This project is part of the @thi.ng/umbrella monorepo.
Purely functional parser combinators & AST generation for generic inputs.
- Parser generation/compilation via built-in grammar DSL
- Small API surface, easy-to-grok syntax
- All parsers implemented as composable, higher-order functions
- All state centrally kept/managed by a parser context given as arg
- Support for custom readers (currently only string & array-like numeric inputs (incl. typed arrays) supported)
- Automatic AST generation & ability to transform/prune nodes during parsing
- Node transforms are composable too
- Each AST node (optionally) retains reader information (position, line num, column) - disabled by default to save memory
- Common, re-usable preset parsers & node transforms included
BETA - possibly breaking changes forthcoming
Search or submit any issues for this package
- @thi.ng/fsm - Composable primitives for building declarative, transducer based Finite-State Machines & matchers for arbitrary data streams
- @thi.ng/transducers-fsm - Transducer-based Finite State Machine transformer
yarn add @thi.ng/parse// ES module
<script type="module" src="https://unpkg.com/@thi.ng/parse?module" crossorigin></script>
// UMD
<script src="https://unpkg.com/@thi.ng/parse/lib/index.umd.js" crossorigin></script>Package sizes (gzipped, pre-treeshake): ESM: 5.24 KB / CJS: 5.63 KB / UMD: 5.29 KB
Several demos in this repo's /examples directory are using this package.
A selection:
| Screenshot | Description | Live demo | Source |
|---|---|---|---|
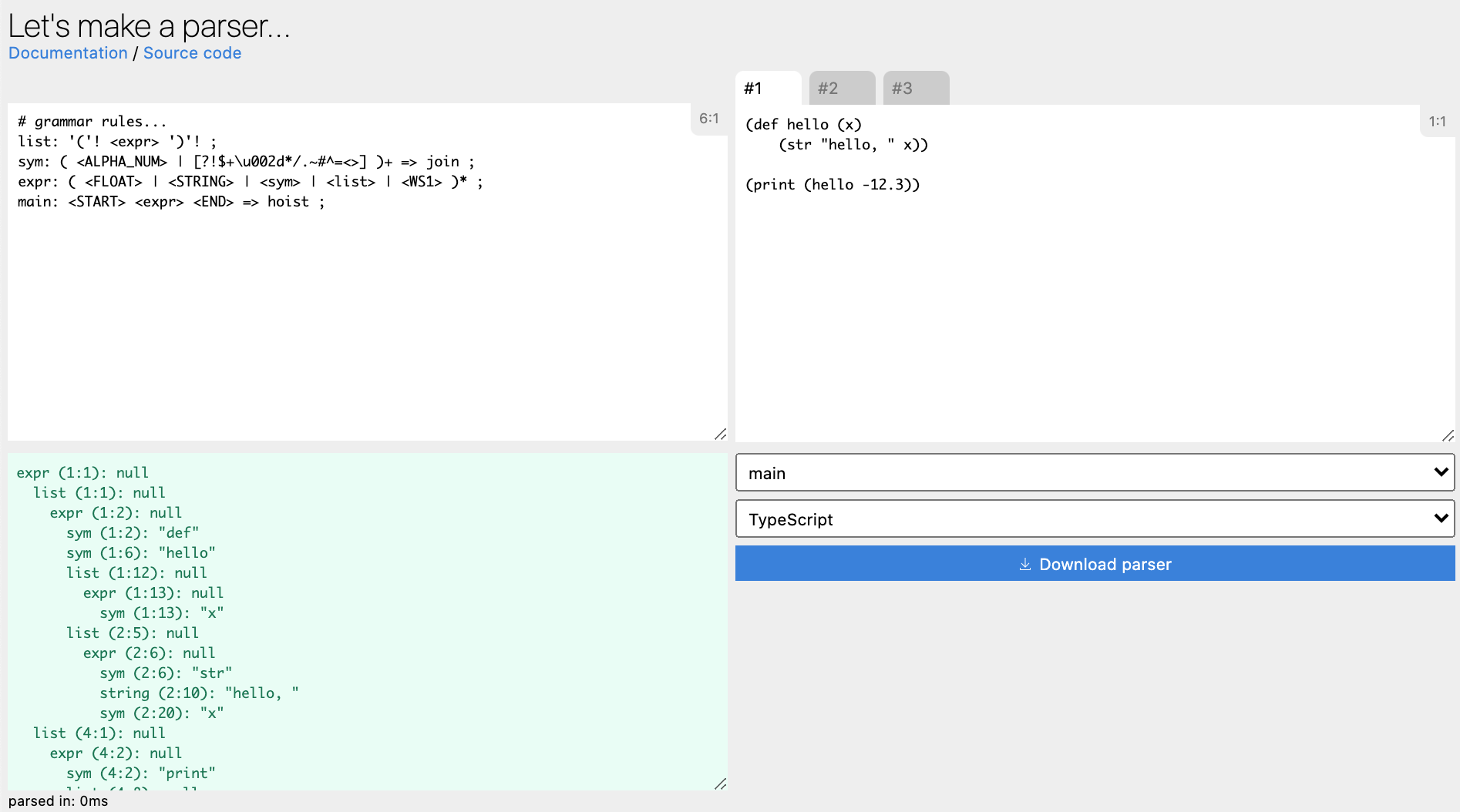 |
Parser grammar livecoding editor/playground & codegen | Demo | Source |
Note: Please also see the dedicated wiki page collecting various grammar examples and links to their playgrounds.
TODO
Source: /readers
defArrayReaderdefStringReader
Source: /presets
WS/WS0/WS1/NL/DNL/SPACE/SPACES/SPACES0ALPHA/LOWER_CASE/UPPER_CASE/ALPHA_NUMESC/UNICODEDIGIT/DIGITS/DIGITS0HEX_DIGIT/HEX_DIGITS/HEX_UINTBIT/BINARY_UINTINT/UINT/REAL/FLOAT/SIGN
Source: /prims
The D suffix is used for discarding behavior, i.e. parsers
