AutoMLOps is a service that generates, provisions, deploys, and monitors CI/CD integrated MLOps pipelines, bridging the gap between Data Science and DevOps. AutoMLOps provides a repeatable process that dramatically reduces the time required to build MLOps pipelines. The service generates a containerized MLOps codebase, provides infrastructure-as-code to provision and maintain the underlying MLOps infra, provides deployment functionalities to trigger and run MLOps pipelines, monitoring capabilities to monitor models deployed to live endpoints, and optional automatic retraining of models on a recurring basis or if anomalies are detected during monitoring.
AutoMLOps gives flexibility over the tools and technologies used in the MLOps pipelines, allowing users to choose from a wide range of options for artifact repositories, build tools, provisioning tools, orchestration frameworks, and source code repositories. AutoMLOps can be configured to either use existing infra, or provision new infra, including source code repositories for versioning the generated MLOps codebase, build configs and triggers, artifact repositories for storing docker containers, storage buckets, service accounts, IAM permissions, APIs needed to run pipelines, RESTful services to allow for triggering and running pipelines asynchronous, and Cloud Scheduler jobs for triggering and running pipelines on a recurring basis.
These automatic integrations empower data scientists to take their experiments to production more quickly, allowing them to focus on what they do best: providing actionable insights through data.
Install AutoMLOps from PyPI: pip install google-cloud-automlops
Or Install locally by cloning the repo and running pip install .
docopt==0.6.2docstring-parser==0.15google-api-python-client==2.97.0google-auth==2.22.0importlib-resources==6.0.1Jinja2==3.1.2kfp>=2.0.0packaging==23.1pipreqs==0.4.13pydantic==2.3.0PyYAML==6.0.1yarg==0.1.9
AutoMLOps provides 2 functions for defining MLOps pipelines:
@AutoMLOps.component(...): Defines a component, which is a containerized python function.@AutoMLOps.pipeline(...): Defines a pipeline, which is a series of components.
AutoMLOps provides 6 functions for building and maintaining MLOps pipelines:
AutoMLOps.generate(...): Generates the MLOps codebase. Users can specify the tooling and technologies they would like to use in their MLOps pipeline.AutoMLOps.provision(...): Runs provisioning scripts to create and maintain necessary infra for MLOps.AutoMLOps.deprovision(...): Runs deprovisioning scripts to tear down MLOps infra created using AutoMLOps.AutoMLOps.deploy(...): Builds and pushes component container, then triggers the pipeline job.AutoMLOps.launchAll(...): Runsgenerate(),provision(), anddeploy()all in succession.AutoMLOps.monitor(...): Creates model monitoring jobs on deployed endpoints.
For a full user-guide, please view these slides.
Training
- 00_introduction_training_example <- start here
- 00_introduction_training_example_no_notebook
- 01_clustering_example
- 02_tensorflow_transfer_learning_gpu_example
- 03_bqml_introduction_training_example
- 04_bqml_forecasting-retail-demand
Inferencing
Artifact Repositories: Stores component docker containers
- Artifact Registry
Deployment Frameworks: Builds component docker containers, compiles pipelines, and submits Pipeline Jobs
- Github Actions
- Cloud Build
- [coming soon] Gitlab CI
- [coming soon] Bitbucket Pipelines
- [coming soon] Jenkins
Orchestration Frameworks: Executes and orchestrates pipelines jobs
- Kubeflow Pipelines (KFP) - Runs on Vertex AI Pipelines
- [coming soon] Tensorflow Extended (TFX) - Runs on Vertex AI Pipelines
- [coming soon] Argo Workflows - Runs on GKE
- [coming soon] Airflow - Runs on Cloud Composer
- [coming soon] Ray - Runs on GKE
Submission Service Compute Environments: RESTful service for submitting pipeline jobs to the orchestrator (e.g. Vertex AI, Cloud Composer, etc.)
