给出两个 非空 的链表用来表示两个非负的整数。其中,它们各自的位数是按照 逆序 的方式存储的,并且它们的每个节点只能存储 一位 数字。
-如果,我们将这两个数相加起来,则会返回一个新的链表来表示它们的和。 +如果,我们将这两个数相加起来,则会返回一个新的链表来表示它们的和。
-您可以假设除了数字 0 之外,这两个数都不会以 0 开头。 +您可以假设除了数字 0 之外,这两个数都不会以 0 开头。
+ +示例:
+ +输入:(2 -> 4 -> 3) + (5 -> 6 -> 4) +输出:7 -> 0 -> 8 +原因:342 + 465 = 807 +-**示例:** -``` -输入:(2 -> 4 -> 3) + (5 -> 6 -> 4) -输出:7 -> 0 -> 8 -原因:342 + 465 = 807 -``` ## 解法 -同时遍历两个链表,对应值相加(还有 quotient)求余数得到值并赋给新创建的结点。而商则用 quotient 存储,供下次相加。 + + +### Python3 + + +```python + +``` ### Java ```java -/** - * Definition for singly-linked list. - * public class ListNode { - * int val; - * ListNode next; - * ListNode(int x) { val = x; } - * } - */ -class Solution { - public ListNode addTwoNumbers(ListNode l1, ListNode l2) { - ListNode res = new ListNode(-1); - ListNode cur = res; - int quotient = 0; - while (l1 != null || l2 != null || quotient != 0) { - int t = (l1 == null ? 0 : l1.val) + (l2 == null ? 0 : l2.val) + quotient; - quotient = t / 10; - ListNode node = new ListNode(t % 10); - cur.next = node; - cur = node; - l1 = (l1 == null) ? l1 : l1.next; - l2 = (l2 == null) ? l2 : l2.next; - } - return res.next; - } -} + +``` + +### ... ``` -### CPP -```cpp -class Solution { -public: - ListNode* addTwoNumbers(ListNode* l1, ListNode* l2) { - - ListNode *ans_l = new ListNode(0); - ListNode *head = ans_l; - int tmp = 0; - while(l1 != NULL && l2 != NULL){ - tmp += l1->val + l2->val; - ans_l->next = new ListNode(tmp % 10); - tmp = tmp / 10; - ans_l = ans_l->next; - l1 = l1->next; - l2 = l2->next; - } - - while(l1 != NULL){ - tmp += l1->val; - ans_l->next = new ListNode(tmp % 10); - tmp = tmp / 10; - ans_l = ans_l->next; - l1 = l1->next; - } - - while(l2 != NULL){ - tmp += l2->val; - ans_l->next = new ListNode(tmp % 10); - tmp = tmp / 10; - ans_l = ans_l->next; - l2 = l2->next; - } - - if(tmp)ans_l->next = new ListNode(tmp); - - return head->next; - } -}; ``` diff --git a/solution/0000-0099/0003.Longest Substring Without Repeating Characters/README.md b/solution/0000-0099/0003.Longest Substring Without Repeating Characters/README.md index ee97033953eb8..1de57d5993c42 100644 --- a/solution/0000-0099/0003.Longest Substring Without Repeating Characters/README.md +++ b/solution/0000-0099/0003.Longest Substring Without Repeating Characters/README.md @@ -1,66 +1,49 @@ -# [3. 无重复字符的最长子串](https://leetcode-cn.com/problems/longest-substring-without-repeating-characters/) +# [3. 无重复字符的最长子串](https://leetcode-cn.com/problems/longest-substring-without-repeating-characters) ## 题目描述 -给定一个字符串,请你找出其中不含有重复字符的**最长子串**的长度。 +
给定一个字符串,请你找出其中不含有重复字符的 最长子串 的长度。
-**示例 1:** +示例 1:
-``` -输入: "abcabcbb" -输出: 3 -解释: 因为无重复字符的最长子串是 "abc",所以其长度为 3。 -``` +输入: "abcabcbb"
+输出: 3
+解释: 因为无重复字符的最长子串是 "abc",所以其长度为 3。
+
-**示例 2:**
+示例 2:
-``` -输入: "bbbbb" -输出: 1 -解释: 因为无重复字符的最长子串是 "b",所以其长度为 1。 -``` +输入: "bbbbb"
+输出: 1
+解释: 因为无重复字符的最长子串是 "b",所以其长度为 1。
+
+
+示例 3:
+ +输入: "pwwkew" +输出: 3 +解释: 因为无重复字符的最长子串是-**示例 3:** -``` -输入: "pwwkew" -输出: 3 -解释: 因为无重复字符的最长子串是 "wke",所以其长度为 3。 - 请注意,你的答案必须是 子串 的长度,"pwke" 是一个子序列,不是子串。 -``` ## 解法 -利用指针 `p`, `q`,初始指向字符串开头。遍历字符串,`q` 向右移动,若指向的字符在 map 中,说明出现了重复字符,此时,`p` 要在出现**重复字符的下一个位置** `map.get(chars[q]) + 1` 和**当前位置** `p` 之间取较大值,防止 `p` 指针回溯。循环的过程中,要将 chars[q] 及对应位置放入 map 中,也需要不断计算出`max` 与 `q - p + 1` 的较大值,赋给 `max`。最后输出 `max` 即可。 + + +### Python3 + + +```python + +``` ### Java ```java -class Solution { - public int lengthOfLongestSubstring(String s) { - if (s == null || s.length() == 0) { - return 0; - } - char[] chars = s.toCharArray(); - int len = chars.length; - int p = 0, q = 0; - int max = 0; - Map"wke",所以其长度为 3。 + 请注意,你的答案必须是 子串 的长度,"pwke"是一个子序列,不是子串。 +
给定两个大小为 m 和 n 的有序数组 nums1 和 nums2。
请你找出这两个有序数组的中位数,并且要求算法的时间复杂度为 O(log(m + n))。
-你可以假设 `nums1` 和 `nums2` 不会同时为空。 +你可以假设 nums1 和 nums2 不会同时为空。
示例 1:
-``` -nums1 = [1, 3] +nums1 = [1, 3] nums2 = [2] 则中位数是 2.0 -``` +-**示例 2:** +
示例 2:
-``` -nums1 = [1, 2] +nums1 = [1, 2] nums2 = [3, 4] 则中位数是 (2 + 3)/2 = 2.5 -``` - -## 解法 - -假设两数组长度分别为 len1, len2,分别将 num1, num2 切成左右两半。 -举个栗子: +-``` -nums1: num1[0] num1[1] num1[2]......num1[i - 1] | num1[i] ...nums1[len1 - 2] nums1[len1 - 1] - -nums2: nums2[0] nums2[1] nums2[2]......nums2[j - 1] | nums2[j] ...nums2[len2 - 2] nums2[len2 - 1] -``` -num1 在[0, i - 1] 是左半部分,[i, len1 - 1] 是右半部分; -num2 在[0, j - 1] 是左半部分,[j, len2 - 1] 是右半部分。 +## 解法 + -若两个左半部分合起来的最大值 `<=` 右半部分合起来的最小值。那么中位数就可以直接拿到了。 -若 nums1[i - 1] > nums2[j],说明 num1 的左边有数据过大,应该放到右边,而这样会使左边总数少了,那么 num2 右边的一个给左边就平衡了。如下: +### Python3 + -``` -nums1: num1[0] num1[1] num1[2]......num1 | [i - 1] num1[i] ...nums1[len1 - 2] nums1[len1 - 1] +```python -nums2: nums2[0] nums2[1] nums2[2]......nums2[j - 1] nums2[j] | ...nums2[len2 - 2] nums2[len2 - 1] ``` -若 nums2[j - 1] > nums1[i],同理。 - -否则,计算中位数。 - ### Java ```java -class Solution { - public double findMedianSortedArrays(int[] nums1, int[] nums2) { - int len1 = nums1.length; - int len2 = nums2.length; - - if (len1 > len2) { - int[] tmp = nums1; - nums1 = nums2; - nums2 = tmp; - int t = len1; - len1 = len2; - len2 = t; - } - - int min = 0; - int max = len1; - - int m = (len1 + len2 + 1) / 2; - - while (min <= max) { - int i = (min + max) / 2; - int j = m - i; - - if (i > min && nums1[i - 1] > nums2[j]) { - --max; - } else if (i < max && nums2[j - 1] > nums1[i]) { - ++min; - } else { - int maxLeft = i == 0 ? nums2[j - 1] : j == 0 ? nums1[i - 1] : Math.max(nums1[i - 1], nums2[j - 1]); - - if (((len1 + len2) & 1) == 1) { - return maxLeft; - } - - int minRight = i == len1 ? nums2[j] : j == len2 ? nums1[i] : Math.min(nums2[j], nums1[i]); - - return (maxLeft + minRight) / 2.0; - - } - - } - - return 0; - } -} ``` - ### ... ``` diff --git a/solution/0000-0099/0005.Longest Palindromic Substring/README.md b/solution/0000-0099/0005.Longest Palindromic Substring/README.md index d90da36d79f00..77236a41b8d94 100644 --- a/solution/0000-0099/0005.Longest Palindromic Substring/README.md +++ b/solution/0000-0099/0005.Longest Palindromic Substring/README.md @@ -1,66 +1,40 @@ -# [5. 最长回文子串](https://leetcode-cn.com/problems/longest-palindromic-substring/) +# [5. 最长回文子串](https://leetcode-cn.com/problems/longest-palindromic-substring) ## 题目描述 -给定一个字符串 `s`,找到 `s` 中最长的回文子串。你可以假设 `s` 的最大长度为 1000。 +
给定一个字符串 s,找到 s 中最长的回文子串。你可以假设 s 的最大长度为 1000。
示例 1:
-``` -输入: "babad" -输出: "bab" -注意: "aba" 也是一个有效答案。 -``` +输入: "babad" +输出: "bab" +注意: "aba" 也是一个有效答案。 ++ +
示例 2:
+ +输入: "cbbd" +输出: "bb" +-**示例 2:** -``` -输入: "cbbd" -输出: "bb" -``` ## 解法 -利用动态规划,二维数组 `res` 存储 `[j, i]` 区间是否为回文串。动态规划递推式: -`res[j][i] = res[j + 1][i - 1] && chars[j] == chars[i]` +### Python3 + + +```python -此方法时间和空间复杂度均为 `O(n²)`。 +``` ### Java + ```java -class Solution { - public String longestPalindrome(String s) { - if (s == null || s.length() < 1) { - return ""; - } - String str = ""; - char[] chars = s.toCharArray(); - int len = chars.length; - boolean[][] res = new boolean[len][len]; - int start = 0; - int max = 1; - for (int i = 0; i < len; ++i) { - for (int j = 0; j <= i; ++j) { - - res[j][i] = i - j < 2 - ? chars[j] == chars[i] - : res[j + 1][i - 1] && chars[j] == chars[i]; - - if (res[j][i] && max < i - j + 1) { - max = i - j + 1; - start = j; - } - - } - } - - return s.substring(start, start + max); - - } -} + ``` ### ... diff --git a/solution/0000-0099/0006.ZigZag Conversion/README.md b/solution/0000-0099/0006.ZigZag Conversion/README.md index bc74424cc343d..d01b991e34da4 100644 --- a/solution/0000-0099/0006.ZigZag Conversion/README.md +++ b/solution/0000-0099/0006.ZigZag Conversion/README.md @@ -1,73 +1,58 @@ -# [6. Z 字形变换](https://leetcode-cn.com/problems/zigzag-conversion/) +# [6. Z 字形变换](https://leetcode-cn.com/problems/zigzag-conversion) ## 题目描述 -将一个给定字符串根据给定的行数,以从上往下、从左到右进行 Z 字形排列。 +
将一个给定字符串根据给定的行数,以从上往下、从左到右进行 Z 字形排列。
-比如输入字符串为 `"LEETCODEISHIRING"` 行数为 3 时,排列如下: +比如输入字符串为 "LEETCODEISHIRING" 行数为 3 时,排列如下:
L C I R E T O E S I I G E D H N -``` +-之后,你的输出需要从左往右逐行读取,产生出一个新的字符串,比如:`"LCIRETOESIIGEDHN"`。 +
之后,你的输出需要从左往右逐行读取,产生出一个新的字符串,比如:"LCIRETOESIIGEDHN"。
请你实现这个将字符串进行指定行数变换的函数:
-``` -string convert(string s, int numRows); -``` +string convert(string s, int numRows);-**示例 1:** +
示例 1:
-``` -输入: s = "LEETCODEISHIRING", numRows = 3 -输出: "LCIRETOESIIGEDHN" -``` +输入: s = "LEETCODEISHIRING", numRows = 3 +输出: "LCIRETOESIIGEDHN" +-**示例 2:** +
示例 2:
-``` -输入: s = "LEETCODEISHIRING", numRows = 4 -输出: "LDREOEIIECIHNTSG" -解释: +输入: s = "LEETCODEISHIRING", numRows = 4 +输出: "LDREOEIIECIHNTSG" +解释: L D R E O E I I E C I H N -T S G -``` +T S G+ + ## 解法 + +### Python3 + + +```python + +``` + ### Java ```java -class Solution { - public String convert(String s, int numRows) { - if (numRows == 1) return s; - StringBuilder result = new StringBuilder(); - int group = 2 * numRows - 2; - for (int i = 1; i <= numRows; i++) { - int interval = 2 * numRows - 2 * i; - if (i == numRows) interval = 2 * numRows - 2; - int index = i; - while (index <= s.length()) { - result.append(s.charAt(index - 1)); - index += interval; - interval = group - interval; - if (interval == 0) interval = group; - } - } - return result.toString(); - } -} -``` +``` ### ... ``` diff --git a/solution/0000-0099/0007.Reverse Integer/README.md b/solution/0000-0099/0007.Reverse Integer/README.md index d796bb4f0574a..d8f85af5c15b2 100644 --- a/solution/0000-0099/0007.Reverse Integer/README.md +++ b/solution/0000-0099/0007.Reverse Integer/README.md @@ -1,81 +1,31 @@ -## 反转整数 -### 题目描述 +# [7. 整数反转](https://leetcode-cn.com/problems/reverse-integer) -给定一个 32 位有符号整数,将整数中的数字进行反转。 - -示例 1: -``` -输入: 123 -输出: 321 -``` - - 示例 2: -``` -输入: -123 -输出: -321 -``` - -示例 3: -``` -输入: 120 -输出: 21 -``` +## 题目描述 + +
给出一个 32 位的有符号整数,你需要将这个整数中每位上的数字进行反转。
-注意: +示例 1:
-假设我们的环境只能存储 32 位有符号整数,其数值范围是 [−231, 231 − 1]。根据这个假设,如果反转后的整数溢出,则返回 0。 +输入: 123 +输出: 321 +-### 解法 -- 解法1 +
示例 2:
-用 long 型存储该整数,取绝对值,然后转成 StringBuilder 进行 reverse,后转回 int。注意判断该数是否在 `[Integer.MIN_VALUE, Integer.MAX_VALUE]` 范围内。 +输入: -123 +输出: -321 +-```java -class Solution { - public int reverse(int x) { - if (x == 0) { - return x; - } - - long tmp = x; - boolean isPositive = true; - if (tmp < 0) { - isPositive = false; - tmp = -tmp; - } - - long val = Long.parseLong(new StringBuilder(String.valueOf(tmp)).reverse().toString()); - - return isPositive ? (val > Integer.MAX_VALUE ? 0 : (int) val) : (-val < Integer.MIN_VALUE ? 0 : (int) (-val)); - - } -} -``` +
示例 3:
-- 解法2 +输入: 120 +输出: 21 +-循环对数字求 `%, /` ,累加,最后返回结果。注意判断值是否溢出。 -```java -class Solution { - public int reverse(int x) { - long res = 0; - // 考虑负数情况,所以这里条件为: x != 0 - while (x != 0) { - res = res * 10 + (x % 10); - x /= 10; - } - return (res < Integer.MIN_VALUE || res > Integer.MAX_VALUE) - ? 0 - : (int) res; - - } -} -``` +
注意:
-# [题目](这里是题目链接,如:https://leetcode-cn.com/problems/shu-zu-zhong-zhong-fu-de-shu-zi-lcof/) +假设我们的环境只能存储得下 32 位的有符号整数,则其数值范围为 [−231, 231 − 1]。请根据这个假设,如果反转后整数溢出那么就返回 0。
-## 题目描述 - ## 解法 diff --git a/solution/0000-0099/0008.String to Integer (atoi)/README.md b/solution/0000-0099/0008.String to Integer (atoi)/README.md index 52e117a698229..e3299552ce5c7 100644 --- a/solution/0000-0099/0008.String to Integer (atoi)/README.md +++ b/solution/0000-0099/0008.String to Integer (atoi)/README.md @@ -1,101 +1,59 @@ -## 8. 字符串转换整数 (atoi) -### 题目描述 -请你来实现一个 `atoi` 函数,使其能将字符串转换成整数。 +# [8. 字符串转换整数 (atoi)](https://leetcode-cn.com/problems/string-to-integer-atoi) -首先,该函数会根据需要丢弃无用的开头空格字符,直到寻找到第一个非空格的字符为止。 +## 题目描述 + +请你来实现一个 atoi 函数,使其能将字符串转换成整数。
首先,该函数会根据需要丢弃无用的开头空格字符,直到寻找到第一个非空格的字符为止。
-该字符串除了有效的整数部分之后也可能会存在多余的字符,这些字符可以被忽略,它们对于函数不应该造成影响。 +当我们寻找到的第一个非空字符为正或者负号时,则将该符号与之后面尽可能多的连续数字组合起来,作为该整数的正负号;假如第一个非空字符是数字,则直接将其与之后连续的数字字符组合起来,形成整数。
-注意:假如该字符串中的第一个非空格字符不是一个有效整数字符、字符串为空或字符串仅包含空白字符时,则你的函数不需要进行转换。 +该字符串除了有效的整数部分之后也可能会存在多余的字符,这些字符可以被忽略,它们对于函数不应该造成影响。
-在任何情况下,若函数不能进行有效的转换时,请返回 0。 +注意:假如该字符串中的第一个非空格字符不是一个有效整数字符、字符串为空或字符串仅包含空白字符时,则你的函数不需要进行转换。
-**说明:** +在任何情况下,若函数不能进行有效的转换时,请返回 0。
-假设我们的环境只能存储 32 位大小的有符号整数,那么其数值范围为 `[−231, 231 − 1]`。如果数值超过这个范围,请返回 `INT_MAX (2^31 − 1)` 或 `INT_MIN (−2^31)` 。 +说明:
-**示例 1:** +假设我们的环境只能存储 32 位大小的有符号整数,那么其数值范围为 [−231, 231 − 1]。如果数值超过这个范围,请返回 INT_MAX (231 − 1) 或 INT_MIN (−231) 。
-``` -输入: "42" -输出: 42 -``` +示例 1:
-**示例 2:** +输入: "42" +输出: 42 +-``` -输入: " -42" -输出: -42 -解释: 第一个非空白字符为 '-', 它是一个负号。 - 我们尽可能将负号与后面所有连续出现的数字组合起来,最后得到 -42 。 -``` +
示例 2:
-**示例 3:** +输入: " -42" +输出: -42 +解释: 第一个非空白字符为 '-', 它是一个负号。 + 我们尽可能将负号与后面所有连续出现的数字组合起来,最后得到 -42 。 +-``` -输入: "4193 with words" -输出: 4193 -解释: 转换截止于数字 '3' ,因为它的下一个字符不为数字。 -``` +
示例 3:
-**示例 4:** +输入: "4193 with words" +输出: 4193 +解释: 转换截止于数字 '3' ,因为它的下一个字符不为数字。 +-``` -输入: "words and 987" -输出: 0 -解释: 第一个非空字符是 'w', 但它不是数字或正、负号。 - 因此无法执行有效的转换。 -``` - -**示例 5:** +
示例 4:
-``` -输入: "-91283472332" -输出: -2147483648 -解释: 数字 "-91283472332" 超过 32 位有符号整数范围。 - 因此返回 INT_MIN (−231) 。 -``` +输入: "words and 987" +输出: 0 +解释: 第一个非空字符是 'w', 但它不是数字或正、负号。 + 因此无法执行有效的转换。-### 解法 -```java -class Solution { - public int myAtoi(String str) { - int len = str.length(); - if (len == 0) return 0; - char[] cs = str.toCharArray(); - int i = 0; - while (i < len && cs[i] == ' ') i++; - if (i==len) return 0; - char c1 = cs[i]; - int sig = 1; - if ((c1 > '9' || c1 < '0')) { - if (c1 == '-') { - sig = -1; - i++; - } else if (c1 == '+') { - i++; - } else return 0; - } - long v = 0,sv = 0; - for (; i < len; i++) { - char c = cs[i]; - if (c < '0' || c > '9') break; - v = v * 10 + (c - '0'); - sv = v * sig; - if (sv > Integer.MAX_VALUE) return Integer.MAX_VALUE; - else if (sv < Integer.MIN_VALUE) return Integer.MIN_VALUE; - } - return (int) sv; - } -} -``` +
示例 5:
-# [题目](这里是题目链接,如:https://leetcode-cn.com/problems/shu-zu-zhong-zhong-fu-de-shu-zi-lcof/) +输入: "-91283472332" +输出: -2147483648 +解释: 数字 "-91283472332" 超过 32 位有符号整数范围。 + 因此返回 INT_MIN (−231) 。 +-## 题目描述 - ## 解法 diff --git a/solution/0000-0099/0009.Palindrome Number/README.md b/solution/0000-0099/0009.Palindrome Number/README.md index 33c98a93c73a4..bd96550771b56 100644 --- a/solution/0000-0099/0009.Palindrome Number/README.md +++ b/solution/0000-0099/0009.Palindrome Number/README.md @@ -1,56 +1,33 @@ -## 回文数 -### 题目描述 +# [9. 回文数](https://leetcode-cn.com/problems/palindrome-number) -判断一个整数是否是回文数。回文数是指正序(从左向右)和倒序(从右向左)读都是一样的整数。 +## 题目描述 + +
判断一个整数是否是回文数。回文数是指正序(从左向右)和倒序(从右向左)读都是一样的整数。
-**示例 1:** -``` -输入: 121 -输出: true -``` +示例 1:
-**示例 2:** -``` -输入: -121 -输出: false -解释: 从左向右读, 为 -121 。 从右向左读, 为 121- 。因此它不是一个回文数。 -``` +输入: 121 +输出: true +-**示例 3:** -``` -输入: 10 -输出: false -解释: 从右向左读, 为 01 。因此它不是一个回文数。 -``` +
示例 2:
-**进阶:** +输入: -121 +输出: false +解释: 从左向右读, 为 -121 。 从右向左读, 为 121- 。因此它不是一个回文数。 +-你能不将整数转为字符串来解决这个问题吗? +
示例 3:
-### 解法 -负数直接返回 false。对于非负数,每次取最后一位`y % 10`,累加到 `res * 10`,之后 `y /= 10`,直到 `y == 0`。判断此时 res 与 x 是否相等。 +输入: 10 +输出: false +解释: 从右向左读, 为 01 。因此它不是一个回文数。 +-```java -class Solution { - public boolean isPalindrome(int x) { - if (x < 0) { - return false; - } - int res = 0; - int y = x; - while (y != 0) { - res = res * 10 + y % 10; - y /= 10; - } - return res == x; - } -} -``` +
进阶:
-# [题目](这里是题目链接,如:https://leetcode-cn.com/problems/shu-zu-zhong-zhong-fu-de-shu-zi-lcof/) +你能不将整数转为字符串来解决这个问题吗?
-## 题目描述 - ## 解法 diff --git a/solution/0000-0099/0010.Regular Expression Matching/README.md b/solution/0000-0099/0010.Regular Expression Matching/README.md index d9b3840c082d2..e360cf1aead91 100644 --- a/solution/0000-0099/0010.Regular Expression Matching/README.md +++ b/solution/0000-0099/0010.Regular Expression Matching/README.md @@ -1,7 +1,65 @@ -# [题目](这里是题目链接,如:https://leetcode-cn.com/problems/shu-zu-zhong-zhong-fu-de-shu-zi-lcof/) +# [10. 正则表达式匹配](https://leetcode-cn.com/problems/regular-expression-matching) ## 题目描述 +给你一个字符串 s 和一个字符规律 p,请你来实现一个支持 '.' 和 '*' 的正则表达式匹配。
'.' 匹配任意单个字符 +'*' 匹配零个或多个前面的那一个元素 ++ +
所谓匹配,是要涵盖 整个 字符串 s的,而不是部分字符串。
说明:
+ +-
+
s可能为空,且只包含从a-z的小写字母。
+ p可能为空,且只包含从a-z的小写字母,以及字符.和*。
+
示例 1:
+ +输入: +s = "aa" +p = "a" +输出: false +解释: "a" 无法匹配 "aa" 整个字符串。 ++ +
示例 2:
+ +输入: +s = "aa" +p = "a*" +输出: true +解释: 因为 '*' 代表可以匹配零个或多个前面的那一个元素, 在这里前面的元素就是 'a'。因此,字符串 "aa" 可被视为 'a' 重复了一次。 ++ +
示例 3:
+ +输入: +s = "ab" +p = ".*" +输出: true +解释: ".*" 表示可匹配零个或多个('*')任意字符('.')。 ++ +
示例 4:
+ +输入: +s = "aab" +p = "c*a*b" +输出: true +解释: 因为 '*' 表示零个或多个,这里 'c' 为 0 个, 'a' 被重复一次。因此可以匹配字符串 "aab"。 ++ +
示例 5:
+ +输入: +s = "mississippi" +p = "mis*is*p*." +输出: false+ ## 解法 diff --git a/solution/0000-0099/0011.Container With Most Water/README.md b/solution/0000-0099/0011.Container With Most Water/README.md index d9b3840c082d2..4a7c3d6fd5a46 100644 --- a/solution/0000-0099/0011.Container With Most Water/README.md +++ b/solution/0000-0099/0011.Container With Most Water/README.md @@ -1,7 +1,24 @@ -# [题目](这里是题目链接,如:https://leetcode-cn.com/problems/shu-zu-zhong-zhong-fu-de-shu-zi-lcof/) +# [11. 盛最多水的容器](https://leetcode-cn.com/problems/container-with-most-water) ## 题目描述 +
给你 n 个非负整数 a1,a2,...,an,每个数代表坐标中的一个点 (i, ai) 。在坐标内画 n 条垂直线,垂直线 i 的两个端点分别为 (i, ai) 和 (i, 0)。找出其中的两条线,使得它们与 x 轴共同构成的容器可以容纳最多的水。
+ +说明:你不能倾斜容器,且 n 的值至少为 2。
+ ++ +

图中垂直线代表输入数组 [1,8,6,2,5,4,8,3,7]。在此情况下,容器能够容纳水(表示为蓝色部分)的最大值为 49。
+ ++ +
示例:
+ +输入:[1,8,6,2,5,4,8,3,7] +输出:49+ ## 解法 diff --git a/solution/0000-0099/0012.Integer to Roman/README.md b/solution/0000-0099/0012.Integer to Roman/README.md index d9b3840c082d2..eb7aa47e61338 100644 --- a/solution/0000-0099/0012.Integer to Roman/README.md +++ b/solution/0000-0099/0012.Integer to Roman/README.md @@ -1,7 +1,58 @@ -# [题目](这里是题目链接,如:https://leetcode-cn.com/problems/shu-zu-zhong-zhong-fu-de-shu-zi-lcof/) +# [12. 整数转罗马数字](https://leetcode-cn.com/problems/integer-to-roman) ## 题目描述 +
罗马数字包含以下七种字符: I, V, X, L,C,D 和 M。
字符 数值 +I 1 +V 5 +X 10 +L 50 +C 100 +D 500 +M 1000+ +
例如, 罗马数字 2 写做 II ,即为两个并列的 1。12 写做 XII ,即为 X + II 。 27 写做 XXVII, 即为 XX + V + II 。
通常情况下,罗马数字中小的数字在大的数字的右边。但也存在特例,例如 4 不写做 IIII,而是 IV。数字 1 在数字 5 的左边,所表示的数等于大数 5 减小数 1 得到的数值 4 。同样地,数字 9 表示为 IX。这个特殊的规则只适用于以下六种情况:
-
+
I可以放在V(5) 和X(10) 的左边,来表示 4 和 9。
+ X可以放在L(50) 和C(100) 的左边,来表示 40 和 90。
+ C可以放在D(500) 和M(1000) 的左边,来表示 400 和 900。
+
给定一个整数,将其转为罗马数字。输入确保在 1 到 3999 的范围内。
+ +示例 1:
+ +输入: 3 +输出: "III"+ +
示例 2:
+ +输入: 4 +输出: "IV"+ +
示例 3:
+ +输入: 9 +输出: "IX"+ +
示例 4:
+ +输入: 58 +输出: "LVIII" +解释: L = 50, V = 5, III = 3. ++ +
示例 5:
+ +输入: 1994 +输出: "MCMXCIV" +解释: M = 1000, CM = 900, XC = 90, IV = 4.+ ## 解法 diff --git a/solution/0000-0099/0013.Roman to Integer/README.md b/solution/0000-0099/0013.Roman to Integer/README.md index b6c5f12fadfc6..d355ae47265e7 100644 --- a/solution/0000-0099/0013.Roman to Integer/README.md +++ b/solution/0000-0099/0013.Roman to Integer/README.md @@ -1,103 +1,58 @@ -## 罗马数字转整数 -### 题目描述 +# [13. 罗马数字转整数](https://leetcode-cn.com/problems/roman-to-integer) -罗马数字包含以下七种字符:`I`, `V`, `X`, `L`,`C`,`D` 和 `M`。 +## 题目描述 + +
罗马数字包含以下七种字符: I, V, X, L,C,D 和 M。
字符 数值 I 1 V 5 X 10 L 50 C 100 D 500 -M 1000 -``` +M 1000-例如, 罗马数字 2 写做 `II` ,即为两个并列的 1。12 写做 `XII` ,即为 `X` + `II` 。 27 写做 `XXVII`, 即为 `XX` + `V` + `II` 。 +
例如, 罗马数字 2 写做 II ,即为两个并列的 1。12 写做 XII ,即为 X + II 。 27 写做 XXVII, 即为 XX + V + II 。
通常情况下,罗马数字中小的数字在大的数字的右边。但也存在特例,例如 4 不写做 IIII,而是 IV。数字 1 在数字 5 的左边,所表示的数等于大数 5 减小数 1 得到的数值 4 。同样地,数字 9 表示为 IX。这个特殊的规则只适用于以下六种情况:
-
+
I可以放在V(5) 和X(10) 的左边,来表示 4 和 9。
+ X可以放在L(50) 和C(100) 的左边,来表示 40 和 90。
+ C可以放在D(500) 和M(1000) 的左边,来表示 400 和 900。
+
给定一个罗马数字,将其转换成整数。输入确保在 1 到 3999 的范围内。
-示例 1: -``` -输入: "III" -输出: 3 -``` +示例 1:
-示例 2: -``` -输入: "IV" -输出: 4 -``` +输入: "III" +输出: 3-示例 3: -``` -输入: "IX" -输出: 9 -``` +
示例 2:
-示例 4: -``` -输入: "LVIII" -输出: 58 -解释: C = 100, L = 50, XXX = 30, III = 3. -``` +输入: "IV" +输出: 4-示例 5: -``` -输入: "MCMXCIV" -输出: 1994 -解释: M = 1000, CM = 900, XC = 90, IV = 4. -``` +
示例 3:
-### 解法 -用 map 存储字符串及对应的值,遍历 `s`,若 s[i, i + 1] 在 map 中,累加对应的值,i 向右移动两格;否则累加 s[i],i 向右移动一格。 +输入: "IX" +输出: 9-```java -class Solution { - public int romanToInt(String s) { - Map
示例 4:
-# [题目](这里是题目链接,如:https://leetcode-cn.com/problems/shu-zu-zhong-zhong-fu-de-shu-zi-lcof/) +输入: "LVIII" +输出: 58 +解释: L = 50, V= 5, III = 3. ++ +
示例 5:
+ +输入: "MCMXCIV" +输出: 1994 +解释: M = 1000, CM = 900, XC = 90, IV = 4.-## 题目描述 - ## 解法 diff --git a/solution/0000-0099/0014.Longest Common Prefix/README.md b/solution/0000-0099/0014.Longest Common Prefix/README.md index 834fa05f857cd..31d97c235bcb4 100644 --- a/solution/0000-0099/0014.Longest Common Prefix/README.md +++ b/solution/0000-0099/0014.Longest Common Prefix/README.md @@ -1,74 +1,28 @@ -## 最长公共前缀 -### 题目描述 +# [14. 最长公共前缀](https://leetcode-cn.com/problems/longest-common-prefix) -编写一个函数来查找字符串数组中的最长公共前缀。 - -如果不存在公共前缀,返回空字符串 ""。 - -示例 1: -``` -输入: ["flower","flow","flight"] -输出: "fl" -``` +## 题目描述 + +
编写一个函数来查找字符串数组中的最长公共前缀。
-示例 2: -``` -输入: ["dog","racecar","car"] -输出: "" -解释: 输入不存在公共前缀。 -``` +如果不存在公共前缀,返回空字符串 ""。
示例 1:
-所有输入只包含小写字母 a-z 。 +输入: ["flower","flow","flight"] +输出: "fl" +-### 解法 -取字符串数组第一个元素,遍历每一个字符,与其他每个字符串的对应位置字符做比较,如果不相等,退出循环,返回当前子串。 +
示例 2:
-注意:其他字符串的长度可能小于第一个字符串长度,所以要注意数组越界异常。 +输入: ["dog","racecar","car"] +输出: "" +解释: 输入不存在公共前缀。 +-```java -class Solution { - public String longestCommonPrefix(String[] strs) { - if (strs == null || strs.length == 0) { - return ""; - } - if (strs.length == 1) { - return strs[0]; - } - - char[] chars = strs[0].toCharArray(); - int i = 0; - boolean flag = true; - for (; i < chars.length; ++i) { - char ch = chars[i]; - - for (int j = 1; j < strs.length; ++j) { - if (strs[j].length() <= i) { - flag = false; - break; - } - if (strs[j].charAt(i) != ch) { - flag = false; - break; - } - - } - if (!flag) { - break; - } - } - return strs[0].substring(0, i); - - - } -} -``` +
说明:
-# [题目](这里是题目链接,如:https://leetcode-cn.com/problems/shu-zu-zhong-zhong-fu-de-shu-zi-lcof/) +所有输入只包含小写字母 a-z 。
给你一个包含 n 个整数的数组 nums,判断 nums 中是否存在三个元素 a,b,c ,使得 a + b + c = 0 ?请你找出所有满足条件且不重复的三元组。
注意:答案中不可以包含重复的三元组。
+ ++ +
示例:
+ +给定数组 nums = [-1, 0, 1, 2, -1, -4], 满足要求的三元组集合为: [ [-1, 0, 1], [-1, -1, 2] ] -``` - -### 解法 -先对数组进行排序,遍历数组,固定第一个数i。利用两个指针 p, q 分别指示 i+1, n-1。如果三数之和为0,移动 p, q;如果大于 0,左移 q;如果小于 0,右移 p。遍历到 nums[i] > 0 时,退出循环。 - -还要注意过滤重复元素。 +-#### Java - -```java -class Solution { - public List
给定一个包括 n 个整数的数组 nums 和 一个目标值 target。找出 nums 中的三个整数,使得它们的和与 target 最接近。返回这三个数的和。假定每组输入只存在唯一答案。
例如,给定数组 nums = [-1,2,1,-4], 和 target = 1. + +与 target 最接近的三个数的和为 2. (-1 + 2 + 1 = 2). ++ ## 解法 diff --git a/solution/0000-0099/0017.Letter Combinations of a Phone Number/README.md b/solution/0000-0099/0017.Letter Combinations of a Phone Number/README.md index d9b3840c082d2..0ea92c2b66a7d 100644 --- a/solution/0000-0099/0017.Letter Combinations of a Phone Number/README.md +++ b/solution/0000-0099/0017.Letter Combinations of a Phone Number/README.md @@ -1,7 +1,22 @@ -# [题目](这里是题目链接,如:https://leetcode-cn.com/problems/shu-zu-zhong-zhong-fu-de-shu-zi-lcof/) +# [17. 电话号码的字母组合](https://leetcode-cn.com/problems/letter-combinations-of-a-phone-number) ## 题目描述 +
给定一个仅包含数字 2-9 的字符串,返回所有它能表示的字母组合。
给出数字到字母的映射如下(与电话按键相同)。注意 1 不对应任何字母。
+ +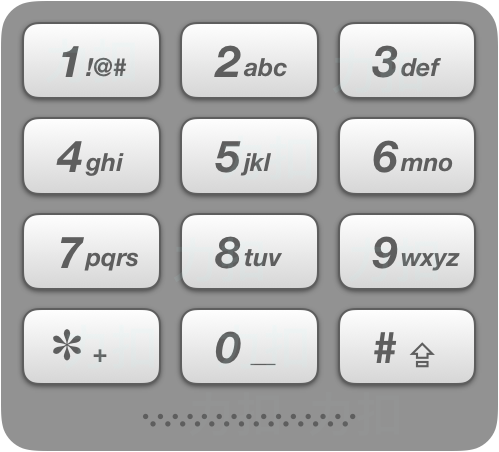
示例:
+ +输入:"23" +输出:["ad", "ae", "af", "bd", "be", "bf", "cd", "ce", "cf"]. ++ +
说明:
+尽管上面的答案是按字典序排列的,但是你可以任意选择答案输出的顺序。
给定一个包含 n 个整数的数组 nums 和一个目标值 target,判断 nums 中是否存在四个元素 a,b,c 和 d ,使得 a + b + c + d 的值与 target 相等?找出所有满足条件且不重复的四元组。
注意:
-答案中不可以包含重复的四元组。 +答案中不可以包含重复的四元组。
-**示例:** -``` -给定数组 nums = [1, 0, -1, 0, -2, 2],和 target = 0。 +示例:
+ +给定数组 nums = [1, 0, -1, 0, -2, 2],和 target = 0。
满足要求的四元组集合为:
[
@@ -17,145 +18,8 @@
[-2, -1, 1, 2],
[-2, 0, 0, 2]
]
-```
-
-
-### 解法
-
-#### 解法一
-1. 将数组排序;
-2. 先假设确定一个数 nums[i] 将 4Sum 问题转换为 3Sum 问题;
-3. 再假设确定一个数将 3Sum 问题转换为 2Sum 问题;
-4. 对排序数组,用首尾指针向中间靠拢的思路寻找满足 target 的 nums[l] 和 nums[k]
-
-```java
-class Solution {
- public List> fourSum(int[] nums, int target) {
-
- List> re = new ArrayList<>();
- if (nums == null || nums.length < 4) {
- return re;
- }
- Arrays.sort(nums);
- for (int i = 0; i < nums.length - 3; i++) {
-
- // 当 nums[i] 对应的最小组合都大于 target 时,后面大于 nums[i] 的组合必然也大于 target,
- if (nums[i] + nums[i + 1] + nums[i + 2] + nums[i + 3] > target) {
- break;
- }
- // 当 nums[i] 对应的最大组合都小于 target 时, nums[i] 的其他组合必然也小于 target
- if (nums[i] + nums[nums.length - 3] + nums[nums.length - 2] + nums[nums.length - 1] < target) {
- continue;
- }
-
- int firstNum = nums[i];
- for (int j = i + 1; j < nums.length - 2; j++) {
-
- // nums[j] 过大时,与 nums[i] 过大同理
- if (nums[i] + nums[j] + nums[j + 1] + nums[j + 2] > target) {
- break;
- }
- // nums[j] 过小时,与 nums[i] 过小同理
- if (nums[i] + nums[j] + nums[nums.length - 2] + nums[nums.length - 1] < target) {
- continue;
- }
-
- int twoSum = target - nums[i] - nums[j];
- int l = j + 1;
- int k = nums.length - 1;
- while (l < k) {
- int tempSum = nums[l] + nums[k];
- if (tempSum == twoSum) {
- ArrayList oneGroup = new ArrayList<>(4);
- oneGroup.add(nums[i]);
- oneGroup.add(nums[j]);
- oneGroup.add(nums[l++]);
- oneGroup.add(nums[k--]);
- re.add(oneGroup);
- while (l < nums.length && l < k && nums[l] == oneGroup.get(2) && nums[k] == oneGroup.get(3)) {
- l++;
- k--;
- }
- } else if (tempSum < twoSum) {
- l++;
- } else {
- k--;
- }
- }
- // 跳过重复项
- while ((j < nums.length - 2) && (twoSum + nums[i] + nums[j + 1] == target)) {
- j++;
- }
- }
- // 跳过重复项
- while (i < nums.length - 3 && nums[i + 1] == firstNum) {
- i++;
- }
- }
- return re;
- }
-}
-```
-
-#### 解法二
-对数组进行排序,利用指针 `i`, `j` 固定前两个数,`p`, `q` 指向剩余数组的首尾,判断四数和是否为 `target`:
-- 若是,添加到 `list` 中。此时 右移 `p` 直到 `nums[p] != nums[p - 1]`(为了去重)。同样,`q` 左移,进行去重。
-- 若四数和大于 `target`,`q` 指针左移;否则 `p` 指针右移。
-- 对于外面的两层 `for` 循环,同样需要进行去重操作。
+
-```java
-class Solution {
- public List给定一个链表,删除链表的倒数第 n 个节点,并且返回链表的头结点。
-给定的 n 保证是有效的。 +示例:
-进阶: +给定一个链表: 1->2->3->4->5, 和 n = 2. -你能尝试使用一趟扫描实现吗? +当删除了倒数第二个节点后,链表变为 1->2->3->5. +-### 解法 -快指针 fast 先走 n 步,接着快指针 fast 与慢指针 slow 同时前进,等到快指针指向链表最后一个结点时,停止前进。然后将 slow 的 next 指向 slow.next.next,即删除了第 n 个结点。最后返回头指针。 +
说明:
-这里设置了 pre 虚拟结点(指向 head )是为了方便处理只有一个结点的情况。 +给定的 n 保证是有效的。
-```java -/** - * Definition for singly-linked list. - * public class ListNode { - * int val; - * ListNode next; - * ListNode(int x) { val = x; } - * } - */ -class Solution { - public ListNode removeNthFromEnd(ListNode head, int n) { - ListNode pre = new ListNode(-1); - pre.next = head; - ListNode fast = pre; - ListNode slow = pre; - - // 快指针先走 n 步 - for (int i = 0; i < n; ++i) { - fast = fast.next; - } - while (fast.next != null) { - fast = fast.next; - slow = slow.next; - } - - slow.next = slow.next.next; - return pre.next; - } -} -``` +进阶:
-# [题目](这里是题目链接,如:https://leetcode-cn.com/problems/shu-zu-zhong-zhong-fu-de-shu-zi-lcof/) +你能尝试使用一趟扫描实现吗?
-## 题目描述 - ## 解法 diff --git a/solution/0000-0099/0020.Valid Parentheses/README.md b/solution/0000-0099/0020.Valid Parentheses/README.md index 09c383a757bf5..ccdb52b16f0ea 100644 --- a/solution/0000-0099/0020.Valid Parentheses/README.md +++ b/solution/0000-0099/0020.Valid Parentheses/README.md @@ -1,177 +1,47 @@ -## 有效的括号 -### 题目描述 +# [20. 有效的括号](https://leetcode-cn.com/problems/valid-parentheses) -给定一个只包括 '(',')','{','}','[',']' 的字符串,判断字符串是否有效。 +## 题目描述 + +给定一个只包括 '(',')','{','}','[',']' 的字符串,判断字符串是否有效。
有效字符串需满足:
-左括号必须用相同类型的右括号闭合。 -左括号必须以正确的顺序闭合。 -注意空字符串可被认为是有效字符串。 +-
+
- 左括号必须用相同类型的右括号闭合。 +
- 左括号必须以正确的顺序闭合。 +
注意空字符串可被认为是有效字符串。
-示例 2: -``` -输入: "()[]{}" -输出: true -``` - -示例 3: -``` -输入: "(]" -输出: false -``` +示例 1:
-示例 4: -``` -输入: "([)]" -输出: false -``` +输入: "()" +输出: true +-示例 5: -``` -输入: "{[]}" -输出: true -``` +
示例 2:
-### 解法 -遍历 string,遇到左括号,压入栈中;遇到右括号,从栈中弹出元素,元素不存在或者元素与该右括号不匹配,返回 false。遍历结束,栈为空则返回 true,否则返回 false。 +输入: "()[]{}"
+输出: true
+
-因为字符串只包含"(){}[]",也可以进行特殊处理,用映射来做。
+示例 3:
-#### Java 版实现 -```java -class Solution { - public boolean isValid(String s) { - if (s == null || s == "") { - return true; - } - char[] chars = s.toCharArray(); - int n = chars.length; - - Stack输入: "(]" +输出: false +-#### C++ 版实现 -```cpp - -class Solution { -public: - bool isValid(string s) { - stack
输入: "([)]" +输出: false ++
示例 5:
-# [题目](这里是题目链接,如:https://leetcode-cn.com/problems/shu-zu-zhong-zhong-fu-de-shu-zi-lcof/) +输入: "{[]}"
+输出: true
-## 题目描述
-
## 解法
diff --git a/solution/0000-0099/0021.Merge Two Sorted Lists/README.md b/solution/0000-0099/0021.Merge Two Sorted Lists/README.md
index 5aa52a90eb368..02e800e8c2592 100644
--- a/solution/0000-0099/0021.Merge Two Sorted Lists/README.md
+++ b/solution/0000-0099/0021.Merge Two Sorted Lists/README.md
@@ -1,48 +1,15 @@
-## 合并两个有序链表
-### 题目描述
+# [21. 合并两个有序链表](https://leetcode-cn.com/problems/merge-two-sorted-lists)
-将两个有序链表合并为一个新的有序链表并返回。新链表是通过拼接给定的两个链表的所有节点组成的。
-
-示例:
-```
-输入:1->2->4, 1->3->4
-输出:1->1->2->3->4->4
-```
-
-### 解法
-利用链表天然的递归性。如果 l1 为空,返回 l2;如果 l2 为空,返回 l1。如果 `l1.val < l2.val`,返回 l1->mergeTwoLists(l1.next, l2);否则返回 l2->mergeTwoLists(l1, l2.next)。
+## 题目描述
+
+将两个有序链表合并为一个新的有序链表并返回。新链表是通过拼接给定的两个链表的所有节点组成的。
-```java -/** - * Definition for singly-linked list. - * public class ListNode { - * int val; - * ListNode next; - * ListNode(int x) { val = x; } - * } - */ -class Solution { - public ListNode mergeTwoLists(ListNode l1, ListNode l2) { - if (l1 == null) { - return l2; - } - if (l2 == null) { - return l1; - } - if (l1.val < l2.val) { - l1.next = mergeTwoLists(l1.next, l2); - return l1; - } - l2.next = mergeTwoLists(l1, l2.next); - return l2; - } -} -``` +示例:
-# [题目](这里是题目链接,如:https://leetcode-cn.com/problems/shu-zu-zhong-zhong-fu-de-shu-zi-lcof/) +输入:1->2->4, 1->3->4 +输出:1->1->2->3->4->4 +-## 题目描述 - ## 解法 diff --git a/solution/0000-0099/0022.Generate Parentheses/README.md b/solution/0000-0099/0022.Generate Parentheses/README.md index d9b3840c082d2..7ac73ff8cd744 100644 --- a/solution/0000-0099/0022.Generate Parentheses/README.md +++ b/solution/0000-0099/0022.Generate Parentheses/README.md @@ -1,7 +1,20 @@ -# [题目](这里是题目链接,如:https://leetcode-cn.com/problems/shu-zu-zhong-zhong-fu-de-shu-zi-lcof/) +# [22. 括号生成](https://leetcode-cn.com/problems/generate-parentheses) ## 题目描述 +
给出 n 代表生成括号的对数,请你写出一个函数,使其能够生成所有可能的并且有效的括号组合。
+ +例如,给出 n = 3,生成结果为:
+ +[ + "((()))", + "(()())", + "(())()", + "()(())", + "()()()" +] ++ ## 解法 diff --git a/solution/0000-0099/0023.Merge k Sorted Lists/README.md b/solution/0000-0099/0023.Merge k Sorted Lists/README.md index 22a4b9a8b3860..85aec1cb02f7a 100644 --- a/solution/0000-0099/0023.Merge k Sorted Lists/README.md +++ b/solution/0000-0099/0023.Merge k Sorted Lists/README.md @@ -1,140 +1,19 @@ -## 合并K个排序链表 -### 题目描述 +# [23. 合并K个排序链表](https://leetcode-cn.com/problems/merge-k-sorted-lists) -合并 k 个排序链表,返回合并后的排序链表。请分析和描述算法的复杂度。 +## 题目描述 + +
合并 k 个排序链表,返回合并后的排序链表。请分析和描述算法的复杂度。
-示例: -``` -输入: +示例:
+ +输入: [ - 1->4->5, - 1->3->4, - 2->6 + 1->4->5, + 1->3->4, + 2->6 ] -输出: 1->1->2->3->4->4->5->6 -``` - -### 解法 -从链表数组索引 0 开始,[合并前后相邻两个有序链表](https://github.com/doocs/leetcode/tree/master/solution/021.Merge%20Two%20Sorted%20Lists),放在后一个链表位置上,依次循环下去...最后 lists[len - 1] 即为合并后的链表。注意处理链表数组元素小于 2 的情况。 - --------------------------------- -思路1: 170ms -用第一个链依次和后面的所有链进行双链合并,利用021的双顺序链合并,秒杀!但是效率极低 +输出: 1->1->2->3->4->4->5->6-时间复杂度是O(x(a+b) + (x-1)(a+b+c) + ... + 1 * (a+b+...+z);[a-z]是各链表长度,x表示链表个数-1 - -可见时间复杂度是极大的 - - -思路2: 20ms -1.因为链表有序,所以用每个链表的首元素构建初试堆(小顶堆) -- 的队列 - -2.首元素出队,该元素next指向元素入队 - -时间复杂度是O(n) - -```java -/** - * Definition for singly-linked list. - * public class ListNode { - * int val; - * ListNode next; - * ListNode(int x) { val = x; } - * } - */ -class Solution { - public ListNode mergeKLists(ListNode[] lists) { - if (lists == null || lists.length == 0) { - return null; - } - - int len = lists.length; - if (len == 1) { - return lists[0]; - } - - // 合并前后两个链表,结果放在后一个链表位置上,依次循环下去 - for (int i = 0; i < len - 1; ++i) { - lists[i + 1] = mergeTwoLists(lists[i], lists[i + 1]); - } - return lists[len - 1]; - - } - - /** - * 合并两个有序链表 - * @param l1 - * @param l2 - * @return listNode - */ - private ListNode mergeTwoLists(ListNode l1, ListNode l2) { - if (l1 == null) { - return l2; - } - if (l2 == null) { - return l1; - } - if (l1.val < l2.val) { - l1.next = mergeTwoLists(l1.next, l2); - return l1; - } - l2.next = mergeTwoLists(l1, l2.next); - return l2; - } -} -``` - -#### CPP - -```C++ -class compare -{ -public: - bool operator()(ListNode *l1,ListNode *l2){ - //if(!l1 || !l2) - // return !l1; - - if(l1 == NULL)return 1; - if(l2 == NULL)return 0; - return l1->val > l2->val; - //这里比较的是优先级,默认优先级排序是“<”号,若 l1Val > l2Val 返回真,即表示l1优先级比l2小,l2先入队 - //队列的top()函数指的就是优先级最高的元素,即队头元素 - } -}; - -class Solution{ -public: - ListNode* mergeKLists(vector
给定一个链表,两两交换其中相邻的节点,并返回交换后的链表。
-示例: -``` -给定 1->2->3->4, 你应该返回 2->1->4->3. -``` -说明: +你不能只是单纯的改变节点内部的值,而是需要实际的进行节点交换。
-- 你的算法只能使用常数的额外空间。 -- 你不能只是单纯的改变节点内部的值,而是需要实际的进行节点交换。 +-### 解法 -指针 p, q 分别指示链表的前后两个结点,利用指针 t 临时保存 q 的下一个结点地址。交换 p, q 指向。 -注意链表为空或者链表个数为奇数的情况,做特殊判断。 -```java -/** - * Definition for singly-linked list. - * public class ListNode { - * int val; - * ListNode next; - * ListNode(int x) { val = x; } - * } - */ -class Solution { - public ListNode swapPairs(ListNode head) { - if (head == null || head.next == null) { - return head; - } - ListNode pre = head.next; - ListNode p = head; - ListNode q = head.next; - - while (q != null) { - ListNode t = q.next; - q.next = p; - if (t == null || t.next == null) { - p.next = t; - break; - } - p.next = t.next; - p = t; - q = p.next; - } - - return pre; - } -} -``` +
示例:
-# [题目](这里是题目链接,如:https://leetcode-cn.com/problems/shu-zu-zhong-zhong-fu-de-shu-zi-lcof/) +给定-## 题目描述 - ## 解法 diff --git a/solution/0000-0099/0025.Reverse Nodes in k-Group/README.md b/solution/0000-0099/0025.Reverse Nodes in k-Group/README.md index 1e7108b1adb58..47a7b5e56572f 100644 --- a/solution/0000-0099/0025.Reverse Nodes in k-Group/README.md +++ b/solution/0000-0099/0025.Reverse Nodes in k-Group/README.md @@ -1,84 +1,32 @@ -## k个一组翻转链表 -### 题目描述 +# [25. K 个一组翻转链表](https://leetcode-cn.com/problems/reverse-nodes-in-k-group) -给出一个链表,每 k 个节点一组进行翻转,并返回翻转后的链表。 +## 题目描述 + +1->2->3->4, 你应该返回2->1->4->3. +
给你一个链表,每 k 个节点一组进行翻转,请你返回翻转后的链表。
-k 是一个正整数,它的值小于或等于链表的长度。如果节点总数不是 k 的整数倍,那么将最后剩余节点保持原有顺序。 +k 是一个正整数,它的值小于或等于链表的长度。
-示例 : +如果节点总数不是 k 的整数倍,那么请将最后剩余的节点保持原有顺序。
-给定这个链表:1->2->3->4->5 +-当 k = 2 时,应当返回: 2->1->4->3->5 +
示例:
-当 k = 3 时,应当返回: 3->2->1->4->5 +给你这个链表:1->2->3->4->5
当 k = 2 时,应当返回: 2->1->4->3->5
当 k = 3 时,应当返回: 3->2->1->4->5
-```java -/** - * Definition for singly-linked list. - * public class ListNode { - * int val; - * ListNode next; - * ListNode(int x) { val = x; } - * } - */ -class Solution { - public ListNode reverseKGroup(ListNode head, int k) { - if(head == null || k < 2) { - return head; - } - int num = 0; - ListNode pNode = head; - ListNode lastNode = new ListNode(0); - ListNode reNode = lastNode; - lastNode.next = head; - while (pNode != null) { - num++; - if(num >= k) { - num = 0; - ListNode tempNode = pNode.next; - reverse(lastNode.next, k); - // k 个节点的尾节点指向下一组的头节点 - lastNode.next.next = tempNode; - // 上一组的尾节点指向当前 k 个节点的头节点 - tempNode = lastNode.next; - lastNode.next = pNode; - - lastNode = tempNode; - pNode = lastNode.next; - } - else { - pNode = pNode.next; - } - } - return reNode.next; - } - - private ListNode reverse(ListNode node, int i) { - if(i <= 1 || node.next == null) { - return node; - } - ListNode lastNode = reverse(node.next, i - 1); - lastNode.next = node; - return node; - } -} -``` +
说明:
-# [题目](这里是题目链接,如:https://leetcode-cn.com/problems/shu-zu-zhong-zhong-fu-de-shu-zi-lcof/) +-
+
- 你的算法只能使用常数的额外空间。 +
- 你不能只是单纯的改变节点内部的值,而是需要实际进行节点交换。 +
给定一个排序数组,你需要在 原地 删除重复出现的元素,使得每个元素只出现一次,返回移除后数组的新长度。
-不要使用额外的数组空间,你必须在原地修改输入数组并在使用 O(1) 额外空间的条件下完成。 +不要使用额外的数组空间,你必须在 原地 修改输入数组 并在使用 O(1) 额外空间的条件下完成。
-示例 1: +-给定数组 nums = [1,1,2], +
示例 1:
-函数应该返回新的长度 2, 并且原数组 nums 的前两个元素被修改为 1, 2。 +给定数组 nums = [1,1,2], -你不需要考虑数组中超出新长度后面的元素。 -示例 2: +函数应该返回新的长度 2, 并且原数组 nums 的前两个元素被修改为+ +1,2。 + +你不需要考虑数组中超出新长度后面的元素。
示例 2:
-给定 nums = [0,0,1,1,1,2,2,3,3,4], +给定 nums = [0,0,1,1,1,2,2,3,3,4], -函数应该返回新的长度 5, 并且原数组 nums 的前五个元素被修改为 0, 1, 2, 3, 4。 +函数应该返回新的长度 5, 并且原数组 nums 的前五个元素被修改为-为什么返回数值是整数,但输出的答案是数组呢? +0,1,2,3,4。 你不需要考虑数组中超出新长度后面的元素。 -说明: +
-请注意,输入数组是以“引用”方式传递的,这意味着在函数里修改输入数组对于调用者是可见的。 +
说明:
-你可以想象内部操作如下: +为什么返回数值是整数,但输出的答案是数组呢?
-// nums 是以“引用”方式传递的。也就是说,不对实参做任何拷贝 -int len = removeDuplicates(nums); +请注意,输入数组是以「引用」方式传递的,这意味着在函数里修改输入数组对于调用者是可见的。
-// 在函数里修改输入数组对于调用者是可见的。 -// 根据你的函数返回的长度, 它会打印出数组中该长度范围内的所有元素。 -``` -for (int i = 0; i < len; i++) { - print(nums[i]); -} -``` +你可以想象内部操作如下:
-### 解法 -1. 维护 i 和 j 两个指针,i 从左向右遍历数组, j 指针指向当前完成去除重复元素的最后一个值。 -2. 通过比较 nums[i] 与 nums[j] 的值判断 i 指向的元素是否为前一个元素的重复,若是,进入步骤3,否则,重复步骤2; -3. j 向左移动,将 nums[i] 拷贝至 nums[j] 成为新的末尾元素。 +// nums 是以“引用”方式传递的。也就是说,不对实参做任何拷贝
+int len = removeDuplicates(nums);
-```java
-class Solution {
- public int removeDuplicates(int[] nums) {
- if(nums == null || nums.length == 0) {
- return 0;
- }
-
- int j = 0;
- for(int i = 1; i < nums.length; i++) {
- if(nums[i] != nums[j]) {
- nums[++j] = nums[i];
- }
- }
- return j + 1;
- }
+// 在函数里修改输入数组对于调用者是可见的。
+// 根据你的函数返回的长度, 它会打印出数组中该长度范围内的所有元素。
+for (int i = 0; i < len; i++) {
+ print(nums[i]);
}
-```
-
-# [题目](这里是题目链接,如:https://leetcode-cn.com/problems/shu-zu-zhong-zhong-fu-de-shu-zi-lcof/)
+
-## 题目描述
-
## 解法
diff --git a/solution/0000-0099/0027.Remove Element/README.md b/solution/0000-0099/0027.Remove Element/README.md
index eddc3660ae5ae..a59682c8fdc0a 100644
--- a/solution/0000-0099/0027.Remove Element/README.md
+++ b/solution/0000-0099/0027.Remove Element/README.md
@@ -1,103 +1,55 @@
-## 移除元素
-### 题目描述
+# [27. 移除元素](https://leetcode-cn.com/problems/remove-element)
-给定一个数组 nums 和一个值 val,你需要原地移除所有数值等于 val 的元素,返回移除后数组的新长度。
+## 题目描述
+
+给你一个数组 nums 和一个值 val,你需要 原地 移除所有数值等于 val 的元素,并返回移除后数组的新长度。
-不要使用额外的数组空间,你必须在原地修改输入数组并在使用 O(1) 额外空间的条件下完成。 +不要使用额外的数组空间,你必须仅使用 O(1) 额外空间并 原地 修改输入数组。
-元素的顺序可以改变。你不需要考虑数组中超出新长度后面的元素。 +元素的顺序可以改变。你不需要考虑数组中超出新长度后面的元素。
-示例 1: +-给定 nums = [3,2,2,3], val = 3, +
示例 1:
-函数应该返回新的长度 2, 并且 nums 中的前两个元素均为 2。 +给定 nums = [3,2,2,3], val = 3, + +函数应该返回新的长度 2, 并且 nums 中的前两个元素均为 2。 你不需要考虑数组中超出新长度后面的元素。 -示例 2: ++ +
示例 2:
-给定 nums = [0,1,2,2,3,0,4,2], val = 2, +给定 nums = [0,1,2,2,3,0,4,2], val = 2, -函数应该返回新的长度 5, 并且 nums 中的前五个元素为 0, 1, 3, 0, 4。 +函数应该返回新的长度-### 解法 -1. 维护 i 和 end 两个指针,end 指向数组尾部,i 从左向右遍历数组, -2. 若 nums[i] == val, 则把数组尾部的值 nums[end] 拷贝至 i 的位置,然后将 end 指针向左移动;否则,i 向右移动,继续遍历数组。 -3. 这样当两个 i 与 end 相遇时,end 左边的所以 val 元素都被 end 右边的非 val 元素替换。 +5, 并且 nums 中的前五个元素为0,1,3,0, 4。 注意这五个元素可为任意顺序。 你不需要考虑数组中超出新长度后面的元素。 +
-```java -class Solution { - public int removeElement(int[] nums, int val) { - if(nums == null || nums.length == 0) { - return 0; - } - - int end = nums.length - 1; - int i = 0; - while(i <= end) { - if(nums[i] == val) { - nums[i] = nums[end]; - end--; - } - else { - i++; - } - } - return end + 1; - - } -} -``` +
说明:
-#### CPP - -```CPP -class Solution { -public: - int removeElement(vector为什么返回数值是整数,但输出的答案是数组呢?
-# [题目](这里是题目链接,如:https://leetcode-cn.com/problems/shu-zu-zhong-zhong-fu-de-shu-zi-lcof/) +请注意,输入数组是以「引用」方式传递的,这意味着在函数里修改输入数组对于调用者是可见的。
+ +你可以想象内部操作如下:
+ +// nums 是以“引用”方式传递的。也就是说,不对实参作任何拷贝
+int len = removeElement(nums, val);
+
+// 在函数里修改输入数组对于调用者是可见的。
+// 根据你的函数返回的长度, 它会打印出数组中 该长度范围内 的所有元素。
+for (int i = 0; i < len; i++) {
+ print(nums[i]);
+}
+
-## 题目描述
-
## 解法
diff --git a/solution/0000-0099/0028.Implement strStr()/README.md b/solution/0000-0099/0028.Implement strStr()/README.md
index c2a9cd6930eb6..e01c464ad2930 100644
--- a/solution/0000-0099/0028.Implement strStr()/README.md
+++ b/solution/0000-0099/0028.Implement strStr()/README.md
@@ -1,67 +1,29 @@
-## 实现strStr()
-### 题目描述
+# [28. 实现 strStr()](https://leetcode-cn.com/problems/implement-strstr)
-实现 [strStr()](https://baike.baidu.com/item/strstr/811469) 函数。
+## 题目描述
+
+实现 strStr() 函数。
-给定一个 haystack 字符串和一个 needle 字符串,在 haystack 字符串中找出 needle 字符串出现的第一个位置 (从0开始)。如果不存在,则返回 -1。 +给定一个 haystack 字符串和一个 needle 字符串,在 haystack 字符串中找出 needle 字符串出现的第一个位置 (从0开始)。如果不存在,则返回 -1。
-**示例 1:** -``` -输入: haystack = "hello", needle = "ll" -输出: 2 -``` +示例 1:
-**示例 2:** -``` -输入: haystack = "aaaaa", needle = "bba" -输出: -1 -``` +输入: haystack = "hello", needle = "ll" +输出: 2 +-**说明:** +
示例 2:
-当 `needle` 是空字符串时,我们应当返回什么值呢?这是一个在面试中很好的问题。 +输入: haystack = "aaaaa", needle = "bba" +输出: -1 +-对于本题而言,当 `needle` 是空字符串时我们应当返回 0 。这与C语言的 [strstr()](https://baike.baidu.com/item/strstr/811469) 以及 Java的 `indexOf()` 定义相符。 +
说明:
-### 解法 -遍历 `haystack` 和 `needle`,利用指针 `p`, `q` 分别指向这两个字符串。对于每一个位置对于的字符,如果两字符相等,继续判断下一个位置的字符是否相等;否则 `q` 置为 0,`p` 置为最初匹配的字符的下一个位置,即 `p - q + 1`。 +当 needle 是空字符串时,我们应当返回什么值呢?这是一个在面试中很好的问题。
对于本题而言,当 needle 是空字符串时我们应当返回 0 。这与C语言的 strstr() 以及 Java的 indexOf() 定义相符。
给定两个整数,被除数 dividend 和除数 divisor。将两数相除,要求不使用乘法、除法和 mod 运算符。
返回被除数 dividend 除以除数 divisor 得到的商。
整数除法的结果应当截去(truncate)其小数部分,例如:truncate(8.345) = 8 以及 truncate(-2.7335) = -2
-输入: dividend = 7, divisor = -3 -输出: -2 -``` +
示例 1:
-说明: +输入: dividend = 10, divisor = 3 +输出: 3 +解释: 10/3 = truncate(3.33333..) = truncate(3) = 3-被除数和除数均为 32 位有符号整数。 -除数不为 0。 -假设我们的环境只能存储 32 位有符号整数,其数值范围是 [−2^31 , 2^31 − 1]。 -本题中,如果除法结果溢出,则返回 2^31 − 1。 +
示例 2:
-### 解法 -1. 考虑用位运算来代替乘除,用二进制表示商,则只要确定了每一个二进制位,则把这些位加和即可得到商; -2. 对除数进行移位,找到最高位,然后从高到低依次比较每一位对应的数与除数的乘积,若大于则说明商的该位为1,否则为0; +输入: dividend = 7, divisor = -3 +输出: -2 +解释: 7/-3 = truncate(-2.33333..) = truncate(-2) = 3-```java -class Solution { - public int divide(int dividend, int divisor) { - if(dividend == 0 || divisor == 1) { - return dividend; - } - if(divisor == 0 || (dividend == Integer.MIN_VALUE && divisor == -1)) { - return Integer.MAX_VALUE; - } - // 商的符号,true 为正,false 为负 - boolean flag = true; - if((dividend < 0 && divisor > 0) || (dividend > 0 && divisor < 0)) { - flag = false; - } - long dividendLong = Math.abs((long)dividend); - long divisorLong = Math.abs((long)divisor); - - int re = 0; - long factor = 0x1; - - while (dividendLong >= (divisorLong << 1)) { - divisorLong <<= 1; - factor <<= 1; - } - - while (factor > 0 && dividendLong > 0) { - if(dividendLong >= divisorLong) { - dividendLong -= divisorLong; - re += factor; - } - factor >>>= 1; - divisorLong >>>= 1; - } - - return flag ? re : -re; - } -} -``` +
-# [题目](这里是题目链接,如:https://leetcode-cn.com/problems/shu-zu-zhong-zhong-fu-de-shu-zi-lcof/) +
提示:
+ +-
+
- 被除数和除数均为 32 位有符号整数。 +
- 除数不为 0。 +
- 假设我们的环境只能存储 32 位有符号整数,其数值范围是 [−231, 231 − 1]。本题中,如果除法结果溢出,则返回 231 − 1。 +
给定一个字符串 s 和一些长度相同的单词 words。找出 s 中恰好可以由 words 中所有单词串联形成的子串的起始位置。
-``` -示例 1: +注意子串要与 words 中的单词完全匹配,中间不能有其他字符,但不需要考虑 words 中单词串联的顺序。
-输入: - s = "barfoothefoobarman", - words = ["foo","bar"] -输出: [0,9] -解释: 从索引 0 和 9 开始的子串分别是 "barfoor" 和 "foobar" 。 -输出的顺序不重要, [9,0] 也是有效答案。 -示例 2: +-输入: - s = "wordgoodstudentgoodword", - words = ["word","good","good"] - (ps:原题的例子为 words = ["word","student"] 和题目描述不符,这里私自改了一下) -输出: [] -``` +
示例 1:
-### 解法 -1. 用 HashMap< 单词, 出现次数 > map 来存储所有单词; -2. 设单词数量为 N ,每个单词长度为 len,则我们只需要对比到 **str.length() - N \* len** , -再往后因为不足 N \* len 个字母,肯定不匹配; -3. 每次从 str 中选取连续的 N \* len 个字母进行匹配时,**从后向前匹配**,因为若后面的单词不匹配, -无论前面的单词是否匹配,当前选取的字串一定不匹配,且,最后一个匹配的单词前的部分一定不在匹配的字串中, -这样下一次选取长度为 N \* len 的字串时,可以**从上次匹配比较中最后一个匹配的单词开始**,减少了比较的次数; -4. 考虑到要点 3 中对前一次匹配结果的利用,遍历 str 时,采用间隔为 len 的形式。 -例如示例 1 ,遍历顺序为:(0 3 6 9 12 15) (1 4 7 10 13)(2 5 8 11 14) - +输入:
+ s = "barfoothefoobarman",
+ words = ["foo","bar"]
+输出:[0,9]
+解释:
+从索引 0 和 9 开始的子串分别是 "barfoo" 和 "foobar" 。
+输出的顺序不重要, [9,0] 也是有效答案。
+
-```java
-class Solution {
- public List示例 2:
-# [题目](这里是题目链接,如:https://leetcode-cn.com/problems/shu-zu-zhong-zhong-fu-de-shu-zi-lcof/) +输入:
+ s = "wordgoodgoodgoodbestword",
+ words = ["word","good","best","word"]
+输出:[]
+
-## 题目描述
-
## 解法
diff --git a/solution/0000-0099/0031.Next Permutation/README.md b/solution/0000-0099/0031.Next Permutation/README.md
index 9ad60c7d4acb1..1f8437777904d 100644
--- a/solution/0000-0099/0031.Next Permutation/README.md
+++ b/solution/0000-0099/0031.Next Permutation/README.md
@@ -1,80 +1,18 @@
-## 下一个排列
-### 题目描述
+# [31. 下一个排列](https://leetcode-cn.com/problems/next-permutation)
-实现获取下一个排列的函数,算法需要将给定数字序列重新排列成字典序中下一个更大的排列。
-
-如果不存在下一个更大的排列,则将数字重新排列成最小的排列(即升序排列)。
-
-必须原地修改,只允许使用额外常数空间。
-
-以下是一些例子,输入位于左侧列,其相应输出位于右侧列。
-
-`1,2,3` → `1,3,2`
-
-`3,2,1` → `1,2,3`
-
-`1,1,5` → `1,5,1`
-
-### 解法
-从后往前,找到第一个升序状态的位置,记为 i-1,在[i, length - 1] 中找到比 nums[i - 1] 大的,且差值最小的元素(如果有多个差值最小且相同的元素,取后者),进行交换。将后面的数组序列升序排列,保存。然后恢复 i,继续循环。
+## 题目描述
+
+实现获取下一个排列的函数,算法需要将给定数字序列重新排列成字典序中下一个更大的排列。
+如果不存在下一个更大的排列,则将数字重新排列成最小的排列(即升序排列)。
-```java -class Solution { - public void nextPermutation(int[] nums) { - boolean flag = false; - for (int i = nums.length - 2; i >= 0; --i) { - if (nums[i] < nums[i + 1]) { - int index = findMinIndex(nums, i, nums[i]); - swap(nums, i, index); - reverse(nums, i + 1); - flag = true; - break; - } - } - if (!flag) { - Arrays.sort(nums); - } - } - - private void reverse(int[] nums, int start) { - int end = nums.length - 1; - while (start < end) { - swap(nums, start++, end--); - } - } - - /** - * 找出从start开始的比val大的最小元素的下标,如果有多个,选择后者 - * - * @param name - * @param start - * @param val - * @return index - */ - private int findMinIndex(int[] nums, int start, int val) { - int end = nums.length - 1; - int i = start; - for (; i < end; ++i) { - if (nums[i + 1] <= val) { - break; - } - } - return i; - } - - private void swap(int[] nums, int i, int j) { - int t = nums[i]; - nums[i] = nums[j]; - nums[j] = t; - } -} -``` +必须原地修改,只允许使用额外常数空间。
-# [题目](这里是题目链接,如:https://leetcode-cn.com/problems/shu-zu-zhong-zhong-fu-de-shu-zi-lcof/) +以下是一些例子,输入位于左侧列,其相应输出位于右侧列。
+1,2,3 → 1,3,2
+3,2,1 → 1,2,3
+1,1,5 → 1,5,1
给定一个只包含 '(' 和 ')' 的字符串,找出最长的包含有效括号的子串的长度。
示例 1:
-- 若 s[i] == '(',res[i] = 0; -- 若 s[i] == ')' && s[i - 1] == '(',res[i] = res[i - 2] + 2; -- 若 s[i] == ')' && s[i - 1] == ')',判断 s[i - 1 - res[i - 1]] 的符号,若为 '(',则 res[i] = res[i - 1] + 2 + res[i - res[i - 1] - 2]。 +输入: "(()"
+输出: 2
+解释: 最长有效括号子串为 "()"
+
-注意数组下标越界检查。
+示例 2:
-```java -class Solution { - public int longestValidParentheses(String s) { - if (s == null || s.length() < 2) { - return 0; - } - char[] chars = s.toCharArray(); - int n = chars.length; - int[] res = new int[n]; - res[0] = 0; - res[1] = chars[1] == ')' && chars[0] == '(' ? 2 : 0; - - int max = res[1]; - - for (int i = 2; i < n; ++i) { - if (chars[i] == ')') { - if (chars[i - 1] == '(') { - res[i] = res[i - 2] + 2; - } else { - int index = i - res[i - 1] - 1; - if (index >= 0 && chars[index] == '(') { - // ()(()) - res[i] = res[i - 1] + 2 + (index - 1 >= 0 ? res[index - 1] : 0); - } - } - } - max = Math.max(max, res[i]); - } - - return max; - - } -} -``` +输入: "-# [题目](这里是题目链接,如:https://leetcode-cn.com/problems/shu-zu-zhong-zhong-fu-de-shu-zi-lcof/) - -## 题目描述 - ## 解法 diff --git a/solution/0000-0099/0033.Search in Rotated Sorted Array/README.md b/solution/0000-0099/0033.Search in Rotated Sorted Array/README.md index f276c703260bc..0386d6576e65c 100644 --- a/solution/0000-0099/0033.Search in Rotated Sorted Array/README.md +++ b/solution/0000-0099/0033.Search in Rotated Sorted Array/README.md @@ -1,104 +1,28 @@ -## 搜索旋转排序数组 -### 题目描述 +# [33. 搜索旋转排序数组](https://leetcode-cn.com/problems/search-in-rotated-sorted-array) -假设按照升序排序的数组在预先未知的某个点上进行了旋转。 - -( 例如,数组 [0,1,2,4,5,6,7] 可能变为 [4,5,6,7,0,1,2] )。 - -搜索一个给定的目标值,如果数组中存在这个目标值,则返回它的索引,否则返回 -1 。 - -你可以假设数组中不存在重复的元素。 - -你的算法时间复杂度必须是 O(log n) 级别。 - -``` -示例 1: -输入: nums = [4,5,6,7,0,1,2], target = 0 -输出: 4 -``` - -``` -示例 2: -输入: nums = [4,5,6,7,0,1,2], target = 3 -输出: -1 -``` - - ----------------------- -### 思路: -因为是排序数组,而且要求是log2(n)时间搜索,所以优先选择用二分搜索法,但是这道题的难点就是不知道原数组的旋转位置在哪里,无法从中间值对比过程中直接进行二分搜索 - -我们还是用题目中给的例子来分析,对于数组[0 1 2 4 5 6 7] 共有下列七种旋转方法: - -0 1 2 4 5 6 7 - -7 0 1 **2 4 5 6** - -6 7 0 **1 2 4 5** - -5 6 7 **0 1 2 4** - -**4 5 6 7** 0 1 2 +## 题目描述 + +)()())" +输出: 4 +解释: 最长有效括号子串为"()()"+
假设按照升序排序的数组在预先未知的某个点上进行了旋转。
-**2 4 5 6** 7 0 1 +( 例如,数组 [0,1,2,4,5,6,7] 可能变为 [4,5,6,7,0,1,2] )。
搜索一个给定的目标值,如果数组中存在这个目标值,则返回它的索引,否则返回 -1 。
你可以假设数组中不存在重复的元素。
-我们观察上面加粗的部分,如果: -中间值比最右值小,则右半部有序递增 -中间值比最右值大,则左半部有序递增 +你的算法时间复杂度必须是 O(log n) 级别。
-通过这个特点,对该数组进行二分搜索 +示例 1:
-```C++ -class Solution { -public: - int search(vector输入: nums = [4,5,6,7,0,1,2], target = 0
+输出: 4
+
-```
--------------------------
-我发现其实这种暴力枚举,时间差不了多少,各位赶时间就直接暴力吧!!!
-
-```C++
-class Solution {
-public:
- int search(vector输入: nums = [4,5,6,7,0,1,2], target = 3
+输出: -1
-## 题目描述
-
## 解法
diff --git a/solution/0000-0099/0034.Find First and Last Position of Element in Sorted Array/README.md b/solution/0000-0099/0034.Find First and Last Position of Element in Sorted Array/README.md
index bad4ab6a10d48..703215a6aed30 100644
--- a/solution/0000-0099/0034.Find First and Last Position of Element in Sorted Array/README.md
+++ b/solution/0000-0099/0034.Find First and Last Position of Element in Sorted Array/README.md
@@ -1,81 +1,23 @@
-## 在排序数组中查找元素的第一个和最后一个位置
+# [34. 在排序数组中查找元素的第一个和最后一个位置](https://leetcode-cn.com/problems/find-first-and-last-position-of-element-in-sorted-array)
-### 问题描述
-
-给定一个按照升序排列的整数数组 nums,和一个目标值 target。找出给定目标值在数组中的开始位置和结束位置。
+## 题目描述
+
+给定一个按照升序排列的整数数组 nums,和一个目标值 target。找出给定目标值在数组中的开始位置和结束位置。
你的算法时间复杂度必须是 O(log n) 级别。
-如果数组中不存在目标值,返回 [-1, -1]。 +如果数组中不存在目标值,返回 [-1, -1]。
示例 1:
-示例 2: -输入: nums = [5,7,7,8,8,10], target = 6 -输出: [-1,-1] -``` +输入: nums = [5,7,7,8,8,10], target = 8
+输出: [3,4]
-### 思路
-
-二分查找找下标,找到下标对其左右查找是否等于目标值就好了
-
-```CPP
-
-class Solution {
-public:
- bool binarySearch(vector输入: nums = [5,7,7,8,8,10], target = 6
+输出: [-1,-1]
-## 题目描述
-
## 解法
diff --git a/solution/0000-0099/0035.Search Insert Position/README.md b/solution/0000-0099/0035.Search Insert Position/README.md
index 3b930fe132f73..d1355190c3a6f 100644
--- a/solution/0000-0099/0035.Search Insert Position/README.md
+++ b/solution/0000-0099/0035.Search Insert Position/README.md
@@ -1,186 +1,35 @@
-## 搜索位置描述
-### 题目描述
+# [35. 搜索插入位置](https://leetcode-cn.com/problems/search-insert-position)
+## 题目描述
+
+给定一个排序数组和一个目标值,在数组中找到目标值,并返回其索引。如果目标值不存在于数组中,返回它将会被按顺序插入的位置。
-给定一个排序数组和一个目标值,在数组中找到目标值,并返回其索引。如果目标值不存在于数组中,返回它将会被按顺序插入的位置。 - -你可以假设数组中无重复元素。 - -**示例 1:** -``` -输入: [1,3,5,6], 5 -输出: 2 -``` - -**示例 2:** -``` -输入: [1,3,5,6], 2 -输出: 1 -``` - -**示例 3:** -``` -输入: [1,3,5,6], 7 -输出: 4 -``` - -**示例 4:** -``` -输入: [1,3,5,6], 0 -输出: 0 -``` - -### 解法 -首先判断传入的数组为 0,1 这样的长度。 - -因为是一个给定的排序数组,在循环时就可以判断是否存在的同时判断大小,有相同的则直接返回索引, -不存在则判断大小,只要相较于当前索引的元素较小,则可以认为该目标数在数组中无对应元素,直接返回索引即可。 +你可以假设数组中无重复元素。
-除此之外还可用二分法做解。 +示例 1:
+输入: [1,3,5,6], 5 +输出: 2 +-```java -class Solution { - public int searchInsert(int[] nums, int target) { - if(nums.length == 0) { - return 0; - } - if(nums.length == 1) { - if(nums[0] < target) { - return 1; - } else { - return 0; - } - } - for(int i = 0;i < nums.length;i++) { - if(nums[i] == target) { - return i; - } else { - int s = Math.min(nums[i],target); - if(s == target) { - return i; - } - } - } - return nums.length; - } -} -``` +
示例 2:
-- 二分法 -```java -class Solution { - public int searchInsert(int[] nums, int target) { - if (nums == null || nums.length == 0) { - return 0; - } - int low = 0; - int high = nums.length - 1; - while (low <= high) { - int mid = low + ((high - low) >> 1); - if (nums[mid] == target) { - return mid; - } - if (nums[mid] < target) { - low = mid + 1; - } else { - high = mid - 1; - } - } - return low; - } -} -``` +输入: [1,3,5,6], 2 +输出: 1 +-#### CPP - -思路1: - -1. 先调函数查找是否存在target元素 -2. 若存在,用二分法进行查找,或者顺序遍历 -3. 若不存在,则顺序遍历插入 - -时间复杂度O(log2(n))~O(n) - -思路2: - 1. 直接顺序遍历---需要点取巧,下标比nums长度小,nums[p]元素要比targat小 - - 时间复杂度O(n) - -```CPP -class Solution { -public: - int searchInsert(vector
输入: [1,3,5,6], 7 +输出: 4 ++
示例 4:
-# [题目](这里是题目链接,如:https://leetcode-cn.com/problems/shu-zu-zhong-zhong-fu-de-shu-zi-lcof/) +输入: [1,3,5,6], 0 +输出: 0 +-## 题目描述 - ## 解法 diff --git a/solution/0000-0099/0036.Valid Sudoku/README.md b/solution/0000-0099/0036.Valid Sudoku/README.md index d9b3840c082d2..7e14c4dc339bc 100644 --- a/solution/0000-0099/0036.Valid Sudoku/README.md +++ b/solution/0000-0099/0036.Valid Sudoku/README.md @@ -1,7 +1,65 @@ -# [题目](这里是题目链接,如:https://leetcode-cn.com/problems/shu-zu-zhong-zhong-fu-de-shu-zi-lcof/) +# [36. 有效的数独](https://leetcode-cn.com/problems/valid-sudoku) ## 题目描述 +
判断一个 9x9 的数独是否有效。只需要根据以下规则,验证已经填入的数字是否有效即可。
+ +-
+
- 数字
1-9在每一行只能出现一次。
+ - 数字
1-9在每一列只能出现一次。
+ - 数字
1-9在每一个以粗实线分隔的3x3宫内只能出现一次。
+

上图是一个部分填充的有效的数独。
+ +数独部分空格内已填入了数字,空白格用 '.' 表示。
示例 1:
+ +输入: +[ + ["5","3",".",".","7",".",".",".","."], + ["6",".",".","1","9","5",".",".","."], + [".","9","8",".",".",".",".","6","."], + ["8",".",".",".","6",".",".",".","3"], + ["4",".",".","8",".","3",".",".","1"], + ["7",".",".",".","2",".",".",".","6"], + [".","6",".",".",".",".","2","8","."], + [".",".",".","4","1","9",".",".","5"], + [".",".",".",".","8",".",".","7","9"] +] +输出: true ++ +
示例 2:
+ +输入: +[ + ["8","3",".",".","7",".",".",".","."], + ["6",".",".","1","9","5",".",".","."], + [".","9","8",".",".",".",".","6","."], + ["8",".",".",".","6",".",".",".","3"], + ["4",".",".","8",".","3",".",".","1"], + ["7",".",".",".","2",".",".",".","6"], + [".","6",".",".",".",".","2","8","."], + [".",".",".","4","1","9",".",".","5"], + [".",".",".",".","8",".",".","7","9"] +] +输出: false +解释: 除了第一行的第一个数字从 5 改为 8 以外,空格内其他数字均与 示例1 相同。 + 但由于位于左上角的 3x3 宫内有两个 8 存在, 因此这个数独是无效的。+ +
说明:
+ +-
+
- 一个有效的数独(部分已被填充)不一定是可解的。 +
- 只需要根据以上规则,验证已经填入的数字是否有效即可。 +
- 给定数独序列只包含数字
1-9和字符'.'。
+ - 给定数独永远是
9x9形式的。
+
编写一个程序,通过已填充的空格来解决数独问题。
+ +一个数独的解法需遵循如下规则:
+ +-
+
- 数字
1-9在每一行只能出现一次。
+ - 数字
1-9在每一列只能出现一次。
+ - 数字
1-9在每一个以粗实线分隔的3x3宫内只能出现一次。
+
空白格用 '.' 表示。

一个数独。
+ +
答案被标成红色。
+ +Note:
+ +-
+
- 给定的数独序列只包含数字
1-9和字符'.'。
+ - 你可以假设给定的数独只有唯一解。 +
- 给定数独永远是
9x9形式的。
+
「外观数列」是一个整数序列,从数字 1 开始,序列中的每一项都是对前一项的描述。前五项如下:
+ +1. 1 2. 11 3. 21 4. 1211 5. 111221 -``` +-`1` 被读作 `"one 1"` (`"一个一"`) , 即 `11`。 -`11` 被读作 `"two 1s"` (`"两个一"`), 即 `21`。 -`21` 被读作 `"one 2"`, `"one 1"` (`"一个二"` , `"一个一"`) , 即 `1211`。 +
1 被读作 "one 1" ("一个一") , 即 11。
+11 被读作 "two 1s" ("两个一"), 即 21。
+21 被读作 "one 2", "one 1" ("一个二" , "一个一") , 即 1211。
给定一个正整数 n(1 ≤ n ≤ 30),输出外观数列的第 n 项。
-注意:整数顺序将表示为一个字符串。 +注意:整数序列中的每一项将表示为一个字符串。
- +-示例 1: -``` -输入: 1 -输出: "1" -``` +
示例 1:
-示例 2: -``` -输入: 4 -输出: "1211" -``` +输入: 1 +输出: "1" +解释:这是一个基本样例。-# [题目](这里是题目链接,如:https://leetcode-cn.com/problems/shu-zu-zhong-zhong-fu-de-shu-zi-lcof/) +
示例 2:
+ +输入: 4 +输出: "1211" +解释:当 n = 3 时,序列是 "21",其中我们有 "2" 和 "1" 两组,"2" 可以读作 "12",也就是出现频次 = 1 而 值 = 2;类似 "1" 可以读作 "11"。所以答案是 "12" 和 "11" 组合在一起,也就是 "1211"。-## 题目描述 - ## 解法 diff --git a/solution/0000-0099/0039.Combination Sum/README.md b/solution/0000-0099/0039.Combination Sum/README.md index 5a9b2fa4ed4af..8028944c19390 100644 --- a/solution/0000-0099/0039.Combination Sum/README.md +++ b/solution/0000-0099/0039.Combination Sum/README.md @@ -1,76 +1,38 @@ -## 组合总和 +# [39. 组合总和](https://leetcode-cn.com/problems/combination-sum) -### 问题描述 +## 题目描述 + +
给定一个无重复元素的数组 candidates 和一个目标数 target ,找出 candidates 中所有可以使数字和为 target 的组合。
candidates 中的数字可以无限制重复被选取。
说明:
-说明: -所有数字(包括 target)都是正整数。 -解集不能包含重复的组合。 -``` -示例 1: -输入: candidates = [2,3,6,7], target = 7, -所求解集为: +-
+
- 所有数字(包括
target)都是正整数。
+ - 解集不能包含重复的组合。 +
示例 1:
+ +输入: candidates =+[2,3,6,7],target =7, +所求解集为: [ [7], [2,2,3] ] +
示例 2:
-示例 2: -输入: candidates = [2,3,5], target = 8, -所求解集为: +输入: candidates = [2,3,5], target = 8,
+所求解集为:
[
- [2,2,2,2],
- [2,3,3],
- [3,5]
-]
-```
-### 思路
-
-这种题肯定是用回溯递归的,和46题全排列那道题很像
+ [2,2,2,2],
+ [2,3,3],
+ [3,5]
+]
-[1,2,3,4]构建成回溯树如下状态,一次循环开始进入一个数,一次循环后pop出来一个数,形成一种对称性回溯
-```
- 1
- / | \
- 12 13 14
- / |
-123 124 .....
-```
-### CPP
-```CPP
-class Solution {
-public:
- vector给定一个数组 candidates 和一个目标数 target ,找出 candidates 中所有可以使数字和为 target 的组合。
candidates 中的每个数字在每个组合中只能使用一次。
说明:
-说明: +-
+
- 所有数字(包括目标数)都是正整数。 +
- 解集不能包含重复的组合。 +
示例 1:
-``` -示例 1: -输入: candidates = [10,1,2,7,6,1,5], target = 8, -所求解集为: +输入: candidates =-示例 2: -输入: candidates = [2,5,2,1,2], target = 5, -所求解集为: -[ - [1,2,2], - [5] -] -``` +[10,1,2,7,6,1,5], target =8, +所求解集为: [ [1, 7], [1, 2, 5], [2, 6], [1, 1, 6] ] +
示例 2:
-### 思路 - -和39题一模一样,注意他有重复数,需要去除重复的结果. - -还要注意回溯是往后回溯,不是原地回溯了 - -```CPP -class Solution { -public: - vector输入: candidates = [2,5,2,1,2], target = 5, +所求解集为: +[ + [1,2,2], + [5] +]-## 题目描述 - ## 解法 diff --git a/solution/0000-0099/0041.First Missing Positive/README.md b/solution/0000-0099/0041.First Missing Positive/README.md index 4b9ba5b1e3ae9..69165f47e5d5d 100644 --- a/solution/0000-0099/0041.First Missing Positive/README.md +++ b/solution/0000-0099/0041.First Missing Positive/README.md @@ -1,60 +1,31 @@ -## 缺失的第一个正数 +# [41. 缺失的第一个正数](https://leetcode-cn.com/problems/first-missing-positive) -### 问题描述 +## 题目描述 + +
给定一个未排序的整数数组,找出其中没有出现的最小的正整数。
-给定一个未排序的整数数组,找出其中没有出现的最小的正整数。 +示例 1:
-``` -示例 1: -输入: [1,2,0] +输入: [1,2,0] 输出: 3 +-示例 2: -输入: [3,4,-1,1] +
示例 2:
+ +输入: [3,4,-1,1] 输出: 2 ++ +
示例 3:
-示例 3: -输入: [7,8,9,11,12] +输入: [7,8,9,11,12]
输出: 1
-```
-说明:
-你的算法的时间复杂度应为O(n),并且只能使用常数级别的空间。
-
-### 思路
-
-题目的描述一看有点不好理解,其实是把它们排序后,[-1,1,2,4,4,5,6]这里面缺的第一个正整数是3,0不算正整数
-
-1. 对数组排序
-2. 过滤小于等于0的部分
-3. 从1开始比较,注意过滤重复的元素
-
-```CPP
-class Solution {
-public:
- int firstMissingPositive(vector& nums) {
- sort(nums.begin(),nums.end());
- int len = nums.size();
- if(len == 0)return 1;
- int i = 0;
- while(nums[i] <= 0 && i < len)i++;
- if(i == len)return 1;
-
- int tmp = 1;
- while(ii+1 && nums[i] == nums[i+1])i++;//去重
- i++;
- tmp++;
- }
- return tmp;
- }
-};
-```
+
-# [题目](这里是题目链接,如:https://leetcode-cn.com/problems/shu-zu-zhong-zhong-fu-de-shu-zi-lcof/)
+说明:
+ +你的算法的时间复杂度应为O(n),并且只能使用常数级别的空间。
-## 题目描述 - ## 解法 diff --git a/solution/0000-0099/0042.Trapping Rain Water/README.md b/solution/0000-0099/0042.Trapping Rain Water/README.md index ccf24c982f4f7..cbee2897dfd0e 100644 --- a/solution/0000-0099/0042.Trapping Rain Water/README.md +++ b/solution/0000-0099/0042.Trapping Rain Water/README.md @@ -1,70 +1,18 @@ -## 接雨水 -### 问题描述 +# [42. 接雨水](https://leetcode-cn.com/problems/trapping-rain-water) -给定 n 个非负整数表示每个宽度为 1 的柱子的高度图,计算按此排列的柱子,下雨之后能接多少雨水。 - - +## 题目描述 + +给定 n 个非负整数表示每个宽度为 1 的柱子的高度图,计算按此排列的柱子,下雨之后能接多少雨水。
-上面是由数组`[0,1,0,2,1,0,1,3,2,1,2,1]` 表示的高度图,在这种情况下,可以接 6 个单位的雨水(蓝色部分表示雨水)。 感谢 Marcos 贡献此图。 +
上面是由数组 [0,1,0,2,1,0,1,3,2,1,2,1] 表示的高度图,在这种情况下,可以接 6 个单位的雨水(蓝色部分表示雨水)。 感谢 Marcos 贡献此图。
-### 思路 - -方法是找凹槽,怎么找呢? - -1. 设置`slow,fast`两个下标代表凹槽的左右边界,一旦遇到`height[fast]>=height[slow]`的情况,计算凹槽的容积 -2. 上面情况是以右边界高度一定大于左边界为准的,当形成凹槽且左边界大于右边界时,要怎么记录呢?答案是设置`stopPoint`点,规则是当`height[fast]>height[stopPoint]`时有`stopPoint = fast`记录右边最高点;同时当fast越界时,会到`stopPoint`上 - -```CPP -class Solution { -public: - int trap(vector输入: [0,1,0,2,1,0,1,3,2,1,2,1] +输出: 6-## 题目描述 - ## 解法 diff --git a/solution/0000-0099/0043.Multiply Strings/README.md b/solution/0000-0099/0043.Multiply Strings/README.md index d9b3840c082d2..60e431ffbb523 100644 --- a/solution/0000-0099/0043.Multiply Strings/README.md +++ b/solution/0000-0099/0043.Multiply Strings/README.md @@ -1,7 +1,28 @@ -# [题目](这里是题目链接,如:https://leetcode-cn.com/problems/shu-zu-zhong-zhong-fu-de-shu-zi-lcof/) +# [43. 字符串相乘](https://leetcode-cn.com/problems/multiply-strings) ## 题目描述 +
给定两个以字符串形式表示的非负整数 num1 和 num2,返回 num1 和 num2 的乘积,它们的乘积也表示为字符串形式。
示例 1:
+ +输入: num1 = "2", num2 = "3" +输出: "6"+ +
示例 2:
+ +输入: num1 = "123", num2 = "456" +输出: "56088"+ +
说明:
+ +-
+
num1和num2的长度小于110。
+ num1和num2只包含数字0-9。
+ num1和num2均不以零开头,除非是数字 0 本身。
+ - 不能使用任何标准库的大数类型(比如 BigInteger)或直接将输入转换为整数来处理。 +
给定一个字符串 (s) 和一个字符模式 (p) ,实现一个支持 '?' 和 '*' 的通配符匹配。
'?' 可以匹配任何单个字符。 +'*' 可以匹配任意字符串(包括空字符串)。 ++ +
两个字符串完全匹配才算匹配成功。
+ +说明:
+ +-
+
s可能为空,且只包含从a-z的小写字母。
+ p可能为空,且只包含从a-z的小写字母,以及字符?和*。
+
示例 1:
+ +输入: +s = "aa" +p = "a" +输出: false +解释: "a" 无法匹配 "aa" 整个字符串。+ +
示例 2:
+ +输入: +s = "aa" +p = "*" +输出: true +解释: '*' 可以匹配任意字符串。 ++ +
示例 3:
+ +输入: +s = "cb" +p = "?a" +输出: false +解释: '?' 可以匹配 'c', 但第二个 'a' 无法匹配 'b'。 ++ +
示例 4:
+ +输入: +s = "adceb" +p = "*a*b" +输出: true +解释: 第一个 '*' 可以匹配空字符串, 第二个 '*' 可以匹配字符串 "dce". ++ +
示例 5:
+ +输入: +s = "acdcb" +p = "a*c?b" +输入: false+ ## 解法 diff --git a/solution/0000-0099/0045.Jump Game II/README.md b/solution/0000-0099/0045.Jump Game II/README.md index d9b3840c082d2..0feec8f73181e 100644 --- a/solution/0000-0099/0045.Jump Game II/README.md +++ b/solution/0000-0099/0045.Jump Game II/README.md @@ -1,7 +1,25 @@ -# [题目](这里是题目链接,如:https://leetcode-cn.com/problems/shu-zu-zhong-zhong-fu-de-shu-zi-lcof/) +# [45. 跳跃游戏 II](https://leetcode-cn.com/problems/jump-game-ii) ## 题目描述 +
给定一个非负整数数组,你最初位于数组的第一个位置。
+ +数组中的每个元素代表你在该位置可以跳跃的最大长度。
+ +你的目标是使用最少的跳跃次数到达数组的最后一个位置。
+ +示例:
+ +输入: [2,3,1,1,4] +输出: 2 +解释: 跳到最后一个位置的最小跳跃数是+ +2。 + 从下标为 0 跳到下标为 1 的位置,跳1步,然后跳3步到达数组的最后一个位置。 +
说明:
+ +假设你总是可以到达数组的最后一个位置。
+ ## 解法 diff --git a/solution/0000-0099/0046.Permutations/README.md b/solution/0000-0099/0046.Permutations/README.md index 6ee0a81e50a0a..c598a3059263b 100644 --- a/solution/0000-0099/0046.Permutations/README.md +++ b/solution/0000-0099/0046.Permutations/README.md @@ -1,12 +1,13 @@ -## 全排列 -### 题目描述 +# [46. 全排列](https://leetcode-cn.com/problems/permutations) -给定一个没有重复数字的序列,返回其所有可能的全排列。 +## 题目描述 + +给定一个没有重复数字的序列,返回其所有可能的全排列。
-示例: -``` -输入: [1,2,3] -输出: +示例:
+ +输入: [1,2,3] +输出: [ [1,2,3], [1,3,2], @@ -14,48 +15,8 @@ [2,3,1], [3,1,2], [3,2,1] -] -``` - -### 解法 -将数组的首元素依次与数组的每个元素交换,对于每一轮交换,对后面的数组进行递归调用。当元素只剩下一个时,添加此时的数组到 list 中。 +]-```java -class Solution { - public List
给定一个可包含重复数字的序列,返回所有不重复的全排列。
-示例: -``` -输入: [1,1,2] -输出: +示例:
+ +输入: [1,1,2]
+输出:
[
[1,1,2],
[1,2,1],
[2,1,1]
-]
-```
-
-### 解法
-
-解法①:
-
-将数组的首元素依次与数组的每个元素交换(两元素不相等才进行交换),对于每一轮交换,对后面的数组进行递归调用。当元素只剩下一个时,添加此时的数组到 list 中。
-
-注意:第 i 个数字与第 j 个数字交换时,要求[i, j) 中没有与第 j 个数字相等的数。
-
-```java
-class Solution {
- public List> permuteUnique(int[] nums) {
- List> list = new ArrayList<>();
- permute(list, nums, 0);
- return list;
- }
-
- private void permute(List> list, int[] nums, int start) {
- int end = nums.length - 1;
- if (start == end) {
- List tmp = new ArrayList<>();
- for (int val : nums) {
- tmp.add(val);
- }
-
- list.add(tmp);
-
- }
-
- for (int i = start; i <= end; ++i) {
- if (isSwap(nums, start, i)) {
- swap(nums, i, start);
- permute(list, nums, start + 1);
- swap(nums, i, start);
- }
-
- }
-
- }
-
- private boolean isSwap(int[] nums, int from, int to) {
- for (int i = from; i < to; ++i) {
- if (nums[i] == nums[to]) {
- // [from, to) 中出现与 第 to 个数相等的数,返回 false,不进行交换和全排列操作
- return false;
- }
- }
- return true;
- }
-
- private void swap(int[] nums, int i, int j) {
- int t = nums[i];
- nums[i] = nums[j];
- nums[j] = t;
- }
-}
-```
-
-解法②:
-
-利用空间换取时间,减少 n^2 复杂度。这里的空间,可以采用数组,或者 HashMap。
+]
-```java
-class Solution {
- public List给定一个 n × n 的二维矩阵表示一个图像。
-将图像顺时针旋转 90 度。 +将图像顺时针旋转 90 度。
-说明: +说明:
-你必须在原地旋转图像,这意味着你需要直接修改输入的二维矩阵。请不要使用另一个矩阵来旋转图像。 -``` -示例 1: -给定 matrix = +你必须在原地旋转图像,这意味着你需要直接修改输入的二维矩阵。请不要使用另一个矩阵来旋转图像。
+ +示例 1:
+ +给定 matrix = [ [1,2,3], [4,5,6], [7,8,9] ], -原地旋转输入矩阵,使其变为: +原地旋转输入矩阵,使其变为: [ [7,4,1], [8,5,2], [9,6,3] ] +-示例 2: -给定 matrix = +
示例 2:
+ +给定 matrix = [ [ 5, 1, 9,11], [ 2, 4, 8,10], @@ -33,65 +37,15 @@ [15,14,12,16] ], -原地旋转输入矩阵,使其变为: +原地旋转输入矩阵,使其变为: [ [15,13, 2, 5], [14, 3, 4, 1], [12, 6, 8, 9], [16, 7,10,11] ] -``` - -### 思路: - -本来以为是矩阵坐标表换的一种,用初等行变换做,但是这里和矩阵坐标没任何关系,而是整个矩阵旋转,所以老实找规律 - -``` -1 2 3 顺90° 7 4 1 -4 5 6 ========> 8 5 2 -7 8 9 9 6 3 - -等价于 - -1 2 3 转置 1 4 7 左右互换 7 4 1 -4 5 6 ========> 2 5 8 ===========> 8 5 2 -7 8 9 3 6 9 9 6 3 - -先当做是一种规律,数学证明以后补 -``` +-1. 先将矩阵转置 -2. 左右各列对称互换 - -```CPP -class Solution { -public: - void rotate(vector
给定一个字符串数组,将字母异位词组合在一起。字母异位词指字母相同,但排列不同的字符串。
+ +示例:
+ +输入: ["eat", "tea", "tan", "ate", "nat", "bat"],
+输出:
+[
+ ["ate","eat","tea"],
+ ["nat","tan"],
+ ["bat"]
+]
+
+说明:
+ +-
+
- 所有输入均为小写字母。 +
- 不考虑答案输出的顺序。 +
实现 pow(x, n) ,即计算 x 的 n 次幂函数。
+ +示例 1:
+ +输入: 2.00000, 10 +输出: 1024.00000 ++ +
示例 2:
+ +输入: 2.10000, 3 +输出: 9.26100 ++ +
示例 3:
+ +输入: 2.00000, -2 +输出: 0.25000 +解释: 2-2 = 1/22 = 1/4 = 0.25+ +
说明:
+ +-
+
- -100.0 < x < 100.0 +
- n 是 32 位有符号整数,其数值范围是 [−231, 231 − 1] 。 +
n 皇后问题研究的是如何将 n 个皇后放置在 n×n 的棋盘上,并且使皇后彼此之间不能相互攻击。
+ +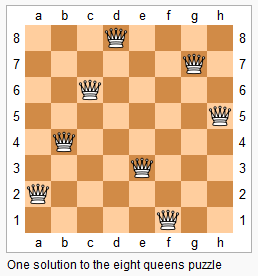
上图为 8 皇后问题的一种解法。
+ +给定一个整数 n,返回所有不同的 n 皇后问题的解决方案。
+ +每一种解法包含一个明确的 n 皇后问题的棋子放置方案,该方案中 'Q' 和 '.' 分别代表了皇后和空位。
示例:
+ +输入: 4 +输出: [ + [".Q..", // 解法 1 + "...Q", + "Q...", + "..Q."], + + ["..Q.", // 解法 2 + "Q...", + "...Q", + ".Q.."] +] +解释: 4 皇后问题存在两个不同的解法。 ++ ## 解法 diff --git a/solution/0000-0099/0052.N-Queens II/README.md b/solution/0000-0099/0052.N-Queens II/README.md index d9b3840c082d2..edcee49002f5b 100644 --- a/solution/0000-0099/0052.N-Queens II/README.md +++ b/solution/0000-0099/0052.N-Queens II/README.md @@ -1,7 +1,33 @@ -# [题目](这里是题目链接,如:https://leetcode-cn.com/problems/shu-zu-zhong-zhong-fu-de-shu-zi-lcof/) +# [52. N皇后 II](https://leetcode-cn.com/problems/n-queens-ii) ## 题目描述 +
n 皇后问题研究的是如何将 n 个皇后放置在 n×n 的棋盘上,并且使皇后彼此之间不能相互攻击。
+ +
上图为 8 皇后问题的一种解法。
+ +给定一个整数 n,返回 n 皇后不同的解决方案的数量。
+ +示例:
+ +输入: 4 +输出: 2 +解释: 4 皇后问题存在如下两个不同的解法。 +[ + [".Q..", // 解法 1 + "...Q", + "Q...", + "..Q."], + + ["..Q.", // 解法 2 + "Q...", + "...Q", + ".Q.."] +] ++ ## 解法 diff --git a/solution/0000-0099/0053.Maximum Subarray/README.md b/solution/0000-0099/0053.Maximum Subarray/README.md index 2bc3b8788c3a8..5a4718e792e2f 100644 --- a/solution/0000-0099/0053.Maximum Subarray/README.md +++ b/solution/0000-0099/0053.Maximum Subarray/README.md @@ -1,88 +1,20 @@ -## 最大子序和 -### 题目描述 +# [53. 最大子序和](https://leetcode-cn.com/problems/maximum-subarray) -给定一个整数数组 nums ,找到一个具有最大和的连续子数组(子数组最少包含一个元素),返回其最大和。 - -示例: -``` -输入: [-2,1,-3,4,-1,2,1,-5,4], -输出: 6 -解释: 连续子数组 [4,-1,2,1] 的和最大,为 6。 -``` - -进阶: - -如果你已经实现复杂度为 O(n) 的解法,尝试使用更为精妙的分治法求解。 - -### 解法 -此题可以用动态规划法,开辟一个数组res,res[i] 表示以当前结点nums[i] 结尾的最大连续子数组的和。最后计算 res 的最大元素即可。 -也可以用分治法,最大连续子数组有三种情况:在原数组左侧、右侧、跨中间结点,返回这三者的最大值即可。 - - -动态规划法: +## 题目描述 + +
给定一个整数数组 nums ,找到一个具有最大和的连续子数组(子数组最少包含一个元素),返回其最大和。
示例:
-分治法: +输入: [-2,1,-3,4,-1,2,1,-5,4], +输出: 6 +解释: 连续子数组 [4,-1,2,1] 的和最大,为 6。 +-```java -class Solution { - public int maxSubArray(int[] nums) { - return maxSubArray(nums, 0, nums.length - 1); - } - - private int maxSubArray(int[] nums, int start, int end) { - if (start == end) { - return nums[start]; - } - int mid = start + ((end - start) >> 1); - int left = maxSubArray(nums, start, mid); - int right = maxSubArray(nums, mid + 1, end); - - int leftSum = 0; - int leftMax = Integer.MIN_VALUE; - for (int i = mid; i >= start; --i) { - leftSum += nums[i]; - leftMax = Math.max(leftSum, leftMax); - } - - int rightSum = 0; - int rightMax = Integer.MIN_VALUE; - for (int i = mid + 1; i <= end; ++i) { - rightSum += nums[i]; - rightMax = Math.max(rightSum, rightMax); - } - - return Math.max(Math.max(left, right), leftMax + rightMax); - - - } -} -``` +
进阶:
-# [题目](这里是题目链接,如:https://leetcode-cn.com/problems/shu-zu-zhong-zhong-fu-de-shu-zi-lcof/) +如果你已经实现复杂度为 O(n) 的解法,尝试使用更为精妙的分治法求解。
-## 题目描述 - ## 解法 diff --git a/solution/0000-0099/0054.Spiral Matrix/README.md b/solution/0000-0099/0054.Spiral Matrix/README.md index ede43dd9ba9a8..d6b8be2c483a1 100644 --- a/solution/0000-0099/0054.Spiral Matrix/README.md +++ b/solution/0000-0099/0054.Spiral Matrix/README.md @@ -1,90 +1,31 @@ -## 螺旋矩阵 -### 题目描述 +# [54. 螺旋矩阵](https://leetcode-cn.com/problems/spiral-matrix) -给定一个包含 m x n 个元素的矩阵(m 行, n 列),请按照顺时针螺旋顺序,返回矩阵中的所有元素。 +## 题目描述 + +给定一个包含 m x n 个元素的矩阵(m 行, n 列),请按照顺时针螺旋顺序,返回矩阵中的所有元素。
-**示例 1:** -``` -输入: +示例 1:
+ +输入: [ [ 1, 2, 3 ], [ 4, 5, 6 ], [ 7, 8, 9 ] ] -输出: [1,2,3,6,9,8,7,4,5] -``` +输出: [1,2,3,6,9,8,7,4,5] +-**示例 2:** -``` -输入: +
示例 2:
+ +输入: [ [1, 2, 3, 4], [5, 6, 7, 8], [9,10,11,12] ] -输出: [1,2,3,4,8,12,11,10,9,5,6,7] -``` +输出: [1,2,3,4,8,12,11,10,9,5,6,7] +-### 解法 -由外往里,一圈圈遍历矩阵即可。遍历时,如果只有 1 行或者 1 列。直接遍历添加这一行/列元素。否则遍历一圈,陆续添加元素。 - - -```java -class Solution { - public List
给定一个非负整数数组,你最初位于数组的第一个位置。
+ +数组中的每个元素代表你在该位置可以跳跃的最大长度。
+ +判断你是否能够到达最后一个位置。
+ +示例 1:
+ +输入: [2,3,1,1,4] +输出: true +解释: 我们可以先跳 1 步,从位置 0 到达 位置 1, 然后再从位置 1 跳 3 步到达最后一个位置。 ++ +
示例 2:
+ +输入: [3,2,1,0,4] +输出: false +解释: 无论怎样,你总会到达索引为 3 的位置。但该位置的最大跳跃长度是 0 , 所以你永远不可能到达最后一个位置。 ++ ## 解法 diff --git a/solution/0000-0099/0056.Merge Intervals/README.md b/solution/0000-0099/0056.Merge Intervals/README.md index 3164e7026037b..825907f29a57d 100644 --- a/solution/0000-0099/0056.Merge Intervals/README.md +++ b/solution/0000-0099/0056.Merge Intervals/README.md @@ -1,69 +1,22 @@ -给出一个区间的集合,请合并所有重叠的区间。 -``` -示例 1: -输入: [[1,3],[2,6],[8,10],[15,18]] -输出: [[1,6],[8,10],[15,18]] -解释: 区间 [1,3] 和 [2,6] 重叠, 将它们合并为 [1,6]. - -示例 2: -输入: [[1,4],[4,5]] -输出: [[1,5]] -解释: 区间 [1,4] 和 [4,5] 可被视为重叠区间。 -``` - -------------------- -思路: - -1. 对容器按start值从小到大排序 -2. 两两顺序比较,用第一个元素的end值和第二个元素的start值比较 -3. 如果后start比前end小,且前end比后end小,则合并! -4. 不满足3,则直接插入 - -时间复杂度O(n) - -```CPP -/** - * Definition for an interval. - * struct Interval { - * int start; - * int end; - * Interval() : start(0), end(0) {} - * Interval(int s, int e) : start(s), end(e) {} - * }; - */ -bool cmp(Interval &val1,Interval &val2){ - return !(val1.start >= val2.start); -} - -class Solution { -public: - vector
给出一个区间的集合,请合并所有重叠的区间。
+ +示例 1:
+ +输入: [[1,3],[2,6],[8,10],[15,18]] +输出: [[1,6],[8,10],[15,18]] +解释: 区间 [1,3] 和 [2,6] 重叠, 将它们合并为 [1,6]. ++ +
示例 2:
+ +输入: [[1,4],[4,5]] +输出: [[1,5]] +解释: 区间 [1,4] 和 [4,5] 可被视为重叠区间。+ ## 解法 diff --git a/solution/0000-0099/0057.Insert Interval/README.md b/solution/0000-0099/0057.Insert Interval/README.md index d9b3840c082d2..b8794de30ee46 100644 --- a/solution/0000-0099/0057.Insert Interval/README.md +++ b/solution/0000-0099/0057.Insert Interval/README.md @@ -1,7 +1,24 @@ -# [题目](这里是题目链接,如:https://leetcode-cn.com/problems/shu-zu-zhong-zhong-fu-de-shu-zi-lcof/) +# [57. 插入区间](https://leetcode-cn.com/problems/insert-interval) ## 题目描述 +
给出一个无重叠的 ,按照区间起始端点排序的区间列表。
+ +在列表中插入一个新的区间,你需要确保列表中的区间仍然有序且不重叠(如果有必要的话,可以合并区间)。
+ +示例 1:
+ +输入: intervals = [[1,3],[6,9]], newInterval = [2,5] +输出: [[1,5],[6,9]] ++ +
示例 2:
+ +输入: intervals =+ ## 解法 diff --git a/solution/0000-0099/0058.Length of Last Word/README.md b/solution/0000-0099/0058.Length of Last Word/README.md index 2884709b3bbcf..6022b37f25eae 100644 --- a/solution/0000-0099/0058.Length of Last Word/README.md +++ b/solution/0000-0099/0058.Length of Last Word/README.md @@ -1,26 +1,21 @@ -## 最后一个单词的长度 -### 题目描述 +# [58. 最后一个单词的长度](https://leetcode-cn.com/problems/length-of-last-word) -给定一个仅包含大小写字母和空格 `' '` 的字符串,返回其最后一个单词的长度。 - -如果不存在最后一个单词,请返回 `0` 。 - -说明:一个单词是指由字母组成,但不包含任何空格的字符串。 +## 题目描述 + +[[1,2],[3,5],[6,7],[8,10],[12,16]], newInterval =[4,8]+输出: [[1,2],[3,10],[12,16]] +解释: 这是因为新的区间[4,8]与[3,5],[6,7],[8,10]重叠。 +
给定一个仅包含大小写字母和空格 ' ' 的字符串 s,返回其最后一个单词的长度。如果字符串从左向右滚动显示,那么最后一个单词就是最后出现的单词。
如果不存在最后一个单词,请返回 0 。
- +说明:一个单词是指仅由字母组成、不包含任何空格字符的 最大子字符串。
-``` -输入: "Hello World" -输出: 5 -``` ++
示例:
-# [题目](这里是题目链接,如:https://leetcode-cn.com/problems/shu-zu-zhong-zhong-fu-de-shu-zi-lcof/) +输入: "Hello World" +输出: 5 +-## 题目描述 - ## 解法 diff --git a/solution/0000-0099/0059.Spiral Matrix II/README.md b/solution/0000-0099/0059.Spiral Matrix II/README.md index c920f7ff74c82..934d8d8400688 100644 --- a/solution/0000-0099/0059.Spiral Matrix II/README.md +++ b/solution/0000-0099/0059.Spiral Matrix II/README.md @@ -1,64 +1,19 @@ -## 螺旋矩阵 II -### 题目描述 +# [59. 螺旋矩阵 II](https://leetcode-cn.com/problems/spiral-matrix-ii) -给定一个正整数 n,生成一个包含 1 到 n² 所有元素,且元素按顺时针顺序螺旋排列的正方形矩阵。 +## 题目描述 + +
给定一个正整数 n,生成一个包含 1 到 n2 所有元素,且元素按顺时针顺序螺旋排列的正方形矩阵。
-**示例:** -``` -输入: 3 -输出: +示例:
+ +输入: 3 +输出: [ [ 1, 2, 3 ], [ 8, 9, 4 ], [ 7, 6, 5 ] -] -``` - -### 解法 -定义一个变量 `val`,由外往里,一圈圈遍历矩阵,进行赋值,每次赋值后 `val++`。 - +]-```java -class Solution { - public int[][] generateMatrix(int n) { - if (n < 1) { - return null; - } - - int[][] res = new int[n][n]; - int val = 1; - - int m1 = 0; - int m2 = n - 1; - while (m1 < m2) { - for (int j = m1; j < m2; ++j) { - res[m1][j] = val++; - } - for (int i = m1; i < m2; ++i) { - res[i][m2] = val++; - } - for (int j = m2; j > m1; --j) { - res[m2][j] = val++; - } - for (int i = m2; i > m1; --i) { - res[i][m1] = val++; - } - ++m1; - --m2; - } - if (m1 == m2) { - res[m1][m1] = val; - } - - return res; - } -} -``` - -# [题目](这里是题目链接,如:https://leetcode-cn.com/problems/shu-zu-zhong-zhong-fu-de-shu-zi-lcof/) - -## 题目描述 - ## 解法 diff --git a/solution/0000-0099/0060.Permutation Sequence/README.md b/solution/0000-0099/0060.Permutation Sequence/README.md index d9b3840c082d2..133936584d4f0 100644 --- a/solution/0000-0099/0060.Permutation Sequence/README.md +++ b/solution/0000-0099/0060.Permutation Sequence/README.md @@ -1,7 +1,41 @@ -# [题目](这里是题目链接,如:https://leetcode-cn.com/problems/shu-zu-zhong-zhong-fu-de-shu-zi-lcof/) +# [60. 第k个排列](https://leetcode-cn.com/problems/permutation-sequence) ## 题目描述 +
给出集合 [1,2,3,…,n],其所有元素共有 n! 种排列。
按大小顺序列出所有排列情况,并一一标记,当 n = 3 时, 所有排列如下:
+ +-
+
"123"
+ "132"
+ "213"
+ "231"
+ "312"
+ "321"
+
给定 n 和 k,返回第 k 个排列。
+ +说明:
+ +-
+
- 给定 n 的范围是 [1, 9]。 +
- 给定 k 的范围是[1, n!]。 +
示例 1:
+ +输入: n = 3, k = 3 +输出: "213" ++ +
示例 2:
+ +输入: n = 4, k = 9 +输出: "2314" ++ ## 解法 diff --git a/solution/0000-0099/0061.Rotate List/README.md b/solution/0000-0099/0061.Rotate List/README.md index 3d1ca098e7995..908221c7e9d32 100644 --- a/solution/0000-0099/0061.Rotate List/README.md +++ b/solution/0000-0099/0061.Rotate List/README.md @@ -1,80 +1,28 @@ -## 旋转链表 -### 题目描述 +# [61. 旋转链表](https://leetcode-cn.com/problems/rotate-list) -给定一个链表,旋转链表,将链表每个节点向右移动 k 个位置,其中 k 是非负数。 +## 题目描述 + +
给定一个链表,旋转链表,将链表每个节点向右移动 k 个位置,其中 k 是非负数。
-**示例 1:** -``` -输入: 1->2->3->4->5->NULL, k = 2 -输出: 4->5->1->2->3->NULL -解释: -向右旋转 1 步: 5->1->2->3->4->NULL -向右旋转 2 步: 4->5->1->2->3->NULL -``` +示例 1:
-**示例 2:** -``` -输入: 0->1->2->NULL, k = 4 -输出: 2->0->1->NULL -解释: -向右旋转 1 步: 2->0->1->NULL -向右旋转 2 步: 1->2->0->NULL -向右旋转 3 步: 0->1->2->NULL -向右旋转 4 步: 2->0->1->NULL -``` +输入: 1->2->3->4->5->NULL, k = 2 +输出: 4->5->1->2->3->NULL +解释: +向右旋转 1 步: 5->1->2->3->4->NULL +向右旋转 2 步: 4->5->1->2->3->NULL +-### 解法 -利用双指针`p`,`q`分别指向链表的头部和尾部,题目是右移 k 个位置,右移时,`q`需要指向`q`的前一个位置,似乎不太好做。换种思路,改用左移,右移 k 位相当于左移 len-k 位。循环移位即可。 +
示例 2:
-```java -/** - * Definition for singly-linked list. - * public class ListNode { - * int val; - * ListNode next; - * ListNode(int x) { val = x; } - * } - */ -class Solution { - public ListNode rotateRight(ListNode head, int k) { - if (head == null) { - return head; - } - int len = 1; - ListNode p = head; - ListNode q = head; - ListNode t = p.next; - - while (q.next != null) { - ++len; - q = q.next; - } - if (len == 1 || k % len == 0) { - return head; - } - - k %= len; - - // 右移 k 个位置,相当于左移 (len-k) 个位置 - k = len - k; - - for (int i = 0; i < k; ++i) { - q.next = p; - p.next = null; - q = q.next; - p = t; - t = p.next; - } - - return p; - } -} -``` - -# [题目](这里是题目链接,如:https://leetcode-cn.com/problems/shu-zu-zhong-zhong-fu-de-shu-zi-lcof/) +输入: 0->1->2->NULL, k = 4 +输出:-## 题目描述 - ## 解法 diff --git a/solution/0000-0099/0062.Unique Paths/README.md b/solution/0000-0099/0062.Unique Paths/README.md index da0f6288952d2..3f20d9d357c39 100644 --- a/solution/0000-0099/0062.Unique Paths/README.md +++ b/solution/0000-0099/0062.Unique Paths/README.md @@ -1,62 +1,44 @@ -## 不同路径 -### 题目描述 +# [62. 不同路径](https://leetcode-cn.com/problems/unique-paths) -一个机器人位于一个 m x n 网格的左上角 (起始点在下图中标记为“Start” )。 +## 题目描述 + +2->0->1->NULL+解释: +向右旋转 1 步: 2->0->1->NULL +向右旋转 2 步: 1->2->0->NULL +向右旋转 3 步:0->1->2->NULL+向右旋转 4 步:2->0->1->NULL
一个机器人位于一个 m x n 网格的左上角 (起始点在下图中标记为“Start” )。
-机器人每次只能向下或者向右移动一步。机器人试图达到网格的右下角(在下图中标记为“Finish”)。 +机器人每次只能向下或者向右移动一步。机器人试图达到网格的右下角(在下图中标记为“Finish”)。
-问总共有多少条不同的路径? +问总共有多少条不同的路径?
- +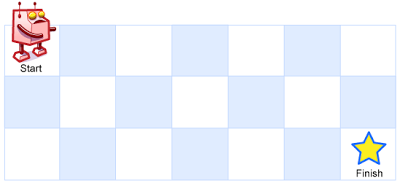
例如,上图是一个7 x 3 的网格。有多少可能的路径?
-说明:m 和 n 的值均不超过 100。 +-示例 1: -``` -输入: m = 3, n = 2 -输出: 3 -解释: +
示例 1:
+ +输入: m = 3, n = 2 +输出: 3 +解释: 从左上角开始,总共有 3 条路径可以到达右下角。 -1. 向右 -> 向右 -> 向下 -2. 向右 -> 向下 -> 向右 -3. 向下 -> 向右 -> 向右 -``` +1. 向右 -> 向右 -> 向下 +2. 向右 -> 向下 -> 向右 +3. 向下 -> 向右 -> 向右 +-示例 2: -``` -输入: m = 7, n = 3 -输出: 28 -``` +
示例 2:
-### 解法 -在网格中,最左侧和最上方每个格子均只有一条可能的路径能到达。而其它格子,是它“左方格子的路径数+上方格子的路径数之和”(递推式)。开辟一个二维数组存放中间结果。 +输入: m = 7, n = 3 +输出: 28-```java -class Solution { - public int uniquePaths(int m, int n) { - int[][] res = new int[n][m]; - for (int i = 0; i < m; ++i) { - res[0][i] = 1; - } - for (int i = 1; i < n; ++i) { - res[i][0] = 1; - } - for (int i = 1; i < n; ++i) { - for (int j = 1; j < m; ++j) { - res[i][j] = res[i - 1][j] + res[i][j - 1]; - } - } - return res[n - 1][m - 1]; - } -} -``` +
-# [题目](这里是题目链接,如:https://leetcode-cn.com/problems/shu-zu-zhong-zhong-fu-de-shu-zi-lcof/) +
提示:
+ +-
+
1 <= m, n <= 100
+ - 题目数据保证答案小于等于
2 * 10 ^ 9
+
一个机器人位于一个 m x n 网格的左上角 (起始点在下图中标记为“Start” )。
-机器人每次只能向下或者向右移动一步。机器人试图达到网格的右下角(在下图中标记为“Finish”)。 +机器人每次只能向下或者向右移动一步。机器人试图达到网格的右下角(在下图中标记为“Finish”)。
-现在考虑网格中有障碍物。那么从左上角到右下角将会有多少条不同的路径? +现在考虑网格中有障碍物。那么从左上角到右下角将会有多少条不同的路径?
- +
网格中的障碍物和空位置分别用 1 和 0 来表示。
说明:m 和 n 的值均不超过 100。
-示例 1: -``` -输入: -[ - [0,0,0], - [0,1,0], - [0,0,0] +示例 1:
+ +输入:
+[
+ [0,0,0],
+ [0,1,0],
+ [0,0,0]
]
-输出: 2
-解释:
+输出: 2
+解释:
3x3 网格的正中间有一个障碍物。
-从左上角到右下角一共有 2 条不同的路径:
-1. 向右 -> 向右 -> 向下 -> 向下
-2. 向下 -> 向下 -> 向右 -> 向右
-```
-
-### 解法
-与上题相比,这一题仅仅多了一个条件,就是网格中存在障碍物。对于最左侧和最上方,如果存在障碍物,那么往右或者往下的网格中路径均为 0。而其它格子,如果该格子有障碍物,那么路径为 0,否则是它“左方格子的路径数+上方格子的路径数之和”(递推式)。同样开辟一个二维数组存放中间结果。
+从左上角到右下角一共有 2 条不同的路径:
+1. 向右 -> 向右 -> 向下 -> 向下
+2. 向下 -> 向下 -> 向右 -> 向右
+
-```java
-class Solution {
- public int uniquePathsWithObstacles(int[][] obstacleGrid) {
- int n = obstacleGrid.length;
- int m = obstacleGrid[0].length;
- int[][] res = new int[n][m];
- int i = 0;
- while (i < n && obstacleGrid[i][0] == 0) {
- // 无障碍物
- res[i++][0] = 1;
- }
- while (i < n) {
- res[i++][0] = 0;
- }
-
- i = 0;
- while (i < m && obstacleGrid[0][i] == 0) {
- // 无障碍物
- res[0][i++] = 1;
- }
- while (i < m) {
- res[0][i++] = 0;
- }
-
- for (int k = 1; k < n; ++k) {
- for (int j = 1; j < m; ++j) {
- res[k][j] = obstacleGrid[k][j] == 1 ? 0 : (res[k - 1][j] + res[k][j - 1]);
- }
- }
-
- return res[n - 1][m - 1];
-
- }
-}
-```
-
-# [题目](这里是题目链接,如:https://leetcode-cn.com/problems/shu-zu-zhong-zhong-fu-de-shu-zi-lcof/)
-
-## 题目描述
-
## 解法
diff --git a/solution/0000-0099/0064.Minimum Path Sum/README.md b/solution/0000-0099/0064.Minimum Path Sum/README.md
index e5926d204ab65..2a734c28deb19 100644
--- a/solution/0000-0099/0064.Minimum Path Sum/README.md
+++ b/solution/0000-0099/0064.Minimum Path Sum/README.md
@@ -1,56 +1,23 @@
-给定一个包含非负整数的 m x n 网格,请找出一条从左上角到右下角的路径,使得路径上的数字总和为最小。
+# [64. 最小路径和](https://leetcode-cn.com/problems/minimum-path-sum)
-说明:每次只能向下或者向右移动一步。
+## 题目描述
+
+给定一个包含非负整数的 m x n 网格,请找出一条从左上角到右下角的路径,使得路径上的数字总和为最小。
-``` -示例: -输入: +说明:每次只能向下或者向右移动一步。
+ +示例:
+ +输入: [ - [1,3,1], + [1,3,1], [1,5,1], [4,2,1] ] -输出: 7 -解释: 因为路径 1→3→1→1→1 的总和最小。 -``` +输出: 7 +解释: 因为路径 1→3→1→1→1 的总和最小。 +--------------- -### 思路: - -和62题《不同路径》是同一个思路,都是动态规划,区别是这里是带权值的路径 - -1. 创建二维数组`path[row][column]`,`path[i][j] i∈[0,row-1],j∈[0,column-1]`表示到坐标`(i+1,j+1)`的**最短路径和** -2. 首行首列初始化;**首行**初始化是**上一行最短路径和+该位置权值**,对应公式`path[i][0] = path[i-1][0] + grid[i][0]; i∈[1,row-1],j∈[1,column-1]` 同理**首列**初始化g公式为`path[0][i] = path[0][i-1] + grid[0][i];` -3. 对各点`path[i][j]`求最短路径和,坐标`(i,j)`的最短路径可以由上一行得来,或者是前一列得来,动态规划方程为:`(前一列最小路径||前一行最小路径)两者较小值+当前坐标权值`,公式为:`path[i][j] = min(path[i-1][j],path[i][j]) + grid[i][j];` - -```CPP -class Solution { -public: - int minPathSum(vector
验证给定的字符串是否可以解释为十进制数字。
+ +例如:
+ +"0" => true
+" 0.1 " => true
+"abc" => false
+"1 a" => false
+"2e10" => true
+" -90e3 " => true
+" 1e" => false
+"e3" => false
+" 6e-1" => true
+" 99e2.5 " => false
+"53.5e93" => true
+" --6 " => false
+"-+3" => false
+"95a54e53" => false
说明: 我们有意将问题陈述地比较模糊。在实现代码之前,你应当事先思考所有可能的情况。这里给出一份可能存在于有效十进制数字中的字符列表:
+ +-
+
- 数字 0-9 +
- 指数 - "e" +
- 正/负号 - "+"/"-" +
- 小数点 - "." +
当然,在输入中,这些字符的上下文也很重要。
+ +更新于 2015-02-10:
+C++函数的形式已经更新了。如果你仍然看见你的函数接收 const char * 类型的参数,请点击重载按钮重置你的代码。
给定一个由整数组成的非空数组所表示的非负整数,在该数的基础上加一。
-最高位数字存放在数组的首位, 数组中每个元素只存储一个数字。 +最高位数字存放在数组的首位, 数组中每个元素只存储单个数字。
-你可以假设除了整数 0 之外,这个整数不会以零开头。 +你可以假设除了整数 0 之外,这个整数不会以零开头。
-``` -示例 1: -输入: [1,2,3] -输出: [1,2,4] -解释: 输入数组表示数字 123。 - -示例 2: -输入: [4,3,2,1] -输出: [4,3,2,2] -解释: 输入数组表示数字 4321。 -``` +示例 1:
-### 思路: -1. 末尾加1,注意超过10的情况,要取余进1 -2. 前后关系式应该是`digits[i-1] = digits[i-1] + digits[i] / 10;`,即前一个元素的值应该是本身加上后一个元素的进位 -3. 若首元素>=10,则需要插入元素 - -```CPP -class Solution { -public: - vector输入: [1,2,3] +输出: [1,2,4] +解释: 输入数组表示数字 123。 +-``` +
示例 2:
-# [题目](这里是题目链接,如:https://leetcode-cn.com/problems/shu-zu-zhong-zhong-fu-de-shu-zi-lcof/) +输入: [4,3,2,1] +输出: [4,3,2,2] +解释: 输入数组表示数字 4321。 +-## 题目描述 - ## 解法 diff --git a/solution/0000-0099/0067.Add Binary/README.md b/solution/0000-0099/0067.Add Binary/README.md index d9b3840c082d2..32cbd8d509e14 100644 --- a/solution/0000-0099/0067.Add Binary/README.md +++ b/solution/0000-0099/0067.Add Binary/README.md @@ -1,7 +1,21 @@ -# [题目](这里是题目链接,如:https://leetcode-cn.com/problems/shu-zu-zhong-zhong-fu-de-shu-zi-lcof/) +# [67. 二进制求和](https://leetcode-cn.com/problems/add-binary) ## 题目描述 +
给定两个二进制字符串,返回他们的和(用二进制表示)。
+ +输入为非空字符串且只包含数字 1 和 0。
示例 1:
+ +输入: a = "11", b = "1" +输出: "100"+ +
示例 2:
+ +输入: a = "1010", b = "1011" +输出: "10101"+ ## 解法 diff --git a/solution/0000-0099/0068.Text Justification/README.md b/solution/0000-0099/0068.Text Justification/README.md index d9b3840c082d2..205d4d02fac3b 100644 --- a/solution/0000-0099/0068.Text Justification/README.md +++ b/solution/0000-0099/0068.Text Justification/README.md @@ -1,7 +1,69 @@ -# [题目](这里是题目链接,如:https://leetcode-cn.com/problems/shu-zu-zhong-zhong-fu-de-shu-zi-lcof/) +# [68. 文本左右对齐](https://leetcode-cn.com/problems/text-justification) ## 题目描述 +
给定一个单词数组和一个长度 maxWidth,重新排版单词,使其成为每行恰好有 maxWidth 个字符,且左右两端对齐的文本。
+ +你应该使用“贪心算法”来放置给定的单词;也就是说,尽可能多地往每行中放置单词。必要时可用空格 ' ' 填充,使得每行恰好有 maxWidth 个字符。
要求尽可能均匀分配单词间的空格数量。如果某一行单词间的空格不能均匀分配,则左侧放置的空格数要多于右侧的空格数。
+ +文本的最后一行应为左对齐,且单词之间不插入额外的空格。
+ +说明:
+ +-
+
- 单词是指由非空格字符组成的字符序列。 +
- 每个单词的长度大于 0,小于等于 maxWidth。 +
- 输入单词数组
words至少包含一个单词。
+
示例:
+ +输入: +words = ["This", "is", "an", "example", "of", "text", "justification."] +maxWidth = 16 +输出: +[ + "This is an", + "example of text", + "justification. " +] ++ +
示例 2:
+ +输入: +words = ["What","must","be","acknowledgment","shall","be"] +maxWidth = 16 +输出: +[ + "What must be", + "acknowledgment ", + "shall be " +] +解释: 注意最后一行的格式应为 "shall be " 而不是 "shall be", + 因为最后一行应为左对齐,而不是左右两端对齐。 + 第二行同样为左对齐,这是因为这行只包含一个单词。 ++ +
示例 3:
+ +输入: +words = ["Science","is","what","we","understand","well","enough","to","explain", + "to","a","computer.","Art","is","everything","else","we","do"] +maxWidth = 20 +输出: +[ + "Science is what we", + "understand well", + "enough to explain to", + "a computer. Art is", + "everything else we", + "do " +] ++ ## 解法 diff --git a/solution/0000-0099/0069.Sqrt(x)/README.md b/solution/0000-0099/0069.Sqrt(x)/README.md index 8a32a78c3090d..ba22ff126986f 100644 --- a/solution/0000-0099/0069.Sqrt(x)/README.md +++ b/solution/0000-0099/0069.Sqrt(x)/README.md @@ -1,32 +1,27 @@ -## x 的平方根 -### 题目描述 +# [69. x 的平方根](https://leetcode-cn.com/problems/sqrtx) -实现 `int sqrt(int x)` 函数。 +## 题目描述 + +
实现 int sqrt(int x) 函数。
计算并返回 x 的平方根,其中 x 是非负整数。
-由于返回类型是整数,结果只保留整数的部分,小数部分将被舍去。 +由于返回类型是整数,结果只保留整数的部分,小数部分将被舍去。
-**示例 1:** -``` -输入: 4 -输出: 2 -``` +示例 1:
-**示例 2:** -``` -输入: 8 -输出: 2 -说明: 8 的平方根是 2.82842..., - 由于返回类型是整数,小数部分将被舍去。 -``` +输入: 4 +输出: 2 +-### 解法 +
示例 2:
-# [题目](这里是题目链接,如:https://leetcode-cn.com/problems/shu-zu-zhong-zhong-fu-de-shu-zi-lcof/) +输入: 8 +输出: 2 +说明: 8 的平方根是 2.82842..., + 由于返回类型是整数,小数部分将被舍去。 +-## 题目描述 - ## 解法 diff --git a/solution/0000-0099/0070.Climbing Stairs/README.md b/solution/0000-0099/0070.Climbing Stairs/README.md index 9b2b635a4dc9f..1c6c4ee2116c8 100644 --- a/solution/0000-0099/0070.Climbing Stairs/README.md +++ b/solution/0000-0099/0070.Climbing Stairs/README.md @@ -1,55 +1,31 @@ -## 爬楼梯 -### 题目描述 +# [70. 爬楼梯](https://leetcode-cn.com/problems/climbing-stairs) -假设你正在爬楼梯。需要 n 阶你才能到达楼顶。 +## 题目描述 + +
假设你正在爬楼梯。需要 n 阶你才能到达楼顶。
-每次你可以爬 1 或 2 个台阶。你有多少种不同的方法可以爬到楼顶呢? +每次你可以爬 1 或 2 个台阶。你有多少种不同的方法可以爬到楼顶呢?
-注意:给定 n 是一个正整数。 +注意:给定 n 是一个正整数。
-示例 1: -``` -输入: 2 -输出: 2 -解释: 有两种方法可以爬到楼顶。 +示例 1:
+ +输入: 2 +输出: 2 +解释: 有两种方法可以爬到楼顶。 1. 1 阶 + 1 阶 -2. 2 阶 -``` +2. 2 阶-示例 2: -``` -输入: 3 -输出: 3 -解释: 有三种方法可以爬到楼顶。 +
示例 2:
+ +输入: 3 +输出: 3 +解释: 有三种方法可以爬到楼顶。 1. 1 阶 + 1 阶 + 1 阶 2. 1 阶 + 2 阶 3. 2 阶 + 1 阶 -``` +-### 解法 -爬上 1 阶有 1 种方法,爬上 2 阶有 2 种方法,爬上 n 阶 f(n) 有 f(n - 1) + f(n - 2) 种方法。可以利用数组记录中间结果,防止重复计算。 - -```java -class Solution { - public int climbStairs(int n) { - if (n < 3) { - return n; - } - int[] res = new int[n + 1]; - res[1] = 1; - res[2] = 2; - for (int i = 3; i < n + 1; ++i) { - res[i] = res[i - 1] + res[i - 2]; - } - return res[n]; - } -} -``` - -# [题目](这里是题目链接,如:https://leetcode-cn.com/problems/shu-zu-zhong-zhong-fu-de-shu-zi-lcof/) - -## 题目描述 - ## 解法 diff --git a/solution/0000-0099/0071.Simplify Path/README.md b/solution/0000-0099/0071.Simplify Path/README.md index d9b3840c082d2..9b82af31f24e6 100644 --- a/solution/0000-0099/0071.Simplify Path/README.md +++ b/solution/0000-0099/0071.Simplify Path/README.md @@ -1,7 +1,53 @@ -# [题目](这里是题目链接,如:https://leetcode-cn.com/problems/shu-zu-zhong-zhong-fu-de-shu-zi-lcof/) +# [71. 简化路径](https://leetcode-cn.com/problems/simplify-path) ## 题目描述 +
以 Unix 风格给出一个文件的绝对路径,你需要简化它。或者换句话说,将其转换为规范路径。
+ +在 Unix 风格的文件系统中,一个点(.)表示当前目录本身;此外,两个点 (..) 表示将目录切换到上一级(指向父目录);两者都可以是复杂相对路径的组成部分。更多信息请参阅:Linux / Unix中的绝对路径 vs 相对路径
请注意,返回的规范路径必须始终以斜杠 / 开头,并且两个目录名之间必须只有一个斜杠 /。最后一个目录名(如果存在)不能以 / 结尾。此外,规范路径必须是表示绝对路径的最短字符串。
+ +
示例 1:
+ +输入:"/home/" +输出:"/home" +解释:注意,最后一个目录名后面没有斜杠。 ++ +
示例 2:
+ +输入:"/../" +输出:"/" +解释:从根目录向上一级是不可行的,因为根是你可以到达的最高级。 ++ +
示例 3:
+ +输入:"/home//foo/" +输出:"/home/foo" +解释:在规范路径中,多个连续斜杠需要用一个斜杠替换。 ++ +
示例 4:
+ +输入:"/a/./b/../../c/" +输出:"/c" ++ +
示例 5:
+ +输入:"/a/../../b/../c//.//" +输出:"/c" ++ +
示例 6:
+ +输入:"/a//b////c/d//././/.." +输出:"/a/b/c"+ ## 解法 diff --git a/solution/0000-0099/0072.Edit Distance/README.md b/solution/0000-0099/0072.Edit Distance/README.md index d9b3840c082d2..94fbd6a962fa5 100644 --- a/solution/0000-0099/0072.Edit Distance/README.md +++ b/solution/0000-0099/0072.Edit Distance/README.md @@ -1,7 +1,39 @@ -# [题目](这里是题目链接,如:https://leetcode-cn.com/problems/shu-zu-zhong-zhong-fu-de-shu-zi-lcof/) +# [72. 编辑距离](https://leetcode-cn.com/problems/edit-distance) ## 题目描述 +
给定两个单词 word1 和 word2,计算出将 word1 转换成 word2 所使用的最少操作数 。
+ +你可以对一个单词进行如下三种操作:
+ +-
+
- 插入一个字符 +
- 删除一个字符 +
- 替换一个字符 +
示例 1:
+ +输入: word1 = "horse", word2 = "ros" +输出: 3 +解释: +horse -> rorse (将 'h' 替换为 'r') +rorse -> rose (删除 'r') +rose -> ros (删除 'e') ++ +
示例 2:
+ +输入: word1 = "intention", word2 = "execution" +输出: 5 +解释: +intention -> inention (删除 't') +inention -> enention (将 'i' 替换为 'e') +enention -> exention (将 'n' 替换为 'x') +exention -> exection (将 'n' 替换为 'c') +exection -> execution (插入 'u') ++ ## 解法 diff --git a/solution/0000-0099/0073.Set Matrix Zeroes/README.md b/solution/0000-0099/0073.Set Matrix Zeroes/README.md index dfac0e1ed3325..3ff18f8b0c7e8 100644 --- a/solution/0000-0099/0073.Set Matrix Zeroes/README.md +++ b/solution/0000-0099/0073.Set Matrix Zeroes/README.md @@ -1,182 +1,48 @@ -给定一个 m x n 的矩阵,如果一个元素为 0,则将其所在行和列的所有元素都设为 0。请使用原地算法。 +# [73. 矩阵置零](https://leetcode-cn.com/problems/set-matrix-zeroes) -``` -示例 1: -输入: +## 题目描述 + +
给定一个 m x n 的矩阵,如果一个元素为 0,则将其所在行和列的所有元素都设为 0。请使用原地算法。
+ +示例 1:
+ +输入: [ - [1,1,1], - [1,0,1], - [1,1,1] + [1,1,1], + [1,0,1], + [1,1,1] ] -输出: +输出: [ - [1,0,1], - [0,0,0], - [1,0,1] + [1,0,1], + [0,0,0], + [1,0,1] ] -示例 2: ++ +
示例 2:
-输入: +输入:
[
- [0,1,2,0],
- [3,4,5,2],
- [1,3,1,5]
+ [0,1,2,0],
+ [3,4,5,2],
+ [1,3,1,5]
]
-输出:
+输出:
[
- [0,0,0,0],
- [0,4,5,0],
- [0,3,1,0]
-]
-```
-
-### 进阶:
-一个直接的解决方案是使用 O(mn) 的额外空间,但这并不是一个好的解决方案。
-
-一个简单的改进方案是使用 O(m + n) 的额外空间,但这仍然不是最好的解决方案。
-
-你能想出一个常数空间的解决方案吗?
-
-### 思路1
-
-1. 创建行列辅助数组,先遍历矩阵,定位元素是0的行列,分别加入行数组,列数组
-2. 从行数组中取出元素,整行置零;同理列数组
-
-空间复杂度`O(m+n)`,而且分别进行处理和列处理时有重复操作
-
-### 思路2(优化思路1)
-
-1. 先检查首行首列有没有0,有的话设置bool标记
-2. 从第二行第二列开始遍历,如果发现有0,设置`matrix[i][0] = 0和matrix[0][j] = 0`,即把首行首列对应行列值设置为0
-3. 遍历首行首列,把值为0的行按行设置为0;列同理
-4. 查看标记位,看是否需要把首行首列设置为0
-
-这种思路没有用额外的空间,但是时间复杂度和思路1一样,都有待解决重复操作的问题
-
-整体好于思路1,时间复杂度比思路1稳定
-
-### Solution1
-
-```CPP
-class Solution {
-public:
- void setZeroes(vector>& matrix) {
- if(matrix.empty())return;
- //行数组,列数组
- int rowNum = matrix.size();
- int columnNum = matrix[0].size();
- vector rowVec;
- vector columnVec;
-
-
- for(int i = 0;i
-### Solution 2
-
-```CPP
-class Solution {
-public:
- void setZeroes(vector>& matrix) {
- if(matrix.empty()) return;
- int m = matrix.size();
- int n = matrix[0].size();
- bool row = false , column = false;
-
-
- for(int i = 0; i < m; i++)//判断第1列的0;
- {
- if(matrix[i][0] == 0)
- {
- column = true;
- break;
- }
- }
- for(int i = 0; i < n; i ++)//判断第1行的0;
- {
- if(matrix[0][i] == 0)
- {
- row = true;
- break;
- }
- }
-
- for(int i = 1; i < m;i++)
- {
- for(int j = 1; j < n;j++)
- {
- if(matrix[i][j] == 0)
- {
- matrix[0][j] = 0;
- matrix[i][0] = 0;
- }
- }
- }
- for(int i = 1; i < m;i++)
- {
- for(int j = 1; j < n;j++)
- {
- if(matrix[i][0] == 0 || matrix[0][j] == 0)
- {
- matrix[i][j] = 0;
- }
- }
- }
- if(row)
- for(int i = 0; i < n;i++)
- matrix[0][i] = 0;
- if(column)
- for(int i = 0; i < m;i++)
- matrix[i][0] = 0;
-
- return;
-
-
- }
-};
-```
+进阶:
-# [题目](这里是题目链接,如:https://leetcode-cn.com/problems/shu-zu-zhong-zhong-fu-de-shu-zi-lcof/)
+
+ - 一个直接的解决方案是使用 O(mn) 的额外空间,但这并不是一个好的解决方案。
+ - 一个简单的改进方案是使用 O(m + n) 的额外空间,但这仍然不是最好的解决方案。
+ - 你能想出一个常数空间的解决方案吗?
+
-## 题目描述
-
## 解法
diff --git a/solution/0000-0099/0074.Search a 2D Matrix/README.md b/solution/0000-0099/0074.Search a 2D Matrix/README.md
index 34d2801434c82..26cc14976ae11 100644
--- a/solution/0000-0099/0074.Search a 2D Matrix/README.md
+++ b/solution/0000-0099/0074.Search a 2D Matrix/README.md
@@ -1,69 +1,37 @@
-## 搜索二维矩阵
+# [74. 搜索二维矩阵](https://leetcode-cn.com/problems/search-a-2d-matrix)
-### 问题描述
-编写一个高效的算法来判断 m x n 矩阵中,是否存在一个目标值。该矩阵具有如下特性:
+## 题目描述
+
+编写一个高效的算法来判断 m x n 矩阵中,是否存在一个目标值。该矩阵具有如下特性:
-- 每行中的整数从左到右按升序排列。
-- 每行的第一个整数大于前一行的最后一个整数。
+
+ - 每行中的整数从左到右按升序排列。
+ - 每行的第一个整数大于前一行的最后一个整数。
+
-```
-示例 1:
-输入:
+示例 1:
+
+输入:
matrix = [
[1, 3, 5, 7],
[10, 11, 16, 20],
[23, 30, 34, 50]
]
target = 3
-输出: true
+输出: true
+
+
+示例 2:
-示例 2:
-输入:
+输入:
matrix = [
[1, 3, 5, 7],
[10, 11, 16, 20],
[23, 30, 34, 50]
]
target = 13
-输出: false
-```
+输出: false
-### 思路
-
-1. 因为矩阵按特性排列,所以先定位行坐标
-2. 定位行坐标后直接调函数
-
-一开始本来想定位到行之后用二分查找的,但是考虑到这个元素本身可能不存在,所以建议不调迭代器的话用顺序查找吧
-
-```CPP
-class Solution {
-public:
- bool searchMatrix(vector>& matrix, int target) {
- if(matrix.empty())return false;
-
- size_t row = matrix.size();
- size_t column = matrix[0].size();
- if(column == 0 || column == 0)return false;
-
- if(target < matrix[0][0] || target > matrix[row-1][column-1])return false;
-
- for(int i = 0;i
## 解法
diff --git a/solution/0000-0099/0075.Sort Colors/README.md b/solution/0000-0099/0075.Sort Colors/README.md
index c76eeb3befa0a..7d8782340ca21 100644
--- a/solution/0000-0099/0075.Sort Colors/README.md
+++ b/solution/0000-0099/0075.Sort Colors/README.md
@@ -1,98 +1,27 @@
-## 颜色分类
-### 题目描述
+# [75. 颜色分类](https://leetcode-cn.com/problems/sort-colors)
-给定一个包含红色、白色和蓝色,一共 n 个元素的数组,原地对它们进行排序,使得相同颜色的元素相邻,并按照红色、白色、蓝色顺序排列。
-
-此题中,我们使用整数 0、 1 和 2 分别表示红色、白色和蓝色。
-
-注意:
-不能使用代码库中的排序函数来解决这道题。
-
-示例:
-```
-输入: [2,0,2,1,1,0]
-输出: [0,0,1,1,2,2]
-```
-
-进阶:
-
-- 一个直观的解决方案是使用计数排序的两趟扫描算法。
-首先,迭代计算出0、1 和 2 元素的个数,然后按照0、1、2的排序,重写当前数组。
-- 你能想出一个仅使用常数空间的一趟扫描算法吗?
-
-### 解法
-指针 p 指示左侧等于 0 区域的最后一个元素,q 指示右侧等于 2 的第一个元素。p, q 初始分别指向 -1, nums.length。
-cur 从 0 开始遍历:
-
-- 若 nums[cur] == 0,则与 p 的下一个位置的元素互换,p+1, cur+1;
-- 若 nums[cur] == 1,++cur;
-- 若 nums[cur] == 2,则与 q 的前一个位置的元素互换,q-1,cur不变。
-
-### 解法2
-
-因为排序元素的类型有限而且不多,比较直观的方法是使用计数排序,就是创建一个包含所有类型的数组`(如创建数组count[3],count[0]=k表示类型是“0”的元素有k个)`,利用下标作为统计标识,在对应下标元素上+-
-
-1. 创建一个含有3个元素的数组并初始化为0 `count[3] = {0}`
-2. 遍历nums,在`count`数组对应数字下+1
-3. 利用计数数组对nums重新赋值
+## 题目描述
+
+给定一个包含红色、白色和蓝色,一共 n 个元素的数组,原地对它们进行排序,使得相同颜色的元素相邻,并按照红色、白色、蓝色顺序排列。
-#### Java(解法1)
+此题中,我们使用整数 0、 1 和 2 分别表示红色、白色和蓝色。
-```java
-class Solution {
- public void sortColors(int[] nums) {
- int p = -1;
- int q = nums.length;
- int cur = 0;
- while (cur < q) {
- if (nums[cur] == 0) {
- swap(nums, cur++, ++p);
- } else if (nums[cur] == 1) {
- ++cur;
- } else {
- swap(nums, --q, cur);
- }
- }
- }
-
- private void swap(int[] nums, int i, int j) {
- int t = nums[i];
- nums[i] = nums[j];
- nums[j] = t;
- }
-}
-```
+注意:
+不能使用代码库中的排序函数来解决这道题。
-#### CPP(解法2)
+示例:
-```
-class Solution {
-public:
- void sortColors(vector& nums) {
- if(nums.empty())return ;
-
- int count[3] = {0};
- size_t len = nums.size();
-
- for(int i = 0;i输入: [2,0,2,1,1,0]
+输出: [0,0,1,1,2,2]
-```
+进阶:
-# [题目](这里是题目链接,如:https://leetcode-cn.com/problems/shu-zu-zhong-zhong-fu-de-shu-zi-lcof/) +-
+
- 一个直观的解决方案是使用计数排序的两趟扫描算法。
+ 首先,迭代计算出0、1 和 2 元素的个数,然后按照0、1、2的排序,重写当前数组。
+ - 你能想出一个仅使用常数空间的一趟扫描算法吗? +
给你一个字符串 S、一个字符串 T,请在字符串 S 里面找出:包含 T 所有字母的最小子串。
+ +示例:
+ +输入: S = "ADOBECODEBANC", T = "ABC" +输出: "BANC"+ +
说明:
+ +-
+
- 如果 S 中不存这样的子串,则返回空字符串
""。
+ - 如果 S 中存在这样的子串,我们保证它是唯一的答案。 +
给定两个整数 n 和 k,返回 1 ... n 中所有可能的 k 个数的组合。
+ +示例:
+ +输入: n = 4, k = 2 +输出: +[ + [2,4], + [3,4], + [2,3], + [1,2], + [1,3], + [1,4], +]+ ## 解法 diff --git a/solution/0000-0099/0078.Subsets/README.md b/solution/0000-0099/0078.Subsets/README.md index d9b3840c082d2..5afd0ecd7027d 100644 --- a/solution/0000-0099/0078.Subsets/README.md +++ b/solution/0000-0099/0078.Subsets/README.md @@ -1,7 +1,26 @@ -# [题目](这里是题目链接,如:https://leetcode-cn.com/problems/shu-zu-zhong-zhong-fu-de-shu-zi-lcof/) +# [78. 子集](https://leetcode-cn.com/problems/subsets) ## 题目描述 +
给定一组不含重复元素的整数数组 nums,返回该数组所有可能的子集(幂集)。
+ +说明:解集不能包含重复的子集。
+ +示例:
+ +输入: nums = [1,2,3] +输出: +[ + [3], + [1], + [2], + [1,2,3], + [1,3], + [2,3], + [1,2], + [] +]+ ## 解法 diff --git a/solution/0000-0099/0079.Word Search/README.md b/solution/0000-0099/0079.Word Search/README.md index d9b3840c082d2..60f649fa37d93 100644 --- a/solution/0000-0099/0079.Word Search/README.md +++ b/solution/0000-0099/0079.Word Search/README.md @@ -1,7 +1,37 @@ -# [题目](这里是题目链接,如:https://leetcode-cn.com/problems/shu-zu-zhong-zhong-fu-de-shu-zi-lcof/) +# [79. 单词搜索](https://leetcode-cn.com/problems/word-search) ## 题目描述 +
给定一个二维网格和一个单词,找出该单词是否存在于网格中。
+ +单词必须按照字母顺序,通过相邻的单元格内的字母构成,其中“相邻”单元格是那些水平相邻或垂直相邻的单元格。同一个单元格内的字母不允许被重复使用。
+ ++ +
示例:
+ +board = +[ + ['A','B','C','E'], + ['S','F','C','S'], + ['A','D','E','E'] +] + +给定 word = "ABCCED", 返回 true +给定 word = "SEE", 返回 true +给定 word = "ABCB", 返回 false+ +
+ +
提示:
+ +-
+
board和word中只包含大写和小写英文字母。
+ 1 <= board.length <= 200
+ 1 <= board[i].length <= 200
+ 1 <= word.length <= 10^3
+
给定一个排序数组,你需要在原地删除重复出现的元素,使得每个元素最多出现两次,返回移除后数组的新长度。
-给定一个排序数组,你需要在原地删除重复出现的元素,使得每个元素最多出现两次,返回移除后数组的新长度。 +不要使用额外的数组空间,你必须在原地修改输入数组并在使用 O(1) 额外空间的条件下完成。
-不要使用额外的数组空间,你必须在原地修改输入数组并在使用 O(1) 额外空间的条件下完成。 -``` -示例 1: -给定 nums = [1,1,1,2,2,3], +示例 1:
-函数应返回新长度 length = 5, 并且原数组的前五个元素被修改为 1, 1, 2, 2, 3 。 +给定 nums = [1,1,1,2,2,3], -你不需要考虑数组中超出新长度后面的元素。 +函数应返回新长度 length =-示例 2: -给定 nums = [0,0,1,1,1,1,2,3,3], +5, 并且原数组的前五个元素被修改为1, 1, 2, 2,3 。 + +你不需要考虑数组中超出新长度后面的元素。
示例 2:
-函数应返回新长度 length = 7, 并且原数组的前五个元素被修改为 0, 0, 1, 1, 2, 3, 3 。 +给定 nums = [0,0,1,1,1,1,2,3,3], + +函数应返回新长度 length =-#### 说明: +7, 并且原数组的前五个元素被修改为0, 0, 1, 1, 2, 3, 3 。 你不需要考虑数组中超出新长度后面的元素。 -``` +
说明:
-``` -为什么返回数值是整数,但输出的答案是数组呢? +为什么返回数值是整数,但输出的答案是数组呢?
-请注意,输入数组是以“引用”方式传递的,这意味着在函数里修改输入数组对于调用者是可见的。 +请注意,输入数组是以“引用”方式传递的,这意味着在函数里修改输入数组对于调用者是可见的。
-你可以想象内部操作如下: +你可以想象内部操作如下:
-// nums 是以“引用”方式传递的。也就是说,不对实参做任何拷贝 +// nums 是以“引用”方式传递的。也就是说,不对实参做任何拷贝
int len = removeDuplicates(nums);
// 在函数里修改输入数组对于调用者是可见的。
-// 根据你的函数返回的长度, 它会打印出数组中该长度范围内的所有元素。
-for (int i = 0; i < len; i++) {
- print(nums[i]);
-}
-```
-
+// 根据你的函数返回的长度, 它会打印出数组中该长度范围内的所有元素。
+for (int i = 0; i < len; i++) {
+ print(nums[i]);
+}
-### 思路[CPP]
-
-本题对CPP而言主要考察STL,遍历+统计+迭代器指针
-
-0. 去除特殊情况(如数组空或长度为1)
-1. 设置统计位k=1,用迭代器指向数组第二位元素
-2. 遍历,让迭代器指向元素与迭代器前一位元素比较,相同则k++,不同则k=1
-3. 若k==3,立即删除当前元素,指针不动,仍是指向当前位置;否则执行指针后移
-
-```
-class Solution {
-public:
- int removeDuplicates(vector假设按照升序排序的数组在预先未知的某个点上进行了旋转。
+ +( 例如,数组 [0,0,1,2,2,5,6] 可能变为 [2,5,6,0,0,1,2] )。
编写一个函数来判断给定的目标值是否存在于数组中。若存在返回 true,否则返回 false。
示例 1:
+ +输入: nums = [2,5,6,0,0,1,2], target = 0
+输出: true
+
+
+示例 2:
+ +输入: nums = [2,5,6,0,0,1,2], target = 3
+输出: false
+
+进阶:
+ +-
+
- 这是 搜索旋转排序数组 的延伸题目,本题中的
nums可能包含重复元素。
+ - 这会影响到程序的时间复杂度吗?会有怎样的影响,为什么? +
给定一个排序链表,删除所有含有重复数字的节点,只保留原始链表中 没有重复出现 的数字。
-示例 1: -``` -输入: 1->2->3->3->4->4->5 -输出: 1->2->5 -``` +示例 1:
-示例 2: -``` -输入: 1->1->1->2->3 -输出: 2->3 -``` +输入: 1->2->3->3->4->4->5 +输出: 1->2->5 +-### 解法 -利用链表的递归性,需要注意处理连续 n(n>=3) 个结点相等的情况。若相邻只有两个结点相等,则直接返回deleteDuplicates(head.next.next);若相邻结点超过 3 个相等,返回 deleteDuplicates(head.next)。 +
示例 2:
-```java -/** - * Definition for singly-linked list. - * public class ListNode { - * int val; - * ListNode next; - * ListNode(int x) { val = x; } - * } - */ -class Solution { - public ListNode deleteDuplicates(ListNode head) { - if (head == null || head.next == null) { - return head; - } - - if (head.val == head.next.val) { - if (head.next.next == null) { - return null; - } - if (head.val == head.next.next.val) { - return deleteDuplicates(head.next); - } - return deleteDuplicates(head.next.next); - } - head.next = deleteDuplicates(head.next); - return head; - } -} -``` - -# [题目](这里是题目链接,如:https://leetcode-cn.com/problems/shu-zu-zhong-zhong-fu-de-shu-zi-lcof/) +输入: 1->1->1->2->3 +输出: 2->3-## 题目描述 - ## 解法 diff --git a/solution/0000-0099/0083.Remove Duplicates from Sorted List/README.md b/solution/0000-0099/0083.Remove Duplicates from Sorted List/README.md index 2960568a42cd1..c5240bb7b2c01 100644 --- a/solution/0000-0099/0083.Remove Duplicates from Sorted List/README.md +++ b/solution/0000-0099/0083.Remove Duplicates from Sorted List/README.md @@ -1,49 +1,20 @@ -## 删除排序链表中的重复元素 -### 题目描述 +# [83. 删除排序链表中的重复元素](https://leetcode-cn.com/problems/remove-duplicates-from-sorted-list) -给定一个排序链表,删除所有重复的元素,使得每个元素只出现一次。 +## 题目描述 + +
给定一个排序链表,删除所有重复的元素,使得每个元素只出现一次。
-示例 1: -``` -输入: 1->1->2 -输出: 1->2 -``` +示例 1:
-示例 2: -``` -输入: 1->1->2->3->3 -输出: 1->2->3 -``` +输入: 1->1->2 +输出: 1->2 +-### 解法 -利用链表的递归性,先判断当前结点的值与下个结点值是否相等,是的话,链表为 deleteDuplicates(ListNode head),否则为 head->deleteDuplicates(head.next)。 +
示例 2:
-```java -/** - * Definition for singly-linked list. - * public class ListNode { - * int val; - * ListNode next; - * ListNode(int x) { val = x; } - * } - */ -class Solution { - public ListNode deleteDuplicates(ListNode head) { - if (head == null || head.next == null) { - return head; - } - - head.next = deleteDuplicates(head.next); - return head.val == head.next.val ? head.next : head; - - } -} -``` - -# [题目](这里是题目链接,如:https://leetcode-cn.com/problems/shu-zu-zhong-zhong-fu-de-shu-zi-lcof/) +输入: 1->1->2->3->3 +输出: 1->2->3-## 题目描述 - ## 解法 diff --git a/solution/0000-0099/0084.Largest Rectangle in Histogram/README.md b/solution/0000-0099/0084.Largest Rectangle in Histogram/README.md index 7ff5935673705..d129cb5b22d47 100644 --- a/solution/0000-0099/0084.Largest Rectangle in Histogram/README.md +++ b/solution/0000-0099/0084.Largest Rectangle in Histogram/README.md @@ -1,127 +1,30 @@ -## 柱状图中最大的矩形 -### 题目描述 +# [84. 柱状图中最大的矩形](https://leetcode-cn.com/problems/largest-rectangle-in-histogram) -给定 n 个非负整数,用来表示柱状图中各个柱子的高度。每个柱子彼此相邻,且宽度为 1 。 - -求在该柱状图中,能够勾勒出来的矩形的最大面积。 - - - -以上是柱状图的示例,其中每个柱子的宽度为 1,给定的高度为 `[2,1,5,6,2,3]`。 - -图中阴影部分为所能勾勒出的最大矩形面积,其面积为 `10` 个单位。 - - - -示例: -``` -输入: [2,1,5,6,2,3] -输出: 10 -``` +## 题目描述 + +
给定 n 个非负整数,用来表示柱状图中各个柱子的高度。每个柱子彼此相邻,且宽度为 1 。
-### 解法 -#### 思路一 -从前往后遍历 heightss[0...n]: +求在该柱状图中,能够勾勒出来的矩形的最大面积。
-- 若 heightss[i] > heightss[i - 1],则将 i 压入栈中; -- 若 heightss[i] <= heightss[i - 1],则依次弹出栈,计算栈中能得到的最大矩形面积。 +-注意,压入栈中的是柱子的索引,而非柱子的高度。(通过索引可以获得高度、距离差) +
以上是柱状图的示例,其中每个柱子的宽度为 1,给定的高度为 [2,1,5,6,2,3]。
-```java -class Solution { - public int largestRectangleArea(int[] heights) { - if (heights == null || heights.length == 0) { - return 0; - } - - int n = heights.length; - if (n == 1) { - return heights[0]; - } - - // 创建一个新的数组,数组长度为 n + 1,最后一个元素值赋为 0 - // 确保在后面的遍历中,原数组最后一个元素值能得到计算 - int[] heightss = new int[n + 1]; - heightss[n] = 0; - for (int i = 0; i < n; ++i) { - heightss[i] = heights[i]; - } - - Stack
图中阴影部分为所能勾勒出的最大矩形面积,其面积为 10 个单位。
-**C++版实现:** - -```CPP -class Solution { -public: - int largestRectangleArea(vector
示例:
-# [题目](这里是题目链接,如:https://leetcode-cn.com/problems/shu-zu-zhong-zhong-fu-de-shu-zi-lcof/) +输入: [2,1,5,6,2,3] +输出: 10-## 题目描述 - ## 解法 diff --git a/solution/0000-0099/0085.Maximal Rectangle/README.md b/solution/0000-0099/0085.Maximal Rectangle/README.md index d9b3840c082d2..be0af4ca77e01 100644 --- a/solution/0000-0099/0085.Maximal Rectangle/README.md +++ b/solution/0000-0099/0085.Maximal Rectangle/README.md @@ -1,7 +1,20 @@ -# [题目](这里是题目链接,如:https://leetcode-cn.com/problems/shu-zu-zhong-zhong-fu-de-shu-zi-lcof/) +# [85. 最大矩形](https://leetcode-cn.com/problems/maximal-rectangle) ## 题目描述 +
给定一个仅包含 0 和 1 的二维二进制矩阵,找出只包含 1 的最大矩形,并返回其面积。
+ +示例:
+ +输入: +[ + ["1","0","1","0","0"], + ["1","0","1","1","1"], + ["1","1","1","1","1"], + ["1","0","0","1","0"] +] +输出: 6+ ## 解法 diff --git a/solution/0000-0099/0086.Partition List/README.md b/solution/0000-0099/0086.Partition List/README.md index f8cc3bab7b657..f959cbec937d0 100644 --- a/solution/0000-0099/0086.Partition List/README.md +++ b/solution/0000-0099/0086.Partition List/README.md @@ -1,60 +1,17 @@ -## 分隔链表 -### 题目描述 +# [86. 分隔链表](https://leetcode-cn.com/problems/partition-list) -给定一个链表和一个特定值 x,对链表进行分隔,使得所有小于 x 的节点都在大于或等于 x 的节点之前。 - -你应当保留两个分区中每个节点的初始相对位置。 - -示例: - -``` -输入: head = 1->4->3->2->5->2, x = 3 -输出: 1->2->2->4->3->5 -``` +## 题目描述 + +
给定一个链表和一个特定值 x,对链表进行分隔,使得所有小于 x 的节点都在大于或等于 x 的节点之前。
-### 解法 -维护 `left`, `right` 两个链表,遍历 `head` 链表,若对应元素值小于 `x`,将该结点插入 `left` 链表中,否则插入 `right` 链表中。最后 `right` 尾部指向空,并将 `left` 尾部指向 `right` 头部,使得它们串在一起。 +你应当保留两个分区中每个节点的初始相对位置。
-```java -/** - * Definition for singly-linked list. - * public class ListNode { - * int val; - * ListNode next; - * ListNode(int x) { val = x; } - * } - */ -class Solution { - public ListNode partition(ListNode head, int x) { - ListNode leftDummy = new ListNode(-1); - ListNode rightDummy = new ListNode(-1); - - ListNode leftCur = leftDummy; - ListNode rightCur = rightDummy; - - while (head != null) { - if (head.val < x) { - leftCur.next = head; - leftCur = leftCur.next; - } else { - rightCur.next = head; - rightCur = rightCur.next; - } - head = head.next; - } - - leftCur.next = rightDummy.next; - rightCur.next = null; - return leftDummy.next; - - } -} -``` +示例:
-# [题目](这里是题目链接,如:https://leetcode-cn.com/problems/shu-zu-zhong-zhong-fu-de-shu-zi-lcof/) +输入: head = 1->4->3->2->5->2, x = 3 +输出: 1->2->2->4->3->5 +-## 题目描述 - ## 解法 diff --git a/solution/0000-0099/0087.Scramble String/README.md b/solution/0000-0099/0087.Scramble String/README.md index d9b3840c082d2..8e2e69c974985 100644 --- a/solution/0000-0099/0087.Scramble String/README.md +++ b/solution/0000-0099/0087.Scramble String/README.md @@ -1,7 +1,61 @@ -# [题目](这里是题目链接,如:https://leetcode-cn.com/problems/shu-zu-zhong-zhong-fu-de-shu-zi-lcof/) +# [87. 扰乱字符串](https://leetcode-cn.com/problems/scramble-string) ## 题目描述 +
给定一个字符串 s1,我们可以把它递归地分割成两个非空子字符串,从而将其表示为二叉树。
+ +下图是字符串 s1 = "great" 的一种可能的表示形式。
great + / \ + gr eat + / \ / \ +g r e at + / \ + a t ++ +
在扰乱这个字符串的过程中,我们可以挑选任何一个非叶节点,然后交换它的两个子节点。
+ +例如,如果我们挑选非叶节点 "gr" ,交换它的两个子节点,将会产生扰乱字符串 "rgeat" 。
rgeat + / \ + rg eat + / \ / \ +r g e at + / \ + a t ++ +
我们将 "rgeat” 称作 "great" 的一个扰乱字符串。
同样地,如果我们继续交换节点 "eat" 和 "at" 的子节点,将会产生另一个新的扰乱字符串 "rgtae" 。
rgtae + / \ + rg tae + / \ / \ +r g ta e + / \ + t a ++ +
我们将 "rgtae” 称作 "great" 的一个扰乱字符串。
给出两个长度相等的字符串 s1 和 s2,判断 s2 是否是 s1 的扰乱字符串。
+ +示例 1:
+ +输入: s1 = "great", s2 = "rgeat" +输出: true ++ +
示例 2:
+ +输入: s1 = "abcde", s2 = "caebd" +输出: false+ ## 解法 diff --git a/solution/0000-0099/0088.Merge Sorted Array/README.md b/solution/0000-0099/0088.Merge Sorted Array/README.md index d9b3840c082d2..eddbe023231ce 100644 --- a/solution/0000-0099/0088.Merge Sorted Array/README.md +++ b/solution/0000-0099/0088.Merge Sorted Array/README.md @@ -1,7 +1,28 @@ -# [题目](这里是题目链接,如:https://leetcode-cn.com/problems/shu-zu-zhong-zhong-fu-de-shu-zi-lcof/) +# [88. 合并两个有序数组](https://leetcode-cn.com/problems/merge-sorted-array) ## 题目描述 +
给你两个有序整数数组 nums1 和 nums2,请你将 nums2 合并到 nums1 中,使 num1 成为一个有序数组。
+ ++ +
说明:
+ +-
+
- 初始化 nums1 和 nums2 的元素数量分别为 m 和 n 。 +
- 你可以假设 nums1 有足够的空间(空间大小大于或等于 m + n)来保存 nums2 中的元素。 +
+ +
示例:
+ +输入: +nums1 = [1,2,3,0,0,0], m = 3 +nums2 = [2,5,6], n = 3 + +输出: [1,2,2,3,5,6]+ ## 解法 diff --git a/solution/0000-0099/0089.Gray Code/README.md b/solution/0000-0099/0089.Gray Code/README.md index d9b3840c082d2..abb10f09884d3 100644 --- a/solution/0000-0099/0089.Gray Code/README.md +++ b/solution/0000-0099/0089.Gray Code/README.md @@ -1,7 +1,38 @@ -# [题目](这里是题目链接,如:https://leetcode-cn.com/problems/shu-zu-zhong-zhong-fu-de-shu-zi-lcof/) +# [89. 格雷编码](https://leetcode-cn.com/problems/gray-code) ## 题目描述 +
格雷编码是一个二进制数字系统,在该系统中,两个连续的数值仅有一个位数的差异。
+ +给定一个代表编码总位数的非负整数 n,打印其格雷编码序列。格雷编码序列必须以 0 开头。
+ +示例 1:
+ +输入: 2 +输出:+ +[0,1,3,2]+解释: +00 - 0 +01 - 1 +11 - 3 +10 - 2 + +对于给定的 n,其格雷编码序列并不唯一。 +例如,[0,2,3,1]也是一个有效的格雷编码序列。 + +00 - 0 +10 - 2 +11 - 3 +01 - 1
示例 2:
+ +输入: 0 +输出:+ ## 解法 diff --git a/solution/0000-0099/0090.Subsets II/README.md b/solution/0000-0099/0090.Subsets II/README.md index 53f32633800f1..f34eb0da73c3f 100644 --- a/solution/0000-0099/0090.Subsets II/README.md +++ b/solution/0000-0099/0090.Subsets II/README.md @@ -1,15 +1,15 @@ -## 子集 II +# [90. 子集 II](https://leetcode-cn.com/problems/subsets-ii) -### 问题描述 +## 题目描述 + +[0] +解释: 我们定义格雷编码序列必须以 0 开头。+ 给定编码总位数为n 的格雷编码序列,其长度为 2n。当 n = 0 时,长度为 20 = 1。 + 因此,当 n = 0 时,其格雷编码序列为 [0]。+
给定一个可能包含重复元素的整数数组 nums,返回该数组所有可能的子集(幂集)。
-给定一个可能包含重复元素的整数数组 nums,返回该数组所有可能的子集(幂集)。 +说明:解集不能包含重复的子集。
-说明:解集不能包含重复的子集。 +示例:
-``` -示例: -输入: [1,2,2] -输出: +输入: [1,2,2] +输出: [ [2], [1], @@ -17,43 +17,8 @@ [2,2], [1,2], [] -] -``` - +]-### 思路 - -回溯+排序去重 - -```CPP -class Solution { -public: - vector
一条包含字母 A-Z 的消息通过以下方式进行了编码:
'A' -> 1 +'B' -> 2 +... +'Z' -> 26 ++ +
给定一个只包含数字的非空字符串,请计算解码方法的总数。
+ +示例 1:
+ +输入: "12" +输出: 2 +解释: 它可以解码为 "AB"(1 2)或者 "L"(12)。 ++ +
示例 2:
+ +输入: "226" +输出: 3 +解释: 它可以解码为 "BZ" (2 26), "VF" (22 6), 或者 "BBF" (2 2 6) 。 ++ ## 解法 diff --git a/solution/0000-0099/0092.Reverse Linked List II/README.md b/solution/0000-0099/0092.Reverse Linked List II/README.md index 85cb58fa1b55d..df6ea5571b05a 100644 --- a/solution/0000-0099/0092.Reverse Linked List II/README.md +++ b/solution/0000-0099/0092.Reverse Linked List II/README.md @@ -1,61 +1,17 @@ -## 反转链表 II -### 题目描述 +# [92. 反转链表 II](https://leetcode-cn.com/problems/reverse-linked-list-ii) -反转从位置 m 到 n 的链表。请使用一趟扫描完成反转。 - -说明: -1 ≤ m ≤ n ≤ 链表长度。 - -示例: - -``` -输入: 1->2->3->4->5->NULL, m = 2, n = 4 -输出: 1->4->3->2->5->NULL -``` +## 题目描述 + +
反转从位置 m 到 n 的链表。请使用一趟扫描完成反转。
-### 解法 -利用头插法,对 [m + 1, n] 范围内的元素逐一插入。 +说明:
+1 ≤ m ≤ n ≤ 链表长度。
示例:
-# [题目](这里是题目链接,如:https://leetcode-cn.com/problems/shu-zu-zhong-zhong-fu-de-shu-zi-lcof/) +输入: 1->2->3->4->5->NULL, m = 2, n = 4 +输出: 1->4->3->2->5->NULL-## 题目描述 - ## 解法 diff --git a/solution/0000-0099/0093.Restore IP Addresses/README.md b/solution/0000-0099/0093.Restore IP Addresses/README.md index d9b3840c082d2..38180fcb61fc1 100644 --- a/solution/0000-0099/0093.Restore IP Addresses/README.md +++ b/solution/0000-0099/0093.Restore IP Addresses/README.md @@ -1,7 +1,14 @@ -# [题目](这里是题目链接,如:https://leetcode-cn.com/problems/shu-zu-zhong-zhong-fu-de-shu-zi-lcof/) +# [93. 复原IP地址](https://leetcode-cn.com/problems/restore-ip-addresses) ## 题目描述 +
给定一个只包含数字的字符串,复原它并返回所有可能的 IP 地址格式。
+ +示例:
+ +输入: "25525511135"
+输出: ["255.255.11.135", "255.255.111.35"]
+
## 解法
diff --git a/solution/0000-0099/0094.Binary Tree Inorder Traversal/README.md b/solution/0000-0099/0094.Binary Tree Inorder Traversal/README.md
index e7b145c93adf5..127ac09812085 100644
--- a/solution/0000-0099/0094.Binary Tree Inorder Traversal/README.md
+++ b/solution/0000-0099/0094.Binary Tree Inorder Traversal/README.md
@@ -1,99 +1,22 @@
-## 二叉树的中序遍历
-### 题目描述
+# [94. 二叉树的中序遍历](https://leetcode-cn.com/problems/binary-tree-inorder-traversal)
-给定一个二叉树,返回它的中序 遍历。
+## 题目描述
+
+给定一个二叉树,返回它的中序 遍历。
-示例: -``` -输入: [1,null,2,3] +示例:
+ +输入: [1,null,2,3]
1
\
2
/
3
-输出: [1,3,2]
-```
-
-进阶: 递归算法很简单,你可以通过迭代算法完成吗?
-
-### 解法
-
-- 递归算法
-
-先递归左子树,再访问根结点,最后递归右子树。
-
-```java
-
-/**
- * Definition for a binary tree node.
- * public class TreeNode {
- * int val;
- * TreeNode left;
- * TreeNode right;
- * TreeNode(int x) { val = x; }
- * }
- */
-class Solution {
- public List inorderTraversal(TreeNode root) {
- List list = new ArrayList<>();
- inorderTraversal(root, list);
- return list;
- }
-
- private void inorderTraversal(TreeNode root, List list) {
- if (root == null) {
- return;
- }
- inorderTraversal(root.left, list);
- list.add(root.val);
- inorderTraversal(root.right, list);
- }
-
-}
-```
-
-- 非递归算法
-
-一直向左找到结点的最左结点,中间每到一个结点,将结点压入栈中。到了最左结点时,输出该结点值,然后对该结点右孩子执行上述循环。
+输出: [1,3,2]
-```java
-/**
- * Definition for a binary tree node.
- * public class TreeNode {
- * int val;
- * TreeNode left;
- * TreeNode right;
- * TreeNode(int x) { val = x; }
- * }
- */
-class Solution {
- public List进阶: 递归算法很简单,你可以通过迭代算法完成吗?
-## 题目描述 - ## 解法 diff --git a/solution/0000-0099/0095.Unique Binary Search Trees II/README.md b/solution/0000-0099/0095.Unique Binary Search Trees II/README.md index d9b3840c082d2..70406eb24e886 100644 --- a/solution/0000-0099/0095.Unique Binary Search Trees II/README.md +++ b/solution/0000-0099/0095.Unique Binary Search Trees II/README.md @@ -1,7 +1,30 @@ -# [题目](这里是题目链接,如:https://leetcode-cn.com/problems/shu-zu-zhong-zhong-fu-de-shu-zi-lcof/) +# [95. 不同的二叉搜索树 II](https://leetcode-cn.com/problems/unique-binary-search-trees-ii) ## 题目描述 +给定一个整数 n,生成所有由 1 ... n 为节点所组成的二叉搜索树。
+ +示例:
+ +输入: 3 +输出: +[ + [1,null,3,2], + [3,2,null,1], + [3,1,null,null,2], + [2,1,3], + [1,null,2,null,3] +] +解释: +以上的输出对应以下 5 种不同结构的二叉搜索树: + + 1 3 3 2 1 + \ / / / \ \ + 3 2 1 1 3 2 + / / \ \ + 2 1 2 3 ++ ## 解法 diff --git a/solution/0000-0099/0096.Unique Binary Search Trees/README.md b/solution/0000-0099/0096.Unique Binary Search Trees/README.md index c82f8bbee26c6..276d15a21b81c 100644 --- a/solution/0000-0099/0096.Unique Binary Search Trees/README.md +++ b/solution/0000-0099/0096.Unique Binary Search Trees/README.md @@ -1,53 +1,22 @@ -## 不同的二叉搜索树 -### 题目描述 +# [96. 不同的二叉搜索树](https://leetcode-cn.com/problems/unique-binary-search-trees) -给定一个整数 `n`,求以 `1 ... n` 为节点组成的二叉搜索树有多少种? +## 题目描述 + +
给定一个整数 n,求以 1 ... n 为节点组成的二叉搜索树有多少种?
-**示例:** -``` -输入: 3 -输出: 5 -解释: -给定 n = 3, 一共有 5 种不同结构的二叉搜索树: +示例:
+ +输入: 3
+输出: 5
+解释:
+给定 n = 3, 一共有 5 种不同结构的二叉搜索树:
1 3 3 2 1
\ / / / \ \
3 2 1 1 3 2
/ / \ \
- 2 1 2 3
-```
-
-### 解法
-原问题可拆解为子问题的求解。
-
-二叉搜索树,可以分别以 `1/2/3..n` 做为根节点。所有情况累加起来,也就得到了最终结果。
-
-res[n] 表示整数n组成的二叉搜索树个数。它的左子树可以有`0/1/2...n-1` 个节点,右子树可以有`n-1/n-2...0` 个节点。res[n] 是所有这些情况的加和。
+ 2 1 2 3
-时间复杂度分析:状态总共有 `n` 个,状态转移的复杂度是 `O(n)`,所以总时间复杂度是 `O(n²)`。
-
-```java
-class Solution {
- public int numTrees(int n) {
-
- // res[n] 表示整数n组成的二叉搜索树个数
- int[] res = new int[n + 1];
- res[0] = 1;
-
- for (int i = 1; i <= n; ++i) {
- for (int j = 0; j < i; ++j) {
- res[i] += res[j] * res[i - j - 1];
- }
- }
- return res[n];
- }
-}
-```
-
-# [题目](这里是题目链接,如:https://leetcode-cn.com/problems/shu-zu-zhong-zhong-fu-de-shu-zi-lcof/)
-
-## 题目描述
-
## 解法
diff --git a/solution/0000-0099/0097.Interleaving String/README.md b/solution/0000-0099/0097.Interleaving String/README.md
index e69de29bb2d1d..a1a86b7b6d731 100644
--- a/solution/0000-0099/0097.Interleaving String/README.md
+++ b/solution/0000-0099/0097.Interleaving String/README.md
@@ -0,0 +1,41 @@
+# [97. 交错字符串](https://leetcode-cn.com/problems/interleaving-string)
+
+## 题目描述
+
+给定三个字符串 s1, s2, s3, 验证 s3 是否是由 s1 和 s2 交错组成的。
+ +示例 1:
+ +输入: s1 = "aabcc", s2 = "dbbca", s3 = "aadbbcbcac" +输出: true ++ +
示例 2:
+ +输入: s1 = "aabcc", s2 = "dbbca", s3 = "aadbbbaccc" +输出: false+ + + +## 解法 + + + +### Python3 + + +```python + +``` + +### Java + + +```java + +``` + +### ... +``` + +``` diff --git a/solution/0000-0099/0098.Validate Binary Search Tree/README.md b/solution/0000-0099/0098.Validate Binary Search Tree/README.md index d9b3840c082d2..3a33eb92c5e58 100644 --- a/solution/0000-0099/0098.Validate Binary Search Tree/README.md +++ b/solution/0000-0099/0098.Validate Binary Search Tree/README.md @@ -1,7 +1,39 @@ -# [题目](这里是题目链接,如:https://leetcode-cn.com/problems/shu-zu-zhong-zhong-fu-de-shu-zi-lcof/) +# [98. 验证二叉搜索树](https://leetcode-cn.com/problems/validate-binary-search-tree) ## 题目描述 +
给定一个二叉树,判断其是否是一个有效的二叉搜索树。
+ +假设一个二叉搜索树具有如下特征:
+ +-
+
- 节点的左子树只包含小于当前节点的数。 +
- 节点的右子树只包含大于当前节点的数。 +
- 所有左子树和右子树自身必须也是二叉搜索树。 +
示例 1:
+ +输入: + 2 + / \ + 1 3 +输出: true ++ +
示例 2:
+ +输入: + 5 + / \ + 1 4 + / \ + 3 6 +输出: false +解释: 输入为: [5,1,4,null,null,3,6]。 + 根节点的值为 5 ,但是其右子节点值为 4 。 ++ ## 解法 diff --git a/solution/0000-0099/0099.Recover Binary Search Tree/README.md b/solution/0000-0099/0099.Recover Binary Search Tree/README.md index d9b3840c082d2..67f64259618f8 100644 --- a/solution/0000-0099/0099.Recover Binary Search Tree/README.md +++ b/solution/0000-0099/0099.Recover Binary Search Tree/README.md @@ -1,7 +1,55 @@ -# [题目](这里是题目链接,如:https://leetcode-cn.com/problems/shu-zu-zhong-zhong-fu-de-shu-zi-lcof/) +# [99. 恢复二叉搜索树](https://leetcode-cn.com/problems/recover-binary-search-tree) ## 题目描述 +
二叉搜索树中的两个节点被错误地交换。
+ +请在不改变其结构的情况下,恢复这棵树。
+ +示例 1:
+ +输入: [1,3,null,null,2] + + 1 + / + 3 + \ + 2 + +输出: [3,1,null,null,2] + + 3 + / + 1 + \ + 2 ++ +
示例 2:
+ +输入: [3,1,4,null,null,2] + + 3 + / \ +1 4 + / + 2 + +输出: [2,1,4,null,null,3] + + 2 + / \ +1 4 + / + 3+ +
进阶:
+ +-
+
- 使用 O(n) 空间复杂度的解法很容易实现。 +
- 你能想出一个只使用常数空间的解决方案吗? +
给定两个二叉树,编写一个函数来检验它们是否相同。
-示例 1: -``` -输入: 1 1 +如果两个树在结构上相同,并且节点具有相同的值,则认为它们是相同的。
+ +示例 1:
+ +输入: 1 1
/ \ / \
2 3 2 3
[1,2,3], [1,2,3]
-输出: true
-```
+输出: true
+示例 2:
-示例 2: -``` -输入: 1 1 +输入: 1 1
/ \
2 2
[1,2], [1,null,2]
-输出: false
-```
+输出: false
+
+示例 3:
-示例 3: -``` -输入: 1 1 +输入: 1 1
/ \ / \
2 1 1 2
[1,2,1], [1,1,2]
-输出: false
-```
-
-# [题目](这里是题目链接,如:https://leetcode-cn.com/problems/shu-zu-zhong-zhong-fu-de-shu-zi-lcof/)
+输出: false
+
-## 题目描述
-
## 解法
diff --git a/solution/0100-0199/0101.Symmetric Tree/README.md b/solution/0100-0199/0101.Symmetric Tree/README.md
index d9b3840c082d2..b4de08dc7d4f5 100644
--- a/solution/0100-0199/0101.Symmetric Tree/README.md
+++ b/solution/0100-0199/0101.Symmetric Tree/README.md
@@ -1,7 +1,31 @@
-# [题目](这里是题目链接,如:https://leetcode-cn.com/problems/shu-zu-zhong-zhong-fu-de-shu-zi-lcof/)
+# [101. 对称二叉树](https://leetcode-cn.com/problems/symmetric-tree)
## 题目描述
+给定一个二叉树,检查它是否是镜像对称的。
+ +例如,二叉树 [1,2,2,3,4,4,3] 是对称的。
1 + / \ + 2 2 + / \ / \ +3 4 4 3 ++ +
但是下面这个 [1,2,2,null,3,null,3] 则不是镜像对称的:
1 + / \ + 2 2 + \ \ + 3 3 ++ +
说明:
+ +如果你可以运用递归和迭代两种方法解决这个问题,会很加分。
+ ## 解法 diff --git a/solution/0100-0199/0102.Binary Tree Level Order Traversal/README.md b/solution/0100-0199/0102.Binary Tree Level Order Traversal/README.md index e400b932db85d..7b55b390a38ab 100644 --- a/solution/0100-0199/0102.Binary Tree Level Order Traversal/README.md +++ b/solution/0100-0199/0102.Binary Tree Level Order Traversal/README.md @@ -1,76 +1,28 @@ -## 二叉树的层次遍历 -### 题目描述 +# [102. 二叉树的层次遍历](https://leetcode-cn.com/problems/binary-tree-level-order-traversal) -给定一个二叉树,返回其按层次遍历的节点值。 (即逐层地,从左到右访问所有节点)。 +## 题目描述 + +给定一个二叉树,返回其按层次遍历的节点值。 (即逐层地,从左到右访问所有节点)。
-例如: -给定二叉树: `[3,9,20,null,null,15,7]`, -``` +例如:
+给定二叉树: [3,9,20,null,null,15,7],
3
/ \
9 20
/ \
15 7
-```
+
-返回其层次遍历结果:
-```
-[
+返回其层次遍历结果:
+ +[ [3], [9,20], [15,7] ] -``` - -### 解法 -利用队列,存储二叉树结点。`size` 表示每一层的结点数量,也就是内层循环的次数。 +-```java -/** - * Definition for a binary tree node. - * public class TreeNode { - * int val; - * TreeNode left; - * TreeNode right; - * TreeNode(int x) { val = x; } - * } - */ -class Solution { - public List
给定一个二叉树,返回其节点值的锯齿形层次遍历。(即先从左往右,再从右往左进行下一层遍历,以此类推,层与层之间交替进行)。
+ +例如:
+给定二叉树 [3,9,20,null,null,15,7],
3 + / \ + 9 20 + / \ + 15 7 ++ +
返回锯齿形层次遍历如下:
+ +[ + [3], + [20,9], + [15,7] +] ++ ## 解法 diff --git a/solution/0100-0199/0104.Maximum Depth of Binary Tree/README.md b/solution/0100-0199/0104.Maximum Depth of Binary Tree/README.md index d9b3840c082d2..7bd85550dfc60 100644 --- a/solution/0100-0199/0104.Maximum Depth of Binary Tree/README.md +++ b/solution/0100-0199/0104.Maximum Depth of Binary Tree/README.md @@ -1,7 +1,24 @@ -# [题目](这里是题目链接,如:https://leetcode-cn.com/problems/shu-zu-zhong-zhong-fu-de-shu-zi-lcof/) +# [104. 二叉树的最大深度](https://leetcode-cn.com/problems/maximum-depth-of-binary-tree) ## 题目描述 +
给定一个二叉树,找出其最大深度。
+ +二叉树的深度为根节点到最远叶子节点的最长路径上的节点数。
+ +说明: 叶子节点是指没有子节点的节点。
+ +示例:
+给定二叉树 [3,9,20,null,null,15,7],
3 + / \ + 9 20 + / \ + 15 7+ +
返回它的最大深度 3 。
+ ## 解法 diff --git a/solution/0100-0199/0105.Construct Binary Tree from Preorder and Inorder Traversal/README.md b/solution/0100-0199/0105.Construct Binary Tree from Preorder and Inorder Traversal/README.md index b08ba6152c02b..24bfdb22ad6f7 100644 --- a/solution/0100-0199/0105.Construct Binary Tree from Preorder and Inorder Traversal/README.md +++ b/solution/0100-0199/0105.Construct Binary Tree from Preorder and Inorder Traversal/README.md @@ -1,77 +1,25 @@ -## 从前序与中序遍历序列构造二叉树 +# [105. 从前序与中序遍历序列构造二叉树](https://leetcode-cn.com/problems/construct-binary-tree-from-preorder-and-inorder-traversal) -### 问题描述 -根据一棵树的前序遍历与中序遍历构造二叉树。 +## 题目描述 + +根据一棵树的前序遍历与中序遍历构造二叉树。
-**注意:** +注意:
+你可以假设树中没有重复的元素。
例如,给出
-例如,给出 -``` -前序遍历 preorder = [3,9,20,15,7] -中序遍历 inorder = [9,3,15,20,7] -``` +前序遍历 preorder = [3,9,20,15,7] +中序遍历 inorder = [9,3,15,20,7]-返回如下的二叉树: -``` - 3 +
返回如下的二叉树:
+ + 3
/ \
9 20
/ \
- 15 7
-```
-
-### 解法
+ 15 7
-利用树的前序遍历和中序遍历特性 + 递归实现。
-
-对树进行前序遍历,每一个元素,在树的中序遍历中找到该元素;在中序遍历中,该元素的左边是它的左子树的全部元素,右边是它的右子树的全部元素,以此为递归条件,确定左右子树的范围。
-
-```java
-/**
- * Definition for a binary tree node.