which do not retain their result in the AST after successful matching.
These should be preferred whenever possible, for lower memory usage and
(possibly) better performance...
The P suffix is used to indicate predicate based parsers, i.e.
using user provided functions applied to individual inputs (characters)
in order to decide about successful matching.
alwaysfaillit/litD/litPnoneOf/noneOfD/noneOfPoneOf/oneOfD/oneOfPpass/passDrange/rangeD/rangePsatisfy/satisfyDskipWhilestring/stringDstringOf
anchorinputStart/inputEndlineStart/lineEndwordBoundarystartsWith/endsWithentireLineentirely
Source: /combinators
alt/altDcheckexpectlookaheadmaybenotoneOrMore/zeroOrMore/oneOrMoreD/zeroOrMoreDrepeat/repeatDseq/seqDxform
Source: /xform
Syntax sugars for xform(parser, fn):
collect- collect child results into arraycount- count number of childrendiscard- discard resulthoist/hoistResult- hoist first child / child resultjoin- join child results into stringnest- apply another parser to resultprint- print ASTreplace- replace AST node result w/ pre-configured valuetrim- trim node result (string only)withID- assign custom AST node ID
Actual transforms:
comp- scope transform compositionxfCollectxfCountxfDiscardxfFloatxfHoist/xfHoistResultxfInt(radix)xfJoinxfNestxfPrintxfReplacexfTrimxfID
Complex parsers can be constructed via
defGrammar(),
which accepts a string of rule definitions in the built-in (and still
WIP) grammar rule definition language, similar to PEGs and regular
expressions:
Example grammar
# line comment
ws: ' '+ => discard ;
sym: [a-z] [a-z0-9_]* => join ;
num: [0-9]+ => int ;
program: ( <num> | <sym> | <ws> )* ;
Here, each line (apart from the first) is a single parse rule definition, with each rule consisting of a sequence of one or more:
.- matches any single char'x'- single char literal"abc"- multi-char string[a-z0-9_@]- regex style char set (incl. char range support, inversion via^)<rule_id>- rule references (order independent)( term | ... | )- choice of sub-terms
Literals, strings and char sets can include \uXXXX unicode escapes (if
given within a JS source string, double escaping must be used, i.e.