- Cloud Functions
- Cloud Run
Provisioning Frameworks: Stands up necessary infra to run MLOps pipelines
- gcloud
- terraform
- [coming soon] pulumi
Source Code Repositories: Repository for versioning generated MLOps code
- Github
- Bitbucket
- Gitlab
- [deprecated] Cloud Source Repositories
In order to use AutoMLOps.generate(...), the following are required:
- Python 3.7 - 3.10
In order to use AutoMLOps.provision(...) with provisioning_framework='gcloud', the following are recommended:
In order to use AutoMLOps.provision(...) with provisioning_framework='terraform', the following are recommended:
In order to use AutoMLOps.deploy(...) with use_ci=False, the following are required:
- Local python environment with these packages installed:
kfp>=2.0.0google-cloud-aiplatformgoogle-cloud-pipeline-componentsgoogle-cloud-storagepyyaml
In order to use AutoMLOps.deploy(...) with use_ci=True, the following are required:
gitinstalledgitlogged-in:
git config --global user.email "you@example.com"
git config --global user.name "Your Name"
- Registered and setup your SSH key if you are using Github, Gitlab, or Bitbucket
In order to use AutoMLOps.monitor(...), the following are required:
-
Local python environment with these packages installed:
google-cloud-aiplatformgoogle-cloud-logginggoogle-cloud-storagepyyaml
-
Application Default Credentials (ADC) are set up. This can be done through the following commands:
gcloud auth application-default login
gcloud config set account <account@example.com>
AutoMLOps makes use of the following products by default:
AutoMLOps will makes use of the following products based on user selected options:
- if
artifact_repo_type='artifact-registry', AutoMLOps will use:
- if
use_ci=Falseandorchestration_framework='kfp'anddeployment_framework='cloud-build', AutoMLOps will use:
- if
use_ci=Trueandorchestration_framework='kfp'anddeployment_framework='cloud-build', AutoMLOps will use:
- if
use_ci=Trueandpipeline_job_submission_service_type='cloud-functions', AutoMLOps will use:
- if
use_ci=Trueandpipeline_job_submission_service_type='cloud-run', AutoMLOps will use:
- if
use_ci=Trueandschedule_patternis specified, AutoMLOps will use:
- if
use_ci=Trueandsetup_model_monitoring=True, AutoMLOps will use:
Based on the above user selection, AutoMLOps will enable up to the following APIs during the provision step:
- aiplatform.googleapis.com
- artifactregistry.googleapis.com
- cloudbuild.googleapis.com
- cloudfunctions.googleapis.com
- cloudresourcemanager.googleapis.com
- cloudscheduler.googleapis.com
- compute.googleapis.com
- iam.googleapis.com
- iamcredentials.googleapis.com
- logging.googleapis.com
- pubsub.googleapis.com
- run.googleapis.com
- storage.googleapis.com
AutoMLOps will create the following service account and update IAM permissions during the provision step:
- Pipeline Runner Service Account (defaults to: vertex-pipelines@PROJECT_ID.iam.gserviceaccount.com). Roles added:
- roles/aiplatform.user
- roles/artifactregistry.reader
- roles/bigquery.user
- roles/bigquery.dataEditor
- roles/iam.serviceAccountUser
- roles/storage.admin
- roles/cloudfunctions.admin
AutoMLOps provides a number of optional prechecks and warnings to provide visibility to the user into what IAM permissions are required to run certain operations.
AutoMLOps.provision(...hide_warnings=False): This will check installation versions and account permissions to determine if the current account has the permissions to provision successfully.AutoMLOps.deploy(...hide_warnings=False): This will check installation versions and account permissions to determine if the current account has the permissions to deploy successfully.AutoMLOps.deploy(...precheck=True): This will check for the necessary infrastructure to deploy successfully (e.g. does the specified artifact registry exist, does the specified storage bucket exist, etc.)AutoMLOps.monitor(...hide_warnings=False): This will check installation versions and account permissions to determine if the current account has the permissions to create model monitoring jobs successfully.
AutoMLOps CI/CD options:
use_ci: Bool that specifies whether to execute using generated files and scripts locally or use cloud CI/CD workflow. Defaults to False. See CI/CD Workflow
Required parameters:
project_id: strpipeline_params: dict
Optional parameters (defaults shown):
artifact_repo_location: str = 'us-central1'artifact_repo_name: str = f'{naming_prefix}-artifact-registry'artifact_repo_type: str = 'artifact-registry'base_image: str = 'python:3.9-slim'build_trigger_location: str = 'us-central1'build_trigger_name: str = f'{naming_prefix}-build-trigger'custom_training_job_specs: list[dict] = Nonedeployment_framework: str = 'github-actions'naming_prefix: str = 'automlops-default-prefix'orchestration_framework: str = 'kfp'pipeline_job_location: str = 'us-central1'pipeline_job_runner_service_account: str = f'vertex-pipelines@{project_id}.iam.gserviceaccount.com'pipeline_job_submission_service_location: str = 'us-central1'pipeline_job_submission_service_name: str = f'{naming_prefix}-job-submission-svc'pipeline_job_submission_service_type: str = 'cloud-functions'project_number: str = Noneprovision_credentials_key: str = Noneprovisioning_framework: str = 'gcloud'pubsub_topic_name: str = f'{naming_prefix}-queueing-svc'schedule_location: str = 'us-central1'schedule_name: str = f'{naming_prefix}-schedule'schedule_pattern: str = 'No Schedule Specified'setup_model_monitoring: Optional[bool] = Falsesource_repo_branch: str = 'automlops'source_repo_name: str = f'{naming_prefix}-repository'source_repo_type: str = 'github'storage_bucket_location: str = 'us-central1'storage_bucket_name: str = f'{project_id}-{naming_prefix}-bucket'use_ci: bool = Falsevpc_connector: str = 'No VPC Specified'workload_identity_pool: str = Noneworkload_identity_provider: str = Noneworkload_identity_service_account: str = None
