{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
In the modern world where crimes are increasing at a phenomenal rate we need a strong system to act against the same. We need a system that is able to capture and store the licence plate of a vehicle in case of a crime. Our aim is Licence Plate Detection and Recognition. We realized our aim through RPNet. It consists of two parts. First the aobject detection part, which detects the licence plate and forms a bounding box around it. Then we use OCR on these detected licence plates to etract the alphabets and digits on the licence plates. This is done end-to-end. We describe our idea in detail in the upcoming 'Approach' section.
- Pytorch 1.1
- numpy
- opencv 3.2
We use the CCPD dataset, the largest openly available dataset of licence plate images (more than 250,000 images). It provides a large and varied dataset for testing our network and effectively generalizing the results obtained. Most other licence plate datasets are very small (4000 - 10000 images) and are not adequate to train such an End-to-End network.
We divide our problem into two fundamental parts
- Predicting the bounding boxes with good enough accuracy
- Recognising the characters of the licence plate
A common way of doing the above, as used in many papers, is having a separate network, typically like YOLO, SSD or even RCNN to detect licence plates in an image and predict accurate bounding boxes around these. These plate detectors are trained first on large databases like ImageNet and then fine-tuned for detecting boxes. Then, a separate character recognition net is trained on only the bounding boxes extracted from the image.
We, instead use an End-to-End training based network to perform both the Box detection, and number plate prediction. We use an architecture called the RPNet, proposed in an ECCV 2018 paper to detect licence plates and recognise their characters. It involves:
- An equivalent to the old "Box detectors" networks made of 2D convolutional layers, which in addition to detecting the licence plate location also gets useful features for character recognition.
- 7 classifiers for extracting the 7 digits in licence plate. They use cross linkages from various deeper convolutional layers for their prediction, in addition to the usual bounding box coordinates. The cross linkages help in recognition of smaller and bigger plates, which is important in generalizing our results as vehicles may be very near or very far away from the camera.
We train our model End-to End, unlike the older approaches and use our large CCPD dataset for it. Both the classification and the box detection loss are used for it. Training the "box detector CNN" too using the 'classification loss + box detector loss' helps in making the convolutional features more useful in recognition of characters.
The Block Digram in straightforward terms is shown below:
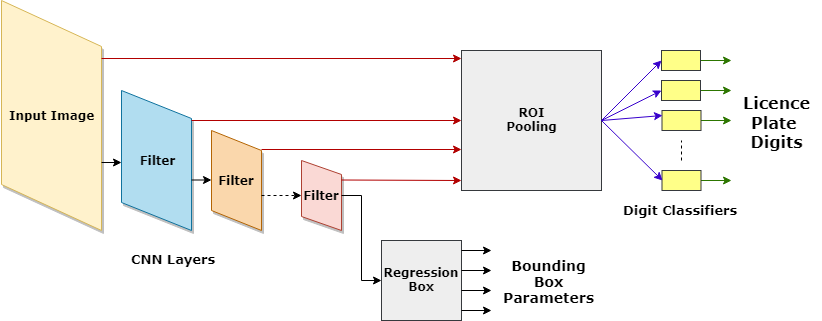
In our quest to achieve better recognition and understand the network better, we conducted quite a few experiments, the most important of which are as mentioned-
- We could not help but wonder if jointly training both, the detector and the character recogniser layers using the classification loss was really useful? So, we put it to test. We tried training only the recogniser using the classification(cross entropy) loss, keeping the weights of the "box detector" the same duringthis training.