\\uXXXX).
All of these terms can be immediately followed by one of these regexp style repetition specs:
?- zero or one occurrence*- zero or more+- one or more{n},{min,}or{min,max}- fixed size, min-infinity or min-max repetitions
All terms can be suffixed with the ! modifier to discard their results
and help produce a cleaner result AST.
link: '['! <linktitle> "]("! <linkurl> ')'! => collect ;
linktitle: [^\\u005d]+ => join ;
linkurl: [^\\u0029]+ => join ;
Given a valid input like [abc](def), the above link parser's result
will just be the array ["abc", "def"] with other terms discarded from
the AST.
Important: A parse rule MUST produce a result for at least one of
its successfully matched terms. Use the discard rule transform to
discard the entire result (instead of the ! modifier)...
All terms can be suffixed with an optional, capturing or non-capturing lookahead group:
(?-...): non-capturing(?+...): capturing
# accept any character until end of current line
# <NL> is a built-in preset rule to match newline chars...
rest: .(?-<NL>!) ;
When using lookahead, both the main and look-ahead parsers are run
repeatedly for as long as the former succeeds and UNTIL the latter
passes or the end of input is reached. If the ahead parser never
passes, the entire term fails and any partial matches are discarded.
Depending on capture behavior, the result of the ahead parser is
captured or omitted and the final read position is adjusted accordingly.
Currently, iff capture is disabled, the ahead parser MUST discard its own result (see section above). On successful match the final read position will then be restored to the beginning of ahead pattern.
Iff capture is enabled, the ahead parser MAY discard its own result, but the final read position will not be re-adjusted as in the non-capturing version.
Important: Since the main term will be repeated automatically, DO
NOT use repetition modifiers ? or *, since both of these will cause
the parser to go into an infinite loop. This is expected behavior and
not a bug.
The above mentioned optional term modifiers MUST always be given in this order:
- Repetitions (
?*+etc.) - Discard flag (
!) - Lookahead (
(?-...)/(?+...))
[a-z]+! # valid
[a-z]{4}! # valid
[a-z]! # valid
[a-z]!(?+[0-9]) # valid
[a-z]!+ # invalid
[a-z]!{4} # invalid
[a-z](?+'X')! # invalid
Furthermore, each rule can specify an optional rule transform function, result
string or even another parser rule, which will only be applied after the rule's
parser has successfully completed. The transform is given at the end of a rule,
separated by =>.
If another parser rule is specified (via <ruleid>), it will be applied to
result of the main rule in a separate parse context and its own results will be
transplanted back into the main AST.
If a result string is given (e.g. "foo"), it will be used as the rule's result
instead and the node's children will be removed.
Custom transforms functions can be supplied via an additional arg to
defGrammar(). The following default transforms are available by default (can
be overwritten) and correspond to the above mentioned
transforms:
binary- parse as binary numbercollect- collect sub terms into arraydiscard- discard resulthoist- replace AST node with its 1st childhoistR- use result of 1st child term onlyjoin- join sub terms into single stringfloat- parse as floating point numberint- parse as integerhex- parse as hex intprint- print out node's subtree (AST)trim- trim result
For convenience, the following built-in parser presets are available as rule references in the grammar definition as well:
ALPHAALPHA_NUMBITDIGITDNL- discarded newlineEND- input endESC- escape sequencesFLOATHEX_DIGITINTLEND- line endLSTART- line startNL- newline charsSTART- input startSTRINGUNICODEWB- word boundaryWSWS0WS1
(Also see @thi.ng/defmulti as a useful tool for processing/interpreting/compiling the result AST)
// define language via grammar DSL
// the upper-cased rule names are built-ins
const lang = defGrammar(`
list: '('! <expr> ')'! ;
sym: ( <ALPHA_NUM> | [?!$+\\u002d*/.~#^=<>] )+ => join ;
expr: ( <FLOAT> | <STRING> | <sym> | <list> | <WS1> )* ;
`);
// define input & parser context
const ctx = defContext(`
(def hello (x) (str "hello, " x))
(print (hello 42))
`);
// parse & print AST
print(lang.rules.expr)(ctx)
// expr: null
// list: null
// expr: null
// sym: "def"
// sym: "hello"
// list: null
// expr: null
// sym: "x"
// list: null
// expr: null
// sym: "str"
// string: "hello, "
// sym: "x"
// list: null
// expr: null
// sym: "print"
// list: null
// expr: null
// sym: "hello"
// real: 42
// parse result
// true
// the two top-level s-expressions...
