

In the previous post of Gemma explained, you reviewed RecurrentGemma architecture. In this blog post, you will explore PaliGemma architecture. Let’s dive into it!
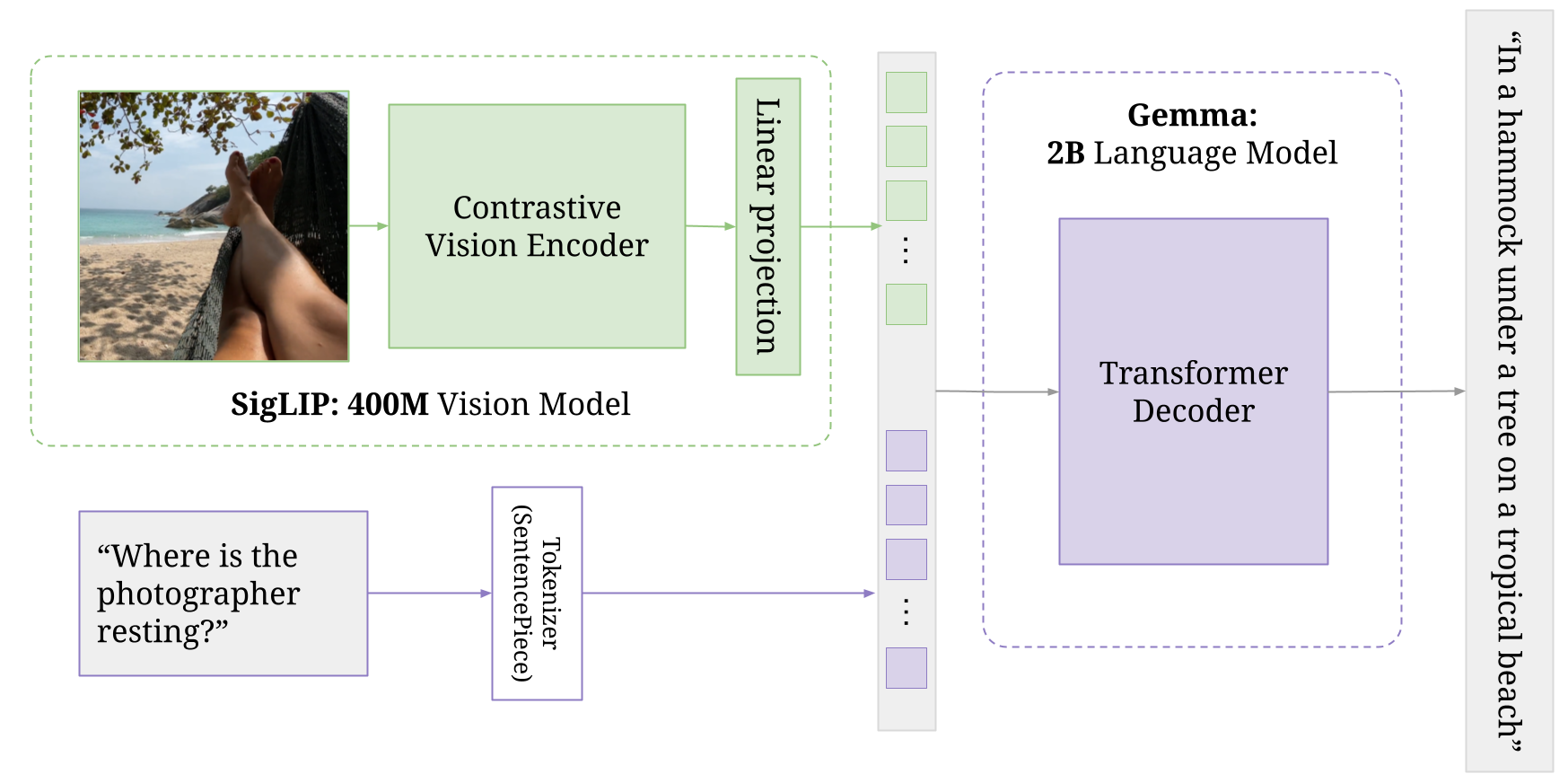
PaliGemma is a lightweight open vision-language model (VLM) inspired by PaLI-3, and based on open components like the SigLIP vision model and the Gemma language model. Pali stands for Pathway Language and Image Model. As the name implies this model is able to take both image and text inputs and produce a text response, as you can see in this fine tuning guide.
PaliGemma adds an additional vision model to the BaseGemma model, which consists of an image encoder. This encoder along with the text tokens is passed to a specialized Gemma 2B model. Both the Vision Model and Gemma model are trained in various stages both independently, and together, to produce the final joint architecture. For full details see Section 3.2 of the Pali-3 paper
PaliGemmaForConditionalGeneration(
(vision_tower): SiglipVisionModel(
(vision_model): SiglipVisionTransformer(
(embeddings): SiglipVisionEmbeddings(
(patch_embedding): Conv2d(3, 1152, kernel_size=(14, 14), stride=(14, 14), padding=valid)
(position_embedding): Embedding(256, 1152)
)
(encoder): SiglipEncoder(
(layers): ModuleList(
(0-26): 27 x SiglipEncoderLayer(
(self_attn): SiglipAttention(
(k_proj): Linear(in_features=1152, out_features=1152, bias=True)
(v_proj): Linear(in_features=1152, out_features=1152, bias=True)
(q_proj): Linear(in_features=1152, out_features=1152, bias=True)
(out_proj): Linear(in_features=1152, out_features=1152, bias=True)
)
(layer_norm1): LayerNorm((1152,), eps=1e-06, elementwise_affine=True)
(mlp): SiglipMLP(
(activation_fn): PytorchGELUTanh()
(fc1): Linear(in_features=1152, out_features=4304, bias=True)
(fc2): Linear(in_features=4304, out_features=1152, bias=True)
)
(layer_norm2): LayerNorm((1152,), eps=1e-06, elementwise_affine=True)
)
)
)
(post_layernorm): LayerNorm((1152,), eps=1e-06, elementwise_affine=True)
)
)
(multi_modal_projector): PaliGemmaMultiModalProjector(
(linear): Linear(in_features=1152, out_features=2048, bias=True)
)
(language_model): GemmaForCausalLM(
(model): GemmaModel(
(embed_tokens): Embedding(257216, 2048, padding_idx=0)
(layers): ModuleList(
(0-17): 18 x GemmaDecoderLayer(
(self_attn): GemmaSdpaAttention(
(q_proj): Linear(in_features=2048, out_features=2048, bias=False)
(k_proj): Linear(in_features=2048, out_features=256, bias=False)
(v_proj): Linear(in_features=2048, out_features=256, bias=False)
(o_proj): Linear(in_features=2048, out_features=2048, bias=False)
(rotary_emb): GemmaRotaryEmbedding()
)
(mlp): GemmaMLP(
(gate_proj): Linear(in_features=2048, out_features=16384, bias=False)
(up_proj): Linear(in_features=2048, out_features=16384, bias=False)
(down_proj): Linear(in_features=16384, out_features=2048, bias=False)
(act_fn): PytorchGELUTanh()
)
(input_layernorm): GemmaRMSNorm()
(post_attention_layernorm): GemmaRMSNorm()
)
)
(norm): GemmaRMSNorm()
)
(lm_head): Linear(in_features=2048, out_features=257216, bias=False)
)
)
This component is responsible for processing the input image.
It uses SiglipVisionTransformer which is a type of transformer architecture designed for vision tasks.
PaliGemma takes as input one or more images, which are turned into “soft tokens” by the SigLIP encoder.
It breaks the image into smaller patches, similar to how a text model processes words in a sentence. The model then learns to capture relationships between these patches, effectively understanding the image’s visual content.
It uses a convolutional layer (Conv2d) with the following parameters.
Position embeddings are added to each patch embedding to encode the spatial information (i.e., where each patch was located in the original image).
This is done using a learned embedding layer (Embedding) that takes as input the position of each patch (up to 256 positions) and outputs a vector of size 1152 (the same as the patch embedding dimension).
The embeddings pass through a series of SiglipEncoderLayer, each consisting of self-attention and feed-forward neural networks. This helps the model capture relationships between different parts of the image.
This component projects the output of the vision tower into a multi-modal space. This is achieved using a simple linear layer and it allows the vision and language representations to be combined effectively.
This component is a language model based on the Gemma 2B model.
It takes as input the multi-modal representation from the projector and generates text output.
For the text input, each checkpoint was trained with various sequence lengths. For example, paligemma-3b-mix-224 was trained with sequence length 256 (input text + output text tokenized by Gemma’s tokenizer).
PaliGemma uses the Gemma tokenizer with 256000 tokens, but extends its vocabulary with 1024 entries that represent coordinates in normalized image-space (<loc0000>...<loc1023>), and another with 128 entries (<seg000>...<seg127>) that are codewords used by a lightweight referring-expression segmentation vector-quantized variational auto-encoder (VQ-VAE). (256000 + 1024 + 128 = 257216)
Additional soft tokens encode object detection and image segmentation. Below is an example output from the paligemma-3b-mix-224. You can try it by yourself from the HuggingFace live demo.

