

Gemma is a family of lightweight, state-of-the art open models built from the same research and technology used to create the Gemini models.
Different variations of Gemma are designed for different use cases and modalities, such as:
Because all these models share a similar DNA, the Gemma family presents a unique way to learn about the architectures and design choices that are available in modern LLM systems. We hope this contributes to a rich ecosystem of open models and promotes a greater understanding of how LLM systems work.
This series will cover:
In this series, we will
To provide information about the model, we use Hugging Face Transformers print module, like the simple code below.
from transformers import AutoModelForCausalLM
model = AutoModelForCausalLM.from_pretrained("google/gemma-7b")
print(model)
You can explore inside the model with torchinfo or summary() in the Keras Model class API as well.
This guide is not an introduction to AI. It assumes working knowledge of neural networks, Transformers and associated terms like tokens. If you need a refresher on these concepts here are some resources to get you started:
A hands on neural network learning tool that works in browser
An introduction to transformers
Gemma is an open weight LLM. It comes in both instruction-tuned and raw, pretrained variants at various parameter sizes. It is based on the LLM architecture introduced by Google Research in the Attention Is All You Need paper. Its primary function is to generate text tokenword by tokenword, based on a prompt provided by a user. In tasks like translation, Gemma takes a sentence from one language as input and outputs its equivalent in another language.
As you’ll soon see Gemma is both a great model by itself, but also lends itself to custom extensions to meet different user needs.
First, let’s see the transformer decoder that Gemma models are based on.
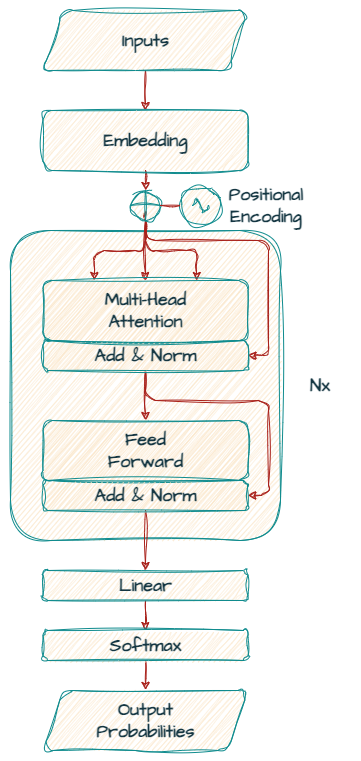
Unlike the original encoder-decoder transformer model architecture introduced in “Attention Is All You Need”, Gemma is solely a “decoder-only” model.
The core parameters of the architecture are summarized in the table below.