- * class TreeNode {
- * int val;
- * TreeNode left;
- * TreeNode right;
- * TreeNode(int x) { val = x; }
- * }
- */
-class Solution {
- public TreeNode buildTree(int[] preorder, int[] inorder) {
- if (preorder == null || inorder == null || preorder.length != inorder.length) {
- return null;
- }
- int n = preorder.length;
- return n > 0 ? buildTree(preorder, 0, n - 1, inorder, 0, n - 1) : null;
- }
-
- private TreeNode buildTree(int[] preorder, int s1, int e1, int[] inorder, int s2, int e2) {
- TreeNode node = new TreeNode(preorder[s1]);
- if (s1 == e1 && s2 == e2) {
- return node;
- }
-
- int p = s2;
- while (inorder[p] != preorder[s1]) {
- ++p;
- if (p > e2) {
- throw new IllegalArgumentException("Invalid input!");
- }
- }
-
- node.left = p > s2 ? buildTree(preorder, s1 + 1, s1 - s2 + p, inorder, s2, p - 1) : null;
- node.right = p < e2 ? buildTree(preorder, s1 - s2 + p + 1, e1, inorder, p + 1, e2) : null;
- return node;
- }
-}
-```
-
-# [题目](这里是题目链接,如:https://leetcode-cn.com/problems/shu-zu-zhong-zhong-fu-de-shu-zi-lcof/)
-
-## 题目描述
-
## 解法
diff --git a/solution/0100-0199/0106.Construct Binary Tree from Inorder and Postorder Traversal/README.md b/solution/0100-0199/0106.Construct Binary Tree from Inorder and Postorder Traversal/README.md
index b6f3496856c3d..09a0d3418ae7b 100644
--- a/solution/0100-0199/0106.Construct Binary Tree from Inorder and Postorder Traversal/README.md
+++ b/solution/0100-0199/0106.Construct Binary Tree from Inorder and Postorder Traversal/README.md
@@ -1,78 +1,26 @@
-## 从中序与后序遍历序列构造二叉树
+# [106. 从中序与后序遍历序列构造二叉树](https://leetcode-cn.com/problems/construct-binary-tree-from-inorder-and-postorder-traversal)
-### 问题描述
-根据一棵树的中序遍历与后序遍历构造二叉树。
+## 题目描述
+
+根据一棵树的中序遍历与后序遍历构造二叉树。
-**注意:** +注意:
+你可以假设树中没有重复的元素。
例如,给出
-例如,给出 -``` -中序遍历 inorder = [9,3,15,20,7] -后序遍历 postorder = [9,15,7,20,3] -``` +中序遍历 inorder = [9,3,15,20,7] +后序遍历 postorder = [9,15,7,20,3]-返回如下的二叉树: -``` - 3 +
返回如下的二叉树:
+ + 3
/ \
9 20
/ \
15 7
-```
-
-### 解法
+
-利用树的后序遍历和中序遍历特性 + 递归实现。
-
-树的后序遍历序列,从后往前,对于每一个元素,在树的中序遍历中找到该元素;在中序遍历中,该元素的左边是它的左子树的全部元素,右边是它的右子树的全部元素,以此为递归条件,确定左右子树的范围。
-
-```java
-/**
- * Definition for a binary tree node.
- * public class TreeNode {
- * int val;
- * TreeNode left;
- * TreeNode right;
- * TreeNode(int x) { val = x; }
- * }
- */
-class Solution {
- public TreeNode buildTree(int[] inorder, int[] postorder) {
- if (inorder == null || postorder == null || inorder.length != postorder.length) {
- return null;
- }
- int n = inorder.length;
- return n > 0 ? buildTree(inorder, 0, n - 1, postorder, 0, n - 1) : null;
- }
-
- private TreeNode buildTree(int[] inorder, int s1, int e1, int[] postorder, int s2, int e2) {
- TreeNode node = new TreeNode(postorder[e2]);
- if (s2 == e2 && s1 == e1) {
- return node;
- }
-
- int p = s1;
- while (inorder[p] != postorder[e2]) {
- ++p;
- if (p > e1) {
- throw new IllegalArgumentException("Invalid input!");
- }
- }
-
- node.left = p > s1 ? buildTree(inorder, s1, p - 1, postorder, s2, p - 1 + s2 - s1) : null;
- node.right = p < e1 ? buildTree(inorder, p + 1, e1, postorder, p + s2 - s1, e2 - 1) : null;
- return node;
-
- }
-}
-```
-
-# [题目](这里是题目链接,如:https://leetcode-cn.com/problems/shu-zu-zhong-zhong-fu-de-shu-zi-lcof/)
-
-## 题目描述
-
## 解法
diff --git a/solution/0100-0199/0107.Binary Tree Level Order Traversal II/README.md b/solution/0100-0199/0107.Binary Tree Level Order Traversal II/README.md
index d9b3840c082d2..c7cda6cb4995d 100644
--- a/solution/0100-0199/0107.Binary Tree Level Order Traversal II/README.md
+++ b/solution/0100-0199/0107.Binary Tree Level Order Traversal II/README.md
@@ -1,7 +1,28 @@
-# [题目](这里是题目链接,如:https://leetcode-cn.com/problems/shu-zu-zhong-zhong-fu-de-shu-zi-lcof/)
+# [107. 二叉树的层次遍历 II](https://leetcode-cn.com/problems/binary-tree-level-order-traversal-ii)
## 题目描述
+给定一个二叉树,返回其节点值自底向上的层次遍历。 (即按从叶子节点所在层到根节点所在的层,逐层从左向右遍历)
+ +例如:
+给定二叉树 [3,9,20,null,null,15,7],
3 + / \ + 9 20 + / \ + 15 7 ++ +
返回其自底向上的层次遍历为:
+ +[ + [15,7], + [9,20], + [3] +] ++ ## 解法 diff --git a/solution/0100-0199/0108.Convert Sorted Array to Binary Search Tree/README.md b/solution/0100-0199/0108.Convert Sorted Array to Binary Search Tree/README.md index d9b3840c082d2..67d3e43f8cad8 100644 --- a/solution/0100-0199/0108.Convert Sorted Array to Binary Search Tree/README.md +++ b/solution/0100-0199/0108.Convert Sorted Array to Binary Search Tree/README.md @@ -1,7 +1,24 @@ -# [题目](这里是题目链接,如:https://leetcode-cn.com/problems/shu-zu-zhong-zhong-fu-de-shu-zi-lcof/) +# [108. 将有序数组转换为二叉搜索树](https://leetcode-cn.com/problems/convert-sorted-array-to-binary-search-tree) ## 题目描述 +
将一个按照升序排列的有序数组,转换为一棵高度平衡二叉搜索树。
+ +本题中,一个高度平衡二叉树是指一个二叉树每个节点 的左右两个子树的高度差的绝对值不超过 1。
+ +示例:
+ +给定有序数组: [-10,-3,0,5,9], + +一个可能的答案是:[0,-3,9,-10,null,5],它可以表示下面这个高度平衡二叉搜索树: + + 0 + / \ + -3 9 + / / + -10 5 ++ ## 解法 diff --git a/solution/0100-0199/0109.Convert Sorted List to Binary Search Tree/README.md b/solution/0100-0199/0109.Convert Sorted List to Binary Search Tree/README.md index d9b3840c082d2..3751d8a479f1c 100644 --- a/solution/0100-0199/0109.Convert Sorted List to Binary Search Tree/README.md +++ b/solution/0100-0199/0109.Convert Sorted List to Binary Search Tree/README.md @@ -1,7 +1,24 @@ -# [题目](这里是题目链接,如:https://leetcode-cn.com/problems/shu-zu-zhong-zhong-fu-de-shu-zi-lcof/) +# [109. 有序链表转换二叉搜索树](https://leetcode-cn.com/problems/convert-sorted-list-to-binary-search-tree) ## 题目描述 +
给定一个单链表,其中的元素按升序排序,将其转换为高度平衡的二叉搜索树。
+ +本题中,一个高度平衡二叉树是指一个二叉树每个节点 的左右两个子树的高度差的绝对值不超过 1。
+ +示例:
+ +给定的有序链表: [-10, -3, 0, 5, 9], + +一个可能的答案是:[0, -3, 9, -10, null, 5], 它可以表示下面这个高度平衡二叉搜索树: + + 0 + / \ + -3 9 + / / + -10 5 ++ ## 解法 diff --git a/solution/0100-0199/0110.Balanced Binary Tree/README.md b/solution/0100-0199/0110.Balanced Binary Tree/README.md index d9b3840c082d2..5316560bafe3c 100644 --- a/solution/0100-0199/0110.Balanced Binary Tree/README.md +++ b/solution/0100-0199/0110.Balanced Binary Tree/README.md @@ -1,7 +1,44 @@ -# [题目](这里是题目链接,如:https://leetcode-cn.com/problems/shu-zu-zhong-zhong-fu-de-shu-zi-lcof/) +# [110. 平衡二叉树](https://leetcode-cn.com/problems/balanced-binary-tree) ## 题目描述 +
给定一个二叉树,判断它是否是高度平衡的二叉树。
+ +本题中,一棵高度平衡二叉树定义为:
+ +++ +一个二叉树每个节点 的左右两个子树的高度差的绝对值不超过1。
+
示例 1:
+ +给定二叉树 [3,9,20,null,null,15,7]
3 + / \ + 9 20 + / \ + 15 7+ +
返回 true 。
+
+示例 2:
给定二叉树 [1,2,2,3,3,null,null,4,4]
1 + / \ + 2 2 + / \ + 3 3 + / \ + 4 4 ++ +
返回 false 。
+ ## 解法 diff --git a/solution/0100-0199/0111.Minimum Depth of Binary Tree/README.md b/solution/0100-0199/0111.Minimum Depth of Binary Tree/README.md index d9b3840c082d2..2a135630006c0 100644 --- a/solution/0100-0199/0111.Minimum Depth of Binary Tree/README.md +++ b/solution/0100-0199/0111.Minimum Depth of Binary Tree/README.md @@ -1,7 +1,25 @@ -# [题目](这里是题目链接,如:https://leetcode-cn.com/problems/shu-zu-zhong-zhong-fu-de-shu-zi-lcof/) +# [111. 二叉树的最小深度](https://leetcode-cn.com/problems/minimum-depth-of-binary-tree) ## 题目描述 +
给定一个二叉树,找出其最小深度。
+ +最小深度是从根节点到最近叶子节点的最短路径上的节点数量。
+ +说明: 叶子节点是指没有子节点的节点。
+ +示例:
+ +给定二叉树 [3,9,20,null,null,15,7],
3 + / \ + 9 20 + / \ + 15 7+ +
返回它的最小深度 2.
+ ## 解法 diff --git a/solution/0100-0199/0112.Path Sum/README.md b/solution/0100-0199/0112.Path Sum/README.md index 6c01b709ab395..4cf81303ff739 100644 --- a/solution/0100-0199/0112.Path Sum/README.md +++ b/solution/0100-0199/0112.Path Sum/README.md @@ -1,66 +1,25 @@ -## 路径总和 +# [112. 路径总和](https://leetcode-cn.com/problems/path-sum) -### 问题描述 +## 题目描述 + +给定一个二叉树和一个目标和,判断该树中是否存在根节点到叶子节点的路径,这条路径上所有节点值相加等于目标和。
-给定一个二叉树和一个目标和,判断该树中是否存在根节点到叶子节点的路径,这条路径上所有节点值相加等于目标和。 +说明: 叶子节点是指没有子节点的节点。
-说明: 叶子节点是指没有子节点的节点。 +示例:
+给定如下二叉树,以及目标和 sum = 22,
5
/ \
- 4 8
+ 4 8
/ / \
- 11 13 4
+ 11 13 4
/ \ \
- 7 2 1
-```
-返回 true, 因为存在目标和为 22 的根节点到叶子节点的路径 5->4->11->2。
-
-
-### 思路
-
-题目要求有没有路径到**叶子节点**使和等于目标值
-
-主要考察对叶子节点是否判断准确
-
-这道题很简单,但是准确率不高,原因是的判断条件不明确,左空右不空返回什么什么,右空左不空返回什么什么,调试一直错
-
-叶子节点唯一判断就是左右空
-
-`root->left == NULL && root->right==NULL`
-
-```CPP
-/**
- * Definition for a binary tree node.
- * struct TreeNode {
- * int val;
- * TreeNode *left;
- * TreeNode *right;
- * TreeNode(int x) : val(x), left(NULL), right(NULL) {}
- * };
- */
-class Solution {
-public:
- bool hasPathSum(TreeNode* root, int sum) {
-
- if(root == NULL)return false;
- if(root->right == NULL && root->left == NULL && sum == root->val)return true;
-
- bool leftTrue = hasPathSum(root->left,sum - root->val);
- bool rightTrue = hasPathSum(root->right,sum - root->val);
-
- return (leftTrue || rightTrue);
- }
-};
-```
+ 7 2 1
+
-# [题目](这里是题目链接,如:https://leetcode-cn.com/problems/shu-zu-zhong-zhong-fu-de-shu-zi-lcof/)
+返回 true, 因为存在目标和为 22 的根节点到叶子节点的路径 5->4->11->2。
给定一个二叉树和一个目标和,找到所有从根节点到叶子节点路径总和等于给定目标和的路径。
+ +说明: 叶子节点是指没有子节点的节点。
+ +示例:
+给定如下二叉树,以及目标和 sum = 22,
5 + / \ + 4 8 + / / \ + 11 13 4 + / \ / \ + 7 2 5 1 ++ +
返回:
+ +[ + [5,4,11,2], + [5,8,4,5] +] ++ ## 解法 diff --git a/solution/0100-0199/0114.Flatten Binary Tree to Linked List/README.md b/solution/0100-0199/0114.Flatten Binary Tree to Linked List/README.md index d9b3840c082d2..34c45aecc4cb3 100644 --- a/solution/0100-0199/0114.Flatten Binary Tree to Linked List/README.md +++ b/solution/0100-0199/0114.Flatten Binary Tree to Linked List/README.md @@ -1,7 +1,31 @@ -# [题目](这里是题目链接,如:https://leetcode-cn.com/problems/shu-zu-zhong-zhong-fu-de-shu-zi-lcof/) +# [114. 二叉树展开为链表](https://leetcode-cn.com/problems/flatten-binary-tree-to-linked-list) ## 题目描述 +
给定一个二叉树,原地将它展开为链表。
+ +例如,给定二叉树
+ +1 + / \ + 2 5 + / \ \ +3 4 6+ +
将其展开为:
+ +1 + \ + 2 + \ + 3 + \ + 4 + \ + 5 + \ + 6+ ## 解法 diff --git a/solution/0100-0199/0115.Distinct Subsequences/README.md b/solution/0100-0199/0115.Distinct Subsequences/README.md index d9b3840c082d2..30d267c5aea71 100644 --- a/solution/0100-0199/0115.Distinct Subsequences/README.md +++ b/solution/0100-0199/0115.Distinct Subsequences/README.md @@ -1,7 +1,48 @@ -# [题目](这里是题目链接,如:https://leetcode-cn.com/problems/shu-zu-zhong-zhong-fu-de-shu-zi-lcof/) +# [115. 不同的子序列](https://leetcode-cn.com/problems/distinct-subsequences) ## 题目描述 +
给定一个字符串 S 和一个字符串 T,计算在 S 的子序列中 T 出现的个数。
+ +一个字符串的一个子序列是指,通过删除一些(也可以不删除)字符且不干扰剩余字符相对位置所组成的新字符串。(例如,"ACE" 是 "ABCDE" 的一个子序列,而 "AEC" 不是)
示例 1:
+ +输入: S =+ +"rabbbit", T ="rabbit" +输出: 3 +解释: + +如下图所示, 有 3 种可以从 S 中得到"rabbit" 的方案。 +(上箭头符号 ^ 表示选取的字母) + +rabbbit+^^^^ ^^ +rabbbit+^^ ^^^^ +rabbbit+^^^ ^^^ +
示例 2:
+ +输入: S =+ ## 解法 diff --git a/solution/0100-0199/0116.Populating Next Right Pointers in Each Node/README.md b/solution/0100-0199/0116.Populating Next Right Pointers in Each Node/README.md index d9b3840c082d2..52af66ec44fb9 100644 --- a/solution/0100-0199/0116.Populating Next Right Pointers in Each Node/README.md +++ b/solution/0100-0199/0116.Populating Next Right Pointers in Each Node/README.md @@ -1,7 +1,42 @@ -# [题目](这里是题目链接,如:https://leetcode-cn.com/problems/shu-zu-zhong-zhong-fu-de-shu-zi-lcof/) +# [116. 填充每个节点的下一个右侧节点指针](https://leetcode-cn.com/problems/populating-next-right-pointers-in-each-node) ## 题目描述 +"babgbag", T ="bag" +输出: 5 +解释: + +如下图所示, 有 5 种可以从 S 中得到"bag" 的方案。 +(上箭头符号 ^ 表示选取的字母) + +babgbag+^^ ^ +babgbag+^^ ^ +babgbag+^ ^^ +babgbag+ ^ ^^ +babgbag+ ^^^
给定一个完美二叉树,其所有叶子节点都在同一层,每个父节点都有两个子节点。二叉树定义如下:
+ +struct Node {
+ int val;
+ Node *left;
+ Node *right;
+ Node *next;
+}
+
+填充它的每个 next 指针,让这个指针指向其下一个右侧节点。如果找不到下一个右侧节点,则将 next 指针设置为 NULL。
初始状态下,所有 next 指针都被设置为 NULL。
+ +
示例:
+ +
输入:{"$id":"1","left":{"$id":"2","left":{"$id":"3","left":null,"next":null,"right":null,"val":4},"next":null,"right":{"$id":"4","left":null,"next":null,"right":null,"val":5},"val":2},"next":null,"right":{"$id":"5","left":{"$id":"6","left":null,"next":null,"right":null,"val":6},"next":null,"right":{"$id":"7","left":null,"next":null,"right":null,"val":7},"val":3},"val":1}
+
+输出:{"$id":"1","left":{"$id":"2","left":{"$id":"3","left":null,"next":{"$id":"4","left":null,"next":{"$id":"5","left":null,"next":{"$id":"6","left":null,"next":null,"right":null,"val":7},"right":null,"val":6},"right":null,"val":5},"right":null,"val":4},"next":{"$id":"7","left":{"$ref":"5"},"next":null,"right":{"$ref":"6"},"val":3},"right":{"$ref":"4"},"val":2},"next":null,"right":{"$ref":"7"},"val":1}
+
+解释:给定二叉树如图 A 所示,你的函数应该填充它的每个 next 指针,以指向其下一个右侧节点,如图 B 所示。
+
+
++ +
提示:
+ +-
+
- 你只能使用常量级额外空间。 +
- 使用递归解题也符合要求,本题中递归程序占用的栈空间不算做额外的空间复杂度。 +
给定一个二叉树
+ +struct Node {
+ int val;
+ Node *left;
+ Node *right;
+ Node *next;
+}
+
+填充它的每个 next 指针,让这个指针指向其下一个右侧节点。如果找不到下一个右侧节点,则将 next 指针设置为 NULL。
初始状态下,所有 next 指针都被设置为 NULL。
+ +
进阶:
+ +-
+
- 你只能使用常量级额外空间。 +
- 使用递归解题也符合要求,本题中递归程序占用的栈空间不算做额外的空间复杂度。 +
+ +
示例:
+ +
输入:root = [1,2,3,4,5,null,7] +输出:[1,#,2,3,#,4,5,7,#] +解释:给定二叉树如图 A 所示,你的函数应该填充它的每个 next 指针,以指向其下一个右侧节点,如图 B 所示。+ +
+ +
提示:
+ +-
+
- 树中的节点数小于
6000
+ -100 <= node.val <= 100
+
+ +
-
+
给定一个非负整数 numRows,生成杨辉三角的前 numRows 行。
- +
在杨辉三角中,每个数是它左上方和右上方的数的和。
-``` -示例: -输入: 5 -输出: +示例:
+ +输入: 5
+输出:
[
[1],
[1,1],
[1,2,1],
[1,3,3,1],
[1,4,6,4,1]
-]
-```
-
-### 思路
-
-杨辉三角的特征是:
-
-- 所有行的首元素和末尾元素都是1
-- 除第一和第二行外,所有非首端末端元素都是前一行同列与前一列之和`matrix[i][j] = matrix[i-1][j]+matrix[i-1][j-1];`
-
-```CPP
-class Solution {
-public:
- vector> generate(int numRows) {
- vector> ans;
-
- for(int i = 0;i tmp(i+1);
- tmp[0] = 1;//最左侧为1
- for(int j = 1;j<=i;j++){
- if(i == j)//最右侧为1
- {
- tmp[j] = 1;
- break;
- }
- tmp[j] = ans[i-1][j-1] + ans[i-1][j];
- }
- ans.push_back(tmp);
- }
- return ans;
- }
-};
-```
+]
-```JS
-const generate = function(numRows){
- let arr = [];
- for(let i = 0; i < numRows; i++){
- let row = [];
- row[0]=1;
- row[i] = 1;
-
- for(let j = 1; j < row.length - 1; j++){
- row[j] = arr[i-1][j-1] + arr[i-1][j];
- }
- arr.push(row);
- }
- return arr;
-}
-
-```
-
-# [题目](这里是题目链接,如:https://leetcode-cn.com/problems/shu-zu-zhong-zhong-fu-de-shu-zi-lcof/)
-
-## 题目描述
-
## 解法
diff --git a/solution/0100-0199/0119.Pascal's Triangle II/README.md b/solution/0100-0199/0119.Pascal's Triangle II/README.md
index 4df0a69920488..81cc457ac5b6e 100644
--- a/solution/0100-0199/0119.Pascal's Triangle II/README.md
+++ b/solution/0100-0199/0119.Pascal's Triangle II/README.md
@@ -1,56 +1,23 @@
-## 杨辉三角 II
+# [119. 杨辉三角 II](https://leetcode-cn.com/problems/pascals-triangle-ii)
-### 问题描述
-给定一个非负索引 k,其中 k ≤ 33,返回杨辉三角的第 k 行。
-
-
-
-在杨辉三角中,每个数是它左上方和右上方的数的和。
-
-```
-示例:
-
-输入: 3
-输出: [1,3,3,1]
-```
-进阶:
-
-你可以优化你的算法到 O(k) 空间复杂度吗?
-
-----------
-### 思路
+## 题目描述
+
+给定一个非负索引 k,其中 k ≤ 33,返回杨辉三角的第 k 行。
-利用滚动数组的思想(和118题一样,省了行坐标): +
在杨辉三角中,每个数是它左上方和右上方的数的和。
-`col[j] = col[j]+col[j-1];` +示例:
-**注意**:因为使用了`j-1`列和`j`列,为了防止重叠,不能从前往后跟新数组;只能从后往前 +输入: 3 +输出: [1,3,3,1] +-```CPP -class Solution { -public: - vector
进阶:
-``` +你可以优化你的算法到 O(k) 空间复杂度吗?
-# [题目](这里是题目链接,如:https://leetcode-cn.com/problems/shu-zu-zhong-zhong-fu-de-shu-zi-lcof/) - -## 题目描述 - ## 解法 diff --git a/solution/0100-0199/0120.Triangle/README.md b/solution/0100-0199/0120.Triangle/README.md index 84eb44224f995..a1ee7d6f6de95 100644 --- a/solution/0100-0199/0120.Triangle/README.md +++ b/solution/0100-0199/0120.Triangle/README.md @@ -1,87 +1,25 @@ -## 三角形最小路径和 +# [120. 三角形最小路径和](https://leetcode-cn.com/problems/triangle) -### 问题描述 +## 题目描述 + +给定一个三角形,找出自顶向下的最小路径和。每一步只能移动到下一行中相邻的结点上。
-给定一个三角形,找出自顶向下的最小路径和。每一步只能移动到下一行中相邻的结点上。 +例如,给定三角形:
-例如,给定三角形: -``` -[ - [2], - [3,4], - [6,5,7], - [4,1,8,3] +[ + [2], + [3,4], + [6,5,7], + [4,1,8,3] ] -``` -自顶向下的最小路径和为 11(即,2 + 3 + 5 + 1 = 11)。 - -说明: - -如果你可以只使用 O(n) 的额外空间(n 为三角形的总行数)来解决这个问题,那么你的算法会很加分。 - ----------- -### 思想: - -方法和119题如出一辙,都是利用**滚动数组**的原理(既对数组按特定规则进行条件层层处理,如同滚动) - -方法是对每一个元素(除第一行)都构建最短路径 - -- 对于**左右边界**,最短路径只能是 +-``` -triangle[i][0] = triangle[i-1][0] -以及 -triangle[i][j] = triangle[i][j] + triangle[i-1][j-1] (j = i时成立) -``` - -- 对于**非左右边界**的其他任意值,其最短路径公式为 - -``` -triangle[i][j] = triangle[i][j] + min(triangle[i-1][j],triangle[i-1][j-1] -``` - -- 对重新整理好的数组,遍历最下面一行元素,找最小值 - -- O(1) 额外空间!!!! - -```CPP -class Solution { -public: - int minimumTotal(vector
自顶向下的最小路径和为 11(即,2 + 3 + 5 + 1 = 11)。
说明:
-# [题目](这里是题目链接,如:https://leetcode-cn.com/problems/shu-zu-zhong-zhong-fu-de-shu-zi-lcof/) +如果你可以只使用 O(n) 的额外空间(n 为三角形的总行数)来解决这个问题,那么你的算法会很加分。
-## 题目描述 - ## 解法 diff --git a/solution/0100-0199/0121.Best Time to Buy and Sell Stock/README.md b/solution/0100-0199/0121.Best Time to Buy and Sell Stock/README.md index 7949a5be0c989..dc8c977892f6c 100644 --- a/solution/0100-0199/0121.Best Time to Buy and Sell Stock/README.md +++ b/solution/0100-0199/0121.Best Time to Buy and Sell Stock/README.md @@ -1,37 +1,28 @@ -## 买卖股票的最佳时机 -### 题目描述 +# [121. 买卖股票的最佳时机](https://leetcode-cn.com/problems/best-time-to-buy-and-sell-stock) -给定一个数组,它的第 i 个元素是一支给定股票第 i 天的价格。 +## 题目描述 + +给定一个数组,它的第 i 个元素是一支给定股票第 i 天的价格。
-如果你最多只允许完成一笔交易(即买入和卖出一支股票),设计一个算法来计算你所能获取的最大利润。 +如果你最多只允许完成一笔交易(即买入和卖出一支股票一次),设计一个算法来计算你所能获取的最大利润。
-注意你不能在买入股票前卖出股票。 +注意你不能在买入股票前卖出股票。
-**示例 1:** -``` -输入: [7,1,5,3,6,4] -输出: 5 -解释: 在第 2 天(股票价格 = 1)的时候买入,在第 5 天(股票价格 = 6)的时候卖出,最大利润 = 6-1 = 5 。 - 注意利润不能是 7-1 = 6, 因为卖出价格需要大于买入价格。 -``` +示例 1:
-**示例 2:** -``` -输入: [7,6,4,3,1] -输出: 0 -解释: 在这种情况下, 没有交易完成, 所以最大利润为 0。 -``` - -### 解法 -可以将整个数组中的数画到一张折现图中, 需要求的就是从图中找到一个波谷和一个波峰, 使其二者的差值最大化(其中波谷点需要在波峰点之前)。 - -我们可以维持两个变量, minprice(可能产生最大差值的波谷)初始值最大整数((1 << 31) -1), maxprofit(产生的最大差值)初始值 0, 然后迭代处理数组中的每个数进而优化两个变量的值; 如果数组元素`prices[i]`不比`minprice`大, 那就是目前为止最小波谷, 将 `minprice=prices[i]`;如果数组元素`prices[i]`比`minprice`大, 那就判断`prices[i]`与`minprice`的差值是否比`maxprofit`大, 如果是就更新`maxprofit=prices[i]-minprice`, 并且`minprice`即为波谷, `prices[i]`为波谷; 否的话继续处理下一个数组元素。 +输入: [7,1,5,3,6,4] +输出: 5 +解释: 在第 2 天(股票价格 = 1)的时候买入,在第 5 天(股票价格 = 6)的时候卖出,最大利润 = 6-1 = 5 。 + 注意利润不能是 7-1 = 6, 因为卖出价格需要大于买入价格。 ++
示例 2:
-# [题目](这里是题目链接,如:https://leetcode-cn.com/problems/shu-zu-zhong-zhong-fu-de-shu-zi-lcof/) +输入: [7,6,4,3,1] +输出: 0 +解释: 在这种情况下, 没有交易完成, 所以最大利润为 0。 +-## 题目描述 - ## 解法 @@ -56,4 +47,3 @@ ``` ``` - diff --git a/solution/0100-0199/0122.Best Time to Buy and Sell Stock II/README.md b/solution/0100-0199/0122.Best Time to Buy and Sell Stock II/README.md index 6ea7938607b59..59ee098538a43 100644 --- a/solution/0100-0199/0122.Best Time to Buy and Sell Stock II/README.md +++ b/solution/0100-0199/0122.Best Time to Buy and Sell Stock II/README.md @@ -1,44 +1,36 @@ -## 买卖股票的最佳时机 II -### 题目描述 +# [122. 买卖股票的最佳时机 II](https://leetcode-cn.com/problems/best-time-to-buy-and-sell-stock-ii) -给定一个数组,它的第 i 个元素是一支给定股票第 i 天的价格。 +## 题目描述 + +
给定一个数组,它的第 i 个元素是一支给定股票第 i 天的价格。
-设计一个算法来计算你所能获取的最大利润。你可以尽可能地完成更多的交易(多次买卖一支股票)。 +设计一个算法来计算你所能获取的最大利润。你可以尽可能地完成更多的交易(多次买卖一支股票)。
-注意:你不能同时参与多笔交易(你必须在再次购买前出售掉之前的股票)。 +注意:你不能同时参与多笔交易(你必须在再次购买前出售掉之前的股票)。
-**示例 1:** -``` -输入: [7,1,5,3,6,4] -输出: 7 -解释: 在第 2 天(股票价格 = 1)的时候买入,在第 3 天(股票价格 = 5)的时候卖出, 这笔交易所能获得利润 = 5-1 = 4 。 - 随后,在第 4 天(股票价格 = 3)的时候买入,在第 5 天(股票价格 = 6)的时候卖出, 这笔交易所能获得利润 = 6-3 = 3 。 -``` +示例 1:
-**示例 2:** -``` -输入: [1,2,3,4,5] -输出: 4 -解释: 在第 1 天(股票价格 = 1)的时候买入,在第 5 天 (股票价格 = 5)的时候卖出, 这笔交易所能获得利润 = 5-1 = 4 。 - 注意你不能在第 1 天和第 2 天接连购买股票,之后再将它们卖出。 - 因为这样属于同时参与了多笔交易,你必须在再次购买前出售掉之前的股票。 -``` +输入: [7,1,5,3,6,4] +输出: 7 +解释: 在第 2 天(股票价格 = 1)的时候买入,在第 3 天(股票价格 = 5)的时候卖出, 这笔交易所能获得利润 = 5-1 = 4 。 + 随后,在第 4 天(股票价格 = 3)的时候买入,在第 5 天(股票价格 = 6)的时候卖出, 这笔交易所能获得利润 = 6-3 = 3 。 +-**示例 3:** -``` -输入: [7,6,4,3,1] -输出: 0 -解释: 在这种情况下, 没有交易完成, 所以最大利润为 0。 -``` +
示例 2:
-### 解法 -问题描述中, 允许我们进行多次买入卖出操作, 同时还有一个隐含的条件---同一天内可以先卖出再买入; -我们只需要遵照涨买跌卖原则中的涨买原则, 不断比较连续两天中后一天是否比前一天股价高, 是的话就进行前一天买入, 后一天卖出, 累加利润。 +输入: [1,2,3,4,5] +输出: 4 +解释: 在第 1 天(股票价格 = 1)的时候买入,在第 5 天 (股票价格 = 5)的时候卖出, 这笔交易所能获得利润 = 5-1 = 4 。 + 注意你不能在第 1 天和第 2 天接连购买股票,之后再将它们卖出。 + 因为这样属于同时参与了多笔交易,你必须在再次购买前出售掉之前的股票。 +-# [题目](这里是题目链接,如:https://leetcode-cn.com/problems/shu-zu-zhong-zhong-fu-de-shu-zi-lcof/) +
示例 3:
+ +输入: [7,6,4,3,1] +输出: 0 +解释: 在这种情况下, 没有交易完成, 所以最大利润为 0。-## 题目描述 - ## 解法 diff --git a/solution/0100-0199/0123.Best Time to Buy and Sell Stock III/README.md b/solution/0100-0199/0123.Best Time to Buy and Sell Stock III/README.md index acd2d9645ac55..8bc4b22999202 100644 --- a/solution/0100-0199/0123.Best Time to Buy and Sell Stock III/README.md +++ b/solution/0100-0199/0123.Best Time to Buy and Sell Stock III/README.md @@ -1,94 +1,35 @@ -## 买卖股票的最佳时机 III +# [123. 买卖股票的最佳时机 III](https://leetcode-cn.com/problems/best-time-to-buy-and-sell-stock-iii) -### 问题描述 -给定一个数组,它的第 i 个元素是一支给定的股票在第 i 天的价格。 +## 题目描述 + +
给定一个数组,它的第 i 个元素是一支给定的股票在第 i 天的价格。
-设计一个算法来计算你所能获取的最大利润。你最多可以完成 两笔 交易。 +设计一个算法来计算你所能获取的最大利润。你最多可以完成 两笔 交易。
-注意: 你不能同时参与多笔交易(你必须在再次购买前出售掉之前的股票)。 +注意: 你不能同时参与多笔交易(你必须在再次购买前出售掉之前的股票)。
-示例 1: -``` -输入: [3,3,5,0,0,3,1,4] -输出: 6 -解释: 在第 4 天(股票价格 = 0)的时候买入,在第 6 天(股票价格 = 3)的时候卖出,这笔交易所能获得利润 = 3-0 = 3 。 - 随后,在第 7 天(股票价格 = 1)的时候买入,在第 8 天 (股票价格 = 4)的时候卖出,这笔交易所能获得利润 = 4-1 = 3 。 -``` -示例 2: -``` -输入: [1,2,3,4,5] -输出: 4 -解释: 在第 1 天(股票价格 = 1)的时候买入,在第 5 天 (股票价格 = 5)的时候卖出, 这笔交易所能获得利润 = 5-1 = 4 。 - 注意你不能在第 1 天和第 2 天接连购买股票,之后再将它们卖出。 - 因为这样属于同时参与了多笔交易,你必须在再次购买前出售掉之前的股票。 -``` -示例 3: -``` -输入: [7,6,4,3,1] -输出: 0 -解释: 在这个情况下, 没有交易完成, 所以最大利润为 0。 -``` -------------- -### 思路: - -建立两个数组,因为是只能两次交易,所以有左右数组 - -- 一个数组是`left[i]`,表示在第i天及之前交易的最大利润 -- 一个数组是`right[i]`,表示在第i天及之后交易的最大利润 - -最后同时遍历,求和取出最大值就可以了 - -```CPP -class Solution { -public: - int maxProfit(vector示例 1:
-# [题目](这里是题目链接,如:https://leetcode-cn.com/problems/shu-zu-zhong-zhong-fu-de-shu-zi-lcof/) +输入: [3,3,5,0,0,3,1,4] +输出: 6 +解释: 在第 4 天(股票价格 = 0)的时候买入,在第 6 天(股票价格 = 3)的时候卖出,这笔交易所能获得利润 = 3-0 = 3 。 + 随后,在第 7 天(股票价格 = 1)的时候买入,在第 8 天 (股票价格 = 4)的时候卖出,这笔交易所能获得利润 = 4-1 = 3 。+ +
示例 2:
+ +输入: [1,2,3,4,5] +输出: 4 +解释: 在第 1 天(股票价格 = 1)的时候买入,在第 5 天 (股票价格 = 5)的时候卖出, 这笔交易所能获得利润 = 5-1 = 4 。 + 注意你不能在第 1 天和第 2 天接连购买股票,之后再将它们卖出。 + 因为这样属于同时参与了多笔交易,你必须在再次购买前出售掉之前的股票。 ++ +
示例 3:
+ +输入: [7,6,4,3,1] +输出: 0 +解释: 在这个情况下, 没有交易完成, 所以最大利润为 0。-## 题目描述 - ## 解法 diff --git a/solution/0100-0199/0124.Binary Tree Maximum Path Sum/README.md b/solution/0100-0199/0124.Binary Tree Maximum Path Sum/README.md index d9b3840c082d2..11035b879e680 100644 --- a/solution/0100-0199/0124.Binary Tree Maximum Path Sum/README.md +++ b/solution/0100-0199/0124.Binary Tree Maximum Path Sum/README.md @@ -1,7 +1,34 @@ -# [题目](这里是题目链接,如:https://leetcode-cn.com/problems/shu-zu-zhong-zhong-fu-de-shu-zi-lcof/) +# [124. 二叉树中的最大路径和](https://leetcode-cn.com/problems/binary-tree-maximum-path-sum) ## 题目描述 +
给定一个非空二叉树,返回其最大路径和。
+ +本题中,路径被定义为一条从树中任意节点出发,达到任意节点的序列。该路径至少包含一个节点,且不一定经过根节点。
+ +示例 1:
+ +输入: [1,2,3] + + 1 + / \ + 2 3 + +输出: 6 ++ +
示例 2:
+ +输入: [-10,9,20,null,null,15,7] + + -10 + / \ + 9 20 + / \ + 15 7 + +输出: 42+ ## 解法 diff --git a/solution/0100-0199/0125.Valid Palindrome/README.md b/solution/0100-0199/0125.Valid Palindrome/README.md index d9b3840c082d2..a60c9ab8430de 100644 --- a/solution/0100-0199/0125.Valid Palindrome/README.md +++ b/solution/0100-0199/0125.Valid Palindrome/README.md @@ -1,7 +1,23 @@ -# [题目](这里是题目链接,如:https://leetcode-cn.com/problems/shu-zu-zhong-zhong-fu-de-shu-zi-lcof/) +# [125. 验证回文串](https://leetcode-cn.com/problems/valid-palindrome) ## 题目描述 +
给定一个字符串,验证它是否是回文串,只考虑字母和数字字符,可以忽略字母的大小写。
+ +说明:本题中,我们将空字符串定义为有效的回文串。
+ +示例 1:
+ +输入: "A man, a plan, a canal: Panama" +输出: true ++ +
示例 2:
+ +输入: "race a car" +输出: false ++ ## 解法 diff --git a/solution/0100-0199/0126.Word Ladder II/README.md b/solution/0100-0199/0126.Word Ladder II/README.md index d9b3840c082d2..3f621df9cfaca 100644 --- a/solution/0100-0199/0126.Word Ladder II/README.md +++ b/solution/0100-0199/0126.Word Ladder II/README.md @@ -1,7 +1,49 @@ -# [题目](这里是题目链接,如:https://leetcode-cn.com/problems/shu-zu-zhong-zhong-fu-de-shu-zi-lcof/) +# [126. 单词接龙 II](https://leetcode-cn.com/problems/word-ladder-ii) ## 题目描述 +
给定两个单词(beginWord 和 endWord)和一个字典 wordList,找出所有从 beginWord 到 endWord 的最短转换序列。转换需遵循如下规则:
+ +-
+
- 每次转换只能改变一个字母。 +
- 转换过程中的中间单词必须是字典中的单词。 +
说明:
+ +-
+
- 如果不存在这样的转换序列,返回一个空列表。 +
- 所有单词具有相同的长度。 +
- 所有单词只由小写字母组成。 +
- 字典中不存在重复的单词。 +
- 你可以假设 beginWord 和 endWord 是非空的,且二者不相同。 +
示例 1:
+ +输入: +beginWord = "hit", +endWord = "cog", +wordList = ["hot","dot","dog","lot","log","cog"] + +输出: +[ + ["hit","hot","dot","dog","cog"], + ["hit","hot","lot","log","cog"] +] ++ +
示例 2:
+ +输入: +beginWord = "hit" +endWord = "cog" +wordList = ["hot","dot","dog","lot","log"] + +输出: [] + +解释: endWord "cog" 不在字典中,所以不存在符合要求的转换序列。+ ## 解法 diff --git a/solution/0100-0199/0127.Word Ladder/README.md b/solution/0100-0199/0127.Word Ladder/README.md index 0d5f44e211cb8..39e0acf7f3e64 100644 --- a/solution/0100-0199/0127.Word Ladder/README.md +++ b/solution/0100-0199/0127.Word Ladder/README.md @@ -1,106 +1,48 @@ -## 单词接龙 -### 题目描述 +# [127. 单词接龙](https://leetcode-cn.com/problems/word-ladder) -给定两个单词(beginWord 和 endWord)和一个字典,找到从 beginWord 到 endWord 的最短转换序列的长度。转换需遵循如下规则: - -- 每次转换只能改变一个字母。 -- 转换过程中的中间单词必须是字典中的单词。 - -说明: +## 题目描述 + +
给定两个单词(beginWord 和 endWord)和一个字典,找到从 beginWord 到 endWord 的最短转换序列的长度。转换需遵循如下规则:
-- 如果不存在这样的转换序列,返回 0。 -- 所有单词具有相同的长度。 -- 所有单词只由小写字母组成。 -- 字典中不存在重复的单词。 -- 你可以假设 beginWord 和 endWord 是非空的,且二者不相同。 +-
+
- 每次转换只能改变一个字母。 +
- 转换过程中的中间单词必须是字典中的单词。 +
说明:
-输出: 5 +-
+
- 如果不存在这样的转换序列,返回 0。 +
- 所有单词具有相同的长度。 +
- 所有单词只由小写字母组成。 +
- 字典中不存在重复的单词。 +
- 你可以假设 beginWord 和 endWord 是非空的,且二者不相同。 +
示例 1:
-示例 2: -``` -输入: -beginWord = "hit" -endWord = "cog" -wordList = ["hot","dot","dog","lot","log"] +输入: +beginWord = "hit", +endWord = "cog", +wordList = ["hot","dot","dog","lot","log","cog"] -输出: 0 +输出: 5 -解释: endWord "cog" 不在字典中,所以无法进行转换。 -``` +解释: 一个最短转换序列是 "hit" -> "hot" -> "dot" -> "dog" -> "cog", + 返回它的长度 5。 +-### 解法 -利用广度优先搜索,`level` 表示层数,`curNum` 表示当前层的单词数,`nextNum` 表示下一层的单词数。 -队首元素出队,对于该字符串,替换其中每一个字符为[a...z] 中的任一字符。判断新替换后的字符串是否在字典中。若是,若该字符串与 endWord 相等,直接返回 level + 1;若不等,该字符串入队,nextNum + 1,并将 该字符串从 wordSet 移除。 +
示例 2:
-注意,每次只能替换一个字符,因此,在下一次替换前,需恢复为上一次替换前的状态。 +输入:
+beginWord = "hit"
+endWord = "cog"
+wordList = ["hot","dot","dog","lot","log"]
-```java
-class Solution {
- public int ladderLength(String beginWord, String endWord, List wordList) {
- Queue queue = new LinkedList<>();
-
- // 需要转hashSet
- Set wordSet = new HashSet<>(wordList);
- queue.offer(beginWord);
- int level = 1;
- int curNum = 1;
- int nextNum = 0;
- while (!queue.isEmpty()) {
- String s = queue.poll();
- --curNum;
- char[] chars = s.toCharArray();
- for (int i = 0; i < chars.length; ++i) {
- char ch = chars[i];
- for (char j = 'a'; j <= 'z'; ++j) {
- chars[i] = j;
- String tmp = new String(chars);
- // 字典中包含生成的中间字符串
- if (wordSet.contains(tmp)) {
- // 中间字符串与 endWord 相等
- if (endWord.equals(tmp)) {
- return level + 1;
- }
-
- // 中间字符串不是 endWord,则入队
- queue.offer(tmp);
- ++nextNum;
-
- // 确保之后不会再保存 tmp 字符串
- wordSet.remove(tmp);
- }
- }
- chars[i] = ch;
- }
-
- if (curNum == 0) {
- curNum = nextNum;
- nextNum = 0;
- ++level;
- }
-
- }
-
- return 0;
- }
-}
+输出: 0
-```
+解释: endWord "cog" 不在字典中,所以无法进行转换。
-# [题目](这里是题目链接,如:https://leetcode-cn.com/problems/shu-zu-zhong-zhong-fu-de-shu-zi-lcof/)
-
-## 题目描述
-
## 解法
diff --git a/solution/0100-0199/0128.Longest Consecutive Sequence/README.md b/solution/0100-0199/0128.Longest Consecutive Sequence/README.md
index d9b3840c082d2..270f7045a1a75 100644
--- a/solution/0100-0199/0128.Longest Consecutive Sequence/README.md
+++ b/solution/0100-0199/0128.Longest Consecutive Sequence/README.md
@@ -1,7 +1,17 @@
-# [题目](这里是题目链接,如:https://leetcode-cn.com/problems/shu-zu-zhong-zhong-fu-de-shu-zi-lcof/)
+# [128. 最长连续序列](https://leetcode-cn.com/problems/longest-consecutive-sequence)
## 题目描述
+给定一个未排序的整数数组,找出最长连续序列的长度。
+ +要求算法的时间复杂度为 O(n)。
+ +示例:
+ +输入: [100, 4, 200, 1, 3, 2]
+输出: 4
+解释: 最长连续序列是 [1, 2, 3, 4]。它的长度为 4。
+
## 解法
diff --git a/solution/0100-0199/0129.Sum Root to Leaf Numbers/README.md b/solution/0100-0199/0129.Sum Root to Leaf Numbers/README.md
index d9b3840c082d2..fd095b878a56a 100644
--- a/solution/0100-0199/0129.Sum Root to Leaf Numbers/README.md
+++ b/solution/0100-0199/0129.Sum Root to Leaf Numbers/README.md
@@ -1,7 +1,42 @@
-# [题目](这里是题目链接,如:https://leetcode-cn.com/problems/shu-zu-zhong-zhong-fu-de-shu-zi-lcof/)
+# [129. 求根到叶子节点数字之和](https://leetcode-cn.com/problems/sum-root-to-leaf-numbers)
## 题目描述
+给定一个二叉树,它的每个结点都存放一个 0-9 的数字,每条从根到叶子节点的路径都代表一个数字。
例如,从根到叶子节点路径 1->2->3 代表数字 123。
计算从根到叶子节点生成的所有数字之和。
+ +说明: 叶子节点是指没有子节点的节点。
+ +示例 1:
+ +输入: [1,2,3] + 1 + / \ + 2 3 +输出: 25 +解释: +从根到叶子节点路径+ +1->2代表数字12. +从根到叶子节点路径1->3代表数字13. +因此,数字总和 = 12 + 13 =25.
示例 2:
+ +输入: [4,9,0,5,1] + 4 + / \ + 9 0 + / \ +5 1 +输出: 1026 +解释: +从根到叶子节点路径+ ## 解法 diff --git a/solution/0100-0199/0130.Surrounded Regions/README.md b/solution/0100-0199/0130.Surrounded Regions/README.md index e59a8596b86ef..041a1e521c5b8 100644 --- a/solution/0100-0199/0130.Surrounded Regions/README.md +++ b/solution/0100-0199/0130.Surrounded Regions/README.md @@ -1,146 +1,31 @@ -## 被围绕的区域 -### 题目描述 +# [130. 被围绕的区域](https://leetcode-cn.com/problems/surrounded-regions) -给定一个二维的矩阵,包含 `'X'` 和 `'O'`(**字母 O**)。 +## 题目描述 + +4->9->5代表数字 495. +从根到叶子节点路径4->9->1代表数字 491. +从根到叶子节点路径4->0代表数字 40. +因此,数字总和 = 495 + 491 + 40 =1026.
给定一个二维的矩阵,包含 'X' 和 'O'(字母 O)。
找到所有被 'X' 围绕的区域,并将这些区域里所有的 'O' 用 'X' 填充。
示例:
+ +X X X X X O O X X X O X X O X X -``` +-运行你的函数后,矩阵变为: -``` -X X X X +
运行你的函数后,矩阵变为:
+ +X X X X X X X X X X X X X O X X -``` - -**解释:** - -被围绕的区间不会存在于边界上,换句话说,任何边界上的 `'O'` 都不会被填充为 `'X'`。 任何不在边界上,或不与边界上的 `'O'` 相连的 `'O'` 最终都会被填充为 `'X'`。如果两个元素在水平或垂直方向相邻,则称它们是“相连”的。 - -### 解法 -逆向思维,从上下左右四个边缘的有效点`'O'`往里搜索,将搜索到的有效点修改为`'Y'`。最后,剩下的`'O'`就是被`'X'`包围的,将它们修改为`'X'`,将`'Y'`修改回`'O'`。 +-```java -class Solution { - - /** - * 坐标点 - */ - private class Point { - int x; - int y; - - Point(int x, int y) { - this.x = x; - this.y = y; - } - } - - public void solve(char[][] board) { - if (board == null || board.length < 3 || board[0].length < 3) { - return; - } - - int m = board.length; - int n = board[0].length; - - // top & bottom - for (int i = 0; i < n; ++i) { - bfs(board, 0, i); - bfs(board, m - 1, i); - } - - // left & right - for (int i = 1; i < m - 1; ++i) { - bfs(board, i, 0); - bfs(board, i, n - 1); - } - - for (int i = 0; i < m; ++i) { - for (int j = 0; j < n; ++j) { - if (board[i][j] == 'O') { - board[i][j] = 'X'; - } else if (board[i][j] == 'Y') { - board[i][j] = 'O'; - } - } - } - } - - /** - * 广度优先搜索 - * @param board - * @param i - * @param j - */ - private void bfs(char[][] board, int i, int j) { - Queue
解释:
-# [题目](这里是题目链接,如:https://leetcode-cn.com/problems/shu-zu-zhong-zhong-fu-de-shu-zi-lcof/) +被围绕的区间不会存在于边界上,换句话说,任何边界上的 'O' 都不会被填充为 'X'。 任何不在边界上,或不与边界上的 'O' 相连的 'O' 最终都会被填充为 'X'。如果两个元素在水平或垂直方向相邻,则称它们是“相连”的。
给定一个字符串 s,将 s 分割成一些子串,使每个子串都是回文串。
+ +返回 s 所有可能的分割方案。
+ +示例:
+ +输入: "aab" +输出: +[ + ["aa","b"], + ["a","a","b"] +]+ + + +## 解法 + + + +### Python3 + + +```python + +``` + +### Java + + +```java + +``` + +### ... +``` + +``` diff --git a/solution/0100-0199/0132.Palindrome Partitioning II/README.md b/solution/0100-0199/0132.Palindrome Partitioning II/README.md index d9b3840c082d2..bbabffa0ff4df 100644 --- a/solution/0100-0199/0132.Palindrome Partitioning II/README.md +++ b/solution/0100-0199/0132.Palindrome Partitioning II/README.md @@ -1,7 +1,18 @@ -# [题目](这里是题目链接,如:https://leetcode-cn.com/problems/shu-zu-zhong-zhong-fu-de-shu-zi-lcof/) +# [132. 分割回文串 II](https://leetcode-cn.com/problems/palindrome-partitioning-ii) ## 题目描述 +
给定一个字符串 s,将 s 分割成一些子串,使每个子串都是回文串。
+ +返回符合要求的最少分割次数。
+ +示例:
+ +输入: "aab" +输出: 1 +解释: 进行一次分割就可将 s 分割成 ["aa","b"] 这样两个回文子串。 ++ ## 解法 diff --git a/solution/0100-0199/0133.Clone Graph/README.md b/solution/0100-0199/0133.Clone Graph/README.md index d9b3840c082d2..cb6ed5a7d301c 100644 --- a/solution/0100-0199/0133.Clone Graph/README.md +++ b/solution/0100-0199/0133.Clone Graph/README.md @@ -1,7 +1,77 @@ -# [题目](这里是题目链接,如:https://leetcode-cn.com/problems/shu-zu-zhong-zhong-fu-de-shu-zi-lcof/) +# [133. 克隆图](https://leetcode-cn.com/problems/clone-graph) ## 题目描述 +
给你无向 连通 图中一个节点的引用,请你返回该图的 深拷贝(克隆)。
+ +图中的每个节点都包含它的值 val(int) 和其邻居的列表(list[Node])。
class Node {
+ public int val;
+ public List<Node> neighbors;
+}
+
++ +
测试用例格式:
+ +简单起见,每个节点的值都和它的索引相同。例如,第一个节点值为 1,第二个节点值为 2,以此类推。该图在测试用例中使用邻接列表表示。
+ +邻接列表是用于表示有限图的无序列表的集合。每个列表都描述了图中节点的邻居集。
+ +给定节点将始终是图中的第一个节点(值为 1)。你必须将 给定节点的拷贝 作为对克隆图的引用返回。
+ ++ +
示例 1:
+ +
输入:adjList = [[2,4],[1,3],[2,4],[1,3]] +输出:[[2,4],[1,3],[2,4],[1,3]] +解释: +图中有 4 个节点。 +节点 1 的值是 1,它有两个邻居:节点 2 和 4 。 +节点 2 的值是 2,它有两个邻居:节点 1 和 3 。 +节点 3 的值是 3,它有两个邻居:节点 2 和 4 。 +节点 4 的值是 4,它有两个邻居:节点 1 和 3 。 ++ +
示例 2:
+ +
输入:adjList = [[]] +输出:[[]] +解释:输入包含一个空列表。该图仅仅只有一个值为 1 的节点,它没有任何邻居。 ++ +
示例 3:
+ +输入:adjList = [] +输出:[] +解释:这个图是空的,它不含任何节点。 ++ +
示例 4:
+ +
输入:adjList = [[2],[1]] +输出:[[2],[1]]+ +
+ +
提示:
+ +-
+
- 节点数介于 1 到 100 之间。 +
- 每个节点值都是唯一的。 +
- 无向图是一个简单图,这意味着图中没有重复的边,也没有自环。 +
- 由于图是无向的,如果节点 p 是节点 q 的邻居,那么节点 q 也必须是节点 p 的邻居。 +
- 图是连通图,你可以从给定节点访问到所有节点。 +
在一条环路上有 N 个加油站,其中第 i 个加油站有汽油 gas[i] 升。
你有一辆油箱容量无限的的汽车,从第 i 个加油站开往第 i+1 个加油站需要消耗汽油 cost[i] 升。你从其中的一个加油站出发,开始时油箱为空。
如果你可以绕环路行驶一周,则返回出发时加油站的编号,否则返回 -1。
+ +说明:
+ +-
+
- 如果题目有解,该答案即为唯一答案。 +
- 输入数组均为非空数组,且长度相同。 +
- 输入数组中的元素均为非负数。 +
示例 1:
+ +输入: +gas = [1,2,3,4,5] +cost = [3,4,5,1,2] + +输出: 3 + +解释: +从 3 号加油站(索引为 3 处)出发,可获得 4 升汽油。此时油箱有 = 0 + 4 = 4 升汽油 +开往 4 号加油站,此时油箱有 4 - 1 + 5 = 8 升汽油 +开往 0 号加油站,此时油箱有 8 - 2 + 1 = 7 升汽油 +开往 1 号加油站,此时油箱有 7 - 3 + 2 = 6 升汽油 +开往 2 号加油站,此时油箱有 6 - 4 + 3 = 5 升汽油 +开往 3 号加油站,你需要消耗 5 升汽油,正好足够你返回到 3 号加油站。 +因此,3 可为起始索引。+ +
示例 2:
+ +输入: +gas = [2,3,4] +cost = [3,4,3] + +输出: -1 + +解释: +你不能从 0 号或 1 号加油站出发,因为没有足够的汽油可以让你行驶到下一个加油站。 +我们从 2 号加油站出发,可以获得 4 升汽油。 此时油箱有 = 0 + 4 = 4 升汽油 +开往 0 号加油站,此时油箱有 4 - 3 + 2 = 3 升汽油 +开往 1 号加油站,此时油箱有 3 - 3 + 3 = 3 升汽油 +你无法返回 2 号加油站,因为返程需要消耗 4 升汽油,但是你的油箱只有 3 升汽油。 +因此,无论怎样,你都不可能绕环路行驶一周。+ ## 解法 diff --git a/solution/0100-0199/0135.Candy/README.md b/solution/0100-0199/0135.Candy/README.md index d9b3840c082d2..10017c612b014 100644 --- a/solution/0100-0199/0135.Candy/README.md +++ b/solution/0100-0199/0135.Candy/README.md @@ -1,7 +1,32 @@ -# [题目](这里是题目链接,如:https://leetcode-cn.com/problems/shu-zu-zhong-zhong-fu-de-shu-zi-lcof/) +# [135. 分发糖果](https://leetcode-cn.com/problems/candy) ## 题目描述 +
老师想给孩子们分发糖果,有 N 个孩子站成了一条直线,老师会根据每个孩子的表现,预先给他们评分。
+ +你需要按照以下要求,帮助老师给这些孩子分发糖果:
+ +-
+
- 每个孩子至少分配到 1 个糖果。 +
- 相邻的孩子中,评分高的孩子必须获得更多的糖果。 +
那么这样下来,老师至少需要准备多少颗糖果呢?
+ +示例 1:
+ +输入: [1,0,2] +输出: 5 +解释: 你可以分别给这三个孩子分发 2、1、2 颗糖果。 ++ +
示例 2:
+ +输入: [1,2,2] +输出: 4 +解释: 你可以分别给这三个孩子分发 1、2、1 颗糖果。 + 第三个孩子只得到 1 颗糖果,这已满足上述两个条件。+ ## 解法 diff --git a/solution/0100-0199/0136.Single Number/README.md b/solution/0100-0199/0136.Single Number/README.md index 2dc3347f8a65a..f5dd15d9f1548 100644 --- a/solution/0100-0199/0136.Single Number/README.md +++ b/solution/0100-0199/0136.Single Number/README.md @@ -1,43 +1,24 @@ -## 只出现一次的数字 -### 题目描述 +# [136. 只出现一次的数字](https://leetcode-cn.com/problems/single-number) -给定一个非空整数数组,除了某个元素只出现一次以外,其余每个元素均出现两次。找出那个只出现了一次的元素。 +## 题目描述 + +
给定一个非空整数数组,除了某个元素只出现一次以外,其余每个元素均出现两次。找出那个只出现了一次的元素。
-说明: +说明:
-你的算法应该具有线性时间复杂度。 你可以不使用额外空间来实现吗? +你的算法应该具有线性时间复杂度。 你可以不使用额外空间来实现吗?
-示例 1: -``` -输入: [2,2,1] -输出: 1 -``` +示例 1:
-示例 2: -``` -输入: [4,1,2,1,2] -输出: 4 -``` +输入: [2,2,1] +输出: 1 +-### 解法 -任意数与 0 异或,都等于它本身。而任意数与自身异或,都等于 0。 +
示例 2:
-```java -class Solution { - public int singleNumber(int[] nums) { - int res = 0; - for (int num : nums) { - res ^= num; - } - return res; - } -} -``` - -# [题目](这里是题目链接,如:https://leetcode-cn.com/problems/shu-zu-zhong-zhong-fu-de-shu-zi-lcof/) +输入: [4,1,2,1,2] +输出: 4-## 题目描述 - ## 解法 diff --git a/solution/0100-0199/0137.Single Number II/README.md b/solution/0100-0199/0137.Single Number II/README.md index e3c758c562534..36172a61795ec 100644 --- a/solution/0100-0199/0137.Single Number II/README.md +++ b/solution/0100-0199/0137.Single Number II/README.md @@ -1,55 +1,24 @@ -## 只出现一次的数字 II +# [137. 只出现一次的数字 II](https://leetcode-cn.com/problems/single-number-ii) -### 题目描述 -给定一个**非空**整数数组,除了某个元素只出现一次以外,其余每个元素均出现了三次。找出那个只出现了一次的元素。 - -说明: - -你的算法应该具有线性时间复杂度。 你可以不使用额外空间来实现吗? +## 题目描述 + +
给定一个非空整数数组,除了某个元素只出现一次以外,其余每个元素均出现了三次。找出那个只出现了一次的元素。
-**示例 1:** -``` -输入: [2,2,3,2] -输出: 3 -``` +说明:
-**示例 2:** -``` -输入: [0,1,0,1,0,1,99] -输出: 99 -``` +你的算法应该具有线性时间复杂度。 你可以不使用额外空间来实现吗?
-### 解法 -遍历数组元素,对于每一个元素,获得二进制位(0/1),累加到 bits 数组中,这样下来,出现三次的元素,bits 数组上的值一定能被 3 整除;找出不能被 3 整除的位,计算出实际的十进制数即可。 +示例 1:
-```java -class Solution { - public int singleNumber(int[] nums) { - int[] bits = new int[32]; - int n = nums.length; - for (int i = 0; i < n; ++i) { - for (int j = 0; j < 32; ++j) { - bits[j] += ((nums[i] >> j) & 1); - } - } - - int res = 0; - for (int i = 0; i < 32; ++i) { - if (bits[i] % 3 != 0) { - res += (1 << i); - } - } - return res; - - } -} -``` +输入: [2,2,3,2] +输出: 3 ++
示例 2:
-# [题目](这里是题目链接,如:https://leetcode-cn.com/problems/shu-zu-zhong-zhong-fu-de-shu-zi-lcof/) +输入: [0,1,0,1,0,1,99] +输出: 99-## 题目描述 - ## 解法 diff --git a/solution/0100-0199/0138.Copy List with Random Pointer/README.md b/solution/0100-0199/0138.Copy List with Random Pointer/README.md index 30c35d76d6d72..8025f118c6b78 100644 --- a/solution/0100-0199/0138.Copy List with Random Pointer/README.md +++ b/solution/0100-0199/0138.Copy List with Random Pointer/README.md @@ -1,75 +1,61 @@ -## 复制带随机指针的链表 +# [138. 复制带随机指针的链表](https://leetcode-cn.com/problems/copy-list-with-random-pointer) -### 题目描述 +## 题目描述 + +
给定一个链表,每个节点包含一个额外增加的随机指针,该指针可以指向链表中的任何节点或空节点。
-给定一个链表,每个节点包含一个额外增加的随机指针,该指针可以指向链表中的任何节点或空节点。 +要求返回这个链表的 深拷贝。
- +我们用一个由 n 个节点组成的链表来表示输入/输出中的链表。每个节点用一个 [val, random_index] 表示:
-
+
val:一个表示Node.val的整数。
+ random_index:随机指针指向的节点索引(范围从0到n-1);如果不指向任何节点,则为null。
+
-- 第二步,对复制节点的 random 链接进行赋值; - +
示例 1:
-- 第三步,分离两个链表。 - +
输入:head = [[7,null],[13,0],[11,4],[10,2],[1,0]] +输出:[[7,null],[13,0],[11,4],[10,2],[1,0]] +-# [题目](这里是题目链接,如:https://leetcode-cn.com/problems/shu-zu-zhong-zhong-fu-de-shu-zi-lcof/) +
示例 2:
+ +
输入:head = [[1,1],[2,1]] +输出:[[1,1],[2,1]] ++ +
示例 3:
+ +
输入:head = [[3,null],[3,0],[3,null]] +输出:[[3,null],[3,0],[3,null]] ++ +
示例 4:
+ +输入:head = [] +输出:[] +解释:给定的链表为空(空指针),因此返回 null。 ++ +
+ +
提示:
+ +-
+
-10000 <= Node.val <= 10000
+ Node.random为空(null)或指向链表中的节点。
+ - 节点数目不超过 1000 。 +
给定一个非空字符串 s 和一个包含非空单词列表的字典 wordDict,判定 s 是否可以被空格拆分为一个或多个在字典中出现的单词。
+ +说明:
+ +-
+
- 拆分时可以重复使用字典中的单词。 +
- 你可以假设字典中没有重复的单词。 +
示例 1:
+ +输入: s = "leetcode", wordDict = ["leet", "code"] +输出: true +解释: 返回 true 因为 "leetcode" 可以被拆分成 "leet code"。 ++ +
示例 2:
+ +输入: s = "applepenapple", wordDict = ["apple", "pen"] +输出: true +解释: 返回 true 因为+ +"applepenapple"可以被拆分成"apple pen apple"。 + 注意你可以重复使用字典中的单词。 +
示例 3:
+ +输入: s = "catsandog", wordDict = ["cats", "dog", "sand", "and", "cat"] +输出: false ++ ## 解法 diff --git a/solution/0100-0199/0140.Word Break II/README.md b/solution/0100-0199/0140.Word Break II/README.md index d9b3840c082d2..e15e3800d0887 100644 --- a/solution/0100-0199/0140.Word Break II/README.md +++ b/solution/0100-0199/0140.Word Break II/README.md @@ -1,7 +1,51 @@ -# [题目](这里是题目链接,如:https://leetcode-cn.com/problems/shu-zu-zhong-zhong-fu-de-shu-zi-lcof/) +# [140. 单词拆分 II](https://leetcode-cn.com/problems/word-break-ii) ## 题目描述 +
给定一个非空字符串 s 和一个包含非空单词列表的字典 wordDict,在字符串中增加空格来构建一个句子,使得句子中所有的单词都在词典中。返回所有这些可能的句子。
+ +说明:
+ +-
+
- 分隔时可以重复使用字典中的单词。 +
- 你可以假设字典中没有重复的单词。 +
示例 1:
+ +输入: +s = "+ +catsanddog" +wordDict =["cat", "cats", "and", "sand", "dog"]+输出: +[ + "cats and dog", + "cat sand dog" +]+
示例 2:
+ +输入: +s = "pineapplepenapple" +wordDict = ["apple", "pen", "applepen", "pine", "pineapple"] +输出: +[ + "pine apple pen apple", + "pineapple pen apple", + "pine applepen apple" +] +解释: 注意你可以重复使用字典中的单词。 ++ +
示例 3:
+ +输入: +s = "catsandog" +wordDict = ["cats", "dog", "sand", "and", "cat"] +输出: +[] ++ ## 解法 diff --git a/solution/0100-0199/0141.Linked List Cycle/README.md b/solution/0100-0199/0141.Linked List Cycle/README.md index 3236ba70752ce..503e33cac177d 100644 --- a/solution/0100-0199/0141.Linked List Cycle/README.md +++ b/solution/0100-0199/0141.Linked List Cycle/README.md @@ -1,47 +1,46 @@ -## 环形链表 -### 题目描述 +# [141. 环形链表](https://leetcode-cn.com/problems/linked-list-cycle) -给定一个链表,判断链表中是否有环。 +## 题目描述 + +
给定一个链表,判断链表中是否有环。
-**进阶:** -你能否不使用额外空间解决此题? +为了表示给定链表中的环,我们使用整数 pos 来表示链表尾连接到链表中的位置(索引从 0 开始)。 如果 pos 是 -1,则在该链表中没有环。
-利用快慢指针,若快指针为 null,则不存在环,若快慢指针相遇,则存在环。 +
示例 1:
-```java -/** - * Definition for singly-linked list. - * class ListNode { - * int val; - * ListNode next; - * ListNode(int x) { - * val = x; - * next = null; - * } - * } - */ -public class Solution { - public boolean hasCycle(ListNode head) { - ListNode slow = head; - ListNode fast = head; - while (fast != null && fast.next != null) { - slow = slow.next; - fast = fast.next.next; - if (slow == fast) { - return true; - } - } - return false; - } -} -``` +输入:head = [3,2,0,-4], pos = 1 +输出:true +解释:链表中有一个环,其尾部连接到第二个节点。 +-# [题目](这里是题目链接,如:https://leetcode-cn.com/problems/shu-zu-zhong-zhong-fu-de-shu-zi-lcof/) +

示例 2:
+ +输入:head = [1,2], pos = 0 +输出:true +解释:链表中有一个环,其尾部连接到第一个节点。 ++ +

示例 3:
+ +输入:head = [1], pos = -1 +输出:false +解释:链表中没有环。 ++ +

+ +
进阶:
+ +你能用 O(1)(即,常量)内存解决此问题吗?
-## 题目描述 - ## 解法 diff --git a/solution/0100-0199/0142.Linked List Cycle II/README.md b/solution/0100-0199/0142.Linked List Cycle II/README.md index 34932a69d8fee..80e9134ede27a 100644 --- a/solution/0100-0199/0142.Linked List Cycle II/README.md +++ b/solution/0100-0199/0142.Linked List Cycle II/README.md @@ -1,106 +1,47 @@ -## 环形链表 II -### 题目描述 +# [142. 环形链表 II](https://leetcode-cn.com/problems/linked-list-cycle-ii) -给定一个链表,返回链表开始入环的第一个节点。 如果链表无环,则返回 `null`。 +## 题目描述 + +给定一个链表,返回链表开始入环的第一个节点。 如果链表无环,则返回 null。
为了表示给定链表中的环,我们使用整数 pos 来表示链表尾连接到链表中的位置(索引从 0 开始)。 如果 pos 是 -1,则在该链表中没有环。
说明:不允许修改给定的链表。
-### 解法 +-利用快慢指针,若快指针为 `null`,则不存在环;若快慢指针相遇,则存在环,此时退出循环,利用 `p1` 指向链表头结点,`p2` 指向快慢指针相遇点,随后 `p1`, `p2` 同时前进,相遇时(`p1 == p2`)即为入环的第一个节点。 +
示例 1:
-**证明如下:** +输入:head = [3,2,0,-4], pos = 1 +输出:tail connects to node index 1 +解释:链表中有一个环,其尾部连接到第二个节点。 +- +
示例 2:
-`p1`, `p2` 同时向前走 `r - b`,`p2` 到达入环点,而 `p1` 距离入环点还有 `(n - 1) * r`,双方同时走 `(n - 1)` 圈即可相遇,此时相遇点就是入环点! +输入:head = [1,2], pos = 0 +输出:tail connects to node index 0 +解释:链表中有一个环,其尾部连接到第一个节点。 +-```java -/** - * Definition for singly-linked list. - * class ListNode { - * int val; - * ListNode next; - * ListNode(int x) { - * val = x; - * next = null; - * } - * } - */ -public class Solution { - public ListNode detectCycle(ListNode head) { - ListNode slow = head; - ListNode fast = head; - boolean hasCycle = false; - while (fast != null && fast.next != null) { - slow = slow.next; - fast = fast.next.next; - if (slow == fast) { - hasCycle = true; - break; - } - } - - if (hasCycle) { - ListNode p1 = head; - ListNode p2 = slow; - while (p1 != p2) { - p1 = p1.next; - p2 = p2.next; - } - return p1; - } - return null; - - } -} -``` +
示例 3:
-``` +输入:head = [1], pos = -1 +输出:no cycle +解释:链表中没有环。 +-# [题目](这里是题目链接,如:https://leetcode-cn.com/problems/shu-zu-zhong-zhong-fu-de-shu-zi-lcof/) +
+ +
进阶:
+你是否可以不用额外空间解决此题?
给定一个单链表 L:L0→L1→…→Ln-1→Ln ,
+将其重新排列后变为: L0→Ln→L1→Ln-1→L2→Ln-2→…
你不能只是单纯的改变节点内部的值,而是需要实际的进行节点交换。
-### 解法 -先利用快慢指针找到链表的中间节点,之后对右半部分的链表进行`reverse`。最后对两个链表进行合并。注意边界的判断。 +示例 1:
+给定链表 1->2->3->4, 重新排列为 1->4->2->3.-```java -/** - * Definition for singly-linked list. - * public class ListNode { - * int val; - * ListNode next; - * ListNode(int x) { val = x; } - * } - */ -class Solution { - public void reorderList(ListNode head) { - if (head == null || head.next == null || head.next.next == null) { - return; - } - - ListNode dummy = new ListNode(-1); - dummy.next = head; - ListNode slow = head; - ListNode fast = head; - ListNode pre = dummy; - while (fast != null && fast.next != null) { - fast = fast.next.next; - slow = slow.next; - pre = pre.next; - } - - pre.next = null; - - // 将后半段的链表进行 reverse - ListNode rightPre = new ListNode(-1); - rightPre.next = null; - ListNode t = null; - while (slow != null) { - t = slow.next; - slow.next = rightPre.next; - rightPre.next = slow; - slow = t; - } - - ListNode p1 = dummy.next; - ListNode p2 = p1.next; - ListNode p3 = rightPre.next; - ListNode p4 = p3.next; - while (p1 != null) { - p3.next = p1.next; - p1.next = p3; - if (p2 == null) { - break; - } - p1 = p2; - p2 = p1.next; - p3 = p4; - p4 = p3.next; - - } - - if (p4 != null) { - p1.next.next = p4; - } - head = dummy.next; - - - - } -} -``` +
示例 2:
-# [题目](这里是题目链接,如:https://leetcode-cn.com/problems/shu-zu-zhong-zhong-fu-de-shu-zi-lcof/) +给定链表 1->2->3->4->5, 重新排列为 1->5->2->4->3.-## 题目描述 - ## 解法 diff --git a/solution/0100-0199/0144.Binary Tree Preorder Traversal/README.md b/solution/0100-0199/0144.Binary Tree Preorder Traversal/README.md index 4d2e5a7fac5c6..a0767525cb0a4 100644 --- a/solution/0100-0199/0144.Binary Tree Preorder Traversal/README.md +++ b/solution/0100-0199/0144.Binary Tree Preorder Traversal/README.md @@ -1,97 +1,23 @@ -## 二叉树的前序遍历 -### 题目描述 +# [144. 二叉树的前序遍历](https://leetcode-cn.com/problems/binary-tree-preorder-traversal) -给定一个二叉树,返回它的 前序 遍历。 +## 题目描述 + +
给定一个二叉树,返回它的 前序 遍历。
- 示例: -``` -输入: [1,null,2,3] +示例:
+ +输入: [1,null,2,3]
1
\
2
/
3
-输出: [1,2,3]
-```
-
-进阶: 递归算法很简单,你可以通过迭代算法完成吗?
-
-### 解法
-
-- 递归算法
-
-先访问根结点,再递归左子树,最后递归右子树。
+输出: [1,2,3]
+
-```java
-/**
- * Definition for a binary tree node.
- * public class TreeNode {
- * int val;
- * TreeNode left;
- * TreeNode right;
- * TreeNode(int x) { val = x; }
- * }
- */
-class Solution {
- public List进阶: 递归算法很简单,你可以通过迭代算法完成吗?
-```java -/** - * Definition for a binary tree node. - * public class TreeNode { - * int val; - * TreeNode left; - * TreeNode right; - * TreeNode(int x) { val = x; } - * } - */ -class Solution { - public List给定一个二叉树,返回它的 后序 遍历。
-示例: -``` -输入: [1,null,2,3] +示例:
+ +输入: [1,null,2,3]
1
\
2
/
3
-输出: [3,2,1]
-```
-
-进阶: 递归算法很简单,你可以通过迭代算法完成吗?
-
-### 解法
-
-- 递归算法
-
-先递归左子树,再递归右子树,最后访问根结点。
-
-```java
-/**
- * Definition for a binary tree node.
- * public class TreeNode {
- * int val;
- * TreeNode left;
- * TreeNode right;
- * TreeNode(int x) { val = x; }
- * }
- */
-class Solution {
- public List postorderTraversal(TreeNode root) {
- List list = new ArrayList<>();
- postorderTraversal(root, list);
- return list;
- }
-
- private void postorderTraversal(TreeNode root, List list) {
- if (root == null) {
- return;
- }
- postorderTraversal(root.left, list);
- postorderTraversal(root.right, list);
- list.add(root.val);
- }
-}
-```
-
-- 非递归算法
-
-
-```java
-
-```
+输出: [3,2,1]
-# [题目](这里是题目链接,如:https://leetcode-cn.com/problems/shu-zu-zhong-zhong-fu-de-shu-zi-lcof/)
+进阶: 递归算法很简单,你可以通过迭代算法完成吗?
-## 题目描述 - ## 解法 diff --git a/solution/0100-0199/0146.Lru Cache/README.md b/solution/0100-0199/0146.Lru Cache/README.md index 0aea942a6ee2d..deac892191ad7 100644 --- a/solution/0100-0199/0146.Lru Cache/README.md +++ b/solution/0100-0199/0146.Lru Cache/README.md @@ -1,13 +1,19 @@ -## LRU缓存 -### 题目描述 +# [146. LRU缓存机制](https://leetcode-cn.com/problems/lru-cache) -运用你所掌握的数据结构,设计和实现一个 LRU (最近最少使用) 缓存机制。它应该支持以下操作: 获取数据 get 和 写入数据 put 。 -获取数据 get(key) - 如果密钥 (key) 存在于缓存中,则获取密钥的值(总是正数),否则返回 -1。 -写入数据 put(key, value) - 如果密钥不存在,则写入其数据值。当缓存容量达到上限时,它应该在写入新数据之前删除最近最少使用的数据值,从而为新的数据值留出空间。 +## 题目描述 + +运用你所掌握的数据结构,设计和实现一个 LRU (最近最少使用) 缓存机制。它应该支持以下操作: 获取数据 get 和 写入数据 put 。
获取数据 get(key) - 如果密钥 (key) 存在于缓存中,则获取密钥的值(总是正数),否则返回 -1。
+写入数据 put(key, value) - 如果密钥不存在,则写入其数据值。当缓存容量达到上限时,它应该在写入新数据之前删除最久未使用的数据值,从而为新的数据值留出空间。
进阶:
+ +你是否可以在 O(1) 时间复杂度内完成这两种操作?
+ +示例:
+ +LRUCache cache = new LRUCache( 2 /* 缓存容量 */ ); cache.put(1, 1); cache.put(2, 2); @@ -18,110 +24,8 @@ cache.put(4, 4); // 该操作会使得密钥 1 作废 cache.get(1); // 返回 -1 (未找到) cache.get(3); // 返回 3 cache.get(4); // 返回 4 -``` +-### 解法 -用一个哈希表和一个双向链表来实现 -- 哈希表保存每个节点的地址 -- 链表头表示上次访问距离现在时间最短,尾部表示最近访问最少 -- 访问节点,若节点存在,要把该节点放到链表头 -- 插入时要考虑是否超过容量 - -```java -//双向链表的节点 -class Node{ - public int key; - public int val; - public Node pre;//指向前面的指针 - public Node next;//指向后面的指针 - public Node(int key,int value){ - this.val = value; - this.key = key; - } -} -class LRUCache { - int capacity;//容量 - Node head;//双向链表的头,维护这个指针,因为set,get时需要在头部操作 - Node end;//双向链表的尾,set时,要是满了,需要将链表的最后一个节点remove - HashMap
对链表进行插入排序。
-插入排序的动画演示如上。从第一个元素开始,该链表可以被认为已经部分排序(用黑色表示)。 -每次迭代时,从输入数据中移除一个元素(用红色表示),并原地将其插入到已排好序的链表中。 +
+插入排序的动画演示如上。从第一个元素开始,该链表可以被认为已经部分排序(用黑色表示)。
+每次迭代时,从输入数据中移除一个元素(用红色表示),并原地将其插入到已排好序的链表中。
-示例1: -``` -输入: 4->2->1->3 -输出: 1->2->3->4 -``` +
插入排序算法:
-示例2: -``` -输入: -1->5->3->4->0 -输出: -1->0->3->4->5 -``` -### 解法 -从链表头部开始遍历,记录当前已完成插入排序的最后一个节点。然后进行以下操作: -- 获得要插入排序的节点 curNode 、其上一个节点 perNode 、其下一个节点 nextNode; -- 判断 curNode 是否应插入在 perNode 之后,若否,将 curNode 从链表中移除准备插入,若是,无需进一步操作,此时已排序的最后一个节点为 curNode; -- 在链表头节点前增加一个节点,应对 curNode 插入位置在 头节点之前的情况; -- 从头节点开始遍历,找到curNode 的插入位置,进行插入; -- 此时已排序的最后一个节点仍为 perNode ,重复以上操作直至链表末尾。 +-
+
- 插入排序是迭代的,每次只移动一个元素,直到所有元素可以形成一个有序的输出列表。 +
- 每次迭代中,插入排序只从输入数据中移除一个待排序的元素,找到它在序列中适当的位置,并将其插入。 +
- 重复直到所有输入数据插入完为止。 +
-# [题目](这里是题目链接,如:https://leetcode-cn.com/problems/shu-zu-zhong-zhong-fu-de-shu-zi-lcof/) +
示例 1:
+ +输入: 4->2->1->3 +输出: 1->2->3->4 ++ +
示例 2:
+ +输入: -1->5->3->4->0 +输出: -1->0->3->4->5 +-## 题目描述 - ## 解法 diff --git a/solution/0100-0199/0148.Sort List/README.md b/solution/0100-0199/0148.Sort List/README.md index d9b3840c082d2..63013fa72f557 100644 --- a/solution/0100-0199/0148.Sort List/README.md +++ b/solution/0100-0199/0148.Sort List/README.md @@ -1,7 +1,20 @@ -# [题目](这里是题目链接,如:https://leetcode-cn.com/problems/shu-zu-zhong-zhong-fu-de-shu-zi-lcof/) +# [148. 排序链表](https://leetcode-cn.com/problems/sort-list) ## 题目描述 +
在 O(n log n) 时间复杂度和常数级空间复杂度下,对链表进行排序。
+ +示例 1:
+ +输入: 4->2->1->3 +输出: 1->2->3->4 ++ +
示例 2:
+ +输入: -1->5->3->4->0 +输出: -1->0->3->4->5+ ## 解法 diff --git a/solution/0100-0199/0149.Max Points on a Line/README.md b/solution/0100-0199/0149.Max Points on a Line/README.md index d9b3840c082d2..bf5cbfc407a43 100644 --- a/solution/0100-0199/0149.Max Points on a Line/README.md +++ b/solution/0100-0199/0149.Max Points on a Line/README.md @@ -1,7 +1,37 @@ -# [题目](这里是题目链接,如:https://leetcode-cn.com/problems/shu-zu-zhong-zhong-fu-de-shu-zi-lcof/) +# [149. 直线上最多的点数](https://leetcode-cn.com/problems/max-points-on-a-line) ## 题目描述 +
给定一个二维平面,平面上有 n 个点,求最多有多少个点在同一条直线上。
+ +示例 1:
+ +输入: [[1,1],[2,2],[3,3]] +输出: 3 +解释: +^ +| +| o +| o +| o ++-------------> +0 1 2 3 4 ++ +
示例 2:
+ +输入: [[1,1],[3,2],[5,3],[4,1],[2,3],[1,4]] +输出: 4 +解释: +^ +| +| o +| o o +| o +| o o ++-------------------> +0 1 2 3 4 5 6+ ## 解法 diff --git a/solution/0100-0199/0150.Evaluate Reverse Polish Notation/README.md b/solution/0100-0199/0150.Evaluate Reverse Polish Notation/README.md index d1af249707def..a5c019fca1b24 100644 --- a/solution/0100-0199/0150.Evaluate Reverse Polish Notation/README.md +++ b/solution/0100-0199/0150.Evaluate Reverse Polish Notation/README.md @@ -1,84 +1,45 @@ -## 逆波兰表达式求值 -### 题目描述 +# [150. 逆波兰表达式求值](https://leetcode-cn.com/problems/evaluate-reverse-polish-notation) -根据逆波兰表示法,求表达式的值。 +## 题目描述 + +
根据逆波兰表示法,求表达式的值。
-有效的运算符包括 `+`, `-`, `*`, `/` 。每个运算对象可以是整数,也可以是另一个逆波兰表达式。 +有效的运算符包括 +, -, *, / 。每个运算对象可以是整数,也可以是另一个逆波兰表达式。
说明:
-整数除法只保留整数部分。 -给定逆波兰表达式总是有效的。换句话说,表达式总会得出有效数值且不存在除数为 0 的情况。 -示例 1: -``` -输入: ["2", "1", "+", "3", "*"] -输出: 9 -解释: ((2 + 1) * 3) = 9 -``` +-
+
- 整数除法只保留整数部分。 +
- 给定逆波兰表达式总是有效的。换句话说,表达式总会得出有效数值且不存在除数为 0 的情况。 +
示例 1:
-示例 3: -``` -输入: ["10", "6", "9", "3", "+", "-11", "*", "/", "*", "17", "+", "5", "+"] -输出: 22 -解释: +输入: ["2", "1", "+", "3", "*"] +输出: 9 +解释: ((2 + 1) * 3) = 9 ++ +
示例 2:
+ +输入: ["4", "13", "5", "/", "+"] +输出: 6 +解释: (4 + (13 / 5)) = 6 ++ +
示例 3:
+ +输入: ["10", "6", "9", "3", "+", "-11", "*", "/", "*", "17", "+", "5", "+"]
+输出: 22
+解释:
((10 * (6 / ((9 + 3) * -11))) + 17) + 5
= ((10 * (6 / (12 * -11))) + 17) + 5
= ((10 * (6 / -132)) + 17) + 5
= ((10 * 0) + 17) + 5
= (0 + 17) + 5
= 17 + 5
-= 22
-```
-
-### 解法
-遍历数组,若遇到操作数,将其压入栈中;若遇到操作符,从栈中弹出右操作数和左操作数,将运算结果压入栈中。最后栈中唯一的元素就是结果。
-
-
-```java
-class Solution {
- public int evalRPN(String[] tokens) {
- Stack stack = new Stack<>();
- for (String e : tokens) {
- if (isNum(e)) {
- stack.push(Integer.parseInt(e));
- } else {
- int y = stack.pop();
- int x = stack.pop();
- int z = 0;
- switch (e) {
- case "+": z = x + y; break;
- case "-": z = x - y; break;
- case "*": z = x * y; break;
- case "/": z = x / y; break;
- }
- stack.push(z);
- }
- }
- return stack.peek();
- }
-
- private boolean isNum(String val) {
- try {
- Integer.parseInt(val);
- return true;
- } catch (Exception e) {
- return false;
- }
- }
-}
-```
-
-# [题目](这里是题目链接,如:https://leetcode-cn.com/problems/shu-zu-zhong-zhong-fu-de-shu-zi-lcof/)
+= 22
-## 题目描述
-
## 解法
diff --git a/solution/0100-0199/0151.Reverse Words in a String/README.md b/solution/0100-0199/0151.Reverse Words in a String/README.md
index d9b3840c082d2..9883604985f1b 100644
--- a/solution/0100-0199/0151.Reverse Words in a String/README.md
+++ b/solution/0100-0199/0151.Reverse Words in a String/README.md
@@ -1,7 +1,47 @@
-# [题目](这里是题目链接,如:https://leetcode-cn.com/problems/shu-zu-zhong-zhong-fu-de-shu-zi-lcof/)
+# [151. 翻转字符串里的单词](https://leetcode-cn.com/problems/reverse-words-in-a-string)
## 题目描述
+给定一个字符串,逐个翻转字符串中的每个单词。
+ ++ +
示例 1:
+ +输入: "+ +the sky is blue" +输出: "blue is sky the" +
示例 2:
+ +输入: " hello world! " +输出: "world! hello" +解释: 输入字符串可以在前面或者后面包含多余的空格,但是反转后的字符不能包括。 ++ +
示例 3:
+ +输入: "a good example" +输出: "example good a" +解释: 如果两个单词间有多余的空格,将反转后单词间的空格减少到只含一个。 ++ +
+ +
说明:
+ +-
+
- 无空格字符构成一个单词。 +
- 输入字符串可以在前面或者后面包含多余的空格,但是反转后的字符不能包括。 +
- 如果两个单词间有多余的空格,将反转后单词间的空格减少到只含一个。 +
+ +
进阶:
+ +请选用 C 语言的用户尝试使用 O(1) 额外空间复杂度的原地解法。
+ ## 解法 diff --git a/solution/0100-0199/0152.Maximum Product Subarray/README.md b/solution/0100-0199/0152.Maximum Product Subarray/README.md index d9b3840c082d2..834553203b338 100644 --- a/solution/0100-0199/0152.Maximum Product Subarray/README.md +++ b/solution/0100-0199/0152.Maximum Product Subarray/README.md @@ -1,7 +1,22 @@ -# [题目](这里是题目链接,如:https://leetcode-cn.com/problems/shu-zu-zhong-zhong-fu-de-shu-zi-lcof/) +# [152. 乘积最大子序列](https://leetcode-cn.com/problems/maximum-product-subarray) ## 题目描述 +给定一个整数数组 nums ,找出一个序列中乘积最大的连续子序列(该序列至少包含一个数)。
示例 1:
+ +输入: [2,3,-2,4]
+输出: 6
+解释: 子数组 [2,3] 有最大乘积 6。
+
+
+示例 2:
+ +输入: [-2,0,-1] +输出: 0 +解释: 结果不能为 2, 因为 [-2,-1] 不是子数组。+ ## 解法 diff --git a/solution/0100-0199/0153.Find Minimum in Rotated Sorted Array/README.md b/solution/0100-0199/0153.Find Minimum in Rotated Sorted Array/README.md index 16180e252d7e1..a704bca706ddc 100644 --- a/solution/0100-0199/0153.Find Minimum in Rotated Sorted Array/README.md +++ b/solution/0100-0199/0153.Find Minimum in Rotated Sorted Array/README.md @@ -1,67 +1,25 @@ -## 寻找旋转排序数组中的最小值 -### 题目描述 +# [153. 寻找旋转排序数组中的最小值](https://leetcode-cn.com/problems/find-minimum-in-rotated-sorted-array) -假设按照升序排序的数组在预先未知的某个点上进行了旋转。 +## 题目描述 + +
假设按照升序排序的数组在预先未知的某个点上进行了旋转。
-( 例如,数组 [0,1,2,4,5,6,7] 可能变为 [4,5,6,7,0,1,2] )。 +( 例如,数组 [0,1,2,4,5,6,7] 可能变为 [4,5,6,7,0,1,2] )。
请找出其中最小的元素。
-你可以假设数组中不存在重复元素。 +你可以假设数组中不存在重复元素。
-示例 1: -``` -输入: [3,4,5,1,2] -输出: 1 -``` +示例 1:
-示例 2: -``` -输入: [4,5,6,7,0,1,2] -输出: 0 -``` +输入: [3,4,5,1,2] +输出: 1-### 解法 -利用两个指针 p,q 指示数组的首尾两端,若 nums[p] <= nums[q],说明数组呈递增趋势,返回 nums[p];否则判断 nums[p] 与 nums[mid] 的大小,从而决定新的数组首尾两端,循环二分查找。 +
示例 2:
-```java -class Solution { - public int findMin(int[] nums) { - int n = nums.length; - if (n == 1) { - return nums[0]; - } - - int p = 0; - int q = n - 1; - - - int mid = p + ((q - p) >> 1); - - while (p < q) { - if (nums[p] <= nums[q]) { - break; - } - - if (nums[p] > nums[mid]) { - q = mid; - } else { - p = mid + 1; - } - - mid = p + ((q - p) >> 1); - } - - return nums[p]; - - } -} -``` - -# [题目](这里是题目链接,如:https://leetcode-cn.com/problems/shu-zu-zhong-zhong-fu-de-shu-zi-lcof/) +输入: [4,5,6,7,0,1,2] +输出: 0-## 题目描述 - ## 解法 diff --git a/solution/0100-0199/0154.Find Minimum in Rotated Sorted Array II/README.md b/solution/0100-0199/0154.Find Minimum in Rotated Sorted Array II/README.md index d9b3840c082d2..31f8301b15d88 100644 --- a/solution/0100-0199/0154.Find Minimum in Rotated Sorted Array II/README.md +++ b/solution/0100-0199/0154.Find Minimum in Rotated Sorted Array II/README.md @@ -1,7 +1,32 @@ -# [题目](这里是题目链接,如:https://leetcode-cn.com/problems/shu-zu-zhong-zhong-fu-de-shu-zi-lcof/) +# [154. 寻找旋转排序数组中的最小值 II](https://leetcode-cn.com/problems/find-minimum-in-rotated-sorted-array-ii) ## 题目描述 +
假设按照升序排序的数组在预先未知的某个点上进行了旋转。
+ +( 例如,数组 [0,1,2,4,5,6,7] 可能变为 [4,5,6,7,0,1,2] )。
请找出其中最小的元素。
+ +注意数组中可能存在重复的元素。
+ +示例 1:
+ +输入: [1,3,5] +输出: 1+ +
示例 2:
+ +输入: [2,2,2,0,1] +输出: 0+ +
说明:
+ +-
+
- 这道题是 寻找旋转排序数组中的最小值 的延伸题目。 +
- 允许重复会影响算法的时间复杂度吗?会如何影响,为什么? +
设计一个支持 push,pop,top 操作,并能在常数时间内检索到最小元素的栈。
-- push(x) -- 将元素 x 推入栈中。 -- pop() -- 删除栈顶的元素。 -- top() -- 获取栈顶元素。 -- getMin() -- 检索栈中的最小元素。 +-
+
- push(x) -- 将元素 x 推入栈中。 +
- pop() -- 删除栈顶的元素。 +
- top() -- 获取栈顶元素。 +
- getMin() -- 检索栈中的最小元素。 +
示例:
+ +MinStack minStack = new MinStack();
minStack.push(-2);
minStack.push(0);
minStack.push(-3);
-minStack.getMin(); --> 返回 -3.
+minStack.getMin(); --> 返回 -3.
minStack.pop();
-minStack.top(); --> 返回 0.
-minStack.getMin(); --> 返回 -2.
-```
-
-### 解法
-创建两个栈 `stack`, `help`,`help`作为辅助栈,每次压栈时,若 `help` 栈顶元素大于/等于要压入的元素 `x`,或者 `help` 栈为空,则压入 `x`,否则重复压入栈顶元素。取最小元素时,从 `help` 中获取栈顶元素即可。
-
-```java
-class MinStack {
-
- private Stack stack;
- private Stack help;
-
- /** initialize your data structure here. */
- public MinStack() {
- stack = new Stack<>();
- help = new Stack<>();
- }
-
- public void push(int x) {
- stack.push(x);
- help.push(help.isEmpty() || help.peek() >= x ? x : help.peek());
- }
-
- public void pop() {
- stack.pop();
- help.pop();
- }
-
- public int top() {
- return stack.peek();
- }
-
- public int getMin() {
- return help.peek();
- }
-}
-
-/**
- * Your MinStack object will be instantiated and called as such:
- * MinStack obj = new MinStack();
- * obj.push(x);
- * obj.pop();
- * int param_3 = obj.top();
- * int param_4 = obj.getMin();
- */
-```
-
-
-然后还可以再优化一点点, 就是在辅助栈存最小值的索引, 这样可以避免辅助栈的大量的重复元素的情况.
-
-``` JavaScript
-/**
- * initialize your data structure here.
- */
-const MinStack = function() {
- this.arr = [];
- this.help = [];
-};
-
-/**
- * @param {number} x
- * @return {void}
- */
-MinStack.prototype.push = function(x) {
- this.arr.push(x);
- if(this.help.length === 0){
- this.help.push(0);
- }else{
- let min = this.getMin();
- if(x < min){
- this.help.push(this.arr.length-1);
- }
- }
-};
-
-/**
- * @return {void}
- */
-MinStack.prototype.pop = function() {
- if(this.arr.length === 0){
- throw new Error('???');
- }
- if(this.arr.length - 1 === this.help[this.help.length - 1]){
- this.help.pop();
- }
- this.arr.pop();
-};
-
-/**
- * @return {number}
- */
-MinStack.prototype.top = function() {
- return this.arr[this.arr.length-1];
-};
-
-/**
- * @return {number}
- */
-MinStack.prototype.getMin = function() {
- if(this.arr.length === 0){
- throw new Error("???");
- }
- return this.arr[this.help[this.help.length-1]];
-};
-
-/**
- * Your MinStack object will be instantiated and called as such:
- * var obj = Object.create(MinStack).createNew()
- * obj.push(x)
- * obj.pop()
- * var param_3 = obj.top()
- * var param_4 = obj.getMin()
- */
-
-```
-
-# [题目](这里是题目链接,如:https://leetcode-cn.com/problems/shu-zu-zhong-zhong-fu-de-shu-zi-lcof/)
+minStack.top(); --> 返回 0.
+minStack.getMin(); --> 返回 -2.
+
-## 题目描述
-
## 解法
diff --git a/solution/0100-0199/0156.Binary Tree Upside Down/README.md b/solution/0100-0199/0156.Binary Tree Upside Down/README.md
new file mode 100644
index 0000000000000..4bce1d02278e3
--- /dev/null
+++ b/solution/0100-0199/0156.Binary Tree Upside Down/README.md
@@ -0,0 +1,29 @@
+# [156. 上下翻转二叉树](https://leetcode-cn.com/problems/binary-tree-upside-down)
+
+## 题目描述
+
+None
+
+
+## 解法
+
+
+
+### Python3
+
+
+```python
+
+```
+
+### Java
+
+
+```java
+
+```
+
+### ...
+```
+
+```
diff --git a/solution/0100-0199/0157.Read N Characters Given Read4/README.md b/solution/0100-0199/0157.Read N Characters Given Read4/README.md
new file mode 100644
index 0000000000000..064c6efb239f6
--- /dev/null
+++ b/solution/0100-0199/0157.Read N Characters Given Read4/README.md
@@ -0,0 +1,29 @@
+# [157. 用 Read4 读取 N 个字符](https://leetcode-cn.com/problems/read-n-characters-given-read4)
+
+## 题目描述
+
+None
+
+
+## 解法
+
+
+
+### Python3
+
+
+```python
+
+```
+
+### Java
+
+
+```java
+
+```
+
+### ...
+```
+
+```
diff --git a/solution/0100-0199/0158.Read N Characters Given Read4 II - Call multiple times/README.md b/solution/0100-0199/0158.Read N Characters Given Read4 II - Call multiple times/README.md
new file mode 100644
index 0000000000000..c81052dc9ef23
--- /dev/null
+++ b/solution/0100-0199/0158.Read N Characters Given Read4 II - Call multiple times/README.md
@@ -0,0 +1,29 @@
+# [158. 用 Read4 读取 N 个字符 II](https://leetcode-cn.com/problems/read-n-characters-given-read4-ii-call-multiple-times)
+
+## 题目描述
+
+None
+
+
+## 解法
+
+
+
+### Python3
+
+
+```python
+
+```
+
+### Java
+
+
+```java
+
+```
+
+### ...
+```
+
+```
diff --git a/solution/0100-0199/0159.Longest Substring with At Most Two Distinct Characters/README.md b/solution/0100-0199/0159.Longest Substring with At Most Two Distinct Characters/README.md
new file mode 100644
index 0000000000000..5070403ca0b9b
--- /dev/null
+++ b/solution/0100-0199/0159.Longest Substring with At Most Two Distinct Characters/README.md
@@ -0,0 +1,29 @@
+# [159. 至多包含两个不同字符的最长子串](https://leetcode-cn.com/problems/longest-substring-with-at-most-two-distinct-characters)
+
+## 题目描述
+
+None
+
+
+## 解法
+
+
+
+### Python3
+
+
+```python
+
+```
+
+### Java
+
+
+```java
+
+```
+
+### ...
+```
+
+```
diff --git a/solution/0100-0199/0160.Intersection of Two Linked Lists/README.md b/solution/0100-0199/0160.Intersection of Two Linked Lists/README.md
index 82ee877d44dc0..f472838e62aab 100644
--- a/solution/0100-0199/0160.Intersection of Two Linked Lists/README.md
+++ b/solution/0100-0199/0160.Intersection of Two Linked Lists/README.md
@@ -1,85 +1,60 @@
-## 相交链表
-### 题目描述
+# [160. 相交链表](https://leetcode-cn.com/problems/intersection-of-two-linked-lists)
-编写一个程序,找到两个单链表相交的起始节点。
+## 题目描述
+
+编写一个程序,找到两个单链表相交的起始节点。
+如下面的两个链表:
-例如,下面的两个链表: -``` -A: a1 → a2 - ↘ - c1 → c2 → c3 - ↗ -B: b1 → b2 → b3 -``` +
在节点 c1 开始相交。
+-注意: +
示例 1:
-- 如果两个链表没有交点,返回 `null`. -- 在返回结果后,两个链表仍须保持原有的结构。 -- 可假定整个链表结构中没有循环。 -- 程序尽量满足 `O(n)` 时间复杂度,且仅用 `O(1)` 内存。 +
输入:intersectVal = 8, listA = [4,1,8,4,5], listB = [5,0,1,8,4,5], skipA = 2, skipB = 3 +输出:Reference of the node with value = 8 +输入解释:相交节点的值为 8 (注意,如果两个列表相交则不能为 0)。从各自的表头开始算起,链表 A 为 [4,1,8,4,5],链表 B 为 [5,0,1,8,4,5]。在 A 中,相交节点前有 2 个节点;在 B 中,相交节点前有 3 个节点。 +-```java -/** - * Definition for singly-linked list. - * public class ListNode { - * int val; - * ListNode next; - * ListNode(int x) { - * val = x; - * next = null; - * } - * } - */ -public class Solution { - public ListNode getIntersectionNode(ListNode headA, ListNode headB) { - if (headA == null || headB == null) { - return null; - } - int lenA = 0, lenB = 0; - ListNode p = headA, q = headB; - while (p != null) { - p = p.next; - ++lenA; - } - while (q != null) { - q = q.next; - ++lenB; - } - - p = headA; - q = headB; - if (lenA > lenB) { - for (int i = 0; i < lenA - lenB; ++i) { - p = p.next; - } - } else { - for (int i = 0; i < lenB - lenA; ++i) { - q = q.next; - } - } - while (p != null && p != q) { - p = p.next; - q = q.next; - } - return p; - - } -} -``` +
-# [题目](这里是题目链接,如:https://leetcode-cn.com/problems/shu-zu-zhong-zhong-fu-de-shu-zi-lcof/) +
示例 2:
+ +
输入:intersectVal = 2, listA = [0,9,1,2,4], listB = [3,2,4], skipA = 3, skipB = 1 +输出:Reference of the node with value = 2 +输入解释:相交节点的值为 2 (注意,如果两个列表相交则不能为 0)。从各自的表头开始算起,链表 A 为 [0,9,1,2,4],链表 B 为 [3,2,4]。在 A 中,相交节点前有 3 个节点;在 B 中,相交节点前有 1 个节点。 ++ +
+ +
示例 3:
+ +
输入:intersectVal = 0, listA = [2,6,4], listB = [1,5], skipA = 3, skipB = 2 +输出:null +输入解释:从各自的表头开始算起,链表 A 为 [2,6,4],链表 B 为 [1,5]。由于这两个链表不相交,所以 intersectVal 必须为 0,而 skipA 和 skipB 可以是任意值。 +解释:这两个链表不相交,因此返回 null。 ++ +
+ +
注意:
+ +-
+
- 如果两个链表没有交点,返回
null.
+ - 在返回结果后,两个链表仍须保持原有的结构。 +
- 可假定整个链表结构中没有循环。 +
- 程序尽量满足 O(n) 时间复杂度,且仅用 O(1) 内存。 +
峰值元素是指其值大于左右相邻值的元素。
+ +给定一个输入数组 nums,其中 nums[i] ≠ nums[i+1],找到峰值元素并返回其索引。
数组可能包含多个峰值,在这种情况下,返回任何一个峰值所在位置即可。
+ +你可以假设 nums[-1] = nums[n] = -∞。
示例 1:
+ +输入: nums = [1,2,3,1]
+输出: 2
+解释: 3 是峰值元素,你的函数应该返回其索引 2。
+
+示例 2:
+ +输入: nums = [1,2,1,3,5,6,4]
+输出: 1 或 5
+解释: 你的函数可以返回索引 1,其峰值元素为 2;
+ 或者返回索引 5, 其峰值元素为 6。
+
+
+说明:
+ +你的解法应该是 O(logN) 时间复杂度的。
+ ## 解法 diff --git a/solution/0100-0199/0163.Missing Ranges/README.md b/solution/0100-0199/0163.Missing Ranges/README.md new file mode 100644 index 0000000000000..95578410a3958 --- /dev/null +++ b/solution/0100-0199/0163.Missing Ranges/README.md @@ -0,0 +1,29 @@ +# [163. 缺失的区间](https://leetcode-cn.com/problems/missing-ranges) + +## 题目描述 + +None + + +## 解法 + + + +### Python3 + + +```python + +``` + +### Java + + +```java + +``` + +### ... +``` + +``` diff --git a/solution/0100-0199/0164.Maximum Gap/README.md b/solution/0100-0199/0164.Maximum Gap/README.md index d9b3840c082d2..b14e2df534fe5 100644 --- a/solution/0100-0199/0164.Maximum Gap/README.md +++ b/solution/0100-0199/0164.Maximum Gap/README.md @@ -1,7 +1,30 @@ -# [题目](这里是题目链接,如:https://leetcode-cn.com/problems/shu-zu-zhong-zhong-fu-de-shu-zi-lcof/) +# [164. 最大间距](https://leetcode-cn.com/problems/maximum-gap) ## 题目描述 +给定一个无序的数组,找出数组在排序之后,相邻元素之间最大的差值。
+ +如果数组元素个数小于 2,则返回 0。
+ +示例 1:
+ +输入: [3,6,9,1] +输出: 3 +解释: 排序后的数组是 [1,3,6,9], 其中相邻元素 (3,6) 和 (6,9) 之间都存在最大差值 3。+ +
示例 2:
+ +输入: [10] +输出: 0 +解释: 数组元素个数小于 2,因此返回 0。+ +
说明:
+ +-
+
- 你可以假设数组中所有元素都是非负整数,且数值在 32 位有符号整数范围内。 +
- 请尝试在线性时间复杂度和空间复杂度的条件下解决此问题。 +
比较两个版本号 version1 和 version2。
+如果 version1 > version2 返回 1,如果 version1 < version2 返回 -1, 除此之外返回 0。
你可以假设版本字符串非空,并且只包含数字和 . 字符。
. 字符不代表小数点,而是用于分隔数字序列。
例如,2.5 不是“两个半”,也不是“差一半到三”,而是第二版中的第五个小版本。
你可以假设版本号的每一级的默认修订版号为 0。例如,版本号 3.4 的第一级(大版本)和第二级(小版本)修订号分别为 3 和 4。其第三级和第四级修订号均为 0。
+
示例 1:
+ +输入:+ +version1= "0.1",version2= "1.1" +输出: -1
示例 2:
+ +输入:+ +version1= "1.0.1",version2= "1" +输出: 1
示例 3:
+ +输入:+ +version1= "7.5.2.4",version2= "7.5.3" +输出: -1
示例 4:
+ ++ +输入:version1= "1.01",version2= "1.001" +输出:0 +解释:忽略前导零,“01” 和 “001” 表示相同的数字 “1”。
示例 5:
+ ++ +输入:version1= "1.0",version2= "1.0.0" +输出:0 +解释:version1没有第三级修订号,这意味着它的第三级修订号默认为 “0”。
+ +
提示:
+ +-
+
- 版本字符串由以点 (
.) 分隔的数字字符串组成。这个数字字符串可能有前导零。
+ - 版本字符串不以点开始或结束,并且其中不会有两个连续的点。 +
给定两个整数,分别表示分数的分子 numerator 和分母 denominator,以字符串形式返回小数。
+ +如果小数部分为循环小数,则将循环的部分括在括号内。
+ +示例 1:
+ +输入: numerator = 1, denominator = 2 +输出: "0.5" ++ +
示例 2:
+ +输入: numerator = 2, denominator = 1 +输出: "2"+ +
示例 3:
+ +输入: numerator = 2, denominator = 3 +输出: "0.(6)" ++ ## 解法 diff --git a/solution/0100-0199/0167.Two Sum II - Input array is sorted/README.md b/solution/0100-0199/0167.Two Sum II - Input array is sorted/README.md index e69de29bb2d1d..d60042026d9d5 100644 --- a/solution/0100-0199/0167.Two Sum II - Input array is sorted/README.md +++ b/solution/0100-0199/0167.Two Sum II - Input array is sorted/README.md @@ -0,0 +1,45 @@ +# [167. 两数之和 II - 输入有序数组](https://leetcode-cn.com/problems/two-sum-ii-input-array-is-sorted) + +## 题目描述 + +
给定一个已按照升序排列 的有序数组,找到两个数使得它们相加之和等于目标数。
+ +函数应该返回这两个下标值 index1 和 index2,其中 index1 必须小于 index2。
+ +说明:
+ +-
+
- 返回的下标值(index1 和 index2)不是从零开始的。 +
- 你可以假设每个输入只对应唯一的答案,而且你不可以重复使用相同的元素。 +
示例:
+ +输入: numbers = [2, 7, 11, 15], target = 9 +输出: [1,2] +解释: 2 与 7 之和等于目标数 9 。因此 index1 = 1, index2 = 2 。+ + + +## 解法 + + + +### Python3 + + +```python + +``` + +### Java + + +```java + +``` + +### ... +``` + +``` diff --git a/solution/0100-0199/0168.Excel Sheet Column Title/README.md b/solution/0100-0199/0168.Excel Sheet Column Title/README.md index d2d1113400342..99bfa1db79f36 100644 --- a/solution/0100-0199/0168.Excel Sheet Column Title/README.md +++ b/solution/0100-0199/0168.Excel Sheet Column Title/README.md @@ -1,66 +1,39 @@ -## Excel表列名称 -### 题目描述 +# [168. Excel表列名称](https://leetcode-cn.com/problems/excel-sheet-column-title) -给定一个正整数,返回它在 Excel 表中相对应的列名称。 +## 题目描述 + +
给定一个正整数,返回它在 Excel 表中相对应的列名称。
-例如, -``` - 1 -> A - 2 -> B - 3 -> C +例如,
+ + 1 -> A
+ 2 -> B
+ 3 -> C
...
- 26 -> Z
- 27 -> AA
- 28 -> AB
+ 26 -> Z
+ 27 -> AA
+ 28 -> AB
...
-```
-
-**示例 1:**
-```
-输入: 1
-输出: "A"
-```
+
-**示例 2:**
-```
-输入: 28
-输出: "AB"
-```
+示例 1:
-**示例 3:** -``` -输入: 701 -输出: "ZY" -``` +输入: 1 +输出: "A" +-### 解法 -1. 将数字 n 减一,则尾数转换为 0-25 的 26 进制数的个位;用除 26 取余的方式,获得尾数对应的符号。 -2. 用除26取余的方式,获得尾数对应的符号; -3. 重复步骤1、2直至 n 为 0。 +
示例 2:
-```java -class Solution { - public String convertToTitle(int n) { - if (n < 0) { - return ""; - } - StringBuilder sb = new StringBuilder(); - while (n > 0) { - n--; - int temp = n % 26; - sb.insert(0,(char)(temp + 'A')); - n /= 26; - } - return sb.toString(); - } -} +输入: 28 +输出: "AB" +-``` +
示例 3:
-# [题目](这里是题目链接,如:https://leetcode-cn.com/problems/shu-zu-zhong-zhong-fu-de-shu-zi-lcof/) +输入: 701 +输出: "ZY" +-## 题目描述 - ## 解法 diff --git a/solution/0100-0199/0169.Majority Element/README.md b/solution/0100-0199/0169.Majority Element/README.md index d9b3840c082d2..e0dfbb85a7525 100644 --- a/solution/0100-0199/0169.Majority Element/README.md +++ b/solution/0100-0199/0169.Majority Element/README.md @@ -1,7 +1,22 @@ -# [题目](这里是题目链接,如:https://leetcode-cn.com/problems/shu-zu-zhong-zhong-fu-de-shu-zi-lcof/) +# [169. 多数元素](https://leetcode-cn.com/problems/majority-element) ## 题目描述 +
给定一个大小为 n 的数组,找到其中的多数元素。多数元素是指在数组中出现次数大于 ⌊ n/2 ⌋ 的元素。
你可以假设数组是非空的,并且给定的数组总是存在多数元素。
+ +示例 1:
+ +输入: [3,2,3] +输出: 3+ +
示例 2:
+ +输入: [2,2,1,1,1,2,2] +输出: 2 ++ ## 解法 diff --git a/solution/0100-0199/0170.Two Sum III - Data structure design/README.md b/solution/0100-0199/0170.Two Sum III - Data structure design/README.md new file mode 100644 index 0000000000000..a78b339aaaa7f --- /dev/null +++ b/solution/0100-0199/0170.Two Sum III - Data structure design/README.md @@ -0,0 +1,29 @@ +# [170. 两数之和 III - 数据结构设计](https://leetcode-cn.com/problems/two-sum-iii-data-structure-design) + +## 题目描述 + +None + + +## 解法 + + + +### Python3 + + +```python + +``` + +### Java + + +```java + +``` + +### ... +``` + +``` diff --git a/solution/0100-0199/0171.Excel Sheet Column Number/README.md b/solution/0100-0199/0171.Excel Sheet Column Number/README.md index d9b3840c082d2..aadb240e918a3 100644 --- a/solution/0100-0199/0171.Excel Sheet Column Number/README.md +++ b/solution/0100-0199/0171.Excel Sheet Column Number/README.md @@ -1,7 +1,41 @@ -# [题目](这里是题目链接,如:https://leetcode-cn.com/problems/shu-zu-zhong-zhong-fu-de-shu-zi-lcof/) +# [171. Excel表列序号](https://leetcode-cn.com/problems/excel-sheet-column-number) ## 题目描述 +
给定一个Excel表格中的列名称,返回其相应的列序号。
+ +例如,
+ +A -> 1 + B -> 2 + C -> 3 + ... + Z -> 26 + AA -> 27 + AB -> 28 + ... ++ +
示例 1:
+ +输入: "A" +输出: 1 ++ +
示例 2:
+ +输入: "AB" +输出: 28 ++ +
示例 3:
+ +输入: "ZY" +输出: 701+ +
致谢:
+特别感谢 @ts 添加此问题并创建所有测试用例。
给定一个整数 n,返回 n! 结果尾数中零的数量。
+ +示例 1:
+ +输入: 3 +输出: 0 +解释: 3! = 6, 尾数中没有零。+ +
示例 2:
+ +输入: 5 +输出: 1 +解释: 5! = 120, 尾数中有 1 个零.+ +
说明: 你算法的时间复杂度应为 O(log n) 。
+ ## 解法 diff --git a/solution/0100-0199/0173.Binary Search Tree Iterator/README.md b/solution/0100-0199/0173.Binary Search Tree Iterator/README.md new file mode 100644 index 0000000000000..c01bd84a20f60 --- /dev/null +++ b/solution/0100-0199/0173.Binary Search Tree Iterator/README.md @@ -0,0 +1,58 @@ +# [173. 二叉搜索树迭代器](https://leetcode-cn.com/problems/binary-search-tree-iterator) + +## 题目描述 + +实现一个二叉搜索树迭代器。你将使用二叉搜索树的根节点初始化迭代器。
+ +调用 next() 将返回二叉搜索树中的下一个最小的数。
+ +
示例:
+ +
BSTIterator iterator = new BSTIterator(root); +iterator.next(); // 返回 3 +iterator.next(); // 返回 7 +iterator.hasNext(); // 返回 true +iterator.next(); // 返回 9 +iterator.hasNext(); // 返回 true +iterator.next(); // 返回 15 +iterator.hasNext(); // 返回 true +iterator.next(); // 返回 20 +iterator.hasNext(); // 返回 false+ +
+ +
提示:
+ +-
+
next()和hasNext()操作的时间复杂度是 O(1),并使用 O(h) 内存,其中 h 是树的高度。
+ - 你可以假设
next()调用总是有效的,也就是说,当调用next()时,BST 中至少存在一个下一个最小的数。
+
一些恶魔抓住了公主(P)并将她关在了地下城的右下角。地下城是由 M x N 个房间组成的二维网格。我们英勇的骑士(K)最初被安置在左上角的房间里,他必须穿过地下城并通过对抗恶魔来拯救公主。
+ +骑士的初始健康点数为一个正整数。如果他的健康点数在某一时刻降至 0 或以下,他会立即死亡。
+ +有些房间由恶魔守卫,因此骑士在进入这些房间时会失去健康点数(若房间里的值为负整数,则表示骑士将损失健康点数);其他房间要么是空的(房间里的值为 0),要么包含增加骑士健康点数的魔法球(若房间里的值为正整数,则表示骑士将增加健康点数)。
+ +为了尽快到达公主,骑士决定每次只向右或向下移动一步。
+ ++ +
编写一个函数来计算确保骑士能够拯救到公主所需的最低初始健康点数。
+ +例如,考虑到如下布局的地下城,如果骑士遵循最佳路径 右 -> 右 -> 下 -> 下,则骑士的初始健康点数至少为 7。
| -2 (K) | +-3 | +3 | +
| -5 | +-10 | +1 | +
| 10 | +30 | +-5 (P) | +
+ +
说明:
+ +-
+
-
+
骑士的健康点数没有上限。
+
+ - 任何房间都可能对骑士的健康点数造成威胁,也可能增加骑士的健康点数,包括骑士进入的左上角房间以及公主被监禁的右下角房间。 +
表1: Person
+-------------+---------+ | 列名 | 类型 | +-------------+---------+ | PersonId | int | @@ -11,11 +12,11 @@ | LastName | varchar | +-------------+---------+ PersonId 是上表主键 -``` +-表2: `Address` -``` -+-------------+---------+ +
表2: Address
+-------------+---------+ | 列名 | 类型 | +-------------+---------+ | AddressId | int | @@ -24,82 +25,17 @@ PersonId 是上表主键 | State | varchar | +-------------+---------+ AddressId 是上表主键 -``` +-编写一个 SQL 查询,满足条件:无论 person 是否有地址信息,都需要基于上述两表提供 person 的以下信息: -``` -FirstName, LastName, City, State -``` - -### 解法 -题意中说无论 `person` 是否有地址信息,都要查出来,因此,使用左外连接查询。注意使用 `on` 关键字。 - -```sql -# Write your MySQL query statement below -select a.FirstName, a.LastName, b.City, b.State from Person a left join Address b on a.PersonId = b.PersonId; - -``` +
-#### Input -```json -{ - "headers": { - "Person": [ - "PersonId", - "LastName", - "FirstName" - ], - "Address": [ - "AddressId", - "PersonId", - "City", - "State" - ] - }, - "rows": { - "Person": [ - [ - 1, - "Wang", - "Allen" - ] - ], - "Address": [ - [ - 1, - 2, - "New York City", - "New York" - ] - ] - } -} -``` +
编写一个 SQL 查询,满足条件:无论 person 是否有地址信息,都需要基于上述两表提供 person 的以下信息:
-#### Output -```json -{ - "headers": [ - "FirstName", - "LastName", - "City", - "State" - ], - "values": [ - [ - "Allen", - "Wang", - null, - null - ] - ] -} -``` +-# [题目](这里是题目链接,如:https://leetcode-cn.com/problems/shu-zu-zhong-zhong-fu-de-shu-zi-lcof/) +
FirstName, LastName, City, State +-## 题目描述 - ## 解法 diff --git a/solution/0100-0199/0176.Second Highest Salary/README.md b/solution/0100-0199/0176.Second Highest Salary/README.md index 62c4b8b2bf406..ba4604958404f 100644 --- a/solution/0100-0199/0176.Second Highest Salary/README.md +++ b/solution/0100-0199/0176.Second Highest Salary/README.md @@ -1,81 +1,27 @@ -## 第二高的薪水 -### 题目描述 +# [176. 第二高的薪水](https://leetcode-cn.com/problems/second-highest-salary) -编写一个 SQL 查询,获取 `Employee` 表中第二高的薪水(Salary) 。 -``` -+----+--------+ +## 题目描述 + +
编写一个 SQL 查询,获取 Employee 表中第二高的薪水(Salary) 。
+----+--------+ | Id | Salary | +----+--------+ | 1 | 100 | | 2 | 200 | | 3 | 300 | +----+--------+ -``` +-例如上述 `Employee` 表,SQL查询应该返回 `200` 作为第二高的薪水。如果不存在第二高的薪水,那么查询应返回 `null`。 -``` -+---------------------+ +
例如上述 Employee 表,SQL查询应该返回 200 作为第二高的薪水。如果不存在第二高的薪水,那么查询应返回 null。
+---------------------+ | SecondHighestSalary | +---------------------+ | 200 | +---------------------+ -``` - -### 解法 -从小于最高薪水的记录里面选最高即可。 +-```sql -# Write your MySQL query statement below -select max(Salary) SecondHighestSalary from Employee where Salary < (Select max(Salary) from Employee) - -``` - -#### Input -```json -{ - "headers": { - "Employee": [ - "Id", - "Salary" - ] - }, - "rows": { - "Employee": [ - [ - 1, - 100 - ], - [ - 2, - 200 - ], - [ - 3, - 300 - ] - ] - } -} -``` - -#### Output -```json -{ - "headers": [ - "SecondHighestSalary" - ], - "values": [ - [ - 200 - ] - ] -} -``` - -# [题目](这里是题目链接,如:https://leetcode-cn.com/problems/shu-zu-zhong-zhong-fu-de-shu-zi-lcof/) - -## 题目描述 - ## 解法 diff --git a/solution/0100-0199/0177.Nth Highest Salary/README.md b/solution/0100-0199/0177.Nth Highest Salary/README.md index 83ff489f82e09..d42d5c4bc03b7 100644 --- a/solution/0100-0199/0177.Nth Highest Salary/README.md +++ b/solution/0100-0199/0177.Nth Highest Salary/README.md @@ -1,88 +1,27 @@ -## 第N高的薪水 -### 题目描述 +# [177. 第N高的薪水](https://leetcode-cn.com/problems/nth-highest-salary) -编写一个 SQL 查询,获取 `Employee` 表中第 n 高的薪水(Salary)。 -``` -+----+--------+ +## 题目描述 + +
编写一个 SQL 查询,获取 Employee 表中第 n 高的薪水(Salary)。
+----+--------+ | Id | Salary | +----+--------+ | 1 | 100 | | 2 | 200 | | 3 | 300 | +----+--------+ -``` +-例如上述 `Employee` 表,n = 2 时,应返回第二高的薪水 `200`。如果不存在第 n 高的薪水,那么查询应返回 null。 -``` -+------------------------+ +
例如上述 Employee 表,n = 2 时,应返回第二高的薪水 200。如果不存在第 n 高的薪水,那么查询应返回 null。
+------------------------+ | getNthHighestSalary(2) | +------------------------+ | 200 | +------------------------+ -``` - -### 解法 -对 Salary 进行分组,然后根据 Salary 降序排列。选出偏移为 n-1 的一个记录即可。 +-```sql -CREATE FUNCTION getNthHighestSalary(N INT) RETURNS INT -BEGIN - SET N = N - 1; - RETURN ( - # Write your MySQL query statement below. - select Salary from Employee group by Salary order by Salary desc limit 1 offset N - ); -END - -``` - -#### Input -```json -{ - "headers": { - "Employee": [ - "Id", - "Salary" - ] - }, - "argument": 2, - "rows": { - "Employee": [ - [ - 1, - 100 - ], - [ - 2, - 200 - ], - [ - 3, - 300 - ] - ] - } -} -``` - -#### Output -```json -{ - "headers": [ - "getNthHighestSalary(2)" - ], - "values": [ - [ - 200 - ] - ] -} -``` - -# [题目](这里是题目链接,如:https://leetcode-cn.com/problems/shu-zu-zhong-zhong-fu-de-shu-zi-lcof/) - -## 题目描述 - ## 解法 diff --git a/solution/0100-0199/0178.Rank Scores/README.md b/solution/0100-0199/0178.Rank Scores/README.md index 3521151ca521a..6f7d60abab4c7 100644 --- a/solution/0100-0199/0178.Rank Scores/README.md +++ b/solution/0100-0199/0178.Rank Scores/README.md @@ -1,9 +1,10 @@ -## 分数排名 -### 题目描述 +# [178. 分数排名](https://leetcode-cn.com/problems/rank-scores) -编写一个 SQL 查询来实现分数排名。如果两个分数相同,则两个分数排名(Rank)相同。请注意,平分后的下一个名次应该是下一个连续的整数值。换句话说,名次之间不应该有“间隔”。 -``` -+----+-------+ +## 题目描述 + +
编写一个 SQL 查询来实现分数排名。如果两个分数相同,则两个分数排名(Rank)相同。请注意,平分后的下一个名次应该是下一个连续的整数值。换句话说,名次之间不应该有“间隔”。
+ ++----+-------+ | Id | Score | +----+-------+ | 1 | 3.50 | @@ -13,112 +14,22 @@ | 5 | 4.00 | | 6 | 3.65 | +----+-------+ -``` +-例如,根据上述给定的 `Scores` 表,你的查询应该返回(按分数从高到低排列): -``` -+-------+------+ +
例如,根据上述给定的 Scores 表,你的查询应该返回(按分数从高到低排列):
+-------+------+ | Score | Rank | +-------+------+ | 4.00 | 1 | | 4.00 | 1 | | 3.85 | 2 | -| 3.65 | 3 | +| 3.65 | 3 | | 3.65 | 3 | | 3.50 | 4 | +-------+------+ -``` - -### 解法 -对于每一个分数,找出表中有多少个 `>=` 该分数的不同的(distinct)分数,然后按降序排列。 +-```sql -# Write your MySQL query statement below - -select Score, (select count(distinct Score) from Scores where Score >= s.Score) Rank from Scores s order by Score desc; - -``` - -#### Input -```json -{ - "headers": { - "Scores": [ - "Id", - "Score" - ] - }, - "rows": { - "Scores": [ - [ - 1, - 3.50 - ], - [ - 2, - 3.65 - ], - [ - 3, - 4.00 - ], - [ - 4, - 3.85 - ], - [ - 5, - 4.00 - ], - [ - 6, - 3.65 - ] - ] - } -} -``` - -#### Output -```json -{ - "headers": [ - "Score", - "Rank" - ], - "values": [ - [ - 4.0, - 1 - ], - [ - 4.0, - 1 - ], - [ - 3.85, - 2 - ], - [ - 3.65, - 3 - ], - [ - 3.65, - 3 - ], - [ - 3.5, - 4 - ] - ] -} -``` - -# [题目](这里是题目链接,如:https://leetcode-cn.com/problems/shu-zu-zhong-zhong-fu-de-shu-zi-lcof/) - -## 题目描述 - ## 解法 diff --git a/solution/0100-0199/0179.Largest Number/README.md b/solution/0100-0199/0179.Largest Number/README.md index d9b3840c082d2..bd6145ada0e77 100644 --- a/solution/0100-0199/0179.Largest Number/README.md +++ b/solution/0100-0199/0179.Largest Number/README.md @@ -1,7 +1,21 @@ -# [题目](这里是题目链接,如:https://leetcode-cn.com/problems/shu-zu-zhong-zhong-fu-de-shu-zi-lcof/) +# [179. 最大数](https://leetcode-cn.com/problems/largest-number) ## 题目描述 +
给定一组非负整数,重新排列它们的顺序使之组成一个最大的整数。
+ +示例 1:
+ +输入:+ +[10,2]+输出:210
示例 2:
+ +输入:+ +[3,30,34,5,9]+输出:9534330
说明: 输出结果可能非常大,所以你需要返回一个字符串而不是整数。
+ ## 解法 diff --git a/solution/0100-0199/0180.Consecutive Numbers/README.md b/solution/0100-0199/0180.Consecutive Numbers/README.md index b730701f7f0f4..258388142b00d 100644 --- a/solution/0100-0199/0180.Consecutive Numbers/README.md +++ b/solution/0100-0199/0180.Consecutive Numbers/README.md @@ -1,9 +1,10 @@ -## 连续出现的数字 -### 题目描述 +# [180. 连续出现的数字](https://leetcode-cn.com/problems/consecutive-numbers) -编写一个 SQL 查询,查找所有至少连续出现三次的数字。 -``` -+----+-----+ +## 题目描述 + +编写一个 SQL 查询,查找所有至少连续出现三次的数字。
+ ++----+-----+ | Id | Num | +----+-----+ | 1 | 1 | @@ -14,46 +15,17 @@ | 6 | 2 | | 7 | 2 | +----+-----+ -``` +-例如,给定上面的 `Logs` 表, `1` 是唯一连续出现至少三次的数字。 -``` -+-----------------+ +
例如,给定上面的 Logs 表, 1 是唯一连续出现至少三次的数字。
+-----------------+ | ConsecutiveNums | +-----------------+ | 1 | +-----------------+ -``` - -### 解法 -联表查询。 - -```sql -# Write your MySQL query statement below +-select distinct l1.Num ConsecutiveNums -from Logs l1 -join Logs l2 on l1.Id = l2.Id - 1 -join Logs l3 on l2.Id = l3.Id - 1 -where l1.Num = l2.Num and l2.Num = l3.Num - - -``` - -#### Input -```json -{"headers": {"Logs": ["Id", "Num"]}, "rows": {"Logs": [[1, 1], [2, 1], [3, 1], [4, 2], [5, 1], [6, 2], [7, 2]]}} -``` - -#### Output -```json -{"headers":["ConsecutiveNums"],"values":[[1]]} -``` - -# [题目](这里是题目链接,如:https://leetcode-cn.com/problems/shu-zu-zhong-zhong-fu-de-shu-zi-lcof/) - -## 题目描述 - ## 解法 diff --git a/solution/0100-0199/0181.Employees Earning More Than Their Managers/README.md b/solution/0100-0199/0181.Employees Earning More Than Their Managers/README.md index aa3fde4504dff..e2a15e5f8bad3 100644 --- a/solution/0100-0199/0181.Employees Earning More Than Their Managers/README.md +++ b/solution/0100-0199/0181.Employees Earning More Than Their Managers/README.md @@ -1,9 +1,10 @@ -## 连续出现的数字 -### 题目描述 +# [181. 超过经理收入的员工](https://leetcode-cn.com/problems/employees-earning-more-than-their-managers) -`Employee` 表包含所有员工,他们的经理也属于员工。每个员工都有一个 Id,此外还有一列对应员工的经理的 Id。 -``` -+----+-------+--------+-----------+ +## 题目描述 + +
Employee 表包含所有员工,他们的经理也属于员工。每个员工都有一个 Id,此外还有一列对应员工的经理的 Id。
+----+-------+--------+-----------+ | Id | Name | Salary | ManagerId | +----+-------+--------+-----------+ | 1 | Joe | 70000 | 3 | @@ -11,50 +12,17 @@ | 3 | Sam | 60000 | NULL | | 4 | Max | 90000 | NULL | +----+-------+--------+-----------+ -``` +-给定 `Employee` 表,编写一个 SQL 查询,该查询可以获取收入超过他们经理的员工的姓名。在上面的表格中,Joe 是唯一一个收入超过他的经理的员工。 -``` -+----------+ +
给定 Employee 表,编写一个 SQL 查询,该查询可以获取收入超过他们经理的员工的姓名。在上面的表格中,Joe 是唯一一个收入超过他的经理的员工。
+----------+ | Employee | +----------+ | Joe | +----------+ -``` - -### 解法 -联表查询。 - -```sql -# Write your MySQL query statement below +-# select s.Name as Employee -# from Employee s -# where s.ManagerId is not null and s.Salary > (select Salary from Employee where Id = s.ManagerId); - - -select s1.Name as Employee -from Employee s1 -inner join Employee s2 -on s1.ManagerId = s2.Id -where s1.Salary > s2.Salary; - -``` - -#### Input -```json -{"headers": {"Employee": ["Id", "Name", "Salary", "ManagerId"]}, "rows": {"Employee": [[1, "Joe", 70000, 3], [2, "Henry", 80000, 4], [3, "Sam", 60000, null], [4, "Max", 90000, null]]}} -``` - -#### Output -```json -{"headers":["Employee"],"values":[["Joe"]]} -``` - -# [题目](这里是题目链接,如:https://leetcode-cn.com/problems/shu-zu-zhong-zhong-fu-de-shu-zi-lcof/) - -## 题目描述 - ## 解法 diff --git a/solution/0100-0199/0182.Duplicate Emails/README.md b/solution/0100-0199/0182.Duplicate Emails/README.md index 4ae18834f0c34..4451e1f69a33e 100644 --- a/solution/0100-0199/0182.Duplicate Emails/README.md +++ b/solution/0100-0199/0182.Duplicate Emails/README.md @@ -1,55 +1,31 @@ -## 查找重复的电子邮箱 -### 题目描述 +# [182. 查找重复的电子邮箱](https://leetcode-cn.com/problems/duplicate-emails) -编写一个 SQL 查询,查找 `Person` 表中所有重复的电子邮箱。 +## 题目描述 + +
编写一个 SQL 查询,查找 Person 表中所有重复的电子邮箱。
示例:
+ ++----+---------+ | Id | Email | +----+---------+ | 1 | a@b.com | | 2 | c@d.com | | 3 | a@b.com | +----+---------+ -``` +-根据以上输入,你的查询应返回以下结果: -``` -+---------+ +
根据以上输入,你的查询应返回以下结果:
+ ++---------+ | Email | +---------+ | a@b.com | +---------+ -``` +-**说明:**所有电子邮箱都是小写字母。 +
说明:所有电子邮箱都是小写字母。
-### 解法 -对 `Email` 进行分组,选出数量大于 1 的 `Email` 即可。 - -```sql -# Write your MySQL query statement below -select Email -from Person -group by Email -having count(Email) > 1; -``` - -#### Input -```json -{"headers": {"Person": ["Id", "Email"]}, "rows": {"Person": [[1, "a@b.com"], [2, "c@d.com"], [3, "a@b.com"]]}} -``` - -#### Output -```json -{"headers":["Email"],"values":[["a@b.com"]]} -``` - -# [题目](这里是题目链接,如:https://leetcode-cn.com/problems/shu-zu-zhong-zhong-fu-de-shu-zi-lcof/) - -## 题目描述 - ## 解法 diff --git a/solution/0100-0199/0183.Customers Who Never Order/README.md b/solution/0100-0199/0183.Customers Who Never Order/README.md index 7e5ee1b2fa340..de2424583146b 100644 --- a/solution/0100-0199/0183.Customers Who Never Order/README.md +++ b/solution/0100-0199/0183.Customers Who Never Order/README.md @@ -1,11 +1,12 @@ -## 从不订购的客户 -### 题目描述 +# [183. 从不订购的客户](https://leetcode-cn.com/problems/customers-who-never-order) -某网站包含两个表,`Customers` 表和 `Orders` 表。编写一个 SQL 查询,找出所有从不订购任何东西的客户。 +## 题目描述 + +某网站包含两个表,Customers 表和 Orders 表。编写一个 SQL 查询,找出所有从不订购任何东西的客户。
Customers 表:
+----+-------+ | Id | Name | +----+-------+ | 1 | Joe | @@ -13,55 +14,28 @@ | 3 | Sam | | 4 | Max | +----+-------+ -``` +-`Orders` 表: -``` -+----+------------+ +
Orders 表:
+----+------------+ | Id | CustomerId | +----+------------+ | 1 | 3 | | 2 | 1 | +----+------------+ -``` +-例如给定上述表格,你的查询应返回: -``` -+-----------+ +
例如给定上述表格,你的查询应返回:
+ ++-----------+
| Customers |
+-----------+
| Henry |
| Max |
+-----------+
-```
-
-### 解法
-两个表左连接,找出 `CustomerId` 为 `null` 的记录即可。
-
-```sql
-# Write your MySQL query statement below
-
-select Name as Customers
-from Customers c
-left join Orders o
-on c.Id = o.CustomerId
-where o.CustomerId is null
-```
-
-#### Input
-```json
-{"headers": {"Customers": ["Id", "Name"], "Orders": ["Id", "CustomerId"]}, "rows": {"Customers": [[1, "Joe"], [2, "Henry"], [3, "Sam"], [4, "Max"]], "Orders": [[1, 3], [2, 1]]}}
-```
-
-#### Output
-```json
-{"headers":["Customers"],"values":[["Henry"],["Max"]]}
-```
+
-# [题目](这里是题目链接,如:https://leetcode-cn.com/problems/shu-zu-zhong-zhong-fu-de-shu-zi-lcof/)
-
-## 题目描述
-
## 解法
diff --git a/solution/0100-0199/0184.Department Highest Salary/README.md b/solution/0100-0199/0184.Department Highest Salary/README.md
index f9a2e387dba1b..393817b6924f8 100644
--- a/solution/0100-0199/0184.Department Highest Salary/README.md
+++ b/solution/0100-0199/0184.Department Highest Salary/README.md
@@ -1,9 +1,10 @@
-## 部门工资最高的员工
-### 题目描述
+# [184. 部门工资最高的员工](https://leetcode-cn.com/problems/department-highest-salary)
-`Employee` 表包含所有员工信息,每个员工有其对应的 Id, salary 和 department Id。
-```
-+----+-------+--------+--------------+
+## 题目描述
+
+Employee 表包含所有员工信息,每个员工有其对应的 Id, salary 和 department Id。
+----+-------+--------+--------------+ | Id | Name | Salary | DepartmentId | +----+-------+--------+--------------+ | 1 | Joe | 70000 | 1 | @@ -11,56 +12,28 @@ | 3 | Sam | 60000 | 2 | | 4 | Max | 90000 | 1 | +----+-------+--------+--------------+ -``` +-`Department` 表包含公司所有部门的信息。 -``` -+----+----------+ +
Department 表包含公司所有部门的信息。
+----+----------+ | Id | Name | +----+----------+ | 1 | IT | | 2 | Sales | +----+----------+ -``` +-编写一个 SQL 查询,找出每个部门工资最高的员工。例如,根据上述给定的表格,Max 在 IT 部门有最高工资,Henry 在 Sales 部门有最高工资。 -``` -+------------+----------+--------+ +
编写一个 SQL 查询,找出每个部门工资最高的员工。例如,根据上述给定的表格,Max 在 IT 部门有最高工资,Henry 在 Sales 部门有最高工资。
+ ++------------+----------+--------+
| Department | Employee | Salary |
+------------+----------+--------+
| IT | Max | 90000 |
| Sales | Henry | 80000 |
+------------+----------+--------+
-```
-
-### 解法
-先对 `Employee` 表根据 `DepartmentId` 进行分组,找出每组中工资最高的员工,再与 `Department` 表进行内连接,即可查出结果。
-
-```sql
-# Write your MySQL query statement below
-
-select d.Name as Department, c.Name as Employee, c.Salary
-from (select a.Name, a.DepartmentId, a.Salary from Employee a
-inner join (select DepartmentId, max(Salary) Salary from Employee group by DepartmentId) b
-on a.DepartMentId = b.DepartMentId and a.Salary = b.Salary) c
-inner join DepartMent d
-on d.Id = c.DepartmentId;
-```
-
-#### Input
-```json
-{"headers": {"Employee": ["Id", "Name", "Salary", "DepartmentId"], "Department": ["Id", "Name"]}, "rows": {"Employee": [[1, "Joe", 70000, 1], [2, "Henry", 80000, 2], [3, "Sam", 60000, 2], [4, "Max", 90000, 1]], "Department": [[1, "IT"], [2, "Sales"]]}}
-```
-
-#### Output
-```json
-{"headers":["Department","Employee","Salary"],"values":[["Sales","Henry",80000],["IT","Max",90000]]}
-```
+
-# [题目](这里是题目链接,如:https://leetcode-cn.com/problems/shu-zu-zhong-zhong-fu-de-shu-zi-lcof/)
-
-## 题目描述
-
## 解法
diff --git a/solution/0100-0199/0185.Department Top Three Salaries/README.md b/solution/0100-0199/0185.Department Top Three Salaries/README.md
new file mode 100644
index 0000000000000..6c70ab793faa1
--- /dev/null
+++ b/solution/0100-0199/0185.Department Top Three Salaries/README.md
@@ -0,0 +1,68 @@
+# [185. 部门工资前三高的所有员工](https://leetcode-cn.com/problems/department-top-three-salaries)
+
+## 题目描述
+
+Employee 表包含所有员工信息,每个员工有其对应的工号 Id,姓名 Name,工资 Salary 和部门编号 DepartmentId 。
+----+-------+--------+--------------+ +| Id | Name | Salary | DepartmentId | ++----+-------+--------+--------------+ +| 1 | Joe | 85000 | 1 | +| 2 | Henry | 80000 | 2 | +| 3 | Sam | 60000 | 2 | +| 4 | Max | 90000 | 1 | +| 5 | Janet | 69000 | 1 | +| 6 | Randy | 85000 | 1 | +| 7 | Will | 70000 | 1 | ++----+-------+--------+--------------++ +
Department 表包含公司所有部门的信息。
+----+----------+ +| Id | Name | ++----+----------+ +| 1 | IT | +| 2 | Sales | ++----+----------++ +
编写一个 SQL 查询,找出每个部门获得前三高工资的所有员工。例如,根据上述给定的表,查询结果应返回:
+ ++------------+----------+--------+ +| Department | Employee | Salary | ++------------+----------+--------+ +| IT | Max | 90000 | +| IT | Randy | 85000 | +| IT | Joe | 85000 | +| IT | Will | 70000 | +| Sales | Henry | 80000 | +| Sales | Sam | 60000 | ++------------+----------+--------++ +
解释:
+ +IT 部门中,Max 获得了最高的工资,Randy 和 Joe 都拿到了第二高的工资,Will 的工资排第三。销售部门(Sales)只有两名员工,Henry 的工资最高,Sam 的工资排第二。
+ + + +## 解法 + + + +### Python3 + + +```python + +``` + +### Java + + +```java + +``` + +### ... +``` + +``` diff --git a/solution/0100-0199/0186.Reverse Words in a String II/README.md b/solution/0100-0199/0186.Reverse Words in a String II/README.md new file mode 100644 index 0000000000000..87add57f3ab28 --- /dev/null +++ b/solution/0100-0199/0186.Reverse Words in a String II/README.md @@ -0,0 +1,29 @@ +# [186. 翻转字符串里的单词 II](https://leetcode-cn.com/problems/reverse-words-in-a-string-ii) + +## 题目描述 + +None + + +## 解法 + + + +### Python3 + + +```python + +``` + +### Java + + +```java + +``` + +### ... +``` + +``` diff --git a/solution/0100-0199/0187.Repeated DNA Sequences/README.md b/solution/0100-0199/0187.Repeated DNA Sequences/README.md index d9b3840c082d2..b3bb4d6a2303c 100644 --- a/solution/0100-0199/0187.Repeated DNA Sequences/README.md +++ b/solution/0100-0199/0187.Repeated DNA Sequences/README.md @@ -1,7 +1,18 @@ -# [题目](这里是题目链接,如:https://leetcode-cn.com/problems/shu-zu-zhong-zhong-fu-de-shu-zi-lcof/) +# [187. 重复的DNA序列](https://leetcode-cn.com/problems/repeated-dna-sequences) ## 题目描述 +所有 DNA 都由一系列缩写为 A,C,G 和 T 的核苷酸组成,例如:“ACGAATTCCG”。在研究 DNA 时,识别 DNA 中的重复序列有时会对研究非常有帮助。
+ +编写一个函数来查找 DNA 分子中所有出现超过一次的 10 个字母长的序列(子串)。
+ ++ +
示例:
+ +输入:s = "AAAAACCCCCAAAAACCCCCCAAAAAGGGTTT" +输出:["AAAAACCCCC", "CCCCCAAAAA"]+ ## 解法 diff --git a/solution/0100-0199/0188.Best Time to Buy and Sell Stock IV/README.md b/solution/0100-0199/0188.Best Time to Buy and Sell Stock IV/README.md index fae9228ada8bb..20e3cb86535c7 100644 --- a/solution/0100-0199/0188.Best Time to Buy and Sell Stock IV/README.md +++ b/solution/0100-0199/0188.Best Time to Buy and Sell Stock IV/README.md @@ -1,38 +1,28 @@ -## 买卖股票的最佳时机 IV +# [188. 买卖股票的最佳时机 IV](https://leetcode-cn.com/problems/best-time-to-buy-and-sell-stock-iv) -### 问题描述 -给定一个数组,它的第 i 个元素是一支给定的股票在第 i 天的价格。 - -设计一个算法来计算你所能获取的最大利润。你最多可以完成 k 笔交易。 - -注意: 你不能同时参与多笔交易(你必须在再次购买前出售掉之前的股票)。 +## 题目描述 + +
给定一个数组,它的第 i 个元素是一支给定的股票在第 i 天的价格。
-示例 1: -``` -输入: [2,4,1], k = 2 -输出: 2 -解释: 在第 1 天 (股票价格 = 2) 的时候买入,在第 2 天 (股票价格 = 4) 的时候卖出,这笔交易所能获得利润 = 4-2 = 2 。 -``` +设计一个算法来计算你所能获取的最大利润。你最多可以完成 k 笔交易。
-示例 2: -``` -输入: [3,2,6,5,0,3], k = 2 -输出: 7 -解释: 在第 2 天 (股票价格 = 2) 的时候买入,在第 3 天 (股票价格 = 6) 的时候卖出, 这笔交易所能获得利润 = 6-2 = 4 。 - 随后,在第 5 天 (股票价格 = 0) 的时候买入,在第 6 天 (股票价格 = 3) 的时候卖出, 这笔交易所能获得利润 = 3-0 = 3 。 -``` +注意: 你不能同时参与多笔交易(你必须在再次购买前出售掉之前的股票)。
-------------- -### 思路: +示例 1:
-以解决DP问题的方式处理此问题, 涉及股票天数, 交易次数, 交易内容(买入OR卖出)三个元素, 枚举这三种元素叠加产生的所有情况, 不断 -在每一个选择之后保证最优解, 最后我们看最后一天股票, 经历最大交易次数后, 并且状态是卖出时所得的收益即为最大收益; +输入: [2,4,1], k = 2 +输出: 2 +解释: 在第 1 天 (股票价格 = 2) 的时候买入,在第 2 天 (股票价格 = 4) 的时候卖出,这笔交易所能获得利润 = 4-2 = 2 。 ++
示例 2:
-# [题目](这里是题目链接,如:https://leetcode-cn.com/problems/shu-zu-zhong-zhong-fu-de-shu-zi-lcof/) +输入: [3,2,6,5,0,3], k = 2 +输出: 7 +解释: 在第 2 天 (股票价格 = 2) 的时候买入,在第 3 天 (股票价格 = 6) 的时候卖出, 这笔交易所能获得利润 = 6-2 = 4 。 + 随后,在第 5 天 (股票价格 = 0) 的时候买入,在第 6 天 (股票价格 = 3) 的时候卖出, 这笔交易所能获得利润 = 3-0 = 3 。 +-## 题目描述 - ## 解法 diff --git a/solution/0100-0199/0189.Rotate Array/README.md b/solution/0100-0199/0189.Rotate Array/README.md index 72d3b627c5d39..0fad3d43b71b3 100644 --- a/solution/0100-0199/0189.Rotate Array/README.md +++ b/solution/0100-0199/0189.Rotate Array/README.md @@ -1,65 +1,34 @@ -## 旋转数组 -### 题目描述 +# [189. 旋转数组](https://leetcode-cn.com/problems/rotate-array) -给定一个数组,将数组中的元素向右移动 k 个位置,其中 k 是非负数。 +## 题目描述 + +
给定一个数组,将数组中的元素向右移动 k 个位置,其中 k 是非负数。
-示例 1: -``` -输入: [1,2,3,4,5,6,7] 和 k = 3 -输出: [5,6,7,1,2,3,4] -解释: -向右旋转 1 步: [7,1,2,3,4,5,6] -向右旋转 2 步: [6,7,1,2,3,4,5] -向右旋转 3 步: [5,6,7,1,2,3,4] -``` +示例 1:
-示例 2: -``` -输入: [-1,-100,3,99] 和 k = 2 -输出: [3,99,-1,-100] -解释: -向右旋转 1 步: [99,-1,-100,3] -向右旋转 2 步: [3,99,-1,-100] -``` +输入:-说明: +[1,2,3,4,5,6,7]和 k = 3 +输出:[5,6,7,1,2,3,4]+解释: +向右旋转 1 步:[7,1,2,3,4,5,6]+向右旋转 2 步:[6,7,1,2,3,4,5] +向右旋转 3 步:[5,6,7,1,2,3,4]+
示例 2:
-- 尽可能想出更多的解决方案,至少有三种不同的方法可以解决这个问题。 -- 要求使用空间复杂度为 O(1) 的原地算法。 - -### 解法 -先对整个数组做翻转,之后分别对 [0, k - 1]、[k, n - 1] 的子数组进行翻转,即可得到结果。 +输入: [-1,-100,3,99] 和 k = 2
+输出: [3,99,-1,-100]
+解释:
+向右旋转 1 步: [99,-1,-100,3]
+向右旋转 2 步: [3,99,-1,-100]
-```java
-class Solution {
- public void rotate(int[] nums, int k) {
- int n = nums.length;
- k %= n;
- if (n < 2 || k == 0) {
- return;
- }
-
- rotate(nums, 0, n - 1);
- rotate(nums, 0, k - 1);
- rotate(nums, k, n - 1);
- }
-
- private void rotate(int[] nums, int start, int end) {
- while (start < end) {
- int t = nums[start];
- nums[start] = nums[end];
- nums[end] = t;
- ++start;
- --end;
- }
- }
-}
-```
+说明:
-# [题目](这里是题目链接,如:https://leetcode-cn.com/problems/shu-zu-zhong-zhong-fu-de-shu-zi-lcof/) +-
+
- 尽可能想出更多的解决方案,至少有三种不同的方法可以解决这个问题。 +
- 要求使用空间复杂度为 O(1) 的 原地 算法。 +
颠倒给定的 32 位无符号整数的二进制位。
+ ++ +
示例 1:
+ +输入: 00000010100101000001111010011100 +输出: 00111001011110000010100101000000 +解释: 输入的二进制串 00000010100101000001111010011100 表示无符号整数 43261596, + 因此返回 964176192,其二进制表示形式为 00111001011110000010100101000000。+ +
示例 2:
+ +输入:11111111111111111111111111111101 +输出:10111111111111111111111111111111 +解释:输入的二进制串 11111111111111111111111111111101 表示无符号整数 4294967293, + 因此返回 3221225471 其二进制表示形式为 10101111110010110010011101101001。+ +
+ +
提示:
+ +-
+
- 请注意,在某些语言(如 Java)中,没有无符号整数类型。在这种情况下,输入和输出都将被指定为有符号整数类型,并且不应影响您的实现,因为无论整数是有符号的还是无符号的,其内部的二进制表示形式都是相同的。 +
- 在 Java 中,编译器使用二进制补码记法来表示有符号整数。因此,在上面的 示例 2 中,输入表示有符号整数
-3,输出表示有符号整数-1073741825。
+
+ +
进阶:
+如果多次调用这个函数,你将如何优化你的算法?
编写一个函数,输入是一个无符号整数,返回其二进制表达式中数字位数为 ‘1’ 的个数(也被称为汉明重量)。
+ ++ +
示例 1:
+ +输入:00000000000000000000000000001011
+输出:3
+解释:输入的二进制串 00000000000000000000000000001011 中,共有三位为 '1'。
+
+
+示例 2:
+ +输入:00000000000000000000000010000000 +输出:1 +解释:输入的二进制串 00000000000000000000000010000000 中,共有一位为 '1'。 ++ +
示例 3:
+ +输入:11111111111111111111111111111101 +输出:31 +解释:输入的二进制串 11111111111111111111111111111101 中,共有 31 位为 '1'。+ +
+ +
提示:
+ +-
+
- 请注意,在某些语言(如 Java)中,没有无符号整数类型。在这种情况下,输入和输出都将被指定为有符号整数类型,并且不应影响您的实现,因为无论整数是有符号的还是无符号的,其内部的二进制表示形式都是相同的。 +
- 在 Java 中,编译器使用二进制补码记法来表示有符号整数。因此,在上面的 示例 3 中,输入表示有符号整数
-3。
+
+ +
进阶:
+如果多次调用这个函数,你将如何优化你的算法?
写一个 bash 脚本以统计一个文本文件 words.txt 中每个单词出现的频率。
为了简单起见,你可以假设:
+ +-
+
words.txt只包括小写字母和' '。
+ - 每个单词只由小写字母组成。 +
- 单词间由一个或多个空格字符分隔。 +
示例:
+ +假设 words.txt 内容如下:
the day is sunny the the +the sunny is is ++ +
你的脚本应当输出(以词频降序排列):
+ +the 4 +is 3 +sunny 2 +day 1 ++ +
说明:
+ +-
+
- 不要担心词频相同的单词的排序问题,每个单词出现的频率都是唯一的。 +
- 你可以使用一行 Unix pipes 实现吗? +
给定一个包含电话号码列表(一行一个电话号码)的文本文件 file.txt,写一个 bash 脚本输出所有有效的电话号码。
你可以假设一个有效的电话号码必须满足以下两种格式: (xxx) xxx-xxxx 或 xxx-xxx-xxxx。(x 表示一个数字)
+ +你也可以假设每行前后没有多余的空格字符。
+ +示例:
+ +假设 file.txt 内容如下:
987-123-4567 +123 456 7890 +(123) 456-7890 ++ +
你的脚本应当输出下列有效的电话号码:
+ +987-123-4567 +(123) 456-7890 ++ ## 解法 diff --git a/solution/0100-0199/0194.Transpose File/README.md b/solution/0100-0199/0194.Transpose File/README.md index d9b3840c082d2..7fb2e66734bd7 100644 --- a/solution/0100-0199/0194.Transpose File/README.md +++ b/solution/0100-0199/0194.Transpose File/README.md @@ -1,7 +1,26 @@ -# [题目](这里是题目链接,如:https://leetcode-cn.com/problems/shu-zu-zhong-zhong-fu-de-shu-zi-lcof/) +# [194. 转置文件](https://leetcode-cn.com/problems/transpose-file) ## 题目描述 +
给定一个文件 file.txt,转置它的内容。
你可以假设每行列数相同,并且每个字段由 ' ' 分隔.
示例:
+ +假设 file.txt 文件内容如下:
name age +alice 21 +ryan 30 ++ +
应当输出:
+ +name alice ryan +age 21 30 ++ ## 解法 diff --git a/solution/0100-0199/0195.Tenth Line/README.md b/solution/0100-0199/0195.Tenth Line/README.md index d9b3840c082d2..8263ebc8b1900 100644 --- a/solution/0100-0199/0195.Tenth Line/README.md +++ b/solution/0100-0199/0195.Tenth Line/README.md @@ -1,7 +1,34 @@ -# [题目](这里是题目链接,如:https://leetcode-cn.com/problems/shu-zu-zhong-zhong-fu-de-shu-zi-lcof/) +# [195. 第十行](https://leetcode-cn.com/problems/tenth-line) ## 题目描述 +
给定一个文本文件 file.txt,请只打印这个文件中的第十行。
示例:
+ +假设 file.txt 有如下内容:
Line 1 +Line 2 +Line 3 +Line 4 +Line 5 +Line 6 +Line 7 +Line 8 +Line 9 +Line 10 ++ +
你的脚本应当显示第十行:
+ +Line 10 ++ +
说明:
+1. 如果文件少于十行,你应当输出什么?
+2. 至少有三种不同的解法,请尝试尽可能多的方法来解题。
编写一个 SQL 查询,来删除 Person 表中所有重复的电子邮箱,重复的邮箱里只保留 Id 最小 的那个。
+----+------------------+ | Id | Email | +----+------------------+ | 1 | john@example.com | @@ -12,56 +12,27 @@ | 3 | john@example.com | +----+------------------+ Id 是这个表的主键。 -``` +-例如,在运行你的查询语句之后,上面的 `Person` 表应返回以下几行: -``` -+----+------------------+ +
例如,在运行你的查询语句之后,上面的 Person 表应返回以下几行:
+----+------------------+ | Id | Email | +----+------------------+ | 1 | john@example.com | | 2 | bob@example.com | +----+------------------+ -``` +-### 解法 -先根据 `Email` 分组,选出每个组中最小的 `Id`,作为一张临时表,再删除掉所有 Id 不在这张临时表的记录。 - -```sql -# Write your MySQL query statement below - -# 用这里注释的语句运行会报错,不能 select 之后再 update -# You can't specify target table 'Person' for update in FROM clause -# delete from Person -# where Id not in( -# select min(Id) as Id -# from Person -# group by Email); - -delete from Person -where Id not in( - select Id from ( - select min(id) as Id - from Person - group by Email - ) a -); -``` +
-#### Input -```json -{"headers": {"Person": ["Id", "Email"]}, "rows": {"Person": [[1, "john@example.com"], [2, "bob@example.com"], [3, "john@example.com"]]}} -``` +
提示:
-#### Output -```json -{"headers":["Id","Email"],"values":[[1,"john@example.com"],[2,"bob@example.com"]]} -``` +-
+
- 执行 SQL 之后,输出是整个
Person表。
+ - 使用
delete语句。
+
给定一个 Weather 表,编写一个 SQL 查询,来查找与之前(昨天的)日期相比温度更高的所有日期的 Id。
+---------+------------------+------------------+ | Id(INT) | RecordDate(DATE) | Temperature(INT) | +---------+------------------+------------------+ | 1 | 2015-01-01 | 10 | | 2 | 2015-01-02 | 25 | | 3 | 2015-01-03 | 20 | | 4 | 2015-01-04 | 30 | -+---------+------------------+------------------+ -``` ++---------+------------------+------------------+-例如,根据上述给定的 `Weather` 表格,返回如下 Id: -``` -+----+ +
例如,根据上述给定的 Weather 表格,返回如下 Id:
+----+ | Id | +----+ | 2 | | 4 | -+----+ -``` ++----+-### 解法 -利用 datediff 函数返回两个日期相差的天数。 - -```sql -# Write your MySQL query statement below -select a.Id -from Weather a -inner join Weather b -on a.Temperature > b.Temperature and datediff(a.RecordDate, b.RecordDate) = 1; -``` - -#### Input -```json -{"headers": {"Weather": ["Id", "RecordDate", "Temperature"]}, "rows": {"Weather": [[1, "2015-01-01", 10], [2, "2015-01-02", 25], [3, "2015-01-03", 20], [4, "2015-01-04", 30]]}} -``` - -#### Output -```json -{"headers":["Id"],"values":[[2],[4]]} -``` - -# [题目](这里是题目链接,如:https://leetcode-cn.com/problems/shu-zu-zhong-zhong-fu-de-shu-zi-lcof/) - -## 题目描述 - ## 解法 diff --git a/solution/0100-0199/0198.House Robber/README.md b/solution/0100-0199/0198.House Robber/README.md index 9c8e54987a14c..e6501ed88ca75 100644 --- a/solution/0100-0199/0198.House Robber/README.md +++ b/solution/0100-0199/0198.House Robber/README.md @@ -1,75 +1,26 @@ -## 打家劫舍 -### 题目描述 +# [198. 打家劫舍](https://leetcode-cn.com/problems/house-robber) -你是一个专业的小偷,计划偷窃沿街的房屋。每间房内都藏有一定的现金,影响你偷窃的唯一制约因素就是相邻的房屋装有相互连通的防盗系统,如果两间相邻的房屋在同一晚上被小偷闯入,系统会自动报警。 - -给定一个代表每个房屋存放金额的非负整数数组,计算你在不触动警报装置的情况下,能够偷窃到的最高金额。 - -示例 1: -``` -输入: [1,2,3,1] -输出: 4 -解释: 偷窃 1 号房屋 (金额 = 1) ,然后偷窃 3 号房屋 (金额 = 3)。偷窃到的最高金额 = 1 + 3 = 4 。 -``` - -示例 2: -``` -输入: [2,7,9,3,1] -输出: 12 -解释: 偷窃 1 号房屋 (金额 = 2), 偷窃 3 号房屋 (金额 = 9),接着偷窃 5 号房屋 (金额 = 1)。偷窃到的最高金额 = 2 + 9 + 1 = 12 。 -``` - -### 解法 -每个房屋都有两种选择,抢 or 不抢。从第 n 个房屋开始往前抢,进行递归。 - -以上递归方式会超时,因为中间有很多重复的计算,我们可以开一个空间,如数组,来记录中间结果,避免重复计算,这也就是动态规划。 +## 题目描述 + +
你是一个专业的小偷,计划偷窃沿街的房屋。每间房内都藏有一定的现金,影响你偷窃的唯一制约因素就是相邻的房屋装有相互连通的防盗系统,如果两间相邻的房屋在同一晚上被小偷闯入,系统会自动报警。
-递归版(超时): +给定一个代表每个房屋存放金额的非负整数数组,计算你在不触动警报装置的情况下,能够偷窃到的最高金额。
-```java -class Solution { - private int process(int n, int[] nums) { - return n < 0 ? 0 : Math.max(nums[n] + process(n - 2, nums), process(n - 1, nums)); - } - - public int rob(int[] nums) { - return (nums == null || nums.length == 0) ? 0 : process(nums.length - 1, nums); - } -} -``` +示例 1:
-动态规划版(改进): +输入: [1,2,3,1] +输出: 4 +解释: 偷窃 1 号房屋 (金额 = 1) ,然后偷窃 3 号房屋 (金额 = 3)。 + 偷窃到的最高金额 = 1 + 3 = 4 。-```java -class Solution { - public int rob(int[] nums) { - if (nums == null || nums.length == 0) { - return 0; - } - - int n = nums.length; - if (n == 1) { - return nums[0]; - } - - int[] result = new int[n]; - result[0] = nums[0]; - result[1] = Math.max(nums[0], nums[1]); - - for (int i = 2; i < n; ++i) { - result[i] = Math.max(nums[i] + result[i - 2], result[i - 1]); - } - - return result[n - 1]; - - } -} -``` +
示例 2:
-# [题目](这里是题目链接,如:https://leetcode-cn.com/problems/shu-zu-zhong-zhong-fu-de-shu-zi-lcof/) +输入: [2,7,9,3,1] +输出: 12 +解释: 偷窃 1 号房屋 (金额 = 2), 偷窃 3 号房屋 (金额 = 9),接着偷窃 5 号房屋 (金额 = 1)。 + 偷窃到的最高金额 = 2 + 9 + 1 = 12 。 +-## 题目描述 - ## 解法 diff --git a/solution/0100-0199/0199.Binary Tree Right Side View/README.md b/solution/0100-0199/0199.Binary Tree Right Side View/README.md new file mode 100644 index 0000000000000..6328a5524892c --- /dev/null +++ b/solution/0100-0199/0199.Binary Tree Right Side View/README.md @@ -0,0 +1,43 @@ +# [199. 二叉树的右视图](https://leetcode-cn.com/problems/binary-tree-right-side-view) + +## 题目描述 + +
给定一棵二叉树,想象自己站在它的右侧,按照从顶部到底部的顺序,返回从右侧所能看到的节点值。
+ +示例:
+ +输入: [1,2,3,null,5,null,4] +输出: [1, 3, 4] +解释: + + 1 <--- + / \ +2 3 <--- + \ \ + 5 4 <--- ++ + + +## 解法 + + + +### Python3 + + +```python + +``` + +### Java + + +```java + +``` + +### ... +``` + +``` diff --git a/solution/0200-0299/0200.Number of Islands/README.md b/solution/0200-0299/0200.Number of Islands/README.md index adc27f1fdf99b..b0cb2d4010ecd 100644 --- a/solution/0200-0299/0200.Number of Islands/README.md +++ b/solution/0200-0299/0200.Number of Islands/README.md @@ -1,52 +1,32 @@ -## 岛屿的个数 -### 题目描述 -给定一个由`'1'`(陆地)和`'0'`(水)组成的的二维网格,计算岛屿的数量。一个岛被水包围,并且它是通过水平方向或垂直方向上相邻的陆地连接而成的。你可以假设网格的四个边均被水包围。 -``` -示例 1: -输入: +# [200. 岛屿数量](https://leetcode-cn.com/problems/number-of-islands) + +## 题目描述 + +
给定一个由 '1'(陆地)和 '0'(水)组成的的二维网格,计算岛屿的数量。一个岛被水包围,并且它是通过水平方向或垂直方向上相邻的陆地连接而成的。你可以假设网格的四个边均被水包围。
示例 1:
+ +输入: 11110 11010 11000 00000 -输出: 1 -``` -``` -示例 2: -输入: + +输出: 1 ++ +
示例 2:
+ +输入: 11000 11000 00100 00011 -输出: 3 -``` -### 解法 -对网格进行遍历,每遇到一个岛屿,都将其中陆地`1`全部变成`0`,则遇到岛屿的总数即为所求。 -```python -class Solution: - def numIslands(self, grid): - def dp(x, y): - if x >= 0 and x < len(grid) and y >= 0 and y < len(grid[x]) and grid[x][y] == '1': - grid[x][y] = '0' - dp(x-1, y) - dp(x+1, y) - dp(x, y-1) - dp(x, y+1) - ans = 0 - for i in range(len(grid)): - for j in range(len(grid[i])): - if grid[i][j] == '1': - ans += 1 - dp(i, j) - return ans -``` +输出: 3 +-# [题目](这里是题目链接,如:https://leetcode-cn.com/problems/shu-zu-zhong-zhong-fu-de-shu-zi-lcof/) - -## 题目描述 - - ## 解法 diff --git a/solution/0200-0299/0201.Bitwise AND of Numbers Range/README.md b/solution/0200-0299/0201.Bitwise AND of Numbers Range/README.md index d9b3840c082d2..9f0ab943fe469 100644 --- a/solution/0200-0299/0201.Bitwise AND of Numbers Range/README.md +++ b/solution/0200-0299/0201.Bitwise AND of Numbers Range/README.md @@ -1,7 +1,19 @@ -# [题目](这里是题目链接,如:https://leetcode-cn.com/problems/shu-zu-zhong-zhong-fu-de-shu-zi-lcof/) +# [201. 数字范围按位与](https://leetcode-cn.com/problems/bitwise-and-of-numbers-range) ## 题目描述 +
给定范围 [m, n],其中 0 <= m <= n <= 2147483647,返回此范围内所有数字的按位与(包含 m, n 两端点)。
+ +示例 1:
+ +输入: [5,7] +输出: 4+ +
示例 2:
+ +输入: [0,1] +输出: 0+ ## 解法 diff --git a/solution/0200-0299/0202.Happy Number/README.md b/solution/0200-0299/0202.Happy Number/README.md index ffa4a8c6d1d10..9a6fc64cbe52b 100644 --- a/solution/0200-0299/0202.Happy Number/README.md +++ b/solution/0200-0299/0202.Happy Number/README.md @@ -1,51 +1,22 @@ -## 快乐数 -### 题目描述 +# [202. 快乐数](https://leetcode-cn.com/problems/happy-number) -编写一个算法来判断一个数是不是“快乐数”。 +## 题目描述 + +
编写一个算法来判断一个数是不是“快乐数”。
-一个“快乐数”定义为: +一个“快乐数”定义为:对于一个正整数,每一次将该数替换为它每个位置上的数字的平方和,然后重复这个过程直到这个数变为 1,也可能是无限循环但始终变不到 1。如果可以变为 1,那么这个数就是快乐数。
-对于一个正整数,每一次将该数替换为它每个位置上的数字的平方和,然后重复这个过程直到这个数变为 1,也可能是无限循环但始终变不到 1。如果可以变为 1,那么这个数就是快乐数。 +示例:
-**示例**: -``` -输入: 19 -输出: true -解释: -1² + 9² = 82 -8² + 2² = 68 -6² + 8² = 100 -1² + 0² + 0² = 1 -``` +输入: 19 +输出: true +解释: +12 + 92 = 82 +82 + 22 = 68 +62 + 82 = 100 +12 + 02 + 02 = 1 +-### 解法 -在进行验算的过程中,发现一个规律,只要过程中得到任意一个结果和为 4,那么就一定会按 `4 → 16 → 37 → 58 → 89 → 145 → 42 → 20 → 4` -进行循环,这样的数就不为快乐数;此外,结果和与若是与输入 n 或者上一轮结果和 n 相同,那也不为快乐数。 - -```java -class Solution { - public boolean isHappy(int n) { - if (n <= 0) return false; - int sum = 0; - while (sum != n) { - while (n > 0) { - sum += Math.pow(n % 10, 2); - n /= 10; - } - if (sum == 1) return true; - if (sum == 4) return false; - n = sum; - sum = 0; - } - return false; - } -} -``` - -# [题目](这里是题目链接,如:https://leetcode-cn.com/problems/shu-zu-zhong-zhong-fu-de-shu-zi-lcof/) - -## 题目描述 - ## 解法 diff --git a/solution/0200-0299/0203.Remove Linked List Elements/README.md b/solution/0200-0299/0203.Remove Linked List Elements/README.md index aadac54851205..1c1e68f480093 100644 --- a/solution/0200-0299/0203.Remove Linked List Elements/README.md +++ b/solution/0200-0299/0203.Remove Linked List Elements/README.md @@ -1,41 +1,15 @@ -## 删除链表中的结点 -### 题目描述 +# [203. 移除链表元素](https://leetcode-cn.com/problems/remove-linked-list-elements) -删除链表中等于给定值 val 的所有节点。 - -示例: -``` -输入: 1->2->6->3->4->5->6, val = 6 -输出: 1->2->3->4->5 -``` - -### 解法 -利用链表天然的递归性。首先判断头结点 `head` 的值是否为 val,若是,那么最终链表是 head->removeElements(head.next, val);若不是,则为 removeElements(head.next, val); +## 题目描述 + +
删除链表中等于给定值 val 的所有节点。
-```java -/** - * Definition for singly-linked list. - * public class ListNode { - * int val; - * ListNode next; - * ListNode(int x) { val = x; } - * } - */ -class Solution { - public ListNode removeElements(ListNode head, int val) { - if (head == null) { - return null; - } - head.next = removeElements(head.next, val); - return head.val != val ? head : head.next; - } -} -``` +示例:
-# [题目](这里是题目链接,如:https://leetcode-cn.com/problems/shu-zu-zhong-zhong-fu-de-shu-zi-lcof/) +输入: 1->2->6->3->4->5->6, val = 6 +输出: 1->2->3->4->5 +-## 题目描述 - ## 解法 diff --git a/solution/0200-0299/0204.Count Primes/README.md b/solution/0200-0299/0204.Count Primes/README.md index d9b3840c082d2..4218a4ca0d43f 100644 --- a/solution/0200-0299/0204.Count Primes/README.md +++ b/solution/0200-0299/0204.Count Primes/README.md @@ -1,7 +1,16 @@ -# [题目](这里是题目链接,如:https://leetcode-cn.com/problems/shu-zu-zhong-zhong-fu-de-shu-zi-lcof/) +# [204. 计数质数](https://leetcode-cn.com/problems/count-primes) ## 题目描述 +
统计所有小于非负整数 n 的质数的数量。
+ +示例:
+ +输入: 10 +输出: 4 +解释: 小于 10 的质数一共有 4 个, 它们是 2, 3, 5, 7 。 ++ ## 解法 diff --git a/solution/0200-0299/0205.Isomorphic Strings/README.md b/solution/0200-0299/0205.Isomorphic Strings/README.md index d9b3840c082d2..e0dca1e6c9ebc 100644 --- a/solution/0200-0299/0205.Isomorphic Strings/README.md +++ b/solution/0200-0299/0205.Isomorphic Strings/README.md @@ -1,7 +1,32 @@ -# [题目](这里是题目链接,如:https://leetcode-cn.com/problems/shu-zu-zhong-zhong-fu-de-shu-zi-lcof/) +# [205. 同构字符串](https://leetcode-cn.com/problems/isomorphic-strings) ## 题目描述 +
给定两个字符串 s 和 t,判断它们是否是同构的。
+ +如果 s 中的字符可以被替换得到 t ,那么这两个字符串是同构的。
+ +所有出现的字符都必须用另一个字符替换,同时保留字符的顺序。两个字符不能映射到同一个字符上,但字符可以映射自己本身。
+ +示例 1:
+ +输入: s =+ +"egg",t ="add"+输出: true +
示例 2:
+ +输入: s =+ +"foo",t ="bar"+输出: false
示例 3:
+ +输入: s =+ +"paper",t ="title"+输出: true
说明:
+你可以假设 s 和 t 具有相同的长度。
反转一个单链表。
+ +示例:
+ +输入: 1->2->3->4->5->NULL +输出: 5->4->3->2->1->NULL+ +
进阶:
+你可以迭代或递归地反转链表。你能否用两种方法解决这道题?
你这个学期必须选修 numCourse 门课程,记为 0 到 numCourse-1 。
在选修某些课程之前需要一些先修课程。 例如,想要学习课程 0 ,你需要先完成课程 1 ,我们用一个匹配来表示他们:[0,1]
给定课程总量以及它们的先决条件,请你判断是否可能完成所有课程的学习?
-**提示:** +-- 这个问题相当于查找一个循环是否存在于有向图中。如果存在循环,则不存在拓扑排序,因此不可能选取所有课程进行学习。 -- 拓扑排序也可以通过 BFS 完成。 +
示例 1:
+输入: 2, [[1,0]] +输出: true +解释: 总共有 2 门课程。学习课程 1 之前,你需要完成课程 0。所以这是可能的。-### 解法 -利用拓扑排序,拓扑排序是说,如果存在 `a -> b` 的边,那么拓扑排序的结果,a 一定在 b 的前面。 +
示例 2:
-如果存在拓扑排序,那么就可以完成所有课程的学习。 +输入: 2, [[1,0],[0,1]] +输出: false +解释: 总共有 2 门课程。学习课程 1 之前,你需要先完成课程 0;并且学习课程 0 之前,你还应先完成课程 1。这是不可能的。-**说明:** +
-- 拓扑排序的本质是不断输出入度为 0 的点,该算法可**用于判断图中是否存在环**; -- 可以用队列(或者栈)保存入度为 0 的点,避免每次遍历所有的点。 +
提示:
-```java -class Solution { - public boolean canFinish(int numCourses, int[][] prerequisites) { - int[] indegree = new int[numCourses]; - int[][] g = new int[numCourses][numCourses]; - for (int[] e : prerequisites) { - int cur = e[0]; - int pre = e[1]; - if (g[pre][cur] == 0) { - ++indegree[cur]; - g[pre][cur] = 1; - } - } - - Queue-
+
- 输入的先决条件是由 边缘列表 表示的图形,而不是 邻接矩阵 。详情请参见图的表示法。 +
- 你可以假定输入的先决条件中没有重复的边。 +
1 <= numCourses <= 10^5
+
实现一个 Trie (前缀树),包含 insert, search, 和 startsWith 这三个操作。
示例:
+ +Trie trie = new Trie();
+
+trie.insert("apple");
+trie.search("apple"); // 返回 true
+trie.search("app"); // 返回 false
+trie.startsWith("app"); // 返回 true
+trie.insert("app");
+trie.search("app"); // 返回 true
+
+说明:
+ +-
+
- 你可以假设所有的输入都是由小写字母
a-z构成的。
+ - 保证所有输入均为非空字符串。 +
给定一个含有 n 个正整数的数组和一个正整数 s ,找出该数组中满足其和 ≥ s 的长度最小的连续子数组。如果不存在符合条件的连续子数组,返回 0。
+ +示例:
+ +输入:+ +s = 7, nums = [2,3,1,2,4,3]+输出: 2 +解释: 子数组[4,3]是该条件下的长度最小的连续子数组。 +
进阶:
+ +如果你已经完成了O(n) 时间复杂度的解法, 请尝试 O(n log n) 时间复杂度的解法。
+ ## 解法 diff --git a/solution/0200-0299/0210.Course Schedule II/README.md b/solution/0200-0299/0210.Course Schedule II/README.md index d9b3840c082d2..cb0680bcae994 100644 --- a/solution/0200-0299/0210.Course Schedule II/README.md +++ b/solution/0200-0299/0210.Course Schedule II/README.md @@ -1,7 +1,46 @@ -# [题目](这里是题目链接,如:https://leetcode-cn.com/problems/shu-zu-zhong-zhong-fu-de-shu-zi-lcof/) +# [210. 课程表 II](https://leetcode-cn.com/problems/course-schedule-ii) ## 题目描述 +现在你总共有 n 门课需要选,记为 0 到 n-1。
在选修某些课程之前需要一些先修课程。 例如,想要学习课程 0 ,你需要先完成课程 1 ,我们用一个匹配来表示他们: [0,1]
给定课程总量以及它们的先决条件,返回你为了学完所有课程所安排的学习顺序。
+ +可能会有多个正确的顺序,你只要返回一种就可以了。如果不可能完成所有课程,返回一个空数组。
+ +示例 1:
+ +输入: 2, [[1,0]] +输出:+ +[0,1]+解释: 总共有 2 门课程。要学习课程 1,你需要先完成课程 0。因此,正确的课程顺序为[0,1] 。
示例 2:
+ +输入: 4, [[1,0],[2,0],[3,1],[3,2]] +输出:+ +[0,1,2,3] or [0,2,1,3]+解释: 总共有 4 门课程。要学习课程 3,你应该先完成课程 1 和课程 2。并且课程 1 和课程 2 都应该排在课程 0 之后。 + 因此,一个正确的课程顺序是[0,1,2,3]。另一个正确的排序是[0,2,1,3]。 +
说明:
+ +-
+
- 输入的先决条件是由边缘列表表示的图形,而不是邻接矩阵。详情请参见图的表示法。 +
- 你可以假定输入的先决条件中没有重复的边。 +
提示:
+ +-
+
- 这个问题相当于查找一个循环是否存在于有向图中。如果存在循环,则不存在拓扑排序,因此不可能选取所有课程进行学习。 +
- 通过 DFS 进行拓扑排序 - 一个关于Coursera的精彩视频教程(21分钟),介绍拓扑排序的基本概念。 +
-
+
拓扑排序也可以通过 BFS 完成。
+
+
设计一个支持以下两种操作的数据结构:
+ +void addWord(word) +bool search(word) ++ +
search(word) 可以搜索文字或正则表达式字符串,字符串只包含字母 . 或 a-z 。 . 可以表示任何一个字母。
示例:
+ +addWord("bad")
+addWord("dad")
+addWord("mad")
+search("pad") -> false
+search("bad") -> true
+search(".ad") -> true
+search("b..") -> true
+
+
+说明:
+ +你可以假设所有单词都是由小写字母 a-z 组成的。
给定一个二维网格 board 和一个字典中的单词列表 words,找出所有同时在二维网格和字典中出现的单词。
+ +单词必须按照字母顺序,通过相邻的单元格内的字母构成,其中“相邻”单元格是那些水平相邻或垂直相邻的单元格。同一个单元格内的字母在一个单词中不允许被重复使用。
+ +示例:
+ +输入: +words =+ +["oath","pea","eat","rain"]and board = +[ + ['o','a','a','n'], + ['e','t','a','e'], + ['i','h','k','r'], + ['i','f','l','v'] +] + +输出:["eat","oath"]
说明:
+你可以假设所有输入都由小写字母 a-z 组成。
提示:
+ +-
+
- 你需要优化回溯算法以通过更大数据量的测试。你能否早点停止回溯? +
- 如果当前单词不存在于所有单词的前缀中,则可以立即停止回溯。什么样的数据结构可以有效地执行这样的操作?散列表是否可行?为什么? 前缀树如何?如果你想学习如何实现一个基本的前缀树,请先查看这个问题: 实现Trie(前缀树)。 +
你是一个专业的小偷,计划偷窃沿街的房屋,每间房内都藏有一定的现金。这个地方所有的房屋都围成一圈,这意味着第一个房屋和最后一个房屋是紧挨着的。同时,相邻的房屋装有相互连通的防盗系统,如果两间相邻的房屋在同一晚上被小偷闯入,系统会自动报警。
+ +给定一个代表每个房屋存放金额的非负整数数组,计算你在不触动警报装置的情况下,能够偷窃到的最高金额。
+ +示例 1:
+ +输入: [2,3,2] +输出: 3 +解释: 你不能先偷窃 1 号房屋(金额 = 2),然后偷窃 3 号房屋(金额 = 2), 因为他们是相邻的。 ++ +
示例 2:
+ +输入: [1,2,3,1] +输出: 4 +解释: 你可以先偷窃 1 号房屋(金额 = 1),然后偷窃 3 号房屋(金额 = 3)。 + 偷窃到的最高金额 = 1 + 3 = 4 。+ ## 解法 diff --git a/solution/0200-0299/0214.Shortest Palindrome/README.md b/solution/0200-0299/0214.Shortest Palindrome/README.md index d9b3840c082d2..0e03098bb8594 100644 --- a/solution/0200-0299/0214.Shortest Palindrome/README.md +++ b/solution/0200-0299/0214.Shortest Palindrome/README.md @@ -1,7 +1,20 @@ -# [题目](这里是题目链接,如:https://leetcode-cn.com/problems/shu-zu-zhong-zhong-fu-de-shu-zi-lcof/) +# [214. 最短回文串](https://leetcode-cn.com/problems/shortest-palindrome) ## 题目描述 +
给定一个字符串 s,你可以通过在字符串前面添加字符将其转换为回文串。找到并返回可以用这种方式转换的最短回文串。
+ +示例 1:
+ +输入:+ +"aacecaaa"+输出:"aaacecaaa"+
示例 2:
+ +输入:+ ## 解法 diff --git a/solution/0200-0299/0215.Kth Largest Element in an Array/README.md b/solution/0200-0299/0215.Kth Largest Element in an Array/README.md index 67b23872adae0..4d401389a7941 100644 --- a/solution/0200-0299/0215.Kth Largest Element in an Array/README.md +++ b/solution/0200-0299/0215.Kth Largest Element in an Array/README.md @@ -1,50 +1,24 @@ -## 数组中的第K个最大元素 -### 题目描述 +# [215. 数组中的第K个最大元素](https://leetcode-cn.com/problems/kth-largest-element-in-an-array) -在未排序的数组中找到第 `k` 个最大的元素。请注意,你需要找的是数组排序后的第 `k` 个最大的元素,而不是第 `k` 个不同的元素。 +## 题目描述 + +"abcd"+输出:"dcbabcd"
在未排序的数组中找到第 k 个最大的元素。请注意,你需要找的是数组排序后的第 k 个最大的元素,而不是第 k 个不同的元素。
-**示例1:** -``` -输入: [3,2,1,5,6,4] 和 k = 2 -输出: 5 -``` +示例 1:
-**示例2:** -``` -输入: [3,2,3,1,2,4,5,5,6] 和 k = 4 -输出: 4 -``` +输入: [3,2,1,5,6,4] 和 k = 2
+输出: 5
+
-### 解法
-建一个小根堆,遍历数组元素:
+示例 2:
-- 当堆中元素个数少于堆容量时,直接添加该数组元素; -- 否则,当堆顶元素小于数组元素时,先弹出堆顶元素,再把数组元素添加进堆。 +输入: [3,2,3,1,2,4,5,5,6] 和 k = 4
+输出: 4
-```java
-class Solution {
- public int findKthLargest(int[] nums, int k) {
- PriorityQueue说明:
-# [题目](这里是题目链接,如:https://leetcode-cn.com/problems/shu-zu-zhong-zhong-fu-de-shu-zi-lcof/) +你可以假设 k 总是有效的,且 1 ≤ k ≤ 数组的长度。
-## 题目描述 - ## 解法 diff --git a/solution/0200-0299/0216.Combination Sum III/README.md b/solution/0200-0299/0216.Combination Sum III/README.md index d9b3840c082d2..dd5a64c2189b8 100644 --- a/solution/0200-0299/0216.Combination Sum III/README.md +++ b/solution/0200-0299/0216.Combination Sum III/README.md @@ -1,7 +1,28 @@ -# [题目](这里是题目链接,如:https://leetcode-cn.com/problems/shu-zu-zhong-zhong-fu-de-shu-zi-lcof/) +# [216. 组合总和 III](https://leetcode-cn.com/problems/combination-sum-iii) ## 题目描述 +找出所有相加之和为 n 的 k 个数的组合。组合中只允许含有 1 - 9 的正整数,并且每种组合中不存在重复的数字。
+ +说明:
+ +-
+
- 所有数字都是正整数。 +
- 解集不能包含重复的组合。 +
示例 1:
+ +输入: k = 3, n = 7 +输出: [[1,2,4]] ++ +
示例 2:
+ +输入: k = 3, n = 9 +输出: [[1,2,6], [1,3,5], [2,3,4]] ++ ## 解法 diff --git a/solution/0200-0299/0217.Contains Duplicate/README.md b/solution/0200-0299/0217.Contains Duplicate/README.md index d9b3840c082d2..3ed23faf70363 100644 --- a/solution/0200-0299/0217.Contains Duplicate/README.md +++ b/solution/0200-0299/0217.Contains Duplicate/README.md @@ -1,7 +1,26 @@ -# [题目](这里是题目链接,如:https://leetcode-cn.com/problems/shu-zu-zhong-zhong-fu-de-shu-zi-lcof/) +# [217. 存在重复元素](https://leetcode-cn.com/problems/contains-duplicate) ## 题目描述 +
给定一个整数数组,判断是否存在重复元素。
+ +如果任何值在数组中出现至少两次,函数返回 true。如果数组中每个元素都不相同,则返回 false。
+ +示例 1:
+ +输入: [1,2,3,1] +输出: true+ +
示例 2:
+ +输入: [1,2,3,4] +输出: false+ +
示例 3:
+ +输入: [1,1,1,3,3,4,3,2,4,2] +输出: true+ ## 解法 diff --git a/solution/0200-0299/0218.The Skyline Problem/README.md b/solution/0200-0299/0218.The Skyline Problem/README.md index d9b3840c082d2..9beaaf6939b11 100644 --- a/solution/0200-0299/0218.The Skyline Problem/README.md +++ b/solution/0200-0299/0218.The Skyline Problem/README.md @@ -1,7 +1,28 @@ -# [题目](这里是题目链接,如:https://leetcode-cn.com/problems/shu-zu-zhong-zhong-fu-de-shu-zi-lcof/) +# [218. 天际线问题](https://leetcode-cn.com/problems/the-skyline-problem) ## 题目描述 +
城市的天际线是从远处观看该城市中所有建筑物形成的轮廓的外部轮廓。现在,假设您获得了城市风光照片(图A)上显示的所有建筑物的位置和高度,请编写一个程序以输出由这些建筑物形成的天际线(图B)。
+ +

每个建筑物的几何信息用三元组 [Li,Ri,Hi] 表示,其中 Li 和 Ri 分别是第 i 座建筑物左右边缘的 x 坐标,Hi 是其高度。可以保证 0 ≤ Li, Ri ≤ INT_MAX, 0 < Hi ≤ INT_MAX 和 Ri - Li > 0。您可以假设所有建筑物都是在绝对平坦且高度为 0 的表面上的完美矩形。
例如,图A中所有建筑物的尺寸记录为:[ [2 9 10], [3 7 15], [5 12 12], [15 20 10], [19 24 8] ] 。
输出是以 [ [x1,y1], [x2, y2], [x3, y3], ... ] 格式的“关键点”(图B中的红点)的列表,它们唯一地定义了天际线。关键点是水平线段的左端点。请注意,最右侧建筑物的最后一个关键点仅用于标记天际线的终点,并始终为零高度。此外,任何两个相邻建筑物之间的地面都应被视为天际线轮廓的一部分。
例如,图B中的天际线应该表示为:[ [2 10], [3 15], [7 12], [12 0], [15 10], [20 8], [24, 0] ]。
说明:
+ +-
+
- 任何输入列表中的建筑物数量保证在
[0, 10000]范围内。
+ - 输入列表已经按左
x坐标Li进行升序排列。
+ - 输出列表必须按 x 位排序。 +
- 输出天际线中不得有连续的相同高度的水平线。例如
[...[2 3], [4 5], [7 5], [11 5], [12 7]...]是不正确的答案;三条高度为 5 的线应该在最终输出中合并为一个:[...[2 3], [4 5], [12 7], ...]
+
给定一个整数数组和一个整数 k,判断数组中是否存在两个不同的索引 i 和 j,使得 nums [i] = nums [j],并且 i 和 j 的差的绝对值最大为 k。
+ +示例 1:
+ +输入: nums = [1,2,3,1], k = 3 +输出: true+ +
示例 2:
+ +输入: nums = [1,0,1,1], k = 1 +输出: true+ +
示例 3:
+ +输入: nums = [1,2,3,1,2,3], k = 2 +输出: false+ ## 解法 diff --git a/solution/0200-0299/0220.Contains Duplicate III/README.md b/solution/0200-0299/0220.Contains Duplicate III/README.md index d9b3840c082d2..a7b1d2833af0b 100644 --- a/solution/0200-0299/0220.Contains Duplicate III/README.md +++ b/solution/0200-0299/0220.Contains Duplicate III/README.md @@ -1,7 +1,24 @@ -# [题目](这里是题目链接,如:https://leetcode-cn.com/problems/shu-zu-zhong-zhong-fu-de-shu-zi-lcof/) +# [220. 存在重复元素 III](https://leetcode-cn.com/problems/contains-duplicate-iii) ## 题目描述 +
给定一个整数数组,判断数组中是否有两个不同的索引 i 和 j,使得 nums [i] 和 nums [j] 的差的绝对值最大为 t,并且 i 和 j 之间的差的绝对值最大为 ķ。
+ +示例 1:
+ +输入: nums = [1,2,3,1], k = 3, t = 0 +输出: true+ +
示例 2:
+ +输入: nums = [1,0,1,1], k = 1, t = 2 +输出: true+ +
示例 3:
+ +输入: nums = [1,5,9,1,5,9], k = 2, t = 3 +输出: false+ ## 解法 diff --git a/solution/0200-0299/0221.Maximal Square/README.md b/solution/0200-0299/0221.Maximal Square/README.md index d9b3840c082d2..7b06c200b2e2d 100644 --- a/solution/0200-0299/0221.Maximal Square/README.md +++ b/solution/0200-0299/0221.Maximal Square/README.md @@ -1,7 +1,20 @@ -# [题目](这里是题目链接,如:https://leetcode-cn.com/problems/shu-zu-zhong-zhong-fu-de-shu-zi-lcof/) +# [221. 最大正方形](https://leetcode-cn.com/problems/maximal-square) ## 题目描述 +
在一个由 0 和 1 组成的二维矩阵内,找到只包含 1 的最大正方形,并返回其面积。
+ +示例:
+ +输入: + +1 0 1 0 0 +1 0 1 1 1 +1 1 1 1 1 +1 0 0 1 0 + +输出: 4+ ## 解法 diff --git a/solution/0200-0299/0222.Count Complete Tree Nodes/README.md b/solution/0200-0299/0222.Count Complete Tree Nodes/README.md index d9b3840c082d2..9f30d22da1159 100644 --- a/solution/0200-0299/0222.Count Complete Tree Nodes/README.md +++ b/solution/0200-0299/0222.Count Complete Tree Nodes/README.md @@ -1,7 +1,24 @@ -# [题目](这里是题目链接,如:https://leetcode-cn.com/problems/shu-zu-zhong-zhong-fu-de-shu-zi-lcof/) +# [222. 完全二叉树的节点个数](https://leetcode-cn.com/problems/count-complete-tree-nodes) ## 题目描述 +
给出一个完全二叉树,求出该树的节点个数。
+ +说明:
+ +完全二叉树的定义如下:在完全二叉树中,除了最底层节点可能没填满外,其余每层节点数都达到最大值,并且最下面一层的节点都集中在该层最左边的若干位置。若最底层为第 h 层,则该层包含 1~ 2h 个节点。
+ +示例:
+ +输入: + 1 + / \ + 2 3 + / \ / +4 5 6 + +输出: 6+ ## 解法 diff --git a/solution/0200-0299/0223.Rectangle Area/README.md b/solution/0200-0299/0223.Rectangle Area/README.md index d9b3840c082d2..358e510447412 100644 --- a/solution/0200-0299/0223.Rectangle Area/README.md +++ b/solution/0200-0299/0223.Rectangle Area/README.md @@ -1,7 +1,20 @@ -# [题目](这里是题目链接,如:https://leetcode-cn.com/problems/shu-zu-zhong-zhong-fu-de-shu-zi-lcof/) +# [223. 矩形面积](https://leetcode-cn.com/problems/rectangle-area) ## 题目描述 +
在二维平面上计算出两个由直线构成的矩形重叠后形成的总面积。
+ +每个矩形由其左下顶点和右上顶点坐标表示,如图所示。
+ +
示例:
+ +输入: -3, 0, 3, 4, 0, -1, 9, 2 +输出: 45+ +
说明: 假设矩形面积不会超出 int 的范围。
+ ## 解法 diff --git a/solution/0200-0299/0224.Basic Calculator/README.md b/solution/0200-0299/0224.Basic Calculator/README.md index d9b3840c082d2..b404a464742e1 100644 --- a/solution/0200-0299/0224.Basic Calculator/README.md +++ b/solution/0200-0299/0224.Basic Calculator/README.md @@ -1,7 +1,34 @@ -# [题目](这里是题目链接,如:https://leetcode-cn.com/problems/shu-zu-zhong-zhong-fu-de-shu-zi-lcof/) +# [224. 基本计算器](https://leetcode-cn.com/problems/basic-calculator) ## 题目描述 +实现一个基本的计算器来计算一个简单的字符串表达式的值。
+ +字符串表达式可以包含左括号 ( ,右括号 ),加号 + ,减号 -,非负整数和空格 。
示例 1:
+ +输入: "1 + 1" +输出: 2 ++ +
示例 2:
+ +输入: " 2-1 + 2 " +输出: 3+ +
示例 3:
+ +输入: "(1+(4+5+2)-3)+(6+8)" +输出: 23+ +
说明:
+ +-
+
- 你可以假设所给定的表达式都是有效的。 +
- 请不要使用内置的库函数
eval。
+
使用队列实现栈的下列操作:
+ +-
+
- push(x) -- 元素 x 入栈 +
- pop() -- 移除栈顶元素 +
- top() -- 获取栈顶元素 +
- empty() -- 返回栈是否为空 +
注意:
+ +-
+
- 你只能使用队列的基本操作-- 也就是
push to back,peek/pop from front,size, 和is empty这些操作是合法的。
+ - 你所使用的语言也许不支持队列。 你可以使用 list 或者 deque(双端队列)来模拟一个队列 , 只要是标准的队列操作即可。 +
- 你可以假设所有操作都是有效的(例如, 对一个空的栈不会调用 pop 或者 top 操作)。 +
翻转一棵二叉树。
+ +示例:
+ +输入:
+ +4 + / \ + 2 7 + / \ / \ +1 3 6 9+ +
输出:
+ +4 + / \ + 7 2 + / \ / \ +9 6 3 1+ +
备注:
+这个问题是受到 Max Howell 的 原问题 启发的 :
谷歌:我们90%的工程师使用您编写的软件(Homebrew),但是您却无法在面试时在白板上写出翻转二叉树这道题,这太糟糕了。+ ## 解法 diff --git a/solution/0200-0299/0227.Basic Calculator II/README.md b/solution/0200-0299/0227.Basic Calculator II/README.md index d9b3840c082d2..557a2dd20cb64 100644 --- a/solution/0200-0299/0227.Basic Calculator II/README.md +++ b/solution/0200-0299/0227.Basic Calculator II/README.md @@ -1,7 +1,35 @@ -# [题目](这里是题目链接,如:https://leetcode-cn.com/problems/shu-zu-zhong-zhong-fu-de-shu-zi-lcof/) +# [227. 基本计算器 II](https://leetcode-cn.com/problems/basic-calculator-ii) ## 题目描述 +
实现一个基本的计算器来计算一个简单的字符串表达式的值。
+ +字符串表达式仅包含非负整数,+, - ,*,/ 四种运算符和空格 。 整数除法仅保留整数部分。
示例 1:
+ +输入: "3+2*2" +输出: 7 ++ +
示例 2:
+ +输入: " 3/2 " +输出: 1+ +
示例 3:
+ +输入: " 3+5 / 2 " +输出: 5 ++ +
说明:
+ +-
+
- 你可以假设所给定的表达式都是有效的。 +
- 请不要使用内置的库函数
eval。
+
给定一个无重复元素的有序整数数组,返回数组区间范围的汇总。
-给定一个无重复元素的有序整数数组,返回数组区间范围的汇总。 +示例 1:
-``` -示例 1: -输入: [0,1,2,4,5,7] -输出: ["0->2","4->5","7"] -解释: 0,1,2 可组成一个连续的区间; 4,5 可组成一个连续的区间。 - -示例 2: -输入: [0,2,3,4,6,8,9] -输出: ["0","2->4","6","8->9"] -解释: 2,3,4 可组成一个连续的区间; 8,9 可组成一个连续的区间。 -``` ------- -### 思路 - -1. 设置count计数有多少个连续数字 -2. 当不连续时,得出一个区间加入答案,更改下标`idx += (count+1)`,且count重新置0 - - - -```CPP -class Solution { -public: - vector输入: [0,1,2,4,5,7] +输出: ["0->2","4->5","7"] +解释: 0,1,2 可组成一个连续的区间; 4,5 可组成一个连续的区间。-``` +
示例 2:
-# [题目](这里是题目链接,如:https://leetcode-cn.com/problems/shu-zu-zhong-zhong-fu-de-shu-zi-lcof/) +输入: [0,2,3,4,6,8,9] +输出: ["0","2->4","6","8->9"] +解释: 2,3,4 可组成一个连续的区间; 8,9 可组成一个连续的区间。-## 题目描述 - ## 解法 diff --git a/solution/0200-0299/0229.Majority Element II/README.md b/solution/0200-0299/0229.Majority Element II/README.md index d9b3840c082d2..70114ca37bc57 100644 --- a/solution/0200-0299/0229.Majority Element II/README.md +++ b/solution/0200-0299/0229.Majority Element II/README.md @@ -1,7 +1,21 @@ -# [题目](这里是题目链接,如:https://leetcode-cn.com/problems/shu-zu-zhong-zhong-fu-de-shu-zi-lcof/) +# [229. 求众数 II](https://leetcode-cn.com/problems/majority-element-ii) ## 题目描述 +
给定一个大小为 n 的数组,找出其中所有出现超过 ⌊ n/3 ⌋ 次的元素。
说明: 要求算法的时间复杂度为 O(n),空间复杂度为 O(1)。
+ +示例 1:
+ +输入: [3,2,3] +输出: [3]+ +
示例 2:
+ +输入: [1,1,1,3,3,2,2,2] +输出: [1,2]+ ## 解法 diff --git a/solution/0200-0299/0230.Kth Smallest Element in a BST/README.md b/solution/0200-0299/0230.Kth Smallest Element in a BST/README.md index d9b3840c082d2..54cc4f604e8c6 100644 --- a/solution/0200-0299/0230.Kth Smallest Element in a BST/README.md +++ b/solution/0200-0299/0230.Kth Smallest Element in a BST/README.md @@ -1,7 +1,37 @@ -# [题目](这里是题目链接,如:https://leetcode-cn.com/problems/shu-zu-zhong-zhong-fu-de-shu-zi-lcof/) +# [230. 二叉搜索树中第K小的元素](https://leetcode-cn.com/problems/kth-smallest-element-in-a-bst) ## 题目描述 +
给定一个二叉搜索树,编写一个函数 kthSmallest 来查找其中第 k 个最小的元素。
说明:
+你可以假设 k 总是有效的,1 ≤ k ≤ 二叉搜索树元素个数。
示例 1:
+ +输入: root = [3,1,4,null,2], k = 1 + 3 + / \ + 1 4 + \ + 2 +输出: 1+ +
示例 2:
+ +输入: root = [5,3,6,2,4,null,null,1], k = 3 + 5 + / \ + 3 6 + / \ + 2 4 + / + 1 +输出: 3+ +
进阶:
+如果二叉搜索树经常被修改(插入/删除操作)并且你需要频繁地查找第 k 小的值,你将如何优化 kthSmallest 函数?
给定一个整数,编写一个函数来判断它是否是 2 的幂次方。
-示例 3: -``` -输入: 218 -输出: false -``` +示例 1:
-### 解法 -#### 解法一 -可以利用 2^31 对该数取余,结果为 0 则为 2 的幂次方。 -```java -class Solution { - public boolean isPowerOfTwo(int n) { - return n > 0 && 1073741824 % n == 0; - } -} -``` +输入: 1 +输出: true +解释: 20 = 1-#### 解法二 -也可以循环取余,每次除以 2,判断最终结果是否为 1。 -```java -class Solution { - public boolean isPowerOfTwo(int n) { - if (n < 1) { - return false; - } - - while (n % 2 == 0) { - n >>= 1; - } - return n == 1; - } -} -``` +
示例 2:
-#### 解法三 -利用 `n & -n`: -``` -n & -n 表示 n 的二进制表示的最右边一个1 -``` +输入: 16 +输出: true +解释: 24 = 16-只要 (n & -n) == n,说明 n 的二进制表示中只有一个 1,那么也就说明它是 2 的幂。 -```java -class Solution { - public boolean isPowerOfTwo(int n) { - return n > 0 && (n & -n) == n; - } -} -``` +
示例 3:
-# [题目](这里是题目链接,如:https://leetcode-cn.com/problems/shu-zu-zhong-zhong-fu-de-shu-zi-lcof/) +输入: 218 +输出: false-## 题目描述 - ## 解法 diff --git a/solution/0200-0299/0232.Implement Queue using Stacks/README.md b/solution/0200-0299/0232.Implement Queue using Stacks/README.md new file mode 100644 index 0000000000000..c39c87829feeb --- /dev/null +++ b/solution/0200-0299/0232.Implement Queue using Stacks/README.md @@ -0,0 +1,55 @@ +# [232. 用栈实现队列](https://leetcode-cn.com/problems/implement-queue-using-stacks) + +## 题目描述 + +
使用栈实现队列的下列操作:
+ +-
+
- push(x) -- 将一个元素放入队列的尾部。 +
- pop() -- 从队列首部移除元素。 +
- peek() -- 返回队列首部的元素。 +
- empty() -- 返回队列是否为空。 +
示例:
+ +MyQueue queue = new MyQueue(); + +queue.push(1); +queue.push(2); +queue.peek(); // 返回 1 +queue.pop(); // 返回 1 +queue.empty(); // 返回 false+ +
说明:
+ +-
+
- 你只能使用标准的栈操作 -- 也就是只有
push to top,peek/pop from top,size, 和is empty操作是合法的。
+ - 你所使用的语言也许不支持栈。你可以使用 list 或者 deque(双端队列)来模拟一个栈,只要是标准的栈操作即可。 +
- 假设所有操作都是有效的 (例如,一个空的队列不会调用 pop 或者 peek 操作)。 +
给定一个整数 n,计算所有小于等于 n 的非负整数中数字 1 出现的个数。
+ +示例:
+ +输入: 13 +输出: 6 +解释: 数字 1 出现在以下数字中: 1, 10, 11, 12, 13 。+ ## 解法 diff --git a/solution/0200-0299/0234.Palindrome Linked List/README.md b/solution/0200-0299/0234.Palindrome Linked List/README.md index 87dff2eabf29a..84e5227b5ab37 100644 --- a/solution/0200-0299/0234.Palindrome Linked List/README.md +++ b/solution/0200-0299/0234.Palindrome Linked List/README.md @@ -1,80 +1,23 @@ -## 回文链表 -### 题目描述 +# [234. 回文链表](https://leetcode-cn.com/problems/palindrome-linked-list) +## 题目描述 + +
请判断一个链表是否为回文链表。
-请判断一个链表是否为回文链表。 - -**示例 1:** -``` -输入: 1->2 -输出: false -``` - -**示例 2:** -``` -输入: 1->2->2->1 -输出: true -``` - -**进阶:** +示例 1:
-你能否用 O(n) 时间复杂度和 O(1) 空间复杂度解决此题? +输入: 1->2 +输出: false-### 解法 -利用快慢指针,找到链表的中间节点,之后对右部分链表进行逆置,然后左右两部分链表依次遍历,若出现对应元素不相等的情况,返回 `false`;否则返回 `true`。 +
示例 2:
+输入: 1->2->2->1 +输出: true +-```java -/** - * Definition for singly-linked list. - * public class ListNode { - * int val; - * ListNode next; - * ListNode(int x) { val = x; } - * } - */ -class Solution { - public boolean isPalindrome(ListNode head) { - if (head == null || head.next == null) { - return true; - } - ListNode slow = head; - ListNode fast = head; - while (fast != null && fast.next != null) { - slow = slow.next; - fast = fast.next.next; - } - if (fast != null) { - slow = slow.next; - } - - ListNode rightPre = new ListNode(-1); - while (slow != null) { - ListNode t = slow.next; - slow.next = rightPre.next; - rightPre.next = slow; - slow = t; - } - - ListNode p1 = rightPre.next; - ListNode p2 = head; - while (p1 != null) { - if (p1.val != p2.val) { - return false; - } - p1 = p1.next; - p2 = p2.next; - } - return true; - - } -} -``` +
进阶:
+你能否用 O(n) 时间复杂度和 O(1) 空间复杂度解决此题?
给定一个二叉搜索树, 找到该树中两个指定节点的最近公共祖先。
-[百度百科](https://baike.baidu.com/item/%E6%9C%80%E8%BF%91%E5%85%AC%E5%85%B1%E7%A5%96%E5%85%88/8918834?fr=aladdin)中最近公共祖先的定义为:“对于有根树 T 的两个结点 p、q,最近公共祖先表示为一个结点 x,满足 x 是 p、q 的祖先且 x 的深度尽可能大(**一个节点也可以是它自己的祖先**)。” +百度百科中最近公共祖先的定义为:“对于有根树 T 的两个结点 p、q,最近公共祖先表示为一个结点 x,满足 x 是 p、q 的祖先且 x 的深度尽可能大(一个节点也可以是它自己的祖先)。”
-例如,给定如下二叉搜索树: root = [6,2,8,0,4,7,9,null,null,3,5] -``` - _______6______ - / \ - ___2__ ___8__ - / \ / \ - 0 _4 7 9 - / \ - 3 5 -``` +例如,给定如下二叉搜索树: root = [6,2,8,0,4,7,9,null,null,3,5]
-示例 1: -``` -输入: root = [6,2,8,0,4,7,9,null,null,3,5], p = 2, q = 8 -输出: 6 -解释: 节点 2 和节点 8 的最近公共祖先是 6。 -``` +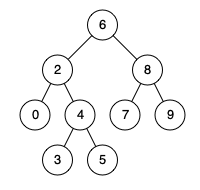
-说明: +
示例 1:
-- 所有节点的值都是唯一的。 -- p、q 为不同节点且均存在于给定的二叉搜索树中。 +输入: root = [6,2,8,0,4,7,9,null,null,3,5], p = 2, q = 8 +输出: 6 +解释: 节点-### 解法 -如果 root 左子树存在 p,右子树存在 q,那么 root 为最近祖先; -如果 p、q 均在 root 左子树,递归左子树;右子树同理。 +2和节点8的最近公共祖先是6。+
示例 2:
+输入: root = [6,2,8,0,4,7,9,null,null,3,5], p = 2, q = 4 +输出: 2 +解释: 节点-```java -/** - * Definition for a binary tree node. - * public class TreeNode { - * int val; - * TreeNode left; - * TreeNode right; - * TreeNode(int x) { val = x; } - * } - */ -class Solution { - public TreeNode lowestCommonAncestor(TreeNode root, TreeNode p, TreeNode q) { - if (root == null || root == p || root == q) { - return root; - } - TreeNode leftNode = lowestCommonAncestor(root.left, p, q); - TreeNode rightNode = lowestCommonAncestor(root.right, p, q); - if (leftNode != null && rightNode != null) { - return root; - } - return leftNode != null ? leftNode : (rightNode != null) ? rightNode : null; - - } -} -``` +2和节点4的最近公共祖先是2, 因为根据定义最近公共祖先节点可以为节点本身。
-# [题目](这里是题目链接,如:https://leetcode-cn.com/problems/shu-zu-zhong-zhong-fu-de-shu-zi-lcof/) +
说明:
+ +-
+
- 所有节点的值都是唯一的。 +
- p、q 为不同节点且均存在于给定的二叉搜索树中。 +
给定一个二叉树, 找到该树中两个指定节点的最近公共祖先。
+ +百度百科中最近公共祖先的定义为:“对于有根树 T 的两个结点 p、q,最近公共祖先表示为一个结点 x,满足 x 是 p、q 的祖先且 x 的深度尽可能大(一个节点也可以是它自己的祖先)。”
+ +例如,给定如下二叉树: root = [3,5,1,6,2,0,8,null,null,7,4]
+ +
+ +
示例 1:
+ +输入: root = [3,5,1,6,2,0,8,null,null,7,4], p = 5, q = 1 +输出: 3 +解释: 节点+ +5和节点1的最近公共祖先是节点3。+
示例 2:
+ +输入: root = [3,5,1,6,2,0,8,null,null,7,4], p = 5, q = 4 +输出: 5 +解释: 节点+ +5和节点4的最近公共祖先是节点5。因为根据定义最近公共祖先节点可以为节点本身。 +
+ +
说明:
+ +-
+
- 所有节点的值都是唯一的。 +
- p、q 为不同节点且均存在于给定的二叉树中。 +
请编写一个函数,使其可以删除某个链表中给定的(非末尾)节点,你将只被给定要求被删除的节点。
-现有一个链表 -- head = [4,5,1,9],它可以表示为: -``` - 4 -> 5 -> 1 -> 9 -``` +现有一个链表 -- head = [4,5,1,9],它可以表示为:
-示例 1: -``` -输入: head = [4,5,1,9], node = 5 -输出: [4,1,9] -解释: 给定你链表中值为 5 的第二个节点,那么在调用了你的函数之后,该链表应变为 4 -> 1 -> 9. -``` +
-说明: +
示例 1:
-- 链表至少包含两个节点。 -- 链表中所有节点的值都是唯一的。 -- 给定的节点为非末尾节点并且一定是链表中的一个有效节点。 -- 不要从你的函数中返回任何结果。 +输入: head = [4,5,1,9], node = 5 +输出: [4,1,9] +解释: 给定你链表中值为 5 的第二个节点,那么在调用了你的函数之后,该链表应变为 4 -> 1 -> 9. +-### 解法 -刚开始看到这道题,有点懵,明明题目给出的输入是 head 跟 node,为什么 solution 中只有 node,后来才明白,只提供 node 依然可以解决此题。只要把下个结点的 值 & next 赋给当前 node,然后删除下个结点,就可以搞定。好题! +
示例 2:
-```java -/** - * Definition for singly-linked list. - * public class ListNode { - * int val; - * ListNode next; - * ListNode(int x) { val = x; } - * } - */ -class Solution { - public void deleteNode(ListNode node) { - // 保存下一个结点 - ListNode tmp = node.next; - - // 将下个结点的值赋给当前要删除的结点 - node.val = node.next.val; - node.next = node.next.next; - - // tmp 置为空,让 jvm 进行垃圾回收 - tmp = null; - - } -} -``` +输入: head = [4,5,1,9], node = 1 +输出: [4,5,9] +解释: 给定你链表中值为 1 的第三个节点,那么在调用了你的函数之后,该链表应变为 4 -> 5 -> 9. +-# [题目](这里是题目链接,如:https://leetcode-cn.com/problems/shu-zu-zhong-zhong-fu-de-shu-zi-lcof/) +
+ +
说明:
+ +-
+
- 链表至少包含两个节点。 +
- 链表中所有节点的值都是唯一的。 +
- 给定的节点为非末尾节点并且一定是链表中的一个有效节点。 +
- 不要从你的函数中返回任何结果。 +
给你一个长度为 n 的整数数组 nums,其中 n > 1,返回输出数组 output ,其中 output[i] 等于 nums 中除 nums[i] 之外其余各元素的乘积。
+ +
示例:
+ +输入:+ +[1,2,3,4]+输出:[24,12,8,6]
+ +
提示:题目数据保证数组之中任意元素的全部前缀元素和后缀(甚至是整个数组)的乘积都在 32 位整数范围内。
+ +说明: 请不要使用除法,且在 O(n) 时间复杂度内完成此题。
+ +进阶:
+你可以在常数空间复杂度内完成这个题目吗?( 出于对空间复杂度分析的目的,输出数组不被视为额外空间。)
给定一个数组 nums,有一个大小为 k 的滑动窗口从数组的最左侧移动到数组的最右侧。你只可以看到在滑动窗口内的 k 个数字。滑动窗口每次只向右移动一位。
+ +返回滑动窗口中的最大值。
+ ++ +
示例:
+ +输入: nums =+ +[1,3,-1,-3,5,3,6,7], 和 k = 3 +输出:[3,3,5,5,6,7] +解释: ++ 滑动窗口的位置 最大值 +--------------- ----- +[1 3 -1] -3 5 3 6 7 3 + 1 [3 -1 -3] 5 3 6 7 3 + 1 3 [-1 -3 5] 3 6 7 5 + 1 3 -1 [-3 5 3] 6 7 5 + 1 3 -1 -3 [5 3 6] 7 6 + 1 3 -1 -3 5 [3 6 7] 7
+ +
提示:
+ +你可以假设 k 总是有效的,在输入数组不为空的情况下,1 ≤ k ≤ 输入数组的大小。
+ ++ +
进阶:
+ +你能在线性时间复杂度内解决此题吗?
+ ## 解法 diff --git a/solution/0200-0299/0240.Search a 2D Matrix II/README.md b/solution/0200-0299/0240.Search a 2D Matrix II/README.md index d9b3840c082d2..dc8cffb5085c0 100644 --- a/solution/0200-0299/0240.Search a 2D Matrix II/README.md +++ b/solution/0200-0299/0240.Search a 2D Matrix II/README.md @@ -1,7 +1,31 @@ -# [题目](这里是题目链接,如:https://leetcode-cn.com/problems/shu-zu-zhong-zhong-fu-de-shu-zi-lcof/) +# [240. 搜索二维矩阵 II](https://leetcode-cn.com/problems/search-a-2d-matrix-ii) ## 题目描述 +编写一个高效的算法来搜索 m x n 矩阵 matrix 中的一个目标值 target。该矩阵具有以下特性:
+ +-
+
- 每行的元素从左到右升序排列。 +
- 每列的元素从上到下升序排列。 +
示例:
+ +现有矩阵 matrix 如下:
+ +[ + [1, 4, 7, 11, 15], + [2, 5, 8, 12, 19], + [3, 6, 9, 16, 22], + [10, 13, 14, 17, 24], + [18, 21, 23, 26, 30] +] ++ +
给定 target = 5,返回 true。
给定 target = 20,返回 false。
给定一个含有数字和运算符的字符串,为表达式添加括号,改变其运算优先级以求出不同的结果。你需要给出所有可能的组合的结果。有效的运算符号包含 +, - 以及 * 。
示例 1:
+ +输入:+ +"2-1-1"+输出:[0, 2]+解释: +((2-1)-1) = 0 +(2-(1-1)) = 2
示例 2:
+ +输入:+ ## 解法 diff --git a/solution/0200-0299/0242.Valid Anagram/README.md b/solution/0200-0299/0242.Valid Anagram/README.md index d9b3840c082d2..d3cd9db216864 100644 --- a/solution/0200-0299/0242.Valid Anagram/README.md +++ b/solution/0200-0299/0242.Valid Anagram/README.md @@ -1,7 +1,26 @@ -# [题目](这里是题目链接,如:https://leetcode-cn.com/problems/shu-zu-zhong-zhong-fu-de-shu-zi-lcof/) +# [242. 有效的字母异位词](https://leetcode-cn.com/problems/valid-anagram) ## 题目描述 +"2*3-4*5"+输出:[-34, -14, -10, -10, 10]+解释: +(2*(3-(4*5))) = -34 +((2*3)-(4*5)) = -14 +((2*(3-4))*5) = -10 +(2*((3-4)*5)) = -10 +(((2*3)-4)*5) = 10
给定两个字符串 s 和 t ,编写一个函数来判断 t 是否是 s 的字母异位词。
+ +示例 1:
+ +输入: s = "anagram", t = "nagaram" +输出: true ++ +
示例 2:
+ +输入: s = "rat", t = "car" +输出: false+ +
说明:
+你可以假设字符串只包含小写字母。
进阶:
+如果输入字符串包含 unicode 字符怎么办?你能否调整你的解法来应对这种情况?
给定一个二叉树,返回所有从根节点到叶子节点的路径。
+ +说明: 叶子节点是指没有子节点的节点。
+ +示例:
+ +输入: + + 1 + / \ +2 3 + \ + 5 + +输出: ["1->2->5", "1->3"] + +解释: 所有根节点到叶子节点的路径为: 1->2->5, 1->3+ ## 解法 diff --git a/solution/0200-0299/0258.Add Digits/README.md b/solution/0200-0299/0258.Add Digits/README.md new file mode 100644 index 0000000000000..2656073e56bd5 --- /dev/null +++ b/solution/0200-0299/0258.Add Digits/README.md @@ -0,0 +1,40 @@ +# [258. 各位相加](https://leetcode-cn.com/problems/add-digits) + +## 题目描述 + +
给定一个非负整数 num,反复将各个位上的数字相加,直到结果为一位数。
示例:
+ +输入:+ +38+输出: 2 +解释: 各位相加的过程为:3 + 8 = 11,1 + 1 = 2。 由于2是一位数,所以返回 2。 +
进阶:
+你可以不使用循环或者递归,且在 O(1) 时间复杂度内解决这个问题吗?
给定一个整数数组 nums,其中恰好有两个元素只出现一次,其余所有元素均出现两次。 找出只出现一次的那两个元素。
示例 :
+ +输入:+ +[1,2,1,3,2,5]+输出:[3,5]
注意:
+ +-
+
- 结果输出的顺序并不重要,对于上面的例子,
[5, 3]也是正确答案。
+ - 你的算法应该具有线性时间复杂度。你能否仅使用常数空间复杂度来实现? +
Trips 表中存所有出租车的行程信息。每段行程有唯一键 Id,Client_Id 和 Driver_Id 是 Users 表中 Users_Id 的外键。Status 是枚举类型,枚举成员为 (‘completed’, ‘cancelled_by_driver’, ‘cancelled_by_client’)。
+----+-----------+-----------+---------+--------------------+----------+ +| Id | Client_Id | Driver_Id | City_Id | Status |Request_at| ++----+-----------+-----------+---------+--------------------+----------+ +| 1 | 1 | 10 | 1 | completed |2013-10-01| +| 2 | 2 | 11 | 1 | cancelled_by_driver|2013-10-01| +| 3 | 3 | 12 | 6 | completed |2013-10-01| +| 4 | 4 | 13 | 6 | cancelled_by_client|2013-10-01| +| 5 | 1 | 10 | 1 | completed |2013-10-02| +| 6 | 2 | 11 | 6 | completed |2013-10-02| +| 7 | 3 | 12 | 6 | completed |2013-10-02| +| 8 | 2 | 12 | 12 | completed |2013-10-03| +| 9 | 3 | 10 | 12 | completed |2013-10-03| +| 10 | 4 | 13 | 12 | cancelled_by_driver|2013-10-03| ++----+-----------+-----------+---------+--------------------+----------+ ++ +
Users 表存所有用户。每个用户有唯一键 Users_Id。Banned 表示这个用户是否被禁止,Role 则是一个表示(‘client’, ‘driver’, ‘partner’)的枚举类型。
+----------+--------+--------+ +| Users_Id | Banned | Role | ++----------+--------+--------+ +| 1 | No | client | +| 2 | Yes | client | +| 3 | No | client | +| 4 | No | client | +| 10 | No | driver | +| 11 | No | driver | +| 12 | No | driver | +| 13 | No | driver | ++----------+--------+--------+ ++ +
写一段 SQL 语句查出 2013年10月1日 至 2013年10月3日 期间非禁止用户的取消率。基于上表,你的 SQL 语句应返回如下结果,取消率(Cancellation Rate)保留两位小数。
+ +取消率的计算方式如下:(被司机或乘客取消的非禁止用户生成的订单数量) / (非禁止用户生成的订单总数)
+ ++------------+-------------------+ +| Day | Cancellation Rate | ++------------+-------------------+ +| 2013-10-01 | 0.33 | +| 2013-10-02 | 0.00 | +| 2013-10-03 | 0.50 | ++------------+-------------------+ ++ +
致谢:
+非常感谢 @cak1erlizhou 详细的提供了这道题和相应的测试用例。
编写一个程序判断给定的数是否为丑数。
+ +丑数就是只包含质因数 2, 3, 5 的正整数。
示例 1:
+ +输入: 6 +输出: true +解释: 6 = 2 × 3+ +
示例 2:
+ +输入: 8 +输出: true +解释: 8 = 2 × 2 × 2 ++ +
示例 3:
+ +输入: 14 +输出: false +解释:+ +14不是丑数,因为它包含了另外一个质因数7。
说明:
+ +-
+
1是丑数。
+ - 输入不会超过 32 位有符号整数的范围: [−231, 231 − 1]。 +
编写一个程序,找出第 n 个丑数。
丑数就是只包含质因数 2, 3, 5 的正整数。
示例:
+ +输入: n = 10
+输出: 12
+解释: 1, 2, 3, 4, 5, 6, 8, 9, 10, 12 是前 10 个丑数。
+
+说明:
+ +-
+
1是丑数。
+ n不超过1690。
+
给定一个包含 0, 1, 2, ..., n 中 n 个数的序列,找出 0 .. n 中没有出现在序列中的那个数。
示例 1:
+ +输入: [3,0,1] +输出: 2 ++ +
示例 2:
+ +输入: [9,6,4,2,3,5,7,0,1] +输出: 8 ++ +
说明:
+你的算法应具有线性时间复杂度。你能否仅使用额外常数空间来实现?
将非负整数转换为其对应的英文表示。可以保证给定输入小于 231 - 1 。
+ +示例 1:
+ +输入: 123 +输出: "One Hundred Twenty Three" ++ +
示例 2:
+ +输入: 12345 +输出: "Twelve Thousand Three Hundred Forty Five"+ +
示例 3:
+ +输入: 1234567 +输出: "One Million Two Hundred Thirty Four Thousand Five Hundred Sixty Seven"+ +
示例 4:
+ +输入: 1234567891 +输出: "One Billion Two Hundred Thirty Four Million Five Hundred Sixty Seven Thousand Eight Hundred Ninety One"+ ## 解法 diff --git a/solution/0200-0299/0274.H-Index/README.md b/solution/0200-0299/0274.H-Index/README.md index d9b3840c082d2..2dbfd8352ab0e 100644 --- a/solution/0200-0299/0274.H-Index/README.md +++ b/solution/0200-0299/0274.H-Index/README.md @@ -1,7 +1,24 @@ -# [题目](这里是题目链接,如:https://leetcode-cn.com/problems/shu-zu-zhong-zhong-fu-de-shu-zi-lcof/) +# [274. H指数](https://leetcode-cn.com/problems/h-index) ## 题目描述 +
给定一位研究者论文被引用次数的数组(被引用次数是非负整数)。编写一个方法,计算出研究者的 h 指数。
+ +h 指数的定义: “h 代表“高引用次数”(high citations),一名科研人员的 h 指数是指他(她)的 (N 篇论文中)至多有 h 篇论文分别被引用了至少 h 次。(其余的 N - h 篇论文每篇被引用次数不多于 h 次。)”
+ ++ +
示例:
+ +输入:+ +citations = [3,0,6,1,5]+输出: 3 +解释: 给定数组表示研究者总共有5篇论文,每篇论文相应的被引用了3, 0, 6, 1, 5次。 + 由于研究者有3篇论文每篇至少被引用了3次,其余两篇论文每篇被引用不多于3次,所以她的 h 指数是3。
+ +
说明: 如果 h 有多种可能的值,h 指数是其中最大的那个。
+ ## 解法 diff --git a/solution/0200-0299/0275.H-Index II/README.md b/solution/0200-0299/0275.H-Index II/README.md index d9b3840c082d2..824287a93ca69 100644 --- a/solution/0200-0299/0275.H-Index II/README.md +++ b/solution/0200-0299/0275.H-Index II/README.md @@ -1,7 +1,35 @@ -# [题目](这里是题目链接,如:https://leetcode-cn.com/problems/shu-zu-zhong-zhong-fu-de-shu-zi-lcof/) +# [275. H指数 II](https://leetcode-cn.com/problems/h-index-ii) ## 题目描述 +给定一位研究者论文被引用次数的数组(被引用次数是非负整数),数组已经按照升序排列。编写一个方法,计算出研究者的 h 指数。
+ +h 指数的定义: “h 代表“高引用次数”(high citations),一名科研人员的 h 指数是指他(她)的 (N 篇论文中)至多有 h 篇论文分别被引用了至少 h 次。(其余的 N - h 篇论文每篇被引用次数不多于 h 次。)"
+ ++ +
示例:
+ +输入:+ +citations = [0,1,3,5,6]+输出: 3 +解释: 给定数组表示研究者总共有5篇论文,每篇论文相应的被引用了 0, 1, 3, 5, 6次。 + 由于研究者有3篇论文每篇至少被引用了3次,其余两篇论文每篇被引用不多于3次,所以她的 h 指数是3。
+ +
说明:
+ +如果 h 有多有种可能的值 ,h 指数是其中最大的那个。
+ ++ +
进阶:
+ +-
+
- 这是 H指数 的延伸题目,本题中的
citations数组是保证有序的。
+ - 你可以优化你的算法到对数时间复杂度吗? +
你是产品经理,目前正在带领一个团队开发新的产品。不幸的是,你的产品的最新版本没有通过质量检测。由于每个版本都是基于之前的版本开发的,所以错误的版本之后的所有版本都是错的。
+ +假设你有 n 个版本 [1, 2, ..., n],你想找出导致之后所有版本出错的第一个错误的版本。
你可以通过调用 bool isBadVersion(version) 接口来判断版本号 version 是否在单元测试中出错。实现一个函数来查找第一个错误的版本。你应该尽量减少对调用 API 的次数。
示例:
+ +给定 n = 5,并且 version = 4 是第一个错误的版本。
+
+调用 isBadVersion(3) -> false
+调用 isBadVersion(5) -> true
+调用 isBadVersion(4) -> true
+
+所以,4 是第一个错误的版本。
+
## 解法
diff --git a/solution/0200-0299/0279.Perfect Squares/README.md b/solution/0200-0299/0279.Perfect Squares/README.md
index d9b3840c082d2..efb87e8d46dee 100644
--- a/solution/0200-0299/0279.Perfect Squares/README.md
+++ b/solution/0200-0299/0279.Perfect Squares/README.md
@@ -1,7 +1,21 @@
-# [题目](这里是题目链接,如:https://leetcode-cn.com/problems/shu-zu-zhong-zhong-fu-de-shu-zi-lcof/)
+# [279. 完全平方数](https://leetcode-cn.com/problems/perfect-squares)
## 题目描述
+给定正整数 n,找到若干个完全平方数(比如 1, 4, 9, 16, ...)使得它们的和等于 n。你需要让组成和的完全平方数的个数最少。
示例 1:
+ +输入: n =+ +12+输出: 3 +解释:12 = 4 + 4 + 4.
示例 2:
+ +输入: n =+ ## 解法 diff --git a/solution/0200-0299/0280.Wiggle Sort/README.md b/solution/0200-0299/0280.Wiggle Sort/README.md new file mode 100644 index 0000000000000..bdd1e11949069 --- /dev/null +++ b/solution/0200-0299/0280.Wiggle Sort/README.md @@ -0,0 +1,29 @@ +# [280. 摆动排序](https://leetcode-cn.com/problems/wiggle-sort) + +## 题目描述 + +None + + +## 解法 + + + +### Python3 + + +```python + +``` + +### Java + + +```java + +``` + +### ... +``` + +``` diff --git a/solution/0200-0299/0281.Zigzag Iterator/README.md b/solution/0200-0299/0281.Zigzag Iterator/README.md new file mode 100644 index 0000000000000..c29d24f898526 --- /dev/null +++ b/solution/0200-0299/0281.Zigzag Iterator/README.md @@ -0,0 +1,29 @@ +# [281. 锯齿迭代器](https://leetcode-cn.com/problems/zigzag-iterator) + +## 题目描述 + +None + + +## 解法 + + + +### Python3 + + +```python + +``` + +### Java + + +```java + +``` + +### ... +``` + +``` diff --git a/solution/0200-0299/0282.Expression Add Operators/README.md b/solution/0200-0299/0282.Expression Add Operators/README.md index d9b3840c082d2..e367d45d0d991 100644 --- a/solution/0200-0299/0282.Expression Add Operators/README.md +++ b/solution/0200-0299/0282.Expression Add Operators/README.md @@ -1,7 +1,37 @@ -# [题目](这里是题目链接,如:https://leetcode-cn.com/problems/shu-zu-zhong-zhong-fu-de-shu-zi-lcof/) +# [282. 给表达式添加运算符](https://leetcode-cn.com/problems/expression-add-operators) ## 题目描述 +13+输出: 2 +解释:13 = 4 + 9.
给定一个仅包含数字 0-9 的字符串和一个目标值,在数字之间添加二元运算符(不是一元)+、- 或 * ,返回所有能够得到目标值的表达式。
示例 1:
+ +输入: num = "123", target = 6
+输出: ["1+2+3", "1*2*3"]
+
+
+示例 2:
+ +输入: num = "232", target = 8
+输出: ["2*3+2", "2+3*2"]
+
+示例 3:
+ +输入: num = "105", target = 5
+输出: ["1*0+5","10-5"]
+
+示例 4:
+ +输入: num = "00", target = 0
+输出: ["0+0", "0-0", "0*0"]
+
+
+示例 5:
+ +输入: num = "3456237490", target = 9191
+输出: []
+
+
## 解法
diff --git a/solution/0200-0299/0283.Move Zeroes/README.md b/solution/0200-0299/0283.Move Zeroes/README.md
index a09102bfeff02..225bbd067bf38 100644
--- a/solution/0200-0299/0283.Move Zeroes/README.md
+++ b/solution/0200-0299/0283.Move Zeroes/README.md
@@ -1,82 +1,21 @@
-## 移动0
+# [283. 移动零](https://leetcode-cn.com/problems/move-zeroes)
-### 问题描述
+## 题目描述
+
+给定一个数组 nums,编写一个函数将所有 0 移动到数组的末尾,同时保持非零元素的相对顺序。
示例:
-``` -示例: -输入: [0,1,0,3,12] -输出: [1,3,12,0,0] -``` -说明: - -1. 必须在原数组上操作,不能拷贝额外的数组。 -2. 尽量减少操作次数。 - -### 思路 - -两种思路,分别是 - -1. 快慢指针,慢指针找0,快指针找慢指针之后的非0元素和慢指针交换,没有找到就直接结束 -2. 也可以通过对非0元素遍历来实现(更好) - -```CPP -class Solution { -public: - void moveZeroes(vector输入:------------------------ -```CPP -class Solution { -public: - void moveZeroes(vector[0,1,0,3,12]+输出:[1,3,12,0,0]
-
+
- 必须在原数组上操作,不能拷贝额外的数组。 +
- 尽量减少操作次数。 +
给定一个迭代器类的接口,接口包含两个方法: next() 和 hasNext()。设计并实现一个支持 peek() 操作的顶端迭代器 -- 其本质就是把原本应由 next() 方法返回的元素 peek() 出来。
示例:
+ +假设迭代器被初始化为列表+ +[1,2,3]。 + +调用next()返回 1,得到列表中的第一个元素。 +现在调用peek()返回 2,下一个元素。在此之后调用next()仍然返回 2。 +最后一次调用next()返回 3,末尾元素。在此之后调用hasNext()应该返回 false。 +
进阶:你将如何拓展你的设计?使之变得通用化,从而适应所有的类型,而不只是整数型?
+ + + +## 解法 + + + +### Python3 + + +```python + +``` + +### Java + + +```java + +``` + +### ... +``` + +``` diff --git a/solution/0200-0299/0285.Inorder Successor in BST/README.md b/solution/0200-0299/0285.Inorder Successor in BST/README.md new file mode 100644 index 0000000000000..7bcf4e9c6a40b --- /dev/null +++ b/solution/0200-0299/0285.Inorder Successor in BST/README.md @@ -0,0 +1,29 @@ +# [285. 二叉搜索树中的顺序后继](https://leetcode-cn.com/problems/inorder-successor-in-bst) + +## 题目描述 + +None + + +## 解法 + + + +### Python3 + + +```python + +``` + +### Java + + +```java + +``` + +### ... +``` + +``` diff --git a/solution/0200-0299/0286.Walls and Gates/README.md b/solution/0200-0299/0286.Walls and Gates/README.md new file mode 100644 index 0000000000000..4cd8a7c6d2893 --- /dev/null +++ b/solution/0200-0299/0286.Walls and Gates/README.md @@ -0,0 +1,29 @@ +# [286. 墙与门](https://leetcode-cn.com/problems/walls-and-gates) + +## 题目描述 + +None + + +## 解法 + + + +### Python3 + + +```python + +``` + +### Java + + +```java + +``` + +### ... +``` + +``` diff --git a/solution/0200-0299/0287.Find the Duplicate Number/README.md b/solution/0200-0299/0287.Find the Duplicate Number/README.md new file mode 100644 index 0000000000000..0a4fa18f371d5 --- /dev/null +++ b/solution/0200-0299/0287.Find the Duplicate Number/README.md @@ -0,0 +1,51 @@ +# [287. 寻找重复数](https://leetcode-cn.com/problems/find-the-duplicate-number) + +## 题目描述 + +给定一个包含 n + 1 个整数的数组 nums,其数字都在 1 到 n 之间(包括 1 和 n),可知至少存在一个重复的整数。假设只有一个重复的整数,找出这个重复的数。
+ +示例 1:
+ +输入: [1,3,4,2,2]
+输出: 2
+
+
+示例 2:
+ +输入: [3,1,3,4,2] +输出: 3 ++ +
说明:
+ +-
+
- 不能更改原数组(假设数组是只读的)。 +
- 只能使用额外的 O(1) 的空间。 +
- 时间复杂度小于 O(n2) 。 +
- 数组中只有一个重复的数字,但它可能不止重复出现一次。 +
根据百度百科,生命游戏,简称为生命,是英国数学家约翰·何顿·康威在1970年发明的细胞自动机。
+ +给定一个包含 m × n 个格子的面板,每一个格子都可以看成是一个细胞。每个细胞具有一个初始状态 live(1)即为活细胞, 或 dead(0)即为死细胞。每个细胞与其八个相邻位置(水平,垂直,对角线)的细胞都遵循以下四条生存定律:
+ +-
+
- 如果活细胞周围八个位置的活细胞数少于两个,则该位置活细胞死亡; +
- 如果活细胞周围八个位置有两个或三个活细胞,则该位置活细胞仍然存活; +
- 如果活细胞周围八个位置有超过三个活细胞,则该位置活细胞死亡; +
- 如果死细胞周围正好有三个活细胞,则该位置死细胞复活; +
根据当前状态,写一个函数来计算面板上细胞的下一个(一次更新后的)状态。下一个状态是通过将上述规则同时应用于当前状态下的每个细胞所形成的,其中细胞的出生和死亡是同时发生的。
+ +示例:
+ +输入: +[ + [0,1,0], + [0,0,1], + [1,1,1], + [0,0,0] +] +输出: +[ + [0,0,0], + [1,0,1], + [0,1,1], + [0,1,0] +]+ +
进阶:
+ +-
+
- 你可以使用原地算法解决本题吗?请注意,面板上所有格子需要同时被更新:你不能先更新某些格子,然后使用它们的更新后的值再更新其他格子。 +
- 本题中,我们使用二维数组来表示面板。原则上,面板是无限的,但当活细胞侵占了面板边界时会造成问题。你将如何解决这些问题? +
给定一种规律 pattern 和一个字符串 str ,判断 str 是否遵循相同的规律。
这里的 遵循 指完全匹配,例如, pattern 里的每个字母和字符串 str 中的每个非空单词之间存在着双向连接的对应规律。
示例1:
+ +输入: pattern =+ +"abba", str ="dog cat cat dog"+输出: true
示例 2:
+ +输入:pattern =+ +"abba", str ="dog cat cat fish"+输出: false
示例 3:
+ +输入: pattern =+ +"aaaa", str ="dog cat cat dog"+输出: false
示例 4:
+ +输入: pattern =+ +"abba", str ="dog dog dog dog"+输出: false
说明:
+你可以假设 pattern 只包含小写字母, str 包含了由单个空格分隔的小写字母。
你和你的朋友,两个人一起玩 Nim 游戏:桌子上有一堆石头,每次你们轮流拿掉 1 - 3 块石头。 拿掉最后一块石头的人就是获胜者。你作为先手。
+ +你们是聪明人,每一步都是最优解。 编写一个函数,来判断你是否可以在给定石头数量的情况下赢得游戏。
+ +示例:
+ +输入: 4
+输出: false
+解释: 如果堆中有 4 块石头,那么你永远不会赢得比赛;
+ 因为无论你拿走 1 块、2 块 还是 3 块石头,最后一块石头总是会被你的朋友拿走。
+
+
## 解法
diff --git a/solution/0200-0299/0293.Flip Game/README.md b/solution/0200-0299/0293.Flip Game/README.md
new file mode 100644
index 0000000000000..207062e34cd44
--- /dev/null
+++ b/solution/0200-0299/0293.Flip Game/README.md
@@ -0,0 +1,29 @@
+# [293. 翻转游戏](https://leetcode-cn.com/problems/flip-game)
+
+## 题目描述
+
+None
+
+
+## 解法
+
+
+
+### Python3
+
+
+```python
+
+```
+
+### Java
+
+
+```java
+
+```
+
+### ...
+```
+
+```
diff --git a/solution/0200-0299/0294.Flip Game II/README.md b/solution/0200-0299/0294.Flip Game II/README.md
new file mode 100644
index 0000000000000..18056bac7ba23
--- /dev/null
+++ b/solution/0200-0299/0294.Flip Game II/README.md
@@ -0,0 +1,29 @@
+# [294. 翻转游戏 II](https://leetcode-cn.com/problems/flip-game-ii)
+
+## 题目描述
+
+None
+
+
+## 解法
+
+
+
+### Python3
+
+
+```python
+
+```
+
+### Java
+
+
+```java
+
+```
+
+### ...
+```
+
+```
diff --git a/solution/0200-0299/0295.Find Median from Data Stream/README.md b/solution/0200-0299/0295.Find Median from Data Stream/README.md
index 745e4fde283d7..f764db5167965 100644
--- a/solution/0200-0299/0295.Find Median from Data Stream/README.md
+++ b/solution/0200-0299/0295.Find Median from Data Stream/README.md
@@ -1,89 +1,37 @@
-## 数据流的中位数
-### 题目描述
+# [295. 数据流的中位数](https://leetcode-cn.com/problems/find-median-from-data-stream)
-中位数是有序列表中间的数。如果列表长度是偶数,中位数则是中间两个数的平均值。
+## 题目描述
+
+中位数是有序列表中间的数。如果列表长度是偶数,中位数则是中间两个数的平均值。
-例如, +例如,
-`[2,3,4]` 的中位数是 `3` +[2,3,4] 的中位数是 3
-`[2,3]` 的中位数是 `(2 + 3) / 2 = 2.5` +[2,3] 的中位数是 (2 + 3) / 2 = 2.5
-设计一个支持以下两种操作的数据结构: +设计一个支持以下两种操作的数据结构:
-- void addNum(int num) - 从数据流中添加一个整数到数据结构中。 -- double findMedian() - 返回目前所有元素的中位数。 +-
+
- void addNum(int num) - 从数据流中添加一个整数到数据结构中。 +
- double findMedian() - 返回目前所有元素的中位数。 +
示例:
+ +addNum(1) addNum(2) -findMedian() -> 1.5 +findMedian() -> 1.5 addNum(3) -findMedian() -> 2 -``` - -进阶: - -- 如果数据流中所有整数都在 0 到 100 范围内,你将如何优化你的算法? -- 如果数据流中 99% 的整数都在 0 到 100 范围内,你将如何优化你的算法? +findMedian() -> 2-### 解法 -维护一个大根堆 bigRoot 和一个小根堆 smallRoot,若有 n 个数,较小的 n/2 个数放在大根堆,而较大的 n/2 个数放在小根堆。 +
进阶:
-- 若其中一个堆的元素个数比另一个堆的元素个数大 1,弹出堆顶元素到另一个堆。 -- 获取中位数时,若两个堆的元素个数相等,返回两个堆堆顶的平均值。否则返回元素个数较多的堆的堆顶。 +-
+
- 如果数据流中所有整数都在 0 到 100 范围内,你将如何优化你的算法? +
- 如果数据流中 99% 的整数都在 0 到 100 范围内,你将如何优化你的算法? +
序列化是将一个数据结构或者对象转换为连续的比特位的操作,进而可以将转换后的数据存储在一个文件或者内存中,同时也可以通过网络传输到另一个计算机环境,采取相反方式重构得到原数据。
+ +请设计一个算法来实现二叉树的序列化与反序列化。这里不限定你的序列 / 反序列化算法执行逻辑,你只需要保证一个二叉树可以被序列化为一个字符串并且将这个字符串反序列化为原始的树结构。
+ +示例:
+ +你可以将以下二叉树:
+
+ 1
+ / \
+ 2 3
+ / \
+ 4 5
+
+序列化为 "[1,2,3,null,null,4,5]"
+
+提示: 这与 LeetCode 目前使用的方式一致,详情请参阅 LeetCode 序列化二叉树的格式。你并非必须采取这种方式,你也可以采用其他的方法解决这个问题。
+ +说明: 不要使用类的成员 / 全局 / 静态变量来存储状态,你的序列化和反序列化算法应该是无状态的。
+ + + +## 解法 + + + +### Python3 + + +```python + +``` + +### Java + + +```java + +``` + +### ... +``` + +``` diff --git a/solution/0200-0299/0298.Binary Tree Longest Consecutive Sequence/README.md b/solution/0200-0299/0298.Binary Tree Longest Consecutive Sequence/README.md new file mode 100644 index 0000000000000..517c8d918eb9b --- /dev/null +++ b/solution/0200-0299/0298.Binary Tree Longest Consecutive Sequence/README.md @@ -0,0 +1,29 @@ +# [298. 二叉树最长连续序列](https://leetcode-cn.com/problems/binary-tree-longest-consecutive-sequence) + +## 题目描述 + +None + + +## 解法 + + + +### Python3 + + +```python + +``` + +### Java + + +```java + +``` + +### ... +``` + +``` diff --git a/solution/0200-0299/0299.Bulls and Cows/README.md b/solution/0200-0299/0299.Bulls and Cows/README.md new file mode 100644 index 0000000000000..e2b17a5d2c52d --- /dev/null +++ b/solution/0200-0299/0299.Bulls and Cows/README.md @@ -0,0 +1,52 @@ +# [299. 猜数字游戏](https://leetcode-cn.com/problems/bulls-and-cows) + +## 题目描述 + +你正在和你的朋友玩 猜数字(Bulls and Cows)游戏:你写下一个数字让你的朋友猜。每次他猜测后,你给他一个提示,告诉他有多少位数字和确切位置都猜对了(称为“Bulls”, 公牛),有多少位数字猜对了但是位置不对(称为“Cows”, 奶牛)。你的朋友将会根据提示继续猜,直到猜出秘密数字。
+ +请写出一个根据秘密数字和朋友的猜测数返回提示的函数,用 A 表示公牛,用 B 表示奶牛。
请注意秘密数字和朋友的猜测数都可能含有重复数字。
+ +示例 1:
+ +输入: secret = "1807", guess = "7810" + +输出: "1A3B" + +解释:+ +1公牛和3奶牛。公牛是8,奶牛是0,1和7。
示例 2:
+ +输入: secret = "1123", guess = "0111" + +输出: "1A1B" + +解释: 朋友猜测数中的第一个+ +1是公牛,第二个或第三个1可被视为奶牛。
说明: 你可以假设秘密数字和朋友的猜测数都只包含数字,并且它们的长度永远相等。
+ + + +## 解法 + + + +### Python3 + + +```python + +``` + +### Java + + +```java + +``` + +### ... +``` + +``` diff --git a/solution/0300-0399/0300.Longest Increasing Subsequence/README.md b/solution/0300-0399/0300.Longest Increasing Subsequence/README.md index 3bf6d497cf2cc..cf25989454b83 100644 --- a/solution/0300-0399/0300.Longest Increasing Subsequence/README.md +++ b/solution/0300-0399/0300.Longest Increasing Subsequence/README.md @@ -1,63 +1,24 @@ -## 最长上升子序列 -### 题目描述 +# [300. 最长上升子序列](https://leetcode-cn.com/problems/longest-increasing-subsequence) -给定一个无序的整数数组,找到其中最长上升子序列的长度。 - -**示例:** -``` -输入: [10,9,2,5,3,7,101,18] -输出: 4 -解释: 最长的上升子序列是 [2,3,7,101],它的长度是 4。 -``` - -**说明:** - -- 可能会有多种最长上升子序列的组合,你只需要输出对应的长度即可。 -- 你算法的时间复杂度应该为 `O(n²)` 。 - -**进阶:** 你能将算法的时间复杂度降低到 `O(n log n)` 吗? +## 题目描述 + +给定一个无序的整数数组,找到其中最长上升子序列的长度。
-### 解法 -记以 `nums[i]` 结尾的最长递增子序列长度为 `res[i]`。 +示例:
-判断 `nums[j](0 < j < i)` 中是否满足 `nums[j] < nums[i]` -- 若是,`res[i + 1]` 可更新为 `res[j] + 1`。求出最大值,即为当前 `res[i + 1]` 的值。 -- 若不满足,`res[i + 1] = 1` +输入:-求解过程中,也求出 `res` 的最大值,即为最长的子序列的长度。 +[10,9,2,5,3,7,101,18] +输出: 4 +解释: 最长的上升子序列是[2,3,7,101],它的长度是4。
说明:
-```java -class Solution { - public int lengthOfLIS(int[] nums) { - if (nums == null) { - return 0; - } - int n = nums.length; - if (n < 2) { - return n; - } - int[] res = new int[n]; - res[0] = 1; - res[1] = nums[1] > nums[0] ? 2 : 1; - int max = res[1]; - for (int i = 2; i < n; ++i) { - res[i] = 1; - for (int j = 0; j < i; ++j) { - if (nums[j] < nums[i]) { - res[i] = Math.max(res[i], res[j] + 1); - } - } - max = Math.max(max, res[i]); - } - return max; - } -} -``` +-
+
- 可能会有多种最长上升子序列的组合,你只需要输出对应的长度即可。 +
- 你算法的时间复杂度应该为 O(n2) 。 +
进阶: 你能将算法的时间复杂度降低到 O(n log n) 吗?
-## 题目描述 - ## 解法 diff --git a/solution/0300-0399/0301.Remove Invalid Parentheses/README.md b/solution/0300-0399/0301.Remove Invalid Parentheses/README.md new file mode 100644 index 0000000000000..d74b37d6da339 --- /dev/null +++ b/solution/0300-0399/0301.Remove Invalid Parentheses/README.md @@ -0,0 +1,49 @@ +# [301. 删除无效的括号](https://leetcode-cn.com/problems/remove-invalid-parentheses) + +## 题目描述 + +删除最小数量的无效括号,使得输入的字符串有效,返回所有可能的结果。
+ +说明: 输入可能包含了除 ( 和 ) 以外的字符。
示例 1:
+ +输入: "()())()" +输出: ["()()()", "(())()"] ++ +
示例 2:
+ +输入: "(a)())()" +输出: ["(a)()()", "(a())()"] ++ +
示例 3:
+ +输入: ")("
+输出: [""]
+
+
+
+## 解法
+
+
+
+### Python3
+
+
+```python
+
+```
+
+### Java
+
+
+```java
+
+```
+
+### ...
+```
+
+```
diff --git a/solution/0300-0399/0302.Smallest Rectangle Enclosing Black Pixels/README.md b/solution/0300-0399/0302.Smallest Rectangle Enclosing Black Pixels/README.md
new file mode 100644
index 0000000000000..275dcb21a5571
--- /dev/null
+++ b/solution/0300-0399/0302.Smallest Rectangle Enclosing Black Pixels/README.md
@@ -0,0 +1,29 @@
+# [302. 包含全部黑色像素的最小矩形](https://leetcode-cn.com/problems/smallest-rectangle-enclosing-black-pixels)
+
+## 题目描述
+
+None
+
+
+## 解法
+
+
+
+### Python3
+
+
+```python
+
+```
+
+### Java
+
+
+```java
+
+```
+
+### ...
+```
+
+```
diff --git a/solution/0300-0399/0303.Range Sum Query - Immutable/README.md b/solution/0300-0399/0303.Range Sum Query - Immutable/README.md
new file mode 100644
index 0000000000000..513980ee73946
--- /dev/null
+++ b/solution/0300-0399/0303.Range Sum Query - Immutable/README.md
@@ -0,0 +1,45 @@
+# [303. 区域和检索 - 数组不可变](https://leetcode-cn.com/problems/range-sum-query-immutable)
+
+## 题目描述
+
+给定一个整数数组 nums,求出数组从索引 i 到 j (i ≤ j) 范围内元素的总和,包含 i, j 两点。
+ +示例:
+ +给定 nums = [-2, 0, 3, -5, 2, -1],求和函数为 sumRange() + +sumRange(0, 2) -> 1 +sumRange(2, 5) -> -1 +sumRange(0, 5) -> -3+ +
说明:
+ +-
+
- 你可以假设数组不可变。 +
- 会多次调用 sumRange 方法。 +
给定一个二维矩阵,计算其子矩形范围内元素的总和,该子矩阵的左上角为 (row1, col1) ,右下角为 (row2, col2)。
+ +
+上图子矩阵左上角 (row1, col1) = (2, 1) ,右下角(row2, col2) = (4, 3),该子矩形内元素的总和为 8。
示例:
+ +给定 matrix = [ + [3, 0, 1, 4, 2], + [5, 6, 3, 2, 1], + [1, 2, 0, 1, 5], + [4, 1, 0, 1, 7], + [1, 0, 3, 0, 5] +] + +sumRegion(2, 1, 4, 3) -> 8 +sumRegion(1, 1, 2, 2) -> 11 +sumRegion(1, 2, 2, 4) -> 12 ++ +
说明:
+ +-
+
- 你可以假设矩阵不可变。 +
- 会多次调用 sumRegion 方法。 +
- 你可以假设 row1 ≤ row2 且 col1 ≤ col2。 +
累加数是一个字符串,组成它的数字可以形成累加序列。
+ +一个有效的累加序列必须至少包含 3 个数。除了最开始的两个数以外,字符串中的其他数都等于它之前两个数相加的和。
+ +给定一个只包含数字 '0'-'9' 的字符串,编写一个算法来判断给定输入是否是累加数。
说明: 累加序列里的数不会以 0 开头,所以不会出现 1, 2, 03 或者 1, 02, 3 的情况。
示例 1:
+ +输入:+ +"112358"+输出: true +解释: 累加序列为:1, 1, 2, 3, 5, 8。1 + 1 = 2, 1 + 2 = 3, 2 + 3 = 5, 3 + 5 = 8 +
示例 2:
+ +输入:+ +"199100199"+输出: true +解释: 累加序列为:1, 99, 100, 199。1 + 99 = 100, 99 + 100 = 199
进阶:
+你如何处理一个溢出的过大的整数输入?
给定一个整数数组 nums,求出数组从索引 i 到 j (i ≤ j) 范围内元素的总和,包含 i, j 两点。
+ +update(i, val) 函数可以通过将下标为 i 的数值更新为 val,从而对数列进行修改。
+ +示例:
+ +Given nums = [1, 3, 5] + +sumRange(0, 2) -> 9 +update(1, 2) +sumRange(0, 2) -> 8 ++ +
说明:
+ +-
+
- 数组仅可以在 update 函数下进行修改。 +
- 你可以假设 update 函数与 sumRange 函数的调用次数是均匀分布的。 +
给定一个整数数组,其中第 i 个元素代表了第 i 天的股票价格 。
+ +设计一个算法计算出最大利润。在满足以下约束条件下,你可以尽可能地完成更多的交易(多次买卖一支股票):
+ +-
+
- 你不能同时参与多笔交易(你必须在再次购买前出售掉之前的股票)。 +
- 卖出股票后,你无法在第二天买入股票 (即冷冻期为 1 天)。 +
示例:
+ +输入: [1,2,3,0,2] +输出: 3 +解释: 对应的交易状态为: [买入, 卖出, 冷冻期, 买入, 卖出]+ + + +## 解法 + + + +### Python3 + + +```python + +``` + +### Java + + +```java + +``` + +### ... +``` + +``` diff --git a/solution/0300-0399/0310.Minimum Height Trees/README.md b/solution/0300-0399/0310.Minimum Height Trees/README.md new file mode 100644 index 0000000000000..e94a62903580a --- /dev/null +++ b/solution/0300-0399/0310.Minimum Height Trees/README.md @@ -0,0 +1,70 @@ +# [310. 最小高度树](https://leetcode-cn.com/problems/minimum-height-trees) + +## 题目描述 + +
对于一个具有树特征的无向图,我们可选择任何一个节点作为根。图因此可以成为树,在所有可能的树中,具有最小高度的树被称为最小高度树。给出这样的一个图,写出一个函数找到所有的最小高度树并返回他们的根节点。
+ +格式
+ +该图包含 n 个节点,标记为 0 到 n - 1。给定数字 n 和一个无向边 edges 列表(每一个边都是一对标签)。
你可以假设没有重复的边会出现在 edges 中。由于所有的边都是无向边, [0, 1]和 [1, 0] 是相同的,因此不会同时出现在 edges 里。
示例 1:
+ +输入:+ +n = 4,edges = [[1, 0], [1, 2], [1, 3]]+ + 0 + | + 1 + / \ + 2 3 + +输出:[1]+
示例 2:
+ +输入:+ +n = 6,edges = [[0, 3], [1, 3], [2, 3], [4, 3], [5, 4]]+ + 0 1 2 + \ | / + 3 + | + 4 + | + 5 + +输出:[3, 4]
说明:
+ +-
+
- 根据树的定义,树是一个无向图,其中任何两个顶点只通过一条路径连接。 换句话说,一个任何没有简单环路的连通图都是一棵树。 +
- 树的高度是指根节点和叶子节点之间最长向下路径上边的数量。 +
有 n 个气球,编号为0 到 n-1,每个气球上都标有一个数字,这些数字存在数组 nums 中。
现在要求你戳破所有的气球。每当你戳破一个气球 i 时,你可以获得 nums[left] * nums[i] * nums[right] 个硬币。 这里的 left 和 right 代表和 i 相邻的两个气球的序号。注意当你戳破了气球 i 后,气球 left 和气球 right 就变成了相邻的气球。
求所能获得硬币的最大数量。
-- 你可以假设 `nums[-1] = nums[n] = 1`,但注意它们不是真实存在的所以并不能被戳破。 -- 0 ≤ `n` ≤ 500, 0 ≤ `nums[i]` ≤ 100 +说明:
-**示例:** -``` -输入: [3,1,5,8] -输出: 167 -解释: nums = [3,1,5,8] --> [3,5,8] --> [3,8] --> [8] --> [] - coins = 3*1*5 + 3*5*8 + 1*3*8 + 1*8*1 = 167 +-
+
- 你可以假设
nums[-1] = nums[n] = 1,但注意它们不是真实存在的所以并不能被戳破。
+ - 0 ≤
n≤ 500, 0 ≤nums[i]≤ 100
+
示例:
-### 解法 -数组 `f` 表示某范围内(开区间)戳破所有气球能获得的最大硬币。那么题意转换为求`f[0][n+1]`。 +输入:-假设最后一个戳破的气球为 `i`,那么: -``` -f[0][n+1] = f[0][i] + f[i][n+1] + nums[i] * nums[0][n+1]。 -``` - -利用记忆化搜索,遍历当最后一个戳破的气球为 `i` 时,求 `f[0][n+1]` 的最大值。 - -```java -class Solution { - - public int maxCoins(int[] nums) { - if (nums == null || nums.length == 0) { - return 0; - } - int n = nums.length; - int[][] f = new int[n + 2][n + 2]; - for (int i= 0; i < n + 2; ++i) { - for (int j = 0; j < n + 2; ++j) { - f[i][j] = -1; - } - } - int[] bak = new int[n + 2]; - bak[0] = bak[n + 1] = 1; - for (int i = 1; i < n + 1; ++i) { - bak[i] = nums[i - 1]; - } - return dp(bak, f, 0, n + 1); - } - - private int dp(int[] nums, int[][] f, int x, int y) { - if (f[x][y] != -1) { - return f[x][y]; - } - - f[x][y] = 0; - - //枚举最后一个戳破的气球的位置 - for (int i = x + 1; i < y; ++i) { - f[x][y] = Math.max(f[x][y], nums[i] * nums[x] * nums[y] + dp(nums,f, x, i) + dp(nums, f, i, y)); - } - return f[x][y]; - - } -} -``` - -# [题目](这里是题目链接,如:https://leetcode-cn.com/problems/shu-zu-zhong-zhong-fu-de-shu-zi-lcof/) - -## 题目描述 - ## 解法 @@ -98,4 +47,3 @@ class Solution { ``` ``` - diff --git a/solution/0300-0399/0313.Super Ugly Number/README.md b/solution/0300-0399/0313.Super Ugly Number/README.md new file mode 100644 index 0000000000000..bb29853fc9b90 --- /dev/null +++ b/solution/0300-0399/0313.Super Ugly Number/README.md @@ -0,0 +1,47 @@ +# [313. 超级丑数](https://leetcode-cn.com/problems/super-ugly-number) + +## 题目描述 + +[3,1,5,8]+输出:167 +解释:nums = [3,1,5,8] --> [3,5,8] --> [3,8] --> [8] --> [] + coins = 3*1*5 + 3*5*8 + 1*3*8 + 1*8*1 = 167 +
编写一段程序来查找第 n 个超级丑数。
超级丑数是指其所有质因数都是长度为 k 的质数列表 primes 中的正整数。
示例:
+ +输入: n = 12,+ +primes=[2,7,13,19]+输出: 32 +解释: 给定长度为 4 的质数列表 primes = [2,7,13,19],前 12 个超级丑数序列为:[1,2,4,7,8,13,14,16,19,26,28,32] 。
说明:
+ +-
+
1是任何给定primes的超级丑数。
+ - 给定
primes中的数字以升序排列。
+ - 0 <
k≤ 100, 0 <n≤ 106, 0 <primes[i]< 1000 。
+ - 第
n个超级丑数确保在 32 位有符整数范围内。
+
给定一个整数数组 nums,按要求返回一个新数组 counts。数组 counts 有该性质: counts[i] 的值是 nums[i] 右侧小于 nums[i] 的元素的数量。
示例:
+ +输入: [5,2,6,1]
+输出: [2,1,1,0]
+解释:
+5 的右侧有 2 个更小的元素 (2 和 1).
+2 的右侧仅有 1 个更小的元素 (1).
+6 的右侧有 1 个更小的元素 (1).
+1 的右侧有 0 个更小的元素.
+
+
+
+
+## 解法
+
+
+
+### Python3
+
+
+```python
+
+```
+
+### Java
+
+
+```java
+
+```
+
+### ...
+```
+
+```
diff --git a/solution/0300-0399/0316.Remove Duplicate Letters/README.md b/solution/0300-0399/0316.Remove Duplicate Letters/README.md
new file mode 100644
index 0000000000000..3796898ec86a2
--- /dev/null
+++ b/solution/0300-0399/0316.Remove Duplicate Letters/README.md
@@ -0,0 +1,47 @@
+# [316. 去除重复字母](https://leetcode-cn.com/problems/remove-duplicate-letters)
+
+## 题目描述
+
+给你一个仅包含小写字母的字符串,请你去除字符串中重复的字母,使得每个字母只出现一次。需保证返回结果的字典序最小(要求不能打乱其他字符的相对位置)。
+ ++ +
示例 1:
+ +输入:+ +"bcabc"+输出:"abc"+
示例 2:
+ +输入:+ +"cbacdcbc"+输出:"acdb"
+ +
注意:该题与 1081 https://leetcode-cn.com/problems/smallest-subsequence-of-distinct-characters 相同
+ + + +## 解法 + + + +### Python3 + + +```python + +``` + +### Java + + +```java + +``` + +### ... +``` + +``` diff --git a/solution/0300-0399/0317.Shortest Distance from All Buildings/README.md b/solution/0300-0399/0317.Shortest Distance from All Buildings/README.md new file mode 100644 index 0000000000000..733e1ad3883e7 --- /dev/null +++ b/solution/0300-0399/0317.Shortest Distance from All Buildings/README.md @@ -0,0 +1,29 @@ +# [317. 离建筑物最近的距离](https://leetcode-cn.com/problems/shortest-distance-from-all-buildings) + +## 题目描述 + +None + + +## 解法 + + + +### Python3 + + +```python + +``` + +### Java + + +```java + +``` + +### ... +``` + +``` diff --git a/solution/0300-0399/0318.Maximum Product of Word Lengths/README.md b/solution/0300-0399/0318.Maximum Product of Word Lengths/README.md index d9b3840c082d2..25d332665eb31 100644 --- a/solution/0300-0399/0318.Maximum Product of Word Lengths/README.md +++ b/solution/0300-0399/0318.Maximum Product of Word Lengths/README.md @@ -1,7 +1,27 @@ -# [题目](这里是题目链接,如:https://leetcode-cn.com/problems/shu-zu-zhong-zhong-fu-de-shu-zi-lcof/) +# [318. 最大单词长度乘积](https://leetcode-cn.com/problems/maximum-product-of-word-lengths) ## 题目描述 +给定一个字符串数组 words,找到 length(word[i]) * length(word[j]) 的最大值,并且这两个单词不含有公共字母。你可以认为每个单词只包含小写字母。如果不存在这样的两个单词,返回 0。
示例 1:
+ +输入:+ +["abcw","baz","foo","bar","xtfn","abcdef"]+输出:16 +解释: 这两个单词为"abcw", "xtfn"。
示例 2:
+ +输入:+ +["a","ab","abc","d","cd","bcd","abcd"]+输出:4 +解释:这两个单词为"ab", "cd"。
示例 3:
+ +输入:+ ## 解法 diff --git a/solution/0300-0399/0319.Bulb Switcher/README.md b/solution/0300-0399/0319.Bulb Switcher/README.md index d9b3840c082d2..89d40b1763dd5 100644 --- a/solution/0300-0399/0319.Bulb Switcher/README.md +++ b/solution/0300-0399/0319.Bulb Switcher/README.md @@ -1,7 +1,22 @@ -# [题目](这里是题目链接,如:https://leetcode-cn.com/problems/shu-zu-zhong-zhong-fu-de-shu-zi-lcof/) +# [319. 灯泡开关](https://leetcode-cn.com/problems/bulb-switcher) ## 题目描述 +["a","aa","aaa","aaaa"]+输出:0 +解释: 不存在这样的两个单词。
初始时有 n 个灯泡关闭。 第 1 轮,你打开所有的灯泡。 第 2 轮,每两个灯泡你关闭一次。 第 3 轮,每三个灯泡切换一次开关(如果关闭则开启,如果开启则关闭)。第 i 轮,每 i 个灯泡切换一次开关。 对于第 n 轮,你只切换最后一个灯泡的开关。 找出 n 轮后有多少个亮着的灯泡。
+ +示例:
+ +输入: 3 +输出: 1 +解释: +初始时, 灯泡状态 [关闭, 关闭, 关闭]. +第一轮后, 灯泡状态 [开启, 开启, 开启]. +第二轮后, 灯泡状态 [开启, 关闭, 开启]. +第三轮后, 灯泡状态 [开启, 关闭, 关闭]. + +你应该返回 1,因为只有一个灯泡还亮着。 ++ ## 解法 diff --git a/solution/0300-0399/0320.Generalized Abbreviation/README.md b/solution/0300-0399/0320.Generalized Abbreviation/README.md new file mode 100644 index 0000000000000..8434259e0f045 --- /dev/null +++ b/solution/0300-0399/0320.Generalized Abbreviation/README.md @@ -0,0 +1,29 @@ +# [320. 列举单词的全部缩写](https://leetcode-cn.com/problems/generalized-abbreviation) + +## 题目描述 + +None + + +## 解法 + + + +### Python3 + + +```python + +``` + +### Java + + +```java + +``` + +### ... +``` + +``` diff --git a/solution/0300-0399/0321.Create Maximum Number/README.md b/solution/0300-0399/0321.Create Maximum Number/README.md new file mode 100644 index 0000000000000..1e0c5dc10ad47 --- /dev/null +++ b/solution/0300-0399/0321.Create Maximum Number/README.md @@ -0,0 +1,61 @@ +# [321. 拼接最大数](https://leetcode-cn.com/problems/create-maximum-number) + +## 题目描述 + +
给定长度分别为 m 和 n 的两个数组,其元素由 0-9 构成,表示两个自然数各位上的数字。现在从这两个数组中选出 k (k <= m + n) 个数字拼接成一个新的数,要求从同一个数组中取出的数字保持其在原数组中的相对顺序。
求满足该条件的最大数。结果返回一个表示该最大数的长度为 k 的数组。
说明: 请尽可能地优化你算法的时间和空间复杂度。
+ +示例 1:
+ +输入: +nums1 =+ +[3, 4, 6, 5]+nums2 =[9, 1, 2, 5, 8, 3]+k =5+输出: +[9, 8, 6, 5, 3]
示例 2:
+ +输入: +nums1 =+ +[6, 7]+nums2 =[6, 0, 4]+k =5+输出: +[6, 7, 6, 0, 4]
示例 3:
+ +输入: +nums1 =+ + + +## 解法 + + + +### Python3 + + +```python + +``` + +### Java + + +```java + +``` + +### ... +``` + +``` diff --git a/solution/0300-0399/0322.Coin Change/README.md b/solution/0300-0399/0322.Coin Change/README.md new file mode 100644 index 0000000000000..d09796ff56999 --- /dev/null +++ b/solution/0300-0399/0322.Coin Change/README.md @@ -0,0 +1,44 @@ +# [322. 零钱兑换](https://leetcode-cn.com/problems/coin-change) + +## 题目描述 + +[3, 9]+nums2 =[8, 9]+k =3+输出: +[9, 8, 9]
给定不同面额的硬币 coins 和一个总金额 amount。编写一个函数来计算可以凑成总金额所需的最少的硬币个数。如果没有任何一种硬币组合能组成总金额,返回 -1。
示例 1:
+ +输入: coins =+ +[1, 2, 5], amount =11+输出:3+解释: 11 = 5 + 5 + 1
示例 2:
+ +输入: coins =+ +[2], amount =3+输出: -1
说明:
+你可以认为每种硬币的数量是无限的。
给定一个无序的数组 nums,将它重新排列成 nums[0] < nums[1] > nums[2] < nums[3]... 的顺序。
示例 1:
+ +输入:+ +nums = [1, 5, 1, 1, 6, 4]+输出: 一个可能的答案是[1, 4, 1, 5, 1, 6]
示例 2:
+ +输入:+ +nums = [1, 3, 2, 2, 3, 1]+输出: 一个可能的答案是[2, 3, 1, 3, 1, 2]
说明:
+你可以假设所有输入都会得到有效的结果。
进阶:
+你能用 O(n) 时间复杂度和 / 或原地 O(1) 额外空间来实现吗?
给定一个整数,写一个函数来判断它是否是 3 的幂次方。
+ +示例 1:
+ +输入: 27 +输出: true ++ +
示例 2:
+ +输入: 0 +输出: false+ +
示例 3:
+ +输入: 9 +输出: true+ +
示例 4:
+ +输入: 45 +输出: false+ +
进阶:
+你能不使用循环或者递归来完成本题吗?
给定一个整数数组 nums,返回区间和在 [lower, upper] 之间的个数,包含 lower 和 upper。
+区间和 S(i, j) 表示在 nums 中,位置从 i 到 j 的元素之和,包含 i 和 j (i ≤ j)。
说明:
+最直观的算法复杂度是 O(n2) ,请在此基础上优化你的算法。
示例:
+ +输入: nums =+ + + +## 解法 + + + +### Python3 + + +```python + +``` + +### Java + + +```java + +``` + +### ... +``` + +``` diff --git a/solution/0300-0399/0328.Odd Even Linked List/README.md b/solution/0300-0399/0328.Odd Even Linked List/README.md index bc38ccc9f5234..2c028fb7b0842 100644 --- a/solution/0300-0399/0328.Odd Even Linked List/README.md +++ b/solution/0300-0399/0328.Odd Even Linked List/README.md @@ -1,74 +1,29 @@ -## 奇偶链表 -### 题目描述 +# [328. 奇偶链表](https://leetcode-cn.com/problems/odd-even-linked-list) -给定一个单链表,把所有的奇数节点和偶数节点分别排在一起。请注意,这里的奇数节点和偶数节点指的是节点编号的奇偶性,而不是节点的值的奇偶性。 - -请尝试使用原地算法完成。你的算法的空间复杂度应为 O(1),时间复杂度应为 O(nodes),nodes 为节点总数。 - -**示例 1:** -``` -输入: 1->2->3->4->5->NULL -输出: 1->3->5->2->4->NULL -``` +## 题目描述 + +[-2,5,-1], lower =-2, upper =2, +输出: 3 +解释: 3个区间分别是:[0,0],[2,2],[0,2],它们表示的和分别为:-2, -1, 2。+
给定一个单链表,把所有的奇数节点和偶数节点分别排在一起。请注意,这里的奇数节点和偶数节点指的是节点编号的奇偶性,而不是节点的值的奇偶性。
-**示例 2:** -``` -输入: 2->1->3->5->6->4->7->NULL -输出: 2->3->6->7->1->5->4->NULL -``` +请尝试使用原地算法完成。你的算法的空间复杂度应为 O(1),时间复杂度应为 O(nodes),nodes 为节点总数。
-**说明:** +示例 1:
-- 应当保持奇数节点和偶数节点的相对顺序。 -- 链表的第一个节点视为奇数节点,第二个节点视为偶数节点,以此类推。 +输入: 1->2->3->4->5->NULL +输出: 1->3->5->2->4->NULL +-### 解法 -利用 `pre`, `cur`指针指向链表的第 1、2 个结点,循环:将 `cur` 的下一个结点挂在 `pre` 的后面,`pre` 和 `cur` 指针向右移动。 +
示例 2:
-eg. -``` -1->2->3->4->5: `pre`指向 1,`cur`指向 2 -第一次循环后:1->3->2->4->5: `pre`指向 2, `cur`指向 4 -... -``` +输入: 2->1->3->5->6->4->7->NULL +输出: 2->3->6->7->1->5->4->NULL-```java -/** - * Definition for singly-linked list. - * public class ListNode { - * int val; - * ListNode next; - * ListNode(int x) { val = x; } - * } - */ -class Solution { - public ListNode oddEvenList(ListNode head) { - // 链表结点数小于 3,直接返回 - if (head == null || head.next == null || head.next.next == null) { - return head; - } - ListNode dummy = new ListNode(-1); - dummy.next = head; - ListNode pre = head, t = pre.next, cur = t; - while (cur != null && cur.next != null) { - pre.next = cur.next; - cur.next = cur.next.next; - pre.next.next = t; - pre = pre.next; - // cur.next可能为空,所以在下一次循环要判断 cur!= null 是否满足 - cur = cur.next; - t = pre.next; - } - - return dummy.next; - } -} -``` +
说明:
-# [题目](这里是题目链接,如:https://leetcode-cn.com/problems/shu-zu-zhong-zhong-fu-de-shu-zi-lcof/) +-
+
- 应当保持奇数节点和偶数节点的相对顺序。 +
- 链表的第一个节点视为奇数节点,第二个节点视为偶数节点,以此类推。 +
给定一个整数矩阵,找出最长递增路径的长度。
+ +对于每个单元格,你可以往上,下,左,右四个方向移动。 你不能在对角线方向上移动或移动到边界外(即不允许环绕)。
+ +示例 1:
+ +输入: nums =
+[
+ [9,9,4],
+ [6,6,8],
+ [2,1,1]
+]
+输出: 4
+解释: 最长递增路径为 [1, 2, 6, 9]。
+
+示例 2:
+ +输入: nums =
+[
+ [3,4,5],
+ [3,2,6],
+ [2,2,1]
+]
+输出: 4
+解释: 最长递增路径是 [3, 4, 5, 6]。注意不允许在对角线方向上移动。
+
+
## 解法
diff --git a/solution/0300-0399/0330.Patching Array/README.md b/solution/0300-0399/0330.Patching Array/README.md
new file mode 100644
index 0000000000000..fc97b8a058adb
--- /dev/null
+++ b/solution/0300-0399/0330.Patching Array/README.md
@@ -0,0 +1,53 @@
+# [330. 按要求补齐数组](https://leetcode-cn.com/problems/patching-array)
+
+## 题目描述
+
+给定一个已排序的正整数数组 nums,和一个正整数 n 。从 [1, n] 区间内选取任意个数字补充到 nums 中,使得 [1, n] 区间内的任何数字都可以用 nums 中某几个数字的和来表示。请输出满足上述要求的最少需要补充的数字个数。
示例 1:
+ +输入: nums =+ +[1,3], n =6+输出: 1 +解释: +根据 nums 里现有的组合[1], [3], [1,3],可以得出1, 3, 4。 +现在如果我们将2添加到 nums 中, 组合变为:[1], [2], [3], [1,3], [2,3], [1,2,3]。 +其和可以表示数字1, 2, 3, 4, 5, 6,能够覆盖[1, 6]区间里所有的数。 +所以我们最少需要添加一个数字。
示例 2:
+ +输入: nums =+ +[1,5,10], n =20+输出: 2 +解释: 我们需要添加[2, 4]。 +
示例 3:
+ +输入: nums =+ + + +## 解法 + + + +### Python3 + + +```python + +``` + +### Java + + +```java + +``` + +### ... +``` + +``` diff --git a/solution/0300-0399/0331.Verify Preorder Serialization of a Binary Tree/README.md b/solution/0300-0399/0331.Verify Preorder Serialization of a Binary Tree/README.md index d9b3840c082d2..d7df42b092a05 100644 --- a/solution/0300-0399/0331.Verify Preorder Serialization of a Binary Tree/README.md +++ b/solution/0300-0399/0331.Verify Preorder Serialization of a Binary Tree/README.md @@ -1,7 +1,42 @@ -# [题目](这里是题目链接,如:https://leetcode-cn.com/problems/shu-zu-zhong-zhong-fu-de-shu-zi-lcof/) +# [331. 验证二叉树的前序序列化](https://leetcode-cn.com/problems/verify-preorder-serialization-of-a-binary-tree) ## 题目描述 +[1,2,2], n =5+输出: 0 +
序列化二叉树的一种方法是使用前序遍历。当我们遇到一个非空节点时,我们可以记录下这个节点的值。如果它是一个空节点,我们可以使用一个标记值记录,例如 #。
_9_ + / \ + 3 2 + / \ / \ + 4 1 # 6 +/ \ / \ / \ +# # # # # # ++ +
例如,上面的二叉树可以被序列化为字符串 "9,3,4,#,#,1,#,#,2,#,6,#,#",其中 # 代表一个空节点。
给定一串以逗号分隔的序列,验证它是否是正确的二叉树的前序序列化。编写一个在不重构树的条件下的可行算法。
+ +每个以逗号分隔的字符或为一个整数或为一个表示 null 指针的 '#' 。
你可以认为输入格式总是有效的,例如它永远不会包含两个连续的逗号,比如 "1,,3" 。
示例 1:
+ +输入:+ +"9,3,4,#,#,1,#,#,2,#,6,#,#"+输出:true
示例 2:
+ +输入:+ +"1,#"+输出:false+
示例 3:
+ +输入:+ ## 解法 diff --git a/solution/0300-0399/0332.Reconstruct Itinerary/README.md b/solution/0300-0399/0332.Reconstruct Itinerary/README.md new file mode 100644 index 0000000000000..ebaab814b77fb --- /dev/null +++ b/solution/0300-0399/0332.Reconstruct Itinerary/README.md @@ -0,0 +1,50 @@ +# [332. 重新安排行程](https://leetcode-cn.com/problems/reconstruct-itinerary) + +## 题目描述 + +"9,#,#,1"+输出:false
给定一个机票的字符串二维数组 [from, to],子数组中的两个成员分别表示飞机出发和降落的机场地点,对该行程进行重新规划排序。所有这些机票都属于一个从JFK(肯尼迪国际机场)出发的先生,所以该行程必须从 JFK 出发。
说明:
+ +-
+
- 如果存在多种有效的行程,你可以按字符自然排序返回最小的行程组合。例如,行程 ["JFK", "LGA"] 与 ["JFK", "LGB"] 相比就更小,排序更靠前 +
- 所有的机场都用三个大写字母表示(机场代码)。 +
- 假定所有机票至少存在一种合理的行程。 +
示例 1:
+ ++ +输入:[["MUC", "LHR"], ["JFK", "MUC"], ["SFO", "SJC"], ["LHR", "SFO"]]+输出:["JFK", "MUC", "LHR", "SFO", "SJC"]+
示例 2:
+ ++ + + +## 解法 + + + +### Python3 + + +```python + +``` + +### Java + + +```java + +``` + +### ... +``` + +``` diff --git a/solution/0300-0399/0333.Largest BST Subtree/README.md b/solution/0300-0399/0333.Largest BST Subtree/README.md new file mode 100644 index 0000000000000..8c1673dac9c0c --- /dev/null +++ b/solution/0300-0399/0333.Largest BST Subtree/README.md @@ -0,0 +1,29 @@ +# [333. 最大 BST 子树](https://leetcode-cn.com/problems/largest-bst-subtree) + +## 题目描述 + +None + + +## 解法 + + + +### Python3 + + +```python + +``` + +### Java + + +```java + +``` + +### ... +``` + +``` diff --git a/solution/0300-0399/0334.Increasing Triplet Subsequence/README.md b/solution/0300-0399/0334.Increasing Triplet Subsequence/README.md new file mode 100644 index 0000000000000..9794446100c8c --- /dev/null +++ b/solution/0300-0399/0334.Increasing Triplet Subsequence/README.md @@ -0,0 +1,48 @@ +# [334. 递增的三元子序列](https://leetcode-cn.com/problems/increasing-triplet-subsequence) + +## 题目描述 + +输入:[["JFK","SFO"],["JFK","ATL"],["SFO","ATL"],["ATL","JFK"],["ATL","SFO"]]+输出:["JFK","ATL","JFK","SFO","ATL","SFO"]+解释: 另一种有效的行程是["JFK","SFO","ATL","JFK","ATL","SFO"]。但是它自然排序更大更靠后。
给定一个未排序的数组,判断这个数组中是否存在长度为 3 的递增子序列。
+ +数学表达式如下:
+ +如果存在这样的 i, j, k, 且满足 0 ≤ i < j < k ≤ n-1,+ +
+使得 arr[i] < arr[j] < arr[k] ,返回 true ; 否则返回 false 。
说明: 要求算法的时间复杂度为 O(n),空间复杂度为 O(1) 。
+ +示例 1:
+ +输入: [1,2,3,4,5] +输出: true ++ +
示例 2:
+ +输入: [5,4,3,2,1] +输出: false+ + + +## 解法 + + + +### Python3 + + +```python + +``` + +### Java + + +```java + +``` + +### ... +``` + +``` diff --git a/solution/0300-0399/0335.Self Crossing/README.md b/solution/0300-0399/0335.Self Crossing/README.md index d9b3840c082d2..5074791020fd0 100644 --- a/solution/0300-0399/0335.Self Crossing/README.md +++ b/solution/0300-0399/0335.Self Crossing/README.md @@ -1,7 +1,46 @@ -# [题目](这里是题目链接,如:https://leetcode-cn.com/problems/shu-zu-zhong-zhong-fu-de-shu-zi-lcof/) +# [335. 路径交叉](https://leetcode-cn.com/problems/self-crossing) ## 题目描述 +
给定一个含有 n 个正数的数组 x。从点 (0,0) 开始,先向北移动 x[0] 米,然后向西移动 x[1] 米,向南移动 x[2] 米,向东移动 x[3] 米,持续移动。也就是说,每次移动后你的方位会发生逆时针变化。
编写一个 O(1) 空间复杂度的一趟扫描算法,判断你所经过的路径是否相交。
+ +
示例 1:
+ +┌───┐
+│ │
+└───┼──>
+ │
+
+输入: [2,1,1,2]
+输出: true
+
+
+示例 2:
+ +┌──────┐
+│ │
+│
+│
+└────────────>
+
+输入: [1,2,3,4]
+输出: false
+
+
+示例 3:
+ +┌───┐
+│ │
+└───┼>
+
+输入: [1,1,1,1]
+输出: true
+
+
## 解法
diff --git a/solution/0300-0399/0336.Palindrome Pairs/README.md b/solution/0300-0399/0336.Palindrome Pairs/README.md
index d9b3840c082d2..eb6834f947b77 100644
--- a/solution/0300-0399/0336.Palindrome Pairs/README.md
+++ b/solution/0300-0399/0336.Palindrome Pairs/README.md
@@ -1,7 +1,22 @@
-# [题目](这里是题目链接,如:https://leetcode-cn.com/problems/shu-zu-zhong-zhong-fu-de-shu-zi-lcof/)
+# [336. 回文对](https://leetcode-cn.com/problems/palindrome-pairs)
## 题目描述
+给定一组唯一的单词, 找出所有不同 的索引对(i, j),使得列表中的两个单词, words[i] + words[j] ,可拼接成回文串。
示例 1:
+ +输入: ["abcd","dcba","lls","s","sssll"]
+输出: [[0,1],[1,0],[3,2],[2,4]]
+解释: 可拼接成的回文串为 ["dcbaabcd","abcddcba","slls","llssssll"]
+
+
+示例 2:
+ +输入: ["bat","tab","cat"]
+输出: [[0,1],[1,0]]
+解释: 可拼接成的回文串为 ["battab","tabbat"]
+
## 解法
diff --git a/solution/0300-0399/0337.House Robber III/README.md b/solution/0300-0399/0337.House Robber III/README.md
index d9b3840c082d2..04358b1af6e39 100644
--- a/solution/0300-0399/0337.House Robber III/README.md
+++ b/solution/0300-0399/0337.House Robber III/README.md
@@ -1,7 +1,38 @@
-# [题目](这里是题目链接,如:https://leetcode-cn.com/problems/shu-zu-zhong-zhong-fu-de-shu-zi-lcof/)
+# [337. 打家劫舍 III](https://leetcode-cn.com/problems/house-robber-iii)
## 题目描述
+在上次打劫完一条街道之后和一圈房屋后,小偷又发现了一个新的可行窃的地区。这个地区只有一个入口,我们称之为“根”。 除了“根”之外,每栋房子有且只有一个“父“房子与之相连。一番侦察之后,聪明的小偷意识到“这个地方的所有房屋的排列类似于一棵二叉树”。 如果两个直接相连的房子在同一天晚上被打劫,房屋将自动报警。
+ +计算在不触动警报的情况下,小偷一晚能够盗取的最高金额。
+ +示例 1:
+ +输入: [3,2,3,null,3,null,1] + + 3 + / \ + 2 3 + \ \ + 3 1 + +输出: 7 +解释: 小偷一晚能够盗取的最高金额 = 3 + 3 + 1 = 7.+ +
示例 2:
+ +输入: [3,4,5,1,3,null,1] + + 3 + / \ + 4 5 + / \ \ + 1 3 1 + +输出: 9 +解释: 小偷一晚能够盗取的最高金额 = 4 + 5 = 9. ++ ## 解法 diff --git a/solution/0300-0399/0338.Counting Bits/README.md b/solution/0300-0399/0338.Counting Bits/README.md new file mode 100644 index 0000000000000..538bbe3577706 --- /dev/null +++ b/solution/0300-0399/0338.Counting Bits/README.md @@ -0,0 +1,48 @@ +# [338. 比特位计数](https://leetcode-cn.com/problems/counting-bits) + +## 题目描述 + +
给定一个非负整数 num。对于 0 ≤ i ≤ num 范围中的每个数字 i ,计算其二进制数中的 1 的数目并将它们作为数组返回。
+ +示例 1:
+ +输入: 2 +输出: [0,1,1]+ +
示例 2:
+ +输入: 5
+输出: [0,1,1,2,1,2]
+
+进阶:
+ +-
+
- 给出时间复杂度为O(n*sizeof(integer))的解答非常容易。但你可以在线性时间O(n)内用一趟扫描做到吗? +
- 要求算法的空间复杂度为O(n)。 +
- 你能进一步完善解法吗?要求在C++或任何其他语言中不使用任何内置函数(如 C++ 中的 __builtin_popcount)来执行此操作。 +
给你一个嵌套的整型列表。请你设计一个迭代器,使其能够遍历这个整型列表中的所有整数。
+ +列表中的每一项或者为一个整数,或者是另一个列表。其中列表的元素也可能是整数或是其他列表。
+ ++ +
示例 1:
+ +输入: [[1,1],2,[1,1]]
+输出: [1,1,2,1,1]
+解释: 通过重复调用 next 直到 hasNext 返回 false,next 返回的元素的顺序应该是: [1,1,2,1,1]。
+
+示例 2:
+ +输入: [1,[4,[6]]]
+输出: [1,4,6]
+解释: 通过重复调用 next 直到 hasNext 返回 false,next 返回的元素的顺序应该是: [1,4,6]。
+
+
+
+
+## 解法
+
+
+
+### Python3
+
+
+```python
+
+```
+
+### Java
+
+
+```java
+
+```
+
+### ...
+```
+
+```
diff --git a/solution/0300-0399/0342.Power of Four/README.md b/solution/0300-0399/0342.Power of Four/README.md
index d9b3840c082d2..1fb72c00a5049 100644
--- a/solution/0300-0399/0342.Power of Four/README.md
+++ b/solution/0300-0399/0342.Power of Four/README.md
@@ -1,7 +1,23 @@
-# [题目](这里是题目链接,如:https://leetcode-cn.com/problems/shu-zu-zhong-zhong-fu-de-shu-zi-lcof/)
+# [342. 4的幂](https://leetcode-cn.com/problems/power-of-four)
## 题目描述
+给定一个整数 (32 位有符号整数),请编写一个函数来判断它是否是 4 的幂次方。
+ +示例 1:
+ +输入: 16 +输出: true ++ +
示例 2:
+ +输入: 5 +输出: false+ +
进阶:
+你能不使用循环或者递归来完成本题吗?
给定一个正整数 n,将其拆分为至少两个正整数的和,并使这些整数的乘积最大化。 返回你可以获得的最大乘积。
-首先,当 n>=5 时,可以证明 2(n-2)>n,并且 3(n-3)>n。也就是说,数字大于等于 5 时,把它拆分为数字 3 或者 2。 +示例 1:
-另外,当 n>=5 时,3(n-3)>=2(n-2)。因此,尽可能多地拆分为整数 3。 +输入: 2 +输出: 1 +解释: 2 = 1 + 1, 1 × 1 = 1。-当 n=4 时,其实没必要拆分,只是题目要求至少要拆分为两个整数。那么就拆分为两个 2。 +
示例 2:
-```java -class Solution { - public int integerBreak(int n) { - if (n < 2) { - return 0; - } - if (n < 4) { - return n - 1; - } - - int timesOf3 = n / 3; - if (n % 3 == 1) { - --timesOf3; - } - int timesOf2 = (n - timesOf3 * 3) >> 1; - return (int) (Math.pow(2, timesOf2) * Math.pow(3, timesOf3)); - } -} -``` +输入: 10 +输出: 36 +解释: 10 = 3 + 3 + 4, 3 × 3 × 4 = 36。-# [题目](这里是题目链接,如:https://leetcode-cn.com/problems/shu-zu-zhong-zhong-fu-de-shu-zi-lcof/) +
说明: 你可以假设 n 不小于 2 且不大于 58。
-## 题目描述 - ## 解法 diff --git a/solution/0300-0399/0344.Reverse String/README.md b/solution/0300-0399/0344.Reverse String/README.md index f0f7424084327..99f681b6e1268 100644 --- a/solution/0300-0399/0344.Reverse String/README.md +++ b/solution/0300-0399/0344.Reverse String/README.md @@ -1,49 +1,26 @@ -## 反转字符串 -### 题目描述 +# [344. 反转字符串](https://leetcode-cn.com/problems/reverse-string) -编写一个函数,其作用是将输入的字符串反转过来。 +## 题目描述 + +编写一个函数,其作用是将输入的字符串反转过来。输入字符串以字符数组 char[] 的形式给出。
不要给另外的数组分配额外的空间,你必须原地修改输入数组、使用 O(1) 的额外空间解决这一问题。
-示例 2: -``` -输入: "A man, a plan, a canal: Panama" -输出: "amanaP :lanac a ,nalp a ,nam A" -``` +你可以假设数组中的所有字符都是 ASCII 码表中的可打印字符。
-### 解法 -本题利用双指针解决。 +-```java -class Solution { - public String reverseString(String s) { - if (s == null || s.length() < 2) { - return s; - } - char[] chars = s.toCharArray(); - int p = 0; - int q = chars.length - 1; - while (p < q) { - char tmp = chars[p]; - chars[p] = chars[q]; - chars[q] = tmp; - ++p; - --q; - } - return String.valueOf(chars); - } - -} -``` +
示例 1:
-# [题目](这里是题目链接,如:https://leetcode-cn.com/problems/shu-zu-zhong-zhong-fu-de-shu-zi-lcof/) +输入:["h","e","l","l","o"] +输出:["o","l","l","e","h"] ++ +
示例 2:
+ +输入:["H","a","n","n","a","h"] +输出:["h","a","n","n","a","H"]-## 题目描述 - ## 解法 diff --git a/solution/0300-0399/0345.Reverse Vowels of a String/README.md b/solution/0300-0399/0345.Reverse Vowels of a String/README.md new file mode 100644 index 0000000000000..0b6d6a7188886 --- /dev/null +++ b/solution/0300-0399/0345.Reverse Vowels of a String/README.md @@ -0,0 +1,44 @@ +# [345. 反转字符串中的元音字母](https://leetcode-cn.com/problems/reverse-vowels-of-a-string) + +## 题目描述 + +
编写一个函数,以字符串作为输入,反转该字符串中的元音字母。
+ +示例 1:
+ +输入: "hello" +输出: "holle" ++ +
示例 2:
+ +输入: "leetcode" +输出: "leotcede"+ +
说明:
+元音字母不包含字母"y"。
给定一个非空的整数数组,返回其中出现频率前 k 高的元素。
+ +示例 1:
+ +输入: nums = [1,1,1,2,2,3], k = 2 +输出: [1,2] ++ +
示例 2:
+ +输入: nums = [1], k = 1 +输出: [1]+ +
说明:
+ +-
+
- 你可以假设给定的 k 总是合理的,且 1 ≤ k ≤ 数组中不相同的元素的个数。 +
- 你的算法的时间复杂度必须优于 O(n log n) , n 是数组的大小。 +
给定两个数组,编写一个函数来计算它们的交集。
+ +示例 1:
+ +输入: nums1 = [1,2,2,1], nums2 = [2,2] +输出: [2] ++ +
示例 2:
+ +输入: nums1 = [4,9,5], nums2 = [9,4,9,8,4] +输出: [9,4]+ +
说明:
+ +-
+
- 输出结果中的每个元素一定是唯一的。 +
- 我们可以不考虑输出结果的顺序。 +
给定两个数组,编写一个函数来计算它们的交集。
+ +示例 1:
+ +输入: nums1 = [1,2,2,1], nums2 = [2,2] +输出: [2,2] ++ +
示例 2:
+ +输入: nums1 = [4,9,5], nums2 = [9,4,9,8,4] +输出: [4,9]+ +
说明:
+ +-
+
- 输出结果中每个元素出现的次数,应与元素在两个数组中出现的次数一致。 +
- 我们可以不考虑输出结果的顺序。 +
进阶:
+ +-
+
- 如果给定的数组已经排好序呢?你将如何优化你的算法? +
- 如果 nums1 的大小比 nums2 小很多,哪种方法更优? +
- 如果 nums2 的元素存储在磁盘上,磁盘内存是有限的,并且你不能一次加载所有的元素到内存中,你该怎么办? +
给定一个非负整数的数据流输入 a1,a2,…,an,…,将到目前为止看到的数字总结为不相交的区间列表。
+ +例如,假设数据流中的整数为 1,3,7,2,6,…,每次的总结为:
+ +[1, 1] +[1, 1], [3, 3] +[1, 1], [3, 3], [7, 7] +[1, 3], [7, 7] +[1, 3], [6, 7] ++ +
+ +
进阶:
+如果有很多合并,并且与数据流的大小相比,不相交区间的数量很小,该怎么办?
提示:
+特别感谢 @yunhong 提供了本问题和其测试用例。
给定一些标记了宽度和高度的信封,宽度和高度以整数对形式 (w, h) 出现。当另一个信封的宽度和高度都比这个信封大的时候,这个信封就可以放进另一个信封里,如同俄罗斯套娃一样。
请计算最多能有多少个信封能组成一组“俄罗斯套娃”信封(即可以把一个信封放到另一个信封里面)。
+ +说明:
+不允许旋转信封。
示例:
+ +输入: envelopes =+ + + +## 解法 + + + +### Python3 + + +```python + +``` + +### Java + + +```java + +``` + +### ... +``` + +``` diff --git a/solution/0300-0399/0355.Design Twitter/README.md b/solution/0300-0399/0355.Design Twitter/README.md index d9b3840c082d2..1a84b83d68efc 100644 --- a/solution/0300-0399/0355.Design Twitter/README.md +++ b/solution/0300-0399/0355.Design Twitter/README.md @@ -1,7 +1,45 @@ -# [题目](这里是题目链接,如:https://leetcode-cn.com/problems/shu-zu-zhong-zhong-fu-de-shu-zi-lcof/) +# [355. 设计推特](https://leetcode-cn.com/problems/design-twitter) ## 题目描述 +[[5,4],[6,4],[6,7],[2,3]]+输出: 3 +解释: 最多信封的个数为3, 组合为:[2,3] => [5,4] => [6,7]。 +
设计一个简化版的推特(Twitter),可以让用户实现发送推文,关注/取消关注其他用户,能够看见关注人(包括自己)的最近十条推文。你的设计需要支持以下的几个功能:
+ +-
+
- postTweet(userId, tweetId): 创建一条新的推文 +
- getNewsFeed(userId): 检索最近的十条推文。每个推文都必须是由此用户关注的人或者是用户自己发出的。推文必须按照时间顺序由最近的开始排序。 +
- follow(followerId, followeeId): 关注一个用户 +
- unfollow(followerId, followeeId): 取消关注一个用户 +
示例:
+ ++Twitter twitter = new Twitter(); + +// 用户1发送了一条新推文 (用户id = 1, 推文id = 5). +twitter.postTweet(1, 5); + +// 用户1的获取推文应当返回一个列表,其中包含一个id为5的推文. +twitter.getNewsFeed(1); + +// 用户1关注了用户2. +twitter.follow(1, 2); + +// 用户2发送了一个新推文 (推文id = 6). +twitter.postTweet(2, 6); + +// 用户1的获取推文应当返回一个列表,其中包含两个推文,id分别为 -> [6, 5]. +// 推文id6应当在推文id5之前,因为它是在5之后发送的. +twitter.getNewsFeed(1); + +// 用户1取消关注了用户2. +twitter.unfollow(1, 2); + +// 用户1的获取推文应当返回一个列表,其中包含一个id为5的推文. +// 因为用户1已经不再关注用户2. +twitter.getNewsFeed(1); ++ ## 解法 diff --git a/solution/0300-0399/0356.Line Reflection/README.md b/solution/0300-0399/0356.Line Reflection/README.md new file mode 100644 index 0000000000000..b88690a81baf6 --- /dev/null +++ b/solution/0300-0399/0356.Line Reflection/README.md @@ -0,0 +1,29 @@ +# [356. 直线镜像](https://leetcode-cn.com/problems/line-reflection) + +## 题目描述 + +None + + +## 解法 + + + +### Python3 + + +```python + +``` + +### Java + + +```java + +``` + +### ... +``` + +``` diff --git a/solution/0300-0399/0357.Count Numbers with Unique Digits/README.md b/solution/0300-0399/0357.Count Numbers with Unique Digits/README.md new file mode 100644 index 0000000000000..be7f30920ba3c --- /dev/null +++ b/solution/0300-0399/0357.Count Numbers with Unique Digits/README.md @@ -0,0 +1,37 @@ +# [357. 计算各个位数不同的数字个数](https://leetcode-cn.com/problems/count-numbers-with-unique-digits) + +## 题目描述 + +
给定一个非负整数 n,计算各位数字都不同的数字 x 的个数,其中 0 ≤ x < 10n 。
+ +示例:
+ +输入: 2
+输出: 91
+解释: 答案应为除去 11,22,33,44,55,66,77,88,99 外,在 [0,100) 区间内的所有数字。
+
+
+
+
+## 解法
+
+
+
+### Python3
+
+
+```python
+
+```
+
+### Java
+
+
+```java
+
+```
+
+### ...
+```
+
+```
diff --git a/solution/0300-0399/0358.Rearrange String k Distance Apart/README.md b/solution/0300-0399/0358.Rearrange String k Distance Apart/README.md
new file mode 100644
index 0000000000000..1b1cb8d4be653
--- /dev/null
+++ b/solution/0300-0399/0358.Rearrange String k Distance Apart/README.md
@@ -0,0 +1,29 @@
+# [358. K 距离间隔重排字符串](https://leetcode-cn.com/problems/rearrange-string-k-distance-apart)
+
+## 题目描述
+
+None
+
+
+## 解法
+
+
+
+### Python3
+
+
+```python
+
+```
+
+### Java
+
+
+```java
+
+```
+
+### ...
+```
+
+```
diff --git a/solution/0300-0399/0359.Logger Rate Limiter/README.md b/solution/0300-0399/0359.Logger Rate Limiter/README.md
new file mode 100644
index 0000000000000..6a9f0cce718ea
--- /dev/null
+++ b/solution/0300-0399/0359.Logger Rate Limiter/README.md
@@ -0,0 +1,29 @@
+# [359. 日志速率限制器](https://leetcode-cn.com/problems/logger-rate-limiter)
+
+## 题目描述
+
+None
+
+
+## 解法
+
+
+
+### Python3
+
+
+```python
+
+```
+
+### Java
+
+
+```java
+
+```
+
+### ...
+```
+
+```
diff --git a/solution/0300-0399/0360.Sort Transformed Array/README.md b/solution/0300-0399/0360.Sort Transformed Array/README.md
new file mode 100644
index 0000000000000..8b1ed831f1819
--- /dev/null
+++ b/solution/0300-0399/0360.Sort Transformed Array/README.md
@@ -0,0 +1,29 @@
+# [360. 有序转化数组](https://leetcode-cn.com/problems/sort-transformed-array)
+
+## 题目描述
+
+None
+
+
+## 解法
+
+
+
+### Python3
+
+
+```python
+
+```
+
+### Java
+
+
+```java
+
+```
+
+### ...
+```
+
+```
diff --git a/solution/0300-0399/0361.Bomb Enemy/README.md b/solution/0300-0399/0361.Bomb Enemy/README.md
new file mode 100644
index 0000000000000..3933d170eae1b
--- /dev/null
+++ b/solution/0300-0399/0361.Bomb Enemy/README.md
@@ -0,0 +1,29 @@
+# [361. 轰炸敌人](https://leetcode-cn.com/problems/bomb-enemy)
+
+## 题目描述
+
+None
+
+
+## 解法
+
+
+
+### Python3
+
+
+```python
+
+```
+
+### Java
+
+
+```java
+
+```
+
+### ...
+```
+
+```
diff --git a/solution/0300-0399/0362.Design Hit Counter/README.md b/solution/0300-0399/0362.Design Hit Counter/README.md
new file mode 100644
index 0000000000000..538964f561d1b
--- /dev/null
+++ b/solution/0300-0399/0362.Design Hit Counter/README.md
@@ -0,0 +1,29 @@
+# [362. 敲击计数器](https://leetcode-cn.com/problems/design-hit-counter)
+
+## 题目描述
+
+None
+
+
+## 解法
+
+
+
+### Python3
+
+
+```python
+
+```
+
+### Java
+
+
+```java
+
+```
+
+### ...
+```
+
+```
diff --git a/solution/0300-0399/0363.Max Sum of Rectangle No Larger Than K/README.md b/solution/0300-0399/0363.Max Sum of Rectangle No Larger Than K/README.md
new file mode 100644
index 0000000000000..c7d1acafbda8f
--- /dev/null
+++ b/solution/0300-0399/0363.Max Sum of Rectangle No Larger Than K/README.md
@@ -0,0 +1,44 @@
+# [363. 矩形区域不超过 K 的最大数值和](https://leetcode-cn.com/problems/max-sum-of-rectangle-no-larger-than-k)
+
+## 题目描述
+
+给定一个非空二维矩阵 matrix 和一个整数 k,找到这个矩阵内部不大于 k 的最大矩形和。
+ +示例:
+ +输入: matrix = [[1,0,1],[0,-2,3]], k = 2
+输出: 2
+解释: 矩形区域 [[0, 1], [-2, 3]] 的数值和是 2,且 2 是不超过 k 的最大数字(k = 2)。
+
+
+说明:
+ +-
+
- 矩阵内的矩形区域面积必须大于 0。 +
- 如果行数远大于列数,你将如何解答呢? +
有两个容量分别为 x升 和 y升 的水壶以及无限多的水。请判断能否通过使用这两个水壶,从而可以得到恰好 z升 的水?
+ +如果可以,最后请用以上水壶中的一或两个来盛放取得的 z升 水。
+ +你允许:
+ +-
+
- 装满任意一个水壶 +
- 清空任意一个水壶 +
- 从一个水壶向另外一个水壶倒水,直到装满或者倒空 +
示例 1: (From the famous "Die Hard" example)
+ +输入: x = 3, y = 5, z = 4 +输出: True ++ +
示例 2:
+ +输入: x = 2, y = 6, z = 5 +输出: False ++ ## 解法 diff --git a/solution/0300-0399/0366.Find Leaves of Binary Tree/README.md b/solution/0300-0399/0366.Find Leaves of Binary Tree/README.md new file mode 100644 index 0000000000000..aa669681e36b0 --- /dev/null +++ b/solution/0300-0399/0366.Find Leaves of Binary Tree/README.md @@ -0,0 +1,29 @@ +# [366. 寻找二叉树的叶子节点](https://leetcode-cn.com/problems/find-leaves-of-binary-tree) + +## 题目描述 + +None + + +## 解法 + + + +### Python3 + + +```python + +``` + +### Java + + +```java + +``` + +### ... +``` + +``` diff --git a/solution/0300-0399/0367.Valid Perfect Square/README.md b/solution/0300-0399/0367.Valid Perfect Square/README.md index d9b3840c082d2..623c1b9dce1ee 100644 --- a/solution/0300-0399/0367.Valid Perfect Square/README.md +++ b/solution/0300-0399/0367.Valid Perfect Square/README.md @@ -1,7 +1,22 @@ -# [题目](这里是题目链接,如:https://leetcode-cn.com/problems/shu-zu-zhong-zhong-fu-de-shu-zi-lcof/) +# [367. 有效的完全平方数](https://leetcode-cn.com/problems/valid-perfect-square) ## 题目描述 +
给定一个正整数 num,编写一个函数,如果 num 是一个完全平方数,则返回 True,否则返回 False。
+ +说明:不要使用任何内置的库函数,如 sqrt。
示例 1:
+ +输入:16 +输出:True+ +
示例 2:
+ +输入:14 +输出:False ++ ## 解法 diff --git a/solution/0300-0399/0368.Largest Divisible Subset/README.md b/solution/0300-0399/0368.Largest Divisible Subset/README.md new file mode 100644 index 0000000000000..8e7caef66caf2 --- /dev/null +++ b/solution/0300-0399/0368.Largest Divisible Subset/README.md @@ -0,0 +1,46 @@ +# [368. 最大整除子集](https://leetcode-cn.com/problems/largest-divisible-subset) + +## 题目描述 + +
给出一个由无重复的正整数组成的集合,找出其中最大的整除子集,子集中任意一对 (Si,Sj) 都要满足:Si % Sj = 0 或 Sj % Si = 0。
+ +如果有多个目标子集,返回其中任何一个均可。
+ ++ +
示例 1:
+ +输入: [1,2,3] +输出: [1,2] (当然, [1,3] 也正确) ++ +
示例 2:
+ +输入: [1,2,4,8] +输出: [1,2,4,8] ++ + + +## 解法 + + + +### Python3 + + +```python + +``` + +### Java + + +```java + +``` + +### ... +``` + +``` diff --git a/solution/0300-0399/0369.Plus One Linked List/README.md b/solution/0300-0399/0369.Plus One Linked List/README.md new file mode 100644 index 0000000000000..f0e67c6e01dad --- /dev/null +++ b/solution/0300-0399/0369.Plus One Linked List/README.md @@ -0,0 +1,29 @@ +# [369. 给单链表加一](https://leetcode-cn.com/problems/plus-one-linked-list) + +## 题目描述 + +None + + +## 解法 + + + +### Python3 + + +```python + +``` + +### Java + + +```java + +``` + +### ... +``` + +``` diff --git a/solution/0300-0399/0370.Range Addition/README.md b/solution/0300-0399/0370.Range Addition/README.md new file mode 100644 index 0000000000000..314fbbc60136b --- /dev/null +++ b/solution/0300-0399/0370.Range Addition/README.md @@ -0,0 +1,29 @@ +# [370. 区间加法](https://leetcode-cn.com/problems/range-addition) + +## 题目描述 + +None + + +## 解法 + + + +### Python3 + + +```python + +``` + +### Java + + +```java + +``` + +### ... +``` + +``` diff --git a/solution/0300-0399/0371.Sum of Two Integers/README.md b/solution/0300-0399/0371.Sum of Two Integers/README.md index d9b3840c082d2..c7306c897fd04 100644 --- a/solution/0300-0399/0371.Sum of Two Integers/README.md +++ b/solution/0300-0399/0371.Sum of Two Integers/README.md @@ -1,7 +1,20 @@ -# [题目](这里是题目链接,如:https://leetcode-cn.com/problems/shu-zu-zhong-zhong-fu-de-shu-zi-lcof/) +# [371. 两整数之和](https://leetcode-cn.com/problems/sum-of-two-integers) ## 题目描述 +
不使用运算符 + 和 - ,计算两整数 a 、b 之和。
示例 1:
+ +输入: a = 1, b = 2 +输出: 3 ++ +
示例 2:
+ +输入: a = -2, b = 3 +输出: 1+ ## 解法 diff --git a/solution/0300-0399/0372.Super Pow/README.md b/solution/0300-0399/0372.Super Pow/README.md new file mode 100644 index 0000000000000..b26c16867d519 --- /dev/null +++ b/solution/0300-0399/0372.Super Pow/README.md @@ -0,0 +1,41 @@ +# [372. 超级次方](https://leetcode-cn.com/problems/super-pow) + +## 题目描述 + +
你的任务是计算 ab 对 1337 取模,a 是一个正整数,b 是一个非常大的正整数且会以数组形式给出。
+ +示例 1:
+ +输入: a = 2, b = [3] +输出: 8 ++ +
示例 2:
+ +输入: a = 2, b = [1,0] +输出: 1024+ + + +## 解法 + + + +### Python3 + + +```python + +``` + +### Java + + +```java + +``` + +### ... +``` + +``` diff --git a/solution/0300-0399/0373.Find K Pairs with Smallest Sums/README.md b/solution/0300-0399/0373.Find K Pairs with Smallest Sums/README.md new file mode 100644 index 0000000000000..03e0ab18dcf79 --- /dev/null +++ b/solution/0300-0399/0373.Find K Pairs with Smallest Sums/README.md @@ -0,0 +1,57 @@ +# [373. 查找和最小的K对数字](https://leetcode-cn.com/problems/find-k-pairs-with-smallest-sums) + +## 题目描述 + +
给定两个以升序排列的整形数组 nums1 和 nums2, 以及一个整数 k。
+ +定义一对值 (u,v),其中第一个元素来自 nums1,第二个元素来自 nums2。
+ +找到和最小的 k 对数字 (u1,v1), (u2,v2) ... (uk,vk)。
+ +示例 1:
+ +输入: nums1 = [1,7,11], nums2 = [2,4,6], k = 3 +输出: [1,2],[1,4],[1,6] +解释: 返回序列中的前 3 对数: + [1,2],[1,4],[1,6],[7,2],[7,4],[11,2],[7,6],[11,4],[11,6] ++ +
示例 2:
+ +输入: nums1 = [1,1,2], nums2 = [1,2,3], k = 2 +输出: [1,1],[1,1] +解释: 返回序列中的前 2 对数: + [1,1],[1,1],[1,2],[2,1],[1,2],[2,2],[1,3],[1,3],[2,3] ++ +
示例 3:
+ +输入: nums1 = [1,2], nums2 = [3], k = 3 +输出: [1,3],[2,3] +解释: 也可能序列中所有的数对都被返回:[1,3],[2,3] ++ + + +## 解法 + + + +### Python3 + + +```python + +``` + +### Java + + +```java + +``` + +### ... +``` + +``` diff --git a/solution/0300-0399/0374.Guess Number Higher or Lower/README.md b/solution/0300-0399/0374.Guess Number Higher or Lower/README.md index d9b3840c082d2..4d15b133c832a 100644 --- a/solution/0300-0399/0374.Guess Number Higher or Lower/README.md +++ b/solution/0300-0399/0374.Guess Number Higher or Lower/README.md @@ -1,7 +1,22 @@ -# [题目](这里是题目链接,如:https://leetcode-cn.com/problems/shu-zu-zhong-zhong-fu-de-shu-zi-lcof/) +# [374. 猜数字大小](https://leetcode-cn.com/problems/guess-number-higher-or-lower) ## 题目描述 +
我们正在玩一个猜数字游戏。 游戏规则如下:
+我从 1 到 n 选择一个数字。 你需要猜我选择了哪个数字。
+每次你猜错了,我会告诉你这个数字是大了还是小了。
+你调用一个预先定义好的接口 guess(int num),它会返回 3 个可能的结果(-1,1 或 0):
-1 : 我的数字比较小 + 1 : 我的数字比较大 + 0 : 恭喜!你猜对了! ++ +
示例 :
+ +输入: n = 10, pick = 6 +输出: 6+ ## 解法 diff --git a/solution/0300-0399/0375.Guess Number Higher or Lower II/README.md b/solution/0300-0399/0375.Guess Number Higher or Lower II/README.md new file mode 100644 index 0000000000000..2657a448e2045 --- /dev/null +++ b/solution/0300-0399/0375.Guess Number Higher or Lower II/README.md @@ -0,0 +1,51 @@ +# [375. 猜数字大小 II](https://leetcode-cn.com/problems/guess-number-higher-or-lower-ii) + +## 题目描述 + +
我们正在玩一个猜数游戏,游戏规则如下:
+ +我从 1 到 n 之间选择一个数字,你来猜我选了哪个数字。
+ +每次你猜错了,我都会告诉你,我选的数字比你的大了或者小了。
+ +然而,当你猜了数字 x 并且猜错了的时候,你需要支付金额为 x 的现金。直到你猜到我选的数字,你才算赢得了这个游戏。
+ +示例:
+ +n = 10, 我选择了8. + +第一轮: 你猜我选择的数字是5,我会告诉你,我的数字更大一些,然后你需要支付5块。 +第二轮: 你猜是7,我告诉你,我的数字更大一些,你支付7块。 +第三轮: 你猜是9,我告诉你,我的数字更小一些,你支付9块。 + +游戏结束。8 就是我选的数字。 + +你最终要支付 5 + 7 + 9 = 21 块钱。 ++ +
给定 n ≥ 1,计算你至少需要拥有多少现金才能确保你能赢得这个游戏。
+ + + +## 解法 + + + +### Python3 + + +```python + +``` + +### Java + + +```java + +``` + +### ... +``` + +``` diff --git a/solution/0300-0399/0376.Wiggle Subsequence/README.md b/solution/0300-0399/0376.Wiggle Subsequence/README.md index d9b3840c082d2..fab969f907b58 100644 --- a/solution/0300-0399/0376.Wiggle Subsequence/README.md +++ b/solution/0300-0399/0376.Wiggle Subsequence/README.md @@ -1,7 +1,34 @@ -# [题目](这里是题目链接,如:https://leetcode-cn.com/problems/shu-zu-zhong-zhong-fu-de-shu-zi-lcof/) +# [376. 摆动序列](https://leetcode-cn.com/problems/wiggle-subsequence) ## 题目描述 +如果连续数字之间的差严格地在正数和负数之间交替,则数字序列称为摆动序列。第一个差(如果存在的话)可能是正数或负数。少于两个元素的序列也是摆动序列。
+ +例如, [1,7,4,9,2,5] 是一个摆动序列,因为差值 (6,-3,5,-7,3) 是正负交替出现的。相反, [1,4,7,2,5] 和 [1,7,4,5,5] 不是摆动序列,第一个序列是因为它的前两个差值都是正数,第二个序列是因为它的最后一个差值为零。
给定一个整数序列,返回作为摆动序列的最长子序列的长度。 通过从原始序列中删除一些(也可以不删除)元素来获得子序列,剩下的元素保持其原始顺序。
+ +示例 1:
+ +输入: [1,7,4,9,2,5] +输出: 6 +解释: 整个序列均为摆动序列。 ++ +
示例 2:
+ +输入: [1,17,5,10,13,15,10,5,16,8] +输出: 7 +解释: 这个序列包含几个长度为 7 摆动序列,其中一个可为[1,17,10,13,10,16,8]。+ +
示例 3:
+ +输入: [1,2,3,4,5,6,7,8,9] +输出: 2+ +
进阶:
+你能否用 O(n) 时间复杂度完成此题?
给定一个由正整数组成且不存在重复数字的数组,找出和为给定目标正整数的组合的个数。
+ +示例:
+ ++nums = [1, 2, 3] +target = 4 + +所有可能的组合为: +(1, 1, 1, 1) +(1, 1, 2) +(1, 2, 1) +(1, 3) +(2, 1, 1) +(2, 2) +(3, 1) + +请注意,顺序不同的序列被视作不同的组合。 + +因此输出为 7。 ++ +
进阶:
+如果给定的数组中含有负数会怎么样?
+问题会产生什么变化?
+我们需要在题目中添加什么限制来允许负数的出现?
致谢:
+特别感谢 @pbrother 添加此问题并创建所有测试用例。
给定一个 n x n 矩阵,其中每行和每列元素均按升序排序,找到矩阵中第k小的元素。
+请注意,它是排序后的第k小元素,而不是第k个元素。
示例:
+ ++matrix = [ + [ 1, 5, 9], + [10, 11, 13], + [12, 13, 15] +], +k = 8, + +返回 13。 ++ +
说明:
+你可以假设 k 的值永远是有效的, 1 ≤ k ≤ n2 。
设计一个支持在平均 时间复杂度 O(1) 下,执行以下操作的数据结构。
+ +-
+
insert(val):当元素 val 不存在时,向集合中插入该项。
+ remove(val):元素 val 存在时,从集合中移除该项。
+ getRandom:随机返回现有集合中的一项。每个元素应该有相同的概率被返回。
+
示例 :
+ ++// 初始化一个空的集合。 +RandomizedSet randomSet = new RandomizedSet(); + +// 向集合中插入 1 。返回 true 表示 1 被成功地插入。 +randomSet.insert(1); + +// 返回 false ,表示集合中不存在 2 。 +randomSet.remove(2); + +// 向集合中插入 2 。返回 true 。集合现在包含 [1,2] 。 +randomSet.insert(2); + +// getRandom 应随机返回 1 或 2 。 +randomSet.getRandom(); + +// 从集合中移除 1 ,返回 true 。集合现在包含 [2] 。 +randomSet.remove(1); + +// 2 已在集合中,所以返回 false 。 +randomSet.insert(2); + +// 由于 2 是集合中唯一的数字,getRandom 总是返回 2 。 +randomSet.getRandom(); ++ + + +## 解法 + + + +### Python3 + + +```python + +``` + +### Java + + +```java + +``` + +### ... +``` + +``` diff --git a/solution/0300-0399/0381.Insert Delete GetRandom O(1) - Duplicates allowed/README.md b/solution/0300-0399/0381.Insert Delete GetRandom O(1) - Duplicates allowed/README.md new file mode 100644 index 0000000000000..e57680183a48f --- /dev/null +++ b/solution/0300-0399/0381.Insert Delete GetRandom O(1) - Duplicates allowed/README.md @@ -0,0 +1,62 @@ +# [381. O(1) 时间插入、删除和获取随机元素 - 允许重复](https://leetcode-cn.com/problems/insert-delete-getrandom-o1-duplicates-allowed) + +## 题目描述 + +
设计一个支持在平均 时间复杂度 O(1) 下, 执行以下操作的数据结构。
+ +注意: 允许出现重复元素。
+ +-
+
insert(val):向集合中插入元素 val。
+ remove(val):当 val 存在时,从集合中移除一个 val。
+ getRandom:从现有集合中随机获取一个元素。每个元素被返回的概率应该与其在集合中的数量呈线性相关。
+
示例:
+ +// 初始化一个空的集合。 +RandomizedCollection collection = new RandomizedCollection(); + +// 向集合中插入 1 。返回 true 表示集合不包含 1 。 +collection.insert(1); + +// 向集合中插入另一个 1 。返回 false 表示集合包含 1 。集合现在包含 [1,1] 。 +collection.insert(1); + +// 向集合中插入 2 ,返回 true 。集合现在包含 [1,1,2] 。 +collection.insert(2); + +// getRandom 应当有 2/3 的概率返回 1 ,1/3 的概率返回 2 。 +collection.getRandom(); + +// 从集合中删除 1 ,返回 true 。集合现在包含 [1,2] 。 +collection.remove(1); + +// getRandom 应有相同概率返回 1 和 2 。 +collection.getRandom(); ++ + + +## 解法 + + + +### Python3 + + +```python + +``` + +### Java + + +```java + +``` + +### ... +``` + +``` diff --git a/solution/0300-0399/0382.Linked List Random Node/README.md b/solution/0300-0399/0382.Linked List Random Node/README.md new file mode 100644 index 0000000000000..8a79995945546 --- /dev/null +++ b/solution/0300-0399/0382.Linked List Random Node/README.md @@ -0,0 +1,46 @@ +# [382. 链表随机节点](https://leetcode-cn.com/problems/linked-list-random-node) + +## 题目描述 + +
给定一个单链表,随机选择链表的一个节点,并返回相应的节点值。保证每个节点被选的概率一样。
+ +进阶:
+如果链表十分大且长度未知,如何解决这个问题?你能否使用常数级空间复杂度实现?
示例:
+ ++// 初始化一个单链表 [1,2,3]. +ListNode head = new ListNode(1); +head.next = new ListNode(2); +head.next.next = new ListNode(3); +Solution solution = new Solution(head); + +// getRandom()方法应随机返回1,2,3中的一个,保证每个元素被返回的概率相等。 +solution.getRandom(); ++ + + +## 解法 + + + +### Python3 + + +```python + +``` + +### Java + + +```java + +``` + +### ... +``` + +``` diff --git a/solution/0300-0399/0383.Ransom Note/README.md b/solution/0300-0399/0383.Ransom Note/README.md new file mode 100644 index 0000000000000..99beba2ee7d76 --- /dev/null +++ b/solution/0300-0399/0383.Ransom Note/README.md @@ -0,0 +1,42 @@ +# [383. 赎金信](https://leetcode-cn.com/problems/ransom-note) + +## 题目描述 + +
给定一个赎金信 (ransom) 字符串和一个杂志(magazine)字符串,判断第一个字符串ransom能不能由第二个字符串magazines里面的字符构成。如果可以构成,返回 true ;否则返回 false。
+ +(题目说明:为了不暴露赎金信字迹,要从杂志上搜索各个需要的字母,组成单词来表达意思。)
+ +注意:
+ +你可以假设两个字符串均只含有小写字母。
+ +
+canConstruct("a", "b") -> false
+canConstruct("aa", "ab") -> false
+canConstruct("aa", "aab") -> true
+
+
+
+
+## 解法
+
+
+
+### Python3
+
+
+```python
+
+```
+
+### Java
+
+
+```java
+
+```
+
+### ...
+```
+
+```
diff --git a/solution/0300-0399/0384.Shuffle an Array/README.md b/solution/0300-0399/0384.Shuffle an Array/README.md
index d9b3840c082d2..f02c4557678e3 100644
--- a/solution/0300-0399/0384.Shuffle an Array/README.md
+++ b/solution/0300-0399/0384.Shuffle an Array/README.md
@@ -1,7 +1,26 @@
-# [题目](这里是题目链接,如:https://leetcode-cn.com/problems/shu-zu-zhong-zhong-fu-de-shu-zi-lcof/)
+# [384. 打乱数组](https://leetcode-cn.com/problems/shuffle-an-array)
## 题目描述
+打乱一个没有重复元素的数组。
+ +示例:
+ +
+// 以数字集合 1, 2 和 3 初始化数组。
+int[] nums = {1,2,3};
+Solution solution = new Solution(nums);
+
+// 打乱数组 [1,2,3] 并返回结果。任何 [1,2,3]的排列返回的概率应该相同。
+solution.shuffle();
+
+// 重设数组到它的初始状态[1,2,3]。
+solution.reset();
+
+// 随机返回数组[1,2,3]打乱后的结果。
+solution.shuffle();
+
+
## 解法
diff --git a/solution/0300-0399/0385.Mini Parser/README.md b/solution/0300-0399/0385.Mini Parser/README.md
new file mode 100644
index 0000000000000..0dad6cdac81c8
--- /dev/null
+++ b/solution/0300-0399/0385.Mini Parser/README.md
@@ -0,0 +1,68 @@
+# [385. 迷你语法分析器](https://leetcode-cn.com/problems/mini-parser)
+
+## 题目描述
+
+给定一个用字符串表示的整数的嵌套列表,实现一个解析它的语法分析器。
+ +列表中的每个元素只可能是整数或整数嵌套列表
+ +提示:你可以假定这些字符串都是格式良好的:
+ +-
+
- 字符串非空 +
- 字符串不包含空格 +
- 字符串只包含数字
0-9,[,-,,]
+
+ +
示例 1:
+ ++给定 s = "324", + +你应该返回一个 NestedInteger 对象,其中只包含整数值 324。 ++ +
+ +
示例 2:
+ ++给定 s = "[123,[456,[789]]]", + +返回一个 NestedInteger 对象包含一个有两个元素的嵌套列表: + +1. 一个 integer 包含值 123 +2. 一个包含两个元素的嵌套列表: + i. 一个 integer 包含值 456 + ii. 一个包含一个元素的嵌套列表 + a. 一个 integer 包含值 789 ++ +
+ + + +## 解法 + + + +### Python3 + + +```python + +``` + +### Java + + +```java + +``` + +### ... +``` + +``` diff --git a/solution/0300-0399/0386.Lexicographical Numbers/README.md b/solution/0300-0399/0386.Lexicographical Numbers/README.md new file mode 100644 index 0000000000000..8f4c36cc5c787 --- /dev/null +++ b/solution/0300-0399/0386.Lexicographical Numbers/README.md @@ -0,0 +1,36 @@ +# [386. 字典序排数](https://leetcode-cn.com/problems/lexicographical-numbers) + +## 题目描述 + +
给定一个整数 n, 返回从 1 到 n 的字典顺序。
+ +例如,
+ +给定 n =1 3,返回 [1,10,11,12,13,2,3,4,5,6,7,8,9] 。
+ +请尽可能的优化算法的时间复杂度和空间复杂度。 输入的数据 n 小于等于 5,000,000。
+ + + +## 解法 + + + +### Python3 + + +```python + +``` + +### Java + + +```java + +``` + +### ... +``` + +``` diff --git a/solution/0300-0399/0387.First Unique Character in a String/README.md b/solution/0300-0399/0387.First Unique Character in a String/README.md index d9b3840c082d2..7d647ef28e5c5 100644 --- a/solution/0300-0399/0387.First Unique Character in a String/README.md +++ b/solution/0300-0399/0387.First Unique Character in a String/README.md @@ -1,7 +1,23 @@ -# [题目](这里是题目链接,如:https://leetcode-cn.com/problems/shu-zu-zhong-zhong-fu-de-shu-zi-lcof/) +# [387. 字符串中的第一个唯一字符](https://leetcode-cn.com/problems/first-unique-character-in-a-string) ## 题目描述 +给定一个字符串,找到它的第一个不重复的字符,并返回它的索引。如果不存在,则返回 -1。
+ +案例:
+ ++s = "leetcode" +返回 0. + +s = "loveleetcode", +返回 2. ++ +
+ +
注意事项:您可以假定该字符串只包含小写字母。
+ ## 解法 diff --git a/solution/0300-0399/0388.Longest Absolute File Path/README.md b/solution/0300-0399/0388.Longest Absolute File Path/README.md new file mode 100644 index 0000000000000..fd5abb6eb65c5 --- /dev/null +++ b/solution/0300-0399/0388.Longest Absolute File Path/README.md @@ -0,0 +1,70 @@ +# [388. 文件的最长绝对路径](https://leetcode-cn.com/problems/longest-absolute-file-path) + +## 题目描述 + +假设我们以下述方式将我们的文件系统抽象成一个字符串:
+ +字符串 "dir\n\tsubdir1\n\tsubdir2\n\t\tfile.ext" 表示:
+dir + subdir1 + subdir2 + file.ext ++ +
目录 dir 包含一个空的子目录 subdir1 和一个包含一个文件 file.ext 的子目录 subdir2 。
字符串 "dir\n\tsubdir1\n\t\tfile1.ext\n\t\tsubsubdir1\n\tsubdir2\n\t\tsubsubdir2\n\t\t\tfile2.ext" 表示:
+dir + subdir1 + file1.ext + subsubdir1 + subdir2 + subsubdir2 + file2.ext ++ +
目录 dir 包含两个子目录 subdir1 和 subdir2。 subdir1 包含一个文件 file1.ext 和一个空的二级子目录 subsubdir1。subdir2 包含一个二级子目录 subsubdir2 ,其中包含一个文件 file2.ext。
我们致力于寻找我们文件系统中文件的最长 (按字符的数量统计) 绝对路径。例如,在上述的第二个例子中,最长路径为 "dir/subdir2/subsubdir2/file2.ext",其长度为 32 (不包含双引号)。
给定一个以上述格式表示文件系统的字符串,返回文件系统中文件的最长绝对路径的长度。 如果系统中没有文件,返回 0。
说明:
+ +-
+
- 文件名至少存在一个
.和一个扩展名。
+ - 目录或者子目录的名字不能包含
.。
+
要求时间复杂度为 O(n) ,其中 n 是输入字符串的大小。
请注意,如果存在路径 aaaaaaaaaaaaaaaaaaaaa/sth.png 的话,那么 a/aa/aaa/file1.txt 就不是一个最长的路径。
给定两个字符串 s 和 t,它们只包含小写字母。
+ +字符串 t 由字符串 s 随机重排,然后在随机位置添加一个字母。
+ +请找出在 t 中被添加的字母。
+ ++ +
示例:
+ +输入: +s = "abcd" +t = "abcde" + +输出: +e + +解释: +'e' 是那个被添加的字母。 ++ + + +## 解法 + + + +### Python3 + + +```python + +``` + +### Java + + +```java + +``` + +### ... +``` + +``` diff --git a/solution/0300-0399/0390.Elimination Game/README.md b/solution/0300-0399/0390.Elimination Game/README.md new file mode 100644 index 0000000000000..2f7211452dfea --- /dev/null +++ b/solution/0300-0399/0390.Elimination Game/README.md @@ -0,0 +1,47 @@ +# [390. 消除游戏](https://leetcode-cn.com/problems/elimination-game) + +## 题目描述 + +
给定一个从1 到 n 排序的整数列表。
+首先,从左到右,从第一个数字开始,每隔一个数字进行删除,直到列表的末尾。
+第二步,在剩下的数字中,从右到左,从倒数第一个数字开始,每隔一个数字进行删除,直到列表开头。
+我们不断重复这两步,从左到右和从右到左交替进行,直到只剩下一个数字。
+返回长度为 n 的列表中,最后剩下的数字。
示例:
+ ++输入: +n = 9, +1 2 3 4 5 6 7 8 9 +2 4 6 8 +2 6 +6 + +输出: +6+ + + +## 解法 + + + +### Python3 + + +```python + +``` + +### Java + + +```java + +``` + +### ... +``` + +``` diff --git a/solution/0300-0399/0391.Perfect Rectangle/README.md b/solution/0300-0399/0391.Perfect Rectangle/README.md new file mode 100644 index 0000000000000..1a0e2471134b6 --- /dev/null +++ b/solution/0300-0399/0391.Perfect Rectangle/README.md @@ -0,0 +1,95 @@ +# [391. 完美矩形](https://leetcode-cn.com/problems/perfect-rectangle) + +## 题目描述 + +
我们有 N 个与坐标轴对齐的矩形, 其中 N > 0, 判断它们是否能精确地覆盖一个矩形区域。
+ +每个矩形用左下角的点和右上角的点的坐标来表示。例如, 一个单位正方形可以表示为 [1,1,2,2]。 ( 左下角的点的坐标为 (1, 1) 以及右上角的点的坐标为 (2, 2) )。
+ +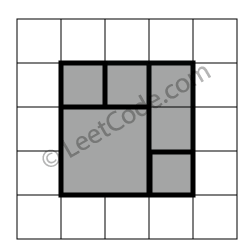
示例 1:
+ +rectangles = [ + [1,1,3,3], + [3,1,4,2], + [3,2,4,4], + [1,3,2,4], + [2,3,3,4] +] + +返回 true。5个矩形一起可以精确地覆盖一个矩形区域。 ++ +
+ +
示例 2:
+ +rectangles = [ + [1,1,2,3], + [1,3,2,4], + [3,1,4,2], + [3,2,4,4] +] + +返回 false。两个矩形之间有间隔,无法覆盖成一个矩形。 ++ +
+ +
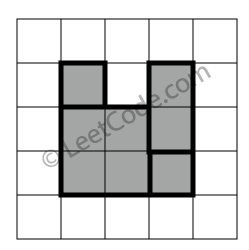
示例 3:
+ +rectangles = [ + [1,1,3,3], + [3,1,4,2], + [1,3,2,4], + [3,2,4,4] +] + +返回 false。图形顶端留有间隔,无法覆盖成一个矩形。 ++ +
+ +
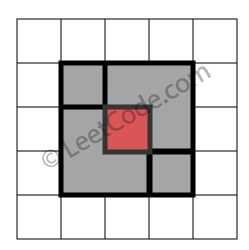
示例 4:
+ +rectangles = [ + [1,1,3,3], + [3,1,4,2], + [1,3,2,4], + [2,2,4,4] +] + +返回 false。因为中间有相交区域,虽然形成了矩形,但不是精确覆盖。 ++ + + +## 解法 + + + +### Python3 + + +```python + +``` + +### Java + + +```java + +``` + +### ... +``` + +``` diff --git a/solution/0300-0399/0392.Is Subsequence/README.md b/solution/0300-0399/0392.Is Subsequence/README.md index d9b3840c082d2..03e692fac5c7e 100644 --- a/solution/0300-0399/0392.Is Subsequence/README.md +++ b/solution/0300-0399/0392.Is Subsequence/README.md @@ -1,7 +1,31 @@ -# [题目](这里是题目链接,如:https://leetcode-cn.com/problems/shu-zu-zhong-zhong-fu-de-shu-zi-lcof/) +# [392. 判断子序列](https://leetcode-cn.com/problems/is-subsequence) ## 题目描述 +
给定字符串 s 和 t ,判断 s 是否为 t 的子序列。
+ +你可以认为 s 和 t 中仅包含英文小写字母。字符串 t 可能会很长(长度 ~= 500,000),而 s 是个短字符串(长度 <=100)。
+ +字符串的一个子序列是原始字符串删除一些(也可以不删除)字符而不改变剩余字符相对位置形成的新字符串。(例如,"ace"是"abcde"的一个子序列,而"aec"不是)。
示例 1:
+s = "abc", t = "ahbgdc"
返回 true.
示例 2:
+s = "axc", t = "ahbgdc"
返回 false.
后续挑战 :
+ +如果有大量输入的 S,称作S1, S2, ... , Sk 其中 k >= 10亿,你需要依次检查它们是否为 T 的子序列。在这种情况下,你会怎样改变代码?
+ +致谢:
+ +特别感谢 @pbrother 添加此问题并且创建所有测试用例。
+ ## 解法 diff --git a/solution/0300-0399/0393.UTF-8 Validation/README.md b/solution/0300-0399/0393.UTF-8 Validation/README.md index d9b3840c082d2..06793e02985c6 100644 --- a/solution/0300-0399/0393.UTF-8 Validation/README.md +++ b/solution/0300-0399/0393.UTF-8 Validation/README.md @@ -1,7 +1,51 @@ -# [题目](这里是题目链接,如:https://leetcode-cn.com/problems/shu-zu-zhong-zhong-fu-de-shu-zi-lcof/) +# [393. UTF-8 编码验证](https://leetcode-cn.com/problems/utf-8-validation) ## 题目描述 +UTF-8 中的一个字符可能的长度为 1 到 4 字节,遵循以下的规则:
+ +-
+
- 对于 1 字节的字符,字节的第一位设为0,后面7位为这个符号的unicode码。 +
- 对于 n 字节的字符 (n > 1),第一个字节的前 n 位都设为1,第 n+1 位设为0,后面字节的前两位一律设为10。剩下的没有提及的二进制位,全部为这个符号的unicode码。 +
这是 UTF-8 编码的工作方式:
+ +
+ Char. number range | UTF-8 octet sequence
+ (hexadecimal) | (binary)
+ --------------------+---------------------------------------------
+ 0000 0000-0000 007F | 0xxxxxxx
+ 0000 0080-0000 07FF | 110xxxxx 10xxxxxx
+ 0000 0800-0000 FFFF | 1110xxxx 10xxxxxx 10xxxxxx
+ 0001 0000-0010 FFFF | 11110xxx 10xxxxxx 10xxxxxx 10xxxxxx
+
+
+给定一个表示数据的整数数组,返回它是否为有效的 utf-8 编码。
+ +注意:
+输入是整数数组。只有每个整数的最低 8 个有效位用来存储数据。这意味着每个整数只表示 1 字节的数据。
示例 1:
+ ++data = [197, 130, 1], 表示 8 位的序列: 11000101 10000010 00000001. + +返回 true 。 +这是有效的 utf-8 编码,为一个2字节字符,跟着一个1字节字符。 ++ +
示例 2:
+ ++data = [235, 140, 4], 表示 8 位的序列: 11101011 10001100 00000100. + +返回 false 。 +前 3 位都是 1 ,第 4 位为 0 表示它是一个3字节字符。 +下一个字节是开头为 10 的延续字节,这是正确的。 +但第二个延续字节不以 10 开头,所以是不符合规则的。 ++ ## 解法 diff --git a/solution/0300-0399/0394.Decode String/README.md b/solution/0300-0399/0394.Decode String/README.md index d7f18d946639d..ac551fc49c261 100644 --- a/solution/0300-0399/0394.Decode String/README.md +++ b/solution/0300-0399/0394.Decode String/README.md @@ -1,77 +1,23 @@ -## 字符串解码 +# [394. 字符串解码](https://leetcode-cn.com/problems/decode-string) -### 问题描述 - -给定一个经过编码的字符串,返回它解码后的字符串。 - -编码规则为: `k[encoded_string]`,表示其中方括号内部的 `encoded_string` 正好重复 `k` - 次。注意 `k` 保证为正整数。 - -你可以认为输入字符串总是有效的;输入字符串中没有额外的空格,且输入的方括号总是符合格式要 -求的。 - -此外,你可以认为原始数据不包含数字,所有的数字只表示重复的次数 `k` ,例如不会出现像 -`3a` 或 `2[4]` 的输入。 - -**示例:** -``` -s = "3[a]2[bc]", 返回 "aaabcbc". -s = "3[a2[c]]", 返回 "accaccacc". -s = "2[abc]3[cd]ef", 返回 "abcabccdcdcdef". -``` +## 题目描述 + +
给定一个经过编码的字符串,返回它解码后的字符串。
+编码规则为: k[encoded_string],表示其中方括号内部的 encoded_string 正好重复 k 次。注意 k 保证为正整数。
你可以认为输入字符串总是有效的;输入字符串中没有额外的空格,且输入的方括号总是符合格式要求的。
-递归求解。设所求为`ans`。遍历字符串,每次遇到字母,则加入`ans`;每次遇到数字,则存下; -遇到`[`,则找到与其匹配的`]`,并个位置之间的进行递归求解,并将所得结果乘以遇到的数字, -再加入`ans`。 +此外,你可以认为原始数据不包含数字,所有的数字只表示重复的次数 k ,例如不会出现像 3a 或 2[4] 的输入。
示例:
-# [题目](这里是题目链接,如:https://leetcode-cn.com/problems/shu-zu-zhong-zhong-fu-de-shu-zi-lcof/) ++s = "3[a]2[bc]", 返回 "aaabcbc". +s = "3[a2[c]]", 返回 "accaccacc". +s = "2[abc]3[cd]ef", 返回 "abcabccdcdcdef". +-## 题目描述 - ## 解法 diff --git a/solution/0300-0399/0395.Longest Substring with At Least K Repeating Characters/README.md b/solution/0300-0399/0395.Longest Substring with At Least K Repeating Characters/README.md new file mode 100644 index 0000000000000..7aed3b7b5c8c6 --- /dev/null +++ b/solution/0300-0399/0395.Longest Substring with At Least K Repeating Characters/README.md @@ -0,0 +1,54 @@ +# [395. 至少有K个重复字符的最长子串](https://leetcode-cn.com/problems/longest-substring-with-at-least-k-repeating-characters) + +## 题目描述 + +
找到给定字符串(由小写字符组成)中的最长子串 T , 要求 T 中的每一字符出现次数都不少于 k 。输出 T 的长度。
+ +示例 1:
+ ++输入: +s = "aaabb", k = 3 + +输出: +3 + +最长子串为 "aaa" ,其中 'a' 重复了 3 次。 ++ +
示例 2:
+ ++输入: +s = "ababbc", k = 2 + +输出: +5 + +最长子串为 "ababb" ,其中 'a' 重复了 2 次, 'b' 重复了 3 次。 ++ + + +## 解法 + + + +### Python3 + + +```python + +``` + +### Java + + +```java + +``` + +### ... +``` + +``` diff --git a/solution/0300-0399/0396.Rotate Function/README.md b/solution/0300-0399/0396.Rotate Function/README.md new file mode 100644 index 0000000000000..1b8dd30ff4197 --- /dev/null +++ b/solution/0300-0399/0396.Rotate Function/README.md @@ -0,0 +1,52 @@ +# [396. 旋转函数](https://leetcode-cn.com/problems/rotate-function) + +## 题目描述 + +
给定一个长度为 n 的整数数组 A 。
假设 Bk 是数组 A 顺时针旋转 k 个位置后的数组,我们定义 A 的“旋转函数” F 为:
F(k) = 0 * Bk[0] + 1 * Bk[1] + ... + (n-1) * Bk[n-1]。
计算F(0), F(1), ..., F(n-1)中的最大值。
注意:
+可以认为 n 的值小于 105。
示例:
+ ++A = [4, 3, 2, 6] + +F(0) = (0 * 4) + (1 * 3) + (2 * 2) + (3 * 6) = 0 + 3 + 4 + 18 = 25 +F(1) = (0 * 6) + (1 * 4) + (2 * 3) + (3 * 2) = 0 + 4 + 6 + 6 = 16 +F(2) = (0 * 2) + (1 * 6) + (2 * 4) + (3 * 3) = 0 + 6 + 8 + 9 = 23 +F(3) = (0 * 3) + (1 * 2) + (2 * 6) + (3 * 4) = 0 + 2 + 12 + 12 = 26 + +所以 F(0), F(1), F(2), F(3) 中的最大值是 F(3) = 26 。 ++ + + +## 解法 + + + +### Python3 + + +```python + +``` + +### Java + + +```java + +``` + +### ... +``` + +``` diff --git a/solution/0300-0399/0397.Integer Replacement/README.md b/solution/0300-0399/0397.Integer Replacement/README.md index d9b3840c082d2..e74645a782971 100644 --- a/solution/0300-0399/0397.Integer Replacement/README.md +++ b/solution/0300-0399/0397.Integer Replacement/README.md @@ -1,7 +1,41 @@ -# [题目](这里是题目链接,如:https://leetcode-cn.com/problems/shu-zu-zhong-zhong-fu-de-shu-zi-lcof/) +# [397. 整数替换](https://leetcode-cn.com/problems/integer-replacement) ## 题目描述 +
给定一个正整数 n,你可以做如下操作:
+ +1. 如果 n 是偶数,则用 n / 2替换 n。
+2. 如果 n 是奇数,则可以用 n + 1或n - 1替换 n。
+n 变为 1 所需的最小替换次数是多少?
示例 1:
+ ++输入: +8 + +输出: +3 + +解释: +8 -> 4 -> 2 -> 1 ++ +
示例 2:
+ ++输入: +7 + +输出: +4 + +解释: +7 -> 8 -> 4 -> 2 -> 1 +或 +7 -> 6 -> 3 -> 2 -> 1 ++ ## 解法 diff --git a/solution/0300-0399/0398.Random Pick Index/README.md b/solution/0300-0399/0398.Random Pick Index/README.md new file mode 100644 index 0000000000000..413482a740044 --- /dev/null +++ b/solution/0300-0399/0398.Random Pick Index/README.md @@ -0,0 +1,46 @@ +# [398. 随机数索引](https://leetcode-cn.com/problems/random-pick-index) + +## 题目描述 + +
给定一个可能含有重复元素的整数数组,要求随机输出给定的数字的索引。 您可以假设给定的数字一定存在于数组中。
+ +注意:
+数组大小可能非常大。 使用太多额外空间的解决方案将不会通过测试。
示例:
+ +
+int[] nums = new int[] {1,2,3,3,3};
+Solution solution = new Solution(nums);
+
+// pick(3) 应该返回索引 2,3 或者 4。每个索引的返回概率应该相等。
+solution.pick(3);
+
+// pick(1) 应该返回 0。因为只有nums[0]等于1。
+solution.pick(1);
+
+
+
+
+## 解法
+
+
+
+### Python3
+
+
+```python
+
+```
+
+### Java
+
+
+```java
+
+```
+
+### ...
+```
+
+```
diff --git a/solution/0300-0399/0399.Evaluate Division/README.md b/solution/0300-0399/0399.Evaluate Division/README.md
new file mode 100644
index 0000000000000..af6f203066bab
--- /dev/null
+++ b/solution/0300-0399/0399.Evaluate Division/README.md
@@ -0,0 +1,47 @@
+# [399. 除法求值](https://leetcode-cn.com/problems/evaluate-division)
+
+## 题目描述
+
+给出方程式 A / B = k, 其中 A 和 B 均为代表字符串的变量, k 是一个浮点型数字。根据已知方程式求解问题,并返回计算结果。如果结果不存在,则返回 -1.0。
示例 :
+给定 a / b = 2.0, b / c = 3.0
+问题: a / c = ?, b / a = ?, a / e = ?, a / a = ?, x / x = ?
+返回 [6.0, 0.5, -1.0, 1.0, -1.0 ]
输入为: vector<pair<string, string>> equations, vector<double>& values, vector<pair<string, string>> queries(方程式,方程式结果,问题方程式), 其中 equations.size() == values.size(),即方程式的长度与方程式结果长度相等(程式与结果一一对应),并且结果值均为正数。以上为方程式的描述。 返回vector<double>类型。
基于上述例子,输入如下:
+ ++equations(方程式) = [ ["a", "b"], ["b", "c"] ], +values(方程式结果) = [2.0, 3.0], +queries(问题方程式) = [ ["a", "c"], ["b", "a"], ["a", "e"], ["a", "a"], ["x", "x"] ]. ++ +
输入总是有效的。你可以假设除法运算中不会出现除数为0的情况,且不存在任何矛盾的结果。
+ + + +## 解法 + + + +### Python3 + + +```python + +``` + +### Java + + +```java + +``` + +### ... +``` + +``` diff --git a/solution/0400-0499/0400.Nth Digit/README.md b/solution/0400-0499/0400.Nth Digit/README.md new file mode 100644 index 0000000000000..d58a40f9ac629 --- /dev/null +++ b/solution/0400-0499/0400.Nth Digit/README.md @@ -0,0 +1,56 @@ +# [400. 第N个数字](https://leetcode-cn.com/problems/nth-digit) + +## 题目描述 + +在无限的整数序列 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, ...中找到第 n 个数字。
+ +注意:
+n 是正数且在32为整形范围内 ( n < 231)。
示例 1:
+ ++输入: +3 + +输出: +3 ++ +
示例 2:
+ ++输入: +11 + +输出: +0 + +说明: +第11个数字在序列 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, ... 里是0,它是10的一部分。 ++ + + +## 解法 + + + +### Python3 + + +```python + +``` + +### Java + + +```java + +``` + +### ... +``` + +``` diff --git a/solution/0400-0499/0401.Binary Watch/README.md b/solution/0400-0499/0401.Binary Watch/README.md index d9b3840c082d2..bd2a24521db16 100644 --- a/solution/0400-0499/0401.Binary Watch/README.md +++ b/solution/0400-0499/0401.Binary Watch/README.md @@ -1,7 +1,33 @@ -# [题目](这里是题目链接,如:https://leetcode-cn.com/problems/shu-zu-zhong-zhong-fu-de-shu-zi-lcof/) +# [401. 二进制手表](https://leetcode-cn.com/problems/binary-watch) ## 题目描述 +
二进制手表顶部有 4 个 LED 代表小时(0-11),底部的 6 个 LED 代表分钟(0-59)。
+ +每个 LED 代表一个 0 或 1,最低位在右侧。
+ +
例如,上面的二进制手表读取 “3:25”。
+ +给定一个非负整数 n 代表当前 LED 亮着的数量,返回所有可能的时间。
+ +案例:
+ ++输入: n = 1 +返回: ["1:00", "2:00", "4:00", "8:00", "0:01", "0:02", "0:04", "0:08", "0:16", "0:32"]+ +
+ +
注意事项:
+ +-
+
- 输出的顺序没有要求。 +
- 小时不会以零开头,比如 “01:00” 是不允许的,应为 “1:00”。 +
- 分钟必须由两位数组成,可能会以零开头,比如 “10:2” 是无效的,应为 “10:02”。 +
给定一个以字符串表示的非负整数 num,移除这个数中的 k 位数字,使得剩下的数字最小。
+ +注意:
+ +-
+
- num 的长度小于 10002 且 ≥ k。 +
- num 不会包含任何前导零。 +
示例 1 :
+ ++输入: num = "1432219", k = 3 +输出: "1219" +解释: 移除掉三个数字 4, 3, 和 2 形成一个新的最小的数字 1219。 ++ +
示例 2 :
+ ++输入: num = "10200", k = 1 +输出: "200" +解释: 移掉首位的 1 剩下的数字为 200. 注意输出不能有任何前导零。 ++ +
示例 3 :
+ ++输入: num = "10", k = 2 +输出: "0" +解释: 从原数字移除所有的数字,剩余为空就是0。 ++ ## 解法 diff --git a/solution/0400-0499/0403.Frog Jump/README.md b/solution/0400-0499/0403.Frog Jump/README.md new file mode 100644 index 0000000000000..807781b105caf --- /dev/null +++ b/solution/0400-0499/0403.Frog Jump/README.md @@ -0,0 +1,67 @@ +# [403. 青蛙过河](https://leetcode-cn.com/problems/frog-jump) + +## 题目描述 + +
一只青蛙想要过河。 假定河流被等分为 x 个单元格,并且在每一个单元格内都有可能放有一石子(也有可能没有)。 青蛙可以跳上石头,但是不可以跳入水中。
+ +给定石子的位置列表(用单元格序号升序表示), 请判定青蛙能否成功过河(即能否在最后一步跳至最后一个石子上)。 开始时, 青蛙默认已站在第一个石子上,并可以假定它第一步只能跳跃一个单位(即只能从单元格1跳至单元格2)。
+ +如果青蛙上一步跳跃了 k 个单位,那么它接下来的跳跃距离只能选择为 k - 1、k 或 k + 1个单位。 另请注意,青蛙只能向前方(终点的方向)跳跃。
+ +请注意:
+ +-
+
- 石子的数量 ≥ 2 且 < 1100; +
- 每一个石子的位置序号都是一个非负整数,且其 < 231; +
- 第一个石子的位置永远是0。 +
示例 1:
+ ++[0,1,3,5,6,8,12,17] + +总共有8个石子。 +第一个石子处于序号为0的单元格的位置, 第二个石子处于序号为1的单元格的位置, +第三个石子在序号为3的单元格的位置, 以此定义整个数组... +最后一个石子处于序号为17的单元格的位置。 + +返回 true。即青蛙可以成功过河,按照如下方案跳跃: +跳1个单位到第2块石子, 然后跳2个单位到第3块石子, 接着 +跳2个单位到第4块石子, 然后跳3个单位到第6块石子, +跳4个单位到第7块石子, 最后,跳5个单位到第8个石子(即最后一块石子)。 ++ +
示例 2:
+ ++[0,1,2,3,4,8,9,11] + +返回 false。青蛙没有办法过河。 +这是因为第5和第6个石子之间的间距太大,没有可选的方案供青蛙跳跃过去。 ++ + + +## 解法 + + + +### Python3 + + +```python + +``` + +### Java + + +```java + +``` + +### ... +``` + +``` diff --git a/solution/0400-0499/0404.Sum of Left Leaves/README.md b/solution/0400-0499/0404.Sum of Left Leaves/README.md index d9b3840c082d2..d6bb92988c7c1 100644 --- a/solution/0400-0499/0404.Sum of Left Leaves/README.md +++ b/solution/0400-0499/0404.Sum of Left Leaves/README.md @@ -1,7 +1,22 @@ -# [题目](这里是题目链接,如:https://leetcode-cn.com/problems/shu-zu-zhong-zhong-fu-de-shu-zi-lcof/) +# [404. 左叶子之和](https://leetcode-cn.com/problems/sum-of-left-leaves) ## 题目描述 +
计算给定二叉树的所有左叶子之和。
+ +示例:
+ ++ 3 + / \ + 9 20 + / \ + 15 7 + +在这个二叉树中,有两个左叶子,分别是 9 和 15,所以返回 24+ +
+ ## 解法 diff --git a/solution/0400-0499/0405.Convert a Number to Hexadecimal/README.md b/solution/0400-0499/0405.Convert a Number to Hexadecimal/README.md index d9b3840c082d2..a4f2186d4f79a 100644 --- a/solution/0400-0499/0405.Convert a Number to Hexadecimal/README.md +++ b/solution/0400-0499/0405.Convert a Number to Hexadecimal/README.md @@ -1,7 +1,38 @@ -# [题目](这里是题目链接,如:https://leetcode-cn.com/problems/shu-zu-zhong-zhong-fu-de-shu-zi-lcof/) +# [405. 数字转换为十六进制数](https://leetcode-cn.com/problems/convert-a-number-to-hexadecimal) ## 题目描述 +
给定一个整数,编写一个算法将这个数转换为十六进制数。对于负整数,我们通常使用 补码运算 方法。
+ +注意:
+ +-
+
- 十六进制中所有字母(
a-f)都必须是小写。
+ - 十六进制字符串中不能包含多余的前导零。如果要转化的数为0,那么以单个字符
'0'来表示;对于其他情况,十六进制字符串中的第一个字符将不会是0字符。
+ - 给定的数确保在32位有符号整数范围内。 +
- 不能使用任何由库提供的将数字直接转换或格式化为十六进制的方法。 +
示例 1:
+ ++输入: +26 + +输出: +"1a" ++ +
示例 2:
+ ++输入: +-1 + +输出: +"ffffffff" ++ ## 解法 diff --git a/solution/0400-0499/0406.Queue Reconstruction by Height/README.md b/solution/0400-0499/0406.Queue Reconstruction by Height/README.md index d9b3840c082d2..d3b3e65219fd8 100644 --- a/solution/0400-0499/0406.Queue Reconstruction by Height/README.md +++ b/solution/0400-0499/0406.Queue Reconstruction by Height/README.md @@ -1,7 +1,22 @@ -# [题目](这里是题目链接,如:https://leetcode-cn.com/problems/shu-zu-zhong-zhong-fu-de-shu-zi-lcof/) +# [406. 根据身高重建队列](https://leetcode-cn.com/problems/queue-reconstruction-by-height) ## 题目描述 +
假设有打乱顺序的一群人站成一个队列。 每个人由一个整数对(h, k)表示,其中h是这个人的身高,k是排在这个人前面且身高大于或等于h的人数。 编写一个算法来重建这个队列。
注意:
+总人数少于1100人。
示例
+ ++输入: +[[7,0], [4,4], [7,1], [5,0], [6,1], [5,2]] + +输出: +[[5,0], [7,0], [5,2], [6,1], [4,4], [7,1]] ++ ## 解法 diff --git a/solution/0400-0499/0407.Trapping Rain Water II/README.md b/solution/0400-0499/0407.Trapping Rain Water II/README.md new file mode 100644 index 0000000000000..da7bcc2389beb --- /dev/null +++ b/solution/0400-0499/0407.Trapping Rain Water II/README.md @@ -0,0 +1,63 @@ +# [407. 接雨水 II](https://leetcode-cn.com/problems/trapping-rain-water-ii) + +## 题目描述 + +
给你一个 m x n 的矩阵,其中的值均为正整数,代表二维高度图每个单元的高度,请计算图中形状最多能接多少体积的雨水。
+ +
示例:
+ +给出如下 3x6 的高度图: +[ + [1,4,3,1,3,2], + [3,2,1,3,2,4], + [2,3,3,2,3,1] +] + +返回 4 。 ++ +
![]()
如上图所示,这是下雨前的高度图[[1,4,3,1,3,2],[3,2,1,3,2,4],[2,3,3,2,3,1]] 的状态。
+ +
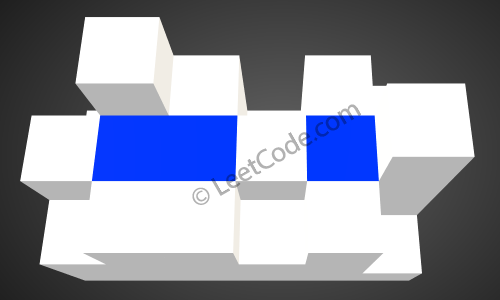
下雨后,雨水将会被存储在这些方块中。总的接雨水量是4。
+ ++ +
提示:
+ +-
+
1 <= m, n <= 110
+ 0 <= heightMap[i][j] <= 20000
+
给定一个包含大写字母和小写字母的字符串,找到通过这些字母构造成的最长的回文串。
+ +在构造过程中,请注意区分大小写。比如 "Aa" 不能当做一个回文字符串。
注意:
+假设字符串的长度不会超过 1010。
示例 1:
+ ++输入: +"abccccdd" + +输出: +7 + +解释: +我们可以构造的最长的回文串是"dccaccd", 它的长度是 7。 ++ + + +## 解法 + + + +### Python3 + + +```python + +``` + +### Java + + +```java + +``` + +### ... +``` + +``` diff --git a/solution/0400-0499/0410.Split Array Largest Sum/README.md b/solution/0400-0499/0410.Split Array Largest Sum/README.md index d9b3840c082d2..fcc16f539fe63 100644 --- a/solution/0400-0499/0410.Split Array Largest Sum/README.md +++ b/solution/0400-0499/0410.Split Array Largest Sum/README.md @@ -1,7 +1,33 @@ -# [题目](这里是题目链接,如:https://leetcode-cn.com/problems/shu-zu-zhong-zhong-fu-de-shu-zi-lcof/) +# [410. 分割数组的最大值](https://leetcode-cn.com/problems/split-array-largest-sum) ## 题目描述 +
给定一个非负整数数组和一个整数 m,你需要将这个数组分成 m 个非空的连续子数组。设计一个算法使得这 m 个子数组各自和的最大值最小。
+ +注意:
+数组长度 n 满足以下条件:
-
+
- 1 ≤ n ≤ 1000 +
- 1 ≤ m ≤ min(50, n) +
示例:
+ ++输入: +nums = [7,2,5,10,8] +m = 2 + +输出: +18 + +解释: +一共有四种方法将nums分割为2个子数组。 +其中最好的方式是将其分为[7,2,5] 和 [10,8], +因为此时这两个子数组各自的和的最大值为18,在所有情况中最小。 ++ ## 解法 diff --git a/solution/0400-0499/0411.Minimum Unique Word Abbreviation/README.md b/solution/0400-0499/0411.Minimum Unique Word Abbreviation/README.md new file mode 100644 index 0000000000000..941b8fff214ea --- /dev/null +++ b/solution/0400-0499/0411.Minimum Unique Word Abbreviation/README.md @@ -0,0 +1,29 @@ +# [411. 最短特异单词缩写](https://leetcode-cn.com/problems/minimum-unique-word-abbreviation) + +## 题目描述 + +None + + +## 解法 + + + +### Python3 + + +```python + +``` + +### Java + + +```java + +``` + +### ... +``` + +``` diff --git a/solution/0400-0499/0412.Fizz Buzz/README.md b/solution/0400-0499/0412.Fizz Buzz/README.md index d9b3840c082d2..6072cd6b85a94 100644 --- a/solution/0400-0499/0412.Fizz Buzz/README.md +++ b/solution/0400-0499/0412.Fizz Buzz/README.md @@ -1,7 +1,39 @@ -# [题目](这里是题目链接,如:https://leetcode-cn.com/problems/shu-zu-zhong-zhong-fu-de-shu-zi-lcof/) +# [412. Fizz Buzz](https://leetcode-cn.com/problems/fizz-buzz) ## 题目描述 +
写一个程序,输出从 1 到 n 数字的字符串表示。
+ +1. 如果 n 是3的倍数,输出“Fizz”;
+ +2. 如果 n 是5的倍数,输出“Buzz”;
+ +3.如果 n 同时是3和5的倍数,输出 “FizzBuzz”。
+ +示例:
+ +n = 15, + +返回: +[ + "1", + "2", + "Fizz", + "4", + "Buzz", + "Fizz", + "7", + "8", + "Fizz", + "Buzz", + "11", + "Fizz", + "13", + "14", + "FizzBuzz" +] ++ ## 解法 diff --git a/solution/0400-0499/0413.Arithmetic Slices/README.md b/solution/0400-0499/0413.Arithmetic Slices/README.md new file mode 100644 index 0000000000000..1b7f5c0938c35 --- /dev/null +++ b/solution/0400-0499/0413.Arithmetic Slices/README.md @@ -0,0 +1,62 @@ +# [413. 等差数列划分](https://leetcode-cn.com/problems/arithmetic-slices) + +## 题目描述 + +
如果一个数列至少有三个元素,并且任意两个相邻元素之差相同,则称该数列为等差数列。
+ +例如,以下数列为等差数列:
+ ++1, 3, 5, 7, 9 +7, 7, 7, 7 +3, -1, -5, -9+ +
以下数列不是等差数列。
+ ++1, 1, 2, 5, 7+ +
+ +
数组 A 包含 N 个数,且索引从0开始。数组 A 的一个子数组划分为数组 (P, Q),P 与 Q 是整数且满足 0<=P<Q<N 。
+ +如果满足以下条件,则称子数组(P, Q)为等差数组:
+ +元素 A[P], A[p + 1], ..., A[Q - 1], A[Q] 是等差的。并且 P + 1 < Q 。
+ +函数要返回数组 A 中所有为等差数组的子数组个数。
+ ++ +
示例:
+ ++A = [1, 2, 3, 4] + +返回: 3, A 中有三个子等差数组: [1, 2, 3], [2, 3, 4] 以及自身 [1, 2, 3, 4]。 ++ + + +## 解法 + + + +### Python3 + + +```python + +``` + +### Java + + +```java + +``` + +### ... +``` + +``` diff --git a/solution/0400-0499/0414.Third Maximum Number/README.md b/solution/0400-0499/0414.Third Maximum Number/README.md index d9b3840c082d2..837e478cf46a1 100644 --- a/solution/0400-0499/0414.Third Maximum Number/README.md +++ b/solution/0400-0499/0414.Third Maximum Number/README.md @@ -1,7 +1,40 @@ -# [题目](这里是题目链接,如:https://leetcode-cn.com/problems/shu-zu-zhong-zhong-fu-de-shu-zi-lcof/) +# [414. 第三大的数](https://leetcode-cn.com/problems/third-maximum-number) ## 题目描述 +
给定一个非空数组,返回此数组中第三大的数。如果不存在,则返回数组中最大的数。要求算法时间复杂度必须是O(n)。
+ +示例 1:
+ ++输入: [3, 2, 1] + +输出: 1 + +解释: 第三大的数是 1. ++ +
示例 2:
+ ++输入: [1, 2] + +输出: 2 + +解释: 第三大的数不存在, 所以返回最大的数 2 . ++ +
示例 3:
+ ++输入: [2, 2, 3, 1] + +输出: 1 + +解释: 注意,要求返回第三大的数,是指第三大且唯一出现的数。 +存在两个值为2的数,它们都排第二。 ++ ## 解法 diff --git a/solution/0400-0499/0415.Add Strings/README.md b/solution/0400-0499/0415.Add Strings/README.md index d9b3840c082d2..d662f4e6ef804 100644 --- a/solution/0400-0499/0415.Add Strings/README.md +++ b/solution/0400-0499/0415.Add Strings/README.md @@ -1,7 +1,18 @@ -# [题目](这里是题目链接,如:https://leetcode-cn.com/problems/shu-zu-zhong-zhong-fu-de-shu-zi-lcof/) +# [415. 字符串相加](https://leetcode-cn.com/problems/add-strings) ## 题目描述 +
给定两个字符串形式的非负整数 num1 和num2 ,计算它们的和。
注意:
+ +-
+
num1和num2的长度都小于 5100.
+ num1和num2都只包含数字0-9.
+ num1和num2都不包含任何前导零。
+ - 你不能使用任何內建 BigInteger 库, 也不能直接将输入的字符串转换为整数形式。 +
给定一个只包含正整数的非空数组。是否可以将这个数组分割成两个子集,使得两个子集的元素和相等。
+ +注意:
+ +-
+
- 每个数组中的元素不会超过 100 +
- 数组的大小不会超过 200 +
示例 1:
+ +输入: [1, 5, 11, 5] + +输出: true + +解释: 数组可以分割成 [1, 5, 5] 和 [11]. ++ +
+ +
示例 2:
+ +输入: [1, 2, 3, 5] + +输出: false + +解释: 数组不能分割成两个元素和相等的子集. ++ +
+ + + +## 解法 + + + +### Python3 + + +```python + +``` + +### Java + + +```java + +``` + +### ... +``` + +``` diff --git a/solution/0400-0499/0417.Pacific Atlantic Water Flow/README.md b/solution/0400-0499/0417.Pacific Atlantic Water Flow/README.md new file mode 100644 index 0000000000000..7ea2fa33df270 --- /dev/null +++ b/solution/0400-0499/0417.Pacific Atlantic Water Flow/README.md @@ -0,0 +1,67 @@ +# [417. 太平洋大西洋水流问题](https://leetcode-cn.com/problems/pacific-atlantic-water-flow) + +## 题目描述 + +
给定一个 m x n 的非负整数矩阵来表示一片大陆上各个单元格的高度。“太平洋”处于大陆的左边界和上边界,而“大西洋”处于大陆的右边界和下边界。
规定水流只能按照上、下、左、右四个方向流动,且只能从高到低或者在同等高度上流动。
+ +请找出那些水流既可以流动到“太平洋”,又能流动到“大西洋”的陆地单元的坐标。
+ ++ +
提示:
+ +-
+
- 输出坐标的顺序不重要 +
- m 和 n 都小于150 +
+ +
示例:
+ ++ +
+给定下面的 5x5 矩阵: + + 太平洋 ~ ~ ~ ~ ~ + ~ 1 2 2 3 (5) * + ~ 3 2 3 (4) (4) * + ~ 2 4 (5) 3 1 * + ~ (6) (7) 1 4 5 * + ~ (5) 1 1 2 4 * + * * * * * 大西洋 + +返回: + +[[0, 4], [1, 3], [1, 4], [2, 2], [3, 0], [3, 1], [4, 0]] (上图中带括号的单元). ++ +
+ + + +## 解法 + + + +### Python3 + + +```python + +``` + +### Java + + +```java + +``` + +### ... +``` + +``` diff --git a/solution/0400-0499/0418.Sentence Screen Fitting/README.md b/solution/0400-0499/0418.Sentence Screen Fitting/README.md new file mode 100644 index 0000000000000..a5dd02e84b9d7 --- /dev/null +++ b/solution/0400-0499/0418.Sentence Screen Fitting/README.md @@ -0,0 +1,29 @@ +# [418. 屏幕可显示句子的数量](https://leetcode-cn.com/problems/sentence-screen-fitting) + +## 题目描述 + +None + + +## 解法 + + + +### Python3 + + +```python + +``` + +### Java + + +```java + +``` + +### ... +``` + +``` diff --git a/solution/0400-0499/0419.Battleships in a Board/README.md b/solution/0400-0499/0419.Battleships in a Board/README.md new file mode 100644 index 0000000000000..fca75ecdac222 --- /dev/null +++ b/solution/0400-0499/0419.Battleships in a Board/README.md @@ -0,0 +1,60 @@ +# [419. 甲板上的战舰](https://leetcode-cn.com/problems/battleships-in-a-board) + +## 题目描述 + +
给定一个二维的甲板, 请计算其中有多少艘战舰。 战舰用 'X'表示,空位用 '.'表示。 你需要遵守以下规则:
-
+
- 给你一个有效的甲板,仅由战舰或者空位组成。 +
- 战舰只能水平或者垂直放置。换句话说,战舰只能由
1xN(1 行, N 列)组成,或者Nx1(N 行, 1 列)组成,其中N可以是任意大小。
+ - 两艘战舰之间至少有一个水平或垂直的空位分隔 - 即没有相邻的战舰。 +
示例 :
+ ++X..X +...X +...X ++ +
在上面的甲板中有2艘战舰。
+ +无效样例 :
+ ++...X +XXXX +...X ++ +
你不会收到这样的无效甲板 - 因为战舰之间至少会有一个空位将它们分开。
+ +进阶:
+ +你可以用一次扫描算法,只使用O(1)额外空间,并且不修改甲板的值来解决这个问题吗?
+ + + +## 解法 + + + +### Python3 + + +```python + +``` + +### Java + + +```java + +``` + +### ... +``` + +``` diff --git a/solution/0400-0499/0420.Strong Password Checker/README.md b/solution/0400-0499/0420.Strong Password Checker/README.md new file mode 100644 index 0000000000000..1bc538130d052 --- /dev/null +++ b/solution/0400-0499/0420.Strong Password Checker/README.md @@ -0,0 +1,40 @@ +# [420. 强密码检验器](https://leetcode-cn.com/problems/strong-password-checker) + +## 题目描述 + +一个强密码应满足以下所有条件:
+ +-
+
- 由至少6个,至多20个字符组成。 +
- 至少包含一个小写字母,一个大写字母,和一个数字。 +
- 同一字符不能连续出现三次 (比如 "...aaa..." 是不允许的, 但是 "...aa...a..." 是可以的)。 +
编写函数 strongPasswordChecker(s),s 代表输入字符串,如果 s 已经符合强密码条件,则返回0;否则返回要将 s 修改为满足强密码条件的字符串所需要进行修改的最小步数。
+ +插入、删除、替换任一字符都算作一次修改。
+ + + +## 解法 + + + +### Python3 + + +```python + +``` + +### Java + + +```java + +``` + +### ... +``` + +``` diff --git a/solution/0400-0499/0421.Maximum XOR of Two Numbers in an Array/README.md b/solution/0400-0499/0421.Maximum XOR of Two Numbers in an Array/README.md index 697a304e03cd6..2ccadfd4f6e82 100644 --- a/solution/0400-0499/0421.Maximum XOR of Two Numbers in an Array/README.md +++ b/solution/0400-0499/0421.Maximum XOR of Two Numbers in an Array/README.md @@ -1,56 +1,23 @@ -## 数组中两个数的最大异或值 -### 题目描述 +# [421. 数组中两个数的最大异或值](https://leetcode-cn.com/problems/maximum-xor-of-two-numbers-in-an-array) -给定一个非空数组,数组中元素为 a0, a1, a2, … , an-1,其中 0 ≤ ai < 231 。 - -找到 ai 和aj 最大的异或 (XOR) 运算结果,其中0 ≤ i, j < n 。 +## 题目描述 + +给定一个非空数组,数组中元素为 a0, a1, a2, … , an-1,其中 0 ≤ ai < 231 。
-**示例:** -``` -输入: [3, 10, 5, 25, 2, 8] -输出: 28 -解释: 最大的结果是 5 ^ 25 = 28. -``` +找到 ai 和aj 最大的异或 (XOR) 运算结果,其中0 ≤ i, j < n 。
-### 解法 -异或运算被称为不做进位的二进制加法运算, 且具有一个性质:如果 a ^ b = c 成立,那么a ^ c = b 与 b ^ c = a 均成立。 +你能在O(n)的时间解决这个问题吗?
-分析一下题目, 要在数组中找到两个数对他们进行异或运算后得到一个最大的异或值, 即这个异或值二进制表示非 0 最高位要尽可能的靠左同时剩余位尽可能为 1; +示例:
-整体使用贪心原则, 依次假设整数从左至右第 i 为 1, 然后再使用一个 mask 与数组中所有数相与得到数据前 i 位的一个前缀集合, 再把之前一次 `i-1` 循环所得到的 max 加第 i 位;为 1 得到当前 i 循环中期望的 `pre-max`, 再与前缀集合中的所有数进行异或运算, 如果得到的值也同时在集合中, 表示假设成立, `max` 变为 `pre-max`, 否则直接 `i+1` 进行下一个循环, 直到 `i=0` 算法结束。 +
+输入: [3, 10, 5, 25, 2, 8]
-```java
-class Solution {
- public int findMaximumXOR(int[] numbers) {
- int max = 0;
- int mask = 0;
- for (int i = 30; i >= 0; i--) {
- int current = 1 << i;
- // 期望的二进制前缀
- mask = mask ^ current;
- // 在当前前缀下, 数组内的前缀位数所有情况集合
- Set set = new HashSet<>();
- for (int j = 0, k = numbers.length; j < k; j++) {
- set.add(mask & numbers[j]);
- }
- // 期望最终异或值的从右数第i位为1, 再根据异或运算的特性推算假设是否成立
- int flag = max | current;
- for (Integer prefix : set) {
- if (set.contains(prefix ^ flag)) {
- max = flag;
- break;
- }
- }
- }
- return max;
- }
-}
-```
+输出: 28
-# [题目](这里是题目链接,如:https://leetcode-cn.com/problems/shu-zu-zhong-zhong-fu-de-shu-zi-lcof/)
+解释: 最大的结果是 5 ^ 25 = 28.
+
-## 题目描述
-
## 解法
@@ -75,4 +42,3 @@ class Solution {
```
```
-
diff --git a/solution/0400-0499/0422.Valid Word Square/README.md b/solution/0400-0499/0422.Valid Word Square/README.md
new file mode 100644
index 0000000000000..fe166fc134283
--- /dev/null
+++ b/solution/0400-0499/0422.Valid Word Square/README.md
@@ -0,0 +1,29 @@
+# [422. 有效的单词方块](https://leetcode-cn.com/problems/valid-word-square)
+
+## 题目描述
+
+None
+
+
+## 解法
+
+
+
+### Python3
+
+
+```python
+
+```
+
+### Java
+
+
+```java
+
+```
+
+### ...
+```
+
+```
diff --git a/solution/0400-0499/0423.Reconstruct Original Digits from English/README.md b/solution/0400-0499/0423.Reconstruct Original Digits from English/README.md
index d9b3840c082d2..37c964814bb67 100644
--- a/solution/0400-0499/0423.Reconstruct Original Digits from English/README.md
+++ b/solution/0400-0499/0423.Reconstruct Original Digits from English/README.md
@@ -1,7 +1,33 @@
-# [题目](这里是题目链接,如:https://leetcode-cn.com/problems/shu-zu-zhong-zhong-fu-de-shu-zi-lcof/)
+# [423. 从英文中重建数字](https://leetcode-cn.com/problems/reconstruct-original-digits-from-english)
## 题目描述
+给定一个非空字符串,其中包含字母顺序打乱的英文单词表示的数字0-9。按升序输出原始的数字。
注意:
+ +-
+
- 输入只包含小写英文字母。 +
- 输入保证合法并可以转换为原始的数字,这意味着像 "abc" 或 "zerone" 的输入是不允许的。 +
- 输入字符串的长度小于 50,000。 +
示例 1:
+ ++输入: "owoztneoer" + +输出: "012" (zeroonetwo) ++ +
示例 2:
+ ++输入: "fviefuro" + +输出: "45" (fourfive) ++ ## 解法 diff --git a/solution/0400-0499/0424.Longest Repeating Character Replacement/README.md b/solution/0400-0499/0424.Longest Repeating Character Replacement/README.md index d9b3840c082d2..3961dab85a488 100644 --- a/solution/0400-0499/0424.Longest Repeating Character Replacement/README.md +++ b/solution/0400-0499/0424.Longest Repeating Character Replacement/README.md @@ -1,7 +1,37 @@ -# [题目](这里是题目链接,如:https://leetcode-cn.com/problems/shu-zu-zhong-zhong-fu-de-shu-zi-lcof/) +# [424. 替换后的最长重复字符](https://leetcode-cn.com/problems/longest-repeating-character-replacement) ## 题目描述 +
给你一个仅由大写英文字母组成的字符串,你可以将任意位置上的字符替换成另外的字符,总共可最多替换 k 次。在执行上述操作后,找到包含重复字母的最长子串的长度。
+ +注意:
+字符串长度 和 k 不会超过 104。
示例 1:
+ +输入: +s = "ABAB", k = 2 + +输出: +4 + +解释: +用两个'A'替换为两个'B',反之亦然。 ++ +
示例 2:
+ +输入: +s = "AABABBA", k = 1 + +输出: +4 + +解释: +将中间的一个'A'替换为'B',字符串变为 "AABBBBA"。 +子串 "BBBB" 有最长重复字母, 答案为 4。 ++ ## 解法 diff --git a/solution/0400-0499/0425.Word Squares/README.md b/solution/0400-0499/0425.Word Squares/README.md new file mode 100644 index 0000000000000..15e583175aa0d --- /dev/null +++ b/solution/0400-0499/0425.Word Squares/README.md @@ -0,0 +1,29 @@ +# [425. 单词方块](https://leetcode-cn.com/problems/word-squares) + +## 题目描述 + +None + + +## 解法 + + + +### Python3 + + +```python + +``` + +### Java + + +```java + +``` + +### ... +``` + +``` diff --git a/solution/0400-0499/0426.Convert Binary Search Tree to Sorted Doubly Linked List/README.md b/solution/0400-0499/0426.Convert Binary Search Tree to Sorted Doubly Linked List/README.md new file mode 100644 index 0000000000000..79d90b90e2bb3 --- /dev/null +++ b/solution/0400-0499/0426.Convert Binary Search Tree to Sorted Doubly Linked List/README.md @@ -0,0 +1,29 @@ +# [426. 将二叉搜索树转化为排序的双向链表](https://leetcode-cn.com/problems/convert-binary-search-tree-to-sorted-doubly-linked-list) + +## 题目描述 + +None + + +## 解法 + + + +### Python3 + + +```python + +``` + +### Java + + +```java + +``` + +### ... +``` + +``` diff --git a/solution/0400-0499/0427.Construct Quad Tree/README.md b/solution/0400-0499/0427.Construct Quad Tree/README.md index d9b3840c082d2..1f15578dadca5 100644 --- a/solution/0400-0499/0427.Construct Quad Tree/README.md +++ b/solution/0400-0499/0427.Construct Quad Tree/README.md @@ -1,7 +1,36 @@ -# [题目](这里是题目链接,如:https://leetcode-cn.com/problems/shu-zu-zhong-zhong-fu-de-shu-zi-lcof/) +# [427. 建立四叉树](https://leetcode-cn.com/problems/construct-quad-tree) ## 题目描述 +
我们想要使用一棵四叉树来储存一个 N x N 的布尔值网络。网络中每一格的值只会是真或假。树的根结点代表整个网络。对于每个结点, 它将被分等成四个孩子结点直到这个区域内的值都是相同的.
每个结点还有另外两个布尔变量: isLeaf 和 val。isLeaf 当这个节点是一个叶子结点时为真。val 变量储存叶子结点所代表的区域的值。
你的任务是使用一个四叉树表示给定的网络。下面的例子将有助于你理解这个问题:
+ +给定下面这个8 x 8 网络,我们将这样建立一个对应的四叉树:
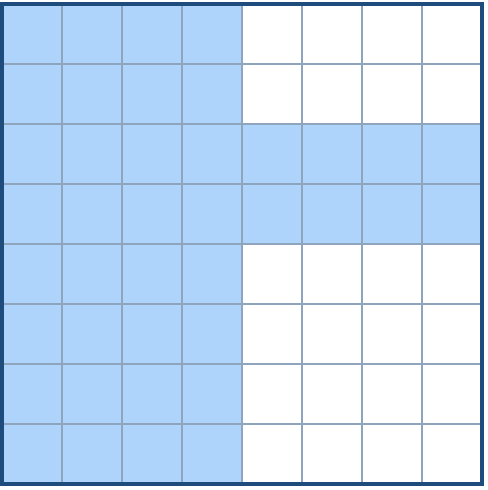
由上文的定义,它能被这样分割:
+ +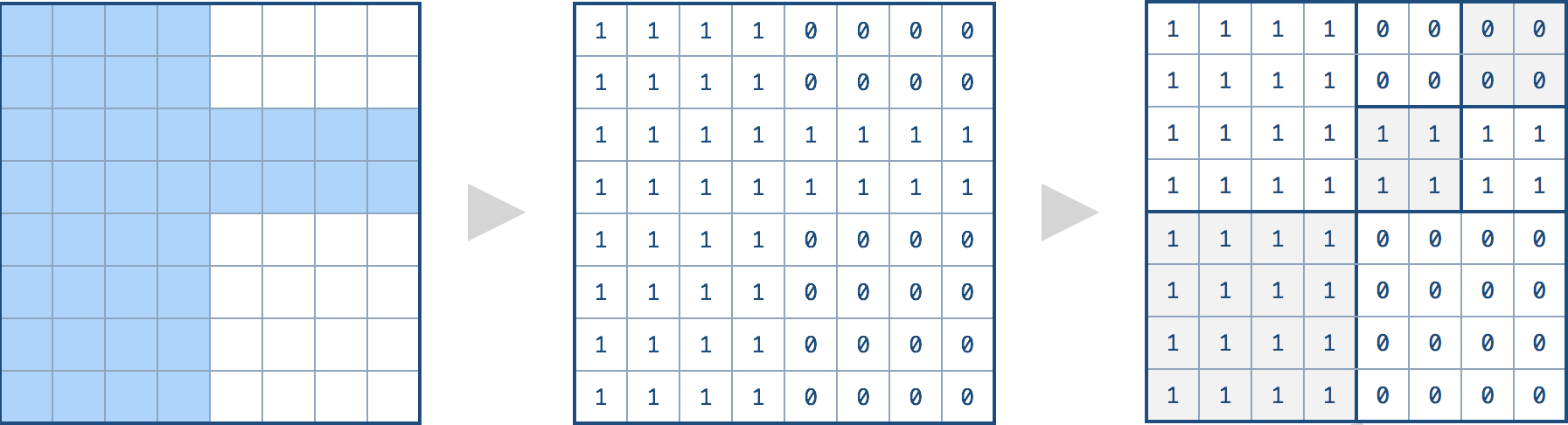
+ +
对应的四叉树应该像下面这样,每个结点由一对 (isLeaf, val) 所代表.
