![]()
Docs | Blog | Use-Cases | Installation | Community Apps | Slack | Youtube
📣 We are in the middle of rebranding from https://github.com/SuperDuperDB/superduperdb to https://github.com/superduper-io/superduper, so bear with us if anything is broken!
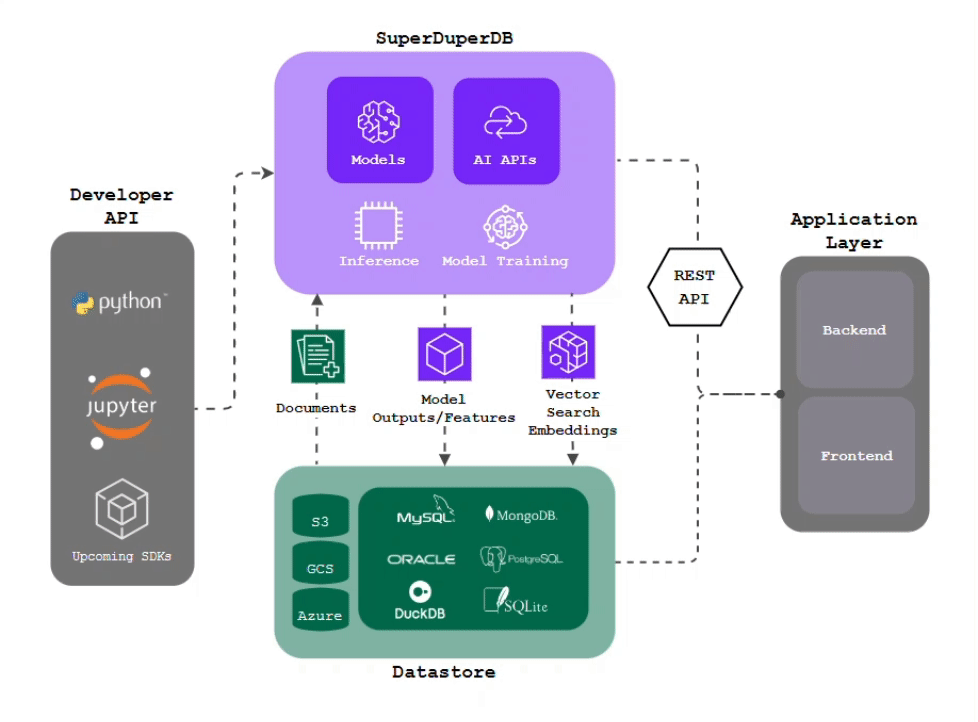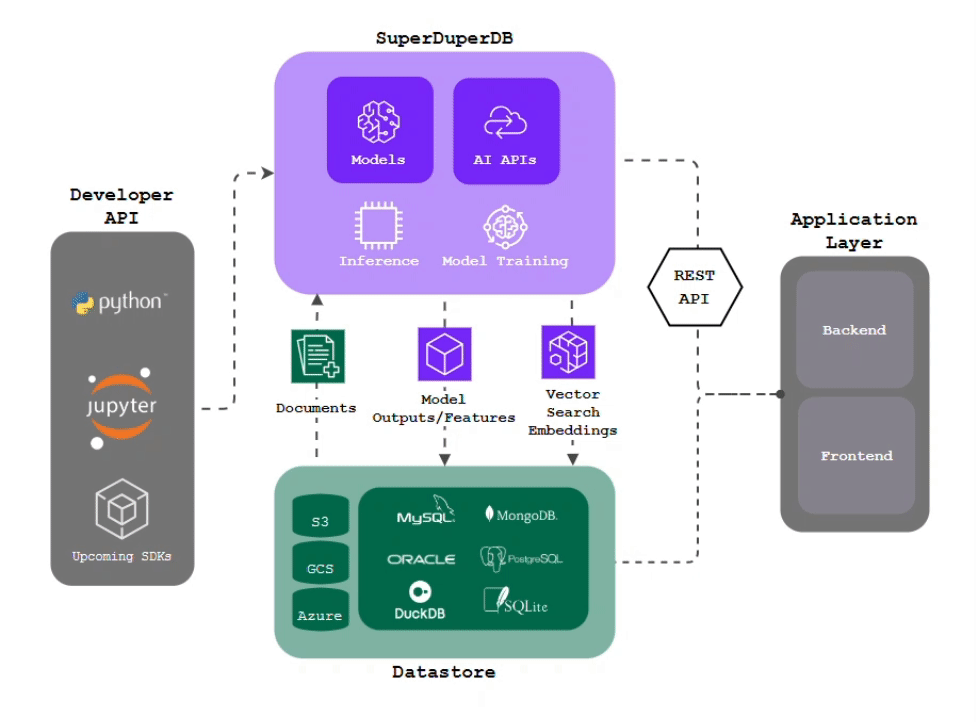