forked from serre-lab/rnn_rts
-
Notifications
You must be signed in to change notification settings - Fork 0
Commit
This commit does not belong to any branch on this repository, and may belong to a fork outside of the repository.
- Loading branch information
1 parent
5569c95
commit 15fcb2a
Showing
63 changed files
with
7,601 additions
and
1 deletion.
There are no files selected for viewing
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
| Original file line number | Diff line number | Diff line change |
|---|---|---|
| @@ -1 +1,98 @@ | ||
| # Comming soon | ||
|
|
||
| <h1 align="center"> | ||
| <br> | ||
| <br> | ||
| Computing a human-like reaction time metric from stable recurrent vision models | ||
| <br> | ||
| </h1> | ||
|
|
||
| <h4 align="center">Lore Goetschalckx*, Lakshmi N. Govindarajan*, Alekh A. Ashok, Aarit Ahuja, David L. Sheinberg, & Thomas Serre</h4> | ||
|
|
||
| <p style="text-align: center"> | ||
| <a href="https://www.python.org"><img src="https://img.shields.io/badge/Python-3.7-3776AB.svg?style=flat&logo=python&logoColor=white" alt="python"></a> | ||
| <a href="https://pytorch.org"><img src="https://img.shields.io/badge/PyTorch-1.8.0-EE4C2C.svg?style=flat&logo=pytorch" alt="pytorch"></a> | ||
| <a href="https://serre-lab.github.io/rnn_rts_site/"><img alt="RNN RTS" src="https://img.shields.io/badge/Project%20page-RNN%20RTs-green"></a> | ||
| <a href="https://opensource.org/licenses/MIT"><img src="https://img.shields.io/badge/License-MIT-yellow.svg" alt="License: MIT"></a> | ||
| </p> | ||
|
|
||
|
|
||
| <p align="center"> | ||
| <a href="#about">About</a> • | ||
| <a href="#datasets">Datasets</a> • | ||
| <a href="#computing-ξ">Computing ξ</a> • | ||
| <a href="#spatial-uncertainty-maps">SU maps</a> • | ||
| <a href="#training">Training</a> • | ||
| <a href="#citation">Citation</a> • | ||
| <a href="#license">License</a> | ||
| </p> | ||
|
|
||
| <div align="center" width="400"> | ||
| <img src="illustrations/metric.png" width="400"> <br> | ||
| <p style="font-size:12px;text-align: left;font-style: italic">We find a way to quantify the internal recurrent dynamics of a large-scale vision model by devising a metric ξ based on subjective logic theory. We use the metric to study <b>temporal</b> human-model alignment on different (and challenging) visual cognition tasks (e.g., incremental grouping task shown here). More in our <a href="https://arxiv.org/abs/2306.11582">paper</a>. | ||
| </p> | ||
|
|
||
| </div> | ||
|
|
||
| ## About | ||
| This repo contains the PyTorch implementation for our framework to train, analyze, and interpret the dynamics of convolutional recurrent neural networks (cRNNs). | ||
| We include Jupyter notebooks to demonstrate how to compute ξ, our stimulus-computable, task- and model-agnostic metric that can be compared directly against human RT data. Code to train your own models is included as well. | ||
|
|
||
| <a href="https://arxiv.org/abs/2306.11582">Paper</a> • <a href="https://serre-lab.github.io/rnn_rts_site/">Project page</a> | ||
|
|
||
| ## Datasets | ||
| Please refer to <a href="./data">the data folder</a> for more information on how to download and use our full datasets for the | ||
| incremental grouping task ("Coco Dots") and the maze task, if you'd like to use those. <b>Note</b>, however, that the notebooks should | ||