对于非叶子结点,val 可以是任意的,所以使用 * 代替。
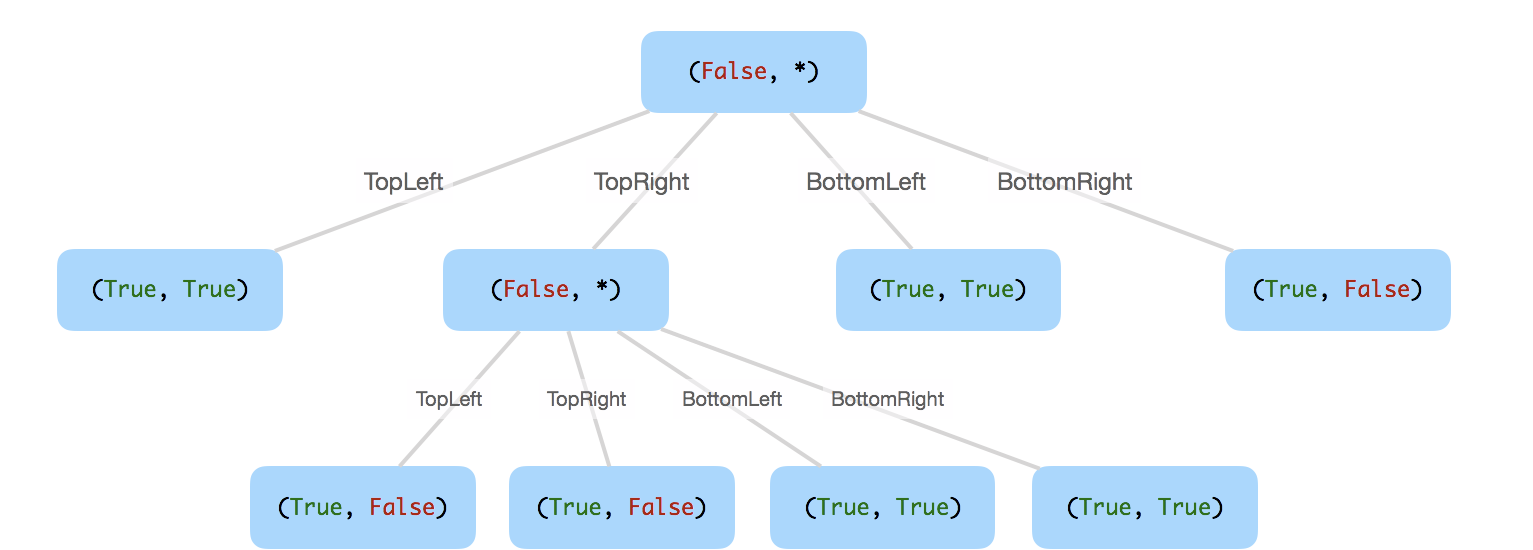
提示:
+ +-
+
N将小于1000且确保是 2 的整次幂。
+ - 如果你想了解更多关于四叉树的知识,你可以参考这个 wiki 页面。 +
给定一个 N 叉树,返回其节点值的层序遍历。 (即从左到右,逐层遍历)。
+ +例如,给定一个 3叉树 :
+ +
+ +
返回其层序遍历:
+ +[ + [1], + [3,2,4], + [5,6] +] ++ +
+ +
说明:
+ +-
+
- 树的深度不会超过
1000。
+ - 树的节点总数不会超过
5000。
+
您将获得一个双向链表,除了下一个和前一个指针之外,它还有一个子指针,可能指向单独的双向链表。这些子列表可能有一个或多个自己的子项,依此类推,生成多级数据结构,如下面的示例所示。
+ +扁平化列表,使所有结点出现在单级双链表中。您将获得列表第一级的头部。
+ ++ +
示例:
+ +输入: + 1---2---3---4---5---6--NULL + | + 7---8---9---10--NULL + | + 11--12--NULL + +输出: +1-2-3-7-8-11-12-9-10-4-5-6-NULL ++ +
+ +
以上示例的说明:
+ +给出以下多级双向链表:
+ ++ +
+ +
我们应该返回如下所示的扁平双向链表:
+ ++ ## 解法 diff --git a/solution/0400-0499/0431.Encode N-ary Tree to Binary Tree/README.md b/solution/0400-0499/0431.Encode N-ary Tree to Binary Tree/README.md new file mode 100644 index 0000000000000..58f83302f69e8 --- /dev/null +++ b/solution/0400-0499/0431.Encode N-ary Tree to Binary Tree/README.md @@ -0,0 +1,29 @@ +# [431. 将 N 叉树编码为二叉树](https://leetcode-cn.com/problems/encode-n-ary-tree-to-binary-tree) + +## 题目描述 + +None + + +## 解法 + + + +### Python3 + + +```python + +``` + +### Java + + +```java + +``` + +### ... +``` + +``` diff --git a/solution/0400-0499/0432.All O`one Data Structure/README.md b/solution/0400-0499/0432.All O`one Data Structure/README.md new file mode 100644 index 0000000000000..940babe72865f --- /dev/null +++ b/solution/0400-0499/0432.All O`one Data Structure/README.md @@ -0,0 +1,39 @@ +# [432. 全 O(1) 的数据结构](https://leetcode-cn.com/problems/all-oone-data-structure) + +## 题目描述 + +

实现一个数据结构支持以下操作:
+ +-
+
- Inc(key) - 插入一个新的值为 1 的 key。或者使一个存在的 key 增加一,保证 key 不为空字符串。 +
- Dec(key) - 如果这个 key 的值是 1,那么把他从数据结构中移除掉。否者使一个存在的 key 值减一。如果这个 key 不存在,这个函数不做任何事情。key 保证不为空字符串。 +
- GetMaxKey() - 返回 key 中值最大的任意一个。如果没有元素存在,返回一个空字符串
""。
+ - GetMinKey() - 返回 key 中值最小的任意一个。如果没有元素存在,返回一个空字符串
""。
+
挑战:以 O(1) 的时间复杂度实现所有操作。
+ + + +## 解法 + + + +### Python3 + + +```python + +``` + +### Java + + +```java + +``` + +### ... +``` + +``` diff --git a/solution/0400-0499/0433.Minimum Genetic Mutation/README.md b/solution/0400-0499/0433.Minimum Genetic Mutation/README.md new file mode 100644 index 0000000000000..210edd5d64bbd --- /dev/null +++ b/solution/0400-0499/0433.Minimum Genetic Mutation/README.md @@ -0,0 +1,76 @@ +# [433. 最小基因变化](https://leetcode-cn.com/problems/minimum-genetic-mutation) + +## 题目描述 + +一条基因序列由一个带有8个字符的字符串表示,其中每个字符都属于 "A", "C", "G", "T"中的任意一个。
假设我们要调查一个基因序列的变化。一次基因变化意味着这个基因序列中的一个字符发生了变化。
+ +例如,基因序列由"AACCGGTT" 变化至 "AACCGGTA" 即发生了一次基因变化。
与此同时,每一次基因变化的结果,都需要是一个合法的基因串,即该结果属于一个基因库。
+ +现在给定3个参数 — start, end, bank,分别代表起始基因序列,目标基因序列及基因库,请找出能够使起始基因序列变化为目标基因序列所需的最少变化次数。如果无法实现目标变化,请返回 -1。
+ +注意:
+ +-
+
- 起始基因序列默认是合法的,但是它并不一定会出现在基因库中。 +
- 所有的目标基因序列必须是合法的。 +
- 假定起始基因序列与目标基因序列是不一样的。 +
示例 1:
+ ++start: "AACCGGTT" +end: "AACCGGTA" +bank: ["AACCGGTA"] + +返回值: 1 ++ +
示例 2:
+ ++start: "AACCGGTT" +end: "AAACGGTA" +bank: ["AACCGGTA", "AACCGCTA", "AAACGGTA"] + +返回值: 2 ++ +
示例 3:
+ ++start: "AAAAACCC" +end: "AACCCCCC" +bank: ["AAAACCCC", "AAACCCCC", "AACCCCCC"] + +返回值: 3 ++ + + +## 解法 + + + +### Python3 + + +```python + +``` + +### Java + + +```java + +``` + +### ... +``` + +``` diff --git a/solution/0400-0499/0434.Number of Segments in a String/README.md b/solution/0400-0499/0434.Number of Segments in a String/README.md index d9b3840c082d2..cc3800a56d985 100644 --- a/solution/0400-0499/0434.Number of Segments in a String/README.md +++ b/solution/0400-0499/0434.Number of Segments in a String/README.md @@ -1,7 +1,17 @@ -# [题目](这里是题目链接,如:https://leetcode-cn.com/problems/shu-zu-zhong-zhong-fu-de-shu-zi-lcof/) +# [434. 字符串中的单词数](https://leetcode-cn.com/problems/number-of-segments-in-a-string) ## 题目描述 +
统计字符串中的单词个数,这里的单词指的是连续的不是空格的字符。
+ +请注意,你可以假定字符串里不包括任何不可打印的字符。
+ +示例:
+ +输入: "Hello, my name is John" +输出: 5 ++ ## 解法 diff --git a/solution/0400-0499/0435.Non-overlapping Intervals/README.md b/solution/0400-0499/0435.Non-overlapping Intervals/README.md new file mode 100644 index 0000000000000..d98e5ac1fdb4f --- /dev/null +++ b/solution/0400-0499/0435.Non-overlapping Intervals/README.md @@ -0,0 +1,67 @@ +# [435. 无重叠区间](https://leetcode-cn.com/problems/non-overlapping-intervals) + +## 题目描述 + +
给定一个区间的集合,找到需要移除区间的最小数量,使剩余区间互不重叠。
+ +注意:
+ +-
+
- 可以认为区间的终点总是大于它的起点。 +
- 区间 [1,2] 和 [2,3] 的边界相互“接触”,但没有相互重叠。 +
示例 1:
+ ++输入: [ [1,2], [2,3], [3,4], [1,3] ] + +输出: 1 + +解释: 移除 [1,3] 后,剩下的区间没有重叠。 ++ +
示例 2:
+ ++输入: [ [1,2], [1,2], [1,2] ] + +输出: 2 + +解释: 你需要移除两个 [1,2] 来使剩下的区间没有重叠。 ++ +
示例 3:
+ ++输入: [ [1,2], [2,3] ] + +输出: 0 + +解释: 你不需要移除任何区间,因为它们已经是无重叠的了。 ++ + + +## 解法 + + + +### Python3 + + +```python + +``` + +### Java + + +```java + +``` + +### ... +``` + +``` diff --git a/solution/0400-0499/0436.Find Right Interval/README.md b/solution/0400-0499/0436.Find Right Interval/README.md new file mode 100644 index 0000000000000..edff4cab63492 --- /dev/null +++ b/solution/0400-0499/0436.Find Right Interval/README.md @@ -0,0 +1,69 @@ +# [436. 寻找右区间](https://leetcode-cn.com/problems/find-right-interval) + +## 题目描述 + +
给定一组区间,对于每一个区间 i,检查是否存在一个区间 j,它的起始点大于或等于区间 i 的终点,这可以称为 j 在 i 的“右侧”。
+ +对于任何区间,你需要存储的满足条件的区间 j 的最小索引,这意味着区间 j 有最小的起始点可以使其成为“右侧”区间。如果区间 j 不存在,则将区间 i 存储为 -1。最后,你需要输出一个值为存储的区间值的数组。
+ +注意:
+ +-
+
- 你可以假设区间的终点总是大于它的起始点。 +
- 你可以假定这些区间都不具有相同的起始点。 +
示例 1:
+ ++输入: [ [1,2] ] +输出: [-1] + +解释:集合中只有一个区间,所以输出-1。 ++ +
示例 2:
+ ++输入: [ [3,4], [2,3], [1,2] ] +输出: [-1, 0, 1] + +解释:对于[3,4],没有满足条件的“右侧”区间。 +对于[2,3],区间[3,4]具有最小的“右”起点; +对于[1,2],区间[2,3]具有最小的“右”起点。 ++ +
示例 3:
+ ++输入: [ [1,4], [2,3], [3,4] ] +输出: [-1, 2, -1] + +解释:对于区间[1,4]和[3,4],没有满足条件的“右侧”区间。 +对于[2,3],区间[3,4]有最小的“右”起点。 ++ + + +## 解法 + + + +### Python3 + + +```python + +``` + +### Java + + +```java + +``` + +### ... +``` + +``` diff --git a/solution/0400-0499/0437.Path Sum III/README.md b/solution/0400-0499/0437.Path Sum III/README.md index d9b3840c082d2..8adbf521851eb 100644 --- a/solution/0400-0499/0437.Path Sum III/README.md +++ b/solution/0400-0499/0437.Path Sum III/README.md @@ -1,7 +1,34 @@ -# [题目](这里是题目链接,如:https://leetcode-cn.com/problems/shu-zu-zhong-zhong-fu-de-shu-zi-lcof/) +# [437. 路径总和 III](https://leetcode-cn.com/problems/path-sum-iii) ## 题目描述 +
给定一个二叉树,它的每个结点都存放着一个整数值。
+ +找出路径和等于给定数值的路径总数。
+ +路径不需要从根节点开始,也不需要在叶子节点结束,但是路径方向必须是向下的(只能从父节点到子节点)。
+ +二叉树不超过1000个节点,且节点数值范围是 [-1000000,1000000] 的整数。
+ +示例:
+ +root = [10,5,-3,3,2,null,11,3,-2,null,1], sum = 8 + + 10 + / \ + 5 -3 + / \ \ + 3 2 11 + / \ \ +3 -2 1 + +返回 3。和等于 8 的路径有: + +1. 5 -> 3 +2. 5 -> 2 -> 1 +3. -3 -> 11 ++ ## 解法 diff --git a/solution/0400-0499/0438.Find All Anagrams in a String/README.md b/solution/0400-0499/0438.Find All Anagrams in a String/README.md index 1fc24f185499d..fd6f15b48ba09 100644 --- a/solution/0400-0499/0438.Find All Anagrams in a String/README.md +++ b/solution/0400-0499/0438.Find All Anagrams in a String/README.md @@ -1,70 +1,47 @@ -## 找到字符串中所有字母异位词 +# [438. 找到字符串中所有字母异位词](https://leetcode-cn.com/problems/find-all-anagrams-in-a-string) -### 问题描述 +## 题目描述 + +
给定一个字符串 s 和一个非空字符串 p,找到 s 中所有是 p 的字母异位词的子串,返回这些子串的起始索引。
-给定一个字符串 `s` 和一个非空字符串 `p`,找到 `s` 中所有是 `p` 的字母异位词的子串,返回这些子串的起始索引。 +字符串只包含小写英文字母,并且字符串 s 和 p 的长度都不超过 20100。
-字符串只包含小写英文字母,并且字符串 `s` 和 `p` 的长度都不超过 20100。 +说明:
-**示例1:** -``` -输入: -s: "cbaebabacd" p: "abc" +-
+
- 字母异位词指字母相同,但排列不同的字符串。 +
- 不考虑答案输出的顺序。 +
示例 1:
-解释: -起始索引等于 0 的子串是 "cba", 它是 "abc" 的字母异位词。 -起始索引等于 6 的子串是 "bac", 它是 "abc" 的字母异位词。 -``` -**示例2:** -``` -输入: -s: "abab" p: "ab" ++输入: +s: "cbaebabacd" p: "abc" -输出: -[0, 1, 2] +输出: +[0, 6] -解释: -起始索引等于 0 的子串是 "ab", 它是 "ab" 的字母异位词。 -起始索引等于 1 的子串是 "ba", 它是 "ab" 的字母异位词。 -起始索引等于 2 的子串是 "ab", 它是 "ab" 的字母异位词。 -``` -**提示:** -- 字母异位词指字母相同,但排列不同的字符串。 -- 不考虑答案输出的顺序。 +解释: +起始索引等于 0 的子串是 "cba", 它是 "abc" 的字母异位词。 +起始索引等于 6 的子串是 "bac", 它是 "abc" 的字母异位词。 +-### 解法 -同`第0567`题。 -使用滑动窗口。窗口宽为`p`的长度,从左到右在`s`上滑动,若窗口内的字母出现频率和`p`中字母出现的频率一样,则此窗口的起始位置为一个起始索引。 +
示例 2:
-```python -class Solution: - def findAnagrams(self, s, p): - lens = len(s) - lenp = len(p) - if lens < lenp: - return [] - flag1 = [0] * 26 - flag2 = [0] * 26 - for i, x in enumerate(p): - flag1[ord(x) - 97] += 1 - ans = [] - for i, x in enumerate(s): - flag2[ord(x) - 97] += 1 - if i >= lenp: - flag2[ord(s[i - lenp]) - 97] -= 1 - if flag1 == flag2: - ans.append(i - lenp + 1) - return ans -``` ++输入: +s: "abab" p: "ab" +输出: +[0, 1, 2] -# [题目](这里是题目链接,如:https://leetcode-cn.com/problems/shu-zu-zhong-zhong-fu-de-shu-zi-lcof/) +解释: +起始索引等于 0 的子串是 "ab", 它是 "ab" 的字母异位词。 +起始索引等于 1 的子串是 "ba", 它是 "ab" 的字母异位词。 +起始索引等于 2 的子串是 "ab", 它是 "ab" 的字母异位词。 +-## 题目描述 - ## 解法 diff --git a/solution/0400-0499/0439.Ternary Expression Parser/README.md b/solution/0400-0499/0439.Ternary Expression Parser/README.md new file mode 100644 index 0000000000000..e256973166038 --- /dev/null +++ b/solution/0400-0499/0439.Ternary Expression Parser/README.md @@ -0,0 +1,29 @@ +# [439. 三元表达式解析器](https://leetcode-cn.com/problems/ternary-expression-parser) + +## 题目描述 + +None + + +## 解法 + + + +### Python3 + + +```python + +``` + +### Java + + +```java + +``` + +### ... +``` + +``` diff --git a/solution/0400-0499/0440.K-th Smallest in Lexicographical Order/README.md b/solution/0400-0499/0440.K-th Smallest in Lexicographical Order/README.md new file mode 100644 index 0000000000000..25d78176610de --- /dev/null +++ b/solution/0400-0499/0440.K-th Smallest in Lexicographical Order/README.md @@ -0,0 +1,45 @@ +# [440. 字典序的第K小数字](https://leetcode-cn.com/problems/k-th-smallest-in-lexicographical-order) + +## 题目描述 + +
给定整数 n 和 k,找到 1 到 n 中字典序第 k 小的数字。
注意:1 ≤ k ≤ n ≤ 109。
+ +示例 :
+ ++输入: +n: 13 k: 2 + +输出: +10 + +解释: +字典序的排列是 [1, 10, 11, 12, 13, 2, 3, 4, 5, 6, 7, 8, 9],所以第二小的数字是 10。 ++ + + +## 解法 + + + +### Python3 + + +```python + +``` + +### Java + + +```java + +``` + +### ... +``` + +``` diff --git a/solution/0400-0499/0441.Arranging Coins/README.md b/solution/0400-0499/0441.Arranging Coins/README.md index d9b3840c082d2..16f17abe85b02 100644 --- a/solution/0400-0499/0441.Arranging Coins/README.md +++ b/solution/0400-0499/0441.Arranging Coins/README.md @@ -1,7 +1,40 @@ -# [题目](这里是题目链接,如:https://leetcode-cn.com/problems/shu-zu-zhong-zhong-fu-de-shu-zi-lcof/) +# [441. 排列硬币](https://leetcode-cn.com/problems/arranging-coins) ## 题目描述 +
你总共有 n 枚硬币,你需要将它们摆成一个阶梯形状,第 k 行就必须正好有 k 枚硬币。
+ +给定一个数字 n,找出可形成完整阶梯行的总行数。
+ +n 是一个非负整数,并且在32位有符号整型的范围内。
+ +示例 1:
+ ++n = 5 + +硬币可排列成以下几行: +¤ +¤ ¤ +¤ ¤ + +因为第三行不完整,所以返回2. ++ +
示例 2:
+ ++n = 8 + +硬币可排列成以下几行: +¤ +¤ ¤ +¤ ¤ ¤ +¤ ¤ + +因为第四行不完整,所以返回3. ++ ## 解法 diff --git a/solution/0400-0499/0442.Find All Duplicates in an Array/README.md b/solution/0400-0499/0442.Find All Duplicates in an Array/README.md new file mode 100644 index 0000000000000..1484e3a7f2967 --- /dev/null +++ b/solution/0400-0499/0442.Find All Duplicates in an Array/README.md @@ -0,0 +1,44 @@ +# [442. 数组中重复的数据](https://leetcode-cn.com/problems/find-all-duplicates-in-an-array) + +## 题目描述 + +
给定一个整数数组 a,其中1 ≤ a[i] ≤ n (n为数组长度), 其中有些元素出现两次而其他元素出现一次。
+ +找到所有出现两次的元素。
+ +你可以不用到任何额外空间并在O(n)时间复杂度内解决这个问题吗?
+ +示例:
+ ++输入: +[4,3,2,7,8,2,3,1] + +输出: +[2,3] ++ + + +## 解法 + + + +### Python3 + + +```python + +``` + +### Java + + +```java + +``` + +### ... +``` + +``` diff --git a/solution/0400-0499/0443.String Compression/README.md b/solution/0400-0499/0443.String Compression/README.md index d9b3840c082d2..16132b08b8aa7 100644 --- a/solution/0400-0499/0443.String Compression/README.md +++ b/solution/0400-0499/0443.String Compression/README.md @@ -1,7 +1,69 @@ -# [题目](这里是题目链接,如:https://leetcode-cn.com/problems/shu-zu-zhong-zhong-fu-de-shu-zi-lcof/) +# [443. 压缩字符串](https://leetcode-cn.com/problems/string-compression) ## 题目描述 +
给定一组字符,使用原地算法将其压缩。
+ +压缩后的长度必须始终小于或等于原数组长度。
+ +数组的每个元素应该是长度为1 的字符(不是 int 整数类型)。
+ +在完成原地修改输入数组后,返回数组的新长度。
+ ++ +
进阶:
+你能否仅使用O(1) 空间解决问题?
+ +
示例 1:
+ ++输入: +["a","a","b","b","c","c","c"] + +输出: +返回6,输入数组的前6个字符应该是:["a","2","b","2","c","3"] + +说明: +"aa"被"a2"替代。"bb"被"b2"替代。"ccc"被"c3"替代。 ++ +
示例 2:
+ ++输入: +["a"] + +输出: +返回1,输入数组的前1个字符应该是:["a"] + +说明: +没有任何字符串被替代。 ++ +
示例 3:
+ ++输入: +["a","b","b","b","b","b","b","b","b","b","b","b","b"] + +输出: +返回4,输入数组的前4个字符应该是:["a","b","1","2"]。 + +说明: +由于字符"a"不重复,所以不会被压缩。"bbbbbbbbbbbb"被“b12”替代。 +注意每个数字在数组中都有它自己的位置。 ++ +
注意:
+ +-
+
- 所有字符都有一个ASCII值在
[35, 126]区间内。
+ 1 <= len(chars) <= 1000。
+
给定两个非空链表来代表两个非负整数。数字最高位位于链表开始位置。它们的每个节点只存储单个数字。将这两数相加会返回一个新的链表。
+ ++ +
你可以假设除了数字 0 之外,这两个数字都不会以零开头。
+ +进阶:
+ +如果输入链表不能修改该如何处理?换句话说,你不能对列表中的节点进行翻转。
+ +示例:
+ ++输入: (7 -> 2 -> 4 -> 3) + (5 -> 6 -> 4) +输出: 7 -> 8 -> 0 -> 7 ++ ## 解法 diff --git a/solution/0400-0499/0446.Arithmetic Slices II - Subsequence/README.md b/solution/0400-0499/0446.Arithmetic Slices II - Subsequence/README.md new file mode 100644 index 0000000000000..fef83204549e7 --- /dev/null +++ b/solution/0400-0499/0446.Arithmetic Slices II - Subsequence/README.md @@ -0,0 +1,75 @@ +# [446. 等差数列划分 II - 子序列](https://leetcode-cn.com/problems/arithmetic-slices-ii-subsequence) + +## 题目描述 + +
如果一个数列至少有三个元素,并且任意两个相邻元素之差相同,则称该数列为等差数列。
+ +例如,以下数列为等差数列:
+ +1, 3, 5, 7, 9 +7, 7, 7, 7 +3, -1, -5, -9+ +
以下数列不是等差数列。
+ +1, 1, 2, 5, 7+ +
+ +
数组 A 包含 N 个数,且索引从 0 开始。该数组子序列将划分为整数序列 (P0, P1, ..., Pk),P 与 Q 是整数且满足 0 ≤ P0 < P1 < ... < Pk < N。
+ ++ +
如果序列 A[P0],A[P1],...,A[Pk-1],A[Pk] 是等差的,那么数组 A 的子序列 (P0,P1,…,PK) 称为等差序列。值得注意的是,这意味着 k ≥ 2。
+ +函数要返回数组 A 中所有等差子序列的个数。
+ +输入包含 N 个整数。每个整数都在 -231 和 231-1 之间,另外 0 ≤ N ≤ 1000。保证输出小于 231-1。
+ ++ +
示例:
+ ++ +
输入:[2, 4, 6, 8, 10] + +输出:7 + +解释: +所有的等差子序列为: +[2,4,6] +[4,6,8] +[6,8,10] +[2,4,6,8] +[4,6,8,10] +[2,4,6,8,10] +[2,6,10] ++ +
+ + + +## 解法 + + + +### Python3 + + +```python + +``` + +### Java + + +```java + +``` + +### ... +``` + +``` diff --git a/solution/0400-0499/0447.Number of Boomerangs/README.md b/solution/0400-0499/0447.Number of Boomerangs/README.md new file mode 100644 index 0000000000000..e72e05cf62a0e --- /dev/null +++ b/solution/0400-0499/0447.Number of Boomerangs/README.md @@ -0,0 +1,45 @@ +# [447. 回旋镖的数量](https://leetcode-cn.com/problems/number-of-boomerangs) + +## 题目描述 + +
给定平面上 n 对不同的点,“回旋镖” 是由点表示的元组 (i, j, k) ,其中 i 和 j 之间的距离和 i 和 k 之间的距离相等(需要考虑元组的顺序)。
找到所有回旋镖的数量。你可以假设 n 最大为 500,所有点的坐标在闭区间 [-10000, 10000] 中。
+ +示例:
+ ++输入: +[[0,0],[1,0],[2,0]] + +输出: +2 + +解释: +两个回旋镖为 [[1,0],[0,0],[2,0]] 和 [[1,0],[2,0],[0,0]] ++ + + +## 解法 + + + +### Python3 + + +```python + +``` + +### Java + + +```java + +``` + +### ... +``` + +``` diff --git a/solution/0400-0499/0448.Find All Numbers Disappeared in an Array/README.md b/solution/0400-0499/0448.Find All Numbers Disappeared in an Array/README.md index 35339b2ad1582..74f101cef7859 100644 --- a/solution/0400-0499/0448.Find All Numbers Disappeared in an Array/README.md +++ b/solution/0400-0499/0448.Find All Numbers Disappeared in an Array/README.md @@ -1,59 +1,23 @@ -## 找到所有数组中消失的数字 +# [448. 找到所有数组中消失的数字](https://leetcode-cn.com/problems/find-all-numbers-disappeared-in-an-array) -### 问题描述 +## 题目描述 + +
给定一个范围在 1 ≤ a[i] ≤ n ( n = 数组大小 ) 的 整型数组,数组中的元素一些出现了两次,另一些只出现一次。
-给定一个范围在 `1 ≤ a[i] ≤ n ( n = 数组大小 )` 的 整型数组,数组中的元素一些出现了两次,另一些只出现一次。 +找到所有在 [1, n] 范围之间没有出现在数组中的数字。
-找到所有在 [1, n] 范围之间没有出现在数组中的数字。 +您能在不使用额外空间且时间复杂度为O(n)的情况下完成这个任务吗? 你可以假定返回的数组不算在额外空间内。
-您能在不使用额外空间且时间复杂度为O(n)的情况下完成这个任务吗? 你可以假定返回的数组不算在额外空间内。 +示例:
-**示例:** -``` -输入: ++输入: [4,3,2,7,8,2,3,1] -输出: +输出: [5,6] -``` +-### 解法 - -题目要求不使用额外空间,所以计数排序的方法不可取; - -根据题目的条件,给定的`a[i]`是在`[1,n]`的范围内,所以可以利用这种关系来对数组进行处理,如`a[a[i]] = -a[a[i]`作反标记,最终若`a[i]>0`的话,则证明该下标`i`没有出现过,加入输出数组 - -```CPP -class Solution { -public: - vector
序列化是将数据结构或对象转换为一系列位的过程,以便它可以存储在文件或内存缓冲区中,或通过网络连接链路传输,以便稍后在同一个或另一个计算机环境中重建。
+ +设计一个算法来序列化和反序列化二叉搜索树。 对序列化/反序列化算法的工作方式没有限制。 您只需确保二叉搜索树可以序列化为字符串,并且可以将该字符串反序列化为最初的二叉搜索树。
+ +编码的字符串应尽可能紧凑。
+ +注意:不要使用类成员/全局/静态变量来存储状态。 你的序列化和反序列化算法应该是无状态的。
+ + + +## 解法 + + + +### Python3 + + +```python + +``` + +### Java + + +```java + +``` + +### ... +``` + +``` diff --git a/solution/0400-0499/0450.Delete Node in a BST/README.md b/solution/0400-0499/0450.Delete Node in a BST/README.md new file mode 100644 index 0000000000000..ece457609e4ce --- /dev/null +++ b/solution/0400-0499/0450.Delete Node in a BST/README.md @@ -0,0 +1,70 @@ +# [450. 删除二叉搜索树中的节点](https://leetcode-cn.com/problems/delete-node-in-a-bst) + +## 题目描述 + +给定一个二叉搜索树的根节点 root 和一个值 key,删除二叉搜索树中的 key 对应的节点,并保证二叉搜索树的性质不变。返回二叉搜索树(有可能被更新)的根节点的引用。
+ +一般来说,删除节点可分为两个步骤:
+ +-
+
- 首先找到需要删除的节点; +
- 如果找到了,删除它。 +
说明: 要求算法时间复杂度为 O(h),h 为树的高度。
+ +示例:
+ ++root = [5,3,6,2,4,null,7] +key = 3 + + 5 + / \ + 3 6 + / \ \ +2 4 7 + +给定需要删除的节点值是 3,所以我们首先找到 3 这个节点,然后删除它。 + +一个正确的答案是 [5,4,6,2,null,null,7], 如下图所示。 + + 5 + / \ + 4 6 + / \ +2 7 + +另一个正确答案是 [5,2,6,null,4,null,7]。 + + 5 + / \ + 2 6 + \ \ + 4 7 ++ + + +## 解法 + + + +### Python3 + + +```python + +``` + +### Java + + +```java + +``` + +### ... +``` + +``` diff --git a/solution/0400-0499/0451.Sort Characters By Frequency/README.md b/solution/0400-0499/0451.Sort Characters By Frequency/README.md new file mode 100644 index 0000000000000..a5f8ccdddefa5 --- /dev/null +++ b/solution/0400-0499/0451.Sort Characters By Frequency/README.md @@ -0,0 +1,72 @@ +# [451. 根据字符出现频率排序](https://leetcode-cn.com/problems/sort-characters-by-frequency) + +## 题目描述 + +
给定一个字符串,请将字符串里的字符按照出现的频率降序排列。
+ +示例 1:
+ ++输入: +"tree" + +输出: +"eert" + +解释: +'e'出现两次,'r'和't'都只出现一次。 +因此'e'必须出现在'r'和't'之前。此外,"eetr"也是一个有效的答案。 ++ +
示例 2:
+ ++输入: +"cccaaa" + +输出: +"cccaaa" + +解释: +'c'和'a'都出现三次。此外,"aaaccc"也是有效的答案。 +注意"cacaca"是不正确的,因为相同的字母必须放在一起。 ++ +
示例 3:
+ ++输入: +"Aabb" + +输出: +"bbAa" + +解释: +此外,"bbaA"也是一个有效的答案,但"Aabb"是不正确的。 +注意'A'和'a'被认为是两种不同的字符。 ++ + + +## 解法 + + + +### Python3 + + +```python + +``` + +### Java + + +```java + +``` + +### ... +``` + +``` diff --git a/solution/0400-0499/0452.Minimum Number of Arrows to Burst Balloons/README.md b/solution/0400-0499/0452.Minimum Number of Arrows to Burst Balloons/README.md new file mode 100644 index 0000000000000..a9411f827a76b --- /dev/null +++ b/solution/0400-0499/0452.Minimum Number of Arrows to Burst Balloons/README.md @@ -0,0 +1,45 @@ +# [452. 用最少数量的箭引爆气球](https://leetcode-cn.com/problems/minimum-number-of-arrows-to-burst-balloons) + +## 题目描述 + +
在二维空间中有许多球形的气球。对于每个气球,提供的输入是水平方向上,气球直径的开始和结束坐标。由于它是水平的,所以y坐标并不重要,因此只要知道开始和结束的x坐标就足够了。开始坐标总是小于结束坐标。平面内最多存在104个气球。
+ +一支弓箭可以沿着x轴从不同点完全垂直地射出。在坐标x处射出一支箭,若有一个气球的直径的开始和结束坐标为 xstart,xend, 且满足 xstart ≤ x ≤ xend,则该气球会被引爆。可以射出的弓箭的数量没有限制。 弓箭一旦被射出之后,可以无限地前进。我们想找到使得所有气球全部被引爆,所需的弓箭的最小数量。
+ +Example:
+ ++输入: +[[10,16], [2,8], [1,6], [7,12]] + +输出: +2 + +解释: +对于该样例,我们可以在x = 6(射爆[2,8],[1,6]两个气球)和 x = 11(射爆另外两个气球)。 ++ + + +## 解法 + + + +### Python3 + + +```python + +``` + +### Java + + +```java + +``` + +### ... +``` + +``` diff --git a/solution/0400-0499/0453.Minimum Moves to Equal Array Elements/README.md b/solution/0400-0499/0453.Minimum Moves to Equal Array Elements/README.md new file mode 100644 index 0000000000000..ef9052cdf75dd --- /dev/null +++ b/solution/0400-0499/0453.Minimum Moves to Equal Array Elements/README.md @@ -0,0 +1,45 @@ +# [453. 最小移动次数使数组元素相等](https://leetcode-cn.com/problems/minimum-moves-to-equal-array-elements) + +## 题目描述 + +
给定一个长度为 n 的非空整数数组,找到让数组所有元素相等的最小移动次数。每次移动可以使 n - 1 个元素增加 1。
+ +示例:
+ ++输入: +[1,2,3] + +输出: +3 + +解释: +只需要3次移动(注意每次移动会增加两个元素的值): + +[1,2,3] => [2,3,3] => [3,4,3] => [4,4,4] ++ + + +## 解法 + + + +### Python3 + + +```python + +``` + +### Java + + +```java + +``` + +### ... +``` + +``` diff --git a/solution/0400-0499/0454.4Sum II/README.md b/solution/0400-0499/0454.4Sum II/README.md new file mode 100644 index 0000000000000..e2da4c0a4701a --- /dev/null +++ b/solution/0400-0499/0454.4Sum II/README.md @@ -0,0 +1,50 @@ +# [454. 四数相加 II](https://leetcode-cn.com/problems/4sum-ii) + +## 题目描述 + +
给定四个包含整数的数组列表 A , B , C , D ,计算有多少个元组 (i, j, k, l) ,使得 A[i] + B[j] + C[k] + D[l] = 0。
为了使问题简单化,所有的 A, B, C, D 具有相同的长度 N,且 0 ≤ N ≤ 500 。所有整数的范围在 -228 到 228 - 1 之间,最终结果不会超过 231 - 1 。
+ +例如:
+ ++输入: +A = [ 1, 2] +B = [-2,-1] +C = [-1, 2] +D = [ 0, 2] + +输出: +2 + +解释: +两个元组如下: +1. (0, 0, 0, 1) -> A[0] + B[0] + C[0] + D[1] = 1 + (-2) + (-1) + 2 = 0 +2. (1, 1, 0, 0) -> A[1] + B[1] + C[0] + D[0] = 2 + (-1) + (-1) + 0 = 0 ++ + + +## 解法 + + + +### Python3 + + +```python + +``` + +### Java + + +```java + +``` + +### ... +``` + +``` diff --git a/solution/0400-0499/0455.Assign Cookies/README.md b/solution/0400-0499/0455.Assign Cookies/README.md new file mode 100644 index 0000000000000..a0e8f9e5cfd02 --- /dev/null +++ b/solution/0400-0499/0455.Assign Cookies/README.md @@ -0,0 +1,61 @@ +# [455. 分发饼干](https://leetcode-cn.com/problems/assign-cookies) + +## 题目描述 + +
假设你是一位很棒的家长,想要给你的孩子们一些小饼干。但是,每个孩子最多只能给一块饼干。对每个孩子 i ,都有一个胃口值 gi ,这是能让孩子们满足胃口的饼干的最小尺寸;并且每块饼干 j ,都有一个尺寸 sj 。如果 sj >= gi ,我们可以将这个饼干 j 分配给孩子 i ,这个孩子会得到满足。你的目标是尽可能满足越多数量的孩子,并输出这个最大数值。
+ +注意:
+ +你可以假设胃口值为正。
+一个小朋友最多只能拥有一块饼干。
示例 1:
+ ++输入: [1,2,3], [1,1] + +输出: 1 + +解释: +你有三个孩子和两块小饼干,3个孩子的胃口值分别是:1,2,3。 +虽然你有两块小饼干,由于他们的尺寸都是1,你只能让胃口值是1的孩子满足。 +所以你应该输出1。 ++ +
示例 2:
+ ++输入: [1,2], [1,2,3] + +输出: 2 + +解释: +你有两个孩子和三块小饼干,2个孩子的胃口值分别是1,2。 +你拥有的饼干数量和尺寸都足以让所有孩子满足。 +所以你应该输出2. ++ + + +## 解法 + + + +### Python3 + + +```python + +``` + +### Java + + +```java + +``` + +### ... +``` + +``` diff --git a/solution/0400-0499/0456.132 Pattern/README.md b/solution/0400-0499/0456.132 Pattern/README.md new file mode 100644 index 0000000000000..31636b7cb5822 --- /dev/null +++ b/solution/0400-0499/0456.132 Pattern/README.md @@ -0,0 +1,62 @@ +# [456. 132模式](https://leetcode-cn.com/problems/132-pattern) + +## 题目描述 + +
给定一个整数序列:a1, a2, ..., an,一个132模式的子序列 ai, aj, ak 被定义为:当 i < j < k 时,ai < ak < aj。设计一个算法,当给定有 n 个数字的序列时,验证这个序列中是否含有132模式的子序列。
+ +注意:n 的值小于15000。
+ +示例1:
+ ++输入: [1, 2, 3, 4] + +输出: False + +解释: 序列中不存在132模式的子序列。 ++ +
示例 2:
+ ++输入: [3, 1, 4, 2] + +输出: True + +解释: 序列中有 1 个132模式的子序列: [1, 4, 2]. ++ +
示例 3:
+ ++输入: [-1, 3, 2, 0] + +输出: True + +解释: 序列中有 3 个132模式的的子序列: [-1, 3, 2], [-1, 3, 0] 和 [-1, 2, 0]. ++ + + +## 解法 + + + +### Python3 + + +```python + +``` + +### Java + + +```java + +``` + +### ... +``` + +``` diff --git a/solution/0400-0499/0457.Circular Array Loop/README.md b/solution/0400-0499/0457.Circular Array Loop/README.md index 63defa83ebc0b..ed468306765e4 100644 --- a/solution/0400-0499/0457.Circular Array Loop/README.md +++ b/solution/0400-0499/0457.Circular Array Loop/README.md @@ -1,84 +1,69 @@ -# 环形数组循环 +# [457. 环形数组循环](https://leetcode-cn.com/problems/circular-array-loop) -### 题目描述 +## 题目描述 + +
给定一个含有正整数和负整数的环形数组 nums。 如果某个索引中的数 k 为正数,则向前移动 k 个索引。相反,如果是负数 (-k),则向后移动 k 个索引。因为数组是环形的,所以可以假设最后一个元素的下一个元素是第一个元素,而第一个元素的前一个元素是最后一个元素。
确定 nums 中是否存在循环(或周期)。循环必须在相同的索引处开始和结束并且循环长度 > 1。此外,一个循环中的所有运动都必须沿着同一方向进行。换句话说,一个循环中不能同时包括向前的运动和向后的运动。
+
示例 1:
+输入:[2,-1,1,2,2] +输出:true +解释:存在循环,按索引 0 -> 2 -> 3 -> 0 。循环长度为 3 。 +-**示例 1** +
示例 2:
-``` -输入:[2,-1,1,2,2] -输出:true -解释:存在循环,按索引 0 -> 2 -> 3 -> 0 。循环长度为 3 。 -``` +输入:[-1,2] +输出:false +解释:按索引 1 -> 1 -> 1 ... 的运动无法构成循环,因为循环的长度为 1 。根据定义,循环的长度必须大于 1 。 +-**示例 2** - -``` -输入:[-1,2] -输出:false -解释:按索引 1 -> 1 -> 1 ... 的运动无法构成循环,因为循环的长度为 1 。根据定义,循环的长度必须大于 1 。 -``` +
示例 3:
-**示例 3** +输入:[-2,1,-1,-2,-2] +输出:false +解释:按索引 1 -> 2 -> 1 -> ... 的运动无法构成循环,因为按索引 1 -> 2 的运动是向前的运动,而按索引 2 -> 1 的运动是向后的运动。一个循环中的所有运动都必须沿着同一方向进行。-``` -输入:[-2,1,-1,-2,-2] -输出:false -解释:按索引 1 -> 2 -> 1 -> ... 的运动无法构成循环,因为按索引 1 -> 2 的运动是向前的运动,而按索引 2 -> 1 的运动是向后的运动。一个循环中的所有运动都必须沿着同一方向进行。 -``` +
-**提示** +
提示:
-1. -1000 ≤ nums[i] ≤ 1000 -2. nums[i] ≠ 0 -3. 1 ≤ nums.length ≤ 5000 +-
+
- -1000 ≤ nums[i] ≤ 1000 +
- nums[i] ≠ 0 +
- 0 ≤ nums.length ≤ 5000 +
-你能写出时间时间复杂度为 **O(n)** 和额外空间复杂度为 **O(1)** 的算法吗? +
进阶:
+你能写出时间时间复杂度为 O(n) 和额外空间复杂度为 O(1) 的算法吗?
-### 解题思路 -**思路** -若时间复杂度为 **O(n^2)** 则不用记录,双重遍历就完事了。降低时间复杂度为 **O(n)** 首先想到设置一个`visit`数组来记录是否被访问。若要空间复杂度为 **O(1)** ,考虑`-1000 ≤ nums[i] ≤ 1000`,可以用大于1000或小于-1000来记录是否被访问。需要注意的是循环长度要大于`1`,在一条链路中可能会出现`0 -> 2 -> 3 -> 3`这种在尾部存在的自循环。 +## 解法 + -**算法** -**python** +### Python3 + ```python -class Solution: - def circularArrayLoop(self, nums: 'List[int]') -> 'bool': - flag = 1000 - lent = len(nums) - drt = 1 # -1->left 1->right - for loc in range(lent): - if nums[loc] > 1000: - continue - if nums[loc] < 0: - drt = -1 - else: - drt = 1 - ct = (loc + nums[loc]) % lent - flag += 1 - nums[loc] = flag - start = flag - tmp = ct - while -1000 <= nums[ct] <= 1000: - if nums[ct] * drt < 0: - break - tmp = ct - ct = (ct + nums[ct]) % lent - flag += 1 - nums[tmp] = flag - else: - if nums[ct] != nums[tmp] and nums[ct] >= start: - return True - return False + +``` + +### Java + + +```java + +``` + +### ... +``` + ``` diff --git a/solution/0400-0499/0458.Poor Pigs/README.md b/solution/0400-0499/0458.Poor Pigs/README.md new file mode 100644 index 0000000000000..3e3d7cd564e31 --- /dev/null +++ b/solution/0400-0499/0458.Poor Pigs/README.md @@ -0,0 +1,50 @@ +# [458. 可怜的小猪](https://leetcode-cn.com/problems/poor-pigs) + +## 题目描述 + +有 1000 只水桶,其中有且只有一桶装的含有毒药,其余装的都是水。它们从外观看起来都一样。如果小猪喝了毒药,它会在 15 分钟内死去。
+ +问题来了,如果需要你在一小时内,弄清楚哪只水桶含有毒药,你最少需要多少只猪?
+ +回答这个问题,并为下列的进阶问题编写一个通用算法。
+ ++ +
进阶:
+ +假设有 n 只水桶,猪饮水中毒后会在 m 分钟内死亡,你需要多少猪(x)就能在 p 分钟内找出 “有毒” 水桶?这 n 只水桶里有且仅有一只有毒的桶。
+ +
提示:
+ +-
+
- 可以允许小猪同时饮用任意数量的桶中的水,并且该过程不需要时间。 +
- 小猪喝完水后,必须有 m 分钟的冷却时间。在这段时间里,只允许观察,而不允许继续饮水。 +
- 任何给定的桶都可以无限次采样(无限数量的猪)。 +
给定一个非空的字符串,判断它是否可以由它的一个子串重复多次构成。给定的字符串只含有小写英文字母,并且长度不超过10000。
+ +示例 1:
+ ++输入: "abab" + +输出: True + +解释: 可由子字符串 "ab" 重复两次构成。 ++ +
示例 2:
+ ++输入: "aba" + +输出: False ++ +
示例 3:
+ ++输入: "abcabcabcabc" + +输出: True + +解释: 可由子字符串 "abc" 重复四次构成。 (或者子字符串 "abcabc" 重复两次构成。) ++ + + +## 解法 + + + +### Python3 + + +```python + +``` + +### Java + + +```java + +``` + +### ... +``` + +``` diff --git a/solution/0400-0499/0460.LFU Cache/README.md b/solution/0400-0499/0460.LFU Cache/README.md new file mode 100644 index 0000000000000..c99986edd70e2 --- /dev/null +++ b/solution/0400-0499/0460.LFU Cache/README.md @@ -0,0 +1,52 @@ +# [460. LFU缓存](https://leetcode-cn.com/problems/lfu-cache) + +## 题目描述 + +
设计并实现最不经常使用(LFU)缓存的数据结构。它应该支持以下操作:get 和 put。
get(key) - 如果键存在于缓存中,则获取键的值(总是正数),否则返回 -1。
+put(key, value) - 如果键不存在,请设置或插入值。当缓存达到其容量时,它应该在插入新项目之前,使最不经常使用的项目无效。在此问题中,当存在平局(即两个或更多个键具有相同使用频率)时,最近最少使用的键将被去除。
进阶:
+你是否可以在 O(1) 时间复杂度内执行两项操作?
示例:
+ ++LFUCache cache = new LFUCache( 2 /* capacity (缓存容量) */ ); + +cache.put(1, 1); +cache.put(2, 2); +cache.get(1); // 返回 1 +cache.put(3, 3); // 去除 key 2 +cache.get(2); // 返回 -1 (未找到key 2) +cache.get(3); // 返回 3 +cache.put(4, 4); // 去除 key 1 +cache.get(1); // 返回 -1 (未找到 key 1) +cache.get(3); // 返回 3 +cache.get(4); // 返回 4+ + + +## 解法 + + + +### Python3 + + +```python + +``` + +### Java + + +```java + +``` + +### ... +``` + +``` diff --git a/solution/0400-0499/0461.Hamming Distance/README.md b/solution/0400-0499/0461.Hamming Distance/README.md new file mode 100644 index 0000000000000..e30d71f097ebb --- /dev/null +++ b/solution/0400-0499/0461.Hamming Distance/README.md @@ -0,0 +1,50 @@ +# [461. 汉明距离](https://leetcode-cn.com/problems/hamming-distance) + +## 题目描述 + +
两个整数之间的汉明距离指的是这两个数字对应二进制位不同的位置的数目。
+ +给出两个整数 x 和 y,计算它们之间的汉明距离。
注意:
+0 ≤ x, y < 231.
示例:
+ ++输入: x = 1, y = 4 + +输出: 2 + +解释: +1 (0 0 0 1) +4 (0 1 0 0) + ↑ ↑ + +上面的箭头指出了对应二进制位不同的位置。 ++ + + +## 解法 + + + +### Python3 + + +```python + +``` + +### Java + + +```java + +``` + +### ... +``` + +``` diff --git a/solution/0400-0499/0462.Minimum Moves to Equal Array Elements II/README.md b/solution/0400-0499/0462.Minimum Moves to Equal Array Elements II/README.md new file mode 100644 index 0000000000000..fc8667465c39c --- /dev/null +++ b/solution/0400-0499/0462.Minimum Moves to Equal Array Elements II/README.md @@ -0,0 +1,45 @@ +# [462. 最少移动次数使数组元素相等 II](https://leetcode-cn.com/problems/minimum-moves-to-equal-array-elements-ii) + +## 题目描述 + +
给定一个非空整数数组,找到使所有数组元素相等所需的最小移动数,其中每次移动可将选定的一个元素加1或减1。 您可以假设数组的长度最多为10000。
+ +例如:
+ ++输入: +[1,2,3] + +输出: +2 + +说明: +只有两个动作是必要的(记得每一步仅可使其中一个元素加1或减1): + +[1,2,3] => [2,2,3] => [2,2,2] ++ + + +## 解法 + + + +### Python3 + + +```python + +``` + +### Java + + +```java + +``` + +### ... +``` + +``` diff --git a/solution/0400-0499/0463.Island Perimeter/README.md b/solution/0400-0499/0463.Island Perimeter/README.md new file mode 100644 index 0000000000000..001d3b238586c --- /dev/null +++ b/solution/0400-0499/0463.Island Perimeter/README.md @@ -0,0 +1,51 @@ +# [463. 岛屿的周长](https://leetcode-cn.com/problems/island-perimeter) + +## 题目描述 + +
给定一个包含 0 和 1 的二维网格地图,其中 1 表示陆地 0 表示水域。
+ +网格中的格子水平和垂直方向相连(对角线方向不相连)。整个网格被水完全包围,但其中恰好有一个岛屿(或者说,一个或多个表示陆地的格子相连组成的岛屿)。
+ +岛屿中没有“湖”(“湖” 指水域在岛屿内部且不和岛屿周围的水相连)。格子是边长为 1 的正方形。网格为长方形,且宽度和高度均不超过 100 。计算这个岛屿的周长。
+ ++ +
示例 :
+ +输入: +[[0,1,0,0], + [1,1,1,0], + [0,1,0,0], + [1,1,0,0]] + +输出: 16 + +解释: 它的周长是下面图片中的 16 个黄色的边: + ++ + + +## 解法 + + + +### Python3 + + +```python + +``` + +### Java + + +```java + +``` + +### ... +``` + +``` diff --git a/solution/0400-0499/0464.Can I Win/README.md b/solution/0400-0499/0464.Can I Win/README.md new file mode 100644 index 0000000000000..81741066cb26b --- /dev/null +++ b/solution/0400-0499/0464.Can I Win/README.md @@ -0,0 +1,55 @@ +# [464. 我能赢吗](https://leetcode-cn.com/problems/can-i-win) + +## 题目描述 + ++
在 "100 game" 这个游戏中,两名玩家轮流选择从 1 到 10 的任意整数,累计整数和,先使得累计整数和达到 100 的玩家,即为胜者。
+ +如果我们将游戏规则改为 “玩家不能重复使用整数” 呢?
+ +例如,两个玩家可以轮流从公共整数池中抽取从 1 到 15 的整数(不放回),直到累计整数和 >= 100。
+ +给定一个整数 maxChoosableInteger (整数池中可选择的最大数)和另一个整数 desiredTotal(累计和),判断先出手的玩家是否能稳赢(假设两位玩家游戏时都表现最佳)?
你可以假设 maxChoosableInteger 不会大于 20, desiredTotal 不会大于 300。
示例:
+ +输入: +maxChoosableInteger = 10 +desiredTotal = 11 + +输出: +false + +解释: +无论第一个玩家选择哪个整数,他都会失败。 +第一个玩家可以选择从 1 到 10 的整数。 +如果第一个玩家选择 1,那么第二个玩家只能选择从 2 到 10 的整数。 +第二个玩家可以通过选择整数 10(那么累积和为 11 >= desiredTotal),从而取得胜利. +同样地,第一个玩家选择任意其他整数,第二个玩家都会赢。 ++ + + +## 解法 + + + +### Python3 + + +```python + +``` + +### Java + + +```java + +``` + +### ... +``` + +``` diff --git a/solution/0400-0499/0465.Optimal Account Balancing/README.md b/solution/0400-0499/0465.Optimal Account Balancing/README.md new file mode 100644 index 0000000000000..6242fc1440c6e --- /dev/null +++ b/solution/0400-0499/0465.Optimal Account Balancing/README.md @@ -0,0 +1,29 @@ +# [465. 最优账单平衡](https://leetcode-cn.com/problems/optimal-account-balancing) + +## 题目描述 + +None + + +## 解法 + + + +### Python3 + + +```python + +``` + +### Java + + +```java + +``` + +### ... +``` + +``` diff --git a/solution/0400-0499/0466.Count The Repetitions/README.md b/solution/0400-0499/0466.Count The Repetitions/README.md new file mode 100644 index 0000000000000..861a129b3fb94 --- /dev/null +++ b/solution/0400-0499/0466.Count The Repetitions/README.md @@ -0,0 +1,44 @@ +# [466. 统计重复个数](https://leetcode-cn.com/problems/count-the-repetitions) + +## 题目描述 + +
定义由 n 个连接的字符串 s 组成字符串 S,即 S = [s,n]。例如,["abc", 3]=“abcabcabc”。
另一方面,如果我们可以从 s2 中删除某些字符使其变为 s1,我们称字符串 s1 可以从字符串 s2 获得。例如,“abc” 可以根据我们的定义从 “abdbec” 获得,但不能从 “acbbe” 获得。
+ +现在给出两个非空字符串 S1 和 S2(每个最多 100 个字符长)和两个整数 0 ≤ N1 ≤ 106 和 1 ≤ N2 ≤ 106。现在考虑字符串 S1 和 S2,其中S1=[s1,n1]和S2=[s2,n2]。找出可以使[S2,M]从 S1 获得的最大整数 M。
示例:
+ +输入: +s1 ="acb",n1 = 4 +s2 ="ab",n2 = 2 + +返回: +2 ++ + + +## 解法 + + + +### Python3 + + +```python + +``` + +### Java + + +```java + +``` + +### ... +``` + +``` diff --git a/solution/0400-0499/0467.Unique Substrings in Wraparound String/README.md b/solution/0400-0499/0467.Unique Substrings in Wraparound String/README.md new file mode 100644 index 0000000000000..3eb483047dd4b --- /dev/null +++ b/solution/0400-0499/0467.Unique Substrings in Wraparound String/README.md @@ -0,0 +1,66 @@ +# [467. 环绕字符串中唯一的子字符串](https://leetcode-cn.com/problems/unique-substrings-in-wraparound-string) + +## 题目描述 + +
把字符串 s 看作是“abcdefghijklmnopqrstuvwxyz”的无限环绕字符串,所以 s 看起来是这样的:"...zabcdefghijklmnopqrstuvwxyzabcdefghijklmnopqrstuvwxyzabcd....".
现在我们有了另一个字符串 p 。你需要的是找出 s 中有多少个唯一的 p 的非空子串,尤其是当你的输入是字符串 p ,你需要输出字符串 s 中 p 的不同的非空子串的数目。
注意: p 仅由小写的英文字母组成,p 的大小可能超过 10000。
+ +
示例 1:
+ ++输入: "a" +输出: 1 +解释: 字符串 S 中只有一个"a"子字符。 ++ +
+ +
示例 2:
+ ++输入: "cac" +输出: 2 +解释: 字符串 S 中的字符串“cac”只有两个子串“a”、“c”。. ++ +
+ +
示例 3:
+ ++输入: "zab" +输出: 6 +解释: 在字符串 S 中有六个子串“z”、“a”、“b”、“za”、“ab”、“zab”。. ++ +
+ + + +## 解法 + + + +### Python3 + + +```python + +``` + +### Java + + +```java + +``` + +### ... +``` + +``` diff --git a/solution/0400-0499/0468.Validate IP Address/README.md b/solution/0400-0499/0468.Validate IP Address/README.md new file mode 100644 index 0000000000000..6d96409186892 --- /dev/null +++ b/solution/0400-0499/0468.Validate IP Address/README.md @@ -0,0 +1,72 @@ +# [468. 验证IP地址](https://leetcode-cn.com/problems/validate-ip-address) + +## 题目描述 + +
编写一个函数来验证输入的字符串是否是有效的 IPv4 或 IPv6 地址。
+ +IPv4 地址由十进制数和点来表示,每个地址包含4个十进制数,其范围为 0 - 255, 用(".")分割。比如,172.16.254.1;
同时,IPv4 地址内的数不会以 0 开头。比如,地址 172.16.254.01 是不合法的。
IPv6 地址由8组16进制的数字来表示,每组表示 16 比特。这些组数字通过 (":")分割。比如, 2001:0db8:85a3:0000:0000:8a2e:0370:7334 是一个有效的地址。而且,我们可以加入一些以 0 开头的数字,字母可以使用大写,也可以是小写。所以, 2001:db8:85a3:0:0:8A2E:0370:7334 也是一个有效的 IPv6 address地址 (即,忽略 0 开头,忽略大小写)。
然而,我们不能因为某个组的值为 0,而使用一个空的组,以至于出现 (::) 的情况。 比如, 2001:0db8:85a3::8A2E:0370:7334 是无效的 IPv6 地址。
同时,在 IPv6 地址中,多余的 0 也是不被允许的。比如, 02001:0db8:85a3:0000:0000:8a2e:0370:7334 是无效的。
说明: 你可以认为给定的字符串里没有空格或者其他特殊字符。
+ +示例 1:
+ ++输入: "172.16.254.1" + +输出: "IPv4" + +解释: 这是一个有效的 IPv4 地址, 所以返回 "IPv4"。 ++ +
示例 2:
+ ++输入: "2001:0db8:85a3:0:0:8A2E:0370:7334" + +输出: "IPv6" + +解释: 这是一个有效的 IPv6 地址, 所以返回 "IPv6"。 ++ +
示例 3:
+ ++输入: "256.256.256.256" + +输出: "Neither" + +解释: 这个地址既不是 IPv4 也不是 IPv6 地址。 ++ + + +## 解法 + + + +### Python3 + + +```python + +``` + +### Java + + +```java + +``` + +### ... +``` + +``` diff --git a/solution/0400-0499/0469.Convex Polygon/README.md b/solution/0400-0499/0469.Convex Polygon/README.md new file mode 100644 index 0000000000000..9b55387186c3f --- /dev/null +++ b/solution/0400-0499/0469.Convex Polygon/README.md @@ -0,0 +1,29 @@ +# [469. 凸多边形](https://leetcode-cn.com/problems/convex-polygon) + +## 题目描述 + +None + + +## 解法 + + + +### Python3 + + +```python + +``` + +### Java + + +```java + +``` + +### ... +``` + +``` diff --git a/solution/0400-0499/0470.Implement Rand10() Using Rand7()/README.md b/solution/0400-0499/0470.Implement Rand10() Using Rand7()/README.md new file mode 100644 index 0000000000000..f915d2d6a7ecf --- /dev/null +++ b/solution/0400-0499/0470.Implement Rand10() Using Rand7()/README.md @@ -0,0 +1,76 @@ +# [470. 用 Rand7() 实现 Rand10()](https://leetcode-cn.com/problems/implement-rand10-using-rand7) + +## 题目描述 + +
已有方法 rand7 可生成 1 到 7 范围内的均匀随机整数,试写一个方法 rand10 生成 1 到 10 范围内的均匀随机整数。
不要使用系统的 Math.random() 方法。
-
+
+ +
示例 1:
+ ++输入: 1 +输出: [7] ++ +
示例 2:
+ ++输入: 2 +输出: [8,4] ++ +
示例 3:
+ ++输入: 3 +输出: [8,1,10] ++ +
+ +
提示:
+ +-
+
rand7已定义。
+ - 传入参数:
n表示rand10的调用次数。
+
+ +
进阶:
+ +-
+
rand7()调用次数的 期望值 是多少 ?
+ - 你能否尽量少调用
rand7()?
+
给定一个不含重复单词的列表,编写一个程序,返回给定单词列表中所有的连接词。
+ +连接词的定义为:一个字符串完全是由至少两个给定数组中的单词组成的。
+ +示例:
+ ++输入: ["cat","cats","catsdogcats","dog","dogcatsdog","hippopotamuses","rat","ratcatdogcat"] + +输出: ["catsdogcats","dogcatsdog","ratcatdogcat"] + +解释: "catsdogcats"由"cats", "dog" 和 "cats"组成; + "dogcatsdog"由"dog", "cats"和"dog"组成; + "ratcatdogcat"由"rat", "cat", "dog"和"cat"组成。 ++ +
说明:
+ +-
+
- 给定数组的元素总数不超过
10000。
+ - 给定数组中元素的长度总和不超过
600000。
+ - 所有输入字符串只包含小写字母。 +
- 不需要考虑答案输出的顺序。 +
还记得童话《卖火柴的小女孩》吗?现在,你知道小女孩有多少根火柴,请找出一种能使用所有火柴拼成一个正方形的方法。不能折断火柴,可以把火柴连接起来,并且每根火柴都要用到。
+ +输入为小女孩拥有火柴的数目,每根火柴用其长度表示。输出即为是否能用所有的火柴拼成正方形。
+ +示例 1:
+ ++输入: [1,1,2,2,2] +输出: true + +解释: 能拼成一个边长为2的正方形,每边两根火柴。 ++ +
示例 2:
+ ++输入: [3,3,3,3,4] +输出: false + +解释: 不能用所有火柴拼成一个正方形。 ++ +
注意:
+ +-
+
- 给定的火柴长度和在
0到10^9之间。
+ - 火柴数组的长度不超过15。 +
在计算机界中,我们总是追求用有限的资源获取最大的收益。
+ +现在,假设你分别支配着 m 个 0 和 n 个 1。另外,还有一个仅包含 0 和 1 字符串的数组。
你的任务是使用给定的 m 个 0 和 n 个 1 ,找到能拼出存在于数组中的字符串的最大数量。每个 0 和 1 至多被使用一次。
注意:
+ +-
+
- 给定
0和1的数量都不会超过100。
+ - 给定字符串数组的长度不会超过
600。
+
示例 1:
+ +
+输入: Array = {"10", "0001", "111001", "1", "0"}, m = 5, n = 3
+输出: 4
+
+解释: 总共 4 个字符串可以通过 5 个 0 和 3 个 1 拼出,即 "10","0001","1","0" 。
+
+
+示例 2:
+ +
+输入: Array = {"10", "0", "1"}, m = 1, n = 1
+输出: 2
+
+解释: 你可以拼出 "10",但之后就没有剩余数字了。更好的选择是拼出 "0" 和 "1" 。
+
+
+
+
+## 解法
+
+
+
+### Python3
+
+
+```python
+
+```
+
+### Java
+
+
+```java
+
+```
+
+### ...
+```
+
+```
diff --git a/solution/0400-0499/0475.Heaters/README.md b/solution/0400-0499/0475.Heaters/README.md
new file mode 100644
index 0000000000000..06e4d086db9d5
--- /dev/null
+++ b/solution/0400-0499/0475.Heaters/README.md
@@ -0,0 +1,59 @@
+# [475. 供暖器](https://leetcode-cn.com/problems/heaters)
+
+## 题目描述
+
+冬季已经来临。 你的任务是设计一个有固定加热半径的供暖器向所有房屋供暖。
+ +现在,给出位于一条水平线上的房屋和供暖器的位置,找到可以覆盖所有房屋的最小加热半径。
+ +所以,你的输入将会是房屋和供暖器的位置。你将输出供暖器的最小加热半径。
+ +说明:
+ +-
+
- 给出的房屋和供暖器的数目是非负数且不会超过 25000。 +
- 给出的房屋和供暖器的位置均是非负数且不会超过10^9。 +
- 只要房屋位于供暖器的半径内(包括在边缘上),它就可以得到供暖。 +
- 所有供暖器都遵循你的半径标准,加热的半径也一样。 +
示例 1:
+ ++输入: [1,2,3],[2] +输出: 1 +解释: 仅在位置2上有一个供暖器。如果我们将加热半径设为1,那么所有房屋就都能得到供暖。 ++ +
示例 2:
+ ++输入: [1,2,3,4],[1,4] +输出: 1 +解释: 在位置1, 4上有两个供暖器。我们需要将加热半径设为1,这样所有房屋就都能得到供暖。 ++ + + +## 解法 + + + +### Python3 + + +```python + +``` + +### Java + + +```java + +``` + +### ... +``` + +``` diff --git a/solution/0400-0499/0476.Number Complement/README.md b/solution/0400-0499/0476.Number Complement/README.md new file mode 100644 index 0000000000000..e459c557d3b1a --- /dev/null +++ b/solution/0400-0499/0476.Number Complement/README.md @@ -0,0 +1,59 @@ +# [476. 数字的补数](https://leetcode-cn.com/problems/number-complement) + +## 题目描述 + +
给定一个正整数,输出它的补数。补数是对该数的二进制表示取反。
+ ++ +
-
+
示例 1:
+ +输入: 5 +输出: 2 +解释: 5 的二进制表示为 101(没有前导零位),其补数为 010。所以你需要输出 2 。 ++ +
示例 2:
+ +输入: 1 +输出: 0 +解释: 1 的二进制表示为 1(没有前导零位),其补数为 0。所以你需要输出 0 。 ++ +
+ +
注意:
+ +-
+
- 给定的整数保证在 32 位带符号整数的范围内。 +
- 你可以假定二进制数不包含前导零位。 +
- 本题与 1009 https://leetcode-cn.com/problems/complement-of-base-10-integer/ 相同 +
两个整数的 汉明距离 指的是这两个数字的二进制数对应位不同的数量。
+ +计算一个数组中,任意两个数之间汉明距离的总和。
+ +示例:
+ ++输入: 4, 14, 2 + +输出: 6 + +解释: 在二进制表示中,4表示为0100,14表示为1110,2表示为0010。(这样表示是为了体现后四位之间关系) +所以答案为: +HammingDistance(4, 14) + HammingDistance(4, 2) + HammingDistance(14, 2) = 2 + 2 + 2 = 6. ++ +
注意:
+ +-
+
- 数组中元素的范围为从
0到10^9。
+ - 数组的长度不超过
10^4。
+
给定圆的半径和圆心的 x、y 坐标,写一个在圆中产生均匀随机点的函数 randPoint 。
说明:
+ +-
+
- 输入值和输出值都将是浮点数。 +
- 圆的半径和圆心的 x、y 坐标将作为参数传递给类的构造函数。 +
- 圆周上的点也认为是在圆中。 +
randPoint返回一个包含随机点的x坐标和y坐标的大小为2的数组。
+
示例 1:
+ ++输入: +["Solution","randPoint","randPoint","randPoint"] +[[1,0,0],[],[],[]] +输出: [null,[-0.72939,-0.65505],[-0.78502,-0.28626],[-0.83119,-0.19803]] ++ +
示例 2:
+ ++输入: +["Solution","randPoint","randPoint","randPoint"] +[[10,5,-7.5],[],[],[]] +输出: [null,[11.52438,-8.33273],[2.46992,-16.21705],[11.13430,-12.42337]]+ +
输入语法说明:
+ +输入是两个列表:调用成员函数名和调用的参数。Solution 的构造函数有三个参数,圆的半径、圆心的 x 坐标、圆心的 y 坐标。randPoint 没有参数。输入参数是一个列表,即使参数为空,也会输入一个 [] 空列表。
你需要找到由两个 n 位数的乘积组成的最大回文数。
+ +由于结果会很大,你只需返回最大回文数 mod 1337得到的结果。
+ +示例:
+ +输入: 2
+ +输出: 987
+ +解释: 99 x 91 = 9009, 9009 % 1337 = 987
+ +说明:
+ +n 的取值范围为 [1,8]。
+ + + +## 解法 + + + +### Python3 + + +```python + +``` + +### Java + + +```java + +``` + +### ... +``` + +``` diff --git a/solution/0400-0499/0480.Sliding Window Median/README.md b/solution/0400-0499/0480.Sliding Window Median/README.md new file mode 100644 index 0000000000000..b35dc8e221b23 --- /dev/null +++ b/solution/0400-0499/0480.Sliding Window Median/README.md @@ -0,0 +1,66 @@ +# [480. 滑动窗口中位数](https://leetcode-cn.com/problems/sliding-window-median) + +## 题目描述 + +中位数是有序序列最中间的那个数。如果序列的大小是偶数,则没有最中间的数;此时中位数是最中间的两个数的平均数。
+ +例如:
+ +-
+
[2,3,4],中位数是3
+ [2,3],中位数是(2 + 3) / 2 = 2.5
+
给你一个数组 nums,有一个大小为 k 的窗口从最左端滑动到最右端。窗口中有 k 个数,每次窗口向右移动 1 位。你的任务是找出每次窗口移动后得到的新窗口中元素的中位数,并输出由它们组成的数组。
+ ++ +
示例:
+ +给出 nums = [1,3,-1,-3,5,3,6,7],以及 k = 3。
窗口位置 中位数 +--------------- ----- +[1 3 -1] -3 5 3 6 7 1 + 1 [3 -1 -3] 5 3 6 7 -1 + 1 3 [-1 -3 5] 3 6 7 -1 + 1 3 -1 [-3 5 3] 6 7 3 + 1 3 -1 -3 [5 3 6] 7 5 + 1 3 -1 -3 5 [3 6 7] 6 ++ +
因此,返回该滑动窗口的中位数数组 [1,-1,-1,3,5,6]。
+ +
提示:
+ +-
+
- 你可以假设
k始终有效,即:k始终小于输入的非空数组的元素个数。
+ - 与真实值误差在
10 ^ -5以内的答案将被视作正确答案。
+
神奇的字符串 S 只包含 '1' 和 '2',并遵守以下规则:
+ +字符串 S 是神奇的,因为串联字符 '1' 和 '2' 的连续出现次数会生成字符串 S 本身。
+ +字符串 S 的前几个元素如下:S = “1221121221221121122 ......”
+ +如果我们将 S 中连续的 1 和 2 进行分组,它将变成:
+ +1 22 11 2 1 22 1 22 11 2 11 22 ......
+ +并且每个组中 '1' 或 '2' 的出现次数分别是:
+ +1 2 2 1 1 2 1 2 2 1 2 2 ......
+ +你可以看到上面的出现次数就是 S 本身。
+ +给定一个整数 N 作为输入,返回神奇字符串 S 中前 N 个数字中的 '1' 的数目。
+ +注意:N 不会超过 100,000。
+ +示例:
+ +输入:6 +输出:3 +解释:神奇字符串 S 的前 6 个元素是 “12211”,它包含三个 1,因此返回 3。 ++ +
+ + + +## 解法 + + + +### Python3 + + +```python + +``` + +### Java + + +```java + +``` + +### ... +``` + +``` diff --git a/solution/0400-0499/0482.License Key Formatting/README.md b/solution/0400-0499/0482.License Key Formatting/README.md new file mode 100644 index 0000000000000..ccd391a032e16 --- /dev/null +++ b/solution/0400-0499/0482.License Key Formatting/README.md @@ -0,0 +1,65 @@ +# [482. 密钥格式化](https://leetcode-cn.com/problems/license-key-formatting) + +## 题目描述 + +
给定一个密钥字符串S,只包含字母,数字以及 '-'(破折号)。N 个 '-' 将字符串分成了 N+1 组。给定一个数字 K,重新格式化字符串,除了第一个分组以外,每个分组要包含 K 个字符,第一个分组至少要包含 1 个字符。两个分组之间用 '-'(破折号)隔开,并且将所有的小写字母转换为大写字母。
+ +给定非空字符串 S 和数字 K,按照上面描述的规则进行格式化。
+ +示例 1:
+ ++输入:S = "5F3Z-2e-9-w", K = 4 + +输出:"5F3Z-2E9W" + +解释:字符串 S 被分成了两个部分,每部分 4 个字符; + 注意,两个额外的破折号需要删掉。 ++ +
示例 2:
+ ++输入:S = "2-5g-3-J", K = 2 + +输出:"2-5G-3J" + +解释:字符串 S 被分成了 3 个部分,按照前面的规则描述,第一部分的字符可以少于给定的数量,其余部分皆为 2 个字符。 ++ +
+ +
提示:
+ +-
+
- S 的长度不超过 12,000,K 为正整数 +
- S 只包含字母数字(a-z,A-Z,0-9)以及破折号'-' +
- S 非空 +
+ + + +## 解法 + + + +### Python3 + + +```python + +``` + +### Java + + +```java + +``` + +### ... +``` + +``` diff --git a/solution/0400-0499/0483.Smallest Good Base/README.md b/solution/0400-0499/0483.Smallest Good Base/README.md new file mode 100644 index 0000000000000..3a4121d0495c5 --- /dev/null +++ b/solution/0400-0499/0483.Smallest Good Base/README.md @@ -0,0 +1,69 @@ +# [483. 最小好进制](https://leetcode-cn.com/problems/smallest-good-base) + +## 题目描述 + +
对于给定的整数 n, 如果n的k(k>=2)进制数的所有数位全为1,则称 k(k>=2)是 n 的一个好进制。
+ +以字符串的形式给出 n, 以字符串的形式返回 n 的最小好进制。
+ ++ +
示例 1:
+ ++输入:"13" +输出:"3" +解释:13 的 3 进制是 111。 ++ +
示例 2:
+ ++输入:"4681" +输出:"8" +解释:4681 的 8 进制是 11111。 ++ +
示例 3:
+ ++输入:"1000000000000000000" +输出:"999999999999999999" +解释:1000000000000000000 的 999999999999999999 进制是 11。 ++ +
+ +
提示:
+ +-
+
- n的取值范围是 [3, 10^18]。 +
- 输入总是有效且没有前导 0。 +
+ + + +## 解法 + + + +### Python3 + + +```python + +``` + +### Java + + +```java + +``` + +### ... +``` + +``` diff --git a/solution/0400-0499/0484.Find Permutation/README.md b/solution/0400-0499/0484.Find Permutation/README.md new file mode 100644 index 0000000000000..eac1e072e87fd --- /dev/null +++ b/solution/0400-0499/0484.Find Permutation/README.md @@ -0,0 +1,29 @@ +# [484. 寻找排列](https://leetcode-cn.com/problems/find-permutation) + +## 题目描述 + +None + + +## 解法 + + + +### Python3 + + +```python + +``` + +### Java + + +```java + +``` + +### ... +``` + +``` diff --git a/solution/0400-0499/0485.Max Consecutive Ones/README.md b/solution/0400-0499/0485.Max Consecutive Ones/README.md new file mode 100644 index 0000000000000..920fca0bc7ed9 --- /dev/null +++ b/solution/0400-0499/0485.Max Consecutive Ones/README.md @@ -0,0 +1,45 @@ +# [485. 最大连续1的个数](https://leetcode-cn.com/problems/max-consecutive-ones) + +## 题目描述 + +
给定一个二进制数组, 计算其中最大连续1的个数。
+ +示例 1:
+ ++输入: [1,1,0,1,1,1] +输出: 3 +解释: 开头的两位和最后的三位都是连续1,所以最大连续1的个数是 3. ++ +
注意:
+ +-
+
- 输入的数组只包含
0和1。
+ - 输入数组的长度是正整数,且不超过 10,000。 +
给定一个表示分数的非负整数数组。 玩家1从数组任意一端拿取一个分数,随后玩家2继续从剩余数组任意一端拿取分数,然后玩家1拿,……。每次一个玩家只能拿取一个分数,分数被拿取之后不再可取。直到没有剩余分数可取时游戏结束。最终获得分数总和最多的玩家获胜。
+ +给定一个表示分数的数组,预测玩家1是否会成为赢家。你可以假设每个玩家的玩法都会使他的分数最大化。
+ +示例 1:
+ ++输入: [1, 5, 2] +输出: False +解释: 一开始,玩家1可以从1和2中进行选择。 +如果他选择2(或者1),那么玩家2可以从1(或者2)和5中进行选择。如果玩家2选择了5,那么玩家1则只剩下1(或者2)可选。 +所以,玩家1的最终分数为 1 + 2 = 3,而玩家2为 5。 +因此,玩家1永远不会成为赢家,返回 False。 ++ +
示例 2:
+ ++输入: [1, 5, 233, 7] +输出: True +解释: 玩家1一开始选择1。然后玩家2必须从5和7中进行选择。无论玩家2选择了哪个,玩家1都可以选择233。 +最终,玩家1(234分)比玩家2(12分)获得更多的分数,所以返回 True,表示玩家1可以成为赢家。 ++ +
注意:
+ +-
+
- 1 <= 给定的数组长度 <= 20. +
- 数组里所有分数都为非负数且不会大于10000000。 +
- 如果最终两个玩家的分数相等,那么玩家1仍为赢家。 +
回忆一下祖玛游戏。现在桌上有一串球,颜色有红色(R),黄色(Y),蓝色(B),绿色(G),还有白色(W)。 现在你手里也有几个球。
+ +每一次,你可以从手里的球选一个,然后把这个球插入到一串球中的某个位置上(包括最左端,最右端)。接着,如果有出现三个或者三个以上颜色相同的球相连的话,就把它们移除掉。重复这一步骤直到桌上所有的球都被移除。
+ +找到插入并可以移除掉桌上所有球所需的最少的球数。如果不能移除桌上所有的球,输出 -1 。
+ ++示例: +输入: "WRRBBW", "RB" +输出: -1 +解释: WRRBBW -> WRR[R]BBW -> WBBW -> WBB[B]W -> WW (翻译者标注:手上球已经用完,桌上还剩两个球无法消除,返回-1) + +输入: "WWRRBBWW", "WRBRW" +输出: 2 +解释: WWRRBBWW -> WWRR[R]BBWW -> WWBBWW -> WWBB[B]WW -> WWWW -> empty + +输入:"G", "GGGGG" +输出: 2 +解释: G -> G[G] -> GG[G] -> empty + +输入: "RBYYBBRRB", "YRBGB" +输出: 3 +解释: RBYYBBRRB -> RBYY[Y]BBRRB -> RBBBRRB -> RRRB -> B -> B[B] -> BB[B] -> empty ++ +
标注:
+ +-
+
- 你可以假设桌上一开始的球中,不会有三个及三个以上颜色相同且连着的球。 +
- 桌上的球不会超过20个,输入的数据中代表这些球的字符串的名字是 "board" 。 +
- 你手中的球不会超过5个,输入的数据中代表这些球的字符串的名字是 "hand"。 +
- 输入的两个字符串均为非空字符串,且只包含字符 'R','Y','B','G','W'。 +
给定一个整型数组, 你的任务是找到所有该数组的递增子序列,递增子序列的长度至少是2。
+ +示例:
+ ++输入: [4, 6, 7, 7] +输出: [[4, 6], [4, 7], [4, 6, 7], [4, 6, 7, 7], [6, 7], [6, 7, 7], [7,7], [4,7,7]]+ +
说明:
+ +-
+
- 给定数组的长度不会超过15。 +
- 数组中的整数范围是 [-100,100]。 +
- 给定数组中可能包含重复数字,相等的数字应该被视为递增的一种情况。 +
作为一位web开发者, 懂得怎样去规划一个页面的尺寸是很重要的。 现给定一个具体的矩形页面面积,你的任务是设计一个长度为 L 和宽度为 W 且满足以下要求的矩形的页面。要求:
+ ++1. 你设计的矩形页面必须等于给定的目标面积。 + +2. 宽度 W 不应大于长度 L,换言之,要求 L >= W 。 + +3. 长度 L 和宽度 W 之间的差距应当尽可能小。 ++ +
你需要按顺序输出你设计的页面的长度 L 和宽度 W。
+ +示例:
+ ++输入: 4 +输出: [2, 2] +解释: 目标面积是 4, 所有可能的构造方案有 [1,4], [2,2], [4,1]。 +但是根据要求2,[1,4] 不符合要求; 根据要求3,[2,2] 比 [4,1] 更能符合要求. 所以输出长度 L 为 2, 宽度 W 为 2。 ++ +
说明:
+ +-
+
- 给定的面积不大于 10,000,000 且为正整数。 +
- 你设计的页面的长度和宽度必须都是正整数。 +
给定一个数组 nums ,如果 i < j 且 nums[i] > 2*nums[j] 我们就将 (i, j) 称作一个重要翻转对。
你需要返回给定数组中的重要翻转对的数量。
+ +示例 1:
+ ++输入: [1,3,2,3,1] +输出: 2 ++ +
示例 2:
+ ++输入: [2,4,3,5,1] +输出: 3 ++ +
注意:
+ +-
+
- 给定数组的长度不会超过
50000。
+ - 输入数组中的所有数字都在32位整数的表示范围内。 +
给定一个非负整数数组,a1, a2, ..., an, 和一个目标数,S。现在你有两个符号 + 和 -。对于数组中的任意一个整数,你都可以从 + 或 -中选择一个符号添加在前面。
返回可以使最终数组和为目标数 S 的所有添加符号的方法数。
+ +示例 1:
+ +输入: nums: [1, 1, 1, 1, 1], S: 3 +输出: 5 +解释: + +-1+1+1+1+1 = 3 ++1-1+1+1+1 = 3 ++1+1-1+1+1 = 3 ++1+1+1-1+1 = 3 ++1+1+1+1-1 = 3 + +一共有5种方法让最终目标和为3。 ++ +
注意:
+ +-
+
- 数组非空,且长度不会超过20。 +
- 初始的数组的和不会超过1000。 +
- 保证返回的最终结果能被32位整数存下。 +
在《英雄联盟》的世界中,有一个叫 “提莫” 的英雄,他的攻击可以让敌方英雄艾希(编者注:寒冰射手)进入中毒状态。现在,给出提莫对艾希的攻击时间序列和提莫攻击的中毒持续时间,你需要输出艾希的中毒状态总时长。
+ +你可以认为提莫在给定的时间点进行攻击,并立即使艾希处于中毒状态。
+ +示例1:
+ +输入: [1,4], 2 +输出: 4 +原因: 在第 1 秒开始时,提莫开始对艾希进行攻击并使其立即中毒。中毒状态会维持 2 秒钟,直到第 2 秒钟结束。 +在第 4 秒开始时,提莫再次攻击艾希,使得艾希获得另外 2 秒的中毒时间。 +所以最终输出 4 秒。 ++ +
示例2:
+ +输入: [1,2], 2 +输出: 3 +原因: 在第 1 秒开始时,提莫开始对艾希进行攻击并使其立即中毒。中毒状态会维持 2 秒钟,直到第 2 秒钟结束。 +但是在第 2 秒开始时,提莫再次攻击了已经处于中毒状态的艾希。 +由于中毒状态不可叠加,提莫在第 2 秒开始时的这次攻击会在第 3 秒钟结束。 +所以最终输出 3。 ++ +
注意:
+ +-
+
- 你可以假定时间序列数组的总长度不超过 10000。 +
- 你可以假定提莫攻击时间序列中的数字和提莫攻击的中毒持续时间都是非负整数,并且不超过 10,000,000。 +
给定两个没有重复元素的数组 nums1 和 nums2 ,其中nums1 是 nums2 的子集。找到 nums1 中每个元素在 nums2 中的下一个比其大的值。
nums1 中数字 x 的下一个更大元素是指 x 在 nums2 中对应位置的右边的第一个比 x 大的元素。如果不存在,对应位置输出-1。
示例 1:
+ ++输入: nums1 = [4,1,2], nums2 = [1,3,4,2]. +输出: [-1,3,-1] +解释: + 对于num1中的数字4,你无法在第二个数组中找到下一个更大的数字,因此输出 -1。 + 对于num1中的数字1,第二个数组中数字1右边的下一个较大数字是 3。 + 对于num1中的数字2,第二个数组中没有下一个更大的数字,因此输出 -1。+ +
示例 2:
+ ++输入: nums1 = [2,4], nums2 = [1,2,3,4]. +输出: [3,-1] +解释: + 对于num1中的数字2,第二个数组中的下一个较大数字是3。 + 对于num1中的数字4,第二个数组中没有下一个更大的数字,因此输出 -1。 ++ +
注意:
+ +-
+
nums1和nums2中所有元素是唯一的。
+ nums1和nums2的数组大小都不超过1000。
+
给定一个非重叠轴对齐矩形的列表 rects,写一个函数 pick 随机均匀地选取矩形覆盖的空间中的整数点。
提示:
+ +-
+
- 整数点是具有整数坐标的点。 +
- 矩形周边上的点包含在矩形覆盖的空间中。 +
- 第
i个矩形rects [i] = [x1,y1,x2,y2],其中[x1,y1]是左下角的整数坐标,[x2,y2]是右上角的整数坐标。
+ - 每个矩形的长度和宽度不超过 2000。 +
1 <= rects.length <= 100
+ pick以整数坐标数组[p_x, p_y]的形式返回一个点。
+ pick最多被调用10000次。
+
+ +
示例 1:
+ ++输入: +["Solution","pick","pick","pick"] +[[[[1,1,5,5]]],[],[],[]] +输出: +[null,[4,1],[4,1],[3,3]] ++ +
示例 2:
+ ++输入: +["Solution","pick","pick","pick","pick","pick"] +[[[[-2,-2,-1,-1],[1,0,3,0]]],[],[],[],[],[]] +输出: +[null,[-1,-2],[2,0],[-2,-1],[3,0],[-2,-2]]+ +
+ +
输入语法的说明:
+ +输入是两个列表:调用的子例程及其参数。Solution 的构造函数有一个参数,即矩形数组 rects。pick 没有参数。参数总是用列表包装的,即使没有也是如此。
+ + + +## 解法 + + + +### Python3 + + +```python + +``` + +### Java + + +```java + +``` + +### ... +``` + +``` diff --git a/solution/0400-0499/0498.Diagonal Traverse/README.md b/solution/0400-0499/0498.Diagonal Traverse/README.md new file mode 100644 index 0000000000000..0ebaa5fcbd9b4 --- /dev/null +++ b/solution/0400-0499/0498.Diagonal Traverse/README.md @@ -0,0 +1,55 @@ +# [498. 对角线遍历](https://leetcode-cn.com/problems/diagonal-traverse) + +## 题目描述 + +
给定一个含有 M x N 个元素的矩阵(M 行,N 列),请以对角线遍历的顺序返回这个矩阵中的所有元素,对角线遍历如下图所示。
+ ++ +
示例:
+ +输入: +[ + [ 1, 2, 3 ], + [ 4, 5, 6 ], + [ 7, 8, 9 ] +] + +输出: [1,2,4,7,5,3,6,8,9] + +解释: ++ ++
+ +
说明:
+ +-
+
- 给定矩阵中的元素总数不会超过 100000 。 +
给定一个单词列表,只返回可以使用在键盘同一行的字母打印出来的单词。键盘如下图所示。
+ ++ +

+ +
示例:
+ +输入: ["Hello", "Alaska", "Dad", "Peace"] +输出: ["Alaska", "Dad"] ++ +
+ +
注意:
+ +-
+
- 你可以重复使用键盘上同一字符。 +
- 你可以假设输入的字符串将只包含字母。 +
给定一个有相同值的二叉搜索树(BST),找出 BST 中的所有众数(出现频率最高的元素)。
+ +假定 BST 有如下定义:
+ +-
+
- 结点左子树中所含结点的值小于等于当前结点的值 +
- 结点右子树中所含结点的值大于等于当前结点的值 +
- 左子树和右子树都是二叉搜索树 +
例如:
+给定 BST [1,null,2,2],
1 + \ + 2 + / + 2 ++ +
返回[2].
提示:如果众数超过1个,不需考虑输出顺序
+ +进阶:你可以不使用额外的空间吗?(假设由递归产生的隐式调用栈的开销不被计算在内)
+ + + +## 解法 + + + +### Python3 + + +```python + +``` + +### Java + + +```java + +``` + +### ... +``` + +``` diff --git a/solution/0500-0599/0502.IPO/README.md b/solution/0500-0599/0502.IPO/README.md new file mode 100644 index 0000000000000..7e77c9b9588c1 --- /dev/null +++ b/solution/0500-0599/0502.IPO/README.md @@ -0,0 +1,60 @@ +# [502. IPO](https://leetcode-cn.com/problems/ipo) + +## 题目描述 + +假设 力扣(LeetCode)即将开始其 IPO。为了以更高的价格将股票卖给风险投资公司,力扣 希望在 IPO 之前开展一些项目以增加其资本。 由于资源有限,它只能在 IPO 之前完成最多 k 个不同的项目。帮助 力扣 设计完成最多 k 个不同项目后得到最大总资本的方式。
+ +给定若干个项目。对于每个项目 i,它都有一个纯利润 Pi,并且需要最小的资本 Ci 来启动相应的项目。最初,你有 W 资本。当你完成一个项目时,你将获得纯利润,且利润将被添加到你的总资本中。
+ +总而言之,从给定项目中选择最多 k 个不同项目的列表,以最大化最终资本,并输出最终可获得的最多资本。
+ +示例 1:
+ +输入: k=2, W=0, Profits=[1,2,3], Capital=[0,1,1]. + +输出: 4 + +解释: +由于你的初始资本为 0,你尽可以从 0 号项目开始。 +在完成后,你将获得 1 的利润,你的总资本将变为 1。 +此时你可以选择开始 1 号或 2 号项目。 +由于你最多可以选择两个项目,所以你需要完成 2 号项目以获得最大的资本。 +因此,输出最后最大化的资本,为 0 + 1 + 3 = 4。 ++ +
+ +
注意:
+ +-
+
- 假设所有输入数字都是非负整数。 +
- 表示利润和资本的数组的长度不超过 50000。 +
- 答案保证在 32 位有符号整数范围内。 +
+ + + +## 解法 + + + +### Python3 + + +```python + +``` + +### Java + + +```java + +``` + +### ... +``` + +``` diff --git a/solution/0500-0599/0503.Next Greater Element II/README.md b/solution/0500-0599/0503.Next Greater Element II/README.md new file mode 100644 index 0000000000000..0ded25989efd4 --- /dev/null +++ b/solution/0500-0599/0503.Next Greater Element II/README.md @@ -0,0 +1,42 @@ +# [503. 下一个更大元素 II](https://leetcode-cn.com/problems/next-greater-element-ii) + +## 题目描述 + +
给定一个循环数组(最后一个元素的下一个元素是数组的第一个元素),输出每个元素的下一个更大元素。数字 x 的下一个更大的元素是按数组遍历顺序,这个数字之后的第一个比它更大的数,这意味着你应该循环地搜索它的下一个更大的数。如果不存在,则输出 -1。
+ +示例 1:
+ ++输入: [1,2,1] +输出: [2,-1,2] +解释: 第一个 1 的下一个更大的数是 2; +数字 2 找不到下一个更大的数; +第二个 1 的下一个最大的数需要循环搜索,结果也是 2。 ++ +
注意: 输入数组的长度不会超过 10000。
+ + + +## 解法 + + + +### Python3 + + +```python + +``` + +### Java + + +```java + +``` + +### ... +``` + +``` diff --git a/solution/0500-0599/0504.Base 7/README.md b/solution/0500-0599/0504.Base 7/README.md new file mode 100644 index 0000000000000..2e8ec8cb7aabd --- /dev/null +++ b/solution/0500-0599/0504.Base 7/README.md @@ -0,0 +1,46 @@ +# [504. 七进制数](https://leetcode-cn.com/problems/base-7) + +## 题目描述 + +给定一个整数,将其转化为7进制,并以字符串形式输出。
+ +示例 1:
+ ++输入: 100 +输出: "202" ++ +
示例 2:
+ ++输入: -7 +输出: "-10" ++ +
注意: 输入范围是 [-1e7, 1e7] 。
+ + + +## 解法 + + + +### Python3 + + +```python + +``` + +### Java + + +```java + +``` + +### ... +``` + +``` diff --git a/solution/0500-0599/0505.The Maze II/README.md b/solution/0500-0599/0505.The Maze II/README.md new file mode 100644 index 0000000000000..7945454e0ae34 --- /dev/null +++ b/solution/0500-0599/0505.The Maze II/README.md @@ -0,0 +1,29 @@ +# [505. 迷宫 II](https://leetcode-cn.com/problems/the-maze-ii) + +## 题目描述 + +None + + +## 解法 + + + +### Python3 + + +```python + +``` + +### Java + + +```java + +``` + +### ... +``` + +``` diff --git a/solution/0500-0599/0506.Relative Ranks/README.md b/solution/0500-0599/0506.Relative Ranks/README.md new file mode 100644 index 0000000000000..0c470658550ce --- /dev/null +++ b/solution/0500-0599/0506.Relative Ranks/README.md @@ -0,0 +1,47 @@ +# [506. 相对名次](https://leetcode-cn.com/problems/relative-ranks) + +## 题目描述 + +给出 N 名运动员的成绩,找出他们的相对名次并授予前三名对应的奖牌。前三名运动员将会被分别授予 “金牌”,“银牌” 和“ 铜牌”("Gold Medal", "Silver Medal", "Bronze Medal")。
+ +(注:分数越高的选手,排名越靠前。)
+ +示例 1:
+ +
+输入: [5, 4, 3, 2, 1]
+输出: ["Gold Medal", "Silver Medal", "Bronze Medal", "4", "5"]
+解释: 前三名运动员的成绩为前三高的,因此将会分别被授予 “金牌”,“银牌”和“铜牌” ("Gold Medal", "Silver Medal" and "Bronze Medal").
+余下的两名运动员,我们只需要通过他们的成绩计算将其相对名次即可。
+
+提示:
+ +-
+
- N 是一个正整数并且不会超过 10000。 +
- 所有运动员的成绩都不相同。 +
对于一个 正整数,如果它和除了它自身以外的所有正因子之和相等,我们称它为“完美数”。
+ +给定一个 整数 n, 如果他是完美数,返回 True,否则返回 False
+ +
示例:
+ +输入: 28 +输出: True +解释: 28 = 1 + 2 + 4 + 7 + 14 ++ +
+ +
提示:
+ +输入的数字 n 不会超过 100,000,000. (1e8)
给出二叉树的根,找出出现次数最多的子树元素和。一个结点的子树元素和定义为以该结点为根的二叉树上所有结点的元素之和(包括结点本身)。然后求出出现次数最多的子树元素和。如果有多个元素出现的次数相同,返回所有出现次数最多的元素(不限顺序)。
+ ++ +
示例 1
+输入:
5 + / \ +2 -3 ++ +
返回 [2, -3, 4],所有的值均只出现一次,以任意顺序返回所有值。
+ +示例 2
+输入:
5 + / \ +2 -5 ++ +
返回 [2],只有 2 出现两次,-5 只出现 1 次。
+ ++ +
提示: 假设任意子树元素和均可以用 32 位有符号整数表示。
+ + + +## 解法 + + + +### Python3 + + +```python + +``` + +### Java + + +```java + +``` + +### ... +``` + +``` diff --git a/solution/0500-0599/0509.Fibonacci Number/README.md b/solution/0500-0599/0509.Fibonacci Number/README.md index 7c38404131d6c..cb1d501ed852e 100644 --- a/solution/0500-0599/0509.Fibonacci Number/README.md +++ b/solution/0500-0599/0509.Fibonacci Number/README.md @@ -1,70 +1,67 @@ -# 斐波那契数 +# [509. 斐波那契数](https://leetcode-cn.com/problems/fibonacci-number) -### 题目描述 +## 题目描述 + +斐波那契数,通常用 F(n) 表示,形成的序列称为斐波那契数列。该数列由 0 和 1 开始,后面的每一项数字都是前面两项数字的和。也就是:
F(0) = 0, F(1) = 1 +F(N) = F(N - 1) + F(N - 2), 其中 N > 1. +-``` -F(0) = 0, F(1) = 1 -F(N) = F(N - 1) + F(N - 2), 其中 N > 1. -``` +
给定 N,计算 F(N)。
-**示例 1:** +
示例 1:
-``` -输入:2 -输出:1 -解释:F(2) = F(1) + F(0) = 1 + 0 = 1. -``` +输入:2 +输出:1 +解释:F(2) = F(1) + F(0) = 1 + 0 = 1. +-**示例 2:** +
示例 2:
-``` -输入:3 -输出:2 -解释:F(3) = F(2) + F(1) = 1 + 1 = 2. -``` +输入:3 +输出:2 +解释:F(3) = F(2) + F(1) = 1 + 1 = 2. +-**示例 3:** +
示例 3:
-``` -输入:4 -输出:3 -解释:F(4) = F(3) + F(2) = 2 + 1 = 3. -``` +输入:4 +输出:3 +解释:F(4) = F(3) + F(2) = 2 + 1 = 3. ++ +
+
提示:
+-
+
- 0 ≤
N≤ 30
+
给定一个二叉树,在树的最后一行找到最左边的值。
+ +示例 1:
+ ++输入: + + 2 + / \ + 1 3 + +输出: +1 ++ +
+ +
示例 2:
+ ++输入: + + 1 + / \ + 2 3 + / / \ + 4 5 6 + / + 7 + +输出: +7 ++ +
+ +
注意: 您可以假设树(即给定的根节点)不为 NULL。
+ + + +## 解法 + + + +### Python3 + + +```python + +``` + +### Java + + +```java + +``` + +### ... +``` + +``` diff --git a/solution/0500-0599/0514.Freedom Trail/README.md b/solution/0500-0599/0514.Freedom Trail/README.md new file mode 100644 index 0000000000000..c95ceb137a17e --- /dev/null +++ b/solution/0500-0599/0514.Freedom Trail/README.md @@ -0,0 +1,64 @@ +# [514. 自由之路](https://leetcode-cn.com/problems/freedom-trail) + +## 题目描述 + +视频游戏“辐射4”中,任务“通向自由”要求玩家到达名为“Freedom Trail Ring”的金属表盘,并使用表盘拼写特定关键词才能开门。
+ +给定一个字符串 ring,表示刻在外环上的编码;给定另一个字符串 key,表示需要拼写的关键词。您需要算出能够拼写关键词中所有字符的最少步数。
+ +最初,ring 的第一个字符与12:00方向对齐。您需要顺时针或逆时针旋转 ring 以使 key 的一个字符在 12:00 方向对齐,然后按下中心按钮,以此逐个拼写完 key 中的所有字符。
+ +旋转 ring 拼出 key 字符 key[i] 的阶段中:
+ +-
+
- 您可以将 ring 顺时针或逆时针旋转一个位置,计为1步。旋转的最终目的是将字符串 ring 的一个字符与 12:00 方向对齐,并且这个字符必须等于字符 key[i] 。 +
- 如果字符 key[i] 已经对齐到12:00方向,您需要按下中心按钮进行拼写,这也将算作 1 步。按完之后,您可以开始拼写 key 的下一个字符(下一阶段), 直至完成所有拼写。 +
示例:
+ ++ +
输入: ring = "godding", key = "gd" +输出: 4 +解释: + 对于 key 的第一个字符 'g',已经在正确的位置, 我们只需要1步来拼写这个字符。 + 对于 key 的第二个字符 'd',我们需要逆时针旋转 ring "godding" 2步使它变成 "ddinggo"。 + 当然, 我们还需要1步进行拼写。 + 因此最终的输出是 4。 ++ +
提示:
+ +-
+
- ring 和 key 的字符串长度取值范围均为 1 至 100; +
- 两个字符串中都只有小写字符,并且均可能存在重复字符; +
- 字符串 key 一定可以由字符串 ring 旋转拼出。 +
您需要在二叉树的每一行中找到最大的值。
+ +示例:
+ ++输入: + + 1 + / \ + 3 2 + / \ \ + 5 3 9 + +输出: [1, 3, 9] ++ + + +## 解法 + + + +### Python3 + + +```python + +``` + +### Java + + +```java + +``` + +### ... +``` + +``` diff --git a/solution/0500-0599/0516.Longest Palindromic Subsequence/README.md b/solution/0500-0599/0516.Longest Palindromic Subsequence/README.md new file mode 100644 index 0000000000000..d87a40d79c218 --- /dev/null +++ b/solution/0500-0599/0516.Longest Palindromic Subsequence/README.md @@ -0,0 +1,60 @@ +# [516. 最长回文子序列](https://leetcode-cn.com/problems/longest-palindromic-subsequence) + +## 题目描述 + +
给定一个字符串s,找到其中最长的回文子序列。可以假设s的最大长度为1000。
示例 1:
+输入:
+"bbbab" ++ +
输出:
+ ++4 ++ +
一个可能的最长回文子序列为 "bbbb"。
+ +示例 2:
+输入:
+"cbbd" ++ +
输出:
+ ++2 ++ +
一个可能的最长回文子序列为 "bb"。
+ + + +## 解法 + + + +### Python3 + + +```python + +``` + +### Java + + +```java + +``` + +### ... +``` + +``` diff --git a/solution/0500-0599/0517.Super Washing Machines/README.md b/solution/0500-0599/0517.Super Washing Machines/README.md new file mode 100644 index 0000000000000..2b8e71731e328 --- /dev/null +++ b/solution/0500-0599/0517.Super Washing Machines/README.md @@ -0,0 +1,80 @@ +# [517. 超级洗衣机](https://leetcode-cn.com/problems/super-washing-machines) + +## 题目描述 + +假设有 n 台超级洗衣机放在同一排上。开始的时候,每台洗衣机内可能有一定量的衣服,也可能是空的。
+ +在每一步操作中,你可以选择任意 m (1 ≤ m ≤ n) 台洗衣机,与此同时将每台洗衣机的一件衣服送到相邻的一台洗衣机。
+ +给定一个非负整数数组代表从左至右每台洗衣机中的衣物数量,请给出能让所有洗衣机中剩下的衣物的数量相等的最少的操作步数。如果不能使每台洗衣机中衣物的数量相等,则返回 -1。
+ ++ +
示例 1:
+ +输入: [1,0,5] + +输出: 3 + +解释: +第一步: 1 0 <-- 5 => 1 1 4 +第二步: 1 <-- 1 <-- 4 => 2 1 3 +第三步: 2 1 <-- 3 => 2 2 2 ++ +
示例 2:
+ +输入: [0,3,0] + +输出: 2 + +解释: +第一步: 0 <-- 3 0 => 1 2 0 +第二步: 1 2 --> 0 => 1 1 1 ++ +
示例 3:
+ +输入: [0,2,0] + +输出: -1 + +解释: +不可能让所有三个洗衣机同时剩下相同数量的衣物。 ++ +
+ +
提示:
+ +-
+
- n 的范围是 [1, 10000]。 +
- 在每台超级洗衣机中,衣物数量的范围是 [0, 1e5]。 +
+ + + +## 解法 + + + +### Python3 + + +```python + +``` + +### Java + + +```java + +``` + +### ... +``` + +``` diff --git a/solution/0500-0599/0518.Coin Change 2/README.md b/solution/0500-0599/0518.Coin Change 2/README.md new file mode 100644 index 0000000000000..7680e8fc1efba --- /dev/null +++ b/solution/0500-0599/0518.Coin Change 2/README.md @@ -0,0 +1,72 @@ +# [518. 零钱兑换 II](https://leetcode-cn.com/problems/coin-change-2) + +## 题目描述 + +
给定不同面额的硬币和一个总金额。写出函数来计算可以凑成总金额的硬币组合数。假设每一种面额的硬币有无限个。
+ ++ +
-
+
示例 1:
+ +输入: amount = 5, coins = [1, 2, 5] +输出: 4 +解释: 有四种方式可以凑成总金额: +5=5 +5=2+2+1 +5=2+1+1+1 +5=1+1+1+1+1 ++ +
示例 2:
+ +输入: amount = 3, coins = [2] +输出: 0 +解释: 只用面额2的硬币不能凑成总金额3。 ++ +
示例 3:
+ +输入: amount = 10, coins = [10] +输出: 1 ++ +
+ +
注意:
+ +你可以假设:
+ +-
+
- 0 <= amount (总金额) <= 5000 +
- 1 <= coin (硬币面额) <= 5000 +
- 硬币种类不超过 500 种 +
- 结果符合 32 位符号整数 +
题中给出一个 n 行 n 列的二维矩阵 (n_rows,n_cols),且所有值被初始化为 0。要求编写一个 flip 函数,均匀随机的将矩阵中的 0 变为 1,并返回该值的位置下标 [row_id,col_id];同样编写一个 reset 函数,将所有的值都重新置为 0。尽量最少调用随机函数 Math.random(),并且优化时间和空间复杂度。
注意:
+ +1.1 <= n_rows, n_cols <= 10000
+ +2. 0 <= row.id < n_rows 并且 0 <= col.id < n_cols
+ +3.当矩阵中没有值为 0 时,不可以调用 flip 函数
+ +4.调用 flip 和 reset 函数的次数加起来不会超过 1000 次
+ +示例 1:
+ ++输入: +["Solution","flip","flip","flip","flip"] +[[2,3],[],[],[],[]] +输出: [null,[0,1],[1,2],[1,0],[1,1]] ++ +
示例 2:
+ ++输入: +["Solution","flip","flip","reset","flip"] +[[1,2],[],[],[],[]] +输出: [null,[0,0],[0,1],null,[0,0]]+ +
输入语法解释:
+ +输入包含两个列表:被调用的子程序和他们的参数。Solution 的构造函数有两个参数,分别为 n_rows 和 n_cols。flip 和 reset 没有参数,参数总会以列表形式给出,哪怕该列表为空
给定一个单词,你需要判断单词的大写使用是否正确。
+ +我们定义,在以下情况时,单词的大写用法是正确的:
+ +-
+
- 全部字母都是大写,比如"USA"。 +
- 单词中所有字母都不是大写,比如"leetcode"。 +
- 如果单词不只含有一个字母,只有首字母大写, 比如 "Google"。 +
否则,我们定义这个单词没有正确使用大写字母。
+ +示例 1:
+ ++输入: "USA" +输出: True ++ +
示例 2:
+ ++输入: "FlaG" +输出: False ++ +
注意: 输入是由大写和小写拉丁字母组成的非空单词。
+ + + +## 解法 + + + +### Python3 + + +```python + +``` + +### Java + + +```java + +``` + +### ... +``` + +``` diff --git a/solution/0500-0599/0521.Longest Uncommon Subsequence I/README.md b/solution/0500-0599/0521.Longest Uncommon Subsequence I/README.md index 01dcc204209fe..09852009345ba 100644 --- a/solution/0500-0599/0521.Longest Uncommon Subsequence I/README.md +++ b/solution/0500-0599/0521.Longest Uncommon Subsequence I/README.md @@ -1,30 +1,48 @@ -## 最长特殊序列 Ⅰ +# [521. 最长特殊序列 Ⅰ](https://leetcode-cn.com/problems/longest-uncommon-subsequence-i) -### 问题描述 +## 题目描述 + +给定两个字符串,你需要从这两个字符串中找出最长的特殊序列。最长特殊序列定义如下:该序列为某字符串独有的最长子序列(即不能是其他字符串的子序列)。
-给定两个字符串,你需要从这两个字符串中找出最长的特殊序列。最长特殊序列定义如下:该序列为某字符串独有的最长子序列(即不能是其他字符串的子序列)。 +子序列可以通过删去字符串中的某些字符实现,但不能改变剩余字符的相对顺序。空序列为所有字符串的子序列,任何字符串为其自身的子序列。
-子序列可以通过删去字符串中的某些字符实现,但不能改变剩余字符的相对顺序。空序列为所有字符串的子序列,任何字符串为其自身的子序列。 +输入为两个字符串,输出最长特殊序列的长度。如果不存在,则返回 -1。
-输入为两个字符串,输出最长特殊序列的长度。如果不存在,则返回 `-1`。 +示例 :
-**示例:** -``` -输入: "aba", "cdc" -输出: 3 -解析: 最长特殊序列可为 "aba" (或 "cdc") -``` +输入: "aba", "cdc" +输出: 3 +解析: 最长特殊序列可为 "aba" (或 "cdc") ++ +
说明:
+ +-
+
- 两个字符串长度均小于100。 +
- 字符串中的字符仅含有 'a'~'z'。 +
给定字符串列表,你需要从它们中找出最长的特殊序列。最长特殊序列定义如下:该序列为某字符串独有的最长子序列(即不能是其他字符串的子序列)。
+ +子序列可以通过删去字符串中的某些字符实现,但不能改变剩余字符的相对顺序。空序列为所有字符串的子序列,任何字符串为其自身的子序列。
+ +输入将是一个字符串列表,输出是最长特殊序列的长度。如果最长特殊序列不存在,返回 -1 。
+ ++ +
示例:
+ +输入: "aba", "cdc", "eae" +输出: 3 ++ +
+ +
提示:
+ +-
+
- 所有给定的字符串长度不会超过 10 。 +
- 给定字符串列表的长度将在 [2, 50 ] 之间。 +
+ + + +## 解法 + + + +### Python3 + + +```python + +``` + +### Java + + +```java + +``` + +### ... +``` + +``` diff --git a/solution/0500-0599/0523.Continuous Subarray Sum/README.md b/solution/0500-0599/0523.Continuous Subarray Sum/README.md new file mode 100644 index 0000000000000..73515396b33f7 --- /dev/null +++ b/solution/0500-0599/0523.Continuous Subarray Sum/README.md @@ -0,0 +1,51 @@ +# [523. 连续的子数组和](https://leetcode-cn.com/problems/continuous-subarray-sum) + +## 题目描述 + +
给定一个包含非负数的数组和一个目标整数 k,编写一个函数来判断该数组是否含有连续的子数组,其大小至少为 2,总和为 k 的倍数,即总和为 n*k,其中 n 也是一个整数。
+ +示例 1:
+ +输入: [23,2,4,6,7], k = 6 +输出: True +解释: [2,4] 是一个大小为 2 的子数组,并且和为 6。 ++ +
示例 2:
+ +输入: [23,2,6,4,7], k = 6 +输出: True +解释: [23,2,6,4,7]是大小为 5 的子数组,并且和为 42。 ++ +
说明:
+ +-
+
- 数组的长度不会超过10,000。 +
- 你可以认为所有数字总和在 32 位有符号整数范围内。 +
给定一个字符串和一个字符串字典,找到字典里面最长的字符串,该字符串可以通过删除给定字符串的某些字符来得到。如果答案不止一个,返回长度最长且字典顺序最小的字符串。如果答案不存在,则返回空字符串。
+ +示例 1:
+ ++输入: +s = "abpcplea", d = ["ale","apple","monkey","plea"] + +输出: +"apple" ++ +
示例 2:
+ ++输入: +s = "abpcplea", d = ["a","b","c"] + +输出: +"a" ++ +
说明:
+ +-
+
- 所有输入的字符串只包含小写字母。 +
- 字典的大小不会超过 1000。 +
- 所有输入的字符串长度不会超过 1000。 +
给定一个二进制数组, 找到含有相同数量的 0 和 1 的最长连续子数组(的长度)。
+ ++ +
示例 1:
+ +输入: [0,1] +输出: 2 +说明: [0, 1] 是具有相同数量0和1的最长连续子数组。+ +
示例 2:
+ +输入: [0,1,0] +输出: 2 +说明: [0, 1] (或 [1, 0]) 是具有相同数量0和1的最长连续子数组。+ +
+ +
注意: 给定的二进制数组的长度不会超过50000。
+ + + +## 解法 + + + +### Python3 + + +```python + +``` + +### Java + + +```java + +``` + +### ... +``` + +``` diff --git a/solution/0500-0599/0526.Beautiful Arrangement/README.md b/solution/0500-0599/0526.Beautiful Arrangement/README.md new file mode 100644 index 0000000000000..5930e2032284d --- /dev/null +++ b/solution/0500-0599/0526.Beautiful Arrangement/README.md @@ -0,0 +1,59 @@ +# [526. 优美的排列](https://leetcode-cn.com/problems/beautiful-arrangement) + +## 题目描述 + +假设有从 1 到 N 的 N 个整数,如果从这 N 个数字中成功构造出一个数组,使得数组的第 i 位 (1 <= i <= N) 满足如下两个条件中的一个,我们就称这个数组为一个优美的排列。条件:
+ +-
+
- 第 i 位的数字能被 i 整除 +
- i 能被第 i 位上的数字整除 +
现在给定一个整数 N,请问可以构造多少个优美的排列?
+ +示例1:
+ ++输入: 2 +输出: 2 +解释: + +第 1 个优美的排列是 [1, 2]: + 第 1 个位置(i=1)上的数字是1,1能被 i(i=1)整除 + 第 2 个位置(i=2)上的数字是2,2能被 i(i=2)整除 + +第 2 个优美的排列是 [2, 1]: + 第 1 个位置(i=1)上的数字是2,2能被 i(i=1)整除 + 第 2 个位置(i=2)上的数字是1,i(i=2)能被 1 整除 ++ +
说明:
+ +-
+
- N 是一个正整数,并且不会超过15。 +
给定一个正整数数组 w ,其中 w[i] 代表位置 i 的权重,请写一个函数 pickIndex ,它可以随机地获取位置 i,选取位置 i 的概率与 w[i] 成正比。
说明:
+ +-
+
1 <= w.length <= 10000
+ 1 <= w[i] <= 10^5
+ pickIndex将被调用不超过10000次
+
示例1:
+ ++输入: +["Solution","pickIndex"] +[[[1]],[]] +输出: [null,0] ++ +
示例2:
+ ++输入: +["Solution","pickIndex","pickIndex","pickIndex","pickIndex","pickIndex"] +[[[1,3]],[],[],[],[],[]] +输出: [null,0,1,1,1,0]+ +
输入语法说明:
+ +输入是两个列表:调用成员函数名和调用的参数。Solution 的构造函数有一个参数,即数组 w。pickIndex 没有参数。输入参数是一个列表,即使参数为空,也会输入一个 [] 空列表。
让我们一起来玩扫雷游戏!
+ +给定一个代表游戏板的二维字符矩阵。 'M' 代表一个未挖出的地雷,'E' 代表一个未挖出的空方块,'B' 代表没有相邻(上,下,左,右,和所有4个对角线)地雷的已挖出的空白方块,数字('1' 到 '8')表示有多少地雷与这块已挖出的方块相邻,'X' 则表示一个已挖出的地雷。
+ +现在给出在所有未挖出的方块中('M'或者'E')的下一个点击位置(行和列索引),根据以下规则,返回相应位置被点击后对应的面板:
+ +-
+
- 如果一个地雷('M')被挖出,游戏就结束了- 把它改为 'X'。 +
- 如果一个没有相邻地雷的空方块('E')被挖出,修改它为('B'),并且所有和其相邻的方块都应该被递归地揭露。 +
- 如果一个至少与一个地雷相邻的空方块('E')被挖出,修改它为数字('1'到'8'),表示相邻地雷的数量。 +
- 如果在此次点击中,若无更多方块可被揭露,则返回面板。 +
+ +
示例 1:
+ +输入: + +[['E', 'E', 'E', 'E', 'E'], + ['E', 'E', 'M', 'E', 'E'], + ['E', 'E', 'E', 'E', 'E'], + ['E', 'E', 'E', 'E', 'E']] + +Click : [3,0] + +输出: + +[['B', '1', 'E', '1', 'B'], + ['B', '1', 'M', '1', 'B'], + ['B', '1', '1', '1', 'B'], + ['B', 'B', 'B', 'B', 'B']] + +解释: ++ ++
示例 2:
+ +输入: + +[['B', '1', 'E', '1', 'B'], + ['B', '1', 'M', '1', 'B'], + ['B', '1', '1', '1', 'B'], + ['B', 'B', 'B', 'B', 'B']] + +Click : [1,2] + +输出: + +[['B', '1', 'E', '1', 'B'], + ['B', '1', 'X', '1', 'B'], + ['B', '1', '1', '1', 'B'], + ['B', 'B', 'B', 'B', 'B']] + +解释: ++ ++
+ +
注意:
+ +-
+
- 输入矩阵的宽和高的范围为 [1,50]。 +
- 点击的位置只能是未被挖出的方块 ('M' 或者 'E'),这也意味着面板至少包含一个可点击的方块。 +
- 输入面板不会是游戏结束的状态(即有地雷已被挖出)。 +
- 简单起见,未提及的规则在这个问题中可被忽略。例如,当游戏结束时你不需要挖出所有地雷,考虑所有你可能赢得游戏或标记方块的情况。 +
给你一棵所有节点为非负值的二叉搜索树,请你计算树中任意两节点的差的绝对值的最小值。
+ ++ +
示例:
+ +输入: + + 1 + \ + 3 + / + 2 + +输出: +1 + +解释: +最小绝对差为 1,其中 2 和 1 的差的绝对值为 1(或者 2 和 3)。 ++ +
+ +
提示:
+ +-
+
- 树中至少有 2 个节点。 +
- 本题与 783 https://leetcode-cn.com/problems/minimum-distance-between-bst-nodes/ 相同 +
给定一个整数数组和一个整数 k, 你需要在数组里找到不同的 k-diff 数对。这里将 k-diff 数对定义为一个整数对 (i, j), 其中 i 和 j 都是数组中的数字,且两数之差的绝对值是 k.
+ +示例 1:
+ ++输入: [3, 1, 4, 1, 5], k = 2 +输出: 2 +解释: 数组中有两个 2-diff 数对, (1, 3) 和 (3, 5)。 +尽管数组中有两个1,但我们只应返回不同的数对的数量。 ++ +
示例 2:
+ ++输入:[1, 2, 3, 4, 5], k = 1 +输出: 4 +解释: 数组中有四个 1-diff 数对, (1, 2), (2, 3), (3, 4) 和 (4, 5)。 ++ +
示例 3:
+ ++输入: [1, 3, 1, 5, 4], k = 0 +输出: 1 +解释: 数组中只有一个 0-diff 数对,(1, 1)。 ++ +
注意:
+ +-
+
- 数对 (i, j) 和数对 (j, i) 被算作同一数对。 +
- 数组的长度不超过10,000。 +
- 所有输入的整数的范围在 [-1e7, 1e7]。 +
TinyURL是一种URL简化服务, 比如:当你输入一个URL https://leetcode.com/problems/design-tinyurl 时,它将返回一个简化的URL http://tinyurl.com/4e9iAk.
要求:设计一个 TinyURL 的加密 encode 和解密 decode 的方法。你的加密和解密算法如何设计和运作是没有限制的,你只需要保证一个URL可以被加密成一个TinyURL,并且这个TinyURL可以用解密方法恢复成原本的URL。
给定两个表示复数的字符串。
+ +返回表示它们乘积的字符串。注意,根据定义 i2 = -1 。
+ +示例 1:
+ ++输入: "1+1i", "1+1i" +输出: "0+2i" +解释: (1 + i) * (1 + i) = 1 + i2 + 2 * i = 2i ,你需要将它转换为 0+2i 的形式。 ++ +
示例 2:
+ ++输入: "1+-1i", "1+-1i" +输出: "0+-2i" +解释: (1 - i) * (1 - i) = 1 + i2 - 2 * i = -2i ,你需要将它转换为 0+-2i 的形式。 ++ +
注意:
+ +-
+
- 输入字符串不包含额外的空格。 +
- 输入字符串将以 a+bi 的形式给出,其中整数 a 和 b 的范围均在 [-100, 100] 之间。输出也应当符合这种形式。 +
给定一个二叉搜索树(Binary Search Tree),把它转换成为累加树(Greater Tree),使得每个节点的值是原来的节点值加上所有大于它的节点值之和。
+ ++ +
例如:
+ +输入: 原始二叉搜索树: + 5 + / \ + 2 13 + +输出: 转换为累加树: + 18 + / \ + 20 13 ++ +
+ +
注意:本题和 1038: https://leetcode-cn.com/problems/binary-search-tree-to-greater-sum-tree/ 相同
+ + + +## 解法 + + + +### Python3 + + +```python + +``` + +### Java + + +```java + +``` + +### ... +``` + +``` diff --git a/solution/0500-0599/0539.Minimum Time Difference/README.md b/solution/0500-0599/0539.Minimum Time Difference/README.md new file mode 100644 index 0000000000000..7132ec3e3059d --- /dev/null +++ b/solution/0500-0599/0539.Minimum Time Difference/README.md @@ -0,0 +1,46 @@ +# [539. 最小时间差](https://leetcode-cn.com/problems/minimum-time-difference) + +## 题目描述 + +给定一个 24 小时制(小时:分钟)的时间列表,找出列表中任意两个时间的最小时间差并已分钟数表示。
+ +
+示例 1:
+输入: ["23:59","00:00"] +输出: 1 ++ +
+备注:
-
+
- 列表中时间数在 2~20000 之间。 +
- 每个时间取值在 00:00~23:59 之间。 +
给定一个只包含整数的有序数组,每个元素都会出现两次,唯有一个数只会出现一次,找出这个数。
+ +示例 1:
+ ++输入: [1,1,2,3,3,4,4,8,8] +输出: 2 ++ +
示例 2:
+ ++输入: [3,3,7,7,10,11,11] +输出: 10 ++ +
注意: 您的方案应该在 O(log n)时间复杂度和 O(1)空间复杂度中运行。
+ + + +## 解法 + + + +### Python3 + + +```python + +``` + +### Java + + +```java + +``` + +### ... +``` + +``` diff --git a/solution/0500-0599/0541.Reverse String II/README.md b/solution/0500-0599/0541.Reverse String II/README.md new file mode 100644 index 0000000000000..fa14c9b731caf --- /dev/null +++ b/solution/0500-0599/0541.Reverse String II/README.md @@ -0,0 +1,44 @@ +# [541. 反转字符串 II](https://leetcode-cn.com/problems/reverse-string-ii) + +## 题目描述 + +给定一个字符串和一个整数 k,你需要对从字符串开头算起的每个 2k 个字符的前k个字符进行反转。如果剩余少于 k 个字符,则将剩余的所有全部反转。如果有小于 2k 但大于或等于 k 个字符,则反转前 k 个字符,并将剩余的字符保持原样。
+ +示例:
+ ++输入: s = "abcdefg", k = 2 +输出: "bacdfeg" ++ +
要求:
+ +-
+
- 该字符串只包含小写的英文字母。 +
- 给定字符串的长度和 k 在[1, 10000]范围内。 +
给定一个由 0 和 1 组成的矩阵,找出每个元素到最近的 0 的距离。
+ +两个相邻元素间的距离为 1 。
+ +示例 1:
+输入:
+0 0 0 +0 1 0 +0 0 0 ++ +
输出:
+ ++0 0 0 +0 1 0 +0 0 0 ++ +
示例 2:
+输入:
+0 0 0 +0 1 0 +1 1 1 ++ +
输出:
+ ++0 0 0 +0 1 0 +1 2 1 ++ +
注意:
+ +-
+
- 给定矩阵的元素个数不超过 10000。 +
- 给定矩阵中至少有一个元素是 0。 +
- 矩阵中的元素只在四个方向上相邻: 上、下、左、右。 +
给定一棵二叉树,你需要计算它的直径长度。一棵二叉树的直径长度是任意两个结点路径长度中的最大值。这条路径可能穿过也可能不穿过根结点。
+ ++ +
示例 :
+给定二叉树
1 + / \ + 2 3 + / \ + 4 5 ++ +
返回 3, 它的长度是路径 [4,2,1,3] 或者 [5,2,1,3]。
+ ++ +
注意:两结点之间的路径长度是以它们之间边的数目表示。
+ + + +## 解法 + + + +### Python3 + + +```python + +``` + +### Java + + +```java + +``` + +### ... +``` + +``` diff --git a/solution/0500-0599/0544.Output Contest Matches/README.md b/solution/0500-0599/0544.Output Contest Matches/README.md new file mode 100644 index 0000000000000..136645f8c0116 --- /dev/null +++ b/solution/0500-0599/0544.Output Contest Matches/README.md @@ -0,0 +1,29 @@ +# [544. 输出比赛匹配对](https://leetcode-cn.com/problems/output-contest-matches) + +## 题目描述 + +None + + +## 解法 + + + +### Python3 + + +```python + +``` + +### Java + + +```java + +``` + +### ... +``` + +``` diff --git a/solution/0500-0599/0545.Boundary of Binary Tree/README.md b/solution/0500-0599/0545.Boundary of Binary Tree/README.md new file mode 100644 index 0000000000000..5f3dd9cfe48d6 --- /dev/null +++ b/solution/0500-0599/0545.Boundary of Binary Tree/README.md @@ -0,0 +1,29 @@ +# [545. 二叉树的边界](https://leetcode-cn.com/problems/boundary-of-binary-tree) + +## 题目描述 + +None + + +## 解法 + + + +### Python3 + + +```python + +``` + +### Java + + +```java + +``` + +### ... +``` + +``` diff --git a/solution/0500-0599/0546.Remove Boxes/README.md b/solution/0500-0599/0546.Remove Boxes/README.md new file mode 100644 index 0000000000000..4b78eaf22fd6f --- /dev/null +++ b/solution/0500-0599/0546.Remove Boxes/README.md @@ -0,0 +1,59 @@ +# [546. 移除盒子](https://leetcode-cn.com/problems/remove-boxes) + +## 题目描述 + +给出一些不同颜色的盒子,盒子的颜色由数字表示,即不同的数字表示不同的颜色。
+你将经过若干轮操作去去掉盒子,直到所有的盒子都去掉为止。每一轮你可以移除具有相同颜色的连续 k 个盒子(k >= 1),这样一轮之后你将得到 k*k 个积分。
+当你将所有盒子都去掉之后,求你能获得的最大积分和。
示例 1:
+输入:
+[1, 3, 2, 2, 2, 3, 4, 3, 1] ++ +
输出:
+ ++23 ++ +
解释:
+ ++[1, 3, 2, 2, 2, 3, 4, 3, 1] +----> [1, 3, 3, 4, 3, 1] (3*3=9 分) +----> [1, 3, 3, 3, 1] (1*1=1 分) +----> [1, 1] (3*3=9 分) +----> [] (2*2=4 分) ++ +
+ +
提示:盒子的总数 n 不会超过 100。
班上有 N 名学生。其中有些人是朋友,有些则不是。他们的友谊具有是传递性。如果已知 A 是 B 的朋友,B 是 C 的朋友,那么我们可以认为 A 也是 C 的朋友。所谓的朋友圈,是指所有朋友的集合。
+ +给定一个 N * N 的矩阵 M,表示班级中学生之间的朋友关系。如果M[i][j] = 1,表示已知第 i 个和 j 个学生互为朋友关系,否则为不知道。你必须输出所有学生中的已知的朋友圈总数。
+ +示例 1:
+ ++输入: +[[1,1,0], + [1,1,0], + [0,0,1]] +输出: 2 +说明:已知学生0和学生1互为朋友,他们在一个朋友圈。 +第2个学生自己在一个朋友圈。所以返回2。 ++ +
示例 2:
+ ++输入: +[[1,1,0], + [1,1,1], + [0,1,1]] +输出: 1 +说明:已知学生0和学生1互为朋友,学生1和学生2互为朋友,所以学生0和学生2也是朋友,所以他们三个在一个朋友圈,返回1。 ++ +
注意:
+ +-
+
- N 在[1,200]的范围内。 +
- 对于所有学生,有M[i][i] = 1。 +
- 如果有M[i][j] = 1,则有M[j][i] = 1。 +
给定一个字符串来代表一个学生的出勤记录,这个记录仅包含以下三个字符:
+ +-
+
- 'A' : Absent,缺勤 +
- 'L' : Late,迟到 +
- 'P' : Present,到场 +
如果一个学生的出勤记录中不超过一个'A'(缺勤)并且不超过两个连续的'L'(迟到),那么这个学生会被奖赏。
+ +你需要根据这个学生的出勤记录判断他是否会被奖赏。
+ +示例 1:
+ +输入: "PPALLP" +输出: True ++ +
示例 2:
+ +输入: "PPALLL" +输出: False ++ + + +## 解法 + + + +### Python3 + + +```python + +``` + +### Java + + +```java + +``` + +### ... +``` + +``` diff --git a/solution/0500-0599/0552.Student Attendance Record II/README.md b/solution/0500-0599/0552.Student Attendance Record II/README.md new file mode 100644 index 0000000000000..0ce4739b037e6 --- /dev/null +++ b/solution/0500-0599/0552.Student Attendance Record II/README.md @@ -0,0 +1,52 @@ +# [552. 学生出勤记录 II](https://leetcode-cn.com/problems/student-attendance-record-ii) + +## 题目描述 + +
给定一个正整数 n,返回长度为 n 的所有可被视为可奖励的出勤记录的数量。 答案可能非常大,你只需返回结果mod 109 + 7的值。
+ +学生出勤记录是只包含以下三个字符的字符串:
+ +-
+
- 'A' : Absent,缺勤 +
- 'L' : Late,迟到 +
- 'P' : Present,到场 +
如果记录不包含多于一个'A'(缺勤)或超过两个连续的'L'(迟到),则该记录被视为可奖励的。
+ +示例 1:
+ ++输入: n = 2 +输出: 8 +解释: +有8个长度为2的记录将被视为可奖励: +"PP" , "AP", "PA", "LP", "PL", "AL", "LA", "LL" +只有"AA"不会被视为可奖励,因为缺勤次数超过一次。+ +
注意:n 的值不会超过100000。
+ + + +## 解法 + + + +### Python3 + + +```python + +``` + +### Java + + +```java + +``` + +### ... +``` + +``` diff --git a/solution/0500-0599/0553.Optimal Division/README.md b/solution/0500-0599/0553.Optimal Division/README.md new file mode 100644 index 0000000000000..9fb9386384a80 --- /dev/null +++ b/solution/0500-0599/0553.Optimal Division/README.md @@ -0,0 +1,57 @@ +# [553. 最优除法](https://leetcode-cn.com/problems/optimal-division) + +## 题目描述 + +给定一组正整数,相邻的整数之间将会进行浮点除法操作。例如, [2,3,4] -> 2 / 3 / 4 。
+ +但是,你可以在任意位置添加任意数目的括号,来改变算数的优先级。你需要找出怎么添加括号,才能得到最大的结果,并且返回相应的字符串格式的表达式。你的表达式不应该含有冗余的括号。
+ +示例:
+ ++输入: [1000,100,10,2] +输出: "1000/(100/10/2)" +解释: +1000/(100/10/2) = 1000/((100/10)/2) = 200 +但是,以下加粗的括号 "1000/((100/10)/2)" 是冗余的, +因为他们并不影响操作的优先级,所以你需要返回 "1000/(100/10/2)"。 + +其他用例: +1000/(100/10)/2 = 50 +1000/(100/(10/2)) = 50 +1000/100/10/2 = 0.5 +1000/100/(10/2) = 2 ++ +
说明:
+ +-
+
- 输入数组的长度在 [1, 10] 之间。 +
- 数组中每个元素的大小都在 [2, 1000] 之间。 +
- 每个测试用例只有一个最优除法解。 +
你的面前有一堵方形的、由多行砖块组成的砖墙。 这些砖块高度相同但是宽度不同。你现在要画一条自顶向下的、穿过最少砖块的垂线。
+ +砖墙由行的列表表示。 每一行都是一个代表从左至右每块砖的宽度的整数列表。
+ +如果你画的线只是从砖块的边缘经过,就不算穿过这块砖。你需要找出怎样画才能使这条线穿过的砖块数量最少,并且返回穿过的砖块数量。
+ +你不能沿着墙的两个垂直边缘之一画线,这样显然是没有穿过一块砖的。
+ ++ +
示例:
+ +输入: [[1,2,2,1], + [3,1,2], + [1,3,2], + [2,4], + [3,1,2], + [1,3,1,1]] + +输出: 2 + +解释: ++ ++
+ +
提示:
+ +-
+
- 每一行砖块的宽度之和应该相等,并且不能超过 INT_MAX。 +
- 每一行砖块的数量在 [1,10,000] 范围内, 墙的高度在 [1,10,000] 范围内, 总的砖块数量不超过 20,000。 +
给定一个32位正整数 n,你需要找到最小的32位整数,其与 n 中存在的位数完全相同,并且其值大于n。如果不存在这样的32位整数,则返回-1。
+ +示例 1:
+ ++输入: 12 +输出: 21 ++ +
示例 2:
+ ++输入: 21 +输出: -1 ++ + + +## 解法 + + + +### Python3 + + +```python + +``` + +### Java + + +```java + +``` + +### ... +``` + +``` diff --git a/solution/0500-0599/0557.Reverse Words in a String III/README.md b/solution/0500-0599/0557.Reverse Words in a String III/README.md new file mode 100644 index 0000000000000..6a262ae3c4b8a --- /dev/null +++ b/solution/0500-0599/0557.Reverse Words in a String III/README.md @@ -0,0 +1,39 @@ +# [557. 反转字符串中的单词 III](https://leetcode-cn.com/problems/reverse-words-in-a-string-iii) + +## 题目描述 + +
给定一个字符串,你需要反转字符串中每个单词的字符顺序,同时仍保留空格和单词的初始顺序。
+ +示例 1:
+ ++输入: "Let's take LeetCode contest" +输出: "s'teL ekat edoCteeL tsetnoc" ++ +
注意:在字符串中,每个单词由单个空格分隔,并且字符串中不会有任何额外的空格。
+ + + +## 解法 + + + +### Python3 + + +```python + +``` + +### Java + + +```java + +``` + +### ... +``` + +``` diff --git a/solution/0500-0599/0558.Logical OR of Two Binary Grids Represented as Quad-Trees/README.md b/solution/0500-0599/0558.Logical OR of Two Binary Grids Represented as Quad-Trees/README.md new file mode 100644 index 0000000000000..5846397efd954 --- /dev/null +++ b/solution/0500-0599/0558.Logical OR of Two Binary Grids Represented as Quad-Trees/README.md @@ -0,0 +1,96 @@ +# [558. 四叉树交集](https://leetcode-cn.com/problems/logical-or-of-two-binary-grids-represented-as-quad-trees) + +## 题目描述 + +四叉树是一种树数据,其中每个结点恰好有四个子结点:topLeft、topRight、bottomLeft 和 bottomRight。四叉树通常被用来划分一个二维空间,递归地将其细分为四个象限或区域。
我们希望在四叉树中存储 True/False 信息。四叉树用来表示 N * N 的布尔网格。对于每个结点, 它将被等分成四个孩子结点直到这个区域内的值都是相同的。每个节点都有另外两个布尔属性:isLeaf 和 val。当这个节点是一个叶子结点时 isLeaf 为真。val 变量储存叶子结点所代表的区域的值。
例如,下面是两个四叉树 A 和 B:
+ +A: ++-------+-------+ T: true +| | | F: false +| T | T | +| | | ++-------+-------+ +| | | +| F | F | +| | | ++-------+-------+ +topLeft: T +topRight: T +bottomLeft: F +bottomRight: F + +B: ++-------+---+---+ +| | F | F | +| T +---+---+ +| | T | T | ++-------+---+---+ +| | | +| T | F | +| | | ++-------+-------+ +topLeft: T +topRight: + topLeft: F + topRight: F + bottomLeft: T + bottomRight: T +bottomLeft: T +bottomRight: F ++ +
+ +
你的任务是实现一个函数,该函数根据两个四叉树返回表示这两个四叉树的逻辑或(或并)的四叉树。
+ +A: B: C (A or B): ++-------+-------+ +-------+---+---+ +-------+-------+ +| | | | | F | F | | | | +| T | T | | T +---+---+ | T | T | +| | | | | T | T | | | | ++-------+-------+ +-------+---+---+ +-------+-------+ +| | | | | | | | | +| F | F | | T | F | | T | F | +| | | | | | | | | ++-------+-------+ +-------+-------+ +-------+-------+ ++ +
+ +
提示:
+ +-
+
A和B都表示大小为N * N的网格。
+ N将确保是 2 的整次幂。
+ - 如果你想了解更多关于四叉树的知识,你可以参考这个 wiki 页面。 +
- 逻辑或的定义如下:如果
A 为 True,或者B 为 True,或者A 和 B 都为 True,则 "A 或 B" 为 True。
+
给定一个 N 叉树,找到其最大深度。
+ +最大深度是指从根节点到最远叶子节点的最长路径上的节点总数。
+ +例如,给定一个 3叉树 :
+ +
+ +
我们应返回其最大深度,3。
+ +说明:
+ +-
+
- 树的深度不会超过
1000。
+ - 树的节点总不会超过
5000。
+
给定一个整数数组和一个整数 k,你需要找到该数组中和为 k 的连续的子数组的个数。
+ +示例 1 :
+ ++输入:nums = [1,1,1], k = 2 +输出: 2 , [1,1] 与 [1,1] 为两种不同的情况。 ++ +
说明 :
+ +-
+
- 数组的长度为 [1, 20,000]。 +
- 数组中元素的范围是 [-1000, 1000] ,且整数 k 的范围是 [-1e7, 1e7]。 +
给定长度为 2n 的数组, 你的任务是将这些数分成 n 对, 例如 (a1, b1), (a2, b2), ..., (an, bn) ,使得从1 到 n 的 min(ai, bi) 总和最大。
-给定长度为 **2n** 的数组, 你的任务是将这些数分成 **n** 对, 例如 (a1, b1), (a2, b2), ..., (an, bn) ,使得从1 到 n 的 min(ai, bi) 总和最大。 +示例 1:
-**示例 1** ++输入: [1,4,3,2] -``` -输入: [1,4,3,2] -输出: 4 -解释: n 等于 2, 最大总和为 4 = min(1, 2) + min(3, 4). -``` - -**提示** - -1. **n** 是正整数,范围在 [1, 10000]. -2. 数组中的元素范围在 [-10000, 10000]. - -**提示1** - -Obviously, brute force won't help here. Think of something else, take some example like 1,2,3,4. +输出: 4 +解释: n 等于 2, 最大总和为 4 = min(1, 2) + min(3, 4). +-显然,蛮力在这里无济于事。想想其他的东西,比如1,2,3,4。 +
提示:
-**提示2** +-
+
- n 是正整数,范围在 [1, 10000]. +
- 数组中的元素范围在 [-10000, 10000]. +
给定一个二叉树,计算整个树的坡度。
+ +一个树的节点的坡度定义即为,该节点左子树的结点之和和右子树结点之和的差的绝对值。空结点的的坡度是0。
+ +整个树的坡度就是其所有节点的坡度之和。
+ +示例:
+ ++输入: + 1 + / \ + 2 3 +输出: 1 +解释: +结点的坡度 2 : 0 +结点的坡度 3 : 0 +结点的坡度 1 : |2-3| = 1 +树的坡度 : 0 + 0 + 1 = 1 ++ +
注意:
+ +-
+
- 任何子树的结点的和不会超过32位整数的范围。 +
- 坡度的值不会超过32位整数的范围。 +
给定一个整数 n ,你需要找到与它最近的回文数(不包括自身)。
+ +“最近的”定义为两个整数差的绝对值最小。
+ +示例 1:
+ ++输入: "123" +输出: "121" ++ +
注意:
+ +-
+
- n 是由字符串表示的正整数,其长度不超过18。 +
- 如果有多个结果,返回最小的那个。 +
索引从0开始长度为N的数组A,包含0到N - 1的所有整数。找到并返回最大的集合S,S[i] = {A[i], A[A[i]], A[A[A[i]]], ... }且遵守以下的规则。
假设选择索引为i的元素A[i]为S的第一个元素,S的下一个元素应该是A[A[i]],之后是A[A[A[i]]]... 以此类推,不断添加直到S出现重复的元素。
示例 1:
+ +
+输入: A = [5,4,0,3,1,6,2]
+输出: 4
+解释:
+A[0] = 5, A[1] = 4, A[2] = 0, A[3] = 3, A[4] = 1, A[5] = 6, A[6] = 2.
+
+其中一种最长的 S[K]:
+S[0] = {A[0], A[5], A[6], A[2]} = {5, 6, 2, 0}
+
+
+注意:
+ +-
+
N是[1, 20,000]之间的整数。
+ A中不含有重复的元素。
+ A中的元素大小在[0, N-1]之间。
+
在MATLAB中,有一个非常有用的函数 reshape,它可以将一个矩阵重塑为另一个大小不同的新矩阵,但保留其原始数据。
给出一个由二维数组表示的矩阵,以及两个正整数r和c,分别表示想要的重构的矩阵的行数和列数。
重构后的矩阵需要将原始矩阵的所有元素以相同的行遍历顺序填充。
+ +如果具有给定参数的reshape操作是可行且合理的,则输出新的重塑矩阵;否则,输出原始矩阵。
示例 1:
+ ++输入: +nums = +[[1,2], + [3,4]] +r = 1, c = 4 +输出: +[[1,2,3,4]] +解释: +行遍历nums的结果是 [1,2,3,4]。新的矩阵是 1 * 4 矩阵, 用之前的元素值一行一行填充新矩阵。 ++ +
示例 2:
+ ++输入: +nums = +[[1,2], + [3,4]] +r = 2, c = 4 +输出: +[[1,2], + [3,4]] +解释: +没有办法将 2 * 2 矩阵转化为 2 * 4 矩阵。 所以输出原矩阵。 ++ +
注意:
+ +-
+
- 给定矩阵的宽和高范围在 [1, 100]。 +
- 给定的 r 和 c 都是正数。 +
给定两个字符串 s1 和 s2,写一个函数来判断 s2 是否包含 s1 的排列。
-给定两个字符串 `s1` 和 `s2`,写一个函数来判断 `s2` 是否包含 `s1` 的排列。 +换句话说,第一个字符串的排列之一是第二个字符串的子串。
-换句话说,第一个字符串的排列之一是第二个字符串的子串。 +示例1:
+ +
+输入: s1 = "ab" s2 = "eidbaooo"
+输出: True
+解释: s2 包含 s1 的排列之一 ("ba").
+
+
++ +
示例2:
+ ++输入: s1= "ab" s2 = "eidboaoo" +输出: False ++ +
+ +
注意:
+ +-
+
- 输入的字符串只包含小写字母 +
- 两个字符串的长度都在 [1, 10,000] 之间 +
给定两个非空二叉树 s 和 t,检验 s 中是否包含和 t 具有相同结构和节点值的子树。s 的一个子树包括 s 的一个节点和这个节点的所有子孙。s 也可以看做它自身的一棵子树。
+ +示例 1:
+给定的树 s:
+ 3 + / \ + 4 5 + / \ + 1 2 ++ +
给定的树 t:
+ ++ 4 + / \ + 1 2 ++ +
返回 true,因为 t 与 s 的一个子树拥有相同的结构和节点值。
+ +示例 2:
+给定的树 s:
+ 3 + / \ + 4 5 + / \ + 1 2 + / + 0 ++ +
给定的树 t:
+ ++ 4 + / \ + 1 2 ++ +
返回 false。
+ + + +## 解法 + + + +### Python3 + + +```python + +``` + +### Java + + +```java + +``` + +### ... +``` + +``` diff --git a/solution/0500-0599/0573.Squirrel Simulation/README.md b/solution/0500-0599/0573.Squirrel Simulation/README.md new file mode 100644 index 0000000000000..f58d6961ece84 --- /dev/null +++ b/solution/0500-0599/0573.Squirrel Simulation/README.md @@ -0,0 +1,29 @@ +# [573. 松鼠模拟](https://leetcode-cn.com/problems/squirrel-simulation) + +## 题目描述 + +None + + +## 解法 + + + +### Python3 + + +```python + +``` + +### Java + + +```java + +``` + +### ... +``` + +``` diff --git a/solution/0500-0599/0574.Winning Candidate/README.md b/solution/0500-0599/0574.Winning Candidate/README.md new file mode 100644 index 0000000000000..bb0aaf23e5934 --- /dev/null +++ b/solution/0500-0599/0574.Winning Candidate/README.md @@ -0,0 +1,29 @@ +# [574. 当选者](https://leetcode-cn.com/problems/winning-candidate) + +## 题目描述 + +None + + +## 解法 + + + +### Python3 + + +```python + +``` + +### Java + + +```java + +``` + +### ... +``` + +``` diff --git a/solution/0500-0599/0575.Distribute Candies/README.md b/solution/0500-0599/0575.Distribute Candies/README.md new file mode 100644 index 0000000000000..04c3cb3b7b76a --- /dev/null +++ b/solution/0500-0599/0575.Distribute Candies/README.md @@ -0,0 +1,57 @@ +# [575. 分糖果](https://leetcode-cn.com/problems/distribute-candies) + +## 题目描述 + +给定一个偶数长度的数组,其中不同的数字代表着不同种类的糖果,每一个数字代表一个糖果。你需要把这些糖果平均分给一个弟弟和一个妹妹。返回妹妹可以获得的最大糖果的种类数。
+ +示例 1:
+ ++输入: candies = [1,1,2,2,3,3] +输出: 3 +解析: 一共有三种种类的糖果,每一种都有两个。 + 最优分配方案:妹妹获得[1,2,3],弟弟也获得[1,2,3]。这样使妹妹获得糖果的种类数最多。 ++ +
示例 2 :
+ ++输入: candies = [1,1,2,3] +输出: 2 +解析: 妹妹获得糖果[2,3],弟弟获得糖果[1,1],妹妹有两种不同的糖果,弟弟只有一种。这样使得妹妹可以获得的糖果种类数最多。 ++ +
注意:
+ +-
+
- 数组的长度为[2, 10,000],并且确定为偶数。 +
- 数组中数字的大小在范围[-100,000, 100,000]内。
+
-
+
+
给定一个 m × n 的网格和一个球。球的起始坐标为 (i,j) ,你可以将球移到相邻的单元格内,或者往上、下、左、右四个方向上移动使球穿过网格边界。但是,你最多可以移动 N 次。找出可以将球移出边界的路径数量。答案可能非常大,返回 结果 mod 109 + 7 的值。
+ ++ +
示例 1:
+ +输入: m = 2, n = 2, N = 2, i = 0, j = 0 +输出: 6 +解释: ++ ++
示例 2:
+ +输入: m = 1, n = 3, N = 3, i = 0, j = 1 +输出: 12 +解释: ++ ++
+ +
说明:
+ +-
+
- 球一旦出界,就不能再被移动回网格内。 +
- 网格的长度和高度在 [1,50] 的范围内。 +
- N 在 [0,50] 的范围内。 +
给定一个整数数组,你需要寻找一个连续的子数组,如果对这个子数组进行升序排序,那么整个数组都会变为升序排序。
-你找到的子数组应是最短的,请输出它的长度。 +你找到的子数组应是最短的,请输出它的长度。
-**示例 1:** -``` -输入: [2, 6, 4, 8, 10, 9, 15] -输出: 5 -解释: 你只需要对 [6, 4, 8, 10, 9] 进行升序排序,那么整个表都会变为升序排序。 -``` +示例 1:
+ ++输入: [2, 6, 4, 8, 10, 9, 15] +输出: 5 +解释: 你只需要对 [6, 4, 8, 10, 9] 进行升序排序,那么整个表都会变为升序排序。 ++ +
说明 :
+ +-
+
- 输入的数组长度范围在 [1, 10,000]。 +
- 输入的数组可能包含重复元素 ,所以升序的意思是<=。 +
给定两个单词 word1 和 word2,找到使得 word1 和 word2 相同所需的最小步数,每步可以删除任意一个字符串中的一个字符。
+ +示例 1:
+ ++输入: "sea", "eat" +输出: 2 +解释: 第一步将"sea"变为"ea",第二步将"eat"变为"ea" ++ +
说明:
+ +-
+
- 给定单词的长度不超过500。 +
- 给定单词中的字符只含有小写字母。 +
在一个二维的花园中,有一些用 (x, y) 坐标表示的树。由于安装费用十分昂贵,你的任务是先用最短的绳子围起所有的树。只有当所有的树都被绳子包围时,花园才能围好栅栏。你需要找到正好位于栅栏边界上的树的坐标。
+ ++ +
示例 1:
+ +输入: [[1,1],[2,2],[2,0],[2,4],[3,3],[4,2]] +输出: [[1,1],[2,0],[4,2],[3,3],[2,4]] +解释: ++ ++
示例 2:
+ +输入: [[1,2],[2,2],[4,2]] +输出: [[1,2],[2,2],[4,2]] +解释: ++ ++即使树都在一条直线上,你也需要先用绳子包围它们。 +
+ +
注意:
+ +-
+
- 所有的树应当被围在一起。你不能剪断绳子来包围树或者把树分成一组以上。 +
- 输入的整数在 0 到 100 之间。 +
- 花园至少有一棵树。 +
- 所有树的坐标都是不同的。 +
- 输入的点没有顺序。输出顺序也没有要求。 +
给定一个 N 叉树,返回其节点值的前序遍历。
+ +例如,给定一个 3叉树 :
+ +
+ +
返回其前序遍历: [1,3,5,6,2,4]。
+ +
说明: 递归法很简单,你可以使用迭代法完成此题吗?
+ + +## 解法 + + + +### Python3 + + +```python + +``` + +### Java + + +```java + +``` + +### ... +``` + +``` diff --git a/solution/0500-0599/0590.N-ary Tree Postorder Traversal/README.md b/solution/0500-0599/0590.N-ary Tree Postorder Traversal/README.md new file mode 100644 index 0000000000000..af7f26cf940c6 --- /dev/null +++ b/solution/0500-0599/0590.N-ary Tree Postorder Traversal/README.md @@ -0,0 +1,43 @@ +# [590. N叉树的后序遍历](https://leetcode-cn.com/problems/n-ary-tree-postorder-traversal) + +## 题目描述 + +给定一个 N 叉树,返回其节点值的后序遍历。
+ +例如,给定一个 3叉树 :
+ +
+ +
返回其后序遍历: [5,6,3,2,4,1].
+ +
说明: 递归法很简单,你可以使用迭代法完成此题吗?
+ + +## 解法 + + + +### Python3 + + +```python + +``` + +### Java + + +```java + +``` + +### ... +``` + +``` diff --git a/solution/0500-0599/0591.Tag Validator/README.md b/solution/0500-0599/0591.Tag Validator/README.md new file mode 100644 index 0000000000000..7e522d309dcfa --- /dev/null +++ b/solution/0500-0599/0591.Tag Validator/README.md @@ -0,0 +1,113 @@ +# [591. 标签验证器](https://leetcode-cn.com/problems/tag-validator) + +## 题目描述 + +给定一个表示代码片段的字符串,你需要实现一个验证器来解析这段代码,并返回它是否合法。合法的代码片段需要遵守以下的所有规则:
+ +-
+
- 代码必须被合法的闭合标签包围。否则,代码是无效的。 +
- 闭合标签(不一定合法)要严格符合格式:
<TAG_NAME>TAG_CONTENT</TAG_NAME>。其中,<TAG_NAME>是起始标签,</TAG_NAME>是结束标签。起始和结束标签中的 TAG_NAME 应当相同。当且仅当 TAG_NAME 和 TAG_CONTENT 都是合法的,闭合标签才是合法的。
+ - 合法的
TAG_NAME仅含有大写字母,长度在范围 [1,9] 之间。否则,该TAG_NAME是不合法的。
+ - 合法的
TAG_CONTENT可以包含其他合法的闭合标签,cdata (请参考规则7)和任意字符(注意参考规则1)除了不匹配的<、不匹配的起始和结束标签、不匹配的或带有不合法 TAG_NAME 的闭合标签。否则,TAG_CONTENT是不合法的。
+ - 一个起始标签,如果没有具有相同 TAG_NAME 的结束标签与之匹配,是不合法的。反之亦然。不过,你也需要考虑标签嵌套的问题。 +
- 一个
<,如果你找不到一个后续的>与之匹配,是不合法的。并且当你找到一个<或</时,所有直到下一个>的前的字符,都应当被解析为 TAG_NAME(不一定合法)。
+ - cdata 有如下格式:
<![CDATA[CDATA_CONTENT]]>。CDATA_CONTENT的范围被定义成<![CDATA[和后续的第一个]]>之间的字符。
+ CDATA_CONTENT可以包含任意字符。cdata 的功能是阻止验证器解析CDATA_CONTENT,所以即使其中有一些字符可以被解析为标签(无论合法还是不合法),也应该将它们视为常规字符。
+
合法代码的例子:
+ ++输入: "<DIV>This is the first line <![CDATA[<div>]]></DIV>" + +输出: True + +解释: + +代码被包含在了闭合的标签内: <DIV> 和 </DIV> 。 + +TAG_NAME 是合法的,TAG_CONTENT 包含了一些字符和 cdata 。 + +即使 CDATA_CONTENT 含有不匹配的起始标签和不合法的 TAG_NAME,它应该被视为普通的文本,而不是标签。 + +所以 TAG_CONTENT 是合法的,因此代码是合法的。最终返回True。 + + +输入: "<DIV>>> ![cdata[]] <![CDATA[<div>]>]]>]]>>]</DIV>" + +输出: True + +解释: + +我们首先将代码分割为: start_tag|tag_content|end_tag 。 + +start_tag -> "<DIV>" + +end_tag -> "</DIV>" + +tag_content 也可被分割为: text1|cdata|text2 。 + +text1 -> ">> ![cdata[]] " + +cdata -> "<![CDATA[<div>]>]]>" ,其中 CDATA_CONTENT 为 "<div>]>" + +text2 -> "]]>>]" + + +start_tag 不是 "<DIV>>>" 的原因参照规则 6 。 +cdata 不是 "<![CDATA[<div>]>]]>]]>" 的原因参照规则 7 。 ++ +
不合法代码的例子:
+ ++输入: "<A> <B> </A> </B>" +输出: False +解释: 不合法。如果 "<A>" 是闭合的,那么 "<B>" 一定是不匹配的,反之亦然。 + +输入: "<DIV> div tag is not closed <DIV>" +输出: False + +输入: "<DIV> unmatched < </DIV>" +输出: False + +输入: "<DIV> closed tags with invalid tag name <b>123</b> </DIV>" +输出: False + +输入: "<DIV> unmatched tags with invalid tag name </1234567890> and <CDATA[[]]> </DIV>" +输出: False + +输入: "<DIV> unmatched start tag <B> and unmatched end tag </C> </DIV>" +输出: False ++ +
注意:
+ +-
+
- 为简明起见,你可以假设输入的代码(包括提到的任意字符)只包含
数字, 字母,'<','>','/','!','[',']'和' '。
+
给定一个表示分数加减运算表达式的字符串,你需要返回一个字符串形式的计算结果。 这个结果应该是不可约分的分数,即最简分数。 如果最终结果是一个整数,例如 2,你需要将它转换成分数形式,其分母为 1。所以在上述例子中, 2 应该被转换为 2/1。
示例 1:
+ ++输入:"-1/2+1/2" +输出: "0/1" ++ +
示例 2:
+ ++输入:"-1/2+1/2+1/3" +输出: "1/3" ++ +
示例 3:
+ ++输入:"1/3-1/2" +输出: "-1/6" ++ +
示例 4:
+ ++输入:"5/3+1/3" +输出: "2/1" ++ +
说明:
+ +-
+
- 输入和输出字符串只包含
'0'到'9'的数字,以及'/','+'和'-'。
+ - 输入和输出分数格式均为
±分子/分母。如果输入的第一个分数或者输出的分数是正数,则'+'会被省略掉。
+ - 输入只包含合法的最简分数,每个分数的分子与分母的范围是 [1,10]。 如果分母是1,意味着这个分数实际上是一个整数。 +
- 输入的分数个数范围是 [1,10]。 +
- 最终结果的分子与分母保证是 32 位整数范围内的有效整数。 +
给定二维空间中四点的坐标,返回四点是否可以构造一个正方形。
+ +一个点的坐标(x,y)由一个有两个整数的整数数组表示。
+ +示例:
+ ++输入: p1 = [0,0], p2 = [1,1], p3 = [1,0], p4 = [0,1] +输出: True ++ +
+ +
注意:
+ +-
+
- 所有输入整数都在 [-10000,10000] 范围内。 +
- 一个有效的正方形有四个等长的正长和四个等角(90度角)。 +
- 输入点没有顺序。 +
和谐数组是指一个数组里元素的最大值和最小值之间的差别正好是1。
+ +现在,给定一个整数数组,你需要在所有可能的子序列中找到最长的和谐子序列的长度。
+ +示例 1:
+ ++输入: [1,3,2,2,5,2,3,7] +输出: 5 +原因: 最长的和谐数组是:[3,2,2,2,3]. ++ +
说明: 输入的数组长度最大不超过20,000.
+ + + +## 解法 + + + +### Python3 + + +```python + +``` + +### Java + + +```java + +``` + +### ... +``` + +``` diff --git a/solution/0500-0599/0595.Big Countries/README.md b/solution/0500-0599/0595.Big Countries/README.md index 874761e161af9..16936699dee28 100644 --- a/solution/0500-0599/0595.Big Countries/README.md +++ b/solution/0500-0599/0595.Big Countries/README.md @@ -1,9 +1,10 @@ -## 大的国家 -### 题目描述 +# [595. 大的国家](https://leetcode-cn.com/problems/big-countries) -这里有张 `World` 表 -``` -+-----------------+------------+------------+--------------+---------------+ +## 题目描述 + +这里有张 World 表
+-----------------+------------+------------+--------------+---------------+ | name | continent | area | population | gdp | +-----------------+------------+------------+--------------+---------------+ | Afghanistan | Asia | 652230 | 25500100 | 20343000 | @@ -12,26 +13,43 @@ | Andorra | Europe | 468 | 78115 | 3712000 | | Angola | Africa | 1246700 | 20609294 | 100990000 | +-----------------+------------+------------+--------------+---------------+ -``` +-如果一个国家的面积超过300万平方公里,或者人口超过2500万,那么这个国家就是大国家。 +
如果一个国家的面积超过300万平方公里,或者人口超过2500万,那么这个国家就是大国家。
-编写一个SQL查询,输出表中所有大国家的名称、人口和面积。 +编写一个SQL查询,输出表中所有大国家的名称、人口和面积。
-例如,根据上表,我们应该输出: -``` -+--------------+-------------+--------------+ +例如,根据上表,我们应该输出:
+ ++--------------+-------------+--------------+ | name | population | area | +--------------+-------------+--------------+ | Afghanistan | 25500100 | 652230 | | Algeria | 37100000 | 2381741 | +--------------+-------------+--------------+ ++ + + +## 解法 + + + +### Python3 + + +```python + ``` -### 解法 +### Java + -```sql -# Write your MySQL query statement below -select distinct name, population, area from World where area > 3000000 or population > 25000000 +```java -``` \ No newline at end of file +``` + +### ... +``` + +``` diff --git a/solution/0500-0599/0596.Classes More Than 5 Students/README.md b/solution/0500-0599/0596.Classes More Than 5 Students/README.md index e8d9ec44f5150..c7284d22e14d0 100644 --- a/solution/0500-0599/0596.Classes More Than 5 Students/README.md +++ b/solution/0500-0599/0596.Classes More Than 5 Students/README.md @@ -1,12 +1,14 @@ -## 超过5名学生的课 -### 题目描述 +# [596. 超过5名学生的课](https://leetcode-cn.com/problems/classes-more-than-5-students) -有一个 `courses` 表 ,有: **student(学生)** 和 **class(课程)**。 +## 题目描述 + +
有一个courses 表 ,有: student (学生) 和 class (课程)。
请列出所有超过或等于5名学生的课。
-例如,表: -``` +例如,表:
+ ++---------+------------+ | student | class | +---------+------------+ @@ -20,25 +22,42 @@ | H | Math | | I | Math | +---------+------------+ -``` +-应该输出: -``` +
应该输出:
+ ++---------+ | class | +---------+ | Math | +---------+ ++ +
Note:
+学生在每个课中不应被重复计算。
给定一个初始元素全部为 0,大小为 m*n 的矩阵 M 以及在 M 上的一系列更新操作。
+ +操作用二维数组表示,其中的每个操作用一个含有两个正整数 a 和 b 的数组表示,含义是将所有符合 0 <= i < a 以及 0 <= j < b 的元素 M[i][j] 的值都增加 1。
+ +在执行给定的一系列操作后,你需要返回矩阵中含有最大整数的元素个数。
+ +示例 1:
+ ++输入: +m = 3, n = 3 +operations = [[2,2],[3,3]] +输出: 4 +解释: +初始状态, M = +[[0, 0, 0], + [0, 0, 0], + [0, 0, 0]] + +执行完操作 [2,2] 后, M = +[[1, 1, 0], + [1, 1, 0], + [0, 0, 0]] + +执行完操作 [3,3] 后, M = +[[2, 2, 1], + [2, 2, 1], + [1, 1, 1]] + +M 中最大的整数是 2, 而且 M 中有4个值为2的元素。因此返回 4。 ++ +
注意:
+ +-
+
- m 和 n 的范围是 [1,40000]。 +
- a 的范围是 [1,m],b 的范围是 [1,n]。 +
- 操作数目不超过 10000。 +
假设Andy和Doris想在晚餐时选择一家餐厅,并且他们都有一个表示最喜爱餐厅的列表,每个餐厅的名字用字符串表示。
+ +你需要帮助他们用最少的索引和找出他们共同喜爱的餐厅。 如果答案不止一个,则输出所有答案并且不考虑顺序。 你可以假设总是存在一个答案。
+ +示例 1:
+ +输入: +["Shogun", "Tapioca Express", "Burger King", "KFC"] +["Piatti", "The Grill at Torrey Pines", "Hungry Hunter Steakhouse", "Shogun"] +输出: ["Shogun"] +解释: 他们唯一共同喜爱的餐厅是“Shogun”。 ++ +
示例 2:
+ +输入: +["Shogun", "Tapioca Express", "Burger King", "KFC"] +["KFC", "Shogun", "Burger King"] +输出: ["Shogun"] +解释: 他们共同喜爱且具有最小索引和的餐厅是“Shogun”,它有最小的索引和1(0+1)。 ++ +
提示:
+ +-
+
- 两个列表的长度范围都在 [1, 1000]内。 +
- 两个列表中的字符串的长度将在[1,30]的范围内。 +
- 下标从0开始,到列表的长度减1。 +
- 两个列表都没有重复的元素。 +
给定一个正整数 n,找出小于或等于 n 的非负整数中,其二进制表示不包含 连续的1 的个数。
+ +示例 1:
+ +输入: 5 +输出: 5 +解释: +下面是带有相应二进制表示的非负整数<= 5: +0 : 0 +1 : 1 +2 : 10 +3 : 11 +4 : 100 +5 : 101 +其中,只有整数3违反规则(有两个连续的1),其他5个满足规则。+ +
说明: 1 <= n <= 109
+ + + +## 解法 + + + +### Python3 + + +```python + +``` + +### Java + + +```java + +``` + +### ... +``` + +``` diff --git a/solution/0600-0699/0601.Human Traffic of Stadium/README.md b/solution/0600-0699/0601.Human Traffic of Stadium/README.md new file mode 100644 index 0000000000000..fe312beb489e0 --- /dev/null +++ b/solution/0600-0699/0601.Human Traffic of Stadium/README.md @@ -0,0 +1,65 @@ +# [601. 体育馆的人流量](https://leetcode-cn.com/problems/human-traffic-of-stadium) + +## 题目描述 + +X 市建了一个新的体育馆,每日人流量信息被记录在这三列信息中:序号 (id)、日期 (visit_date)、 人流量 (people)。
+ +请编写一个查询语句,找出人流量的高峰期。高峰期时,至少连续三行记录中的人流量不少于100。
+ +例如,表 stadium:
+------+------------+-----------+ +| id | visit_date | people | ++------+------------+-----------+ +| 1 | 2017-01-01 | 10 | +| 2 | 2017-01-02 | 109 | +| 3 | 2017-01-03 | 150 | +| 4 | 2017-01-04 | 99 | +| 5 | 2017-01-05 | 145 | +| 6 | 2017-01-06 | 1455 | +| 7 | 2017-01-07 | 199 | +| 8 | 2017-01-08 | 188 | ++------+------------+-----------+ ++ +
对于上面的示例数据,输出为:
+ ++------+------------+-----------+ +| id | visit_date | people | ++------+------------+-----------+ +| 5 | 2017-01-05 | 145 | +| 6 | 2017-01-06 | 1455 | +| 7 | 2017-01-07 | 199 | +| 8 | 2017-01-08 | 188 | ++------+------------+-----------+ ++ +
+ +
提示:
+每天只有一行记录,日期随着 id 的增加而增加。
假设你有一个很长的花坛,一部分地块种植了花,另一部分却没有。可是,花卉不能种植在相邻的地块上,它们会争夺水源,两者都会死去。
-给定一个花坛(表示为一个数组包含 0 和 1,其中 0 表示没种植花,1 表示种植了花),和一个数 `n` 。能否在不打破种植规则的情况下种入 `n` 朵花?能则返回 `True`,不能则返回 `False`。 +给定一个花坛(表示为一个数组包含0和1,其中0表示没种植花,1表示种植了花),和一个数 n 。能否在不打破种植规则的情况下种入 n 朵花?能则返回True,不能则返回False。
+ +示例 1:
+ ++输入: flowerbed = [1,0,0,0,1], n = 1 +输出: True ++ +
示例 2:
+ ++输入: flowerbed = [1,0,0,0,1], n = 2 +输出: False ++ +
注意:
+ +-
+
- 数组内已种好的花不会违反种植规则。 +
- 输入的数组长度范围为 [1, 20000]。 +
- n 是非负整数,且不会超过输入数组的大小。 +
你需要采用前序遍历的方式,将一个二叉树转换成一个由括号和整数组成的字符串。
+ +空节点则用一对空括号 "()" 表示。而且你需要省略所有不影响字符串与原始二叉树之间的一对一映射关系的空括号对。
+ +示例 1:
+ ++输入: 二叉树: [1,2,3,4] + 1 + / \ + 2 3 + / + 4 + +输出: "1(2(4))(3)" + +解释: 原本将是“1(2(4)())(3())”, +在你省略所有不必要的空括号对之后, +它将是“1(2(4))(3)”。 ++ +
示例 2:
+ ++输入: 二叉树: [1,2,3,null,4] + 1 + / \ + 2 3 + \ + 4 + +输出: "1(2()(4))(3)" + +解释: 和第一个示例相似, +除了我们不能省略第一个对括号来中断输入和输出之间的一对一映射关系。 ++ + + +## 解法 + + + +### Python3 + + +```python + +``` + +### Java + + +```java + +``` + +### ... +``` + +``` diff --git a/solution/0600-0699/0607.Sales Person/README.md b/solution/0600-0699/0607.Sales Person/README.md new file mode 100644 index 0000000000000..466d6cf9c7c46 --- /dev/null +++ b/solution/0600-0699/0607.Sales Person/README.md @@ -0,0 +1,29 @@ +# [607. 销售员](https://leetcode-cn.com/problems/sales-person) + +## 题目描述 + +None + + +## 解法 + + + +### Python3 + + +```python + +``` + +### Java + + +```java + +``` + +### ... +``` + +``` diff --git a/solution/0600-0699/0608.Tree Node/README.md b/solution/0600-0699/0608.Tree Node/README.md new file mode 100644 index 0000000000000..3221254f11faf --- /dev/null +++ b/solution/0600-0699/0608.Tree Node/README.md @@ -0,0 +1,29 @@ +# [608. 树节点](https://leetcode-cn.com/problems/tree-node) + +## 题目描述 + +None + + +## 解法 + + + +### Python3 + + +```python + +``` + +### Java + + +```java + +``` + +### ... +``` + +``` diff --git a/solution/0600-0699/0609.Find Duplicate File in System/README.md b/solution/0600-0699/0609.Find Duplicate File in System/README.md new file mode 100644 index 0000000000000..eb1d59fc0d146 --- /dev/null +++ b/solution/0600-0699/0609.Find Duplicate File in System/README.md @@ -0,0 +1,72 @@ +# [609. 在系统中查找重复文件](https://leetcode-cn.com/problems/find-duplicate-file-in-system) + +## 题目描述 + +
给定一个目录信息列表,包括目录路径,以及该目录中的所有包含内容的文件,您需要找到文件系统中的所有重复文件组的路径。一组重复的文件至少包括二个具有完全相同内容的文件。
+ +输入列表中的单个目录信息字符串的格式如下:
+ +"root/d1/d2/.../dm f1.txt(f1_content) f2.txt(f2_content) ... fn.txt(fn_content)"
这意味着有 n 个文件(f1.txt, f2.txt ... fn.txt 的内容分别是 f1_content, f2_content ... fn_content)在目录 root/d1/d2/.../dm 下。注意:n>=1 且 m>=0。如果 m=0,则表示该目录是根目录。
该输出是重复文件路径组的列表。对于每个组,它包含具有相同内容的文件的所有文件路径。文件路径是具有下列格式的字符串:
+ +"directory_path/file_name.txt"
示例 1:
+ +输入: +["root/a 1.txt(abcd) 2.txt(efgh)", "root/c 3.txt(abcd)", "root/c/d 4.txt(efgh)", "root 4.txt(efgh)"] +输出: +[["root/a/2.txt","root/c/d/4.txt","root/4.txt"],["root/a/1.txt","root/c/3.txt"]] ++ +
+ +
注:
+ +-
+
- 最终输出不需要顺序。 +
- 您可以假设目录名、文件名和文件内容只有字母和数字,并且文件内容的长度在 [1,50] 的范围内。 +
- 给定的文件数量在 [1,20000] 个范围内。 +
- 您可以假设在同一目录中没有任何文件或目录共享相同的名称。 +
- 您可以假设每个给定的目录信息代表一个唯一的目录。目录路径和文件信息用一个空格分隔。 +
+ +
超越竞赛的后续行动:
+ +-
+
- 假设您有一个真正的文件系统,您将如何搜索文件?广度搜索还是宽度搜索? +
- 如果文件内容非常大(GB级别),您将如何修改您的解决方案? +
- 如果每次只能读取 1 kb 的文件,您将如何修改解决方案? +
- 修改后的解决方案的时间复杂度是多少?其中最耗时的部分和消耗内存的部分是什么?如何优化? +
- 如何确保您发现的重复文件不是误报? +
给定一个包含非负整数的数组,你的任务是统计其中可以组成三角形三条边的三元组个数。
+ +示例 1:
+ ++输入: [2,2,3,4] +输出: 3 +解释: +有效的组合是: +2,3,4 (使用第一个 2) +2,3,4 (使用第二个 2) +2,2,3 ++ +
注意:
+ +-
+
- 数组长度不超过1000。 +
- 数组里整数的范围为 [0, 1000]。 +
给定两个二叉树,想象当你将它们中的一个覆盖到另一个上时,两个二叉树的一些节点便会重叠。
+ +你需要将他们合并为一个新的二叉树。合并的规则是如果两个节点重叠,那么将他们的值相加作为节点合并后的新值,否则不为 NULL 的节点将直接作为新二叉树的节点。
+ +示例 1:
+ ++输入: + Tree 1 Tree 2 + 1 2 + / \ / \ + 3 2 1 3 + / \ \ + 5 4 7 +输出: +合并后的树: + 3 + / \ + 4 5 + / \ \ + 5 4 7 ++ +
注意: 合并必须从两个树的根节点开始。
+ + + +## 解法 + + + +### Python3 + + +```python + +``` + +### Java + + +```java + +``` + +### ... +``` + +``` diff --git a/solution/0600-0699/0618.Students Report By Geography/README.md b/solution/0600-0699/0618.Students Report By Geography/README.md new file mode 100644 index 0000000000000..a3dff8ef628c8 --- /dev/null +++ b/solution/0600-0699/0618.Students Report By Geography/README.md @@ -0,0 +1,29 @@ +# [618. 学生地理信息报告](https://leetcode-cn.com/problems/students-report-by-geography) + +## 题目描述 + +None + + +## 解法 + + + +### Python3 + + +```python + +``` + +### Java + + +```java + +``` + +### ... +``` + +``` diff --git a/solution/0600-0699/0619.Biggest Single Number/README.md b/solution/0600-0699/0619.Biggest Single Number/README.md new file mode 100644 index 0000000000000..a3bceeb50ec43 --- /dev/null +++ b/solution/0600-0699/0619.Biggest Single Number/README.md @@ -0,0 +1,29 @@ +# [619. 只出现一次的最大数字](https://leetcode-cn.com/problems/biggest-single-number) + +## 题目描述 + +None + + +## 解法 + + + +### Python3 + + +```python + +``` + +### Java + + +```java + +``` + +### ... +``` + +``` diff --git a/solution/0600-0699/0620.Not Boring Movies/README.md b/solution/0600-0699/0620.Not Boring Movies/README.md index cf8a122c7c62e..6636a8c6b4b90 100644 --- a/solution/0600-0699/0620.Not Boring Movies/README.md +++ b/solution/0600-0699/0620.Not Boring Movies/README.md @@ -1,15 +1,16 @@ -## 有趣的电影 -### 题目描述 +# [620. 有趣的电影](https://leetcode-cn.com/problems/not-boring-movies) +## 题目描述 + +某城市开了一家新的电影院,吸引了很多人过来看电影。该电影院特别注意用户体验,专门有个 LED显示板做电影推荐,上面公布着影评和相关电影描述。
-某城市开了一家新的电影院,吸引了很多人过来看电影。该电影院特别注意用户体验,专门有个 LED显示板做电影推荐,上面公布着影评和相关电影描述。 +作为该电影院的信息部主管,您需要编写一个 SQL查询,找出所有影片描述为非 boring (不无聊) 的并且 id 为奇数 的影片,结果请按等级 rating 排列。
- +
例如,下表 cinema:
+---------+-----------+--------------+-----------+ | id | movie | description | rating | +---------+-----------+--------------+-----------+ @@ -19,37 +20,42 @@ | 4 | Ice song | Fantacy | 8.6 | | 5 | House card| Interesting| 9.1 | +---------+-----------+--------------+-----------+ -``` +-对于上面的例子,则正确的输出是为: -``` +
对于上面的例子,则正确的输出是为:
+ ++---------+-----------+--------------+-----------+ | id | movie | description | rating | +---------+-----------+--------------+-----------+ | 5 | House card| Interesting| 9.1 | | 1 | War | great 3D | 8.9 | +---------+-----------+--------------+-----------+ -``` ++ +
+ -### 解法 -简单查询即可。 -```sql -# Write your MySQL query statement below +## 解法 + -select id, movie, description, rating -from cinema -where description != 'boring' and mod(id, 2) = 1 -order by rating desc; + +### Python3 + + +```python ``` -#### Input -```json -{"headers":{"cinema":["id", "movie", "description", "rating"]},"rows":{"cinema":[[1, "War", "great 3D", 8.9], [2, "Science", "fiction", 8.5], [3, "irish", "boring", 6.2], [4, "Ice song", "Fantacy", 8.6], [5, "House card", "Interesting", 9.1]]}} +### Java + + +```java + ``` -#### Output -```json -{"headers":["id","movie","description","rating"],"values":[[5,"House card","Interesting",9.1],[1,"War","great 3D",8.9]]} -``` \ No newline at end of file +### ... +``` + +``` diff --git a/solution/0600-0699/0621.Task Scheduler/README.md b/solution/0600-0699/0621.Task Scheduler/README.md new file mode 100644 index 0000000000000..b33d79aa4367f --- /dev/null +++ b/solution/0600-0699/0621.Task Scheduler/README.md @@ -0,0 +1,49 @@ +# [621. 任务调度器](https://leetcode-cn.com/problems/task-scheduler) + +## 题目描述 + +
给定一个用字符数组表示的 CPU 需要执行的任务列表。其中包含使用大写的 A - Z 字母表示的26 种不同种类的任务。任务可以以任意顺序执行,并且每个任务都可以在 1 个单位时间内执行完。CPU 在任何一个单位时间内都可以执行一个任务,或者在待命状态。
+ +然而,两个相同种类的任务之间必须有长度为 n 的冷却时间,因此至少有连续 n 个单位时间内 CPU 在执行不同的任务,或者在待命状态。
+ +你需要计算完成所有任务所需要的最短时间。
+ +示例 1:
+ ++输入: tasks = ["A","A","A","B","B","B"], n = 2 +输出: 8 +执行顺序: A -> B -> (待命) -> A -> B -> (待命) -> A -> B. ++ +
注:
+ +-
+
- 任务的总个数为 [1, 10000]。 +
- n 的取值范围为 [0, 100]。 +
设计你的循环队列实现。 循环队列是一种线性数据结构,其操作表现基于 FIFO(先进先出)原则并且队尾被连接在队首之后以形成一个循环。它也被称为“环形缓冲器”。
+ +循环队列的一个好处是我们可以利用这个队列之前用过的空间。在一个普通队列里,一旦一个队列满了,我们就不能插入下一个元素,即使在队列前面仍有空间。但是使用循环队列,我们能使用这些空间去存储新的值。
+ +你的实现应该支持如下操作:
+ +-
+
MyCircularQueue(k): 构造器,设置队列长度为 k 。
+ Front: 从队首获取元素。如果队列为空,返回 -1 。
+ Rear: 获取队尾元素。如果队列为空,返回 -1 。
+ enQueue(value): 向循环队列插入一个元素。如果成功插入则返回真。
+ deQueue(): 从循环队列中删除一个元素。如果成功删除则返回真。
+ isEmpty(): 检查循环队列是否为空。
+ isFull(): 检查循环队列是否已满。
+
+ +
示例:
+ +MyCircularQueue circularQueue = new MycircularQueue(3); // 设置长度为 3 + +circularQueue.enQueue(1); // 返回 true + +circularQueue.enQueue(2); // 返回 true + +circularQueue.enQueue(3); // 返回 true + +circularQueue.enQueue(4); // 返回 false,队列已满 + +circularQueue.Rear(); // 返回 3 + +circularQueue.isFull(); // 返回 true + +circularQueue.deQueue(); // 返回 true + +circularQueue.enQueue(4); // 返回 true + +circularQueue.Rear(); // 返回 4 ++ +
+ +
提示:
+ +-
+
- 所有的值都在 0 至 1000 的范围内; +
- 操作数将在 1 至 1000 的范围内; +
- 请不要使用内置的队列库。 +
给定一个二叉树,根节点为第1层,深度为 1。在其第 d 层追加一行值为 v 的节点。
添加规则:给定一个深度值 d (正整数),针对深度为 d-1 层的每一非空节点 N,为 N 创建两个值为 v 的左子树和右子树。
将 N 原先的左子树,连接为新节点 v 的左子树;将 N 原先的右子树,连接为新节点 v 的右子树。
如果 d 的值为 1,深度 d - 1 不存在,则创建一个新的根节点 v,原先的整棵树将作为 v 的左子树。
示例 1:
+ ++输入: +二叉树如下所示: + 4 + / \ + 2 6 + / \ / + 3 1 5 + +v = 1 + +d = 2 + +输出: + 4 + / \ + 1 1 + / \ + 2 6 + / \ / + 3 1 5 + ++ +
示例 2:
+ ++输入: +二叉树如下所示: + 4 + / + 2 + / \ + 3 1 + +v = 1 + +d = 3 + +输出: + 4 + / + 2 + / \ + 1 1 + / \ +3 1 ++ +
注意:
+ +-
+
- 输入的深度值 d 的范围是:[1,二叉树最大深度 + 1]。 +
- 输入的二叉树至少有一个节点。 +
小美是一所中学的信息科技老师,她有一张 seat 座位表,平时用来储存学生名字和与他们相对应的座位 id。
其中纵列的 id 是连续递增的
+ +小美想改变相邻俩学生的座位。
+ +你能不能帮她写一个 SQL query 来输出小美想要的结果呢?
+ ++ +
示例:
+ +++---------+---------+ +| id | student | ++---------+---------+ +| 1 | Abbot | +| 2 | Doris | +| 3 | Emerson | +| 4 | Green | +| 5 | Jeames | ++---------+---------+ ++ +
假如数据输入的是上表,则输出结果如下:
+ +++---------+---------+ +| id | student | ++---------+---------+ +| 1 | Doris | +| 2 | Abbot | +| 3 | Green | +| 4 | Emerson | +| 5 | Jeames | ++---------+---------++ +
注意:
+ +如果学生人数是奇数,则不需要改变最后一个同学的座位。
+ + + +## 解法 + + + +### Python3 + + +```python + +``` + +### Java + + +```java + +``` + +### ... +``` + +``` diff --git a/solution/0600-0699/0627.Swap Salary/README.md b/solution/0600-0699/0627.Swap Salary/README.md index 4e53b40a2a9ef..46d430191b47a 100644 --- a/solution/0600-0699/0627.Swap Salary/README.md +++ b/solution/0600-0699/0627.Swap Salary/README.md @@ -1,47 +1,52 @@ -## 交换工资 -### 题目描述 +# [627. 交换工资](https://leetcode-cn.com/problems/swap-salary) -给定一个 `salary` 表,如下所示,有m=男性 和 f=女性的值 。交换所有的 f 和 m 值(例如,将所有 f 值更改为 m,反之亦然)。要求使用一个更新查询,并且没有中间临时表。 +## 题目描述 + +给定一个 salary 表,如下所示,有 m = 男性 和 f = 女性 的值。交换所有的 f 和 m 值(例如,将所有 f 值更改为 m,反之亦然)。要求只使用一个更新(Update)语句,并且没有中间的临时表。
注意,您必只能写一个 Update 语句,请不要编写任何 Select 语句。
+ +例如:
+ +| id | name | sex | salary | |----|------|-----|--------| | 1 | A | m | 2500 | | 2 | B | f | 1500 | | 3 | C | m | 5500 | | 4 | D | f | 500 | -``` +-运行你所编写的查询语句之后,将会得到以下表: -``` -| id | name | sex | salary | +
运行你所编写的更新语句之后,将会得到以下表:
+ +| id | name | sex | salary | |----|------|-----|--------| | 1 | A | f | 2500 | | 2 | B | m | 1500 | | 3 | C | f | 5500 | | 4 | D | m | 500 | -``` ++ -### 解法 -使用 `if` 函数 或者 `case when .. then .. else ... end`。 -```sql -# Write your MySQL query statement below -# update salary -# set sex = if(sex = 'm', 'f', 'm') +## 解法 + -update salary -set sex = (case when sex = 'f' then 'm' else 'f' end) + +### Python3 + + +```python ``` -#### Input -```json -{"headers":{"salary":["id","name","sex","salary"]},"rows":{"salary":[[1,"A","m",2500],[2,"B","f",1500],[3,"C","m",5500],[4,"D","f",500]]}} +### Java + + +```java + ``` -#### Output -```json -{"headers":["id","name","sex","salary"],"values":[[1,"A","f",2500],[2,"B","m",1500],[3,"C","f",5500],[4,"D","m",500]]} -``` \ No newline at end of file +### ... +``` + +``` diff --git a/solution/0600-0699/0628.Maximum Product of Three Numbers/README.md b/solution/0600-0699/0628.Maximum Product of Three Numbers/README.md new file mode 100644 index 0000000000000..2f20512547935 --- /dev/null +++ b/solution/0600-0699/0628.Maximum Product of Three Numbers/README.md @@ -0,0 +1,51 @@ +# [628. 三个数的最大乘积](https://leetcode-cn.com/problems/maximum-product-of-three-numbers) + +## 题目描述 + +
给定一个整型数组,在数组中找出由三个数组成的最大乘积,并输出这个乘积。
+ +示例 1:
+ ++输入: [1,2,3] +输出: 6 ++ +
示例 2:
+ ++输入: [1,2,3,4] +输出: 24 ++ +
注意:
+ +-
+
- 给定的整型数组长度范围是[3,104],数组中所有的元素范围是[-1000, 1000]。 +
- 输入的数组中任意三个数的乘积不会超出32位有符号整数的范围。 +
给出两个整数 n 和 k,找出所有包含从 1 到 n 的数字,且恰好拥有 k 个逆序对的不同的数组的个数。
逆序对的定义如下:对于数组的第i个和第 j个元素,如果满i < j且 a[i] > a[j],则其为一个逆序对;否则不是。
由于答案可能很大,只需要返回 答案 mod 109 + 7 的值。
+ +示例 1:
+ ++输入: n = 3, k = 0 +输出: 1 +解释: +只有数组 [1,2,3] 包含了从1到3的整数并且正好拥有 0 个逆序对。 ++ +
示例 2:
+ ++输入: n = 3, k = 1 +输出: 2 +解释: +数组 [1,3,2] 和 [2,1,3] 都有 1 个逆序对。 ++ +
说明:
+ +-
+
-
n的范围是 [1, 1000] 并且k的范围是 [0, 1000]。
+
这里有 n 门不同的在线课程,他们按从 1 到 n 编号。每一门课程有一定的持续上课时间(课程时间)t 以及关闭时间第 d 天。一门课要持续学习 t 天直到第 d 天时要完成,你将会从第 1 天开始。
给出 n 个在线课程用 (t, d) 对表示。你的任务是找出最多可以修几门课。
+ +
示例:
+ ++输入: [[100, 200], [200, 1300], [1000, 1250], [2000, 3200]] +输出: 3 +解释: +这里一共有 4 门课程, 但是你最多可以修 3 门: +首先, 修第一门课时, 它要耗费 100 天,你会在第 100 天完成, 在第 101 天准备下门课。 +第二, 修第三门课时, 它会耗费 1000 天,所以你将在第 1100 天的时候完成它, 以及在第 1101 天开始准备下门课程。 +第三, 修第二门课时, 它会耗时 200 天,所以你将会在第 1300 天时完成它。 +第四门课现在不能修,因为你将会在第 3300 天完成它,这已经超出了关闭日期。+ +
+ +
提示:
+ +-
+
- 整数 1 <= d, t, n <= 10,000 。 +
- 你不能同时修两门课程。 +
+ + + +## 解法 + + + +### Python3 + + +```python + +``` + +### Java + + +```java + +``` + +### ... +``` + +``` diff --git a/solution/0600-0699/0631.Design Excel Sum Formula/README.md b/solution/0600-0699/0631.Design Excel Sum Formula/README.md new file mode 100644 index 0000000000000..8688ba95b59f8 --- /dev/null +++ b/solution/0600-0699/0631.Design Excel Sum Formula/README.md @@ -0,0 +1,29 @@ +# [631. 设计 Excel 求和公式](https://leetcode-cn.com/problems/design-excel-sum-formula) + +## 题目描述 + +None + + +## 解法 + + + +### Python3 + + +```python + +``` + +### Java + + +```java + +``` + +### ... +``` + +``` diff --git a/solution/0600-0699/0632.Smallest Range Covering Elements from K Lists/README.md b/solution/0600-0699/0632.Smallest Range Covering Elements from K Lists/README.md new file mode 100644 index 0000000000000..45c4dce2844b7 --- /dev/null +++ b/solution/0600-0699/0632.Smallest Range Covering Elements from K Lists/README.md @@ -0,0 +1,52 @@ +# [632. 最小区间](https://leetcode-cn.com/problems/smallest-range-covering-elements-from-k-lists) + +## 题目描述 + +
你有 k 个升序排列的整数数组。找到一个最小区间,使得 k 个列表中的每个列表至少有一个数包含在其中。
我们定义如果 b-a < d-c 或者在 b-a == d-c 时 a < c,则区间 [a,b] 比 [c,d] 小。
示例 1:
+ ++输入:[[4,10,15,24,26], [0,9,12,20], [5,18,22,30]] +输出: [20,24] +解释: +列表 1:[4, 10, 15, 24, 26],24 在区间 [20,24] 中。 +列表 2:[0, 9, 12, 20],20 在区间 [20,24] 中。 +列表 3:[5, 18, 22, 30],22 在区间 [20,24] 中。 ++ +
注意:
+ +-
+
- 给定的列表可能包含重复元素,所以在这里升序表示 >= 。 +
- 1 <=
k<= 3500
+ - -105 <=
元素的值<= 105
+ - 对于使用Java的用户,请注意传入类型已修改为List<List<Integer>>。重置代码模板后可以看到这项改动。 +
给定一个非负整数 c ,你要判断是否存在两个整数 a 和 b,使得 a2 + b2 = c。
示例1:
+ ++输入: 5 +输出: True +解释: 1 * 1 + 2 * 2 = 5 ++ +
+ +
示例2:
+ ++输入: 3 +输出: False ++ + + +## 解法 + + + +### Python3 + + +```python + +``` + +### Java + + +```java + +``` + +### ... +``` + +``` diff --git a/solution/0600-0699/0634.Find the Derangement of An Array/README.md b/solution/0600-0699/0634.Find the Derangement of An Array/README.md new file mode 100644 index 0000000000000..91e6379041857 --- /dev/null +++ b/solution/0600-0699/0634.Find the Derangement of An Array/README.md @@ -0,0 +1,29 @@ +# [634. 寻找数组的错位排列](https://leetcode-cn.com/problems/find-the-derangement-of-an-array) + +## 题目描述 + +None + + +## 解法 + + + +### Python3 + + +```python + +``` + +### Java + + +```java + +``` + +### ... +``` + +``` diff --git a/solution/0600-0699/0635.Design Log Storage System/README.md b/solution/0600-0699/0635.Design Log Storage System/README.md new file mode 100644 index 0000000000000..a49227a7b931f --- /dev/null +++ b/solution/0600-0699/0635.Design Log Storage System/README.md @@ -0,0 +1,29 @@ +# [635. 设计日志存储系统](https://leetcode-cn.com/problems/design-log-storage-system) + +## 题目描述 + +None + + +## 解法 + + + +### Python3 + + +```python + +``` + +### Java + + +```java + +``` + +### ... +``` + +``` diff --git a/solution/0600-0699/0636.Exclusive Time of Functions/README.md b/solution/0600-0699/0636.Exclusive Time of Functions/README.md new file mode 100644 index 0000000000000..544555d6b9336 --- /dev/null +++ b/solution/0600-0699/0636.Exclusive Time of Functions/README.md @@ -0,0 +1,63 @@ +# [636. 函数的独占时间](https://leetcode-cn.com/problems/exclusive-time-of-functions) + +## 题目描述 + +
给出一个非抢占单线程CPU的 n 个函数运行日志,找到函数的独占时间。
+ +每个函数都有一个唯一的 Id,从 0 到 n-1,函数可能会递归调用或者被其他函数调用。
+ +日志是具有以下格式的字符串:function_id:start_or_end:timestamp。例如:"0:start:0" 表示函数 0 从 0 时刻开始运行。"0:end:0" 表示函数 0 在 0 时刻结束。
函数的独占时间定义是在该方法中花费的时间,调用其他函数花费的时间不算该函数的独占时间。你需要根据函数的 Id 有序地返回每个函数的独占时间。
+ +示例 1:
+ +输入: +n = 2 +logs = +["0:start:0", + "1:start:2", + "1:end:5", + "0:end:6"] +输出:[3, 4] +说明: +函数 0 在时刻 0 开始,在执行了 2个时间单位结束于时刻 1。 +现在函数 0 调用函数 1,函数 1 在时刻 2 开始,执行 4 个时间单位后结束于时刻 5。 +函数 0 再次在时刻 6 开始执行,并在时刻 6 结束运行,从而执行了 1 个时间单位。 +所以函数 0 总共的执行了 2 +1 =3 个时间单位,函数 1 总共执行了 4 个时间单位。 ++ +
说明:
+ +-
+
- 输入的日志会根据时间戳排序,而不是根据日志Id排序。 +
- 你的输出会根据函数Id排序,也就意味着你的输出数组中序号为 0 的元素相当于函数 0 的执行时间。 +
- 两个函数不会在同时开始或结束。 +
- 函数允许被递归调用,直到运行结束。 +
- 1 <= n <= 100 +
给定一个非空二叉树, 返回一个由每层节点平均值组成的数组.
