Training a few epoch memory suddenly OOM #467
Comments
|
@mpj1234 what's your batch size? Reducing that might help. |
|
The bug of OOM is batch size = 120. Now it is batch size = 100, and eight epoch have been run, so there is no problem for the time being. |
|
👋 Hello! Thanks for asking about CUDA memory issues. YOLOv5/v8 🚀 can be trained on CPU, single-GPU, or multi-GPU. When training on GPU it is important to keep your batch-size small enough that you do not use all of your GPU memory, otherwise you will see a CUDA Out Of Memory (OOM) Error and your training will crash. You can observe your CUDA memory utilization using either the
CUDA Out of Memory SolutionsIf you encounter a CUDA OOM error, the steps you can take to reduce your memory usage are:
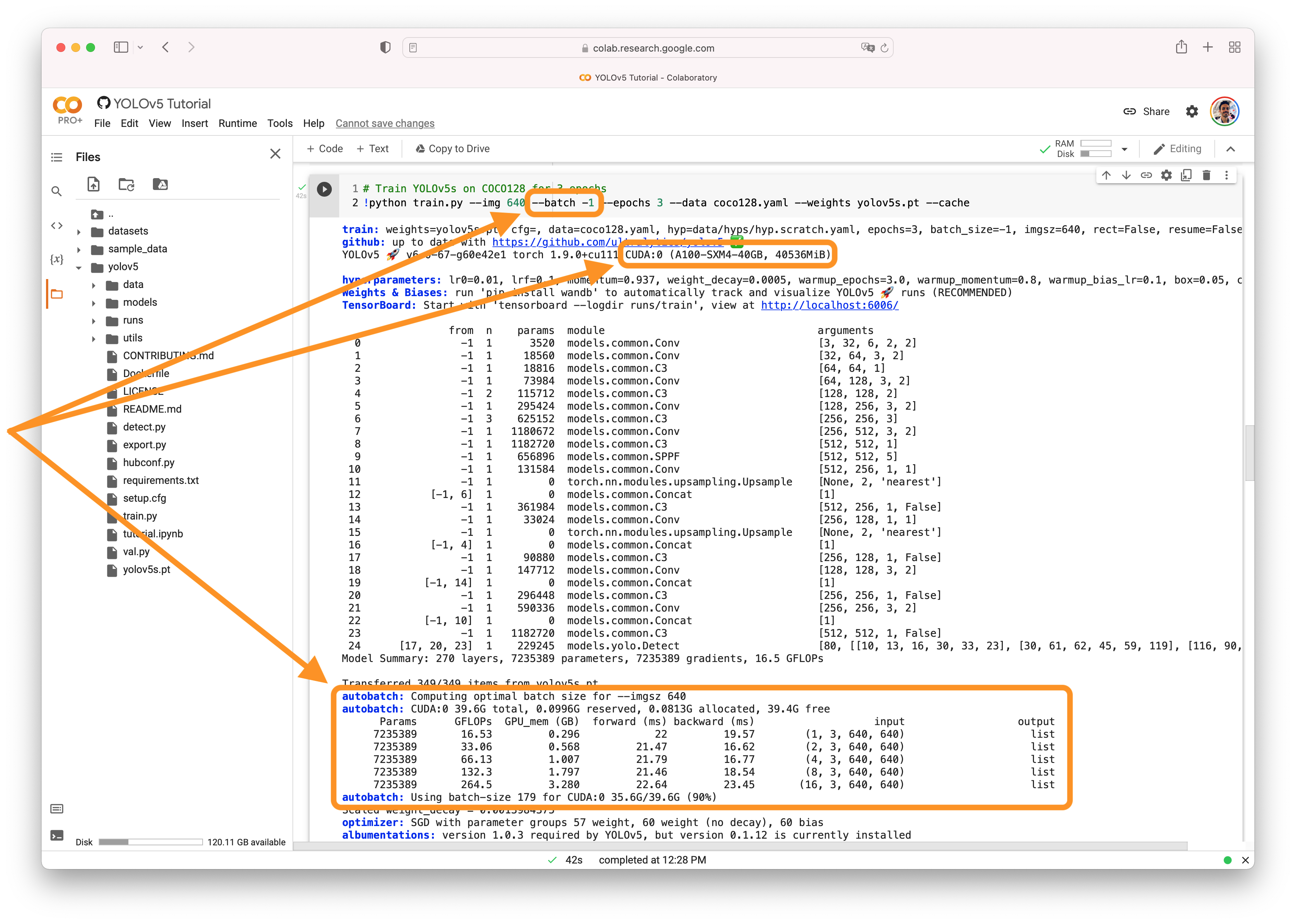
AutoBatchYou can use YOLOv5 AutoBatch (NEW) to find the best batch size for your training by passing
Good luck 🍀 and let us know if you have any other questions! |

|
Yesterday, after I switched batch size=100, I ran 67 epochs normally, but at 68epoch, I suddenly allocated a lot of memory, and OOM appeared. I think there may be memory leakage in the code.
I'm switching to automatic batch now, and I'm still experimenting. The automatic batch allocation is 151.
I hope if it's not a bug, explain why after training so many epoch, I suddenly have to allocate a lot of video memory. |


|
This is the automatic batch, and it is still OOM.
|

|
@mpj1234 hi, looks the number of instances in your dataset is variable. The memory is instances-related, the more instances you got the more memory would be occupied. So the OOM could happen when you got more instances for a sudden in one batch. You have to reduce batch-size or use small model to solve this OOM issue. |

|
ok, Thanks♪(・ω・)ノ |
|
for me the following things seem to work:
|
|
@Petros626 thank you for sharing these suggestions! Reducing batch size and using |
Search before asking
YOLOv8 Component
Training
Bug
During the training, there was no problem with the first few epoch, but suddenly OOM happened.
Environment
YOLOV8S
device:A40 48G
environment:
torch 1.10.0+cu113
torchvision 0.11.1+cu113
opencv-contrib-python 4.2.0.32
opencv-python 4.2.0.32
python 3.8.10
Minimal Reproducible Example
No response
Additional
No response
Are you willing to submit a PR?
The text was updated successfully, but these errors were encountered: