

Graph-based genome alignment and genotyping with HISAT2 and HISAT-genotype
- PMID: 31375807
- PMCID: PMC7605509
- DOI: 10.1038/s41587-019-0201-4
Graph-based genome alignment and genotyping with HISAT2 and HISAT-genotype
Abstract
The human reference genome represents only a small number of individuals, which limits its usefulness for genotyping. We present a method named HISAT2 (hierarchical indexing for spliced alignment of transcripts 2) that can align both DNA and RNA sequences using a graph Ferragina Manzini index. We use HISAT2 to represent and search an expanded model of the human reference genome in which over 14.5 million genomic variants in combination with haplotypes are incorporated into the data structure used for searching and alignment. We benchmark HISAT2 using simulated and real datasets to demonstrate that our strategy of representing a population of genomes, together with a fast, memory-efficient search algorithm, provides more detailed and accurate variant analyses than other methods. We apply HISAT2 for HLA typing and DNA fingerprinting; both applications form part of the HISAT-genotype software that enables analysis of haplotype-resolved genes or genomic regions. HISAT-genotype outperforms other computational methods and matches or exceeds the performance of laboratory-based assays.
Figures
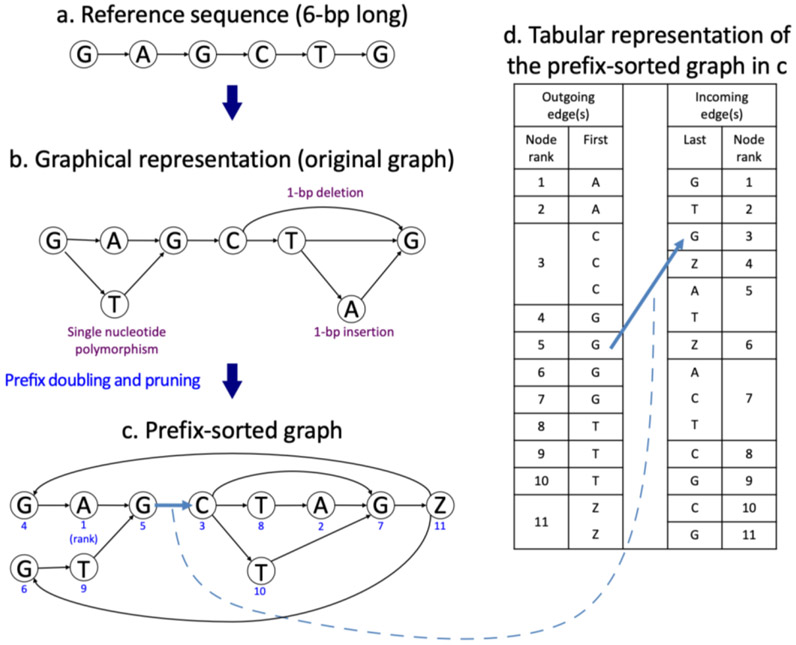
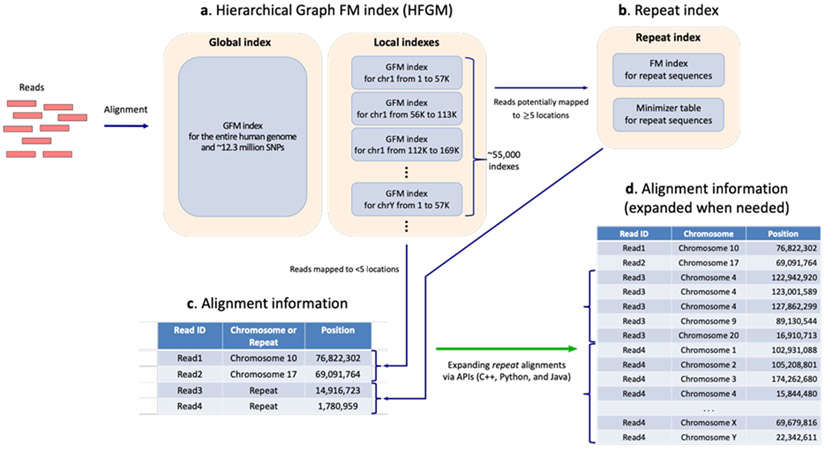
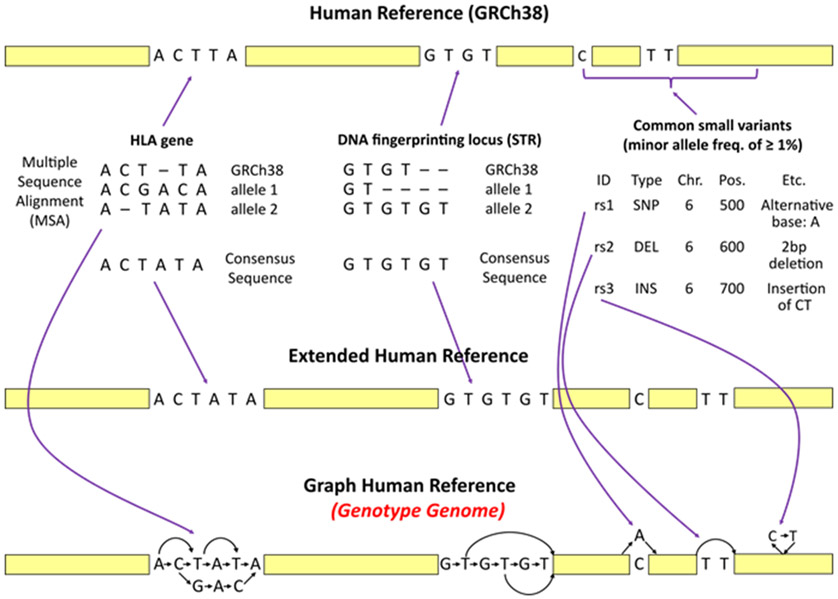
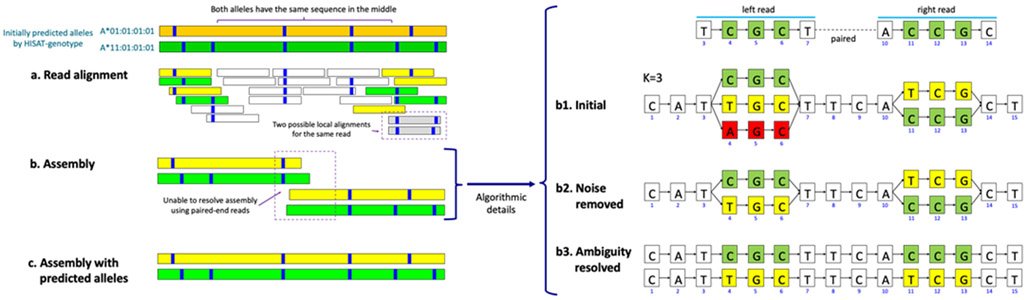
Similar articles
-
HISAT: a fast spliced aligner with low memory requirements.Nat Methods. 2015 Apr;12(4):357-60. doi: 10.1038/nmeth.3317. Epub 2015 Mar 9. Nat Methods. 2015. PMID: 25751142 Free PMC article.
-
Graphtyper enables population-scale genotyping using pangenome graphs.Nat Genet. 2017 Nov;49(11):1654-1660. doi: 10.1038/ng.3964. Epub 2017 Sep 25. Nat Genet. 2017. PMID: 28945251