+ +示例 1:
+ +输入: + 3 + / \ + 9 20 + / \ + 15 7 +输出: [3, 14.5, 11] +解释: +第0层的平均值是 3, 第1层是 14.5, 第2层是 11. 因此返回 [3, 14.5, 11]. ++ +
注意:
+ +-
+
- 节点值的范围在32位有符号整数范围内。 +
在LeetCode商店中, 有许多在售的物品。
+ +然而,也有一些大礼包,每个大礼包以优惠的价格捆绑销售一组物品。
+ +现给定每个物品的价格,每个大礼包包含物品的清单,以及待购物品清单。请输出确切完成待购清单的最低花费。
+ +每个大礼包的由一个数组中的一组数据描述,最后一个数字代表大礼包的价格,其他数字分别表示内含的其他种类物品的数量。
+ +任意大礼包可无限次购买。
+ +示例 1:
+ +输入: [2,5], [[3,0,5],[1,2,10]], [3,2] +输出: 14 +解释: +有A和B两种物品,价格分别为¥2和¥5。 +大礼包1,你可以以¥5的价格购买3A和0B。 +大礼包2, 你可以以¥10的价格购买1A和2B。 +你需要购买3个A和2个B, 所以你付了¥10购买了1A和2B(大礼包2),以及¥4购买2A。+ +
示例 2:
+ +输入: [2,3,4], [[1,1,0,4],[2,2,1,9]], [1,2,1] +输出: 11 +解释: +A,B,C的价格分别为¥2,¥3,¥4. +你可以用¥4购买1A和1B,也可以用¥9购买2A,2B和1C。 +你需要买1A,2B和1C,所以你付了¥4买了1A和1B(大礼包1),以及¥3购买1B, ¥4购买1C。 +你不可以购买超出待购清单的物品,尽管购买大礼包2更加便宜。 ++ +
说明:
+ +-
+
- 最多6种物品, 100种大礼包。 +
- 每种物品,你最多只需要购买6个。 +
- 你不可以购买超出待购清单的物品,即使更便宜。 +
一条包含字母 A-Z 的消息通过以下的方式进行了编码:
'A' -> 1 +'B' -> 2 +... +'Z' -> 26 ++ +
除了上述的条件以外,现在加密字符串可以包含字符 '*'了,字符'*'可以被当做1到9当中的任意一个数字。
+ +给定一条包含数字和字符'*'的加密信息,请确定解码方法的总数。
+ +同时,由于结果值可能会相当的大,所以你应当对109 + 7取模。(翻译者标注:此处取模主要是为了防止溢出)
+ +示例 1 :
+ +输入: "*" +输出: 9 +解释: 加密的信息可以被解密为: "A", "B", "C", "D", "E", "F", "G", "H", "I". ++ +
示例 2 :
+ +输入: "1*" +输出: 9 + 9 = 18(翻译者标注:这里1*可以分解为1,* 或者当做1*来处理,所以结果是9+9=18) ++ +
说明 :
+ +-
+
- 输入的字符串长度范围是 [1, 105]。 +
- 输入的字符串只会包含字符 '*' 和 数字'0' - '9'。 +
求解一个给定的方程,将x以字符串"x=#value"的形式返回。该方程仅包含'+',' - '操作,变量 x 和其对应系数。
如果方程没有解,请返回“No solution”。
+ +如果方程有无限解,则返回“Infinite solutions”。
+ +如果方程中只有一个解,要保证返回值 x 是一个整数。
示例 1:
+ +输入: "x+5-3+x=6+x-2" +输出: "x=2" ++ +
示例 2:
+ +输入: "x=x" +输出: "Infinite solutions" ++ +
示例 3:
+ +输入: "2x=x" +输出: "x=0" ++ +
示例 4:
+ +输入: "2x+3x-6x=x+2" +输出: "x=-1" ++ +
示例 5:
+ +输入: "x=x+2" +输出: "No solution" ++ + + +## 解法 + + + +### Python3 + + +```python + +``` + +### Java + + +```java + +``` + +### ... +``` + +``` diff --git a/solution/0600-0699/0641.Design Circular Deque/README.md b/solution/0600-0699/0641.Design Circular Deque/README.md new file mode 100644 index 0000000000000..f6717bcfecd10 --- /dev/null +++ b/solution/0600-0699/0641.Design Circular Deque/README.md @@ -0,0 +1,67 @@ +# [641. 设计循环双端队列](https://leetcode-cn.com/problems/design-circular-deque) + +## 题目描述 + +
设计实现双端队列。
+你的实现需要支持以下操作:
-
+
- MyCircularDeque(k):构造函数,双端队列的大小为k。 +
- insertFront():将一个元素添加到双端队列头部。 如果操作成功返回 true。 +
- insertLast():将一个元素添加到双端队列尾部。如果操作成功返回 true。 +
- deleteFront():从双端队列头部删除一个元素。 如果操作成功返回 true。 +
- deleteLast():从双端队列尾部删除一个元素。如果操作成功返回 true。 +
- getFront():从双端队列头部获得一个元素。如果双端队列为空,返回 -1。 +
- getRear():获得双端队列的最后一个元素。 如果双端队列为空,返回 -1。 +
- isEmpty():检查双端队列是否为空。 +
- isFull():检查双端队列是否满了。 +
示例:
+ +MyCircularDeque circularDeque = new MycircularDeque(3); // 设置容量大小为3 +circularDeque.insertLast(1); // 返回 true +circularDeque.insertLast(2); // 返回 true +circularDeque.insertFront(3); // 返回 true +circularDeque.insertFront(4); // 已经满了,返回 false +circularDeque.getRear(); // 返回 2 +circularDeque.isFull(); // 返回 true +circularDeque.deleteLast(); // 返回 true +circularDeque.insertFront(4); // 返回 true +circularDeque.getFront(); // 返回 4 ++ +
+ +
提示:
+ +-
+
- 所有值的范围为 [1, 1000] +
- 操作次数的范围为 [1, 1000] +
- 请不要使用内置的双端队列库。 +
给定 n 个整数,找出平均数最大且长度为 k 的连续子数组,并输出该最大平均数。
示例 1:
+ +输入: [1,12,-5,-6,50,3], k = 4 +输出: 12.75 +解释: 最大平均数 (12-5-6+50)/4 = 51/4 = 12.75 ++ +
+ +
注意:
+ +-
+
- 1 <=
k<=n<= 30,000。
+ - 所给数据范围 [-10,000,10,000]。 +
集合 S 包含从1到 n 的整数。不幸的是,因为数据错误,导致集合里面某一个元素复制了成了集合里面的另外一个元素的值,导致集合丢失了一个整数并且有一个元素重复。
给定一个数组 nums 代表了集合 S 发生错误后的结果。你的任务是首先寻找到重复出现的整数,再找到丢失的整数,将它们以数组的形式返回。
示例 1:
+ ++输入: nums = [1,2,2,4] +输出: [2,3] ++ +
注意:
+ +-
+
- 给定数组的长度范围是 [2, 10000]。 +
- 给定的数组是无序的。 +
给出 n 个数对。 在每一个数对中,第一个数字总是比第二个数字小。
现在,我们定义一种跟随关系,当且仅当 b < c 时,数对(c, d) 才可以跟在 (a, b) 后面。我们用这种形式来构造一个数对链。
给定一个对数集合,找出能够形成的最长数对链的长度。你不需要用到所有的数对,你可以以任何顺序选择其中的一些数对来构造。
+ +示例 :
+ ++输入: [[1,2], [2,3], [3,4]] +输出: 2 +解释: 最长的数对链是 [1,2] -> [3,4] ++ +
注意:
+ +-
+
- 给出数对的个数在 [1, 1000] 范围内。 +
给定一个字符串,你的任务是计算这个字符串中有多少个回文子串。
+ +具有不同开始位置或结束位置的子串,即使是由相同的字符组成,也会被计为是不同的子串。
+ +示例 1:
+ ++输入: "abc" +输出: 3 +解释: 三个回文子串: "a", "b", "c". ++ +
示例 2:
+ ++输入: "aaa" +输出: 6 +说明: 6个回文子串: "a", "a", "a", "aa", "aa", "aaa". ++ +
注意:
+ +-
+
- 输入的字符串长度不会超过1000。 +
在英语中,我们有一个叫做 词根(root)的概念,它可以跟着其他一些词组成另一个较长的单词——我们称这个词为 继承词(successor)。例如,词根an,跟随着单词 other(其他),可以形成新的单词 another(另一个)。
现在,给定一个由许多词根组成的词典和一个句子。你需要将句子中的所有继承词用词根替换掉。如果继承词有许多可以形成它的词根,则用最短的词根替换它。
你需要输出替换之后的句子。
+ +示例 1:
+ ++输入: dict(词典) = ["cat", "bat", "rat"] +sentence(句子) = "the cattle was rattled by the battery" +输出: "the cat was rat by the bat" ++ +
注:
+ +-
+
- 输入只包含小写字母。 +
- 1 <= 字典单词数 <=1000 +
- 1 <= 句中词语数 <= 1000 +
- 1 <= 词根长度 <= 100 +
- 1 <= 句中词语长度 <= 1000 +
Dota2 的世界里有两个阵营:Radiant(天辉)和 Dire(夜魇)
Dota2 参议院由来自两派的参议员组成。现在参议院希望对一个 Dota2 游戏里的改变作出决定。他们以一个基于轮为过程的投票进行。在每一轮中,每一位参议员都可以行使两项权利中的一项:
-
+
-
+
+ +禁止一名参议员的权利:参议员可以让另一位参议员在这一轮和随后的几轮中丧失所有的权利。
+
+ -
+
+宣布胜利:
+
如果参议员发现有权利投票的参议员都是同一个阵营的,他可以宣布胜利并决定在游戏中的有关变化。
+ ++ +
给定一个字符串代表每个参议员的阵营。字母 “R” 和 “D” 分别代表了 Radiant(天辉)和 Dire(夜魇)。然后,如果有 n 个参议员,给定字符串的大小将是 n。
以轮为基础的过程从给定顺序的第一个参议员开始到最后一个参议员结束。这一过程将持续到投票结束。所有失去权利的参议员将在过程中被跳过。
+ +假设每一位参议员都足够聪明,会为自己的政党做出最好的策略,你需要预测哪一方最终会宣布胜利并在 Dota2 游戏中决定改变。输出应该是 Radiant 或 Dire。
+ +
示例 1:
+ +输入: "RD"
+输出: "Radiant"
+解释: 第一个参议员来自 Radiant 阵营并且他可以使用第一项权利让第二个参议员失去权力,因此第二个参议员将被跳过因为他没有任何权利。然后在第二轮的时候,第一个参议员可以宣布胜利,因为他是唯一一个有投票权的人
+
+
+示例 2:
+ +输入: "RDD" +输出: "Dire" +解释: +第一轮中,第一个+ +来自 Radiant 阵营的参议员可以使用第一项权利禁止第二个参议员的权利 +第二个来自 Dire 阵营的参议员会被跳过因为他的权利被禁止 +第三个来自 Dire 阵营的参议员可以使用他的第一项权利禁止第一个参议员的权利 +因此在第二轮只剩下第三个参议员拥有投票的权利,于是他可以宣布胜利 +
+ +
注意:
+ +-
+
- 给定字符串的长度在 [1, 10,000] 之间. +
+ + + +## 解法 + + + +### Python3 + + +```python + +``` + +### Java + + +```java + +``` + +### ... +``` + +``` diff --git a/solution/0600-0699/0650.2 Keys Keyboard/README.md b/solution/0600-0699/0650.2 Keys Keyboard/README.md new file mode 100644 index 0000000000000..dbabc8674b08f --- /dev/null +++ b/solution/0600-0699/0650.2 Keys Keyboard/README.md @@ -0,0 +1,55 @@ +# [650. 只有两个键的键盘](https://leetcode-cn.com/problems/2-keys-keyboard) + +## 题目描述 + +
最初在一个记事本上只有一个字符 'A'。你每次可以对这个记事本进行两种操作:
+ +-
+
Copy All(复制全部) : 你可以复制这个记事本中的所有字符(部分的复制是不允许的)。
+ Paste(粘贴) : 你可以粘贴你上一次复制的字符。
+
给定一个数字 n 。你需要使用最少的操作次数,在记事本中打印出恰好 n 个 'A'。输出能够打印出 n 个 'A' 的最少操作次数。
示例 1:
+ ++输入: 3 +输出: 3 +解释: +最初, 我们只有一个字符 'A'。 +第 1 步, 我们使用 Copy All 操作。 +第 2 步, 我们使用 Paste 操作来获得 'AA'。 +第 3 步, 我们使用 Paste 操作来获得 'AAA'。 ++ +
说明:
+ +-
+
n的取值范围是 [1, 1000] 。
+
给定一棵二叉树,返回所有重复的子树。对于同一类的重复子树,你只需要返回其中任意一棵的根结点即可。
+ +两棵树重复是指它们具有相同的结构以及相同的结点值。
+ +示例 1:
+ +1 + / \ + 2 3 + / / \ + 4 2 4 + / + 4 ++ +
下面是两个重复的子树:
+ +2 + / + 4 ++ +
和
+ +4 ++ +
因此,你需要以列表的形式返回上述重复子树的根结点。
+ + + +## 解法 + + + +### Python3 + + +```python + +``` + +### Java + + +```java + +``` + +### ... +``` + +``` diff --git a/solution/0600-0699/0653.Two Sum IV - Input is a BST/README.md b/solution/0600-0699/0653.Two Sum IV - Input is a BST/README.md new file mode 100644 index 0000000000000..7fc29f06a1aad --- /dev/null +++ b/solution/0600-0699/0653.Two Sum IV - Input is a BST/README.md @@ -0,0 +1,64 @@ +# [653. 两数之和 IV - 输入 BST](https://leetcode-cn.com/problems/two-sum-iv-input-is-a-bst) + +## 题目描述 + +给定一个二叉搜索树和一个目标结果,如果 BST 中存在两个元素且它们的和等于给定的目标结果,则返回 true。
+ +案例 1:
+ ++输入: + 5 + / \ + 3 6 + / \ \ +2 4 7 + +Target = 9 + +输出: True ++ +
+ +
案例 2:
+ ++输入: + 5 + / \ + 3 6 + / \ \ +2 4 7 + +Target = 28 + +输出: False ++ +
+ + + +## 解法 + + + +### Python3 + + +```python + +``` + +### Java + + +```java + +``` + +### ... +``` + +``` diff --git a/solution/0600-0699/0654.Maximum Binary Tree/README.md b/solution/0600-0699/0654.Maximum Binary Tree/README.md new file mode 100644 index 0000000000000..7571ee9f37aa0 --- /dev/null +++ b/solution/0600-0699/0654.Maximum Binary Tree/README.md @@ -0,0 +1,62 @@ +# [654. 最大二叉树](https://leetcode-cn.com/problems/maximum-binary-tree) + +## 题目描述 + +
给定一个不含重复元素的整数数组。一个以此数组构建的最大二叉树定义如下:
+ +-
+
- 二叉树的根是数组中的最大元素。 +
- 左子树是通过数组中最大值左边部分构造出的最大二叉树。 +
- 右子树是通过数组中最大值右边部分构造出的最大二叉树。 +
通过给定的数组构建最大二叉树,并且输出这个树的根节点。
+ ++ +
示例 :
+ +输入:[3,2,1,6,0,5] +输出:返回下面这棵树的根节点: + + 6 + / \ + 3 5 + \ / + 2 0 + \ + 1 ++ +
+ +
提示:
+ +-
+
- 给定的数组的大小在 [1, 1000] 之间。 +
在一个 m*n 的二维字符串数组中输出二叉树,并遵守以下规则:
+ +-
+
- 行数
m应当等于给定二叉树的高度。
+ - 列数
n应当总是奇数。
+ - 根节点的值(以字符串格式给出)应当放在可放置的第一行正中间。根节点所在的行与列会将剩余空间划分为两部分(左下部分和右下部分)。你应该将左子树输出在左下部分,右子树输出在右下部分。左下和右下部分应当有相同的大小。即使一个子树为空而另一个非空,你不需要为空的子树输出任何东西,但仍需要为另一个子树留出足够的空间。然而,如果两个子树都为空则不需要为它们留出任何空间。 +
- 每个未使用的空间应包含一个空的字符串
""。
+ - 使用相同的规则输出子树。 +
示例 1:
+ ++输入: + 1 + / + 2 +输出: +[["", "1", ""], + ["2", "", ""]] ++ +
示例 2:
+ ++输入: + 1 + / \ + 2 3 + \ + 4 +输出: +[["", "", "", "1", "", "", ""], + ["", "2", "", "", "", "3", ""], + ["", "", "4", "", "", "", ""]] ++ +
示例 3:
+ ++输入: + 1 + / \ + 2 5 + / + 3 + / +4 +输出: +[["", "", "", "", "", "", "", "1", "", "", "", "", "", "", ""] + ["", "", "", "2", "", "", "", "", "", "", "", "5", "", "", ""] + ["", "3", "", "", "", "", "", "", "", "", "", "", "", "", ""] + ["4", "", "", "", "", "", "", "", "", "", "", "", "", "", ""]] ++ +
注意: 二叉树的高度在范围 [1, 10] 中。
+ + + +## 解法 + + + +### Python3 + + +```python + +``` + +### Java + + +```java + +``` + +### ... +``` + +``` diff --git a/solution/0600-0699/0656.Coin Path/README.md b/solution/0600-0699/0656.Coin Path/README.md new file mode 100644 index 0000000000000..2645a9be6f101 --- /dev/null +++ b/solution/0600-0699/0656.Coin Path/README.md @@ -0,0 +1,29 @@ +# [656. 金币路径](https://leetcode-cn.com/problems/coin-path) + +## 题目描述 + +None + + +## 解法 + + + +### Python3 + + +```python + +``` + +### Java + + +```java + +``` + +### ... +``` + +``` diff --git a/solution/0600-0699/0657.Robot Return to Origin/README.md b/solution/0600-0699/0657.Robot Return to Origin/README.md new file mode 100644 index 0000000000000..76ae26ebe6424 --- /dev/null +++ b/solution/0600-0699/0657.Robot Return to Origin/README.md @@ -0,0 +1,48 @@ +# [657. 机器人能否返回原点](https://leetcode-cn.com/problems/robot-return-to-origin) + +## 题目描述 + +在二维平面上,有一个机器人从原点 (0, 0) 开始。给出它的移动顺序,判断这个机器人在完成移动后是否在 (0, 0) 处结束。
+ +移动顺序由字符串表示。字符 move[i] 表示其第 i 次移动。机器人的有效动作有 R(右),L(左),U(上)和 D(下)。如果机器人在完成所有动作后返回原点,则返回 true。否则,返回 false。
注意:机器人“面朝”的方向无关紧要。 “R” 将始终使机器人向右移动一次,“L” 将始终向左移动等。此外,假设每次移动机器人的移动幅度相同。
+ ++ +
示例 1:
+ +输入: "UD" +输出: true +解释:机器人向上移动一次,然后向下移动一次。所有动作都具有相同的幅度,因此它最终回到它开始的原点。因此,我们返回 true。+ +
示例 2:
+ +输入: "LL" +输出: false +解释:机器人向左移动两次。它最终位于原点的左侧,距原点有两次 “移动” 的距离。我们返回 false,因为它在移动结束时没有返回原点。+ + + +## 解法 + + + +### Python3 + + +```python + +``` + +### Java + + +```java + +``` + +### ... +``` + +``` diff --git a/solution/0600-0699/0658.Find K Closest Elements/README.md b/solution/0600-0699/0658.Find K Closest Elements/README.md new file mode 100644 index 0000000000000..55b0cacd66ad7 --- /dev/null +++ b/solution/0600-0699/0658.Find K Closest Elements/README.md @@ -0,0 +1,61 @@ +# [658. 找到 K 个最接近的元素](https://leetcode-cn.com/problems/find-k-closest-elements) + +## 题目描述 + +
给定一个排序好的数组,两个整数 k 和 x,从数组中找到最靠近 x(两数之差最小)的 k 个数。返回的结果必须要是按升序排好的。如果有两个数与 x 的差值一样,优先选择数值较小的那个数。
示例 1:
+ ++输入: [1,2,3,4,5], k=4, x=3 +输出: [1,2,3,4] ++ +
+ +
示例 2:
+ ++输入: [1,2,3,4,5], k=4, x=-1 +输出: [1,2,3,4] ++ +
+ +
说明:
+ +-
+
- k 的值为正数,且总是小于给定排序数组的长度。 +
- 数组不为空,且长度不超过 104 +
- 数组里的每个元素与 x 的绝对值不超过 104 +
+ +
更新(2017/9/19):
+这个参数 arr 已经被改变为一个整数数组(而不是整数列表)。 请重新加载代码定义以获取最新更改。
输入一个按升序排序的整数数组(可能包含重复数字),你需要将它们分割成几个子序列,其中每个子序列至少包含三个连续整数。返回你是否能做出这样的分割?
+ ++ +
示例 1:
+ ++输入: [1,2,3,3,4,5] +输出: True +解释: +你可以分割出这样两个连续子序列 : +1, 2, 3 +3, 4, 5 ++ +
+ +
示例 2:
+ ++输入: [1,2,3,3,4,4,5,5] +输出: True +解释: +你可以分割出这样两个连续子序列 : +1, 2, 3, 4, 5 +3, 4, 5 ++ +
+ +
示例 3:
+ ++输入: [1,2,3,4,4,5] +输出: False ++ +
+ +
提示:
+ +-
+
- 输入的数组长度范围为 [1, 10000] +
+ + + +## 解法 + + + +### Python3 + + +```python + +``` + +### Java + + +```java + +``` + +### ... +``` + +``` diff --git a/solution/0600-0699/0660.Remove 9/README.md b/solution/0600-0699/0660.Remove 9/README.md new file mode 100644 index 0000000000000..ab9955da44c52 --- /dev/null +++ b/solution/0600-0699/0660.Remove 9/README.md @@ -0,0 +1,29 @@ +# [660. 移除 9](https://leetcode-cn.com/problems/remove-9) + +## 题目描述 + +None + + +## 解法 + + + +### Python3 + + +```python + +``` + +### Java + + +```java + +``` + +### ... +``` + +``` diff --git a/solution/0600-0699/0661.Image Smoother/README.md b/solution/0600-0699/0661.Image Smoother/README.md new file mode 100644 index 0000000000000..1c4894f12ca4d --- /dev/null +++ b/solution/0600-0699/0661.Image Smoother/README.md @@ -0,0 +1,54 @@ +# [661. 图片平滑器](https://leetcode-cn.com/problems/image-smoother) + +## 题目描述 + +
包含整数的二维矩阵 M 表示一个图片的灰度。你需要设计一个平滑器来让每一个单元的灰度成为平均灰度 (向下舍入) ,平均灰度的计算是周围的8个单元和它本身的值求平均,如果周围的单元格不足八个,则尽可能多的利用它们。
+ +示例 1:
+ ++输入: +[[1,1,1], + [1,0,1], + [1,1,1]] +输出: +[[0, 0, 0], + [0, 0, 0], + [0, 0, 0]] +解释: +对于点 (0,0), (0,2), (2,0), (2,2): 平均(3/4) = 平均(0.75) = 0 +对于点 (0,1), (1,0), (1,2), (2,1): 平均(5/6) = 平均(0.83333333) = 0 +对于点 (1,1): 平均(8/9) = 平均(0.88888889) = 0 ++ +
注意:
+ +-
+
- 给定矩阵中的整数范围为 [0, 255]。 +
- 矩阵的长和宽的范围均为 [1, 150]。 +
给定一个二叉树,编写一个函数来获取这个树的最大宽度。树的宽度是所有层中的最大宽度。这个二叉树与满二叉树(full binary tree)结构相同,但一些节点为空。
+ +每一层的宽度被定义为两个端点(该层最左和最右的非空节点,两端点间的null节点也计入长度)之间的长度。
示例 1:
+ ++输入: + + 1 + / \ + 3 2 + / \ \ + 5 3 9 + +输出: 4 +解释: 最大值出现在树的第 3 层,宽度为 4 (5,3,null,9)。 ++ +
示例 2:
+ ++输入: + + 1 + / + 3 + / \ + 5 3 + +输出: 2 +解释: 最大值出现在树的第 3 层,宽度为 2 (5,3)。 ++ +
示例 3:
+ ++输入: + + 1 + / \ + 3 2 + / + 5 + +输出: 2 +解释: 最大值出现在树的第 2 层,宽度为 2 (3,2)。 ++ +
示例 4:
+ ++输入: + + 1 + / \ + 3 2 + / \ + 5 9 + / \ + 6 7 +输出: 8 +解释: 最大值出现在树的第 4 层,宽度为 8 (6,null,null,null,null,null,null,7)。 ++ +
注意: 答案在32位有符号整数的表示范围内。
+ + + +## 解法 + + + +### Python3 + + +```python + +``` + +### Java + + +```java + +``` + +### ... +``` + +``` diff --git a/solution/0600-0699/0663.Equal Tree Partition/README.md b/solution/0600-0699/0663.Equal Tree Partition/README.md new file mode 100644 index 0000000000000..85354aa74a65c --- /dev/null +++ b/solution/0600-0699/0663.Equal Tree Partition/README.md @@ -0,0 +1,29 @@ +# [663. 均匀树划分](https://leetcode-cn.com/problems/equal-tree-partition) + +## 题目描述 + +None + + +## 解法 + + + +### Python3 + + +```python + +``` + +### Java + + +```java + +``` + +### ... +``` + +``` diff --git a/solution/0600-0699/0664.Strange Printer/README.md b/solution/0600-0699/0664.Strange Printer/README.md new file mode 100644 index 0000000000000..0a89ad404a55f --- /dev/null +++ b/solution/0600-0699/0664.Strange Printer/README.md @@ -0,0 +1,54 @@ +# [664. 奇怪的打印机](https://leetcode-cn.com/problems/strange-printer) + +## 题目描述 + +有台奇怪的打印机有以下两个特殊要求:
+ +-
+
- 打印机每次只能打印同一个字符序列。 +
- 每次可以在任意起始和结束位置打印新字符,并且会覆盖掉原来已有的字符。 +
给定一个只包含小写英文字母的字符串,你的任务是计算这个打印机打印它需要的最少次数。
+ +示例 1:
+ ++输入: "aaabbb" +输出: 2 +解释: 首先打印 "aaa" 然后打印 "bbb"。 ++ +
示例 2:
+ ++输入: "aba" +输出: 2 +解释: 首先打印 "aaa" 然后在第二个位置打印 "b" 覆盖掉原来的字符 'a'。+ +
提示: 输入字符串的长度不会超过 100。
+ + + +## 解法 + + + +### Python3 + + +```python + +``` + +### Java + + +```java + +``` + +### ... +``` + +``` diff --git a/solution/0600-0699/0665.Non-decreasing Array/README.md b/solution/0600-0699/0665.Non-decreasing Array/README.md index c0caed1cb4974..ac9f349c815eb 100644 --- a/solution/0600-0699/0665.Non-decreasing Array/README.md +++ b/solution/0600-0699/0665.Non-decreasing Array/README.md @@ -1,48 +1,50 @@ -## 非递减数列 +# [665. 非递减数列](https://leetcode-cn.com/problems/non-decreasing-array) -### 问题描述 +## 题目描述 + +给定一个长度为 n 的整数数组,你的任务是判断在最多改变 1 个元素的情况下,该数组能否变成一个非递减数列。
我们是这样定义一个非递减数列的: 对于数组中所有的 i (1 <= i < n),满足 array[i] <= array[i + 1]。
示例 1:
+ ++输入: [4,2,3] +输出: True +解释: 你可以通过把第一个4变成1来使得它成为一个非递减数列。 ++ +
示例 2:
+ ++输入: [4,2,1] +输出: False +解释: 你不能在只改变一个元素的情况下将其变为非递减数列。 ++ +
说明: n 的范围为 [1, 10,000]。
给定两个整数 n 和 k,你需要实现一个数组,这个数组包含从 1 到 n 的 n 个不同整数,同时满足以下条件:
① 如果这个数组是 [a1, a2, a3, ... , an] ,那么数组 [|a1 - a2|, |a2 - a3|, |a3 - a4|, ... , |an-1 - an|] 中应该有且仅有 k 个不同整数;.
+ +② 如果存在多种答案,你只需实现并返回其中任意一种.
+ +示例 1:
+ ++输入: n = 3, k = 1 +输出: [1, 2, 3] +解释: [1, 2, 3] 包含 3 个范围在 1-3 的不同整数, 并且 [1, 1] 中有且仅有 1 个不同整数 : 1 ++ +
+ +
示例 2:
+ ++输入: n = 3, k = 2 +输出: [1, 3, 2] +解释: [1, 3, 2] 包含 3 个范围在 1-3 的不同整数, 并且 [2, 1] 中有且仅有 2 个不同整数: 1 和 2 ++ +
+ +
提示:
+ +-
+
-
n和k满足条件 1 <= k < n <= 104.
+
+ + + +## 解法 + + + +### Python3 + + +```python + +``` + +### Java + + +```java + +``` + +### ... +``` + +``` diff --git a/solution/0600-0699/0668.Kth Smallest Number in Multiplication Table/README.md b/solution/0600-0699/0668.Kth Smallest Number in Multiplication Table/README.md new file mode 100644 index 0000000000000..cc6304a3bd32c --- /dev/null +++ b/solution/0600-0699/0668.Kth Smallest Number in Multiplication Table/README.md @@ -0,0 +1,66 @@ +# [668. 乘法表中第k小的数](https://leetcode-cn.com/problems/kth-smallest-number-in-multiplication-table) + +## 题目描述 + +
几乎每一个人都用 乘法表。但是你能在乘法表中快速找到第k小的数字吗?
给定高度m 、宽度n 的一张 m * n的乘法表,以及正整数k,你需要返回表中第k 小的数字。
例 1:
+ ++输入: m = 3, n = 3, k = 5 +输出: 3 +解释: +乘法表: +1 2 3 +2 4 6 +3 6 9 + +第5小的数字是 3 (1, 2, 2, 3, 3). ++ +
例 2:
+ ++输入: m = 2, n = 3, k = 6 +输出: 6 +解释: +乘法表: +1 2 3 +2 4 6 + +第6小的数字是 6 (1, 2, 2, 3, 4, 6). ++ +
注意:
+ +-
+
m和n的范围在 [1, 30000] 之间。
+ k的范围在 [1, m * n] 之间。
+
给定一个二叉搜索树,同时给定最小边界L 和最大边界 R。通过修剪二叉搜索树,使得所有节点的值在[L, R]中 (R>=L) 。你可能需要改变树的根节点,所以结果应当返回修剪好的二叉搜索树的新的根节点。
示例 1:
+ ++输入: + 1 + / \ + 0 2 + + L = 1 + R = 2 + +输出: + 1 + \ + 2 ++ +
示例 2:
+ ++输入: + 3 + / \ + 0 4 + \ + 2 + / + 1 + + L = 1 + R = 3 + +输出: + 3 + / + 2 + / + 1 ++ + + +## 解法 + + + +### Python3 + + +```python + +``` + +### Java + + +```java + +``` + +### ... +``` + +``` diff --git a/solution/0600-0699/0670.Maximum Swap/README.md b/solution/0600-0699/0670.Maximum Swap/README.md index 4d4a382f50dac..d3dd3a5443cb6 100644 --- a/solution/0600-0699/0670.Maximum Swap/README.md +++ b/solution/0600-0699/0670.Maximum Swap/README.md @@ -1,54 +1,52 @@ -## 最大交换 +# [670. 最大交换](https://leetcode-cn.com/problems/maximum-swap) -### 问题描述 +## 题目描述 + +
给定一个非负整数,你至多可以交换一次数字中的任意两位。返回你能得到的最大值。
+ +示例 1 :
+ ++输入: 2736 +输出: 7236 +解释: 交换数字2和数字7。 ++ +
示例 2 :
+ ++输入: 9973 +输出: 9973 +解释: 不需要交换。 ++ +
注意:
+ +-
+
- 给定数字的范围是 [0, 108] +
给定一个非空特殊的二叉树,每个节点都是正数,并且每个节点的子节点数量只能为 2 或 0。如果一个节点有两个子节点的话,那么这个节点的值不大于它的子节点的值。
给出这样的一个二叉树,你需要输出所有节点中的第二小的值。如果第二小的值不存在的话,输出 -1 。
+ +示例 1:
+ ++输入: + 2 + / \ + 2 5 + / \ + 5 7 + +输出: 5 +说明: 最小的值是 2 ,第二小的值是 5 。 ++ +
示例 2:
+ ++输入: + 2 + / \ + 2 2 + +输出: -1 +说明: 最小的值是 2, 但是不存在第二小的值。 ++ + + +## 解法 + + + +### Python3 + + +```python + +``` + +### Java + + +```java + +``` + +### ... +``` + +``` diff --git a/solution/0600-0699/0672.Bulb Switcher II/README.md b/solution/0600-0699/0672.Bulb Switcher II/README.md new file mode 100644 index 0000000000000..84dea128c622f --- /dev/null +++ b/solution/0600-0699/0672.Bulb Switcher II/README.md @@ -0,0 +1,62 @@ +# [672. 灯泡开关 Ⅱ](https://leetcode-cn.com/problems/bulb-switcher-ii) + +## 题目描述 + +
现有一个房间,墙上挂有 n 只已经打开的灯泡和 4 个按钮。在进行了 m 次未知操作后,你需要返回这 n 只灯泡可能有多少种不同的状态。
假设这 n 只灯泡被编号为 [1, 2, 3 ..., n],这 4 个按钮的功能如下:
-
+
- 将所有灯泡的状态反转(即开变为关,关变为开) +
- 将编号为偶数的灯泡的状态反转 +
- 将编号为奇数的灯泡的状态反转 +
- 将编号为
3k+1的灯泡的状态反转(k = 0, 1, 2, ...)
+
示例 1:
+ +输入: n = 1, m = 1. +输出: 2 +说明: 状态为: [开], [关] ++ +
示例 2:
+ +输入: n = 2, m = 1. +输出: 3 +说明: 状态为: [开, 关], [关, 开], [关, 关] ++ +
示例 3:
+ +输入: n = 3, m = 1. +输出: 4 +说明: 状态为: [关, 开, 关], [开, 关, 开], [关, 关, 关], [关, 开, 开]. ++ +
注意: n 和 m 都属于 [0, 1000].
给定一个未排序的整数数组,找到最长递增子序列的个数。
+ +示例 1:
+ ++输入: [1,3,5,4,7] +输出: 2 +解释: 有两个最长递增子序列,分别是 [1, 3, 4, 7] 和[1, 3, 5, 7]。 ++ +
示例 2:
+ ++输入: [2,2,2,2,2] +输出: 5 +解释: 最长递增子序列的长度是1,并且存在5个子序列的长度为1,因此输出5。 ++ +
注意: 给定的数组长度不超过 2000 并且结果一定是32位有符号整数。
+ + + +## 解法 + + + +### Python3 + + +```python + +``` + +### Java + + +```java + +``` + +### ... +``` + +``` diff --git a/solution/0600-0699/0674.Longest Continuous Increasing Subsequence/README.md b/solution/0600-0699/0674.Longest Continuous Increasing Subsequence/README.md new file mode 100644 index 0000000000000..b90a3666ec4da --- /dev/null +++ b/solution/0600-0699/0674.Longest Continuous Increasing Subsequence/README.md @@ -0,0 +1,49 @@ +# [674. 最长连续递增序列](https://leetcode-cn.com/problems/longest-continuous-increasing-subsequence) + +## 题目描述 + +给定一个未经排序的整数数组,找到最长且连续的的递增序列。
+ +示例 1:
+ ++输入: [1,3,5,4,7] +输出: 3 +解释: 最长连续递增序列是 [1,3,5], 长度为3。 +尽管 [1,3,5,7] 也是升序的子序列, 但它不是连续的,因为5和7在原数组里被4隔开。 ++ +
示例 2:
+ ++输入: [2,2,2,2,2] +输出: 1 +解释: 最长连续递增序列是 [2], 长度为1。 ++ +
注意:数组长度不会超过10000。
+ + + +## 解法 + + + +### Python3 + + +```python + +``` + +### Java + + +```java + +``` + +### ... +``` + +``` diff --git a/solution/0600-0699/0675.Cut Off Trees for Golf Event/README.md b/solution/0600-0699/0675.Cut Off Trees for Golf Event/README.md new file mode 100644 index 0000000000000..1fa00923ba9ee --- /dev/null +++ b/solution/0600-0699/0675.Cut Off Trees for Golf Event/README.md @@ -0,0 +1,90 @@ +# [675. 为高尔夫比赛砍树](https://leetcode-cn.com/problems/cut-off-trees-for-golf-event) + +## 题目描述 + +你被请来给一个要举办高尔夫比赛的树林砍树. 树林由一个非负的二维数组表示, 在这个数组中:
+ +-
+
0表示障碍,无法触碰到.
+ 1表示可以行走的地面.
+ 比 1 大的数表示一颗允许走过的树的高度.
+
每一步,你都可以向上、下、左、右四个方向之一移动一个单位,如果你站的地方有一棵树,那么你可以决定是否要砍倒它。
+ +你被要求按照树的高度从低向高砍掉所有的树,每砍过一颗树,树的高度变为 1 。
+ +你将从(0,0)点开始工作,你应该返回你砍完所有树需要走的最小步数。 如果你无法砍完所有的树,返回 -1 。
+ +可以保证的是,没有两棵树的高度是相同的,并且你至少需要砍倒一棵树。
+ ++ +
示例 1:
+ +输入: +[ + [1,2,3], + [0,0,4], + [7,6,5] +] +输出: 6 ++ +
示例 2:
+ +输入: +[ + [1,2,3], + [0,0,0], + [7,6,5] +] +输出: -1 ++ +
示例 3:
+ +输入: +[ + [2,3,4], + [0,0,5], + [8,7,6] +] +输出: 6 +解释: (0,0) 位置的树,你可以直接砍去,不用算步数 ++ +
+ +
提示:
+ +-
+
1 <= forest.length <= 50
+ 1 <= forest[i].length <= 50
+ 0 <= forest[i][j] <= 10^9
+
实现一个带有buildDict, 以及 search方法的魔法字典。
对于buildDict方法,你将被给定一串不重复的单词来构建一个字典。
对于search方法,你将被给定一个单词,并且判定能否只将这个单词中一个字母换成另一个字母,使得所形成的新单词存在于你构建的字典中。
示例 1:
+ +
+Input: buildDict(["hello", "leetcode"]), Output: Null
+Input: search("hello"), Output: False
+Input: search("hhllo"), Output: True
+Input: search("hell"), Output: False
+Input: search("leetcoded"), Output: False
+
+
+注意:
+ +-
+
- 你可以假设所有输入都是小写字母
a-z。
+ - 为了便于竞赛,测试所用的数据量很小。你可以在竞赛结束后,考虑更高效的算法。 +
- 请记住重置MagicDictionary类中声明的类变量,因为静态/类变量会在多个测试用例中保留。 请参阅这里了解更多详情。 +
实现一个 MapSum 类里的两个方法,insert 和 sum。
对于方法 insert,你将得到一对(字符串,整数)的键值对。字符串表示键,整数表示值。如果键已经存在,那么原来的键值对将被替代成新的键值对。
对于方法 sum,你将得到一个表示前缀的字符串,你需要返回所有以该前缀开头的键的值的总和。
示例 1:
+ +输入: insert("apple", 3), 输出: Null
+输入: sum("ap"), 输出: 3
+输入: insert("app", 2), 输出: Null
+输入: sum("ap"), 输出: 5
+
+
+
+
+## 解法
+
+
+
+### Python3
+
+
+```python
+
+```
+
+### Java
+
+
+```java
+
+```
+
+### ...
+```
+
+```
diff --git a/solution/0600-0699/0678.Valid Parenthesis String/README.md b/solution/0600-0699/0678.Valid Parenthesis String/README.md
new file mode 100644
index 0000000000000..027ecd36ecc0a
--- /dev/null
+++ b/solution/0600-0699/0678.Valid Parenthesis String/README.md
@@ -0,0 +1,65 @@
+# [678. 有效的括号字符串](https://leetcode-cn.com/problems/valid-parenthesis-string)
+
+## 题目描述
+
+给定一个只包含三种字符的字符串:( ,) 和 *,写一个函数来检验这个字符串是否为有效字符串。有效字符串具有如下规则:
-
+
- 任何左括号
(必须有相应的右括号)。
+ - 任何右括号
)必须有相应的左括号(。
+ - 左括号
(必须在对应的右括号之前)。
+ *可以被视为单个右括号),或单个左括号(,或一个空字符串。
+ - 一个空字符串也被视为有效字符串。 +
示例 1:
+ ++输入: "()" +输出: True ++ +
示例 2:
+ ++输入: "(*)" +输出: True ++ +
示例 3:
+ ++输入: "(*))" +输出: True ++ +
注意:
+ +-
+
- 字符串大小将在 [1,100] 范围内。 +
你有 4 张写有 1 到 9 数字的牌。你需要判断是否能通过 *,/,+,-,(,) 的运算得到 24。
示例 1:
+ +输入: [4, 1, 8, 7] +输出: True +解释: (8-4) * (7-1) = 24 ++ +
示例 2:
+ +输入: [1, 2, 1, 2] +输出: False ++ +
注意:
+ +-
+
- 除法运算符
/表示实数除法,而不是整数除法。例如 4 / (1 - 2/3) = 12 。
+ - 每个运算符对两个数进行运算。特别是我们不能用
-作为一元运算符。例如,[1, 1, 1, 1]作为输入时,表达式-1 - 1 - 1 - 1是不允许的。
+ - 你不能将数字连接在一起。例如,输入为
[1, 2, 1, 2]时,不能写成 12 + 12 。
+
给定一个非空字符串 s,最多删除一个字符。判断是否能成为回文字符串。
示例 1:
+ ++输入: "aba" +输出: True ++ +
示例 2:
+ ++输入: "abca" +输出: True +解释: 你可以删除c字符。 ++ +
注意:
+ +-
+
- 字符串只包含从 a-z 的小写字母。字符串的最大长度是50000。 +
你现在是棒球比赛记录员。
+给定一个字符串列表,每个字符串可以是以下四种类型之一:
+1.整数(一轮的得分):直接表示您在本轮中获得的积分数。
+2. "+"(一轮的得分):表示本轮获得的得分是前两轮有效 回合得分的总和。
+3. "D"(一轮的得分):表示本轮获得的得分是前一轮有效 回合得分的两倍。
+4. "C"(一个操作,这不是一个回合的分数):表示您获得的最后一个有效 回合的分数是无效的,应该被移除。
+
+每一轮的操作都是永久性的,可能会对前一轮和后一轮产生影响。
+你需要返回你在所有回合中得分的总和。
示例 1:
+ +输入: ["5","2","C","D","+"] +输出: 30 +解释: +第1轮:你可以得到5分。总和是:5。 +第2轮:你可以得到2分。总和是:7。 +操作1:第2轮的数据无效。总和是:5。 +第3轮:你可以得到10分(第2轮的数据已被删除)。总数是:15。 +第4轮:你可以得到5 + 10 = 15分。总数是:30。 ++ +
示例 2:
+ +输入: ["5","-2","4","C","D","9","+","+"] +输出: 27 +解释: +第1轮:你可以得到5分。总和是:5。 +第2轮:你可以得到-2分。总数是:3。 +第3轮:你可以得到4分。总和是:7。 +操作1:第3轮的数据无效。总数是:3。 +第4轮:你可以得到-4分(第三轮的数据已被删除)。总和是:-1。 +第5轮:你可以得到9分。总数是:8。 +第6轮:你可以得到-4 + 9 = 5分。总数是13。 +第7轮:你可以得到9 + 5 = 14分。总数是27。 ++ +
注意:
+ +-
+
- 输入列表的大小将介于1和1000之间。 +
- 列表中的每个整数都将介于-30000和30000之间。 +
在本问题中, 树指的是一个连通且无环的无向图。
+ +输入一个图,该图由一个有着N个节点 (节点值不重复1, 2, ..., N) 的树及一条附加的边构成。附加的边的两个顶点包含在1到N中间,这条附加的边不属于树中已存在的边。
+ +结果图是一个以边组成的二维数组。每一个边的元素是一对[u, v] ,满足 u < v,表示连接顶点u 和v的无向图的边。
返回一条可以删去的边,使得结果图是一个有着N个节点的树。如果有多个答案,则返回二维数组中最后出现的边。答案边 [u, v] 应满足相同的格式 u < v。
示例 1:
+ +输入: [[1,2], [1,3], [2,3]] +输出: [2,3] +解释: 给定的无向图为: + 1 + / \ +2 - 3 ++ +
示例 2:
+ +输入: [[1,2], [2,3], [3,4], [1,4], [1,5]] +输出: [1,4] +解释: 给定的无向图为: +5 - 1 - 2 + | | + 4 - 3 ++ +
注意:
+ +-
+
- 输入的二维数组大小在 3 到 1000。 +
- 二维数组中的整数在1到N之间,其中N是输入数组的大小。 +
更新(2017-09-26):
+我们已经重新检查了问题描述及测试用例,明确图是无向 图。对于有向图详见冗余连接II。对于造成任何不便,我们深感歉意。
在本问题中,有根树指满足以下条件的有向图。该树只有一个根节点,所有其他节点都是该根节点的后继。每一个节点只有一个父节点,除了根节点没有父节点。
+ +输入一个有向图,该图由一个有着N个节点 (节点值不重复1, 2, ..., N) 的树及一条附加的边构成。附加的边的两个顶点包含在1到N中间,这条附加的边不属于树中已存在的边。
+ +结果图是一个以边组成的二维数组。 每一个边 的元素是一对 [u, v],用以表示有向图中连接顶点 u and v和顶点的边,其中父节点u是子节点v的一个父节点。
返回一条能删除的边,使得剩下的图是有N个节点的有根树。若有多个答案,返回最后出现在给定二维数组的答案。
+ +示例 1:
+ ++输入: [[1,2], [1,3], [2,3]] +输出: [2,3] +解释: 给定的有向图如下: + 1 + / \ +v v +2-->3 ++ +
示例 2:
+ ++输入: [[1,2], [2,3], [3,4], [4,1], [1,5]] +输出: [4,1] +解释: 给定的有向图如下: +5 <- 1 -> 2 + ^ | + | v + 4 <- 3 ++ +
注意:
+ +-
+
- 二维数组大小的在3到1000范围内。 +
- 二维数组中的每个整数在1到N之间,其中 N 是二维数组的大小。 +
给定两个字符串 A 和 B, 寻找重复叠加字符串A的最小次数,使得字符串B成为叠加后的字符串A的子串,如果不存在则返回 -1。
+ +举个例子,A = "abcd",B = "cdabcdab"。
+ +答案为 3, 因为 A 重复叠加三遍后为 “abcdabcdabcd”,此时 B 是其子串;A 重复叠加两遍后为"abcdabcd",B 并不是其子串。
+ +注意:
+ + A 与 B 字符串的长度在1和10000区间范围内。
给定一个二叉树,找到最长的路径,这个路径中的每个节点具有相同值。 这条路径可以经过也可以不经过根节点。
+ +注意:两个节点之间的路径长度由它们之间的边数表示。
+ +示例 1:
+ +输入:
+ ++ 5 + / \ + 4 5 + / \ \ + 1 1 5 ++ +
输出:
+ ++2 ++ +
示例 2:
+ +输入:
+ ++ 1 + / \ + 4 5 + / \ \ + 4 4 5 ++ +
输出:
+ ++2 ++ +
注意: 给定的二叉树不超过10000个结点。 树的高度不超过1000。
+ + + +## 解法 + + + +### Python3 + + +```python + +``` + +### Java + + +```java + +``` + +### ... +``` + +``` diff --git a/solution/0600-0699/0688.Knight Probability in Chessboard/README.md b/solution/0600-0699/0688.Knight Probability in Chessboard/README.md new file mode 100644 index 0000000000000..36a0a4698c02e --- /dev/null +++ b/solution/0600-0699/0688.Knight Probability in Chessboard/README.md @@ -0,0 +1,66 @@ +# [688. “马”在棋盘上的概率](https://leetcode-cn.com/problems/knight-probability-in-chessboard) + +## 题目描述 + +已知一个 NxN 的国际象棋棋盘,棋盘的行号和列号都是从 0 开始。即最左上角的格子记为 (0, 0),最右下角的记为 (N-1, N-1)。
现有一个 “马”(也译作 “骑士”)位于 (r, c) ,并打算进行 K 次移动。
如下图所示,国际象棋的 “马” 每一步先沿水平或垂直方向移动 2 个格子,然后向与之相垂直的方向再移动 1 个格子,共有 8 个可选的位置。
+ ++ +

+ +
现在 “马” 每一步都从可选的位置(包括棋盘外部的)中独立随机地选择一个进行移动,直到移动了 K 次或跳到了棋盘外面。
求移动结束后,“马” 仍留在棋盘上的概率。
+ ++ +
示例:
+ +输入: 3, 2, 0, 0 +输出: 0.0625 +解释: +输入的数据依次为 N, K, r, c +第 1 步时,有且只有 2 种走法令 “马” 可以留在棋盘上(跳到(1,2)或(2,1))。对于以上的两种情况,各自在第2步均有且只有2种走法令 “马” 仍然留在棋盘上。 +所以 “马” 在结束后仍在棋盘上的概率为 0.0625。 ++ +
+ +
注意:
+ +-
+
N的取值范围为 [1, 25]
+ K的取值范围为 [0, 100]
+ - 开始时,“马” 总是位于棋盘上 +
给定数组 nums 由正整数组成,找到三个互不重叠的子数组的最大和。
每个子数组的长度为k,我们要使这3*k个项的和最大化。
返回每个区间起始索引的列表(索引从 0 开始)。如果有多个结果,返回字典序最小的一个。
+ +示例:
+ ++输入: [1,2,1,2,6,7,5,1], 2 +输出: [0, 3, 5] +解释: 子数组 [1, 2], [2, 6], [7, 5] 对应的起始索引为 [0, 3, 5]。 +我们也可以取 [2, 1], 但是结果 [1, 3, 5] 在字典序上更大。 ++ +
注意:
+ +-
+
nums.length的范围在[1, 20000]之间。
+ nums[i]的范围在[1, 65535]之间。
+ k的范围在[1, floor(nums.length / 3)]之间。
+
给定一个保存员工信息的数据结构,它包含了员工唯一的id,重要度 和 直系下属的id。
+ +比如,员工1是员工2的领导,员工2是员工3的领导。他们相应的重要度为15, 10, 5。那么员工1的数据结构是[1, 15, [2]],员工2的数据结构是[2, 10, [3]],员工3的数据结构是[3, 5, []]。注意虽然员工3也是员工1的一个下属,但是由于并不是直系下属,因此没有体现在员工1的数据结构中。
+ +现在输入一个公司的所有员工信息,以及单个员工id,返回这个员工和他所有下属的重要度之和。
+ +示例 1:
+ ++输入: [[1, 5, [2, 3]], [2, 3, []], [3, 3, []]], 1 +输出: 11 +解释: +员工1自身的重要度是5,他有两个直系下属2和3,而且2和3的重要度均为3。因此员工1的总重要度是 5 + 3 + 3 = 11。 ++ +
注意:
+ +-
+
- 一个员工最多有一个直系领导,但是可以有多个直系下属 +
- 员工数量不超过2000。 +
我们给出了 N 种不同类型的贴纸。每个贴纸上都有一个小写的英文单词。
+ +你希望从自己的贴纸集合中裁剪单个字母并重新排列它们,从而拼写出给定的目标字符串 target。
如果你愿意的话,你可以不止一次地使用每一张贴纸,而且每一张贴纸的数量都是无限的。
+ +拼出目标 target 所需的最小贴纸数量是多少?如果任务不可能,则返回 -1。
+ +
示例 1:
+ +输入:
+ +["with", "example", "science"], "thehat" ++ +
输出:
+ +3 ++ +
解释:
+ +我们可以使用 2 个 "with" 贴纸,和 1 个 "example" 贴纸。 +把贴纸上的字母剪下来并重新排列后,就可以形成目标 “thehat“ 了。 +此外,这是形成目标字符串所需的最小贴纸数量。 ++ +
示例 2:
+ +输入:
+ +["notice", "possible"], "basicbasic" ++ +
输出:
+ +-1 ++ +
解释:
+ +我们不能通过剪切给定贴纸的字母来形成目标“basicbasic”。 ++ +
+ +
提示:
+ +-
+
stickers长度范围是[1, 50]。
+ stickers由小写英文单词组成(不带撇号)。
+ target的长度在[1, 15]范围内,由小写字母组成。
+ - 在所有的测试案例中,所有的单词都是从 1000 个最常见的美国英语单词中随机选取的,目标是两个随机单词的串联。 +
- 时间限制可能比平时更具挑战性。预计 50 个贴纸的测试案例平均可在35ms内解决。 +
+ + + +## 解法 + + + +### Python3 + + +```python + +``` + +### Java + + +```java + +``` + +### ... +``` + +``` diff --git a/solution/0600-0699/0692.Top K Frequent Words/README.md b/solution/0600-0699/0692.Top K Frequent Words/README.md new file mode 100644 index 0000000000000..aff940587c190 --- /dev/null +++ b/solution/0600-0699/0692.Top K Frequent Words/README.md @@ -0,0 +1,69 @@ +# [692. 前K个高频单词](https://leetcode-cn.com/problems/top-k-frequent-words) + +## 题目描述 + +
给一非空的单词列表,返回前 k 个出现次数最多的单词。
+ +返回的答案应该按单词出现频率由高到低排序。如果不同的单词有相同出现频率,按字母顺序排序。
+ +示例 1:
+ ++输入: ["i", "love", "leetcode", "i", "love", "coding"], k = 2 +输出: ["i", "love"] +解析: "i" 和 "love" 为出现次数最多的两个单词,均为2次。 + 注意,按字母顺序 "i" 在 "love" 之前。 ++ +
+ +
示例 2:
+ ++输入: ["the", "day", "is", "sunny", "the", "the", "the", "sunny", "is", "is"], k = 4 +输出: ["the", "is", "sunny", "day"] +解析: "the", "is", "sunny" 和 "day" 是出现次数最多的四个单词, + 出现次数依次为 4, 3, 2 和 1 次。 ++ +
+ +
注意:
+ +-
+
- 假定 k 总为有效值, 1 ≤ k ≤ 集合元素数。 +
- 输入的单词均由小写字母组成。 +
+ +
扩展练习:
+ +-
+
- 尝试以 O(n log k) 时间复杂度和 O(n) 空间复杂度解决。 +
给定一个正整数,检查他是否为交替位二进制数:换句话说,就是他的二进制数相邻的两个位数永不相等。
+ +示例 1:
+ ++输入: 5 +输出: True +解释: +5的二进制数是: 101 ++ +
示例 2:
+ ++输入: 7 +输出: False +解释: +7的二进制数是: 111 ++ +
示例 3:
+ ++输入: 11 +输出: False +解释: +11的二进制数是: 1011 ++ +
示例 4:
+ ++输入: 10 +输出: True +解释: +10的二进制数是: 1010 ++ + + +## 解法 + + + +### Python3 + + +```python + +``` + +### Java + + +```java + +``` + +### ... +``` + +``` diff --git a/solution/0600-0699/0694.Number of Distinct Islands/README.md b/solution/0600-0699/0694.Number of Distinct Islands/README.md new file mode 100644 index 0000000000000..61bc6c6202930 --- /dev/null +++ b/solution/0600-0699/0694.Number of Distinct Islands/README.md @@ -0,0 +1,29 @@ +# [694. 不同岛屿的数量](https://leetcode-cn.com/problems/number-of-distinct-islands) + +## 题目描述 + +None + + +## 解法 + + + +### Python3 + + +```python + +``` + +### Java + + +```java + +``` + +### ... +``` + +``` diff --git a/solution/0600-0699/0695.Max Area of Island/README.md b/solution/0600-0699/0695.Max Area of Island/README.md index 29ecd210004c9..2608f584a9c44 100644 --- a/solution/0600-0699/0695.Max Area of Island/README.md +++ b/solution/0600-0699/0695.Max Area of Island/README.md @@ -1,61 +1,60 @@ -## 岛屿的最大面积 -### 题目描述 +# [695. 岛屿的最大面积](https://leetcode-cn.com/problems/max-area-of-island) -给定一个包含了一些 0 和 1的非空二维数组 `grid` , 一个 岛屿 是由四个方向 (水平或垂直) 的 `1` (代表土地) 构成的组合。你可以假设二维矩阵的四个边缘都被水包围着。 +## 题目描述 + +
给定一个包含了一些 0 和 1 的非空二维数组 grid 。
一个 岛屿 是由一些相邻的 1 (代表土地) 构成的组合,这里的「相邻」要求两个 1 必须在水平或者竖直方向上相邻。你可以假设 grid 的四个边缘都被 0(代表水)包围着。
找到给定的二维数组中最大的岛屿面积。(如果没有岛屿,则返回面积为 0 。)
+ +
示例 1:
+ +[[0,0,1,0,0,0,0,1,0,0,0,0,0], [0,0,0,0,0,0,0,1,1,1,0,0,0], [0,1,1,0,1,0,0,0,0,0,0,0,0], - [0,1,0,0,1,1,0,0,1,0,1,0,0], - [0,1,0,0,1,1,0,0,1,1,1,0,0], - [0,0,0,0,0,0,0,0,0,0,1,0,0], + [0,1,0,0,1,1,0,0,1,0,1,0,0], + [0,1,0,0,1,1,0,0,1,1,1,0,0], + [0,0,0,0,0,0,0,0,0,0,1,0,0], [0,0,0,0,0,0,0,1,1,1,0,0,0], [0,0,0,0,0,0,0,1,1,0,0,0,0]] -``` +-对于上面这个给定矩阵应返回 `6`。注意答案不应该是 11,因为岛屿只能包含水平或垂直的四个方向的‘1’。 +
对于上面这个给定矩阵应返回 6。注意答案不应该是 11 ,因为岛屿只能包含水平或垂直的四个方向的 1 。
示例 2:
+ +[[0,0,0,0,0,0,0,0]]+ +
对于上面这个给定的矩阵, 返回 0。
+ +
注意: 给定的矩阵grid 的长度和宽度都不超过 50。
给定一个字符串 s,计算具有相同数量0和1的非空(连续)子字符串的数量,并且这些子字符串中的所有0和所有1都是组合在一起的。
重复出现的子串要计算它们出现的次数。
+ +示例 1 :
+ ++输入: "00110011" +输出: 6 +解释: 有6个子串具有相同数量的连续1和0:“0011”,“01”,“1100”,“10”,“0011” 和 “01”。 + +请注意,一些重复出现的子串要计算它们出现的次数。 + +另外,“00110011”不是有效的子串,因为所有的0(和1)没有组合在一起。 ++ +
示例 2 :
+ ++输入: "10101" +输出: 4 +解释: 有4个子串:“10”,“01”,“10”,“01”,它们具有相同数量的连续1和0。 ++ +
注意:
+ +-
+
s.length在1到50,000之间。
+ s只包含“0”或“1”字符。
+
给定一个非空且只包含非负数的整数数组 nums, 数组的度的定义是指数组里任一元素出现频数的最大值。
你的任务是找到与 nums 拥有相同大小的度的最短连续子数组,返回其长度。
示例 1:
+ ++输入: [1, 2, 2, 3, 1] +输出: 2 +解释: +输入数组的度是2,因为元素1和2的出现频数最大,均为2. +连续子数组里面拥有相同度的有如下所示: +[1, 2, 2, 3, 1], [1, 2, 2, 3], [2, 2, 3, 1], [1, 2, 2], [2, 2, 3], [2, 2] +最短连续子数组[2, 2]的长度为2,所以返回2. ++ +
示例 2:
+ ++输入: [1,2,2,3,1,4,2] +输出: 6 ++ +
注意:
+ +-
+
nums.length在1到50,000区间范围内。
+ nums[i]是一个在0到49,999范围内的整数。
+
给定一个整数数组 nums 和一个正整数 k,找出是否有可能把这个数组分成 k 个非空子集,其总和都相等。
示例 1:
+ ++输入: nums = [4, 3, 2, 3, 5, 2, 1], k = 4 +输出: True +说明: 有可能将其分成 4 个子集(5),(1,4),(2,3),(2,3)等于总和。+ +
+ +
注意:
+ +-
+
1 <= k <= len(nums) <= 16
+ 0 < nums[i] < 10000
+
在无限长的数轴(即 x 轴)上,我们根据给定的顺序放置对应的正方形方块。
+ +第 i 个掉落的方块(positions[i] = (left, side_length))是正方形,其中 left 表示该方块最左边的点位置(positions[i][0]),side_length 表示该方块的边长(positions[i][1])。
每个方块的底部边缘平行于数轴(即 x 轴),并且从一个比目前所有的落地方块更高的高度掉落而下。在上一个方块结束掉落,并保持静止后,才开始掉落新方块。
+ +方块的底边具有非常大的粘性,并将保持固定在它们所接触的任何长度表面上(无论是数轴还是其他方块)。邻接掉落的边不会过早地粘合在一起,因为只有底边才具有粘性。
+ +
返回一个堆叠高度列表 ans 。每一个堆叠高度 ans[i] 表示在通过 positions[0], positions[1], ..., positions[i] 表示的方块掉落结束后,目前所有已经落稳的方块堆叠的最高高度。
+ +
+ +
示例 1:
+ +输入: [[1, 2], [2, 3], [6, 1]] +输出: [2, 5, 5] +解释: + +第一个方块+ +positions[0] = [1, 2]掉落: +_aa +_aa +------- +方块最大高度为 2 。 + +第二个方块positions[1] = [2, 3]掉落: +__aaa +__aaa +__aaa +_aa__ +_aa__ +-------------- +方块最大高度为5。 +大的方块保持在较小的方块的顶部,不论它的重心在哪里,因为方块的底部边缘有非常大的粘性。 + +第三个方块positions[1] = [6, 1]掉落: +__aaa +__aaa +__aaa +_aa +_aa___a +-------------- +方块最大高度为5。 + +因此,我们返回结果[2, 5, 5]。+
+ +
示例 2:
+ +输入: [[100, 100], [200, 100]] +输出: [100, 100] +解释: 相邻的方块不会过早地卡住,只有它们的底部边缘才能粘在表面上。 ++ +
+ +
注意:
+ +-
+
1 <= positions.length <= 1000.
+ 1 <= positions[i][0] <= 10^8.
+ 1 <= positions[i][1] <= 10^6.
+
+ + + +## 解法 + + + +### Python3 + + +```python + +``` + +### Java + + +```java + +``` + +### ... +``` + +``` diff --git a/solution/0700-0799/0700.Search in a Binary Search Tree/README.md b/solution/0700-0799/0700.Search in a Binary Search Tree/README.md new file mode 100644 index 0000000000000..603adbefa21da --- /dev/null +++ b/solution/0700-0799/0700.Search in a Binary Search Tree/README.md @@ -0,0 +1,54 @@ +# [700. 二叉搜索树中的搜索](https://leetcode-cn.com/problems/search-in-a-binary-search-tree) + +## 题目描述 + +
给定二叉搜索树(BST)的根节点和一个值。 你需要在BST中找到节点值等于给定值的节点。 返回以该节点为根的子树。 如果节点不存在,则返回 NULL。
+ +例如,
+ ++给定二叉搜索树: + + 4 + / \ + 2 7 + / \ + 1 3 + +和值: 2 ++ +
你应该返回如下子树:
+ ++ 2 + / \ + 1 3 ++ +
在上述示例中,如果要找的值是 5,但因为没有节点值为 5,我们应该返回 NULL。
给定二叉搜索树(BST)的根节点和要插入树中的值,将值插入二叉搜索树。 返回插入后二叉搜索树的根节点。 保证原始二叉搜索树中不存在新值。
-注意,可能存在多种有效的插入方式,只要树在插入后仍保持为二叉搜索树即可。 你可以返回任意有效的结果。 +注意,可能存在多种有效的插入方式,只要树在插入后仍保持为二叉搜索树即可。 你可以返回任意有效的结果。
-**示例 :** -``` +例如,
+ +
给定二叉搜索树:
4
@@ -16,63 +18,51 @@
1 3
和 插入的值: 5
-```
-你可以返回这个二叉搜索树:
-```
- 4
- / \
- 2 7
- / \ /
- 1 3 5
-```
-或者这个树也是有效的:
-```
- 5
- / \
- 2 7
- / \
- 1 3
+
+
+你可以返回这个二叉搜索树:
+ ++ 4 + / \ + 2 7 + / \ / + 1 3 5 ++ +
或者这个树也是有效的:
+ +
+ 5
+ / \
+ 2 7
+ / \
+ 1 3
\
4
-```
+
+
-### 解法一
-返回第一种类型。遍历每个节点,若节点值大于插入值,搜索其左子节点,若小于插入值,则搜索其右子节点。若其节点不存在,则该位置为需要插入的值所在节点。使用递归会使运行时间相对增加,而循环语句的运行更快。
+## 解法
+
+
+
+### Python3
+
```python
-class Solution:
- def insertIntoBST(self, root, val):
- if not root:
- return TreeNode(val)
- if root.val < val:
- if root.right:
- self.insertIntoBST(root.right, val)
- else:
- root.right = TreeNode(val)
- if root.val > val:
- if root.left:
- self.insertIntoBST(root.left, val)
- else:
- root.left = TreeNode(val)
- return root
+
```
-### 解法二(无法AC)
-返回第二种类型。先将根节点替换为插入值,再将根节点的值放到其左子节点中的最右子节点。但是这种解法无法AC,个人认为是题目并不支持返回第二种类型的结果。
+### Java
+
+
+```java
+
+```
+
+### ...
+```
-```python
-class Solution:
- def insertIntoBST(self, root, val):
- if not root:
- return TreeNode(val)
- elif root.left is None:
- root.left = TreeNode(root.val)
- root.val = val
- root.val, val = val, root.val
- node = root.left
- while node.right:
- node = node.right
- node.right = TreeNode(val)
- return root
```
diff --git a/solution/0700-0799/0702.Search in a Sorted Array of Unknown Size/README.md b/solution/0700-0799/0702.Search in a Sorted Array of Unknown Size/README.md
new file mode 100644
index 0000000000000..38e21d36590a1
--- /dev/null
+++ b/solution/0700-0799/0702.Search in a Sorted Array of Unknown Size/README.md
@@ -0,0 +1,29 @@
+# [702. 搜索长度未知的有序数组](https://leetcode-cn.com/problems/search-in-a-sorted-array-of-unknown-size)
+
+## 题目描述
+
+None
+
+
+## 解法
+
+
+
+### Python3
+
+
+```python
+
+```
+
+### Java
+
+
+```java
+
+```
+
+### ...
+```
+
+```
diff --git a/solution/0700-0799/0703.Kth Largest Element in a Stream/README.md b/solution/0700-0799/0703.Kth Largest Element in a Stream/README.md
index 102f063d03537..9b9c95f94b6b5 100644
--- a/solution/0700-0799/0703.Kth Largest Element in a Stream/README.md
+++ b/solution/0700-0799/0703.Kth Largest Element in a Stream/README.md
@@ -1,63 +1,48 @@
-## 数据流中的第K大元素
-### 题目描述
+# [703. 数据流中的第K大元素](https://leetcode-cn.com/problems/kth-largest-element-in-a-stream)
-设计一个找到数据流中第 K 大元素的类(class)。注意是排序后的第 K 大元素,不是第 K 个不同的元素。
+## 题目描述
+
+设计一个找到数据流中第K大元素的类(class)。注意是排序后的第K大元素,不是第K个不同的元素。
-你的 `KthLargest` 类需要一个同时接收整数 `k` 和整数数组`nums` 的构造器,它包含数据流中的初始元素。每次调用 `KthLargest.add`,返回当前数据流中第 K 大的元素。 +你的 KthLargest 类需要一个同时接收整数 k 和整数数组nums 的构造器,它包含数据流中的初始元素。每次调用 KthLargest.add,返回当前数据流中第K大的元素。
示例:
-``` +int k = 3; int[] arr = [4,5,8,2]; KthLargest kthLargest = new KthLargest(3, arr); -kthLargest.add(3); // returns 4 -kthLargest.add(5); // returns 5 -kthLargest.add(10); // returns 5 -kthLargest.add(9); // returns 8 -kthLargest.add(4); // returns 8 -``` +kthLargest.add(3); // returns 4 +kthLargest.add(5); // returns 5 +kthLargest.add(10); // returns 5 +kthLargest.add(9); // returns 8 +kthLargest.add(4); // returns 8 ++ +
说明:
+你可以假设 nums 的长度≥ k-1 且k ≥ 1。
给定一个 n 个元素有序的(升序)整型数组 nums 和一个目标值 target ,写一个函数搜索 nums 中的 target,如果目标值存在返回下标,否则返回 -1。
+示例 1:
输入:+ +nums= [-1,0,3,5,9,12],target= 9 +输出: 4 +解释: 9 出现在nums中并且下标为 4 +
示例 2:
+ +输入:+ +nums= [-1,0,3,5,9,12],target= 2 +输出: -1 +解释: 2 不存在nums中因此返回 -1 +
+ +
提示:
+ +-
+
- 你可以假设
nums中的所有元素是不重复的。
+ n将在[1, 10000]之间。
+ nums的每个元素都将在[-9999, 9999]之间。
+
不使用任何内建的哈希表库设计一个哈希集合
+ +具体地说,你的设计应该包含以下的功能
+ +-
+
add(value):向哈希集合中插入一个值。
+ contains(value):返回哈希集合中是否存在这个值。
+ remove(value):将给定值从哈希集合中删除。如果哈希集合中没有这个值,什么也不做。
+
+示例:
MyHashSet hashSet = new MyHashSet(); +hashSet.add(1); +hashSet.add(2); +hashSet.contains(1); // 返回 true +hashSet.contains(3); // 返回 false (未找到) +hashSet.add(2); +hashSet.contains(2); // 返回 true +hashSet.remove(2); +hashSet.contains(2); // 返回 false (已经被删除) ++ +
+注意:
-
+
- 所有的值都在
[0, 1000000]的范围内。
+ - 操作的总数目在
[1, 10000]范围内。
+ - 不要使用内建的哈希集合库。 +
不使用任何内建的哈希表库设计一个哈希映射
+ +具体地说,你的设计应该包含以下的功能
+ +-
+
put(key, value):向哈希映射中插入(键,值)的数值对。如果键对应的值已经存在,更新这个值。
+ get(key):返回给定的键所对应的值,如果映射中不包含这个键,返回-1。
+ remove(key):如果映射中存在这个键,删除这个数值对。
+
+示例:
+MyHashMap hashMap = new MyHashMap(); +hashMap.put(1, 1); +hashMap.put(2, 2); +hashMap.get(1); // 返回 1 +hashMap.get(3); // 返回 -1 (未找到) +hashMap.put(2, 1); // 更新已有的值 +hashMap.get(2); // 返回 1 +hashMap.remove(2); // 删除键为2的数据 +hashMap.get(2); // 返回 -1 (未找到) ++ +
+注意:
-
+
- 所有的值都在
[1, 1000000]的范围内。
+ - 操作的总数目在
[1, 10000]范围内。
+ - 不要使用内建的哈希库。 +
设计链表的实现。您可以选择使用单链表或双链表。单链表中的节点应该具有两个属性:val 和 next。val 是当前节点的值,next 是指向下一个节点的指针/引用。如果要使用双向链表,则还需要一个属性 prev 以指示链表中的上一个节点。假设链表中的所有节点都是 0-index 的。
在链表类中实现这些功能:
-- get(index):获取链表中第 `index` 个节点的值。如果索引无效,则返回`-1`。 -- addAtHead(val):在链表的第一个元素之前添加一个值为 `val` 的节点。插入后,新节点将成为链表的第一个节点。 -- addAtTail(val):将值为 `val` 的节点追加到链表的最后一个元素。 -- addAtIndex(index,val):在链表中的第 `index` 个节点之前添加值为 `val` 的节点。如果 `index` 等于链表的长度,则该节点将附加到链表的末尾。如果 `index` 大于链表长度,则不会插入节点。 -- deleteAtIndex(index):如果索引 `index` 有效,则删除链表中的第 `index` 个节点。 - +-
+
- get(index):获取链表中第
index个节点的值。如果索引无效,则返回-1。
+ - addAtHead(val):在链表的第一个元素之前添加一个值为
val的节点。插入后,新节点将成为链表的第一个节点。
+ - addAtTail(val):将值为
val的节点追加到链表的最后一个元素。
+ - addAtIndex(index,val):在链表中的第
index个节点之前添加值为val的节点。如果index等于链表的长度,则该节点将附加到链表的末尾。如果index大于链表长度,则不会插入节点。如果index小于0,则在头部插入节点。
+ - deleteAtIndex(index):如果索引
index有效,则删除链表中的第index个节点。
+
+ +
示例:
+ +MyLinkedList linkedList = new MyLinkedList(); linkedList.addAtHead(1); linkedList.addAtTail(3); -linkedList.addAtIndex(1,2); //链表变为1-> 2-> 3 +linkedList.addAtIndex(1,2); //链表变为1-> 2-> 3 linkedList.get(1); //返回2 -linkedList.deleteAtIndex(1); //现在链表是1-> 3 +linkedList.deleteAtIndex(1); //现在链表是1-> 3 linkedList.get(1); //返回3 -``` ++ +
+ +
提示:
+ +-
+
- 所有
val值都在[1, 1000]之内。
+ - 操作次数将在
[1, 1000]之内。
+ - 请不要使用内置的 LinkedList 库。 +
实现函数 ToLowerCase(),该函数接收一个字符串参数 str,并将该字符串中的大写字母转换成小写字母,之后返回新的字符串。
+ ++ +
示例 1:
+ ++输入: "Hello" +输出: "hello"+ +
示例 2:
+ ++输入: "here" +输出: "here"+ +
示例 3:
+ ++输入: "LOVELY" +输出: "lovely" ++ + + +## 解法 + + + +### Python3 + + +```python + +``` + +### Java + + +```java + +``` + +### ... +``` + +``` diff --git a/solution/0700-0799/0710.Random Pick with Blacklist/README.md b/solution/0700-0799/0710.Random Pick with Blacklist/README.md new file mode 100644 index 0000000000000..25bcc2ded1cce --- /dev/null +++ b/solution/0700-0799/0710.Random Pick with Blacklist/README.md @@ -0,0 +1,80 @@ +# [710. 黑名单中的随机数](https://leetcode-cn.com/problems/random-pick-with-blacklist) + +## 题目描述 + +
给定一个包含 [0,n ) 中独特的整数的黑名单 B,写一个函数从 [ 0,n ) 中返回一个不在 B 中的随机整数。
+ +对它进行优化使其尽量少调用系统方法 Math.random() 。
提示:
+ +-
+
1 <= N <= 1000000000
+ 0 <= B.length < min(100000, N)
+ [0, N)不包含 N,详细参见 interval notation 。
+
示例 1:
+ ++输入: +["Solution","pick","pick","pick"] +[[1,[]],[],[],[]] +输出: [null,0,0,0] ++ +
示例 2:
+ ++输入: +["Solution","pick","pick","pick"] +[[2,[]],[],[],[]] +输出: [null,1,1,1] ++ +
示例 3:
+ ++输入: +["Solution","pick","pick","pick"] +[[3,[1]],[],[],[]] +Output: [null,0,0,2] ++ +
示例 4:
+ ++输入: +["Solution","pick","pick","pick"] +[[4,[2]],[],[],[]] +输出: [null,1,3,1] ++ +
输入语法说明:
+ +输入是两个列表:调用成员函数名和调用的参数。Solution的构造函数有两个参数,N 和黑名单 B。pick 没有参数,输入参数是一个列表,即使参数为空,也会输入一个 [] 空列表。
给定两个字符串s1, s2,找到使两个字符串相等所需删除字符的ASCII值的最小和。
示例 1:
+ ++输入: s1 = "sea", s2 = "eat" +输出: 231 +解释: 在 "sea" 中删除 "s" 并将 "s" 的值(115)加入总和。 +在 "eat" 中删除 "t" 并将 116 加入总和。 +结束时,两个字符串相等,115 + 116 = 231 就是符合条件的最小和。 ++ +
示例 2:
+ ++输入: s1 = "delete", s2 = "leet" +输出: 403 +解释: 在 "delete" 中删除 "dee" 字符串变成 "let", +将 100[d]+101[e]+101[e] 加入总和。在 "leet" 中删除 "e" 将 101[e] 加入总和。 +结束时,两个字符串都等于 "let",结果即为 100+101+101+101 = 403 。 +如果改为将两个字符串转换为 "lee" 或 "eet",我们会得到 433 或 417 的结果,比答案更大。 ++ +
注意:
+ +-
+
0 < s1.length, s2.length <= 1000。
+ - 所有字符串中的字符ASCII值在
[97, 122]之间。
+
给定一个正整数数组 nums。
找出该数组内乘积小于 k 的连续的子数组的个数。
示例 1:
+ ++输入: nums = [10,5,2,6], k = 100 +输出: 8 +解释: 8个乘积小于100的子数组分别为: [10], [5], [2], [6], [10,5], [5,2], [2,6], [5,2,6]。 +需要注意的是 [10,5,2] 并不是乘积小于100的子数组。 ++ +
说明:
+ +-
+
0 < nums.length <= 50000
+ 0 < nums[i] < 1000
+ 0 <= k < 10^6
+
给定一个整数数组 prices,其中第 i 个元素代表了第 i 天的股票价格 ;非负整数 fee 代表了交易股票的手续费用。
你可以无限次地完成交易,但是你每次交易都需要付手续费。如果你已经购买了一个股票,在卖出它之前你就不能再继续购买股票了。
+ +返回获得利润的最大值。
+ +示例 1:
+ +输入: prices = [1, 3, 2, 8, 4, 9], fee = 2 +输出: 8 +解释: 能够达到的最大利润: +在此处买入 prices[0] = 1 +在此处卖出 prices[3] = 8 +在此处买入 prices[4] = 4 +在此处卖出 prices[5] = 9 +总利润: ((8 - 1) - 2) + ((9 - 4) - 2) = 8.+ +
注意:
+ +-
+
0 < prices.length <= 50000.
+ 0 < prices[i] < 50000.
+ 0 <= fee < 50000.
+
Range 模块是跟踪数字范围的模块。你的任务是以一种有效的方式设计和实现以下接口。
+ +-
+
addRange(int left, int right)添加半开区间[left, right),跟踪该区间中的每个实数。添加与当前跟踪的数字部分重叠的区间时,应当添加在区间[left, right)中尚未跟踪的任何数字到该区间中。
+ queryRange(int left, int right)只有在当前正在跟踪区间[left, right)中的每一个实数时,才返回 true。
+ removeRange(int left, int right)停止跟踪区间[left, right)中当前正在跟踪的每个实数。
+
+ +
示例:
+ +addRange(10, 20): null +removeRange(14, 16): null +queryRange(10, 14): true (区间 [10, 14) 中的每个数都正在被跟踪) +queryRange(13, 15): false (未跟踪区间 [13, 15) 中像 14, 14.03, 14.17 这样的数字) +queryRange(16, 17): true (尽管执行了删除操作,区间 [16, 17) 中的数字 16 仍然会被跟踪) ++ +
+ +
提示:
+ +-
+
- 半开区间
[left, right)表示所有满足left <= x < right的实数。
+ - 对
addRange, queryRange, removeRange的所有调用中0 < left < right < 10^9。
+ - 在单个测试用例中,对
addRange的调用总数不超过1000次。
+ - 在单个测试用例中,对
queryRange的调用总数不超过5000次。
+ - 在单个测试用例中,对
removeRange的调用总数不超过1000次。
+
+ + + +## 解法 + + + +### Python3 + + +```python + +``` + +### Java + + +```java + +``` + +### ... +``` + +``` diff --git a/solution/0700-0799/0716.Max Stack/README.md b/solution/0700-0799/0716.Max Stack/README.md new file mode 100644 index 0000000000000..0ae6c94c8f486 --- /dev/null +++ b/solution/0700-0799/0716.Max Stack/README.md @@ -0,0 +1,29 @@ +# [716. 最大栈](https://leetcode-cn.com/problems/max-stack) + +## 题目描述 + +None + + +## 解法 + + + +### Python3 + + +```python + +``` + +### Java + + +```java + +``` + +### ... +``` + +``` diff --git a/solution/0700-0799/0717.1-bit and 2-bit Characters/README.md b/solution/0700-0799/0717.1-bit and 2-bit Characters/README.md new file mode 100644 index 0000000000000..8e58418ef6f18 --- /dev/null +++ b/solution/0700-0799/0717.1-bit and 2-bit Characters/README.md @@ -0,0 +1,59 @@ +# [717. 1比特与2比特字符](https://leetcode-cn.com/problems/1-bit-and-2-bit-characters) + +## 题目描述 + +
有两种特殊字符。第一种字符可以用一比特0来表示。第二种字符可以用两比特(10 或 11)来表示。
现给一个由若干比特组成的字符串。问最后一个字符是否必定为一个一比特字符。给定的字符串总是由0结束。
+ +示例 1:
+ ++输入: +bits = [1, 0, 0] +输出: True +解释: +唯一的编码方式是一个两比特字符和一个一比特字符。所以最后一个字符是一比特字符。 ++ +
示例 2:
+ ++输入: +bits = [1, 1, 1, 0] +输出: False +解释: +唯一的编码方式是两比特字符和两比特字符。所以最后一个字符不是一比特字符。 ++ +
注意:
+ +-
+
1 <= len(bits) <= 1000.
+ bits[i]总是0或1.
+
给两个整数数组 A 和 B ,返回两个数组中公共的、长度最长的子数组的长度。
示例 1:
+ ++输入: +A: [1,2,3,2,1] +B: [3,2,1,4,7] +输出: 3 +解释: +长度最长的公共子数组是 [3, 2, 1]。 ++ +
说明:
+ +-
+
- 1 <= len(A), len(B) <= 1000 +
- 0 <= A[i], B[i] < 100 +
给定一个整数数组,返回所有数对之间的第 k 个最小距离。一对 (A, B) 的距离被定义为 A 和 B 之间的绝对差值。
+ +示例 1:
+ ++输入: +nums = [1,3,1] +k = 1 +输出:0 +解释: +所有数对如下: +(1,3) -> 2 +(1,1) -> 0 +(3,1) -> 2 +因此第 1 个最小距离的数对是 (1,1),它们之间的距离为 0。 ++ +
提示:
+ +-
+
2 <= len(nums) <= 10000.
+ 0 <= nums[i] < 1000000.
+ 1 <= k <= len(nums) * (len(nums) - 1) / 2.
+
给出一个字符串数组words组成的一本英语词典。从中找出最长的一个单词,该单词是由words词典中其他单词逐步添加一个字母组成。若其中有多个可行的答案,则返回答案中字典序最小的单词。
若无答案,则返回空字符串。
+ +示例 1:
+ ++输入: +words = ["w","wo","wor","worl", "world"] +输出: "world" +解释: +单词"world"可由"w", "wo", "wor", 和 "worl"添加一个字母组成。 ++ +
示例 2:
+ ++输入: +words = ["a", "banana", "app", "appl", "ap", "apply", "apple"] +输出: "apple" +解释: +"apply"和"apple"都能由词典中的单词组成。但是"apple"得字典序小于"apply"。 ++ +
注意:
+ +-
+
- 所有输入的字符串都只包含小写字母。 +
words数组长度范围为[1,1000]。
+ words[i]的长度范围为[1,30]。
+
给定一个列表 accounts,每个元素 accounts[i] 是一个字符串列表,其中第一个元素 accounts[i][0] 是 名称 (name),其余元素是 emails 表示该帐户的邮箱地址。
现在,我们想合并这些帐户。如果两个帐户都有一些共同的邮件地址,则两个帐户必定属于同一个人。请注意,即使两个帐户具有相同的名称,它们也可能属于不同的人,因为人们可能具有相同的名称。一个人最初可以拥有任意数量的帐户,但其所有帐户都具有相同的名称。
+ +合并帐户后,按以下格式返回帐户:每个帐户的第一个元素是名称,其余元素是按顺序排列的邮箱地址。accounts 本身可以以任意顺序返回。
+ +例子 1:
+ ++Input: +accounts = [["John", "johnsmith@mail.com", "john00@mail.com"], ["John", "johnnybravo@mail.com"], ["John", "johnsmith@mail.com", "john_newyork@mail.com"], ["Mary", "mary@mail.com"]] +Output: [["John", 'john00@mail.com', 'john_newyork@mail.com', 'johnsmith@mail.com'], ["John", "johnnybravo@mail.com"], ["Mary", "mary@mail.com"]] +Explanation: + 第一个和第三个 John 是同一个人,因为他们有共同的电子邮件 "johnsmith@mail.com"。 + 第二个 John 和 Mary 是不同的人,因为他们的电子邮件地址没有被其他帐户使用。 + 我们可以以任何顺序返回这些列表,例如答案[['Mary','mary@mail.com'],['John','johnnybravo@mail.com'], + ['John','john00@mail.com','john_newyork@mail.com','johnsmith@mail.com']]仍然会被接受。 + ++ +
注意:
+ +-
+
accounts的长度将在[1,1000]的范围内。
+ accounts[i]的长度将在[1,10]的范围内。
+ accounts[i][j]的长度将在[1,30]的范围内。
+
给一个 C++ 程序,删除程序中的注释。这个程序source是一个数组,其中source[i]表示第i行源码。 这表示每行源码由\n分隔。
在 C++ 中有两种注释风格,行内注释和块注释。
+ +字符串// 表示行注释,表示//和其右侧的其余字符应该被忽略。
字符串/* 表示一个块注释,它表示直到*/的下一个(非重叠)出现的所有字符都应该被忽略。(阅读顺序为从左到右)非重叠是指,字符串/*/并没有结束块注释,因为注释的结尾与开头相重叠。
第一个有效注释优先于其他注释:如果字符串//出现在块注释中会被忽略。 同样,如果字符串/*出现在行或块注释中也会被忽略。
如果一行在删除注释之后变为空字符串,那么不要输出该行。即,答案列表中的每个字符串都是非空的。
+ +样例中没有控制字符,单引号或双引号字符。比如,source = "string s = "/* Not a comment. */";" 不会出现在测试样例里。(此外,没有其他内容(如定义或宏)会干扰注释。)
我们保证每一个块注释最终都会被闭合, 所以在行或块注释之外的/*总是开始新的注释。
最后,隐式换行符可以通过块注释删除。 有关详细信息,请参阅下面的示例。
+ +从源代码中删除注释后,需要以相同的格式返回源代码。
+ +示例 1:
+ +
+输入:
+source = ["/*Test program */", "int main()", "{ ", " // variable declaration ", "int a, b, c;", "/* This is a test", " multiline ", " comment for ", " testing */", "a = b + c;", "}"]
+
+示例代码可以编排成这样:
+/*Test program */
+int main()
+{
+ // variable declaration
+int a, b, c;
+/* This is a test
+ multiline
+ comment for
+ testing */
+a = b + c;
+}
+
+输出: ["int main()","{ "," ","int a, b, c;","a = b + c;","}"]
+
+编排后:
+int main()
+{
+
+int a, b, c;
+a = b + c;
+}
+
+解释:
+第 1 行和第 6-9 行的字符串 /* 表示块注释。第 4 行的字符串 // 表示行注释。
+
+
+示例 2:
+ ++输入: +source = ["a/*comment", "line", "more_comment*/b"] +输出: ["ab"] +解释: 原始的 source 字符串是 "a/*comment\nline\nmore_comment*/b", 其中我们用粗体显示了换行符。删除注释后,隐含的换行符被删除,留下字符串 "ab" 用换行符分隔成数组时就是 ["ab"]. ++ +
注意:
+ +-
+
source的长度范围为[1, 100].
+ source[i]的长度范围为[0, 80].
+ - 每个块注释都会被闭合。 +
- 给定的源码中不会有单引号、双引号或其他控制字符。 +
给定一个整数类型的数组 nums,请编写一个能够返回数组“中心索引”的方法。
我们是这样定义数组中心索引的:数组中心索引的左侧所有元素相加的和等于右侧所有元素相加的和。
+ +如果数组不存在中心索引,那么我们应该返回 -1。如果数组有多个中心索引,那么我们应该返回最靠近左边的那一个。
+ +示例 1:
+ ++输入: +nums = [1, 7, 3, 6, 5, 6] +输出: 3 +解释: +索引3 (nums[3] = 6) 的左侧数之和(1 + 7 + 3 = 11),与右侧数之和(5 + 6 = 11)相等。 +同时, 3 也是第一个符合要求的中心索引。 ++ +
示例 2:
+ ++输入: +nums = [1, 2, 3] +输出: -1 +解释: +数组中不存在满足此条件的中心索引。+ +
说明:
+ +-
+
nums的长度范围为[0, 10000]。
+ - 任何一个
nums[i]将会是一个范围在[-1000, 1000]的整数。
+
给定一个头结点为 root 的链表, 编写一个函数以将链表分隔为 k 个连续的部分。
每部分的长度应该尽可能的相等: 任意两部分的长度差距不能超过 1,也就是说可能有些部分为 null。
+ +这k个部分应该按照在链表中出现的顺序进行输出,并且排在前面的部分的长度应该大于或等于后面的长度。
+ +返回一个符合上述规则的链表的列表。
+ +举例: 1->2->3->4, k = 5 // 5 结果 [ [1], [2], [3], [4], null ]
+ +示例 1:
+ ++输入: +root = [1, 2, 3], k = 5 +输出: [[1],[2],[3],[],[]] +解释: +输入输出各部分都应该是链表,而不是数组。 +例如, 输入的结点 root 的 val= 1, root.next.val = 2, \root.next.next.val = 3, 且 root.next.next.next = null。 +第一个输出 output[0] 是 output[0].val = 1, output[0].next = null。 +最后一个元素 output[4] 为 null, 它代表了最后一个部分为空链表。 ++ +
示例 2:
+ ++输入: +root = [1, 2, 3, 4, 5, 6, 7, 8, 9, 10], k = 3 +输出: [[1, 2, 3, 4], [5, 6, 7], [8, 9, 10]] +解释: +输入被分成了几个连续的部分,并且每部分的长度相差不超过1.前面部分的长度大于等于后面部分的长度。 ++ +
+ +
提示:
+ +-
+
root的长度范围:[0, 1000].
+ - 输入的每个节点的大小范围:
[0, 999].
+ k的取值范围:[1, 50].
+
+ + + +## 解法 + + + +### Python3 + + +```python + +``` + +### Java + + +```java + +``` + +### ... +``` + +``` diff --git a/solution/0700-0799/0726.Number of Atoms/README.md b/solution/0700-0799/0726.Number of Atoms/README.md new file mode 100644 index 0000000000000..df3a35f05b1bc --- /dev/null +++ b/solution/0700-0799/0726.Number of Atoms/README.md @@ -0,0 +1,78 @@ +# [726. 原子的数量](https://leetcode-cn.com/problems/number-of-atoms) + +## 题目描述 + +
给定一个化学式formula(作为字符串),返回每种原子的数量。
原子总是以一个大写字母开始,接着跟随0个或任意个小写字母,表示原子的名字。
+ +如果数量大于 1,原子后会跟着数字表示原子的数量。如果数量等于 1 则不会跟数字。例如,H2O 和 H2O2 是可行的,但 H1O2 这个表达是不可行的。
+ +两个化学式连在一起是新的化学式。例如 H2O2He3Mg4 也是化学式。
+ +一个括号中的化学式和数字(可选择性添加)也是化学式。例如 (H2O2) 和 (H2O2)3 是化学式。
+ +给定一个化学式,输出所有原子的数量。格式为:第一个(按字典序)原子的名子,跟着它的数量(如果数量大于 1),然后是第二个原子的名字(按字典序),跟着它的数量(如果数量大于 1),以此类推。
+ +示例 1:
+ +
+输入:
+formula = "H2O"
+输出: "H2O"
+解释:
+原子的数量是 {'H': 2, 'O': 1}。
+
+
+示例 2:
+ +
+输入:
+formula = "Mg(OH)2"
+输出: "H2MgO2"
+解释:
+原子的数量是 {'H': 2, 'Mg': 1, 'O': 2}。
+
+
+示例 3:
+ +
+输入:
+formula = "K4(ON(SO3)2)2"
+输出: "K4N2O14S4"
+解释:
+原子的数量是 {'K': 4, 'N': 2, 'O': 14, 'S': 4}。
+
+
+注意:
+ +-
+
- 所有原子的第一个字母为大写,剩余字母都是小写。 +
formula的长度在[1, 1000]之间。
+ formula只包含字母、数字和圆括号,并且题目中给定的是合法的化学式。
+
自除数 是指可以被它包含的每一位数除尽的数。
+ +例如,128 是一个自除数,因为 128 % 1 == 0,128 % 2 == 0,128 % 8 == 0。
还有,自除数不允许包含 0 。
+ +给定上边界和下边界数字,输出一个列表,列表的元素是边界(含边界)内所有的自除数。
+ +示例 1:
+ ++输入: +上边界left = 1, 下边界right = 22 +输出: [1, 2, 3, 4, 5, 6, 7, 8, 9, 11, 12, 15, 22] ++ +
注意:
+ +-
+
- 每个输入参数的边界满足
1 <= left <= right <= 10000。
+
实现一个 MyCalendar 类来存放你的日程安排。如果要添加的时间内没有其他安排,则可以存储这个新的日程安排。
MyCalendar 有一个 book(int start, int end)方法。它意味着在 start 到 end 时间内增加一个日程安排,注意,这里的时间是半开区间,即 [start, end), 实数 x 的范围为, start <= x < end。
当两个日程安排有一些时间上的交叉时(例如两个日程安排都在同一时间内),就会产生重复预订。
+ +每次调用 MyCalendar.book方法时,如果可以将日程安排成功添加到日历中而不会导致重复预订,返回 true。否则,返回 false 并且不要将该日程安排添加到日历中。
请按照以下步骤调用 MyCalendar 类: MyCalendar cal = new MyCalendar(); MyCalendar.book(start, end)
示例 1:
+ +MyCalendar(); +MyCalendar.book(10, 20); // returns true +MyCalendar.book(15, 25); // returns false +MyCalendar.book(20, 30); // returns true +解释: +第一个日程安排可以添加到日历中. 第二个日程安排不能添加到日历中,因为时间 15 已经被第一个日程安排预定了。 +第三个日程安排可以添加到日历中,因为第一个日程安排并不包含时间 20 。 ++ +
说明:
+ +-
+
- 每个测试用例,调用
MyCalendar.book函数最多不超过100次。
+ - 调用函数
MyCalendar.book(start, end)时,start和end的取值范围为[0, 10^9]。
+
给定一个字符串 S,找出 S 中不同的非空回文子序列个数,并返回该数字与 10^9 + 7 的模。
通过从 S 中删除 0 个或多个字符来获得子字符序列。
+ +如果一个字符序列与它反转后的字符序列一致,那么它是回文字符序列。
+ +如果对于某个 i,A_i != B_i,那么 A_1, A_2, ... 和 B_1, B_2, ... 这两个字符序列是不同的。
+ +
示例 1:
+ +输入: +S = 'bccb' +输出:6 +解释: +6 个不同的非空回文子字符序列分别为:'b', 'c', 'bb', 'cc', 'bcb', 'bccb'。 +注意:'bcb' 虽然出现两次但仅计数一次。 ++ +
示例 2:
+ +输入: +S = 'abcdabcdabcdabcdabcdabcdabcdabcddcbadcbadcbadcbadcbadcbadcbadcba' +输出:104860361 +解释: +共有 3104860382 个不同的非空回文子字符序列,对 10^9 + 7 取模为 104860361。 ++ +
+ +
提示:
+ +-
+
- 字符串
S的长度将在[1, 1000]范围内。
+ - 每个字符
S[i]将会是集合{'a', 'b', 'c', 'd'}中的某一个。
+
+ + + +## 解法 + + + +### Python3 + + +```python + +``` + +### Java + + +```java + +``` + +### ... +``` + +``` diff --git a/solution/0700-0799/0731.My Calendar II/README.md b/solution/0700-0799/0731.My Calendar II/README.md new file mode 100644 index 0000000000000..ff0699e4314fd --- /dev/null +++ b/solution/0700-0799/0731.My Calendar II/README.md @@ -0,0 +1,66 @@ +# [731. 我的日程安排表 II](https://leetcode-cn.com/problems/my-calendar-ii) + +## 题目描述 + +
实现一个 MyCalendar 类来存放你的日程安排。如果要添加的时间内不会导致三重预订时,则可以存储这个新的日程安排。
MyCalendar 有一个 book(int start, int end)方法。它意味着在 start 到 end 时间内增加一个日程安排,注意,这里的时间是半开区间,即 [start, end), 实数 x 的范围为, start <= x < end。
当三个日程安排有一些时间上的交叉时(例如三个日程安排都在同一时间内),就会产生三重预订。
+ +每次调用 MyCalendar.book方法时,如果可以将日程安排成功添加到日历中而不会导致三重预订,返回 true。否则,返回 false 并且不要将该日程安排添加到日历中。
请按照以下步骤调用MyCalendar 类: MyCalendar cal = new MyCalendar(); MyCalendar.book(start, end)
+ +
示例:
+ +MyCalendar(); +MyCalendar.book(10, 20); // returns true +MyCalendar.book(50, 60); // returns true +MyCalendar.book(10, 40); // returns true +MyCalendar.book(5, 15); // returns false +MyCalendar.book(5, 10); // returns true +MyCalendar.book(25, 55); // returns true +解释: +前两个日程安排可以添加至日历中。 第三个日程安排会导致双重预订,但可以添加至日历中。 +第四个日程安排活动(5,15)不能添加至日历中,因为它会导致三重预订。 +第五个日程安排(5,10)可以添加至日历中,因为它未使用已经双重预订的时间10。 +第六个日程安排(25,55)可以添加至日历中,因为时间 [25,40] 将和第三个日程安排双重预订; +时间 [40,50] 将单独预订,时间 [50,55)将和第二个日程安排双重预订。 ++ +
+ +
提示:
+ +-
+
- 每个测试用例,调用
MyCalendar.book函数最多不超过1000次。
+ - 调用函数
MyCalendar.book(start, end)时,start和end的取值范围为[0, 10^9]。
+
实现一个 MyCalendar 类来存放你的日程安排,你可以一直添加新的日程安排。
MyCalendar 有一个 book(int start, int end)方法。它意味着在start到end时间内增加一个日程安排,注意,这里的时间是半开区间,即 [start, end), 实数 x 的范围为, start <= x < end。
当 K 个日程安排有一些时间上的交叉时(例如K个日程安排都在同一时间内),就会产生 K 次预订。
+ +每次调用 MyCalendar.book方法时,返回一个整数 K ,表示最大的 K 次预订。
请按照以下步骤调用MyCalendar 类: MyCalendar cal = new MyCalendar(); MyCalendar.book(start, end)
示例 1:
+ ++MyCalendarThree(); +MyCalendarThree.book(10, 20); // returns 1 +MyCalendarThree.book(50, 60); // returns 1 +MyCalendarThree.book(10, 40); // returns 2 +MyCalendarThree.book(5, 15); // returns 3 +MyCalendarThree.book(5, 10); // returns 3 +MyCalendarThree.book(25, 55); // returns 3 +解释: +前两个日程安排可以预订并且不相交,所以最大的K次预订是1。 +第三个日程安排[10,40]与第一个日程安排相交,最高的K次预订为2。 +其余的日程安排的最高K次预订仅为3。 +请注意,最后一次日程安排可能会导致局部最高K次预订为2,但答案仍然是3,原因是从开始到最后,时间[10,20],[10,40]和[5,15]仍然会导致3次预订。 ++ +
说明:
+ +-
+
- 每个测试用例,调用
MyCalendar.book函数最多不超过400次。
+ - 调用函数
MyCalendar.book(start, end)时,start和end的取值范围为[0, 10^9]。
+
有一幅以二维整数数组表示的图画,每一个整数表示该图画的像素值大小,数值在 0 到 65535 之间。
+ +给你一个坐标 (sr, sc) 表示图像渲染开始的像素值(行 ,列)和一个新的颜色值 newColor,让你重新上色这幅图像。
为了完成上色工作,从初始坐标开始,记录初始坐标的上下左右四个方向上像素值与初始坐标相同的相连像素点,接着再记录这四个方向上符合条件的像素点与他们对应四个方向上像素值与初始坐标相同的相连像素点,……,重复该过程。将所有有记录的像素点的颜色值改为新的颜色值。
+ +最后返回经过上色渲染后的图像。
+ +示例 1:
+ ++输入: +image = [[1,1,1],[1,1,0],[1,0,1]] +sr = 1, sc = 1, newColor = 2 +输出: [[2,2,2],[2,2,0],[2,0,1]] +解析: +在图像的正中间,(坐标(sr,sc)=(1,1)), +在路径上所有符合条件的像素点的颜色都被更改成2。 +注意,右下角的像素没有更改为2, +因为它不是在上下左右四个方向上与初始点相连的像素点。 ++ +
注意:
+ +-
+
image和image[0]的长度在范围[1, 50]内。
+ - 给出的初始点将满足
0 <= sr < image.length和0 <= sc < image[0].length。
+ image[i][j]和newColor表示的颜色值在范围[0, 65535]内。
+
给定一个整数数组 asteroids,表示在同一行的行星。
对于数组中的每一个元素,其绝对值表示行星的大小,正负表示行星的移动方向(正表示向右移动,负表示向左移动)。每一颗行星以相同的速度移动。
-对于数组中的每一个元素,其绝对值表示行星的大小,正负表示行星的移动方向(正表示向右移动,负表示向左移动)。每一颗行星以相同的速度移动。 +找出碰撞后剩下的所有行星。碰撞规则:两个行星相互碰撞,较小的行星会爆炸。如果两颗行星大小相同,则两颗行星都会爆炸。两颗移动方向相同的行星,永远不会发生碰撞。
-找出碰撞后剩下的所有行星。碰撞规则:两个行星相互碰撞,较小的行星会爆炸。如果两颗行星大小相同,则两颗行星都会爆炸。两颗移动方向相同的行星,永远不会发生碰撞。 +示例 1:
-**示例1:** -``` -输入: ++输入: asteroids = [5, 10, -5] -输出: [5, 10] -解释: +输出: [5, 10] +解释: 10 和 -5 碰撞后只剩下 10。 5 和 10 永远不会发生碰撞。 -``` -**示例2:** -``` -输入: ++ +
示例 2:
+ ++输入: asteroids = [8, -8] -输出: [] -解释: +输出: [] +解释: 8 和 -8 碰撞后,两者都发生爆炸。 -``` -**说明:** -- 数组 asteroids 的长度不超过 10000。 -- 每一颗行星的大小都是非零整数,范围是 [-1000, 1000] 。 ++ +
示例 3:
+ ++输入: +asteroids = [10, 2, -5] +输出: [10] +解释: +2 和 -5 发生碰撞后剩下 -5。10 和 -5 发生碰撞后剩下 10。 ++ +
示例 4:
+ ++输入: +asteroids = [-2, -1, 1, 2] +输出: [-2, -1, 1, 2] +解释: +-2 和 -1 向左移动,而 1 和 2 向右移动。 +由于移动方向相同的行星不会发生碰撞,所以最终没有行星发生碰撞。 ++ +
说明:
+ +-
+
- 数组
asteroids的长度不超过10000。
+ - 每一颗行星的大小都是非零整数,范围是
[-1000, 1000]。
+
给定一个类似 Lisp 语句的表达式 expression,求出其计算结果。
表达式语法如下所示:
+ +-
+
- 表达式可以为整数,let 语法,add 语法,mult 语法。表达式的结果总是一个整数。 +
- (整数可以是正整数、负整数、0) +
- let 语法表示为
(let v1 e1 v2 e2 ... vn en expr), 其中let语法总是以字符串"let"来表示,接下来会跟随一个或多个交替变量或表达式,也就是说,第一个变量v1被分配为表达式e1的值,第二个变量v2被分配为表达式e2的值,以此类推;最终 let 语法的值为expr表达式的值。
+ - add语法表示为
(add e1 e2),其中add语法总是以字符串"add"来表示,该语法总是有两个表达式e1、e2, 该语法的最终结果是e1表达式的值与e2表达式的值之和。
+ - mult语法表示为
(mult e1 e2),其中mult语法总是以字符串"mult"表示, 该语法总是有两个表达式e1、e2,该语法的最终结果是e1表达式的值与e2表达式的值之积。
+ - 在该题目中,变量的命名以小写字符开始,之后跟随0个或多个小写字符或数字。为了方便,"add","let","mult"会被定义为"关键字",不会在表达式的变量命名中出现。 +
- 最后,要说一下范围的概念。在做计算时,需要注意优先级,在最内层(根据括号)的表达式的值应该先计算,然后依次计算外层的表达式。我们将保证每一个测试的表达式都是合法的。有关范围的更多详细信息,请参阅示例。 +
+ +
示例:
+ ++输入: (add 1 2) +输出: 3 + +输入: (mult 3 (add 2 3)) +输出: 15 + +输入: (let x 2 (mult x 5)) +输出: 10 + +输入: (let x 2 (mult x (let x 3 y 4 (add x y)))) +输出: 14 +解释: +表达式 (add x y), 在获取 x 值时, 我们应当由最内层依次向外计算, 首先遇到了 x=3, 所以此处的 x 值是 3. + + +输入: (let x 3 x 2 x) +输出: 2 +解释: let 语句中的赋值运算按顺序处理即可 + +输入: (let x 1 y 2 x (add x y) (add x y)) +输出: 5 +解释: +第一个 (add x y) 计算结果是 3,并且将此值赋给了 x 。 +第二个 (add x y) 计算结果就是 3+2 = 5 。 + +输入: (let x 2 (add (let x 3 (let x 4 x)) x)) +输出: 6 +解释: +(let x 4 x) 中的 x 的作用范围仅在()之内。所以最终做加法操作时,x 的值是 2 。 + +输入: (let a1 3 b2 (add a1 1) b2) +输出: 4 +解释: +变量命名时可以在第一个小写字母后跟随数字. + ++ +
+ +
注意:
+ +-
+
- 我们给定的
expression表达式都是格式化后的:表达式前后没有多余的空格,表达式的不同部分(关键字、变量、表达式)之间仅使用一个空格分割,并且在相邻括号之间也没有空格。我们给定的表达式均为合法的且最终结果为整数。
+ - 我们给定的表达式长度最多为 2000 (表达式也不会为空,因为那不是一个合法的表达式)。 +
- 最终的结果和中间的计算结果都将是一个 32 位整数。 +
+ + + +## 解法 + + + +### Python3 + + +```python + +``` + +### Java + + +```java + +``` + +### ... +``` + +``` diff --git a/solution/0700-0799/0737.Sentence Similarity II/README.md b/solution/0700-0799/0737.Sentence Similarity II/README.md new file mode 100644 index 0000000000000..d26959f9f6fe0 --- /dev/null +++ b/solution/0700-0799/0737.Sentence Similarity II/README.md @@ -0,0 +1,29 @@ +# [737. 句子相似性 II](https://leetcode-cn.com/problems/sentence-similarity-ii) + +## 题目描述 + +None + + +## 解法 + + + +### Python3 + + +```python + +``` + +### Java + + +```java + +``` + +### ... +``` + +``` diff --git a/solution/0700-0799/0738.Monotone Increasing Digits/README.md b/solution/0700-0799/0738.Monotone Increasing Digits/README.md new file mode 100644 index 0000000000000..f745c714314e4 --- /dev/null +++ b/solution/0700-0799/0738.Monotone Increasing Digits/README.md @@ -0,0 +1,52 @@ +# [738. 单调递增的数字](https://leetcode-cn.com/problems/monotone-increasing-digits) + +## 题目描述 + +
给定一个非负整数 N,找出小于或等于 N 的最大的整数,同时这个整数需要满足其各个位数上的数字是单调递增。
(当且仅当每个相邻位数上的数字 x 和 y 满足 x <= y 时,我们称这个整数是单调递增的。)
示例 1:
+ +输入: N = 10 +输出: 9 ++ +
示例 2:
+ +输入: N = 1234 +输出: 1234 ++ +
示例 3:
+ +输入: N = 332 +输出: 299 ++ +
说明: N 是在 [0, 10^9] 范围内的一个整数。
根据每日 气温 列表,请重新生成一个列表,对应位置的输入是你需要再等待多久温度才会升高超过该日的天数。如果之后都不会升高,请在该位置用 0 来代替。
例如,给定一个列表 temperatures = [73, 74, 75, 71, 69, 72, 76, 73],你的输出应该是 [1, 1, 4, 2, 1, 1, 0, 0]。
提示:气温 列表长度的范围是 [1, 30000]。每个气温的值的均为华氏度,都是在 [30, 100] 范围内的整数。
给定一个整数数组 nums ,你可以对它进行一些操作。
每次操作中,选择任意一个 nums[i] ,删除它并获得 nums[i] 的点数。之后,你必须删除每个等于 nums[i] - 1 或 nums[i] + 1 的元素。
开始你拥有 0 个点数。返回你能通过这些操作获得的最大点数。
+ +示例 1:
+ ++输入: nums = [3, 4, 2] +输出: 6 +解释: +删除 4 来获得 4 个点数,因此 3 也被删除。 +之后,删除 2 来获得 2 个点数。总共获得 6 个点数。 ++ +
示例 2:
+ ++输入: nums = [2, 2, 3, 3, 3, 4] +输出: 9 +解释: +删除 3 来获得 3 个点数,接着要删除两个 2 和 4 。 +之后,再次删除 3 获得 3 个点数,再次删除 3 获得 3 个点数。 +总共获得 9 个点数。 ++ +
注意:
+ +-
+
nums的长度最大为20000。
+ - 每个整数
nums[i]的大小都在[1, 10000]范围内。
+
一个N x N的网格(grid) 代表了一块樱桃地,每个格子由以下三种数字的一种来表示:
-
+
- 0 表示这个格子是空的,所以你可以穿过它。 +
- 1 表示这个格子里装着一个樱桃,你可以摘到樱桃然后穿过它。 +
- -1 表示这个格子里有荆棘,挡着你的路。 +
你的任务是在遵守下列规则的情况下,尽可能的摘到最多樱桃:
+ +-
+
- 从位置 (0, 0) 出发,最后到达 (N-1, N-1) ,只能向下或向右走,并且只能穿越有效的格子(即只可以穿过值为0或者1的格子); +
- 当到达 (N-1, N-1) 后,你要继续走,直到返回到 (0, 0) ,只能向上或向左走,并且只能穿越有效的格子; +
- 当你经过一个格子且这个格子包含一个樱桃时,你将摘到樱桃并且这个格子会变成空的(值变为0); +
- 如果在 (0, 0) 和 (N-1, N-1) 之间不存在一条可经过的路径,则没有任何一个樱桃能被摘到。 +
示例 1:
+ ++输入: grid = +[[0, 1, -1], + [1, 0, -1], + [1, 1, 1]] +输出: 5 +解释: +玩家从(0,0)点出发,经过了向下走,向下走,向右走,向右走,到达了点(2, 2)。 +在这趟单程中,总共摘到了4颗樱桃,矩阵变成了[[0,1,-1],[0,0,-1],[0,0,0]]。 +接着,这名玩家向左走,向上走,向上走,向左走,返回了起始点,又摘到了1颗樱桃。 +在旅程中,总共摘到了5颗樱桃,这是可以摘到的最大值了。 ++ +
说明:
+ +-
+
grid是一个N*N的二维数组,N的取值范围是1 <= N <= 50。
+ - 每一个
grid[i][j]都是集合{-1, 0, 1}其中的一个数。
+ - 可以保证起点
grid[0][0]和终点grid[N-1][N-1]的值都不会是 -1。
+
有 N 个网络节点,标记为 1 到 N。
给定一个列表 times,表示信号经过有向边的传递时间。 times[i] = (u, v, w),其中 u 是源节点,v 是目标节点, w 是一个信号从源节点传递到目标节点的时间。
现在,我们向当前的节点 K 发送了一个信号。需要多久才能使所有节点都收到信号?如果不能使所有节点收到信号,返回 -1。
注意:
+ +-
+
N的范围在[1, 100]之间。
+ K的范围在[1, N]之间。
+ times的长度在[1, 6000]之间。
+ - 所有的边
times[i] = (u, v, w)都有1 <= u, v <= N且0 <= w <= 100。
+
给定一个只包含小写字母的有序数组letters 和一个目标字母 target,寻找有序数组里面比目标字母大的最小字母。
数组里字母的顺序是循环的。举个例子,如果目标字母target = 'z' 并且有序数组为 letters = ['a', 'b'],则答案返回 'a'。
示例:
+ ++输入: +letters = ["c", "f", "j"] +target = "a" +输出: "c" + +输入: +letters = ["c", "f", "j"] +target = "c" +输出: "f" + +输入: +letters = ["c", "f", "j"] +target = "d" +输出: "f" + +输入: +letters = ["c", "f", "j"] +target = "g" +输出: "j" + +输入: +letters = ["c", "f", "j"] +target = "j" +输出: "c" + +输入: +letters = ["c", "f", "j"] +target = "k" +输出: "c" ++ +
注:
+ +-
+
letters长度范围在[2, 10000]区间内。
+ letters仅由小写字母组成,最少包含两个不同的字母。
+ - 目标字母
target是一个小写字母。
+
给定多个 words,words[i] 的权重为 i 。
设计一个类 WordFilter 实现函数WordFilter.f(String prefix, String suffix)。这个函数将返回具有前缀 prefix 和后缀suffix 的词的最大权重。如果没有这样的词,返回 -1。
例子:
+ +
+输入:
+WordFilter(["apple"])
+WordFilter.f("a", "e") // 返回 0
+WordFilter.f("b", "") // 返回 -1
+
+
+注意:
+ +-
+
words的长度在[1, 15000]之间。
+ - 对于每个测试用例,最多会有
words.length次对WordFilter.f的调用。
+ words[i]的长度在[1, 10]之间。
+ prefix, suffix的长度在[0, 10]之前。
+ words[i]和prefix, suffix只包含小写字母。
+
数组的每个索引做为一个阶梯,第 i个阶梯对应着一个非负数的体力花费值 cost[i](索引从0开始)。
每当你爬上一个阶梯你都要花费对应的体力花费值,然后你可以选择继续爬一个阶梯或者爬两个阶梯。
+ +您需要找到达到楼层顶部的最低花费。在开始时,你可以选择从索引为 0 或 1 的元素作为初始阶梯。
+ +示例 1:
+ ++输入: cost = [10, 15, 20] +输出: 15 +解释: 最低花费是从cost[1]开始,然后走两步即可到阶梯顶,一共花费15。 ++ +
示例 2:
+ ++输入: cost = [1, 100, 1, 1, 1, 100, 1, 1, 100, 1] +输出: 6 +解释: 最低花费方式是从cost[0]开始,逐个经过那些1,跳过cost[3],一共花费6。 ++ +
注意:
+ +-
+
cost的长度将会在[2, 1000]。
+ - 每一个
cost[i]将会是一个Integer类型,范围为[0, 999]。
+
在一个给定的数组nums中,总是存在一个最大元素 。
查找数组中的最大元素是否至少是数组中每个其他数字的两倍。
+ +如果是,则返回最大元素的索引,否则返回-1。
+ +示例 1:
+ +输入: nums = [3, 6, 1, 0] +输出: 1 +解释: 6是最大的整数, 对于数组中的其他整数, +6大于数组中其他元素的两倍。6的索引是1, 所以我们返回1. ++ +
+ +
示例 2:
+ +输入: nums = [1, 2, 3, 4] +输出: -1 +解释: 4没有超过3的两倍大, 所以我们返回 -1. ++ +
+ +
提示:
+ +-
+
nums的长度范围在[1, 50].
+ - 每个
nums[i]的整数范围在[0, 100].
+
如果单词列表(words)中的一个单词包含牌照(licensePlate)中所有的字母,那么我们称之为完整词。在所有完整词中,最短的单词我们称之为最短完整词。
单词在匹配牌照中的字母时不区分大小写,比如牌照中的 "P" 依然可以匹配单词中的 "p" 字母。
我们保证一定存在一个最短完整词。当有多个单词都符合最短完整词的匹配条件时取单词列表中最靠前的一个。
+ +牌照中可能包含多个相同的字符,比如说:对于牌照 "PP",单词 "pair" 无法匹配,但是 "supper" 可以匹配。
+ +
示例 1:
+ +输入:licensePlate = "1s3 PSt", words = ["step", "steps", "stripe", "stepple"] +输出:"steps" +说明:最短完整词应该包括 "s"、"p"、"s" 以及 "t"。对于 "step" 它只包含一个 "s" 所以它不符合条件。同时在匹配过程中我们忽略牌照中的大小写。+ +
+ +
示例 2:
+ +输入:licensePlate = "1s3 456", words = ["looks", "pest", "stew", "show"] +输出:"pest" +说明:存在 3 个包含字母 "s" 且有着最短长度的完整词,但我们返回最先出现的完整词。 ++ +
+ +
注意:
+ +-
+
- 牌照
(licensePlate)的长度在区域[1, 7]中。
+ - 牌照
(licensePlate)将会包含数字、空格、或者字母(大写和小写)。
+ - 单词列表
(words)长度在区间[10, 1000]中。
+ - 每一个单词
words[i]都是小写,并且长度在区间[1, 15]中。
+
+ + + +## 解法 + + + +### Python3 + + +```python + +``` + +### Java + + +```java + +``` + +### ... +``` + +``` diff --git a/solution/0700-0799/0749.Contain Virus/README.md b/solution/0700-0799/0749.Contain Virus/README.md new file mode 100644 index 0000000000000..3d91ee35df94a --- /dev/null +++ b/solution/0700-0799/0749.Contain Virus/README.md @@ -0,0 +1,92 @@ +# [749. 隔离病毒](https://leetcode-cn.com/problems/contain-virus) + +## 题目描述 + +
病毒扩散得很快,现在你的任务是尽可能地通过安装防火墙来隔离病毒。
+ +假设世界由二维矩阵组成,0 表示该区域未感染病毒,而 1 表示该区域已感染病毒。可以在任意 2 个四方向相邻单元之间的共享边界上安装一个防火墙(并且只有一个防火墙)。
每天晚上,病毒会从被感染区域向相邻未感染区域扩散,除非被防火墙隔离。现由于资源有限,每天你只能安装一系列防火墙来隔离其中一个被病毒感染的区域(一个区域或连续的一片区域),且该感染区域对未感染区域的威胁最大且保证唯一。
+ +你需要努力使得最后有部分区域不被病毒感染,如果可以成功,那么返回需要使用的防火墙个数; 如果无法实现,则返回在世界被病毒全部感染时已安装的防火墙个数。
+ ++ +
示例 1:
+ +输入: grid = +[[0,1,0,0,0,0,0,1], + [0,1,0,0,0,0,0,1], + [0,0,0,0,0,0,0,1], + [0,0,0,0,0,0,0,0]] +输出: 10 +说明: +一共有两块被病毒感染的区域: 从左往右第一块需要 5 个防火墙,同时若该区域不隔离,晚上将感染 5 个未感染区域(即被威胁的未感染区域个数为 5); +第二块需要 4 个防火墙,同理被威胁的未感染区域个数是 4。因此,第一天先隔离左边的感染区域,经过一晚后,病毒传播后世界如下: +[[0,1,0,0,0,0,1,1], + [0,1,0,0,0,0,1,1], + [0,0,0,0,0,0,1,1], + [0,0,0,0,0,0,0,1]] +第二题,只剩下一块未隔离的被感染的连续区域,此时需要安装 5 个防火墙,且安装完毕后病毒隔离任务完成。 ++ +
示例 2:
+ +输入: grid = +[[1,1,1], + [1,0,1], + [1,1,1]] +输出: 4 +说明: +此时只需要安装 4 面防火墙,就有一小区域可以幸存,不被病毒感染。 +注意不需要在世界边界建立防火墙。+ +
+ +
示例 3:
+ +输入: grid = +[[1,1,1,0,0,0,0,0,0], + [1,0,1,0,1,1,1,1,1], + [1,1,1,0,0,0,0,0,0]] +输出: 13 +说明: +在隔离右边感染区域后,隔离左边病毒区域只需要 2 个防火墙了。 ++ +
+ +
说明:
+ +-
+
grid的行数和列数范围是 [1, 50]。
+ -
grid[i][j]只包含0或1。
+ - 题目保证每次选取感染区域进行隔离时,一定存在唯一一个对未感染区域的威胁最大的区域。 +
+ + + +## 解法 + + + +### Python3 + + +```python + +``` + +### Java + + +```java + +``` + +### ... +``` + +``` diff --git a/solution/0700-0799/0750.Number Of Corner Rectangles/README.md b/solution/0700-0799/0750.Number Of Corner Rectangles/README.md new file mode 100644 index 0000000000000..1f8259d280fd1 --- /dev/null +++ b/solution/0700-0799/0750.Number Of Corner Rectangles/README.md @@ -0,0 +1,29 @@ +# [750. 角矩形的数量](https://leetcode-cn.com/problems/number-of-corner-rectangles) + +## 题目描述 + +None + + +## 解法 + + + +### Python3 + + +```python + +``` + +### Java + + +```java + +``` + +### ... +``` + +``` diff --git a/solution/0700-0799/0751.IP to CIDR/README.md b/solution/0700-0799/0751.IP to CIDR/README.md new file mode 100644 index 0000000000000..d48705c5e49e4 --- /dev/null +++ b/solution/0700-0799/0751.IP to CIDR/README.md @@ -0,0 +1,29 @@ +# [751. IP 到 CIDR](https://leetcode-cn.com/problems/ip-to-cidr) + +## 题目描述 + +None + + +## 解法 + + + +### Python3 + + +```python + +``` + +### Java + + +```java + +``` + +### ... +``` + +``` diff --git a/solution/0700-0799/0752.Open the Lock/README.md b/solution/0700-0799/0752.Open the Lock/README.md new file mode 100644 index 0000000000000..9651ab357874e --- /dev/null +++ b/solution/0700-0799/0752.Open the Lock/README.md @@ -0,0 +1,84 @@ +# [752. 打开转盘锁](https://leetcode-cn.com/problems/open-the-lock) + +## 题目描述 + +
你有一个带有四个圆形拨轮的转盘锁。每个拨轮都有10个数字: '0', '1', '2', '3', '4', '5', '6', '7', '8', '9' 。每个拨轮可以自由旋转:例如把 '9' 变为 '0','0' 变为 '9' 。每次旋转都只能旋转一个拨轮的一位数字。
锁的初始数字为 '0000' ,一个代表四个拨轮的数字的字符串。
列表 deadends 包含了一组死亡数字,一旦拨轮的数字和列表里的任何一个元素相同,这个锁将会被永久锁定,无法再被旋转。
字符串 target 代表可以解锁的数字,你需要给出最小的旋转次数,如果无论如何不能解锁,返回 -1。
+ +
示例 1:
+ ++输入:deadends = ["0201","0101","0102","1212","2002"], target = "0202" +输出:6 +解释: +可能的移动序列为 "0000" -> "1000" -> "1100" -> "1200" -> "1201" -> "1202" -> "0202"。 +注意 "0000" -> "0001" -> "0002" -> "0102" -> "0202" 这样的序列是不能解锁的, +因为当拨动到 "0102" 时这个锁就会被锁定。 ++ +
示例 2:
+ ++输入: deadends = ["8888"], target = "0009" +输出:1 +解释: +把最后一位反向旋转一次即可 "0000" -> "0009"。 ++ +
示例 3:
+ ++输入: deadends = ["8887","8889","8878","8898","8788","8988","7888","9888"], target = "8888" +输出:-1 +解释: +无法旋转到目标数字且不被锁定。 ++ +
示例 4:
+ ++输入: deadends = ["0000"], target = "8888" +输出:-1 ++ +
+ +
提示:
+ +-
+
- 死亡列表
deadends的长度范围为[1, 500]。
+ - 目标数字
target不会在deadends之中。
+ - 每个
deadends和target中的字符串的数字会在 10,000 个可能的情况'0000'到'9999'中产生。
+
有一个需要密码才能打开的保险箱。密码是 n 位数, 密码的每一位是 k 位序列 0, 1, ..., k-1 中的一个 。
你可以随意输入密码,保险箱会自动记住最后 n 位输入,如果匹配,则能够打开保险箱。
举个例子,假设密码是 "345",你可以输入 "012345" 来打开它,只是你输入了 6 个字符.
请返回一个能打开保险箱的最短字符串。
+ ++ +
示例1:
+ +输入: n = 1, k = 2 +输出: "01" +说明: "10"也可以打开保险箱。 ++ +
+ +
示例2:
+ +输入: n = 2, k = 2 +输出: "00110" +说明: "01100", "10011", "11001" 也能打开保险箱。 ++ +
+ +
提示:
+ +-
+
n的范围是[1, 4]。
+ k的范围是[1, 10]。
+ k^n最大可能为4096。
+
+ + + +## 解法 + + + +### Python3 + + +```python + +``` + +### Java + + +```java + +``` + +### ... +``` + +``` diff --git a/solution/0700-0799/0754.Reach a Number/README.md b/solution/0700-0799/0754.Reach a Number/README.md new file mode 100644 index 0000000000000..aeaad9f9225a9 --- /dev/null +++ b/solution/0700-0799/0754.Reach a Number/README.md @@ -0,0 +1,61 @@ +# [754. 到达终点数字](https://leetcode-cn.com/problems/reach-a-number) + +## 题目描述 + +
在一根无限长的数轴上,你站在0的位置。终点在target的位置。
每次你可以选择向左或向右移动。第 n 次移动(从 1 开始),可以走 n 步。
+ +返回到达终点需要的最小移动次数。
+ +示例 1:
+ ++输入: target = 3 +输出: 2 +解释: +第一次移动,从 0 到 1 。 +第二次移动,从 1 到 3 。 ++ +
示例 2:
+ ++输入: target = 2 +输出: 3 +解释: +第一次移动,从 0 到 1 。 +第二次移动,从 1 到 -1 。 +第三次移动,从 -1 到 2 。 ++ +
注意:
+ +-
+
target是在[-10^9, 10^9]范围中的非零整数。
+
现在,我们用一些方块来堆砌一个金字塔。 每个方块用仅包含一个字母的字符串表示。
+ +使用三元组表示金字塔的堆砌规则如下:
+ +对于三元组(A, B, C) ,“C”为顶层方块,方块“A”、“B”分别作为方块“C”下一层的的左、右子块。当且仅当(A, B, C)是被允许的三元组,我们才可以将其堆砌上。
+ +初始时,给定金字塔的基层 bottom,用一个字符串表示。一个允许的三元组列表 allowed,每个三元组用一个长度为 3 的字符串表示。
如果可以由基层一直堆到塔尖就返回 true,否则返回 false。
+ ++ +
示例 1:
+ +输入: bottom = "BCD", allowed = ["BCG", "CDE", "GEA", "FFF"]
+输出: true
+解析:
+可以堆砌成这样的金字塔:
+ A
+ / \
+ G E
+ / \ / \
+B C D
+
+因为符合('B', 'C', 'G'), ('C', 'D', 'E') 和 ('G', 'E', 'A') 三种规则。
+
+
+示例 2:
+ +输入: bottom = "AABA", allowed = ["AAA", "AAB", "ABA", "ABB", "BAC"] +输出: false +解析: +无法一直堆到塔尖。 +注意, 允许存在像 (A, B, C) 和 (A, B, D) 这样的三元组,其中 C != D。 ++ +
+ +
注意:
+ +-
+
bottom的长度范围在[2, 8]。
+ allowed的长度范围在[0, 200]。
+ - 方块的标记字母范围为
{'A', 'B', 'C', 'D', 'E', 'F', 'G'}。
+
一个整数区间 [a, b] ( a < b ) 代表着从 a 到 b 的所有连续整数,包括 a 和 b。
给你一组整数区间intervals,请找到一个最小的集合 S,使得 S 里的元素与区间intervals中的每一个整数区间都至少有2个元素相交。
输出这个最小集合S的大小。
+ +示例 1:
+ +
+输入: intervals = [[1, 3], [1, 4], [2, 5], [3, 5]]
+输出: 3
+解释:
+考虑集合 S = {2, 3, 4}. S与intervals中的四个区间都有至少2个相交的元素。
+且这是S最小的情况,故我们输出3。
+
+
+示例 2:
+ +
+输入: intervals = [[1, 2], [2, 3], [2, 4], [4, 5]]
+输出: 5
+解释:
+最小的集合S = {1, 2, 3, 4, 5}.
+
+
+注意:
+ +-
+
intervals的长度范围为[1, 3000]。
+ intervals[i]长度为2,分别代表左、右边界。
+ intervals[i][j]的值是[0, 10^8]范围内的整数。
+
特殊的二进制序列是具有以下两个性质的二进制序列:
+ +-
+
- 0 的数量与 1 的数量相等。 +
- 二进制序列的每一个前缀码中 1 的数量要大于等于 0 的数量。 +
给定一个特殊的二进制序列 S,以字符串形式表示。定义一个操作 为首先选择 S 的两个连续且非空的特殊的子串,然后将它们交换。(两个子串为连续的当且仅当第一个子串的最后一个字符恰好为第二个子串的第一个字符的前一个字符。)
在任意次数的操作之后,交换后的字符串按照字典序排列的最大的结果是什么?
+ +示例 1:
+ ++输入: S = "11011000" +输出: "11100100" +解释: +将子串 "10" (在S[1]出现) 和 "1100" (在S[3]出现)进行交换。 +这是在进行若干次操作后按字典序排列最大的结果。 ++ +
说明:
+ +-
+
S的长度不超过50。
+ S保证为一个满足上述定义的特殊 的二进制序列。
+
给定两个整数 L 和 R ,找到闭区间 [L, R] 范围内,计算置位位数为质数的整数个数。
(注意,计算置位代表二进制表示中1的个数。例如 21 的二进制表示 10101 有 3 个计算置位。还有,1 不是质数。)
示例 1:
-**示例1:** ++输入: L = 6, R = 10 +输出: 4 +解释: +6 -> 110 (2 个计算置位,2 是质数) +7 -> 111 (3 个计算置位,3 是质数) +9 -> 1001 (2 个计算置位,2 是质数) +10-> 1010 (2 个计算置位,2 是质数) +-``` -输入: L = 6, R = 10 -输出: 4 -解释: -6 -> 110 (2 个计算置位,2 是质数) -7 -> 111 (3 个计算置位,3 是质数) -9 -> 1001 (2 个计算置位,2 是质数) -10-> 1010 (2 个计算置位,2 是质数) -``` +
示例 2:
-**示例2:** ++输入: L = 10, R = 15 +输出: 5 +解释: +10 -> 1010 (2 个计算置位, 2 是质数) +11 -> 1011 (3 个计算置位, 3 是质数) +12 -> 1100 (2 个计算置位, 2 是质数) +13 -> 1101 (3 个计算置位, 3 是质数) +14 -> 1110 (3 个计算置位, 3 是质数) +15 -> 1111 (4 个计算置位, 4 不是质数) +-``` -输入: L = 10, R = 15 -输出: 5 -解释: -10 -> 1010 (2 个计算置位, 2 是质数) -11 -> 1011 (3 个计算置位, 3 是质数) -12 -> 1100 (2 个计算置位, 2 是质数) -13 -> 1101 (3 个计算置位, 3 是质数) -14 -> 1110 (3 个计算置位, 3 是质数) -15 -> 1111 (4 个计算置位, 4 不是质数) -``` +
注意:
+-
+
L, R是L <= R且在[1, 10^6]中的整数。
+ R - L的最大值为 10000。
+
字符串 S 由小写字母组成。我们要把这个字符串划分为尽可能多的片段,同一个字母只会出现在其中的一个片段。返回一个表示每个字符串片段的长度的列表。
示例 1:
+ +输入: S = "ababcbacadefegdehijhklij" +输出: [9,7,8] +解释: +划分结果为 "ababcbaca", "defegde", "hijhklij"。 +每个字母最多出现在一个片段中。 +像 "ababcbacadefegde", "hijhklij" 的划分是错误的,因为划分的片段数较少。 ++ +
注意:
+ +-
+
S的长度在[1, 500]之间。
+ S只包含小写字母'a'到'z'。
+
在一个大小在 (0, 0) 到 (N-1, N-1) 的2D网格 grid 中,除了在 mines 中给出的单元为 0,其他每个单元都是 1。网格中包含 1 的最大的轴对齐加号标志是多少阶?返回加号标志的阶数。如果未找到加号标志,则返回 0。
一个 k" 阶由 1 组成的“轴对称”加号标志具有中心网格 grid[x][y] = 1 ,以及4个从中心向上、向下、向左、向右延伸,长度为 k-1,由 1 组成的臂。下面给出 k" 阶“轴对称”加号标志的示例。注意,只有加号标志的所有网格要求为 1,别的网格可能为 0 也可能为 1。
+ +
k 阶轴对称加号标志示例:
+ ++阶 1: +000 +010 +000 + +阶 2: +00000 +00100 +01110 +00100 +00000 + +阶 3: +0000000 +0001000 +0001000 +0111110 +0001000 +0001000 +0000000 ++ +
+ +
示例 1:
+ ++输入: N = 5, mines = [[4, 2]] +输出: 2 +解释: + +11111 +11111 +11111 +11111 +11011 + +在上面的网格中,最大加号标志的阶只能是2。一个标志已在图中标出。 ++ +
+ +
示例 2:
+ ++输入: N = 2, mines = [] +输出: 1 +解释: + +11 +11 + +没有 2 阶加号标志,有 1 阶加号标志。 ++ +
+ +
示例 3:
+ ++输入: N = 1, mines = [[0, 0]] +输出: 0 +解释: + +0 + +没有加号标志,返回 0 。 ++ +
+ +
提示:
+ +-
+
- 整数
N的范围:[1, 500].
+ mines的最大长度为5000.
+ mines[i]是长度为2的由2个[0, N-1]中的数组成.
+ - (另外,使用 C, C++, 或者 C# 编程将以稍小的时间限制进行判断.) +
+ + + +## 解法 + + + +### Python3 + + +```python + +``` + +### Java + + +```java + +``` + +### ... +``` + +``` diff --git a/solution/0700-0799/0765.Couples Holding Hands/README.md b/solution/0700-0799/0765.Couples Holding Hands/README.md new file mode 100644 index 0000000000000..c44e03d4474a4 --- /dev/null +++ b/solution/0700-0799/0765.Couples Holding Hands/README.md @@ -0,0 +1,57 @@ +# [765. 情侣牵手](https://leetcode-cn.com/problems/couples-holding-hands) + +## 题目描述 + +
N 对情侣坐在连续排列的 2N 个座位上,想要牵到对方的手。 计算最少交换座位的次数,以便每对情侣可以并肩坐在一起。 一次交换可选择任意两人,让他们站起来交换座位。
+ +人和座位用 0 到 2N-1 的整数表示,情侣们按顺序编号,第一对是 (0, 1),第二对是 (2, 3),以此类推,最后一对是 (2N-2, 2N-1)。
这些情侣的初始座位 row[i] 是由最初始坐在第 i 个座位上的人决定的。
示例 1:
+ ++输入: row = [0, 2, 1, 3] +输出: 1 +解释: 我们只需要交换row[1]和row[2]的位置即可。 ++ +
示例 2:
+ ++输入: row = [3, 2, 0, 1] +输出: 0 +解释: 无需交换座位,所有的情侣都已经可以手牵手了。 ++ +
说明:
+ +-
+
len(row)是偶数且数值在[4, 60]范围内。
+ - 可以保证
row是序列0...len(row)-1的一个全排列。
+
如果一个矩阵的每一方向由左上到右下的对角线上具有相同元素,那么这个矩阵是托普利茨矩阵。
+ +给定一个 M x N 的矩阵,当且仅当它是托普利茨矩阵时返回 True。
示例 1:
+ +输入: +matrix = [ + [1,2,3,4], + [5,1,2,3], + [9,5,1,2] +] +输出: True +解释: +在上述矩阵中, 其对角线为: +"[9]", "[5, 5]", "[1, 1, 1]", "[2, 2, 2]", "[3, 3]", "[4]"。 +各条对角线上的所有元素均相同, 因此答案是True。 ++ +
示例 2:
+ +输入: +matrix = [ + [1,2], + [2,2] +] +输出: False +解释: +对角线"[1, 2]"上的元素不同。 ++ +
说明:
+ +-
+
-
matrix是一个包含整数的二维数组。
+ matrix的行数和列数均在[1, 20]范围内。
+ matrix[i][j]包含的整数在[0, 99]范围内。
+
进阶:
+ +-
+
- 如果矩阵存储在磁盘上,并且磁盘内存是有限的,因此一次最多只能将一行矩阵加载到内存中,该怎么办? +
- 如果矩阵太大以至于只能一次将部分行加载到内存中,该怎么办? +
给定一个字符串S,检查是否能重新排布其中的字母,使得两相邻的字符不同。
若可行,输出任意可行的结果。若不可行,返回空字符串。
+ +示例 1:
+ ++输入: S = "aab" +输出: "aba" ++ +
示例 2:
+ ++输入: S = "aaab" +输出: "" ++ +
注意:
+ +-
+
S只包含小写字母并且长度在[1, 500]区间内。
+
这个问题和“最多能完成排序的块”相似,但给定数组中的元素可以重复,输入数组最大长度为2000,其中的元素最大为10**8。
arr是一个可能包含重复元素的整数数组,我们将这个数组分割成几个“块”,并将这些块分别进行排序。之后再连接起来,使得连接的结果和按升序排序后的原数组相同。
我们最多能将数组分成多少块?
+ +示例 1:
+ ++输入: arr = [5,4,3,2,1] +输出: 1 +解释: +将数组分成2块或者更多块,都无法得到所需的结果。 +例如,分成 [5, 4], [3, 2, 1] 的结果是 [4, 5, 1, 2, 3],这不是有序的数组。 ++ +
示例 2:
+ ++输入: arr = [2,1,3,4,4] +输出: 4 +解释: +我们可以把它分成两块,例如 [2, 1], [3, 4, 4]。 +然而,分成 [2, 1], [3], [4], [4] 可以得到最多的块数。 ++ +
注意:
+ +-
+
arr的长度在[1, 2000]之间。
+ arr[i]的大小在[0, 10**8]之间。
+
数组arr是[0, 1, ..., arr.length - 1]的一种排列,我们将这个数组分割成几个“块”,并将这些块分别进行排序。之后再连接起来,使得连接的结果和按升序排序后的原数组相同。
我们最多能将数组分成多少块?
-我们最多能将数组分成多少块? +示例 1:
-**示例1:** -``` -输入: arr = [4,3,2,1,0] -输出: 1 -解释: +输入: arr = [4,3,2,1,0] +输出: 1 +解释: 将数组分成2块或者更多块,都无法得到所需的结果。 例如,分成 [4, 3], [2, 1, 0] 的结果是 [3, 4, 0, 1, 2],这不是有序的数组。 -``` -**示例2:** -``` -输入: arr = [1,0,2,3,4] -输出: 4 -解释: ++ +
示例 2:
+ +输入: arr = [1,0,2,3,4] +输出: 4 +解释: 我们可以把它分成两块,例如 [1, 0], [2, 3, 4]。 然而,分成 [1, 0], [2], [3], [4] 可以得到最多的块数。 -``` -**提示:** -- arr 的长度在 [1, 10] 之间。 -- arr[i]是 [0, 1, ..., arr.length - 1]的一种排列。 ++ +
注意:
+ +-
+
arr的长度在[1, 10]之间。
+ arr[i]是[0, 1, ..., arr.length - 1]的一种排列。
+
给定一个表达式 expression 如 expression = "e + 8 - a + 5" 和一个求值映射,如 {"e": 1}(给定的形式为 evalvars = ["e"] 和 evalints = [1]),返回表示简化表达式的标记列表,例如 ["-1*a","14"]
-
+
- 表达式交替使用块和符号,每个块和符号之间有一个空格。 +
- 块要么是括号中的表达式,要么是变量,要么是非负整数。 +
- 块是括号中的表达式,变量或非负整数。 +
- 变量是一个由小写字母组成的字符串(不包括数字)。请注意,变量可以是多个字母,并注意变量从不具有像
"2x"或"-x"这样的前导系数或一元运算符 。
+
表达式按通常顺序进行求值:先是括号,然后求乘法,再计算加法和减法。例如,expression = "1 + 2 * 3" 的答案是 ["7"]。
输出格式如下:
+ +-
+
- 对于系数非零的每个自变量项,我们按字典排序的顺序将自变量写在一个项中。例如,我们永远不会写像
“b*a*c”这样的项,只写“a*b*c”。
+ - 项的次数等于被乘的自变量的数目,并计算重复项。(例如,
"a*a*b*c"的次数为 4。)。我们先写出答案的最大次数项,用字典顺序打破关系,此时忽略词的前导系数。
+ - 项的前导系数直接放在左边,用星号将它与变量分隔开(如果存在的话)。前导系数 1 仍然要打印出来。 +
- 格式良好的一个示例答案是
["-2*a*a*a", "3*a*a*b", "3*b*b", "4*a", "5*c", "-6"]。
+ - 系数为 0 的项(包括常数项)不包括在内。例如,“0” 的表达式输出为 []。 +
+ +
示例:
+ +输入:expression = "e + 8 - a + 5", evalvars = ["e"], evalints = [1] +输出:["-1*a","14"] + +输入:expression = "e - 8 + temperature - pressure", +evalvars = ["e", "temperature"], evalints = [1, 12] +输出:["-1*pressure","5"] + +输入:expression = "(e + 8) * (e - 8)", evalvars = [], evalints = [] +输出:["1*e*e","-64"] + +输入:expression = "7 - 7", evalvars = [], evalints = [] +输出:[] + +输入:expression = "a * b * c + b * a * c * 4", evalvars = [], evalints = [] +输出:["5*a*b*c"] + +输入:expression = "((a - b) * (b - c) + (c - a)) * ((a - b) + (b - c) * (c - a))", +evalvars = [], evalints = [] +输出:["-1*a*a*b*b","2*a*a*b*c","-1*a*a*c*c","1*a*b*b*b","-1*a*b*b*c","-1*a*b*c*c","1*a*c*c*c","-1*b*b*b*c","2*b*b*c*c","-1*b*c*c*c","2*a*a*b","-2*a*a*c","-2*a*b*b","2*a*c*c","1*b*b*b","-1*b*b*c","1*b*c*c","-1*c*c*c","-1*a*a","1*a*b","1*a*c","-1*b*c"] ++ +
+ +
提示:
+ +-
+
expression的长度在[1, 250]范围内。
+ evalvars, evalints在范围[0, 100]内,且长度相同。
+
给定字符串J 代表石头中宝石的类型,和字符串 S代表你拥有的石头。 S 中每个字符代表了一种你拥有的石头的类型,你想知道你拥有的石头中有多少是宝石。
J 中的字母不重复,J 和 S中的所有字符都是字母。字母区分大小写,因此"a"和"A"是不同类型的石头。
示例 1:
-**示例1:** +输入: J = "aA", S = "aAAbbbb" +输出: 3 +-``` -输入: J = "aA", S = "aAAbbbb" -输出: 3 -``` +
示例 2:
-**示例2:** +输入: J = "z", S = "ZZ" +输出: 0 +-``` -输入: J = "z", S = "ZZ" -输出: 0 -``` +
注意:
-**注意:** +-
+
S和J最多含有50个字母。
+ -
J中的字符不重复。
+
在一个 2 x 3 的板上(board)有 5 块砖瓦,用数字 1~5 来表示, 以及一块空缺用 0 来表示.
一次移动定义为选择 0 与一个相邻的数字(上下左右)进行交换.
最终当板 board 的结果是 [[1,2,3],[4,5,0]] 谜板被解开。
给出一个谜板的初始状态,返回最少可以通过多少次移动解开谜板,如果不能解开谜板,则返回 -1 。
+ +示例:
+ ++输入:board = [[1,2,3],[4,0,5]] +输出:1 +解释:交换 0 和 5 ,1 步完成 ++ +
+输入:board = [[1,2,3],[5,4,0]] +输出:-1 +解释:没有办法完成谜板 ++ +
+输入:board = [[4,1,2],[5,0,3]] +输出:5 +解释: +最少完成谜板的最少移动次数是 5 , +一种移动路径: +尚未移动: [[4,1,2],[5,0,3]] +移动 1 次: [[4,1,2],[0,5,3]] +移动 2 次: [[0,1,2],[4,5,3]] +移动 3 次: [[1,0,2],[4,5,3]] +移动 4 次: [[1,2,0],[4,5,3]] +移动 5 次: [[1,2,3],[4,5,0]] ++ +
+输入:board = [[3,2,4],[1,5,0]] +输出:14 ++ +
提示:
+ +-
+
board是一个如上所述的 2 x 3 的数组.
+ board[i][j]是一个[0, 1, 2, 3, 4, 5]的排列.
+
数组 A 是 [0, 1, ..., N - 1] 的一种排列,N 是数组 A 的长度。全局倒置指的是 i,j 满足 0 <= i < j < N 并且 A[i] > A[j] ,局部倒置指的是 i 满足 0 <= i < N 并且 A[i] > A[i+1] 。
当数组 A 中全局倒置的数量等于局部倒置的数量时,返回 true 。
+ +
示例 1:
+ ++输入: A = [1,0,2] +输出: true +解释: 有 1 个全局倒置,和 1 个局部倒置。 ++ +
示例 2:
+ ++输入: A = [1,2,0] +输出: false +解释: 有 2 个全局倒置,和 1 个局部倒置。 ++ +
注意:
+ +-
+
A是[0, 1, ..., A.length - 1]的一种排列
+ A的长度在[1, 5000]之间
+ - 这个问题的时间限制已经减少了。 +
在一个由 'L' , 'R' 和 'X' 三个字符组成的字符串(例如"RXXLRXRXL")中进行移动操作。一次移动操作指用一个"LX"替换一个"XL",或者用一个"XR"替换一个"RX"。现给定起始字符串start和结束字符串end,请编写代码,当且仅当存在一系列移动操作使得start可以转换成end时, 返回True。
示例 :
+ ++输入: start = "RXXLRXRXL", end = "XRLXXRRLX" +输出: True +解释: +我们可以通过以下几步将start转换成end: +RXXLRXRXL -> +XRXLRXRXL -> +XRLXRXRXL -> +XRLXXRRXL -> +XRLXXRRLX ++ +
注意:
+ +-
+
1 <= len(start) = len(end) <= 10000。
+ start和end中的字符串仅限于'L','R'和'X'。
+
在一个 N x N 的坐标方格 grid 中,每一个方格的值 grid[i][j] 表示在位置 (i,j) 的平台高度。
现在开始下雨了。当时间为 t 时,此时雨水导致水池中任意位置的水位为 t 。你可以从一个平台游向四周相邻的任意一个平台,但是前提是此时水位必须同时淹没这两个平台。假定你可以瞬间移动无限距离,也就是默认在方格内部游动是不耗时的。当然,在你游泳的时候你必须待在坐标方格里面。
你从坐标方格的左上平台 (0,0) 出发。最少耗时多久你才能到达坐标方格的右下平台 (N-1, N-1)?
示例 1:
+ +
+输入: [[0,2],[1,3]]
+输出: 3
+解释:
+时间为0时,你位于坐标方格的位置为 (0, 0)。
+此时你不能游向任意方向,因为四个相邻方向平台的高度都大于当前时间为 0 时的水位。
+
+等时间到达 3 时,你才可以游向平台 (1, 1). 因为此时的水位是 3,坐标方格中的平台没有比水位 3 更高的,所以你可以游向坐标方格中的任意位置
+
+
+示例2:
+ ++输入: [[0,1,2,3,4],[24,23,22,21,5],[12,13,14,15,16],[11,17,18,19,20],[10,9,8,7,6]] +输入: 16 +解释: + 0 1 2 3 4 +24 23 22 21 5 +12 13 14 15 16 +11 17 18 19 20 +10 9 8 7 6 + +最终的路线用加粗进行了标记。 +我们必须等到时间为 16,此时才能保证平台 (0, 0) 和 (4, 4) 是连通的 ++ +
提示:
+ +-
+
2 <= N <= 50.
+ - grid[i][j] 位于区间 [0, ..., N*N - 1] 内。 +
在第一行我们写上一个 0。接下来的每一行,将前一行中的0替换为01,1替换为10。
给定行数 N 和序数 K,返回第 N 行中第 K个字符。(K从1开始)
+例子:
输入: N = 1, K = 1 +输出: 0 + +输入: N = 2, K = 1 +输出: 0 + +输入: N = 2, K = 2 +输出: 1 + +输入: N = 4, K = 5 +输出: 1 + +解释: +第一行: 0 +第二行: 01 +第三行: 0110 +第四行: 01101001 ++ +
+注意:
-
+
N的范围[1, 30].
+ K的范围[1, 2^(N-1)].
+
从点 (x, y) 可以转换到 (x, x+y) 或者 (x+y, y)。
给定一个起点 (sx, sy) 和一个终点 (tx, ty),如果通过一系列的转换可以从起点到达终点,则返回 True ,否则返回 False。
+示例: +输入: sx = 1, sy = 1, tx = 3, ty = 5 +输出: True +解释: +可以通过以下一系列转换从起点转换到终点: +(1, 1) -> (1, 2) +(1, 2) -> (3, 2) +(3, 2) -> (3, 5) + +输入: sx = 1, sy = 1, tx = 2, ty = 2 +输出: False + +输入: sx = 1, sy = 1, tx = 1, ty = 1 +输出: True + ++ +
注意:
+ +-
+
sx, sy, tx, ty是范围在[1, 10^9]的整数。
+
森林中,每个兔子都有颜色。其中一些兔子(可能是全部)告诉你还有多少其他的兔子和自己有相同的颜色。我们将这些回答放在 answers 数组里。
返回森林中兔子的最少数量。
+ ++示例: +输入: answers = [1, 1, 2] +输出: 5 +解释: +两只回答了 "1" 的兔子可能有相同的颜色,设为红色。 +之后回答了 "2" 的兔子不会是红色,否则他们的回答会相互矛盾。 +设回答了 "2" 的兔子为蓝色。 +此外,森林中还应有另外 2 只蓝色兔子的回答没有包含在数组中。 +因此森林中兔子的最少数量是 5: 3 只回答的和 2 只没有回答的。 + +输入: answers = [10, 10, 10] +输出: 11 + +输入: answers = [] +输出: 0 ++ +
说明:
+ +-
+
answers的长度最大为1000。
+ answers[i]是在[0, 999]范围内的整数。
+
一个 N x N的 board 仅由 0 和 1 组成 。每次移动,你能任意交换两列或是两行的位置。
输出将这个矩阵变为 “棋盘” 所需的最小移动次数。“棋盘” 是指任意一格的上下左右四个方向的值均与本身不同的矩阵。如果不存在可行的变换,输出 -1。
+ +示例: +输入: board = [[0,1,1,0],[0,1,1,0],[1,0,0,1],[1,0,0,1]] +输出: 2 +解释: +一种可行的变换方式如下,从左到右: + +0110 1010 1010 +0110 --> 1010 --> 0101 +1001 0101 1010 +1001 0101 0101 + +第一次移动交换了第一列和第二列。 +第二次移动交换了第二行和第三行。 + + +输入: board = [[0, 1], [1, 0]] +输出: 0 +解释: +注意左上角的格值为0时也是合法的棋盘,如: + +01 +10 + +也是合法的棋盘. + +输入: board = [[1, 0], [1, 0]] +输出: -1 +解释: +任意的变换都不能使这个输入变为合法的棋盘。 ++ +
+ +
提示:
+ +-
+
board是方阵,且行列数的范围是[2, 30]。
+ board[i][j]将只包含0或1。
+
给定一个二叉搜索树的根结点 root,返回树中任意两节点的差的最小值。
+ +
示例:
+ +输入: root = [4,2,6,1,3,null,null] +输出: 1 +解释: +注意,root是树结点对象(TreeNode object),而不是数组。 + +给定的树 [4,2,6,1,3,null,null] 可表示为下图: + + 4 + / \ + 2 6 + / \ + 1 3 + +最小的差值是 1, 它是节点1和节点2的差值, 也是节点3和节点2的差值。+ +
+ +
注意:
+ +-
+
- 二叉树的大小范围在
2到100。
+ - 二叉树总是有效的,每个节点的值都是整数,且不重复。 +
- 本题与 530:https://leetcode-cn.com/problems/minimum-absolute-difference-in-bst/ 相同 +
给定一个字符串S,通过将字符串S中的每个字母转变大小写,我们可以获得一个新的字符串。返回所有可能得到的字符串集合。
+示例: +输入: S = "a1b2" +输出: ["a1b2", "a1B2", "A1b2", "A1B2"] + +输入: S = "3z4" +输出: ["3z4", "3Z4"] + +输入: S = "12345" +输出: ["12345"] ++ +
注意:
+ +-
+
S的长度不超过12。
+ S仅由数字和字母组成。
+
给定一个无向图graph,当这个图为二分图时返回true。
如果我们能将一个图的节点集合分割成两个独立的子集A和B,并使图中的每一条边的两个节点一个来自A集合,一个来自B集合,我们就将这个图称为二分图。
+ +graph将会以邻接表方式给出,graph[i]表示图中与节点i相连的所有节点。每个节点都是一个在0到graph.length-1之间的整数。这图中没有自环和平行边: graph[i] 中不存在i,并且graph[i]中没有重复的值。
+
+示例 1:
+输入: [[1,3], [0,2], [1,3], [0,2]]
+输出: true
+解释:
+无向图如下:
+0----1
+| |
+| |
+3----2
+我们可以将节点分成两组: {0, 2} 和 {1, 3}。
+
+
+
+
+示例 2:
+输入: [[1,2,3], [0,2], [0,1,3], [0,2]]
+输出: false
+解释:
+无向图如下:
+0----1
+| \ |
+| \ |
+3----2
+我们不能将节点分割成两个独立的子集。
+
+
+注意:
+ +-
+
graph的长度范围为[1, 100]。
+ graph[i]中的元素的范围为[0, graph.length - 1]。
+ graph[i]不会包含i或者有重复的值。
+ - 图是无向的: 如果
j在graph[i]里边, 那么i也会在graph[j]里边。
+
一个已排序好的表 A,其包含 1 和其他一些素数. 当列表中的每一个 p<q 时,我们可以构造一个分数 p/q 。
那么第 k 个最小的分数是多少呢? 以整数数组的形式返回你的答案, 这里 answer[0] = p 且 answer[1] = q.
示例: +输入: A = [1, 2, 3, 5], K = 3 +输出: [2, 5] +解释: +已构造好的分数,排序后如下所示: +1/5, 1/3, 2/5, 1/2, 3/5, 2/3. +很明显第三个最小的分数是 2/5. + +输入: A = [1, 7], K = 1 +输出: [1, 7] ++ +
注意:
+ +-
+
A长度的取值范围在2—2000.
+ - 每个
A[i]的值在1—30000.
+ K取值范围为1—A.length * (A.length - 1) / 2
+
有 n 个城市通过 m 个航班连接。每个航班都从城市 u 开始,以价格 w 抵达 v。
现在给定所有的城市和航班,以及出发城市 src 和目的地 dst,你的任务是找到从 src 到 dst 最多经过 k 站中转的最便宜的价格。 如果没有这样的路线,则输出 -1。
+ +
示例 1:
+ +输入: +n = 3, edges = [[0,1,100],[1,2,100],[0,2,500]] +src = 0, dst = 2, k = 1 +输出: 200 +解释: +城市航班图如下 ++ ++ +从城市 0 到城市 2 在 1 站中转以内的最便宜价格是 200,如图中红色所示。
示例 2:
+ +输入: +n = 3, edges = [[0,1,100],[1,2,100],[0,2,500]] +src = 0, dst = 2, k = 0 +输出: 500 +解释: +城市航班图如下 ++ +
+ +
提示:
+ +-
+
n范围是[1, 100],城市标签从0到n- 1.
+ - 航班数量范围是
[0, n * (n - 1) / 2].
+ - 每个航班的格式
(src,dst, price).
+ - 每个航班的价格范围是
[1, 10000].
+ k范围是[0, n - 1].
+ - 航班没有重复,且不存在环路 +
我们称一个数 X 为好数, 如果它的每位数字逐个地被旋转 180 度后,我们仍可以得到一个有效的,且和 X 不同的数。要求每位数字都要被旋转。
+ +如果一个数的每位数字被旋转以后仍然还是一个数字, 则这个数是有效的。0, 1, 和 8 被旋转后仍然是它们自己;2 和 5 可以互相旋转成对方;6 和 9 同理,除了这些以外其他的数字旋转以后都不再是有效的数字。
+ +现在我们有一个正整数 N, 计算从 1 到 N 中有多少个数 X 是好数?
+示例: +输入: 10 +输出: 4 +解释: +在[1, 10]中有四个好数: 2, 5, 6, 9。 +注意 1 和 10 不是好数, 因为他们在旋转之后不变。 ++ +
注意:
+ +-
+
- N 的取值范围是
[1, 10000]。
+
你在进行一个简化版的吃豆人游戏。你从 (0, 0) 点开始出发,你的目的地是 (target[0], target[1]) 。地图上有一些阻碍者,第 i 个阻碍者从 (ghosts[i][0], ghosts[i][1]) 出发。
每一回合,你和阻碍者们*可以*同时向东,西,南,北四个方向移动,每次可以移动到距离原位置1个单位的新位置。
-如果你可以在任何阻碍者抓住你之前到达目的地(阻碍者可以采取任意行动方式),则被视为逃脱成功。如果你和阻碍者同时到达了一个位置(包括目的地)都不算是逃脱成功。 +如果你可以在任何阻碍者抓住你之前到达目的地(阻碍者可以采取任意行动方式),则被视为逃脱成功。如果你和阻碍者同时到达了一个位置(包括目的地)都不算是逃脱成功。
-当且仅当你有可能成功逃脱时,输出 `True`。 +当且仅当你有可能成功逃脱时,输出 True。
-``` -示例 1: -输入: +示例 1: +输入: ghosts = [[1, 0], [0, 3]] target = [0, 1] -输出:true -解释: -你可以直接一步到达目的地(0,1),在(1, 0)或者(0, 3)位置的阻碍者都不可能抓住你。 -``` -``` -示例 2: -输入: +输出:true +解释: +你可以直接一步到达目的地(0,1),在(1, 0)或者(0, 3)位置的阻碍者都不可能抓住你。 ++ +
示例 2: +输入: ghosts = [[1, 0]] target = [2, 0] -输出:false -解释: -你需要走到位于(2, 0)的目的地,但是在(1, 0)的阻碍者位于你和目的地之间。 -``` -``` -示例 3: -输入: +输出:false +解释: +你需要走到位于(2, 0)的目的地,但是在(1, 0)的阻碍者位于你和目的地之间。 ++ +
示例 3: +输入: ghosts = [[2, 0]] target = [1, 0] -输出:false -解释: -阻碍者可以和你同时达到目的地。 -``` +输出:false +解释: +阻碍者可以和你同时达到目的地。 ++ +
说明:
+ +-
+
- 所有的点的坐标值的绝对值 <=
10000。
+ - 阻碍者的数量不会超过
100。
+
有两种形状的瓷砖:一种是 2x1 的多米诺形,另一种是形如 "L" 的托米诺形。两种形状都可以旋转。
+ ++XX <- 多米诺 + +XX <- "L" 托米诺 +X ++ +
给定 N 的值,有多少种方法可以平铺 2 x N 的面板?返回值 mod 10^9 + 7。
+ +(平铺指的是每个正方形都必须有瓷砖覆盖。两个平铺不同,当且仅当面板上有四个方向上的相邻单元中的两个,使得恰好有一个平铺有一个瓷砖占据两个正方形。)
+ ++示例: +输入: 3 +输出: 5 +解释: +下面列出了五种不同的方法,不同字母代表不同瓷砖: +XYZ XXZ XYY XXY XYY +XYZ YYZ XZZ XYY XXY+ +
提示:
+ +-
+
- N 的范围是
[1, 1000]
+
+ + + +## 解法 + + + +### Python3 + + +```python + +``` + +### Java + + +```java + +``` + +### ... +``` + +``` diff --git a/solution/0700-0799/0791.Custom Sort String/README.md b/solution/0700-0799/0791.Custom Sort String/README.md new file mode 100644 index 0000000000000..ba671d682acfb --- /dev/null +++ b/solution/0700-0799/0791.Custom Sort String/README.md @@ -0,0 +1,53 @@ +# [791. 自定义字符串排序](https://leetcode-cn.com/problems/custom-sort-string) + +## 题目描述 + +
字符串S和 T 只包含小写字符。在S中,所有字符只会出现一次。
S 已经根据某种规则进行了排序。我们要根据S中的字符顺序对T进行排序。更具体地说,如果S中x在y之前出现,那么返回的字符串中x也应出现在y之前。
返回任意一种符合条件的字符串T。
+示例: +输入: +S = "cba" +T = "abcd" +输出: "cbad" +解释: +S中出现了字符 "a", "b", "c", 所以 "a", "b", "c" 的顺序应该是 "c", "b", "a". +由于 "d" 没有在S中出现, 它可以放在T的任意位置. "dcba", "cdba", "cbda" 都是合法的输出。 ++ +
注意:
+ +-
+
S的最大长度为26,其中没有重复的字符。
+ T的最大长度为200。
+ S和T只包含小写字符。
+
给定字符串 S 和单词字典 words, 求 words[i] 中是 S 的子序列的单词个数。
+示例: +输入: +S = "abcde" +words = ["a", "bb", "acd", "ace"] +输出: 3 +解释: 有三个是 S 的子序列的单词: "a", "acd", "ace"。 ++ +
注意:
+ +-
+
- 所有在
words和S里的单词都只由小写字母组成。
+ S的长度在[1, 50000]。
+ words的长度在[1, 5000]。
+ words[i]的长度在[1, 50]。
+
f(x) 是 x! 末尾是0的数量。(回想一下 x! = 1 * 2 * 3 * ... * x,且0! = 1)
例如, f(3) = 0 ,因为3! = 6的末尾没有0;而 f(11) = 2 ,因为11!= 39916800末端有2个0。给定 K,找出多少个非负整数x ,有 f(x) = K 的性质。
+示例 1: +输入:K = 0 +输出:5 +解释: 0!, 1!, 2!, 3!, and 4! 均符合 K = 0 的条件。 + +示例 2: +输入:K = 5 +输出:0 +解释:没有匹配到这样的 x!,符合K = 5 的条件。 ++ +
注意:
+ +-
+
-
+
+K是范围在[0, 10^9]的整数。
+
用字符串数组作为井字游戏的游戏板 board。当且仅当在井字游戏过程中,玩家有可能将字符放置成游戏板所显示的状态时,才返回 true。
该游戏板是一个 3 x 3 数组,由字符 " ","X" 和 "O" 组成。字符 " " 代表一个空位。
以下是井字游戏的规则:
+ +-
+
- 玩家轮流将字符放入空位(" ")中。 +
- 第一个玩家总是放字符 “X”,且第二个玩家总是放字符 “O”。 +
- “X” 和 “O” 只允许放置在空位中,不允许对已放有字符的位置进行填充。 +
- 当有 3 个相同(且非空)的字符填充任何行、列或对角线时,游戏结束。 +
- 当所有位置非空时,也算为游戏结束。 +
- 如果游戏结束,玩家不允许再放置字符。 +
+示例 1: +输入: board = ["O ", " ", " "] +输出: false +解释: 第一个玩家总是放置“X”。 + +示例 2: +输入: board = ["XOX", " X ", " "] +输出: false +解释: 玩家应该是轮流放置的。 + +示例 3: +输入: board = ["XXX", " ", "OOO"] +输出: false + +示例 4: +输入: board = ["XOX", "O O", "XOX"] +输出: true ++ +
说明:
+ +-
+
- 游戏板
board是长度为 3 的字符串数组,其中每个字符串board[i]的长度为 3。
+ -
board[i][j]是集合{" ", "X", "O"}中的一个字符。
+
给定一个元素都是正整数的数组A ,正整数 L 以及 R (L <= R)。
求连续、非空且其中最大元素满足大于等于L 小于等于R的子数组个数。
例如 : +输入: +A = [2, 1, 4, 3] +L = 2 +R = 3 +输出: 3 +解释: 满足条件的子数组: [2], [2, 1], [3]. ++ +
注意:
+ +-
+
- L, R 和
A[i]都是整数,范围在[0, 10^9]。
+ - 数组
A的长度范围在[1, 50000]。
+
给定两个字符串, A 和 B。
A 的旋转操作就是将 A 最左边的字符移动到最右边。 例如, 若 A = 'abcde',在移动一次之后结果就是'bcdea' 。如果在若干次旋转操作之后,A 能变成B,那么返回True。
+示例 1: +输入: A = 'abcde', B = 'cdeab' +输出: true + +示例 2: +输入: A = 'abcde', B = 'abced' +输出: false+ +
注意:
+ +-
+
A和B长度不超过100。
+
给一个有 n 个结点的有向无环图,找到所有从 0 到 n-1 的路径并输出(不要求按顺序)
二维数组的第 i 个数组中的单元都表示有向图中 i 号结点所能到达的下一些结点(译者注:有向图是有方向的,即规定了a→b你就不能从b→a)空就是没有下一个结点了。
+ +示例: +输入: [[1,2], [3], [3], []] +输出: [[0,1,3],[0,2,3]] +解释: 图是这样的: +0--->1 +| | +v v +2--->3 +这有两条路: 0 -> 1 -> 3 和 0 -> 2 -> 3. ++ +
提示:
+ +-
+
- 结点的数量会在范围
[2, 15]内。
+ - 你可以把路径以任意顺序输出,但在路径内的结点的顺序必须保证。 +
给定一个数组 A,我们可以将它按一个非负整数 K 进行轮调,这样可以使数组变为 A[K], A[K+1], A{K+2], ... A[A.length - 1], A[0], A[1], ..., A[K-1] 的形式。此后,任何值小于或等于其索引的项都可以记作一分。
例如,如果数组为 [2, 4, 1, 3, 0],我们按 K = 2 进行轮调后,它将变成 [1, 3, 0, 2, 4]。这将记作 3 分,因为 1 > 0 [no points], 3 > 1 [no points], 0 <= 2 [one point], 2 <= 3 [one point], 4 <= 4 [one point]。
在所有可能的轮调中,返回我们所能得到的最高分数对应的轮调索引 K。如果有多个答案,返回满足条件的最小的索引 K。
+ +示例 1: +输入:[2, 3, 1, 4, 0] +输出:3 +解释: +下面列出了每个 K 的得分: +K = 0, A = [2,3,1,4,0], score 2 +K = 1, A = [3,1,4,0,2], score 3 +K = 2, A = [1,4,0,2,3], score 3 +K = 3, A = [4,0,2,3,1], score 4 +K = 4, A = [0,2,3,1,4], score 3 +所以我们应当选择 K = 3,得分最高。+ +
+ +
示例 2: +输入:[1, 3, 0, 2, 4] +输出:0 +解释: +A 无论怎么变化总是有 3 分。 +所以我们将选择最小的 K,即 0。 ++ +
提示:
+ +-
+
A的长度最大为20000。
+ A[i]的取值范围是[0, A.length]。
+
我们把玻璃杯摆成金字塔的形状,其中第一层有1个玻璃杯,第二层有2个,依次类推到第100层,每个玻璃杯(250ml)将盛有香槟。
+ +从顶层的第一个玻璃杯开始倾倒一些香槟,当顶层的杯子满了,任何溢出的香槟都会立刻等流量的流向左右两侧的玻璃杯。当左右两边的杯子也满了,就会等流量的流向它们左右两边的杯子,依次类推。(当最底层的玻璃杯满了,香槟会流到地板上)
+ +例如,在倾倒一杯香槟后,最顶层的玻璃杯满了。倾倒了两杯香槟后,第二层的两个玻璃杯各自盛放一半的香槟。在倒三杯香槟后,第二层的香槟满了 - 此时总共有三个满的玻璃杯。在倒第四杯后,第三层中间的玻璃杯盛放了一半的香槟,他两边的玻璃杯各自盛放了四分之一的香槟,如下图所示。
+ +
现在当倾倒了非负整数杯香槟后,返回第 i 行 j 个玻璃杯所盛放的香槟占玻璃杯容积的比例(i 和 j都从0开始)。
+ ++ +
+示例 1: +输入: poured(倾倒香槟总杯数) = 1, query_glass(杯子的位置数) = 1, query_row(行数) = 1 +输出: 0.0 +解释: 我们在顶层(下标是(0,0))倒了一杯香槟后,没有溢出,因此所有在顶层以下的玻璃杯都是空的。 + +示例 2: +输入: poured(倾倒香槟总杯数) = 2, query_glass(杯子的位置数) = 1, query_row(行数) = 1 +输出: 0.5 +解释: 我们在顶层(下标是(0,0)倒了两杯香槟后,有一杯量的香槟将从顶层溢出,位于(1,0)的玻璃杯和(1,1)的玻璃杯平分了这一杯香槟,所以每个玻璃杯有一半的香槟。 ++ +
注意:
+ +-
+
poured的范围[0, 10 ^ 9]。
+ query_glass和query_row的范围[0, 99]。
+
我们有两个长度相等且不为空的整型数组 A 和 B 。
我们可以交换 A[i] 和 B[i] 的元素。注意这两个元素在各自的序列中应该处于相同的位置。
在交换过一些元素之后,数组 A 和 B 都应该是严格递增的(数组严格递增的条件仅为A[0] < A[1] < A[2] < ... < A[A.length - 1])。
给定数组 A 和 B ,请返回使得两个数组均保持严格递增状态的最小交换次数。假设给定的输入总是有效的。
+示例: +输入: A = [1,3,5,4], B = [1,2,3,7] +输出: 1 +解释: +交换 A[3] 和 B[3] 后,两个数组如下: +A = [1, 3, 5, 7] , B = [1, 2, 3, 4] +两个数组均为严格递增的。+ +
注意:
+ +-
+
A, B两个数组的长度总是相等的,且长度的范围为[1, 1000]。
+ A[i], B[i]均为[0, 2000]区间内的整数。
+
在有向图中, 我们从某个节点和每个转向处开始, 沿着图的有向边走。 如果我们到达的节点是终点 (即它没有连出的有向边), 我们停止。
+ +现在, 如果我们最后能走到终点,那么我们的起始节点是最终安全的。 更具体地说, 存在一个自然数 K, 无论选择从哪里开始行走, 我们走了不到 K 步后必能停止在一个终点。
哪些节点最终是安全的? 结果返回一个有序的数组。
+ +该有向图有 N 个节点,标签为 0, 1, ..., N-1, 其中 N 是 graph 的节点数. 图以以下的形式给出: graph[i] 是节点 j 的一个列表,满足 (i, j) 是图的一条有向边。
+示例: +输入:graph = [[1,2],[2,3],[5],[0],[5],[],[]] +输出:[2,4,5,6] +这里是上图的示意图。 + ++ +
提示:
+ +-
+
graph节点数不超过10000.
+ - 图的边数不会超过
32000.
+ - 每个
graph[i]被排序为不同的整数列表, 在区间[0, graph.length - 1]中选取。
+
我们有一组包含1和0的网格;其中1表示砖块。 当且仅当一块砖直接连接到网格的顶部,或者它至少有一块相邻(4 个方向之一)砖块不会掉落时,它才不会落下。
+ +我们会依次消除一些砖块。每当我们消除 (i, j) 位置时, 对应位置的砖块(若存在)会消失,然后其他的砖块可能因为这个消除而落下。
+ +返回一个数组表示每次消除操作对应落下的砖块数目。
+ +示例 1: +输入: +grid = [[1,0,0,0],[1,1,1,0]] +hits = [[1,0]] +输出: [2] +解释: +如果我们消除(1, 0)位置的砖块, 在(1, 1) 和(1, 2) 的砖块会落下。所以我们应该返回2。+ +
示例 2: +输入: +grid = [[1,0,0,0],[1,1,0,0]] +hits = [[1,1],[1,0]] +输出:[0,0] +解释: +当我们消除(1, 0)的砖块时,(1, 1)的砖块已经由于上一步消除而消失了。所以每次消除操作不会造成砖块落下。注意(1, 0)砖块不会记作落下的砖块。+ +
注意:
+ +-
+
- 网格的行数和列数的范围是[1, 200]。 +
- 消除的数字不会超过网格的区域。 +
- 可以保证每次的消除都不相同,并且位于网格的内部。 +
- 一个消除的位置可能没有砖块,如果这样的话,就不会有砖块落下。 +
国际摩尔斯密码定义一种标准编码方式,将每个字母对应于一个由一系列点和短线组成的字符串, 比如: "a" 对应 ".-", "b" 对应 "-...", "c" 对应 "-.-.", 等等。
为了方便,所有26个英文字母对应摩尔斯密码表如下:
+ +[".-","-...","-.-.","-..",".","..-.","--.","....","..",".---","-.-",".-..","--","-.","---",".--.","--.-",".-.","...","-","..-","...-",".--","-..-","-.--","--.."]+ +
给定一个单词列表,每个单词可以写成每个字母对应摩尔斯密码的组合。例如,"cab" 可以写成 "-.-..--...",(即 "-.-." + "-..." + ".-"字符串的结合)。我们将这样一个连接过程称作单词翻译。
+ +返回我们可以获得所有词不同单词翻译的数量。
+ +例如: +输入: words = ["gin", "zen", "gig", "msg"] +输出: 2 +解释: +各单词翻译如下: +"gin" -> "--...-." +"zen" -> "--...-." +"gig" -> "--...--." +"msg" -> "--...--." + +共有 2 种不同翻译, "--...-." 和 "--...--.". ++ +
+ +
注意:
+ +-
+
- 单词列表
words的长度不会超过100。
+ - 每个单词
words[i]的长度范围为[1, 12]。
+ - 每个单词
words[i]只包含小写字母。
+
给定的整数数组 A ,我们要将 A数组 中的每个元素移动到 B数组 或者 C数组中。(B数组和C数组在开始的时候都为空)
+ +返回true ,当且仅当在我们的完成这样的移动后,可使得B数组的平均值和C数组的平均值相等,并且B数组和C数组都不为空。
+示例: +输入: +[1,2,3,4,5,6,7,8] +输出: true +解释: 我们可以将数组分割为 [1,4,5,8] 和 [2,3,6,7], 他们的平均值都是4.5。 ++ +
注意:
+ +-
+
A数组的长度范围为[1, 30].
+ A[i]的数据范围为[0, 10000].
+
我们要把给定的字符串 S 从左到右写到每一行上,每一行的最大宽度为100个单位,如果我们在写某个字母的时候会使这行超过了100 个单位,那么我们应该把这个字母写到下一行。我们给定了一个数组 widths ,这个数组 widths[0] 代表 'a' 需要的单位, widths[1] 代表 'b' 需要的单位,..., widths[25] 代表 'z' 需要的单位。
现在回答两个问题:至少多少行能放下S,以及最后一行使用的宽度是多少个单位?将你的答案作为长度为2的整数列表返回。
+示例 1: +输入: +widths = [10,10,10,10,10,10,10,10,10,10,10,10,10,10,10,10,10,10,10,10,10,10,10,10,10,10] +S = "abcdefghijklmnopqrstuvwxyz" +输出: [3, 60] +解释: +所有的字符拥有相同的占用单位10。所以书写所有的26个字母, +我们需要2个整行和占用60个单位的一行。 ++ +
+示例 2: +输入: +widths = [4,10,10,10,10,10,10,10,10,10,10,10,10,10,10,10,10,10,10,10,10,10,10,10,10,10] +S = "bbbcccdddaaa" +输出: [2, 4] +解释: +除去字母'a'所有的字符都是相同的单位10,并且字符串 "bbbcccdddaa" 将会覆盖 9 * 10 + 2 * 4 = 98 个单位. +最后一个字母 'a' 将会被写到第二行,因为第一行只剩下2个单位了。 +所以,这个答案是2行,第二行有4个单位宽度。 ++ +
+ +
注:
+ +-
+
- 字符串
S的长度在 [1, 1000] 的范围。
+ S只包含小写字母。
+ widths是长度为26的数组。
+ widths[i]值的范围在[2, 10]。
+
在二维数组grid中,grid[i][j]代表位于某处的建筑物的高度。 我们被允许增加任何数量(不同建筑物的数量可能不同)的建筑物的高度。 高度 0 也被认为是建筑物。
最后,从新数组的所有四个方向(即顶部,底部,左侧和右侧)观看的“天际线”必须与原始数组的天际线相同。 城市的天际线是从远处观看时,由所有建筑物形成的矩形的外部轮廓。 请看下面的例子。
+ +建筑物高度可以增加的最大总和是多少?
+ ++例子: +输入: grid = [[3,0,8,4],[2,4,5,7],[9,2,6,3],[0,3,1,0]] +输出: 35 +解释: +The grid is: +[ [3, 0, 8, 4], + [2, 4, 5, 7], + [9, 2, 6, 3], + [0, 3, 1, 0] ] + +从数组竖直方向(即顶部,底部)看“天际线”是:[9, 4, 8, 7] +从水平水平方向(即左侧,右侧)看“天际线”是:[8, 7, 9, 3] + +在不影响天际线的情况下对建筑物进行增高后,新数组如下: + +gridNew = [ [8, 4, 8, 7], + [7, 4, 7, 7], + [9, 4, 8, 7], + [3, 3, 3, 3] ] ++ +
说明:
+ +-
+
1 < grid.length = grid[0].length <= 50。
+ -
grid[i][j]的高度范围是:[0, 100]。
+ - 一座建筑物占据一个
grid[i][j]:换言之,它们是1 x 1 x grid[i][j]的长方体。
+
有 A 和 B 两种类型的汤。一开始每种类型的汤有 N 毫升。有四种分配操作:
-
+
- 提供 100ml 的汤A 和 0ml 的汤B。 +
- 提供 75ml 的汤A 和 25ml 的汤B。 +
- 提供 50ml 的汤A 和 50ml 的汤B。 +
- 提供 25ml 的汤A 和 75ml 的汤B。 +
当我们把汤分配给某人之后,汤就没有了。每个回合,我们将从四种概率同为0.25的操作中进行分配选择。如果汤的剩余量不足以完成某次操作,我们将尽可能分配。当两种类型的汤都分配完时,停止操作。
+ +注意不存在先分配100 ml汤B的操作。
+ +需要返回的值: 汤A先分配完的概率 + 汤A和汤B同时分配完的概率 / 2。
+ ++示例: +输入: N = 50 +输出: 0.625 +解释: +如果我们选择前两个操作,A将首先变为空。对于第三个操作,A和B会同时变为空。对于第四个操作,B将首先变为空。 +所以A变为空的总概率加上A和B同时变为空的概率的一半是 0.25 *(1 + 1 + 0.5 + 0)= 0.625。 ++ +
注释:
+ +-
+
0 <= N <= 10^9。
+ -
+
返回值在
+10^-6的范围将被认为是正确的。
+
有时候人们会用重复写一些字母来表示额外的感受,比如 "hello" -> "heeellooo", "hi" -> "hiii"。我们将相邻字母都相同的一串字符定义为相同字母组,例如:"h", "eee", "ll", "ooo"。
对于一个给定的字符串 S ,如果另一个单词能够通过将一些字母组扩张从而使其和 S 相同,我们将这个单词定义为可扩张的(stretchy)。扩张操作定义如下:选择一个字母组(包含字母 c ),然后往其中添加相同的字母 c 使其长度达到 3 或以上。
例如,以 "hello" 为例,我们可以对字母组 "o" 扩张得到 "hellooo",但是无法以同样的方法得到 "helloo" 因为字母组 "oo" 长度小于 3。此外,我们可以进行另一种扩张 "ll" -> "lllll" 以获得 "helllllooo"。如果 S = "helllllooo",那么查询词 "hello" 是可扩张的,因为可以对它执行这两种扩张操作使得 query = "hello" -> "hellooo" -> "helllllooo" = S。
输入一组查询单词,输出其中可扩张的单词数量。
+ ++ +
示例:
+ +输入: +S = "heeellooo" +words = ["hello", "hi", "helo"] +输出:1 +解释: +我们能通过扩张 "hello" 的 "e" 和 "o" 来得到 "heeellooo"。 +我们不能通过扩张 "helo" 来得到 "heeellooo" 因为 "ll" 的长度小于 3 。 ++ +
+ +
说明:
+ +-
+
0 <= len(S) <= 100。
+ 0 <= len(words) <= 100。
+ 0 <= len(words[i]) <= 100。
+ S和所有在words中的单词都只由小写字母组成。
+
一个黑板上写着一个非负整数数组 nums[i] 。小红和小明轮流从黑板上擦掉一个数字,小红先手。如果擦除一个数字后,剩余的所有数字按位异或运算得出的结果等于 0 的话,当前玩家游戏失败。 (另外,如果只剩一个数字,按位异或运算得到它本身;如果无数字剩余,按位异或运算结果为 0。)
+ +换种说法就是,轮到某个玩家时,如果当前黑板上所有数字按位异或运算结果等于 0,这个玩家获胜。
+ +假设两个玩家每步都使用最优解,当且仅当小红获胜时返回 true。
+ +
示例:
+ +输入: nums = [1, 1, 2] +输出: false +解释: +小红有两个选择: 擦掉数字 1 或 2。 +如果擦掉 1, 数组变成 [1, 2]。剩余数字按位异或得到 1 XOR 2 = 3。那么小明可以擦掉任意数字,因为小红会成为擦掉最后一个数字的人,她总是会输。 +如果小红擦掉 2,那么数组变成[1, 1]。剩余数字按位异或得到 1 XOR 1 = 0。小红仍然会输掉游戏。 ++ +
+ +
提示:
+ +-
+
1 <= N <= 1000
+ 0 <= nums[i] <= 2^16
+
一个网站域名,如"discuss.leetcode.com",包含了多个子域名。作为顶级域名,常用的有"com",下一级则有"leetcode.com",最低的一级为"discuss.leetcode.com"。当我们访问域名"discuss.leetcode.com"时,也同时访问了其父域名"leetcode.com"以及顶级域名 "com"。
+ +给定一个带访问次数和域名的组合,要求分别计算每个域名被访问的次数。其格式为访问次数+空格+地址,例如:"9001 discuss.leetcode.com"。
+ +接下来会给出一组访问次数和域名组合的列表cpdomains 。要求解析出所有域名的访问次数,输出格式和输入格式相同,不限定先后顺序。
+示例 1: +输入: +["9001 discuss.leetcode.com"] +输出: +["9001 discuss.leetcode.com", "9001 leetcode.com", "9001 com"] +说明: +例子中仅包含一个网站域名:"discuss.leetcode.com"。按照前文假设,子域名"leetcode.com"和"com"都会被访问,所以它们都被访问了9001次。 ++ +
+示例 2 +输入: +["900 google.mail.com", "50 yahoo.com", "1 intel.mail.com", "5 wiki.org"] +输出: +["901 mail.com","50 yahoo.com","900 google.mail.com","5 wiki.org","5 org","1 intel.mail.com","951 com"] +说明: +按照假设,会访问"google.mail.com" 900次,"yahoo.com" 50次,"intel.mail.com" 1次,"wiki.org" 5次。 +而对于父域名,会访问"mail.com" 900+1 = 901次,"com" 900 + 50 + 1 = 951次,和 "org" 5 次。 ++ +
注意事项:
+ +-
+
-
cpdomains的长度小于100。
+ - 每个域名的长度小于
100。
+ - 每个域名地址包含一个或两个"."符号。 +
- 输入中任意一个域名的访问次数都小于
10000。
+
给定包含多个点的集合,从其中取三个点组成三角形,返回能组成的最大三角形的面积。
+ ++示例: +输入: points = [[0,0],[0,1],[1,0],[0,2],[2,0]] +输出: 2 +解释: +这五个点如下图所示。组成的橙色三角形是最大的,面积为2。 ++ +
注意:
+ +-
+
3 <= points.length <= 50.
+ - 不存在重复的点。 +
-
-50 <= points[i][j] <= 50.
+ - 结果误差值在
10^-6以内都认为是正确答案。
+
我们将给定的数组 A 分成 K 个相邻的非空子数组 ,我们的分数由每个子数组内的平均值的总和构成。计算我们所能得到的最大分数是多少。
注意我们必须使用 A 数组中的每一个数进行分组,并且分数不一定需要是整数。
+ ++示例: +输入: +A = [9,1,2,3,9] +K = 3 +输出: 20 +解释: +A 的最优分组是[9], [1, 2, 3], [9]. 得到的分数是 9 + (1 + 2 + 3) / 3 + 9 = 20. +我们也可以把 A 分成[9, 1], [2], [3, 9]. +这样的分组得到的分数为 5 + 2 + 6 = 13, 但不是最大值. ++ +
说明:
+ +-
+
1 <= A.length <= 100.
+ 1 <= A[i] <= 10000.
+ 1 <= K <= A.length.
+ - 答案误差在
10^-6内被视为是正确的。
+
给定二叉树根结点 root ,此外树的每个结点的值要么是 0,要么是 1。
返回移除了所有不包含 1 的子树的原二叉树。
+ +( 节点 X 的子树为 X 本身,以及所有 X 的后代。)
+ ++示例1: +输入: [1,null,0,0,1] +输出: [1,null,0,null,1] + +解释: +只有红色节点满足条件“所有不包含 1 的子树”。 +右图为返回的答案。 + ++ ++
+示例2: +输入: [1,0,1,0,0,0,1] +输出: [1,null,1,null,1] + + ++ ++
+示例3: +输入: [1,1,0,1,1,0,1,0] +输出: [1,1,0,1,1,null,1] + + ++ ++
说明:
+ +-
+
- 给定的二叉树最多有
100个节点。
+ - 每个节点的值只会为
0或1。
+
我们有一系列公交路线。每一条路线 routes[i] 上都有一辆公交车在上面循环行驶。例如,有一条路线 routes[0] = [1, 5, 7],表示第一辆 (下标为0) 公交车会一直按照 1->5->7->1->5->7->1->... 的车站路线行驶。
假设我们从 S 车站开始(初始时不在公交车上),要去往 T 站。 期间仅可乘坐公交车,求出最少乘坐的公交车数量。返回 -1 表示不可能到达终点车站。
+示例: +输入: +routes = [[1, 2, 7], [3, 6, 7]] +S = 1 +T = 6 +输出: 2 +解释: +最优策略是先乘坐第一辆公交车到达车站 7, 然后换乘第二辆公交车到车站 6。 ++ +
说明:
+ +-
+
1 <= routes.length <= 500.
+ 1 <= routes[i].length <= 500.
+ 0 <= routes[i][j] < 10 ^ 6.
+
我们有一些二维坐标,如 "(1, 3)" 或 "(2, 0.5)",然后我们移除所有逗号,小数点和空格,得到一个字符串S。返回所有可能的原始字符串到一个列表中。
原始的坐标表示法不会存在多余的零,所以不会出现类似于"00", "0.0", "0.00", "1.0", "001", "00.01"或一些其他更小的数来表示坐标。此外,一个小数点前至少存在一个数,所以也不会出现“.1”形式的数字。
+ +最后返回的列表可以是任意顺序的。而且注意返回的两个数字中间(逗号之后)都有一个空格。
+ ++ +
+示例 1: +输入: "(123)" +输出: ["(1, 23)", "(12, 3)", "(1.2, 3)", "(1, 2.3)"] ++ +
+示例 2: +输入: "(00011)" +输出: ["(0.001, 1)", "(0, 0.011)"] +解释: +0.0, 00, 0001 或 00.01 是不被允许的。 ++ +
+示例 3: +输入: "(0123)" +输出: ["(0, 123)", "(0, 12.3)", "(0, 1.23)", "(0.1, 23)", "(0.1, 2.3)", "(0.12, 3)"] ++ +
+示例 4: +输入: "(100)" +输出: [(10, 0)] +解释: +1.0 是不被允许的。 ++ +
+ +
提示:
+ +-
+
4 <= S.length <= 12.
+ S[0]= "(",S[S.length - 1]= ")", 且字符串S中的其他元素都是数字。
+
+ + + +## 解法 + + + +### Python3 + + +```python + +``` + +### Java + + +```java + +``` + +### ... +``` + +``` diff --git a/solution/0800-0899/0817.Linked List Components/README.md b/solution/0800-0899/0817.Linked List Components/README.md index e9b7bfadb5a14..509ba90cfbb29 100644 --- a/solution/0800-0899/0817.Linked List Components/README.md +++ b/solution/0800-0899/0817.Linked List Components/README.md @@ -1,56 +1,63 @@ -## 链表组件 -### 题目描述 +# [817. 链表组件](https://leetcode-cn.com/problems/linked-list-components) -给定一个链表(链表结点包含一个整型值)的头结点 head。 +## 题目描述 + +
给定一个链表(链表结点包含一个整型值)的头结点 head。
同时给定列表 G,该列表是上述链表中整型值的一个子集。
返回列表 G 中组件的个数,这里对组件的定义为:链表中一段最长连续结点的值(该值必须在列表 G 中)构成的集合。
示例 1:
+ ++输入: +head: 0->1->2->3 G = [0, 1, 3] -输出: 2 -解释: -链表中,0 和 1 是相连接的,且 G 中不包含 2,所以 [0, 1] 是 G 的一个组件,同理 [3] 也是一个组件,故返回 2。 -``` -**示例2:** -``` -输入: -head: 0->1->2->3->4 +输出: 2 +解释: +链表中,0 和 1 是相连接的,且 G 中不包含 2,所以 [0, 1] 是 G 的一个组件,同理 [3] 也是一个组件,故返回 2。+ +
示例 2:
+ ++输入: +head: 0->1->2->3->4 G = [0, 3, 1, 4] -输出: 2 -解释: -链表中,0 和 1 是相连接的,3 和 4 是相连接的,所以 [0, 1] 和 [3, 4] 是两个组件,故返回 2。 -``` -**注意:** -- 如果 N 是给定链表 head 的长度,1 <= N <= 10000。 -- 链表中每个结点的值所在范围为 [0, N - 1]。 -- 1 <= G.length <= 10000 -- G 是链表中所有结点的值的一个子集. +输出: 2 +解释: +链表中,0 和 1 是相连接的,3 和 4 是相连接的,所以 [0, 1] 和 [3, 4] 是两个组件,故返回 2。+ +
注意:
+ +-
+
- 如果
N是给定链表head的长度,1 <= N <= 10000。
+ - 链表中每个结点的值所在范围为
[0, N - 1]。
+ 1 <= G.length <= 10000
+ G是链表中所有结点的值的一个子集.
+
你的赛车起始停留在位置 0,速度为 +1,正行驶在一个无限长的数轴上。(车也可以向负数方向行驶。)
+ +你的车会根据一系列由 A(加速)和 R(倒车)组成的指令进行自动驾驶 。
+ +当车得到指令 "A" 时, 将会做出以下操作: position += speed, speed *= 2。
当车得到指令 "R" 时, 将会做出以下操作:如果当前速度是正数,则将车速调整为 speed = -1 ;否则将车速调整为 speed = 1。 (当前所处位置不变。)
例如,当得到一系列指令 "AAR" 后, 你的车将会走过位置 0->1->3->3,并且速度变化为 1->2->4->-1。
+ +现在给定一个目标位置,请给出能够到达目标位置的最短指令列表的长度。
+ +示例 1: +输入: +target = 3 +输出: 2 +解释: +最短指令列表为 "AA" +位置变化为 0->1->3 ++ +
示例 2: +输入: +target = 6 +输出: 5 +解释: +最短指令列表为 "AAARA" +位置变化为 0->1->3->7->7->6 ++ +
说明:
+ +-
+
1 <= target(目标位置) <= 10000。
+
给定一个段落 (paragraph) 和一个禁用单词列表 (banned)。返回出现次数最多,同时不在禁用列表中的单词。题目保证至少有一个词不在禁用列表中,而且答案唯一。
+ +禁用列表中的单词用小写字母表示,不含标点符号。段落中的单词不区分大小写。答案都是小写字母。
+ ++ +
示例:
+ +输入: +paragraph = "Bob hit a ball, the hit BALL flew far after it was hit." +banned = ["hit"] +输出: "ball" +解释: +"hit" 出现了3次,但它是一个禁用的单词。 +"ball" 出现了2次 (同时没有其他单词出现2次),所以它是段落里出现次数最多的,且不在禁用列表中的单词。 +注意,所有这些单词在段落里不区分大小写,标点符号需要忽略(即使是紧挨着单词也忽略, 比如 "ball,"), +"hit"不是最终的答案,虽然它出现次数更多,但它在禁用单词列表中。 ++ +
+ +
说明:
+ +-
+
1 <= 段落长度 <= 1000.
+ 1 <= 禁用单词个数 <= 100.
+ 1 <= 禁用单词长度 <= 10.
+ - 答案是唯一的, 且都是小写字母 (即使在
paragraph里是大写的,即使是一些特定的名词,答案都是小写的。)
+ paragraph只包含字母、空格和下列标点符号!?',;.
+ - 不存在没有连字符或者带有连字符的单词。 +
- 单词里只包含字母,不会出现省略号或者其他标点符号。 +
给定一个单词列表,我们将这个列表编码成一个索引字符串 S 与一个索引列表 A。
例如,如果这个列表是 ["time", "me", "bell"],我们就可以将其表示为 S = "time#bell#" 和 indexes = [0, 2, 5]。
对于每一个索引,我们可以通过从字符串 S 中索引的位置开始读取字符串,直到 "#" 结束,来恢复我们之前的单词列表。
那么成功对给定单词列表进行编码的最小字符串长度是多少呢?
+ ++ +
示例:
+ +输入: words =+ +["time", "me", "bell"]+输出: 10 +说明: S ="time#bell#" , indexes = [0, 2, 5] 。 +
+ +
提示:
+ +-
+
1 <= words.length <= 2000
+ 1 <= words[i].length <= 7
+ - 每个单词都是小写字母 。 +
给定一个字符串 S 和一个字符 C。返回一个代表字符串 S 中每个字符到字符串 S 中的字符 C 的最短距离的数组。
示例 1:
+ ++输入: S = "loveleetcode", C = 'e' +输出: [3, 2, 1, 0, 1, 0, 0, 1, 2, 2, 1, 0] ++ +
说明:
+ +-
+
- 字符串
S的长度范围为[1, 10000]。
+ C是一个单字符,且保证是字符串S里的字符。
+ S和C中的所有字母均为小写字母。
+
在桌子上有 N 张卡片,每张卡片的正面和背面都写着一个正数(正面与背面上的数有可能不一样)。
我们可以先翻转任意张卡片,然后选择其中一张卡片。
+ +如果选中的那张卡片背面的数字 X 与任意一张卡片的正面的数字都不同,那么这个数字是我们想要的数字。
哪个数是这些想要的数字中最小的数(找到这些数中的最小值)呢?如果没有一个数字符合要求的,输出 0。
+ +其中, fronts[i] 和 backs[i] 分别代表第 i 张卡片的正面和背面的数字。
如果我们通过翻转卡片来交换正面与背面上的数,那么当初在正面的数就变成背面的数,背面的数就变成正面的数。
+ +示例:
+ ++输入:fronts = [1,2,4,4,7], backs = [1,3,4,1,3] +输出:+ +2+解释:假设我们翻转第二张卡片,那么在正面的数变成了[1,3,4,4,7], 背面的数变成了[1,2,4,1,3]。+接着我们选择第二张卡片,因为现在该卡片的背面的数是 2,2 与任意卡片上正面的数都不同,所以 2 就是我们想要的数字。
+ +
提示:
+ +-
+
1 <= fronts.length == backs.length <= 1000
+ 1 <= fronts[i] <= 2000
+ 1 <= backs[i] <= 2000
+
给出一个含有不重复整数元素的数组,每个整数均大于 1。
+ +我们用这些整数来构建二叉树,每个整数可以使用任意次数。
+ +其中:每个非叶结点的值应等于它的两个子结点的值的乘积。
+ +满足条件的二叉树一共有多少个?返回的结果应模除 10 ** 9 + 7。
+ ++ +
示例 1:
+ ++输入:+ +A = [2, 4]+输出: 3 +解释: 我们可以得到这些二叉树:[2], [4], [4, 2, 2]
示例 2:
+ ++输入:+ +A = [2, 4, 5, 10]+输出:7+解释: 我们可以得到这些二叉树:[2], [4], [5], [10], [4, 2, 2], [10, 2, 5], [10, 5, 2].
+ +
提示:
+ +-
+
1 <= A.length <= 1000.
+ 2 <= A[i] <= 10 ^ 9.
+
给定一个由空格分割单词的句子 S。每个单词只包含大写或小写字母。
我们要将句子转换为 “Goat Latin”(一种类似于 猪拉丁文 - Pig Latin 的虚构语言)。
+ +山羊拉丁文的规则如下:
+ +-
+
- 如果单词以元音开头(a, e, i, o, u),在单词后添加
"ma"。
+ 例如,单词"apple"变为"applema"。
+ - 如果单词以辅音字母开头(即非元音字母),移除第一个字符并将它放到末尾,之后再添加
"ma"。
+ 例如,单词"goat"变为"oatgma"。
+ - 根据单词在句子中的索引,在单词最后添加与索引相同数量的字母
'a',索引从1开始。
+ 例如,在第一个单词后添加"a",在第二个单词后添加"aa",以此类推。
+
+
+
返回将 S 转换为山羊拉丁文后的句子。
示例 1:
+ ++输入: "I speak Goat Latin" +输出: "Imaa peaksmaaa oatGmaaaa atinLmaaaaa" ++ +
示例 2:
+ ++输入: "The quick brown fox jumped over the lazy dog" +输出: "heTmaa uickqmaaa rownbmaaaa oxfmaaaaa umpedjmaaaaaa overmaaaaaaa hetmaaaaaaaa azylmaaaaaaaaa ogdmaaaaaaaaaa" ++ +
说明:
+ +-
+
S中仅包含大小写字母和空格。单词间有且仅有一个空格。
+ 1 <= S.length <= 150。
+
人们会互相发送好友请求,现在给定一个包含有他们年龄的数组,ages[i] 表示第 i 个人的年龄。
当满足以下条件时,A 不能给 B(A、B不为同一人)发送好友请求:
+ +-
+
age[B] <= 0.5 * age[A] + 7
+ age[B] > age[A]
+ age[B] > 100 && age[A] < 100
+
否则,A 可以给 B 发送好友请求。
+ +注意如果 A 向 B 发出了请求,不等于 B 也一定会向 A 发出请求。而且,人们不会给自己发送好友请求。
+ +求总共会发出多少份好友请求?
