Client library to download and publish reinforcement learning environments/agents on the huggingbutt.com hub. Join our Discord: https://discord.gg/fnrKcgPR9r
Removed dependency on ml-agents and added support for tiptoestep in the current version.
Create a new python environment using anaconda/miniconda.
conda create -n hbactivate the new python environment.
conda activate hbinstall huggingbutt from pypi
pip install huggingbutt==0.0.5or from source code
git clone -b v0.0.5 https://github.com/huggingbutt/huggingbutt.git
cd huggingbutt
python -m pip install .If there is no error message printed during the installation, congratulations, you have successfully installed this package. Next, you need to apply an access token from the official website https://huggingbutt.com.
Register an account and login, just do as shown in the image below.
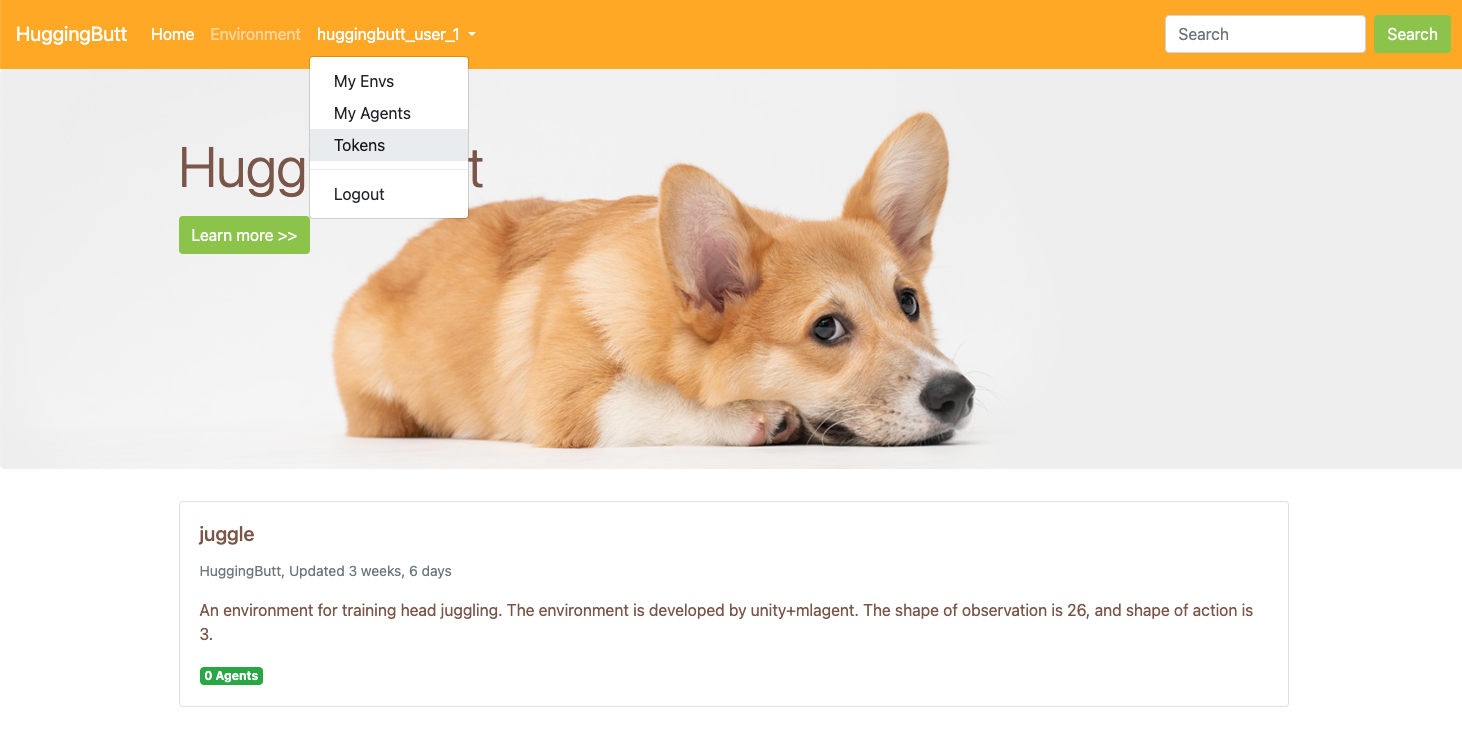
Click new token button generate a new token. This access token is mainly used to restrict the download times of each user, as the server cost is relatively high.
