Paper: EfficientNet: Rethinking Model Scaling for Convolutional Neural Networks
https://arxiv.org/pdf/1905.11946.pdf

ATTACH AND CONFIGURE GOOGLE COMPUTE ENGINE DISK
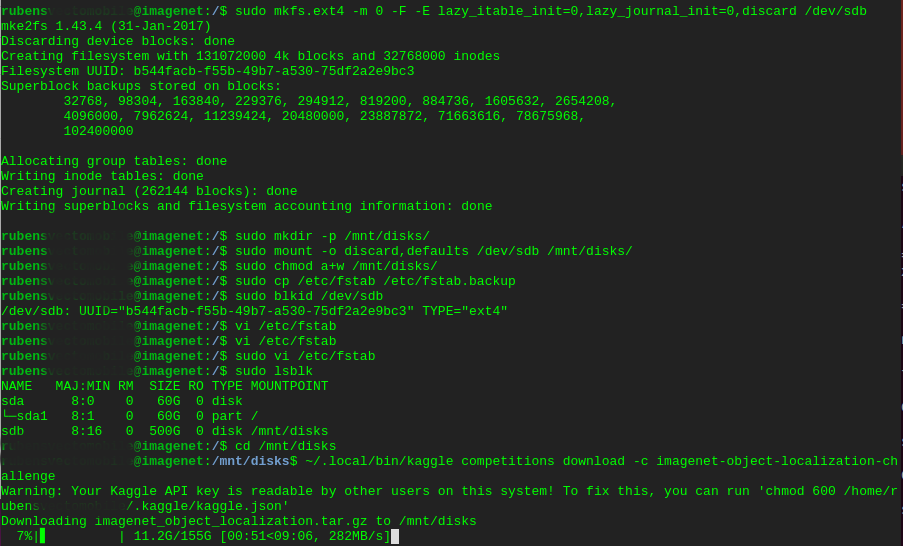
$ sudo mkfs.ext4 -m 0 -F -E lazy_itable_init=0,lazy_journal_init=0,discard /dev/sdb
$ sudo mkdir -p /mnt/disks/
$ sudo mount -o discard,defaults /dev/sdb /mnt/disks/
$ sudo chmod a+w /mnt/disks/
$ sudo cp /etc/fstab /etc/fstab.backup
$ sudo blkid /dev/sdb
$ sudo vi /etc/fstab
UUID=3f228fd9-1dce-4197-b1b2b3-12345 /mnt/disks/ ext4 discard,defaults,nobootwait 0 2
# ESC : wq
$ sudo lsblk
NAME MAJ:MIN RM SIZE RO TYPE MOUNTPOINT
sda 8:0 0 60G 0 disk
└─sda1 8:1 0 60G 0 part /
sdb 8:16 0 500G 0 disk /mnt/disks
$ cd /mnt/disks
Download IMAGENET -- SIZE = 155 GB
$ pip install kaggle
$ export KAGGLE_USERNAME=rubens
$ export KAGGLE_KEY=xxxxxxxxxxxxxx
$ touch kaggle.json
$ vi kaggle.json # ADD CREDENTIALS
/mnt/disks/$ ~/.local/bin/kaggle competitions download -c imagenet-object-localization-challenge
/mnt/disks/$ tar -xvf imagenet_object_localization.tar.gz
$ du -hs
# OR
$ mkdir data && cd data
$ wget https://raw.githubusercontent.com/RubensZimbres/Repo-2019/master/Google-EfficientNet/download_imagenet.sh
$ sudo bash download_imagenet.sh
$ git clone https://github.com/tensorflow/tpu
tpu $ python /tools/datasets/imagenet_to_gcs.py
$ exit
$ sudo chmod -R +X /home
$ ...