+ ++ +
示例 1:
+ +输入: [16,16] +输出: 2 +解释: 二人可以互发好友申请。 ++ +
示例 2:
+ +输入: [16,17,18] +输出: 2 +解释: 好友请求可产生于 17 -> 16, 18 -> 17.+ +
示例 3:
+ +输入: [20,30,100,110,120] +输出: 3 +解释: 好友请求可产生于 110 -> 100, 120 -> 110, 120 -> 100. ++ +
+ +
说明:
+ +-
+
1 <= ages.length <= 20000.
+ 1 <= ages[i] <= 120.
+
有一些工作:difficulty[i] 表示第i个工作的难度,profit[i]表示第i个工作的收益。
现在我们有一些工人。worker[i]是第i个工人的能力,即该工人只能完成难度小于等于worker[i]的工作。
每一个工人都最多只能安排一个工作,但是一个工作可以完成多次。
-每一个工人都最多只能安排一个工作,但是一个工作可以完成多次。 +举个例子,如果3个工人都尝试完成一份报酬为1的同样工作,那么总收益为 $3。如果一个工人不能完成任何工作,他的收益为 $0 。
-举个例子,如果3个工人都尝试完成一份报酬为1的同样工作,那么总收益为 $3。如果一个工人不能完成任何工作,他的收益为 $0 。 +我们能得到的最大收益是多少?
-我们能得到的最大收益是多少? +示例:
-**示例:** -``` -输入: difficulty = [2,4,6,8,10], profit = [10,20,30,40,50], worker = [4,5,6,7] -输出: 100 -解释: 工人被分配的工作难度是 [4,4,6,6] ,分别获得 [20,20,30,30] 的收益。 -``` +输入: difficulty = [2,4,6,8,10], profit = [10,20,30,40,50], worker = [4,5,6,7] +输出: 100 +解释: 工人被分配的工作难度是 [4,4,6,6] ,分别获得 [20,20,30,30] 的收益。+ +
提示:
+ +-
+
1 <= difficulty.length = profit.length <= 10000
+ 1 <= worker.length <= 10000
+ difficulty[i], profit[i], worker[i]的范围是[1, 10^5]
+
在二维地图上, 0代表海洋, 1代表陆地,我们最多只能将一格 0 海洋变成 1变成陆地。
进行填海之后,地图上最大的岛屿面积是多少?(上、下、左、右四个方向相连的 1 可形成岛屿)
示例 1:
+ ++输入: [[1, 0], [0, 1]] +输出: 3 +解释: 将一格0变成1,最终连通两个小岛得到面积为 3 的岛屿。 ++ +
示例 2:
+ ++输入: [[1, 1], [1, 0]] +输出: 4 +解释: 将一格0变成1,岛屿的面积扩大为 4。+ +
示例 3:
+ ++输入: [[1, 1], [1, 1]] +输出: 4 +解释: 没有0可以让我们变成1,面积依然为 4。+ +
说明:
+ +-
+
1 <= grid.length = grid[0].length <= 50
+ 0 <= grid[i][j] <= 1
+
我们定义了一个函数 countUniqueChars(s) 来统计字符串 s 中的唯一字符,并返回唯一字符的个数。
例如:s = "LEETCODE" ,则其中 "L", "T","C","O","D" 都是唯一字符,因为它们只出现一次,所以 countUniqueChars(s) = 5 。
本题将会给你一个字符串 s ,我们需要返回 countUniqueChars(t) 的总和,其中 t 是 s 的子字符串。注意,某些子字符串可能是重复的,但你统计时也必须算上这些重复的子字符串(也就是说,你必须统计 s 的所有子字符串中的唯一字符)。
由于答案可能非常大,请将结果 mod 10 ^ 9 + 7 后再返回。
+ ++ +
示例 1:
+ +输入: "ABC" +输出: 10 +解释: 所有可能的子串为:"A","B","C","AB","BC" 和 "ABC"。 + 其中,每一个子串都由独特字符构成。 + 所以其长度总和为:1 + 1 + 1 + 2 + 2 + 3 = 10 ++ +
示例 2:
+ +输入: "ABA"
+输出: 8
+解释: 除了 countUniqueChars("ABA") = 1 之外,其余与示例 1 相同。
+
+
+示例 3:
+ +输入:s = "LEETCODE" +输出:92 ++ +
+ +
提示:
+ +-
+
0 <= s.length <= 10^4
+ s只包含大写英文字符
+
给定一个正整数 N,试求有多少组连续正整数满足所有数字之和为 N?
示例 1:
+ ++输入: 5 +输出: 2 +解释: 5 = 5 = 2 + 3,共有两组连续整数([5],[2,3])求和后为 5。+ +
示例 2:
+ ++输入: 9 +输出: 3 +解释: 9 = 9 = 4 + 5 = 2 + 3 + 4+ +
示例 3:
+ ++输入: 15 +输出: 4 +解释: 15 = 15 = 8 + 7 = 4 + 5 + 6 = 1 + 2 + 3 + 4 + 5+ +
说明: 1 <= N <= 10 ^ 9
在一个由小写字母构成的字符串 S 中,包含由一些连续的相同字符所构成的分组。
例如,在字符串 S = "abbxxxxzyy" 中,就含有 "a", "bb", "xxxx", "z" 和 "yy" 这样的一些分组。
我们称所有包含大于或等于三个连续字符的分组为较大分组。找到每一个较大分组的起始和终止位置。
+ +最终结果按照字典顺序输出。
+ +示例 1:
+ +
+输入: "abbxxxxzzy"
+输出: [[3,6]]
+解释: "xxxx" 是一个起始于 3 且终止于 6 的较大分组。
+
+
+示例 2:
+ ++输入: "abc" +输出: [] +解释: "a","b" 和 "c" 均不是符合要求的较大分组。 ++ +
示例 3:
+ ++输入: "abcdddeeeeaabbbcd" +输出: [[3,5],[6,9],[12,14]]+ +
说明: 1 <= S.length <= 1000
给你一条个人信息 string S,它可能是一个邮箱地址,也可能是一个电话号码。
我们将隐藏它的隐私信息,通过如下规则:
+ ++ +
<u>1. 电子邮箱</u>
+ +定义名称 <name> 是长度大于等于 2 (length ≥ 2),并且只包含小写字母 a-z 和大写字母 A-Z 的字符串。
电子邮箱地址由名称 <name> 开头,紧接着是符号 <font face="Menlo, Monaco, Consolas, Courier New, monospace">'@'</font>,后面接着一个名称 <name>,再接着一个点号 '.',然后是一个名称 <name>。
电子邮箱地址确定为有效的,并且格式是 "name1@name2.name3"。
为了隐藏电子邮箱,所有的名称 <name> 必须被转换成小写的,并且第一个名称 <name> 的第一个字母和最后一个字母的中间的所有字母由 5 个 '*' 代替。
+ +
<u>2. 电话号码</u>
+ +电话号码是一串包括数字 0-9,以及 {'+', '-', '(', ')', ' '} 这几个字符的字符串。你可以假设电话号码包含 10 到 13 个数字。
电话号码的最后 10 个数字组成本地号码,在这之前的数字组成国际号码。注意,国际号码是可选的。我们只暴露最后 4 个数字并隐藏所有其他数字。
+ +本地号码是有格式的,并且如 "***-***-1111" 这样显示,这里的 1 表示暴露的数字。
为了隐藏有国际号码的电话号码,像 "+111 111 111 1111",我们以 "+***-***-***-1111" 的格式来显示。在本地号码前面的 '+' 号和第一个 '-' 号仅当电话号码中包含国际号码时存在。例如,一个 12 位的电话号码应当以 "+**-" 开头进行显示。
注意:像 "(",")"," " 这样的不相干的字符以及不符合上述格式的额外的减号或者加号都应当被删除。
+ +
最后,将提供的信息正确隐藏后返回。
+ ++ +
示例 1:
+ +输入: "LeetCode@LeetCode.com" +输出: "l*****e@leetcode.com" +解释: +所有的名称转换成小写, 第一个名称的第一个字符和最后一个字符中间由 5 个星号代替。 +因此,"leetcode" -> "l*****e"。 ++ +
示例 2:
+ +输入: "AB@qq.com" +输出: "a*****b@qq.com" +解释: +第一个名称"ab"的第一个字符和最后一个字符的中间必须有 5 个星号 +因此,"ab" -> "a*****b"。 ++ +
示例 3:
+ +输入: "1(234)567-890" +输出: "***-***-7890" +解释: +10 个数字的电话号码,那意味着所有的数字都是本地号码。 ++ +
示例 4:
+ +输入: "86-(10)12345678" +输出: "+**-***-***-5678" +解释: +12 位数字,2 个数字是国际号码另外 10 个数字是本地号码 。 ++ +
+ +
注意:
+ +-
+
S.length <= 40。
+ - 邮箱的长度至少是 8。 +
- 电话号码的长度至少是 10。 +
给定一个二进制矩阵 A,我们想先水平翻转图像,然后反转图像并返回结果。
水平翻转图片就是将图片的每一行都进行翻转,即逆序。例如,水平翻转 [1, 1, 0] 的结果是 [0, 1, 1]。
反转图片的意思是图片中的 0 全部被 1 替换, 1 全部被 0 替换。例如,反转 [0, 1, 1] 的结果是 [1, 0, 0]。
示例 1:
-**示例 1** ++输入: [[1,1,0],[1,0,1],[0,0,0]] +输出: [[1,0,0],[0,1,0],[1,1,1]] +解释: 首先翻转每一行: [[0,1,1],[1,0,1],[0,0,0]]; + 然后反转图片: [[1,0,0],[0,1,0],[1,1,1]] +-``` -输入: [[1,1,0],[1,0,1],[0,0,0]] -输出: [[1,0,0],[0,1,0],[1,1,1]] -解释: 首先翻转每一行: [[0,1,1],[1,0,1],[0,0,0]]; - 然后反转图片: [[1,0,0],[0,1,0],[1,1,1]] -``` - -**示例 2** +
示例 2:
-``` -输入: [[1,1,0,0],[1,0,0,1],[0,1,1,1],[1,0,1,0]] -输出: [[1,1,0,0],[0,1,1,0],[0,0,0,1],[1,0,1,0]] -解释: 首先翻转每一行: [[0,0,1,1],[1,0,0,1],[1,1,1,0],[0,1,0,1]]; +
+输入: [[1,1,0,0],[1,0,0,1],[0,1,1,1],[1,0,1,0]]
+输出: [[1,1,0,0],[0,1,1,0],[0,0,0,1],[1,0,1,0]]
+解释: 首先翻转每一行: [[0,0,1,1],[1,0,0,1],[1,1,1,0],[0,1,0,1]];
然后反转图片: [[1,1,0,0],[0,1,1,0],[0,0,0,1],[1,0,1,0]]
-```
-
-**说明**
+
-- `1 <= A.length = A[0].length <= 20`
-- `0 <= A[i][j] <= 1`
+说明:
-### 解法 +-
+
1 <= A.length = A[0].length <= 20
+ 0 <= A[i][j] <= 1
+
对于某些字符串 S,我们将执行一些替换操作,用新的字母组替换原有的字母组(不一定大小相同)。
每个替换操作具有 3 个参数:起始索引 i,源字 x 和目标字 y。规则是如果 x 从原始字符串 S 中的位置 i 开始,那么我们将用 y 替换出现的 x。如果没有,我们什么都不做。
举个例子,如果我们有 S = “abcd” 并且我们有一些替换操作 i = 2,x = “cd”,y = “ffff”,那么因为 “cd” 从原始字符串 S 中的位置 2 开始,我们将用 “ffff” 替换它。
再来看 S = “abcd” 上的另一个例子,如果我们有替换操作 i = 0,x = “ab”,y = “eee”,以及另一个替换操作 i = 2,x = “ec”,y = “ffff”,那么第二个操作将不执行任何操作,因为原始字符串中 S[2] = 'c',与 x[0] = 'e' 不匹配。
所有这些操作同时发生。保证在替换时不会有任何重叠: S = "abc", indexes = [0, 1], sources = ["ab","bc"] 不是有效的测试用例。
+ +
示例 1:
+ +输入:S = "abcd", indexes = [0,2], sources = ["a","cd"], targets = ["eee","ffff"] +输出:"eeebffff" +解释: +"a" 从 S 中的索引 0 开始,所以它被替换为 "eee"。 +"cd" 从 S 中的索引 2 开始,所以它被替换为 "ffff"。 ++ +
示例 2:
+ +输入:S = "abcd", indexes = [0,2], sources = ["ab","ec"], targets = ["eee","ffff"] +输出:"eeecd" +解释: +"ab" 从 S 中的索引 0 开始,所以它被替换为 "eee"。 +"ec" 没有从原始的 S 中的索引 2 开始,所以它没有被替换。 ++ +
+ +
提示:
+ +-
+
0 <= indexes.length = sources.length = targets.length <= 100
+ 0 < indexes[i] < S.length <= 1000
+ - 给定输入中的所有字符都是小写字母。 +
+ + + +## 解法 + + + +### Python3 + + +```python + +``` + +### Java + + +```java + +``` + +### ... +``` + +``` diff --git a/solution/0800-0899/0834.Sum of Distances in Tree/README.md b/solution/0800-0899/0834.Sum of Distances in Tree/README.md new file mode 100644 index 0000000000000..36b9853bf2782 --- /dev/null +++ b/solution/0800-0899/0834.Sum of Distances in Tree/README.md @@ -0,0 +1,53 @@ +# [834. 树中距离之和](https://leetcode-cn.com/problems/sum-of-distances-in-tree) + +## 题目描述 + +
给定一个无向、连通的树。树中有 N 个标记为 0...N-1 的节点以及 N-1 条边 。
第 i 条边连接节点 edges[i][0] 和 edges[i][1] 。
返回一个表示节点 i 与其他所有节点距离之和的列表 ans。
示例 1:
+ ++输入: N = 6, edges = [[0,1],[0,2],[2,3],[2,4],[2,5]] +输出: [8,12,6,10,10,10] +解释: +如下为给定的树的示意图: + 0 + / \ +1 2 + /|\ + 3 4 5 + +我们可以计算出 dist(0,1) + dist(0,2) + dist(0,3) + dist(0,4) + dist(0,5) +也就是 1 + 1 + 2 + 2 + 2 = 8。 因此,answer[0] = 8,以此类推。 ++ +
说明: 1 <= N <= 10000
给出两个图像 A 和 B ,A 和 B 为大小相同的二维正方形矩阵。(并且为二进制矩阵,只包含0和1)。
我们转换其中一个图像,向左,右,上,或下滑动任何数量的单位,并把它放在另一个图像的上面。之后,该转换的重叠是指两个图像都具有 1 的位置的数目。
+ +(请注意,转换不包括向任何方向旋转。)
+ +最大可能的重叠是什么?
+ +示例 1:
+ +输入:A = [[1,1,0], + [0,1,0], + [0,1,0]] + B = [[0,0,0], + [0,1,1], + [0,0,1]] +输出:3 +解释: 将 A 向右移动一个单位,然后向下移动一个单位。+ +
注意:
+ +-
+
1 <= A.length = A[0].length = B.length = B[0].length <= 30
+ 0 <= A[i][j], B[i][j] <= 1
+
矩形以列表 [x1, y1, x2, y2] 的形式表示,其中 (x1, y1) 为左下角的坐标,(x2, y2) 是右上角的坐标。
如果相交的面积为正,则称两矩形重叠。需要明确的是,只在角或边接触的两个矩形不构成重叠。
+ +给出两个矩形,判断它们是否重叠并返回结果。
+ +示例 1:
+ +输入:rec1 = [0,0,2,2], rec2 = [1,1,3,3] +输出:true ++ +
示例 2:
+ +输入:rec1 = [0,0,1,1], rec2 = [1,0,2,1] +输出:false ++ +
说明:
+ +-
+
- 两个矩形
rec1和rec2都以含有四个整数的列表的形式给出。
+ - 矩形中的所有坐标都处于
-10^9和10^9之间。
+
爱丽丝参与一个大致基于纸牌游戏 “21点” 规则的游戏,描述如下:
+ +爱丽丝以 0 分开始,并在她的得分少于 K 分时抽取数字。 抽取时,她从 [1, W] 的范围中随机获得一个整数作为分数进行累计,其中 W 是整数。 每次抽取都是独立的,其结果具有相同的概率。
当爱丽丝获得不少于 K 分时,她就停止抽取数字。 爱丽丝的分数不超过 N 的概率是多少?
示例 1:
+ +输入:N = 10, K = 1, W = 10 +输出:1.00000 +说明:爱丽丝得到一张卡,然后停止。+ +
示例 2:
+ +输入:N = 6, K = 1, W = 10 +输出:0.60000 +说明:爱丽丝得到一张卡,然后停止。 +在 W = 10 的 6 种可能下,她的得分不超过 N = 6 分。+ +
示例 3:
+ +输入:N = 21, K = 17, W = 10 +输出:0.73278+ +
提示:
+ +-
+
0 <= K <= N <= 10000
+ 1 <= W <= 10000
+ - 如果答案与正确答案的误差不超过
10^-5,则该答案将被视为正确答案通过。
+ - 此问题的判断限制时间已经减少。 +
一行中有 N 张多米诺骨牌,我们将每张多米诺骨牌垂直竖立。
在开始时,我们同时把一些多米诺骨牌向左或向右推。
+ +
每过一秒,倒向左边的多米诺骨牌会推动其左侧相邻的多米诺骨牌。
+ +同样地,倒向右边的多米诺骨牌也会推动竖立在其右侧的相邻多米诺骨牌。
+ +如果同时有多米诺骨牌落在一张垂直竖立的多米诺骨牌的两边,由于受力平衡, 该骨牌仍然保持不变。
+ +就这个问题而言,我们会认为正在下降的多米诺骨牌不会对其它正在下降或已经下降的多米诺骨牌施加额外的力。
+ +给定表示初始状态的字符串 "S" 。如果第 i 张多米诺骨牌被推向左边,则 S[i] = 'L';如果第 i 张多米诺骨牌被推向右边,则 S[i] = 'R';如果第 i 张多米诺骨牌没有被推动,则 S[i] = '.'。
返回表示最终状态的字符串。
+ +示例 1:
+ +输入:".L.R...LR..L.." +输出:"LL.RR.LLRRLL.."+ +
示例 2:
+ +输入:"RR.L" +输出:"RR.L" +说明:第一张多米诺骨牌没有给第二张施加额外的力。+ +
提示:
+ +-
+
0 <= N <= 10^5
+ - 表示多米诺骨牌状态的字符串只含有
'L','R'; 以及'.';
+
如果我们交换字符串 X 中的两个不同位置的字母,使得它和字符串 Y 相等,那么称 X 和 Y 两个字符串相似。如果这两个字符串本身是相等的,那它们也是相似的。
例如,"tars" 和 "rats" 是相似的 (交换 0 与 2 的位置); "rats" 和 "arts" 也是相似的,但是 "star" 不与 "tars","rats",或 "arts" 相似。
总之,它们通过相似性形成了两个关联组:{"tars", "rats", "arts"} 和 {"star"}。注意,"tars" 和 "arts" 是在同一组中,即使它们并不相似。形式上,对每个组而言,要确定一个单词在组中,只需要这个词和该组中至少一个单词相似。
我们给出了一个不包含重复的字符串列表 A。列表中的每个字符串都是 A 中其它所有字符串的一个字母异位词。请问 A 中有多少个相似字符串组?
+ +
示例:
+ +输入:["tars","rats","arts","star"] +输出:2+ +
+ +
提示:
+ +-
+
A.length <= 2000
+ A[i].length <= 1000
+ A.length * A[i].length <= 20000
+ A中的所有单词都只包含小写字母。
+ A中的所有单词都具有相同的长度,且是彼此的字母异位词。
+ - 此问题的判断限制时间已经延长。 +
+ +
备注:
+ +字母异位词[anagram],一种把某个字符串的字母的位置(顺序)加以改换所形成的新词。
+ + + +## 解法 + + + +### Python3 + + +```python + +``` + +### Java + + +```java + +``` + +### ... +``` + +``` diff --git a/solution/0800-0899/0840.Magic Squares In Grid/README.md b/solution/0800-0899/0840.Magic Squares In Grid/README.md new file mode 100644 index 0000000000000..464d80fb27468 --- /dev/null +++ b/solution/0800-0899/0840.Magic Squares In Grid/README.md @@ -0,0 +1,62 @@ +# [840. 矩阵中的幻方](https://leetcode-cn.com/problems/magic-squares-in-grid) + +## 题目描述 + +3 x 3 的幻方是一个填充有从 1 到 9 的不同数字的 3 x 3 矩阵,其中每行,每列以及两条对角线上的各数之和都相等。
+ +给定一个由整数组成的 grid,其中有多少个 3 × 3 的 “幻方” 子矩阵?(每个子矩阵都是连续的)。
+ +
示例:
+ +输入: [[4,3,8,4], + [9,5,1,9], + [2,7,6,2]] +输出: 1 +解释: +下面的子矩阵是一个 3 x 3 的幻方: +438 +951 +276 + +而这一个不是: +384 +519 +762 + +总的来说,在本示例所给定的矩阵中只有一个 3 x 3 的幻方子矩阵。 ++ +
提示:
+ +-
+
1 <= grid.length <= 10
+ 1 <= grid[0].length <= 10
+ 0 <= grid[i][j] <= 15
+
有 N 个房间,开始时你位于 0 号房间。每个房间有不同的号码:0,1,2,...,N-1,并且房间里可能有一些钥匙能使你进入下一个房间。
在形式上,对于每个房间 i 都有一个钥匙列表 rooms[i],每个钥匙 rooms[i][j] 由 [0,1,...,N-1] 中的一个整数表示,其中 N = rooms.length。 钥匙 rooms[i][j] = v 可以打开编号为 v 的房间。
最初,除 0 号房间外的其余所有房间都被锁住。
你可以自由地在房间之间来回走动。
+ +如果能进入每个房间返回 true,否则返回 false。
-
+
示例 1:
+ +输入: [[1],[2],[3],[]] +输出: true +解释: +我们从 0 号房间开始,拿到钥匙 1。 +之后我们去 1 号房间,拿到钥匙 2。 +然后我们去 2 号房间,拿到钥匙 3。 +最后我们去了 3 号房间。 +由于我们能够进入每个房间,我们返回 true。 ++ +
示例 2:
+ +输入:[[1,3],[3,0,1],[2],[0]] +输出:false +解释:我们不能进入 2 号房间。 ++ +
提示:
+ +-
+
1 <= rooms.length <= 1000
+ 0 <= rooms[i].length <= 1000
+ - 所有房间中的钥匙数量总计不超过
3000。
+
给定一个数字字符串 S,比如 S = "123456579",我们可以将它分成斐波那契式的序列 [123, 456, 579]。
形式上,斐波那契式序列是一个非负整数列表 F,且满足:
-
+
0 <= F[i] <= 2^31 - 1,(也就是说,每个整数都符合 32 位有符号整数类型);
+ F.length >= 3;
+ - 对于所有的
0 <= i < F.length - 2,都有F[i] + F[i+1] = F[i+2]成立。
+
另外,请注意,将字符串拆分成小块时,每个块的数字一定不要以零开头,除非这个块是数字 0 本身。
+ +返回从 S 拆分出来的所有斐波那契式的序列块,如果不能拆分则返回 []。
示例 1:
+ +输入:"123456579" +输出:[123,456,579] ++ +
示例 2:
+ +输入: "11235813" +输出: [1,1,2,3,5,8,13] ++ +
示例 3:
+ +输入: "112358130" +输出: [] +解释: 这项任务无法完成。 ++ +
示例 4:
+ +输入:"0123" +输出:[] +解释:每个块的数字不能以零开头,因此 "01","2","3" 不是有效答案。 ++ +
示例 5:
+ +输入: "1101111" +输出: [110, 1, 111] +解释: 输出 [11,0,11,11] 也同样被接受。 ++ +
提示:
+ +-
+
1 <= S.length <= 200
+ - 字符串
S中只含有数字。
+
这个问题是 LeetCode 平台新增的交互式问题 。
+ +我们给出了一个由一些独特的单词组成的单词列表,每个单词都是 6 个字母长,并且这个列表中的一个单词将被选作秘密。
+ +你可以调用 master.guess(word) 来猜单词。你所猜的单词应当是存在于原列表并且由 6 个小写字母组成的类型字符串。
此函数将会返回一个整型数字,表示你的猜测与秘密单词的准确匹配(值和位置同时匹配)的数目。此外,如果你的猜测不在给定的单词列表中,它将返回 -1。
对于每个测试用例,你有 10 次机会来猜出这个单词。当所有调用都结束时,如果您对 master.guess 的调用不超过 10 次,并且至少有一次猜到秘密,那么您将通过该测试用例。
除了下面示例给出的测试用例外,还会有 5 个额外的测试用例,每个单词列表中将会有 100 个单词。这些测试用例中的每个单词的字母都是从 'a' 到 'z' 中随机选取的,并且保证给定单词列表中的每个单词都是唯一的。
示例 1: +输入: secret = "acckzz", wordlist = ["acckzz","ccbazz","eiowzz","abcczz"] + +解释: + ++ +master.guess("aaaaaa")返回 -1, 因为"aaaaaa"不在 wordlist 中. +master.guess("acckzz") 返回6, 因为"acckzz"就是秘密,6个字母完全匹配。 +master.guess("ccbazz")返回 3, 因为"ccbazz"有 3 个匹配项。 +master.guess("eiowzz")返回 2, 因为"eiowzz"有 2 个匹配项。 +master.guess("abcczz")返回 4, 因为"abcczz"有 4 个匹配项。 + +我们调用了 5 次master.guess,其中一次猜到了秘密,所以我们通过了这个测试用例。 +
提示:任何试图绕过评判的解决方案都将导致比赛资格被取消。
+ + + +## 解法 + + + +### Python3 + + +```python + +``` + +### Java + + +```java + +``` + +### ... +``` + +``` diff --git a/solution/0800-0899/0844.Backspace String Compare/README.md b/solution/0800-0899/0844.Backspace String Compare/README.md new file mode 100644 index 0000000000000..1923392c40983 --- /dev/null +++ b/solution/0800-0899/0844.Backspace String Compare/README.md @@ -0,0 +1,71 @@ +# [844. 比较含退格的字符串](https://leetcode-cn.com/problems/backspace-string-compare) + +## 题目描述 + +给定 S 和 T 两个字符串,当它们分别被输入到空白的文本编辑器后,判断二者是否相等,并返回结果。 # 代表退格字符。
+ +
示例 1:
+ +输入:S = "ab#c", T = "ad#c" +输出:true +解释:S 和 T 都会变成 “ac”。 ++ +
示例 2:
+ +输入:S = "ab##", T = "c#d#" +输出:true +解释:S 和 T 都会变成 “”。 ++ +
示例 3:
+ +输入:S = "a##c", T = "#a#c" +输出:true +解释:S 和 T 都会变成 “c”。 ++ +
示例 4:
+ +输入:S = "a#c", T = "b" +输出:false +解释:S 会变成 “c”,但 T 仍然是 “b”。+ +
+ +
提示:
+ +-
+
1 <= S.length <= 200
+ 1 <= T.length <= 200
+ S和T只含有小写字母以及字符'#'。
+
+ + + +## 解法 + + + +### Python3 + + +```python + +``` + +### Java + + +```java + +``` + +### ... +``` + +``` diff --git a/solution/0800-0899/0845.Longest Mountain in Array/README.md b/solution/0800-0899/0845.Longest Mountain in Array/README.md new file mode 100644 index 0000000000000..9593d82a66537 --- /dev/null +++ b/solution/0800-0899/0845.Longest Mountain in Array/README.md @@ -0,0 +1,66 @@ +# [845. 数组中的最长山脉](https://leetcode-cn.com/problems/longest-mountain-in-array) + +## 题目描述 + +
我们把数组 A 中符合下列属性的任意连续子数组 B 称为 “山脉”:
+ +-
+
B.length >= 3
+ - 存在
0 < i < B.length - 1使得B[0] < B[1] < ... B[i-1] < B[i] > B[i+1] > ... > B[B.length - 1]
+
(注意:B 可以是 A 的任意子数组,包括整个数组 A。)
+ +给出一个整数数组 A,返回最长 “山脉” 的长度。
如果不含有 “山脉” 则返回 0。
+ +
示例 1:
+ +输入:[2,1,4,7,3,2,5] +输出:5 +解释:最长的 “山脉” 是 [1,4,7,3,2],长度为 5。 ++ +
示例 2:
+ +输入:[2,2,2] +输出:0 +解释:不含 “山脉”。 ++ +
+ +
提示:
+ +-
+
0 <= A.length <= 10000
+ 0 <= A[i] <= 10000
+
爱丽丝有一手(hand)由整数数组给定的牌。
现在她想把牌重新排列成组,使得每个组的大小都是 W,且由 W 张连续的牌组成。
如果她可以完成分组就返回 true,否则返回 false。
+ +
-
+
示例 1:
+ +输入:hand = [1,2,3,6,2,3,4,7,8], W = 3
+输出:true
+解释:爱丽丝的手牌可以被重新排列为 [1,2,3],[2,3,4],[6,7,8]。
+
+示例 2:
+ +输入:hand = [1,2,3,4,5], W = 4 +输出:false +解释:爱丽丝的手牌无法被重新排列成几个大小为 4 的组。+ +
+ +
提示:
+ +-
+
1 <= hand.length <= 10000
+ 0 <= hand[i] <= 10^9
+ 1 <= W <= hand.length
+
给出 graph 为有 N 个节点(编号为 0, 1, 2, ..., N-1)的无向连通图。
graph.length = N,且只有节点 i 和 j 连通时,j != i 在列表 graph[i] 中恰好出现一次。
返回能够访问所有节点的最短路径的长度。你可以在任一节点开始和停止,也可以多次重访节点,并且可以重用边。
+ ++ +
-
+
示例 1:
+ +输入:[[1,2,3],[0],[0],[0]] +输出:4 +解释:一个可能的路径为 [1,0,2,0,3]+ +
示例 2:
+ +输入:[[1],[0,2,4],[1,3,4],[2],[1,2]] +输出:4 +解释:一个可能的路径为 [0,1,4,2,3] ++ +
+ +
提示:
+ +-
+
1 <= graph.length <= 12
+ 0 <= graph[i].length < graph.length
+
有一个由小写字母组成的字符串 S,和一个整数数组 shifts。
我们将字母表中的下一个字母称为原字母的 移位(由于字母表是环绕的, 'z' 将会变成 'a')。
例如·,shift('a') = 'b', shift('t') = 'u',, 以及 shift('z') = 'a'。
对于每个 shifts[i] = x , 我们会将 S 中的前 i+1 个字母移位 x 次。
返回将所有这些移位都应用到 S 后最终得到的字符串。
示例:
-**示例:** -``` -输入:S = "abc", shifts = [3,5,9] -输出:"rpl" -解释: -我们以 "abc" 开始。 -将 S 中的第 1 个字母移位 3 次后,我们得到 "dbc"。 -再将 S 中的前 2 个字母移位 5 次后,我们得到 "igc"。 -最后将 S 中的这 3 个字母移位 9 次后,我们得到答案 "rpl"。 -``` +输入:S = "abc", shifts = [3,5,9] +输出:"rpl" +解释: +我们以 "abc" 开始。 +将 S 中的第 1 个字母移位 3 次后,我们得到 "dbc"。 +再将 S 中的前 2 个字母移位 5 次后,我们得到 "igc"。 +最后将 S 中的这 3 个字母移位 9 次后,我们得到答案 "rpl"。 ++ +
提示:
+ +-
+
1 <= S.length = shifts.length <= 20000
+ 0 <= shifts[i] <= 10 ^ 9
+
在一排座位( seats)中,1 代表有人坐在座位上,0 代表座位上是空的。
至少有一个空座位,且至少有一人坐在座位上。
+ +亚历克斯希望坐在一个能够使他与离他最近的人之间的距离达到最大化的座位上。
+ +返回他到离他最近的人的最大距离。
+ +示例 1:
+ +输入:[1,0,0,0,1,0,1] +输出:2 +解释: +如果亚历克斯坐在第二个空位(seats[2])上,他到离他最近的人的距离为 2 。 +如果亚历克斯坐在其它任何一个空位上,他到离他最近的人的距离为 1 。 +因此,他到离他最近的人的最大距离是 2 。 ++ +
示例 2:
+ +输入:[1,0,0,0]
+输出:3
+解释:
+如果亚历克斯坐在最后一个座位上,他离最近的人有 3 个座位远。
+这是可能的最大距离,所以答案是 3 。
+
+
+提示:
+ +-
+
1 <= seats.length <= 20000
+ seats中只含有 0 和 1,至少有一个0,且至少有一个1。
+
我们给出了一个(轴对齐的)矩形列表 rectangles 。 对于 rectangle[i] = [x1, y1, x2, y2],其中(x1,y1)是矩形 i 左下角的坐标,(x2,y2)是该矩形右上角的坐标。
找出平面中所有矩形叠加覆盖后的总面积。 由于答案可能太大,请返回它对 10 ^ 9 + 7 取模的结果。
+ +
示例 1:
+ +输入:[[0,0,2,2],[1,0,2,3],[1,0,3,1]] +输出:6 +解释:如图所示。 ++ +
示例 2:
+ +输入:[[0,0,1000000000,1000000000]] +输出:49 +解释:答案是 10^18 对 (10^9 + 7) 取模的结果, 即 (10^9)^2 → (-7)^2 = 49 。 ++ +
提示:
+ +-
+
1 <= rectangles.length <= 200
+ rectanges[i].length = 4
+ 0 <= rectangles[i][j] <= 10^9
+ - 矩形叠加覆盖后的总面积不会超越
2^63 - 1,这意味着可以用一个 64 位有符号整数来保存面积结果。
+
在一组 N 个人(编号为 0, 1, 2, ..., N-1)中,每个人都有不同数目的钱,以及不同程度的安静(quietness)。
为了方便起见,我们将编号为 x 的人简称为 "person x "。
如果能够肯定 person x 比 person y 更有钱的话,我们会说 richer[i] = [x, y] 。注意 richer 可能只是有效观察的一个子集。
另外,如果 person x 的安静程度为 q ,我们会说 quiet[x] = q 。
现在,返回答案 answer ,其中 answer[x] = y 的前提是,在所有拥有的钱不少于 person x 的人中,person y 是最安静的人(也就是安静值 quiet[y] 最小的人)。
示例:
+ +输入:richer = [[1,0],[2,1],[3,1],[3,7],[4,3],[5,3],[6,3]], quiet = [3,2,5,4,6,1,7,0] +输出:[5,5,2,5,4,5,6,7] +解释: +answer[0] = 5, +person 5 比 person 3 有更多的钱,person 3 比 person 1 有更多的钱,person 1 比 person 0 有更多的钱。 +唯一较为安静(有较低的安静值 quiet[x])的人是 person 7, +但是目前还不清楚他是否比 person 0 更有钱。 + +answer[7] = 7, +在所有拥有的钱肯定不少于 person 7 的人中(这可能包括 person 3,4,5,6 以及 7), +最安静(有较低安静值 quiet[x])的人是 person 7。 + +其他的答案也可以用类似的推理来解释。 ++ +
提示:
+ +-
+
1 <= quiet.length = N <= 500
+ 0 <= quiet[i] < N,所有quiet[i]都不相同。
+ 0 <= richer.length <= N * (N-1) / 2
+ 0 <= richer[i][j] < N
+ richer[i][0] != richer[i][1]
+ richer[i]都是不同的。
+ - 对
richer的观察在逻辑上是一致的。
+
我们把符合下列属性的数组 A 称作山脉:
-
+
A.length >= 3
+ - 存在
0 < i < A.length - 1使得A[0] < A[1] < ... A[i-1] < A[i] > A[i+1] > ... > A[A.length - 1]
+
给定一个确定为山脉的数组,返回任何满足 A[0] < A[1] < ... A[i-1] < A[i] > A[i+1] > ... > A[A.length - 1] 的 i 的值。
+ +
示例 1:
+ +输入:[0,1,0] +输出:1 ++ +
示例 2:
+ +输入:[0,2,1,0] +输出:1+ +
+ +
提示:
+ +-
+
3 <= A.length <= 10000
+ - 0 <= A[i] <= 10^6 +
- A 是如上定义的山脉 +
+ + + +## 解法 + + + +### Python3 + + +```python + +``` + +### Java + + +```java + +``` + +### ... +``` + +``` diff --git a/solution/0800-0899/0853.Car Fleet/README.md b/solution/0800-0899/0853.Car Fleet/README.md index 4069908165c61..20395fd1abb43 100644 --- a/solution/0800-0899/0853.Car Fleet/README.md +++ b/solution/0800-0899/0853.Car Fleet/README.md @@ -1,55 +1,68 @@ -## 车队 +# [853. 车队](https://leetcode-cn.com/problems/car-fleet) -### 问题描述 +## 题目描述 + +
N 辆车沿着一条车道驶向位于 target 英里之外的共同目的地。
每辆车 i 以恒定的速度 speed[i] (英里/小时),从初始位置 position[i] (英里) 沿车道驶向目的地。
一辆车永远不会超过前面的另一辆车,但它可以追上去,并与前车以相同的速度紧接着行驶。
-一辆车永远不会超过前面的另一辆车,但它可以追上去,并与前车以相同的速度紧接着行驶。 +此时,我们会忽略这两辆车之间的距离,也就是说,它们被假定处于相同的位置。
-此时,我们会忽略这两辆车之间的距离,也就是说,它们被假定处于相同的位置。 +车队 是一些由行驶在相同位置、具有相同速度的车组成的非空集合。注意,一辆车也可以是一个车队。
-车队 是一些由行驶在相同位置、具有相同速度的车组成的非空集合。注意,一辆车也可以是一个车队。 +即便一辆车在目的地才赶上了一个车队,它们仍然会被视作是同一个车队。
-即便一辆车在目的地才赶上了一个车队,它们仍然会被视作是同一个车队。 +-会有多少车队到达目的地? +
会有多少车队到达目的地?
-**示例:** -``` -输入:target = 12, position = [10,8,0,5,3], speed = [2,4,1,1,3] -输出:3 -解释: ++ +
示例:
+ +输入:target = 12, position = [10,8,0,5,3], speed = [2,4,1,1,3] +输出:3 +解释: 从 10 和 8 开始的车会组成一个车队,它们在 12 处相遇。 从 0 处开始的车无法追上其它车,所以它自己就是一个车队。 从 5 和 3 开始的车会组成一个车队,它们在 6 处相遇。 请注意,在到达目的地之前没有其它车会遇到这些车队,所以答案是 3。 -``` ++ +
+提示:
-
+
0 <= N <= 10 ^ 4
+ 0 < target <= 10 ^ 6
+ 0 < speed[i] <= 10 ^ 6
+ 0 <= position[i] < target
+ - 所有车的初始位置各不相同。 +
如果可以通过将 A 中的两个小写字母精确地交换位置 K 次得到与 B 相等的字符串,我们称字符串 A 和 B 的相似度为 K(K 为非负整数)。
给定两个字母异位词 A 和 B ,返回 A 和 B 的相似度 K 的最小值。
+ +
示例 1:
+ +输入:A = "ab", B = "ba" +输出:1 ++ +
示例 2:
+ +输入:A = "abc", B = "bca" +输出:2 ++ +
示例 3:
+ +输入:A = "abac", B = "baca" +输出:2 ++ +
示例 4:
+ +输入:A = "aabc", B = "abca" +输出:2+ +
+ +
提示:
+ +-
+
1 <= A.length == B.length <= 20
+ A和B只包含集合{'a', 'b', 'c', 'd', 'e', 'f'}中的小写字母。
+
在考场里,一排有 N 个座位,分别编号为 0, 1, 2, ..., N-1 。
当学生进入考场后,他必须坐在能够使他与离他最近的人之间的距离达到最大化的座位上。如果有多个这样的座位,他会坐在编号最小的座位上。(另外,如果考场里没有人,那么学生就坐在 0 号座位上。)
+ +返回 ExamRoom(int N) 类,它有两个公开的函数:其中,函数 ExamRoom.seat() 会返回一个 int (整型数据),代表学生坐的位置;函数 ExamRoom.leave(int p) 代表坐在座位 p 上的学生现在离开了考场。每次调用 ExamRoom.leave(p) 时都保证有学生坐在座位 p 上。
+ +
示例:
+ +输入:["ExamRoom","seat","seat","seat","seat","leave","seat"], [[10],[],[],[],[],[4],[]] +输出:[null,0,9,4,2,null,5] +解释: +ExamRoom(10) -> null +seat() -> 0,没有人在考场里,那么学生坐在 0 号座位上。 +seat() -> 9,学生最后坐在 9 号座位上。 +seat() -> 4,学生最后坐在 4 号座位上。 +seat() -> 2,学生最后坐在 2 号座位上。 +leave(4) -> null +seat() -> 5,学生最后坐在 5 号座位上。 ++ +
+ +
提示:
+ +-
+
1 <= N <= 10^9
+ - 在所有的测试样例中
ExamRoom.seat()和ExamRoom.leave()最多被调用10^4次。
+ - 保证在调用
ExamRoom.leave(p)时有学生正坐在座位p上。
+
给定一个平衡括号字符串 S,按下述规则计算该字符串的分数:
-
+
()得 1 分。
+ AB得A + B分,其中 A 和 B 是平衡括号字符串。
+ (A)得2 * A分,其中 A 是平衡括号字符串。
+
+ +
示例 1:
+ +输入: "()" +输出: 1 ++ +
示例 2:
+ +输入: "(())" +输出: 2 ++ +
示例 3:
+ +输入: "()()" +输出: 2 ++ +
示例 4:
+ +输入: "(()(()))" +输出: 6 ++ +
+ +
提示:
+ +-
+
S是平衡括号字符串,且只含有(和)。
+ 2 <= S.length <= 50
+
有 N 名工人。 第 i 名工人的工作质量为 quality[i] ,其最低期望工资为 wage[i] 。
现在我们想雇佣 K 名工人组成一个工资组。在雇佣 一组 K 名工人时,我们必须按照下述规则向他们支付工资:
-
+
- 对工资组中的每名工人,应当按其工作质量与同组其他工人的工作质量的比例来支付工资。 +
- 工资组中的每名工人至少应当得到他们的最低期望工资。 +
返回组成一个满足上述条件的工资组至少需要多少钱。
+ ++ +
-
+
示例 1:
+ +输入: quality = [10,20,5], wage = [70,50,30], K = 2 +输出: 105.00000 +解释: 我们向 0 号工人支付 70,向 2 号工人支付 35。+ +
示例 2:
+ +输入: quality = [3,1,10,10,1], wage = [4,8,2,2,7], K = 3 +输出: 30.66667 +解释: 我们向 0 号工人支付 4,向 2 号和 3 号分别支付 13.33333。+ +
+ +
提示:
+ +-
+
1 <= K <= N <= 10000,其中N = quality.length = wage.length
+ 1 <= quality[i] <= 10000
+ 1 <= wage[i] <= 10000
+ - 与正确答案误差在
10^-5之内的答案将被视为正确的。
+
有一个特殊的正方形房间,每面墙上都有一面镜子。除西南角以外,每个角落都放有一个接受器,编号为 0, 1,以及 2。
正方形房间的墙壁长度为 p,一束激光从西南角射出,首先会与东墙相遇,入射点到接收器 0 的距离为 q 。
返回光线最先遇到的接收器的编号(保证光线最终会遇到一个接收器)。
+ ++ +
示例:
+ +输入: p = 2, q = 1 +输出: 2 +解释: 这条光线在第一次被反射回左边的墙时就遇到了接收器 2 。 ++ +

+ +
提示:
+ +-
+
1 <= p <= 1000
+ 0 <= q <= p
+
给定两个由小写字母构成的字符串 A 和 B ,只要我们可以通过交换 A 中的两个字母得到与 B 相等的结果,就返回 true ;否则返回 false 。
+ +
示例 1:
+ +输入: A = "ab", B = "ba" +输出: true ++ +
示例 2:
+ +输入: A = "ab", B = "ab" +输出: false ++ +
示例 3:
+ +输入: A = "aa", B = "aa" +输出: true ++ +
示例 4:
+ +输入: A = "aaaaaaabc", B = "aaaaaaacb" +输出: true ++ +
示例 5:
+ +输入: A = "", B = "aa" +输出: false ++ +
+ +
提示:
+ +-
+
0 <= A.length <= 20000
+ 0 <= B.length <= 20000
+ A和B仅由小写字母构成。
+
在柠檬水摊上,每一杯柠檬水的售价为 5 美元。
顾客排队购买你的产品,(按账单 bills 支付的顺序)一次购买一杯。
每位顾客只买一杯柠檬水,然后向你付 5 美元、10 美元或 20 美元。你必须给每个顾客正确找零,也就是说净交易是每位顾客向你支付 5 美元。
注意,一开始你手头没有任何零钱。
+ +如果你能给每位顾客正确找零,返回 true ,否则返回 false 。
示例 1:
+ +输入:[5,5,5,10,20] +输出:true +解释: +前 3 位顾客那里,我们按顺序收取 3 张 5 美元的钞票。 +第 4 位顾客那里,我们收取一张 10 美元的钞票,并返还 5 美元。 +第 5 位顾客那里,我们找还一张 10 美元的钞票和一张 5 美元的钞票。 +由于所有客户都得到了正确的找零,所以我们输出 true。 ++ +
示例 2:
+ +输入:[5,5,10] +输出:true ++ +
示例 3:
+ +输入:[10,10] +输出:false ++ +
示例 4:
+ +输入:[5,5,10,10,20] +输出:false +解释: +前 2 位顾客那里,我们按顺序收取 2 张 5 美元的钞票。 +对于接下来的 2 位顾客,我们收取一张 10 美元的钞票,然后返还 5 美元。 +对于最后一位顾客,我们无法退回 15 美元,因为我们现在只有两张 10 美元的钞票。 +由于不是每位顾客都得到了正确的找零,所以答案是 false。 ++ +
+ +
提示:
+ +-
+
0 <= bills.length <= 10000
+ bills[i]不是5就是10或是20
+
有一个二维矩阵 A 其中每个元素的值为 0 或 1 。
移动是指选择任一行或列,并转换该行或列中的每一个值:将所有 0 都更改为 1,将所有 1 都更改为 0。
在做出任意次数的移动后,将该矩阵的每一行都按照二进制数来解释,矩阵的得分就是这些数字的总和。
+ +返回尽可能高的分数。
+ ++ +
-
+
示例:
+ +输入:[[0,0,1,1],[1,0,1,0],[1,1,0,0]] +输出:39 +解释: +转换为 [[1,1,1,1],[1,0,0,1],[1,1,1,1]] +0b1111 + 0b1001 + 0b1111 = 15 + 9 + 15 = 39+ +
+ +
提示:
+ +-
+
1 <= A.length <= 20
+ 1 <= A[0].length <= 20
+ A[i][j]是0或1
+
返回 A 的最短的非空连续子数组的长度,该子数组的和至少为 K 。
如果没有和至少为 K 的非空子数组,返回 -1 。
+ +
-
+
示例 1:
+ +输入:A = [1], K = 1 +输出:1 ++ +
示例 2:
+ +输入:A = [1,2], K = 4 +输出:-1 ++ +
示例 3:
+ +输入:A = [2,-1,2], K = 3 +输出:3 ++ +
+ +
提示:
+ +-
+
1 <= A.length <= 50000
+ -10 ^ 5 <= A[i] <= 10 ^ 5
+ 1 <= K <= 10 ^ 9
+
给定一个二叉树(具有根结点 root), 一个目标结点 target ,和一个整数值 K 。
返回到目标结点 target 距离为 K 的所有结点的值的列表。 答案可以以任何顺序返回。
+ +
-
+
示例 1:
+ +输入:root = [3,5,1,6,2,0,8,null,null,7,4], target = 5, K = 2 + +输出:[7,4,1] + +解释: +所求结点为与目标结点(值为 5)距离为 2 的结点, +值分别为 7,4,以及 1 + ++ ++ +注意,输入的 "root" 和 "target" 实际上是树上的结点。 +上面的输入仅仅是对这些对象进行了序列化描述。 +
+ +
提示:
+ +-
+
- 给定的树是非空的,且最多有
K个结点。
+ - 树上的每个结点都具有唯一的值
0 <= node.val <= 500。
+ - 目标结点
target是树上的结点。
+ 0 <= K <= 1000.
+
给定一个二维网格 grid。 "." 代表一个空房间, "#" 代表一堵墙, "@" 是起点,("a", "b", ...)代表钥匙,("A", "B", ...)代表锁。
我们从起点开始出发,一次移动是指向四个基本方向之一行走一个单位空间。我们不能在网格外面行走,也无法穿过一堵墙。如果途经一个钥匙,我们就把它捡起来。除非我们手里有对应的钥匙,否则无法通过锁。
+ +假设 K 为钥匙/锁的个数,且满足 1 <= K <= 6,字母表中的前 K 个字母在网格中都有自己对应的一个小写和一个大写字母。换言之,每个锁有唯一对应的钥匙,每个钥匙也有唯一对应的锁。另外,代表钥匙和锁的字母互为大小写并按字母顺序排列。
返回获取所有钥匙所需要的移动的最少次数。如果无法获取所有钥匙,返回 -1 。
+ +
示例 1:
+ +输入:["@.a.#","###.#","b.A.B"] +输出:8 ++ +
示例 2:
+ +输入:["@..aA","..B#.","....b"] +输出:6 ++ +
+ +
提示:
+ +-
+
1 <= grid.length <= 30
+ 1 <= grid[0].length <= 30
+ grid[i][j]只含有'.','#','@','a'-'f'以及'A'-'F'
+ - 钥匙的数目范围是
[1, 6],每个钥匙都对应一个不同的字母,正好打开一个对应的锁。
+
给定一个根为 root 的二叉树,每个结点的深度是它到根的最短距离。
如果一个结点在整个树的任意结点之间具有最大的深度,则该结点是最深的。
+ +一个结点的子树是该结点加上它的所有后代的集合。
+ +返回能满足“以该结点为根的子树中包含所有最深的结点”这一条件的具有最大深度的结点。
+ ++ +
示例:
+ +输入:[3,5,1,6,2,0,8,null,null,7,4] +输出:[2,7,4] +解释: ++ ++我们返回值为 2 的结点,在图中用黄色标记。 +在图中用蓝色标记的是树的最深的结点。 +输入 "[3, 5, 1, 6, 2, 0, 8, null, null, 7, 4]" 是对给定的树的序列化表述。 +输出 "[2, 7, 4]" 是对根结点的值为 2 的子树的序列化表述。 +输入和输出都具有 TreeNode 类型。 +
+ +
提示:
+ +-
+
- 树中结点的数量介于 1 和 500 之间。 +
- 每个结点的值都是独一无二的。 +
求出大于或等于 N 的最小回文素数。
回顾一下,如果一个数大于 1,且其因数只有 1 和它自身,那么这个数是素数。
+ +例如,2,3,5,7,11 以及 13 是素数。
+ +回顾一下,如果一个数从左往右读与从右往左读是一样的,那么这个数是回文数。
+ +例如,12321 是回文数。
+ ++ +
示例 1:
+ +输入:6 +输出:7 ++ +
示例 2:
+ +输入:8 +输出:11 ++ +
示例 3:
+ +输入:13 +输出:101+ +
+ +
提示:
+ +-
+
1 <= N <= 10^8
+ - 答案肯定存在,且小于
2 * 10^8。
+
+ +
+ + + +## 解法 + + + +### Python3 + + +```python + +``` + +### Java + + +```java + +``` + +### ... +``` + +``` diff --git a/solution/0800-0899/0867.Transpose Matrix/README.md b/solution/0800-0899/0867.Transpose Matrix/README.md index ab453d03d6cfa..6aeecf4121ad5 100644 --- a/solution/0800-0899/0867.Transpose Matrix/README.md +++ b/solution/0800-0899/0867.Transpose Matrix/README.md @@ -1,55 +1,55 @@ -# 转置矩阵 +# [867. 转置矩阵](https://leetcode-cn.com/problems/transpose-matrix) -### 题目描述 +## 题目描述 + +
给定一个矩阵 A, 返回 A 的转置矩阵。
矩阵的转置是指将矩阵的主对角线翻转,交换矩阵的行索引与列索引。
-矩阵的转置是指将矩阵的主对角线翻转,交换矩阵的行索引与列索引。 +-**示例 1** +
示例 1:
-``` -输入:[[1,2,3],[4,5,6],[7,8,9]] -输出:[[1,4,7],[2,5,8],[3,6,9]] -``` +输入:[[1,2,3],[4,5,6],[7,8,9]] +输出:[[1,4,7],[2,5,8],[3,6,9]] +-**示例 2** +
示例 2:
-``` -输入:[[1,2,3],[4,5,6]] -输出:[[1,4],[2,5],[3,6]] -``` +输入:[[1,2,3],[4,5,6]] +输出:[[1,4],[2,5],[3,6]] ++ +
+ +
提示:
-**提示** +-
+
1 <= A.length <= 1000
+ 1 <= A[0].length <= 1000
+
给定一个正整数 N,找到并返回 N 的二进制表示中两个连续的 1 之间的最长距离。
如果没有两个连续的 1,返回 0 。
+ +
-
+
示例 1:
+ +输入:22 +输出:2 +解释: +22 的二进制是 0b10110 。 +在 22 的二进制表示中,有三个 1,组成两对连续的 1 。 +第一对连续的 1 中,两个 1 之间的距离为 2 。 +第二对连续的 1 中,两个 1 之间的距离为 1 。 +答案取两个距离之中最大的,也就是 2 。 ++ +
示例 2:
+ +输入:5 +输出:2 +解释: +5 的二进制是 0b101 。 ++ +
示例 3:
+ +输入:6 +输出:1 +解释: +6 的二进制是 0b110 。 ++ +
示例 4:
+ +输入:8 +输出:0 +解释: +8 的二进制是 0b1000 。 +在 8 的二进制表示中没有连续的 1,所以返回 0 。 ++ +
+ +
提示:
+ +-
+
1 <= N <= 10^9
+
给定正整数 N ,我们按任何顺序(包括原始顺序)将数字重新排序,注意其前导数字不能为零。
如果我们可以通过上述方式得到 2 的幂,返回 true;否则,返回 false。
+ +
-
+
示例 1:
+ +输入:1 +输出:true ++ +
示例 2:
+ +输入:10 +输出:false ++ +
示例 3:
+ +输入:16 +输出:true ++ +
示例 4:
+ +输入:24 +输出:false ++ +
示例 5:
+ +输入:46 +输出:true ++ +
+ +
提示:
+ +-
+
1 <= N <= 10^9
+
给定两个大小相等的数组 A 和 B,A 相对于 B 的优势可以用满足 A[i] > B[i] 的索引 i 的数目来描述。
返回 A 的任意排列,使其相对于 B 的优势最大化。
+ +
示例 1:
+ +输入:A = [2,7,11,15], B = [1,10,4,11] +输出:[2,11,7,15] ++ +
示例 2:
+ +输入:A = [12,24,8,32], B = [13,25,32,11] +输出:[24,32,8,12] ++ +
+ +
提示:
+ +-
+
1 <= A.length = B.length <= 10000
+ 0 <= A[i] <= 10^9
+ 0 <= B[i] <= 10^9
+
汽车从起点出发驶向目的地,该目的地位于出发位置东面 target 英里处。
沿途有加油站,每个 station[i] 代表一个加油站,它位于出发位置东面 station[i][0] 英里处,并且有 station[i][1] 升汽油。
假设汽车油箱的容量是无限的,其中最初有 startFuel 升燃料。它每行驶 1 英里就会用掉 1 升汽油。
当汽车到达加油站时,它可能停下来加油,将所有汽油从加油站转移到汽车中。
+ +为了到达目的地,汽车所必要的最低加油次数是多少?如果无法到达目的地,则返回 -1 。
注意:如果汽车到达加油站时剩余燃料为 0,它仍然可以在那里加油。如果汽车到达目的地时剩余燃料为 0,仍然认为它已经到达目的地。
+ ++ +
示例 1:
+ +输入:target = 1, startFuel = 1, stations = [] +输出:0 +解释:我们可以在不加油的情况下到达目的地。 ++ +
示例 2:
+ +输入:target = 100, startFuel = 1, stations = [[10,100]] +输出:-1 +解释:我们无法抵达目的地,甚至无法到达第一个加油站。 ++ +
示例 3:
+ +输入:target = 100, startFuel = 10, stations = [[10,60],[20,30],[30,30],[60,40]] +输出:2 +解释: +我们出发时有 10 升燃料。 +我们开车来到距起点 10 英里处的加油站,消耗 10 升燃料。将汽油从 0 升加到 60 升。 +然后,我们从 10 英里处的加油站开到 60 英里处的加油站(消耗 50 升燃料), +并将汽油从 10 升加到 50 升。然后我们开车抵达目的地。 +我们沿途在1两个加油站停靠,所以返回 2 。 ++ +
+ +
提示:
+ +-
+
1 <= target, startFuel, stations[i][1] <= 10^9
+ 0 <= stations.length <= 500
+ 0 < stations[0][0] < stations[1][0] < ... < stations[stations.length-1][0] < target
+
请考虑一颗二叉树上所有的叶子,这些叶子的值按从左到右的顺序排列形成一个 叶值序列 。
+ +
举个例子,如上图所示,给定一颗叶值序列为 (6, 7, 4, 9, 8) 的树。
如果有两颗二叉树的叶值序列是相同,那么我们就认为它们是 叶相似 的。
+ +如果给定的两个头结点分别为 root1 和 root2 的树是叶相似的,则返回 true;否则返回 false 。
+ +
提示:
+ +-
+
- 给定的两颗树可能会有
1到100个结点。
+
如果序列 X_1, X_2, ..., X_n 满足下列条件,就说它是 斐波那契式 的:
-
+
n >= 3
+ - 对于所有
i + 2 <= n,都有X_i + X_{i+1} = X_{i+2}
+
给定一个严格递增的正整数数组形成序列,找到 A 中最长的斐波那契式的子序列的长度。如果一个不存在,返回 0 。
(回想一下,子序列是从原序列 A 中派生出来的,它从 A 中删掉任意数量的元素(也可以不删),而不改变其余元素的顺序。例如, [3, 5, 8] 是 [3, 4, 5, 6, 7, 8] 的一个子序列)
+ +
-
+
示例 1:
+ +输入: [1,2,3,4,5,6,7,8] +输出: 5 +解释: +最长的斐波那契式子序列为:[1,2,3,5,8] 。 ++ +
示例 2:
+ +输入: [1,3,7,11,12,14,18] +输出: 3 +解释: +最长的斐波那契式子序列有: +[1,11,12],[3,11,14] 以及 [7,11,18] 。 ++ +
+ +
提示:
+ +-
+
3 <= A.length <= 1000
+ 1 <= A[0] < A[1] < ... < A[A.length - 1] <= 10^9
+ - (对于以 Java,C,C++,以及 C# 的提交,时间限制被减少了 50%) +
机器人在一个无限大小的网格上行走,从点 (0, 0) 处开始出发,面向北方。该机器人可以接收以下三种类型的命令:
+ +-
+
-2:向左转 90 度
+ -1:向右转 90 度
+ 1 <= x <= 9:向前移动x个单位长度
+
在网格上有一些格子被视为障碍物。
+ +第 i 个障碍物位于网格点 (obstacles[i][0], obstacles[i][1])
如果机器人试图走到障碍物上方,那么它将停留在障碍物的前一个网格方块上,但仍然可以继续该路线的其余部分。
+ +返回从原点到机器人的最大欧式距离的平方。
+ ++ +
示例 1:
+ +输入: commands = [4,-1,3], obstacles = [] +输出: 25 +解释: 机器人将会到达 (3, 4) ++ +
示例 2:
+ +输入: commands = [4,-1,4,-2,4], obstacles = [[2,4]] +输出: 65 +解释: 机器人在左转走到 (1, 8) 之前将被困在 (1, 4) 处 ++ +
+ +
提示:
+ +-
+
0 <= commands.length <= 10000
+ 0 <= obstacles.length <= 10000
+ -30000 <= obstacle[i][0] <= 30000
+ -30000 <= obstacle[i][1] <= 30000
+ - 答案保证小于
2 ^ 31
+
珂珂喜欢吃香蕉。这里有 N 堆香蕉,第 i 堆中有 piles[i] 根香蕉。警卫已经离开了,将在 H 小时后回来。
珂珂可以决定她吃香蕉的速度 K (单位:根/小时)。每个小时,她将会选择一堆香蕉,从中吃掉 K 根。如果这堆香蕉少于 K 根,她将吃掉这堆的所有香蕉,然后这一小时内不会再吃更多的香蕉。
珂珂喜欢慢慢吃,但仍然想在警卫回来前吃掉所有的香蕉。
+ +返回她可以在 H 小时内吃掉所有香蕉的最小速度 K(K 为整数)。
+ +
-
+
示例 1:
+ +输入: piles = [3,6,7,11], H = 8 +输出: 4 ++ +
示例 2:
+ +输入: piles = [30,11,23,4,20], H = 5 +输出: 30 ++ +
示例 3:
+ +输入: piles = [30,11,23,4,20], H = 6 +输出: 23 ++ +
+ +
提示:
+ +-
+
1 <= piles.length <= 10^4
+ piles.length <= H <= 10^9
+ 1 <= piles[i] <= 10^9
+
给定一个带有头结点 head 的非空单链表,返回链表的中间结点。
如果有两个中间结点,则返回第二个中间结点。
+-示例 1: -``` -输入:[1,2,3,4,5] -输出:此列表中的结点 3 (序列化形式:[3,4,5]) +
示例 1:
+ +输入:[1,2,3,4,5] +输出:此列表中的结点 3 (序列化形式:[3,4,5]) 返回的结点值为 3 。 (测评系统对该结点序列化表述是 [3,4,5])。 注意,我们返回了一个 ListNode 类型的对象 ans,这样: ans.val = 3, ans.next.val = 4, ans.next.next.val = 5, 以及 ans.next.next.next = NULL. -``` +-示例 2: -``` -输入:[1,2,3,4,5,6] -输出:此列表中的结点 4 (序列化形式:[4,5,6]) +
示例 2:
+ +输入:[1,2,3,4,5,6] +输出:此列表中的结点 4 (序列化形式:[4,5,6]) 由于该列表有两个中间结点,值分别为 3 和 4,我们返回第二个结点。 -``` ++ +
+ +
提示:
+ +-
+
- 给定链表的结点数介于
1和100之间。
+
亚历克斯和李用几堆石子在做游戏。偶数堆石子排成一行,每堆都有正整数颗石子 piles[i] 。
游戏以谁手中的石子最多来决出胜负。石子的总数是奇数,所以没有平局。
+ +亚历克斯和李轮流进行,亚历克斯先开始。 每回合,玩家从行的开始或结束处取走整堆石头。 这种情况一直持续到没有更多的石子堆为止,此时手中石子最多的玩家获胜。
+ +假设亚历克斯和李都发挥出最佳水平,当亚历克斯赢得比赛时返回 true ,当李赢得比赛时返回 false 。
+ +
示例:
+ +输入:[5,3,4,5] +输出:true +解释: +亚历克斯先开始,只能拿前 5 颗或后 5 颗石子 。 +假设他取了前 5 颗,这一行就变成了 [3,4,5] 。 +如果李拿走前 3 颗,那么剩下的是 [4,5],亚历克斯拿走后 5 颗赢得 10 分。 +如果李拿走后 5 颗,那么剩下的是 [3,4],亚历克斯拿走后 4 颗赢得 9 分。 +这表明,取前 5 颗石子对亚历克斯来说是一个胜利的举动,所以我们返回 true 。 ++ +
+ +
提示:
+ +-
+
2 <= piles.length <= 500
+ piles.length是偶数。
+ 1 <= piles[i] <= 500
+ sum(piles)是奇数。
+
如果正整数可以被 A 或 B 整除,那么它是神奇的。
+ +返回第 N 个神奇数字。由于答案可能非常大,返回它模 10^9 + 7 的结果。
+ +
-
+
示例 1:
+ +输入:N = 1, A = 2, B = 3 +输出:2 ++ +
示例 2:
+ +输入:N = 4, A = 2, B = 3 +输出:6 ++ +
示例 3:
+ +输入:N = 5, A = 2, B = 4 +输出:10 ++ +
示例 4:
+ +输入:N = 3, A = 6, B = 4 +输出:8 ++ +
+ +
提示:
+ +-
+
1 <= N <= 10^9
+ 2 <= A <= 40000
+ 2 <= B <= 40000
+
帮派里有 G 名成员,他们可能犯下各种各样的罪行。
+ +第 i 种犯罪会产生 profit[i] 的利润,它要求 group[i] 名成员共同参与。
让我们把这些犯罪的任何子集称为盈利计划,该计划至少产生 P 的利润。
有多少种方案可以选择?因为答案很大,所以返回它模 10^9 + 7 的值。
+ +
示例 1:
+ +输入:G = 5, P = 3, group = [2,2], profit = [2,3] +输出:2 +解释: +至少产生 3 的利润,该帮派可以犯下罪 0 和罪 1 ,或仅犯下罪 1 。 +总的来说,有两种方案。 ++ +
示例 2:
+ +输入:G = 10, P = 5, group = [2,3,5], profit = [6,7,8] +输出:7 +解释: +至少产生 5 的利润,只要他们犯其中一种罪就行,所以该帮派可以犯下任何罪行 。 +有 7 种可能的计划:(0),(1),(2),(0,1),(0,2),(1,2),以及 (0,1,2) 。 ++ +
+ +
提示:
+ +-
+
1 <= G <= 100
+ 0 <= P <= 100
+ 1 <= group[i] <= 100
+ 0 <= profit[i] <= 100
+ 1 <= group.length = profit.length <= 100
+
+ + + +## 解法 + + + +### Python3 + + +```python + +``` + +### Java + + +```java + +``` + +### ... +``` + +``` diff --git a/solution/0800-0899/0880.Decoded String at Index/README.md b/solution/0800-0899/0880.Decoded String at Index/README.md new file mode 100644 index 0000000000000..8199839636604 --- /dev/null +++ b/solution/0800-0899/0880.Decoded String at Index/README.md @@ -0,0 +1,76 @@ +# [880. 索引处的解码字符串](https://leetcode-cn.com/problems/decoded-string-at-index) + +## 题目描述 + +
给定一个编码字符串 S。为了找出解码字符串并将其写入磁带,从编码字符串中每次读取一个字符,并采取以下步骤:
-
+
- 如果所读的字符是字母,则将该字母写在磁带上。 +
- 如果所读的字符是数字(例如
d),则整个当前磁带总共会被重复写d-1次。
+
现在,对于给定的编码字符串 S 和索引 K,查找并返回解码字符串中的第 K 个字母。
+ +
示例 1:
+ +输入:S = "leet2code3", K = 10 +输出:"o" +解释: +解码后的字符串为 "leetleetcodeleetleetcodeleetleetcode"。 +字符串中的第 10 个字母是 "o"。 ++ +
示例 2:
+ +输入:S = "ha22", K = 5 +输出:"h" +解释: +解码后的字符串为 "hahahaha"。第 5 个字母是 "h"。 ++ +
示例 3:
+ +输入:S = "a2345678999999999999999", K = 1 +输出:"a" +解释: +解码后的字符串为 "a" 重复 8301530446056247680 次。第 1 个字母是 "a"。 ++ +
+ +
提示:
+ +-
+
2 <= S.length <= 100
+ S只包含小写字母与数字2到9。
+ S以字母开头。
+ 1 <= K <= 10^9
+ - 解码后的字符串保证少于
2^63个字母。
+
第 i 个人的体重为 people[i],每艘船可以承载的最大重量为 limit。
每艘船最多可同时载两人,但条件是这些人的重量之和最多为 limit。
返回载到每一个人所需的最小船数。(保证每个人都能被船载)。
-返回载到每一个人所需的最小船数。(保证每个人都能被船载)。 ++ +
示例 1:
+ +输入:people = [1,2], limit = 3 +输出:1 +解释:1 艘船载 (1, 2) ++ +
示例 2:
+ +输入:people = [3,2,2,1], limit = 3 +输出:3 +解释:3 艘船分别载 (1, 2), (2) 和 (3) ++ +
示例 3:
+ +输入:people = [3,5,3,4], limit = 5 +输出:4 +解释:4 艘船分别载 (3), (3), (4), (5)+ +
提示:
+ +-
+
1 <= people.length <= 50000
+ 1 <= people[i] <= limit <= 30000
+
从具有 0 到 N-1 的结点的无向图(“原始图”)开始,对一些边进行细分。
该图给出如下:edges[k] 是整数对 (i, j, n) 组成的列表,使 (i, j) 是原始图的边。
n 是该边上新结点的总数
然后,将边 (i, j) 从原始图中删除,将 n 个新结点 (x_1, x_2, ..., x_n) 添加到原始图中,
将 n+1 条新边 (i, x_1), (x_1, x_2), (x_2, x_3), ..., (x_{n-1}, x_n), (x_n, j) 添加到原始图中。
现在,你将从原始图中的结点 0 处出发,并且每次移动,你都将沿着一条边行进。
返回最多 M 次移动可以达到的结点数。
+ +
示例 1:
+ +输入:+ +edges= [[0,1,10],[0,2,1],[1,2,2]], M = 6, N = 3 +输出:13 +解释: +在 M = 6 次移动之后在最终图中可到达的结点如下所示。 ++
示例 2:
+ +输入:edges = [[0,1,4],[1,2,6],[0,2,8],[1,3,1]], M = 10, N = 4
+输出:23
+
++ +
提示:
+ +-
+
0 <= edges.length <= 10000
+ 0 <= edges[i][0] < edges[i][1] < N
+ - 不存在任何
i != j情况下edges[i][0] == edges[j][0]且edges[i][1] == edges[j][1].
+ - 原始图没有平行的边。 +
0 <= edges[i][2] <= 10000
+ 0 <= M <= 10^9
+ 1 <= N <= 3000
+ - 可到达结点是可以从结点
0开始使用最多M次移动到达的结点。
+
+ + + +## 解法 + + + +### Python3 + + +```python + +``` + +### Java + + +```java + +``` + +### ... +``` + +``` diff --git a/solution/0800-0899/0883.Projection Area of 3D Shapes/README.md b/solution/0800-0899/0883.Projection Area of 3D Shapes/README.md new file mode 100644 index 0000000000000..0395f7b5600c5 --- /dev/null +++ b/solution/0800-0899/0883.Projection Area of 3D Shapes/README.md @@ -0,0 +1,96 @@ +# [883. 三维形体投影面积](https://leetcode-cn.com/problems/projection-area-of-3d-shapes) + +## 题目描述 + +
在 N * N 的网格中,我们放置了一些与 x,y,z 三轴对齐的 1 * 1 * 1 立方体。
每个值 v = grid[i][j] 表示 v 个正方体叠放在单元格 (i, j) 上。
现在,我们查看这些立方体在 xy、yz 和 zx 平面上的投影。
+ +投影就像影子,将三维形体映射到一个二维平面上。
+ +在这里,从顶部、前面和侧面看立方体时,我们会看到“影子”。
+ +返回所有三个投影的总面积。
+ ++ +
-
+
-
+
-
+
-
+
示例 1:
+ +输入:[[2]] +输出:5 ++ +
示例 2:
+ +输入:[[1,2],[3,4]] +输出:17 +解释: +这里有该形体在三个轴对齐平面上的三个投影(“阴影部分”)。 ++ ++
示例 3:
+ +输入:[[1,0],[0,2]] +输出:8 ++ +
示例 4:
+ +输入:[[1,1,1],[1,0,1],[1,1,1]] +输出:14 ++ +
示例 5:
+ +输入:[[2,2,2],[2,1,2],[2,2,2]] +输出:21 ++ +
+ +
提示:
+ +-
+
1 <= grid.length = grid[0].length <= 50
+ 0 <= grid[i][j] <= 50
+
给定两个句子 A 和 B 。 (句子是一串由空格分隔的单词。每个单词仅由小写字母组成。)
如果一个单词在其中一个句子中只出现一次,在另一个句子中却没有出现,那么这个单词就是不常见的。
+ +返回所有不常用单词的列表。
+ +您可以按任何顺序返回列表。
+ ++ +
-
+
示例 1:
+ +输入:A = "this apple is sweet", B = "this apple is sour" +输出:["sweet","sour"] ++ +
示例 2:
+ +输入:A = "apple apple", B = "banana" +输出:["banana"] ++ +
+ +
提示:
+ +-
+
0 <= A.length <= 200
+ 0 <= B.length <= 200
+ A和B都只包含空格和小写字母。
+
在 R 行 C 列的矩阵上,我们从 (r0, c0) 面朝东面开始
这里,网格的西北角位于第一行第一列,网格的东南角位于最后一行最后一列。
+ +现在,我们以顺时针按螺旋状行走,访问此网格中的每个位置。
+ +每当我们移动到网格的边界之外时,我们会继续在网格之外行走(但稍后可能会返回到网格边界)。
+ +最终,我们到过网格的所有 R * C 个空间。
按照访问顺序返回表示网格位置的坐标列表。
+ ++ +
示例 1:
+ +输入:R = 1, C = 4, r0 = 0, c0 = 0 +输出:[[0,0],[0,1],[0,2],[0,3]] + ++ ++
+ +
示例 2:
+ +输入:R = 5, C = 6, r0 = 1, c0 = 4 +输出:[[1,4],[1,5],[2,5],[2,4],[2,3],[1,3],[0,3],[0,4],[0,5],[3,5],[3,4],[3,3],[3,2],[2,2],[1,2],[0,2],[4,5],[4,4],[4,3],[4,2],[4,1],[3,1],[2,1],[1,1],[0,1],[4,0],[3,0],[2,0],[1,0],[0,0]] + ++ ++
+ +
提示:
+ +-
+
1 <= R <= 100
+ 1 <= C <= 100
+ 0 <= r0 < R
+ 0 <= c0 < C
+
给定一组 N 人(编号为 1, 2, ..., N), 我们想把每个人分进任意大小的两组。
每个人都可能不喜欢其他人,那么他们不应该属于同一组。
+ +形式上,如果 dislikes[i] = [a, b],表示不允许将编号为 a 和 b 的人归入同一组。
当可以用这种方法将每个人分进两组时,返回 true;否则返回 false。
+ +
-
+
示例 1:
+ +输入:N = 4, dislikes = [[1,2],[1,3],[2,4]] +输出:true +解释:group1 [1,4], group2 [2,3] ++ +
示例 2:
+ +输入:N = 3, dislikes = [[1,2],[1,3],[2,3]] +输出:false ++ +
示例 3:
+ +输入:N = 5, dislikes = [[1,2],[2,3],[3,4],[4,5],[1,5]] +输出:false ++ +
+ +
提示:
+ +-
+
1 <= N <= 2000
+ 0 <= dislikes.length <= 10000
+ 1 <= dislikes[i][j] <= N
+ dislikes[i][0] < dislikes[i][1]
+ - 对于
dislikes[i] == dislikes[j]不存在i != j
+
你将获得 K 个鸡蛋,并可以使用一栋从 1 到 N 共有 N 层楼的建筑。
每个蛋的功能都是一样的,如果一个蛋碎了,你就不能再把它掉下去。
+ +你知道存在楼层 F ,满足 0 <= F <= N 任何从高于 F 的楼层落下的鸡蛋都会碎,从 F 楼层或比它低的楼层落下的鸡蛋都不会破。
每次移动,你可以取一个鸡蛋(如果你有完整的鸡蛋)并把它从任一楼层 X 扔下(满足 1 <= X <= N)。
你的目标是确切地知道 F 的值是多少。
无论 F 的初始值如何,你确定 F 的值的最小移动次数是多少?
+ +
-
+
示例 1:
+ +输入:K = 1, N = 2 +输出:2 +解释: 鸡蛋从 1 楼掉落。如果它碎了,我们肯定知道 F = 0 。 否则,鸡蛋从 2 楼掉落。如果它碎了,我们肯定知道 F = 1 。 如果它没碎,那么我们肯定知道 F = 2 。 因此,在最坏的情况下我们需要移动 2 次以确定 F 是多少。 -``` +-示例 2: -``` -输入:K = 2, N = 6 -输出:3 -``` +
示例 2:
+ +输入:K = 2, N = 6 +输出:3 ++ +
示例 3:
+ +输入:K = 3, N = 14 +输出:4 ++ +
+ +
提示:
+ +-
+
1 <= K <= 100
+ 1 <= N <= 10000
+
爱丽丝和鲍勃有不同大小的糖果棒:A[i] 是爱丽丝拥有的第 i 块糖的大小,B[j] 是鲍勃拥有的第 j 块糖的大小。
因为他们是朋友,所以他们想交换一个糖果棒,这样交换后,他们都有相同的糖果总量。(一个人拥有的糖果总量是他们拥有的糖果棒大小的总和。)
+ +返回一个整数数组 ans,其中 ans[0] 是爱丽丝必须交换的糖果棒的大小,ans[1] 是 Bob 必须交换的糖果棒的大小。
如果有多个答案,你可以返回其中任何一个。保证答案存在。
+ ++ +
示例 1:
+ +输入:A = [1,1], B = [2,2] +输出:[1,2] ++ +
示例 2:
+ +输入:A = [1,2], B = [2,3] +输出:[1,2] ++ +
示例 3:
+ +输入:A = [2], B = [1,3] +输出:[2,3] ++ +
示例 4:
+ +输入:A = [1,2,5], B = [2,4] +输出:[5,4] ++ +
+ +
提示:
+ +-
+
1 <= A.length <= 10000
+ 1 <= B.length <= 10000
+ 1 <= A[i] <= 100000
+ 1 <= B[i] <= 100000
+ - 保证爱丽丝与鲍勃的糖果总量不同。 +
- 答案肯定存在。 +
返回与给定的前序和后序遍历匹配的任何二叉树。
- `pre` 和 `post` 遍历中的值是不同的正整数。 + pre 和 post 遍历中的值是不同的正整数。
-示例 : -``` -输入:pre = [1,2,4,5,3,6,7], post = [4,5,2,6,7,3,1] -输出:[1,2,3,4,5,6,7] -``` +
示例:
+ +输入:pre = [1,2,4,5,3,6,7], post = [4,5,2,6,7,3,1] +输出:[1,2,3,4,5,6,7] ++ +
+
提示:
-提示: +-
+
1 <= pre.length == post.length <= 30
+ pre[]和post[]都是1, 2, ..., pre.length的排列
+ - 每个输入保证至少有一个答案。如果有多个答案,可以返回其中一个。 +
你有一个单词列表 words 和一个模式 pattern,你想知道 words 中的哪些单词与模式匹配。
如果存在字母的排列 p ,使得将模式中的每个字母 x 替换为 p(x) 之后,我们就得到了所需的单词,那么单词与模式是匹配的。
(回想一下,字母的排列是从字母到字母的双射:每个字母映射到另一个字母,没有两个字母映射到同一个字母。)
+ +返回 words 中与给定模式匹配的单词列表。
你可以按任何顺序返回答案。
+ ++ +
示例:
+ +输入:words = ["abc","deq","mee","aqq","dkd","ccc"], pattern = "abb"
+输出:["mee","aqq"]
+解释:
+"mee" 与模式匹配,因为存在排列 {a -> m, b -> e, ...}。
+"ccc" 与模式不匹配,因为 {a -> c, b -> c, ...} 不是排列。
+因为 a 和 b 映射到同一个字母。
+
++ +
提示:
+ +-
+
1 <= words.length <= 50
+ 1 <= pattern.length = words[i].length <= 20
+
给定一个整数数组 A ,考虑 A 的所有非空子序列。
对于任意序列 S ,设 S 的宽度是 S 的最大元素和最小元素的差。
+ +返回 A 的所有子序列的宽度之和。
+ +由于答案可能非常大,请返回答案模 10^9+7。
+ ++ +
示例:
+ +输入:[2,1,3] +输出:6 +解释: +子序列为 [1],[2],[3],[2,1],[2,3],[1,3],[2,1,3] 。 +相应的宽度是 0,0,0,1,1,2,2 。 +这些宽度之和是 6 。 ++ +
+ +
提示:
+ +-
+
1 <= A.length <= 20000
+ 1 <= A[i] <= 20000
+
在 N * N 的网格上,我们放置一些 1 * 1 * 1 的立方体。
每个值 v = grid[i][j] 表示 v 个正方体叠放在对应单元格 (i, j) 上。
请你返回最终形体的表面积。
+ ++ +
-
+
示例 1:
+ +输入:[[2]] +输出:10 ++ +
示例 2:
+ +输入:[[1,2],[3,4]] +输出:34 ++ +
示例 3:
+ +输入:[[1,0],[0,2]] +输出:16 ++ +
示例 4:
+ +输入:[[1,1,1],[1,0,1],[1,1,1]] +输出:32 ++ +
示例 5:
+ +输入:[[2,2,2],[2,1,2],[2,2,2]] +输出:46 ++ +
+ +
提示:
+ +-
+
1 <= N <= 50
+ 0 <= grid[i][j] <= 50
+
你将得到一个字符串数组 A。
如果经过任意次数的移动,S == T,那么两个字符串 S 和 T 是特殊等价的。
一次移动包括选择两个索引 i 和 j,且 i % 2 == j % 2,交换 S[j] 和 S [i]。
现在规定,A 中的特殊等价字符串组是 A 的非空子集 S,这样不在 S 中的任何字符串与 S 中的任何字符串都不是特殊等价的。
返回 A 中特殊等价字符串组的数量。
+ +
-
+
示例 1:
+ +输入:["a","b","c","a","c","c"] +输出:3 +解释:3 组 ["a","a"],["b"],["c","c","c"] ++ +
示例 2:
+ +输入:["aa","bb","ab","ba"] +输出:4 +解释:4 组 ["aa"],["bb"],["ab"],["ba"] ++ +
示例 3:
+ +输入:["abc","acb","bac","bca","cab","cba"] +输出:3 +解释:3 组 ["abc","cba"],["acb","bca"],["bac","cab"] ++ +
示例 4:
+ +输入:["abcd","cdab","adcb","cbad"] +输出:1 +解释:1 组 ["abcd","cdab","adcb","cbad"] ++ +
+ +
提示:
+ +-
+
1 <= A.length <= 1000
+ 1 <= A[i].length <= 20
+ - 所有
A[i]都具有相同的长度。
+ - 所有
A[i]都只由小写字母组成。
+
满二叉树是一类二叉树,其中每个结点恰好有 0 或 2 个子结点。
+ +返回包含 N 个结点的所有可能满二叉树的列表。 答案的每个元素都是一个可能树的根结点。
答案中每个树的每个结点都必须有 node.val=0。
你可以按任何顺序返回树的最终列表。
+ ++ +
示例:
+ +输入:7 +输出:[[0,0,0,null,null,0,0,null,null,0,0],[0,0,0,null,null,0,0,0,0],[0,0,0,0,0,0,0],[0,0,0,0,0,null,null,null,null,0,0],[0,0,0,0,0,null,null,0,0]] +解释: ++ ++
+ +
提示:
+ +-
+
1 <= N <= 20
+
实现 FreqStack,模拟类似栈的数据结构的操作的一个类。
FreqStack 有两个函数:
-
+
push(int x),将整数x推入栈中。
+ pop(),它移除并返回栈中出现最频繁的元素。 +-
+
- 如果最频繁的元素不只一个,则移除并返回最接近栈顶的元素。 +
+
+ +
示例:
+ +输入: +["FreqStack","push","push","push","push","push","push","pop","pop","pop","pop"], +[[],[5],[7],[5],[7],[4],[5],[],[],[],[]] +输出:[null,null,null,null,null,null,null,5,7,5,4] +解释: +执行六次 .push 操作后,栈自底向上为 [5,7,5,7,4,5]。然后: + +pop() -> 返回 5,因为 5 是出现频率最高的。 +栈变成 [5,7,5,7,4]。 + +pop() -> 返回 7,因为 5 和 7 都是频率最高的,但 7 最接近栈顶。 +栈变成 [5,7,5,4]。 + +pop() -> 返回 5 。 +栈变成 [5,7,4]。 + +pop() -> 返回 4 。 +栈变成 [5,7]。 ++ +
+ +
提示:
+ +-
+
- 对
FreqStack.push(int x)的调用中0 <= x <= 10^9。
+ - 如果栈的元素数目为零,则保证不会调用
FreqStack.pop()。
+ - 单个测试样例中,对
FreqStack.push的总调用次数不会超过10000。
+ - 单个测试样例中,对
FreqStack.pop的总调用次数不会超过10000。
+ - 所有测试样例中,对
FreqStack.push和FreqStack.pop的总调用次数不会超过150000。
+
+ + + +## 解法 + + + +### Python3 + + +```python + +``` + +### Java + + +```java + +``` + +### ... +``` + +``` diff --git a/solution/0800-0899/0896.Monotonic Array/README.md b/solution/0800-0899/0896.Monotonic Array/README.md index c421769cb403a..f7cd16a0ffe32 100644 --- a/solution/0800-0899/0896.Monotonic Array/README.md +++ b/solution/0800-0899/0896.Monotonic Array/README.md @@ -1,37 +1,78 @@ -# Monotonic Array +# [896. 单调数列](https://leetcode-cn.com/problems/monotonic-array) -An array is monotonic if it is either monotone increasing or monotone decreasing. +## 题目描述 + +
如果数组是单调递增或单调递减的,那么它是单调的。
-An array A is monotone increasing if for all i <= j, A[i] <= A[j]. An array A is monotone decreasing if for all i <= j, A[i] >= A[j]. +如果对于所有 i <= j,A[i] <= A[j],那么数组 A 是单调递增的。 如果对于所有 i <= j,A[i]> = A[j],那么数组 A 是单调递减的。
当给定的数组 A 是单调数组时返回 true,否则返回 false。
-## Example 2: -``` - Input: [6,5,4,4] - Output: true -``` +
-
+
示例 1:
+ +输入:[1,2,2,3] +输出:true ++ +
示例 2:
+ +输入:[6,5,4,4] +输出:true ++ +
示例 3:
+ +输入:[1,3,2] +输出:false ++ +
示例 4:
+ +输入:[1,2,4,5] +输出:true ++ +
示例 5:
+ +输入:[1,1,1] +输出:true ++ +
+ +
提示:
+ +-
+
1 <= A.length <= 50000
+ -100000 <= A[i] <= 100000
+
给你一个树,请你 按中序遍历 重新排列树,使树中最左边的结点现在是树的根,并且每个结点没有左子结点,只有一个右子结点。
+ ++ +
示例 :
+ +输入:[5,3,6,2,4,null,8,1,null,null,null,7,9] + + 5 + / \ + 3 6 + / \ \ + 2 4 8 + / / \ +1 7 9 + +输出:[1,null,2,null,3,null,4,null,5,null,6,null,7,null,8,null,9] + + 1 + \ + 2 + \ + 3 + \ + 4 + \ + 5 + \ + 6 + \ + 7 + \ + 8 + \ + 9+ +
+ +
提示:
+ +-
+
- 给定树中的结点数介于
1和100之间。
+ - 每个结点都有一个从
0到1000范围内的唯一整数值。
+
我们有一个非负整数数组 A。
对于每个(连续的)子数组 B = [A[i], A[i+1], ..., A[j]] ( i <= j),我们对 B 中的每个元素进行按位或操作,获得结果 A[i] | A[i+1] | ... | A[j]。
返回可能结果的数量。 (多次出现的结果在最终答案中仅计算一次。)
+ ++ +
示例 1:
+ +输入:[0] +输出:1 +解释: +只有一个可能的结果 0 。 ++ +
示例 2:
+ +输入:[1,1,2] +输出:3 +解释: +可能的子数组为 [1],[1],[2],[1, 1],[1, 2],[1, 1, 2]。 +产生的结果为 1,1,2,1,3,3 。 +有三个唯一值,所以答案是 3 。 ++ +
示例 3:
+ +输入:[1,2,4] +输出:6 +解释: +可能的结果是 1,2,3,4,6,以及 7 。 ++ +
+ +
提示:
+ +-
+
1 <= A.length <= 50000
+ 0 <= A[i] <= 10^9
+
给出了一个由小写字母组成的字符串 S。然后,我们可以进行任意次数的移动。
在每次移动中,我们选择前 K 个字母中的一个(从左侧开始),将其从原位置移除,并放置在字符串的末尾。
返回我们在任意次数的移动之后可以拥有的按字典顺序排列的最小字符串。
+ ++ +
示例 1:
+ +输入:S = "cba", K = 1 +输出:"acb" +解释: +在第一步中,我们将第一个字符(“c”)移动到最后,获得字符串 “bac”。 +在第二步中,我们将第一个字符(“b”)移动到最后,获得最终结果 “acb”。 ++ +
示例 2:
+ +输入:S = "baaca", K = 3 +输出:"aaabc" +解释: +在第一步中,我们将第一个字符(“b”)移动到最后,获得字符串 “aacab”。 +在第二步中,我们将第三个字符(“c”)移动到最后,获得最终结果 “aaabc”。 ++ +
+ +
提示:
+ +-
+
1 <= K <= S.length <= 1000
+ S只由小写字母组成。
+
编写一个遍历游程编码序列的迭代器。
+ +迭代器由 RLEIterator(int[] A) 初始化,其中 A 是某个序列的游程编码。更具体地,对于所有偶数 i,A[i] 告诉我们在序列中重复非负整数值 A[i + 1] 的次数。
迭代器支持一个函数:next(int n),它耗尽接下来的 n 个元素(n >= 1)并返回以这种方式耗去的最后一个元素。如果没有剩余的元素可供耗尽,则 next 返回 -1 。
例如,我们以 A = [3,8,0,9,2,5] 开始,这是序列 [8,8,8,5,5] 的游程编码。这是因为该序列可以读作 “三个八,零个九,两个五”。
+ +
示例:
+ +输入:["RLEIterator","next","next","next","next"], [[[3,8,0,9,2,5]],[2],[1],[1],[2]] +输出:[null,8,8,5,-1] +解释: +RLEIterator 由 RLEIterator([3,8,0,9,2,5]) 初始化。 +这映射到序列 [8,8,8,5,5]。 +然后调用 RLEIterator.next 4次。 + +.next(2) 耗去序列的 2 个项,返回 8。现在剩下的序列是 [8, 5, 5]。 + +.next(1) 耗去序列的 1 个项,返回 8。现在剩下的序列是 [5, 5]。 + +.next(1) 耗去序列的 1 个项,返回 5。现在剩下的序列是 [5]。 + +.next(2) 耗去序列的 2 个项,返回 -1。 这是由于第一个被耗去的项是 5, +但第二个项并不存在。由于最后一个要耗去的项不存在,我们返回 -1。 ++ +
+ +
提示:
+ +-
+
0 <= A.length <= 1000
+ A.length是偶数。
+ 0 <= A[i] <= 10^9
+ - 每个测试用例最多调用
1000次RLEIterator.next(int n)。
+ - 每次调用
RLEIterator.next(int n)都有1 <= n <= 10^9。
+
编写一个 StockSpanner 类,它收集某些股票的每日报价,并返回该股票当日价格的跨度。
今天股票价格的跨度被定义为股票价格小于或等于今天价格的最大连续日数(从今天开始往回数,包括今天)。
+ +例如,如果未来7天股票的价格是 [100, 80, 60, 70, 60, 75, 85],那么股票跨度将是 [1, 1, 1, 2, 1, 4, 6]。
+ +
示例:
+ +输入:["StockSpanner","next","next","next","next","next","next","next"], [[],[100],[80],[60],[70],[60],[75],[85]] +输出:[null,1,1,1,2,1,4,6] +解释: +首先,初始化 S = StockSpanner(),然后: +S.next(100) 被调用并返回 1, +S.next(80) 被调用并返回 1, +S.next(60) 被调用并返回 1, +S.next(70) 被调用并返回 2, +S.next(60) 被调用并返回 1, +S.next(75) 被调用并返回 4, +S.next(85) 被调用并返回 6。 + +注意 (例如) S.next(75) 返回 4,因为截至今天的最后 4 个价格 +(包括今天的价格 75) 小于或等于今天的价格。 ++ +
+ +
提示:
+ +-
+
- 调用
StockSpanner.next(int price)时,将有1 <= price <= 10^5。
+ - 每个测试用例最多可以调用
10000次StockSpanner.next。
+ - 在所有测试用例中,最多调用
150000次StockSpanner.next。
+ - 此问题的总时间限制减少了 50%。 +
我们有一组排序的数字 D,它是 {'1','2','3','4','5','6','7','8','9'} 的非空子集。(请注意,'0' 不包括在内。)
现在,我们用这些数字进行组合写数字,想用多少次就用多少次。例如 D = {'1','3','5'},我们可以写出像 '13', '551', '1351315' 这样的数字。
返回可以用 D 中的数字写出的小于或等于 N 的正整数的数目。
+ +
示例 1:
+ +输入:D = ["1","3","5","7"], N = 100 +输出:20 +解释: +可写出的 20 个数字是: +1, 3, 5, 7, 11, 13, 15, 17, 31, 33, 35, 37, 51, 53, 55, 57, 71, 73, 75, 77. ++ +
示例 2:
+ +输入:D = ["1","4","9"], N = 1000000000 +输出:29523 +解释: +我们可以写 3 个一位数字,9 个两位数字,27 个三位数字, +81 个四位数字,243 个五位数字,729 个六位数字, +2187 个七位数字,6561 个八位数字和 19683 个九位数字。 +总共,可以使用D中的数字写出 29523 个整数。+ +
+ +
提示:
+ +-
+
D是按排序顺序的数字'1'-'9'的子集。
+ 1 <= N <= 10^9
+
我们给出 S,一个源于 {'D', 'I'} 的长度为 n 的字符串 。(这些字母代表 “减少” 和 “增加”。)
+有效排列 是对整数 {0, 1, ..., n} 的一个排列 P[0], P[1], ..., P[n],使得对所有的 i:
-
+
- 如果
S[i] == 'D',那么P[i] > P[i+1],以及;
+ - 如果
S[i] == 'I',那么P[i] < P[i+1]。
+
有多少个有效排列?因为答案可能很大,所以请返回你的答案模 10^9 + 7.
+ +
示例:
+ +输入:"DID" +输出:5 +解释: +(0, 1, 2, 3) 的五个有效排列是: +(1, 0, 3, 2) +(2, 0, 3, 1) +(2, 1, 3, 0) +(3, 0, 2, 1) +(3, 1, 2, 0) ++ +
+ +
提示:
+ +-
+
1 <= S.length <= 200
+ S仅由集合{'D', 'I'}中的字符组成。
+
+ + + +## 解法 + + + +### Python3 + + +```python + +``` + +### Java + + +```java + +``` + +### ... +``` + +``` diff --git a/solution/0900-0999/0904.Fruit Into Baskets/README.md b/solution/0900-0999/0904.Fruit Into Baskets/README.md new file mode 100644 index 0000000000000..7034644e54c8f --- /dev/null +++ b/solution/0900-0999/0904.Fruit Into Baskets/README.md @@ -0,0 +1,83 @@ +# [904. 水果成篮](https://leetcode-cn.com/problems/fruit-into-baskets) + +## 题目描述 + +
在一排树中,第 i 棵树产生 tree[i] 型的水果。
+你可以从你选择的任何树开始,然后重复执行以下步骤:
-
+
- 把这棵树上的水果放进你的篮子里。如果你做不到,就停下来。 +
- 移动到当前树右侧的下一棵树。如果右边没有树,就停下来。 +
请注意,在选择一颗树后,你没有任何选择:你必须执行步骤 1,然后执行步骤 2,然后返回步骤 1,然后执行步骤 2,依此类推,直至停止。
+ +你有两个篮子,每个篮子可以携带任何数量的水果,但你希望每个篮子只携带一种类型的水果。
+用这个程序你能收集的水果总量是多少?
+ +
示例 1:
+ +输入:[1,2,1] +输出:3 +解释:我们可以收集 [1,2,1]。 ++ +
示例 2:
+ +输入:[0,1,2,2] +输出:3 +解释:我们可以收集 [1,2,2]. +如果我们从第一棵树开始,我们将只能收集到 [0, 1]。 ++ +
示例 3:
+ +输入:[1,2,3,2,2] +输出:4 +解释:我们可以收集 [2,3,2,2]. +如果我们从第一棵树开始,我们将只能收集到 [1, 2]。 ++ +
示例 4:
+ +输入:[3,3,3,1,2,1,1,2,3,3,4] +输出:5 +解释:我们可以收集 [1,2,1,1,2]. +如果我们从第一棵树或第八棵树开始,我们将只能收集到 4 个水果。 ++ +
+ +
提示:
+ +-
+
1 <= tree.length <= 40000
+ 0 <= tree[i] < tree.length
+
给定一个非负整数数组 A,返回一个数组,在该数组中, A 的所有偶数元素之后跟着所有奇数元素。
你可以返回满足此条件的任何数组作为答案。
-你可以返回满足此条件的任何数组作为答案。 +-**示例** +
示例:
-``` -输入:[3,1,2,4] -输出:[2,4,3,1] +输入:[3,1,2,4] +输出:[2,4,3,1] 输出 [4,2,3,1],[2,4,1,3] 和 [4,2,1,3] 也会被接受。 -``` - -**提示** +-1. `1 <= A.length <= 5000` -2. `0 <= A[i] <= 5000` +
-### 解法 +
提示:
-官方题解缺失 +-
+
1 <= A.length <= 5000
+ 0 <= A[i] <= 5000
+
如果一个正整数自身是回文数,而且它也是一个回文数的平方,那么我们称这个数为超级回文数。
+ +现在,给定两个正整数 L 和 R (以字符串形式表示),返回包含在范围 [L, R] 中的超级回文数的数目。
+ +
示例:
+ +输入:L = "4", R = "1000" +输出:4 +解释: +4,9,121,以及 484 是超级回文数。 +注意 676 不是一个超级回文数: 26 * 26 = 676,但是 26 不是回文数。+ +
+ +
提示:
+ +-
+
1 <= len(L) <= 18
+ 1 <= len(R) <= 18
+ L和R是表示[1, 10^18)范围的整数的字符串。
+ int(L) <= int(R)
+
+ + + +## 解法 + + + +### Python3 + + +```python + +``` + +### Java + + +```java + +``` + +### ... +``` + +``` diff --git a/solution/0900-0999/0907.Sum of Subarray Minimums/README.md b/solution/0900-0999/0907.Sum of Subarray Minimums/README.md new file mode 100644 index 0000000000000..026495edf3581 --- /dev/null +++ b/solution/0900-0999/0907.Sum of Subarray Minimums/README.md @@ -0,0 +1,53 @@ +# [907. 子数组的最小值之和](https://leetcode-cn.com/problems/sum-of-subarray-minimums) + +## 题目描述 + +
给定一个整数数组 A,找到 min(B) 的总和,其中 B 的范围为 A 的每个(连续)子数组。
由于答案可能很大,因此返回答案模 10^9 + 7。
+ +
示例:
+ +输入:[3,1,2,4] +输出:17 +解释: +子数组为 [3],[1],[2],[4],[3,1],[1,2],[2,4],[3,1,2],[1,2,4],[3,1,2,4]。 +最小值为 3,1,2,4,1,1,2,1,1,1,和为 17。+ +
+ +
提示:
+ +-
+
1 <= A <= 30000
+ 1 <= A[i] <= 30000
+
+ + + +## 解法 + + + +### Python3 + + +```python + +``` + +### Java + + +```java + +``` + +### ... +``` + +``` diff --git a/solution/0900-0999/0908.Smallest Range I/README.md b/solution/0900-0999/0908.Smallest Range I/README.md new file mode 100644 index 0000000000000..684efb87c406d --- /dev/null +++ b/solution/0900-0999/0908.Smallest Range I/README.md @@ -0,0 +1,70 @@ +# [908. 最小差值 I](https://leetcode-cn.com/problems/smallest-range-i) + +## 题目描述 + +
给定一个整数数组 A,对于每个整数 A[i],我们可以选择任意 x 满足 -K <= x <= K,并将 x 加到 A[i] 中。
在此过程之后,我们得到一些数组 B。
返回 B 的最大值和 B 的最小值之间可能存在的最小差值。
+ +
-
+
示例 1:
+ +输入:A = [1], K = 0 +输出:0 +解释:B = [1] ++ +
示例 2:
+ +输入:A = [0,10], K = 2 +输出:6 +解释:B = [2,8] ++ +
示例 3:
+ +输入:A = [1,3,6], K = 3 +输出:0 +解释:B = [3,3,3] 或 B = [4,4,4] ++ +
+ +
提示:
+ +-
+
1 <= A.length <= 10000
+ 0 <= A[i] <= 10000
+ 0 <= K <= 10000
+
在一块 N x N 的棋盘 board 上,从棋盘的左下角开始,每一行交替方向,按从 1 到 N*N 的数字给方格编号。例如,对于一块 6 x 6 大小的棋盘,可以编号如下:
+ ++
玩家从棋盘上的方格 1 (总是在最后一行、第一列)开始出发。
每一次从方格 x 起始的移动都由以下部分组成:
-
+
- 你选择一个目标方块
S,它的编号是x+1,x+2,x+3,x+4,x+5,或者x+6,只要这个数字<= N*N。
+ - 如果
S有一个蛇或梯子,你就移动到那个蛇或梯子的目的地。否则,你会移动到S。
+
在 r 行 c 列上的方格里有 “蛇” 或 “梯子”;如果 board[r][c] != -1,那个蛇或梯子的目的地将会是 board[r][c]。
注意,你每次移动最多只能爬过蛇或梯子一次:就算目的地是另一条蛇或梯子的起点,你也不会继续移动。
+ +返回达到方格 N*N 所需的最少移动次数,如果不可能,则返回 -1。
+ +
示例:
+ +输入:[ +[-1,-1,-1,-1,-1,-1], +[-1,-1,-1,-1,-1,-1], +[-1,-1,-1,-1,-1,-1], +[-1,35,-1,-1,13,-1], +[-1,-1,-1,-1,-1,-1], +[-1,15,-1,-1,-1,-1]] +输出:4 +解释: +首先,从方格 1 [第 5 行,第 0 列] 开始。 +你决定移动到方格 2,并必须爬过梯子移动到到方格 15。 +然后你决定移动到方格 17 [第 3 行,第 5 列],必须爬过蛇到方格 13。 +然后你决定移动到方格 14,且必须通过梯子移动到方格 35。 +然后你决定移动到方格 36, 游戏结束。 +可以证明你需要至少 4 次移动才能到达第 N*N 个方格,所以答案是 4。 ++ +
+ +
提示:
+ +-
+
2 <= board.length = board[0].length <= 20
+ board[i][j]介于1和N*N之间或者等于-1。
+ - 编号为
1的方格上没有蛇或梯子。
+ - 编号为
N*N的方格上没有蛇或梯子。
+
给定一个整数数组 A,对于每个整数 A[i],我们可以选择 x = -K 或是 x = K,并将 x 加到 A[i] 中。
在此过程之后,我们得到一些数组 B。
返回 B 的最大值和 B 的最小值之间可能存在的最小差值。
+ +
-
+
示例 1:
+ +输入:A = [1], K = 0 +输出:0 +解释:B = [1] ++ +
示例 2:
+ +输入:A = [0,10], K = 2 +输出:6 +解释:B = [2,8] ++ +
示例 3:
+ +输入:A = [1,3,6], K = 3 +输出:3 +解释:B = [4,6,3] ++ +
+ +
提示:
+ +-
+
1 <= A.length <= 10000
+ 0 <= A[i] <= 10000
+ 0 <= K <= 10000
+
在选举中,第 i 张票是在时间为 times[i] 时投给 persons[i] 的。
现在,我们想要实现下面的查询函数: TopVotedCandidate.q(int t) 将返回在 t 时刻主导选举的候选人的编号。
在 t 时刻投出的选票也将被计入我们的查询之中。在平局的情况下,最近获得投票的候选人将会获胜。
示例:
+ +输入:["TopVotedCandidate","q","q","q","q","q","q"], [[[0,1,1,0,0,1,0],[0,5,10,15,20,25,30]],[3],[12],[25],[15],[24],[8]] +输出:[null,0,1,1,0,0,1] +解释: +时间为 3,票数分布情况是 [0],编号为 0 的候选人领先。 +时间为 12,票数分布情况是 [0,1,1],编号为 1 的候选人领先。 +时间为 25,票数分布情况是 [0,1,1,0,0,1],编号为 1 的候选人领先(因为最近的投票结果是平局)。 +在时间 15、24 和 8 处继续执行 3 个查询。 ++ +
+ +
提示:
+ +-
+
1 <= persons.length = times.length <= 5000
+ 0 <= persons[i] <= persons.length
+ times是严格递增的数组,所有元素都在[0, 10^9]范围中。
+ - 每个测试用例最多调用
10000次TopVotedCandidate.q。
+ TopVotedCandidate.q(int t)被调用时总是满足t >= times[0]。
+
给定一个整数数组 nums,将该数组升序排列。
+ +
-
+
示例 1:
+ ++输入:[5,2,3,1] +输出:[1,2,3,5] ++ +
示例 2:
+ ++输入:[5,1,1,2,0,0] +输出:[0,0,1,1,2,5] ++ +
+ +
提示:
+ +-
+
1 <= A.length <= 10000
+ -50000 <= A[i] <= 50000
+
两个玩家分别扮演猫(Cat)和老鼠(Mouse)在无向图上进行游戏,他们轮流行动。
+ +该图按下述规则给出:graph[a] 是所有结点 b 的列表,使得 ab 是图的一条边。
老鼠从结点 1 开始并率先出发,猫从结点 2 开始且随后出发,在结点 0 处有一个洞。
+ +在每个玩家的回合中,他们必须沿着与他们所在位置相吻合的图的一条边移动。例如,如果老鼠位于结点 1,那么它只能移动到 graph[1] 中的(任何)结点去。
此外,猫无法移动到洞(结点 0)里。
+ +然后,游戏在出现以下三种情形之一时结束:
+ +-
+
- 如果猫和老鼠占据相同的结点,猫获胜。 +
- 如果老鼠躲入洞里,老鼠获胜。 +
- 如果某一位置重复出现(即,玩家们的位置和移动顺序都与上一个回合相同),游戏平局。 +
给定 graph,并假设两个玩家都以最佳状态参与游戏,如果老鼠获胜,则返回 1;如果猫获胜,则返回 2;如果平局,则返回 0。
+ +
-
+
示例:
+ +输入:[[2,5],[3],[0,4,5],[1,4,5],[2,3],[0,2,3]] +输出:0 +解释: +4---3---1 +| | +2---5 + \ / + 0 ++ +
+ +
提示:
+ +-
+
3 <= graph.length <= 200
+ - 保证
graph[1]非空。
+ - 保证
graph[2]包含非零元素。
+
给定一副牌,每张牌上都写着一个整数。
+ +此时,你需要选定一个数字 X,使我们可以将整副牌按下述规则分成 1 组或更多组:
-
+
- 每组都有
X张牌。
+ - 组内所有的牌上都写着相同的整数。 +
仅当你可选的 X >= 2 时返回 true。
+ +
示例 1:
+ +输入:[1,2,3,4,4,3,2,1] +输出:true +解释:可行的分组是 [1,1],[2,2],[3,3],[4,4] ++ +
示例 2:
+ +输入:[1,1,1,2,2,2,3,3] +输出:false +解释:没有满足要求的分组。 ++ +
示例 3:
+ +输入:[1] +输出:false +解释:没有满足要求的分组。 ++ +
示例 4:
+ +输入:[1,1] +输出:true +解释:可行的分组是 [1,1] ++ +
示例 5:
+ +输入:[1,1,2,2,2,2] +输出:true +解释:可行的分组是 [1,1],[2,2],[2,2] ++ +
+提示:
-
+
1 <= deck.length <= 10000
+ 0 <= deck[i] < 10000
+
+ + + +## 解法 + + + +### Python3 + + +```python + +``` + +### Java + + +```java + +``` + +### ... +``` + +``` diff --git a/solution/0900-0999/0915.Partition Array into Disjoint Intervals/README.md b/solution/0900-0999/0915.Partition Array into Disjoint Intervals/README.md index 8fcf8f2432338..549ae95eb0ad9 100644 --- a/solution/0900-0999/0915.Partition Array into Disjoint Intervals/README.md +++ b/solution/0900-0999/0915.Partition Array into Disjoint Intervals/README.md @@ -1,45 +1,66 @@ -## 分割数组 +# [915. 分割数组](https://leetcode-cn.com/problems/partition-array-into-disjoint-intervals) -### 问题描述 +## 题目描述 + +
给定一个数组 A,将其划分为两个不相交(没有公共元素)的连续子数组 left 和 right, 使得:
-
+
left中的每个元素都小于或等于right中的每个元素。
+ left和right都是非空的。
+ left要尽可能小。
+
在完成这样的分组后返回 left 的长度。可以保证存在这样的划分方法。
+ +
示例 1:
+ +输入:[5,0,3,8,6] +输出:3 +解释:left = [5,0,3],right = [8,6] ++ +
示例 2:
+ +输入:[1,1,1,0,6,12] +输出:4 +解释:left = [1,1,1,0],right = [6,12] ++ +
+ +
提示:
+ +-
+
2 <= A.length <= 30000
+ 0 <= A[i] <= 10^6
+ - 可以保证至少有一种方法能够按题目所描述的那样对
A进行划分。
+
+ + + +## 解法 + + + +### Python3 + + +```python -**示例1:** -``` -输入:[5,0,3,8,6] -输出:3 -解释:left = [5,0,3],right = [8,6] ``` -**示例2:** + +### Java + + +```java + ``` -输入:[1,1,1,0,6,12] -输出:4 -解释:left = [1,1,1,0],right = [6,12] + +### ... ``` -**提示:** -- 2 <= A.length <= 30000 -- 0 <= A[i] <= 10^6 -- 可以保证至少有一种方法能够按题目所描述的那样对 A 进行划分。 -### 解法 -从左到右遍历数组,维持三个标志,即left的结束位置`loc`、left中最大的值`vmx`、数组的第`0`位与访问位置之间最大的值`mx`。每次访问一个位置,若其值大于`mx`,则应将其值赋予`mx`,若其值小于`vmx`,则应将其位置赋予`loc`、将`mx`赋予`vmx`。 -```python -class Solution: - def partitionDisjoint(self, A): - loc = 0 - vmx = A[0] - mx = A[0] - for i, el in enumerate(A): - if el > mx: - mx = el - if el < vmx: - loc = i - vmx = mx - return loc + 1 ``` diff --git a/solution/0900-0999/0916.Word Subsets/README.md b/solution/0900-0999/0916.Word Subsets/README.md new file mode 100644 index 0000000000000..4222249dff022 --- /dev/null +++ b/solution/0900-0999/0916.Word Subsets/README.md @@ -0,0 +1,82 @@ +# [916. 单词子集](https://leetcode-cn.com/problems/word-subsets) + +## 题目描述 + +
我们给出两个单词数组 A 和 B。每个单词都是一串小写字母。
现在,如果 b 中的每个字母都出现在 a 中,包括重复出现的字母,那么称单词 b 是单词 a 的子集。 例如,“wrr” 是 “warrior” 的子集,但不是 “world” 的子集。
如果对 B 中的每一个单词 b,b 都是 a 的子集,那么我们称 A 中的单词 a 是通用的。
你可以按任意顺序以列表形式返回 A 中所有的通用单词。
+ +
-
+
示例 1:
+ +输入:A = ["amazon","apple","facebook","google","leetcode"], B = ["e","o"] +输出:["facebook","google","leetcode"] ++ +
示例 2:
+ +输入:A = ["amazon","apple","facebook","google","leetcode"], B = ["l","e"] +输出:["apple","google","leetcode"] ++ +
示例 3:
+ +输入:A = ["amazon","apple","facebook","google","leetcode"], B = ["e","oo"] +输出:["facebook","google"] ++ +
示例 4:
+ +输入:A = ["amazon","apple","facebook","google","leetcode"], B = ["lo","eo"] +输出:["google","leetcode"] ++ +
示例 5:
+ +输入:A = ["amazon","apple","facebook","google","leetcode"], B = ["ec","oc","ceo"] +输出:["facebook","leetcode"] ++ +
+ +
提示:
+ +-
+
1 <= A.length, B.length <= 10000
+ 1 <= A[i].length, B[i].length <= 10
+ A[i]和B[i]只由小写字母组成。
+ A[i]中所有的单词都是独一无二的,也就是说不存在i != j使得A[i] == A[j]。
+
给定一个字符串 S,返回 “反转后的” 字符串,其中不是字母的字符都保留在原地,而所有字母的位置发生反转。
+ +
-
+
示例 1:
+ +输入:"ab-cd" +输出:"dc-ba" ++ +
示例 2:
+ +输入:"a-bC-dEf-ghIj" +输出:"j-Ih-gfE-dCba" ++ +
示例 3:
+ +输入:"Test1ng-Leet=code-Q!" +输出:"Qedo1ct-eeLg=ntse-T!" ++ +
+ +
提示:
+ +-
+
S.length <= 100
+ 33 <= S[i].ASCIIcode <= 122
+ S中不包含\or"
+
给定一个由整数数组 A 表示的环形数组 C,求 C 的非空子数组的最大可能和。
在此处,环形数组意味着数组的末端将会与开头相连呈环状。(形式上,当0 <= i < A.length 时 C[i] = A[i],而当 i >= 0 时 C[i+A.length] = C[i])
此外,子数组最多只能包含固定缓冲区 A 中的每个元素一次。(形式上,对于子数组 C[i], C[i+1], ..., C[j],不存在 i <= k1, k2 <= j 其中 k1 % A.length = k2 % A.length)
+ +
示例 1:
+ +输入:[1,-2,3,-2] +输出:3 +解释:从子数组 [3] 得到最大和 3 ++ +
示例 2:
+ +输入:[5,-3,5] +输出:10 +解释:从子数组 [5,5] 得到最大和 5 + 5 = 10 ++ +
示例 3:
+ +输入:[3,-1,2,-1] +输出:4 +解释:从子数组 [2,-1,3] 得到最大和 2 + (-1) + 3 = 4 ++ +
示例 4:
+ +输入:[3,-2,2,-3] +输出:3 +解释:从子数组 [3] 和 [3,-2,2] 都可以得到最大和 3 ++ +
示例 5:
+ +输入:[-2,-3,-1] +输出:-1 +解释:从子数组 [-1] 得到最大和 -1 ++ +
+ +
提示:
+ +-
+
-30000 <= A[i] <= 30000
+ 1 <= A.length <= 30000
+
完全二叉树是每一层(除最后一层外)都是完全填充(即,结点数达到最大)的,并且所有的结点都尽可能地集中在左侧。
+ +设计一个用完全二叉树初始化的数据结构 CBTInserter,它支持以下几种操作:
-
+
CBTInserter(TreeNode root)使用头结点为root的给定树初始化该数据结构;
+ CBTInserter.insert(int v)将TreeNode插入到存在值为node.val = v的树中以使其保持完全二叉树的状态,并返回插入的TreeNode的父结点的值;
+ CBTInserter.get_root()将返回树的头结点。
+
+ +
-
+
示例 1:
+ +输入:inputs = ["CBTInserter","insert","get_root"], inputs = [[[1]],[2],[]] +输出:[null,1,[1,2]] ++ +
示例 2:
+ +输入:inputs = ["CBTInserter","insert","insert","get_root"], inputs = [[[1,2,3,4,5,6]],[7],[8],[]] +输出:[null,3,4,[1,2,3,4,5,6,7,8]] ++ +
+ +
提示:
+ +-
+
- 最初给定的树是完全二叉树,且包含
1到1000个结点。
+ - 每个测试用例最多调用
CBTInserter.insert操作10000次。
+ - 给定结点或插入结点的每个值都在
0到5000之间。
+
你的音乐播放器里有 N 首不同的歌,在旅途中,你的旅伴想要听 L 首歌(不一定不同,即,允许歌曲重复)。请你为她按如下规则创建一个播放列表:
-
+
- 每首歌至少播放一次。 +
- 一首歌只有在其他
K首歌播放完之后才能再次播放。
+
返回可以满足要求的播放列表的数量。由于答案可能非常大,请返回它模 10^9 + 7 的结果。
+ +
示例 1:
+ +输入:N = 3, L = 3, K = 1 +输出:6 +解释:有 6 种可能的播放列表。[1, 2, 3],[1, 3, 2],[2, 1, 3],[2, 3, 1],[3, 1, 2],[3, 2, 1]. ++ +
示例 2:
+ +输入:N = 2, L = 3, K = 0 +输出:6 +解释:有 6 种可能的播放列表。[1, 1, 2],[1, 2, 1],[2, 1, 1],[2, 2, 1],[2, 1, 2],[1, 2, 2] ++ +
示例 3:
+ +输入:N = 2, L = 3, K = 1 +输出:2 +解释:有 2 种可能的播放列表。[1, 2, 1],[2, 1, 2] ++ +
+ +
提示:
+ +-
+
0 <= K < N <= L <= 100
+
给定一个由 '(' 和 ')' 括号组成的字符串 S,我们需要添加最少的括号( '(' 或是 ')',可以在任何位置),以使得到的括号字符串有效。
从形式上讲,只有满足下面几点之一,括号字符串才是有效的:
+ +-
+
- 它是一个空字符串,或者 +
- 它可以被写成
AB(A与B连接), 其中A和B都是有效字符串,或者
+ - 它可以被写作
(A),其中A是有效字符串。
+
给定一个括号字符串,返回为使结果字符串有效而必须添加的最少括号数。
+ ++ +
示例 1:
+ +输入:"())" +输出:1 ++ +
示例 2:
+ +输入:"((("
+输出:3
+
+
+示例 3:
+ +输入:"()" +输出:0 ++ +
示例 4:
+ +输入:"()))(("
+输出:4
+
++ +
提示:
+ +-
+
S.length <= 1000
+ S只包含'('和')'字符。
+
+ + + +## 解法 + + + +### Python3 + + +```python + +``` + +### Java + + +```java + +``` + +### ... +``` + +``` diff --git a/solution/0900-0999/0922.Sort Array By Parity II/README.md b/solution/0900-0999/0922.Sort Array By Parity II/README.md index 6d7ea48b85c68..73fa5e96a3ecb 100644 --- a/solution/0900-0999/0922.Sort Array By Parity II/README.md +++ b/solution/0900-0999/0922.Sort Array By Parity II/README.md @@ -1,52 +1,55 @@ -# 按奇偶排序数组 II +# [922. 按奇偶排序数组 II](https://leetcode-cn.com/problems/sort-array-by-parity-ii) -### 题目描述 +## 题目描述 + +
给定一个非负整数数组 A, A 中一半整数是奇数,一半整数是偶数。
对数组进行排序,以便当 A[i] 为奇数时,i 也是奇数;当 A[i] 为偶数时, i 也是偶数。
你可以返回任何满足上述条件的数组作为答案。
-你可以返回任何满足上述条件的数组作为答案。 +-**示例** +
示例:
-``` -输入:[4,2,5,7] -输出:[4,5,2,7] -解释:[4,7,2,5],[2,5,4,7],[2,7,4,5] 也会被接受。 -``` +输入:[4,2,5,7] +输出:[4,5,2,7] +解释:[4,7,2,5],[2,5,4,7],[2,7,4,5] 也会被接受。 ++ +
+ +
提示:
+ +-
+
2 <= A.length <= 20000
+ A.length % 2 == 0
+ 0 <= A[i] <= 1000
+
-**提示** -1. `2 <= A.length <= 20000` -2. `A.length % 2 == 0` -3. `0 <= A[i] <= 1000` -### 解题思路 +## 解法 + -**思路** -两个指针`i`、`j`分别指向偶数位和奇数位,当`A[i]`是奇数时,寻找最近的`A[j]`是偶数的位置,交换两个数字。直至遍历完整个数组的偶数位。 +### Python3 + -**算法** +```python -```javascript -var sortArrayByParityII = function(A) { - let index = A.length - 1, i = 0, j = 1; // index A的索引,i偶数位,j奇数位。 - for( ; i < index; i += 2 ){ - if( (A[i] & 1) != 0 ){ // 寻找A[i]是奇数的情况。 - while( (A[j] & 1) != 0 ){ // 寻找A[j]是偶数的情况。 - j += 2; - } - let temp = A[j]; - A[j] = A[i]; - A[i] = temp; - } - } - return A; -}; ``` -**复杂度分析** +### Java + -暂无 \ No newline at end of file +```java + +``` + +### ... +``` + +``` diff --git a/solution/0900-0999/0923.3Sum With Multiplicity/README.md b/solution/0900-0999/0923.3Sum With Multiplicity/README.md new file mode 100644 index 0000000000000..936a54f53487a --- /dev/null +++ b/solution/0900-0999/0923.3Sum With Multiplicity/README.md @@ -0,0 +1,66 @@ +# [923. 三数之和的多种可能](https://leetcode-cn.com/problems/3sum-with-multiplicity) + +## 题目描述 + +
给定一个整数数组 A,以及一个整数 target 作为目标值,返回满足 i < j < k 且 A[i] + A[j] + A[k] == target 的元组 i, j, k 的数量。
由于结果会非常大,请返回 结果除以 10^9 + 7 的余数。
+ +
示例 1:
+ +输入:A = [1,1,2,2,3,3,4,4,5,5], target = 8 +输出:20 +解释: +按值枚举(A[i],A[j],A[k]): +(1, 2, 5) 出现 8 次; +(1, 3, 4) 出现 8 次; +(2, 2, 4) 出现 2 次; +(2, 3, 3) 出现 2 次。 ++ +
示例 2:
+ +输入:A = [1,1,2,2,2,2], target = 5 +输出:12 +解释: +A[i] = 1,A[j] = A[k] = 2 出现 12 次: +我们从 [1,1] 中选择一个 1,有 2 种情况, +从 [2,2,2,2] 中选出两个 2,有 6 种情况。 ++ +
+ +
提示:
+ +-
+
3 <= A.length <= 3000
+ 0 <= A[i] <= 100
+ 0 <= target <= 300
+
在节点网络中,只有当 graph[i][j] = 1 时,每个节点 i 能够直接连接到另一个节点 j。
一些节点 initial 最初被恶意软件感染。只要两个节点直接连接,且其中至少一个节点受到恶意软件的感染,那么两个节点都将被恶意软件感染。这种恶意软件的传播将继续,直到没有更多的节点可以被这种方式感染。
假设 M(initial) 是在恶意软件停止传播之后,整个网络中感染恶意软件的最终节点数。
我们可以从初始列表中删除一个节点。如果移除这一节点将最小化 M(initial), 则返回该节点。如果有多个节点满足条件,就返回索引最小的节点。
请注意,如果某个节点已从受感染节点的列表 initial 中删除,它以后可能仍然因恶意软件传播而受到感染。
+ +
-
+
示例 1:
+ +输入:graph = [[1,1,0],[1,1,0],[0,0,1]], initial = [0,1] +输出:0 ++ +
示例 2:
+ +输入:graph = [[1,0,0],[0,1,0],[0,0,1]], initial = [0,2] +输出:0 ++ +
示例 3:
+ +输入:graph = [[1,1,1],[1,1,1],[1,1,1]], initial = [1,2] +输出:1 ++ +
+ +
提示:
+ +-
+
1 < graph.length = graph[0].length <= 300
+ 0 <= graph[i][j] == graph[j][i] <= 1
+ graph[i][i] = 1
+ 1 <= initial.length < graph.length
+ 0 <= initial[i] < graph.length
+
你的朋友正在使用键盘输入他的名字 name。偶尔,在键入字符 c 时,按键可能会被长按,而字符可能被输入 1 次或多次。
你将会检查键盘输入的字符 typed。如果它对应的可能是你的朋友的名字(其中一些字符可能被长按),那么就返回 True。
+ +
示例 1:
+ +输入:name = "alex", typed = "aaleex" +输出:true +解释:'alex' 中的 'a' 和 'e' 被长按。 ++ +
示例 2:
+ +输入:name = "saeed", typed = "ssaaedd" +输出:false +解释:'e' 一定需要被键入两次,但在 typed 的输出中不是这样。 ++ +
示例 3:
+ +输入:name = "leelee", typed = "lleeelee" +输出:true ++ +
示例 4:
+ +输入:name = "laiden", typed = "laiden" +输出:true +解释:长按名字中的字符并不是必要的。 ++ +
+ +
提示:
+ +-
+
name.length <= 1000
+ typed.length <= 1000
+ name和typed的字符都是小写字母。
+
+ +
+ + + +## 解法 + + + +### Python3 + + +```python + +``` + +### Java + + +```java + +``` + +### ... +``` + +``` diff --git a/solution/0900-0999/0926.Flip String to Monotone Increasing/README.md b/solution/0900-0999/0926.Flip String to Monotone Increasing/README.md new file mode 100644 index 0000000000000..85ee360b64c62 --- /dev/null +++ b/solution/0900-0999/0926.Flip String to Monotone Increasing/README.md @@ -0,0 +1,66 @@ +# [926. 将字符串翻转到单调递增](https://leetcode-cn.com/problems/flip-string-to-monotone-increasing) + +## 题目描述 + +
如果一个由 '0' 和 '1' 组成的字符串,是以一些 '0'(可能没有 '0')后面跟着一些 '1'(也可能没有 '1')的形式组成的,那么该字符串是单调递增的。
我们给出一个由字符 '0' 和 '1' 组成的字符串 S,我们可以将任何 '0' 翻转为 '1' 或者将 '1' 翻转为 '0'。
返回使 S 单调递增的最小翻转次数。
+ +
示例 1:
+ +输入:"00110" +输出:1 +解释:我们翻转最后一位得到 00111. ++ +
示例 2:
+ +输入:"010110" +输出:2 +解释:我们翻转得到 011111,或者是 000111。 ++ +
示例 3:
+ +输入:"00011000" +输出:2 +解释:我们翻转得到 00000000。 ++ +
+ +
提示:
+ +-
+
1 <= S.length <= 20000
+ S中只包含字符'0'和'1'
+
给定一个由 0 和 1 组成的数组 A,将数组分成 3 个非空的部分,使得所有这些部分表示相同的二进制值。
如果可以做到,请返回任何 [i, j],其中 i+1 < j,这样一来:
-
+
A[0], A[1], ..., A[i]组成第一部分;
+ A[i+1], A[i+2], ..., A[j-1]作为第二部分;
+ A[j], A[j+1], ..., A[A.length - 1]是第三部分。
+ - 这三个部分所表示的二进制值相等。 +
如果无法做到,就返回 [-1, -1]。
注意,在考虑每个部分所表示的二进制时,应当将其看作一个整体。例如,[1,1,0] 表示十进制中的 6,而不会是 3。此外,前导零也是被允许的,所以 [0,1,1] 和 [1,1] 表示相同的值。
+ +
示例 1:
+ +输入:[1,0,1,0,1] +输出:[0,3] ++ +
示例 2:
+ +输出:[1,1,0,1,1] +输出:[-1,-1]+ +
+ +
提示:
+ +-
+
3 <= A.length <= 30000
+ A[i] == 0或A[i] == 1
+
+ + + +## 解法 + + + +### Python3 + + +```python + +``` + +### Java + + +```java + +``` + +### ... +``` + +``` diff --git a/solution/0900-0999/0928.Minimize Malware Spread II/README.md b/solution/0900-0999/0928.Minimize Malware Spread II/README.md new file mode 100644 index 0000000000000..d8c4fd0bf622d --- /dev/null +++ b/solution/0900-0999/0928.Minimize Malware Spread II/README.md @@ -0,0 +1,73 @@ +# [928. 尽量减少恶意软件的传播 II](https://leetcode-cn.com/problems/minimize-malware-spread-ii) + +## 题目描述 + +
(这个问题与 尽量减少恶意软件的传播 是一样的,不同之处用粗体表示。)
+ +在节点网络中,只有当 graph[i][j] = 1 时,每个节点 i 能够直接连接到另一个节点 j。
一些节点 initial 最初被恶意软件感染。只要两个节点直接连接,且其中至少一个节点受到恶意软件的感染,那么两个节点都将被恶意软件感染。这种恶意软件的传播将继续,直到没有更多的节点可以被这种方式感染。
假设 M(initial) 是在恶意软件停止传播之后,整个网络中感染恶意软件的最终节点数。
我们可以从初始列表中删除一个节点,并完全移除该节点以及从该节点到任何其他节点的任何连接。如果移除这一节点将最小化 M(initial), 则返回该节点。如果有多个节点满足条件,就返回索引最小的节点。
+ +
-
+
示例 1:
+ +输出:graph = [[1,1,0],[1,1,0],[0,0,1]], initial = [0,1] +输入:0 ++ +
示例 2:
+ +输入:graph = [[1,1,0],[1,1,1],[0,1,1]], initial = [0,1] +输出:1 ++ +
示例 3:
+ +输入:graph = [[1,1,0,0],[1,1,1,0],[0,1,1,1],[0,0,1,1]], initial = [0,1] +输出:1 ++ +
+ +
提示:
+ +-
+
1 < graph.length = graph[0].length <= 300
+ 0 <= graph[i][j] == graph[j][i] <= 1
+ graph[i][i] = 1
+ 1 <= initial.length < graph.length
+ 0 <= initial[i] < graph.length
+
每封电子邮件都由一个本地名称和一个域名组成,以 @ 符号分隔。
+ +例如,在 alice@leetcode.com中, alice 是本地名称,而 leetcode.com 是域名。
除了小写字母,这些电子邮件还可能包含 '.' 或 '+'。
如果在电子邮件地址的本地名称部分中的某些字符之间添加句点('.'),则发往那里的邮件将会转发到本地名称中没有点的同一地址。例如,"alice.z@leetcode.com” 和 “alicez@leetcode.com” 会转发到同一电子邮件地址。 (请注意,此规则不适用于域名。)
如果在本地名称中添加加号('+'),则会忽略第一个加号后面的所有内容。这允许过滤某些电子邮件,例如 m.y+name@email.com 将转发到 my@email.com。 (同样,此规则不适用于域名。)
可以同时使用这两个规则。
+ +给定电子邮件列表 emails,我们会向列表中的每个地址发送一封电子邮件。实际收到邮件的不同地址有多少?
+ +
示例:
+ +输入:["test.email+alex@leetcode.com","test.e.mail+bob.cathy@leetcode.com","testemail+david@lee.tcode.com"] +输出:2 +解释:实际收到邮件的是 "testemail@leetcode.com" 和 "testemail@lee.tcode.com"。 ++ +
+ +
提示:
+ +-
+
1 <= emails[i].length <= 100
+ 1 <= emails.length <= 100
+ - 每封
emails[i]都包含有且仅有一个'@'字符。
+
在由若干 0 和 1 组成的数组 A 中,有多少个和为 S 的非空子数组。
+ +
示例:
+ +输入:A = [1,0,1,0,1], S = 2 +输出:4 +解释: +如下面黑体所示,有 4 个满足题目要求的子数组: +[1,0,1,0,1] +[1,0,1,0,1] +[1,0,1,0,1] +[1,0,1,0,1] ++ +
+ +
提示:
+ +-
+
A.length <= 30000
+ 0 <= S <= A.length
+ A[i]为0或1
+
给定一个方形整数数组 A,我们想要得到通过 A 的下降路径的最小和。
下降路径可以从第一行中的任何元素开始,并从每一行中选择一个元素。在下一行选择的元素和当前行所选元素最多相隔一列。
+ ++ +
示例:
+ +输入:[[1,2,3],[4,5,6],[7,8,9]] +输出:12 +解释: +可能的下降路径有: ++ +
-
+
[1,4,7], [1,4,8], [1,5,7], [1,5,8], [1,5,9]
+ [2,4,7], [2,4,8], [2,5,7], [2,5,8], [2,5,9], [2,6,8], [2,6,9]
+ [3,5,7], [3,5,8], [3,5,9], [3,6,8], [3,6,9]
+
和最小的下降路径是 [1,4,7],所以答案是 12。
+ +
提示:
+ +-
+
1 <= A.length == A[0].length <= 100
+ -100 <= A[i][j] <= 100
+
对于某些固定的 N,如果数组 A 是整数 1, 2, ..., N 组成的排列,使得:
对于每个 i < j,都不存在 k 满足 i < k < j 使得 A[k] * 2 = A[i] + A[j]。
那么数组 A 是漂亮数组。
+ +
给定 N,返回任意漂亮数组 A(保证存在一个)。
+ +
示例 1:
+ +输入:4 +输出:[2,1,4,3] ++ +
示例 2:
+ +输入:5 +输出:[3,1,2,5,4]+ +
+ +
提示:
+ +-
+
1 <= N <= 1000
+
+ + + +## 解法 + + + +### Python3 + + +```python + +``` + +### Java + + +```java + +``` + +### ... +``` + +``` diff --git a/solution/0900-0999/0933.Number of Recent Calls/README.md b/solution/0900-0999/0933.Number of Recent Calls/README.md new file mode 100644 index 0000000000000..d2e582a52f4b8 --- /dev/null +++ b/solution/0900-0999/0933.Number of Recent Calls/README.md @@ -0,0 +1,57 @@ +# [933. 最近的请求次数](https://leetcode-cn.com/problems/number-of-recent-calls) + +## 题目描述 + +
写一个 RecentCounter 类来计算最近的请求。
它只有一个方法:ping(int t),其中 t 代表以毫秒为单位的某个时间。
返回从 3000 毫秒前到现在的 ping 数。
任何处于 [t - 3000, t] 时间范围之内的 ping 都将会被计算在内,包括当前(指 t 时刻)的 ping。
保证每次对 ping 的调用都使用比之前更大的 t 值。
+ +
示例:
+ +输入:inputs = ["RecentCounter","ping","ping","ping","ping"], inputs = [[],[1],[100],[3001],[3002]] +输出:[null,1,2,3,3]+ +
+ +
提示:
+ +-
+
- 每个测试用例最多调用
10000次ping。
+ - 每个测试用例会使用严格递增的
t值来调用ping。
+ - 每次调用
ping都有1 <= t <= 10^9。
+
+ + + +## 解法 + + + +### Python3 + + +```python + +``` + +### Java + + +```java + +``` + +### ... +``` + +``` diff --git a/solution/0900-0999/0934.Shortest Bridge/README.md b/solution/0900-0999/0934.Shortest Bridge/README.md new file mode 100644 index 0000000000000..b9ec5f61c972f --- /dev/null +++ b/solution/0900-0999/0934.Shortest Bridge/README.md @@ -0,0 +1,64 @@ +# [934. 最短的桥](https://leetcode-cn.com/problems/shortest-bridge) + +## 题目描述 + +
在给定的二维二进制数组 A 中,存在两座岛。(岛是由四面相连的 1 形成的一个最大组。)
现在,我们可以将 0 变为 1,以使两座岛连接起来,变成一座岛。
返回必须翻转的 0 的最小数目。(可以保证答案至少是 1。)
+ +
示例 1:
+ +输入:[[0,1],[1,0]] +输出:1 ++ +
示例 2:
+ +输入:[[0,1,0],[0,0,0],[0,0,1]] +输出:2 ++ +
示例 3:
+ +输入:[[1,1,1,1,1],[1,0,0,0,1],[1,0,1,0,1],[1,0,0,0,1],[1,1,1,1,1]] +输出:1+ +
+ +
提示:
+ +-
+
1 <= A.length = A[0].length <= 100
+ A[i][j] == 0或A[i][j] == 1
+
+ + + +## 解法 + + + +### Python3 + + +```python + +``` + +### Java + + +```java + +``` + +### ... +``` + +``` diff --git a/solution/0900-0999/0935.Knight Dialer/README.md b/solution/0900-0999/0935.Knight Dialer/README.md new file mode 100644 index 0000000000000..5a3b84bb45c9e --- /dev/null +++ b/solution/0900-0999/0935.Knight Dialer/README.md @@ -0,0 +1,72 @@ +# [935. 骑士拨号器](https://leetcode-cn.com/problems/knight-dialer) + +## 题目描述 + +
国际象棋中的骑士可以按下图所示进行移动:
+ + .
. 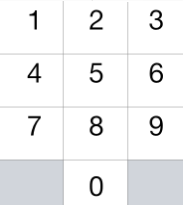
+这一次,我们将 “骑士” 放在电话拨号盘的任意数字键(如上图所示)上,接下来,骑士将会跳 N-1 步。每一步必须是从一个数字键跳到另一个数字键。
每当它落在一个键上(包括骑士的初始位置),都会拨出键所对应的数字,总共按下 N 位数字。
你能用这种方式拨出多少个不同的号码?
+ +因为答案可能很大,所以输出答案模 10^9 + 7。
+ +
-
+
示例 1:
+ +输入:1 +输出:10 ++ +
示例 2:
+ +输入:2 +输出:20 ++ +
示例 3:
+ +输入:3 +输出:46 ++ +
+ +
提示:
+ +-
+
1 <= N <= 5000
+
你想要用小写字母组成一个目标字符串 target。
开始的时候,序列由 target.length 个 '?' 记号组成。而你有一个小写字母印章 stamp。
在每个回合,你可以将印章放在序列上,并将序列中的每个字母替换为印章上的相应字母。你最多可以进行 10 * target.length 个回合。
举个例子,如果初始序列为 "?????",而你的印章 stamp 是 "abc",那么在第一回合,你可以得到 "abc??"、"?abc?"、"??abc"。(请注意,印章必须完全包含在序列的边界内才能盖下去。)
如果可以印出序列,那么返回一个数组,该数组由每个回合中被印下的最左边字母的索引组成。如果不能印出序列,就返回一个空数组。
+ +例如,如果序列是 "ababc",印章是 "abc",那么我们就可以返回与操作 "?????" -> "abc??" -> "ababc" 相对应的答案 [0, 2];
另外,如果可以印出序列,那么需要保证可以在 10 * target.length 个回合内完成。任何超过此数字的答案将不被接受。
+ +
示例 1:
+ +输入:stamp = "abc", target = "ababc" +输出:[0,2] +([1,0,2] 以及其他一些可能的结果也将作为答案被接受) ++ +
示例 2:
+ +输入:stamp = "abca", target = "aabcaca" +输出:[3,0,1] ++ +
+ +
提示:
+ +-
+
1 <= stamp.length <= target.length <= 1000
+ stamp和target只包含小写字母。
+
你有一个日志数组 logs。每条日志都是以空格分隔的字串。
对于每条日志,其第一个字为字母数字标识符。然后,要么:
+ +-
+
- 标识符后面的每个字将仅由小写字母组成,或; +
- 标识符后面的每个字将仅由数字组成。 +
我们将这两种日志分别称为字母日志和数字日志。保证每个日志在其标识符后面至少有一个字。
+ +将日志重新排序,使得所有字母日志都排在数字日志之前。字母日志按内容字母顺序排序,忽略标识符;在内容相同时,按标识符排序。数字日志应该按原来的顺序排列。
+ +返回日志的最终顺序。
+ ++ +
示例 :
+ +输入:["a1 9 2 3 1","g1 act car","zo4 4 7","ab1 off key dog","a8 act zoo"] +输出:["g1 act car","a8 act zoo","ab1 off key dog","a1 9 2 3 1","zo4 4 7"] ++ +
+ +
提示:
+ +-
+
0 <= logs.length <= 100
+ 3 <= logs[i].length <= 100
+ logs[i]保证有一个标识符,并且标识符后面有一个字。
+
给定二叉搜索树的根结点 root,返回 L 和 R(含)之间的所有结点的值的和。
二叉搜索树保证具有唯一的值。
-二叉搜索树保证具有唯一的值。 ++ +
示例 1:
+ +输入:root = [10,5,15,3,7,null,18], L = 7, R = 15 +输出:32 ++ +
示例 2:
+ +输入:root = [10,5,15,3,7,13,18,1,null,6], L = 6, R = 10 +输出:23 ++ +
+ +
提示:
+ +-
+
- 树中的结点数量最多为
10000个。
+ - 最终的答案保证小于
2^31。
+
给定在 xy 平面上的一组点,确定由这些点组成的矩形的最小面积,其中矩形的边平行于 x 轴和 y 轴。
+ +如果没有任何矩形,就返回 0。
+ ++ +
示例 1:
+ +输入:[[1,1],[1,3],[3,1],[3,3],[2,2]] +输出:4 ++ +
示例 2:
+ +输入:[[1,1],[1,3],[3,1],[3,3],[4,1],[4,3]] +输出:2 ++ +
+ +
提示:
+ +-
+
1 <= points.length <= 500
+ 0 <= points[i][0] <= 40000
+ 0 <= points[i][1] <= 40000
+ - 所有的点都是不同的。 +
给定一个字符串 S,计算 S 的不同非空子序列的个数。
因为结果可能很大,所以返回答案模 10^9 + 7.
+ +
示例 1:
+ +输入:"abc" +输出:7 +解释:7 个不同的子序列分别是 "a", "b", "c", "ab", "ac", "bc", 以及 "abc"。 ++ +
示例 2:
+ +输入:"aba" +输出:6 +解释:6 个不同的子序列分别是 "a", "b", "ab", "ba", "aa" 以及 "aba"。 ++ +
示例 3:
+ +输入:"aaa" +输出:3 +解释:3 个不同的子序列分别是 "a", "aa" 以及 "aaa"。 ++ +
+ +
+ +
提示:
+ +-
+
S只包含小写字母。
+ 1 <= S.length <= 2000
+
+ +
+ + + +## 解法 + + + +### Python3 + + +```python + +``` + +### Java + + +```java + +``` + +### ... +``` + +``` diff --git a/solution/0900-0999/0941.Valid Mountain Array/README.md b/solution/0900-0999/0941.Valid Mountain Array/README.md new file mode 100644 index 0000000000000..fde0c1528e006 --- /dev/null +++ b/solution/0900-0999/0941.Valid Mountain Array/README.md @@ -0,0 +1,74 @@ +# [941. 有效的山脉数组](https://leetcode-cn.com/problems/valid-mountain-array) + +## 题目描述 + +
给定一个整数数组 A,如果它是有效的山脉数组就返回 true,否则返回 false。
让我们回顾一下,如果 A 满足下述条件,那么它是一个山脉数组:
+ +-
+
A.length >= 3
+ - 在
0 < i < A.length - 1条件下,存在i使得: +-
+
A[0] < A[1] < ... A[i-1] < A[i]
+ A[i] > A[i+1] > ... > A[B.length - 1]
+
+
+ +
示例 1:
+ +输入:[2,1] +输出:false ++ +
示例 2:
+ +输入:[3,5,5] +输出:false ++ +
示例 3:
+ +输入:[0,3,2,1] +输出:true+ +
+ +
提示:
+ +-
+
0 <= A.length <= 10000
+ 0 <= A[i] <= 10000
+
+ +
+ + + +## 解法 + + + +### Python3 + + +```python + +``` + +### Java + + +```java + +``` + +### ... +``` + +``` diff --git a/solution/0900-0999/0942.DI String Match/README.md b/solution/0900-0999/0942.DI String Match/README.md new file mode 100644 index 0000000000000..0fd87bac9f3fe --- /dev/null +++ b/solution/0900-0999/0942.DI String Match/README.md @@ -0,0 +1,65 @@ +# [942. 增减字符串匹配](https://leetcode-cn.com/problems/di-string-match) + +## 题目描述 + +
给定只含 "I"(增大)或 "D"(减小)的字符串 S ,令 N = S.length。
返回 [0, 1, ..., N] 的任意排列 A 使得对于所有 i = 0, ..., N-1,都有:
-
+
- 如果
S[i] == "I",那么A[i] < A[i+1]
+ - 如果
S[i] == "D",那么A[i] > A[i+1]
+
+ +
示例 1:
+ +输出:"IDID" +输出:[0,4,1,3,2] ++ +
示例 2:
+ +输出:"III" +输出:[0,1,2,3] ++ +
示例 3:
+ +输出:"DDI" +输出:[3,2,0,1]+ +
+ +
提示:
+ +-
+
1 <= S.length <= 10000
+ S只包含字符"I"或"D"。
+
给定一个字符串数组 A,找到以 A 中每个字符串作为子字符串的最短字符串。
我们可以假设 A 中没有字符串是 A 中另一个字符串的子字符串。
+ +
示例 1:
+ +输入:["alex","loves","leetcode"] +输出:"alexlovesleetcode" +解释:"alex","loves","leetcode" 的所有排列都会被接受。+ +
示例 2:
+ +输入:["catg","ctaagt","gcta","ttca","atgcatc"] +输出:"gctaagttcatgcatc"+ +
+ +
提示:
+ +-
+
1 <= A.length <= 12
+ 1 <= A[i].length <= 20
+
+ + + +## 解法 + + + +### Python3 + + +```python + +``` + +### Java + + +```java + +``` + +### ... +``` + +``` diff --git a/solution/0900-0999/0944.Delete Columns to Make Sorted/README.md b/solution/0900-0999/0944.Delete Columns to Make Sorted/README.md new file mode 100644 index 0000000000000..ddfcf7ef89f83 --- /dev/null +++ b/solution/0900-0999/0944.Delete Columns to Make Sorted/README.md @@ -0,0 +1,76 @@ +# [944. 删列造序](https://leetcode-cn.com/problems/delete-columns-to-make-sorted) + +## 题目描述 + +
给定由 N 个小写字母字符串组成的数组 A,其中每个字符串长度相等。
删除 操作的定义是:选出一组要删掉的列,删去 A 中对应列中的所有字符,形式上,第 n 列为 [A[0][n], A[1][n], ..., A[A.length-1][n]])。
比如,有 A = ["abcdef", "uvwxyz"],

要删掉的列为 {0, 2, 3},删除后 A 为["bef", "vyz"], A 的列分别为["b","v"], ["e","y"], ["f","z"]。
你需要选出一组要删掉的列 D,对 A 执行删除操作,使 A 中剩余的每一列都是 非降序 排列的,然后请你返回 D.length 的最小可能值。
+ +
示例 1:
+ +输入:["cba", "daf", "ghi"]
+输出:1
+解释:
+当选择 D = {1},删除后 A 的列为:["c","d","g"] 和 ["a","f","i"],均为非降序排列。
+若选择 D = {},那么 A 的列 ["b","a","h"] 就不是非降序排列了。
+
+
+示例 2:
+ +输入:["a", "b"]
+输出:0
+解释:D = {}
+
+
+示例 3:
+ +输入:["zyx", "wvu", "tsr"]
+输出:3
+解释:D = {0, 1, 2}
+
+
++ +
提示:
+ +-
+
1 <= A.length <= 100
+ 1 <= A[i].length <= 1000
+
给定整数数组 A,每次 move 操作将会选择任意 A[i],并将其递增 1。
返回使 A 中的每个值都是唯一的最少操作次数。
示例 1:
+ +输入:[1,2,2] +输出:1 +解释:经过一次 move 操作,数组将变为 [1, 2, 3]。+ +
示例 2:
+ +输入:[3,2,1,2,1,7] +输出:6 +解释:经过 6 次 move 操作,数组将变为 [3, 4, 1, 2, 5, 7]。 +可以看出 5 次或 5 次以下的 move 操作是不能让数组的每个值唯一的。 ++ +
提示:
+ +-
+
0 <= A.length <= 40000
+ 0 <= A[i] < 40000
+
给定 pushed 和 popped 两个序列,每个序列中的 值都不重复,只有当它们可能是在最初空栈上进行的推入 push 和弹出 pop 操作序列的结果时,返回 true;否则,返回 false 。
+ +
示例 1:
+ +输入:pushed = [1,2,3,4,5], popped = [4,5,3,2,1] +输出:true +解释:我们可以按以下顺序执行: +push(1), push(2), push(3), push(4), pop() -> 4, +push(5), pop() -> 5, pop() -> 3, pop() -> 2, pop() -> 1 ++ +
示例 2:
+ +输入:pushed = [1,2,3,4,5], popped = [4,3,5,1,2] +输出:false +解释:1 不能在 2 之前弹出。 ++ +
+ +
提示:
+ +-
+
0 <= pushed.length == popped.length <= 1000
+ 0 <= pushed[i], popped[i] < 1000
+ pushed是popped的排列。
+
在二维平面上,我们将石头放置在一些整数坐标点上。每个坐标点上最多只能有一块石头。
+
+现在,move 操作将会移除与网格上的某一块石头共享一列或一行的一块石头。
+
+我们最多能执行多少次 move 操作?
+ +
示例 1:
+ +输入:stones = [[0,0],[0,1],[1,0],[1,2],[2,1],[2,2]] +输出:5 ++ +
示例 2:
+ +输入:stones = [[0,0],[0,2],[1,1],[2,0],[2,2]] +输出:3 ++ +
示例 3:
+ +输入:stones = [[0,0]] +输出:0 ++ +
+ +
提示:
+ +-
+
1 <= stones.length <= 1000
+ 0 <= stones[i][j] < 10000
+
你的初始能量为 P,初始分数为 0,只有一包令牌。
令牌的值为 token[i],每个令牌最多只能使用一次,可能的两种使用方法如下:
-
+
- 如果你至少有
token[i]点能量,可以将令牌置为正面朝上,失去token[i]点能量,并得到1分。
+ - 如果我们至少有
1分,可以将令牌置为反面朝上,获得token[i]点能量,并失去1分。
+
在使用任意数量的令牌后,返回我们可以得到的最大分数。
+ ++ +
-
+
示例 1:
+ +输入:tokens = [100], P = 50 +输出:0 ++ +
示例 2:
+ +输入:tokens = [100,200], P = 150 +输出:1 ++ +
示例 3:
+ +输入:tokens = [100,200,300,400], P = 200 +输出:2 ++ +
+ +
提示:
+ +-
+
tokens.length <= 1000
+ 0 <= tokens[i] < 10000
+ 0 <= P < 10000
+
给定一个由 4 位数字组成的数组,返回可以设置的符合 24 小时制的最大时间。
+ +最小的 24 小时制时间是 00:00,而最大的是 23:59。从 00:00 (午夜)开始算起,过得越久,时间越大。
+ +以长度为 5 的字符串返回答案。如果不能确定有效时间,则返回空字符串。
+ ++ +
示例 1:
+ +输入:[1,2,3,4] +输出:"23:41" ++ +
示例 2:
+ +输入:[5,5,5,5] +输出:"" ++ +
+ +
提示:
+ +-
+
A.length == 4
+ 0 <= A[i] <= 9
+
牌组中的每张卡牌都对应有一个唯一的整数。你可以按你想要的顺序对这套卡片进行排序。
+ +最初,这些卡牌在牌组里是正面朝下的(即,未显示状态)。
+ +现在,重复执行以下步骤,直到显示所有卡牌为止:
+ +-
+
- 从牌组顶部抽一张牌,显示它,然后将其从牌组中移出。 +
- 如果牌组中仍有牌,则将下一张处于牌组顶部的牌放在牌组的底部。 +
- 如果仍有未显示的牌,那么返回步骤 1。否则,停止行动。 +
返回能以递增顺序显示卡牌的牌组顺序。
+ +答案中的第一张牌被认为处于牌堆顶部。
+ ++ +
示例:
+ +输入:[17,13,11,2,3,5,7] +输出:[2,13,3,11,5,17,7] +解释: +我们得到的牌组顺序为 [17,13,11,2,3,5,7](这个顺序不重要),然后将其重新排序。 +重新排序后,牌组以 [2,13,3,11,5,17,7] 开始,其中 2 位于牌组的顶部。 +我们显示 2,然后将 13 移到底部。牌组现在是 [3,11,5,17,7,13]。 +我们显示 3,并将 11 移到底部。牌组现在是 [5,17,7,13,11]。 +我们显示 5,然后将 17 移到底部。牌组现在是 [7,13,11,17]。 +我们显示 7,并将 13 移到底部。牌组现在是 [11,17,13]。 +我们显示 11,然后将 17 移到底部。牌组现在是 [13,17]。 +我们展示 13,然后将 17 移到底部。牌组现在是 [17]。 +我们显示 17。 +由于所有卡片都是按递增顺序排列显示的,所以答案是正确的。 ++ +
+ +
提示:
+ +-
+
1 <= A.length <= 1000
+ 1 <= A[i] <= 10^6
+ - 对于所有的
i != j,A[i] != A[j]
+
我们可以为二叉树 T 定义一个翻转操作,如下所示:选择任意节点,然后交换它的左子树和右子树。
+ +只要经过一定次数的翻转操作后,能使 X 等于 Y,我们就称二叉树 X 翻转等价于二叉树 Y。
+ +编写一个判断两个二叉树是否是翻转等价的函数。这些树由根节点 root1 和 root2 给出。
+ +
示例:
+ +输入:root1 = [1,2,3,4,5,6,null,null,null,7,8], root2 = [1,3,2,null,6,4,5,null,null,null,null,8,7] +输出:true +解释:We flipped at nodes with values 1, 3, and 5. ++ ++
+ +
提示:
+ +-
+
- 每棵树最多有
100个节点。
+ - 每棵树中的每个值都是唯一的、在
[0, 99]范围内的整数。
+
+ + + +## 解法 + + + +### Python3 + + +```python + +``` + +### Java + + +```java + +``` + +### ... +``` + +``` diff --git a/solution/0900-0999/0952.Largest Component Size by Common Factor/README.md b/solution/0900-0999/0952.Largest Component Size by Common Factor/README.md index be2c37bb17a86..ce6e02945d965 100644 --- a/solution/0900-0999/0952.Largest Component Size by Common Factor/README.md +++ b/solution/0900-0999/0952.Largest Component Size by Common Factor/README.md @@ -1,239 +1,72 @@ -## 按公因数计算最大组件大小 +# [952. 按公因数计算最大组件大小](https://leetcode-cn.com/problems/largest-component-size-by-common-factor) -### 问题描述 +## 题目描述 + +
给定一个由不同正整数的组成的非空数组 A,考虑下面的图:
-
+
- 有
A.length个节点,按从A[0]到A[A.length - 1]标记;
+ - 只有当
A[i]和A[j]共用一个大于 1 的公因数时,A[i]和A[j]之间才有一条边。
+
返回图中最大连通组件的大小。
-返回图中最大连通组件的大小。 +-**示例1:** +
-
+
示例 1:
-**示例2:** +输入:[4,6,15,35] +输出:4 +-``` -输入: [20,50,9,63] -输出: 2 -``` - ++

示例 2:
-**示例3** - -``` -输入: [2,3,6,7,4,12,21,39] -输出: 8 -``` +输入:[20,50,9,63] +输出:2 +- ++
示例 3:
-**提示:** +输入:[2,3,6,7,4,12,21,39] +输出:8 +-* `1 <= A.length <= 20000` ++
-* `1 <= A[i] <= 100000` +
提示:
-### 解法 +-
+
1 <= A.length <= 20000
+ 1 <= A[i] <= 100000
+
某种外星语也使用英文小写字母,但可能顺序 order 不同。字母表的顺序(order)是一些小写字母的排列。
给定一组用外星语书写的单词 words,以及其字母表的顺序 order,只有当给定的单词在这种外星语中按字典序排列时,返回 true;否则,返回 false。
+ +
示例 1:
+ +输入:words = ["hello","leetcode"], order = "hlabcdefgijkmnopqrstuvwxyz" +输出:true +解释:在该语言的字母表中,'h' 位于 'l' 之前,所以单词序列是按字典序排列的。+ +
示例 2:
+ +输入:words = ["word","world","row"], order = "worldabcefghijkmnpqstuvxyz" +输出:false +解释:在该语言的字母表中,'d' 位于 'l' 之后,那么 words[0] > words[1],因此单词序列不是按字典序排列的。+ +
示例 3:
+ +输入:words = ["apple","app"], order = "abcdefghijklmnopqrstuvwxyz" +输出:false +解释:当前三个字符 "app" 匹配时,第二个字符串相对短一些,然后根据词典编纂规则 "apple" > "app",因为 'l' > '∅',其中 '∅' 是空白字符,定义为比任何其他字符都小(更多信息)。 ++ +
+ +
提示:
+ +-
+
1 <= words.length <= 100
+ 1 <= words[i].length <= 20
+ order.length == 26
+ - 在
words[i]和order中的所有字符都是英文小写字母。
+
给定一个长度为偶数的整数数组 A,只有对 A 进行重组后可以满足 “对于每个 0 <= i < len(A) / 2,都有 A[2 * i + 1] = 2 * A[2 * i]” 时,返回 true;否则,返回 false。
+ +
示例 1:
+ +输入:[3,1,3,6] +输出:false ++ +
示例 2:
+ +输入:[2,1,2,6] +输出:false ++ +
示例 3:
+ +输入:[4,-2,2,-4] +输出:true +解释:我们可以用 [-2,-4] 和 [2,4] 这两组组成 [-2,-4,2,4] 或是 [2,4,-2,-4]+ +
示例 4:
+ +输入:[1,2,4,16,8,4] +输出:false ++ +
+ +
提示:
+ +-
+
0 <= A.length <= 30000
+ A.length为偶数
+ -100000 <= A[i] <= 100000
+
给定由 N 个小写字母字符串组成的数组 A,其中每个字符串长度相等。
选取一个删除索引序列,对于 A 中的每个字符串,删除对应每个索引处的字符。
比如,有 A = ["abcdef", "uvwxyz"],删除索引序列 {0, 2, 3},删除后 A 为["bef", "vyz"]。
假设,我们选择了一组删除索引 D,那么在执行删除操作之后,最终得到的数组的元素是按 字典序(A[0] <= A[1] <= A[2] ... <= A[A.length - 1])排列的,然后请你返回 D.length 的最小可能值。
-**示例1:** +
-
+
示例 1:
+ +输入:["ca","bb","ac"] +输出:1 +解释: +删除第一列后,A = ["a", "b", "c"]。 +现在 A 中元素是按字典排列的 (即,A[0] <= A[1] <= A[2])。 我们至少需要进行 1 次删除,因为最初 A 不是按字典序排列的,所以答案是 1。 -``` +-**示例2:** +
示例 2:
-``` -输入:["xc","yb","za"] -输出:0 -解释: +输入:["xc","yb","za"] +输出:0 +解释: A 的列已经是按字典序排列了,所以我们不需要删除任何东西。 注意 A 的行不需要按字典序排列。 -也就是说,A[0][0] <= A[0][1] <= ... 不一定成立。 -``` +也就是说,A[0][0] <= A[0][1] <= ... 不一定成立。 +-**示例3** +
示例 3:
-``` -输入:["zyx","wvu","tsr"] -输出:3 -解释: +输入:["zyx","wvu","tsr"] +输出:3 +解释: 我们必须删掉每一列。 -``` - -**提示:** - -- `1 <= A.length <= 100` -- `1 <= A[i].length <= 100` +-### 解法 +
-#### 基本解法 +
提示:
-原题中考虑的是对于某一列,我们是不是应该**删掉**它,那么反过来则可以考虑为:对于某一列,我们**保留**的条件是什么。 +-
+
1 <= A.length <= 100
+ 1 <= A[i].length <= 100
+
你正在安装一个广告牌,并希望它高度最大。这块广告牌将有两个钢制支架,两边各一个。每个钢支架的高度必须相等。
+ +你有一堆可以焊接在一起的钢筋 rods。举个例子,如果钢筋的长度为 1、2 和 3,则可以将它们焊接在一起形成长度为 6 的支架。
返回广告牌的最大可能安装高度。如果没法安装广告牌,请返回 0。
+ ++ +
示例 1:
+ +输入:[1,2,3,6]
+输出:6
+解释:我们有两个不相交的子集 {1,2,3} 和 {6},它们具有相同的和 sum = 6。
+
+
+示例 2:
+ +输入:[1,2,3,4,5,6]
+输出:10
+解释:我们有两个不相交的子集 {2,3,5} 和 {4,6},它们具有相同的和 sum = 10。
+
+示例 3:
+ +输入:[1,2] +输出:0 +解释:没法安装广告牌,所以返回 0。+ +
+ +
提示:
+ +-
+
0 <= rods.length <= 20
+ 1 <= rods[i] <= 1000
+ 钢筋的长度总和最多为 5000
+
8 间牢房排成一排,每间牢房不是有人住就是空着。
+ +每天,无论牢房是被占用或空置,都会根据以下规则进行更改:
+ +-
+
- 如果一间牢房的两个相邻的房间都被占用或都是空的,那么该牢房就会被占用。 +
- 否则,它就会被空置。 +
(请注意,由于监狱中的牢房排成一行,所以行中的第一个和最后一个房间无法有两个相邻的房间。)
+ +我们用以下方式描述监狱的当前状态:如果第 i 间牢房被占用,则 cell[i]==1,否则 cell[i]==0。
根据监狱的初始状态,在 N 天后返回监狱的状况(和上述 N 种变化)。
+ +
-
+
示例 1:
+ +输入:cells = [0,1,0,1,1,0,0,1], N = 7 +输出:[0,0,1,1,0,0,0,0] +解释: +下表概述了监狱每天的状况: +Day 0: [0, 1, 0, 1, 1, 0, 0, 1] +Day 1: [0, 1, 1, 0, 0, 0, 0, 0] +Day 2: [0, 0, 0, 0, 1, 1, 1, 0] +Day 3: [0, 1, 1, 0, 0, 1, 0, 0] +Day 4: [0, 0, 0, 0, 0, 1, 0, 0] +Day 5: [0, 1, 1, 1, 0, 1, 0, 0] +Day 6: [0, 0, 1, 0, 1, 1, 0, 0] +Day 7: [0, 0, 1, 1, 0, 0, 0, 0] + ++ +
示例 2:
+ +输入:cells = [1,0,0,1,0,0,1,0], N = 1000000000 +输出:[0,0,1,1,1,1,1,0] ++ +
+ +
提示:
+ +-
+
cells.length == 8
+ cells[i]的值为0或1
+ 1 <= N <= 10^9
+
给定一个二叉树,确定它是否是一个完全二叉树。
+ +百度百科中对完全二叉树的定义如下:
+ +若设二叉树的深度为 h,除第 h 层外,其它各层 (1~h-1) 的结点数都达到最大个数,第 h 层所有的结点都连续集中在最左边,这就是完全二叉树。(注:第 h 层可能包含 1~ 2h 个节点。)
+ ++ +
示例 1:
+ +
输入:[1,2,3,4,5,6]
+输出:true
+解释:最后一层前的每一层都是满的(即,结点值为 {1} 和 {2,3} 的两层),且最后一层中的所有结点({4,5,6})都尽可能地向左。
+
+
+示例 2:
+ +
输入:[1,2,3,4,5,null,7] +输出:false +解释:值为 7 的结点没有尽可能靠向左侧。 ++ +
+ +
提示:
+ +-
+
- 树中将会有 1 到 100 个结点。 +
在由 1 x 1 方格组成的 N x N 网格 grid 中,每个 1 x 1 方块由 /、\ 或空格构成。这些字符会将方块划分为一些共边的区域。
(请注意,反斜杠字符是转义的,因此 \ 用 "\\" 表示。)。
返回区域的数目。
+ ++ +
-
+
示例 1:
+ +输入: +[ + " /", + "/ " +] +输出:2 +解释:2x2 网格如下: ++ +
示例 2:
+ +输入: +[ + " /", + " " +] +输出:1 +解释:2x2 网格如下: ++ +
示例 3:
+ +输入: +[ + "\\/", + "/\\" +] +输出:4 +解释:(回想一下,因为 \ 字符是转义的,所以 "\\/" 表示 \/,而 "/\\" 表示 /\。) +2x2 网格如下: ++ +
示例 4:
+ +输入: +[ + "/\\", + "\\/" +] +输出:5 +解释:(回想一下,因为 \ 字符是转义的,所以 "/\\" 表示 /\,而 "\\/" 表示 \/。) +2x2 网格如下: ++ +
示例 5:
+ +输入: +[ + "//", + "/ " +] +输出:3 +解释:2x2 网格如下: ++ ++
+ +
提示:
+ +-
+
1 <= grid.length == grid[0].length <= 30
+ grid[i][j]是'/'、'\'、或' '。
+
给定由 N 个小写字母字符串组成的数组 A,其中每个字符串长度相等。
选取一个删除索引序列,对于 A 中的每个字符串,删除对应每个索引处的字符。
比如,有 A = ["babca","bbazb"],删除索引序列 {0, 1, 4},删除后 A 为["bc","az"]。
假设,我们选择了一组删除索引 D,那么在执行删除操作之后,最终得到的数组的行中的每个元素都是按字典序排列的。
清楚起见,A[0] 是按字典序排列的(即,A[0][0] <= A[0][1] <= ... <= A[0][A[0].length - 1]),A[1] 是按字典序排列的(即,A[1][0] <= A[1][1] <= ... <= A[1][A[1].length - 1]),依此类推。
请你返回 D.length 的最小可能值。
+ +
示例 1:
+ +输入:["babca","bbazb"] +输出:3 +解释: +删除 0、1 和 4 这三列后,最终得到的数组是 A = ["bc", "az"]。 +这两行是分别按字典序排列的(即,A[0][0] <= A[0][1] 且 A[1][0] <= A[1][1])。 +注意,A[0] > A[1] —— 数组 A 不一定是按字典序排列的。 ++ +
示例 2:
+ +输入:["edcba"] +输出:4 +解释:如果删除的列少于 4 列,则剩下的行都不会按字典序排列。 ++ +
示例 3:
+ +输入:["ghi","def","abc"] +输出:0 +解释:所有行都已按字典序排列。 ++ +
+ +
提示:
+ +-
+
1 <= A.length <= 100
+ 1 <= A[i].length <= 100
+
在大小为 2N 的数组 A 中有 N+1 个不同的元素,其中有一个元素重复了 N 次。
返回重复了 N 次的那个元素。
-**示例1:** +
-
+
示例 1:
-**示例2:** +输入:[1,2,3,3] +输出:3 +-``` -输入:[2,1,2,5,3,2] -输出:2 -``` +
示例 2:
-**示例3:** +输入:[2,1,2,5,3,2] +输出:2 ++ +
示例 3:
+ +输入:[5,1,5,2,5,3,5,4] +输出:5 ++ +
+ +
提示:
+ +-
+
4 <= A.length <= 10000
+ 0 <= A[i] < 10000
+ A.length为偶数
+
给定一个整数数组 A,坡是元组 (i, j),其中 i < j 且 A[i] <= A[j]。这样的坡的宽度为 j - i。
找出 A 中的坡的最大宽度,如果不存在,返回 0 。
+ +
示例 1:
+ +输入:[6,0,8,2,1,5] +输出:4 +解释: +最大宽度的坡为 (i, j) = (1, 5): A[1] = 0 且 A[5] = 5. ++ +
示例 2:
+ +输入:[9,8,1,0,1,9,4,0,4,1] +输出:7 +解释: +最大宽度的坡为 (i, j) = (2, 9): A[2] = 1 且 A[9] = 1. ++ +
+ +
提示:
+ +-
+
2 <= A.length <= 50000
+ 0 <= A[i] <= 50000
+
+ + + +## 解法 + + + +### Python3 + + +```python + +``` + +### Java + + +```java + +``` + +### ... +``` + +``` diff --git a/solution/0900-0999/0963.Minimum Area Rectangle II/README.md b/solution/0900-0999/0963.Minimum Area Rectangle II/README.md new file mode 100644 index 0000000000000..b772113b075f4 --- /dev/null +++ b/solution/0900-0999/0963.Minimum Area Rectangle II/README.md @@ -0,0 +1,81 @@ +# [963. 最小面积矩形 II](https://leetcode-cn.com/problems/minimum-area-rectangle-ii) + +## 题目描述 + +
给定在 xy 平面上的一组点,确定由这些点组成的任何矩形的最小面积,其中矩形的边不一定平行于 x 轴和 y 轴。
+ +如果没有任何矩形,就返回 0。
+ ++ +
示例 1:
+ +
输入:[[1,2],[2,1],[1,0],[0,1]] +输出:2.00000 +解释:最小面积的矩形出现在 [1,2],[2,1],[1,0],[0,1] 处,面积为 2。+ +
示例 2:
+ +
输入:[[0,1],[2,1],[1,1],[1,0],[2,0]] +输出:1.00000 +解释:最小面积的矩形出现在 [1,0],[1,1],[2,1],[2,0] 处,面积为 1。 ++ +
示例 3:
+ +
输入:[[0,3],[1,2],[3,1],[1,3],[2,1]] +输出:0 +解释:没法从这些点中组成任何矩形。 ++ +
示例 4:
+ +
输入:[[3,1],[1,1],[0,1],[2,1],[3,3],[3,2],[0,2],[2,3]] +输出:2.00000 +解释:最小面积的矩形出现在 [2,1],[2,3],[3,3],[3,1] 处,面积为 2。 ++ +
+ +
提示:
+ +-
+
1 <= points.length <= 50
+ 0 <= points[i][0] <= 40000
+ 0 <= points[i][1] <= 40000
+ - 所有的点都是不同的。 +
- 与真实值误差不超过
10^-5的答案将视为正确结果。
+
给定一个正整数 x,我们将会写出一个形如 x (op1) x (op2) x (op3) x ... 的表达式,其中每个运算符 op1,op2,… 可以是加、减、乘、除(+,-,*,或是 /)之一。例如,对于 x = 3,我们可以写出表达式 3 * 3 / 3 + 3 - 3,该式的值为 3 。
在写这样的表达式时,我们需要遵守下面的惯例:
+ +-
+
- 除运算符(
/)返回有理数。
+ - 任何地方都没有括号。 +
- 我们使用通常的操作顺序:乘法和除法发生在加法和减法之前。 +
- 不允许使用一元否定运算符(
-)。例如,“x - x” 是一个有效的表达式,因为它只使用减法,但是 “-x + x” 不是,因为它使用了否定运算符。
+
我们希望编写一个能使表达式等于给定的目标值 target 且运算符最少的表达式。返回所用运算符的最少数量。
+ +
示例 1:
+ +输入:x = 3, target = 19 +输出:5 +解释:3 * 3 + 3 * 3 + 3 / 3 。表达式包含 5 个运算符。 ++ +
示例 2:
+ +输入:x = 5, target = 501 +输出:8 +解释:5 * 5 * 5 * 5 - 5 * 5 * 5 + 5 / 5 。表达式包含 8 个运算符。 ++ +
示例 3:
+ +输入:x = 100, target = 100000000 +输出:3 +解释:100 * 100 * 100 * 100 。表达式包含 3 个运算符。+ +
+ +
提示:
+ +-
+
2 <= x <= 100
+ 1 <= target <= 2 * 10^8
+
+ + + +## 解法 + + + +### Python3 + + +```python + +``` + +### Java + + +```java + +``` + +### ... +``` + +``` diff --git a/solution/0900-0999/0965.Univalued Binary Tree/README.md b/solution/0900-0999/0965.Univalued Binary Tree/README.md new file mode 100644 index 0000000000000..ac29d2c0601c7 --- /dev/null +++ b/solution/0900-0999/0965.Univalued Binary Tree/README.md @@ -0,0 +1,59 @@ +# [965. 单值二叉树](https://leetcode-cn.com/problems/univalued-binary-tree) + +## 题目描述 + +
如果二叉树每个节点都具有相同的值,那么该二叉树就是单值二叉树。
+ +只有给定的树是单值二叉树时,才返回 true;否则返回 false。
+ +
示例 1:
+ +
输入:[1,1,1,1,1,null,1] +输出:true ++ +
示例 2:
+ +
输入:[2,2,2,5,2] +输出:false ++ +
+ +
提示:
+ +-
+
- 给定树的节点数范围是
[1, 100]。
+ - 每个节点的值都是整数,范围为
[0, 99]。
+
在给定单词列表 wordlist 的情况下,我们希望实现一个拼写检查器,将查询单词转换为正确的单词。
对于给定的查询单词 query,拼写检查器将会处理两类拼写错误:
-
+
- 大小写:如果查询匹配单词列表中的某个单词(不区分大小写),则返回的正确单词与单词列表中的大小写相同。
+
+
-
+
- 例如:
wordlist = ["yellow"],query = "YellOw":correct = "yellow"
+ - 例如:
wordlist = ["Yellow"],query = "yellow":correct = "Yellow"
+ - 例如:
wordlist = ["yellow"],query = "yellow":correct = "yellow"
+
+ - 例如:
- 元音错误:如果在将查询单词中的元音(‘a’、‘e’、‘i’、‘o’、‘u’)分别替换为任何元音后,能与单词列表中的单词匹配(不区分大小写),则返回的正确单词与单词列表中的匹配项大小写相同。
+
-
+
- 例如:
wordlist = ["YellOw"],query = "yollow":correct = "YellOw"
+ - 例如:
wordlist = ["YellOw"],query = "yeellow":correct = ""(无匹配项)
+ - 例如:
wordlist = ["YellOw"],query = "yllw":correct = ""(无匹配项)
+
+ - 例如:
此外,拼写检查器还按照以下优先级规则操作:
+ +-
+
- 当查询完全匹配单词列表中的某个单词(区分大小写)时,应返回相同的单词。 +
- 当查询匹配到大小写问题的单词时,您应该返回单词列表中的第一个这样的匹配项。 +
- 当查询匹配到元音错误的单词时,您应该返回单词列表中的第一个这样的匹配项。 +
- 如果该查询在单词列表中没有匹配项,则应返回空字符串。 +
给出一些查询 queries,返回一个单词列表 answer,其中 answer[i] 是由查询 query = queries[i] 得到的正确单词。
+ +
示例:
+ +输入:wordlist = ["KiTe","kite","hare","Hare"], queries = ["kite","Kite","KiTe","Hare","HARE","Hear","hear","keti","keet","keto"] +输出:["kite","KiTe","KiTe","Hare","hare","","","KiTe","","KiTe"]+ +
+ +
提示:
+ +-
+
1 <= wordlist.length <= 5000
+ 1 <= queries.length <= 5000
+ 1 <= wordlist[i].length <= 7
+ 1 <= queries[i].length <= 7
+ wordlist和queries中的所有字符串仅由英文字母组成。
+
返回所有长度为 N 且满足其每两个连续位上的数字之间的差的绝对值为 K 的非负整数。
请注意,除了数字 0 本身之外,答案中的每个数字都不能有前导零。例如,01 因为有一个前导零,所以是无效的;但 0 是有效的。
你可以按任何顺序返回答案。
+ ++ +
示例 1:
+ +输入:N = 3, K = 7 +输出:[181,292,707,818,929] +解释:注意,070 不是一个有效的数字,因为它有前导零。 ++ +
示例 2:
+ +输入:N = 2, K = 1 +输出:[10,12,21,23,32,34,43,45,54,56,65,67,76,78,87,89,98]+ +
+ +
提示:
+ +-
+
1 <= N <= 9
+ 0 <= K <= 9
+
给定一个二叉树,我们在树的节点上安装摄像头。
+ +节点上的每个摄影头都可以监视其父对象、自身及其直接子对象。
+ +计算监控树的所有节点所需的最小摄像头数量。
+ ++ +
示例 1:
+ +
输入:[0,0,null,0,0] +输出:1 +解释:如图所示,一台摄像头足以监控所有节点。 ++ +
示例 2:
+ +
输入:[0,0,null,0,null,0,null,null,0] +输出:2 +解释:需要至少两个摄像头来监视树的所有节点。 上图显示了摄像头放置的有效位置之一。 ++ +
+提示:
-
+
- 给定树的节点数的范围是
[1, 1000]。
+ - 每个节点的值都是 0。 +
给定数组 A,我们可以对其进行煎饼翻转:我们选择一些正整数 k <= A.length,然后反转 A 的前 k 个元素的顺序。我们要执行零次或多次煎饼翻转(按顺序一次接一次地进行)以完成对数组 A 的排序。
返回能使 A 排序的煎饼翻转操作所对应的 k 值序列。任何将数组排序且翻转次数在 10 * A.length 范围内的有效答案都将被判断为正确。
+ +
示例 1:
+ +输入:[3,2,4,1] +输出:[4,2,4,3] +解释: +我们执行 4 次煎饼翻转,k 值分别为 4,2,4,和 3。 +初始状态 A = [3, 2, 4, 1] +第一次翻转后 (k=4): A = [1, 4, 2, 3] +第二次翻转后 (k=2): A = [4, 1, 2, 3] +第三次翻转后 (k=4): A = [3, 2, 1, 4] +第四次翻转后 (k=3): A = [1, 2, 3, 4],此时已完成排序。 ++ +
示例 2:
+ +输入:[1,2,3] +输出:[] +解释: +输入已经排序,因此不需要翻转任何内容。 +请注意,其他可能的答案,如[3,3],也将被接受。 ++ +
+ +
提示:
+ +-
+
1 <= A.length <= 100
+ A[i]是[1, 2, ..., A.length]的排列
+
给定两个正整数 x 和 y,如果某一整数等于 x^i + y^j,其中整数 i >= 0 且 j >= 0,那么我们认为该整数是一个强整数。
返回值小于或等于 bound 的所有强整数组成的列表。
你可以按任何顺序返回答案。在你的回答中,每个值最多出现一次。
+ ++ +
示例 1:
+ +输入:x = 2, y = 3, bound = 10 +输出:[2,3,4,5,7,9,10] +解释: +2 = 2^0 + 3^0 +3 = 2^1 + 3^0 +4 = 2^0 + 3^1 +5 = 2^1 + 3^1 +7 = 2^2 + 3^1 +9 = 2^3 + 3^0 +10 = 2^0 + 3^2 ++ +
示例 2:
+ +输入:x = 3, y = 5, bound = 15 +输出:[2,4,6,8,10,14] ++ +
+ +
提示:
+ +-
+
1 <= x <= 100
+ 1 <= y <= 100
+ 0 <= bound <= 10^6
+
给定一个有 N 个节点的二叉树,每个节点都有一个不同于其他节点且处于 {1, ..., N} 中的值。
通过交换节点的左子节点和右子节点,可以翻转该二叉树中的节点。
+ +考虑从根节点开始的先序遍历报告的 N 值序列。将这一 N 值序列称为树的行程。
(回想一下,节点的先序遍历意味着我们报告当前节点的值,然后先序遍历左子节点,再先序遍历右子节点。)
+ +我们的目标是翻转最少的树中节点,以便树的行程与给定的行程 voyage 相匹配。
如果可以,则返回翻转的所有节点的值的列表。你可以按任何顺序返回答案。
+ +如果不能,则返回列表 [-1]。
+ +
示例 1:
+ +
输入:root = [1,2], voyage = [2,1] +输出:[-1] ++ +
示例 2:
+ +
输入:root = [1,2,3], voyage = [1,3,2] +输出:[1] ++ +
示例 3:
+ +
输入:root = [1,2,3], voyage = [1,2,3] +输出:[] ++ +
+ +
提示:
+ +-
+
1 <= N <= 100
+
给定两个字符串 S 和 T,每个字符串代表一个非负有理数,只有当它们表示相同的数字时才返回 true;否则,返回 false。字符串中可以使用括号来表示有理数的重复部分。
通常,有理数最多可以用三个部分来表示:整数部分 <IntegerPart>、小数非重复部分 <NonRepeatingPart> 和小数重复部分 <(><RepeatingPart><)>。数字可以用以下三种方法之一来表示:
-
+
<IntegerPart>(例:0,12,123)
+ <IntegerPart><.><NonRepeatingPart>(例:0.5,2.12,2.0001)
+ <IntegerPart><.><NonRepeatingPart><(><RepeatingPart><)>(例:0.1(6),0.9(9),0.00(1212))
+
十进制展开的重复部分通常在一对圆括号内表示。例如:
+ +1 / 6 = 0.16666666... = 0.1(6) = 0.1666(6) = 0.166(66)
+ +0.1(6) 或 0.1666(6) 或 0.166(66) 都是 1 / 6 的正确表示形式。
+ ++ +
示例 1:
+ +输入:S = "0.(52)", T = "0.5(25)" +输出:true +解释:因为 "0.(52)" 代表 0.52525252...,而 "0.5(25)" 代表 0.52525252525.....,则这两个字符串表示相同的数字。 ++ +
示例 2:
+ +输入:S = "0.1666(6)", T = "0.166(66)" +输出:true ++ +
示例 3:
+ +输入:S = "0.9(9)", T = "1." +输出:true +解释: +"0.9(9)" 代表 0.999999999... 永远重复,等于 1 。[有关说明,请参阅此链接] +"1." 表示数字 1,其格式正确:(IntegerPart) = "1" 且 (NonRepeatingPart) = "" 。+ +
+ +
提示:
+ +-
+
- 每个部分仅由数字组成。 +
- 整数部分
<IntegerPart>不会以 2 个或更多的零开头。(对每个部分的数字没有其他限制)。
+ 1 <= <IntegerPart>.length <= 4
+ 0 <= <NonRepeatingPart>.length <= 4
+ 1 <= <RepeatingPart>.length <= 4
+
我们有一个由平面上的点组成的列表 points。需要从中找出 K 个距离原点 (0, 0) 最近的点。
(这里,平面上两点之间的距离是欧几里德距离。)
+ +你可以按任何顺序返回答案。除了点坐标的顺序之外,答案确保是唯一的。
+ ++ +
示例 1:
+ +输入:points = [[1,3],[-2,2]], K = 1 +输出:[[-2,2]] +解释: +(1, 3) 和原点之间的距离为 sqrt(10), +(-2, 2) 和原点之间的距离为 sqrt(8), +由于 sqrt(8) < sqrt(10),(-2, 2) 离原点更近。 +我们只需要距离原点最近的 K = 1 个点,所以答案就是 [[-2,2]]。 ++ +
示例 2:
+ +输入:points = [[3,3],[5,-1],[-2,4]], K = 2 +输出:[[3,3],[-2,4]] +(答案 [[-2,4],[3,3]] 也会被接受。) ++ +
+ +
提示:
+ +-
+
1 <= K <= points.length <= 10000
+ -10000 < points[i][0] < 10000
+ -10000 < points[i][1] < 10000
+
给定一个整数数组 A,返回其中元素之和可被 K 整除的(连续、非空)子数组的数目。
+ +
示例:
+ +输入:A = [4,5,0,-2,-3,1], K = 5 +输出:7 +解释: +有 7 个子数组满足其元素之和可被 K = 5 整除: +[4, 5, 0, -2, -3, 1], [5], [5, 0], [5, 0, -2, -3], [0], [0, -2, -3], [-2, -3] ++ +
+ +
提示:
+ +-
+
1 <= A.length <= 30000
+ -10000 <= A[i] <= 10000
+ 2 <= K <= 10000
+
给定一个整数数组 A,你可以从某一起始索引出发,跳跃一定次数。在你跳跃的过程中,第 1、3、5... 次跳跃称为奇数跳跃,而第 2、4、6... 次跳跃称为偶数跳跃。
你可以按以下方式从索引 i 向后跳转到索引 j(其中 i < j):
-
+
- 在进行奇数跳跃时(如,第 1,3,5... 次跳跃),你将会跳到索引
j,使得A[i] <= A[j],A[j]是可能的最小值。如果存在多个这样的索引j,你只能跳到满足要求的最小索引j上。
+ - 在进行偶数跳跃时(如,第 2,4,6... 次跳跃),你将会跳到索引
j,使得A[i] => A[j],A[j]是可能的最大值。如果存在多个这样的索引j,你只能跳到满足要求的最小索引j上。
+ - (对于某些索引
i,可能无法进行合乎要求的跳跃。)
+
如果从某一索引开始跳跃一定次数(可能是 0 次或多次),就可以到达数组的末尾(索引 A.length - 1),那么该索引就会被认为是好的起始索引。
返回好的起始索引的数量。
+ ++ +
示例 1:
+ +输入:[10,13,12,14,15] +输出:2 +解释: +从起始索引 i = 0 出发,我们可以跳到 i = 2,(因为 A[2] 是 A[1],A[2],A[3],A[4] 中大于或等于 A[0] 的最小值),然后我们就无法继续跳下去了。 +从起始索引 i = 1 和 i = 2 出发,我们可以跳到 i = 3,然后我们就无法继续跳下去了。 +从起始索引 i = 3 出发,我们可以跳到 i = 4,到达数组末尾。 +从起始索引 i = 4 出发,我们已经到达数组末尾。 +总之,我们可以从 2 个不同的起始索引(i = 3, i = 4)出发,通过一定数量的跳跃到达数组末尾。 ++ +
示例 2:
+ +输入:[2,3,1,1,4] +输出:3 +解释: +从起始索引 i=0 出发,我们依次可以跳到 i = 1,i = 2,i = 3: + +在我们的第一次跳跃(奇数)中,我们先跳到 i = 1,因为 A[1] 是(A[1],A[2],A[3],A[4])中大于或等于 A[0] 的最小值。 + +在我们的第二次跳跃(偶数)中,我们从 i = 1 跳到 i = 2,因为 A[2] 是(A[2],A[3],A[4])中小于或等于 A[1] 的最大值。A[3] 也是最大的值,但 2 是一个较小的索引,所以我们只能跳到 i = 2,而不能跳到 i = 3。 + +在我们的第三次跳跃(奇数)中,我们从 i = 2 跳到 i = 3,因为 A[3] 是(A[3],A[4])中大于或等于 A[2] 的最小值。 + +我们不能从 i = 3 跳到 i = 4,所以起始索引 i = 0 不是好的起始索引。 + +类似地,我们可以推断: +从起始索引 i = 1 出发, 我们跳到 i = 4,这样我们就到达数组末尾。 +从起始索引 i = 2 出发, 我们跳到 i = 3,然后我们就不能再跳了。 +从起始索引 i = 3 出发, 我们跳到 i = 4,这样我们就到达数组末尾。 +从起始索引 i = 4 出发,我们已经到达数组末尾。 +总之,我们可以从 3 个不同的起始索引(i = 1, i = 3, i = 4)出发,通过一定数量的跳跃到达数组末尾。 ++ +
示例 3:
+ +输入:[5,1,3,4,2] +输出:3 +解释: +我们可以从起始索引 1,2,4 出发到达数组末尾。 ++ +
+ +
提示:
+ +-
+
1 <= A.length <= 20000
+ 0 <= A[i] < 100000
+
给定由一些正数(代表长度)组成的数组 A,返回由其中三个长度组成的、面积不为零的三角形的最大周长。
如果不能形成任何面积不为零的三角形,返回 0。
+ +
-
+
示例 1:
+ +输入:[2,1,2] +输出:5 ++ +
示例 2:
+ +输入:[1,2,1] +输出:0 ++ +
示例 3:
+ +输入:[3,2,3,4] +输出:10 ++ +
示例 4:
+ +输入:[3,6,2,3] +输出:8 ++ +
+ +
提示:
+ +-
+
3 <= A.length <= 10000
+ 1 <= A[i] <= 10^6
+
给定一个按非递减顺序排序的整数数组 A,返回每个数字的平方组成的新数组,要求也按非递减顺序排序。
-**示例 1:** -``` -输入:[-4,-1,0,3,10] -输出:[0,1,9,16,100] -``` +
示例 1:
+ +输入:[-4,-1,0,3,10] +输出:[0,1,9,16,100] ++ +
示例 2:
+ +输入:[-7,-3,2,3,11] +输出:[4,9,9,49,121] ++ +
+ +
提示:
+ +-
+
1 <= A.length <= 10000
+ -10000 <= A[i] <= 10000
+ A已按非递减顺序排序。
+
当 A 的子数组 A[i], A[i+1], ..., A[j] 满足下列条件时,我们称其为湍流子数组:
-
+
- 若
i <= k < j,当k为奇数时,A[k] > A[k+1],且当k为偶数时,A[k] < A[k+1];
+ - 或 若
i <= k < j,当k为偶数时,A[k] > A[k+1],且当k为奇数时,A[k] < A[k+1]。
+
也就是说,如果比较符号在子数组中的每个相邻元素对之间翻转,则该子数组是湍流子数组。
+ +返回 A 的最大湍流子数组的长度。
+ +
示例 1:
+ +输入:[9,4,2,10,7,8,8,1,9] +输出:5 +解释:(A[1] > A[2] < A[3] > A[4] < A[5]) ++ +
示例 2:
+ +输入:[4,8,12,16] +输出:2 ++ +
示例 3:
+ +输入:[100] +输出:1 ++ +
+ +
提示:
+ +-
+
1 <= A.length <= 40000
+ 0 <= A[i] <= 10^9
+
给定一个有 N 个结点的二叉树的根结点 root,树中的每个结点上都对应有 node.val 枚硬币,并且总共有 N 枚硬币。
在一次移动中,我们可以选择两个相邻的结点,然后将一枚硬币从其中一个结点移动到另一个结点。(移动可以是从父结点到子结点,或者从子结点移动到父结点。)。
+ +返回使每个结点上只有一枚硬币所需的移动次数。
+ ++ +
示例 1:
+ +
输入:[3,0,0] +输出:2 +解释:从树的根结点开始,我们将一枚硬币移到它的左子结点上,一枚硬币移到它的右子结点上。 ++ +
示例 2:
+ +
输入:[0,3,0] +输出:3 +解释:从根结点的左子结点开始,我们将两枚硬币移到根结点上 [移动两次]。然后,我们把一枚硬币从根结点移到右子结点上。 ++ +
示例 3:
+ +
输入:[1,0,2] +输出:2 ++ +
示例 4:
+ +
输入:[1,0,0,null,3] +输出:4 ++ +
+ +
提示:
+ +-
+
1<= N <= 100
+ 0 <= node.val <= N
+
在二维网格 grid 上,有 4 种类型的方格:
-
+
1表示起始方格。且只有一个起始方格。
+ 2表示结束方格,且只有一个结束方格。
+ 0表示我们可以走过的空方格。
+ -1表示我们无法跨越的障碍。
+
返回在四个方向(上、下、左、右)上行走时,从起始方格到结束方格的不同路径的数目,每一个无障碍方格都要通过一次。
+ ++ +
示例 1:
+ +输入:[[1,0,0,0],[0,0,0,0],[0,0,2,-1]] +输出:2 +解释:我们有以下两条路径: +1. (0,0),(0,1),(0,2),(0,3),(1,3),(1,2),(1,1),(1,0),(2,0),(2,1),(2,2) +2. (0,0),(1,0),(2,0),(2,1),(1,1),(0,1),(0,2),(0,3),(1,3),(1,2),(2,2)+ +
示例 2:
+ +输入:[[1,0,0,0],[0,0,0,0],[0,0,0,2]] +输出:4 +解释:我们有以下四条路径: +1. (0,0),(0,1),(0,2),(0,3),(1,3),(1,2),(1,1),(1,0),(2,0),(2,1),(2,2),(2,3) +2. (0,0),(0,1),(1,1),(1,0),(2,0),(2,1),(2,2),(1,2),(0,2),(0,3),(1,3),(2,3) +3. (0,0),(1,0),(2,0),(2,1),(2,2),(1,2),(1,1),(0,1),(0,2),(0,3),(1,3),(2,3) +4. (0,0),(1,0),(2,0),(2,1),(1,1),(0,1),(0,2),(0,3),(1,3),(1,2),(2,2),(2,3)+ +
示例 3:
+ +输入:[[0,1],[2,0]] +输出:0 +解释: +没有一条路能完全穿过每一个空的方格一次。 +请注意,起始和结束方格可以位于网格中的任意位置。 ++ +
+ +
提示:
+ +-
+
1 <= grid.length * grid[0].length <= 20
+
创建一个基于时间的键值存储类 TimeMap,它支持下面两个操作:
1. set(string key, string value, int timestamp)
-
+
- 存储键
key、值value,以及给定的时间戳timestamp。
+
2. get(string key, int timestamp)
-
+
- 返回先前调用
set(key, value, timestamp_prev)所存储的值,其中timestamp_prev <= timestamp。
+ - 如果有多个这样的值,则返回对应最大的
timestamp_prev的那个值。
+ - 如果没有值,则返回空字符串(
"")。
+
+ +
示例 1:
+ +输入:inputs = ["TimeMap","set","get","get","set","get","get"], inputs = [[],["foo","bar",1],["foo",1],["foo",3],["foo","bar2",4],["foo",4],["foo",5]]
+输出:[null,null,"bar","bar",null,"bar2","bar2"]
+解释:
+TimeMap kv;
+kv.set("foo", "bar", 1); // 存储键 "foo" 和值 "bar" 以及时间戳 timestamp = 1
+kv.get("foo", 1); // 输出 "bar"
+kv.get("foo", 3); // 输出 "bar" 因为在时间戳 3 和时间戳 2 处没有对应 "foo" 的值,所以唯一的值位于时间戳 1 处(即 "bar")
+kv.set("foo", "bar2", 4);
+kv.get("foo", 4); // 输出 "bar2"
+kv.get("foo", 5); // 输出 "bar2"
+
+
+
+示例 2:
+ +输入:inputs = ["TimeMap","set","set","get","get","get","get","get"], inputs = [[],["love","high",10],["love","low",20],["love",5],["love",10],["love",15],["love",20],["love",25]] +输出:[null,null,null,"","high","high","low","low"] ++ +
+ +
提示:
+ +-
+
- 所有的键/值字符串都是小写的。 +
- 所有的键/值字符串长度都在
[1, 100]范围内。
+ - 所有
TimeMap.set操作中的时间戳timestamps都是严格递增的。
+ 1 <= timestamp <= 10^7
+ TimeMap.set和TimeMap.get函数在每个测试用例中将(组合)调用总计120000次。
+
给定一个整数数组 A,找出索引为 (i, j, k) 的三元组,使得:
-
+
0 <= i < A.length
+ 0 <= j < A.length
+ 0 <= k < A.length
+ A[i] & A[j] & A[k] == 0,其中&表示按位与(AND)操作符。
+
+ +
示例:
+ +输入:[2,1,3] +输出:12 +解释:我们可以选出如下 i, j, k 三元组: +(i=0, j=0, k=1) : 2 & 2 & 1 +(i=0, j=1, k=0) : 2 & 1 & 2 +(i=0, j=1, k=1) : 2 & 1 & 1 +(i=0, j=1, k=2) : 2 & 1 & 3 +(i=0, j=2, k=1) : 2 & 3 & 1 +(i=1, j=0, k=0) : 1 & 2 & 2 +(i=1, j=0, k=1) : 1 & 2 & 1 +(i=1, j=0, k=2) : 1 & 2 & 3 +(i=1, j=1, k=0) : 1 & 1 & 2 +(i=1, j=2, k=0) : 1 & 3 & 2 +(i=2, j=0, k=1) : 3 & 2 & 1 +(i=2, j=1, k=0) : 3 & 1 & 2 ++ +
+ +
提示:
+ +-
+
1 <= A.length <= 1000
+ 0 <= A[i] < 2^16
+
在一个火车旅行很受欢迎的国度,你提前一年计划了一些火车旅行。在接下来的一年里,你要旅行的日子将以一个名为 days 的数组给出。每一项是一个从 1 到 365 的整数。
火车票有三种不同的销售方式:
+ +-
+
- 一张为期一天的通行证售价为
costs[0]美元;
+ - 一张为期七天的通行证售价为
costs[1]美元;
+ - 一张为期三十天的通行证售价为
costs[2]美元。
+
通行证允许数天无限制的旅行。 例如,如果我们在第 2 天获得一张为期 7 天的通行证,那么我们可以连着旅行 7 天:第 2 天、第 3 天、第 4 天、第 5 天、第 6 天、第 7 天和第 8 天。
+ +返回你想要完成在给定的列表 days 中列出的每一天的旅行所需要的最低消费。
+ +
示例 1:
+ +输入:days = [1,4,6,7,8,20], costs = [2,7,15] +输出:11 +解释: +例如,这里有一种购买通行证的方法,可以让你完成你的旅行计划: +在第 1 天,你花了 costs[0] = $2 买了一张为期 1 天的通行证,它将在第 1 天生效。 +在第 3 天,你花了 costs[1] = $7 买了一张为期 7 天的通行证,它将在第 3, 4, ..., 9 天生效。 +在第 20 天,你花了 costs[0] = $2 买了一张为期 1 天的通行证,它将在第 20 天生效。 +你总共花了 $11,并完成了你计划的每一天旅行。 ++ +
示例 2:
+ +输入:days = [1,2,3,4,5,6,7,8,9,10,30,31], costs = [2,7,15] +输出:17 +解释: +例如,这里有一种购买通行证的方法,可以让你完成你的旅行计划: +在第 1 天,你花了 costs[2] = $15 买了一张为期 30 天的通行证,它将在第 1, 2, ..., 30 天生效。 +在第 31 天,你花了 costs[0] = $2 买了一张为期 1 天的通行证,它将在第 31 天生效。 +你总共花了 $17,并完成了你计划的每一天旅行。 ++ +
+ +
提示:
+ +-
+
1 <= days.length <= 365
+ 1 <= days[i] <= 365
+ days按顺序严格递增
+ costs.length == 3
+ 1 <= costs[i] <= 1000
+
给定两个整数 A 和 B,返回任意字符串 S,要求满足:
-
+
S的长度为A + B,且正好包含A个'a'字母与B个'b'字母;
+ - 子串
'aaa'没有出现在S中;
+ - 子串
'bbb'没有出现在S中。
+
+ +
示例 1:
+ +输入:A = 1, B = 2 +输出:"abb" +解释:"abb", "bab" 和 "bba" 都是正确答案。 ++ +
示例 2:
+ +输入:A = 4, B = 1 +输出:"aabaa"+ +
+ +
提示:
+ +-
+
0 <= A <= 100
+ 0 <= B <= 100
+ - 对于给定的
A和B,保证存在满足要求的S。
+
给出一个整数数组 A 和一个查询数组 queries。
对于第 i 次查询,有 val = queries[i][0], index = queries[i][1],我们会把 val 加到 A[index] 上。然后,第 i 次查询的答案是 A 中偶数值的和。
(此处给定的 index = queries[i][1] 是从 0 开始的索引,每次查询都会永久修改数组 A。)
返回所有查询的答案。你的答案应当以数组 answer 给出,answer[i] 为第 i 次查询的答案。
-**示例** +
示例:
-``` -输入:A = [1,2,3,4], queries = [[1,0],[-3,1],[-4,0],[2,3]] -输出:[8,6,2,4] -解释: +输入:A = [1,2,3,4], queries = [[1,0],[-3,1],[-4,0],[2,3]] +输出:[8,6,2,4] +解释: 开始时,数组为 [1,2,3,4]。 将 1 加到 A[0] 上之后,数组为 [2,2,3,4],偶数值之和为 2 + 2 + 4 = 8。 将 -3 加到 A[1] 上之后,数组为 [2,-1,3,4],偶数值之和为 2 + 4 = 6。 将 -4 加到 A[0] 上之后,数组为 [-2,-1,3,4],偶数值之和为 -2 + 4 = 2。 将 2 加到 A[3] 上之后,数组为 [-2,-1,3,6],偶数值之和为 -2 + 6 = 4。 ++ +
+ +
提示:
+ +-
+
1 <= A.length <= 10000
+ -10000 <= A[i] <= 10000
+ 1 <= queries.length <= 10000
+ -10000 <= queries[i][0] <= 10000
+ 0 <= queries[i][1] < A.length
+
给定两个由一些闭区间组成的列表,每个区间列表都是成对不相交的,并且已经排序。
+ +返回这两个区间列表的交集。
+ +(形式上,闭区间 [a, b](其中 a <= b)表示实数 x 的集合,而 a <= x <= b。两个闭区间的交集是一组实数,要么为空集,要么为闭区间。例如,[1, 3] 和 [2, 4] 的交集为 [2, 3]。)
+ +
示例:
+ +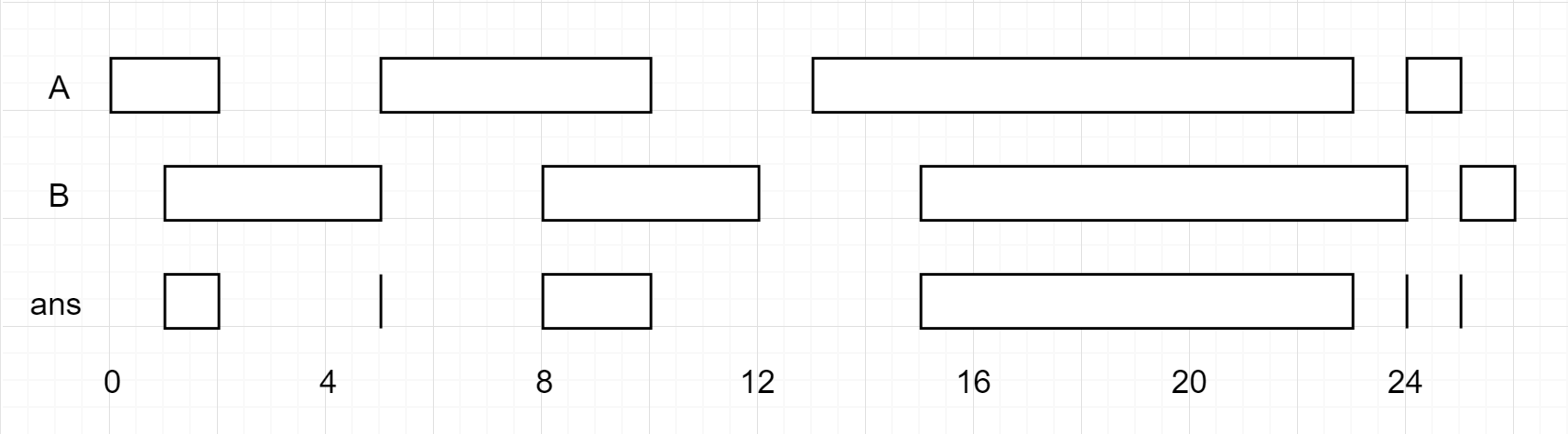
输入:A = [[0,2],[5,10],[13,23],[24,25]], B = [[1,5],[8,12],[15,24],[25,26]] +输出:[[1,2],[5,5],[8,10],[15,23],[24,24],[25,25]] +注意:输入和所需的输出都是区间对象组成的列表,而不是数组或列表。 ++ +
+ +
提示:
+ +-
+
0 <= A.length < 1000
+ 0 <= B.length < 1000
+ 0 <= A[i].start, A[i].end, B[i].start, B[i].end < 10^9
+
给定二叉树,按垂序遍历返回其结点值。
+ +对位于 (X, Y) 的每个结点而言,其左右子结点分别位于 (X-1, Y-1) 和 (X+1, Y-1)。
把一条垂线从 X = -infinity 移动到 X = +infinity ,每当该垂线与结点接触时,我们按从上到下的顺序报告结点的值( Y 坐标递减)。
如果两个结点位置相同,则首先报告的结点值较小。
+ +按 X 坐标顺序返回非空报告的列表。每个报告都有一个结点值列表。
+ +
示例 1:
+ +
输入:[3,9,20,null,null,15,7] +输出:[[9],[3,15],[20],[7]] +解释: +在不丧失其普遍性的情况下,我们可以假设根结点位于 (0, 0): +然后,值为 9 的结点出现在 (-1, -1); +值为 3 和 15 的两个结点分别出现在 (0, 0) 和 (0, -2); +值为 20 的结点出现在 (1, -1); +值为 7 的结点出现在 (2, -2)。 ++ +
示例 2:
+ +
输入:[1,2,3,4,5,6,7] +输出:[[4],[2],[1,5,6],[3],[7]] +解释: +根据给定的方案,值为 5 和 6 的两个结点出现在同一位置。 +然而,在报告 "[1,5,6]" 中,结点值 5 排在前面,因为 5 小于 6。 ++ +
+ +
提示:
+ +-
+
- 树的结点数介于
1和1000之间。
+ - 每个结点值介于
0和1000之间。
+
给定一颗根结点为 root 的二叉树,树中的每一个结点都有一个从 0 到 25 的值,分别代表字母 'a' 到 'z':值 0 代表 'a',值 1 代表 'b',依此类推。
找出按字典序最小的字符串,该字符串从这棵树的一个叶结点开始,到根结点结束。
+ +(小贴士:字符串中任何较短的前缀在字典序上都是较小的:例如,在字典序上 "ab" 比 "aba" 要小。叶结点是指没有子结点的结点。)
+ +
-
+
示例 1:
+ +
输入:[0,1,2,3,4,3,4] +输出:"dba" ++ +
示例 2:
+ +
输入:[25,1,3,1,3,0,2] +输出:"adz" ++ +
示例 3:
+ +
输入:[2,2,1,null,1,0,null,0] +输出:"abc" ++ +
+ +
提示:
+ +-
+
- 给定树的结点数介于
1和8500之间。
+ - 树中的每个结点都有一个介于
0和25之间的值。
+
对于非负整数 X 而言,X 的数组形式是每位数字按从左到右的顺序形成的数组。例如,如果 X = 1231,那么其数组形式为 [1,2,3,1]。
给定非负整数 X 的数组形式 A,返回整数 X+K 的数组形式。
+ +
-
+
示例 1:
+ +输入:A = [1,2,0,0], K = 34 +输出:[1,2,3,4] +解释:1200 + 34 = 1234 ++ +
示例 2:
+ +输入:A = [2,7,4], K = 181 +输出:[4,5,5] +解释:274 + 181 = 455 ++ +
示例 3:
+ +输入:A = [2,1,5], K = 806 +输出:[1,0,2,1] +解释:215 + 806 = 1021 ++ +
示例 4:
+ +输入:A = [9,9,9,9,9,9,9,9,9,9], K = 1 +输出:[1,0,0,0,0,0,0,0,0,0,0] +解释:9999999999 + 1 = 10000000000 ++ +
+ +
提示:
+ +-
+
1 <= A.length <= 10000
+ 0 <= A[i] <= 9
+ 0 <= K <= 10000
+ - 如果
A.length > 1,那么A[0] != 0
+
给定一个由表示变量之间关系的字符串方程组成的数组,每个字符串方程 equations[i] 的长度为 4,并采用两种不同的形式之一:"a==b" 或 "a!=b"。在这里,a 和 b 是小写字母(不一定不同),表示单字母变量名。
只有当可以将整数分配给变量名,以便满足所有给定的方程时才返回 true,否则返回 false。
+ +
-
+
示例 1:
+ +输入:["a==b","b!=a"] +输出:false +解释:如果我们指定,a = 1 且 b = 1,那么可以满足第一个方程,但无法满足第二个方程。没有办法分配变量同时满足这两个方程。 ++ +
示例 2:
+ +输出:["b==a","a==b"] +输入:true +解释:我们可以指定 a = 1 且 b = 1 以满足满足这两个方程。 ++ +
示例 3:
+ +输入:["a==b","b==c","a==c"] +输出:true ++ +
示例 4:
+ +输入:["a==b","b!=c","c==a"] +输出:false ++ +
示例 5:
+ +输入:["c==c","b==d","x!=z"] +输出:true ++ +
+ +
提示:
+ +-
+
1 <= equations.length <= 500
+ equations[i].length == 4
+ equations[i][0]和equations[i][3]是小写字母
+ equations[i][1]要么是'=',要么是'!'