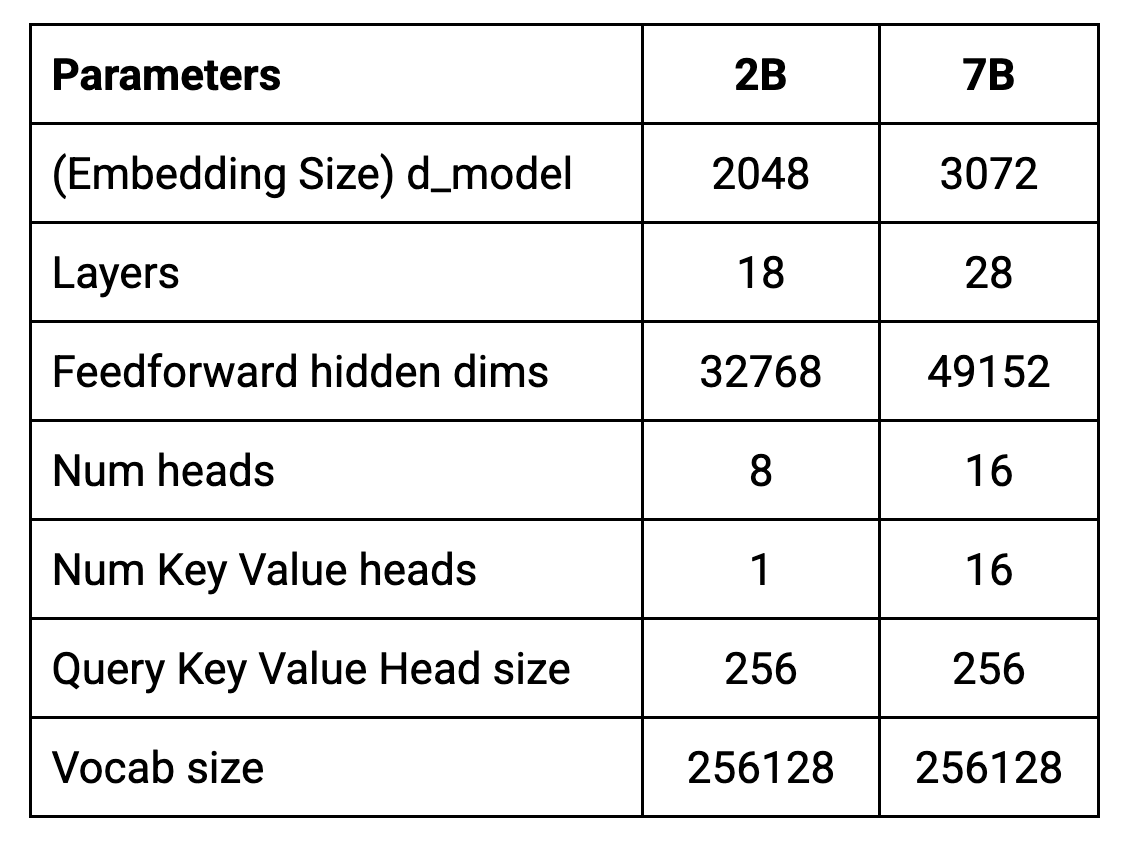
Models are trained on a context length of 8192 tokens. This means they can process up to approximately 6144 words (using the rule of thumb of 100 tokens ~= 75 words) at a time.
It's worth noting that the practical input limit can vary based on the task and usage. This is because text generation consumes tokens within the context window, effectively reducing space for new input. Although the technical input limit remains constant, generated output becomes part of the subsequent input, influencing further generations.
d_model represents the size of the embeddings (vector representations of words or subwords a.k.a tokens) used as input to the decoder. It also determines the size of the internal representation within the decoder layers.
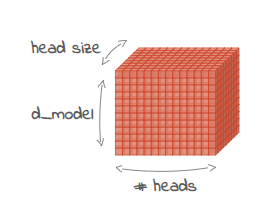
A larger d_model value means the model has more “space” to represent the nuances of different words and their relationships. This can lead to better performance, especially for complex language tasks. However, increasing d_model also makes the model larger and more computationally expensive to train and use.
Transformers consist of multiple stacked layers. Deeper models have more layers, and therefore more parameters and can learn more intricate patterns. However these additional parameters mean they are also more prone to overfitting and require more computational resources.
This augmented representational capacity might result in the model learning noise or specific training data patterns that lack the ability to generalize to novel examples.
Furthermore, deeper models often necessitate more training data to avert overfitting. In cases where available data is limited, the model might lack sufficient examples to learn a generalizable representation, leading to the memorization of training data instead.
Each Transformer layer includes a feedforward network after the attention mechanism. This network has its own dimensionality, often larger than the d_model size to increase the model’s expressive power.
It is implemented as a multi-layer perceptron (MLP), a kind of neural network, to further transform the embeddings and extract more intricate patterns.