ILSVRC/Annotations/CLS-LOC/train/ILSVRC2012_train_0012345.JPEG
ILSVRC/Data/CLS-LOC/train/ILSVRC2012_train_0012345.JPEG
ILSVRC/Data/CLS-LOC/val/ILSVRC2012_val_0012345.JPEG
ILSVRC/ImageSets/CLS-LOC/train_loc.txt
ILSVRC/ImageSets/CLS-LOC/train_cls.txt
ILSVRC/ImageSets/CLS-LOC/val.txt
ILSVRC/ImageSets/CLS-LOC/test.txt
$ cd ILSVRC/Data/CLS-LOC/train/n04562935/
$ gcloud auth login
$ sudo chmod -R 755 /mnt/disks/
$ cp $(ls | head -n 1000) /path/
$ gsutil cp /mnt/disks/ILSVRC/Data/CLS-LOC/train/n04562935/* gs://efficient-net/data/train
$ gsutil cp /mnt/disks/ILSVRC/Annotations/CLS-LOC/train/n04562935/* gs://efficient-net/data/train
$ gsutil du -s gs://efficient-net
Project
$ export MODEL=efficientnet-b0
$ wget https://storage.googleapis.com/cloud-tpu-checkpoints/efficientnet/efficientnet-b0.tar.gz
$ mkdir weights
$ tar -xvf efficientnet-b0.tar.gz
$ gsutil cp home/rubens/weights/* gs://efficient-net
$ wget https://upload.wikimedia.org/wikipedia/commons/f/fe/Giant_Panda_in_Beijing_Zoo_1.JPG -O panda.jpg
$ wget https://storage.googleapis.com/cloud-tpu-checkpoints/efficientnet/eval_data/labels_map.txt
$ python eval_ckpt_main.py --model_name=efficientnet-b3 --ckpt_dir=efficientnet-b3 --example_img=panda.jpg --labels_map_file=labels_map.txt


$ git clone https://github.com/tensorflow/tpu
$ mkdir train
$ cd train
$ tar xvf ~/Downloads/ILSVRC2012_img_train.tar
$ find . -name "*.tar" | while read NAME ; do mkdir -p "${NAME%.tar}"; tar -xvf "${NAME}" -C "${NAME%.tar}"; rm -f "${NAME}"; done
### extract val data
$ cd ..
$ mkdir val
$ cd val
$ tar xvf ~/Downloads/ILSVRC2012_img_val.tar
$ wget
https://raw.githubusercontent.com/jkjung-avt/jkjung-avt.github.io/master/assets/2017-12-01-ilsvrc2012-in-digits/valprep.sh
$ bash ./valprep.sh
$ find train/ -name "*.JPEG" | wc -l
$ export PYTHONPATH="$PYTHONPATH:/home/rubens/efficient"
$ cd /tpu/models/official/efficientnet
$ python main.py --tpu=rubens --data_dir=gs://efficient-net/data --model_dir=gs://efficient-net


$ python main.py --helpshort
--base_learning_rate: Base learning rate when train batch size is 256.
(default: '0.016')
(a number)
--batch_norm_epsilon: Batch normalization layer epsilon to override..
(a number)
--batch_norm_momentum: Batch normalization layer momentum of moving average to override.
(a number)
--bigtable_column_family: The column family storing TFExamples.
(default: 'tfexample')
--bigtable_column_qualifier: The column name storing TFExamples.
(default: 'example')
--bigtable_eval_prefix: The prefix identifying evaluation rows.
(default: 'validation_')
--bigtable_instance: The Cloud Bigtable instance to load data from.
--bigtable_project: The Cloud Bigtable project. If None, --gcp_project will be used.
--bigtable_table: The Cloud Bigtable table to load data from.
(default: 'imagenet')
--bigtable_train_prefix: The prefix identifying training rows.
(default: 'train_')
--data_dir: The directory where the ImageNet input data is stored. Please see the README.md for the expected data
format.
(default: 'gs://cloud-tpu-test-datasets/fake_imagenet')
--data_format: A flag to override the data format used in the model. The value is either channels_first or
channels_last. To run the network on CPU or TPU, channels_last should be used. For GPU, channels_first will
improve performance.
(default: 'channels_last')
--depth_coefficient: Depth coefficient for scaling number of layers.
(a number)
--drop_connect_rate: Drop connect rate for the network.
(a number)
--dropout_rate: Dropout rate for the final output layer.
(a number)
--eval_batch_size: Batch size for evaluation.
(default: '1024')
(an integer)
--eval_timeout: Maximum seconds between checkpoints before evaluation terminates.
(an integer)
--export_dir: The directory where the exported SavedModel will be stored.
--[no]export_to_tpu: Whether to export additional metagraph with "serve, tpu" tags in addition to "serve" only
metagraph.
(default: 'false')
--gcp_project: Project name for the Cloud TPU-enabled project. If not specified, we will attempt to automatically
detect the GCE project from metadata.
--input_image_size: Input image size: it depends on specific model name.
(an integer)
--iterations_per_loop: Number of steps to run on TPU before outfeeding metrics to the CPU. If the number of
iterations in the loop would exceed the number of train steps, the loop will exit before reaching
--iterations_per_loop. The larger this value is, the higher the utilization on the TPU.
(default: '1251')
(an integer)
--label_smoothing: Label smoothing parameter used in the softmax_cross_entropy
(default: '0.1')
(a number)
--log_step_count_steps: The number of steps at which the global step information is logged.
(default: '64')
(an integer)
--mode: One of {"train_and_eval", "train", "eval"}.
(default: 'train_and_eval')
--model_dir: The directory where the model and training/evaluation summaries are stored.
--model_name: The model name among existing configurations.
(default: 'efficientnet-b0')
--momentum: Momentum parameter used in the MomentumOptimizer.
(default: '0.9')
(a number)
--moving_average_decay: Moving average decay rate.
(default: '0.9999')
(a number)
--num_eval_images: Size of evaluation data set.
(default: '50000')
(an integer)
--num_label_classes: Number of classes, at least 2
(default: '1000')
(an integer)
--num_parallel_calls: Number of parallel threads in CPU for the input pipeline
(default: '64')
(an integer)
--num_train_images: Size of training data set.
(default: '1281167')
(an integer)
--[no]skip_host_call: Skip the host_call which is executed every training step. This is generally used for
generating training summaries (train loss, learning rate, etc...). When --skip_host_call=false, there could be
a performance drop if host_call function is slow and cannot keep up with the TPU-side computation.
(default: 'false')
--steps_per_eval: Controls how often evaluation is performed. Since evaluation is fairly expensive, it is advised
to evaluate as infrequently as possible (i.e. up to --train_steps, which evaluates the model only after
finishing the entire training regime).
(default: '6255')
(an integer)
--tpu: The Cloud TPU to use for training. This should be either the name used when creating the Cloud TPU, or a
grpc://ip.address.of.tpu:8470 url.
--tpu_zone: GCE zone where the Cloud TPU is located in. If not specified, we will attempt to automatically detect
the GCE project from metadata.
--train_batch_size: Batch size for training.
(default: '2048')
(an integer)
--train_steps: The number of steps to use for training. Default is 218949 steps which is approximately 350 epochs
at batch size 2048. This flag should be adjusted according to the --train_batch_size flag.
(default: '218949')
(an integer)
--[no]transpose_input: Use TPU double transpose optimization
(default: 'true')
--[no]use_async_checkpointing: Enable async checkpoint
(default: 'false')
--[no]use_bfloat16: Whether to use bfloat16 as activation for training.
(default: 'false')
--[no]use_cache: Enable cache for training input.
(default: 'true')
--[no]use_tpu: Use TPU to execute the model for training and evaluation. If --use_tpu=false, will use whatever
devices are available to TensorFlow by default (e.g. CPU and GPU)
(default: 'true')
--weight_decay: Weight decay coefficiant for l2 regularization.
(default: '1e-05')
(a number)
--width_coefficient: WIdth coefficient for scaling channel size.
(a number)
GCLOUD EXAMPLE:
$ git clone https://github.com/tensorflow/tpu
$ cd tpu/models/official/efficientnet/
$ sudo gsutil cp -r gs://cloud-tpu-test-datasets/fake_imagenet /mnt/disks/fake-imagenet/
$ python main.py --data_dir=gs://cloud-tpu-test-datasets/fake_imagenet --model_dir=gs://cls-loc-output --model_name='efficientnet-b0' --skip_host_call=true --train_batch_size=1024 --train_steps=80000 --dropout_rate=0.1 --eval_batch_size=1024 --export_dir=gs://cls-loc-output/saved --num_eval_images=10000 --steps_per_eval=4000 --tpu=rubens --base_learning_rate=1.8e-2