ctx.children
// [
// { id: 'list', state: null, children: [ [Object] ], result: null },
// { id: 'list', state: null, children: [ [Object] ], result: null }
// ]import {
INT, WS0,
alt, oneOf, seq, zeroOrMore,
collect, discard, xform,
defContext
} from "@thi.ng/parse";
// whitespace parser
// discard() removes results from AST
const wsc = discard(zeroOrMore(oneOf(" ,")));
// svg path parser rules
// collect() collects child results in array, then removes children
// INT & WS0 are preset parsers (see section above)
const point = collect(seq([INT, wsc, INT]));
const move = collect(seq([oneOf("Mm"), WS0, point, WS0]));
const line = collect(seq([oneOf("Ll"), WS0, point, WS0]));
const curve = collect(seq([oneOf("Cc"), WS0, point, wsc, point, wsc, point, WS0]));
// xform used here to wrap result in array
// (to produce same result format as parsers above)
const close = xform(oneOf("Zz"), ($) => ($.result = [$.result], $));
// main path parser
const path = collect(zeroOrMore(alt([move, line, curve, close])));
// prepare parse context & reader
const ctx = defContext("M0,1L2 3c4,5-6,7 8 9z");
// parse input into AST
path(ctx);
// true
// transformed result of AST root node
ctx.result
// [["M", [0, 1]], ["L", [2, 3]], ["c", [4, 5], [-6, 7], [8, 9]], ["z"]]import {
INT, WS0,
alt, oneOf, xform, zeroOrMore
defContext
} from "@thi.ng/parse";
// data stack for execution
const stack = [];
// operator implementations
const ops = {
"+": (a, b) => a + b,
"-": (a, b) => a - b,
"*": (a, b) => a * b,
"/": (a, b) => a / b,
};
// signed integer parser (using INT preset) with transform fn.
// the user fn here is only used for pushing values on data stack
// also, if a transform returns null, the parse scope will
// be removed from the result AST
const value = xform(INT, (scope) => {
stack.push(scope.result);
return null;
});
// parser for any of the registered operators (again w/ transform)
// the transform here applies the op in RPN fashion to the data stack
// stack underflow handling omitted for brevity
const op = xform(oneOf(Object.keys(ops)), (scope) => {
const b = stack.pop();
const a = stack.pop();
stack.push(ops[scope.result](a, b));
return null;
});
// parser for complete RPN program, combines above two parsers
// and the whitespace preset as alternatives
const program = zeroOrMore(alt([value, op, WS0]))
// prepare parser context (incl. reader) and execute
program(defContext("10 5 3 * + -2 * 10 /"));
// print result data stack, i.e. result of:
// (3 * 5 + 10) * -2 / 10 (in infix notation)
console.log(stack);
// [-5]Karsten Schmidt
If this project contributes to an academic publication, please cite it as:
@misc{thing-parse,
title = "@thi.ng/parse",
author = "Karsten Schmidt",
note = "https://thi.ng/parse",
year = 2020
}© 2020 - 2021 Karsten Schmidt // Apache Software License 2.0