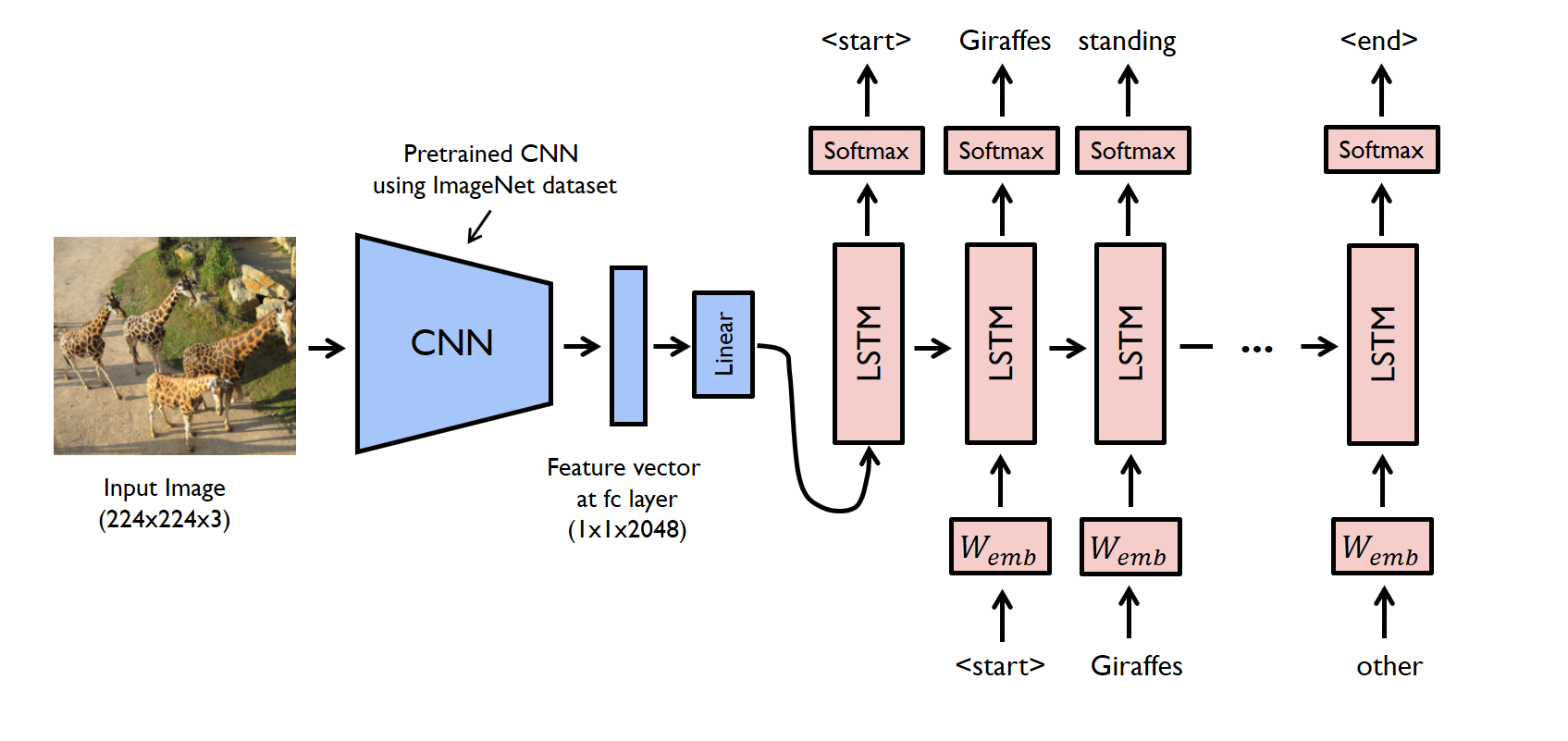
This project is all about defining and training a combination of CNN and LSTM to provide a caption for the given input image, Used Encoder Decoder Architecture which are CNN & LSTM respectively to train the model.
Image Captioning is the process of generating textual description of an image. It uses both Natural Language Processing and Computer Vision to generate the captions.
This model uses Word Embedding Technique which converts every word in a particular vocabulary into one-hot vector.