+ equations[i][2]是'='
+
在显示着数字的坏计算器上,我们可以执行以下两种操作:
+ +-
+
- 双倍(Double):将显示屏上的数字乘 2; +
- 递减(Decrement):将显示屏上的数字减 1 。 +
最初,计算器显示数字 X。
返回显示数字 Y 所需的最小操作数。
+ +
示例 1:
+ +输入:X = 2, Y = 3
+输出:2
+解释:先进行双倍运算,然后再进行递减运算 {2 -> 4 -> 3}.
+
+
+示例 2:
+ +输入:X = 5, Y = 8
+输出:2
+解释:先递减,再双倍 {5 -> 4 -> 8}.
+
+
+示例 3:
+ +输入:X = 3, Y = 10
+输出:3
+解释:先双倍,然后递减,再双倍 {3 -> 6 -> 5 -> 10}.
+
+
+示例 4:
+ +输入:X = 1024, Y = 1 +输出:1023 +解释:执行递减运算 1023 次 ++ +
+ +
提示:
+ +-
+
1 <= X <= 10^9
+ 1 <= Y <= 10^9
+
给定一个正整数数组 A,如果 A 的某个子数组中不同整数的个数恰好为 K,则称 A 的这个连续、不一定独立的子数组为好子数组。
(例如,[1,2,3,1,2] 中有 3 个不同的整数:1,2,以及 3。)
返回 A 中好子数组的数目。
+ +
示例 1:
+ +输出:A = [1,2,1,2,3], K = 2 +输入:7 +解释:恰好由 2 个不同整数组成的子数组:[1,2], [2,1], [1,2], [2,3], [1,2,1], [2,1,2], [1,2,1,2]. ++ +
示例 2:
+ +输入:A = [1,2,1,3,4], K = 3 +输出:3 +解释:恰好由 3 个不同整数组成的子数组:[1,2,1,3], [2,1,3], [1,3,4]. ++ +
+ +
提示:
+ +-
+
1 <= A.length <= 20000
+ 1 <= A[i] <= A.length
+ 1 <= K <= A.length
+
在二叉树中,根节点位于深度 0 处,每个深度为 k 的节点的子节点位于深度 k+1 处。
如果二叉树的两个节点深度相同,但父节点不同,则它们是一对堂兄弟节点。
+ +我们给出了具有唯一值的二叉树的根节点 root,以及树中两个不同节点的值 x 和 y。
只有与值 x 和 y 对应的节点是堂兄弟节点时,才返回 true。否则,返回 false。
+ +
示例 1:
+
输入:root = [1,2,3,4], x = 4, y = 3 +输出:false ++ +
示例 2:
+
输入:root = [1,2,3,null,4,null,5], x = 5, y = 4 +输出:true ++ +
示例 3:
+ +
输入:root = [1,2,3,null,4], x = 2, y = 3 +输出:false+ +
+ +
提示:
+ +-
+
- 二叉树的节点数介于
2到100之间。
+ - 每个节点的值都是唯一的、范围为
1到100的整数。
+
+ + + +## 解法 + + + +### Python3 + + +```python + +``` + +### Java + + +```java + +``` + +### ... +``` + +``` diff --git a/solution/0900-0999/0994.Rotting Oranges/README.md b/solution/0900-0999/0994.Rotting Oranges/README.md new file mode 100644 index 0000000000000..0c0f5fc1da5b4 --- /dev/null +++ b/solution/0900-0999/0994.Rotting Oranges/README.md @@ -0,0 +1,74 @@ +# [994. 腐烂的橘子](https://leetcode-cn.com/problems/rotting-oranges) + +## 题目描述 + +
在给定的网格中,每个单元格可以有以下三个值之一:
+ +-
+
- 值
0代表空单元格;
+ - 值
1代表新鲜橘子;
+ - 值
2代表腐烂的橘子。
+
每分钟,任何与腐烂的橘子(在 4 个正方向上)相邻的新鲜橘子都会腐烂。
+ +返回直到单元格中没有新鲜橘子为止所必须经过的最小分钟数。如果不可能,返回 -1。
+ +
示例 1:
+ +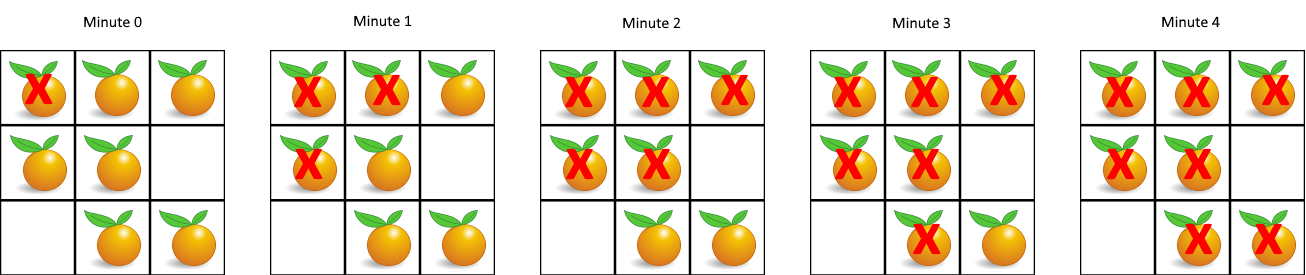
输入:[[2,1,1],[1,1,0],[0,1,1]] +输出:4 ++ +
示例 2:
+ +输入:[[2,1,1],[0,1,1],[1,0,1]] +输出:-1 +解释:左下角的橘子(第 2 行, 第 0 列)永远不会腐烂,因为腐烂只会发生在 4 个正向上。 ++ +
示例 3:
+ +输入:[[0,2]] +输出:0 +解释:因为 0 分钟时已经没有新鲜橘子了,所以答案就是 0 。 ++ +
+ +
提示:
+ +-
+
1 <= grid.length <= 10
+ 1 <= grid[0].length <= 10
+ grid[i][j]仅为0、1或2
+
在仅包含 0 和 1 的数组 A 中,一次 K 位翻转包括选择一个长度为 K 的(连续)子数组,同时将子数组中的每个 0 更改为 1,而每个 1 更改为 0。
返回所需的 K 位翻转的次数,以便数组没有值为 0 的元素。如果不可能,返回 -1。
+ +
示例 1:
+ +输入:A = [0,1,0], K = 1 +输出:2 +解释:先翻转 A[0],然后翻转 A[2]。 ++ +
示例 2:
+ +输入:A = [1,1,0], K = 2 +输出:-1 +解释:无论我们怎样翻转大小为 2 的子数组,我们都不能使数组变为 [1,1,1]。 ++ +
示例 3:
+ +输入:A = [0,0,0,1,0,1,1,0], K = 3 +输出:3 +解释: +翻转 A[0],A[1],A[2]: A变成 [1,1,1,1,0,1,1,0] +翻转 A[4],A[5],A[6]: A变成 [1,1,1,1,1,0,0,0] +翻转 A[5],A[6],A[7]: A变成 [1,1,1,1,1,1,1,1] ++ +
+ +
提示:
+ +-
+
1 <= A.length <= 30000
+ 1 <= K <= A.length
+
给定一个非负整数数组 A,如果该数组每对相邻元素之和是一个完全平方数,则称这一数组为正方形数组。
返回 A 的正方形排列的数目。两个排列 A1 和 A2 不同的充要条件是存在某个索引 i,使得 A1[i] != A2[i]。
+ +
示例 1:
+ +输入:[1,17,8] +输出:2 +解释: +[1,8,17] 和 [17,8,1] 都是有效的排列。 ++ +
示例 2:
+ +输入:[2,2,2] +输出:1 ++ +
+ +
提示:
+ +-
+
1 <= A.length <= 12
+ 0 <= A[i] <= 1e9
+
在一个小镇里,按从 1 到 N 标记了 N 个人。传言称,这些人中有一个是小镇上的秘密法官。
如果小镇的法官真的存在,那么:
+ +-
+
- 小镇的法官不相信任何人。 +
- 每个人(除了小镇法官外)都信任小镇的法官。 +
- 只有一个人同时满足属性 1 和属性 2 。 +
给定数组 trust,该数组由信任对 trust[i] = [a, b] 组成,表示标记为 a 的人信任标记为 b 的人。
如果小镇存在秘密法官并且可以确定他的身份,请返回该法官的标记。否则,返回 -1。
+ +
示例 1:
+ +输入:N = 2, trust = [[1,2]] +输出:2 ++ +
示例 2:
+ +输入:N = 3, trust = [[1,3],[2,3]] +输出:3 ++ +
示例 3:
+ +输入:N = 3, trust = [[1,3],[2,3],[3,1]] +输出:-1 ++ +
示例 4:
+ +输入:N = 3, trust = [[1,2],[2,3]] +输出:-1 ++ +
示例 5:
+ +输入:N = 4, trust = [[1,3],[1,4],[2,3],[2,4],[4,3]] +输出:3+ +
+ +
提示:
+ +-
+
1 <= N <= 1000
+ trust.length <= 10000
+ trust[i]是完全不同的
+ trust[i][0] != trust[i][1]
+ 1 <= trust[i][0], trust[i][1] <= N
+
最大树定义:一个树,其中每个节点的值都大于其子树中的任何其他值。
+ +给出最大树的根节点 root。
就像之前的问题那样,给定的树是从表 A(root = Construct(A))递归地使用下述 Construct(A) 例程构造的:
-
+
- 如果
A为空,返回null
+ - 否则,令
A[i]作为 A 的最大元素。创建一个值为A[i]的根节点root
+ root的左子树将被构建为Construct([A[0], A[1], ..., A[i-1]])
+ root的右子树将被构建为Construct([A[i+1], A[i+2], ..., A[A.length - 1]])
+ - 返回
root
+
请注意,我们没有直接给定 A,只有一个根节点 root = Construct(A).
假设 B 是 A 的副本,并附加值 val。保证 B 中的值是不同的。
返回 Construct(B)。
+ +
示例 1:
+ +
输入:root = [4,1,3,null,null,2], val = 5 +输出:[5,4,null,1,3,null,null,2] +解释:A = [1,4,2,3], B = [1,4,2,3,5] ++ +
示例 2:
+
输入:root = [5,2,4,null,1], val = 3 +输出:[5,2,4,null,1,null,3] +解释:A = [2,1,5,4], B = [2,1,5,4,3] ++ +
示例 3:
+
输入:root = [5,2,3,null,1], val = 4 +输出:[5,2,4,null,1,3] +解释:A = [2,1,5,3], B = [2,1,5,3,4] ++ +
+ +
提示:
+ +-
+
1 <= B.length <= 100
+
+ +
+ + + +## 解法 + + + +### Python3 + + +```python + +``` + +### Java + + +```java + +``` + +### ... +``` + +``` diff --git a/solution/0900-0999/0999.Available Captures for Rook/README.md b/solution/0900-0999/0999.Available Captures for Rook/README.md new file mode 100644 index 0000000000000..728675aeb2748 --- /dev/null +++ b/solution/0900-0999/0999.Available Captures for Rook/README.md @@ -0,0 +1,75 @@ +# [999. 车的可用捕获量](https://leetcode-cn.com/problems/available-captures-for-rook) + +## 题目描述 + +
在一个 8 x 8 的棋盘上,有一个白色车(rook)。也可能有空方块,白色的象(bishop)和黑色的卒(pawn)。它们分别以字符 “R”,“.”,“B” 和 “p” 给出。大写字符表示白棋,小写字符表示黑棋。
+ +车按国际象棋中的规则移动:它选择四个基本方向中的一个(北,东,西和南),然后朝那个方向移动,直到它选择停止、到达棋盘的边缘或移动到同一方格来捕获该方格上颜色相反的卒。另外,车不能与其他友方(白色)象进入同一个方格。
+ +返回车能够在一次移动中捕获到的卒的数量。
+
示例 1:
+ +
输入:[[".",".",".",".",".",".",".","."],[".",".",".","p",".",".",".","."],[".",".",".","R",".",".",".","p"],[".",".",".",".",".",".",".","."],[".",".",".",".",".",".",".","."],[".",".",".","p",".",".",".","."],[".",".",".",".",".",".",".","."],[".",".",".",".",".",".",".","."]] +输出:3 +解释: +在本例中,车能够捕获所有的卒。 ++ +
示例 2:
+ +
输入:[[".",".",".",".",".",".",".","."],[".","p","p","p","p","p",".","."],[".","p","p","B","p","p",".","."],[".","p","B","R","B","p",".","."],[".","p","p","B","p","p",".","."],[".","p","p","p","p","p",".","."],[".",".",".",".",".",".",".","."],[".",".",".",".",".",".",".","."]] +输出:0 +解释: +象阻止了车捕获任何卒。 ++ +
示例 3:
+ +
输入:[[".",".",".",".",".",".",".","."],[".",".",".","p",".",".",".","."],[".",".",".","p",".",".",".","."],["p","p",".","R",".","p","B","."],[".",".",".",".",".",".",".","."],[".",".",".","B",".",".",".","."],[".",".",".","p",".",".",".","."],[".",".",".",".",".",".",".","."]] +输出:3 +解释: +车可以捕获位置 b5,d6 和 f5 的卒。 ++ +
+ +
提示:
+ +-
+
board.length == board[i].length == 8
+ board[i][j]可以是'R','.','B'或'p'
+ - 只有一个格子上存在
board[i][j] == 'R'
+
有 N 堆石头排成一排,第 i 堆中有 stones[i] 块石头。
每次移动(move)需要将连续的 K 堆石头合并为一堆,而这个移动的成本为这 K 堆石头的总数。
找出把所有石头合并成一堆的最低成本。如果不可能,返回 -1 。
+ +
示例 1:
+ +输入:stones = [3,2,4,1], K = 2 +输出:20 +解释: +从 [3, 2, 4, 1] 开始。 +合并 [3, 2],成本为 5,剩下 [5, 4, 1]。 +合并 [4, 1],成本为 5,剩下 [5, 5]。 +合并 [5, 5],成本为 10,剩下 [10]。 +总成本 20,这是可能的最小值。 ++ +
示例 2:
+ +输入:stones = [3,2,4,1], K = 3 +输出:-1 +解释:任何合并操作后,都会剩下 2 堆,我们无法再进行合并。所以这项任务是不可能完成的。. ++ +
示例 3:
+ +输入:stones = [3,5,1,2,6], K = 3 +输出:25 +解释: +从 [3, 5, 1, 2, 6] 开始。 +合并 [5, 1, 2],成本为 8,剩下 [3, 8, 6]。 +合并 [3, 8, 6],成本为 17,剩下 [17]。 +总成本 25,这是可能的最小值。 ++ +
+ +
提示:
+ +-
+
1 <= stones.length <= 30
+ 2 <= K <= 30
+ 1 <= stones[i] <= 100
+
在 N x N 的网格上,每个单元格 (x, y) 上都有一盏灯,其中 0 <= x < N 且 0 <= y < N 。
最初,一定数量的灯是亮着的。lamps[i] 告诉我们亮着的第 i 盏灯的位置。每盏灯都照亮其所在 x 轴、y 轴和两条对角线上的每个正方形(类似于国际象棋中的皇后)。
对于第 i 次查询 queries[i] = (x, y),如果单元格 (x, y) 是被照亮的,则查询结果为 1,否则为 0 。
在每个查询 (x, y) 之后 [按照查询的顺序],我们关闭位于单元格 (x, y) 上或其相邻 8 个方向上(与单元格 (x, y) 共享一个角或边)的任何灯。
返回答案数组 answer。每个值 answer[i] 应等于第 i 次查询 queries[i] 的结果。
+ +
示例:
+ +输入:N = 5, lamps = [[0,0],[4,4]], queries = [[1,1],[1,0]] +输出:[1,0] +解释: +在执行第一次查询之前,我们位于 [0, 0] 和 [4, 4] 灯是亮着的。 +表示哪些单元格亮起的网格如下所示,其中 [0, 0] 位于左上角: +1 1 1 1 1 +1 1 0 0 1 +1 0 1 0 1 +1 0 0 1 1 +1 1 1 1 1 +然后,由于单元格 [1, 1] 亮着,第一次查询返回 1。在此查询后,位于 [0,0] 处的灯将关闭,网格现在如下所示: +1 0 0 0 1 +0 1 0 0 1 +0 0 1 0 1 +0 0 0 1 1 +1 1 1 1 1 +在执行第二次查询之前,我们只有 [4, 4] 处的灯亮着。现在,[1, 0] 处的查询返回 0,因为该单元格不再亮着。 ++ +
+ +
提示:
+ +-
+
1 <= N <= 10^9
+ 0 <= lamps.length <= 20000
+ 0 <= queries.length <= 20000
+ lamps[i].length == queries[i].length == 2
+
给定仅有小写字母组成的字符串数组 A,返回列表中的每个字符串中都显示的全部字符(包括重复字符)组成的列表。例如,如果一个字符在每个字符串中出现 3 次,但不是 4 次,则需要在最终答案中包含该字符 3 次。
你可以按任意顺序返回答案。
+ ++ +
示例 1:
+ +输入:["bella","label","roller"] +输出:["e","l","l"] ++ +
示例 2:
+ +输入:["cool","lock","cook"] +输出:["c","o"] ++ +
+ +
提示:
+ +-
+
1 <= A.length <= 100
+ 1 <= A[i].length <= 100
+ A[i][j]是小写字母
+
给定有效字符串 "abc"。
对于任何有效的字符串 V,我们可以将 V 分成两个部分 X 和 Y,使得 X + Y(X 与 Y 连接)等于 V。(X 或 Y 可以为空。)那么,X + "abc" + Y 也同样是有效的。
例如,如果 S = "abc",则有效字符串的示例是:"abc","aabcbc","abcabc","abcabcababcc"。无效字符串的示例是:"abccba","ab","cababc","bac"。
如果给定字符串 S 有效,则返回 true;否则,返回 false。
+ +
示例 1:
+ +输入:"aabcbc" +输出:true +解释: +从有效字符串 "abc" 开始。 +然后我们可以在 "a" 和 "bc" 之间插入另一个 "abc",产生 "a" + "abc" + "bc",即 "aabcbc"。 ++ +
示例 2:
+ +输入:"abcabcababcc" +输出:true +解释: +"abcabcabc" 是有效的,它可以视作在原串后连续插入 "abc"。 +然后我们可以在最后一个字母之前插入 "abc",产生 "abcabcab" + "abc" + "c",即 "abcabcababcc"。 ++ +
示例 3:
+ +输入:"abccba" +输出:false ++ +
示例 4:
+ +输入:"cababc" +输出:false+ +
+ +
提示:
+ +-
+
1 <= S.length <= 20000
+ S[i]为'a'、'b'、或'c'
+
+ + + +## 解法 + + + +### Python3 + + +```python + +``` + +### Java + + +```java + +``` + +### ... +``` + +``` diff --git a/solution/1000-1099/1004.Max Consecutive Ones III/README.md b/solution/1000-1099/1004.Max Consecutive Ones III/README.md new file mode 100644 index 0000000000000..0a39e99b54178 --- /dev/null +++ b/solution/1000-1099/1004.Max Consecutive Ones III/README.md @@ -0,0 +1,60 @@ +# [1004. 最大连续1的个数 III](https://leetcode-cn.com/problems/max-consecutive-ones-iii) + +## 题目描述 + +
给定一个由若干 0 和 1 组成的数组 A,我们最多可以将 K 个值从 0 变成 1 。
返回仅包含 1 的最长(连续)子数组的长度。
+ ++ +
示例 1:
+ +输入:A = [1,1,1,0,0,0,1,1,1,1,0], K = 2 +输出:6 +解释: +[1,1,1,0,0,1,1,1,1,1,1] +粗体数字从 0 翻转到 1,最长的子数组长度为 6。+ +
示例 2:
+ +输入:A = [0,0,1,1,0,0,1,1,1,0,1,1,0,0,0,1,1,1,1], K = 3 +输出:10 +解释: +[0,0,1,1,1,1,1,1,1,1,1,1,0,0,0,1,1,1,1] +粗体数字从 0 翻转到 1,最长的子数组长度为 10。+ +
+ +
提示:
+ +-
+
1 <= A.length <= 20000
+ 0 <= K <= A.length
+ A[i]为0或1
+
给定一个整数数组 A,我们只能用以下方法修改该数组:我们选择某个个索引 i 并将 A[i] 替换为 -A[i],然后总共重复这个过程 K 次。(我们可以多次选择同一个索引 i。)
以这种方式修改数组后,返回数组可能的最大和。
+ ++ +
示例 1:
+ +输入:A = [4,2,3], K = 1 +输出:5 +解释:选择索引 (1,) ,然后 A 变为 [4,-2,3]。 ++ +
示例 2:
+ +输入:A = [3,-1,0,2], K = 3 +输出:6 +解释:选择索引 (1, 2, 2) ,然后 A 变为 [3,1,0,2]。 ++ +
示例 3:
+ +输入:A = [2,-3,-1,5,-4], K = 2 +输出:13 +解释:选择索引 (1, 4) ,然后 A 变为 [2,3,-1,5,4]。 ++ +
+ +
提示:
+ +-
+
1 <= A.length <= 10000
+ 1 <= K <= 10000
+ -100 <= A[i] <= 100
+
通常,正整数 n 的阶乘是所有小于或等于 n 的正整数的乘积。例如,factorial(10) = 10 * 9 * 8 * 7 * 6 * 5 * 4 * 3 * 2 * 1。
相反,我们设计了一个笨阶乘 clumsy:在整数的递减序列中,我们以一个固定顺序的操作符序列来依次替换原有的乘法操作符:乘法(*),除法(/),加法(+)和减法(-)。
例如,clumsy(10) = 10 * 9 / 8 + 7 - 6 * 5 / 4 + 3 - 2 * 1。然而,这些运算仍然使用通常的算术运算顺序:我们在任何加、减步骤之前执行所有的乘法和除法步骤,并且按从左到右处理乘法和除法步骤。
另外,我们使用的除法是地板除法(floor division),所以 10 * 9 / 8 等于 11。这保证结果是一个整数。
实现上面定义的笨函数:给定一个整数 N,它返回 N 的笨阶乘。
+ +
示例 1:
+ +输入:4 +输出:7 +解释:7 = 4 * 3 / 2 + 1 ++ +
示例 2:
+ +输入:10 +输出:12 +解释:12 = 10 * 9 / 8 + 7 - 6 * 5 / 4 + 3 - 2 * 1 ++ +
+ +
提示:
+ +-
+
1 <= N <= 10000
+ -2^31 <= answer <= 2^31 - 1(答案保证符合 32 位整数。)
+
在一排多米诺骨牌中,A[i] 和 B[i] 分别代表第 i 个多米诺骨牌的上半部分和下半部分。(一个多米诺是两个从 1 到 6 的数字同列平铺形成的 —— 该平铺的每一半上都有一个数字。)
我们可以旋转第 i 张多米诺,使得 A[i] 和 B[i] 的值交换。
返回能使 A 中所有值或者 B 中所有值都相同的最小旋转次数。
如果无法做到,返回 -1.
+ +
示例 1:
+ +
输入:A = [2,1,2,4,2,2], B = [5,2,6,2,3,2] +输出:2 +解释: +图一表示:在我们旋转之前, A 和 B 给出的多米诺牌。 +如果我们旋转第二个和第四个多米诺骨牌,我们可以使上面一行中的每个值都等于 2,如图二所示。 ++ +
示例 2:
+ +输入:A = [3,5,1,2,3], B = [3,6,3,3,4] +输出:-1 +解释: +在这种情况下,不可能旋转多米诺牌使一行的值相等。 ++ +
+ +
提示:
+ +-
+
1 <= A[i], B[i] <= 6
+ 2 <= A.length == B.length <= 20000
+
返回与给定先序遍历 preorder 相匹配的二叉搜索树(binary search tree)的根结点。
(回想一下,二叉搜索树是二叉树的一种,其每个节点都满足以下规则,对于 node.left 的任何后代,值总 < node.val,而 node.right 的任何后代,值总 > node.val。此外,先序遍历首先显示节点的值,然后遍历 node.left,接着遍历 node.right。)
-``` -输入:[8,5,1,7,10,12] -输出:[8,5,10,1,7,null,12] -``` +
示例:
+ +输入:[8,5,1,7,10,12] +输出:[8,5,10,1,7,null,12] ++ ++
+ +
提示:
- +-
+
1 <= preorder.length <= 100
+ - 先序
preorder中的值是不同的。
+
每个非负整数 N 都有其二进制表示。例如, 5 可以被表示为二进制 "101",11 可以用二进制 "1011" 表示,依此类推。注意,除 N = 0 外,任何二进制表示中都不含前导零。
二进制的反码表示是将每个 1 改为 0 且每个 0 变为 1。例如,二进制数 "101" 的二进制反码为 "010"。
给你一个十进制数 N,请你返回其二进制表示的反码所对应的十进制整数。
+ +
-
+
示例 1:
+ +输入:5 +输出:2 +解释:5 的二进制表示为 "101",其二进制反码为 "010",也就是十进制中的 2 。 ++ +
示例 2:
+ +输入:7 +输出:0 +解释:7 的二进制表示为 "111",其二进制反码为 "000",也就是十进制中的 0 。 ++ +
示例 3:
+ +输入:10 +输出:5 +解释:10 的二进制表示为 "1010",其二进制反码为 "0101",也就是十进制中的 5 。 ++ +
+ +
提示:
+ +-
+
0 <= N < 10^9
+ - 本题与 476:https://leetcode-cn.com/problems/number-complement/ 相同 +
在歌曲列表中,第 i 首歌曲的持续时间为 time[i] 秒。
返回其总持续时间(以秒为单位)可被 60 整除的歌曲对的数量。形式上,我们希望索引的数字 i < j 且有 (time[i] + time[j]) % 60 == 0。
+ +
示例 1:
+ +输入:[30,20,150,100,40] +输出:3 +解释:这三对的总持续时间可被 60 整数: +(time[0] = 30, time[2] = 150): 总持续时间 180 +(time[1] = 20, time[3] = 100): 总持续时间 120 +(time[1] = 20, time[4] = 40): 总持续时间 60 ++ +
示例 2:
+ +输入:[60,60,60] +输出:3 +解释:所有三对的总持续时间都是 120,可以被 60 整数。 ++ +
+ +
提示:
+ +-
+
1 <= time.length <= 60000
+ 1 <= time[i] <= 500
+
传送带上的包裹必须在 D 天内从一个港口运送到另一个港口。
+ +传送带上的第 i 个包裹的重量为 weights[i]。每一天,我们都会按给出重量的顺序往传送带上装载包裹。我们装载的重量不会超过船的最大运载重量。
返回能在 D 天内将传送带上的所有包裹送达的船的最低运载能力。
+ +
示例 1:
+ +输入:weights = [1,2,3,4,5,6,7,8,9,10], D = 5 +输出:15 +解释: +船舶最低载重 15 就能够在 5 天内送达所有包裹,如下所示: +第 1 天:1, 2, 3, 4, 5 +第 2 天:6, 7 +第 3 天:8 +第 4 天:9 +第 5 天:10 + +请注意,货物必须按照给定的顺序装运,因此使用载重能力为 14 的船舶并将包装分成 (2, 3, 4, 5), (1, 6, 7), (8), (9), (10) 是不允许的。 ++ +
示例 2:
+ +输入:weights = [3,2,2,4,1,4], D = 3 +输出:6 +解释: +船舶最低载重 6 就能够在 3 天内送达所有包裹,如下所示: +第 1 天:3, 2 +第 2 天:2, 4 +第 3 天:1, 4 ++ +
示例 3:
+ +输入:weights = [1,2,3,1,1], D = 4 +输出:3 +解释: +第 1 天:1 +第 2 天:2 +第 3 天:3 +第 4 天:1, 1 ++ +
+ +
提示:
+ +-
+
1 <= D <= weights.length <= 50000
+ 1 <= weights[i] <= 500
+
给定正整数 N,返回小于等于 N 且具有至少 1 位重复数字的正整数。
+ +
示例 1:
+ +输入:20 +输出:1 +解释:具有至少 1 位重复数字的正数(<= 20)只有 11 。 ++ +
示例 2:
+ +输入:100 +输出:10 +解释:具有至少 1 位重复数字的正数(<= 100)有 11,22,33,44,55,66,77,88,99 和 100 。 ++ +
示例 3:
+ +输入:1000 +输出:262 ++ +
+ +
提示:
+ +-
+
1 <= N <= 10^9
+
给你一个整数数组 A,只有可以将其划分为三个和相等的非空部分时才返回 true,否则返回 false。
形式上,如果可以找出索引 i+1 < j 且满足 (A[0] + A[1] + ... + A[i] == A[i+1] + A[i+2] + ... + A[j-1] == A[j] + A[j-1] + ... + A[A.length - 1]) 就可以将数组三等分。
+ +
示例 1:
+ +输出:[0,2,1,-6,6,-7,9,1,2,0,1] +输出:true +解释:0 + 2 + 1 = -6 + 6 - 7 + 9 + 1 = 2 + 0 + 1 ++ +
示例 2:
+ +输入:[0,2,1,-6,6,7,9,-1,2,0,1] +输出:false ++ +
示例 3:
+ +输入:[3,3,6,5,-2,2,5,1,-9,4] +输出:true +解释:3 + 3 = 6 = 5 - 2 + 2 + 5 + 1 - 9 + 4 ++ +
+ +
提示:
+ +-
+
3 <= A.length <= 50000
+ -10^4 <= A[i] <= 10^4
+
给定正整数数组 A,A[i] 表示第 i 个观光景点的评分,并且两个景点 i 和 j 之间的距离为 j - i。
一对景点(i < j)组成的观光组合的得分为(A[i] + A[j] + i - j):景点的评分之和减去它们两者之间的距离。
返回一对观光景点能取得的最高分。
+ ++ +
示例:
+ +输入:[8,1,5,2,6]
+输出:11
+解释:i = 0, j = 2, A[i] + A[j] + i - j = 8 + 5 + 0 - 2 = 11
+
+
++ +
提示:
+ +-
+
2 <= A.length <= 50000
+ 1 <= A[i] <= 1000
+
给定正整数 K,你需要找出可以被 K 整除的、仅包含数字 1 的最小正整数 N。
返回 N 的长度。如果不存在这样的 N,就返回 -1。
+ +
示例 1:
+ +输入:1 +输出:1 +解释:最小的答案是 N = 1,其长度为 1。+ +
示例 2:
+ +输入:2 +输出:-1 +解释:不存在可被 2 整除的正整数 N 。+ +
示例 3:
+ +输入:3 +输出:3 +解释:最小的答案是 N = 111,其长度为 3。+ +
+ +
提示:
+ +-
+
1 <= K <= 10^5
+
给定一个二进制字符串 S(一个仅由若干 '0' 和 '1' 构成的字符串)和一个正整数 N,如果对于从 1 到 N 的每个整数 X,其二进制表示都是 S 的子串,就返回 true,否则返回 false。
+ +
示例 1:
+ +输入:S = "0110", N = 3 +输出:true ++ +
示例 2:
+ +输入:S = "0110", N = 4 +输出:false ++ +
+ +
提示:
+ +-
+
1 <= S.length <= 1000
+ 1 <= N <= 10^9
+
给出数字 N,返回由若干 "0" 和 "1"组成的字符串,该字符串为 N 的负二进制(base -2)表示。
除非字符串就是 "0",否则返回的字符串中不能含有前导零。
+ +
示例 1:
+ +输入:2 +输出:"110" +解释:(-2) ^ 2 + (-2) ^ 1 = 2 ++ +
示例 2:
+ +输入:3 +输出:"111" +解释:(-2) ^ 2 + (-2) ^ 1 + (-2) ^ 0 = 3 ++ +
示例 3:
+ +输入:4 +输出:"100" +解释:(-2) ^ 2 = 4 ++ +
+ +
提示:
+ +-
+
0 <= N <= 10^9
+
给定由若干 0 和 1 组成的数组 A。我们定义 N_i:从 A[0] 到 A[i] 的第 i 个子数组被解释为一个二进制数(从最高有效位到最低有效位)。
返回布尔值列表 answer,只有当 N_i 可以被 5 整除时,答案 answer[i] 为 true,否则为 false。
+ +
示例 1:
+ +输入:[0,1,1] +输出:[true,false,false] +解释: +输入数字为 0, 01, 011;也就是十进制中的 0, 1, 3 。只有第一个数可以被 5 整除,因此 answer[0] 为真。 ++ +
示例 2:
+ +输入:[1,1,1] +输出:[false,false,false] ++ +
示例 3:
+ +输入:[0,1,1,1,1,1] +输出:[true,false,false,false,true,false] ++ +
示例 4:
+ +输入:[1,1,1,0,1] +输出:[false,false,false,false,false] ++ +
+ +
提示:
+ +-
+
1 <= A.length <= 30000
+ A[i]为0或1
+
给出一个以头节点 head 作为第一个节点的链表。链表中的节点分别编号为:node_1, node_2, node_3, ... 。
每个节点都可能有下一个更大值(next larger value):对于 node_i,如果其 next_larger(node_i) 是 node_j.val,那么就有 j > i 且 node_j.val > node_i.val,而 j 是可能的选项中最小的那个。如果不存在这样的 j,那么下一个更大值为 0 。
返回整数答案数组 answer,其中 answer[i] = next_larger(node_{i+1}) 。
注意:在下面的示例中,诸如 [2,1,5] 这样的输入(不是输出)是链表的序列化表示,其头节点的值为 2,第二个节点值为 1,第三个节点值为 5 。
+ +
示例 1:
+ +输入:[2,1,5] +输出:[5,5,0] ++ +
示例 2:
+ +输入:[2,7,4,3,5] +输出:[7,0,5,5,0] ++ +
示例 3:
+ +输入:[1,7,5,1,9,2,5,1] +输出:[7,9,9,9,0,5,0,0] ++ +
+ +
提示:
+ +-
+
- 对于链表中的每个节点,
1 <= node.val <= 10^9
+ - 给定列表的长度在
[0, 10000]范围内
+
给出一个二维数组 A,每个单元格为 0(代表海)或 1(代表陆地)。
移动是指在陆地上从一个地方走到另一个地方(朝四个方向之一)或离开网格的边界。
+ +返回网格中无法在任意次数的移动中离开网格边界的陆地单元格的数量。
+ ++ +
示例 1:
+ +输入:[[0,0,0,0],[1,0,1,0],[0,1,1,0],[0,0,0,0]] +输出:3 +解释: +有三个 1 被 0 包围。一个 1 没有被包围,因为它在边界上。+ +
示例 2:
+ +输入:[[0,1,1,0],[0,0,1,0],[0,0,1,0],[0,0,0,0]] +输出:0 +解释: +所有 1 都在边界上或可以到达边界。+ +
+ +
提示:
+ +-
+
1 <= A.length <= 500
+ 1 <= A[i].length <= 500
+ 0 <= A[i][j] <= 1
+ - 所有行的大小都相同 +
有效括号字符串为空 ("")、"(" + A + ")" 或 A + B,其中 A 和 B 都是有效的括号字符串,+ 代表字符串的连接。例如,"","()","(())()" 和 "(()(()))" 都是有效的括号字符串。
如果有效字符串 S 非空,且不存在将其拆分为 S = A+B 的方法,我们称其为原语(primitive),其中 A 和 B 都是非空有效括号字符串。
给出一个非空有效字符串 S,考虑将其进行原语化分解,使得:S = P_1 + P_2 + ... + P_k,其中 P_i 是有效括号字符串原语。
对 S 进行原语化分解,删除分解中每个原语字符串的最外层括号,返回 S 。
+ +
示例 1:
+ +输入:"(()())(())" +输出:"()()()" +解释: +输入字符串为 "(()())(())",原语化分解得到 "(()())" + "(())", +删除每个部分中的最外层括号后得到 "()()" + "()" = "()()()"。+ +
示例 2:
+ +输入:"(()())(())(()(()))" +输出:"()()()()(())" +解释: +输入字符串为 "(()())(())(()(()))",原语化分解得到 "(()())" + "(())" + "(()(()))", +删除每隔部分中的最外层括号后得到 "()()" + "()" + "()(())" = "()()()()(())"。 ++ +
示例 3:
+ +输入:"()()" +输出:"" +解释: +输入字符串为 "()()",原语化分解得到 "()" + "()", +删除每个部分中的最外层括号后得到 "" + "" = ""。 ++ +
+ +
提示:
+ +-
+
S.length <= 10000
+ S[i]为"("或")"
+ S是一个有效括号字符串
+
给出一棵二叉树,其上每个结点的值都是 0 或 1 。每一条从根到叶的路径都代表一个从最高有效位开始的二进制数。例如,如果路径为 0 -> 1 -> 1 -> 0 -> 1,那么它表示二进制数 01101,也就是 13 。
对树上的每一片叶子,我们都要找出从根到该叶子的路径所表示的数字。
+ +以 10^9 + 7 为模,返回这些数字之和。
+ +
示例:
+ +
输入:[1,0,1,0,1,0,1] +输出:22 +解释:(100) + (101) + (110) + (111) = 4 + 5 + 6 + 7 = 22 ++ +
+ +
提示:
+ +-
+
- 树中的结点数介于
1和1000之间。
+ - node.val 为
0或1。
+
如果我们可以将小写字母插入模式串 pattern 得到待查询项 query,那么待查询项与给定模式串匹配。(我们可以在任何位置插入每个字符,也可以插入 0 个字符。)
给定待查询列表 queries,和模式串 pattern,返回由布尔值组成的答案列表 answer。只有在待查项 queries[i] 与模式串 pattern 匹配时, answer[i] 才为 true,否则为 false。
+ +
示例 1:
+ +输入:queries = ["FooBar","FooBarTest","FootBall","FrameBuffer","ForceFeedBack"], pattern = "FB" +输出:[true,false,true,true,false] +示例: +"FooBar" 可以这样生成:"F" + "oo" + "B" + "ar"。 +"FootBall" 可以这样生成:"F" + "oot" + "B" + "all". +"FrameBuffer" 可以这样生成:"F" + "rame" + "B" + "uffer".+ +
示例 2:
+ +输入:queries = ["FooBar","FooBarTest","FootBall","FrameBuffer","ForceFeedBack"], pattern = "FoBa" +输出:[true,false,true,false,false] +解释: +"FooBar" 可以这样生成:"Fo" + "o" + "Ba" + "r". +"FootBall" 可以这样生成:"Fo" + "ot" + "Ba" + "ll". ++ +
示例 3:
+ +输出:queries = ["FooBar","FooBarTest","FootBall","FrameBuffer","ForceFeedBack"], pattern = "FoBaT" +输入:[false,true,false,false,false] +解释: +"FooBarTest" 可以这样生成:"Fo" + "o" + "Ba" + "r" + "T" + "est". ++ +
+ +
提示:
+ +-
+
1 <= queries.length <= 100
+ 1 <= queries[i].length <= 100
+ 1 <= pattern.length <= 100
+ - 所有字符串都仅由大写和小写英文字母组成。 +
你将会获得一系列视频片段,这些片段来自于一项持续时长为 T 秒的体育赛事。这些片段可能有所重叠,也可能长度不一。
视频片段 clips[i] 都用区间进行表示:开始于 clips[i][0] 并于 clips[i][1] 结束。我们甚至可以对这些片段自由地再剪辑,例如片段 [0, 7] 可以剪切成 [0, 1] + [1, 3] + [3, 7] 三部分。
我们需要将这些片段进行再剪辑,并将剪辑后的内容拼接成覆盖整个运动过程的片段([0, T])。返回所需片段的最小数目,如果无法完成该任务,则返回 -1 。
+ +
示例 1:
+ +输入:clips = [[0,2],[4,6],[8,10],[1,9],[1,5],[5,9]], T = 10 +输出:3 +解释: +我们选中 [0,2], [8,10], [1,9] 这三个片段。 +然后,按下面的方案重制比赛片段: +将 [1,9] 再剪辑为 [1,2] + [2,8] + [8,9] 。 +现在我们手上有 [0,2] + [2,8] + [8,10],而这些涵盖了整场比赛 [0, 10]。 ++ +
示例 2:
+ +输入:clips = [[0,1],[1,2]], T = 5 +输出:-1 +解释: +我们无法只用 [0,1] 和 [0,2] 覆盖 [0,5] 的整个过程。 ++ +
示例 3:
+ +输入:clips = [[0,1],[6,8],[0,2],[5,6],[0,4],[0,3],[6,7],[1,3],[4,7],[1,4],[2,5],[2,6],[3,4],[4,5],[5,7],[6,9]], T = 9 +输出:3 +解释: +我们选取片段 [0,4], [4,7] 和 [6,9] 。 ++ +
示例 4:
+ +输入:clips = [[0,4],[2,8]], T = 5 +输出:2 +解释: +注意,你可能录制超过比赛结束时间的视频。 ++ +
+ +
提示:
+ +-
+
1 <= clips.length <= 100
+ 0 <= clips[i][0], clips[i][1] <= 100
+ 0 <= T <= 100
+
爱丽丝和鲍勃一起玩游戏,他们轮流行动。爱丽丝先手开局。
+ +最初,黑板上有一个数字 N 。在每个玩家的回合,玩家需要执行以下操作:
-
+
- 选出任一
x,满足0 < x < N且N % x == 0。
+ - 用
N - x替换黑板上的数字N。
+
如果玩家无法执行这些操作,就会输掉游戏。
+ +只有在爱丽丝在游戏中取得胜利时才返回 True,否则返回 false。假设两个玩家都以最佳状态参与游戏。
+ +
-
+
示例 1:
+ +输入:2 +输出:true +解释:爱丽丝选择 1,鲍勃无法进行操作。 ++ +
示例 2:
+ +输入:3 +输出:false +解释:爱丽丝选择 1,鲍勃也选择 1,然后爱丽丝无法进行操作。 ++ +
+ +
提示:
+ +-
+
1 <= N <= 1000
+
给定二叉树的根节点 root,找出存在于不同节点 A 和 B 之间的最大值 V,其中 V = |A.val - B.val|,且 A 是 B 的祖先。
(如果 A 的任何子节点之一为 B,或者 A 的任何子节点是 B 的祖先,那么我们认为 A 是 B 的祖先)
+ ++ +
示例:
+ +
输入:[8,3,10,1,6,null,14,null,null,4,7,13] +输出:7 +解释: +我们有大量的节点与其祖先的差值,其中一些如下: +|8 - 3| = 5 +|3 - 7| = 4 +|8 - 1| = 7 +|10 - 13| = 3 +在所有可能的差值中,最大值 7 由 |8 - 1| = 7 得出。 ++ +
+ +
提示:
+ +-
+
- 树中的节点数在
2到5000之间。
+ - 每个节点的值介于
0到100000之间。
+
给定一个整数数组 A,返回 A 中最长等差子序列的长度。
回想一下,A 的子序列是列表 A[i_1], A[i_2], ..., A[i_k] 其中 0 <= i_1 < i_2 < ... < i_k <= A.length - 1。并且如果 B[i+1] - B[i]( 0 <= i < B.length - 1) 的值都相同,那么序列 B 是等差的。
+ +
示例 1:
+ +输入:[3,6,9,12] +输出:4 +解释: +整个数组是公差为 3 的等差数列。 ++ +
示例 2:
+ +输入:[9,4,7,2,10] +输出:3 +解释: +最长的等差子序列是 [4,7,10]。 ++ +
示例 3:
+ +输入:[20,1,15,3,10,5,8] +输出:4 +解释: +最长的等差子序列是 [20,15,10,5]。 ++ +
+ +
提示:
+ +-
+
2 <= A.length <= 2000
+ 0 <= A[i] <= 10000
+
我们从二叉树的根节点 root 开始进行深度优先搜索。
在遍历中的每个节点处,我们输出 D 条短划线(其中 D 是该节点的深度),然后输出该节点的值。(如果节点的深度为 D,则其直接子节点的深度为 D + 1。根节点的深度为 0)。
如果节点只有一个子节点,那么保证该子节点为左子节点。
+ +给出遍历输出 S,还原树并返回其根节点 root。
+ +
示例 1:
+ +
输入:"1-2--3--4-5--6--7" +输出:[1,2,5,3,4,6,7] ++ +
示例 2:
+ +
输入:"1-2--3---4-5--6---7" +输出:[1,2,5,3,null,6,null,4,null,7] ++ +
示例 3:
+ +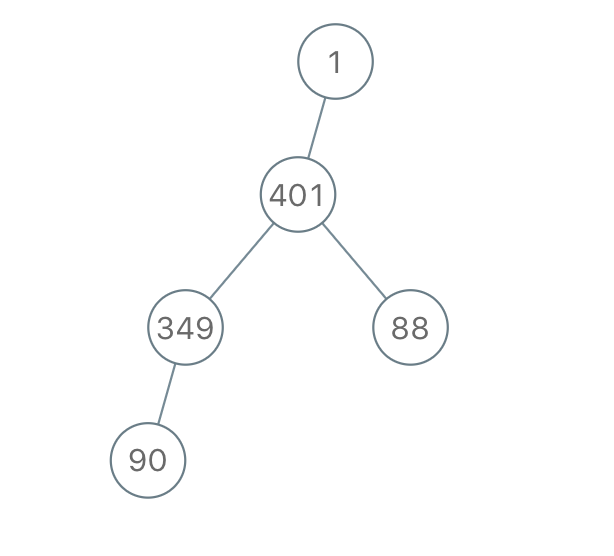
输入:"1-401--349---90--88" +输出:[1,401,null,349,88,90] ++ +
+ +
提示:
+ +-
+
- 原始树中的节点数介于
1和1000之间。
+ - 每个节点的值介于
1和10 ^ 9之间。
+
公司计划面试 2N 人。第 i 人飞往 A 市的费用为 costs[i][0],飞往 B 市的费用为 costs[i][1]。
返回将每个人都飞到某座城市的最低费用,要求每个城市都有 N 人抵达。
+ +
示例:
+ +输入:[[10,20],[30,200],[400,50],[30,20]] +输出:110 +解释: +第一个人去 A 市,费用为 10。 +第二个人去 A 市,费用为 30。 +第三个人去 B 市,费用为 50。 +第四个人去 B 市,费用为 20。 + +最低总费用为 10 + 30 + 50 + 20 = 110,每个城市都有一半的人在面试。 ++ +
+ +
提示:
+ +-
+
1 <= costs.length <= 100
+ costs.length为偶数
+ 1 <= costs[i][0], costs[i][1] <= 1000
+
给出 R 行 C 列的矩阵,其中的单元格的整数坐标为 (r, c),满足 0 <= r < R 且 0 <= c < C。
另外,我们在该矩阵中给出了一个坐标为 (r0, c0) 的单元格。
返回矩阵中的所有单元格的坐标,并按到 (r0, c0) 的距离从最小到最大的顺序排,其中,两单元格(r1, c1) 和 (r2, c2) 之间的距离是曼哈顿距离,|r1 - r2| + |c1 - c2|。(你可以按任何满足此条件的顺序返回答案。)
+ +
示例 1:
+ +输入:R = 1, C = 2, r0 = 0, c0 = 0 +输出:[[0,0],[0,1]] +解释:从 (r0, c0) 到其他单元格的距离为:[0,1] ++ +
示例 2:
+ +输入:R = 2, C = 2, r0 = 0, c0 = 1 +输出:[[0,1],[0,0],[1,1],[1,0]] +解释:从 (r0, c0) 到其他单元格的距离为:[0,1,1,2] +[[0,1],[1,1],[0,0],[1,0]] 也会被视作正确答案。 ++ +
示例 3:
+ +输入:R = 2, C = 3, r0 = 1, c0 = 2 +输出:[[1,2],[0,2],[1,1],[0,1],[1,0],[0,0]] +解释:从 (r0, c0) 到其他单元格的距离为:[0,1,1,2,2,3] +其他满足题目要求的答案也会被视为正确,例如 [[1,2],[1,1],[0,2],[1,0],[0,1],[0,0]]。 ++ +
+ +
提示:
+ +-
+
1 <= R <= 100
+ 1 <= C <= 100
+ 0 <= r0 < R
+ 0 <= c0 < C
+
给出非负整数数组 A ,返回两个非重叠(连续)子数组中元素的最大和,子数组的长度分别为 L 和 M。(这里需要澄清的是,长为 L 的子数组可以出现在长为 M 的子数组之前或之后。)
从形式上看,返回最大的 V,而 V = (A[i] + A[i+1] + ... + A[i+L-1]) + (A[j] + A[j+1] + ... + A[j+M-1]) 并满足下列条件之一:
+ +
-
+
0 <= i < i + L - 1 < j < j + M - 1 < A.length, 或
+ 0 <= j < j + M - 1 < i < i + L - 1 < A.length.
+
+ +
示例 1:
+ +输入:A = [0,6,5,2,2,5,1,9,4], L = 1, M = 2 +输出:20 +解释:子数组的一种选择中,[9] 长度为 1,[6,5] 长度为 2。 ++ +
示例 2:
+ +输入:A = [3,8,1,3,2,1,8,9,0], L = 3, M = 2 +输出:29 +解释:子数组的一种选择中,[3,8,1] 长度为 3,[8,9] 长度为 2。 ++ +
示例 3:
+ +输入:A = [2,1,5,6,0,9,5,0,3,8], L = 4, M = 3 +输出:31 +解释:子数组的一种选择中,[5,6,0,9] 长度为 4,[0,3,8] 长度为 3。+ +
+ +
提示:
+ +-
+
L >= 1
+ M >= 1
+ L + M <= A.length <= 1000
+ 0 <= A[i] <= 1000
+
按下述要求实现 StreamChecker 类:
-
+
StreamChecker(words):构造函数,用给定的字词初始化数据结构。
+ query(letter):如果存在某些k >= 1,可以用查询的最后k个字符(按从旧到新顺序,包括刚刚查询的字母)拼写出给定字词表中的某一字词时,返回true。否则,返回false。
+
+ +
示例:
+ +StreamChecker streamChecker = new StreamChecker(["cd","f","kl"]); // 初始化字典
+streamChecker.query('a'); // 返回 false
+streamChecker.query('b'); // 返回 false
+streamChecker.query('c'); // 返回 false
+streamChecker.query('d'); // 返回 true,因为 'cd' 在字词表中
+streamChecker.query('e'); // 返回 false
+streamChecker.query('f'); // 返回 true,因为 'f' 在字词表中
+streamChecker.query('g'); // 返回 false
+streamChecker.query('h'); // 返回 false
+streamChecker.query('i'); // 返回 false
+streamChecker.query('j'); // 返回 false
+streamChecker.query('k'); // 返回 false
+streamChecker.query('l'); // 返回 true,因为 'kl' 在字词表中。
+
++ +
提示:
+ +-
+
1 <= words.length <= 2000
+ 1 <= words[i].length <= 2000
+ - 字词只包含小写英文字母。 +
- 待查项只包含小写英文字母。 +
- 待查项最多 40000 个。 +
三枚石子放置在数轴上,位置分别为 a,b,c。
每一回合,我们假设这三枚石子当前分别位于位置 x, y, z 且 x < y < z。从位置 x 或者是位置 z 拿起一枚石子,并将该石子移动到某一整数位置 k 处,其中 x < k < z 且 k != y。
当你无法进行任何移动时,即,这些石子的位置连续时,游戏结束。
+ +要使游戏结束,你可以执行的最小和最大移动次数分别是多少? 以长度为 2 的数组形式返回答案:answer = [minimum_moves, maximum_moves]
+ +
示例 1:
+ +输入:a = 1, b = 2, c = 5 +输出:[1, 2] +解释:将石子从 5 移动到 4 再移动到 3,或者我们可以直接将石子移动到 3。 ++ +
示例 2:
+ +输入:a = 4, b = 3, c = 2 +输出:[0, 0] +解释:我们无法进行任何移动。 ++ +
+ +
提示:
+ +-
+
1 <= a <= 100
+ 1 <= b <= 100
+ 1 <= c <= 100
+ a != b, b != c, c != a
+
给出一个二维整数网格 grid,网格中的每个值表示该位置处的网格块的颜色。
只有当两个网格块的颜色相同,而且在四个方向中任意一个方向上相邻时,它们属于同一连通分量。
+ +连通分量的边界是指连通分量中的所有与不在分量中的正方形相邻(四个方向上)的所有正方形,或者在网格的边界上(第一行/列或最后一行/列)的所有正方形。
+ +给出位于 (r0, c0) 的网格块和颜色 color,使用指定颜色 color 为所给网格块的连通分量的边界进行着色,并返回最终的网格 grid 。
+ +
示例 1:
+ +输入:grid = [[1,1],[1,2]], r0 = 0, c0 = 0, color = 3 +输出:[[3, 3], [3, 2]] ++ +
示例 2:
+ +输入:grid = [[1,2,2],[2,3,2]], r0 = 0, c0 = 1, color = 3 +输出:[[1, 3, 3], [2, 3, 3]] ++ +
示例 3:
+ +输入:grid = [[1,1,1],[1,1,1],[1,1,1]], r0 = 1, c0 = 1, color = 2 +输出:[[2, 2, 2], [2, 1, 2], [2, 2, 2]]+ +
+ +
提示:
+ +-
+
1 <= grid.length <= 50
+ 1 <= grid[0].length <= 50
+ 1 <= grid[i][j] <= 1000
+ 0 <= r0 < grid.length
+ 0 <= c0 < grid[0].length
+ 1 <= color <= 1000
+
+ + + +## 解法 + + + +### Python3 + + +```python + +``` + +### Java + + +```java + +``` + +### ... +``` + +``` diff --git a/solution/1000-1099/1035.Uncrossed Lines/README.md b/solution/1000-1099/1035.Uncrossed Lines/README.md new file mode 100644 index 0000000000000..8eeac7598bce7 --- /dev/null +++ b/solution/1000-1099/1035.Uncrossed Lines/README.md @@ -0,0 +1,69 @@ +# [1035. 不相交的线](https://leetcode-cn.com/problems/uncrossed-lines) + +## 题目描述 + +
我们在两条独立的水平线上按给定的顺序写下 A 和 B 中的整数。
现在,我们可以绘制一些连接两个数字 A[i] 和 B[j] 的直线,只要 A[i] == B[j],且我们绘制的直线不与任何其他连线(非水平线)相交。
以这种方法绘制线条,并返回我们可以绘制的最大连线数。
+ ++ +
示例 1:
+ +
输入:A = [1,4,2], B = [1,2,4] +输出:2 +解释: +我们可以画出两条不交叉的线,如上图所示。 +我们无法画出第三条不相交的直线,因为从 A[1]=4 到 B[2]=4 的直线将与从 A[2]=2 到 B[1]=2 的直线相交。+ +
示例 2:
+ +输入:A = [2,5,1,2,5], B = [10,5,2,1,5,2] +输出:3 ++ +
示例 3:
+ +输入:A = [1,3,7,1,7,5], B = [1,9,2,5,1] +输出:2+ +
+ +
提示:
+ +-
+
1 <= A.length <= 500
+ 1 <= B.length <= 500
+ 1 <= A[i], B[i] <= 2000
+
+ + + +## 解法 + + + +### Python3 + + +```python + +``` + +### Java + + +```java + +``` + +### ... +``` + +``` diff --git a/solution/1000-1099/1036.Escape a Large Maze/README.md b/solution/1000-1099/1036.Escape a Large Maze/README.md new file mode 100644 index 0000000000000..fb880ede1b0a0 --- /dev/null +++ b/solution/1000-1099/1036.Escape a Large Maze/README.md @@ -0,0 +1,65 @@ +# [1036. 逃离大迷宫](https://leetcode-cn.com/problems/escape-a-large-maze) + +## 题目描述 + +
在一个 10^6 x 10^6 的网格中,每个网格块的坐标为 (x, y),其中 0 <= x, y < 10^6。
我们从源方格 source 开始出发,意图赶往目标方格 target。每次移动,我们都可以走到网格中在四个方向上相邻的方格,只要该方格不在给出的封锁列表 blocked 上。
只有在可以通过一系列的移动到达目标方格时才返回 true。否则,返回 false。
+ +
示例 1:
+ +输入:blocked = [[0,1],[1,0]], source = [0,0], target = [0,2] +输出:false +解释: +从源方格无法到达目标方格,因为我们无法在网格中移动。 ++ +
示例 2:
+ +输入:blocked = [], source = [0,0], target = [999999,999999] +输出:true +解释: +因为没有方格被封锁,所以一定可以到达目标方格。 ++ +
+ +
提示:
+ +-
+
0 <= blocked.length <= 200
+ blocked[i].length == 2
+ 0 <= blocked[i][j] < 10^6
+ source.length == target.length == 2
+ 0 <= source[i][j], target[i][j] < 10^6
+ source != target
+
回旋镖定义为一组三个点,这些点各不相同且不在一条直线上。
+ +给出平面上三个点组成的列表,判断这些点是否可以构成回旋镖。
+ ++ +
示例 1:
+ +输入:[[1,1],[2,3],[3,2]] +输出:true ++ +
示例 2:
+ +输入:[[1,1],[2,2],[3,3]] +输出:false+ +
+ +
提示:
+ +-
+
points.length == 3
+ points[i].length == 2
+ 0 <= points[i][j] <= 100
+
给出二叉 搜索 树的根节点,该二叉树的节点值各不相同,修改二叉树,使每个节点 node 的新值等于原树中大于或等于 node.val 的值之和。
提醒一下,二叉搜索树满足下列约束条件:
+ +-
+
- 节点的左子树仅包含键 小于 节点键的节点。 +
- 节点的右子树仅包含键 大于 节点键的节点。 +
- 左右子树也必须是二叉搜索树。 +
+ +
示例:
+ +
输入:[4,1,6,0,2,5,7,null,null,null,3,null,null,null,8] +输出:[30,36,21,36,35,26,15,null,null,null,33,null,null,null,8] ++ +
+ +
提示:
+ +-
+
- 树中的节点数介于
1和100之间。
+ - 每个节点的值介于
0和100之间。
+ - 给定的树为二叉搜索树。 +
+ +
注意:该题目与 538: https://leetcode-cn.com/problems/convert-bst-to-greater-tree/ 相同
+ + + +## 解法 + + + +### Python3 + + +```python + +``` + +### Java + + +```java + +``` + +### ... +``` + +``` diff --git a/solution/1000-1099/1039.Minimum Score Triangulation of Polygon/README.md b/solution/1000-1099/1039.Minimum Score Triangulation of Polygon/README.md new file mode 100644 index 0000000000000..5bf37c4de4be0 --- /dev/null +++ b/solution/1000-1099/1039.Minimum Score Triangulation of Polygon/README.md @@ -0,0 +1,70 @@ +# [1039. 多边形三角剖分的最低得分](https://leetcode-cn.com/problems/minimum-score-triangulation-of-polygon) + +## 题目描述 + +给定 N,想象一个凸 N 边多边形,其顶点按顺时针顺序依次标记为 A[0], A[i], ..., A[N-1]。
假设您将多边形剖分为 N-2 个三角形。对于每个三角形,该三角形的值是顶点标记的乘积,三角剖分的分数是进行三角剖分后所有 N-2 个三角形的值之和。
返回多边形进行三角剖分后可以得到的最低分。
+
-
+
示例 1:
+ +输入:[1,2,3] +输出:6 +解释:多边形已经三角化,唯一三角形的分数为 6。 ++ +
示例 2:
+ +
输入:[3,7,4,5] +输出:144 +解释:有两种三角剖分,可能得分分别为:3*7*5 + 4*5*7 = 245,或 3*4*5 + 3*4*7 = 144。最低分数为 144。 ++ +
示例 3:
+ +输入:[1,3,1,4,1,5] +输出:13 +解释:最低分数三角剖分的得分情况为 1*1*3 + 1*1*4 + 1*1*5 + 1*1*1 = 13。 ++ +
+ +
提示:
+ +-
+
3 <= A.length <= 50
+ 1 <= A[i] <= 100
+
在一个长度无限的数轴上,第 i 颗石子的位置为 stones[i]。如果一颗石子的位置最小/最大,那么该石子被称作端点石子。
每个回合,你可以将一颗端点石子拿起并移动到一个未占用的位置,使得该石子不再是一颗端点石子。
+ +值得注意的是,如果石子像 stones = [1,2,5] 这样,你将无法移动位于位置 5 的端点石子,因为无论将它移动到任何位置(例如 0 或 3),该石子都仍然会是端点石子。
当你无法进行任何移动时,即,这些石子的位置连续时,游戏结束。
+ +要使游戏结束,你可以执行的最小和最大移动次数分别是多少? 以长度为 2 的数组形式返回答案:answer = [minimum_moves, maximum_moves] 。
+ +
示例 1:
+ +输入:[7,4,9] +输出:[1,2] +解释: +我们可以移动一次,4 -> 8,游戏结束。 +或者,我们可以移动两次 9 -> 5,4 -> 6,游戏结束。 ++ +
示例 2:
+ +输入:[6,5,4,3,10] +输出:[2,3] +解释: +我们可以移动 3 -> 8,接着是 10 -> 7,游戏结束。 +或者,我们可以移动 3 -> 7, 4 -> 8, 5 -> 9,游戏结束。 +注意,我们无法进行 10 -> 2 这样的移动来结束游戏,因为这是不合要求的移动。 ++ +
示例 3:
+ +输入:[100,101,104,102,103] +输出:[0,0]+ +
+ +
提示:
+ +-
+
3 <= stones.length <= 10^4
+ 1 <= stones[i] <= 10^9
+ stones[i]的值各不相同。
+
+ + + +## 解法 + + + +### Python3 + + +```python + +``` + +### Java + + +```java + +``` + +### ... +``` + +``` diff --git a/solution/1000-1099/1041.Robot Bounded In Circle/README.md b/solution/1000-1099/1041.Robot Bounded In Circle/README.md new file mode 100644 index 0000000000000..1a5d8e75909b3 --- /dev/null +++ b/solution/1000-1099/1041.Robot Bounded In Circle/README.md @@ -0,0 +1,75 @@ +# [1041. 困于环中的机器人](https://leetcode-cn.com/problems/robot-bounded-in-circle) + +## 题目描述 + +
在无限的平面上,机器人最初位于 (0, 0) 处,面朝北方。机器人可以接受下列三条指令之一:
-
+
"G":直走 1 个单位
+ "L":左转 90 度
+ "R":右转 90 度
+
机器人按顺序执行指令 instructions,并一直重复它们。
只有在平面中存在环使得机器人永远无法离开时,返回 true。否则,返回 false。
+ +
示例 1:
+ +输入:"GGLLGG" +输出:true +解释: +机器人从 (0,0) 移动到 (0,2),转 180 度,然后回到 (0,0)。 +重复这些指令,机器人将保持在以原点为中心,2 为半径的环中进行移动。 ++ +
示例 2:
+ +输入:"GG" +输出:false +解释: +机器人无限向北移动。 ++ +
示例 3:
+ +输入:"GL" +输出:true +解释: +机器人按 (0, 0) -> (0, 1) -> (-1, 1) -> (-1, 0) -> (0, 0) -> ... 进行移动。+ +
+ +
提示:
+ +-
+
1 <= instructions.length <= 100
+ instructions[i]在{'G', 'L', 'R'}中
+
有 N 个花园,按从 1 到 N 标记。在每个花园中,你打算种下四种花之一。
paths[i] = [x, y] 描述了花园 x 到花园 y 的双向路径。
另外,没有花园有 3 条以上的路径可以进入或者离开。
+ +你需要为每个花园选择一种花,使得通过路径相连的任何两个花园中的花的种类互不相同。
+ +以数组形式返回选择的方案作为答案 answer,其中 answer[i] 为在第 (i+1) 个花园中种植的花的种类。花的种类用 1, 2, 3, 4 表示。保证存在答案。
+ +
示例 1:
+ +输入:N = 3, paths = [[1,2],[2,3],[3,1]] +输出:[1,2,3] ++ +
示例 2:
+ +输入:N = 4, paths = [[1,2],[3,4]] +输出:[1,2,1,2] ++ +
示例 3:
+ +输入:N = 4, paths = [[1,2],[2,3],[3,4],[4,1],[1,3],[2,4]] +输出:[1,2,3,4] ++ +
+ +
提示:
+ +-
+
1 <= N <= 10000
+ 0 <= paths.size <= 20000
+ - 不存在花园有 4 条或者更多路径可以进入或离开。 +
- 保证存在答案。 +
给出整数数组 A,将该数组分隔为长度最多为 K 的几个(连续)子数组。分隔完成后,每个子数组的中的值都会变为该子数组中的最大值。
返回给定数组完成分隔后的最大和。
+ ++ +
示例:
+ +输入:A = [1,15,7,9,2,5,10], K = 3 +输出:84 +解释:A 变为 [15,15,15,9,10,10,10]+ +
+ +
提示:
+ +-
+
1 <= K <= A.length <= 500
+ 0 <= A[i] <= 10^6
+
给出一个字符串 S,考虑其所有重复子串(S 的连续子串,出现两次或多次,可能会有重叠)。
返回任何具有最长可能长度的重复子串。(如果 S 不含重复子串,那么答案为 ""。)
+ +
示例 1:
+ +输入:"banana" +输出:"ana" ++ +
示例 2:
+ +输入:"abcd" +输出:"" ++ +
+ +
提示:
+ +-
+
2 <= S.length <= 10^5
+ S由小写英文字母组成。
+
有一堆石头,每块石头的重量都是正整数。
+ +每一回合,从中选出两块最重的石头,然后将它们一起粉碎。假设石头的重量分别为 x 和 y,且 x <= y。那么粉碎的可能结果如下:
-
+
- 如果
x == y,那么两块石头都会被完全粉碎;
+ - 如果
x != y,那么重量为x的石头将会完全粉碎,而重量为y的石头新重量为y-x。
+
最后,最多只会剩下一块石头。返回此石头的重量。如果没有石头剩下,就返回 0。
+ +
提示:
+ +-
+
1 <= stones.length <= 30
+ 1 <= stones[i] <= 1000
+
给出由小写字母组成的字符串 S,重复项删除操作会选择两个相邻且相同的字母,并删除它们。
在 S 上反复执行重复项删除操作,直到无法继续删除。
+ +在完成所有重复项删除操作后返回最终的字符串。答案保证唯一。
+ ++ +
示例:
+ +输入:"abbaca" +输出:"ca" +解释: +例如,在 "abbaca" 中,我们可以删除 "bb" 由于两字母相邻且相同,这是此时唯一可以执行删除操作的重复项。之后我们得到字符串 "aaca",其中又只有 "aa" 可以执行重复项删除操作,所以最后的字符串为 "ca"。 ++ +
+ +
提示:
+ +-
+
1 <= S.length <= 20000
+ S仅由小写英文字母组成。
+
给出一个单词列表,其中每个单词都由小写英文字母组成。
+ +如果我们可以在 word1 的任何地方添加一个字母使其变成 word2,那么我们认为 word1 是 word2 的前身。例如,"abc" 是 "abac" 的前身。
词链是单词 [word_1, word_2, ..., word_k] 组成的序列,k >= 1,其中 word_1 是 word_2 的前身,word_2 是 word_3 的前身,依此类推。
从给定单词列表 words 中选择单词组成词链,返回词链的最长可能长度。
+
示例:
+ +输入:["a","b","ba","bca","bda","bdca"] +输出:4 +解释:最长单词链之一为 "a","ba","bda","bdca"。 ++ +
+ +
提示:
+ +-
+
1 <= words.length <= 1000
+ 1 <= words[i].length <= 16
+ words[i]仅由小写英文字母组成。
+
+ + + +## 解法 + + + +### Python3 + + +```python + +``` + +### Java + + +```java + +``` + +### ... +``` + +``` diff --git a/solution/1000-1099/1049.Last Stone Weight II/README.md b/solution/1000-1099/1049.Last Stone Weight II/README.md new file mode 100644 index 0000000000000..b06ce319eae8b --- /dev/null +++ b/solution/1000-1099/1049.Last Stone Weight II/README.md @@ -0,0 +1,61 @@ +# [1049. 最后一块石头的重量 II](https://leetcode-cn.com/problems/last-stone-weight-ii) + +## 题目描述 + +
有一堆石头,每块石头的重量都是正整数。
+ +每一回合,从中选出任意两块石头,然后将它们一起粉碎。假设石头的重量分别为 x 和 y,且 x <= y。那么粉碎的可能结果如下:
-
+
- 如果
x == y,那么两块石头都会被完全粉碎;
+ - 如果
x != y,那么重量为x的石头将会完全粉碎,而重量为y的石头新重量为y-x。
+
最后,最多只会剩下一块石头。返回此石头最小的可能重量。如果没有石头剩下,就返回 0。
+ +
示例:
+ +输入:[2,7,4,1,8,1] +输出:1 +解释: +组合 2 和 4,得到 2,所以数组转化为 [2,7,1,8,1], +组合 7 和 8,得到 1,所以数组转化为 [2,1,1,1], +组合 2 和 1,得到 1,所以数组转化为 [1,1,1], +组合 1 和 1,得到 0,所以数组转化为 [1],这就是最优值。 ++ +
+ +
提示:
+ +-
+
1 <= stones.length <= 30
+ 1 <= stones[i] <= 1000
+
学校在拍年度纪念照时,一般要求学生按照 非递减 的高度顺序排列。
+ +请你返回能让所有学生以 非递减 高度排列的最小必要移动人数。
+ +注意,当一组学生被选中时,他们之间可以以任何可能的方式重新排序,而未被选中的学生应该保持不动。
+ ++ +
示例:
+ +输入:heights = [1,1,4,2,1,3] +输出:3 +解释: +当前数组:[1,1,4,2,1,3] +目标数组:[1,1,1,2,3,4] +在下标 2 处(从 0 开始计数)出现 4 vs 1 ,所以我们必须移动这名学生。 +在下标 4 处(从 0 开始计数)出现 1 vs 3 ,所以我们必须移动这名学生。 +在下标 5 处(从 0 开始计数)出现 3 vs 4 ,所以我们必须移动这名学生。+ +
示例 2:
+ +输入:heights = [5,1,2,3,4] +输出:5 ++ +
示例 3:
+ +输入:heights = [1,2,3,4,5] +输出:0 ++ +
+ +
提示:
+ +-
+
1 <= heights.length <= 100
+ 1 <= heights[i] <= 100
+
今天,书店老板有一家店打算试营业 customers.length 分钟。每分钟都有一些顾客(customers[i])会进入书店,所有这些顾客都会在那一分钟结束后离开。
在某些时候,书店老板会生气。 如果书店老板在第 i 分钟生气,那么 grumpy[i] = 1,否则 grumpy[i] = 0。 当书店老板生气时,那一分钟的顾客就会不满意,不生气则他们是满意的。
书店老板知道一个秘密技巧,能抑制自己的情绪,可以让自己连续 X 分钟不生气,但却只能使用一次。
请你返回这一天营业下来,最多有多少客户能够感到满意的数量。
+
示例:
+ +输入:customers = [1,0,1,2,1,1,7,5], grumpy = [0,1,0,1,0,1,0,1], X = 3 +输出:16 +解释: +书店老板在最后 3 分钟保持冷静。 +感到满意的最大客户数量 = 1 + 1 + 1 + 1 + 7 + 5 = 16. ++ +
+ +
提示:
+ +-
+
1 <= X <= customers.length == grumpy.length <= 20000
+ 0 <= customers[i] <= 1000
+ 0 <= grumpy[i] <= 1
+
给你一个正整数的数组 A(其中的元素不一定完全不同),请你返回可在 一次交换(交换两数字 A[i] 和 A[j] 的位置)后得到的、按字典序排列小于 A 的最大可能排列。
如果无法这么操作,就请返回原数组。
+ ++ +
示例 1:
+ +输入:[3,2,1] +输出:[3,1,2] +解释: +交换 2 和 1 ++ +
+ +
示例 2:
+ +输入:[1,1,5] +输出:[1,1,5] +解释: +这已经是最小排列 ++ +
+ +
示例 3:
+ +输入:[1,9,4,6,7] +输出:[1,7,4,6,9] +解释: +交换 9 和 7 ++ +
+ +
示例 4:
+ +输入:[3,1,1,3] +输出:[1,3,1,3] +解释: +交换 1 和 3 ++ +
+ +
提示:
+ +-
+
1 <= A.length <= 10000
+ 1 <= A[i] <= 10000
+
在一个仓库里,有一排条形码,其中第 i 个条形码为 barcodes[i]。
请你重新排列这些条形码,使其中两个相邻的条形码 不能 相等。 你可以返回任何满足该要求的答案,此题保证存在答案。
+ ++ +
示例 1:
+ +输入:[1,1,1,2,2,2] +输出:[2,1,2,1,2,1] ++ +
示例 2:
+ +输入:[1,1,1,1,2,2,3,3] +输出:[1,3,1,3,2,1,2,1]+ +
+ +
提示:
+ +-
+
1 <= barcodes.length <= 10000
+ 1 <= barcodes[i] <= 10000
+
+ + + +## 解法 + + + +### Python3 + + +```python + +``` + +### Java + + +```java + +``` + +### ... +``` + +``` diff --git a/solution/1000-1099/1055.Shortest Way to Form String/README.md b/solution/1000-1099/1055.Shortest Way to Form String/README.md new file mode 100644 index 0000000000000..d3aaaa2be4cd6 --- /dev/null +++ b/solution/1000-1099/1055.Shortest Way to Form String/README.md @@ -0,0 +1,29 @@ +# [1055. 形成字符串的最短路径](https://leetcode-cn.com/problems/shortest-way-to-form-string) + +## 题目描述 + +None + + +## 解法 + + + +### Python3 + + +```python + +``` + +### Java + + +```java + +``` + +### ... +``` + +``` diff --git a/solution/1000-1099/1056.Confusing Number/README.md b/solution/1000-1099/1056.Confusing Number/README.md new file mode 100644 index 0000000000000..8505f897904ff --- /dev/null +++ b/solution/1000-1099/1056.Confusing Number/README.md @@ -0,0 +1,29 @@ +# [1056. 易混淆数](https://leetcode-cn.com/problems/confusing-number) + +## 题目描述 + +None + + +## 解法 + + + +### Python3 + + +```python + +``` + +### Java + + +```java + +``` + +### ... +``` + +``` diff --git a/solution/1000-1099/1057.Campus Bikes/README.md b/solution/1000-1099/1057.Campus Bikes/README.md new file mode 100644 index 0000000000000..f4e25bf25f860 --- /dev/null +++ b/solution/1000-1099/1057.Campus Bikes/README.md @@ -0,0 +1,29 @@ +# [1057. 校园自行车分配](https://leetcode-cn.com/problems/campus-bikes) + +## 题目描述 + +None + + +## 解法 + + + +### Python3 + + +```python + +``` + +### Java + + +```java + +``` + +### ... +``` + +``` diff --git a/solution/1000-1099/1058.Minimize Rounding Error to Meet Target/README.md b/solution/1000-1099/1058.Minimize Rounding Error to Meet Target/README.md new file mode 100644 index 0000000000000..307cdd5b6a6fc --- /dev/null +++ b/solution/1000-1099/1058.Minimize Rounding Error to Meet Target/README.md @@ -0,0 +1,29 @@ +# [1058. 最小化舍入误差以满足目标](https://leetcode-cn.com/problems/minimize-rounding-error-to-meet-target) + +## 题目描述 + +None + + +## 解法 + + + +### Python3 + + +```python + +``` + +### Java + + +```java + +``` + +### ... +``` + +``` diff --git a/solution/1000-1099/1059.All Paths from Source Lead to Destination/README.md b/solution/1000-1099/1059.All Paths from Source Lead to Destination/README.md new file mode 100644 index 0000000000000..9d0cb710c53fe --- /dev/null +++ b/solution/1000-1099/1059.All Paths from Source Lead to Destination/README.md @@ -0,0 +1,29 @@ +# [1059. 从始点到终点的所有路径](https://leetcode-cn.com/problems/all-paths-from-source-lead-to-destination) + +## 题目描述 + +None + + +## 解法 + + + +### Python3 + + +```python + +``` + +### Java + + +```java + +``` + +### ... +``` + +``` diff --git a/solution/1000-1099/1060.Missing Element in Sorted Array/README.md b/solution/1000-1099/1060.Missing Element in Sorted Array/README.md new file mode 100644 index 0000000000000..34b8dc7927d9d --- /dev/null +++ b/solution/1000-1099/1060.Missing Element in Sorted Array/README.md @@ -0,0 +1,29 @@ +# [1060. 有序数组中的缺失元素](https://leetcode-cn.com/problems/missing-element-in-sorted-array) + +## 题目描述 + +None + + +## 解法 + + + +### Python3 + + +```python + +``` + +### Java + + +```java + +``` + +### ... +``` + +``` diff --git a/solution/1000-1099/1061.Lexicographically Smallest Equivalent String/README.md b/solution/1000-1099/1061.Lexicographically Smallest Equivalent String/README.md new file mode 100644 index 0000000000000..e182cdd4031e9 --- /dev/null +++ b/solution/1000-1099/1061.Lexicographically Smallest Equivalent String/README.md @@ -0,0 +1,29 @@ +# [1061. 按字典序排列最小的等效字符串](https://leetcode-cn.com/problems/lexicographically-smallest-equivalent-string) + +## 题目描述 + +None + + +## 解法 + + + +### Python3 + + +```python + +``` + +### Java + + +```java + +``` + +### ... +``` + +``` diff --git a/solution/1000-1099/1062.Longest Repeating Substring/README.md b/solution/1000-1099/1062.Longest Repeating Substring/README.md new file mode 100644 index 0000000000000..fe9a8c8b665c0 --- /dev/null +++ b/solution/1000-1099/1062.Longest Repeating Substring/README.md @@ -0,0 +1,29 @@ +# [1062. 最长重复子串](https://leetcode-cn.com/problems/longest-repeating-substring) + +## 题目描述 + +None + + +## 解法 + + + +### Python3 + + +```python + +``` + +### Java + + +```java + +``` + +### ... +``` + +``` diff --git a/solution/1000-1099/1063.Number of Valid Subarrays/README.md b/solution/1000-1099/1063.Number of Valid Subarrays/README.md new file mode 100644 index 0000000000000..8c03d5cfa7134 --- /dev/null +++ b/solution/1000-1099/1063.Number of Valid Subarrays/README.md @@ -0,0 +1,29 @@ +# [1063. 有效子数组的数目](https://leetcode-cn.com/problems/number-of-valid-subarrays) + +## 题目描述 + +None + + +## 解法 + + + +### Python3 + + +```python + +``` + +### Java + + +```java + +``` + +### ... +``` + +``` diff --git a/solution/1000-1099/1064.Fixed Point/README.md b/solution/1000-1099/1064.Fixed Point/README.md new file mode 100644 index 0000000000000..e9f6b128eeb1e --- /dev/null +++ b/solution/1000-1099/1064.Fixed Point/README.md @@ -0,0 +1,29 @@ +# [1064. 不动点](https://leetcode-cn.com/problems/fixed-point) + +## 题目描述 + +None + + +## 解法 + + + +### Python3 + + +```python + +``` + +### Java + + +```java + +``` + +### ... +``` + +``` diff --git a/solution/1000-1099/1065.Index Pairs of a String/README.md b/solution/1000-1099/1065.Index Pairs of a String/README.md new file mode 100644 index 0000000000000..58db82d5dbbe5 --- /dev/null +++ b/solution/1000-1099/1065.Index Pairs of a String/README.md @@ -0,0 +1,29 @@ +# [1065. 字符串的索引对](https://leetcode-cn.com/problems/index-pairs-of-a-string) + +## 题目描述 + +None + + +## 解法 + + + +### Python3 + + +```python + +``` + +### Java + + +```java + +``` + +### ... +``` + +``` diff --git a/solution/1000-1099/1066.Campus Bikes II/README.md b/solution/1000-1099/1066.Campus Bikes II/README.md new file mode 100644 index 0000000000000..c66cdb7e0ae4c --- /dev/null +++ b/solution/1000-1099/1066.Campus Bikes II/README.md @@ -0,0 +1,29 @@ +# [1066. 校园自行车分配 II](https://leetcode-cn.com/problems/campus-bikes-ii) + +## 题目描述 + +None + + +## 解法 + + + +### Python3 + + +```python + +``` + +### Java + + +```java + +``` + +### ... +``` + +``` diff --git a/solution/1000-1099/1067.Digit Count in Range/README.md b/solution/1000-1099/1067.Digit Count in Range/README.md new file mode 100644 index 0000000000000..fea658bc29981 --- /dev/null +++ b/solution/1000-1099/1067.Digit Count in Range/README.md @@ -0,0 +1,29 @@ +# [1067. 范围内的数字计数](https://leetcode-cn.com/problems/digit-count-in-range) + +## 题目描述 + +None + + +## 解法 + + + +### Python3 + + +```python + +``` + +### Java + + +```java + +``` + +### ... +``` + +``` diff --git a/solution/1000-1099/1068.Product Sales Analysis I/README.md b/solution/1000-1099/1068.Product Sales Analysis I/README.md new file mode 100644 index 0000000000000..79477e6d1370b --- /dev/null +++ b/solution/1000-1099/1068.Product Sales Analysis I/README.md @@ -0,0 +1,29 @@ +# [1068. 产品销售分析 I](https://leetcode-cn.com/problems/product-sales-analysis-i) + +## 题目描述 + +None + + +## 解法 + + + +### Python3 + + +```python + +``` + +### Java + + +```java + +``` + +### ... +``` + +``` diff --git a/solution/1000-1099/1069.Product Sales Analysis II/README.md b/solution/1000-1099/1069.Product Sales Analysis II/README.md new file mode 100644 index 0000000000000..26acf55365313 --- /dev/null +++ b/solution/1000-1099/1069.Product Sales Analysis II/README.md @@ -0,0 +1,29 @@ +# [1069. 产品销售分析 II](https://leetcode-cn.com/problems/product-sales-analysis-ii) + +## 题目描述 + +None + + +## 解法 + + + +### Python3 + + +```python + +``` + +### Java + + +```java + +``` + +### ... +``` + +``` diff --git a/solution/1000-1099/1070.Product Sales Analysis III/README.md b/solution/1000-1099/1070.Product Sales Analysis III/README.md new file mode 100644 index 0000000000000..5a26ec470b1d4 --- /dev/null +++ b/solution/1000-1099/1070.Product Sales Analysis III/README.md @@ -0,0 +1,29 @@ +# [1070. 产品销售分析 III](https://leetcode-cn.com/problems/product-sales-analysis-iii) + +## 题目描述 + +None + + +## 解法 + + + +### Python3 + + +```python + +``` + +### Java + + +```java + +``` + +### ... +``` + +``` diff --git a/solution/1000-1099/1071.Greatest Common Divisor of Strings/README.md b/solution/1000-1099/1071.Greatest Common Divisor of Strings/README.md new file mode 100644 index 0000000000000..00bf2098891d8 --- /dev/null +++ b/solution/1000-1099/1071.Greatest Common Divisor of Strings/README.md @@ -0,0 +1,62 @@ +# [1071. 字符串的最大公因子](https://leetcode-cn.com/problems/greatest-common-divisor-of-strings) + +## 题目描述 + +
对于字符串 S 和 T,只有在 S = T + ... + T(T 与自身连接 1 次或多次)时,我们才认定 “T 能除尽 S”。
返回最长字符串 X,要求满足 X 能除尽 str1 且 X 能除尽 str2。
+ +
示例 1:
+ +输入:str1 = "ABCABC", str2 = "ABC" +输出:"ABC" ++ +
示例 2:
+ +输入:str1 = "ABABAB", str2 = "ABAB" +输出:"AB" ++ +
示例 3:
+ +输入:str1 = "LEET", str2 = "CODE" +输出:"" ++ +
+ +
提示:
+ +-
+
1 <= str1.length <= 1000
+ 1 <= str2.length <= 1000
+ str1[i]和str2[i]为大写英文字母
+
给定由若干 0 和 1 组成的矩阵 matrix,从中选出任意数量的列并翻转其上的 每个 单元格。翻转后,单元格的值从 0 变成 1,或者从 1 变为 0 。
返回经过一些翻转后,行上所有值都相等的最大行数。
+ ++ +
-
+
示例 1:
+ +输入:[[0,1],[1,1]] +输出:1 +解释:不进行翻转,有 1 行所有值都相等。 ++ +
示例 2:
+ +输入:[[0,1],[1,0]] +输出:2 +解释:翻转第一列的值之后,这两行都由相等的值组成。 ++ +
示例 3:
+ +输入:[[0,0,0],[0,0,1],[1,1,0]] +输出:2 +解释:翻转前两列的值之后,后两行由相等的值组成。+ +
+ +
提示:
+ +-
+
1 <= matrix.length <= 300
+ 1 <= matrix[i].length <= 300
+ - 所有
matrix[i].length都相等
+ matrix[i][j]为0或1
+
给出基数为 -2 的两个数 arr1 和 arr2,返回两数相加的结果。
数字以 数组形式 给出:数组由若干 0 和 1 组成,按最高有效位到最低有效位的顺序排列。例如,arr = [1,1,0,1] 表示数字 (-2)^3 + (-2)^2 + (-2)^0 = -3。数组形式 的数字也同样不含前导零:以 arr 为例,这意味着要么 arr == [0],要么 arr[0] == 1。
返回相同表示形式的 arr1 和 arr2 相加的结果。两数的表示形式为:不含前导零、由若干 0 和 1 组成的数组。
+ +
示例:
+ +输入:arr1 = [1,1,1,1,1], arr2 = [1,0,1] +输出:[1,0,0,0,0] +解释:arr1 表示 11,arr2 表示 5,输出表示 16 。 ++ +
+ +
提示:
+ +-
+
1 <= arr1.length <= 1000
+ 1 <= arr2.length <= 1000
+ arr1和arr2都不含前导零
+ arr1[i]为0或1
+ arr2[i]为0或1
+
给出矩阵 matrix 和目标值 target,返回元素总和等于目标值的非空子矩阵的数量。
子矩阵 x1, y1, x2, y2 是满足 x1 <= x <= x2 且 y1 <= y <= y2 的所有单元 matrix[x][y] 的集合。
如果 (x1, y1, x2, y2) 和 (x1', y1', x2', y2') 两个子矩阵中部分坐标不同(如:x1 != x1'),那么这两个子矩阵也不同。
+ +
示例 1:
+ +输入:matrix = [[0,1,0],[1,1,1],[0,1,0]], target = 0 +输出:4 +解释:四个只含 0 的 1x1 子矩阵。 ++ +
示例 2:
+ +输入:matrix = [[1,-1],[-1,1]], target = 0 +输出:5 +解释:两个 1x2 子矩阵,加上两个 2x1 子矩阵,再加上一个 2x2 子矩阵。 ++ +
+ +
提示:
+ +-
+
1 <= matrix.length <= 300
+ 1 <= matrix[0].length <= 300
+ -1000 <= matrix[i] <= 1000
+ -10^8 <= target <= 10^8
+
给出第一个词 first 和第二个词 second,考虑在某些文本 text 中可能以 "first second third" 形式出现的情况,其中 second 紧随 first 出现,third 紧随 second 出现。
对于每种这样的情况,将第三个词 "third" 添加到答案中,并返回答案。
+ +
示例 1:
+ +输入:text = "alice is a good girl she is a good student", first = "a", second = "good" +输出:["girl","student"] ++ +
示例 2:
+ +输入:text = "we will we will rock you", first = "we", second = "will" +输出:["we","rock"] ++ +
+ +
提示:
+ +-
+
1 <= text.length <= 1000
+ text由一些用空格分隔的单词组成,每个单词都由小写英文字母组成
+ 1 <= first.length, second.length <= 10
+ first和second由小写英文字母组成
+
你有一套活字字模 tiles,其中每个字模上都刻有一个字母 tiles[i]。返回你可以印出的非空字母序列的数目。
+ +
示例 1:
+ +输入:"AAB" +输出:8 +解释:可能的序列为 "A", "B", "AA", "AB", "BA", "AAB", "ABA", "BAA"。 ++ +
示例 2:
+ +输入:"AAABBC" +输出:188 ++ +
+ +
提示:
+ +-
+
1 <= tiles.length <= 7
+ tiles由大写英文字母组成
+
给定一棵二叉树的根 root,请你考虑它所有 从根到叶的路径:从根到任何叶的路径。(所谓一个叶子节点,就是一个没有子节点的节点)
假如通过节点 node 的每种可能的 “根-叶” 路径上值的总和全都小于给定的 limit,则该节点被称之为「不足节点」,需要被删除。
请你删除所有不足节点,并返回生成的二叉树的根。
+ ++ +
示例 1:
+ ++ ++输入:root = [1,2,3,4,-99,-99,7,8,9,-99,-99,12,13,-99,14], limit = 1 +
+输出:[1,2,3,4,null,null,7,8,9,null,14] +
示例 2:
+ ++ ++输入:root = [5,4,8,11,null,17,4,7,1,null,null,5,3], limit = 22 +
+输出:[5,4,8,11,null,17,4,7,null,null,null,5]
示例 3:
+ ++ ++输入:root = [5,-6,-6], limit = 0 +输出:[]
+ +
提示:
+ +-
+
- 给定的树有
1到5000个节点
+ -10^5 <= node.val <= 10^5
+ -10^9 <= limit <= 10^9
+
+ + + +## 解法 + + + +### Python3 + + +```python + +``` + +### Java + + +```java + +``` + +### ... +``` + +``` diff --git a/solution/1000-1099/1081.Smallest Subsequence of Distinct Characters/README.md b/solution/1000-1099/1081.Smallest Subsequence of Distinct Characters/README.md new file mode 100644 index 0000000000000..2fee8c45df848 --- /dev/null +++ b/solution/1000-1099/1081.Smallest Subsequence of Distinct Characters/README.md @@ -0,0 +1,69 @@ +# [1081. 不同字符的最小子序列](https://leetcode-cn.com/problems/smallest-subsequence-of-distinct-characters) + +## 题目描述 + +
返回字符串 text 中按字典序排列最小的子序列,该子序列包含 text 中所有不同字符一次。
+ +
示例 1:
+ +输入:"cdadabcc" +输出:"adbc" ++ +
示例 2:
+ +输入:"abcd" +输出:"abcd" ++ +
示例 3:
+ +输入:"ecbacba" +输出:"eacb" ++ +
示例 4:
+ +输入:"leetcode" +输出:"letcod" ++ +
+ +
提示:
+ +-
+
1 <= text.length <= 1000
+ text由小写英文字母组成
+
+ +
注意:本题目与 316 https://leetcode-cn.com/problems/remove-duplicate-letters/ 相同
+ + + +## 解法 + + + +### Python3 + + +```python + +``` + +### Java + + +```java + +``` + +### ... +``` + +``` diff --git a/solution/1000-1099/1082.Sales Analysis I/README.md b/solution/1000-1099/1082.Sales Analysis I/README.md new file mode 100644 index 0000000000000..a29a10ea73df8 --- /dev/null +++ b/solution/1000-1099/1082.Sales Analysis I/README.md @@ -0,0 +1,29 @@ +# [1082. 销售分析 I](https://leetcode-cn.com/problems/sales-analysis-i) + +## 题目描述 + +None + + +## 解法 + + + +### Python3 + + +```python + +``` + +### Java + + +```java + +``` + +### ... +``` + +``` diff --git a/solution/1000-1099/1083.Sales Analysis II/README.md b/solution/1000-1099/1083.Sales Analysis II/README.md new file mode 100644 index 0000000000000..1dc84e88676ea --- /dev/null +++ b/solution/1000-1099/1083.Sales Analysis II/README.md @@ -0,0 +1,29 @@ +# [1083. 销售分析 II](https://leetcode-cn.com/problems/sales-analysis-ii) + +## 题目描述 + +None + + +## 解法 + + + +### Python3 + + +```python + +``` + +### Java + + +```java + +``` + +### ... +``` + +``` diff --git a/solution/1000-1099/1084.Sales Analysis III/README.md b/solution/1000-1099/1084.Sales Analysis III/README.md new file mode 100644 index 0000000000000..7a9562723f8ed --- /dev/null +++ b/solution/1000-1099/1084.Sales Analysis III/README.md @@ -0,0 +1,29 @@ +# [1084. 销售分析III](https://leetcode-cn.com/problems/sales-analysis-iii) + +## 题目描述 + +None + + +## 解法 + + + +### Python3 + + +```python + +``` + +### Java + + +```java + +``` + +### ... +``` + +``` diff --git a/solution/1000-1099/1085.Sum of Digits in the Minimum Number/README.md b/solution/1000-1099/1085.Sum of Digits in the Minimum Number/README.md new file mode 100644 index 0000000000000..bd9ae0c96055a --- /dev/null +++ b/solution/1000-1099/1085.Sum of Digits in the Minimum Number/README.md @@ -0,0 +1,29 @@ +# [1085. 最小元素各数位之和](https://leetcode-cn.com/problems/sum-of-digits-in-the-minimum-number) + +## 题目描述 + +None + + +## 解法 + + + +### Python3 + + +```python + +``` + +### Java + + +```java + +``` + +### ... +``` + +``` diff --git a/solution/1000-1099/1086.High Five/README.md b/solution/1000-1099/1086.High Five/README.md new file mode 100644 index 0000000000000..9be2662fda62d --- /dev/null +++ b/solution/1000-1099/1086.High Five/README.md @@ -0,0 +1,29 @@ +# [1086. 前五科的均分](https://leetcode-cn.com/problems/high-five) + +## 题目描述 + +None + + +## 解法 + + + +### Python3 + + +```python + +``` + +### Java + + +```java + +``` + +### ... +``` + +``` diff --git a/solution/1000-1099/1087.Brace Expansion/README.md b/solution/1000-1099/1087.Brace Expansion/README.md new file mode 100644 index 0000000000000..bb36fa7405848 --- /dev/null +++ b/solution/1000-1099/1087.Brace Expansion/README.md @@ -0,0 +1,29 @@ +# [1087. 字母切换](https://leetcode-cn.com/problems/brace-expansion) + +## 题目描述 + +None + + +## 解法 + + + +### Python3 + + +```python + +``` + +### Java + + +```java + +``` + +### ... +``` + +``` diff --git a/solution/1000-1099/1088.Confusing Number II/README.md b/solution/1000-1099/1088.Confusing Number II/README.md new file mode 100644 index 0000000000000..b6f3b71c90948 --- /dev/null +++ b/solution/1000-1099/1088.Confusing Number II/README.md @@ -0,0 +1,29 @@ +# [1088. 易混淆数 II](https://leetcode-cn.com/problems/confusing-number-ii) + +## 题目描述 + +None + + +## 解法 + + + +### Python3 + + +```python + +``` + +### Java + + +```java + +``` + +### ... +``` + +``` diff --git a/solution/1000-1099/1089.Duplicate Zeros/README.md b/solution/1000-1099/1089.Duplicate Zeros/README.md new file mode 100644 index 0000000000000..05b278c51862b --- /dev/null +++ b/solution/1000-1099/1089.Duplicate Zeros/README.md @@ -0,0 +1,59 @@ +# [1089. 复写零](https://leetcode-cn.com/problems/duplicate-zeros) + +## 题目描述 + +给你一个长度固定的整数数组 arr,请你将该数组中出现的每个零都复写一遍,并将其余的元素向右平移。
注意:请不要在超过该数组长度的位置写入元素。
+ +要求:请对输入的数组 就地 进行上述修改,不要从函数返回任何东西。
+ ++ +
示例 1:
+ +输入:[1,0,2,3,0,4,5,0] +输出:null +解释:调用函数后,输入的数组将被修改为:[1,0,0,2,3,0,0,4] ++ +
示例 2:
+ +输入:[1,2,3] +输出:null +解释:调用函数后,输入的数组将被修改为:[1,2,3] ++ +
+ +
提示:
+ +-
+
1 <= arr.length <= 10000
+ 0 <= arr[i] <= 9
+
我们有一个项的集合,其中第 i 项的值为 values[i],标签为 labels[i]。
我们从这些项中选出一个子集 S,这样一来:
-
+
|S| <= num_wanted
+ - 对于任意的标签
L,子集S中标签为L的项的数目总满足<= use_limit。
+
返回子集 S 的最大可能的 和。
+ +
示例 1:
+ +输入:values = [5,4,3,2,1], labels = [1,1,2,2,3], num_wanted = 3, use_limit = 1
+输出:9
+解释:选出的子集是第一项,第三项和第五项。
+
+
+示例 2:
+ +输入:values = [5,4,3,2,1], labels = [1,3,3,3,2], num_wanted = 3, use_limit = 2
+输出:12
+解释:选出的子集是第一项,第二项和第三项。
+
+
+示例 3:
+ +输入:values = [9,8,8,7,6], labels = [0,0,0,1,1], num_wanted = 3, use_limit = 1
+输出:16
+解释:选出的子集是第一项和第四项。
+
+
+示例 4:
+ +输入:values = [9,8,8,7,6], labels = [0,0,0,1,1], num_wanted = 3, use_limit = 2
+输出:24
+解释:选出的子集是第一项,第二项和第四项。
+
+
++ +
提示:
+ +-
+
1 <= values.length == labels.length <= 20000
+ 0 <= values[i], labels[i] <= 20000
+ 1 <= num_wanted, use_limit <= values.length
+
在一个 N × N 的方形网格中,每个单元格有两种状态:空(0)或者阻塞(1)。
+ +一条从左上角到右下角、长度为 k 的畅通路径,由满足下述条件的单元格 C_1, C_2, ..., C_k 组成:
-
+
- 相邻单元格
C_i和C_{i+1}在八个方向之一上连通(此时,C_i和C_{i+1}不同且共享边或角)
+ C_1位于(0, 0)(即,值为grid[0][0])
+ C_k位于(N-1, N-1)(即,值为grid[N-1][N-1])
+ - 如果
C_i位于(r, c),则grid[r][c]为空(即,grid[r][c] == 0)
+
返回这条从左上角到右下角的最短畅通路径的长度。如果不存在这样的路径,返回 -1 。
+ ++ +
示例 1:
+ +输入:[[0,1],[1,0]] ++ ++输出:2 +
+
示例 2:
+ +输入:[[0,0,0],[1,1,0],[1,1,0]] ++ ++输出:4 +
+
+ +
提示:
+ +-
+
1 <= grid.length == grid[0].length <= 100
+ grid[i][j]为0或1
+
给出两个字符串 str1 和 str2,返回同时以 str1 和 str2 作为子序列的最短字符串。如果答案不止一个,则可以返回满足条件的任意一个答案。
(如果从字符串 T 中删除一些字符(也可能不删除,并且选出的这些字符可以位于 T 中的 任意位置),可以得到字符串 S,那么 S 就是 T 的子序列)
+ ++ +
示例:
+ +输入:str1 = "abac", str2 = "cab" +输出:"cabac" +解释: +str1 = "abac" 是 "cabac" 的一个子串,因为我们可以删去 "cabac" 的第一个 "c"得到 "abac"。 +str2 = "cab" 是 "cabac" 的一个子串,因为我们可以删去 "cabac" 末尾的 "ac" 得到 "cab"。 +最终我们给出的答案是满足上述属性的最短字符串。 ++ +
+ +
提示:
+ +-
+
1 <= str1.length, str2.length <= 1000
+ str1和str2都由小写英文字母组成。
+
我们对 0 到 255 之间的整数进行采样,并将结果存储在数组 count 中:count[k] 就是整数 k 的采样个数。
我们以 浮点数 数组的形式,分别返回样本的最小值、最大值、平均值、中位数和众数。其中,众数是保证唯一的。
+ +我们先来回顾一下中位数的知识:
+ +-
+
- 如果样本中的元素有序,并且元素数量为奇数时,中位数为最中间的那个元素; +
- 如果样本中的元素有序,并且元素数量为偶数时,中位数为中间的两个元素的平均值。 +
+ +
示例 1:
+ +输入:count = [0,1,3,4,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0] +输出:[1.00000,3.00000,2.37500,2.50000,3.00000] ++ +
示例 2:
+ +输入:count = [0,4,3,2,2,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0] +输出:[1.00000,4.00000,2.18182,2.00000,1.00000] ++ +
+ +
提示:
+ +-
+
count.length == 256
+ 1 <= sum(count) <= 10^9
+ - 计数表示的众数是唯一的 +
- 答案与真实值误差在
10^-5以内就会被视为正确答案
+
假设你是一位顺风车司机,车上最初有 capacity 个空座位可以用来载客。由于道路的限制,车 只能 向一个方向行驶(也就是说,不允许掉头或改变方向,你可以将其想象为一个向量)。
这儿有一份行程计划表 trips[][],其中 trips[i] = [num_passengers, start_location, end_location] 包含了你的第 i 次行程信息:
-
+
- 必须接送的乘客数量; +
- 乘客的上车地点; +
- 以及乘客的下车地点。 +
这些给出的地点位置是从你的 初始 出发位置向前行驶到这些地点所需的距离(它们一定在你的行驶方向上)。
+ +请你根据给出的行程计划表和车子的座位数,来判断你的车是否可以顺利完成接送所用乘客的任务(当且仅当你可以在所有给定的行程中接送所有乘客时,返回 true,否则请返回 false)。
+ +
示例 1:
+ +输入:trips = [[2,1,5],[3,3,7]], capacity = 4 +输出:false ++ +
示例 2:
+ +输入:trips = [[2,1,5],[3,3,7]], capacity = 5 +输出:true ++ +
示例 3:
+ +输入:trips = [[2,1,5],[3,5,7]], capacity = 3 +输出:true ++ +
示例 4:
+ +输入:trips = [[3,2,7],[3,7,9],[8,3,9]], capacity = 11 +输出:true ++ +
+ +
提示:
+ +-
+
- 你可以假设乘客会自觉遵守 “先下后上” 的良好素质 +
trips.length <= 1000
+ trips[i].length == 3
+ 1 <= trips[i][0] <= 100
+ 0 <= trips[i][1] < trips[i][2] <= 1000
+ 1 <= capacity <= 100000
+
(这是一个 交互式问题 )
+ +给你一个 山脉数组 mountainArr,请你返回能够使得 mountainArr.get(index) 等于 target 最小 的下标 index 值。
如果不存在这样的下标 index,就请返回 -1。
+ +
所谓山脉数组,即数组 A 假如是一个山脉数组的话,需要满足如下条件:
首先,A.length >= 3
其次,在 0 < i < A.length - 1 条件下,存在 i 使得:
-
+
A[0] < A[1] < ... A[i-1] < A[i]
+ A[i] > A[i+1] > ... > A[A.length - 1]
+
+ +
你将 不能直接访问该山脉数组,必须通过 MountainArray 接口来获取数据:
-
+
MountainArray.get(k)- 会返回数组中索引为k的元素(下标从 0 开始)
+ MountainArray.length()- 会返回该数组的长度
+
+ +
注意:
+ +对 MountainArray.get 发起超过 100 次调用的提交将被视为错误答案。此外,任何试图规避判题系统的解决方案都将会导致比赛资格被取消。
为了帮助大家更好地理解交互式问题,我们准备了一个样例 “答案”:https://leetcode-cn.com/playground/RKhe3ave,请注意这 不是一个正确答案。
+ +-
+
+ +
示例 1:
+ +输入:array = [1,2,3,4,5,3,1], target = 3 +输出:2 +解释:3 在数组中出现了两次,下标分别为 2 和 5,我们返回最小的下标 2。+ +
示例 2:
+ +输入:array = [0,1,2,4,2,1], target = 3 +输出:-1 +解释:3 在数组中没有出现,返回 -1。 ++ +
+ +
提示:
+ +-
+
3 <= mountain_arr.length() <= 10000
+ 0 <= target <= 10^9
+ 0 <= mountain_arr.get(index) <= 10^9
+
如果你熟悉 Shell 编程,那么一定了解过花括号展开,它可以用来生成任意字符串。
+ +花括号展开的表达式可以看作一个由 花括号、逗号 和 小写英文字母 组成的字符串,定义下面几条语法规则:
+ +-
+
- 如果只给出单一的元素
x,那么表达式表示的字符串就只有"x"。 + +-
+
- 例如,表达式
{a}表示字符串"a"。
+ - 而表达式
{ab}就表示字符串"ab"。
+
+ - 例如,表达式
- 当两个或多个表达式并列,以逗号分隔时,我们取这些表达式中元素的并集。
+
-
+
- 例如,表达式
{a,b,c}表示字符串"a","b","c"。
+ - 而表达式
{a,b},{b,c}也可以表示字符串"a","b","c"。
+
+ - 例如,表达式
- 要是两个或多个表达式相接,中间没有隔开时,我们从这些表达式中各取一个元素依次连接形成字符串。
+
-
+
- 例如,表达式
{a,b}{c,d}表示字符串"ac","ad","bc","bd"。
+
+ - 例如,表达式
- 表达式之间允许嵌套,单一元素与表达式的连接也是允许的。
+
-
+
- 例如,表达式
a{b,c,d}表示字符串"ab","ac","ad"。
+ - 例如,表达式
{a{b,c}}{{d,e}f{g,h}}可以代换为{ab,ac}{dfg,dfh,efg,efh},表示字符串"abdfg", "abdfh", "abefg", "abefh", "acdfg", "acdfh", "acefg", "acefh"。
+
+ - 例如,表达式
给出表示基于给定语法规则的表达式 expression,返回它所表示的所有字符串组成的有序列表。
假如你希望以「集合」的概念了解此题,也可以通过点击 “显示英文描述” 获取详情。
+ ++ +
示例 1:
+ +输入:"{a,b}{c{d,e}}"
+输出:["acd","ace","bcd","bce"]
+
+
+示例 2:
+ +输入:"{{a,z}, a{b,c}, {ab,z}}"
+输出:["a","ab","ac","z"]
+解释:输出中 不应 出现重复的组合结果。
+
+
++ +
提示:
+ +-
+
1 <= expression.length <= 50
+ expression[i]由'{','}',','或小写英文字母组成
+ - 给出的表达式
expression用以表示一组基于题目描述中语法构造的字符串
+
排排坐,分糖果。
+ +我们买了一些糖果 candies,打算把它们分给排好队的 n = num_people 个小朋友。
给第一个小朋友 1 颗糖果,第二个小朋友 2 颗,依此类推,直到给最后一个小朋友 n 颗糖果。
然后,我们再回到队伍的起点,给第一个小朋友 n + 1 颗糖果,第二个小朋友 n + 2 颗,依此类推,直到给最后一个小朋友 2 * n 颗糖果。
重复上述过程(每次都比上一次多给出一颗糖果,当到达队伍终点后再次从队伍起点开始),直到我们分完所有的糖果。注意,就算我们手中的剩下糖果数不够(不比前一次发出的糖果多),这些糖果也会全部发给当前的小朋友。
+ +返回一个长度为 num_people、元素之和为 candies 的数组,以表示糖果的最终分发情况(即 ans[i] 表示第 i 个小朋友分到的糖果数)。
+ +
示例 1:
+ +输入:candies = 7, num_people = 4 +输出:[1,2,3,1] +解释: +第一次,ans[0] += 1,数组变为 [1,0,0,0]。 +第二次,ans[1] += 2,数组变为 [1,2,0,0]。 +第三次,ans[2] += 3,数组变为 [1,2,3,0]。 +第四次,ans[3] += 1(因为此时只剩下 1 颗糖果),最终数组变为 [1,2,3,1]。 ++ +
示例 2:
+ +输入:candies = 10, num_people = 3 +输出:[5,2,3] +解释: +第一次,ans[0] += 1,数组变为 [1,0,0]。 +第二次,ans[1] += 2,数组变为 [1,2,0]。 +第三次,ans[2] += 3,数组变为 [1,2,3]。 +第四次,ans[0] += 4,最终数组变为 [5,2,3]。 ++ +
+ +
提示:
+ +-
+
1 <= candies <= 10^9
+ 1 <= num_people <= 1000
+
在一棵无限的二叉树上,每个节点都有两个子节点,树中的节点 逐行 依次按 “之” 字形进行标记。
+ +如下图所示,在奇数行(即,第一行、第三行、第五行……)中,按从左到右的顺序进行标记;
+ +而偶数行(即,第二行、第四行、第六行……)中,按从右到左的顺序进行标记。
+ +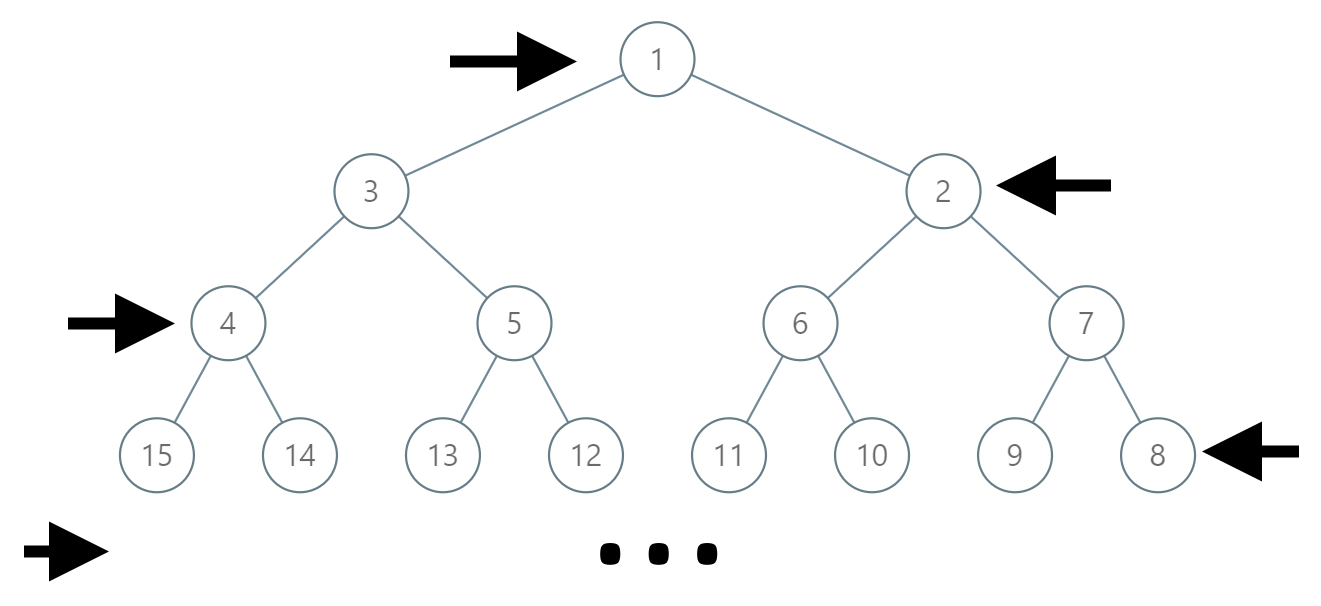
给你树上某一个节点的标号 label,请你返回从根节点到该标号为 label 节点的路径,该路径是由途经的节点标号所组成的。
+ +
示例 1:
+ +输入:label = 14 +输出:[1,3,4,14] ++ +
示例 2:
+ +输入:label = 26 +输出:[1,2,6,10,26] ++ +
+ +
提示:
+ +-
+
1 <= label <= 10^6
+
附近的家居城促销,你买回了一直心仪的可调节书架,打算把自己的书都整理到新的书架上。
+ +你把要摆放的书 books 都整理好,叠成一摞:从上往下,第 i 本书的厚度为 books[i][0],高度为 books[i][1]。
按顺序 将这些书摆放到总宽度为 shelf_width 的书架上。
先选几本书放在书架上(它们的厚度之和小于等于书架的宽度 shelf_width),然后再建一层书架。重复这个过程,直到把所有的书都放在书架上。
需要注意的是,在上述过程的每个步骤中,摆放书的顺序与你整理好的顺序相同。 例如,如果这里有 5 本书,那么可能的一种摆放情况是:第一和第二本书放在第一层书架上,第三本书放在第二层书架上,第四和第五本书放在最后一层书架上。
+ +每一层所摆放的书的最大高度就是这一层书架的层高,书架整体的高度为各层高之和。
+ +以这种方式布置书架,返回书架整体可能的最小高度。
+ ++ +
示例:
+ +
输入:books = [[1,1],[2,3],[2,3],[1,1],[1,1],[1,1],[1,2]], shelf_width = 4 +输出:6 +解释: +3 层书架的高度和为 1 + 3 + 2 = 6 。 +第 2 本书不必放在第一层书架上。 ++ +
+ +
提示:
+ +-
+
1 <= books.length <= 1000
+ 1 <= books[i][0] <= shelf_width <= 1000
+ 1 <= books[i][1] <= 1000
+
给你一个以字符串形式表述的 布尔表达式(boolean) expression,返回该式的运算结果。
有效的表达式需遵循以下约定:
+ +-
+
"t",运算结果为True
+ "f",运算结果为False
+ "!(expr)",运算过程为对内部表达式expr进行逻辑 非的运算(NOT)
+ "&(expr1,expr2,...)",运算过程为对 2 个或以上内部表达式expr1, expr2, ...进行逻辑 与的运算(AND)
+ "|(expr1,expr2,...)",运算过程为对 2 个或以上内部表达式expr1, expr2, ...进行逻辑 或的运算(OR)
+
+ +
示例 1:
+ +输入:expression = "!(f)" +输出:true ++ +
示例 2:
+ +输入:expression = "|(f,t)" +输出:true ++ +
示例 3:
+ +输入:expression = "&(t,f)" +输出:false ++ +
示例 4:
+ +输入:expression = "|(&(t,f,t),!(t))" +输出:false ++ +
+ +
提示:
+ +-
+
1 <= expression.length <= 20000
+ expression[i]由{'(', ')', '&', '|', '!', 't', 'f', ','}中的字符组成。
+ expression是以上述形式给出的有效表达式,表示一个布尔值。
+
给你一个有效的 IPv4 地址 address,返回这个 IP 地址的无效化版本。
所谓无效化 IP 地址,其实就是用 "[.]" 代替了每个 "."。
+ +
示例 1:
+ +输入:address = "1.1.1.1" +输出:"1[.]1[.]1[.]1" ++ +
示例 2:
+ +输入:address = "255.100.50.0" +输出:"255[.]100[.]50[.]0" ++ +
+ +
提示:
+ +-
+
- 给出的
address是一个有效的 IPv4 地址
+
这里有 n 个航班,它们分别从 1 到 n 进行编号。
我们这儿有一份航班预订表,表中第 i 条预订记录 bookings[i] = [i, j, k] 意味着我们在从 i 到 j 的每个航班上预订了 k 个座位。
请你返回一个长度为 n 的数组 answer,按航班编号顺序返回每个航班上预订的座位数。
+ +
示例:
+ +输入:bookings = [[1,2,10],[2,3,20],[2,5,25]], n = 5 +输出:[10,55,45,25,25] ++ +
+ +
提示:
+ +-
+
1 <= bookings.length <= 20000
+ 1 <= bookings[i][0] <= bookings[i][1] <= n <= 20000
+ 1 <= bookings[i][2] <= 10000
+
给出二叉树的根节点 root,树上每个节点都有一个不同的值。
如果节点值在 to_delete 中出现,我们就把该节点从树上删去,最后得到一个森林(一些不相交的树构成的集合)。
返回森林中的每棵树。你可以按任意顺序组织答案。
+ ++ +
示例:
+ +
输入:root = [1,2,3,4,5,6,7], to_delete = [3,5] +输出:[[1,2,null,4],[6],[7]] ++ +
+ +
提示:
+ +-
+
- 树中的节点数最大为
1000。
+ - 每个节点都有一个介于
1到1000之间的值,且各不相同。
+ to_delete.length <= 1000
+ to_delete包含一些从1到1000、各不相同的值。
+
有效括号字符串 仅由 "(" 和 ")" 构成,并符合下述几个条件之一:
-
+
- 空字符串 +
- 连接,可以记作
AB(A与B连接),其中A和B都是有效括号字符串
+ - 嵌套,可以记作
(A),其中A是有效括号字符串
+
类似地,我们可以定义任意有效括号字符串 s 的 嵌套深度 depth(S):
-
+
s为空时,depth("") = 0
+ s为A与B连接时,depth(A + B) = max(depth(A), depth(B)),其中A和B都是有效括号字符串
+ s为嵌套情况,depth("(" + A + ")") = 1 + depth(A),其中 A 是有效括号字符串
+
例如:"","()()",和 "()(()())" 都是有效括号字符串,嵌套深度分别为 0,1,2,而 ")(" 和 "(()" 都不是有效括号字符串。
+ +
给你一个有效括号字符串 seq,将其分成两个不相交的子序列 A 和 B,且 A 和 B 满足有效括号字符串的定义(注意:A.length + B.length = seq.length)。
现在,你需要从中选出 任意 一组有效括号字符串 A 和 B,使 max(depth(A), depth(B)) 的可能取值最小。
返回长度为 seq.length 答案数组 answer ,选择 A 还是 B 的编码规则是:如果 seq[i] 是 A 的一部分,那么 answer[i] = 0。否则,answer[i] = 1。即便有多个满足要求的答案存在,你也只需返回 一个。
+ +
示例 1:
+ +输入:seq = "(()())" +输出:[0,1,1,1,1,0] ++ +
示例 2:
+ +输入:seq = "()(())()" +输出:[0,0,0,1,1,0,1,1] ++ +
+ +
提示:
+ +-
+
1 <= text.size <= 10000
+
我们提供了一个类:
-我们提供了一个类: - -``` +
public class Foo {
- public void one() { print("one"); }
- public void two() { print("two"); }
- public void three() { print("three"); }
+ public void one() { print("one"); }
+ public void two() { print("two"); }
+ public void three() { print("three"); }
}
-```
+
-三个不同的线程将会共用一个 `Foo` 实例。
+三个不同的线程将会共用一个 Foo 实例。
-
+
- 线程 A 将会调用
one()方法
+ - 线程 B 将会调用
two()方法
+ - 线程 C 将会调用
three()方法
+
请设计修改程序,以确保 two() 方法在 one() 方法之后被执行,three() 方法在 two() 方法之后被执行。
-**示例 1:** +
示例 1:
-``` -输入: [1,2,3] -输出: "onetwothree" -解释: ++输入: [1,2,3] +输出: "onetwothree" +解释: 有三个线程会被异步启动。 输入 [1,2,3] 表示线程 A 将会调用 one() 方法,线程 B 将会调用 two() 方法,线程 C 将会调用 three() 方法。 -正确的输出是 "onetwothree"。 -``` +正确的输出是 "onetwothree"。 +-**示例 2:** +
示例 2:
-``` -输入: [1,3,2] -输出: "onetwothree" -解释: ++输入: [1,3,2] +输出: "onetwothree" +解释: 输入 [1,3,2] 表示线程 A 将会调用 one() 方法,线程 B 将会调用 three() 方法,线程 C 将会调用 two() 方法。 -正确的输出是 "onetwothree"。 -``` +正确的输出是 "onetwothree"。+ +
+ +
注意:
+ +尽管输入中的数字似乎暗示了顺序,但是我们并不保证线程在操作系统中的调度顺序。
+ +你看到的输入格式主要是为了确保测试的全面性。
+ + + +## 解法 + + + +### Python3 + + +```python -### 解法 - -多线程同步问题,很好理解。 - -1. C++ 解法 - -```cpp -class Foo { //C++ 11 -public: - Foo() { - _mutex1.lock(); - _mutex2.lock(); - } - - void first(function我们提供一个类:
-``` +
class FooBar {
public void foo() {
- for (int i = 0; i < n; i++) {
- print("foo");
- }
+ for (int i = 0; i < n; i++) {
+ print("foo");
+ }
}
public void bar() {
- for (int i = 0; i < n; i++) {
- print("bar");
- }
+ for (int i = 0; i < n; i++) {
+ print("bar");
+ }
}
}
-```
+
-两个不同的线程将会共用一个 `FooBar` 实例。其中一个线程将会调用 `foo()` 方法,另一个线程将会调用 `bar()` 方法。
+两个不同的线程将会共用一个 FooBar 实例。其中一个线程将会调用 foo() 方法,另一个线程将会调用 bar() 方法。
请设计修改程序,以确保 "foobar" 被输出 n 次。
- +-**示例 1:** +
示例 1:
-``` -输入: n = 1 -输出: "foobar" -解释: 这里有两个线程被异步启动。其中一个调用 foo() 方法, 另一个调用 bar() 方法,"foobar" 将被输出一次。 -``` ++输入: n = 1 +输出: "foobar" +解释: 这里有两个线程被异步启动。其中一个调用 foo() 方法, 另一个调用 bar() 方法,"foobar" 将被输出一次。 +-**示例 2:** +
示例 2:
-``` -输入: n = 2 -输出: "foobarfoobar" -解释: "foobar" 将被输出两次。 -``` ++输入: n = 2 +输出: "foobarfoobar" +解释: "foobar" 将被输出两次。 +-### 思路 +## 解法 + -两锁交替的同步,后进行的代码先加锁原则 -```cpp -class FooBar { -private: - int n; - std::mutex _mutex1; - std::mutex _mutex2; - -public: - FooBar(int n) { - this->n = n; - _mutex2.lock(); - } - - void foo(function
假设有这么一个类:
-``` -class ZeroEvenOdd { - public ZeroEvenOdd(int n) { ... } // constructor - public void zero(printNumber) { ... } // only output 0's - public void even(printNumber) { ... } // only output even numbers - public void odd(printNumber) { ... } // only output odd numbers +class ZeroEvenOdd {
+ public ZeroEvenOdd(int n) { ... } // 构造函数
+ public void zero(printNumber) { ... } // 仅打印出 0
+ public void even(printNumber) { ... } // 仅打印出 偶数
+ public void odd(printNumber) { ... } // 仅打印出 奇数
}
-```
+
-The same instance of `ZeroEvenOdd` will be passed to three different threads:
+相同的一个 ZeroEvenOdd 类实例将会传递给三个不同的线程:
-
+
- 线程 A 将调用
zero(),它只输出 0 。
+ - 线程 B 将调用
even(),它只输出偶数。
+ - 线程 C 将调用
odd(),它只输出奇数。
+
每个线程都有一个 printNumber 方法来输出一个整数。请修改给出的代码以输出整数序列 010203040506... ,其中序列的长度必须为 2n。
-**Example 1:** +
示例 1:
-``` -Input: n = 2 -Output: "0102" -Explanation: There are three threads being fired asynchronously. One of them calls zero(), the other calls even(), and the last one calls odd(). "0102" is the correct output. -``` +输入:n = 2 +输出:"0102" +说明:三条线程异步执行,其中一个调用 zero(),另一个线程调用 even(),最后一个线程调用odd()。正确的输出为 "0102"。 +-**Example 2:** +
示例 2:
+ +输入:n = 5 +输出:"0102030405" ++ + + +## 解法 + + + +### Python3 + + +```python -``` -Input: n = 5 -Output: "0102030405" ``` +### Java + +```java -### 思路 - -一个同步问题,一个互斥问题,奇偶打印是互斥,0和奇/偶的打印是同步问题,所以用到3把锁 - -```cpp -class ZeroEvenOdd { -private: - int n; - int flag; - mutex m1,m2,m3; - -public: - ZeroEvenOdd(int n) { - this->n = n; - flag = 1; //奇偶判断 - m1.lock(); - m2.lock(); - m3.lock(); - } - - // printNumber(x) outputs "x", where x is an integer. - void zero(function
现在有两种线程,氢 oxygen 和氧 hydrogen,你的目标是组织这两种线程来产生水分子。
存在一个屏障(barrier)使得每个线程必须等候直到一个完整水分子能够被产生出来。
-存在一个屏障(barrier)使得每个线程必须等候直到一个完整水分子能够被产生出来。 +氢和氧线程会被分别给予 releaseHydrogen 和 releaseOxygen 方法来允许它们突破屏障。
这些线程应该三三成组突破屏障并能立即组合产生一个水分子。
-这些线程应该三三成组突破屏障并能立即组合产生一个水分子。 +你必须保证产生一个水分子所需线程的结合必须发生在下一个水分子产生之前。
-你必须保证产生一个水分子所需线程的结合必须发生在下一个水分子产生之前。 +换句话说:
-换句话说: +-
+
- 如果一个氧线程到达屏障时没有氢线程到达,它必须等候直到两个氢线程到达。 +
- 如果一个氢线程到达屏障时没有其它线程到达,它必须等候直到一个氧线程和另一个氢线程到达。 +
书写满足这些限制条件的氢、氧线程同步代码。
-书写满足这些限制条件的氢、氧线程同步代码。 +- +
示例 1:
-**示例 1:** ++输入: "HOH" +输出: "HHO" +解释: "HOH" 和 "OHH" 依然都是有效解。 +-``` -输入: "HOH" -输出: "HHO" -解释: "HOH" 和 "OHH" 依然都是有效解。 -``` +
示例 2:
-**示例 2:** ++输入: "OOHHHH" +输出: "HHOHHO" +解释: "HOHHHO", "OHHHHO", "HHOHOH", "HOHHOH", "OHHHOH", "HHOOHH", "HOHOHH" 和 "OHHOHH" 依然都是有效解。 +-``` -输入: "OOHHHH" -输出: "HHOHHO" -解释: "HOHHHO", "OHHHHO", "HHOHOH", "HOHHOH", "OHHHOH", "HHOOHH", "HOHOHH" 和 "OHHOHH" 依然都是有效解。 -``` +
+ +
限制条件:
+ +-
+
- 输入字符串的总长将会是 3n, 1 ≤ n ≤ 50; +
- 输入字符串中的 “H” 总数将会是 2n; +
- 输入字符串中的 “O” 总数将会是 n。 +
给你两个数组,arr1 和 arr2,
-
+
arr2中的元素各不相同
+ arr2中的每个元素都出现在arr1中
+
对 arr1 中的元素进行排序,使 arr1 中项的相对顺序和 arr2 中的相对顺序相同。未在 arr2 中出现过的元素需要按照升序放在 arr1 的末尾。
+ +
示例:
+ +输入:arr1 = [2,3,1,3,2,4,6,7,9,2,19], arr2 = [2,1,4,3,9,6] +输出:[2,2,2,1,4,3,3,9,6,7,19] ++ +
+ +
提示:
+ +-
+
arr1.length, arr2.length <= 1000
+ 0 <= arr1[i], arr2[i] <= 1000
+ arr2中的元素arr2[i]各不相同
+ arr2中的每个元素arr2[i]都出现在arr1中
+
给你一个有根节点的二叉树,找到它最深的叶节点的最近公共祖先。
+ +回想一下:
+ +-
+
- 叶节点 是二叉树中没有子节点的节点 +
- 树的根节点的 深度 为
0,如果某一节点的深度为d,那它的子节点的深度就是d+1
+ - 如果我们假定
A是一组节点S的 最近公共祖先,S中的每个节点都在以A为根节点的子树中,且A的深度达到此条件下可能的最大值。
+
+ +
示例 1:
+ +输入:root = [1,2,3] +输出:[1,2,3] ++ +
示例 2:
+ +输入:root = [1,2,3,4] +输出:[4] ++ +
示例 3:
+ +输入:root = [1,2,3,4,5] +输出:[2,4,5] ++ +
+ +
提示:
+ +-
+
- 给你的树中将有 1 到 1000 个节点。 +
- 树中每个节点的值都在 1 到 1000 之间。 +
给你一份工作时间表 hours,上面记录着某一位员工每天的工作小时数。
我们认为当员工一天中的工作小时数大于 8 小时的时候,那么这一天就是「劳累的一天」。
所谓「表现良好的时间段」,意味在这段时间内,「劳累的天数」是严格 大于「不劳累的天数」。
+ +请你返回「表现良好时间段」的最大长度。
+ ++ +
示例 1:
+ +输入:hours = [9,9,6,0,6,6,9] +输出:3 +解释:最长的表现良好时间段是 [9,9,6]。+ +
+ +
提示:
+ +-
+
1 <= hours.length <= 10000
+ 0 <= hours[i] <= 16
+
作为项目经理,你规划了一份需求的技能清单 req_skills,并打算从备选人员名单 people 中选出些人组成一个「必要团队」( 编号为 i 的备选人员 people[i] 含有一份该备选人员掌握的技能列表)。
所谓「必要团队」,就是在这个团队中,对于所需求的技能列表 req_skills 中列出的每项技能,团队中至少有一名成员已经掌握。
我们可以用每个人的编号来表示团队中的成员:例如,团队 team = [0, 1, 3] 表示掌握技能分别为 people[0],people[1],和 people[3] 的备选人员。
请你返回 任一 规模最小的必要团队,团队成员用人员编号表示。你可以按任意顺序返回答案,本题保证答案存在。
+ ++ +
示例 1:
+ +输入:req_skills = ["java","nodejs","reactjs"], people = [["java"],["nodejs"],["nodejs","reactjs"]] +输出:[0,2] ++ +
示例 2:
+ +输入:req_skills = ["algorithms","math","java","reactjs","csharp","aws"], people = [["algorithms","math","java"],["algorithms","math","reactjs"],["java","csharp","aws"],["reactjs","csharp"],["csharp","math"],["aws","java"]] +输出:[1,2] ++ +
+ +
提示:
+ +-
+
1 <= req_skills.length <= 16
+ 1 <= people.length <= 60
+ 1 <= people[i].length, req_skills[i].length, people[i][j].length <= 16
+ req_skills和people[i]中的元素分别各不相同
+ req_skills[i][j], people[i][j][k]都由小写英文字母组成
+ - 本题保证「必要团队」一定存在 +
给你一个由一些多米诺骨牌组成的列表 dominoes。
如果其中某一张多米诺骨牌可以通过旋转 0 度或 180 度得到另一张多米诺骨牌,我们就认为这两张牌是等价的。
形式上,dominoes[i] = [a, b] 和 dominoes[j] = [c, d] 等价的前提是 a==c 且 b==d,或是 a==d 且 b==c。
在 0 <= i < j < dominoes.length 的前提下,找出满足 dominoes[i] 和 dominoes[j] 等价的骨牌对 (i, j) 的数量。
+ +
示例:
+ +输入:dominoes = [[1,2],[2,1],[3,4],[5,6]] +输出:1 ++ +
+ +
提示:
+ +-
+
1 <= dominoes.length <= 40000
+ 1 <= dominoes[i][j] <= 9
+
在一个有向图中,节点分别标记为 0, 1, ..., n-1。这个图中的每条边不是红色就是蓝色,且存在自环或平行边。
red_edges 中的每一个 [i, j] 对表示从节点 i 到节点 j 的红色有向边。类似地,blue_edges 中的每一个 [i, j] 对表示从节点 i 到节点 j 的蓝色有向边。
返回长度为 n 的数组 answer,其中 answer[X] 是从节点 0 到节点 X 的最短路径的长度,且路径上红色边和蓝色边交替出现。如果不存在这样的路径,那么 answer[x] = -1。
+ +
示例 1:
+ +输入:n = 3, red_edges = [[0,1],[1,2]], blue_edges = [] +输出:[0,1,-1] ++ +
示例 2:
+ +输入:n = 3, red_edges = [[0,1]], blue_edges = [[2,1]] +输出:[0,1,-1] ++ +
示例 3:
+ +输入:n = 3, red_edges = [[1,0]], blue_edges = [[2,1]] +输出:[0,-1,-1] ++ +
示例 4:
+ +输入:n = 3, red_edges = [[0,1]], blue_edges = [[1,2]] +输出:[0,1,2] ++ +
示例 5:
+ +输入:n = 3, red_edges = [[0,1],[0,2]], blue_edges = [[1,0]] +输出:[0,1,1] ++ +
+ +
提示:
+ +-
+
1 <= n <= 100
+ red_edges.length <= 400
+ blue_edges.length <= 400
+ red_edges[i].length == blue_edges[i].length == 2
+ 0 <= red_edges[i][j], blue_edges[i][j] < n
+
给你一个正整数数组 arr,考虑所有满足以下条件的二叉树:
-
+
- 每个节点都有 0 个或是 2 个子节点。 +
- 数组
arr中的值与树的中序遍历中每个叶节点的值一一对应。(知识回顾:如果一个节点有 0 个子节点,那么该节点为叶节点。)
+ - 每个非叶节点的值等于其左子树和右子树中叶节点的最大值的乘积。 +
在所有这样的二叉树中,返回每个非叶节点的值的最小可能总和。这个和的值是一个 32 位整数。
+ ++ +
示例:
+ +输入:arr = [6,2,4] +输出:32 +解释: +有两种可能的树,第一种的非叶节点的总和为 36,第二种非叶节点的总和为 32。 + + 24 24 + / \ / \ + 12 4 6 8 + / \ / \ +6 2 2 4+ +
+ +
提示:
+ +-
+
2 <= arr.length <= 40
+ 1 <= arr[i] <= 15
+ - 答案保证是一个 32 位带符号整数,即小于
2^31。
+
给你两个长度相等的整数数组,返回下面表达式的最大值:
+ +|arr1[i] - arr1[j]| + |arr2[i] - arr2[j]| + |i - j|
其中下标 i,j 满足 0 <= i, j < arr1.length。
+ +
示例 1:
+ +输入:arr1 = [1,2,3,4], arr2 = [-1,4,5,6] +输出:13 ++ +
示例 2:
+ +输入:arr1 = [1,-2,-5,0,10], arr2 = [0,-2,-1,-7,-4] +输出:20+ +
+ +
提示:
+ +-
+
2 <= arr1.length == arr2.length <= 40000
+ -10^6 <= arr1[i], arr2[i] <= 10^6
+
泰波那契序列 Tn 定义如下:
+ +T0 = 0, T1 = 1, T2 = 1, 且在 n >= 0 的条件下 Tn+3 = Tn + Tn+1 + Tn+2
+ +给你整数 n,请返回第 n 个泰波那契数 Tn 的值。
+ +
示例 1:
+ +输入:n = 4 +输出:4 +解释: +T_3 = 0 + 1 + 1 = 2 +T_4 = 1 + 1 + 2 = 4 ++ +
示例 2:
+ +输入:n = 25 +输出:1389537 ++ +
+ +
提示:
+ +-
+
0 <= n <= 37
+ - 答案保证是一个 32 位整数,即
answer <= 2^31 - 1。
+
我们从一块字母板上的位置 (0, 0) 出发,该坐标对应的字符为 board[0][0]。
在本题里,字母板为board = ["abcde", "fghij", "klmno", "pqrst", "uvwxy", "z"].
我们可以按下面的指令规则行动:
+ +-
+
- 如果方格存在,
'U'意味着将我们的位置上移一行;
+ - 如果方格存在,
'D'意味着将我们的位置下移一行;
+ - 如果方格存在,
'L'意味着将我们的位置左移一列;
+ - 如果方格存在,
'R'意味着将我们的位置右移一列;
+ '!'会把在我们当前位置(r, c)的字符board[r][c]添加到答案中。
+
返回指令序列,用最小的行动次数让答案和目标 target 相同。你可以返回任何达成目标的路径。
+ +
示例 1:
+ +输入:target = "leet" +输出:"DDR!UURRR!!DDD!" ++ +
示例 2:
+ +输入:target = "code" +输出:"RR!DDRR!UUL!R!" ++ +
+ +
提示:
+ +-
+
1 <= target.length <= 100
+ target仅含有小写英文字母。
+
给你一个由若干 0 和 1 组成的二维网格 grid,请你找出边界全部由 1 组成的最大 正方形 子网格,并返回该子网格中的元素数量。如果不存在,则返回 0。
+ +
示例 1:
+ +输入:grid = [[1,1,1],[1,0,1],[1,1,1]] +输出:9 ++ +
示例 2:
+ +输入:grid = [[1,1,0,0]] +输出:1 ++ +
+ +
提示:
+ +-
+
1 <= grid.length <= 100
+ 1 <= grid[0].length <= 100
+ grid[i][j]为0或1
+
亚历克斯和李继续他们的石子游戏。许多堆石子 排成一行,每堆都有正整数颗石子 piles[i]。游戏以谁手中的石子最多来决出胜负。
亚历克斯和李轮流进行,亚历克斯先开始。最初,M = 1。
在每个玩家的回合中,该玩家可以拿走剩下的 前 X 堆的所有石子,其中 1 <= X <= 2M。然后,令 M = max(M, X)。
游戏一直持续到所有石子都被拿走。
+ +假设亚历克斯和李都发挥出最佳水平,返回亚历克斯可以得到的最大数量的石头。
+ ++ +
示例:
+ +输入:piles = [2,7,9,4,4] +输出:10 +解释: +如果亚历克斯在开始时拿走一堆石子,李拿走两堆,接着亚历克斯也拿走两堆。在这种情况下,亚历克斯可以拿到 2 + 4 + 4 = 10 颗石子。 +如果亚历克斯在开始时拿走两堆石子,那么李就可以拿走剩下全部三堆石子。在这种情况下,亚历克斯可以拿到 2 + 7 = 9 颗石子。 +所以我们返回更大的 10。 ++ +
+ +
提示:
+ +-
+
1 <= piles.length <= 100
+ 1 <= piles[i] <= 10 ^ 4
+
给定两个字符串 text1 和 text2,返回这两个字符串的最长公共子序列。
一个字符串的 子序列 是指这样一个新的字符串:它是由原字符串在不改变字符的相对顺序的情况下删除某些字符(也可以不删除任何字符)后组成的新字符串。
+例如,"ace" 是 "abcde" 的子序列,但 "aec" 不是 "abcde" 的子序列。两个字符串的「公共子序列」是这两个字符串所共同拥有的子序列。
若这两个字符串没有公共子序列,则返回 0。
+ ++ +
示例 1:
+ +输入:text1 = "abcde", text2 = "ace" +输出:3 +解释:最长公共子序列是 "ace",它的长度为 3。 ++ +
示例 2:
+ +输入:text1 = "abc", text2 = "abc" +输出:3 +解释:最长公共子序列是 "abc",它的长度为 3。 ++ +
示例 3:
+ +输入:text1 = "abc", text2 = "def" +输出:0 +解释:两个字符串没有公共子序列,返回 0。 ++ +
+ +
提示:
+ +-
+
1 <= text1.length <= 1000
+ 1 <= text2.length <= 1000
+ - 输入的字符串只含有小写英文字符。 +
给你一个整数数组 nums,每次 操作 会从中选择一个元素并 将该元素的值减少 1。
如果符合下列情况之一,则数组 A 就是 锯齿数组:
-
+
- 每个偶数索引对应的元素都大于相邻的元素,即
A[0] > A[1] < A[2] > A[3] < A[4] > ...
+ - 或者,每个奇数索引对应的元素都大于相邻的元素,即
A[0] < A[1] > A[2] < A[3] > A[4] < ...
+
返回将数组 nums 转换为锯齿数组所需的最小操作次数。
+ +
示例 1:
+ +输入:nums = [1,2,3] +输出:2 +解释:我们可以把 2 递减到 0,或把 3 递减到 1。 ++ +
示例 2:
+ +输入:nums = [9,6,1,6,2] +输出:4 ++ +
+ +
提示:
+ +-
+
1 <= nums.length <= 1000
+ 1 <= nums[i] <= 1000
+
有两位极客玩家参与了一场「二叉树着色」的游戏。游戏中,给出二叉树的根节点 root,树上总共有 n 个节点,且 n 为奇数,其中每个节点上的值从 1 到 n 各不相同。
+ +
游戏从「一号」玩家开始(「一号」玩家为红色,「二号」玩家为蓝色),最开始时,
+ +「一号」玩家从 [1, n] 中取一个值 x(1 <= x <= n);
「二号」玩家也从 [1, n] 中取一个值 y(1 <= y <= n)且 y != x。
「一号」玩家给值为 x 的节点染上红色,而「二号」玩家给值为 y 的节点染上蓝色。
+ +
之后两位玩家轮流进行操作,每一回合,玩家选择一个他之前涂好颜色的节点,将所选节点一个 未着色 的邻节点(即左右子节点、或父节点)进行染色。
+ +如果当前玩家无法找到这样的节点来染色时,他的回合就会被跳过。
+ +若两个玩家都没有可以染色的节点时,游戏结束。着色节点最多的那位玩家获得胜利 ✌️。
+ ++ +
现在,假设你是「二号」玩家,根据所给出的输入,假如存在一个 y 值可以确保你赢得这场游戏,则返回 true;若无法获胜,就请返回 false。
+ +
示例:
+ +
输入:root = [1,2,3,4,5,6,7,8,9,10,11], n = 11, x = 3 +输出:True +解释:第二个玩家可以选择值为 2 的节点。 ++ +
+ +
提示:
+ +-
+
- 二叉树的根节点为
root,树上由n个节点,节点上的值从1到n各不相同。
+ n为奇数。
+ 1 <= x <= n <= 100
+
实现支持下列接口的「快照数组」- SnapshotArray:
+ +-
+
SnapshotArray(int length)- 初始化一个与指定长度相等的 类数组 的数据结构。初始时,每个元素都等于 0。
+ void set(index, val)- 会将指定索引index处的元素设置为val。
+ int snap()- 获取该数组的快照,并返回快照的编号snap_id(快照号是调用snap()的总次数减去1)。
+ int get(index, snap_id)- 根据指定的snap_id选择快照,并返回该快照指定索引index的值。
+
+ +
示例:
+ +输入:["SnapshotArray","set","snap","set","get"] + [[3],[0,5],[],[0,6],[0,0]] +输出:[null,null,0,null,5] +解释: +SnapshotArray snapshotArr = new SnapshotArray(3); // 初始化一个长度为 3 的快照数组 +snapshotArr.set(0,5); // 令 array[0] = 5 +snapshotArr.snap(); // 获取快照,返回 snap_id = 0 +snapshotArr.set(0,6); +snapshotArr.get(0,0); // 获取 snap_id = 0 的快照中 array[0] 的值,返回 5+ +
+ +
提示:
+ +-
+
1 <= length <= 50000
+ - 题目最多进行
50000次set,snap,和get的调用 。
+ 0 <= index < length
+ 0 <= snap_id <我们调用snap()的总次数
+ 0 <= val <= 10^9
+
段式回文 其实与 一般回文 类似,只不过是最小的单位是 一段字符 而不是 单个字母。
+ +举个例子,对于一般回文 "abcba" 是回文,而 "volvo" 不是,但如果我们把 "volvo" 分为 "vo"、"l"、"vo" 三段,则可以认为 “(vo)(l)(vo)” 是段式回文(分为 3 段)。
+ +
给你一个字符串 text,在确保它满足段式回文的前提下,请你返回 段 的 最大数量 k。
如果段的最大数量为 k,那么存在满足以下条件的 a_1, a_2, ..., a_k:
-
+
- 每个
a_i都是一个非空字符串;
+ - 将这些字符串首位相连的结果
a_1 + a_2 + ... + a_k和原始字符串text相同;
+ - 对于所有
1 <= i <= k,都有a_i = a_{k+1 - i}。
+
+ +
示例 1:
+ +输入:text = "ghiabcdefhelloadamhelloabcdefghi" +输出:7 +解释:我们可以把字符串拆分成 "(ghi)(abcdef)(hello)(adam)(hello)(abcdef)(ghi)"。 ++ +
示例 2:
+ +输入:text = "merchant" +输出:1 +解释:我们可以把字符串拆分成 "(merchant)"。 ++ +
示例 3:
+ +输入:text = "antaprezatepzapreanta" +输出:11 +解释:我们可以把字符串拆分成 "(a)(nt)(a)(pre)(za)(tpe)(za)(pre)(a)(nt)(a)"。 ++ +
示例 4:
+ +输入:text = "aaa" +输出:3 +解释:我们可以把字符串拆分成 "(a)(a)(a)"。 ++ +
+ +
提示:
+ +-
+
text仅由小写英文字符组成。
+ 1 <= text.length <= 1000
+
给你一个按 YYYY-MM-DD 格式表示日期的字符串 date,请你计算并返回该日期是当年的第几天。
通常情况下,我们认为 1 月 1 日是每年的第 1 天,1 月 2 日是每年的第 2 天,依此类推。每个月的天数与现行公元纪年法(格里高利历)一致。
-## Example 2: -``` - Input: date = "2019-02-10" - Output: 41 -``` +-## Example 3: -``` - Input: date = "2003-03-01" - Output: 60 -``` +
示例 1:
+ +输入:date = "2019-01-09" +输出:9 ++ +
示例 2:
+ +输入:date = "2019-02-10" +输出:41 ++ +
示例 3:
+ +输入:date = "2003-03-01" +输出:60 ++ +
示例 4:
+ +输入:date = "2004-03-01" +输出:61+ +
+ +
提示:
+ +-
+
date.length == 10
+ date[4] == date[7] == '-',其他的date[i]都是数字。
+ date表示的范围从 1900 年 1 月 1 日至 2019 年 12 月 31 日。
+
这里有 d 个一样的骰子,每个骰子上都有 f 个面,分别标号为 1, 2, ..., f。
我们约定:掷骰子的得到总点数为各骰子面朝上的数字的总和。
+ +如果需要掷出的总点数为 target,请你计算出有多少种不同的组合情况(所有的组合情况总共有 f^d 种),模 10^9 + 7 后返回。
+ +
示例 1:
+ +输入:d = 1, f = 6, target = 3 +输出:1 ++ +
示例 2:
+ +输入:d = 2, f = 6, target = 7 +输出:6 ++ +
示例 3:
+ +输入:d = 2, f = 5, target = 10 +输出:1 ++ +
示例 4:
+ +输入:d = 1, f = 2, target = 3 +输出:0 ++ +
示例 5:
+ +输入:d = 30, f = 30, target = 500 +输出:222616187+ +
+ +
提示:
+ +-
+
1 <= d, f <= 30
+ 1 <= target <= 1000
+
如果字符串中的所有字符都相同,那么这个字符串是单字符重复的字符串。
+ +给你一个字符串 text,你只能交换其中两个字符一次或者什么都不做,然后得到一些单字符重复的子串。返回其中最长的子串的长度。
+ +
示例 1:
+ +输入:text = "ababa" +输出:3 ++ +
示例 2:
+ +输入:text = "aaabaaa" +输出:6 ++ +
示例 3:
+ +输入:text = "aaabbaaa" +输出:4 ++ +
示例 4:
+ +输入:text = "aaaaa" +输出:5 ++ +
示例 5:
+ +输入:text = "abcdef" +输出:1 ++ +
+ +
提示:
+ +-
+
1 <= text.length <= 20000
+ text仅由小写英文字母组成。
+
实现一个 MajorityChecker 的类,它应该具有下述几个 API:
-
+
MajorityChecker(int[] arr)会用给定的数组arr来构造一个MajorityChecker的实例。
+ int query(int left, int right, int threshold)有这么几个参数: +-
+
0 <= left <= right < arr.length表示数组arr的子数组的长度。
+ 2 * threshold > right - left + 1,也就是说阈值threshold始终比子序列长度的一半还要大。
+
+
每次查询 query(...) 会返回在 arr[left], arr[left+1], ..., arr[right] 中至少出现阈值次数 threshold 的元素,如果不存在这样的元素,就返回 -1。
+ +
示例:
+ +MajorityChecker majorityChecker = new MajorityChecker([1,1,2,2,1,1]); +majorityChecker.query(0,5,4); // 返回 1 +majorityChecker.query(0,3,3); // 返回 -1 +majorityChecker.query(2,3,2); // 返回 2 ++ +
+ +
提示:
+ +-
+
1 <= arr.length <= 20000
+ 1 <= arr[i] <= 20000
+ - 对于每次查询,
0 <= left <= right < len(arr)
+ - 对于每次查询,
2 * threshold > right - left + 1
+ - 查询次数最多为
10000
+
给你一份『词汇表』(字符串数组) words 和一张『字母表』(字符串) chars。
假如你可以用 chars 中的『字母』(字符)拼写出 words 中的某个『单词』(字符串),那么我们就认为你掌握了这个单词。
注意:每次拼写时,chars 中的每个字母都只能用一次。
返回词汇表 words 中你掌握的所有单词的 长度之和。
+ +
示例 1:
+ +输入:words = ["cat","bt","hat","tree"], chars = "atach" +输出:6 +解释: +可以形成字符串 "cat" 和 "hat",所以答案是 3 + 3 = 6。 ++ +
示例 2:
+ +输入:words = ["hello","world","leetcode"], chars = "welldonehoneyr" +输出:10 +解释: +可以形成字符串 "hello" 和 "world",所以答案是 5 + 5 = 10。 ++ +
+ +
提示:
+ +-
+
1 <= words.length <= 1000
+ 1 <= words[i].length, chars.length <= 100
+ - 所有字符串中都仅包含小写英文字母 +
给你一个二叉树的根节点 root。设根节点位于二叉树的第 1 层,而根节点的子节点位于第 2 层,依此类推。
请你找出层内元素之和 最大 的那几层(可能只有一层)的层号,并返回其中 最小 的那个。
+ ++ +
示例:
+ +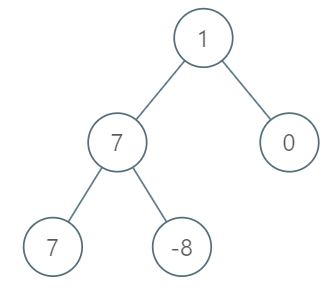
输入:[1,7,0,7,-8,null,null] +输出:2 +解释: +第 1 层各元素之和为 1, +第 2 层各元素之和为 7 + 0 = 7, +第 3 层各元素之和为 7 + -8 = -1, +所以我们返回第 2 层的层号,它的层内元素之和最大。 ++ +
+ +
提示:
+ +-
+
- 树中的节点数介于
1和10^4之间
+ -10^5 <= node.val <= 10^5
+
你现在手里有一份大小为 N x N 的『地图』(网格) grid,上面的每个『区域』(单元格)都用 0 和 1 标记好了。其中 0 代表海洋,1 代表陆地,你知道距离陆地区域最远的海洋区域是是哪一个吗?请返回该海洋区域到离它最近的陆地区域的距离。
我们这里说的距离是『曼哈顿距离』( Manhattan Distance):(x0, y0) 和 (x1, y1) 这两个区域之间的距离是 |x0 - x1| + |y0 - y1| 。
如果我们的地图上只有陆地或者海洋,请返回 -1。
+ +
示例 1:
+ +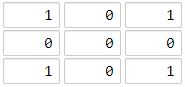
输入:[[1,0,1],[0,0,0],[1,0,1]] +输出:2 +解释: +海洋区域 (1, 1) 和所有陆地区域之间的距离都达到最大,最大距离为 2。 ++ +
示例 2:
+ +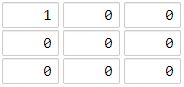
输入:[[1,0,0],[0,0,0],[0,0,0]] +输出:4 +解释: +海洋区域 (2, 2) 和所有陆地区域之间的距离都达到最大,最大距离为 4。 ++ +
+ +
提示:
+ +-
+
1 <= grid.length == grid[0].length <= 100
+ grid[i][j]不是0就是1
+
给你一个字符串 s,找出它的所有子串并按字典序排列,返回排在最后的那个子串。
+ +
示例 1:
+ +输入:"abab" +输出:"bab" +解释:我们可以找出 7 个子串 ["a", "ab", "aba", "abab", "b", "ba", "bab"]。按字典序排在最后的子串是 "bab"。 ++ +
示例 2:
+ +输入:"leetcode" +输出:"tcode" ++ +
+ +
提示:
+ +-
+
1 <= s.length <= 4 * 10^5
+ - s 仅含有小写英文字符。 +
如果出现下述两种情况,交易 可能无效:
+ +-
+
- 交易金额超过 ¥1000 +
- 或者,它和另一个城市中同名的另一笔交易相隔不超过 60 分钟(包含 60 分钟整) +
每个交易字符串 transactions[i] 由一些用逗号分隔的值组成,这些值分别表示交易的名称,时间(以分钟计),金额以及城市。
给你一份交易清单 transactions,返回可能无效的交易列表。你可以按任何顺序返回答案。
+ +
示例 1:
+ +输入:transactions = ["alice,20,800,mtv","alice,50,100,beijing"] +输出:["alice,20,800,mtv","alice,50,100,beijing"] +解释:第一笔交易是无效的,因为第二笔交易和它间隔不超过 60 分钟、名称相同且发生在不同的城市。同样,第二笔交易也是无效的。+ +
示例 2:
+ +输入:transactions = ["alice,20,800,mtv","alice,50,1200,mtv"] +输出:["alice,50,1200,mtv"] ++ +
示例 3:
+ +输入:transactions = ["alice,20,800,mtv","bob,50,1200,mtv"] +输出:["bob,50,1200,mtv"] ++ +
+ +
提示:
+ +-
+
transactions.length <= 1000
+ - 每笔交易
transactions[i]按"{name},{time},{amount},{city}"的格式进行记录
+ - 每个交易名称
{name}和城市{city}都由小写英文字母组成,长度在1到10之间
+ - 每个交易时间
{time}由一些数字组成,表示一个0到1000之间的整数
+ - 每笔交易金额
{amount}由一些数字组成,表示一个0到2000之间的整数
+
我们来定义一个函数 f(s),其中传入参数 s 是一个非空字符串;该函数的功能是统计 s 中(按字典序比较)最小字母的出现频次。
例如,若 s = "dcce",那么 f(s) = 2,因为最小的字母是 "c",它出现了 2 次。
现在,给你两个字符串数组待查表 queries 和词汇表 words,请你返回一个整数数组 answer 作为答案,其中每个 answer[i] 是满足 f(queries[i]) < f(W) 的词的数目,W 是词汇表 words 中的词。
+ +
示例 1:
+ +输入:queries = ["cbd"], words = ["zaaaz"]
+输出:[1]
+解释:查询 f("cbd") = 1,而 f("zaaaz") = 3 所以 f("cbd") < f("zaaaz")。
+
+
+示例 2:
+ +输入:queries = ["bbb","cc"], words = ["a","aa","aaa","aaaa"]
+输出:[1,2]
+解释:第一个查询 f("bbb") < f("aaaa"),第二个查询 f("aaa") 和 f("aaaa") 都 > f("cc")。
+
+
++ +
提示:
+ +-
+
1 <= queries.length <= 2000
+ 1 <= words.length <= 2000
+ 1 <= queries[i].length, words[i].length <= 10
+ queries[i][j],words[i][j]都是小写英文字母
+
给你一个链表的头节点 head,请你编写代码,反复删去链表中由 总和 值为 0 的连续节点组成的序列,直到不存在这样的序列为止。
删除完毕后,请你返回最终结果链表的头节点。
+ ++ +
你可以返回任何满足题目要求的答案。
+ +(注意,下面示例中的所有序列,都是对 ListNode 对象序列化的表示。)
示例 1:
+ +输入:head = [1,2,-3,3,1] +输出:[3,1] +提示:答案 [1,2,1] 也是正确的。 ++ +
示例 2:
+ +输入:head = [1,2,3,-3,4] +输出:[1,2,4] ++ +
示例 3:
+ +输入:head = [1,2,3,-3,-2] +输出:[1] ++ +
+ +
提示:
+ +-
+
- 给你的链表中可能有
1到1000个节点。
+ - 对于链表中的每个节点,节点的值:
-1000 <= node.val <= 1000.
+
我们把无限数量 ∞ 的栈排成一行,按从左到右的次序从 0 开始编号。每个栈的的最大容量 capacity 都相同。
实现一个叫「餐盘」的类 DinnerPlates:
-
+
DinnerPlates(int capacity)- 给出栈的最大容量capacity。
+ void push(int val)- 将给出的正整数val推入 从左往右第一个 没有满的栈。
+ int pop()- 返回 从右往左第一个 非空栈顶部的值,并将其从栈中删除;如果所有的栈都是空的,请返回-1。
+ int popAtStack(int index)- 返回编号index的栈顶部的值,并将其从栈中删除;如果编号index的栈是空的,请返回-1。
+
+ +
示例:
+ +输入: +["DinnerPlates","push","push","push","push","push","popAtStack","push","push","popAtStack","popAtStack","pop","pop","pop","pop","pop"] +[[2],[1],[2],[3],[4],[5],[0],[20],[21],[0],[2],[],[],[],[],[]] +输出: +[null,null,null,null,null,null,2,null,null,20,21,5,4,3,1,-1] + +解释: +DinnerPlates D = DinnerPlates(2); // 初始化,栈最大容量 capacity = 2 +D.push(1); +D.push(2); +D.push(3); +D.push(4); +D.push(5); // 栈的现状为: 2 4 + 1 3 5 + +D.popAtStack(0); // 返回 2。栈的现状为: 4 + 1 3 5 + +D.push(20); // 栈的现状为: 20 4 + 1 3 5 + +D.push(21); // 栈的现状为: 20 4 21 + 1 3 5 + +D.popAtStack(0); // 返回 20。栈的现状为: 4 21 + 1 3 5 + +D.popAtStack(2); // 返回 21。栈的现状为: 4 + 1 3 5 + +D.pop() // 返回 5。栈的现状为: 4 + 1 3 + +D.pop() // 返回 4。栈的现状为: 1 3 + +D.pop() // 返回 3。栈的现状为: 1 + +D.pop() // 返回 1。现在没有栈。 +D.pop() // 返回 -1。仍然没有栈。 ++ +
+ +
提示:
+ +-
+
1 <= capacity <= 20000
+ 1 <= val <= 20000
+ 0 <= index <= 100000
+ - 最多会对
push,pop,和popAtStack进行200000次调用。
+
请你帮忙给从 1 到 n 的数设计排列方案,使得所有的「质数」都应该被放在「质数索引」(索引从 1 开始)上;你需要返回可能的方案总数。
让我们一起来回顾一下「质数」:质数一定是大于 1 的,并且不能用两个小于它的正整数的乘积来表示。
+ +由于答案可能会很大,所以请你返回答案 模 mod 10^9 + 7 之后的结果即可。
+ +
示例 1:
+ +输入:n = 5 +输出:12 +解释:举个例子,[1,2,5,4,3] 是一个有效的排列,但 [5,2,3,4,1] 不是,因为在第二种情况里质数 5 被错误地放在索引为 1 的位置上。 ++ +
示例 2:
+ +输入:n = 100 +输出:682289015 ++ +
+ +
提示:
+ +-
+
1 <= n <= 100
+
给你一个字符串 s,请你对 s 的子串进行检测。
每次检测,待检子串都可以表示为 queries[i] = [left, right, k]。我们可以 重新排列 子串 s[left], ..., s[right],并从中选择 最多 k 项替换成任何小写英文字母。
如果在上述检测过程中,子串可以变成回文形式的字符串,那么检测结果为 true,否则结果为 false。
返回答案数组 answer[],其中 answer[i] 是第 i 个待检子串 queries[i] 的检测结果。
注意:在替换时,子串中的每个字母都必须作为 独立的 项进行计数,也就是说,如果 s[left..right] = "aaa" 且 k = 2,我们只能替换其中的两个字母。(另外,任何检测都不会修改原始字符串 s,可以认为每次检测都是独立的)
+ +
示例:
+ +输入:s = "abcda", queries = [[3,3,0],[1,2,0],[0,3,1],[0,3,2],[0,4,1]] +输出:[true,false,false,true,true] +解释: +queries[0] : 子串 = "d",回文。 +queries[1] : 子串 = "bc",不是回文。 +queries[2] : 子串 = "abcd",只替换 1 个字符是变不成回文串的。 +queries[3] : 子串 = "abcd",可以变成回文的 "abba"。 也可以变成 "baab",先重新排序变成 "bacd",然后把 "cd" 替换为 "ab"。 +queries[4] : 子串 = "abcda",可以变成回文的 "abcba"。 ++ +
+ +
提示:
+ +-
+
1 <= s.length, queries.length <= 10^5
+ 0 <= queries[i][0] <= queries[i][1] < s.length
+ 0 <= queries[i][2] <= s.length
+ s中只有小写英文字母
+
外国友人仿照中国字谜设计了一个英文版猜字谜小游戏,请你来猜猜看吧。
+ +字谜的迷面 puzzle 按字符串形式给出,如果一个单词 word 符合下面两个条件,那么它就可以算作谜底:
-
+
- 单词
word中包含谜面puzzle的第一个字母。
+ - 单词
word中的每一个字母都可以在谜面puzzle中找到。
+ 例如,如果字谜的谜面是 "abcdefg",那么可以作为谜底的单词有 "faced", "cabbage", 和 "baggage";而 "beefed"(不含字母 "a")以及 "based"(其中的 "s" 没有出现在谜面中)。
+
返回一个答案数组 answer,数组中的每个元素 answer[i] 是在给出的单词列表 words 中可以作为字谜迷面 puzzles[i] 所对应的谜底的单词数目。
+ +
示例:
+ +输入: +words = ["aaaa","asas","able","ability","actt","actor","access"], +puzzles = ["aboveyz","abrodyz","abslute","absoryz","actresz","gaswxyz"] +输出:[1,1,3,2,4,0] +解释: +1 个单词可以作为 "aboveyz" 的谜底 : "aaaa" +1 个单词可以作为 "abrodyz" 的谜底 : "aaaa" +3 个单词可以作为 "abslute" 的谜底 : "aaaa", "asas", "able" +2 个单词可以作为 "absoryz" 的谜底 : "aaaa", "asas" +4 个单词可以作为 "actresz" 的谜底 : "aaaa", "asas", "actt", "access" +没有单词可以作为 "gaswxyz" 的谜底,因为列表中的单词都不含字母 'g'。 ++ +
+ +
提示:
+ +-
+
1 <= words.length <= 10^5
+ 4 <= words[i].length <= 50
+ 1 <= puzzles.length <= 10^4
+ puzzles[i].length == 7
+ words[i][j],puzzles[i][j]都是小写英文字母。
+ - 每个
puzzles[i]所包含的字符都不重复。
+
部门表 Department:
++---------------+---------+ +| Column Name | Type | ++---------------+---------+ +| id | int | +| revenue | int | +| month | varchar | ++---------------+---------+ +(id, month) 是表的联合主键。 +这个表格有关于每个部门每月收入的信息。 +月份(month)可以取下列值 ["Jan","Feb","Mar","Apr","May","Jun","Jul","Aug","Sep","Oct","Nov","Dec"]。 ++ +
+ +
编写一个 SQL 查询来重新格式化表,使得新的表中有一个部门 id 列和一些对应 每个月 的收入(revenue)列。
+ +查询结果格式如下面的示例所示:
+ ++Department 表: ++------+---------+-------+ +| id | revenue | month | ++------+---------+-------+ +| 1 | 8000 | Jan | +| 2 | 9000 | Jan | +| 3 | 10000 | Feb | +| 1 | 7000 | Feb | +| 1 | 6000 | Mar | ++------+---------+-------+ + +查询得到的结果表: ++------+-------------+-------------+-------------+-----+-------------+ +| id | Jan_Revenue | Feb_Revenue | Mar_Revenue | ... | Dec_Revenue | ++------+-------------+-------------+-------------+-----+-------------+ +| 1 | 8000 | 7000 | 6000 | ... | null | +| 2 | 9000 | null | null | ... | null | +| 3 | null | 10000 | null | ... | null | ++------+-------------+-------------+-------------+-----+-------------+ + +注意,结果表有 13 列 (1个部门 id 列 + 12个月份的收入列)。 ++ + + +## 解法 + + + +### Python3 + + +```python + +``` + +### Java + + +```java + +``` + +### ... +``` + +``` diff --git a/solution/1100-1199/1180.Count Substrings with Only One Distinct Letter/README.md b/solution/1100-1199/1180.Count Substrings with Only One Distinct Letter/README.md new file mode 100644 index 0000000000000..6f30e4c699a9d --- /dev/null +++ b/solution/1100-1199/1180.Count Substrings with Only One Distinct Letter/README.md @@ -0,0 +1,29 @@ +# [1180. 统计只含单一字母的子串](https://leetcode-cn.com/problems/count-substrings-with-only-one-distinct-letter) + +## 题目描述 + +None + + +## 解法 + + + +### Python3 + + +```python + +``` + +### Java + + +```java + +``` + +### ... +``` + +``` diff --git a/solution/1100-1199/1181.Before and After Puzzle/README.md b/solution/1100-1199/1181.Before and After Puzzle/README.md new file mode 100644 index 0000000000000..3edd96676b90d --- /dev/null +++ b/solution/1100-1199/1181.Before and After Puzzle/README.md @@ -0,0 +1,29 @@ +# [1181. 前后拼接](https://leetcode-cn.com/problems/before-and-after-puzzle) + +## 题目描述 + +None + + +## 解法 + + + +### Python3 + + +```python + +``` + +### Java + + +```java + +``` + +### ... +``` + +``` diff --git a/solution/1100-1199/1182.Shortest Distance to Target Color/README.md b/solution/1100-1199/1182.Shortest Distance to Target Color/README.md new file mode 100644 index 0000000000000..b73f0f8c88f0d --- /dev/null +++ b/solution/1100-1199/1182.Shortest Distance to Target Color/README.md @@ -0,0 +1,29 @@ +# [1182. 与目标颜色间的最短距离](https://leetcode-cn.com/problems/shortest-distance-to-target-color) + +## 题目描述 + +None + + +## 解法 + + + +### Python3 + + +```python + +``` + +### Java + + +```java + +``` + +### ... +``` + +``` diff --git a/solution/1100-1199/1183.Maximum Number of Ones/README.md b/solution/1100-1199/1183.Maximum Number of Ones/README.md new file mode 100644 index 0000000000000..6f2998be4fee6 --- /dev/null +++ b/solution/1100-1199/1183.Maximum Number of Ones/README.md @@ -0,0 +1,29 @@ +# [1183. 矩阵中 1 的最大数量](https://leetcode-cn.com/problems/maximum-number-of-ones) + +## 题目描述 + +None + + +## 解法 + + + +### Python3 + + +```python + +``` + +### Java + + +```java + +``` + +### ... +``` + +``` diff --git a/solution/1100-1199/1184.Distance Between Bus Stops/README.md b/solution/1100-1199/1184.Distance Between Bus Stops/README.md new file mode 100644 index 0000000000000..508c6dc8fbfdd --- /dev/null +++ b/solution/1100-1199/1184.Distance Between Bus Stops/README.md @@ -0,0 +1,77 @@ +# [1184. 公交站间的距离](https://leetcode-cn.com/problems/distance-between-bus-stops) + +## 题目描述 + +
环形公交路线上有 n 个站,按次序从 0 到 n - 1 进行编号。我们已知每一对相邻公交站之间的距离,distance[i] 表示编号为 i 的车站和编号为 (i + 1) % n 的车站之间的距离。
环线上的公交车都可以按顺时针和逆时针的方向行驶。
+ +返回乘客从出发点 start 到目的地 destination 之间的最短距离。
+ +
示例 1:
+ +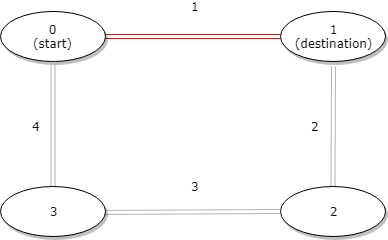
输入:distance = [1,2,3,4], start = 0, destination = 1 +输出:1 +解释:公交站 0 和 1 之间的距离是 1 或 9,最小值是 1。+ +
+ +
示例 2:
+ +
输入:distance = [1,2,3,4], start = 0, destination = 2 +输出:3 +解释:公交站 0 和 2 之间的距离是 3 或 7,最小值是 3。 ++ +
+ +
示例 3:
+ +
输入:distance = [1,2,3,4], start = 0, destination = 3 +输出:4 +解释:公交站 0 和 3 之间的距离是 6 或 4,最小值是 4。 ++ +
+ +
提示:
+ +-
+
1 <= n <= 10^4
+ distance.length == n
+ 0 <= start, destination < n
+ 0 <= distance[i] <= 10^4
+
给你一个日期,请你设计一个算法来判断它是对应一周中的哪一天。
+ +输入为三个整数:day、month 和 year,分别表示日、月、年。
您返回的结果必须是这几个值中的一个 {"Sunday", "Monday", "Tuesday", "Wednesday", "Thursday", "Friday", "Saturday"}。
+ +
示例 1:
+ +输入:day = 31, month = 8, year = 2019 +输出:"Saturday" ++ +
示例 2:
+ +输入:day = 18, month = 7, year = 1999 +输出:"Sunday" ++ +
示例 3:
+ +输入:day = 15, month = 8, year = 1993 +输出:"Sunday" ++ +
+ +
提示:
+ +-
+
- 给出的日期一定是在
1971到2100年之间的有效日期。
+
给你一个整数数组,返回它的某个 非空 子数组(连续元素)在执行一次可选的删除操作后,所能得到的最大元素总和。
+ +换句话说,你可以从原数组中选出一个子数组,并可以决定要不要从中删除一个元素(只能删一次哦),(删除后)子数组中至少应当有一个元素,然后该子数组(剩下)的元素总和是所有子数组之中最大的。
+ +注意,删除一个元素后,子数组 不能为空。
+ +请看示例:
+ +示例 1:
+ +输入:arr = [1,-2,0,3] +输出:4 +解释:我们可以选出 [1, -2, 0, 3],然后删掉 -2,这样得到 [1, 0, 3],和最大。+ +
示例 2:
+ +输入:arr = [1,-2,-2,3] +输出:3 +解释:我们直接选出 [3],这就是最大和。 ++ +
示例 3:
+ +输入:arr = [-1,-1,-1,-1] +输出:-1 +解释:最后得到的子数组不能为空,所以我们不能选择 [-1] 并从中删去 -1 来得到 0。 + 我们应该直接选择 [-1],或者选择 [-1, -1] 再从中删去一个 -1。 ++ +
+ +
提示:
+ +-
+
1 <= arr.length <= 10^5
+ -10^4 <= arr[i] <= 10^4
+
给你两个整数数组 arr1 和 arr2,返回使 arr1 严格递增所需要的最小「操作」数(可能为 0)。
每一步「操作」中,你可以分别从 arr1 和 arr2 中各选出一个索引,分别为 i 和 j,0 <= i < arr1.length 和 0 <= j < arr2.length,然后进行赋值运算 arr1[i] = arr2[j]。
如果无法让 arr1 严格递增,请返回 -1。
+ +
示例 1:
+ +输入:arr1 = [1,5,3,6,7], arr2 = [1,3,2,4] +输出:1 +解释:用 2 来替换+ +5,之后arr1 = [1, 2, 3, 6, 7]。 +
示例 2:
+ +输入:arr1 = [1,5,3,6,7], arr2 = [4,3,1] +输出:2 +解释:用 3 来替换+ +5,然后用 4 来替换 3,得到arr1 = [1, 3, 4, 6, 7]。 +
示例 3:
+ +输入:arr1 = [1,5,3,6,7], arr2 = [1,6,3,3]
+输出:-1
+解释:无法使 arr1 严格递增。
+
++ +
提示:
+ +-
+
1 <= arr1.length, arr2.length <= 2000
+ 0 <= arr1[i], arr2[i] <= 10^9
+
+ + + +## 解法 + + + +### Python3 + + +```python + +``` + +### Java + + +```java + +``` + +### ... +``` + +``` diff --git a/solution/1100-1199/1188.Design Bounded Blocking Queue/README.md b/solution/1100-1199/1188.Design Bounded Blocking Queue/README.md new file mode 100644 index 0000000000000..245df54662f0a --- /dev/null +++ b/solution/1100-1199/1188.Design Bounded Blocking Queue/README.md @@ -0,0 +1,29 @@ +# [1188. 设计有限阻塞队列](https://leetcode-cn.com/problems/design-bounded-blocking-queue) + +## 题目描述 + +None + + +## 解法 + + + +### Python3 + + +```python + +``` + +### Java + + +```java + +``` + +### ... +``` + +``` diff --git a/solution/1100-1199/1189.Maximum Number of Balloons/README.md b/solution/1100-1199/1189.Maximum Number of Balloons/README.md new file mode 100644 index 0000000000000..0d45804da1156 --- /dev/null +++ b/solution/1100-1199/1189.Maximum Number of Balloons/README.md @@ -0,0 +1,65 @@ +# [1189. “气球” 的最大数量](https://leetcode-cn.com/problems/maximum-number-of-balloons) + +## 题目描述 + +
给你一个字符串 text,你需要使用 text 中的字母来拼凑尽可能多的单词 "balloon"(气球)。
字符串 text 中的每个字母最多只能被使用一次。请你返回最多可以拼凑出多少个单词 "balloon"。
+ +
示例 1:
+ +
输入:text = "nlaebolko" +输出:1 ++ +
示例 2:
+ +
输入:text = "loonbalxballpoon" +输出:2 ++ +
示例 3:
+ +输入:text = "leetcode" +输出:0 ++ +
+ +
提示:
+ +-
+
1 <= text.length <= 10^4
+ text全部由小写英文字母组成
+
给出一个字符串 s(仅含有小写英文字母和括号)。
请你按照从括号内到外的顺序,逐层反转每对匹配括号中的字符串,并返回最终的结果。
+ +注意,您的结果中 不应 包含任何括号。
+ ++ +
示例 1:
+ +输入:s = "(abcd)" +输出:"dcba" ++ +
示例 2:
+ +输入:s = "(u(love)i)" +输出:"iloveu" ++ +
示例 3:
+ +输入:s = "(ed(et(oc))el)" +输出:"leetcode" ++ +
示例 4:
+ +输入:s = "a(bcdefghijkl(mno)p)q" +输出:"apmnolkjihgfedcbq" ++ +
+ +
提示:
+ +-
+
0 <= s.length <= 2000
+ s中只有小写英文字母和括号
+ - 我们确保所有括号都是成对出现的 +
给你一个整数数组 arr 和一个整数 k。
首先,我们要对该数组进行修改,即把原数组 arr 重复 k 次。
++ +举个例子,如果
+arr = [1, 2]且k = 3,那么修改后的数组就是[1, 2, 1, 2, 1, 2]。
然后,请你返回修改后的数组中的最大的子数组之和。
+ +注意,子数组长度可以是 0,在这种情况下它的总和也是 0。
由于 结果可能会很大,所以需要 模(mod) 10^9 + 7 后再返回。
+ +
示例 1:
+ +输入:arr = [1,2], k = 3 +输出:9 ++ +
示例 2:
+ +输入:arr = [1,-2,1], k = 5 +输出:2 ++ +
示例 3:
+ +输入:arr = [-1,-2], k = 7 +输出:0 ++ +
+ +
提示:
+ +-
+
1 <= arr.length <= 10^5
+ 1 <= k <= 10^5
+ -10^4 <= arr[i] <= 10^4
+
力扣数据中心有 n 台服务器,分别按从 0 到 n-1 的方式进行了编号。
它们之间以「服务器到服务器」点对点的形式相互连接组成了一个内部集群,其中连接 connections 是无向的。
从形式上讲,connections[i] = [a, b] 表示服务器 a 和 b 之间形成连接。任何服务器都可以直接或者间接地通过网络到达任何其他服务器。
「关键连接」是在该集群中的重要连接,也就是说,假如我们将它移除,便会导致某些服务器无法访问其他服务器。
+ +请你以任意顺序返回该集群内的所有 「关键连接」。
+ ++ +
示例 1:
+ +
输入:n = 4, connections = [[0,1],[1,2],[2,0],[1,3]] +输出:[[1,3]] +解释:[[3,1]] 也是正确的。+ +
+ +
提示:
+ +-
+
1 <= n <= 10^5
+ n-1 <= connections.length <= 10^5
+ connections[i][0] != connections[i][1]
+ - 不存在重复的连接 +
编写一个可以从 1 到 n 输出代表这个数字的字符串的程序,但是:
+ +-
+
- 如果这个数字可以被 3 整除,输出 "fizz"。 +
- 如果这个数字可以被 5 整除,输出 "buzz"。 +
- 如果这个数字可以同时被 3 和 5 整除,输出 "fizzbuzz"。 +
例如,当 n = 15,输出: 1, 2, fizz, 4, buzz, fizz, 7, 8, fizz, buzz, 11, fizz, 13, 14, fizzbuzz。
假设有这么一个类:
+ +class FizzBuzz {
+ public FizzBuzz(int n) { ... } // constructor
+ public void fizz(printFizz) { ... } // only output "fizz"
+ public void buzz(printBuzz) { ... } // only output "buzz"
+ public void fizzbuzz(printFizzBuzz) { ... } // only output "fizzbuzz"
+ public void number(printNumber) { ... } // only output the numbers
+}
+
+请你实现一个有四个线程的多线程版 FizzBuzz, 同一个 FizzBuzz 实例会被如下四个线程使用:
-
+
- 线程A将调用
fizz()来判断是否能被 3 整除,如果可以,则输出fizz。
+ - 线程B将调用
buzz()来判断是否能被 5 整除,如果可以,则输出buzz。
+ - 线程C将调用
fizzbuzz()来判断是否同时能被 3 和 5 整除,如果可以,则输出fizzbuzz。
+ - 线程D将调用
number()来实现输出既不能被 3 整除也不能被 5 整除的数字。
+
给你个整数数组 arr,其中每个元素都 不相同。
请你找到所有具有最小绝对差的元素对,并且按升序的顺序返回。
+ ++ +
示例 1:
+ +输入:arr = [4,2,1,3] +输出:[[1,2],[2,3],[3,4]] ++ +
示例 2:
+ +输入:arr = [1,3,6,10,15] +输出:[[1,3]] ++ +
示例 3:
+ +输入:arr = [3,8,-10,23,19,-4,-14,27] +输出:[[-14,-10],[19,23],[23,27]] ++ +
+ +
提示:
+ +-
+
2 <= arr.length <= 10^5
+ -10^6 <= arr[i] <= 10^6
+
请你帮忙设计一个程序,用来找出第 n 个丑数。
丑数是可以被 a 或 b 或 c 整除的 正整数。
+ +
示例 1:
+ +输入:n = 3, a = 2, b = 3, c = 5 +输出:4 +解释:丑数序列为 2, 3, 4, 5, 6, 8, 9, 10... 其中第 3 个是 4。+ +
示例 2:
+ +输入:n = 4, a = 2, b = 3, c = 4 +输出:6 +解释:丑数序列为 2, 3, 4, 6, 8, 9, 12... 其中第 4 个是 6。 ++ +
示例 3:
+ +输入:n = 5, a = 2, b = 11, c = 13 +输出:10 +解释:丑数序列为 2, 4, 6, 8, 10, 11, 12, 13... 其中第 5 个是 10。 ++ +
示例 4:
+ +输入:n = 1000000000, a = 2, b = 217983653, c = 336916467 +输出:1999999984 ++ +
+ +
提示:
+ +-
+
1 <= n, a, b, c <= 10^9
+ 1 <= a * b * c <= 10^18
+ - 本题结果在
[1, 2 * 10^9]的范围内
+
给你一个字符串 s,以及该字符串中的一些「索引对」数组 pairs,其中 pairs[i] = [a, b] 表示字符串中的两个索引(编号从 0 开始)。
你可以 任意多次交换 在 pairs 中任意一对索引处的字符。
返回在经过若干次交换后,s 可以变成的按字典序最小的字符串。
+ +
示例 1:
+ +输入:s = "dcab", pairs = [[0,3],[1,2]] +输出:"bacd" +解释: +交换 s[0] 和 s[3], s = "bcad" +交换 s[1] 和 s[2], s = "bacd" ++ +
示例 2:
+ +输入:s = "dcab", pairs = [[0,3],[1,2],[0,2]] +输出:"abcd" +解释: +交换 s[0] 和 s[3], s = "bcad" +交换 s[0] 和 s[2], s = "acbd" +交换 s[1] 和 s[2], s = "abcd"+ +
示例 3:
+ +输入:s = "cba", pairs = [[0,1],[1,2]] +输出:"abc" +解释: +交换 s[0] 和 s[1], s = "bca" +交换 s[1] 和 s[2], s = "bac" +交换 s[0] 和 s[1], s = "abc" ++ +
+ +
提示:
+ +-
+
1 <= s.length <= 10^5
+ 0 <= pairs.length <= 10^5
+ 0 <= pairs[i][0], pairs[i][1] < s.length
+ s中只含有小写英文字母
+
公司共有 n 个项目和 m 个小组,每个项目要不没有归属,要不就由其中的一个小组负责。
我们用 group[i] 代表第 i 个项目所属的小组,如果这个项目目前无人接手,那么 group[i] 就等于 -1。(项目和小组都是从零开始编号的)
请你帮忙按要求安排这些项目的进度,并返回排序后的项目列表:
+ +-
+
- 同一小组的项目,排序后在列表中彼此相邻。 +
- 项目之间存在一定的依赖关系,我们用一个列表
beforeItems来表示,其中beforeItems[i]表示在进行第i个项目前(位于第i个项目左侧)应该完成的所有项目。
+
结果要求:
+ +如果存在多个解决方案,只需要返回其中任意一个即可。
+ +如果没有合适的解决方案,就请返回一个 空列表。
+ ++ +
示例 1:
+ +
输入:n = 8, m = 2, group = [-1,-1,1,0,0,1,0,-1], beforeItems = [[],[6],[5],[6],[3,6],[],[],[]] +输出:[6,3,4,1,5,2,0,7] ++ +
示例 2:
+ +输入:n = 8, m = 2, group = [-1,-1,1,0,0,1,0,-1], beforeItems = [[],[6],[5],[6],[3],[],[4],[]] +输出:[] +解释:与示例 1 大致相同,但是在排序后的列表中,4 必须放在 6 的前面。 ++ +
+ +
提示:
+ +-
+
1 <= m <= n <= 3*10^4
+ group.length == beforeItems.length == n
+ -1 <= group[i] <= m-1
+ 0 <= beforeItems[i].length <= n-1
+ 0 <= beforeItems[i][j] <= n-1
+ i != beforeItems[i][j]
+
不使用任何库函数,设计一个跳表。
+ +跳表是在 O(log(n)) 时间内完成增加、删除、搜索操作的数据结构。跳表相比于树堆与红黑树,其功能与性能相当,并且跳表的代码长度相较下更短,其设计思想与链表相似。
+ +例如,一个跳表包含 [30, 40, 50, 60, 70, 90],然后增加 80、45 到跳表中,以下图的方式操作:
+ +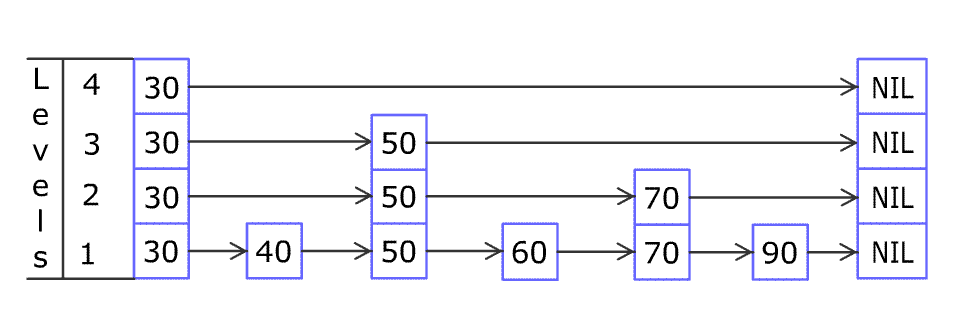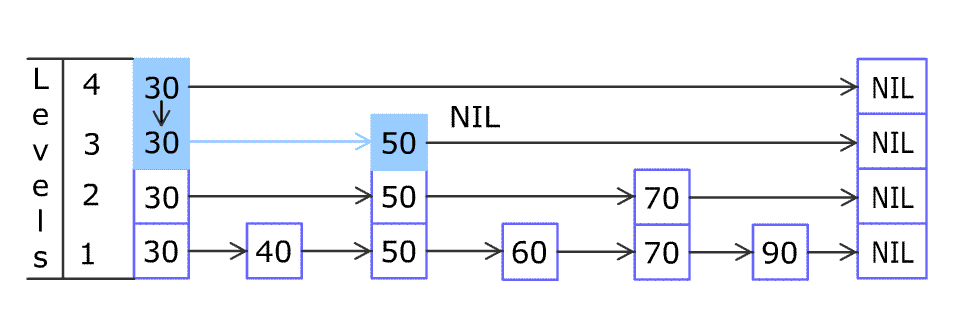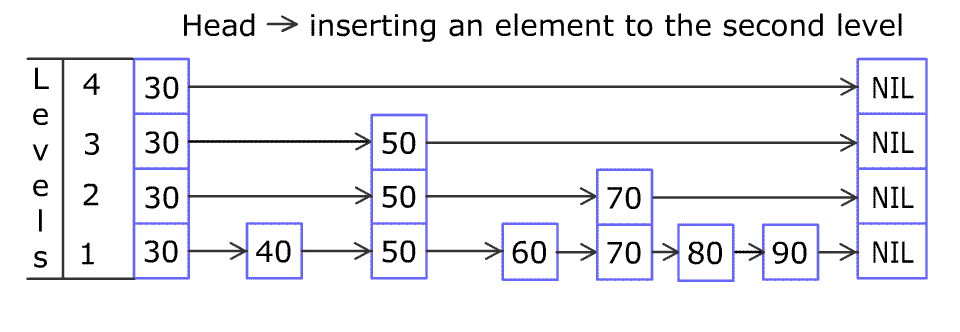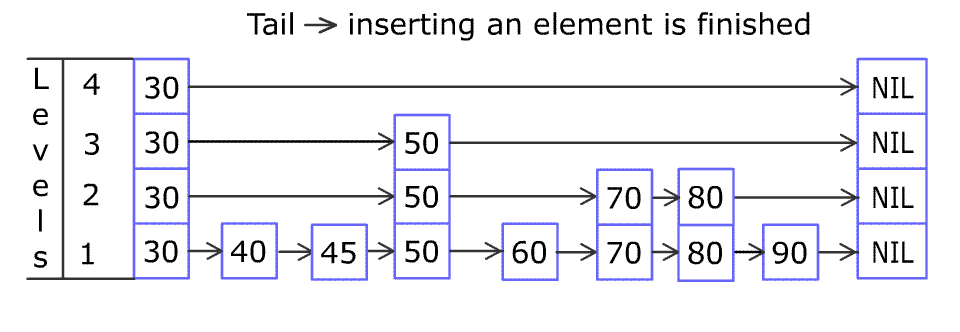
+Artyom Kalinin [CC BY-SA 3.0], via Wikimedia Commons
跳表中有很多层,每一层是一个短的链表。在第一层的作用下,增加、删除和搜索操作的时间复杂度不超过 O(n)。跳表的每一个操作的平均时间复杂度是 O(log(n)),空间复杂度是 O(n)。
+ +在本题中,你的设计应该要包含这些函数:
+ +-
+
bool search(int target): 返回target是否存在于跳表中。
+ void add(int num): 插入一个元素到跳表。
+ bool erase(int num): 在跳表中删除一个值,如果num不存在,直接返回false. 如果存在多个num,删除其中任意一个即可。
+
了解更多 : https://en.wikipedia.org/wiki/Skip_list
+ +注意,跳表中可能存在多个相同的值,你的代码需要处理这种情况。
+ +样例:
+ +Skiplist skiplist = new Skiplist(); + +skiplist.add(1); +skiplist.add(2); +skiplist.add(3); +skiplist.search(0); // 返回 false +skiplist.add(4); +skiplist.search(1); // 返回 true +skiplist.erase(0); // 返回 false,0 不在跳表中 +skiplist.erase(1); // 返回 true +skiplist.search(1); // 返回 false,1 已被擦除 ++ +
约束条件:
+ +-
+
0 <= num, target <= 20000
+ - 最多调用
50000次search,add, 以及erase操作。
+
给你一个整数数组 arr,请你帮忙统计数组中每个数的出现次数。
如果每个数的出现次数都是独一无二的,就返回 true;否则返回 false。
+ +
示例 1:
+ +输入:arr = [1,2,2,1,1,3] +输出:true +解释:在该数组中,1 出现了 3 次,2 出现了 2 次,3 只出现了 1 次。没有两个数的出现次数相同。+ +
示例 2:
+ +输入:arr = [1,2] +输出:false ++ +
示例 3:
+ +输入:arr = [-3,0,1,-3,1,1,1,-3,10,0] +输出:true ++ +
+ +
提示:
+ +-
+
1 <= arr.length <= 1000
+ -1000 <= arr[i] <= 1000
+
给你两个长度相同的字符串,s 和 t。
将 s 中的第 i 个字符变到 t 中的第 i 个字符需要 |s[i] - t[i]| 的开销(开销可能为 0),也就是两个字符的 ASCII 码值的差的绝对值。
用于变更字符串的最大预算是 maxCost。在转化字符串时,总开销应当小于等于该预算,这也意味着字符串的转化可能是不完全的。
如果你可以将 s 的子字符串转化为它在 t 中对应的子字符串,则返回可以转化的最大长度。
如果 s 中没有子字符串可以转化成 t 中对应的子字符串,则返回 0。
+ +
示例 1:
+ +输入:s = "abcd", t = "bcdf", cost = 3 +输出:3 +解释:s 中的 "abc" 可以变为 "bcd"。开销为 3,所以最大长度为 3。+ +
示例 2:
+ +输入:s = "abcd", t = "cdef", cost = 3
+输出:1
+解释:s 中的任一字符要想变成 t 中对应的字符,其开销都是 2。因此,最大长度为 1。
+
+
+示例 3:
+ +输入:s = "abcd", t = "acde", cost = 0 +输出:1 +解释:你无法作出任何改动,所以最大长度为 1。 ++ +
+ +
提示:
+ +-
+
1 <= s.length, t.length <= 10^5
+ 0 <= maxCost <= 10^6
+ s和t都只含小写英文字母。
+
给你一个字符串 s,「k 倍重复项删除操作」将会从 s 中选择 k 个相邻且相等的字母,并删除它们,使被删去的字符串的左侧和右侧连在一起。
你需要对 s 重复进行无限次这样的删除操作,直到无法继续为止。
在执行完所有删除操作后,返回最终得到的字符串。
+ +本题答案保证唯一。
+ ++ +
示例 1:
+ +输入:s = "abcd", k = 2 +输出:"abcd" +解释:没有要删除的内容。+ +
示例 2:
+ +输入:s = "deeedbbcccbdaa", k = 3 +输出:"aa" +解释: +先删除 "eee" 和 "ccc",得到 "ddbbbdaa" +再删除 "bbb",得到 "dddaa" +最后删除 "ddd",得到 "aa"+ +
示例 3:
+ +输入:s = "pbbcggttciiippooaais", k = 2 +输出:"ps" ++ +
+ +
提示:
+ +-
+
1 <= s.length <= 10^5
+ 2 <= k <= 10^4
+ s中只含有小写英文字母。
+
你还记得那条风靡全球的贪吃蛇吗?