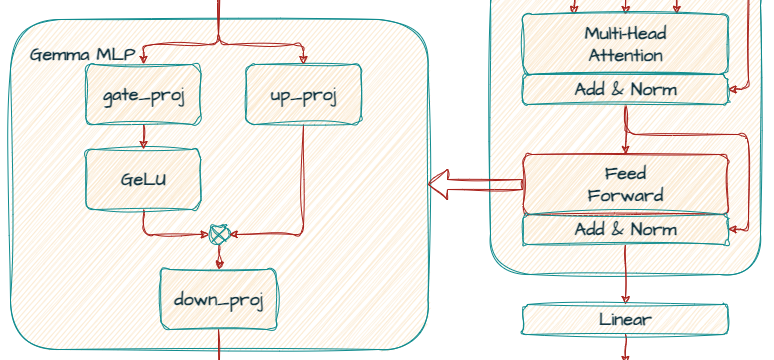
In Gemma, the standard ReLU non-linearity is replaced by the GeGLU activation function, a variation of GLU (Gate Linear Unit). GeGLU divides the activation into two parts: a sigmoidal part and a linear projection. The output of the sigmoidal part is element-wise multiplied with the linear projection, resulting in a non-linear activation function.
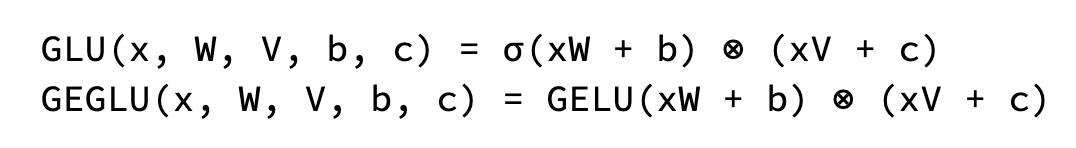
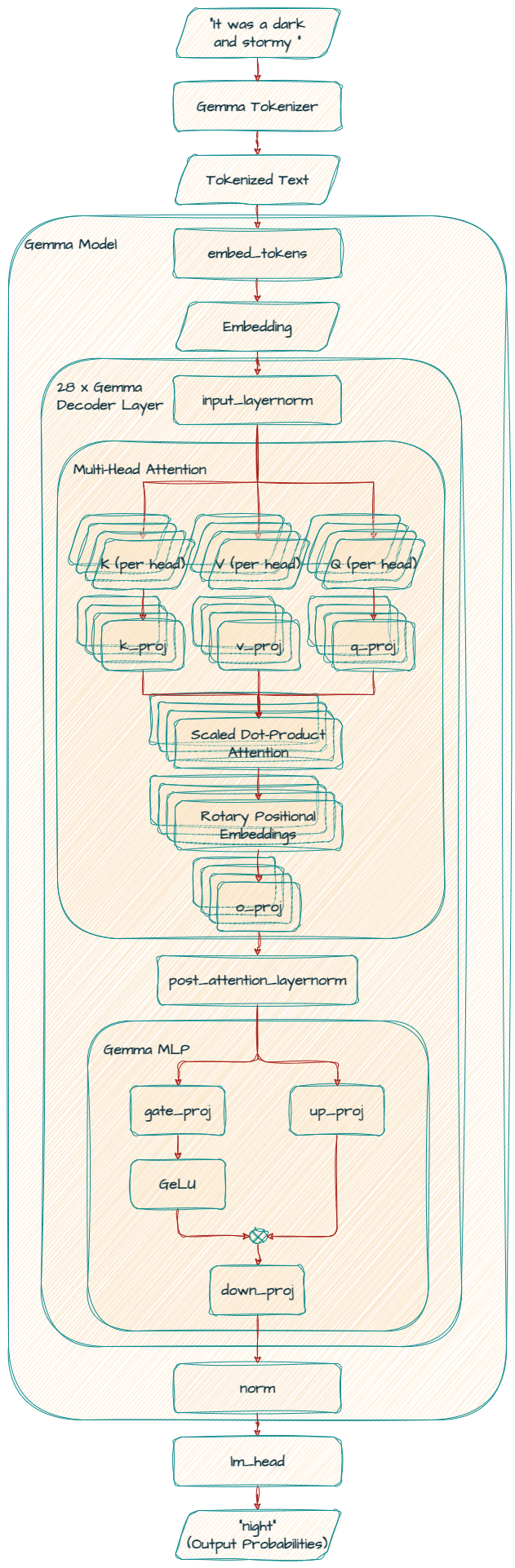
Each Transformer layer contains multiple attention mechanisms working in parallel. These “heads” allow the model to focus on different aspects of the input sequence simultaneously. Increasing the number of heads can enhance the model's ability to capture diverse relationships in the data.