Parameter Options:
artifact_repo_type=:- 'artifact-registry' (default)
deployment_framework=:- 'github-actions' (default)
- 'cloud-build'
- [coming soon] 'gitlab-ci'
- [coming soon] 'bitbucket-pipelines'
- [coming soon] 'jenkins'
orchestration_framework=:- 'kfp' (default)
- [coming soon] 'tfx'
- [coming soon] 'argo-workflows'
- [coming soon] 'airflow'
- [coming soon] 'ray'
pipeline_job_submission_service_type=:- 'cloud-functions' (default)
- 'cloud-run'
provisioning_framework=:- 'gcloud' (default)
- 'terraform'
- [coming soon] 'pulumi'
source_repo_type=:- 'github' (default)
- 'gitlab'
- 'bitbucket'
A description of the parameters is below:
project_id: The project ID.pipeline_params: Dictionary containing runtime pipeline parameters.artifact_repo_location: Region of the artifact repo (default use with Artifact Registry).artifact_repo_name: Artifact repo name where components are stored (default use with Artifact Registry).artifact_repo_type: The type of artifact repository to use (e.g. Artifact Registry, JFrog, etc.)base_image: The image to use in the component base dockerfile.build_trigger_location: The location of the build trigger (for cloud build).build_trigger_name: The name of the build trigger (for cloud build).custom_training_job_specs: Specifies the specs to run the training job with.deployment_framework: The CI tool to use (e.g. cloud build, github actions, etc.)naming_prefix: Unique value used to differentiate pipelines and services across AutoMLOps runs.orchestration_framework: The orchestration framework to use (e.g. kfp, tfx, etc.)pipeline_job_location: The location to run the Pipeline Job in.pipeline_job_runner_service_account: Service Account to run PipelineJobs (specify the full string).pipeline_job_submission_service_location: The location of the cloud submission service.pipeline_job_submission_service_name: The name of the cloud submission service.pipeline_job_submission_service_type: The tool to host for the cloud submission service (e.g. cloud run, cloud functions).precheck: Boolean used to specify whether to check for provisioned resources before deploying.project_number: The project number.provision_credentials_key: Either a path to or the contents of a service account key file in JSON format.provisioning_framework: The IaC tool to use (e.g. Terraform, Pulumi, etc.)pubsub_topic_name: The name of the pubsub topic to publish to.schedule_location: The location of the scheduler resource.schedule_name: The name of the scheduler resource.schedule_pattern: Cron formatted value used to create a Scheduled retrain job.setup_model_monitoring: Boolean parameter which specifies whether to set up a Vertex AI Model Monitoring Job.source_repo_branch: The branch to use in the source repository.source_repo_name: The name of the source repository to use.source_repo_type: The type of source repository to use (e.g. gitlab, github, etc.)storage_bucket_location: Region of the GS bucket.storage_bucket_name: GS bucket name where pipeline run metadata is stored.hide_warnings: Boolean used to specify whether to show provision/deploy permission warningsuse_ci: Flag that determines whether to use Cloud CI/CD.vpc_connector: The name of the vpc connector to use.workload_identity_pool: Pool for workload identity federation.workload_identity_provider: Provider for workload identity federation.workload_identity_service_account: Service account for workload identity federation (specify the full string).
AutoMLOps will generate the resources specified by these parameters (e.g. Artifact Registry, GCS bucket, etc.). If use_ci is set to True, AutoMLOps will turn the outputted AutoMLOps/ directory into a Git repo and use it for the source repo. If a cron formatted str is given as an arg for schedule_pattern then it will set up a Cloud Schedule to run accordingly. If setup_model_monitoring is set to true, a model_monitoring/ directory will be created and a monitoring section will be added to config/defaults.yaml with empty values. These values are then set by running AutoMLOps.monitor().
AutoMLOps generates code that is compatible with kfp>=2.0.0. Upon running AutoMLOps.generate(project_id='project-id', pipeline_params=pipeline_params, setup_model_monitoring=True, use_ci=True), a series of directories will be generated automatically:
.
├── components : Custom vertex pipeline components.
├──component_base : Contains all the python files, Dockerfile and requirements.txt
├── Dockerfile : Dockerfile containing all the python files for the components.
├── requirements.txt : Package requirements for all the python files for the components.
├── src : Python source code directory.
├──component_a.py : Python file containing code for the component.
├──...(for each component)
├──component_a : Components specs generated using AutoMLOps
├── component.yaml : Component yaml spec, acts as an I/O wrapper around the Docker container.