+ +我们在一个 n*n 的网格上构建了新的迷宫地图,蛇的长度为 2,也就是说它会占去两个单元格。蛇会从左上角((0, 0) 和 (0, 1))开始移动。我们用 0 表示空单元格,用 1 表示障碍物。蛇需要移动到迷宫的右下角((n-1, n-2) 和 (n-1, n-1))。
每次移动,蛇可以这样走:
+ +-
+
- 如果没有障碍,则向右移动一个单元格。并仍然保持身体的水平/竖直状态。 +
- 如果没有障碍,则向下移动一个单元格。并仍然保持身体的水平/竖直状态。 +
- 如果它处于水平状态并且其下面的两个单元都是空的,就顺时针旋转 90 度。蛇从(
(r, c)、(r, c+1))移动到 ((r, c)、(r+1, c))。
+ +
+ - 如果它处于竖直状态并且其右面的两个单元都是空的,就逆时针旋转 90 度。蛇从(
(r, c)、(r+1, c))移动到((r, c)、(r, c+1))。
+ +
+
返回蛇抵达目的地所需的最少移动次数。
+ +如果无法到达目的地,请返回 -1。
+ +
示例 1:
+ +
输入:grid = [[0,0,0,0,0,1], + [1,1,0,0,1,0], + [0,0,0,0,1,1], + [0,0,1,0,1,0], + [0,1,1,0,0,0], + [0,1,1,0,0,0]] +输出:11 +解释: +一种可能的解决方案是 [右, 右, 顺时针旋转, 右, 下, 下, 下, 下, 逆时针旋转, 右, 下]。 ++ +
示例 2:
+ +输入:grid = [[0,0,1,1,1,1], + [0,0,0,0,1,1], + [1,1,0,0,0,1], + [1,1,1,0,0,1], + [1,1,1,0,0,1], + [1,1,1,0,0,0]] +输出:9 ++ +
+ +
提示:
+ +-
+
2 <= n <= 100
+ 0 <= grid[i][j] <= 1
+ - 蛇保证从空单元格开始出发。 +
数轴上放置了一些筹码,每个筹码的位置存在数组 chips 当中。
你可以对 任何筹码 执行下面两种操作之一(不限操作次数,0 次也可以):
+ +-
+
- 将第
i个筹码向左或者右移动 2 个单位,代价为 0。
+ - 将第
i个筹码向左或者右移动 1 个单位,代价为 1。
+
最开始的时候,同一位置上也可能放着两个或者更多的筹码。
+ +返回将所有筹码移动到同一位置(任意位置)上所需要的最小代价。
+ ++ +
示例 1:
+ +输入:chips = [1,2,3] +输出:1 +解释:第二个筹码移动到位置三的代价是 1,第一个筹码移动到位置三的代价是 0,总代价为 1。 ++ +
示例 2:
+ +输入:chips = [2,2,2,3,3] +输出:2 +解释:第四和第五个筹码移动到位置二的代价都是 1,所以最小总代价为 2。 ++ +
+ +
提示:
+ +-
+
1 <= chips.length <= 100
+ 1 <= chips[i] <= 10^9
+
给你一个整数数组 arr 和一个整数 difference,请你找出 arr 中所有相邻元素之间的差等于给定 difference 的等差子序列,并返回其中最长的等差子序列的长度。
+ +
示例 1:
+ +输入:arr = [1,2,3,4], difference = 1 +输出:4 +解释:最长的等差子序列是 [1,2,3,4]。+ +
示例 2:
+ +输入:arr = [1,3,5,7], difference = 1 +输出:1 +解释:最长的等差子序列是任意单个元素。 ++ +
示例 3:
+ +输入:arr = [1,5,7,8,5,3,4,2,1], difference = -2 +输出:4 +解释:最长的等差子序列是 [7,5,3,1]。 ++ +
+ +
提示:
+ +-
+
1 <= arr.length <= 10^5
+ -10^4 <= arr[i], difference <= 10^4
+
你要开发一座金矿,地质勘测学家已经探明了这座金矿中的资源分布,并用大小为 m * n 的网格 grid 进行了标注。每个单元格中的整数就表示这一单元格中的黄金数量;如果该单元格是空的,那么就是 0。
为了使收益最大化,矿工需要按以下规则来开采黄金:
+ +-
+
- 每当矿工进入一个单元,就会收集该单元格中的所有黄金。 +
- 矿工每次可以从当前位置向上下左右四个方向走。 +
- 每个单元格只能被开采(进入)一次。 +
- 不得开采(进入)黄金数目为
0的单元格。
+ - 矿工可以从网格中 任意一个 有黄金的单元格出发或者是停止。 +
+ +
示例 1:
+ +输入:grid = [[0,6,0],[5,8,7],[0,9,0]] +输出:24 +解释: +[[0,6,0], + [5,8,7], + [0,9,0]] +一种收集最多黄金的路线是:9 -> 8 -> 7。 ++ +
示例 2:
+ +输入:grid = [[1,0,7],[2,0,6],[3,4,5],[0,3,0],[9,0,20]] +输出:28 +解释: +[[1,0,7], + [2,0,6], + [3,4,5], + [0,3,0], + [9,0,20]] +一种收集最多黄金的路线是:1 -> 2 -> 3 -> 4 -> 5 -> 6 -> 7。 ++ +
+ +
提示:
+ +-
+
1 <= grid.length, grid[i].length <= 15
+ 0 <= grid[i][j] <= 100
+ - 最多 25 个单元格中有黄金。 +
给你一个整数 n,请你帮忙统计一下我们可以按下述规则形成多少个长度为 n 的字符串:
-
+
- 字符串中的每个字符都应当是小写元音字母(
'a','e','i','o','u')
+ - 每个元音
'a'后面都只能跟着'e'
+ - 每个元音
'e'后面只能跟着'a'或者是'i'
+ - 每个元音
'i'后面 不能 再跟着另一个'i'
+ - 每个元音
'o'后面只能跟着'i'或者是'u'
+ - 每个元音
'u'后面只能跟着'a'
+
由于答案可能会很大,所以请你返回 模 10^9 + 7 之后的结果。
+ +
示例 1:
+ +输入:n = 1 +输出:5 +解释:所有可能的字符串分别是:"a", "e", "i" , "o" 和 "u"。 ++ +
示例 2:
+ +输入:n = 2 +输出:10 +解释:所有可能的字符串分别是:"ae", "ea", "ei", "ia", "ie", "io", "iu", "oi", "ou" 和 "ua"。 ++ +
示例 3:
+ +输入:n = 5 +输出:68+ +
+ +
提示:
+ +-
+
1 <= n <= 2 * 10^4
+
在一个「平衡字符串」中,'L' 和 'R' 字符的数量是相同的。
+ +给出一个平衡字符串 s,请你将它分割成尽可能多的平衡字符串。
返回可以通过分割得到的平衡字符串的最大数量。
+ ++ +
示例 1:
+ +输入:s = "RLRRLLRLRL" +输出:4 +解释:s 可以分割为 "RL", "RRLL", "RL", "RL", 每个子字符串中都包含相同数量的 'L' 和 'R'。 ++ +
示例 2:
+ +输入:s = "RLLLLRRRLR" +输出:3 +解释:s 可以分割为 "RL", "LLLRRR", "LR", 每个子字符串中都包含相同数量的 'L' 和 'R'。 ++ +
示例 3:
+ +输入:s = "LLLLRRRR" +输出:1 +解释:s 只能保持原样 "LLLLRRRR". ++ +
+ +
提示:
+ +-
+
1 <= s.length <= 1000
+ s[i] = 'L' 或 'R'
+
在一个 8x8 的棋盘上,放置着若干「黑皇后」和一个「白国王」。
+ +「黑皇后」在棋盘上的位置分布用整数坐标数组 queens 表示,「白国王」的坐标用数组 king 表示。
「黑皇后」的行棋规定是:横、直、斜都可以走,步数不受限制,但是,不能越子行棋。
+ +请你返回可以直接攻击到「白国王」的所有「黑皇后」的坐标(任意顺序)。
+ ++ +
示例 1:
+ +
输入:queens = [[0,1],[1,0],[4,0],[0,4],[3,3],[2,4]], king = [0,0] +输出:[[0,1],[1,0],[3,3]] +解释: +[0,1] 的皇后可以攻击到国王,因为他们在同一行上。 +[1,0] 的皇后可以攻击到国王,因为他们在同一列上。 +[3,3] 的皇后可以攻击到国王,因为他们在同一条对角线上。 +[0,4] 的皇后无法攻击到国王,因为她被位于 [0,1] 的皇后挡住了。 +[4,0] 的皇后无法攻击到国王,因为她被位于 [1,0] 的皇后挡住了。 +[2,4] 的皇后无法攻击到国王,因为她和国王不在同一行/列/对角线上。 ++ +
示例 2:
+ +
输入:queens = [[0,0],[1,1],[2,2],[3,4],[3,5],[4,4],[4,5]], king = [3,3] +输出:[[2,2],[3,4],[4,4]] ++ +
示例 3:
+ +
输入:queens = [[5,6],[7,7],[2,1],[0,7],[1,6],[5,1],[3,7],[0,3],[4,0],[1,2],[6,3],[5,0],[0,4],[2,2],[1,1],[6,4],[5,4],[0,0],[2,6],[4,5],[5,2],[1,4],[7,5],[2,3],[0,5],[4,2],[1,0],[2,7],[0,1],[4,6],[6,1],[0,6],[4,3],[1,7]], king = [3,4] +输出:[[2,3],[1,4],[1,6],[3,7],[4,3],[5,4],[4,5]] ++ +
+ +
提示:
+ +-
+
1 <= queens.length <= 63
+ queens[0].length == 2
+ 0 <= queens[i][j] < 8
+ king.length == 2
+ 0 <= king[0], king[1] < 8
+ - 一个棋盘格上最多只能放置一枚棋子。 +
有一个骰子模拟器会每次投掷的时候生成一个 1 到 6 的随机数。
+ +不过我们在使用它时有个约束,就是使得投掷骰子时,连续 掷出数字 i 的次数不能超过 rollMax[i](i 从 1 开始编号)。
现在,给你一个整数数组 rollMax 和一个整数 n,请你来计算掷 n 次骰子可得到的不同点数序列的数量。
假如两个序列中至少存在一个元素不同,就认为这两个序列是不同的。由于答案可能很大,所以请返回 模 10^9 + 7 之后的结果。
+ +
示例 1:
+ +输入:n = 2, rollMax = [1,1,2,2,2,3] +输出:34 +解释:我们掷 2 次骰子,如果没有约束的话,共有 6 * 6 = 36 种可能的组合。但是根据 rollMax 数组,数字 1 和 2 最多连续出现一次,所以不会出现序列 (1,1) 和 (2,2)。因此,最终答案是 36-2 = 34。 ++ +
示例 2:
+ +输入:n = 2, rollMax = [1,1,1,1,1,1] +输出:30 ++ +
示例 3:
+ +输入:n = 3, rollMax = [1,1,1,2,2,3] +输出:181 ++ +
+ +
提示:
+ +-
+
1 <= n <= 5000
+ rollMax.length == 6
+ 1 <= rollMax[i] <= 15
+
给出一个正整数数组 nums,请你帮忙从该数组中找出能满足下面要求的 最长 前缀,并返回其长度:
-
+
- 从前缀中 删除一个 元素后,使得所剩下的每个数字的出现次数相同。 +
如果删除这个元素后没有剩余元素存在,仍可认为每个数字都具有相同的出现次数(也就是 0 次)。
+ ++ +
示例 1:
+ +输入:nums = [2,2,1,1,5,3,3,5] +输出:7 +解释:对于长度为 7 的子数组 [2,2,1,1,5,3,3],如果我们从中删去 nums[4]=5,就可以得到 [2,2,1,1,3,3],里面每个数字都出现了两次。 ++ +
示例 2:
+ +输入:nums = [1,1,1,2,2,2,3,3,3,4,4,4,5] +输出:13 ++ +
示例 3:
+ +输入:nums = [1,1,1,2,2,2] +输出:5 ++ +
示例 4:
+ +输入:nums = [10,2,8,9,3,8,1,5,2,3,7,6] +输出:8 ++ +
+ +
提示:
+ +-
+
2 <= nums.length <= 10^5
+ 1 <= nums[i] <= 10^5
+
5 个沉默寡言的哲学家围坐在圆桌前,每人面前一盘意面。叉子放在哲学家之间的桌面上。(5 个哲学家,5 根叉子)
+ +所有的哲学家都只会在思考和进餐两种行为间交替。哲学家只有同时拿到左边和右边的叉子才能吃到面,而同一根叉子在同一时间只能被一个哲学家使用。每个哲学家吃完面后都需要把叉子放回桌面以供其他哲学家吃面。只要条件允许,哲学家可以拿起左边或者右边的叉子,但在没有同时拿到左右叉子时不能进食。
+ +假设面的数量没有限制,哲学家也能随便吃,不需要考虑吃不吃得下。
+ +设计一个进餐规则(并行算法)使得每个哲学家都不会挨饿;也就是说,在没有人知道别人什么时候想吃东西或思考的情况下,每个哲学家都可以在吃饭和思考之间一直交替下去。
+ +
问题描述和图片来自维基百科 wikipedia.org
+ ++ +
哲学家从 0 到 4 按 顺时针 编号。请实现函数 void wantsToEat(philosopher, pickLeftFork, pickRightFork, eat, putLeftFork, putRightFork):
-
+
philosopher哲学家的编号。
+ pickLeftFork和pickRightFork表示拿起左边或右边的叉子。
+ eat表示吃面。
+ putLeftFork和putRightFork表示放下左边或右边的叉子。
+ - 由于哲学家不是在吃面就是在想着啥时候吃面,所以思考这个方法没有对应的回调。 +
给你 5 个线程,每个都代表一个哲学家,请你使用类的同一个对象来模拟这个过程。在最后一次调用结束之前,可能会为同一个哲学家多次调用该函数。
+ ++ +
示例:
+ +输入:n = 1
+输出:[[4,2,1],[4,1,1],[0,1,1],[2,2,1],[2,1,1],[2,0,3],[2,1,2],[2,2,2],[4,0,3],[4,1,2],[0,2,1],[4,2,2],[3,2,1],[3,1,1],[0,0,3],[0,1,2],[0,2,2],[1,2,1],[1,1,1],[3,0,3],[3,1,2],[3,2,2],[1,0,3],[1,1,2],[1,2,2]]
+解释:
+n 表示每个哲学家需要进餐的次数。
+输出数组描述了叉子的控制和进餐的调用,它的格式如下:
+output[i] = [a, b, c] (3个整数)
+- a 哲学家编号。
+- b 指定叉子:{1 : 左边, 2 : 右边}.
+- c 指定行为:{1 : 拿起, 2 : 放下, 3 : 吃面}。
+如 [4,2,1] 表示 4 号哲学家拿起了右边的叉子。
+
+
++ +
提示:
+ +-
+
1 <= n <= 60
+
有 n 位乘客即将登机,飞机正好有 n 个座位。第一位乘客的票丢了,他随便选了一个座位坐下。
剩下的乘客将会:
+ +-
+
-
+
如果他们自己的座位还空着,就坐到自己的座位上,
+
+ - 当他们自己的座位被占用时,随机选择其他座位 +
第 n 位乘客坐在自己的座位上的概率是多少?
+ +
示例 1:
+ ++输入:n = 1 +输出:1.00000 +解释:第一个人只会坐在自己的位置上。+ +
示例 2:
+ ++输入: n = 2 +输出: 0.50000 +解释:在第一个人选好座位坐下后,第二个人坐在自己的座位上的概率是 0.5。 ++ +
+ +
提示:
+ +-
+
1 <= n <= 10^5
+
在一个 XY 坐标系中有一些点,我们用数组 coordinates 来分别记录它们的坐标,其中 coordinates[i] = [x, y] 表示横坐标为 x、纵坐标为 y 的点。
请你来判断,这些点是否在该坐标系中属于同一条直线上,是则返回 true,否则请返回 false。
+ +
示例 1:
+ +
输入:coordinates = [[1,2],[2,3],[3,4],[4,5],[5,6],[6,7]] +输出:true ++ +
示例 2:
+ +
输入:coordinates = [[1,1],[2,2],[3,4],[4,5],[5,6],[7,7]] +输出:false ++ +
+ +
提示:
+ +-
+
2 <= coordinates.length <= 1000
+ coordinates[i].length == 2
+ -10^4 <= coordinates[i][0], coordinates[i][1] <= 10^4
+ coordinates中不含重复的点
+
你是一位系统管理员,手里有一份文件夹列表 folder,你的任务是要删除该列表中的所有 子文件夹,并以 任意顺序 返回剩下的文件夹。
我们这样定义「子文件夹」:
+ +-
+
- 如果文件夹
folder[i]位于另一个文件夹folder[j]下,那么folder[i]就是folder[j]的子文件夹。
+
文件夹的「路径」是由一个或多个按以下格式串联形成的字符串:
+ +-
+
/后跟一个或者多个小写英文字母。
+
例如,/leetcode 和 /leetcode/problems 都是有效的路径,而空字符串和 / 不是。
+ +
示例 1:
+ +输入:folder = ["/a","/a/b","/c/d","/c/d/e","/c/f"] +输出:["/a","/c/d","/c/f"] +解释:"/a/b/" 是 "/a" 的子文件夹,而 "/c/d/e" 是 "/c/d" 的子文件夹。 ++ +
示例 2:
+ +输入:folder = ["/a","/a/b/c","/a/b/d"] +输出:["/a"] +解释:文件夹 "/a/b/c" 和 "/a/b/d/" 都会被删除,因为它们都是 "/a" 的子文件夹。 ++ +
示例 3:
+ +输入:folder = ["/a/b/c","/a/b/d","/a/b/ca"] +输出:["/a/b/c","/a/b/ca","/a/b/d"] ++ +
+ +
提示:
+ +-
+
1 <= folder.length <= 4 * 10^4
+ 2 <= folder[i].length <= 100
+ folder[i]只包含小写字母和/
+ folder[i]总是以字符/起始
+ - 每个文件夹名都是唯一的 +
有一个只含有 'Q', 'W', 'E', 'R' 四种字符,且长度为 n 的字符串。
假如在该字符串中,这四个字符都恰好出现 n/4 次,那么它就是一个「平衡字符串」。
+ +
给你一个这样的字符串 s,请通过「替换一个子串」的方式,使原字符串 s 变成一个「平衡字符串」。
你可以用和「待替换子串」长度相同的 任何 其他字符串来完成替换。
+ +请返回待替换子串的最小可能长度。
+ +如果原字符串自身就是一个平衡字符串,则返回 0。
+ +
示例 1:
+ +输入:s = "QWER" +输出:0 +解释:s 已经是平衡的了。+ +
示例 2:
+ +输入:s = "QQWE" +输出:1 +解释:我们需要把一个 'Q' 替换成 'R',这样得到的 "RQWE" (或 "QRWE") 是平衡的。 ++ +
示例 3:
+ +输入:s = "QQQW" +输出:2 +解释:我们可以把前面的 "QQ" 替换成 "ER"。 ++ +
示例 4:
+ +输入:s = "QQQQ" +输出:3 +解释:我们可以替换后 3 个 'Q',使 s = "QWER"。 ++ +
+ +
提示:
+ +-
+
1 <= s.length <= 10^5
+ s.length是4的倍数
+ s中只含有'Q','W','E','R'四种字符
+
你打算利用空闲时间来做兼职工作赚些零花钱。
+ +这里有 n 份兼职工作,每份工作预计从 startTime[i] 开始到 endTime[i] 结束,报酬为 profit[i]。
给你一份兼职工作表,包含开始时间 startTime,结束时间 endTime 和预计报酬 profit 三个数组,请你计算并返回可以获得的最大报酬。
注意,时间上出现重叠的 2 份工作不能同时进行。
+ +如果你选择的工作在时间 X 结束,那么你可以立刻进行在时间 X 开始的下一份工作。
+ +
示例 1:
+ +
输入:startTime = [1,2,3,3], endTime = [3,4,5,6], profit = [50,10,40,70] +输出:120 +解释: +我们选出第 1 份和第 4 份工作, +时间范围是 [1-3]+[3-6],共获得报酬 120 = 50 + 70。 ++ +
示例 2:
+ +
输入:startTime = [1,2,3,4,6], endTime = [3,5,10,6,9], profit = [20,20,100,70,60] +输出:150 +解释: +我们选择第 1,4,5 份工作。 +共获得报酬 150 = 20 + 70 + 60。 ++ +
示例 3:
+ +
输入:startTime = [1,1,1], endTime = [2,3,4], profit = [5,6,4] +输出:6 ++ +
+ +
提示:
+ +-
+
1 <= startTime.length == endTime.length == profit.length <= 5 * 10^4
+ 1 <= startTime[i] < endTime[i] <= 10^9
+ 1 <= profit[i] <= 10^4
+
给出一个函数 f(x, y) 和一个目标结果 z,请你计算方程 f(x,y) == z 所有可能的正整数 数对 x 和 y。
给定函数是严格单调的,也就是说:
+ +-
+
f(x, y) < f(x + 1, y)
+ f(x, y) < f(x, y + 1)
+
函数接口定义如下:
+ +interface CustomFunction {
+public:
+ // Returns positive integer f(x, y) for any given positive integer x and y.
+ int f(int x, int y);
+};
+
+
+如果你想自定义测试,你可以输入整数 function_id 和一个目标结果 z 作为输入,其中 function_id 表示一个隐藏函数列表中的一个函数编号,题目只会告诉你列表中的 2 个函数。
你可以将满足条件的 结果数对 按任意顺序返回。
+ ++ +
示例 1:
+ +输入:function_id = 1, z = 5 +输出:[[1,4],[2,3],[3,2],[4,1]] +解释:function_id = 1 表示 f(x, y) = x + y+ +
示例 2:
+ +输入:function_id = 2, z = 5 +输出:[[1,5],[5,1]] +解释:function_id = 2 表示 f(x, y) = x * y ++ +
+ +
提示:
+ +-
+
1 <= function_id <= 9
+ 1 <= z <= 100
+ - 题目保证
f(x, y) == z的解处于1 <= x, y <= 1000的范围内。
+ - 在
1 <= x, y <= 1000的前提下,题目保证f(x, y)是一个 32 位有符号整数。
+
给你两个整数 n 和 start。你的任务是返回任意 (0,1,2,,...,2^n-1) 的排列 p,并且满足:
-
+
p[0] = start
+ p[i]和p[i+1]的二进制表示形式只有一位不同
+ p[0]和p[2^n -1]的二进制表示形式也只有一位不同
+
+ +
示例 1:
+ +输入:n = 2, start = 3 +输出:[3,2,0,1] +解释:这个排列的二进制表示是 (11,10,00,01) + 所有的相邻元素都有一位是不同的,另一个有效的排列是 [3,1,0,2] ++ +
示例 2:
+ +输出:n = 3, start = 2 +输出:[2,6,7,5,4,0,1,3] +解释:这个排列的二进制表示是 (010,110,111,101,100,000,001,011) ++ +
+ +
提示:
+ +-
+
1 <= n <= 16
+ 0 <= start < 2^n
+
给定一个字符串数组 arr,字符串 s 是将 arr 某一子序列字符串连接所得的字符串,如果 s 中的每一个字符都只出现过一次,那么它就是一个可行解。
请返回所有可行解 s 中最长长度。
+ +
示例 1:
+ +输入:arr = ["un","iq","ue"] +输出:4 +解释:所有可能的串联组合是 "","un","iq","ue","uniq" 和 "ique",最大长度为 4。 ++ +
示例 2:
+ +输入:arr = ["cha","r","act","ers"] +输出:6 +解释:可能的解答有 "chaers" 和 "acters"。 ++ +
示例 3:
+ +输入:arr = ["abcdefghijklmnopqrstuvwxyz"] +输出:26 ++ +
+ +
提示:
+ +-
+
1 <= arr.length <= 16
+ 1 <= arr[i].length <= 26
+ arr[i]中只含有小写英文字母
+
你是一位施工队的工长,根据设计师的要求准备为一套设计风格独特的房子进行室内装修。
+ +房子的客厅大小为 n x m,为保持极简的风格,需要使用尽可能少的 正方形 瓷砖来铺盖地面。
假设正方形瓷砖的规格不限,边长都是整数。
+ +请你帮设计师计算一下,最少需要用到多少块方形瓷砖?
+ ++ +
示例 1:
+ +
输入:n = 2, m = 3 +输出:3 ++ +解释:3块地砖就可以铺满卧室。 +2块1x1 地砖+1块2x2 地砖
示例 2:
+ +
输入:n = 5, m = 8 +输出:5 ++ +
示例 3:
+ +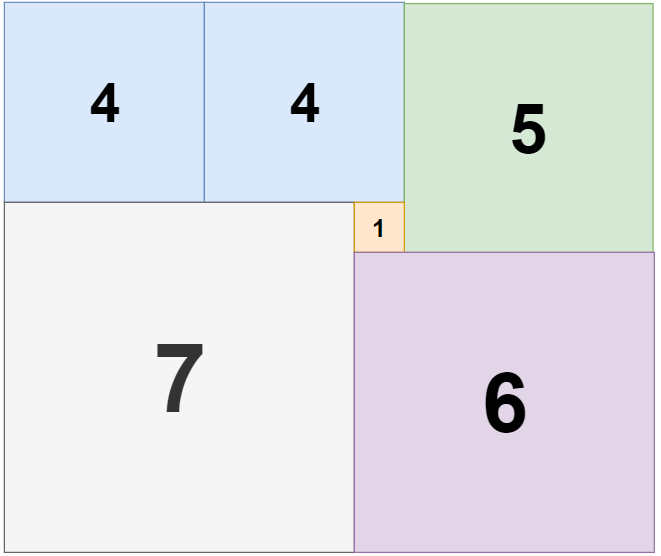
输入:n = 11, m = 13 +输出:6 ++ +
+ +
提示:
+ +-
+
1 <= n <= 13
+ 1 <= m <= 13
+
有两个长度相同的字符串 s1 和 s2,且它们其中 只含有 字符 "x" 和 "y",你需要通过「交换字符」的方式使这两个字符串相同。
每次「交换字符」的时候,你都可以在两个字符串中各选一个字符进行交换。
+ +交换只能发生在两个不同的字符串之间,绝对不能发生在同一个字符串内部。也就是说,我们可以交换 s1[i] 和 s2[j],但不能交换 s1[i] 和 s1[j]。
最后,请你返回使 s1 和 s2 相同的最小交换次数,如果没有方法能够使得这两个字符串相同,则返回 -1 。
+ +
示例 1:
+ +输入:s1 = "xx", s2 = "yy" +输出:1 +解释: +交换 s1[0] 和 s2[1],得到 s1 = "yx",s2 = "yx"。+ +
示例 2:
+ +输入:s1 = "xy", s2 = "yx" +输出:2 +解释: +交换 s1[0] 和 s2[0],得到 s1 = "yy",s2 = "xx" 。 +交换 s1[0] 和 s2[1],得到 s1 = "xy",s2 = "xy" 。 +注意,你不能交换 s1[0] 和 s1[1] 使得 s1 变成 "yx",因为我们只能交换属于两个不同字符串的字符。+ +
示例 3:
+ +输入:s1 = "xx", s2 = "xy" +输出:-1 ++ +
示例 4:
+ +输入:s1 = "xxyyxyxyxx", s2 = "xyyxyxxxyx" +输出:4 ++ +
+ +
提示:
+ +-
+
1 <= s1.length, s2.length <= 1000
+ s1, s2只包含'x'或'y'。
+
给你一个整数数组 nums 和一个整数 k。
如果某个 连续 子数组中恰好有 k 个奇数数字,我们就认为这个子数组是「优美子数组」。
请返回这个数组中「优美子数组」的数目。
+ ++ +
示例 1:
+ +输入:nums = [1,1,2,1,1], k = 3 +输出:2 +解释:包含 3 个奇数的子数组是 [1,1,2,1] 和 [1,2,1,1] 。 ++ +
示例 2:
+ +输入:nums = [2,4,6], k = 1 +输出:0 +解释:数列中不包含任何奇数,所以不存在优美子数组。 ++ +
示例 3:
+ +输入:nums = [2,2,2,1,2,2,1,2,2,2], k = 2 +输出:16 ++ +
+ +
提示:
+ +-
+
1 <= nums.length <= 50000
+ 1 <= nums[i] <= 10^5
+ 1 <= k <= nums.length
+
给你一个由 '('、')' 和小写字母组成的字符串 s。
你需要从字符串中删除最少数目的 '(' 或者 ')' (可以删除任意位置的括号),使得剩下的「括号字符串」有效。
请返回任意一个合法字符串。
+ +有效「括号字符串」应当符合以下 任意一条 要求:
+ +-
+
- 空字符串或只包含小写字母的字符串 +
- 可以被写作
AB(A连接B)的字符串,其中A和B都是有效「括号字符串」
+ - 可以被写作
(A)的字符串,其中A是一个有效的「括号字符串」
+
+ +
示例 1:
+ +输入:s = "lee(t(c)o)de)" +输出:"lee(t(c)o)de" +解释:"lee(t(co)de)" , "lee(t(c)ode)" 也是一个可行答案。 ++ +
示例 2:
+ +输入:s = "a)b(c)d" +输出:"ab(c)d" ++ +
示例 3:
+ +输入:s = "))(("
+输出:""
+解释:空字符串也是有效的
+
+
+示例 4:
+ +输入:s = "(a(b(c)d)" +输出:"a(b(c)d)" ++ +
+ +
提示:
+ +-
+
1 <= s.length <= 10^5
+ s[i]可能是'('、')'或英文小写字母
+
给你一个正整数数组 nums,你需要从中任选一些子集,然后将子集中每一个数乘以一个 任意整数,并求出他们的和。
假如该和结果为 1,那么原数组就是一个「好数组」,则返回 True;否则请返回 False。
+ +
示例 1:
+ +输入:nums = [12,5,7,23] +输出:true +解释:挑选数字 5 和 7。 +5*3 + 7*(-2) = 1 ++ +
示例 2:
+ +输入:nums = [29,6,10] +输出:true +解释:挑选数字 29, 6 和 10。 +29*1 + 6*(-3) + 10*(-1) = 1 ++ +
示例 3:
+ +输入:nums = [3,6] +输出:false ++ +
+ +
提示:
+ +-
+
1 <= nums.length <= 10^5
+ 1 <= nums[i] <= 10^9
+
给你一个 n 行 m 列的矩阵,最开始的时候,每个单元格中的值都是 0。
另有一个索引数组 indices,indices[i] = [ri, ci] 中的 ri 和 ci 分别表示指定的行和列(从 0 开始编号)。
你需要将每对 [ri, ci] 指定的行和列上的所有单元格的值加 1。
请你在执行完所有 indices 指定的增量操作后,返回矩阵中 「奇数值单元格」 的数目。
+ +
示例 1:
+ +
输入:n = 2, m = 3, indices = [[0,1],[1,1]] +输出:6 +解释:最开始的矩阵是 [[0,0,0],[0,0,0]]。 +第一次增量操作后得到 [[1,2,1],[0,1,0]]。 +最后的矩阵是 [[1,3,1],[1,3,1]],里面有 6 个奇数。 ++ +
示例 2:
+ +
输入:n = 2, m = 2, indices = [[1,1],[0,0]] +输出:0 +解释:最后的矩阵是 [[2,2],[2,2]],里面没有奇数。 ++ +
+ +
提示:
+ +-
+
1 <= n <= 50
+ 1 <= m <= 50
+ 1 <= indices.length <= 100
+ 0 <= indices[i][0] < n
+ 0 <= indices[i][1] < m
+
给你一个 2 行 n 列的二进制数组:
-
+
- 矩阵是一个二进制矩阵,这意味着矩阵中的每个元素不是
0就是1。
+ - 第
0行的元素之和为upper。
+ - 第
1行的元素之和为lower。
+ - 第
i列(从0开始编号)的元素之和为colsum[i],colsum是一个长度为n的整数数组。
+
你需要利用 upper,lower 和 colsum 来重构这个矩阵,并以二维整数数组的形式返回它。
如果有多个不同的答案,那么任意一个都可以通过本题。
+ +如果不存在符合要求的答案,就请返回一个空的二维数组。
+ ++ +
示例 1:
+ +输入:upper = 2, lower = 1, colsum = [1,1,1] +输出:[[1,1,0],[0,0,1]] +解释:[[1,0,1],[0,1,0]] 和 [[0,1,1],[1,0,0]] 也是正确答案。 ++ +
示例 2:
+ +输入:upper = 2, lower = 3, colsum = [2,2,1,1] +输出:[] ++ +
示例 3:
+ +输入:upper = 5, lower = 5, colsum = [2,1,2,0,1,0,1,2,0,1] +输出:[[1,1,1,0,1,0,0,1,0,0],[1,0,1,0,0,0,1,1,0,1]] ++ +
+ +
提示:
+ +-
+
1 <= colsum.length <= 10^5
+ 0 <= upper, lower <= colsum.length
+ 0 <= colsum[i] <= 2
+
有一个二维矩阵 grid ,每个位置要么是陆地(记号为 0 )要么是水域(记号为 1 )。
我们从一块陆地出发,每次可以往上下左右 4 个方向相邻区域走,能走到的所有陆地区域,我们将其称为一座「岛屿」。
+ +如果一座岛屿 完全 由水域包围,即陆地边缘上下左右所有相邻区域都是水域,那么我们将其称为 「封闭岛屿」。
+ +请返回封闭岛屿的数目。
+ ++ +
示例 1:
+ +
输入:grid = [[1,1,1,1,1,1,1,0],[1,0,0,0,0,1,1,0],[1,0,1,0,1,1,1,0],[1,0,0,0,0,1,0,1],[1,1,1,1,1,1,1,0]] +输出:2 +解释: +灰色区域的岛屿是封闭岛屿,因为这座岛屿完全被水域包围(即被 1 区域包围)。+ +
示例 2:
+ +
输入:grid = [[0,0,1,0,0],[0,1,0,1,0],[0,1,1,1,0]] +输出:1 ++ +
示例 3:
+ +输入:grid = [[1,1,1,1,1,1,1], + [1,0,0,0,0,0,1], + [1,0,1,1,1,0,1], + [1,0,1,0,1,0,1], + [1,0,1,1,1,0,1], + [1,0,0,0,0,0,1], + [1,1,1,1,1,1,1]] +输出:2 ++ +
+ +
提示:
+ +-
+
1 <= grid.length, grid[0].length <= 100
+ 0 <= grid[i][j] <=1
+
你将会得到一份单词表 words,一个字母表 letters (可能会有重复字母),以及每个字母对应的得分情况表 score。
请你帮忙计算玩家在单词拼写游戏中所能获得的「最高得分」:能够由 letters 里的字母拼写出的 任意 属于 words 单词子集中,分数最高的单词集合的得分。
单词拼写游戏的规则概述如下:
+ +-
+
- 玩家需要用字母表
letters里的字母来拼写单词表words中的单词。
+ - 可以只使用字母表
letters中的部分字母,但是每个字母最多被使用一次。
+ - 单词表
words中每个单词只能计分(使用)一次。
+ - 根据字母得分情况表
score,字母'a','b','c', ... ,'z'对应的得分分别为score[0],score[1], ...,score[25]。
+ - 本场游戏的「得分」是指:玩家所拼写出的单词集合里包含的所有字母的得分之和。 +
+ +
示例 1:
+ +输入:words = ["dog","cat","dad","good"], letters = ["a","a","c","d","d","d","g","o","o"], score = [1,0,9,5,0,0,3,0,0,0,0,0,0,0,2,0,0,0,0,0,0,0,0,0,0,0] +输出:23 +解释: +字母得分为 a=1, c=9, d=5, g=3, o=2 +使用给定的字母表 letters,我们可以拼写单词 "dad" (5+1+5)和 "good" (3+2+2+5),得分为 23 。 +而单词 "dad" 和 "dog" 只能得到 21 分。+ +
示例 2:
+ +输入:words = ["xxxz","ax","bx","cx"], letters = ["z","a","b","c","x","x","x"], score = [4,4,4,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,5,0,10] +输出:27 +解释: +字母得分为 a=4, b=4, c=4, x=5, z=10 +使用给定的字母表 letters,我们可以组成单词 "ax" (4+5), "bx" (4+5) 和 "cx" (4+5) ,总得分为 27 。 +单词 "xxxz" 的得分仅为 25 。+ +
示例 3:
+ +输入:words = ["leetcode"], letters = ["l","e","t","c","o","d"], score = [0,0,1,1,1,0,0,0,0,0,0,1,0,0,1,0,0,0,0,1,0,0,0,0,0,0] +输出:0 +解释: +字母 "e" 在字母表 letters 中只出现了一次,所以无法组成单词表 words 中的单词。+ +
+ +
提示:
+ +-
+
1 <= words.length <= 14
+ 1 <= words[i].length <= 15
+ 1 <= letters.length <= 100
+ letters[i].length == 1
+ score.length == 26
+ 0 <= score[i] <= 10
+ words[i]和letters[i]只包含小写的英文字母。
+
给你一个 m 行 n 列的二维网格 grid 和一个整数 k。你需要将 grid 迁移 k 次。
每次「迁移」操作将会引发下述活动:
+ +-
+
- 位于
grid[i][j]的元素将会移动到grid[i][j + 1]。
+ - 位于
grid[i][n - 1]的元素将会移动到grid[i + 1][0]。
+ - 位于
grid[m - 1][n - 1]的元素将会移动到grid[0][0]。
+
请你返回 k 次迁移操作后最终得到的 二维网格。
+ +
示例 1:
+ +
输入:grid = [[1,2,3],[4,5,6],[7,8,9]], k = 1
+输出:[[9,1,2],[3,4,5],[6,7,8]]
+示例 2:
+ +
输入:grid = [[3,8,1,9],[19,7,2,5],[4,6,11,10],[12,0,21,13]], k = 4
+输出:[[12,0,21,13],[3,8,1,9],[19,7,2,5],[4,6,11,10]]
+示例 3:
+ +输入:grid = [[1,2,3],[4,5,6],[7,8,9]], k = 9
+输出:[[1,2,3],[4,5,6],[7,8,9]]
++ +
提示:
+ +-
+
1 <= grid.length <= 50
+ 1 <= grid[i].length <= 50
+ -1000 <= grid[i][j] <= 1000
+ 0 <= k <= 100
+
给出一个满足下述规则的二叉树:
+ +-
+
root.val == 0
+ - 如果
treeNode.val == x且treeNode.left != null,那么treeNode.left.val == 2 * x + 1
+ - 如果
treeNode.val == x且treeNode.right != null,那么treeNode.right.val == 2 * x + 2
+
现在这个二叉树受到「污染」,所有的 treeNode.val 都变成了 -1。
请你先还原二叉树,然后实现 FindElements 类:
-
+
FindElements(TreeNode* root)用受污染的二叉树初始化对象,你需要先把它还原。
+ bool find(int target)判断目标值target是否存在于还原后的二叉树中并返回结果。
+
+ +
示例 1:
+ +
输入: +["FindElements","find","find"] +[[[-1,null,-1]],[1],[2]] +输出: +[null,false,true] +解释: +FindElements findElements = new FindElements([-1,null,-1]); +findElements.find(1); // return False +findElements.find(2); // return True+ +
示例 2:
+ +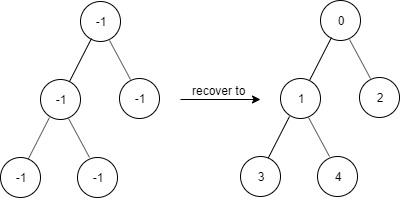
输入: +["FindElements","find","find","find"] +[[[-1,-1,-1,-1,-1]],[1],[3],[5]] +输出: +[null,true,true,false] +解释: +FindElements findElements = new FindElements([-1,-1,-1,-1,-1]); +findElements.find(1); // return True +findElements.find(3); // return True +findElements.find(5); // return False+ +
示例 3:
+ +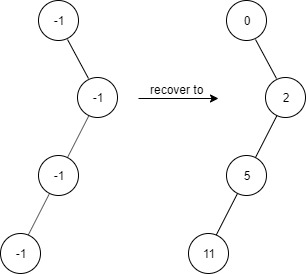
输入: +["FindElements","find","find","find","find"] +[[[-1,null,-1,-1,null,-1]],[2],[3],[4],[5]] +输出: +[null,true,false,false,true] +解释: +FindElements findElements = new FindElements([-1,null,-1,-1,null,-1]); +findElements.find(2); // return True +findElements.find(3); // return False +findElements.find(4); // return False +findElements.find(5); // return True ++ +
+ +
提示:
+ +-
+
TreeNode.val == -1
+ - 二叉树的高度不超过
20
+ - 节点的总数在
[1, 10^4]之间
+ - 调用
find()的总次数在[1, 10^4]之间
+ 0 <= target <= 10^6
+
给你一个整数数组 nums,请你找出并返回能被三整除的元素最大和。
-
+
+ +
示例 1:
+ +输入:nums = [3,6,5,1,8] +输出:18 +解释:选出数字 3, 6, 1 和 8,它们的和是 18(可被 3 整除的最大和)。+ +
示例 2:
+ +输入:nums = [4] +输出:0 +解释:4 不能被 3 整除,所以无法选出数字,返回 0。 ++ +
示例 3:
+ +输入:nums = [1,2,3,4,4] +输出:12 +解释:选出数字 1, 3, 4 以及 4,它们的和是 12(可被 3 整除的最大和)。 ++ +
+ +
提示:
+ +-
+
1 <= nums.length <= 4 * 10^4
+ 1 <= nums[i] <= 10^4
+
「推箱子」是一款风靡全球的益智小游戏,玩家需要将箱子推到仓库中的目标位置。
+ +游戏地图用大小为 n * m 的网格 grid 表示,其中每个元素可以是墙、地板或者是箱子。
现在你将作为玩家参与游戏,按规则将箱子 'B' 移动到目标位置 'T' :
-
+
- 玩家用字符
'S'表示,只要他在地板上,就可以在网格中向上、下、左、右四个方向移动。
+ - 地板用字符
'.'表示,意味着可以自由行走。
+ - 墙用字符
'#'表示,意味着障碍物,不能通行。
+ - 箱子仅有一个,用字符
'B'表示。相应地,网格上有一个目标位置'T'。
+ - 玩家需要站在箱子旁边,然后沿着箱子的方向进行移动,此时箱子会被移动到相邻的地板单元格。记作一次「推动」。 +
- 玩家无法越过箱子。 +
返回将箱子推到目标位置的最小 推动 次数,如果无法做到,请返回 -1。
+ +
示例 1:
+ +
输入:grid = [["#","#","#","#","#","#"], + ["#","T","#","#","#","#"], + ["#",".",".","B",".","#"], + ["#",".","#","#",".","#"], + ["#",".",".",".","S","#"], + ["#","#","#","#","#","#"]] +输出:3 +解释:我们只需要返回推箱子的次数。+ +
示例 2:
+ +输入:grid = [["#","#","#","#","#","#"], + ["#","T","#","#","#","#"], + ["#",".",".","B",".","#"], + ["#","#","#","#",".","#"], + ["#",".",".",".","S","#"], + ["#","#","#","#","#","#"]] +输出:-1 ++ +
示例 3:
+ +输入:grid = [["#","#","#","#","#","#"], + ["#","T",".",".","#","#"], + ["#",".","#","B",".","#"], + ["#",".",".",".",".","#"], + ["#",".",".",".","S","#"], + ["#","#","#","#","#","#"]] +输出:5 +解释:向下、向左、向左、向上再向上。 ++ +
示例 4:
+ +输入:grid = [["#","#","#","#","#","#","#"], + ["#","S","#",".","B","T","#"], + ["#","#","#","#","#","#","#"]] +输出:-1 ++ +
+ +
提示:
+ +-
+
1 <= grid.length <= 20
+ 1 <= grid[i].length <= 20
+ grid仅包含字符'.','#','S','T', 以及'B'。
+ grid中'S','B'和'T'各只能出现一个。
+
平面上有 n 个点,点的位置用整数坐标表示 points[i] = [xi, yi]。请你计算访问所有这些点需要的最小时间(以秒为单位)。
你可以按照下面的规则在平面上移动:
+ +-
+
- 每一秒沿水平或者竖直方向移动一个单位长度,或者跨过对角线(可以看作在一秒内向水平和竖直方向各移动一个单位长度)。 +
- 必须按照数组中出现的顺序来访问这些点。 +
+ +
示例 1:
+ +
输入:points = [[1,1],[3,4],[-1,0]] +输出:7 +解释:一条最佳的访问路径是: [1,1] -> [2,2] -> [3,3] -> [3,4] -> [2,3] -> [1,2] -> [0,1] -> [-1,0] +从 [1,1] 到 [3,4] 需要 3 秒 +从 [3,4] 到 [-1,0] 需要 4 秒 +一共需要 7 秒+ +
示例 2:
+ +输入:points = [[3,2],[-2,2]] +输出:5 ++ +
+ +
提示:
+ +-
+
points.length == n
+ 1 <= n <= 100
+ points[i].length == 2
+ -1000 <= points[i][0], points[i][1] <= 1000
+
这里有一幅服务器分布图,服务器的位置标识在 m * n 的整数矩阵网格 grid 中,1 表示单元格上有服务器,0 表示没有。
如果两台服务器位于同一行或者同一列,我们就认为它们之间可以进行通信。
+ +请你统计并返回能够与至少一台其他服务器进行通信的服务器的数量。
+ ++ +
示例 1:
+ +
输入:grid = [[1,0],[0,1]] +输出:0 +解释:没有一台服务器能与其他服务器进行通信。+ +
示例 2:
+ +
输入:grid = [[1,0],[1,1]] +输出:3 +解释:所有这些服务器都至少可以与一台别的服务器进行通信。 ++ +
示例 3:
+ +
输入:grid = [[1,1,0,0],[0,0,1,0],[0,0,1,0],[0,0,0,1]] +输出:4 +解释:第一行的两台服务器互相通信,第三列的两台服务器互相通信,但右下角的服务器无法与其他服务器通信。 ++ +
+ +
提示:
+ +-
+
m == grid.length
+ n == grid[i].length
+ 1 <= m <= 250
+ 1 <= n <= 250
+ grid[i][j] == 0 or 1
+
给你一个产品数组 products 和一个字符串 searchWord ,products 数组中每个产品都是一个字符串。
请你设计一个推荐系统,在依次输入单词 searchWord 的每一个字母后,推荐 products 数组中前缀与 searchWord 相同的最多三个产品。如果前缀相同的可推荐产品超过三个,请按字典序返回最小的三个。
请你以二维列表的形式,返回在输入 searchWord 每个字母后相应的推荐产品的列表。
+ +
示例 1:
+ +输入:products = ["mobile","mouse","moneypot","monitor","mousepad"], searchWord = "mouse" +输出:[ +["mobile","moneypot","monitor"], +["mobile","moneypot","monitor"], +["mouse","mousepad"], +["mouse","mousepad"], +["mouse","mousepad"] +] +解释:按字典序排序后的产品列表是 ["mobile","moneypot","monitor","mouse","mousepad"] +输入 m 和 mo,由于所有产品的前缀都相同,所以系统返回字典序最小的三个产品 ["mobile","moneypot","monitor"] +输入 mou, mous 和 mouse 后系统都返回 ["mouse","mousepad"] ++ +
示例 2:
+ +输入:products = ["havana"], searchWord = "havana" +输出:[["havana"],["havana"],["havana"],["havana"],["havana"],["havana"]] ++ +
示例 3:
+ +输入:products = ["bags","baggage","banner","box","cloths"], searchWord = "bags" +输出:[["baggage","bags","banner"],["baggage","bags","banner"],["baggage","bags"],["bags"]] ++ +
示例 4:
+ +输入:products = ["havana"], searchWord = "tatiana" +输出:[[],[],[],[],[],[],[]] ++ +
+ +
提示:
+ +-
+
1 <= products.length <= 1000
+ 1 <= Σ products[i].length <= 2 * 10^4
+ products[i]中所有的字符都是小写英文字母。
+ 1 <= searchWord.length <= 1000
+ searchWord中所有字符都是小写英文字母。
+
有一个长度为 arrLen 的数组,开始有一个指针在索引 0 处。
每一步操作中,你可以将指针向左或向右移动 1 步,或者停在原地(指针不能被移动到数组范围外)。
+ +给你两个整数 steps 和 arrLen ,请你计算并返回:在恰好执行 steps 次操作以后,指针仍然指向索引 0 处的方案数。
由于答案可能会很大,请返回方案数 模 10^9 + 7 后的结果。
+ +
示例 1:
+ +输入:steps = 3, arrLen = 2 +输出:4 +解释:3 步后,总共有 4 种不同的方法可以停在索引 0 处。 +向右,向左,不动 +不动,向右,向左 +向右,不动,向左 +不动,不动,不动 ++ +
示例 2:
+ +输入:steps = 2, arrLen = 4 +输出:2 +解释:2 步后,总共有 2 种不同的方法可以停在索引 0 处。 +向右,向左 +不动,不动 ++ +
示例 3:
+ +输入:steps = 4, arrLen = 2 +输出:8 ++ +
+ +
提示:
+ +-
+
1 <= steps <= 500
+ 1 <= arrLen <= 10^6
+
A 和 B 在一个 3 x 3 的网格上玩井字棋。
+ +井字棋游戏的规则如下:
+ +-
+
- 玩家轮流将棋子放在空方格 (" ") 上。 +
- 第一个玩家 A 总是用 "X" 作为棋子,而第二个玩家 B 总是用 "O" 作为棋子。 +
- "X" 和 "O" 只能放在空方格中,而不能放在已经被占用的方格上。 +
- 只要有 3 个相同的(非空)棋子排成一条直线(行、列、对角线)时,游戏结束。 +
- 如果所有方块都放满棋子(不为空),游戏也会结束。 +
- 游戏结束后,棋子无法再进行任何移动。 +
给你一个数组 moves,其中每个元素是大小为 2 的另一个数组(元素分别对应网格的行和列),它按照 A 和 B 的行动顺序(先 A 后 B)记录了两人各自的棋子位置。
如果游戏存在获胜者(A 或 B),就返回该游戏的获胜者;如果游戏以平局结束,则返回 "Draw";如果仍会有行动(游戏未结束),则返回 "Pending"。
+ +你可以假设 moves 都 有效(遵循井字棋规则),网格最初是空的,A 将先行动。
+ +
示例 1:
+ +输入:moves = [[0,0],[2,0],[1,1],[2,1],[2,2]] +输出:"A" +解释:"A" 获胜,他总是先走。 +"X " "X " "X " "X " "X " +" " -> " " -> " X " -> " X " -> " X " +" " "O " "O " "OO " "OOX" ++ +
示例 2:
+ +输入:moves = [[0,0],[1,1],[0,1],[0,2],[1,0],[2,0]] +输出:"B" +解释:"B" 获胜。 +"X " "X " "XX " "XXO" "XXO" "XXO" +" " -> " O " -> " O " -> " O " -> "XO " -> "XO " +" " " " " " " " " " "O " ++ +
示例 3:
+ +输入:moves = [[0,0],[1,1],[2,0],[1,0],[1,2],[2,1],[0,1],[0,2],[2,2]] +输出:"Draw" +输出:由于没有办法再行动,游戏以平局结束。 +"XXO" +"OOX" +"XOX" ++ +
示例 4:
+ +输入:moves = [[0,0],[1,1]] +输出:"Pending" +解释:游戏还没有结束。 +"X " +" O " +" " ++ +
+ +
提示:
+ +-
+
1 <= moves.length <= 9
+ moves[i].length == 2
+ 0 <= moves[i][j] <= 2
+ moves里没有重复的元素。
+ moves遵循井字棋的规则。
+
圣诞活动预热开始啦,汉堡店推出了全新的汉堡套餐。为了避免浪费原料,请你帮他们制定合适的制作计划。
+ +给你两个整数 tomatoSlices 和 cheeseSlices,分别表示番茄片和奶酪片的数目。不同汉堡的原料搭配如下:
-
+
- 巨无霸汉堡:4 片番茄和 1 片奶酪 +
- 小皇堡:2 片番茄和 1 片奶酪 +
请你以 [total_jumbo, total_small]([巨无霸汉堡总数,小皇堡总数])的格式返回恰当的制作方案,使得剩下的番茄片 tomatoSlices 和奶酪片 cheeseSlices 的数量都是 0。
如果无法使剩下的番茄片 tomatoSlices 和奶酪片 cheeseSlices 的数量为 0,就请返回 []。
+ +
示例 1:
+ +输入:tomatoSlices = 16, cheeseSlices = 7 +输出:[1,6] +解释:制作 1 个巨无霸汉堡和 6 个小皇堡需要 4*1 + 2*6 = 16 片番茄和 1 + 6 = 7 片奶酪。不会剩下原料。 ++ +
示例 2:
+ +输入:tomatoSlices = 17, cheeseSlices = 4 +输出:[] +解释:只制作小皇堡和巨无霸汉堡无法用光全部原料。 ++ +
示例 3:
+ +输入:tomatoSlices = 4, cheeseSlices = 17 +输出:[] +解释:制作 1 个巨无霸汉堡会剩下 16 片奶酪,制作 2 个小皇堡会剩下 15 片奶酪。 ++ +
示例 4:
+ +输入:tomatoSlices = 0, cheeseSlices = 0 +输出:[0,0] ++ +
示例 5:
+ +输入:tomatoSlices = 2, cheeseSlices = 1 +输出:[0,1] ++ +
+ +
提示:
+ +-
+
0 <= tomatoSlices <= 10^7
+ 0 <= cheeseSlices <= 10^7
+
给你一个 m * n 的矩阵,矩阵中的元素不是 0 就是 1,请你统计并返回其中完全由 1 组成的 正方形 子矩阵的个数。
+ +
示例 1:
+ +输入:matrix = +[ + [0,1,1,1], + [1,1,1,1], + [0,1,1,1] +] +输出:15 +解释: +边长为 1 的正方形有 10 个。 +边长为 2 的正方形有 4 个。 +边长为 3 的正方形有 1 个。 +正方形的总数 = 10 + 4 + 1 = 15. ++ +
示例 2:
+ +输入:matrix = +[ + [1,0,1], + [1,1,0], + [1,1,0] +] +输出:7 +解释: +边长为 1 的正方形有 6 个。 +边长为 2 的正方形有 1 个。 +正方形的总数 = 6 + 1 = 7. ++ +
+ +
提示:
+ +-
+
1 <= arr.length <= 300
+ 1 <= arr[0].length <= 300
+ 0 <= arr[i][j] <= 1
+
给你一个由小写字母组成的字符串 s,和一个整数 k。
请你按下面的要求分割字符串:
+ +-
+
- 首先,你可以将
s中的部分字符修改为其他的小写英文字母。
+ - 接着,你需要把
s分割成k个非空且不相交的子串,并且每个子串都是回文串。
+
请返回以这种方式分割字符串所需修改的最少字符数。
+ ++ +
示例 1:
+ +输入:s = "abc", k = 2 +输出:1 +解释:你可以把字符串分割成 "ab" 和 "c",并修改 "ab" 中的 1 个字符,将它变成回文串。 ++ +
示例 2:
+ +输入:s = "aabbc", k = 3 +输出:0 +解释:你可以把字符串分割成 "aa"、"bb" 和 "c",它们都是回文串。+ +
示例 3:
+ +输入:s = "leetcode", k = 8 +输出:0 ++ +
+ +
提示:
+ +-
+
1 <= k <= s.length <= 100
+ s中只含有小写英文字母。
+
给你一个整数 n,请你帮忙计算并返回该整数「各位数字之积」与「各位数字之和」的差。
+ +
示例 1:
+ +输入:n = 234 +输出:15 +解释: +各位数之积 = 2 * 3 * 4 = 24 +各位数之和 = 2 + 3 + 4 = 9 +结果 = 24 - 9 = 15 ++ +
示例 2:
+ +输入:n = 4421 +输出:21 +解释: +各位数之积 = 4 * 4 * 2 * 1 = 32 +各位数之和 = 4 + 4 + 2 + 1 = 11 +结果 = 32 - 11 = 21 ++ +
+ +
提示:
+ +-
+
1 <= n <= 10^5
+
有 n 位用户参加活动,他们的 ID 从 0 到 n - 1,每位用户都 恰好 属于某一用户组。给你一个长度为 n 的数组 groupSizes,其中包含每位用户所处的用户组的大小,请你返回用户分组情况(存在的用户组以及每个组中用户的 ID)。
你可以任何顺序返回解决方案,ID 的顺序也不受限制。此外,题目给出的数据保证至少存在一种解决方案。
+ ++ +
示例 1:
+ +输入:groupSizes = [3,3,3,3,3,1,3] +输出:[[5],[0,1,2],[3,4,6]] +解释: +其他可能的解决方案有 [[2,1,6],[5],[0,4,3]] 和 [[5],[0,6,2],[4,3,1]]。 ++ +
示例 2:
+ +输入:groupSizes = [2,1,3,3,3,2] +输出:[[1],[0,5],[2,3,4]] ++ +
+ +
提示:
+ +-
+
groupSizes.length == n
+ 1 <= n <= 500
+ 1 <= groupSizes[i] <= n
+
给你一个整数数组 nums 和一个正整数 threshold ,你需要选择一个正整数作为除数,然后将数组里每个数都除以它,并对除法结果求和。
请你找出能够使上述结果小于等于阈值 threshold 的除数中 最小 的那个。
每个数除以除数后都向上取整,比方说 7/3 = 3 , 10/2 = 5 。
+ +题目保证一定有解。
+ ++ +
示例 1:
+ ++输入:nums = [1,2,5,9], threshold = 6 +输出:5 +解释:如果除数为 1 ,我们可以得到和为 17 (1+2+5+9)。 +如果除数为 4 ,我们可以得到和为 7 (1+1+2+3) 。如果除数为 5 ,和为 5 (1+1+1+2)。 ++ +
示例 2:
+ ++输入:nums = [2,3,5,7,11], threshold = 11 +输出:3 ++ +
示例 3:
+ ++输入:nums = [19], threshold = 5 +输出:4 ++ +
+ +
提示:
+ +-
+
1 <= nums.length <= 5 * 10^4
+ 1 <= nums[i] <= 10^6
+ nums.length <= threshold <= 10^6
+
给你一个 m x n 的二进制矩阵 mat。
每一步,你可以选择一个单元格并将它反转(反转表示 0 变 1 ,1 变 0 )。如果存在和它相邻的单元格,那么这些相邻的单元格也会被反转。(注:相邻的两个单元格共享同一条边。)
+ +请你返回将矩阵 mat 转化为全零矩阵的最少反转次数,如果无法转化为全零矩阵,请返回 -1 。
二进制矩阵的每一个格子要么是 0 要么是 1 。
+ +全零矩阵是所有格子都为 0 的矩阵。
+ ++ +
示例 1:
+ +
输入:mat = [[0,0],[0,1]] +输出:3 +解释:一个可能的解是反转 (1, 0),然后 (0, 1) ,最后是 (1, 1) 。 ++ +
示例 2:
+ +输入:mat = [[0]] +输出:0 +解释:给出的矩阵是全零矩阵,所以你不需要改变它。 ++ +
示例 3:
+ +输入:mat = [[1,1,1],[1,0,1],[0,0,0]] +输出:6 ++ +
示例 4:
+ +输入:mat = [[1,0,0],[1,0,0]] +输出:-1 +解释:该矩阵无法转变成全零矩阵 ++ +
+ +
提示:
+ +-
+
m == mat.length
+ n == mat[0].length
+ 1 <= m <= 3
+ 1 <= n <= 3
+ mat[i][j]是 0 或 1 。
+
请你设计一个迭代器类,包括以下内容:
+ +-
+
- 一个构造函数,输入参数包括:一个 有序且字符唯一 的字符串
characters(该字符串只包含小写英文字母)和一个数字combinationLength。
+ - 函数 next() ,按 字典序 返回长度为
combinationLength的下一个字母组合。
+ - 函数 hasNext() ,只有存在长度为
combinationLength的下一个字母组合时,才返回True;否则,返回False。
+
+ +
示例:
+ +CombinationIterator iterator = new CombinationIterator("abc", 2); // 创建迭代器 iterator
+
+iterator.next(); // 返回 "ab"
+iterator.hasNext(); // 返回 true
+iterator.next(); // 返回 "ac"
+iterator.hasNext(); // 返回 true
+iterator.next(); // 返回 "bc"
+iterator.hasNext(); // 返回 false
+
+
++ +
提示:
+ +-
+
1 <= combinationLength <= characters.length <= 15
+ - 每组测试数据最多包含
10^4次函数调用。
+ - 题目保证每次调用函数
next时都存在下一个字母组合。
+
给你一个非递减的 有序 整数数组,已知这个数组中恰好有一个整数,它的出现次数超过数组元素总数的 25%。
+ +请你找到并返回这个整数
+ ++ +
示例:
+ ++输入:arr = [1,2,2,6,6,6,6,7,10] +输出:6 ++ +
+ +
提示:
+ +-
+
1 <= arr.length <= 10^4
+ 0 <= arr[i] <= 10^5
+
给你一个区间列表,请你删除列表中被其他区间所覆盖的区间。
+ +只有当 c <= a 且 b <= d 时,我们才认为区间 [a,b) 被区间 [c,d) 覆盖。
在完成所有删除操作后,请你返回列表中剩余区间的数目。
+ ++ +
示例:
+ ++输入:intervals = [[1,4],[3,6],[2,8]] +输出:2 +解释:区间 [3,6] 被区间 [2,8] 覆盖,所以它被删除了。 ++ +
+ +
提示:
+ +-
+
1 <= intervals.length <= 1000
+ 0 <= intervals[i][0] < intervals[i][1] <= 10^5
+ - 对于所有的
i != j:intervals[i] != intervals[j]
+
给你一个整数方阵 arr ,定义「非零偏移下降路径」为:从 arr 数组中的每一行选择一个数字,且按顺序选出来的数字中,相邻数字不在原数组的同一列。
请你返回非零偏移下降路径数字和的最小值。
+ ++ +
示例 1:
+ ++输入:arr = [[1,2,3],[4,5,6],[7,8,9]] +输出:13 +解释: +所有非零偏移下降路径包括: +[1,5,9], [1,5,7], [1,6,7], [1,6,8], +[2,4,8], [2,4,9], [2,6,7], [2,6,8], +[3,4,8], [3,4,9], [3,5,7], [3,5,9] +下降路径中数字和最小的是 [1,5,7] ,所以答案是 13 。 ++ +
+ +
提示:
+ +-
+
1 <= arr.length == arr[i].length <= 200
+ -99 <= arr[i][j] <= 99
+
给你一个单链表的引用结点 head。链表中每个结点的值不是 0 就是 1。已知此链表是一个整数数字的二进制表示形式。
请你返回该链表所表示数字的 十进制值 。
+ ++ +
示例 1:
+ +
输入:head = [1,0,1] +输出:5 +解释:二进制数 (101) 转化为十进制数 (5) ++ +
示例 2:
+ +输入:head = [0] +输出:0 ++ +
示例 3:
+ +输入:head = [1] +输出:1 ++ +
示例 4:
+ +输入:head = [1,0,0,1,0,0,1,1,1,0,0,0,0,0,0] +输出:18880 ++ +
示例 5:
+ +输入:head = [0,0] +输出:0 ++ +
+ +
提示:
+ +-
+
- 链表不为空。 +
- 链表的结点总数不超过
30。
+ - 每个结点的值不是
0就是1。
+
我们定义「顺次数」为:每一位上的数字都比前一位上的数字大 1 的整数。
请你返回由 [low, high] 范围内所有顺次数组成的 有序 列表(从小到大排序)。
+ +
示例 1:
+ +输出:low = 100, high = 300 +输出:[123,234] ++ +
示例 2:
+ +输出:low = 1000, high = 13000 +输出:[1234,2345,3456,4567,5678,6789,12345] ++ +
+ +
提示:
+ +-
+
10 <= low <= high <= 10^9
+
给你一个大小为 m x n 的矩阵 mat 和一个整数阈值 threshold。
请你返回元素总和小于或等于阈值的正方形区域的最大边长;如果没有这样的正方形区域,则返回 0 。
+
示例 1:
+ +
输入:mat = [[1,1,3,2,4,3,2],[1,1,3,2,4,3,2],[1,1,3,2,4,3,2]], threshold = 4 +输出:2 +解释:总和小于 4 的正方形的最大边长为 2,如图所示。 ++ +
示例 2:
+ +输入:mat = [[2,2,2,2,2],[2,2,2,2,2],[2,2,2,2,2],[2,2,2,2,2],[2,2,2,2,2]], threshold = 1 +输出:0 ++ +
示例 3:
+ +输入:mat = [[1,1,1,1],[1,0,0,0],[1,0,0,0],[1,0,0,0]], threshold = 6 +输出:3 ++ +
示例 4:
+ +输入:mat = [[18,70],[61,1],[25,85],[14,40],[11,96],[97,96],[63,45]], threshold = 40184 +输出:2 ++ +
+ +
提示:
+ +-
+
1 <= m, n <= 300
+ m == mat.length
+ n == mat[i].length
+ 0 <= mat[i][j] <= 10000
+ 0 <= threshold <= 10^5
+
给你一个 m * n 的网格,其中每个单元格不是 0(空)就是 1(障碍物)。每一步,您都可以在空白单元格中上、下、左、右移动。
如果您 最多 可以消除 k 个障碍物,请找出从左上角 (0, 0) 到右下角 (m-1, n-1) 的最短路径,并返回通过该路径所需的步数。如果找不到这样的路径,则返回 -1。
+ +
示例 1:
+ +输入:
+grid =
+[[0,0,0],
+ [1,1,0],
+ [0,0,0],
+ [0,1,1],
+ [0,0,0]],
+k = 1
+输出:6
+解释:
+不消除任何障碍的最短路径是 10。
+消除位置 (3,2) 处的障碍后,最短路径是 6 。该路径是 (0,0) -> (0,1) -> (0,2) -> (1,2) -> (2,2) -> (3,2) -> (4,2).
+
+
++ +
示例 2:
+ +输入: +grid = +[[0,1,1], + [1,1,1], + [1,0,0]], +k = 1 +输出:-1 +解释: +我们至少需要消除两个障碍才能找到这样的路径。 ++ +
+ +
提示:
+ +-
+
grid.length == m
+ grid[0].length == n
+ 1 <= m, n <= 40
+ 1 <= k <= m*n
+ grid[i][j] == 0 or 1
+ grid[0][0] == grid[m-1][n-1] == 0
+
给你一个整数数组 nums,请你返回其中位数为 偶数 的数字的个数。
+ +
示例 1:
+ +输入:nums = [12,345,2,6,7896] +输出:2 +解释: +12 是 2 位数字(位数为偶数) +345 是 3 位数字(位数为奇数) +2 是 1 位数字(位数为奇数) +6 是 1 位数字 位数为奇数) +7896 是 4 位数字(位数为偶数) +因此只有 12 和 7896 是位数为偶数的数字 ++ +
示例 2:
+ +输入:nums = [555,901,482,1771] +输出:1 +解释: +只有 1771 是位数为偶数的数字。 ++ +
+ +
提示:
+ +-
+
1 <= nums.length <= 500
+ 1 <= nums[i] <= 10^5
+
给你一个整数数组 nums 和一个正整数 k,请你判断是否可以把这个数组划分成一些由 k 个连续数字组成的集合。
+如果可以,请返回 True;否则,返回 False。
+ +
示例 1:
+ +输入:nums = [1,2,3,3,4,4,5,6], k = 4 +输出:true +解释:数组可以分成 [1,2,3,4] 和 [3,4,5,6]。 ++ +
示例 2:
+ +输入:nums = [3,2,1,2,3,4,3,4,5,9,10,11], k = 3 +输出:true +解释:数组可以分成 [1,2,3] , [2,3,4] , [3,4,5] 和 [9,10,11]。 ++ +
示例 3:
+ +输入:nums = [3,3,2,2,1,1], k = 3 +输出:true ++ +
示例 4:
+ +输入:nums = [1,2,3,4], k = 3 +输出:false +解释:数组不能分成几个大小为 3 的子数组。 ++ +
+ +
提示:
+ +-
+
1 <= nums.length <= 10^5
+ 1 <= nums[i] <= 10^9
+ 1 <= k <= nums.length
+
给你一个字符串 s ,请你返回满足以下条件且出现次数最大的 任意 子串的出现次数:
-
+
- 子串中不同字母的数目必须小于等于
maxLetters。
+ - 子串的长度必须大于等于
minSize且小于等于maxSize。
+
+ +
示例 1:
+ +输入:s = "aababcaab", maxLetters = 2, minSize = 3, maxSize = 4 +输出:2 +解释:子串 "aab" 在原字符串中出现了 2 次。 +它满足所有的要求:2 个不同的字母,长度为 3 (在 minSize 和 maxSize 范围内)。 ++ +
示例 2:
+ +输入:s = "aaaa", maxLetters = 1, minSize = 3, maxSize = 3 +输出:2 +解释:子串 "aaa" 在原字符串中出现了 2 次,且它们有重叠部分。 ++ +
示例 3:
+ +输入:s = "aabcabcab", maxLetters = 2, minSize = 2, maxSize = 3 +输出:3 ++ +
示例 4:
+ +输入:s = "abcde", maxLetters = 2, minSize = 3, maxSize = 3 +输出:0 ++ +
+ +
提示:
+ +-
+
1 <= s.length <= 10^5
+ 1 <= maxLetters <= 26
+ 1 <= minSize <= maxSize <= min(26, s.length)
+ s只包含小写英文字母。
+
给你 n 个盒子,每个盒子的格式为 [status, candies, keys, containedBoxes] ,其中:
-
+
- 状态字
status[i]:整数,如果box[i]是开的,那么是 1 ,否则是 0 。
+ - 糖果数
candies[i]: 整数,表示box[i]中糖果的数目。
+ - 钥匙
keys[i]:数组,表示你打开box[i]后,可以得到一些盒子的钥匙,每个元素分别为该钥匙对应盒子的下标。
+ - 内含的盒子
containedBoxes[i]:整数,表示放在box[i]里的盒子所对应的下标。
+
给你一个 initialBoxes 数组,表示你现在得到的盒子,你可以获得里面的糖果,也可以用盒子里的钥匙打开新的盒子,还可以继续探索从这个盒子里找到的其他盒子。
请你按照上述规则,返回可以获得糖果的 最大数目 。
+ ++ +
示例 1:
+ +输入:status = [1,0,1,0], candies = [7,5,4,100], keys = [[],[],[1],[]], containedBoxes = [[1,2],[3],[],[]], initialBoxes = [0] +输出:16 +解释: +一开始你有盒子 0 。你将获得它里面的 7 个糖果和盒子 1 和 2。 +盒子 1 目前状态是关闭的,而且你还没有对应它的钥匙。所以你将会打开盒子 2 ,并得到里面的 4 个糖果和盒子 1 的钥匙。 +在盒子 1 中,你会获得 5 个糖果和盒子 3 ,但是你没法获得盒子 3 的钥匙所以盒子 3 会保持关闭状态。 +你总共可以获得的糖果数目 = 7 + 4 + 5 = 16 个。 ++ +
示例 2:
+ +输入:status = [1,0,0,0,0,0], candies = [1,1,1,1,1,1], keys = [[1,2,3,4,5],[],[],[],[],[]], containedBoxes = [[1,2,3,4,5],[],[],[],[],[]], initialBoxes = [0] +输出:6 +解释: +你一开始拥有盒子 0 。打开它你可以找到盒子 1,2,3,4,5 和它们对应的钥匙。 +打开这些盒子,你将获得所有盒子的糖果,所以总糖果数为 6 个。 ++ +
示例 3:
+ +输入:status = [1,1,1], candies = [100,1,100], keys = [[],[0,2],[]], containedBoxes = [[],[],[]], initialBoxes = [1] +输出:1 ++ +
示例 4:
+ +输入:status = [1], candies = [100], keys = [[]], containedBoxes = [[]], initialBoxes = [] +输出:0 ++ +
示例 5:
+ +输入:status = [1,1,1], candies = [2,3,2], keys = [[],[],[]], containedBoxes = [[],[],[]], initialBoxes = [2,1,0] +输出:7 ++ +
+ +
提示:
+ +-
+
1 <= status.length <= 1000
+ status.length == candies.length == keys.length == containedBoxes.length == n
+ status[i]要么是0要么是1。
+ 1 <= candies[i] <= 1000
+ 0 <= keys[i].length <= status.length
+ 0 <= keys[i][j] < status.length
+ keys[i]中的值都是互不相同的。
+ 0 <= containedBoxes[i].length <= status.length
+ 0 <= containedBoxes[i][j] < status.length
+ containedBoxes[i]中的值都是互不相同的。
+ - 每个盒子最多被一个盒子包含。 +
0 <= initialBoxes.length <= status.length
+ 0 <= initialBoxes[i] < status.length
+
给你一个数组 arr ,请你将每个元素用它右边最大的元素替换,如果是最后一个元素,用 -1 替换。
完成所有替换操作后,请你返回这个数组。
+ ++ +
示例:
+ ++输入:arr = [17,18,5,4,6,1] +输出:[18,6,6,6,1,-1] ++ +
+ +
提示:
+ +-
+
1 <= arr.length <= 10^4
+ 1 <= arr[i] <= 10^5
+
给你一个整数数组 arr 和一个目标值 target ,请你返回一个整数 value ,使得将数组中所有大于 value 的值变成 value 后,数组的和最接近 target (最接近表示两者之差的绝对值最小)。
如果有多种使得和最接近 target 的方案,请你返回这些整数中的最小值。
请注意,答案不一定是 arr 中的数字。
+ +
示例 1:
+ +输入:arr = [4,9,3], target = 10 +输出:3 +解释:当选择 value 为 3 时,数组会变成 [3, 3, 3],和为 9 ,这是最接近 target 的方案。 ++ +
示例 2:
+ +输入:arr = [2,3,5], target = 10 +输出:5 ++ +
示例 3:
+ +输入:arr = [60864,25176,27249,21296,20204], target = 56803 +输出:11361 ++ +
+ +
提示:
+ +-
+
1 <= arr.length <= 10^4
+ 1 <= arr[i], target <= 10^5
+
给你一个正方形字符数组 board ,你从数组最右下方的字符 'S' 出发。
你的目标是到达数组最左上角的字符 'E' ,数组剩余的部分为数字字符 1, 2, ..., 9 或者障碍 'X'。在每一步移动中,你可以向上、向左或者左上方移动,可以移动的前提是到达的格子没有障碍。
一条路径的 「得分」 定义为:路径上所有数字的和。
+ +请你返回一个列表,包含两个整数:第一个整数是 「得分」 的最大值,第二个整数是得到最大得分的方案数,请把结果对 10^9 + 7 取余。
如果没有任何路径可以到达终点,请返回 [0, 0] 。
+ +
示例 1:
+ ++输入:board = ["E23","2X2","12S"] +输出:[7,1] ++ +
示例 2:
+ ++输入:board = ["E12","1X1","21S"] +输出:[4,2] ++ +
示例 3:
+ ++输入:board = ["E11","XXX","11S"] +输出:[0,0] ++ +
+ +
提示:
+ +-
+
2 <= board.length == board[i].length <= 100
+
给你一棵二叉树,请你返回层数最深的叶子节点的和。
+ ++ +
示例:
+ +
输入:root = [1,2,3,4,5,null,6,7,null,null,null,null,8] +输出:15 ++ +
+ +
提示:
+ +-
+
- 树中节点数目在
1到10^4之间。
+ - 每个节点的值在
1到100之间。
+
给你一个整数 n,请你返回 任意 一个由 n 个 各不相同 的整数组成的数组,并且这 n 个数相加和为 0 。
+ +
示例 1:
+ +输入:n = 5 +输出:[-7,-1,1,3,4] +解释:这些数组也是正确的 [-5,-1,1,2,3],[-3,-1,2,-2,4]。 ++ +
示例 2:
+ +输入:n = 3 +输出:[-1,0,1] ++ +
示例 3:
+ +输入:n = 1 +输出:[0] ++ +
+ +
提示:
+ +-
+
1 <= n <= 1000
+
给你 root1 和 root2 这两棵二叉搜索树。
请你返回一个列表,其中包含 两棵树 中的所有整数并按 升序 排序。.
+ ++ +
示例 1:
+ +
输入:root1 = [2,1,4], root2 = [1,0,3] +输出:[0,1,1,2,3,4] ++ +
示例 2:
+ +输入:root1 = [0,-10,10], root2 = [5,1,7,0,2] +输出:[-10,0,0,1,2,5,7,10] ++ +
示例 3:
+ +输入:root1 = [], root2 = [5,1,7,0,2] +输出:[0,1,2,5,7] ++ +
示例 4:
+ +输入:root1 = [0,-10,10], root2 = [] +输出:[-10,0,10] ++ +
示例 5:
+ +
输入:root1 = [1,null,8], root2 = [8,1] +输出:[1,1,8,8] ++ +
+ +
提示:
+ +-
+
- 每棵树最多有
5000个节点。
+ - 每个节点的值在
[-10^5, 10^5]之间。
+
这里有一个非负整数数组 arr,你最开始位于该数组的起始下标 start 处。当你位于下标 i 处时,你可以跳到 i + arr[i] 或者 i - arr[i]。
请你判断自己是否能够跳到对应元素值为 0 的 任意 下标处。
+ +注意,不管是什么情况下,你都无法跳到数组之外。
+ ++ +
示例 1:
+ +输入:arr = [4,2,3,0,3,1,2], start = 5 +输出:true +解释: +到达值为 0 的下标 3 有以下可能方案: +下标 5 -> 下标 4 -> 下标 1 -> 下标 3 +下标 5 -> 下标 6 -> 下标 4 -> 下标 1 -> 下标 3 ++ +
示例 2:
+ +输入:arr = [4,2,3,0,3,1,2], start = 0 +输出:true +解释: +到达值为 0 的下标 3 有以下可能方案: +下标 0 -> 下标 4 -> 下标 1 -> 下标 3 ++ +
示例 3:
+ +输入:arr = [3,0,2,1,2], start = 2 +输出:false +解释:无法到达值为 0 的下标 1 处。 ++ +
+ +
提示:
+ +-
+
1 <= arr.length <= 5 * 10^4
+ 0 <= arr[i] < arr.length
+ 0 <= start < arr.length
+
给你一个方程,左边用 words 表示,右边用 result 表示。
你需要根据以下规则检查方程是否可解:
+ +-
+
- 每个字符都会被解码成一位数字(0 - 9)。 +
- 每对不同的字符必须映射到不同的数字。 +
- 每个
words[i]和result都会被解码成一个没有前导零的数字。
+ - 左侧数字之和(
words)等于右侧数字(result)。
+
如果方程可解,返回 True,否则返回 False。
+ +
示例 1:
+ +输入:words = ["SEND","MORE"], result = "MONEY" +输出:true +解释:映射 'S'-> 9, 'E'->5, 'N'->6, 'D'->7, 'M'->1, 'O'->0, 'R'->8, 'Y'->'2' +所以 "SEND" + "MORE" = "MONEY" , 9567 + 1085 = 10652+ +
示例 2:
+ +输入:words = ["SIX","SEVEN","SEVEN"], result = "TWENTY" +输出:true +解释:映射 'S'-> 6, 'I'->5, 'X'->0, 'E'->8, 'V'->7, 'N'->2, 'T'->1, 'W'->'3', 'Y'->4 +所以 "SIX" + "SEVEN" + "SEVEN" = "TWENTY" , 650 + 68782 + 68782 = 138214+ +
示例 3:
+ +输入:words = ["THIS","IS","TOO"], result = "FUNNY" +输出:true ++ +
示例 4:
+ +输入:words = ["LEET","CODE"], result = "POINT" +输出:false ++ +
+ +
提示:
+ +-
+
2 <= words.length <= 5
+ 1 <= words[i].length, results.length <= 7
+ words[i], result只含有大写英文字母
+ - 表达式中使用的不同字符数最大为 10 +
给你一个字符串 s,它由数字('0' - '9')和 '#' 组成。我们希望按下述规则将 s 映射为一些小写英文字符:
-
+
- 字符(
'a'-'i')分别用('1'-'9')表示。
+ - 字符(
'j'-'z')分别用('10#'-'26#')表示。
+
返回映射之后形成的新字符串。
+ +题目数据保证映射始终唯一。
+ ++ +
示例 1:
+ +输入:s = "10#11#12" +输出:"jkab" +解释:"j" -> "10#" , "k" -> "11#" , "a" -> "1" , "b" -> "2". ++ +
示例 2:
+ +输入:s = "1326#" +输出:"acz" ++ +
示例 3:
+ +输入:s = "25#" +输出:"y" ++ +
示例 4:
+ +输入:s = "12345678910#11#12#13#14#15#16#17#18#19#20#21#22#23#24#25#26#" +输出:"abcdefghijklmnopqrstuvwxyz" ++ +
+ +
提示:
+ +-
+
1 <= s.length <= 1000
+ s[i]只包含数字('0'-'9')和'#'字符。
+ s是映射始终存在的有效字符串。
+
有一个正整数数组 arr,现给你一个对应的查询数组 queries,其中 queries[i] = [Li, Ri]。
对于每个查询 i,请你计算从 Li 到 Ri 的 XOR 值(即 arr[Li] xor arr[Li+1] xor ... xor arr[Ri])作为本次查询的结果。
并返回一个包含给定查询 queries 所有结果的数组。
+ +
示例 1:
+ +输入:arr = [1,3,4,8], queries = [[0,1],[1,2],[0,3],[3,3]] +输出:[2,7,14,8] +解释: +数组中元素的二进制表示形式是: +1 = 0001 +3 = 0011 +4 = 0100 +8 = 1000 +查询的 XOR 值为: +[0,1] = 1 xor 3 = 2 +[1,2] = 3 xor 4 = 7 +[0,3] = 1 xor 3 xor 4 xor 8 = 14 +[3,3] = 8 ++ +
示例 2:
+ +输入:arr = [4,8,2,10], queries = [[2,3],[1,3],[0,0],[0,3]] +输出:[8,0,4,4] ++ +
+ +
提示:
+ +-
+
1 <= arr.length <= 3 * 10^4
+ 1 <= arr[i] <= 10^9
+ 1 <= queries.length <= 3 * 10^4
+ queries[i].length == 2
+ 0 <= queries[i][0] <= queries[i][1] < arr.length
+
有 n 个人,每个人都有一个 0 到 n-1 的唯一 id 。
给你数组 watchedVideos 和 friends ,其中 watchedVideos[i] 和 friends[i] 分别表示 id = i 的人观看过的视频列表和他的好友列表。
Level 1 的视频包含所有你好友观看过的视频,level 2 的视频包含所有你好友的好友观看过的视频,以此类推。一般的,Level 为 k 的视频包含所有从你出发,最短距离为 k 的好友观看过的视频。
+ +给定你的 id 和一个 level 值,请你找出所有指定 level 的视频,并将它们按观看频率升序返回。如果有频率相同的视频,请将它们按字母顺序从小到大排列。
+ +
示例 1:
+ +
输入:watchedVideos = [["A","B"],["C"],["B","C"],["D"]], friends = [[1,2],[0,3],[0,3],[1,2]], id = 0, level = 1 +输出:["B","C"] +解释: +你的 id 为 0(绿色),你的朋友包括(黄色): +id 为 1 -> watchedVideos = ["C"] +id 为 2 -> watchedVideos = ["B","C"] +你朋友观看过视频的频率为: +B -> 1 +C -> 2 ++ +
示例 2:
+ +
输入:watchedVideos = [["A","B"],["C"],["B","C"],["D"]], friends = [[1,2],[0,3],[0,3],[1,2]], id = 0, level = 2 +输出:["D"] +解释: +你的 id 为 0(绿色),你朋友的朋友只有一个人,他的 id 为 3(黄色)。 ++ +
+ +
提示:
+ +-
+
n == watchedVideos.length == friends.length
+ 2 <= n <= 100
+ 1 <= watchedVideos[i].length <= 100
+ 1 <= watchedVideos[i][j].length <= 8
+ 0 <= friends[i].length < n
+ 0 <= friends[i][j] < n
+ 0 <= id < n
+ 1 <= level < n
+ - 如果
friends[i]包含j,那么friends[j]包含i
+
给你一个字符串 s ,每一次操作你都可以在字符串的任意位置插入任意字符。
请你返回让 s 成为回文串的 最少操作次数 。
「回文串」是正读和反读都相同的字符串。
+ ++ +
示例 1:
+ ++输入:s = "zzazz" +输出:0 +解释:字符串 "zzazz" 已经是回文串了,所以不需要做任何插入操作。 ++ +
示例 2:
+ ++输入:s = "mbadm" +输出:2 +解释:字符串可变为 "mbdadbm" 或者 "mdbabdm" 。 ++ +
示例 3:
+ ++输入:s = "leetcode" +输出:5 +解释:插入 5 个字符后字符串变为 "leetcodocteel" 。 ++ +
示例 4:
+ ++输入:s = "g" +输出:0 ++ +
示例 5:
+ ++输入:s = "no" +输出:1 ++ +
+ +
提示:
+ +-
+
1 <= s.length <= 500
+ s中所有字符都是小写字母。
+
给你一个以行程长度编码压缩的整数列表 nums 。
考虑每对相邻的两个元素 freq, val] = [nums[2*i], nums[2*i+1]] (其中 i >= 0 ),每一对都表示解压后子列表中有 freq 个值为 val 的元素,你需要从左到右连接所有子列表以生成解压后的列表。
请你返回解压后的列表。
+ ++ +
示例:
+ +输入:nums = [1,2,3,4] +输出:[2,4,4,4] +解释:第一对 [1,2] 代表着 2 的出现频次为 1,所以生成数组 [2]。 +第二对 [3,4] 代表着 4 的出现频次为 3,所以生成数组 [4,4,4]。 +最后将它们串联到一起 [2] + [4,4,4] = [2,4,4,4]。+ +
示例 2:
+ +输入:nums = [1,1,2,3] +输出:[1,3,3] ++ +
+ +
提示:
+ +-
+
2 <= nums.length <= 100
+ nums.length % 2 == 0
+ 1 <= nums[i] <= 100
+
给你一个 m * n 的矩阵 mat 和一个整数 K ,请你返回一个矩阵 answer ,其中每个 answer[i][j] 是所有满足下述条件的元素 mat[r][c] 的和:
-
+
i - K <= r <= i + K, j - K <= c <= j + K
+ (r, c)在矩阵内。
+
+ +
示例 1:
+ +输入:mat = [[1,2,3],[4,5,6],[7,8,9]], K = 1 +输出:[[12,21,16],[27,45,33],[24,39,28]] ++ +
示例 2:
+ +输入:mat = [[1,2,3],[4,5,6],[7,8,9]], K = 2 +输出:[[45,45,45],[45,45,45],[45,45,45]] ++ +
+ +
提示:
+ +-
+
m == mat.length
+ n == mat[i].length
+ 1 <= m, n, K <= 100
+ 1 <= mat[i][j] <= 100
+
给你一棵二叉树,请你返回满足以下条件的所有节点的值之和:
+ +-
+
- 该节点的祖父节点的值为偶数。(一个节点的祖父节点是指该节点的父节点的父节点。) +
如果不存在祖父节点值为偶数的节点,那么返回 0 。
+ +
示例:
+ +
输入:root = [6,7,8,2,7,1,3,9,null,1,4,null,null,null,5] +输出:18 +解释:图中红色节点的祖父节点的值为偶数,蓝色节点为这些红色节点的祖父节点。 ++ +
+ +
提示:
+ +-
+
- 树中节点的数目在
1到10^4之间。
+ - 每个节点的值在
1到100之间。
+
给你一个字符串 text ,请你返回满足下述条件的 不同 非空子字符串的数目:
-
+
- 可以写成某个字符串与其自身相连接的形式(即,可以写为
a + a,其中a是某个字符串)。
+
例如,abcabc 就是 abc 和它自身连接形成的。
+ +
示例 1:
+ +输入:text = "abcabcabc" +输出:3 +解释:3 个子字符串分别为 "abcabc","bcabca" 和 "cabcab" 。 ++ +
示例 2:
+ +输入:text = "leetcodeleetcode" +输出:2 +解释:2 个子字符串为 "ee" 和 "leetcodeleetcode" 。 ++ +
+ +
提示:
+ +-
+
1 <= text.length <= 2000
+ text只包含小写英文字母。
+
「无零整数」是十进制表示中 不含任何 0 的正整数。
+ +给你一个整数 n,请你返回一个 由两个整数组成的列表 [A, B],满足:
-
+
A和B都是无零整数
+ A + B = n
+
题目数据保证至少有一个有效的解决方案。
+ +如果存在多个有效解决方案,你可以返回其中任意一个。
+ ++ +
示例 1:
+ +输入:n = 2 +输出:[1,1] +解释:A = 1, B = 1. A + B = n 并且 A 和 B 的十进制表示形式都不包含任何 0 。 ++ +
示例 2:
+ +输入:n = 11 +输出:[2,9] ++ +
示例 3:
+ +输入:n = 10000 +输出:[1,9999] ++ +
示例 4:
+ +输入:n = 69 +输出:[1,68] ++ +
示例 5:
+ +输入:n = 1010 +输出:[11,999] ++ +
+ +
提示:
+ +-
+
2 <= n <= 10^4
+
给你三个正整数 a、b 和 c。
你可以对 a 和 b 的二进制表示进行位翻转操作,返回能够使按位或运算 a OR b == c 成立的最小翻转次数。
「位翻转操作」是指将一个数的二进制表示任何单个位上的 1 变成 0 或者 0 变成 1 。
+ ++ +
示例 1:
+ +
输入:a = 2, b = 6, c = 5 +输出:3 +解释:翻转后 a = 1 , b = 4 , c = 5 使得+ +aORb==c
示例 2:
+ +输入:a = 4, b = 2, c = 7 +输出:1 ++ +
示例 3:
+ +输入:a = 1, b = 2, c = 3 +输出:0 ++ +
+ +
提示:
+ +-
+
1 <= a <= 10^9
+ 1 <= b <= 10^9
+ 1 <= c <= 10^9
+
用以太网线缆将 n 台计算机连接成一个网络,计算机的编号从 0 到 n-1。线缆用 connections 表示,其中 connections[i] = [a, b] 连接了计算机 a 和 b。
网络中的任何一台计算机都可以通过网络直接或者间接访问同一个网络中其他任意一台计算机。
+ +给你这个计算机网络的初始布线 connections,你可以拔开任意两台直连计算机之间的线缆,并用它连接一对未直连的计算机。请你计算并返回使所有计算机都连通所需的最少操作次数。如果不可能,则返回 -1 。
+ +
示例 1:
+ +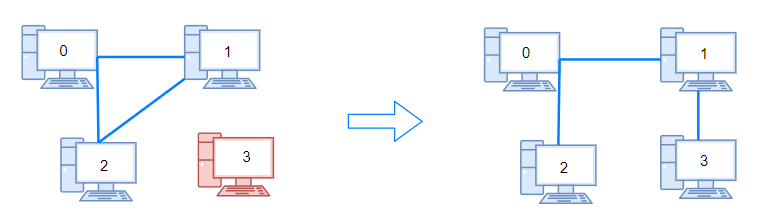
输入:n = 4, connections = [[0,1],[0,2],[1,2]] +输出:1 +解释:拔下计算机 1 和 2 之间的线缆,并将它插到计算机 1 和 3 上。 ++ +
示例 2:
+ +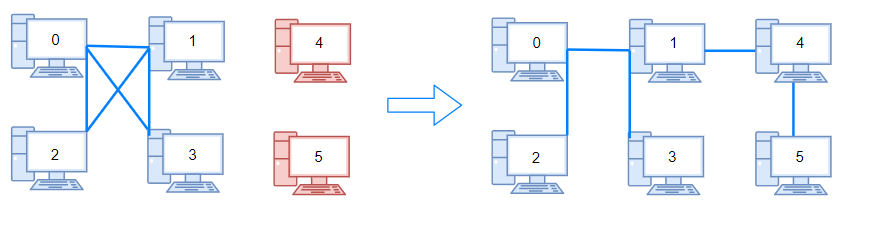
输入:n = 6, connections = [[0,1],[0,2],[0,3],[1,2],[1,3]] +输出:2 ++ +
示例 3:
+ +输入:n = 6, connections = [[0,1],[0,2],[0,3],[1,2]] +输出:-1 +解释:线缆数量不足。 ++ +
示例 4:
+ +输入:n = 5, connections = [[0,1],[0,2],[3,4],[2,3]] +输出:0 ++ +
+ +
提示:
+ +-
+
1 <= n <= 10^5
+ 1 <= connections.length <= min(n*(n-1)/2, 10^5)
+ connections[i].length == 2
+ 0 <= connections[i][0], connections[i][1] < n
+ connections[i][0] != connections[i][1]
+ - 没有重复的连接。 +
- 两台计算机不会通过多条线缆连接。 +

二指输入法定制键盘在 XY 平面上的布局如上图所示,其中每个大写英文字母都位于某个坐标处,例如字母 A 位于坐标 (0,0),字母 B 位于坐标 (0,1),字母 P 位于坐标 (2,3) 且字母 Z 位于坐标 (4,1)。
+ +给你一个待输入字符串 word,请你计算并返回在仅使用两根手指的情况下,键入该字符串需要的最小移动总距离。坐标 (x1,y1) 和 (x2,y2) 之间的距离是 |x1 - x2| + |y1 - y2|。
注意,两根手指的起始位置是零代价的,不计入移动总距离。你的两根手指的起始位置也不必从首字母或者前两个字母开始。
+ ++ +
示例 1:
+ +输入:word = "CAKE" +输出:3 +解释: +使用两根手指输入 "CAKE" 的最佳方案之一是: +手指 1 在字母 'C' 上 -> 移动距离 = 0 +手指 1 在字母 'A' 上 -> 移动距离 = 从字母 'C' 到字母 'A' 的距离 = 2 +手指 2 在字母 'K' 上 -> 移动距离 = 0 +手指 2 在字母 'E' 上 -> 移动距离 = 从字母 'K' 到字母 'E' 的距离 = 1 +总距离 = 3 ++ +
示例 2:
+ +输入:word = "HAPPY" +输出:6 +解释: +使用两根手指输入 "HAPPY" 的最佳方案之一是: +手指 1 在字母 'H' 上 -> 移动距离 = 0 +手指 1 在字母 'A' 上 -> 移动距离 = 从字母 'H' 到字母 'A' 的距离 = 2 +手指 2 在字母 'P' 上 -> 移动距离 = 0 +手指 2 在字母 'P' 上 -> 移动距离 = 从字母 'P' 到字母 'P' 的距离 = 0 +手指 1 在字母 'Y' 上 -> 移动距离 = 从字母 'A' 到字母 'Y' 的距离 = 4 +总距离 = 6 ++ +
示例 3:
+ +输入:word = "NEW" +输出:3 ++ +
示例 4:
+ +输入:word = "YEAR" +输出:7 ++ +
+ +
提示:
+ +-
+
2 <= word.length <= 300
+ - 每个
word[i]都是一个大写英文字母。
+
给你一个仅由数字 6 和 9 组成的正整数 num。
你最多只能翻转一位数字,将 6 变成 9,或者把 9 变成 6 。
+ +请返回你可以得到的最大数字。
+ ++ +
示例 1:
+ +输入:num = 9669 +输出:9969 +解释: +改变第一位数字可以得到 6669 。 +改变第二位数字可以得到 9969 。 +改变第三位数字可以得到 9699 。 +改变第四位数字可以得到 9666 。 +其中最大的数字是 9969 。 ++ +
示例 2:
+ +输入:num = 9996 +输出:9999 +解释:将最后一位从 6 变到 9,其结果 9999 是最大的数。+ +
示例 3:
+ +输入:num = 9999 +输出:9999 +解释:无需改变就已经是最大的数字了。+ +
+ +
提示:
+ +-
+
1 <= num <= 10^4
+ num每一位上的数字都是 6 或者 9 。
+
给你一个字符串 s。请你按照单词在 s 中的出现顺序将它们全部竖直返回。
+单词应该以字符串列表的形式返回,必要时用空格补位,但输出尾部的空格需要删除(不允许尾随空格)。
+每个单词只能放在一列上,每一列中也只能有一个单词。
+ +
示例 1:
+ +输入:s = "HOW ARE YOU" +输出:["HAY","ORO","WEU"] +解释:每个单词都应该竖直打印。 + "HAY" + "ORO" + "WEU" ++ +
示例 2:
+ +输入:s = "TO BE OR NOT TO BE" +输出:["TBONTB","OEROOE"," T"] +解释:题目允许使用空格补位,但不允许输出末尾出现空格。 +"TBONTB" +"OEROOE" +" T" ++ +
示例 3:
+ +输入:s = "CONTEST IS COMING" +输出:["CIC","OSO","N M","T I","E N","S G","T"] ++ +
+ +
提示:
+ +-
+
1 <= s.length <= 200
+ s仅含大写英文字母。
+ - 题目数据保证两个单词之间只有一个空格。 +
给你一棵以 root 为根的二叉树和一个整数 target ,请你删除所有值为 target 的 叶子节点 。
注意,一旦删除值为 target 的叶子节点,它的父节点就可能变成叶子节点;如果新叶子节点的值恰好也是 target ,那么这个节点也应该被删除。
也就是说,你需要重复此过程直到不能继续删除。
+ ++ +
示例 1:
+ +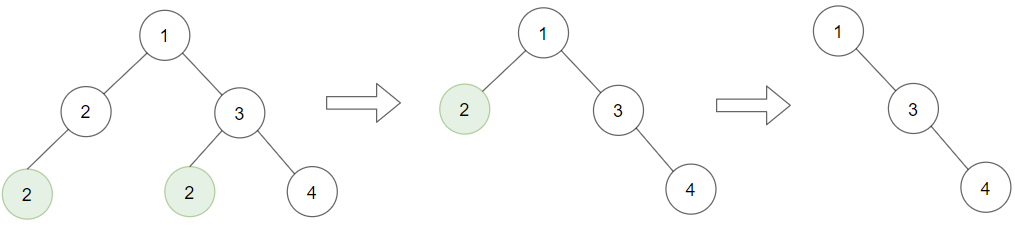
输入:root = [1,2,3,2,null,2,4], target = 2 +输出:[1,null,3,null,4] +解释: +上面左边的图中,绿色节点为叶子节点,且它们的值与 target 相同(同为 2 ),它们会被删除,得到中间的图。 +有一个新的节点变成了叶子节点且它的值与 target 相同,所以将再次进行删除,从而得到最右边的图。 ++ +
示例 2:
+ +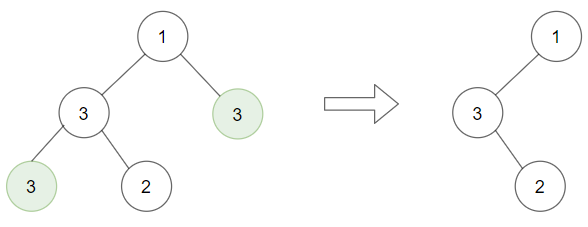
输入:root = [1,3,3,3,2], target = 3 +输出:[1,3,null,null,2] ++ +
示例 3:
+ +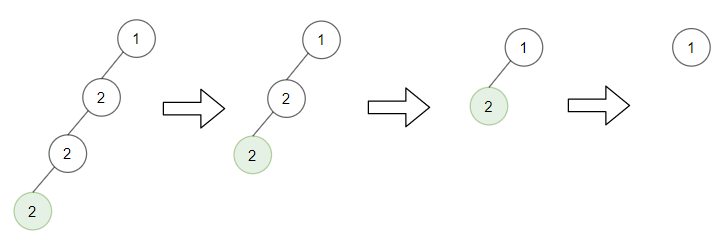
输入:root = [1,2,null,2,null,2], target = 2 +输出:[1] +解释:每一步都删除一个绿色的叶子节点(值为 2)。+ +
示例 4:
+ +输入:root = [1,1,1], target = 1 +输出:[] ++ +
示例 5:
+ +输入:root = [1,2,3], target = 1 +输出:[1,2,3] ++ +
+ +
提示:
+ +-
+
1 <= target <= 1000
+ - 每一棵树最多有
3000个节点。
+ - 每一个节点值的范围是
[1, 1000]。
+
在 x 轴上有一个一维的花园。花园长度为 n,从点 0 开始,到点 n 结束。
花园里总共有 n + 1 个水龙头,分别位于 [0, 1, ..., n] 。
给你一个整数 n 和一个长度为 n + 1 的整数数组 ranges ,其中 ranges[i] (下标从 0 开始)表示:如果打开点 i 处的水龙头,可以灌溉的区域为 [i - ranges[i], i + ranges[i]] 。
请你返回可以灌溉整个花园的 最少水龙头数目 。如果花园始终存在无法灌溉到的地方,请你返回 -1 。
+ ++ +
示例 1:
+ +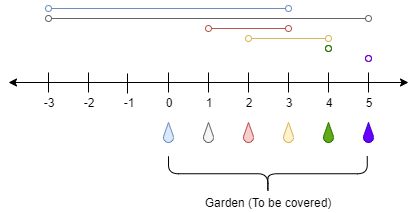
输入:n = 5, ranges = [3,4,1,1,0,0] +输出:1 +解释: +点 0 处的水龙头可以灌溉区间 [-3,3] +点 1 处的水龙头可以灌溉区间 [-3,5] +点 2 处的水龙头可以灌溉区间 [1,3] +点 3 处的水龙头可以灌溉区间 [2,4] +点 4 处的水龙头可以灌溉区间 [4,4] +点 5 处的水龙头可以灌溉区间 [5,5] +只需要打开点 1 处的水龙头即可灌溉整个花园 [0,5] 。 ++ +
示例 2:
+ +输入:n = 3, ranges = [0,0,0,0] +输出:-1 +解释:即使打开所有水龙头,你也无法灌溉整个花园。 ++ +
示例 3:
+ +输入:n = 7, ranges = [1,2,1,0,2,1,0,1] +输出:3 ++ +
示例 4:
+ +输入:n = 8, ranges = [4,0,0,0,0,0,0,0,4] +输出:2 ++ +
示例 5:
+ +输入:n = 8, ranges = [4,0,0,0,4,0,0,0,4] +输出:1 ++ +
+ +
提示:
+ +-
+
1 <= n <= 10^4
+ ranges.length == n + 1
+ 0 <= ranges[i] <= 100
+
给你一个回文字符串 palindrome ,请你将其中 一个 字符用任意小写英文字母替换,使得结果字符串的字典序最小,且 不是 回文串。
请你返回结果字符串。如果无法做到,则返回一个空串。
+ ++ +
示例 1:
+ +输入:palindrome = "abccba" +输出:"aaccba" ++ +
示例 2:
+ +输入:palindrome = "a" +输出:"" ++ +
+ +
提示:
+ +-
+
1 <= palindrome.length <= 1000
+ palindrome只包含小写英文字母。
+
给你一个 m * n 的整数矩阵 mat ,请你将同一条对角线上的元素(从左上到右下)按升序排序后,返回排好序的矩阵。
+ +
示例 1:
+ +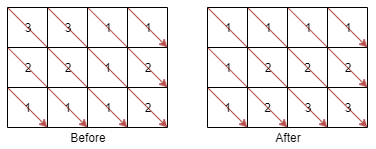
输入:mat = [[3,3,1,1],[2,2,1,2],[1,1,1,2]] +输出:[[1,1,1,1],[1,2,2,2],[1,2,3,3]] ++ +
+ +
提示:
+ +-
+
m == mat.length
+ n == mat[i].length
+ 1 <= m, n <= 100
+ 1 <= mat[i][j] <= 100
+
给你一个整数数组 nums 。「数组值」定义为所有满足 0 <= i < nums.length-1 的 |nums[i]-nums[i+1]| 的和。
你可以选择给定数组的任意子数组,并将该子数组翻转。但你只能执行这个操作 一次 。
+ +请你找到可行的最大 数组值 。
+ ++ +
示例 1:
+ +输入:nums = [2,3,1,5,4] +输出:10 +解释:通过翻转子数组 [3,1,5] ,数组变成 [2,5,1,3,4] ,数组值为 10 。 ++ +
示例 2:
+ +输入:nums = [2,4,9,24,2,1,10] +输出:68 ++ +
+ +
提示:
+ +-
+
1 <= nums.length <= 3*10^4
+ -10^5 <= nums[i] <= 10^5
+
给你一个整数数组 arr ,请你将数组中的每个元素替换为它们排序后的序号。
序号代表了一个元素有多大。序号编号的规则如下:
+ +-
+
- 序号从 1 开始编号。 +
- 一个元素越大,那么序号越大。如果两个元素相等,那么它们的序号相同。 +
- 每个数字的序号都应该尽可能地小。 +
+ +
示例 1:
+ +输入:arr = [40,10,20,30] +输出:[4,1,2,3] +解释:40 是最大的元素。 10 是最小的元素。 20 是第二小的数字。 30 是第三小的数字。+ +
示例 2:
+ +输入:arr = [100,100,100] +输出:[1,1,1] +解释:所有元素有相同的序号。 ++ +
示例 3:
+ +输入:arr = [37,12,28,9,100,56,80,5,12] +输出:[5,3,4,2,8,6,7,1,3] ++ +
+ +
提示:
+ +-
+
0 <= arr.length <= 105
+ -109 <= arr[i] <= 109
+
给你一个字符串 s,它仅由字母 'a' 和 'b' 组成。每一次删除操作都可以从 s 中删除一个回文 子序列。
返回删除给定字符串中所有字符(字符串为空)的最小删除次数。
+ +「子序列」定义:如果一个字符串可以通过删除原字符串某些字符而不改变原字符顺序得到,那么这个字符串就是原字符串的一个子序列。
+ +「回文」定义:如果一个字符串向后和向前读是一致的,那么这个字符串就是一个回文。
+ ++ +
示例 1:
+ +输入:s = "ababa" +输出:1 +解释:字符串本身就是回文序列,只需要删除一次。 ++ +
示例 2:
+ +输入:s = "abb" +输出:2 +解释:"abb" -> "bb" -> "". +先删除回文子序列 "a",然后再删除 "bb"。 ++ +
示例 3:
+ +输入:s = "baabb" +输出:2 +解释:"baabb" -> "b" -> "". +先删除回文子序列 "baab",然后再删除 "b"。 ++ +
示例 4:
+ +输入:s = "" +输出:0 ++ +
+ +
提示:
+ +-
+
0 <= s.length <= 1000
+ s仅包含字母 'a' 和 'b'
+
给你一个餐馆信息数组 restaurants,其中 restaurants[i] = [idi, ratingi, veganFriendlyi, pricei, distancei]。你必须使用以下三个过滤器来过滤这些餐馆信息。
其中素食者友好过滤器 veganFriendly 的值可以为 true 或者 false,如果为 true 就意味着你应该只包括 veganFriendlyi 为 true 的餐馆,为 false 则意味着可以包括任何餐馆。此外,我们还有最大价格 maxPrice 和最大距离 maxDistance 两个过滤器,它们分别考虑餐厅的价格因素和距离因素的最大值。
过滤后返回餐馆的 id,按照 rating 从高到低排序。如果 rating 相同,那么按 id 从高到低排序。简单起见, veganFriendlyi 和 veganFriendly 为 true 时取值为 1,为 false 时,取值为 0 。
+ +
示例 1:
+ +输入:restaurants = [[1,4,1,40,10],[2,8,0,50,5],[3,8,1,30,4],[4,10,0,10,3],[5,1,1,15,1]], veganFriendly = 1, maxPrice = 50, maxDistance = 10 +输出:[3,1,5] +解释: +这些餐馆为: +餐馆 1 [id=1, rating=4, veganFriendly=1, price=40, distance=10] +餐馆 2 [id=2, rating=8, veganFriendly=0, price=50, distance=5] +餐馆 3 [id=3, rating=8, veganFriendly=1, price=30, distance=4] +餐馆 4 [id=4, rating=10, veganFriendly=0, price=10, distance=3] +餐馆 5 [id=5, rating=1, veganFriendly=1, price=15, distance=1] +在按照 veganFriendly = 1, maxPrice = 50 和 maxDistance = 10 进行过滤后,我们得到了餐馆 3, 餐馆 1 和 餐馆 5(按评分从高到低排序)。 ++ +
示例 2:
+ +输入:restaurants = [[1,4,1,40,10],[2,8,0,50,5],[3,8,1,30,4],[4,10,0,10,3],[5,1,1,15,1]], veganFriendly = 0, maxPrice = 50, maxDistance = 10 +输出:[4,3,2,1,5] +解释:餐馆与示例 1 相同,但在 veganFriendly = 0 的过滤条件下,应该考虑所有餐馆。 ++ +
示例 3:
+ +输入:restaurants = [[1,4,1,40,10],[2,8,0,50,5],[3,8,1,30,4],[4,10,0,10,3],[5,1,1,15,1]], veganFriendly = 0, maxPrice = 30, maxDistance = 3 +输出:[4,5] ++ +
+ +
提示:
+ +-
+
1 <= restaurants.length <= 10^4
+ restaurants[i].length == 5
+ 1 <= idi, ratingi, pricei, distancei <= 10^5
+ 1 <= maxPrice, maxDistance <= 10^5
+ veganFriendlyi和veganFriendly的值为 0 或 1 。
+ - 所有
idi各不相同。
+
有 n 个城市,按从 0 到 n-1 编号。给你一个边数组 edges,其中 edges[i] = [fromi, toi, weighti] 代表 fromi 和 toi 两个城市之间的双向加权边,距离阈值是一个整数 distanceThreshold。
返回能通过某些路径到达其他城市数目最少、且路径距离 最大 为 distanceThreshold 的城市。如果有多个这样的城市,则返回编号最大的城市。
注意,连接城市 i 和 j 的路径的距离等于沿该路径的所有边的权重之和。
+ ++ +
示例 1:
+ +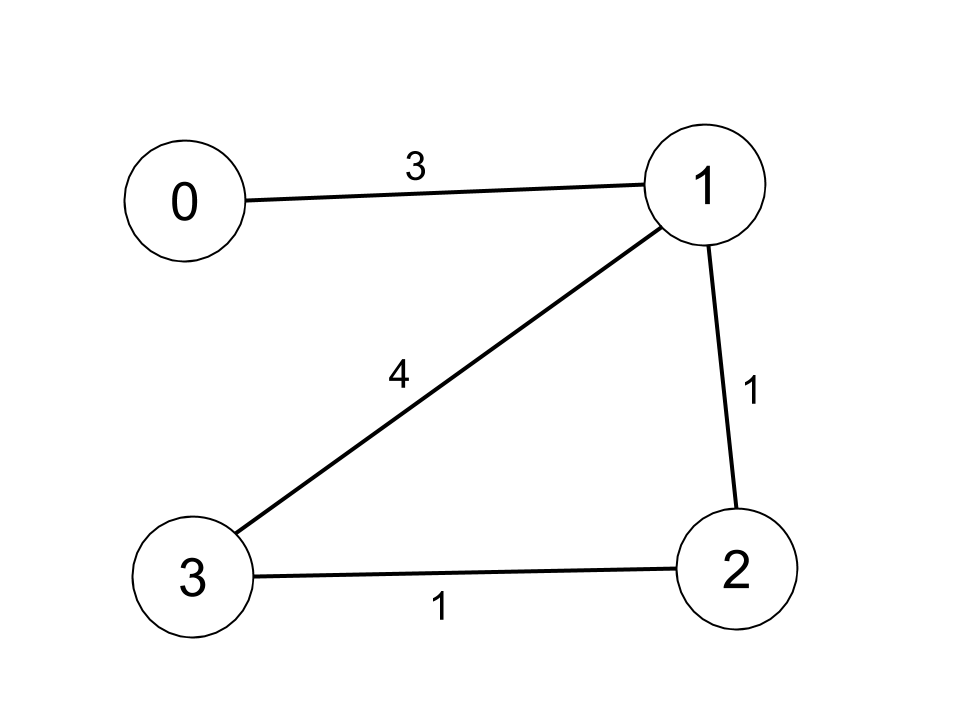
输入:n = 4, edges = [[0,1,3],[1,2,1],[1,3,4],[2,3,1]], distanceThreshold = 4 +输出:3 +解释:城市分布图如上。 +每个城市阈值距离 distanceThreshold = 4 内的邻居城市分别是: +城市 0 -> [城市 1, 城市 2] +城市 1 -> [城市 0, 城市 2, 城市 3] +城市 2 -> [城市 0, 城市 1, 城市 3] +城市 3 -> [城市 1, 城市 2] +城市 0 和 3 在阈值距离 4 以内都有 2 个邻居城市,但是我们必须返回城市 3,因为它的编号最大。 ++ +
示例 2:
+ +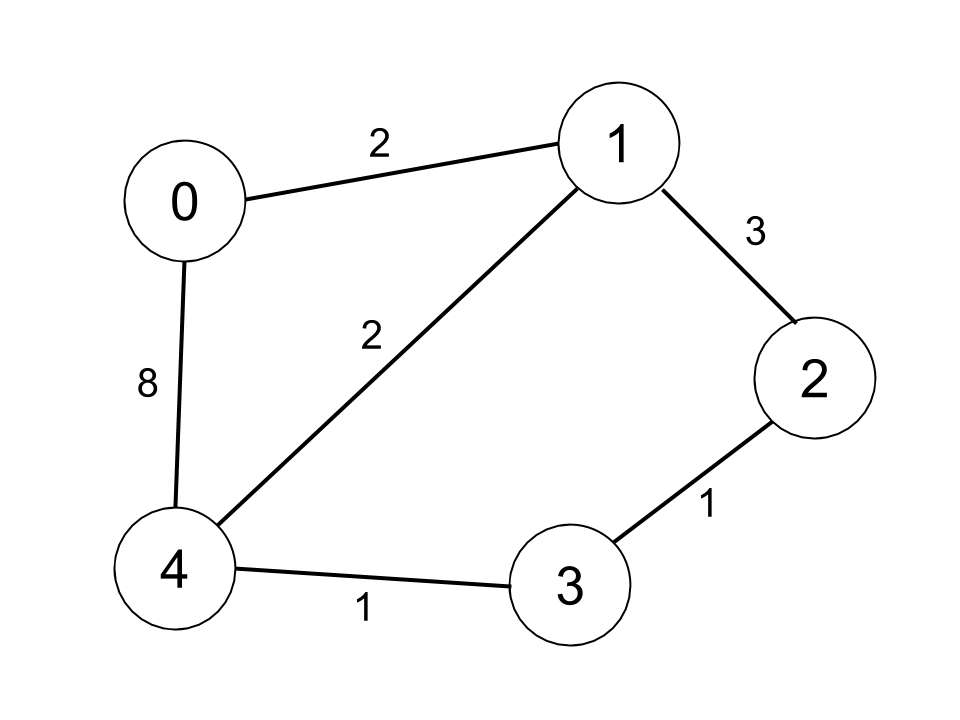
输入:n = 5, edges = [[0,1,2],[0,4,8],[1,2,3],[1,4,2],[2,3,1],[3,4,1]], distanceThreshold = 2 +输出:0 +解释:城市分布图如上。 +每个城市阈值距离 distanceThreshold = 2 内的邻居城市分别是: +城市 0 -> [城市 1] +城市 1 -> [城市 0, 城市 4] +城市 2 -> [城市 3, 城市 4] +城市 3 -> [城市 2, 城市 4] +城市 4 -> [城市 1, 城市 2, 城市 3] +城市 0 在阈值距离 4 以内只有 1 个邻居城市。 ++ +
+ +
提示:
+ +-
+
2 <= n <= 100
+ 1 <= edges.length <= n * (n - 1) / 2
+ edges[i].length == 3
+ 0 <= fromi < toi < n
+ 1 <= weighti, distanceThreshold <= 10^4
+ - 所有
(fromi, toi)都是不同的。
+
你需要制定一份 d 天的工作计划表。工作之间存在依赖,要想执行第 i 项工作,你必须完成全部 j 项工作( 0 <= j < i)。
你每天 至少 需要完成一项任务。工作计划的总难度是这 d 天每一天的难度之和,而一天的工作难度是当天应该完成工作的最大难度。
给你一个整数数组 jobDifficulty 和一个整数 d,分别代表工作难度和需要计划的天数。第 i 项工作的难度是 jobDifficulty[i]。
返回整个工作计划的 最小难度 。如果无法制定工作计划,则返回 -1 。
+ ++ +
示例 1:
+ +
输入:jobDifficulty = [6,5,4,3,2,1], d = 2 +输出:7 +解释:第一天,您可以完成前 5 项工作,总难度 = 6. +第二天,您可以完成最后一项工作,总难度 = 1. +计划表的难度 = 6 + 1 = 7 ++ +
示例 2:
+ +输入:jobDifficulty = [9,9,9], d = 4 +输出:-1 +解释:就算你每天完成一项工作,仍然有一天是空闲的,你无法制定一份能够满足既定工作时间的计划表。 ++ +
示例 3:
+ +输入:jobDifficulty = [1,1,1], d = 3 +输出:3 +解释:工作计划为每天一项工作,总难度为 3 。 ++ +
示例 4:
+ +输入:jobDifficulty = [7,1,7,1,7,1], d = 3 +输出:15 ++ +
示例 5:
+ +输入:jobDifficulty = [11,111,22,222,33,333,44,444], d = 6 +输出:843 ++ +
+ +
提示:
+ +-
+
1 <= jobDifficulty.length <= 300
+ 0 <= jobDifficulty[i] <= 1000
+ 1 <= d <= 10
+
给你一个大小为 m * n 的方阵 mat,方阵由若干军人和平民组成,分别用 0 和 1 表示。
请你返回方阵中战斗力最弱的 k 行的索引,按从最弱到最强排序。
如果第 i 行的军人数量少于第 j 行,或者两行军人数量相同但 i 小于 j,那么我们认为第 i 行的战斗力比第 j 行弱。
+ +军人 总是 排在一行中的靠前位置,也就是说 1 总是出现在 0 之前。
+ ++ +
示例 1:
+ +输入:mat = +[[1,1,0,0,0], + [1,1,1,1,0], + [1,0,0,0,0], + [1,1,0,0,0], + [1,1,1,1,1]], +k = 3 +输出:[2,0,3] +解释: +每行中的军人数目: +行 0 -> 2 +行 1 -> 4 +行 2 -> 1 +行 3 -> 2 +行 4 -> 5 +从最弱到最强对这些行排序后得到 [2,0,3,1,4] ++ +
示例 2:
+ +输入:mat = +[[1,0,0,0], + [1,1,1,1], + [1,0,0,0], + [1,0,0,0]], +k = 2 +输出:[0,2] +解释: +每行中的军人数目: +行 0 -> 1 +行 1 -> 4 +行 2 -> 1 +行 3 -> 1 +从最弱到最强对这些行排序后得到 [0,2,3,1] ++ +
+ +
提示:
+ +-
+
m == mat.length
+ n == mat[i].length
+ 2 <= n, m <= 100
+ 1 <= k <= m
+ matrix[i][j]不是 0 就是 1
+
给你一个整数数组 arr。你可以从中选出一个整数集合,并删除这些整数在数组中的每次出现。
返回 至少 能删除数组中的一半整数的整数集合的最小大小。
+ ++ +
示例 1:
+ +输入:arr = [3,3,3,3,5,5,5,2,2,7]
+输出:2
+解释:选择 {3,7} 使得结果数组为 [5,5,5,2,2]、长度为 5(原数组长度的一半)。
+大小为 2 的可行集合有 {3,5},{3,2},{5,2}。
+选择 {2,7} 是不可行的,它的结果数组为 [3,3,3,3,5,5,5],新数组长度大于原数组的二分之一。
+
+
+示例 2:
+ +输入:arr = [7,7,7,7,7,7]
+输出:1
+解释:我们只能选择集合 {7},结果数组为空。
+
+
+示例 3:
+ +输入:arr = [1,9] +输出:1 ++ +
示例 4:
+ +输入:arr = [1000,1000,3,7] +输出:1 ++ +
示例 5:
+ +输入:arr = [1,2,3,4,5,6,7,8,9,10] +输出:5 ++ +
+ +
提示:
+ +-
+
1 <= arr.length <= 10^5
+ arr.length为偶数
+ 1 <= arr[i] <= 10^5
+
给你一棵二叉树,它的根为 root 。请你删除 1 条边,使二叉树分裂成两棵子树,且它们子树和的乘积尽可能大。
由于答案可能会很大,请你将结果对 10^9 + 7 取模后再返回。
+ ++ +
示例 1:
+ +
输入:root = [1,2,3,4,5,6] +输出:110 +解释:删除红色的边,得到 2 棵子树,和分别为 11 和 10 。它们的乘积是 110 (11*10) ++ +
示例 2:
+ +
输入:root = [1,null,2,3,4,null,null,5,6] +输出:90 +解释:移除红色的边,得到 2 棵子树,和分别是 15 和 6 。它们的乘积为 90 (15*6) ++ +
示例 3:
+ +输入:root = [2,3,9,10,7,8,6,5,4,11,1] +输出:1025 ++ +
示例 4:
+ +输入:root = [1,1] +输出:1 ++ +
+ +
提示:
+ +-
+
- 每棵树最多有
50000个节点,且至少有2个节点。
+ - 每个节点的值在
[1, 10000]之间。
+
给你一个整数数组 arr 和一个整数 d 。每一步你可以从下标 i 跳到:
-
+
i + x,其中i + x < arr.length且0 < x <= d。
+ i - x,其中i - x >= 0且0 < x <= d。
+
除此以外,你从下标 i 跳到下标 j 需要满足:arr[i] > arr[j] 且 arr[i] > arr[k] ,其中下标 k 是所有 i 到 j 之间的数字(更正式的,min(i, j) < k < max(i, j))。
你可以选择数组的任意下标开始跳跃。请你返回你 最多 可以访问多少个下标。
+ +请注意,任何时刻你都不能跳到数组的外面。
+ ++ +
示例 1:
+ +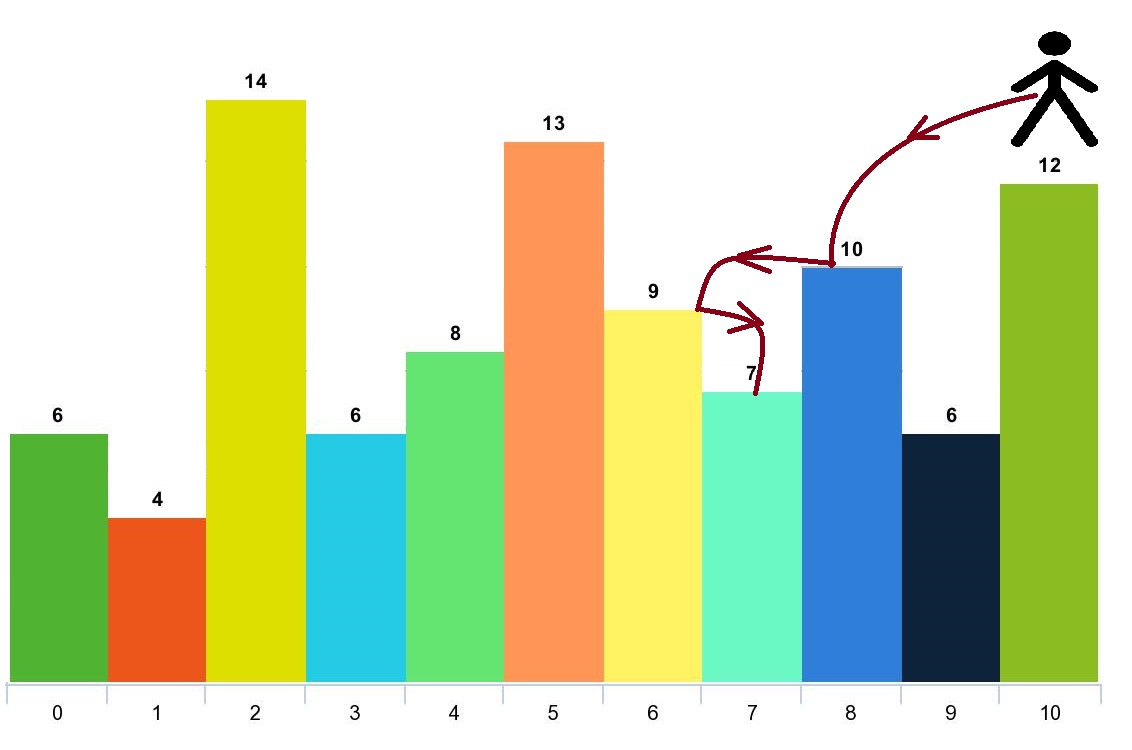
输入:arr = [6,4,14,6,8,13,9,7,10,6,12], d = 2 +输出:4 +解释:你可以从下标 10 出发,然后如上图依次经过 10 --> 8 --> 6 --> 7 。 +注意,如果你从下标 6 开始,你只能跳到下标 7 处。你不能跳到下标 5 处因为 13 > 9 。你也不能跳到下标 4 处,因为下标 5 在下标 4 和 6 之间且 13 > 9 。 +类似的,你不能从下标 3 处跳到下标 2 或者下标 1 处。 ++ +
示例 2:
+ +输入:arr = [3,3,3,3,3], d = 3 +输出:1 +解释:你可以从任意下标处开始且你永远无法跳到任何其他坐标。 ++ +
示例 3:
+ +输入:arr = [7,6,5,4,3,2,1], d = 1 +输出:7 +解释:从下标 0 处开始,你可以按照数值从大到小,访问所有的下标。 ++ +
示例 4:
+ +输入:arr = [7,1,7,1,7,1], d = 2 +输出:2 ++ +
示例 5:
+ +输入:arr = [66], d = 1 +输出:1 ++ +
+ +
提示:
+ +-
+
1 <= arr.length <= 1000
+ 1 <= arr[i] <= 10^5
+ 1 <= d <= arr.length
+
给你一个非负整数 num ,请你返回将它变成 0 所需要的步数。 如果当前数字是偶数,你需要把它除以 2 ;否则,减去 1 。
+ +
示例 1:
+ +输入:num = 14 +输出:6 +解释: +步骤 1) 14 是偶数,除以 2 得到 7 。 +步骤 2) 7 是奇数,减 1 得到 6 。 +步骤 3) 6 是偶数,除以 2 得到 3 。 +步骤 4) 3 是奇数,减 1 得到 2 。 +步骤 5) 2 是偶数,除以 2 得到 1 。 +步骤 6) 1 是奇数,减 1 得到 0 。 ++ +
示例 2:
+ +输入:num = 8 +输出:4 +解释: +步骤 1) 8 是偶数,除以 2 得到 4 。 +步骤 2) 4 是偶数,除以 2 得到 2 。 +步骤 3) 2 是偶数,除以 2 得到 1 。 +步骤 4) 1 是奇数,减 1 得到 0 。 ++ +
示例 3:
+ +输入:num = 123 +输出:12 ++ +
+ +
提示:
+ +-
+
0 <= num <= 10^6
+
给你一个整数数组 arr 和两个整数 k 和 threshold 。
请你返回长度为 k 且平均值大于等于 threshold 的子数组数目。
+ +
示例 1:
+ +输入:arr = [2,2,2,2,5,5,5,8], k = 3, threshold = 4 +输出:3 +解释:子数组 [2,5,5],[5,5,5] 和 [5,5,8] 的平均值分别为 4,5 和 6 。其他长度为 3 的子数组的平均值都小于 4 (threshold 的值)。 ++ +
示例 2:
+ +输入:arr = [1,1,1,1,1], k = 1, threshold = 0 +输出:5 ++ +
示例 3:
+ +输入:arr = [11,13,17,23,29,31,7,5,2,3], k = 3, threshold = 5 +输出:6 +解释:前 6 个长度为 3 的子数组平均值都大于 5 。注意平均值不是整数。 ++ +
示例 4:
+ +输入:arr = [7,7,7,7,7,7,7], k = 7, threshold = 7 +输出:1 ++ +
示例 5:
+ +输入:arr = [4,4,4,4], k = 4, threshold = 1 +输出:1 ++ +
+ +
提示:
+ +-
+
1 <= arr.length <= 10^5
+ 1 <= arr[i] <= 10^4
+ 1 <= k <= arr.length
+ 0 <= threshold <= 10^4
+
给你两个数 hour 和 minutes 。请你返回在时钟上,由给定时间的时针和分针组成的较小角的角度(60 单位制)。
+ +
示例 1:
+ +
输入:hour = 12, minutes = 30 +输出:165 ++ +
示例 2:
+ +
输入:hour = 3, minutes = 30 +输出;75 ++ +
示例 3:
+ +
输入:hour = 3, minutes = 15 +输出:7.5 ++ +
示例 4:
+ +输入:hour = 4, minutes = 50 +输出:155 ++ +
示例 5:
+ +输入:hour = 12, minutes = 0 +输出:0 ++ +
+ +
提示:
+ +-
+
1 <= hour <= 12
+ 0 <= minutes <= 59
+ - 与标准答案误差在
10^-5以内的结果都被视为正确结果。
+
给你一个整数数组 arr ,你一开始在数组的第一个元素处(下标为 0)。
每一步,你可以从下标 i 跳到下标:
-
+
i + 1满足:i + 1 < arr.length
+ i - 1满足:i - 1 >= 0
+ j满足:arr[i] == arr[j]且i != j
+
请你返回到达数组最后一个元素的下标处所需的 最少操作次数 。
+ +注意:任何时候你都不能跳到数组外面。
+ ++ +
示例 1:
+ +输入:arr = [100,-23,-23,404,100,23,23,23,3,404] +输出:3 +解释:那你需要跳跃 3 次,下标依次为 0 --> 4 --> 3 --> 9 。下标 9 为数组的最后一个元素的下标。 ++ +
示例 2:
+ +输入:arr = [7] +输出:0 +解释:一开始就在最后一个元素处,所以你不需要跳跃。 ++ +
示例 3:
+ +输入:arr = [7,6,9,6,9,6,9,7] +输出:1 +解释:你可以直接从下标 0 处跳到下标 7 处,也就是数组的最后一个元素处。 ++ +
示例 4:
+ +输入:arr = [6,1,9] +输出:2 ++ +
示例 5:
+ +输入:arr = [11,22,7,7,7,7,7,7,7,22,13] +输出:3 ++ +
+ +
提示:
+ +-
+
1 <= arr.length <= 5 * 10^4
+ -10^8 <= arr[i] <= 10^8
+
给你一个整数数组 arr,请你检查是否存在两个整数 N 和 M,满足 N 是 M 的两倍(即,N = 2 * M)。
更正式地,检查是否存在两个下标 i 和 j 满足:
-
+
i != j
+ 0 <= i, j < arr.length
+ arr[i] == 2 * arr[j]
+
+ +
示例 1:
+ +输入:arr = [10,2,5,3] +输出:true +解释:N+ += 10是 M= 5 的两倍,即10 = 2 * 5 。+
示例 2:
+ +输入:arr = [7,1,14,11] +输出:true +解释:N+ += 14是 M= 7 的两倍,即14 = 2 * 7。 +
示例 3:
+ +输入:arr = [3,1,7,11] +输出:false +解释:在该情况下不存在 N 和 M 满足 N = 2 * M 。 ++ +
+ +
提示:
+ +-
+
2 <= arr.length <= 500
+ -10^3 <= arr[i] <= 10^3
+
给你两个长度相等的字符串 s 和 t。每一个步骤中,你可以选择将 t 中的 任一字符 替换为 另一个字符。
返回使 t 成为 s 的字母异位词的最小步骤数。
字母异位词 指字母相同,但排列不同的字符串。
+ ++ +
示例 1:
+ +输出:s = "bab", t = "aba" +输出:1 +提示:用 'b' 替换 t 中的第一个 'a',t = "bba" 是 s 的一个字母异位词。 ++ +
示例 2:
+ +输出:s = "leetcode", t = "practice" +输出:5 +提示:用合适的字符替换 t 中的 'p', 'r', 'a', 'i' 和 'c',使 t 变成 s 的字母异位词。 ++ +
示例 3:
+ +输出:s = "anagram", t = "mangaar" +输出:0 +提示:"anagram" 和 "mangaar" 本身就是一组字母异位词。 ++ +
示例 4:
+ +输出:s = "xxyyzz", t = "xxyyzz" +输出:0 ++ +
示例 5:
+ +输出:s = "friend", t = "family" +输出:4 ++ +
+ +
提示:
+ +-
+
1 <= s.length <= 50000
+ s.length == t.length
+ s和t只包含小写英文字母
+
请你实现一个能够支持以下两种方法的推文计数类 TweetCounts:
1. recordTweet(string tweetName, int time)
-
+
- 记录推文发布情况:用户
tweetName在time(以 秒 为单位)时刻发布了一条推文。
+
2. getTweetCountsPerFrequency(string freq, string tweetName, int startTime, int endTime)
-
+
- 返回从开始时间
startTime(以 秒 为单位)到结束时间endTime(以 秒 为单位)内,每 分 minute,时 hour 或者 日 day (取决于freq)内指定用户tweetName发布的推文总数。
+ freq的值始终为 分 minute,时 hour 或者 日 day 之一,表示获取指定用户tweetName发布推文次数的时间间隔。
+ - 第一个时间间隔始终从
startTime开始,因此时间间隔为[startTime, startTime + delta*1>, [startTime + delta*1, startTime + delta*2>, [startTime + delta*2, startTime + delta*3>, ... , [startTime + delta*i, min(startTime + delta*(i+1), endTime + 1)>,其中i和delta(取决于freq)都是非负整数。
+
+ +
示例:
+ +输入:
+["TweetCounts","recordTweet","recordTweet","recordTweet","getTweetCountsPerFrequency","getTweetCountsPerFrequency","recordTweet","getTweetCountsPerFrequency"]
+[[],["tweet3",0],["tweet3",60],["tweet3",10],["minute","tweet3",0,59],["minute","tweet3",0,60],["tweet3",120],["hour","tweet3",0,210]]
+
+输出:
+[null,null,null,null,[2],[2,1],null,[4]]
+
+解释:
+TweetCounts tweetCounts = new TweetCounts();
+tweetCounts.recordTweet("tweet3", 0);
+tweetCounts.recordTweet("tweet3", 60);
+tweetCounts.recordTweet("tweet3", 10); // "tweet3" 发布推文的时间分别是 0, 10 和 60 。
+tweetCounts.getTweetCountsPerFrequency("minute", "tweet3", 0, 59); // 返回 [2]。统计频率是每分钟(60 秒),因此只有一个有效时间间隔 [0,60> - > 2 条推文。
+tweetCounts.getTweetCountsPerFrequency("minute", "tweet3", 0, 60); // 返回 [2,1]。统计频率是每分钟(60 秒),因此有两个有效时间间隔 1) [0,60> - > 2 条推文,和 2) [60,61> - > 1 条推文。
+tweetCounts.recordTweet("tweet3", 120); // "tweet3" 发布推文的时间分别是 0, 10, 60 和 120 。
+tweetCounts.getTweetCountsPerFrequency("hour", "tweet3", 0, 210); // 返回 [4]。统计频率是每小时(3600 秒),因此只有一个有效时间间隔 [0,211> - > 4 条推文。
+
+
++ +
提示:
+ +-
+
- 同时考虑
recordTweet和getTweetCountsPerFrequency,最多有10000次操作。
+ 0 <= time, startTime, endTime <= 10^9
+ 0 <= endTime - startTime <= 10^4
+
给你一个 m * n 的矩阵 seats 表示教室中的座位分布。如果座位是坏的(不可用),就用 '#' 表示;否则,用 '.' 表示。
学生可以看到左侧、右侧、左上、右上这四个方向上紧邻他的学生的答卷,但是看不到直接坐在他前面或者后面的学生的答卷。请你计算并返回该考场可以容纳的一起参加考试且无法作弊的最大学生人数。
+ +学生必须坐在状况良好的座位上。
+ ++ +
示例 1:
+ +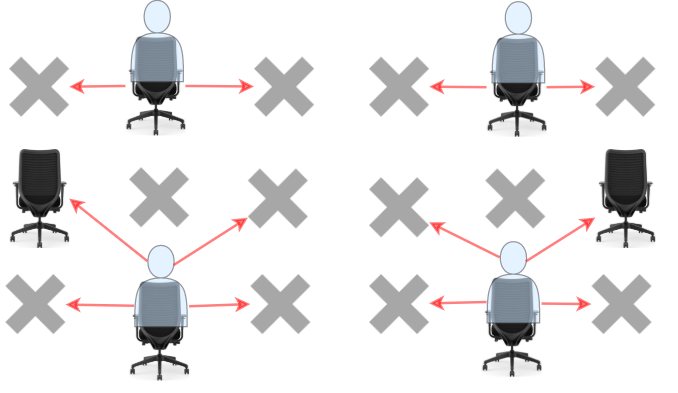
输入:seats = [["#",".","#","#",".","#"], + [".","#","#","#","#","."], + ["#",".","#","#",".","#"]] +输出:4 +解释:教师可以让 4 个学生坐在可用的座位上,这样他们就无法在考试中作弊。 ++ +
示例 2:
+ +输入:seats = [[".","#"], + ["#","#"], + ["#","."], + ["#","#"], + [".","#"]] +输出:3 +解释:让所有学生坐在可用的座位上。 ++ +
示例 3:
+ +输入:seats = [["#",".",".",".","#"], + [".","#",".","#","."], + [".",".","#",".","."], + [".","#",".","#","."], + ["#",".",".",".","#"]] +输出:10 +解释:让学生坐在第 1、3 和 5 列的可用座位上。 ++ +
+ +
提示:
+ +-
+
seats只包含字符'.' 和'#'
+ m == seats.length
+ n == seats[i].length
+ 1 <= m <= 8
+ 1 <= n <= 8
+
给你一个 m * n 的矩阵 grid,矩阵中的元素无论是按行还是按列,都以非递增顺序排列。
请你统计并返回 grid 中 负数 的数目。
+ +
示例 1:
+ +输入:grid = [[4,3,2,-1],[3,2,1,-1],[1,1,-1,-2],[-1,-1,-2,-3]] +输出:8 +解释:矩阵中共有 8 个负数。 ++ +
示例 2:
+ +输入:grid = [[3,2],[1,0]] +输出:0 ++ +
示例 3:
+ +输入:grid = [[1,-1],[-1,-1]] +输出:3 ++ +
示例 4:
+ +输入:grid = [[-1]] +输出:1 ++ +
+ +
提示:
+ +-
+
m == grid.length
+ n == grid[i].length
+ 1 <= m, n <= 100
+ -100 <= grid[i][j] <= 100
+
请你实现一个「数字乘积类」ProductOfNumbers,要求支持下述两种方法:
1. add(int num)
-
+
- 将数字
num添加到当前数字列表的最后面。
+
2. getProduct(int k)
-
+
- 返回当前数字列表中,最后
k个数字的乘积。
+ - 你可以假设当前列表中始终 至少 包含
k个数字。
+
题目数据保证:任何时候,任一连续数字序列的乘积都在 32-bit 整数范围内,不会溢出。
+ ++ +
示例:
+ +输入: +["ProductOfNumbers","add","add","add","add","add","getProduct","getProduct","getProduct","add","getProduct"] +[[],[3],[0],[2],[5],[4],[2],[3],[4],[8],[2]] + +输出: +[null,null,null,null,null,null,20,40,0,null,32] + +解释: +ProductOfNumbers productOfNumbers = new ProductOfNumbers(); +productOfNumbers.add(3); // [3] +productOfNumbers.add(0); // [3,0] +productOfNumbers.add(2); // [3,0,2] +productOfNumbers.add(5); // [3,0,2,5] +productOfNumbers.add(4); // [3,0,2,5,4] +productOfNumbers.getProduct(2); // 返回 20 。最后 2 个数字的乘积是 5 * 4 = 20 +productOfNumbers.getProduct(3); // 返回 40 。最后 3 个数字的乘积是 2 * 5 * 4 = 40 +productOfNumbers.getProduct(4); // 返回 0 。最后 4 个数字的乘积是 0 * 2 * 5 * 4 = 0 +productOfNumbers.add(8); // [3,0,2,5,4,8] +productOfNumbers.getProduct(2); // 返回 32 。最后 2 个数字的乘积是 4 * 8 = 32 ++ +
+ +
提示:
+ +-
+
add和getProduct两种操作加起来总共不会超过40000次。
+ 0 <= num <= 100
+ 1 <= k <= 40000
+
给你一个数组 events,其中 events[i] = [startDayi, endDayi] ,表示会议 i 开始于 startDayi ,结束于 endDayi 。
你可以在满足 startDayi <= d <= endDayi 中的任意一天 d 参加会议 i 。注意,一天只能参加一个会议。
请你返回你可以参加的 最大 会议数目。
+ ++ +
示例 1:
+ +
输入:events = [[1,2],[2,3],[3,4]] +输出:3 +解释:你可以参加所有的三个会议。 +安排会议的一种方案如上图。 +第 1 天参加第一个会议。 +第 2 天参加第二个会议。 +第 3 天参加第三个会议。 ++ +
示例 2:
+ +输入:events= [[1,2],[2,3],[3,4],[1,2]] +输出:4 ++ +
示例 3:
+ +输入:events = [[1,4],[4,4],[2,2],[3,4],[1,1]] +输出:4 ++ +
示例 4:
+ +输入:events = [[1,100000]] +输出:1 ++ +
示例 5:
+ +输入:events = [[1,1],[1,2],[1,3],[1,4],[1,5],[1,6],[1,7]] +输出:7 ++ +
+ +
提示:
+ +-
+
1 <= events.length <= 10^5
+ events[i].length == 2
+ 1 <= events[i][0] <= events[i][1] <= 10^5
+
给你一个整数数组 target 。一开始,你有一个数组 A ,它的所有元素均为 1 ,你可以执行以下操作:
-
+
- 令
x为你数组里所有元素的和
+ - 选择满足
0 <= i < target.size的任意下标i,并让A数组里下标为i处的值为x。
+ - 你可以重复该过程任意次 +
如果能从 A 开始构造出目标数组 target ,请你返回 True ,否则返回 False 。
+ +
示例 1:
+ +输入:target = [9,3,5] +输出:true +解释:从 [1, 1, 1] 开始 +[1, 1, 1], 和为 3 ,选择下标 1 +[1, 3, 1], 和为 5, 选择下标 2 +[1, 3, 5], 和为 9, 选择下标 0 +[9, 3, 5] 完成 ++ +
示例 2:
+ +输入:target = [1,1,1,2] +输出:false +解释:不可能从 [1,1,1,1] 出发构造目标数组。 ++ +
示例 3:
+ +输入:target = [8,5] +输出:true ++ +
+ +
提示:
+ +-
+
N == target.length
+ 1 <= target.length <= 5 * 10^4
+ 1 <= target[i] <= 10^9
+
给你一个整数数组 arr 。请你将数组中的元素按照其二进制表示中数字 1 的数目升序排序。
如果存在多个数字二进制中 1 的数目相同,则必须将它们按照数值大小升序排列。
+ +请你返回排序后的数组。
+ ++ +
示例 1:
+ +输入:arr = [0,1,2,3,4,5,6,7,8] +输出:[0,1,2,4,8,3,5,6,7] +解释:[0] 是唯一一个有 0 个 1 的数。 +[1,2,4,8] 都有 1 个 1 。 +[3,5,6] 有 2 个 1 。 +[7] 有 3 个 1 。 +按照 1 的个数排序得到的结果数组为 [0,1,2,4,8,3,5,6,7] ++ +
示例 2:
+ +输入:arr = [1024,512,256,128,64,32,16,8,4,2,1] +输出:[1,2,4,8,16,32,64,128,256,512,1024] +解释:数组中所有整数二进制下都只有 1 个 1 ,所以你需要按照数值大小将它们排序。 ++ +
示例 3:
+ +输入:arr = [10000,10000] +输出:[10000,10000] ++ +
示例 4:
+ +输入:arr = [2,3,5,7,11,13,17,19] +输出:[2,3,5,17,7,11,13,19] ++ +
示例 5:
+ +输入:arr = [10,100,1000,10000] +输出:[10,100,10000,1000] ++ +
+ +
提示:
+ +-
+
1 <= arr.length <= 500
+ 0 <= arr[i] <= 10^4
+
超市里正在举行打折活动,每隔 n 个顾客会得到 discount 的折扣。
超市里有一些商品,第 i 种商品为 products[i] 且每件单品的价格为 prices[i] 。
结账系统会统计顾客的数目,每隔 n 个顾客结账时,该顾客的账单都会打折,折扣为 discount (也就是如果原本账单为 x ,那么实际金额会变成 x - (discount * x) / 100 ),然后系统会重新开始计数。
顾客会购买一些商品, product[i] 是顾客购买的第 i 种商品, amount[i] 是对应的购买该种商品的数目。
请你实现 Cashier 类:
-
+
Cashier(int n, int discount, int[] products, int[] prices)初始化实例对象,参数分别为打折频率n,折扣大小discount,超市里的商品列表products和它们的价格prices。
+ double getBill(int[] product, int[] amount)返回账单的实际金额(如果有打折,请返回打折后的结果)。返回结果与标准答案误差在10^-5以内都视为正确结果。
+
+ +
示例 1:
+ +输入 +["Cashier","getBill","getBill","getBill","getBill","getBill","getBill","getBill"] +[[3,50,[1,2,3,4,5,6,7],[100,200,300,400,300,200,100]],[[1,2],[1,2]],[[3,7],[10,10]],[[1,2,3,4,5,6,7],[1,1,1,1,1,1,1]],[[4],[10]],[[7,3],[10,10]],[[7,5,3,1,6,4,2],[10,10,10,9,9,9,7]],[[2,3,5],[5,3,2]]] +输出 +[null,500.0,4000.0,800.0,4000.0,4000.0,7350.0,2500.0] +解释 +Cashier cashier = new Cashier(3,50,[1,2,3,4,5,6,7],[100,200,300,400,300,200,100]); +cashier.getBill([1,2],[1,2]); // 返回 500.0, 账单金额为 = 1 * 100 + 2 * 200 = 500. +cashier.getBill([3,7],[10,10]); // 返回 4000.0 +cashier.getBill([1,2,3,4,5,6,7],[1,1,1,1,1,1,1]); // 返回 800.0 ,账单原本为 1600.0 ,但由于该顾客是第三位顾客,他将得到 50% 的折扣,所以实际金额为 1600 - 1600 * (50 / 100) = 800 。 +cashier.getBill([4],[10]); // 返回 4000.0 +cashier.getBill([7,3],[10,10]); // 返回 4000.0 +cashier.getBill([7,5,3,1,6,4,2],[10,10,10,9,9,9,7]); // 返回 7350.0 ,账单原本为 14700.0 ,但由于系统计数再次达到三,该顾客将得到 50% 的折扣,实际金额为 7350.0 。 +cashier.getBill([2,3,5],[5,3,2]); // 返回 2500.0 ++ +
+ +
提示:
+ +-
+
1 <= n <= 10^4
+ 0 <= discount <= 100
+ 1 <= products.length <= 200
+ 1 <= products[i] <= 200
+ products列表中 不会 有重复的元素。
+ prices.length == products.length
+ 1 <= prices[i] <= 1000
+ 1 <= product.length <= products.length
+ product[i]在products出现过。
+ amount.length == product.length
+ 1 <= amount[i] <= 1000
+ - 最多有
1000次对getBill函数的调用。
+ - 返回结果与标准答案误差在
10^-5以内都视为正确结果。
+
给你一个字符串 s ,它只包含三种字符 a, b 和 c 。
请你返回 a,b 和 c 都 至少 出现过一次的子字符串数目。
+ ++ +
示例 1:
+ +输入:s = "abcabc" +输出:10 +解释:包含 a,b 和 c 各至少一次的子字符串为 "abc", "abca", "abcab", "abcabc", "bca", "bcab", "bcabc", "cab", "cabc" 和 "abc" (相同字符串算多次)。 ++ +
示例 2:
+ +输入:s = "aaacb" +输出:3 +解释:包含 a,b 和 c 各至少一次的子字符串为 "aaacb", "aacb" 和 "acb" 。 ++ +
示例 3:
+ +输入:s = "abc" +输出:1 ++ +
+ +
提示:
+ +-
+
3 <= s.length <= 5 x 10^4
+ s只包含字符 a,b 和 c 。
+
给你 n 笔订单,每笔订单都需要快递服务。
请你统计所有有效的 收件/配送 序列的数目,确保第 i 个物品的配送服务 delivery(i) 总是在其收件服务 pickup(i) 之后。
由于答案可能很大,请返回答案对 10^9 + 7 取余的结果。
+ +
示例 1:
+ +输入:n = 1 +输出:1 +解释:只有一种序列 (P1, D1),物品 1 的配送服务(D1)在物品 1 的收件服务(P1)后。 ++ +
示例 2:
+ +输入:n = 2 +输出:6 +解释:所有可能的序列包括: +(P1,P2,D1,D2),(P1,P2,D2,D1),(P1,D1,P2,D2),(P2,P1,D1,D2),(P2,P1,D2,D1) 和 (P2,D2,P1,D1)。 +(P1,D2,P2,D1) 是一个无效的序列,因为物品 2 的收件服务(P2)不应在物品 2 的配送服务(D2)之后。 ++ +
示例 3:
+ +输入:n = 3 +输出:90 ++ +
+ +
提示:
+ +-
+
1 <= n <= 500
+
请你编写一个程序来计算两个日期之间隔了多少天。
+ +日期以字符串形式给出,格式为 YYYY-MM-DD,如示例所示。
+ +
示例 1:
+ +输入:date1 = "2019-06-29", date2 = "2019-06-30" +输出:1 ++ +
示例 2:
+ +输入:date1 = "2020-01-15", date2 = "2019-12-31" +输出:15 ++ +
+ +
提示:
+ +-
+
- 给定的日期是
1971年到2100年之间的有效日期。
+
二叉树上有 n 个节点,按从 0 到 n - 1 编号,其中节点 i 的两个子节点分别是 leftChild[i] 和 rightChild[i]。
只有 所有 节点能够形成且 只 形成 一颗 有效的二叉树时,返回 true;否则返回 false。
如果节点 i 没有左子节点,那么 leftChild[i] 就等于 -1。右子节点也符合该规则。
注意:节点没有值,本问题中仅仅使用节点编号。
+ ++ +
示例 1:
+ +
输入:n = 4, leftChild = [1,-1,3,-1], rightChild = [2,-1,-1,-1] +输出:true ++ +
示例 2:
+ +
输入:n = 4, leftChild = [1,-1,3,-1], rightChild = [2,3,-1,-1] +输出:false ++ +
示例 3:
+ +
输入:n = 2, leftChild = [1,0], rightChild = [-1,-1] +输出:false ++ +
示例 4:
+ +
输入:n = 6, leftChild = [1,-1,-1,4,-1,-1], rightChild = [2,-1,-1,5,-1,-1] +输出:false ++ +
+ +
提示:
+ +-
+
1 <= n <= 10^4
+ leftChild.length == rightChild.length == n
+ -1 <= leftChild[i], rightChild[i] <= n - 1
+
给你一个整数 num,请你找出同时满足下面全部要求的两个整数:
-
+
- 两数乘积等于
num + 1或num + 2
+ - 以绝对差进行度量,两数大小最接近 +
你可以按任意顺序返回这两个整数。
+ ++ +
示例 1:
+ +输入:num = 8 +输出:[3,3] +解释:对于 num + 1 = 9,最接近的两个因数是 3 & 3;对于 num + 2 = 10, 最接近的两个因数是 2 & 5,因此返回 3 & 3 。 ++ +
示例 2:
+ +输入:num = 123 +输出:[5,25] ++ +
示例 3:
+ +输入:num = 999 +输出:[40,25] ++ +
+ +
提示:
+ +-
+
1 <= num <= 10^9
+
给你一个整数数组 digits,你可以通过按任意顺序连接其中某些数字来形成 3 的倍数,请你返回所能得到的最大的 3 的倍数。
由于答案可能不在整数数据类型范围内,请以字符串形式返回答案。
+ +如果无法得到答案,请返回一个空字符串。
+ ++ +
示例 1:
+ +输入:digits = [8,1,9] +输出:"981" ++ +
示例 2:
+ +输入:digits = [8,6,7,1,0] +输出:"8760" ++ +
示例 3:
+ +输入:digits = [1] +输出:"" ++ +
示例 4:
+ +输入:digits = [0,0,0,0,0,0] +输出:"0" ++ +
+ +
提示:
+ +-
+
1 <= digits.length <= 10^4
+ 0 <= digits[i] <= 9
+ - 返回的结果不应包含不必要的前导零。 +
给你一个数组 nums,对于其中每个元素 nums[i],请你统计数组中比它小的所有数字的数目。
换而言之,对于每个 nums[i] 你必须计算出有效的 j 的数量,其中 j 满足 j != i 且 nums[j] < nums[i] 。
以数组形式返回答案。
+ ++ +
示例 1:
+ +输入:nums = [8,1,2,2,3] +输出:[4,0,1,1,3] +解释: +对于 nums[0]=8 存在四个比它小的数字:(1,2,2 和 3)。 +对于 nums[1]=1 不存在比它小的数字。 +对于 nums[2]=2 存在一个比它小的数字:(1)。 +对于 nums[3]=2 存在一个比它小的数字:(1)。 +对于 nums[4]=3 存在三个比它小的数字:(1,2 和 2)。 ++ +
示例 2:
+ +输入:nums = [6,5,4,8] +输出:[2,1,0,3] ++ +
示例 3:
+ +输入:nums = [7,7,7,7] +输出:[0,0,0,0] ++ +
+ +
提示:
+ +-
+
2 <= nums.length <= 500
+ 0 <= nums[i] <= 100
+
现在有一个特殊的排名系统,依据参赛团队在投票人心中的次序进行排名,每个投票者都需要按从高到低的顺序对参与排名的所有团队进行排位。
+ +排名规则如下:
+ +-
+
- 参赛团队的排名次序依照其所获「排位第一」的票的多少决定。如果存在多个团队并列的情况,将继续考虑其「排位第二」的票的数量。以此类推,直到不再存在并列的情况。 +
- 如果在考虑完所有投票情况后仍然出现并列现象,则根据团队字母的字母顺序进行排名。 +
给你一个字符串数组 votes 代表全体投票者给出的排位情况,请你根据上述排名规则对所有参赛团队进行排名。
请你返回能表示按排名系统 排序后 的所有团队排名的字符串。
+ ++ +
示例 1:
+ +输入:votes = ["ABC","ACB","ABC","ACB","ACB"] +输出:"ACB" +解释:A 队获得五票「排位第一」,没有其他队获得「排位第一」,所以 A 队排名第一。 +B 队获得两票「排位第二」,三票「排位第三」。 +C 队获得三票「排位第二」,两票「排位第三」。 +由于 C 队「排位第二」的票数较多,所以 C 队排第二,B 队排第三。 ++ +
示例 2:
+ +输入:votes = ["WXYZ","XYZW"] +输出:"XWYZ" +解释:X 队在并列僵局打破后成为排名第一的团队。X 队和 W 队的「排位第一」票数一样,但是 X 队有一票「排位第二」,而 W 没有获得「排位第二」。 ++ +
示例 3:
+ +输入:votes = ["ZMNAGUEDSJYLBOPHRQICWFXTVK"] +输出:"ZMNAGUEDSJYLBOPHRQICWFXTVK" +解释:只有一个投票者,所以排名完全按照他的意愿。 ++ +
示例 4:
+ +输入:votes = ["BCA","CAB","CBA","ABC","ACB","BAC"] +输出:"ABC" +解释: +A 队获得两票「排位第一」,两票「排位第二」,两票「排位第三」。 +B 队获得两票「排位第一」,两票「排位第二」,两票「排位第三」。 +C 队获得两票「排位第一」,两票「排位第二」,两票「排位第三」。 +完全并列,所以我们需要按照字母升序排名。 ++ +
示例 5:
+ +输入:votes = ["M","M","M","M"] +输出:"M" +解释:只有 M 队参赛,所以它排名第一。 ++ +
+ +
提示:
+ +-
+
1 <= votes.length <= 1000
+ 1 <= votes[i].length <= 26
+ votes[i].length == votes[j].lengthfor0 <= i, j < votes.length
+ votes[i][j]是英文 大写 字母
+ votes[i]中的所有字母都是唯一的
+ votes[0]中出现的所有字母 同样也 出现在votes[j]中,其中1 <= j < votes.length
+
给你一棵以 root 为根的二叉树和一个 head 为第一个节点的链表。
如果在二叉树中,存在一条一直向下的路径,且每个点的数值恰好一一对应以 head 为首的链表中每个节点的值,那么请你返回 True ,否则返回 False 。
一直向下的路径的意思是:从树中某个节点开始,一直连续向下的路径。
+ ++ +
示例 1:
+ +
输入:head = [4,2,8], root = [1,4,4,null,2,2,null,1,null,6,8,null,null,null,null,1,3] +输出:true +解释:树中蓝色的节点构成了与链表对应的子路径。 ++ +
示例 2:
+ +
输入:head = [1,4,2,6], root = [1,4,4,null,2,2,null,1,null,6,8,null,null,null,null,1,3] +输出:true ++ +
示例 3:
+ +输入:head = [1,4,2,6,8], root = [1,4,4,null,2,2,null,1,null,6,8,null,null,null,null,1,3] +输出:false +解释:二叉树中不存在一一对应链表的路径。 ++ +
+ +
提示:
+ +-
+
- 二叉树和链表中的每个节点的值都满足
1 <= node.val <= 100。
+ - 链表包含的节点数目在
1到100之间。
+ - 二叉树包含的节点数目在
1到2500之间。
+
给你一个 m x n 的网格图 grid 。 grid 中每个格子都有一个数字,对应着从该格子出发下一步走的方向。 grid[i][j] 中的数字可能为以下几种情况:
-
+
- 1 ,下一步往右走,也就是你会从
grid[i][j]走到grid[i][j + 1]
+ - 2 ,下一步往左走,也就是你会从
grid[i][j]走到grid[i][j - 1]
+ - 3 ,下一步往下走,也就是你会从
grid[i][j]走到grid[i + 1][j]
+ - 4 ,下一步往上走,也就是你会从
grid[i][j]走到grid[i - 1][j]
+
注意网格图中可能会有 无效数字 ,因为它们可能指向 grid 以外的区域。
一开始,你会从最左上角的格子 (0,0) 出发。我们定义一条 有效路径 为从格子 (0,0) 出发,每一步都顺着数字对应方向走,最终在最右下角的格子 (m - 1, n - 1) 结束的路径。有效路径 不需要是最短路径 。
你可以花费 cost = 1 的代价修改一个格子中的数字,但每个格子中的数字 只能修改一次 。
请你返回让网格图至少有一条有效路径的最小代价。
+ ++ +
示例 1:
+ +
输入:grid = [[1,1,1,1],[2,2,2,2],[1,1,1,1],[2,2,2,2]] +输出:3 +解释:你将从点 (0, 0) 出发。 +到达 (3, 3) 的路径为: (0, 0) --> (0, 1) --> (0, 2) --> (0, 3) 花费代价 cost = 1 使方向向下 --> (1, 3) --> (1, 2) --> (1, 1) --> (1, 0) 花费代价 cost = 1 使方向向下 --> (2, 0) --> (2, 1) --> (2, 2) --> (2, 3) 花费代价 cost = 1 使方向向下 --> (3, 3) +总花费为 cost = 3. ++ +
示例 2:
+ +
输入:grid = [[1,1,3],[3,2,2],[1,1,4]] +输出:0 +解释:不修改任何数字你就可以从 (0, 0) 到达 (2, 2) 。 ++ +
示例 3:
+ +
输入:grid = [[1,2],[4,3]] +输出:1 ++ +
示例 4:
+ +输入:grid = [[2,2,2],[2,2,2]] +输出:3 ++ +
示例 5:
+ +输入:grid = [[4]] +输出:0 ++ +
+ +
提示:
+ +-
+
m == grid.length
+ n == grid[i].length
+ 1 <= m, n <= 100
+
给你一个字符串 s ,请你根据下面的算法重新构造字符串:
-
+
- 从
s中选出 最小 的字符,将它 接在 结果字符串的后面。
+ - 从
s剩余字符中选出 最小 的字符,且该字符比上一个添加的字符大,将它 接在 结果字符串后面。
+ - 重复步骤 2 ,直到你没法从
s中选择字符。
+ - 从
s中选出 最大 的字符,将它 接在 结果字符串的后面。
+ - 从
s剩余字符中选出 最大 的字符,且该字符比上一个添加的字符小,将它 接在 结果字符串后面。
+ - 重复步骤 5 ,直到你没法从
s中选择字符。
+ - 重复步骤 1 到 6 ,直到
s中所有字符都已经被选过。
+
在任何一步中,如果最小或者最大字符不止一个 ,你可以选择其中任意一个,并将其添加到结果字符串。
+ +请你返回将 s 中字符重新排序后的 结果字符串 。
+ +
示例 1:
+ +输入:s = "aaaabbbbcccc" +输出:"abccbaabccba" +解释:第一轮的步骤 1,2,3 后,结果字符串为 result = "abc" +第一轮的步骤 4,5,6 后,结果字符串为 result = "abccba" +第一轮结束,现在 s = "aabbcc" ,我们再次回到步骤 1 +第二轮的步骤 1,2,3 后,结果字符串为 result = "abccbaabc" +第二轮的步骤 4,5,6 后,结果字符串为 result = "abccbaabccba" ++ +
示例 2:
+ +输入:s = "rat" +输出:"art" +解释:单词 "rat" 在上述算法重排序以后变成 "art" ++ +
示例 3:
+ +输入:s = "leetcode" +输出:"cdelotee" ++ +
示例 4:
+ +输入:s = "ggggggg" +输出:"ggggggg" ++ +
示例 5:
+ +输入:s = "spo" +输出:"ops" ++ +
+ +
提示:
+ +-
+
1 <= s.length <= 500
+ s只包含小写英文字母。
+
给你一个字符串 s ,请你返回满足以下条件的最长子字符串的长度:每个元音字母,即 'a','e','i','o','u' ,在子字符串中都恰好出现了偶数次。
+ +
示例 1:
+ ++输入:s = "eleetminicoworoep" +输出:13 +解释:最长子字符串是 "leetminicowor" ,它包含 e,i,o 各 2 个,以及 0 个 a,u 。 ++ +
示例 2:
+ ++输入:s = "leetcodeisgreat" +输出:5 +解释:最长子字符串是 "leetc" ,其中包含 2 个 e 。 ++ +
示例 3:
+ ++输入:s = "bcbcbc" +输出:6 +解释:这个示例中,字符串 "bcbcbc" 本身就是最长的,因为所有的元音 a,e,i,o,u 都出现了 0 次。 ++ +
+ +
提示:
+ +-
+
1 <= s.length <= 5 x 10^5
+ s只包含小写英文字母。
+
给你一棵以 root 为根的二叉树,二叉树中的交错路径定义如下:
-
+
- 选择二叉树中 任意 节点和一个方向(左或者右)。 +
- 如果前进方向为右,那么移动到当前节点的的右子节点,否则移动到它的左子节点。 +
- 改变前进方向:左变右或者右变左。 +
- 重复第二步和第三步,直到你在树中无法继续移动。 +
交错路径的长度定义为:访问过的节点数目 - 1(单个节点的路径长度为 0 )。
+ +请你返回给定树中最长 交错路径 的长度。
+ ++ +
示例 1:
+ +
输入:root = [1,null,1,1,1,null,null,1,1,null,1,null,null,null,1,null,1] +输出:3 +解释:蓝色节点为树中最长交错路径(右 -> 左 -> 右)。 ++ +
示例 2:
+ +
输入:root = [1,1,1,null,1,null,null,1,1,null,1] +输出:4 +解释:蓝色节点为树中最长交错路径(左 -> 右 -> 左 -> 右)。 ++ +
示例 3:
+ +输入:root = [1] +输出:0 ++ +
+ +
提示:
+ +-
+
- 每棵树最多有
50000个节点。
+ - 每个节点的值在
[1, 100]之间。
+
给你一棵以 root 为根的 二叉树 ,请你返回 任意 二叉搜索子树的最大键值和。
二叉搜索树的定义如下:
+ +-
+
- 任意节点的左子树中的键值都 小于 此节点的键值。 +
- 任意节点的右子树中的键值都 大于 此节点的键值。 +
- 任意节点的左子树和右子树都是二叉搜索树。 +
+ +
示例 1:
+ +
输入:root = [1,4,3,2,4,2,5,null,null,null,null,null,null,4,6] +输出:20 +解释:键值为 3 的子树是和最大的二叉搜索树。 ++ +
示例 2:
+ +
输入:root = [4,3,null,1,2] +输出:2 +解释:键值为 2 的单节点子树是和最大的二叉搜索树。 ++ +
示例 3:
+ +输入:root = [-4,-2,-5] +输出:0 +解释:所有节点键值都为负数,和最大的二叉搜索树为空。 ++ +
示例 4:
+ +输入:root = [2,1,3] +输出:6 ++ +
示例 5:
+ +输入:root = [5,4,8,3,null,6,3] +输出:7 ++ +
+ +
提示:
+ +-
+
- 每棵树最多有
40000个节点。
+ - 每个节点的键值在
[-4 * 10^4 , 4 * 10^4]之间。
+
给你一个整数 n,请你返回一个含 n 个字符的字符串,其中每种字符在该字符串中都恰好出现 奇数次 。
返回的字符串必须只含小写英文字母。如果存在多个满足题目要求的字符串,则返回其中任意一个即可。
+ ++ +
示例 1:
+ +输入:n = 4 +输出:"pppz" +解释:"pppz" 是一个满足题目要求的字符串,因为 'p' 出现 3 次,且 'z' 出现 1 次。当然,还有很多其他字符串也满足题目要求,比如:"ohhh" 和 "love"。 ++ +
示例 2:
+ +输入:n = 2 +输出:"xy" +解释:"xy" 是一个满足题目要求的字符串,因为 'x' 和 'y' 各出现 1 次。当然,还有很多其他字符串也满足题目要求,比如:"ag" 和 "ur"。 ++ +
示例 3:
+ +输入:n = 7 +输出:"holasss" ++ +
+ +
提示:
+ +-
+
1 <= n <= 500
+
房间中有 n 枚灯泡,编号从 1 到 n,自左向右排成一排。最初,所有的灯都是关着的。
在 k 时刻( k 的取值范围是 0 到 n - 1),我们打开 light[k] 这个灯。
灯的颜色要想 变成蓝色 就必须同时满足下面两个条件:
+ +-
+
- 灯处于打开状态。 +
- 排在它之前(左侧)的所有灯也都处于打开状态。 +
请返回能够让 所有开着的 灯都 变成蓝色 的时刻 数目 。
+ ++ +
示例 1:
+ +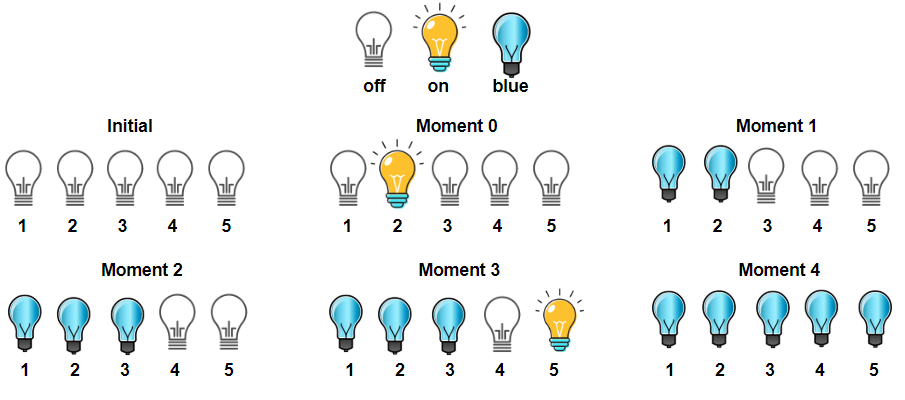
输入:light = [2,1,3,5,4] +输出:3 +解释:所有开着的灯都变蓝的时刻分别是 1,2 和 4 。 ++ +
示例 2:
+ +输入:light = [3,2,4,1,5] +输出:2 +解释:所有开着的灯都变蓝的时刻分别是 3 和 4(index-0)。 ++ +
示例 3:
+ +输入:light = [4,1,2,3] +输出:1 +解释:所有开着的灯都变蓝的时刻是 3(index-0)。 +第 4 个灯在时刻 3 变蓝。 ++ +
示例 4:
+ +输入:light = [2,1,4,3,6,5] +输出:3 ++ +
示例 5:
+ +输入:light = [1,2,3,4,5,6] +输出:6 ++ +
+ +
提示:
+ +-
+
n == light.length
+ 1 <= n <= 5 * 10^4
+ light是[1, 2, ..., n]的一个排列。
+
公司里有 n 名员工,每个员工的 ID 都是独一无二的,编号从 0 到 n - 1。公司的总负责人通过 headID 进行标识。
在 manager 数组中,每个员工都有一个直属负责人,其中 manager[i] 是第 i 名员工的直属负责人。对于总负责人,manager[headID] = -1。题目保证从属关系可以用树结构显示。
公司总负责人想要向公司所有员工通告一条紧急消息。他将会首先通知他的直属下属们,然后由这些下属通知他们的下属,直到所有的员工都得知这条紧急消息。
+ +第 i 名员工需要 informTime[i] 分钟来通知它的所有直属下属(也就是说在 informTime[i] 分钟后,他的所有直属下属都可以开始传播这一消息)。
返回通知所有员工这一紧急消息所需要的 分钟数 。
+ ++ +
示例 1:
+ +输入:n = 1, headID = 0, manager = [-1], informTime = [0] +输出:0 +解释:公司总负责人是该公司的唯一一名员工。 ++ +
示例 2:
+ +
输入:n = 6, headID = 2, manager = [2,2,-1,2,2,2], informTime = [0,0,1,0,0,0] +输出:1 +解释:id = 2 的员工是公司的总负责人,也是其他所有员工的直属负责人,他需要 1 分钟来通知所有员工。 +上图显示了公司员工的树结构。 ++ +
示例 3:
+ +
输入:n = 7, headID = 6, manager = [1,2,3,4,5,6,-1], informTime = [0,6,5,4,3,2,1] +输出:21 +解释:总负责人 id = 6。他将在 1 分钟内通知 id = 5 的员工。 +id = 5 的员工将在 2 分钟内通知 id = 4 的员工。 +id = 4 的员工将在 3 分钟内通知 id = 3 的员工。 +id = 3 的员工将在 4 分钟内通知 id = 2 的员工。 +id = 2 的员工将在 5 分钟内通知 id = 1 的员工。 +id = 1 的员工将在 6 分钟内通知 id = 0 的员工。 +所需时间 = 1 + 2 + 3 + 4 + 5 + 6 = 21 。 ++ +
示例 4:
+ +输入:n = 15, headID = 0, manager = [-1,0,0,1,1,2,2,3,3,4,4,5,5,6,6], informTime = [1,1,1,1,1,1,1,0,0,0,0,0,0,0,0] +输出:3 +解释:第一分钟总负责人通知员工 1 和 2 。 +第二分钟他们将会通知员工 3, 4, 5 和 6 。 +第三分钟他们将会通知剩下的员工。 ++ +
示例 5:
+ +输入:n = 4, headID = 2, manager = [3,3,-1,2], informTime = [0,0,162,914] +输出:1076 ++ +
+ +
提示:
+ +-
+
1 <= n <= 10^5
+ 0 <= headID < n
+ manager.length == n
+ 0 <= manager[i] < n
+ manager[headID] == -1
+ informTime.length == n
+ 0 <= informTime[i] <= 1000
+ - 如果员工
i没有下属,informTime[i] == 0。
+ - 题目 保证 所有员工都可以收到通知。 +
给你一棵由 n 个顶点组成的无向树,顶点编号从 1 到 n。青蛙从 顶点 1 开始起跳。规则如下:
-
+
- 在一秒内,青蛙从它所在的当前顶点跳到另一个 未访问 过的顶点(如果它们直接相连)。 +
- 青蛙无法跳回已经访问过的顶点。 +
- 如果青蛙可以跳到多个不同顶点,那么它跳到其中任意一个顶点上的机率都相同。 +
- 如果青蛙不能跳到任何未访问过的顶点上,那么它每次跳跃都会停留在原地。 +
无向树的边用数组 edges 描述,其中 edges[i] = [fromi, toi] 意味着存在一条直接连通 fromi 和 toi 两个顶点的边。
返回青蛙在 t 秒后位于目标顶点 target 上的概率。
+ +
示例 1:
+ +
输入:n = 7, edges = [[1,2],[1,3],[1,7],[2,4],[2,6],[3,5]], t = 2, target = 4 +输出:0.16666666666666666 +解释:上图显示了青蛙的跳跃路径。青蛙从顶点 1 起跳,第 1 秒 有 1/3 的概率跳到顶点 2 ,然后第 2 秒 有 1/2 的概率跳到顶点 4,因此青蛙在 2 秒后位于顶点 4 的概率是 1/3 * 1/2 = 1/6 = 0.16666666666666666 。 ++ +
示例 2:
+ +
输入:n = 7, edges = [[1,2],[1,3],[1,7],[2,4],[2,6],[3,5]], t = 1, target = 7 +输出:0.3333333333333333 +解释:上图显示了青蛙的跳跃路径。青蛙从顶点 1 起跳,有 1/3 = 0.3333333333333333 的概率能够 1 秒 后跳到顶点 7 。 ++ +
示例 3:
+ +输入:n = 7, edges = [[1,2],[1,3],[1,7],[2,4],[2,6],[3,5]], t = 20, target = 6 +输出:0.16666666666666666 ++ +
+ +
提示:
+ +-
+
1 <= n <= 100
+ edges.length == n-1
+ edges[i].length == 2
+ 1 <= edges[i][0], edges[i][1] <= n
+ 1 <= t <= 50
+ 1 <= target <= n
+ - 与准确值误差在
10^-5之内的结果将被判定为正确。
+
给你两棵二叉树,原始树 original 和克隆树 cloned,以及一个位于原始树 original 中的目标节点 target。
其中,克隆树 cloned 是原始树 original 的一个 副本 。
请找出在树 cloned 中,与 target 相同 的节点,并返回对该节点的引用(在 C/C++ 等有指针的语言中返回 节点指针,其他语言返回节点本身)。
+ +
注意:
+ +-
+
- 你 不能 对两棵二叉树,以及
target节点进行更改。
+ - 只能 返回对克隆树
cloned中已有的节点的引用。
+
-
+
进阶:如果树中允许出现值相同的节点,你将如何解答?
+ ++ +
-
+
示例 1:
+ +
输入: tree = [7,4,3,null,null,6,19], target = 3 +输出: 3 +解释: 上图画出了树 original 和 cloned。target 节点在树 original 中,用绿色标记。答案是树 cloned 中的黄颜色的节点(其他示例类似)。+ +
示例 2:
+ +
输入: tree = [7], target = 7 +输出: 7 ++ +
示例 3:
+ +
输入: tree = [8,null,6,null,5,null,4,null,3,null,2,null,1], target = 4 +输出: 4 ++ +
示例 4:
+ +
输入: tree = [1,2,3,4,5,6,7,8,9,10], target = 5 +输出: 5 ++ +
示例 5:
+ +
输入: tree = [1,2,null,3], target = 2 +输出: 2+ +
+ +
提示:
+ +-
+
- 树中节点的数量范围为
[1, 10^4]。
+ - 同一棵树中,没有值相同的节点。 +
target节点是树original中的一个节点,并且不会是null。
+
给你一个 m * n 的矩阵,矩阵中的数字 各不相同 。请你按 任意 顺序返回矩阵中的所有幸运数。
幸运数是指矩阵中满足同时下列两个条件的元素:
+ +-
+
- 在同一行的所有元素中最小 +
- 在同一列的所有元素中最大 +
+ +
示例 1:
+ +输入:matrix = [[3,7,8],[9,11,13],[15,16,17]] +输出:[15] +解释:15 是唯一的幸运数,因为它是其所在行中的最小值,也是所在列中的最大值。 ++ +
示例 2:
+ +输入:matrix = [[1,10,4,2],[9,3,8,7],[15,16,17,12]] +输出:[12] +解释:12 是唯一的幸运数,因为它是其所在行中的最小值,也是所在列中的最大值。 ++ +
示例 3:
+ +输入:matrix = [[7,8],[1,2]] +输出:[7] ++ +
+ +
提示:
+ +-
+
m == mat.length
+ n == mat[i].length
+ 1 <= n, m <= 50
+ 1 <= matrix[i][j] <= 10^5
+ - 矩阵中的所有元素都是不同的 +
请你设计一个支持下述操作的栈。
+ +实现自定义栈类 CustomStack :
-
+
CustomStack(int maxSize):用maxSize初始化对象,maxSize是栈中最多能容纳的元素数量,栈在增长到maxSize之后则不支持push操作。
+ void push(int x):如果栈还未增长到maxSize,就将x添加到栈顶。
+ int pop():返回栈顶的值,或栈为空时返回 -1 。
+ void inc(int k, int val):栈底的k个元素的值都增加val。如果栈中元素总数小于k,则栈中的所有元素都增加val。
+
+ +
示例:
+ +输入: +["CustomStack","push","push","pop","push","push","push","increment","increment","pop","pop","pop","pop"] +[[3],[1],[2],[],[2],[3],[4],[5,100],[2,100],[],[],[],[]] +输出: +[null,null,null,2,null,null,null,null,null,103,202,201,-1] +解释: +CustomStack customStack = new CustomStack(3); // 栈是空的 [] +customStack.push(1); // 栈变为 [1] +customStack.push(2); // 栈变为 [1, 2] +customStack.pop(); // 返回 2 --> 返回栈顶值 2,栈变为 [1] +customStack.push(2); // 栈变为 [1, 2] +customStack.push(3); // 栈变为 [1, 2, 3] +customStack.push(4); // 栈仍然是 [1, 2, 3],不能添加其他元素使栈大小变为 4 +customStack.increment(5, 100); // 栈变为 [101, 102, 103] +customStack.increment(2, 100); // 栈变为 [201, 202, 103] +customStack.pop(); // 返回 103 --> 返回栈顶值 103,栈变为 [201, 202] +customStack.pop(); // 返回 202 --> 返回栈顶值 202,栈变为 [201] +customStack.pop(); // 返回 201 --> 返回栈顶值 201,栈变为 [] +customStack.pop(); // 返回 -1 --> 栈为空,返回 -1 ++ +
+ +
提示:
+ +-
+
1 <= maxSize <= 1000
+ 1 <= x <= 1000
+ 1 <= k <= 1000
+ 0 <= val <= 100
+ - 每种方法
increment,push以及pop分别最多调用1000次
+
给你一棵二叉搜索树,请你返回一棵 平衡后 的二叉搜索树,新生成的树应该与原来的树有着相同的节点值。
+ +如果一棵二叉搜索树中,每个节点的两棵子树高度差不超过 1 ,我们就称这棵二叉搜索树是 平衡的 。
+ +如果有多种构造方法,请你返回任意一种。
+ ++ +
示例:
+ +
输入:root = [1,null,2,null,3,null,4,null,null] +输出:[2,1,3,null,null,null,4] +解释:这不是唯一的正确答案,[3,1,4,null,2,null,null] 也是一个可行的构造方案。 ++ +
+ +
提示:
+ +-
+
- 树节点的数目在
1到10^4之间。
+ - 树节点的值互不相同,且在
1到10^5之间。
+
公司有编号为 1 到 n 的 n 个工程师,给你两个数组 speed 和 efficiency ,其中 speed[i] 和 efficiency[i] 分别代表第 i 位工程师的速度和效率。请你返回由最多 k 个工程师组成的 最大团队表现值 ,由于答案可能很大,请你返回结果对 10^9 + 7 取余后的结果。
团队表现值 的定义为:一个团队中「所有工程师速度的和」乘以他们「效率值中的最小值」。
+ ++ +
示例 1:
+ +输入:n = 6, speed = [2,10,3,1,5,8], efficiency = [5,4,3,9,7,2], k = 2 +输出:60 +解释: +我们选择工程师 2(speed=10 且 efficiency=4)和工程师 5(speed=5 且 efficiency=7)。他们的团队表现值为 performance = (10 + 5) * min(4, 7) = 60 。 ++ +
示例 2:
+ +输入:n = 6, speed = [2,10,3,1,5,8], efficiency = [5,4,3,9,7,2], k = 3 +输出:68 +解释: +此示例与第一个示例相同,除了 k = 3 。我们可以选择工程师 1 ,工程师 2 和工程师 5 得到最大的团队表现值。表现值为 performance = (2 + 10 + 5) * min(5, 4, 7) = 68 。 ++ +
示例 3:
+ +输入:n = 6, speed = [2,10,3,1,5,8], efficiency = [5,4,3,9,7,2], k = 4 +输出:72 ++ +
+ +
提示:
+ +-
+
1 <= n <= 10^5
+ speed.length == n
+ efficiency.length == n
+ 1 <= speed[i] <= 10^5
+ 1 <= efficiency[i] <= 10^8
+ 1 <= k <= n
+