| run without any additional downloads too. The demonstrations use a mini version of the Coco Dots dataset that's included in this repo. | ||
|
|
||
|
|
||
| ## Computing ξ | ||
| As explained in the paper, we model uncertainty (ϵ) explicitly and track its evolution over time in the cRNN. | ||
| We formulate our RT metric (ξcRNN) as the area under this uncertainty curve. You can find a demo of how to generate these | ||
| curves and extract ξ in: | ||
|
|
||
| <a href="uncertainty_curves.ipynb">uncertainty_curves.ipynb </a> | ||
|
|
||
| <img src="illustrations/zebra.gif"> | ||
|
|
||
| ## Spatial uncertainty maps | ||
| Specifically for the incremental task, we introduced spatial uncertainty maps to probe a cRNN's visual strategies. For a given outline stimulus, one dot (indicated in white) is kept fixed while the position of the other is varied. Each position in the map has a value corresponding to the ξ for the respective dot configuration (fixed dot + other dot). You can find a demo of how to produce such maps in: | ||
|
|
||
| <a href="spatial_uncertainty_maps.ipynb">spatial_uncertainty_maps.ipynb</a>. | ||
|
|
||
| <img src="illustrations/su_map.png" width="400"> | ||
|
|
||
| ## Training | ||
| Below is an example of how to use <a href="train.py">train.py</a> for the incremental grouping task. | ||
|
|
||
|
|
||
| ``` | ||
| python train.py cocodots_train cocodots_val --batch_size 32 --data_root ./data/coco --name mymodel --model hgru --kernel_size 5 --timesteps 40 --loss_fn EDL --annealing_step 16 --algo rbp --penalty --penalty_gamma 100 | ||
| ``` | ||
|
|
||
| <b>Note</b> that this assumes you have downloaded the MS COCO training and valiation images in ./data/coco and downloaded | ||
| our Coco Dots annotation files in ./data. More details in <a href="data"> data </a>. If you'd like to try out the code without downloading more data, you can play | ||
| around with cocodots_val_mini, which is included here already for demo purposes. | ||
|
|
||
| ## Citation | ||
| If you'd like to use any of the code, figures, weights, or data in this repo for your own work, please cite our paper: | ||
|
|
||
|
|
||
| ``` | ||
| @misc{goetschalckx2023computing, | ||
| title={Computing a human-like reaction time metric from stable recurrent vision models}, | ||
| author={Lore Goetschalckx and Lakshmi Narasimhan Govindarajan and Alekh Karkada Ashok and Aarit Ahuja and David L. Sheinberg and Thomas Serre}, | ||
| year={2023}, | ||
| eprint={2306.11582}, | ||
| archivePrefix={arXiv}, | ||
| primaryClass={cs.CV} | ||
| } | ||
| ``` | ||
|
|
||
| ## License | ||
|
|
||
| MIT | ||
|
|
||
| --- | ||
|
|
||
|
|
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
| Original file line number | Diff line number | Diff line change |
|---|---|---|
| @@ -0,0 +1,146 @@ | ||
| # Data | ||
|
|
||
| We include instructions on how to download and use the datasets used in our <a href="https://arxiv.org/abs/2306.11582">paper</a> on computing a human-like RT metric from recurrent vision models. | ||
| - <a href="#coco-dots">Coco Dots</a> (incremental grouping task) | ||
| - <a href="#mazes">Mazes</a> | ||
|
|
||
| <b>Note</b>: both of these datasets used prior datasets as a starting point. | ||
|
|
||
|
|
||
| ## Coco Dots | ||
| <img src="../illustrations/task_grouping.png" width="220"> | ||
|
|
||