├──...(for each component)
├── configs : Configurations for defining vertex ai pipeline and MLOps infra.
├── defaults.yaml : Runtime configuration variables.
├── images : Custom container images for training models (optional).
├── pipelines : Vertex ai pipeline definitions.
├── pipeline.py : Full pipeline definition; compiles pipeline spec and uploads to GCS.
├── pipeline_runner.py : Sends a PipelineJob to Vertex AI.
├── requirements.txt : Package requirements for running pipeline.py.
├── runtime_parameters : Variables to be used in a PipelineJob.
├── pipeline_parameter_values.json : Json containing pipeline parameters.
├── provision : Provision configurations and details.
├── provision_resources.sh : Provisions the necessary infra to run the MLOps pipeline.
├── provisioning_configs : (Optional) Relevant terraform/Pulumi config files for provisioning infa.
├── scripts : Scripts for manually triggering the cloud run service.
├── build_components.sh : Submits a Cloud Build job that builds and pushes the components to the registry.
├── build_pipeline_spec.sh : Compiles the pipeline specs.
├── run_pipeline.sh : Submit the PipelineJob to Vertex AI.
├── run_all.sh : Builds components, compiles pipeline specs, and submits the PipelineJob.
├── publish_to_topic.sh : Publishes a message to a Pub/Sub topic to invoke the pipeline job submission service.