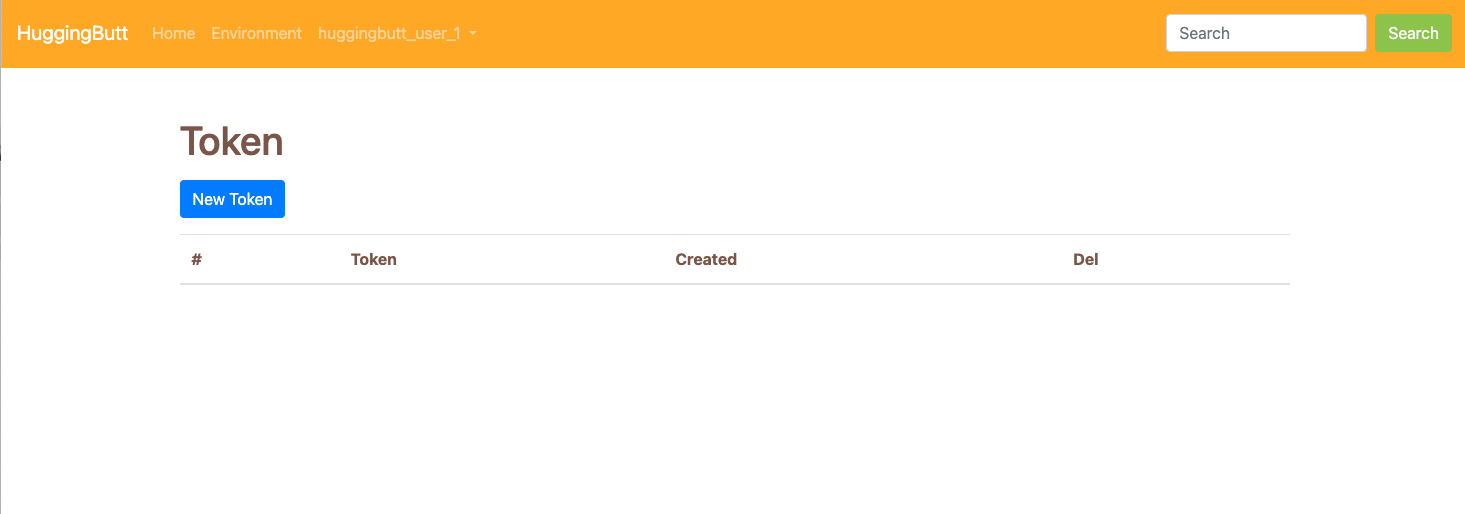
Congratulations, you now have an access token!
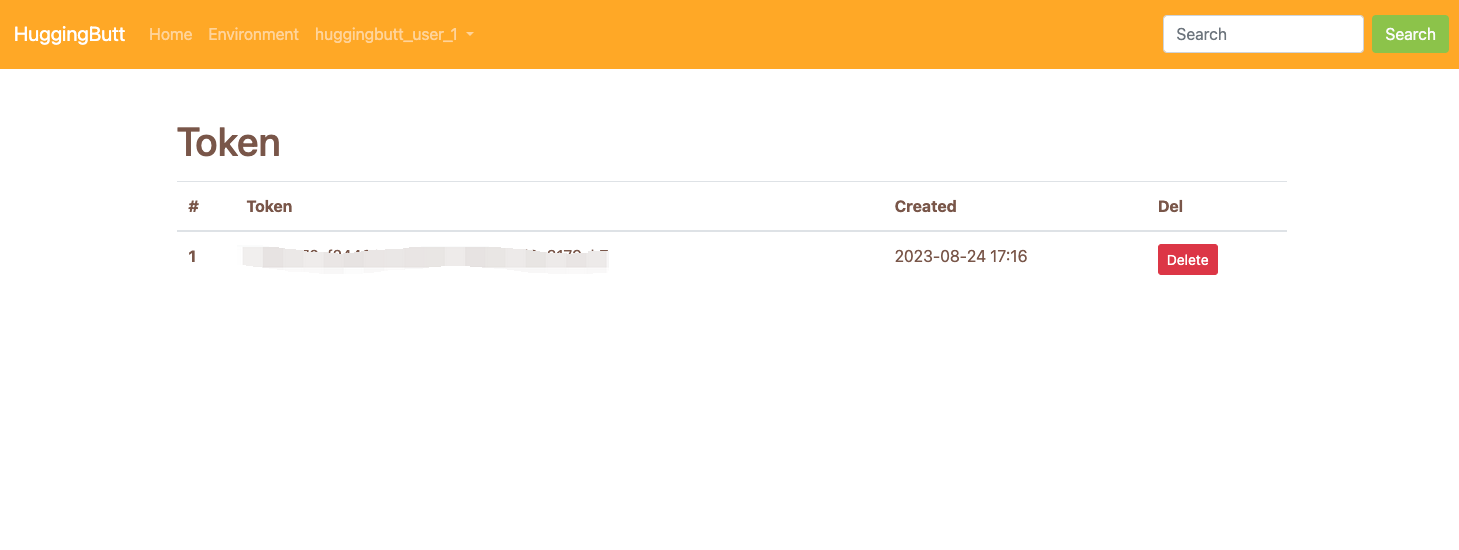
Just put the generated token in the task code and you're gooooood to go.