| COCO Dots is based on the original COCO panoptic segmentation dataset. It was designed to train models on an incremental grouping task similar to the one used in a human psychophysics study by Jeurissen et al. (2016). The most important addition to the original COCO panoptic json-file is the `serrelab_anns` key. | ||
|
|
||
| The format of the original annotation file can be found here: [COCO 2017 Annotations Format](https://cocodataset.org/#format-data) | ||
|
|
||
| We have modified the annotations file to include the following, highlighted fields: | ||
|
|
||
| 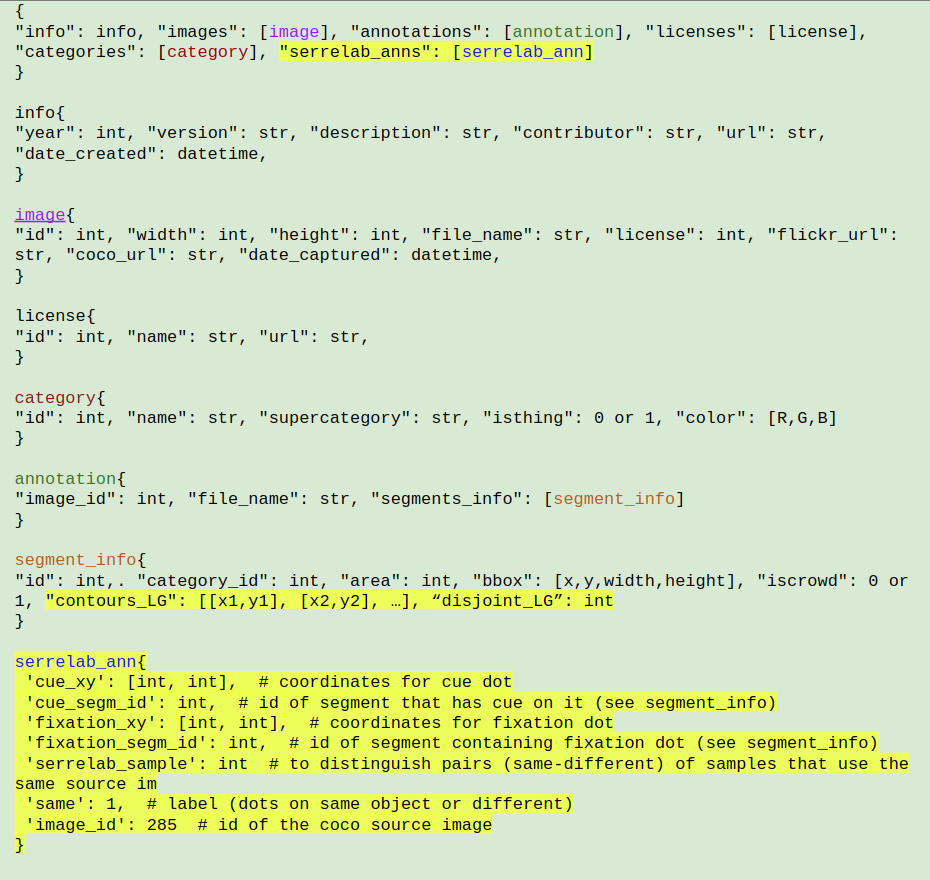 | ||
|
|
||
| ### Usage | ||
| 1. Download the COCO 2017 train and validation datasets and: | ||
| - [2017 Train Images](http://images.cocodataset.org/zips/train2017.zip) | ||
| - [2017 Val Images](http://images.cocodataset.org/zips/val2017.zip) | ||
|
|
||
| 2. Download our modified Annotation files and save them in ./data: | ||
| - [SerreLab Train Annotations](https://drive.google.com/file/d/18ZINTHV2ySURONqc_1gWLq3vS7GSqvqC/view?usp=sharing) | ||
| - [SerreLab Val Annotations](https://drive.google.com/file/d/1EvuhzoNJq0eTYaBQpdfqukY9v1B_-jqs/view?usp=sharing) | ||
|
|
||
| 3. Create the DataLoaders as follows: | ||
| ```python | ||
| from datasets import CocoDots | ||
|
|
||
| dataset_train = CocoDots("<PATH_TO_TRAIN_ANNOTATIONS_JSON>", | ||
| "<PATH_TO_COCO_2017_TRAIN_IMAGES>", | ||
| size=(150, 150), | ||
| stimulus_condition='WhiteOutline') | ||
|
|
||
| train_loader = torch.utils.data.DataLoader(dataset_train, | ||
| batch_size=128, | ||
| num_workers=4, | ||
| pin_memory=False, | ||
| drop_last=True) | ||
|
|
||
| dataset_val = CocoDots("<PATH_TO_VAL_ANNOTATIONS_JSON>", | ||
| "<PATH_TO_COCO_2017_VAL_IMAGES>", | ||
| size=(150, 150), | ||
| stimulus_condition='WhiteOutline') | ||
|
|
||
| val_loader = torch.utils.data.DataLoader(dataset_val, | ||
| batch_size=128, | ||
| num_workers=4, | ||
| pin_memory=False, | ||
| drop_last=True) | ||
| ``` | ||
|
|
||
| ## Mazes | ||
| <img src="../illustrations/task_mazes.png" width="220"> | ||
|
|
||
| Our Mazes dataset is based on 10K original mazes (maze_data_test_59) by <a href="https://openreview.net/forum?id=PPjSKy40XUB">Bansal et al. (2022)</a>. | ||
| In the original mazes ("base mazes"), which were designed for a segmentation task, every location in the maze was connected to any other location. Here, we derived new mazes from these "base mazes" | ||
| to accommodate a binary classification task (i.e., "are two cued locations connected by a path?"). We added more walls ("blocks"), repositioned the cues, etc. | ||
| All specifications needed to create the new mazes are contained in an annotations file. | ||
|
|
||
|
|
||
| ### Usage | ||
| 1. Download Bansal et al.'s base mazes (please cite them as well): | ||
| - [Train Mazes](https://drive.google.com/file/d/1eYIjsRMewia3Qezq-eYuL_fqEzBWGfe5/view?usp=sharing) | ||
| - [Val Mazes](https://drive.google.com/file/d/1fHlBYlIzU_PjFn4dARw5L7PotKHfzR20/view?usp=sharing) | ||
|
|
||
| <b>Note</b>: We don't use the same train/val split as Bansal et al. The download links refer to what was train and val in our paper. | ||
| The annotation files are still needed to generate our final train and val mazes. | ||
|
|
||
| 2. Download our Annotation files and save them in ./data: | ||
| - [SerreLab Train Annotations](https://drive.google.com/file/d/13mPb1AiUOIwqD0yZLIMcS2RvAgOqaKWP/view?usp=sharing) | ||
| - [SerreLab Val Annotations](https://drive.google.com/file/d/15E9eZ7AXoaLuOVTNdupftIsHGOARztMM/view?usp=sharing) | ||