- Activation functions do matter a lot! To try out something new, we tried using the recently proposed swish activation function- which has been proven to improve accuracy in object detection and recognition. We use the Swish function which is actually x multiplied by sigmoid. It's graph is shown below:
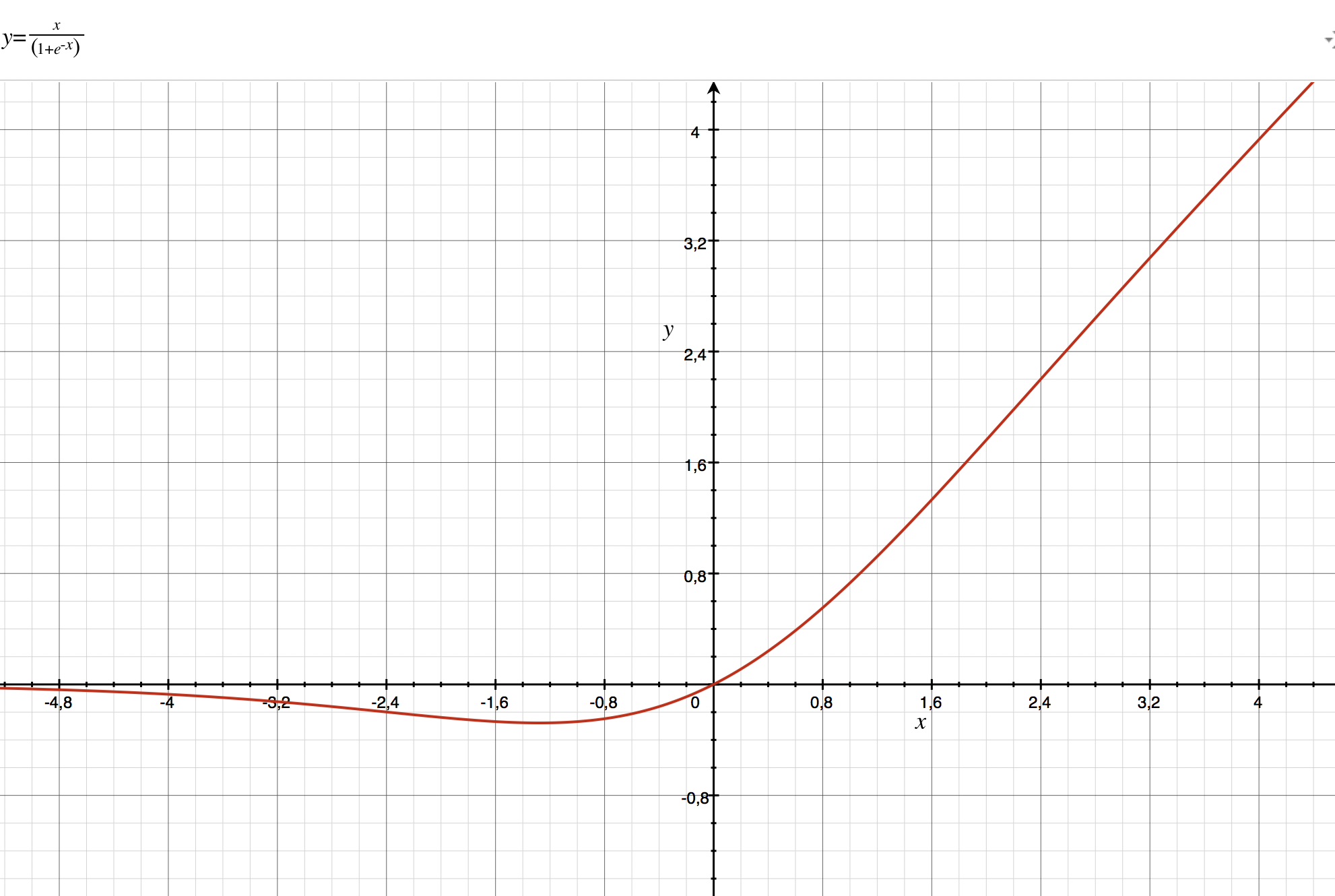 We see that the gradient of the swish function does not trivially go to zero, for high values of positive x (as compared to sigmoid), and also for negative x (as compared to ReLU), thus preserving the gradients while backpropogation. This in-turn helps in better training in deeper networks.
We see that the gradient of the swish function does not trivially go to zero, for high values of positive x (as compared to sigmoid), and also for negative x (as compared to ReLU), thus preserving the gradients while backpropogation. This in-turn helps in better training in deeper networks. - To see which cross links/features from which layer are the most helpful in recognition, we test out different cross links one at a time.
- We also try out different combinations of cross-links to see which one gives the best accuracy.