Here is a simple inference code:
import numpy as np
from huggingbutt import set_access_token, load_env, load_agent
HB_TOKEN = "YOUR_TOKEN"
set_access_token(HB_TOKEN)
if __name__ == '__main__':
env = load_env("huggingbutt/roller_ball", "mac", silent=False, num=1, time_scale=20)
agent = load_agent(4)
obs, info = env.reset()
steps = []
rewards = []
prev_i = 0
epoch_reward = 0
for i in range(1_000):
act, _status_ = agent.predict(obs)
obs, reward, terminated, truncated, info = env.step(act)
epoch_reward += reward
if terminated:
obs, info = env.reset()
# Statistics
steps.append(i - prev_i)
rewards.append(epoch_reward)
prev_i = i
epoch_reward = 0
env.close()
print(f"Played {len(steps)} times.")
print("Mean steps:{}".format(np.mean(steps)))
print("Mean reward:{}".format(np.mean(rewards)))Training your agent for this environment.
import numpy as np
from huggingbutt import set_access_token, load_env, load_agent
HB_TOKEN = "YOUR_TOKEN"
set_access_token(HB_TOKEN)
if __name__ == '__main__':
env = load_env("huggingbutt/roller_ball", "mac", silent=True, num=3, time_scale=20)
model = PPO(
"MlpPolicy",
env,
verbose=1,
n_steps=512,
tensorboard_log="./logs")
model.learn(total_timesteps=1_000_000)
model.save(f"roller_ball.zip")
env.close()I'm incredibly excited for you to upload the environment/agent you trained to huggingbutt.com. It would be amazing for everyone to study!
Example: ~/huggingbutt/your_environment_name
Build your environment created based on Unity ML-Agents, save it to "your_environment_name/unity_package_name"
Filesystem structure:
Mac:
└── huggingbutt
└── your_environment_name
├── your_environment_name.app
└── your_environment_name_BurstDebugInformation_DoNotShip
Windows:
└── huggingbutt
└── your_environment_name
├── your_environment_name.exe
└── ...
└── ...
Create a config.toml file in "your_environment_name" directory to specify where to load the executable from for the environment.
Filesystem structure:
└── huggingbutt
├── config.toml
└── your_environment_name
├── your_environment_name.app
└── your_environment_name_BurstDebugInformation_DoNotShip
Add the following content to config.toml
Mac:
[app]
exe_file="unity_package_name/game.app"Windows:
[app]
exe_file="unity_package_name/game.exe"Example:
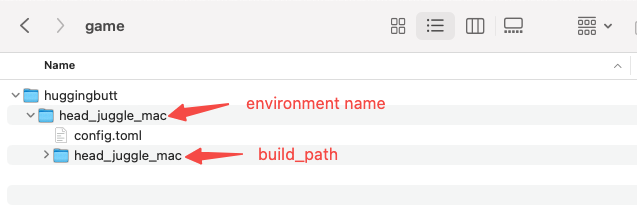
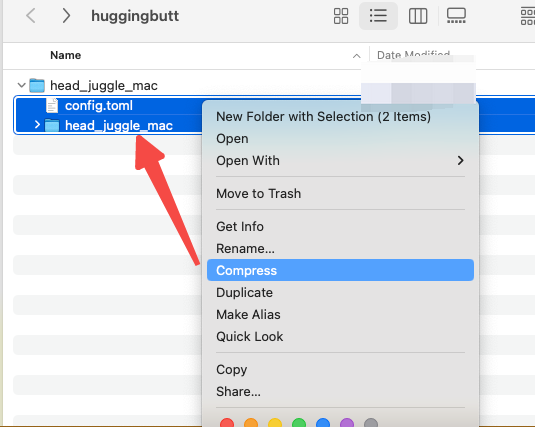
You must ensure that after extracting the zip file, config.toml file is located in the root directory.