-
A space and time-efficient index for the compacted colored de Bruijn graph.Bioinformatics. 2018 Jul 1;34(13):i169-i177. doi: 10.1093/bioinformatics/bty292. Bioinformatics. 2018. PMID: 29949982 Free PMC article.
-
Whole genome sequencing.Methods Mol Biol. 2010;628:215-26. doi: 10.1007/978-1-60327-367-1_12. Methods Mol Biol. 2010. PMID: 20238084 Review.
-
Impacts of variation in the human genome on gene regulation.J Mol Biol. 2013 Nov 1;425(21):3970-7. doi: 10.1016/j.jmb.2013.07.015. Epub 2013 Jul 16. J Mol Biol. 2013. PMID: 23871684 Review.
Cited by
-
Molecular cloning of PRD-like homeobox genes expressed in bovine oocytes and early IVF embryos.BMC Genomics. 2024 Nov 6;25(1):1048. doi: 10.1186/s12864-024-10969-w. BMC Genomics. 2024. PMID: 39506635
-
Chromosome-level genome assembly of the ivory shell Babylonia areolata.Sci Data. 2024 Nov 6;11(1):1201. doi: 10.1038/s41597-024-04001-9. Sci Data. 2024. PMID: 39505919
-
Discovering a novel glycosyltransferase gene CmUGT1 enhances main metabolites production of Cordyceps militaris.Front Microbiol. 2024 Oct 22;15:1437963. doi: 10.3389/fmicb.2024.1437963. eCollection 2024. Front Microbiol. 2024. PMID: 39502416 Free PMC article.
-
HES1 revitalizes the functionality of aged adipose-derived stem cells by inhibiting the transcription of STAT1.Stem Cell Res Ther. 2024 Nov 5;15(1):399. doi: 10.1186/s13287-024-04002-w. Stem Cell Res Ther. 2024. PMID: 39501364 Free PMC article.
References
-
- t Hoen PA et al. Reproducibility of high-throughput mRNA and small RNA sequencing across laboratories. Nat Biotechnol 31, 1015–1022 (2013). - PubMed
Publication types
MeSH terms
Grants and funding
LinkOut - more resources
Full Text Sources
Other Literature Sources
Research Materials