├── create_model_monitoring_job.sh : Creates or updated a Vertex AI model monitoring job for a given deployed model endpoint.
├── model_monitoring : Code for building and maintaining model monitoring jobs.
├── requirements.txt : Package requirements for creating and updating model monitoring jobs.
├── monitor.py : Creates a ModelDeploymentMonitoringJob and optionally creates a Log Sink for automatic retraining.
├── services : MLOps services related to continuous training.
├── submission_service : REST API service used to submit pipeline jobs to Vertex AI.
├── Dockerfile : Dockerfile for running the REST API service.
├── requirements.txt : Package requirements for the REST API service.
├── main.py : Python REST API source code.
├── README.md : Readme markdown file describing the contents of the generated directories.
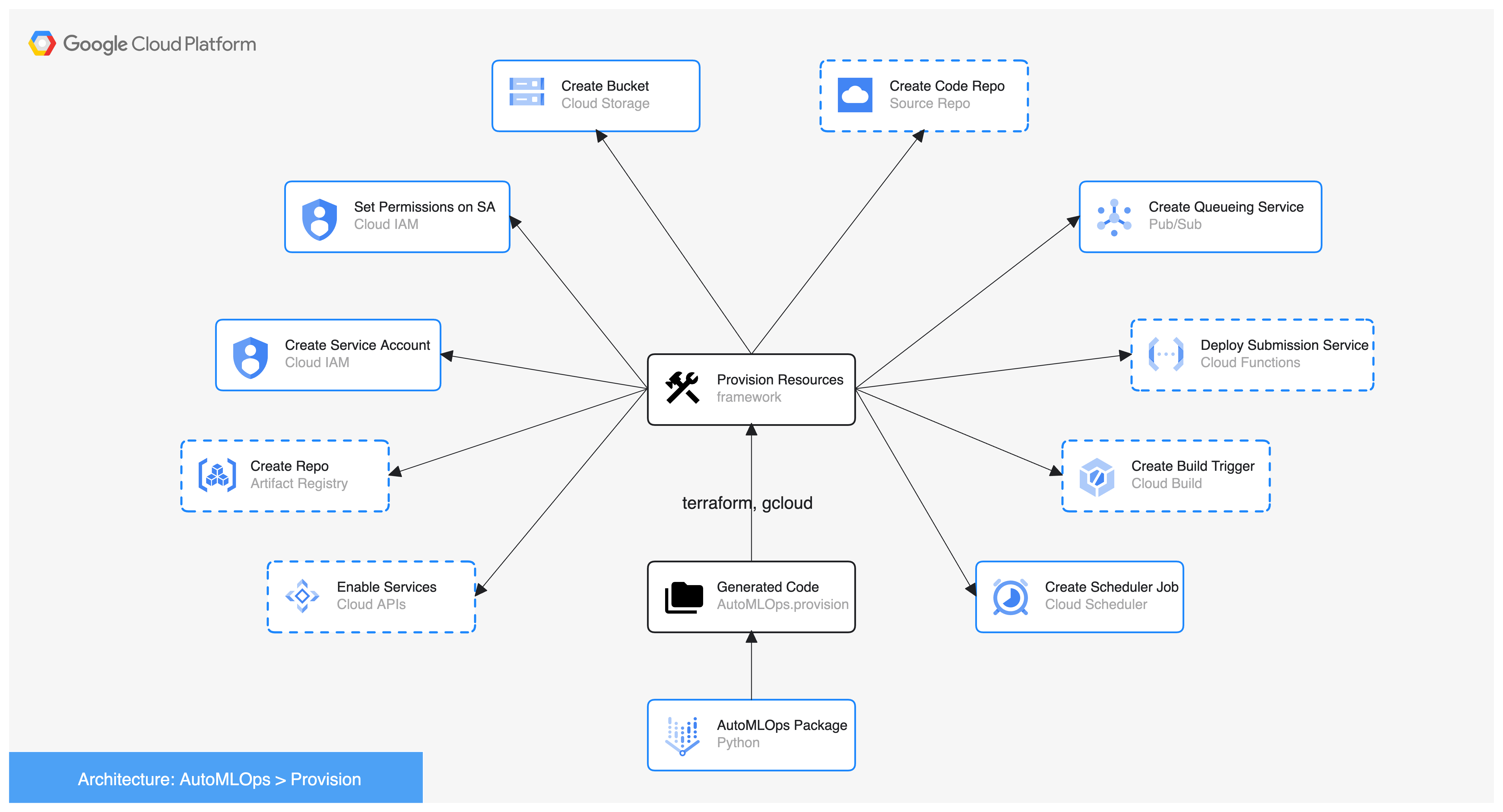
└── Build config yaml : Build configuration file for building custom components.AutoMLOps currently provides 2 primary options for provisioning infrastructure: gcloud and terraform. In the diagram below dashed boxes show areas users can select and customize their tooling.
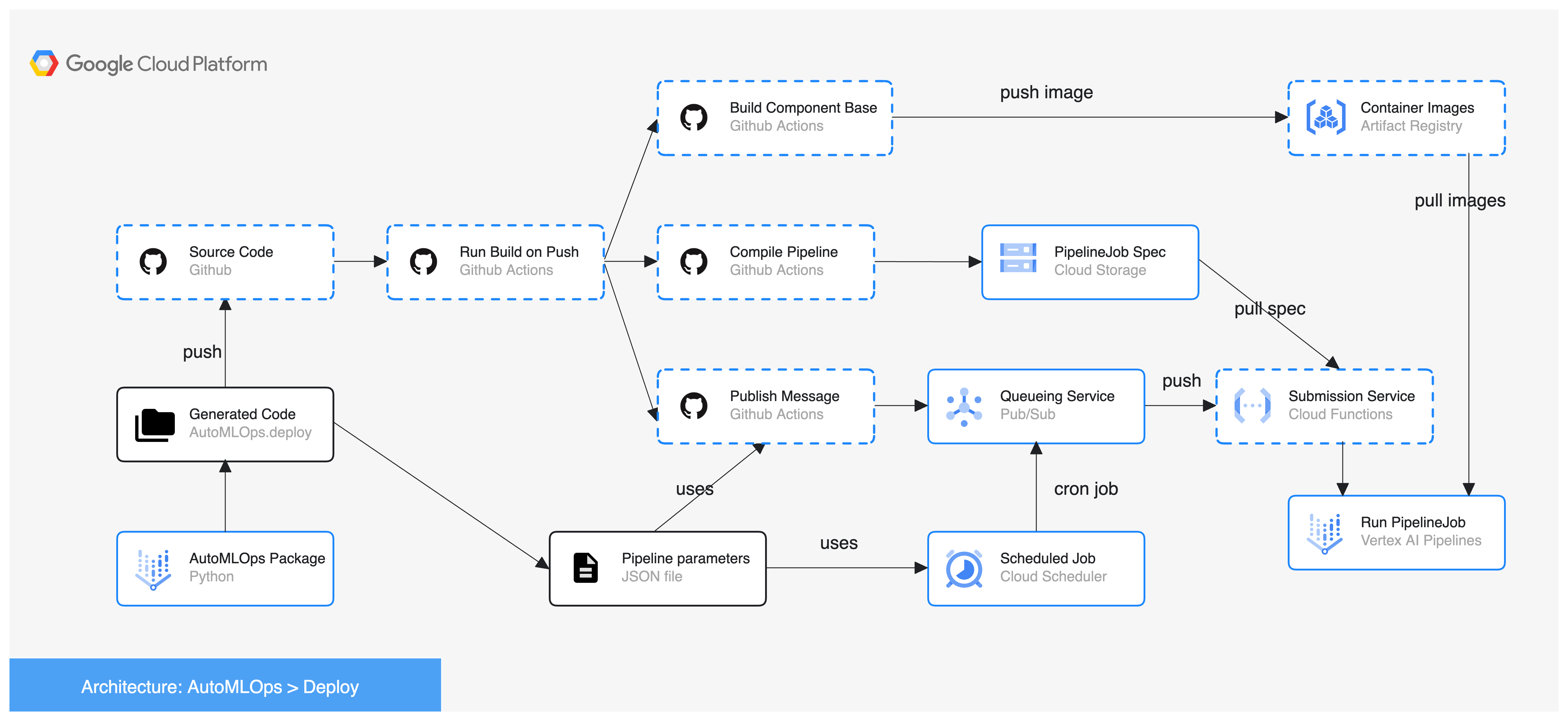
If use_ci=True, AutoMLOps will generate and use a fully featured CI/CD environment for the pipeline. Otherwise, it will use the local scripts to build and run the pipeline. In the diagrams below dashed boxes show areas users can select and customize their tooling.