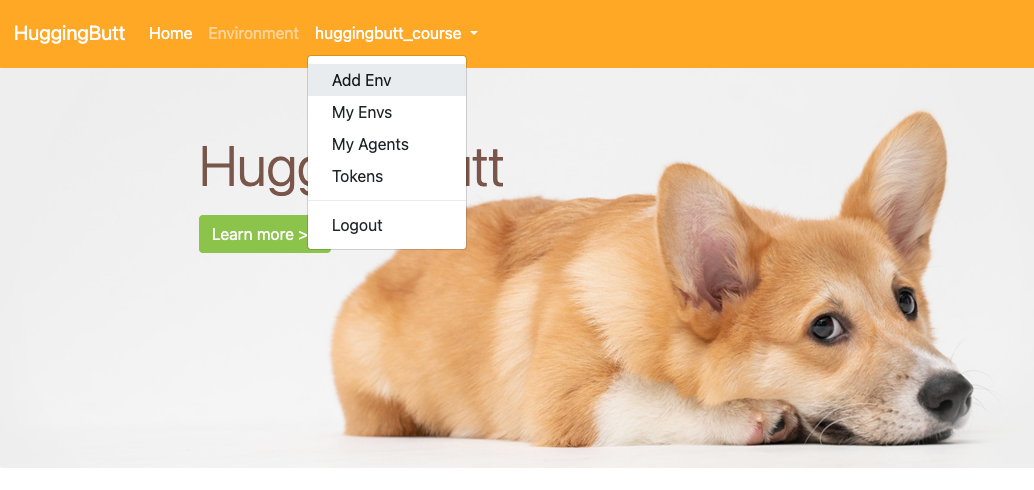
Click "Add Env"
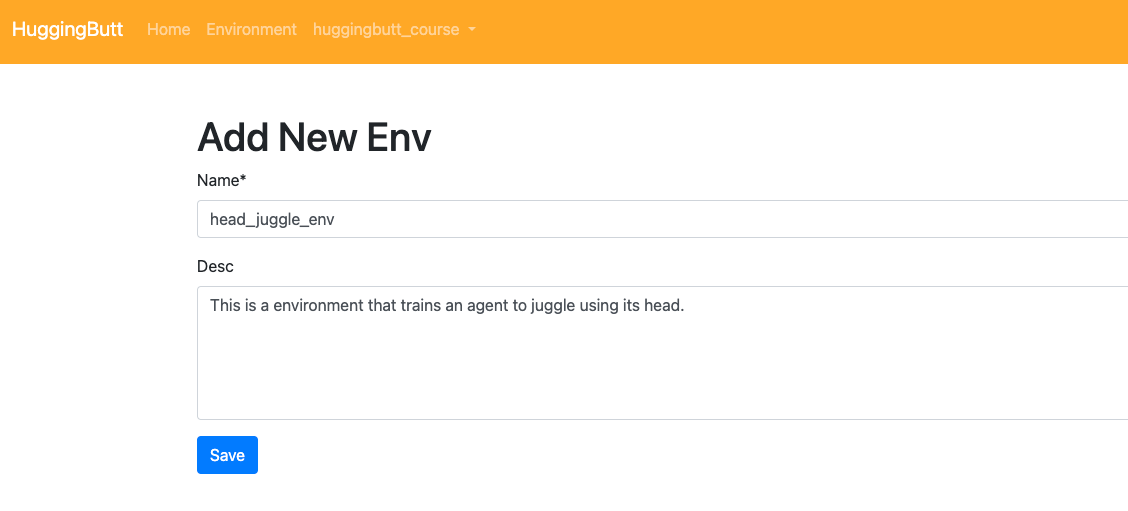
Fill in basic information
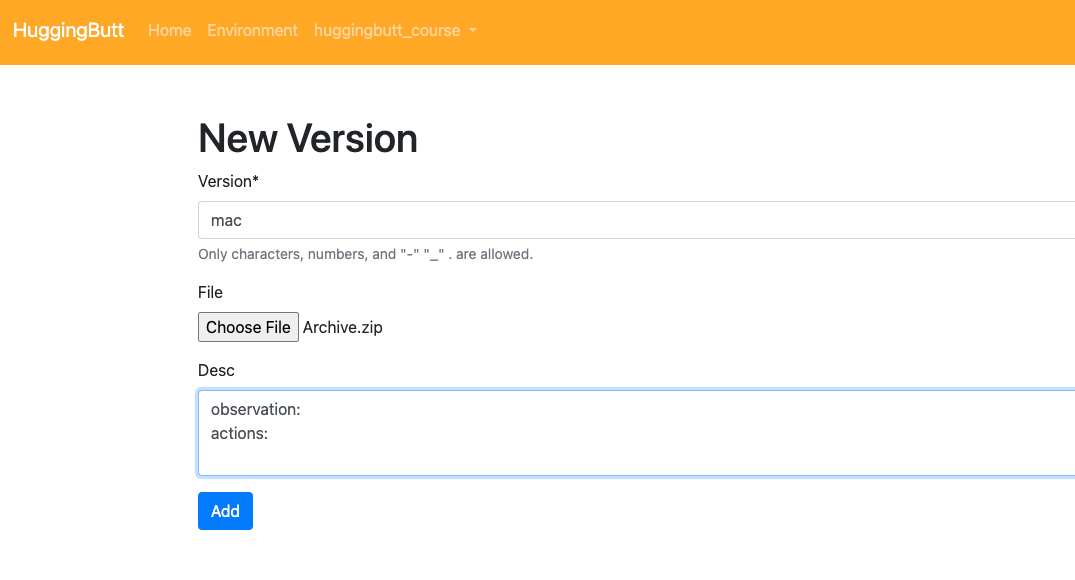
We will redirect into add new version page after clicking "Save" button.
