

Pfam: the protein families database
- PMID: 24288371
- PMCID: PMC3965110
- DOI: 10.1093/nar/gkt1223
Pfam: the protein families database
Abstract
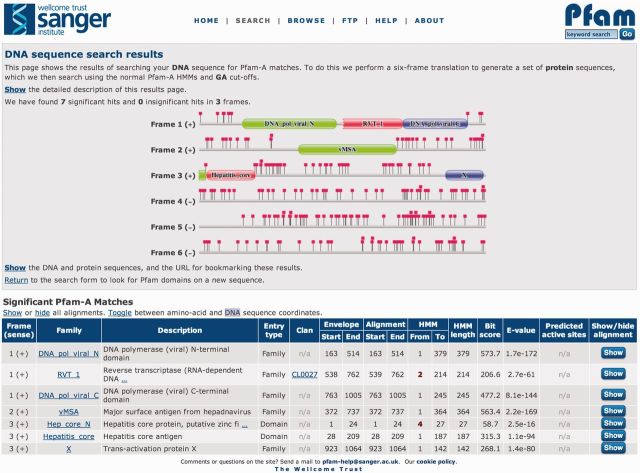
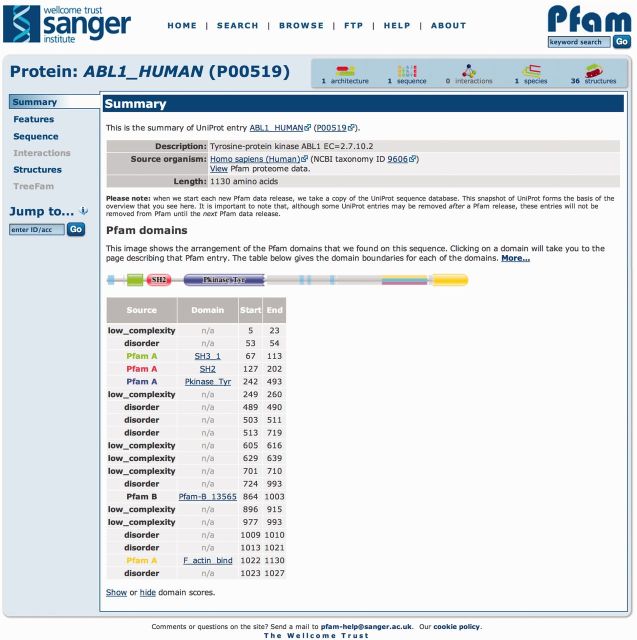
Pfam, available via servers in the UK (http://pfam.sanger.ac.uk/) and the USA (http://pfam.janelia.org/), is a widely used database of protein families, containing 14 831 manually curated entries in the current release, version 27.0. Since the last update article 2 years ago, we have generated 1182 new families and maintained sequence coverage of the UniProt Knowledgebase (UniProtKB) at nearly 80%, despite a 50% increase in the size of the underlying sequence database. Since our 2012 article describing Pfam, we have also undertaken a comprehensive review of the features that are provided by Pfam over and above the basic family data. For each feature, we determined the relevance, computational burden, usage statistics and the functionality of the feature in a website context. As a consequence of this review, we have removed some features, enhanced others and developed new ones to meet the changing demands of computational biology. Here, we describe the changes to Pfam content. Notably, we now provide family alignments based on four different representative proteome sequence data sets and a new interactive DNA search interface. We also discuss the mapping between Pfam and known 3D structures.
Figures

Similar articles
-
Depressing time: Waiting, melancholia, and the psychoanalytic practice of care.In: Kirtsoglou E, Simpson B, editors. The Time of Anthropology: Studies of Contemporary Chronopolitics. Abingdon: Routledge; 2020. Chapter 5. In: Kirtsoglou E, Simpson B, editors. The Time of Anthropology: Studies of Contemporary Chronopolitics. Abingdon: Routledge; 2020. Chapter 5. PMID: 36137063 Free Books & Documents. Review.
-
"I've Spent My Whole Life Striving to Be Normal": Internalized Stigma and Perceived Impact of Diagnosis in Autistic Adults.Autism Adulthood. 2023 Dec 1;5(4):423-436. doi: 10.1089/aut.2022.0066. Epub 2023 Dec 12. Autism Adulthood. 2023. PMID: 38116050 Free PMC article.
-
Using Experience Sampling Methodology to Capture Disclosure Opportunities for Autistic Adults.Autism Adulthood. 2023 Dec 1;5(4):389-400. doi: 10.1089/aut.2022.0090. Epub 2023 Dec 12. Autism Adulthood. 2023. PMID: 38116059 Free PMC article.
-
Antioxidants for female subfertility.Cochrane Database Syst Rev. 2020 Aug 27;8(8):CD007807. doi: 10.1002/14651858.CD007807.pub4. Cochrane Database Syst Rev. 2020. PMID: 32851663 Free PMC article.
-
Trends in Surgical and Nonsurgical Aesthetic Procedures: A 14-Year Analysis of the International Society of Aesthetic Plastic Surgery-ISAPS.Aesthetic Plast Surg. 2024 Oct;48(20):4217-4227. doi: 10.1007/s00266-024-04260-2. Epub 2024 Aug 5. Aesthetic Plast Surg. 2024. PMID: 39103642 Review.
Cited by
-
TXNDC5, a newly discovered disulfide isomerase with a key role in cell physiology and pathology.Int J Mol Sci. 2014 Dec 17;15(12):23501-18. doi: 10.3390/ijms151223501. Int J Mol Sci. 2014. PMID: 25526565 Free PMC article. Review.
-
Genome-wide transcriptome profiling uncovers differential miRNAs and lncRNAs in ovaries of Hu sheep at different developmental stages.Sci Rep. 2021 Mar 12;11(1):5865. doi: 10.1038/s41598-021-85245-y. Sci Rep. 2021. PMID: 33712687 Free PMC article.
-
Two distinct domains of the UVR8 photoreceptor interact with COP1 to initiate UV-B signaling in Arabidopsis.Plant Cell. 2015 Jan;27(1):202-13. doi: 10.1105/tpc.114.133868. Epub 2015 Jan 27. Plant Cell. 2015. PMID: 25627067 Free PMC article.
-
FR database 1.0: a resource focused on fruit development and ripening.Database (Oxford). 2015 Feb 27;2015:bav002. doi: 10.1093/database/bav002. Print 2015. Database (Oxford). 2015. PMID: 25725058 Free PMC article.
-
Binding of Cyclic Di-AMP to the Staphylococcus aureus Sensor Kinase KdpD Occurs via the Universal Stress Protein Domain and Downregulates the Expression of the Kdp Potassium Transporter.J Bacteriol. 2015 Jul 20;198(1):98-110. doi: 10.1128/JB.00480-15. Print 2016 Jan 1. J Bacteriol. 2015. PMID: 26195599 Free PMC article.
References
-
- Krogh A, Brown M, Mian IS, Sjölander K, Haussler D. Hidden Markov models in computational biology. Applications to protein modeling. J. Mol. Biol. 1994;235:1501–1531. - PubMed
-
- Eddy SR. Profile hidden Markov models. Bioinformatics. 1998;14:755–763. - PubMed
-
- Eddy SR. A new generation of homology search tools based on probabilistic inference. Genome Inform. 2009;23:205–211. - PubMed
Publication types
MeSH terms
Substances
Grants and funding
LinkOut - more resources
Full Text Sources
Other Literature Sources
Molecular Biology Databases
Research Materials