Github Actions option:
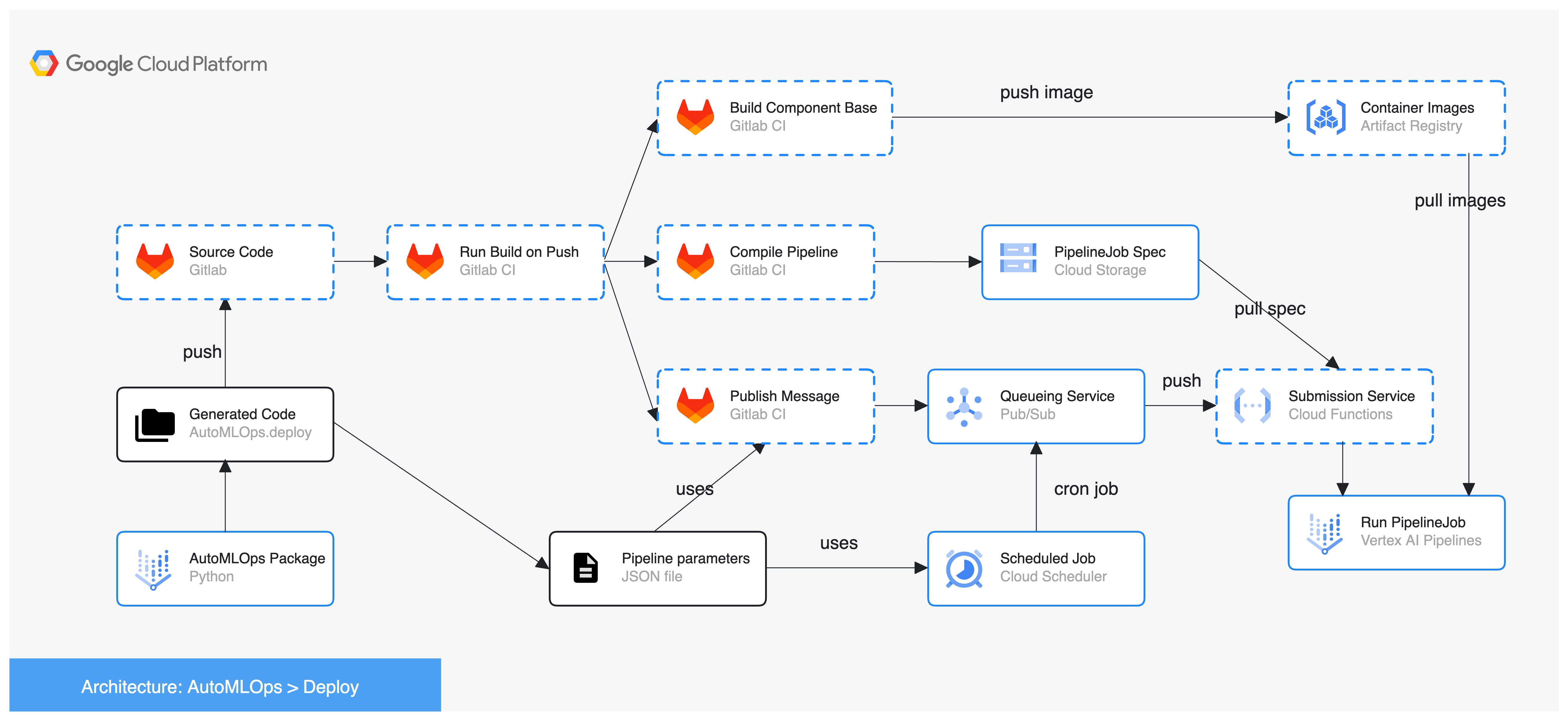
Gitlab CI option:
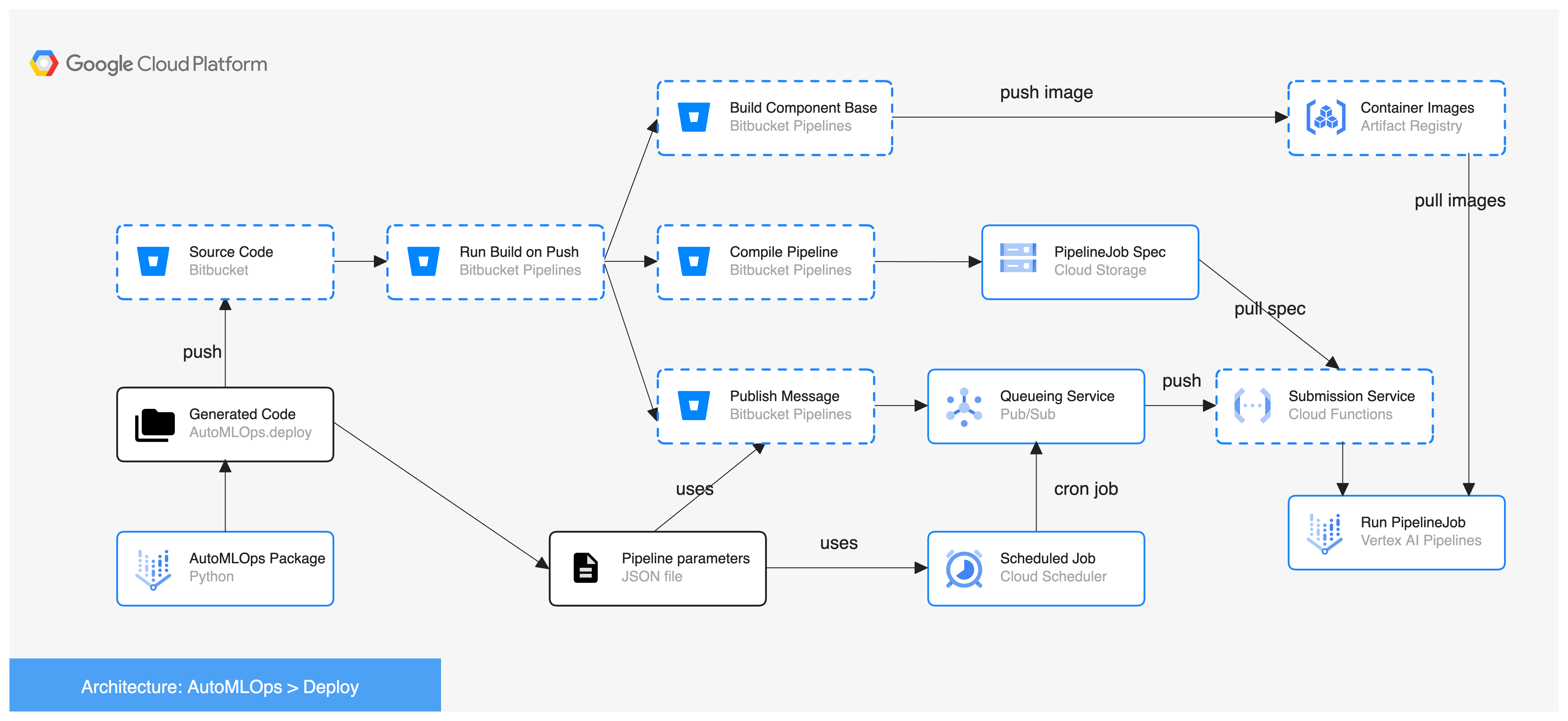
Bitbucket Pipelines option:
To use AutoMLOps for setting up and creating model monitoring jobs, the setup_model_monitoring parameter must be set to True during the generate step. This will create the necessary files under AutoMLOps/scripts and AutoMLOps/model_monitoring. From there, configurations can be set using AutoMLOps.monitor. This operation requires a functioning Vertex AI model endpoint, and the name of the endpoint's prediction column. Monitoring can be set to check for anomalies in 2 ways:
- Data Drift: This compares incoming feature distributions to past feature distributions that the model endpoint has seen, within a given window of time.
- Data Skew: This compares incoming feature distributions to feature distributions within the training dataset to check for training/serving skew.
At least one of these monitoring types must be used. To specify drift and skew, provide a dictionary of feature names and their threshold values to the drift_thresholds and skew_thresholds parameters.
When an anomaly is detected, actions can be taken in 2 ways:
- Generate email alerts: This will send an email to the specified email(s) informing the user of a detected data drift or skew.
- Automatically retrain the model: This will send anomaly alerts to the Pub/Sub Queueing service and trigger a retraining of the model, with the parameters specified, when a data drift or skew is detected.
These can be configured using the alert_emails and auto_retraining_params parameters, which are left null by default. If auto_retraining_params are specified, AutoMLOps.monitor will set up a Log Sink to connect the Vertex AI Model Monitoring Job to the Pub/Sub Queueing service, and filter on only ModelMonitoringJob anomalies.
