

A proteome-scale map of the human interactome network
- PMID: 25416956
- PMCID: PMC4266588
- DOI: 10.1016/j.cell.2014.10.050
A proteome-scale map of the human interactome network
Abstract
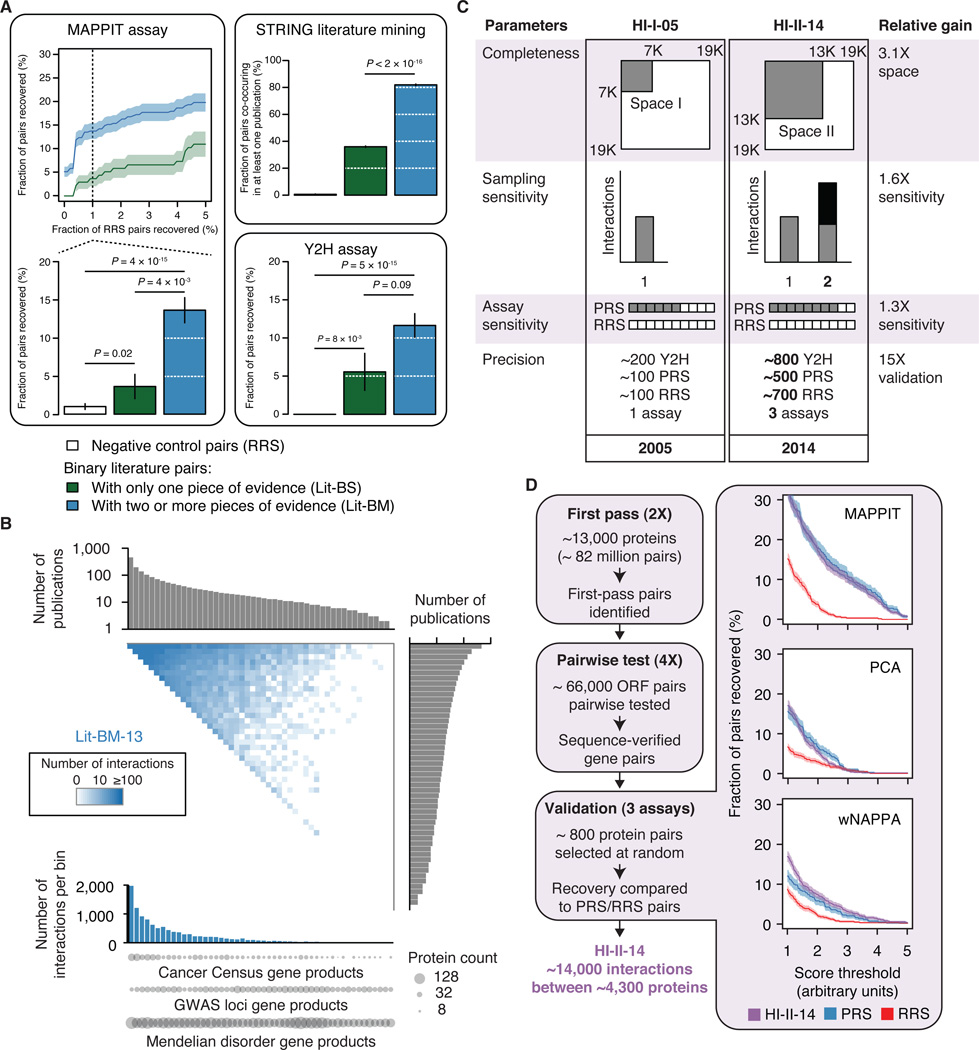
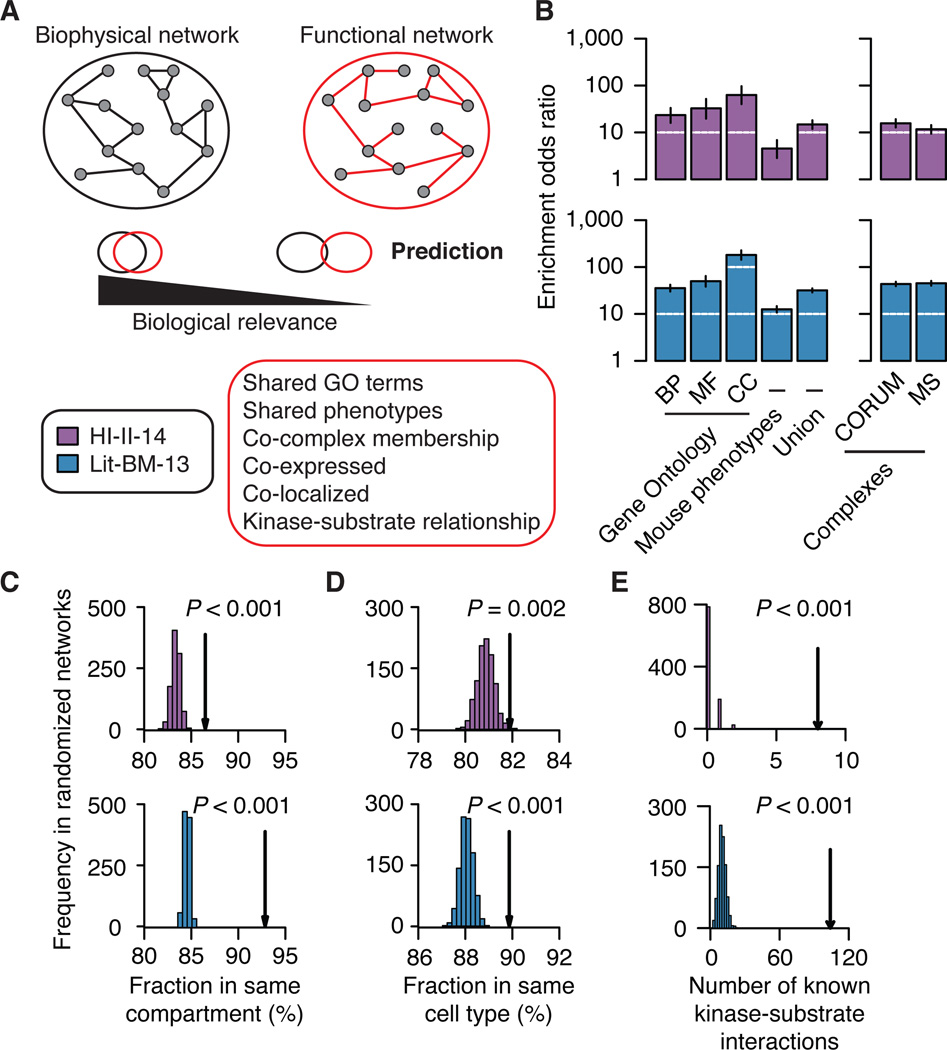
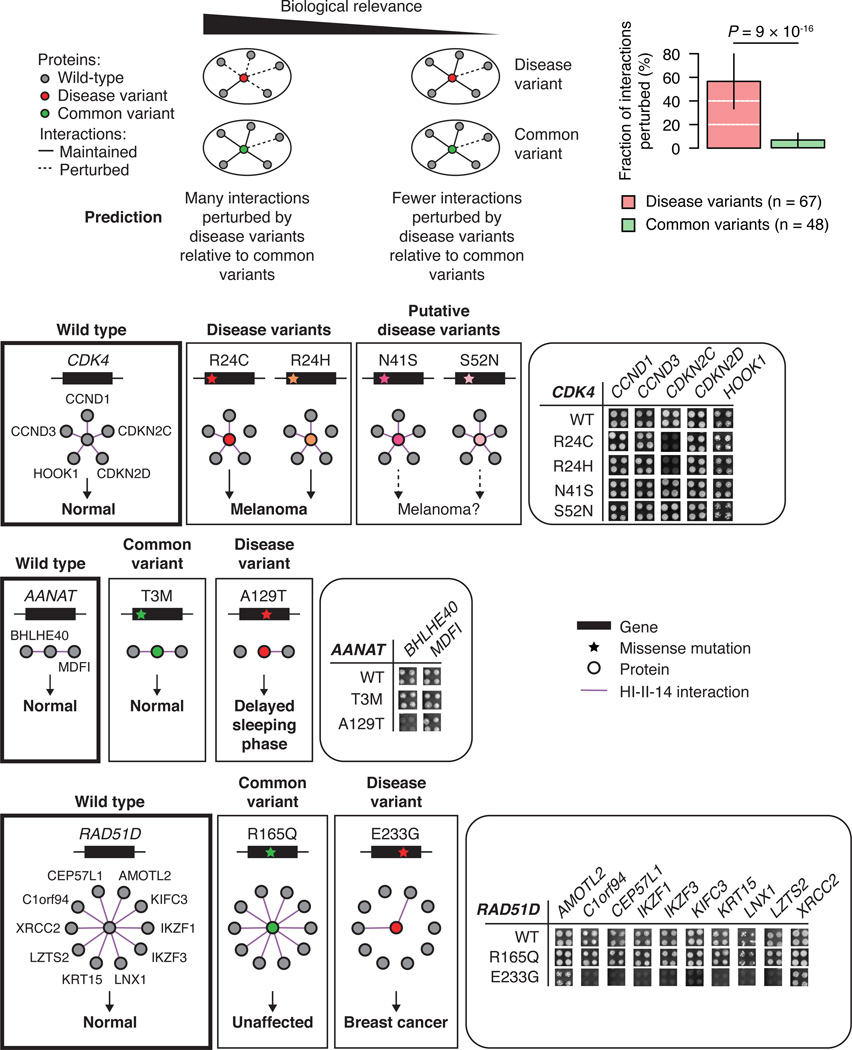
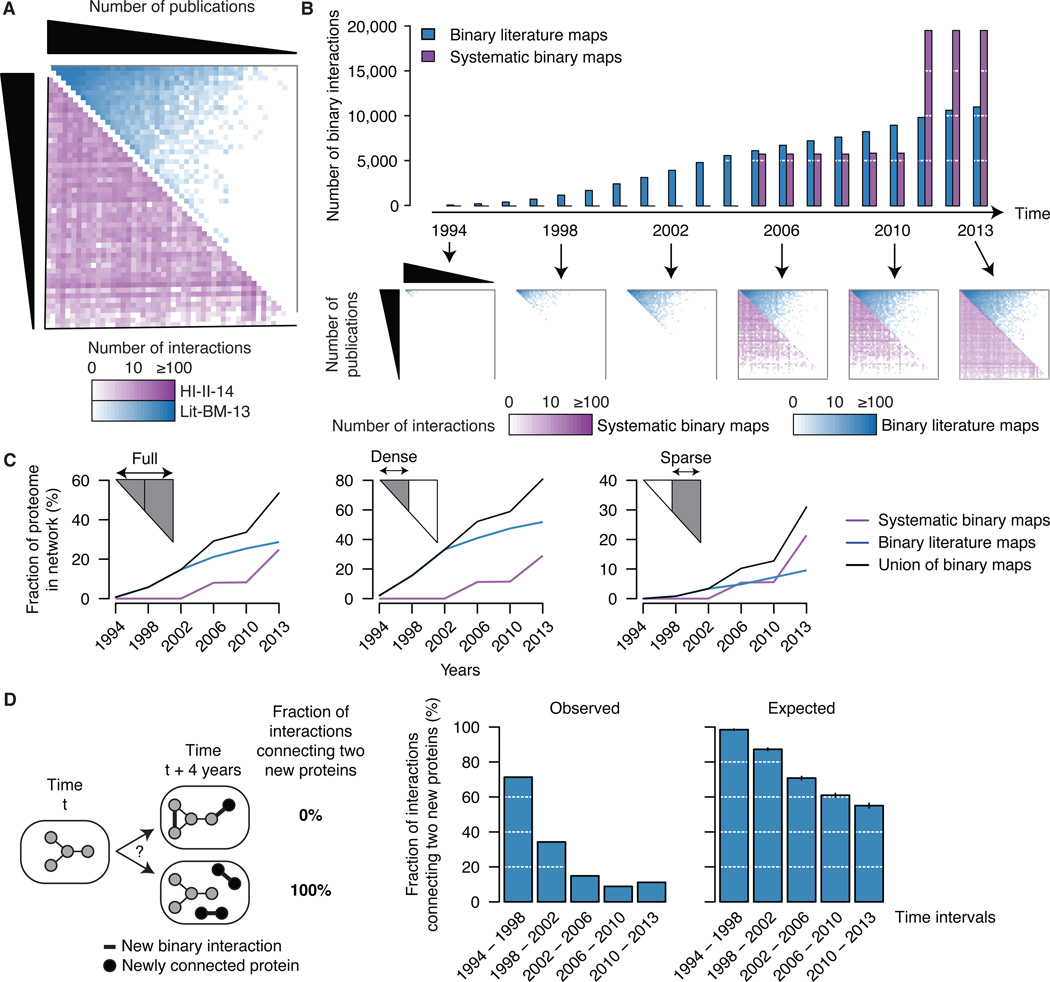
Just as reference genome sequences revolutionized human genetics, reference maps of interactome networks will be critical to fully understand genotype-phenotype relationships. Here, we describe a systematic map of ?14,000 high-quality human binary protein-protein interactions. At equal quality, this map is ?30% larger than what is available from small-scale studies published in the literature in the last few decades. While currently available information is highly biased and only covers a relatively small portion of the proteome, our systematic map appears strikingly more homogeneous, revealing a "broader" human interactome network than currently appreciated. The map also uncovers significant interconnectivity between known and candidate cancer gene products, providing unbiased evidence for an expanded functional cancer landscape, while demonstrating how high-quality interactome models will help "connect the dots" of the genomic revolution.