Click "My Envs" will list your environments.
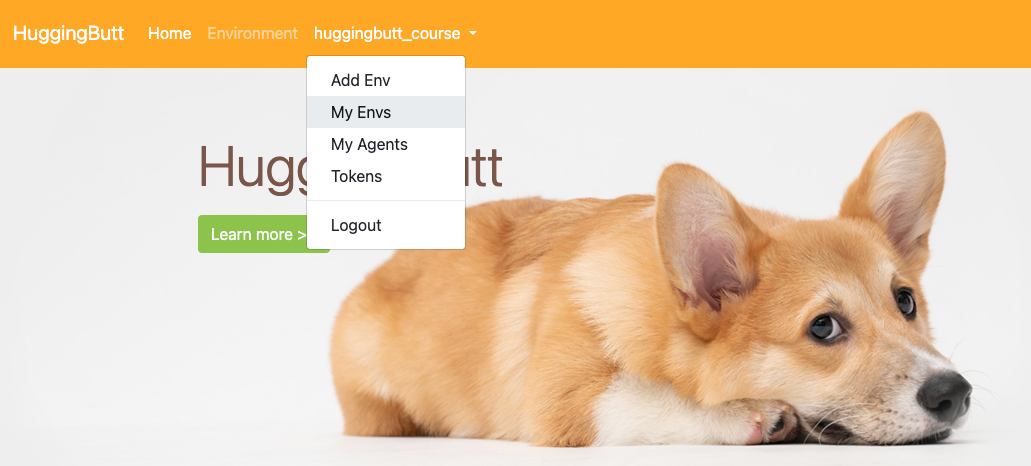
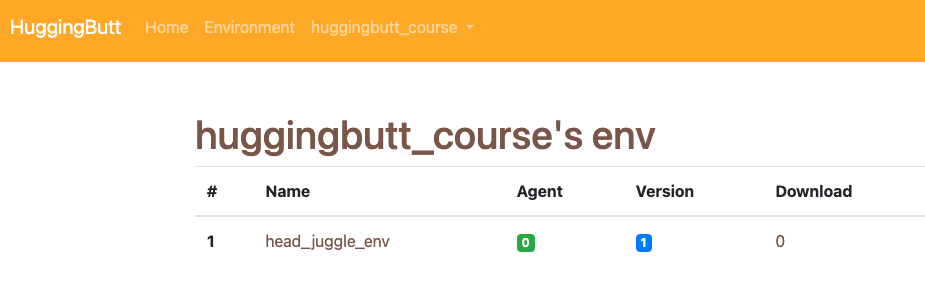
Click the name of your environment will enter the detail page.