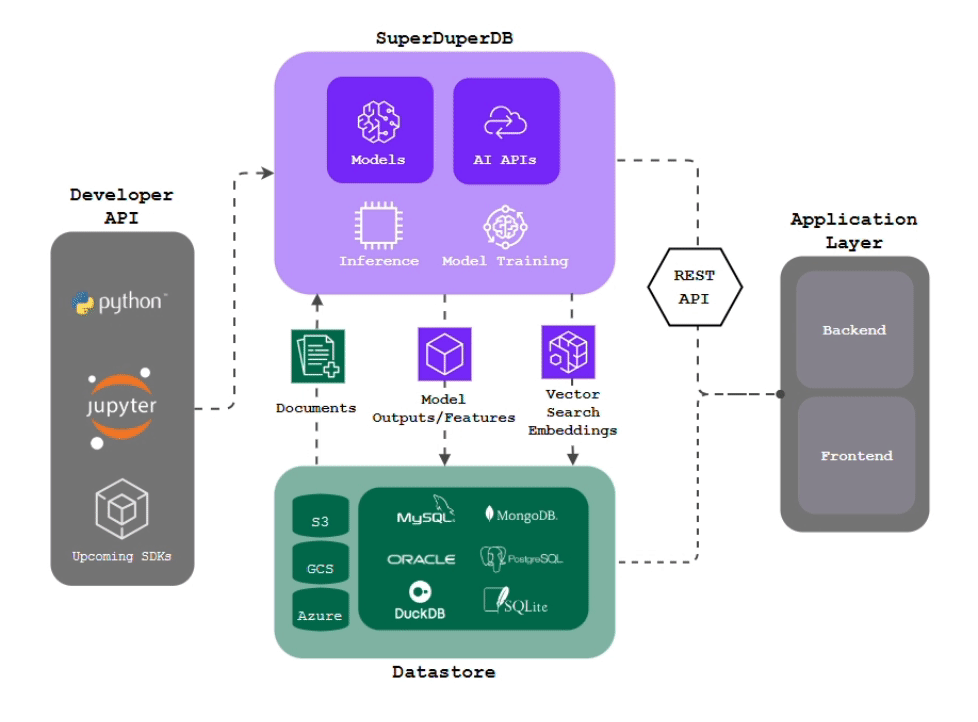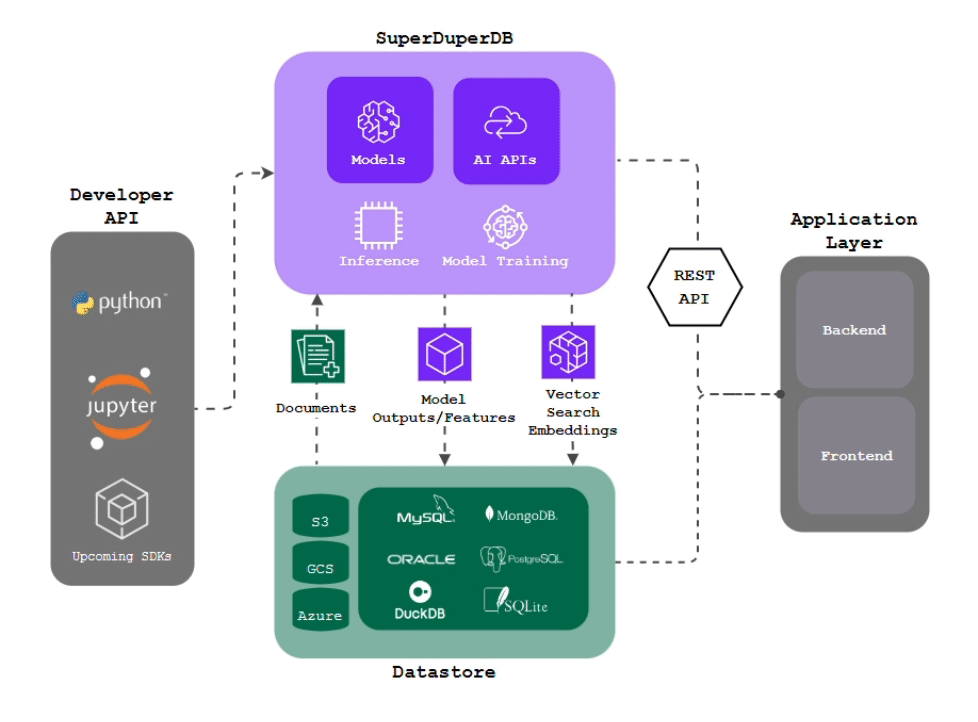
superduper.io is a Python framework for integrating AI models, APIs, and vector search engines directly with your existing databases, including hosting of your own models, streaming inference and scalable model training/fine-tuning.