The model is trained on a huge data set of images with captions COCO Dataset then used to generate output for any input image with error around 5%
We should be able to get less error < 5%
This project uses opncv library opencv and PyTorch to install these libraries.
pip install opencv-pythonpip3 install torch torchvisionUsed ResNet as the Encoder CNN part to extract features that will be given later to the LSTM.
class EncoderCNN(nn.Module):
def __init__(self, embed_size):
super(EncoderCNN, self).__init__()
resnet = models.resnet50(pretrained=True)
for param in resnet.parameters():
param.requires_grad_(False)
modules = list(resnet.children())[:-1]
self.resnet = nn.Sequential(*modules)
self.fc1 = nn.Linear(resnet.fc.in_features, 1024)
self.bn1 = nn.BatchNorm1d(num_features=1024)
self.embed = nn.Linear(1024, embed_size)
def forward(self, images):
features = self.resnet(images)
features = features.view(features.size(0), -1)
features = self.fc1(features)
features = self.bn1(features)
features = self.embed(features)
return featuresUsed LSTM as the Decoder part of the Network which recieves two inputs :
- Feature Vector that is extracted from an input image
- A start word, then the next word, the next word, and so on!
class DecoderRNN(nn.Module):
def __init__(self, embed_size, hidden_size, vocab_size, batch_size, num_layers=2):
super(DecoderRNN, self).__init__()
self.embed_size = embed_size
self.hidden_size = hidden_size
self.vocab_size = vocab_size
self.num_layers = num_layers
self.batch_size = batch_size
self.word_embeddings = nn.Embedding(self.vocab_size, self.embed_size)
self.lstm = nn.LSTM(self.embed_size, self.hidden_size, self.num_layers,
dropout=.2, batch_first=True)
self.fc = nn.Linear(self.hidden_size, self.vocab_size)
self.dropout = nn.Dropout(p=.2)
self.hidden = self.init_hidden()
def forward(self, features, captions):
captions = captions[:, :-1]
embeds = self.word_embeddings(captions)
inputs = torch.cat((features.unsqueeze(1), embeds), 1)
# print('hidden_states Shape ',(self.hidden.shape)) # should be [2,10,512]
out, self.hidden = self.lstm(inputs)
out = self.dropout(out)
out = self.fc(out)
return out
def init_hidden(self):
# The axes dimensions are (n_layers, batch_size, hidden_dim)
return torch.zeros(self.num_layers, self.batch_size, self.hidden_size)
def sample(self, inputs, states=None, max_len=20):
"""
Greedy search:
Samples captions for pre-processed image tensor (inputs)
and returns predicted sentence (list of tensor ids of length max_len)
"""
predicted_sentence = []
for i in range(max_len):
lstm_out, states = self.lstm(inputs, states)
lstm_out = lstm_out.squeeze(1)
lstm_out = lstm_out.squeeze(1)
outputs = self.fc(lstm_out)
# Get maximum probabilities
target = outputs.max(1)[1]
# Append result into predicted_sentence list
predicted_sentence.append(target.item())
# Update the input for next iteration
inputs = self.word_embeddings(target).unsqueeze(1)
return predicted_sentenceimport torch.optim as optim
# Define the loss function.
criterion = nn.CrossEntropyLoss().cuda() if torch.cuda.is_available() else nn.CrossEntropyLoss()
# Specify the learnable parameters of the model.
params = list(decoder.parameters()) + list(encoder.embed.parameters())+list(encoder.fc1.parameters())
# Define the optimizer.
optimizer = torch.optim.Adam(params , lr = .001)Feel free to test the code yourself by just two simple steps
- Define and declare the needed parameters and pass them to the Encoder and Decoder Class.
- Load the Saved state dict which has the pre-trained model.
- Move the Encoder and Decoder to evaluation mode i.e.
encoder.eval(),decoder.eval() - Select an input image to be fed it into the encoder to extract features from it
features = encoder(image).unsqueeze(1) - Use the sample method in Decoder class which creates output indicies each index corresponds to a particular word in the word
vocabularyfor the given imageoutput = decoder.sample(features) - You can convert the output vector to a real sentence using
clean_sentence()Function.
You can find the full test code in the notebook named
3_inference.ipynb
- Ahmed Abd-Elbakey Ghonem - Github
Pull requests are welcome. For major changes, please open an issue first to discuss what you would like to change.
Please make sure to update tests as appropriate.