The 7B model uses multi-head attention(MHA), while the 2B model uses multi-query attention(MQA). MQA shares the same key and value projections, which means each head focuses on the same underlying representation but with different query projections.
The original MHA offers richer representation learning but comes with higher computational costs. MQA provides an efficient alternative that has been shown to be effective.
It refers to the dimensionality of each attention head within the multi-head attention mechanism. It is calculated by dividing the embedding dimension by the number of heads. For example, if the embedding dimension is 2048 and there are 8 heads, then each head would have a size of 256.
It defines the number of unique tokens (words, sub words or characters) that the model understands and can process. Gemma tokenizer is based on SentencePiece. The size of the vocabulary is predetermined before training. SentencePiece then learns the optimal subword segmentation based on the chosen vocabulary size and the training data. Gemma’s large 256k vocabulary allows it to handle diverse text inputs and potentially improve performance on various tasks, e.g. handling multilingual text inputs.
GemmaForCausalLM(
(model): GemmaModel(
(embed_tokens): Embedding(256000, 3072, padding_idx=0)
(layers): ModuleList(
(0-27): 28 x GemmaDecoderLayer(
(self_attn): GemmaSdpaAttention(
(q_proj): Linear(in_features=3072, out_features=4096, bias=False)
(k_proj): Linear(in_features=3072, out_features=4096, bias=False)
(v_proj): Linear(in_features=3072, out_features=4096, bias=False)
(o_proj): Linear(in_features=4096, out_features=3072, bias=False)
(rotary_emb): GemmaRotaryEmbedding()
)
(mlp): GemmaMLP(
(gate_proj): Linear(in_features=3072, out_features=24576, bias=False)
(up_proj): Linear(in_features=3072, out_features=24576, bias=False)
(down_proj): Linear(in_features=24576, out_features=3072, bias=False)
(act_fn): PytorchGELUTanh()
)
(input_layernorm): GemmaRMSNorm()
(post_attention_layernorm): GemmaRMSNorm()
)
)
(norm): GemmaRMSNorm()
)
(lm_head): Linear(in_features=3072, out_features=256000, bias=False)
)
This layer converts the input tokens (words or subwords) into dense numerical representations (embeddings) that the model can process. It has a vocabulary size of 256,000 and creates embeddings of dimension 3072.
This is the heart of the model, consisting of 28 stacked GemmaDecoderLayer blocks. Each of these layers refines the token embeddings to capture complex relationships between words and their context.
In the self-attention mechanism, the model assigns different weights to the words in the input when creating the next word. Leveraging a scaled dot-product attention mechanism, the model employs linear projections (q_proj, k_proj, v_proj, and o_proj) to generate query, key, value, and output representations.
All out_features values are the same 4096 for q_proj, k_proj and v_proj as this model uses Multi Head Attention (MHA). They have 16 heads with a size of 256 in parallel, totaling 4096 (256 x 16).
Furthermore, the model leverages positional information more effectively by employing rotary_emb (GemmaRotaryEmbedding) for positional encoding (a.k.a RoPE).
Finally, o_proj layer projects the attention output back to the original dimension (3072).
Note that the Gemma 2B model uses Multi Query Attention (MQA).