Output from the PaliGemma with the prompt “segment floor;cat;person;”

The outputs from the model are unintuitive to decode if you are not familiar with ML and computer vision tasks.
The initial four location tokens represent the coordinate of the bounding box, ranging from 0 to 1023. These coordinates are independent of the aspect ratio, as the image is assumed to be resized to 1024 x 1024.
For instance, the output displays the cat's location within the coordinates (382, 637) and (696, 784). In this coordinate system, the top left corner is denoted as (0,0) and the vertical coordinate is listed before the horizontal coordinate.

The mask is encoded with the following 16 segmentation tokens. A neural network model (VQ-VAE) can reconstruct masks from quantized representations (codebook indices) by decoding those values. You can explore the actual code from here.
At last, you can obtain this beautiful outcome from the output of the PaliGemma.

In this article, you learned about PaliGemma.
The Gemma family presents a unique opportunity to understand modern large language model systems by offering a collection of open weights models with similar core architectures but designed for different use cases. These models, released by Google for researchers, developers, and end users, span various functionalities and complexities.
We hope this overview provides a concise understanding of the Gemma model family, highlighting its versatility and suitability for a wide array of tasks.
The Google Developer Community Discord server is an excellent platform to showcase your projects, establish connections with fellow developers, and engage in interactive discussions. Consider joining the server to explore these exciting opportunities.
Thanks for reading!

Gemini API and Google AI Studio now offer Grounding with Google Search

Bringing AI Agents to production with Gemini API

Gemma explained: RecurrentGemma architecture
Towards Global Understanding – Advancing Multilingual AI with Gemma 2 and a $150K Challenge

Gemma explained: What’s new in Gemma 2
Introducing Keras Hub: Your one-stop shop for pretrained models