|
|
||
| 3. Create the DataLoaders as follows: | ||
|
|
||
| ```python | ||
| from datasets import Mazes | ||
|
|
||
| dataset_train = Mazes("<PATH_TO_TRAIN_ANNOTATIONS_JSON>", | ||
| "<PATH_TO_TRAIN_BASE_MAZES>") | ||
|
|
||
| train_loader = torch.utils.data.DataLoader(dataset_train, | ||
| batch_size=128, | ||
| num_workers=4, | ||
| pin_memory=False, | ||
| drop_last=True) | ||
|
|
||
| dataset_val = Mazes("<PATH_TO_VAL_ANNOTATIONS_JSON>", | ||
| "<PATH_TO_VAL_BASE_MAZES>") | ||
|
|
||
| val_loader = torch.utils.data.DataLoader(dataset_val, | ||
| batch_size=128, | ||
| num_workers=4, | ||
| pin_memory=False, | ||
| drop_last=True) | ||
|
|
||
| ``` | ||
|
|
||
| ## Citations | ||
| ``` | ||
| @misc{goetschalckx2023computing, | ||
| title={Computing a human-like reaction time metric from stable recurrent vision models}, | ||
| author={Lore Goetschalckx and Lakshmi Narasimhan Govindarajan and Alekh Karkada Ashok and Aarit Ahuja and David L. Sheinberg and Thomas Serre}, | ||
| year={2023}, | ||
| eprint={2306.11582}, | ||
| archivePrefix={arXiv}, | ||
| primaryClass={cs.CV} | ||
| } | ||
| @inproceedings{ | ||
| bansal2022endtoend, | ||
| title={End-to-end Algorithm Synthesis with Recurrent Networks: Extrapolation without Overthinking}, | ||
| author={Arpit Bansal and Avi Schwarzschild and Eitan Borgnia and Zeyad Emam and Furong Huang and Micah Goldblum and Tom Goldstein}, | ||
| booktitle={Advances in Neural Information Processing Systems}, | ||
| editor={Alice H. Oh and Alekh Agarwal and Danielle Belgrave and Kyunghyun Cho}, | ||
| year={2022}, | ||
| url={https://openreview.net/forum?id=PPjSKy40XUB} | ||
| } | ||
| @InProceedings{coco, | ||
| author="Lin, Tsung-Yi | ||
| and Maire, Michael | ||
| and Belongie, Serge | ||
| and Hays, James | ||
| and Perona, Pietro | ||
| and Ramanan, Deva | ||
| and Doll{\'a}r, Piotr | ||
| and Zitnick, C. Lawrence", | ||
| editor="Fleet, David | ||
| and Pajdla, Tomas | ||
| and Schiele, Bernt | ||
| and Tuytelaars, Tinne", | ||
| title="Microsoft {COCO}: Common Objects in Context", | ||
| booktitle="{T}he {E}uropean {C}onference on {C}omputer {V}ision ({ECCV}) 2014", | ||
| year="2014", | ||
| publisher="Springer International Publishing", | ||
| pages="740--755", | ||
| abstract="We present a new dataset with the goal of advancing the state-of-the-art in object recognition by placing the question of object recognition in the context of the broader question of scene understanding. This is achieved by gathering images of complex everyday scenes containing common objects in their natural context. Objects are labeled using per-instance segmentations to aid in precise object localization. Our dataset contains photos of 91 objects types that would be easily recognizable by a 4 year old. With a total of 2.5 million labeled instances in 328k images, the creation of our dataset drew upon extensive crowd worker involvement via novel user interfaces for category detection, instance spotting and instance segmentation. We present a detailed statistical analysis of the dataset in comparison to PASCAL, ImageNet, and SUN. Finally, we provide baseline performance analysis for bounding box and segmentation detection results using a Deformable Parts Model.", | ||
| isbn="978-3-319-10602-1" | ||
| } | ||
| ``` |
{kind=link}
Loading
Sorry, something went wrong. Reload?