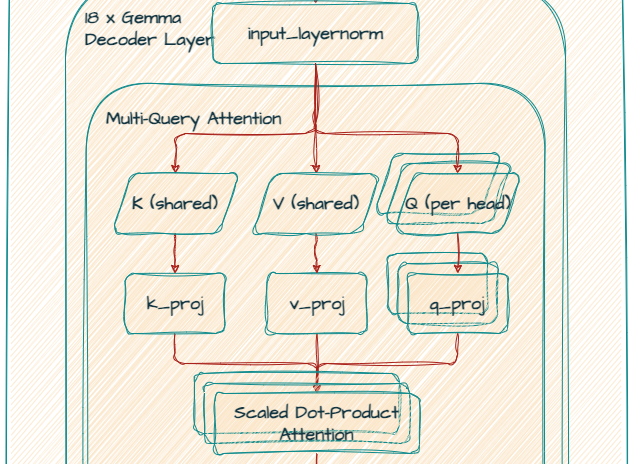
k_proj and v_proj share the same head with a size of 256, resulting in out_features of 256. In contrast, q_proj and o_proj have 8 heads (256 x 8 = 2048) in parallel.
(self_attn): GemmaSdpaAttention(
(q_proj): Linear(in_features=2048, out_features=2048, bias=False)
(k_proj): Linear(in_features=2048, out_features=256, bias=False)
(v_proj): Linear(in_features=2048, out_features=256, bias=False)
(o_proj): Linear(in_features=2048, out_features=2048, bias=False)
(rotary_emb): GemmaRotaryEmbedding()
)
It utilizes gate_proj and up_proj for a gating mechanism, followed by down_proj to reduce the dimension back to 3072.
These normalization layers stabilize training and improve the model’s ability to learn effectively.
This final layer maps the refined embeddings (3072) back to a probability distribution for the next token over the vocabulary space (256000).
CodeGemma models are fine-tuned Gemma models that are optimized for code completion and coding chat assistance. CodeGemma models are trained on more than 500 billion tokens of primarily code. In addition CodeGemma adds fill-in-the- middle capability, allowing completions that occur between two pieces of existing text.
CodeGemma highlights the finetunability of the Gemma checkpoints. Through additional training the models become specialized at a certain task, learning a more complex completion than pure suffix completion.
You can use 4 user-defined tokens - 3 for FIM and a "<|file_separator|>" token for multi-file context support.
BEFORE_CURSOR = "<|fim_prefix|>"
AFTER_CURSOR = "<|fim_suffix|>"
AT_CURSOR = "<|fim_middle|>"
FILE_SEPARATOR = "<|file_separator|>"
Imagine that you are trying to complete the code like the screen below.
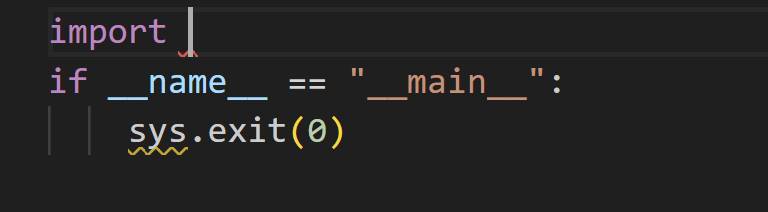
And the input prompt should look like this
<|fim_prefix|>import <|fim_suffix|>if __name__ == "__main__":\n sys.exit(0)<|fim_middle|>
The model will provide "sys" as the suggested code completion.
You can explore more about CodeGemma on CodeGemma / Quickstart.
This article discussed the Gemma architecture.
In our next series of posts, you will explore the latest model, Gemma 2. With substantial enhancements in safety measures, this model surpasses its predecessor in terms of performance and efficiency during inference.
Stay tuned and thanks for reading!
Gemma
CodeGemma

Gemini API and Google AI Studio now offer Grounding with Google Search

Bringing AI Agents to production with Gemini API

Gemma explained: RecurrentGemma architecture
Gemma explained: PaliGemma architecture
Towards Global Understanding – Advancing Multilingual AI with Gemma 2 and a $150K Challenge
Introducing Keras Hub: Your one-stop shop for pretrained models