Cartesian Product (CP) is a knowledge management platform that allows you to visualize data, explore deeper insight, and use your own data to help you answer your most pressing questions and contribute to clean energy development around the globe.
What really distinguishes CP is its backend system that gives users the power to contribute their own data and insights or download the current state of our ever growing open source datasets. By crowd sourcing our knowledge management system, we strive to convert the linear process of one-off data science consulting into an iterative cycle of community contribution and engagement, driving data-informed decision making.
Most of us are in the Advanced Data Engineering class at GalavanizeU Data Science Master's Program in San Francisco. We also have other members coming from the Galvanize Web Development Immersive program, but all of us are part of the Galvanize community.
We're doing this because climate change is one the paramount issues of our generation. Decision makers need to have open and easy access to data that comes together in a single place.
Class Project for DSCI-6009-SU17
So far: Kafka broker that ingests data from plume.io [work in progress]
Start Zookeeper.
If you have installed zookeeper, start it, or run the command:
> bin/zookeeper-server-start.sh config/zookeeper.properties
Start Kafka with default configuration
> bin/kafka-server-start.sh config/server.properties
Create a Topic - 'plume_pollution'
> bin/kafka-topics.sh --create --zookeeper localhost:2181 --replication-factor 1 --partitions 10 --topic plume_pollution
To show all content in a topic (and to check the Producer is working), have the command line consumer running:
bin/kafka-console-consumer.sh --bootstrap-server localhost:9092 --topic plume_pollution --from-beginning
Package project
sbt assembly
It will package compiled classes and its dependencies into a jar.
Run the Producer
The Producer is a Scala file located at src\main\scala\KafkaBroker.Scala
Once packaged in a JAR you can run the producer with the following arguments:
scala cartesianproduct2-assembly-1.0.jar plume_pollution localhost:9092 48.85 2.294 1000
where:
- title: plume_pollution
- broker: localhost:9092
- latitude: 48.85
- longitude: 2.294
- sleepTime: 1000
For additional information about Kafka, Plume API or Plume token check the WIKI
Output
If all is working, you should see the following output:
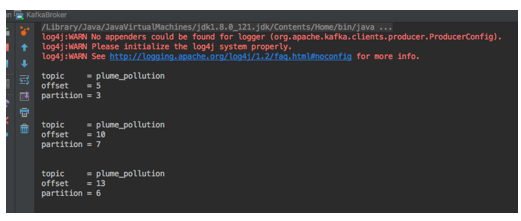
List topics
Install pip and python-dev:
sudo apt-get install python-pip python-dev
Install IPython. Since the machine will most likely be running Python 2.7, it is necessary to install an older version:
sudo pip install IPython=5.0
Install Jupyter:
sudo pip install jupyter
In order to run Jupyter with PySpark, the drivers need to be changed. Create a bash script called jupyter-pyspark with the following code:
#!/usr/bin/env bash
export PYSPARK_DRIVER_PYTHON=
which jupyter
export PYSPARK_DRIVER_PYTHON_OPTS="notebook --NotebookApp.open_browser=False --NotebookApp.ip='*' --NotebookApp.port=8888"
dse pyspark
Change permissions on the file:
chmod a+x jupyter-pyspark
Move jupyter-pyspark to /usr/bin. Now running the jupyter-pyspark command from anywhere in the machine will begin a browserless Jupyter notebook running with a PySpark driver.
In order to access the notebook remotely, ports must be opened to the relevant IPs. This may be done using the Google Cloud networking dashboard.
Having a single build.sbt file is an issue if you want to develop multiple scala projects, as it becomes a dependency nightmare. Instead, we have a Build.scala file in /project which specifies the dependencies on a per-project level. This makes development much simpler.