Sorry, we cannot display this file.
Sorry, this file is invalid so it cannot be displayed.
{kind=link}
Loading
Sorry, something went wrong. Reload?
Sorry, we cannot display this file.
Sorry, this file is invalid so it cannot be displayed.
{kind=link}
Loading
Sorry, something went wrong. Reload?
Sorry, we cannot display this file.
Sorry, this file is invalid so it cannot be displayed.
{kind=link}
Loading
Sorry, something went wrong. Reload?
Sorry, we cannot display this file.
Sorry, this file is invalid so it cannot be displayed.
{kind=link}
Loading
Sorry, something went wrong. Reload?
Sorry, we cannot display this file.
Sorry, this file is invalid so it cannot be displayed.
{kind=link}
Loading
Sorry, something went wrong. Reload?
Sorry, we cannot display this file.
Sorry, this file is invalid so it cannot be displayed.
{kind=link}
Loading
Sorry, something went wrong. Reload?
Sorry, we cannot display this file.
Sorry, this file is invalid so it cannot be displayed.
{kind=link}
Loading
Sorry, something went wrong. Reload?
Sorry, we cannot display this file.
Sorry, this file is invalid so it cannot be displayed.
{kind=link}
Loading
Sorry, something went wrong. Reload?
Sorry, we cannot display this file.
Sorry, this file is invalid so it cannot be displayed.
{kind=link}
Loading
Sorry, something went wrong. Reload?
Sorry, we cannot display this file.
Sorry, this file is invalid so it cannot be displayed.
{kind=link}
Loading
Sorry, something went wrong. Reload?
Sorry, we cannot display this file.
Sorry, this file is invalid so it cannot be displayed.
{kind=link}
Loading
Sorry, something went wrong. Reload?
Sorry, we cannot display this file.
Sorry, this file is invalid so it cannot be displayed.
{kind=link}
Loading
Sorry, something went wrong. Reload?
Sorry, we cannot display this file.
Sorry, this file is invalid so it cannot be displayed.
{kind=link}
Loading
Sorry, something went wrong. Reload?
Sorry, we cannot display this file.
Sorry, this file is invalid so it cannot be displayed.
{kind=link}
Loading
Sorry, something went wrong. Reload?
Sorry, we cannot display this file.
Sorry, this file is invalid so it cannot be displayed.
{kind=link}
Loading
Sorry, something went wrong. Reload?
Sorry, we cannot display this file.
Sorry, this file is invalid so it cannot be displayed.
{kind=link}
Loading
Sorry, something went wrong. Reload?
Sorry, we cannot display this file.
Sorry, this file is invalid so it cannot be displayed.
{kind=link}
Loading
Sorry, something went wrong. Reload?
Sorry, we cannot display this file.
Sorry, this file is invalid so it cannot be displayed.
{kind=link}
Loading
Sorry, something went wrong. Reload?
Sorry, we cannot display this file.
Sorry, this file is invalid so it cannot be displayed.
{kind=link}
Loading
Sorry, something went wrong. Reload?
Sorry, we cannot display this file.
Sorry, this file is invalid so it cannot be displayed.
{kind=link}
Loading
Sorry, something went wrong. Reload?
Sorry, we cannot display this file.
Sorry, this file is invalid so it cannot be displayed.
{kind=link}
Loading
Sorry, something went wrong. Reload?
Sorry, we cannot display this file.
Sorry, this file is invalid so it cannot be displayed.
{kind=link}
Loading
Sorry, something went wrong. Reload?
Sorry, we cannot display this file.
Sorry, this file is invalid so it cannot be displayed.
{kind=link}
Loading
Sorry, something went wrong. Reload?
Sorry, we cannot display this file.
Sorry, this file is invalid so it cannot be displayed.
Large diffs are not rendered by default.
Oops, something went wrong.
This file contains bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
| Original file line number | Diff line number | Diff line change |
|---|---|---|
| @@ -0,0 +1,2 @@ | ||
| from .cocodots import CocoDots | ||
| from .setup_dataset import setup_dataset |
Oops, something went wrong.