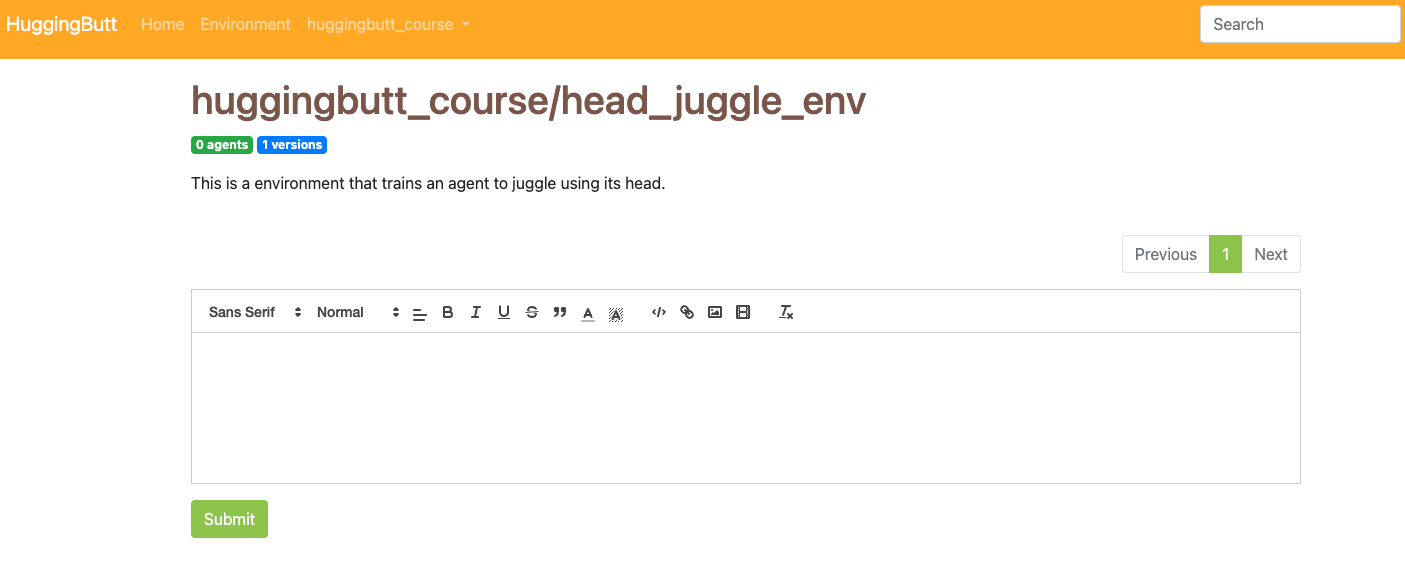
Click the blue badge named "* Versions" will list all versions of this environment.
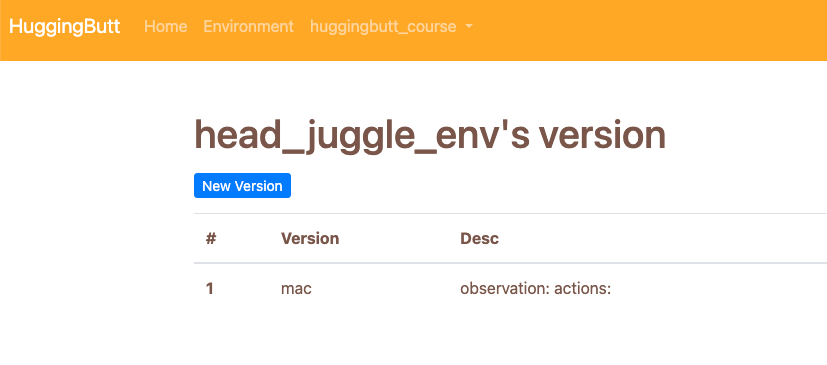
Click "New Version" will enter add new version page.
- Support more types learning environment, such as native game wrapped by python, pygame, class gym...