| Experiment | Accuracy | Speed of predictions | |
|---|---|---|---|
| Activation function | ReLU | 93.6% | High |
| Swish | 94.2% | Slower | |
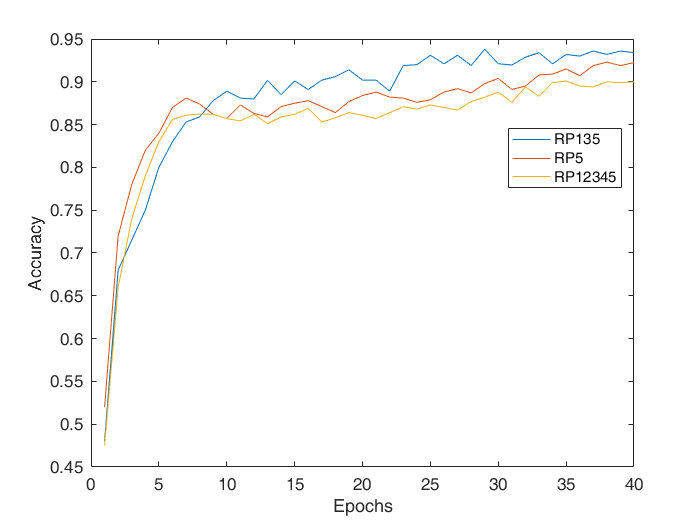
| Features cross linked | RP135 | 93.6% | High |
| RP5 | 92.3% | Highest | |
| RP12345 | 90.1% | Slowest | |
| Training | Full End to End | 93.6% | Slower training |
| Not training Box detector in End to End | 90.7% | Faster training |
- Out best model is available on this link (too large to upload on Github): https://drive.google.com/open?id=15q4ZpZ08IQm0pzIw8Pc1DFB9s2RamnYA
Now we show some plots obtained while experimenting:
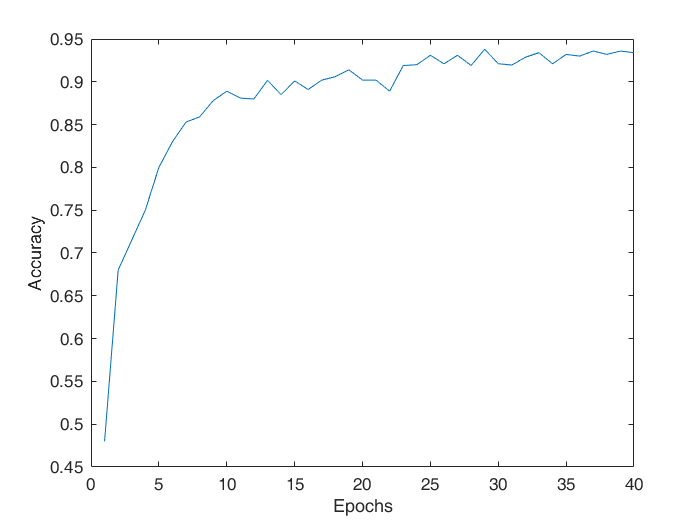
- The following is the plot generated for accurracy vs epochs, for the case when RP135 is used (i.e. the 1st, 3rd and 5th convolutional layers are used in the classifer) with ReLU as the activation funtion, with training being performed fully end to end
- Testing the accuracy vs epochs, when varying the cross links/features that go into the digit classifier.
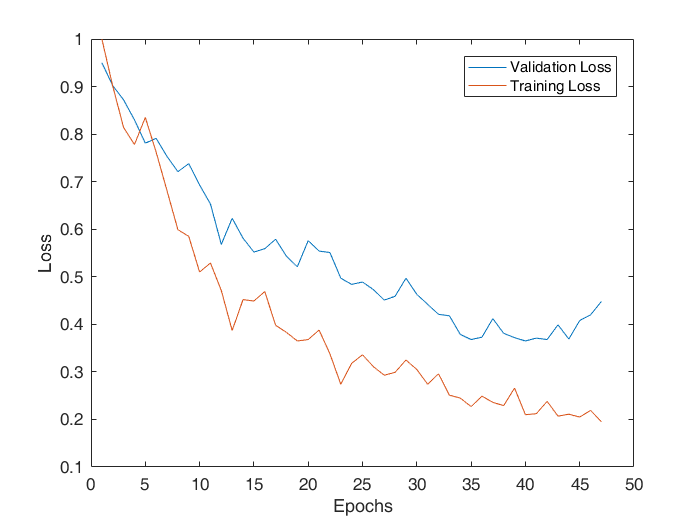
-The following is the plot obtained fpr the validation loss and training loss vs epochs, for our best model.
-The following few images are the images which are output from our network:




- Our project is based on the 2018 ECCV paper - https://github.com/detectRecog/CCPD We used a modified version of their code for ROI pooling and loading our dataset (which would have anyway been similar and slower if written by us). We also used their pre-trained box-detector model (wR2 only not the End-to-End) for initialising the weights of our box-detector before training.
- Swish original paper-https://arxiv.org/abs/1710.05941
We would like to express our grattiude to Prof. Arjun Jain, who provided us with alot of knowloedge and inspiration by the means of his lectures. We would also like to express our thanks to Rishabh and Safeer for their continuous help, support and guidance.