- Integration of AI with your existing data infrastructure: Integrate any AI models and APIs with your databases in a single scalable deployment, without the need for additional pre-processing steps, ETL or boilerplate code.
- Inference via change-data-capture: Have your models compute outputs automatically and immediately as new data arrives, keeping your deployment always up-to-date.
- Scalable Model Training: Train AI models on large, diverse datasets simply by querying your training data. Ensured optimal performance via in-build computational optimizations.
- Model Chaining: Easily setup complex workflows by connecting models and APIs to work together in an interdependent and sequential manner.
- Simple Python Interface: Replace writing thousand of lines of glue code with simple Python commands, while being able to drill down to any layer of implementation detail, like the inner workings of your models or your training details.
- Python-First: Bring and leverage any function, program, script or algorithm from the Python ecosystem to enhance your workflows and applications.
- Difficult Data-Types: Work directly with images, video, audio in your database, and any type which can be encoded as
bytesin Python. - Feature Storing: Turn your database into a centralized repository for storing and managing inputs and outputs of AI models of arbitrary data-types, making them available in a structured format and known environment.
- Vector Search: No need to duplicate and migrate your data to additional specialized vector databases - turn your existing battle-tested database into a fully-fledged multi-modal vector-search database, including easy generation of vector embeddings and vector indexes of your data with preferred models and APIs.

The notebooks below are examples how to make use of different frameworks, model providers, vector databases, retrieval techniques and so on.
To learn more about how to use superduper.io with your database, please check our Docs and official Tutorials.
Also find use-cases and apps built by the community in the superduper-community-apps repository.
| Name | Link |
|---|---|
| Multimodal vector-search with a range of models and datatypes | |
| RAG with self-hosted LLM | |
| Fine-tune an LLM on your database | |
| Featurization and fransfer learning |
For more information about superduper.io and why we believe it is much needed, read this blog post.
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Transform your existing database into a Python-only AI development and deployment stack with one command:
db = superduper('mongodb|postgres|mysql|sqlite|duckdb|snowflake://<your-db-uri>')
|
|
|
|
Integrate, train and manage any AI model (whether from open-source, commercial models or self-developed) directly with your datastore to automatically compute outputs with a single Python command:
|
|
|
|
|
Integrate externally hosted models accessible via API to work together with your other models with a simple Python command:
Ideal for building new AI applications.
pip install superduper-frameworkIdeal for learning basic superduper.io functionalities and testing notebooks.
docker pull superduperio/superduper
docker run -p 8888:8888 superduperio/superduperIdeal for learning advanced superduper.io functionalities and testing whole AI stacks.
make build_sandbox
make testenv_initBrowse the re-usable snippets to understand how to accomplish difficult AI end-functionality with few lines of code using superduper.io.
- Join our Slack (we look forward to seeing you there).
- Search through our GitHub Discussions, or add a new question.
- Comment an existing issue or create a new one.
- Help us to improve superduper.io by providing your valuable feedback here!
- Email us at
gethelp@superduper.io. - Feel free to contact a maintainer or community volunteer directly!
There are many ways to contribute, and they are not limited to writing code. We welcome all contributions such as:
- Bug reports
- Documentation improvements
- Enhancement suggestions
- Feature requests
- Expanding the tutorials and use case examples
Please see our Contributing Guide for details.
superduper.io is open-source and intended to be a community effort, and it wouldn't be possible without your support and enthusiasm. It is distributed under the terms of the Apache 2.0 license. Any contribution made to this project will be subject to the same provisions.
We are looking for nice people who are invested in the problem we are trying to solve to join us full-time. Find roles that we are trying to fill here!