Before running AutoMLOps.monitor(), be sure to install the package dependencies using the following command: pip3 install -r AutoMLOps/model_monitoring/requirements.txt --user
Required parameters:
target_field: strmodel_endpoint: str
Optional parameters (defaults shown):
alert_emails: list = Noneauto_retraining_params: dict = Nonedrift_thresholds: dict = Nonehide_warnings: bool = Truejob_display_name: str = f'{naming_prefix}-model-monitoring-job'monitoring_interval: int = 1monitoring_location: str = 'us-central1'sample_rate: float = 0.8skew_thresholds: dict = Nonetraining_dataset: str = None
A description of the parameters is below:
target_field: Prediction target column name in training dataset.model_endpoint: Endpoint resource name of the deployed model to monitoring. Format: projects/{project}/locations/{location}/endpoints/{endpoint}alert_emails: Optional list of emails to send monitoring alerts. Email alerts not used if this value is set to None.auto_retraining_params: Pipeline parameter values to use when retraining the model. Defaults to None; if left None, the model will not be retrained if an alert is generated.drift_thresholds: Compares incoming data to data previously seen to check for drift.hide_warnings: Boolean that specifies whether to show permissions warnings before monitoring.job_display_name: Display name of the ModelDeploymentMonitoringJob. The name can be up to 128 characters long and can be consist of any UTF-8 characters.monitoring_interval: Configures model monitoring job scheduling interval in hours. This defines how often the monitoring jobs are triggered.monitoring_location: Location to retrieve ModelDeploymentMonitoringJob from.sample_rate: Used for drift detection, specifies what percent of requests to the endpoint are randomly sampled for drift detection analysis. This value most range between (0, 1].skew_thresholds: Compares incoming data to the training dataset to check for skew.training_dataset: Training dataset used to train the deployed model. This field is required if using skew detection.

Using Github Actions:
To use Github Actions integration, you must first have a Workload Identity Federation set up properly. You must use a pre-existing Github repo, and you must also have already set up and registered your ssh keys with your Github Repo. If you meet all of these prerequisites, you can use github actions as follows:
AutoMLOps.generate(project_id=PROJECT_ID,
pipeline_params=pipeline_params,
use_ci=True,
deployment_framework='github-actions',
project_number='<project_number>',
source_repo_type='github',
source_repo_name='source/repo/string',
workload_identity_pool='identity_pool_string',
workload_identity_provider='identity_provider_string',
workload_identity_service_account='workload_identity_sa')
More specific details for setting up AutoMLOps to use Github and Github Actions can be found in this doc.
Set scheduled run:
Use the schedule_pattern parameter to specify a cron job schedule to run the pipeline job on a recurring basis.
schedule_pattern = '0 */12 * * *'
Use Vertex AI Experiments:
To use Vertex AI Experiments, include key-value pair for vertex_experiment_tracking_name in your pipeline parameters dictionary. An experiment will be created if one does not already exist with the specified name.
pipeline_params = {
'project_id': PROJECT_ID,
'region': 'us-central1',
'vertex_experiment_tracking_name': 'my-experiment-name'
}
AutoMLOps.generate(project_id=PROJECT_ID,
pipeline_params=pipeline_params)
Set pipeline compute resources:
Use the base_image and custom_training_job_specs parameter to specify resources for any custom component in the pipeline.
base_image = 'us-docker.pkg.dev/vertex-ai/training/tf-gpu.2-11.py310:latest',
custom_training_job_specs = [{
'component_spec': 'train_model',
'display_name': 'train-model-accelerated',
'machine_type': 'a2-highgpu-1g',
'accelerator_type': 'NVIDIA_TESLA_A100',
'accelerator_count': 1
}]
Use a VPC connector:
Use the vpc_connector parameter to specify a vpc connector.
vpc_connector = 'example-vpc-connector'
Specify package versions:
Use the packages_to_install parameter of @AutoMLOps.component to explicitly specify packages and versions.
@AutoMLOps.component(
packages_to_install=[
"google-cloud-bigquery==2.34.4",
"pandas",
"pyarrow",
"db_dtypes"
]
)
def create_dataset(
bq_table: str,
data_path: str,
project_id: str
):
...
Sean Rastatter: Tech Lead
Tony DiLoreto: Project Manager
Allegra Noto: Senior Project Engineer
Ahmad Khan: Engineer
Jesus Orozco: Engineer
Erin Horning: Engineer
Alex Ho: Engineer
Kyle Sorensen: Engineer
Matt Sokoloff: Engineer
Andrew Chasin: Engineer
Atulan Zaman: Use Case Development
Nelly Wilson: Use Case Development
This is not an officially supported Google product.
Copyright 2024 Google LLC. All Rights Reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the specific language governing permissions and limitations under the License.