Figures
Comment in
-
Systems biology: an expanded human interactome.Nat Methods. 2015 Feb;12(2):107. doi: 10.1038/nmeth.3276. Nat Methods. 2015. PMID: 25798472 No abstract available.
Similar articles
-
A reference map of the human binary protein interactome.Nature. 2020 Apr;580(7803):402-408. doi: 10.1038/s41586-020-2188-x. Epub 2020 Apr 8. Nature. 2020. PMID: 32296183 Free PMC article.
-
Towards a proteome-scale map of the human protein-protein interaction network.Nature. 2005 Oct 20;437(7062):1173-8. doi: 10.1038/nature04209. Epub 2005 Sep 28. Nature. 2005. PMID: 16189514
-
Proteome-Scale Human Interactomics.Trends Biochem Sci. 2017 May;42(5):342-354. doi: 10.1016/j.tibs.2017.02.006. Epub 2017 Mar 8. Trends Biochem Sci. 2017. PMID: 28284537 Free PMC article. Review.
-
A Proteome-wide Fission Yeast Interactome Reveals Network Evolution Principles from Yeasts to Human.Cell. 2016 Jan 14;164(1-2):310-323. doi: 10.1016/j.cell.2015.11.037. Cell. 2016. PMID: 26771498 Free PMC article.
-
Proteome-wide prediction of protein-protein interactions from high-throughput data.Protein Cell. 2012 Jul;3(7):508-20. doi: 10.1007/s13238-012-2945-1. Epub 2012 Jun 22. Protein Cell. 2012. PMID: 22729399 Free PMC article. Review.
Cited by
-
inFRank: a ranking-based identification of influential genes in biological networks.Oncotarget. 2017 Jul 4;8(27):43810-43821. doi: 10.18632/oncotarget.11878. Oncotarget. 2017. PMID: 27623074 Free PMC article.
-
Increased signaling entropy in cancer requires the scale-free property of protein interaction networks.Sci Rep. 2015 Apr 28;5:9646. doi: 10.1038/srep09646. Sci Rep. 2015. PMID: 25919796 Free PMC article.
-
Network diffusion-based analysis of high-throughput data for the detection of differentially enriched modules.Sci Rep. 2016 Oct 12;6:34841. doi: 10.1038/srep34841. Sci Rep. 2016. PMID: 27731320 Free PMC article.
-
Virus-Host Protein Interaction Network of the Hepatitis E Virus ORF2-4 by Mammalian Two-Hybrid Assays.Viruses. 2023 Dec 12;15(12):2412. doi: 10.3390/v15122412. Viruses. 2023. PMID: 38140653 Free PMC article.
-
NESM: a network embedding method for tumor stratification by integrating multi-omics data.G3 (Bethesda). 2022 Nov 4;12(11):jkac243. doi: 10.1093/g3journal/jkac243. G3 (Bethesda). 2022. PMID: 36124952 Free PMC article.
References
Publication types
MeSH terms
Substances
Grants and funding
- P50HG004233/HG/NHGRI NIH HHS/United States
- R01 HG001715/HG/NHGRI NIH HHS/United States
- R01 MH091350/MH/NIMH NIH HHS/United States
- U01HL108630/HL/NHLBI NIH HHS/United States
- R33CA132073/CA/NCI NIH HHS/United States
- P50 HG004233/HG/NHGRI NIH HHS/United States
- R21 MH104766/MH/NIMH NIH HHS/United States
- R33 CA132073/CA/NCI NIH HHS/United States
- R01MH105524/MH/NIMH NIH HHS/United States
- U01HG001715/HG/NHGRI NIH HHS/United States
- U01 HL098166/HL/NHLBI NIH HHS/United States
- RC4HG006066/HG/NHGRI NIH HHS/United States
- RC4 HG006066/HG/NHGRI NIH HHS/United States
- U01 HL108630/HL/NHLBI NIH HHS/United States
- R01 HD065288/HD/NICHD NIH HHS/United States
- 340941/European Research Council/International
- U54CA112962/CA/NCI NIH HHS/United States
- U01 HG001715/HG/NHGRI NIH HHS/United States
- R21MH104766/MH/NIMH NIH HHS/United States
- R01 MH105524/MH/NIMH NIH HHS/United States
- U01HL098166/HL/NHLBI NIH HHS/United States
- R01MH091350/MH/NIMH NIH HHS/United States
- R01HD065288/HD/NICHD NIH HHS/United States
- U54 CA112962/CA/NCI NIH HHS/United States
LinkOut - more resources
Full Text Sources
Other Literature Sources
Molecular Biology Databases
