03, 46.2KB/s]
To run the testing suite please make sure tox (https://testrun.org/tox/latest/)
is installed, then type tox from the command line.
Where tox is unavailable, a Makefile-like setup is
provided with the following command:
$ python setup.py make alltestsTo see all options, run:
$ python setup.py makeSee the CONTRIBUTE file for more information.
Open Source (OSI approved):
Citation information:
Ranked by contributions.
- Casper da Costa-Luis (casperdcl)
- Stephen Larroque (lrq3000)
- Hadrien Mary (hadim)
- Noam Yorav-Raphael (noamraph)*
- Ivan Ivanov (obiwanus)
- Mikhail Korobov (kmike)
* Original author
(Since 19 May 2016)